Вы здесь
Главные вкладки
5. "Долгосрочный предсказатель" и TD-обучение
- 1.5.1 Краткое содержание / Оглавление
- 2.5.2 Игрушечная модель схемы «долгосрочного предсказателя»
- 3.5.3 Вычисление функции ценности (обучение методом Временных Разниц) как особый случай долгосрочного предсказания
- 4.5.4 Массив долгосрочных предсказателей с участием конечного мозга и мозгового ствола
- 5.5.5 Шесть причин, почему мне нравится эта картина «массива долгосрочных предсказателей»
- 5.1.5.5.1 Это разумный способ реализовать биологически-полезные способности
- 5.2.5.5.2 Это интроспективно правдоподобно
- 5.3.5.5.3 Это эволюционно правдоподобно
- 5.4.5.5.4 Это позволяет согласовать «висцемоторный» и «мотивационный» способы описания медиальной префронтальной коры (mPFC)
- 5.5.5.5.5 Это объясняет эксперимент с Солью Мёртвого Моря
- 5.6.5.5.6 Это предлагает хорошее объяснение разнообразию активности дофаминовых нейронов
- 6.5.6 Заключение
Примечание переводчика - с момента перевода оригинальные посты несколько обновились, через некоторое время обновлю и перевод. На общие выводы цепочки это, вроде бы, не влияет.
5.1 Краткое содержание / Оглавление
В предыдущем посте я описал «краткосрочные предсказатели» – схемы, которые благодаря обучающемуся алгоритму выводят предсказание управляющего сигнала, который прибудет через некоторое небольшое время (например, долю секунды).
В этом посте я выдвигаю идею, что можно взять краткосрочный предсказатель, обернуть его замкнутой петлёй, включающей ещё некоторые схемы, и получить новый модуль, который я называю «долгосрочным предсказателем». Как и кажется по названию, такая схема может делать долгосрочные предсказания, например, «Я скорее всего поем в следующие 10 минут». Как мы увидим, эта схема тесно связана с обучением методом Временных Разниц (TD).
Я считаю, что в мозгу есть большой набор расположенных рядом долгосрочных предсказателей, каждый из которых состоит из краткосрочного предсказателя в конечном мозге (включая специфические его области вроде полосатого тела, медиальной префронтальной коры и миндалевидного тела), образующим петлю с Направляющей Подсистемой (гипоталамус и мозговой ствол) с помощью дофаминовых нейронов. Эти долгосрочные предсказатели прогнозируют биологически-важные вводы и выводы – к примеру, один из них может предсказывать, почувствую ли я боль в своей руке, другой – произойдёт ли выброс кортизола, третий – поем ли я, и так далее. Более того, один из этих долгосрочных предсказателей – по сути, функция ценности для обучения с подкреплением.
Все эти предсказатели будут играть большую роль в мотивации – об этом я закончу рассказывать в следующем посте.
Содержание:
- Раздел 5.2 начинается с игрушечной модели схемы «долгосрочного предсказателя», состоящей из «краткосрочного предсказателя» из предыдущего поста и ещё некоторых частей, соединённых в замкнутую петлю. Хорошее интуитивное понимание этой модели будет важно в дальнейшем, и я пройдусь по тому, как это модель будет себя вести в разных обстоятельствах.
- Раздел 5.3 связывает эту модель с обучением методом Временных Разниц (TD), близким родственником «долгосрочного предсказателя». Я покажу два варианта схемы долгосрочного предсказателя, «суммирующую» (приводящую к функции ценности, приближённо суммирующей будущие награды) и «переключающуюся» (приводящую к функции ценности, приближённо оценивающей следующую награду, когда бы она ни пришла, даже если до неё ещё долго). «Суммирующая» версия повсеместна в связанной с ИИ литературе, но я предполагаю, что «переключающаяся» версия скорее всего ближе к тому, что происходит в мозге. По совпадению, эти две модели эквивалентны в случаях вроде AlphaGo, который получает всю награду сразу в конце каждого эпизода (= игры в го).
