2. "Обучение с чистого листа" в мозгу
- 1.2.1 Краткое содержание / Оглавление
- 2.2.2 Что такое «обучение с чистого листа»?
- 3.2.3 Три вещи, которыми «обучение с чистого листа» НЕ ЯВЛЯЕТСЯ
- 4.2.4 Моя гипотеза: конечный мозг и мозжечок обучаются с чистого листа, гипоталамус и мозговой ствол – нет
- 5.2.5 Свидетельства того, что конечный мозг и мозжечок обучаются с чистого листа
2.1 Краткое содержание / Оглавление
В предыдущем посте я представил задачу «безопасности подобного-мозгу СИИ». Следующие 6 постов (№2-№7) будут в основном про нейробиологию, в них я буду выстраивать более детальное понимание того, как может выглядеть подобный-мозгу СИИ (или, по крайней мере, его относящиеся к безопасности аспекты).
Этот пост сосредоточен на концепции, которую я называю «обучением с чистого листа», я выдвину гипотезу разделения, в котором 96% человеческого мозга (включая неокортекс) «обучается с чистого листа», а остальные 4% (включая ствол головного мозга) – нет. Эта гипотеза – центральная часть моего представления о том, как работает мозг, так что она требуется для дальнейших рассуждений в этой цепочке.
- В Разделе 2.2 я определю концепцию «обучения с чистого листа». Например, заявляя, что неокортекс «обучается с чистого листа», я имею в виду, что он изначально совершенно бесполезен для организма – выводит улучшающие приспособленность сигналы не чаще, чем случайно – пока не начинает обучаться (во время жизни индивида). Вот пара повседневных примеров штук, которые «обучаются с чистого листа»:
- В большинстве статей по глубинному обучению модель «учится с чистого листа» – она инициализирована случайными весами, так что поначалу её вывод – случайный мусор. Но по ходу обучения её веса обновляются и вывод модели со временем становится весьма полезным.
- Пустой жёсткий диск тоже «учится с чистого листа» – нельзя вытащить оттуда полезную информацию, пока её туда не запихнули.
- В Разделе 2.3 я проясню некоторые частые поводы к замешательству:
- «Обучение с чистого листа» – не то же самое, что «с нуля», потому что существуют встроенные алгоритм обучения, нейронная архитектура, гиперпараметры и т.д.
- «Обучение с чистого листа» – не то же самое, что «воспитание превыше природы», потому что (1) только некоторые части мозга обучаются с чистого листа, а другие – нет, и (2) алгоритмы обучения вовсе не обязательно обучаются внешнему окружению – они так же могут обучаться, например, как контролировать собственное тело.
- «Обучение с чистого листа» – не то же самое (и конкретнее), чем «пластичность мозга», потому что последняя также включает (например) жёстко генетически заданную цепь с всего одним конкретным подстраиваемым параметром, полу-перманентно изменяющимся в некоторых условиях.
- В Разделе 2.4 я опишу свою гипотезу о том, что две большие части мозга существуют исключительно для того, чтобы исполнять алгоритмы обучения с чистого листа – конкретно, конечный мозг (неокортекс, гиппокампус, миндалевидное тело, большая часть базальных ганглиев) и мозжечок. Вместе они составляют 96% от объёма человеческого мозга.
- В Разделе 2.5 я коснусь четырёх источников свидетельств, относящихся к моей гипотезе о том, что конечный мозг и мозжечок обучаются с нуля: (1) размышления о том, как мозг работает на высоком уровне, (2) неонатальные данные, (3) связь с гипотезой «однородности коры» и относящимися к ней проблемами, и (4) возможность, что некоторое свойство предварительной обработки в мозгу – так называемое «разделение паттернов» – включает рандомизацию, заставляющую последующие алгоритмы обучаться с чистого листа.
- В Разделе 2.6 я немного поговорю о том, является ли моя гипотеза мэйнстримной или выделяющейся. (Ответ: я не уверен.)
- В Разделе 2.7 я выдам намёки на то, почему обучение с чистого листа важно для безопасности СИИ – мы попадаем в ситуацию, где то, что мы хотим, чтобы пытался сделать СИИ (например, вылечить болезнь Альцгеймера) – концепт, погребённый в большой и сложной-для-интерпретации структуре данных. Поэтому написание относящегося к мотивации кода весьма не прямолинейно. Подробнее об этом будет в будущих постах.
- Раздел 2.8 будет первой из трёх частей моего обсуждения «сроков до подобного-мозгу СИИ», сосредоточенной на том, сколько времени займёт у учёных реверс-инжиниринг ключевых управляющих принципов обучающейся с чистого листа части мозга. (Остальное обсуждение сроков будет в следующем посте.)
2.2 Что такое «обучение с чистого листа»?
Как указано в введении выше, я предлагаю гипотезу, утверждающую, что большие части мозга – конечный мозг и мозжечок (см. Раздел 2.4 ниже) – «обучаются с чистого листа», в том смысле, что изначально они выдают не вкладывающиеся в эволюционно-адаптивное поведение случайные мусорные сигналы, но со временем становятся всё более полезными благодаря работающему во время жизни алгоритму обучения.