- Раздел 5.4 свяжет долгосрочные предсказатели с нейроанатомией (частей) конечного мозга и мозгового ствола.
- По «вертикальной» нейроанатомии,[1] я опишу как в мозге размещается огромное количество параллельных «петель кора-базальные ганглии-таламус-кора», и предположу, что некоторые их этих петель функционируют как краткосрочные предсказатели с управляющим дофаминовым сигналом.
- По «горизонтальной» нейроанатомии, я предложу, что в обучении с учителем, о котором я говорю, участвуют (к примеру) медиальная префронтальная кора, полосатое тело, внешняя островковая кора и миндалевидное тело.
- Раздел 5.5 предложит шесть источников свидетельств, которые привели меня к убеждённости в этой модели: (1) это разумный способ реализовать биологически-полезные способности; (2) это интроспективно правдоподобно; (3) это эволюционно правдоподобно; (4) это позволяет согласовать «висцемоторный» и «мотивационный» способы описания медиальной префронтальной коры; (5) это объясняет эксперимент с Солью Мёртвого Моря; и (6) это предлагает хорошее объяснение разнообразию активности дофаминовых нейронов.
5.2 Игрушечная модель схемы «долгосрочного предсказателя»
«Долгосрочный предсказатель» – это, по сути, краткосрочный предсказатель, чей выходной сигнал помогает определить его собственный управляющий сигнал. Вот игрушечная модель того, как это может выглядеть:
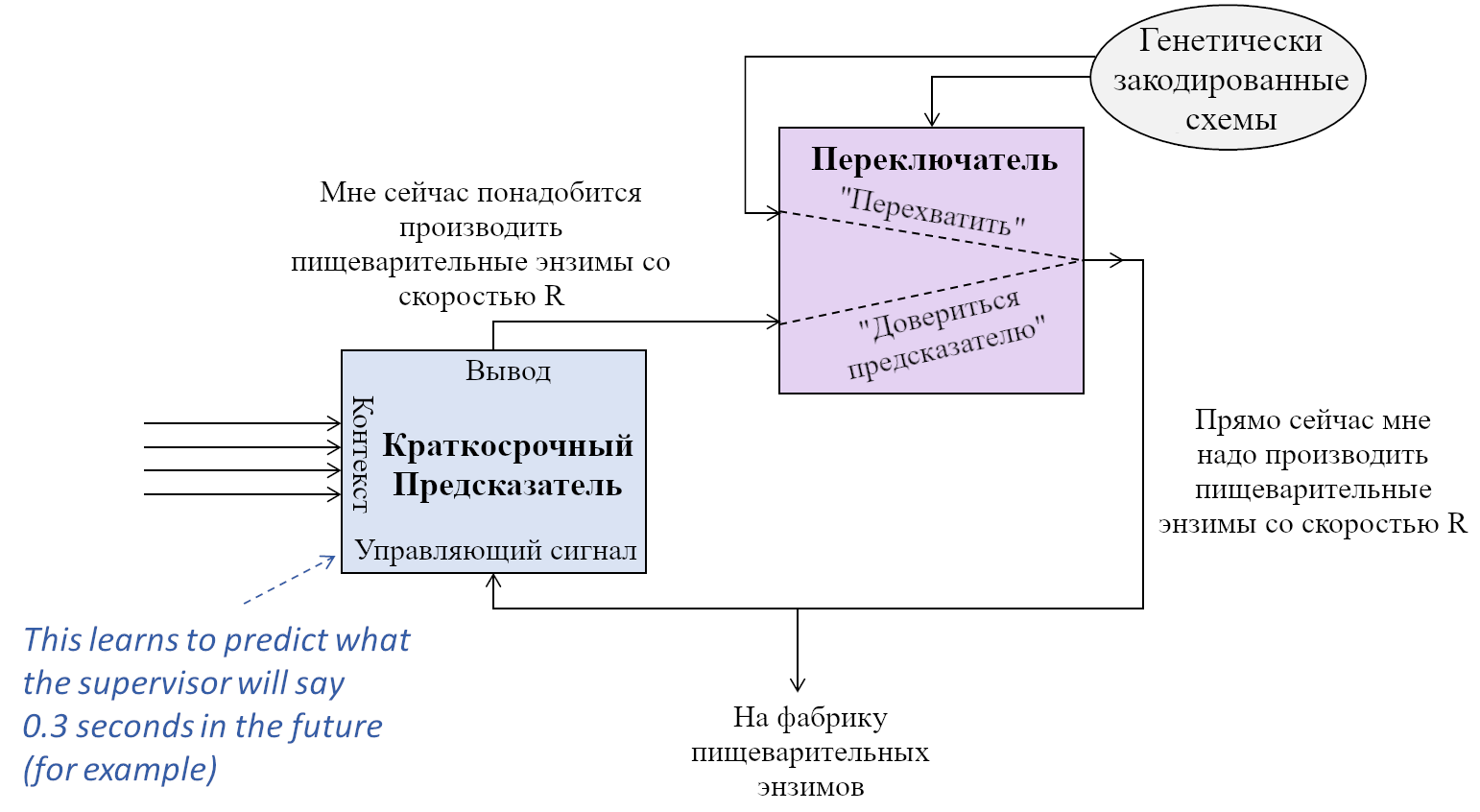
Игрушечная модель схемы долгосрочного предсказателя. Следующую пару подразделов я буду описывать, как это работает. На этой и похожих диаграммах в этом посте, все блоки в каждый момент времени работают параллельно, и, аналогично, каждая стрелка в каждый момент времени несёт числовое значение. Так что это НЕ диаграмма потока выполнения последовательного кода, это скорее похоже на, например, диаграммы, которые можно увидеть в описании FPGA.
- Синий прямоугольник – краткосрочный предсказатель из предыдущего поста. Он оптимизирует выходной сигнал, приближая его к тому, каким будет управляющий сигнал через 0.3 секунды (в этом примере).
- Фиолетовый прямоугольник – переключатель между двумя вариантами. Его контролирует генетически закодированная схема (серый овал) согласно следующим правилам:
- В основном переключатель находится в нижнем положении (довериться предсказателю). Это сродни тому, что генетически закодированная схема «доверяет» тому, что вывод краткосрочного предсказателя осмысленен, и, в этом примере, производит предложенное количество пищеварительных энзимов.
- Если генетически закодированная схема получает сигнал, что я что-то ем прямо сейчас, и у меня нет адекватного количества пищеварительных энзимов, то она переводит переключатель в вариант «перехватить», и посылает сигнал начать производство пищеварительных энзимов независимо от того, что говорит краткосрочный предсказатель.
- Если генетически-прошитая схема долгое время получала запросы на производство пищеварительных энзимов, но всё ещё ничего не было съедено, то она опять же переключает на вариант «перехватить» и посылает сигнал прекратить производство энзимов, независимо от того, что говорит краткосрочный предсказатель.
Замечу: Вы можете считать, что все сигналы на диаграмме могут непрерывно изменяться по диапазону значений (в противоположность дискретным сигналам вкл/выкл), за исключением сигнала управления переключателем.[2] В мозгу плавно-настраиваемые сигналы могут создаваться, к примеру, кодированием через частоту активаций нейрона.
5.2.1 Разбор игрушечной модели, часть 1: статичный контекст
Давайте пройдёмся по тому, что происходит в этой игрушечной модели.[3] Для начала, предположим, что на протяжении некоторого протяжённого периода времени «контекст» статичен. К примеру, представьте, как какое-нибудь древнее червеподобное существо много последовательных минут копается в песчаном дне океана. Правдоподобно, что пока оно копает, его сенсорное окружение будет оставаться довольно постоянным, и также постоянными будут оставаться его мысли и планы (в той мере, в которой у древнего червеподобного существа вообще есть «мысли и планы»). Или, если хотите другой пример (приблизительно) статичного контекста – с участием человека, а не червя – подождите следующего подраздела.