Вот два способа думать о гипотезе обучения с чистого листа:
- Как вам следует думать об обучении с чистого листа (если вы из машинного обучения): Представьте глубокую нейросеть, инициализированную случайными весами. Её нейронная архитектура может быть простой или невероятно сложной, это не важно. У неё точно есть склонности, из-за которых выучить одни виды паттернов для нее легче чем другие. Но их в любом случае надо выучить! Если её веса изначально случайны, то она изначально бесполезна и становится более полезной по мере получения обучающих данных. Идея в том, что эти части мозга (неокортекс и т.д.) схожим образом «инициализированы случайными весами» или обладают каким-то эквивалентным свойством.
- Как вам следует думать об обучении с чистого листа (если вы из нейробиологии): Представьте о связанной с памятью системе, вроде гиппокампуса. Способность формировать воспоминания – очень полезная для организма! …Но она не помогает от рождения!![1] Вам нужно накопить воспоминания перед тем, как их использовать! Моё предположение – что всё в конечном мозге и мозжечке попадает в ту же категорию – это всё разновидности модулей памяти. Они могут быть очень особыми разновидностями модулей памяти! Неокортекс, например, может обучиться и запомнить суперсложную сеть взаимосвязанных паттернов, к нему прилагаются мощные возможности составления запросов, он даже может делать запросы самому себе рекуррентными петлями, и т.д. Но всё равно, это форма памяти, и она изначально бесполезна, и становится всё более полезной для организма, накапливая выученное содержание.
2.3 Три вещи, которыми «обучение с чистого листа» НЕ ЯВЛЯЕТСЯ
2.3.1 Обучение с чистого листа – это НЕ «с нуля»
Я уже упомянул это, но я хочу быть максимально ясным: если неокортекс (к примеру) обучается с чистого листа, это не означает, что в нём нет жёстко генетически закодированного информационного содержания. Это означает, что жёстко генетически закодированное информационное содержание скорее всего что-то в этом духе:
- Обучающий(е) алгоритм(ы) – т.е. встроенные правила полу-перманентных изменений нейронов или их связей в зависимости от ситуации.
- Алгоритм(ы) вывода – т.е. встроенные правила того, какие выходные сигналы следует послать прямо сейчас, чтобы помочь выжить и преуспеть. Сами выходные сигналы, конечно, также зависят от ранее выученной информации.
- Архитектура нейронной сети – т.е. встроенная высокоуровневая диаграмма связей, определяющая, как разные части обучающегося модуля соединены друг с другом, входными и выходными сигналами.
- Гиперпараметры – т.е. разные части архитектуры могут иметь разные встроенные скорости обучения. Эти гиперпараметры тоже могут меняться при развитии (см. сенситивные периоды). Также может быть и встроенная способность изменять гиперпараметры от момента к моменту в ответ на специальные управляющие сигналы (в виде нейромодуляторов вроде ацетилхолина).
При наличии всех этих встроенных составляющих алгоритм обучения с чистого листа готов принимать снаружи входные данные и управляющие сигналы[2], и постепенно обучается делать что-то полезное.
Эта встроенная информация не обязательно проста. Может быть 50000 совершенно разных алгоритмов обучения в 50000 разных частях неокортекса, и это всё ещё будет с моей точки зрения считаться обучением с чистого листа! (Впрочем, я не думаю, что это так – см. Раздел 2.5.3 про «однородность».)
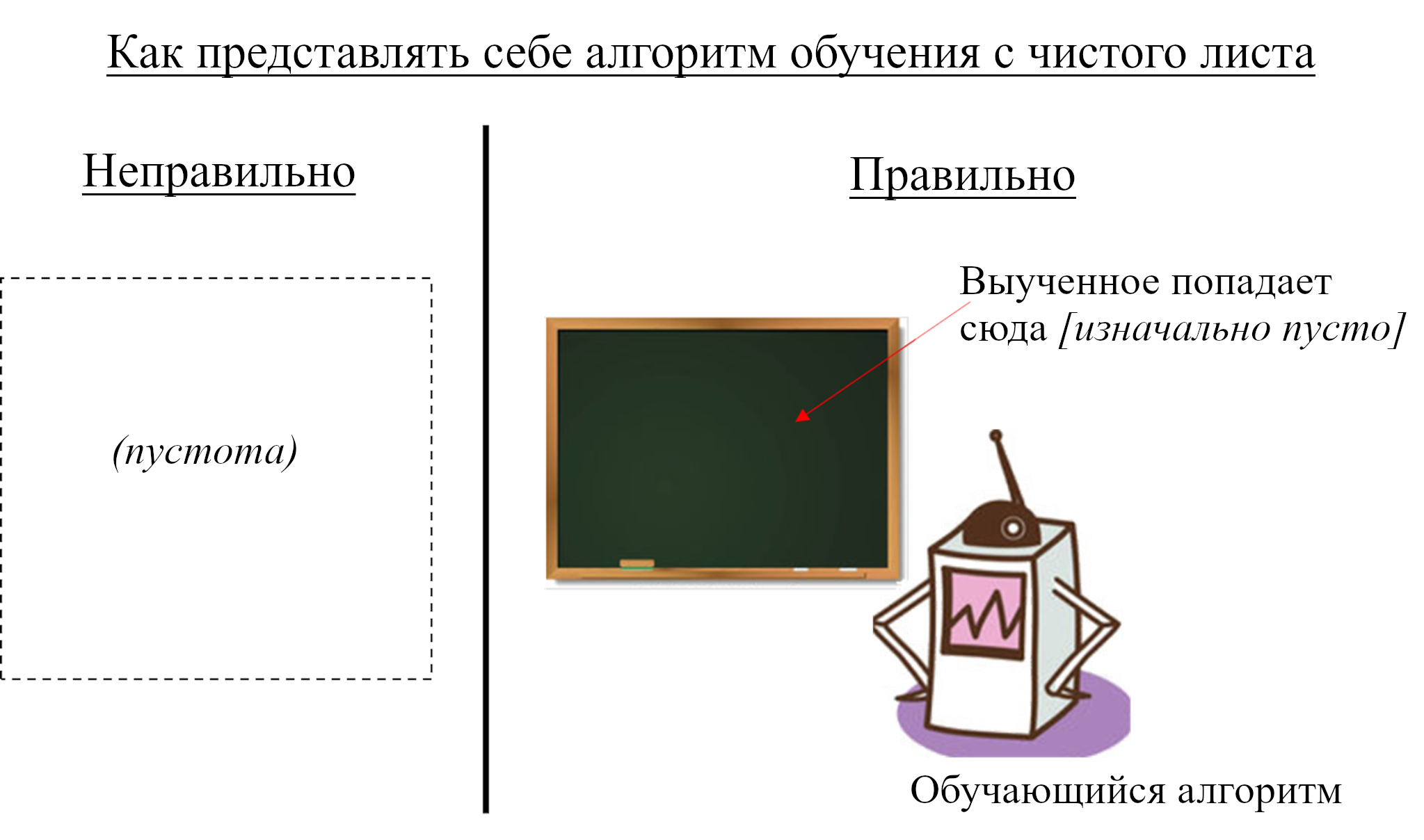
Представляя себе обучающийся с чистого листа алгоритм, *не* следует представлять пустоту, наполняемую данными. Стоит представлять *механизм*, который постоянно (1) записывает информацию в хранилище памяти, и (2) выполняет запросы к текущему содержанию хранилища памяти. «С чистого листа» просто означает, что хранилище памяти изначально пусто. Таких механизмов *много*, они следуют разным процедурам того, что записывать и как запрашивать. К примеру «справочная таблица» соответствует простому механизму, который просто записывает то, что видит. Другим механизмам соответствуют алгоритмы обучения с учителем, алгоритмы обучения с подкреплением, автокодировщики, и т.д., и т.п.
2.3.2 Обучение с чистого листа НЕ означает «воспитание превыше природы»
Есть тенденция ассоциировать «алгоритмы обучения с чистого листа» с стороной «воспитания» споров «природа против воспитания». Я думаю, это неверно. Даже напротив. Я думаю, что гипотеза обучения с чистого листа полностью совместима с возможностью того, что эволюционировавшее встроенное поведение играет большую роль.
Две причины:
Во-первых, некоторые части мозга совершенно точно НЕ выполняют алгоритмы обучения с чистого листа! Это в основном мозговой ствол и гипоталамус (больше про это ниже и в следующем посте). Эти не-обучающиеся-с-чистого-листа части мозга должны быть полностью ответственны за любое адаптивное поведение при рождении.[1] Правдоподобно ли это? Думаю, да, учитывая впечатляющий диапазон функциональности мозгового ствола. К примеру, в неокортексе есть цепи обработки визуальных и других сенсорных данных – но в мозговом стволе тоже! В неокортексе есть цепи моторного контроля – и в мозговом стволе тоже! В по крайней мере некоторых случаях полностью адаптивное поведение кажется исполняемым целиком в мозговом стволе: к примеру, у мышей есть цепь-обнаружения-приближающихся-птиц в мозговом стволе, напрямую соединённая с цепью-убегания-прочь в нём же. Так что моя гипотеза обучения с чистого листа не делает никаких общих заявлений о том, какие алгоритмы или функциональности присутствуют или отсутствуют в мозгу. Только заявления о том, что некоторые виды алгоритмов есть только в некоторых конкретных частях мозга.
Во-вторых, «обучение с чистого листа» - не то же самое, что «обучение из окружения». Вот искусственный пример.[3] Представьте, что мозговой ствол птицы имеет встроенную способность судить о том, как должно звучать хорошее птичье пение, но не инструкцию, как произвести хорошее птичье пение. Ну, алгоритм обучения с чистого листа может заполнить эту дыру – методом проб и ошибок вывести вторую способность из первой. Этот пример показывает, что алгоритмы обучения с чистого листа могут управлять поведением, которое мы естественно и корректно описываем как встроенное / «природное, а не воспитанное».
2.3.3 Обучение с чистого листа – это НЕ более общее понятие «пластичности»
«Пластичность» - это термин, означающий, что мозг полу-перманентно изменяет себя, обычно изменяя присутствие / отсутствие / силу синаптических связей нейронов, но иногда и другими механизмами, вроде изменений в экспрессии генов в нейронах.
Любой алгоритм обучения с чистого листа обязательно включает пластичность. Но не вся пластичность мозга – часть алгоритмов обучения с чистого листа. Другая возможность – то, что я называю «отдельными встроенными настраиваемыми параметрами». Вот таблица с примерами и того, и другого и тем, чем они отличаются:
| Алгоритмы обучения с чистого листа | Отдельные встроенные настраиваемые параметры | |
| Стереотипный пример | Любая статья о глубоком обучении: есть *обучающий алгоритм*, который постепенно создаёт *обученную модель*, настраивая много её параметров. | Некоторые связи в крысином мозгу усиливаются, когда крыса выигрывает драку – по сути, считают, сколько драк крыса выиграла за свою жизнь. Потом такая связь используется для выполнения поведения «Выиграв много драк за свою жизнь – будь агрессивнее.» (ссылка) |
| Количество параметров, изменяемых на основании входных данных (т.е. как много измерений в пространстве всех возможных обученных моделей?) | Может быть много – сотни, тысячи, миллионы, и т.д. | Скорее всего мало, может даже один |
| Если масштабировать это вверх, будет ли это работать лучше после обучения? | Да, наверное. | А?? Что, чёрт побери, вообще значит «масштабировать»? |
Я не думаю, что между этими штуками есть чёткая граница; наверное, есть спорная область, где одна перетекает в другую. По крайней мере, я думаю, что в теории она есть. На практике, мне кажется, существует довольно явное разделение – всегда, когда я узнаю о конкретном примере пластичности мозга, она явным образом попадает в одну или другую категорию.
К слову, как мне кажется, моя категоризация для нейробиологии несколько необычна. Нейробиологи чаще сосредотачиваются на низкоуровневых деталях реализации: «Источник пластичности – синаптические изменения или изменения экспрессии генов?», «Каков биохимический механизм?» и т.д. Это совсем другая тема. К примеру, готов поспорить, что один и то же низкоуровневый биохимический механизм синаптической пластичности может быть вовлечён и в алгоритмы обучения с чистого листа и в изменение отдельного встроенного настраиваемого параметра.
Почему я подымаю эту тему? Потому что я планирую заявить, что гипоталамус и мозговой ствол не выполняют или почти не выполняют алгоритмы обучения с чистого листа. Но они точно имеют отдельные встроенные настраиваемые параметры.
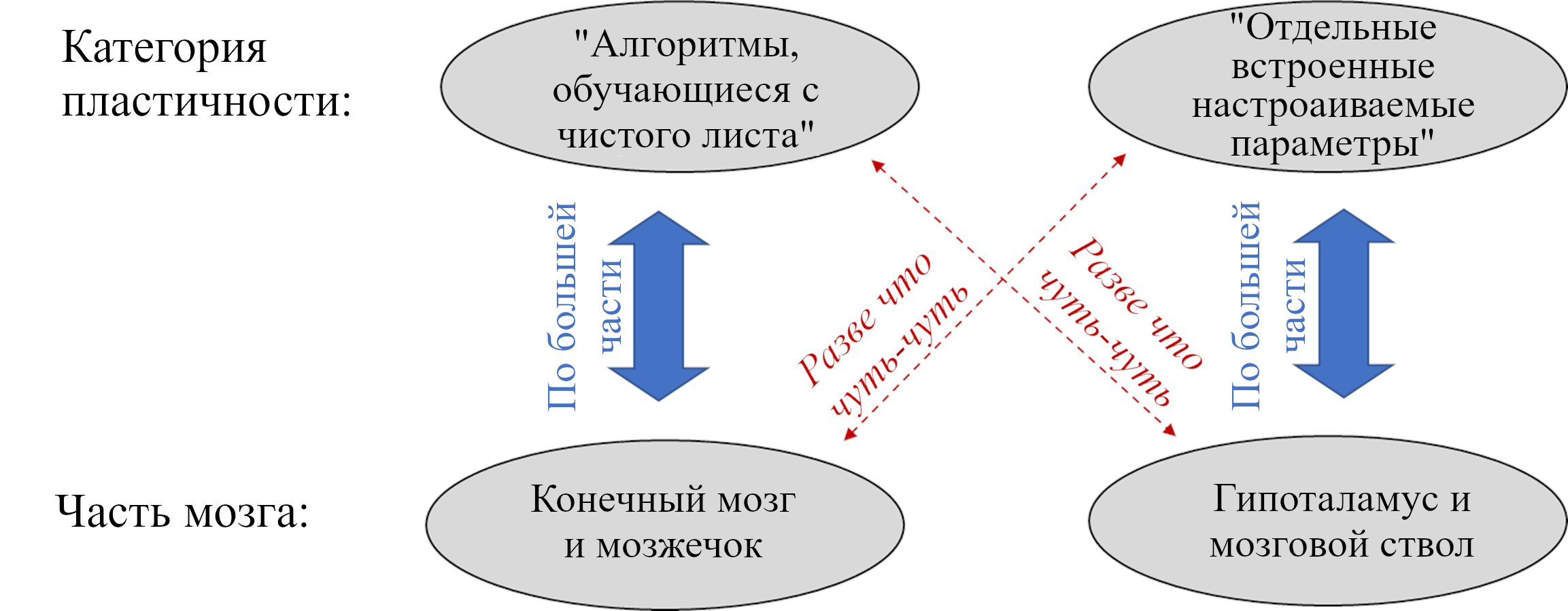
Для конкретики, вот три примера «отдельных встроенных настраиваемых параметров» в гипоталамусе и мозговом стволе:
- Уже упомянутая цепь в крысином гипоталамусе «если ты продолжаешь выигрывать драки, становись агрессивнее» – ссылка.
- Вот цепь в крысином гипоталамусе «если тебе опасно не хватает соли, увеличь базовое желание соли».
- Верхнее двухолмие в мозговом стволе содержит зрительную, слуховую и саккадную моторную область, и механизм, связывающий все три – так что, когда ты видишь вспышку или слышишь шум, ты немедленно направляешь взгляд в точности в правильном направлении. В этом механизме есть пластичность – к примеру, он может самокорректироваться у животного, носящего призматические очки. Я не знаю точных деталей, но полагаю, что это что-то вроде: Если видишь движение и переводишь на него взгляд, но движение не центрировано даже после саккады, то это генерирует сигнал об ошибке, сдвигающий соответствие областей. Может, вся эта система включает 8 настраиваемых параметров (масштаб и смещение, горизонталь и вертикаль, три области для выравнивания), а может она сложнее – опять же, я не знаю деталей.
Видна разница? Вернитесь к таблице, если всё ещё в замешательстве.
2.4 Моя гипотеза: конечный мозг и мозжечок обучаются с чистого листа, гипоталамус и мозговой ствол – нет
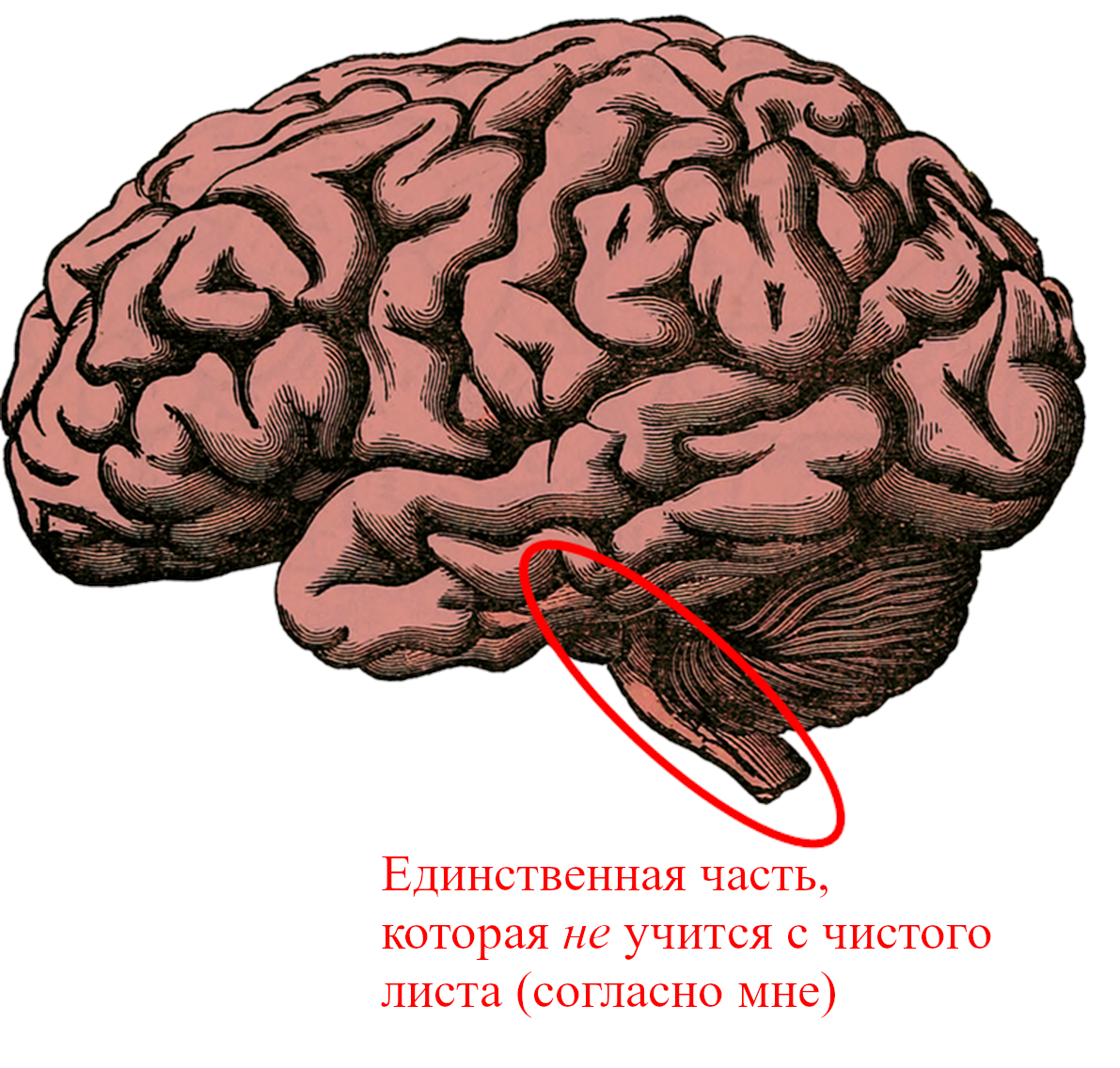
Моя гипотеза заключается в том, что ~96% человеческого мозга выполняет алгоритмы обучения с чистого листа. Главные исключения – мозговой ствол и гипоталамус, общим размером с большой палец. Источник картинки.
Вот моя гипотеза в трёх утверждениях:
Во-первых, я думаю, что весь конечный мозг обучается с чистого листа (и бесполезен при рождении[1]). Конечный мозг (также известный как «большой мозг») у людей – это в основном неокортекс, плюс гиппокампус, миндалевидное тело, большая часть базальных ганглиев и разнообразные более загадочные кусочки.
Несмотря на внешний вид, нравящаяся мне модель (изначально принадлежащая гениальному Ларри Свансону) заявляет, что весь конечный мозг организован в трёхслойную структуру (кора, полосатое тело, паллидум), и эта структура согласуется относительно маленьким количеством взаимосвязанных алгоритмов обучения. См. мой (довольно длинный и технический) пост Большая Картина Фазового Дофамина за подробностями.
(ОБНОВЛЕНИЕ: Узнав больше, я хочу это пересмотреть. Я думаю, что вся «кортикальная мантия» и всё «расширенное полосатое тело» обучаются с чистого листа. (Это включает штуки вроде гиппокампуса, миндалевидного тела, боковой перегородки, и т.д. - которые эмбриологически и/или цитоархитектурно развиваются вместе с корой и/или полосатым телом). Кто касается паллидума, я думаю, некоторые его части по сути являются расширением RAS мозгового ствола, так что им точно не место в этом списке. Про другие его части может оказаться и так, и так, в зависимости от того, как определить поверхность ввода/вывода некоторых алгоритмов обучения. Паллидум довольно маленький, так что мне не надо менять оценки объёма, включая число 96%. Я не буду проходить по всей цепочке и менять «конечный мозг» на «кортикальная мантия и расширенное полосатое тело» в миллионе мест, извините, придётся просто запомнить.)
Таламус технически не входит в конечный мозг, но по крайней мере его часть тесно связана с корой – некоторые исследователи описывают его функциональность как «дополнительный слой» коры. Так что я буду считать и его частью обучающегося с чистого листа конечного мозга.
Конечный мозг и таламус вместе составляют ~86% объёма человеческого мозга (ссылка).
Во-вторых, я думаю, что мозжечок тоже обучается с чистого листа (и тоже бесполезен при рождении). Мозжечок – это ~10% объёма взрослого мозга (ссылка). Больше про мозжечок будет в Посте №4.
В третьих, я думаю, что гипоталамус и мозговой ствол совершенно точно НЕ обучаются с чистого листа (и они очень активны и полезны прямо с рождения). Думаю, другие части промежуточного мозга – например, хабенула и шишковидное тело – тоже попадают в эту категорию.
Я не буду удивлён, если обнаружатся мелкие исключения из этой картины. Может, где-то в конечном мозге есть маленькое ядро, управляющее биологически-активным поведением, не обучаясь ему с чистого листа. Конечно, почему нет. Но сейчас я считаю, что такая картина по крайней мере приблизительно верна.
В следующих двух разделах я расскажу о свидетельствах, относящихся к моей гипотезе, и о том, что о ней думают другие люди из этой области.
2.5 Свидетельства того, что конечный мозг и мозжечок обучаются с чистого листа
2.5.1 Свидетельства общей картины
Из чтения и разговоров с людьми я вижу, что самые большие преграды к тому, чтобы поверить, что конечный мозг и мозжечок обучаются с чистого листа – это в подавляющем большинстве случаев не детализированные аргументы о данных нейробиологии, а скорее:
- Нерассмотрение этой гипотезы как возможности вовсе
- Замешательство касательно следствий гипотезы, в частности – как она встраивается в одну осмысленную картину мозга и поведения.
Раз вы досюда дочитали, №1 уже не должно быть проблемой.
Что по поводу №2? Типичный тип вопросов – это «Если конечный мозг и мозжечок обучаются с чистого листа, то как они делают X?» – для разных X. Если есть X, для которого мы совсем не можем ответить на этот вопрос, то это подразумевает, что гипотеза обучения с чистого листа неверна. Напротив, если мы можем найти действительно хорошие ответы на этот вопрос для многих X, то это свидетельство (хоть и не доказательство), того что гипотеза обучения с чистого листа верна. Следующие посты, я надеюсь, обеспечат вам такие свидетельства.
2.5.2 Неонатальное свидетельство
Если конечный мозг и мозжечок не могут производить биологически-адаптивный вывод, не научившись этому со временем, то из этого следует, что любое биологически-адаптивное поведение новорожденных[1] должно управляться мозговым стволом и гипоталамусом. Так ли это? Кажется, такие вещи должны быть экспериментально измеримы, верно? И в этой статье 1991 года действительно говорится «накопившиеся свидетельства приводят к выводу, что перцептомоторная активность новорожденных в основном контролируется подкорковыми механизмами». Но не знаю, изменилось ли что за прошедшие 30 лет – дайте мне знать, если видели другие упоминания этого.
На самом деле, этот вопрос сложнее, чем кажется. Представьте, что младенец совершает что-то биологически-адаптивное…
- Первый вопрос, который надо задать: в самом деле? Может, это плохой (или неверно интерпретированный) эксперимент. К примеру, если взрослый покажет младенцу язык, высунет ли младенец язык тоже, имитируя? Кажется простым вопросом, верно? Не-а, это источник споров уже десятилетия. Конкурирующая теория строится вокруг орального исследования: «высовывание языка кажется общим ответом на заметные стимулы и зависит от интереса ребёнка к стимулу»; показывающий язык взрослый просто активирует этот ответ, но так же делают мелькающие огоньки и звуки музыки. Я уверен, кто-то знает, каким экспериментам с новорожденными можно доверять, но я, по крайней мере пока не знаю. И я очень параноидально отношусь к тому, что две уважаемые книги в этой области (Учёный в кроватке,Происхождение Концептов) повторяют заявление об имитации будто это твёрдый как скала факт.
- Второй вопрос, который надо задать: результат ли это прижизненного обучения? Помните, даже у трёхмесячного ребёнка есть 4 миллиона секунд «обучающих данных». На самом деле, даже только что рождённый ребёнок возможно выполнял алгоритмы обучения с чистого листа в утробе.[1]
- Третий вопрос, который надо задать: какая часть мозга управляет этим поведением? Моя гипотеза заявляет, что не-выученное адаптивное поведение не может управляться конечным мозгом или мозжечком. Но моя гипотеза позволяет мозговому стволу управление таким поведением! И выяснение, какая часть мозга новорожденного в ответе за некоторое поведение может быть экспериментально сложным.
2.5.3 Свидетельство «однородности»
Гипотеза «однородности коры» заявляет, что все части неокортекса выполняют более-менее похожие алгоритмы. (…С некоторыми нюансами, особенно связанными с неоднородной нейронной архитектурой и гиперпараметрами). Мнения по поводу того, верна ли эта гипотеза (и в какой степени) расходятся – я кратко обсуждал свидетельства и аргументы тут. Я считаю, что весьма вероятно, что она верна, по крайней мере в слабом смысле, что будущий исследователь, имеющий очень хорошее детальное понимание того, как работает Область Неокортекса №147 будет очень хорошо продвинут в понимании того, как работает буквально любая другая часть неокортекса. Я не буду тут погружаться в это подробнее; мне кажется, это не совсем укладывается в тему этой цепочки.
Я упоминаю это потому, что если вы верите в однородность коры, то вам, наверное, следует верить и в то, что она обучается с чистого листа. Аргументация такая:
Неокортекс взрослого делает много явно различающихся вещей: обрабатывает зрительную информацию, слуховую информацию, занимается моторным контролем, языком, планированием и т.д. Как это совместимо с однородностью коры?
Обучение с чистого листа предоставляет правдоподобный способ. В конце концов, мы знаем, что один и тот же алгоритм обучения с чистого листа, если ему скормить очень разные входные данные и управляющие сигналы, может начать делать очень разные вещи: посмотрите как глубокие нейросети-трансформеры можно обучить генерировать текст на естественном языке, или картинки, или музыку, или сигналы моторного контроля робота, и т.д.
Если мы, напротив, примем однородность коры, но отвергнем обучение с чистого листа, то, эм-м-м, я не вижу осмысленных вариантов того, как это может работать.
Аналогично (но куда реже обсуждаемо, чем случай неокортекса), стоит ли нам верить в «однородность аллокортекса»? Для справки, аллокортекс – что-то вроде упрощённой версии неокортекса с тремя слоями вместо шести; считается, что до того, как эволюционировал неокортекс, ранние амниоты имели только аллокортекс. Он, как и неокортекс, делает много всякого разного: у взрослых людей гиппокампус вовлечён в ориентирование в пространстве и эпизодическую память, а грушевидная кора – в обработку запахов. Так что тут можно сделать аналогичный аргумент про обучение с чистого листа.
Двигаясь дальше, я уже упоминал выше (и больше в Большой Картине Фазового Дофамина, а ещё в Посте №5, Разделе 5.4.1) идею (Ларри Свансона), что весь конечный мозг кажется организованным в три слоя – «кору», «полосатое тело» и «паллидум». Я пока говорил только про кору; что насчёт «однородности полосатого тела» и «однородности паллидума»? Не ожидайте найти посвящённый этому обзор – на самом деле, предыдущее предложение судя по всему первое, где встречаются эти словосочетания. Но в каждом из этих слоёв есть как минимум некоторые общие черты: например, средние шиповатые нейроны вроде бы есть по всему полосатому телу. И я продолжаю считать, что описанная мной в Большой Картине Фазового Дофамина (и Постах №5-№6) модель – осмысленное первое приближение того, как может сочетаться «всё, что мы знаем о полосатом теле и паллидуме» с «несколькими вариациями конкретных алгоритмов обучения с чистого листа».
В случае мозжечка, есть по крайней мере какая-то литература по гипотезе однородности (ищите термин «universal cerebellar transform»), но, опять же, нет консенсуса. Мозжечок взрослого так же вовлечён в явно разные функции вроде моторной координации, языка, сознания и эмоций. Я лично считаю, что там тоже есть однородность, подробнее будут в Посте №4.
2.5.4 Локально-случайное разделение паттернов
Это другая причина, по которой лично я готов многое поставить на то, что конечный мозг и мозжечок обучаются с нуля. Она несколько специфична, но для меня довольно заметна; посмотрим, примете ли вы её.
2.5.4.1 Что такое разделение паттернов?
В мозгу есть частый мотив, называемый «разделением паттернов». Давайте я объясню, что это и откуда берётся.
Представьте, что вы инженер машинного обучения, работающий на сеть ресторанов. Ваш начальник даёт вам задание предсказать продажи для разных локаций, куда можно распространить франшизу.
Первое, что вы можете сделать – это собрать кучу потоков данных – местные уровни безработицы, местные рейтинги ресторанов, местные цены в магазинах, распространяется ли по миру сейчас новый коронавирус, и т.д. Я называю это «контекстные данные». Вы можете использовать контекстные данные как ввод нейросети. Выводом сети должно быть предсказание уровня продаж. Вы подправляете веса нейросети (используя обучения с учителем, собрав данные от существующих ресторанов), чтобы всё получилось. Никаких проблем!
Разделение паттернов – это когда вы добавляете в начало ещё один шаг. Вы берёте различные потоки контекстных данных и случайно комбинируете их многими разными способами. Затем вы добавляете немного нелинейности, и вуаля! Теперь у вас есть куда больше потоков контекстных данных, чем было изначально! Теперь они могут быть вводом для обучаемой нейросети.[4]
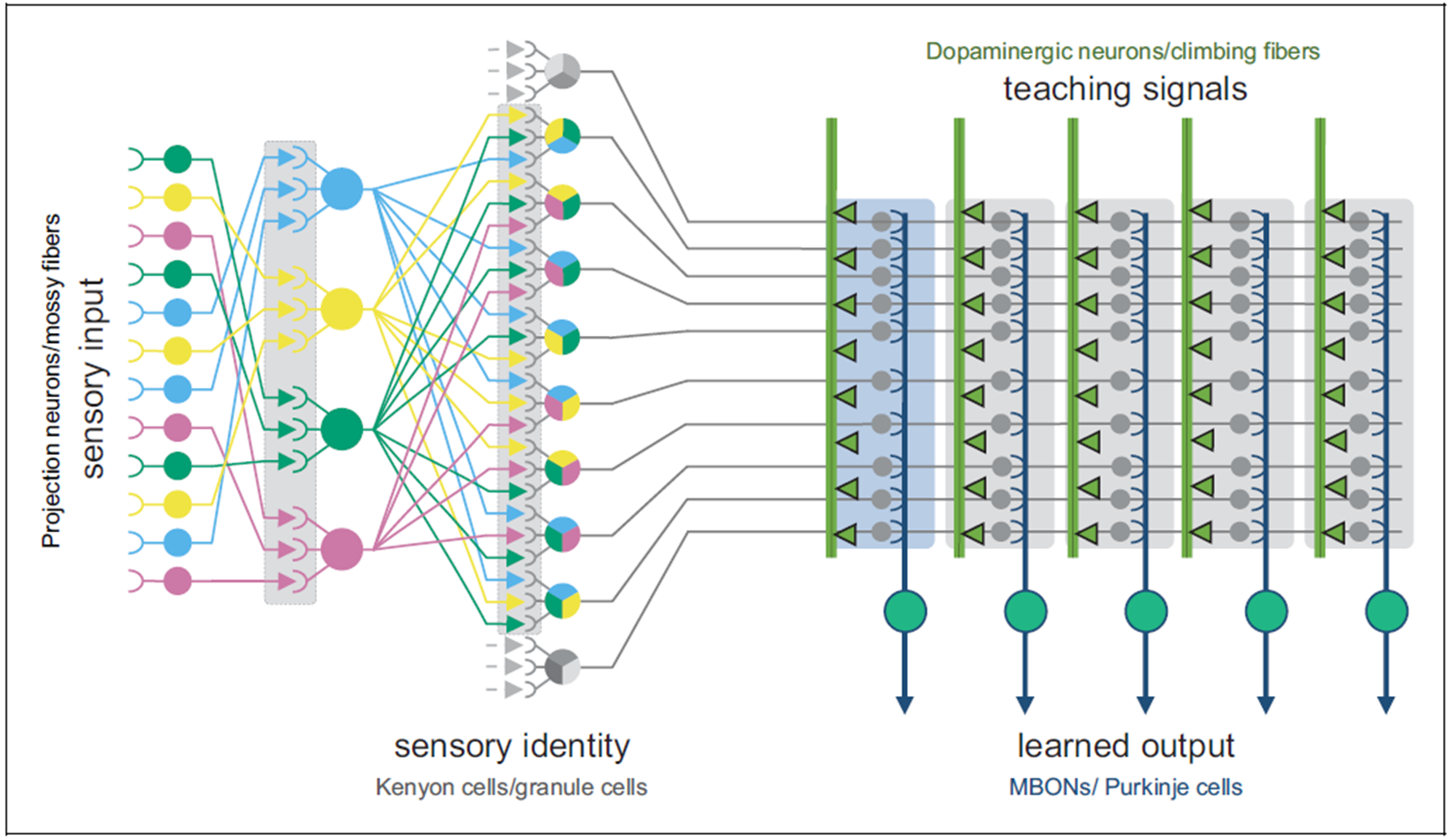
Иллюстрация (части) обработки сенсорных данных плодовой мухи. Высокий вертикальный серый прямоугольник чуть левее центра – это слой «разделения паттернов»; он принимает организованные сенсорные сигналы слева и перемешивает их большим количеством разных (локально) случайных комбинаций. Потом они посылаются направо, чтобы служить «контекстными» вводами модуля обучения с учителем. Источник картинки: Ли и пр..