В этом случае, давайте посмотрим, что происходит, когда переключатель находится в положении «довериться-предсказателю»: поскольку вывод связан с управляющим сигналом, обучающийся модуль не получит сигнала об ошибке. Предсказание верно. Синапсы не меняются. Эта ситуация, сколь бы ни была частой, не повлияет на поведение краткосрочного предсказателя.
Что на него повлияет – те редкие случаи, когда переключатель переходит в режим «перехватить». Можно думать об этом как о периодическом «впрыскивании эмпирической истины». В этих случаях обучающийся алгоритм краткосрочного предсказания получает сигнал об ошибке, что меняет его настраиваемые параметры (например, силу синапсов).
Набрав достаточно жизненного опыта (или, что то же самое, после достаточного обучения), краткосрочный предсказатель должен получить свойство балансирования перехватов. Перехваты всё ещё могут увеличивать производство энзимов, а иногда могут его снижать, но эти два типа перехватов должны происходить с примерно одинаковой частотой. Ведь если бы они не были сбалансированы, то алгоритм обучения краткосрочного предсказания постепенно изменил бы его параметры, чтобы перехваты всё же были сбалансированы.
И это как раз то, что нам надо! Мы получаем подходящее производство энзимов в подходящее время, способом, в нужной мере учитывающим доступную контекстную информацию – что животное сейчас делает, что планирует делать, его сенсорные вводы, и т.д.
5.2.1.1 Экспозиционная терапия в стиле Дэвида Бернса – возможный реальный пример игрушечной модели с статичным контекстом?
Так вышло, что я недавно прочёл книгу Дэвида Бернса Терапия Настроения (мой обзор). У Дэвида Бернса очень интересный подход к экспозиционной терапии – служащий отличным примером того, как моя игрушечная модель работает в ситуации статичного контекста!
Вот короткая версия. (Предупреждение: если вы думаете самостоятельно заниматься экспозиционной терапией в домашних условиях, по меньшей мере сначала прочитайте всю книгу!) Отрывок из книги:
Во время обучения в старшей школе я хотел попасть в команду технических помощников сцены для постановки мюзикла «Бригадун». Учитель драмы, мистер Крэнстон, сказал мне, что помощники сцены должны забираться на высокие лестницы и ползать по балкам под потолком, чтобы регулировать свет. Я ответил, что для меня это может оказаться проблемой, ведь я боюсь высоты. Он объяснил, что я не смогу стать частью команды помощников сцены, пока не захочу преодолеть свой страх. Я спросил, как это сделать.
Мистер Крэнстон ответил, что это довольно просто. Он установил 18-футовую лестницу по центру сцены, сказал мне забраться на нее и встать на верхнюю перекладину. Я доверял ему, поэтому поднимался по лестнице, перекладина за перекладиной, пока не оказался наверху. Вдруг я увидел, что там не за что держаться, и пришел в ужас! Я спросил, что мне делать дальше. Мистер Крэнстон ответил, что не нужно ничего делать, просто стоять там, пока не уйдет страх. Он ждал меня внизу лестницы и подбадривал, чтобы я продолжал стоять.
В течение 15 минут я пребывал в полном оцепенении. Затем мой страх вдруг начал уходить. Через минуту или две он полностью исчез. Я с гордостью объявил: «Мистер Крэнстон, думаю, я исцелился. Я больше не боюсь высоты».
Он сказал: «Прекрасно, Дэвид! Ты можешь спускаться. Будет здорово, если ты присоединишься к команде помощников сцены для мюзикла «Бригадун»».
Я гордился тем, что стал помощником сцены. Мне понравилось ползать по балкам под потолком, закрепляя занавес и свет. Я удивлялся, что прежний источник моих страхов может приносить столько восторга.
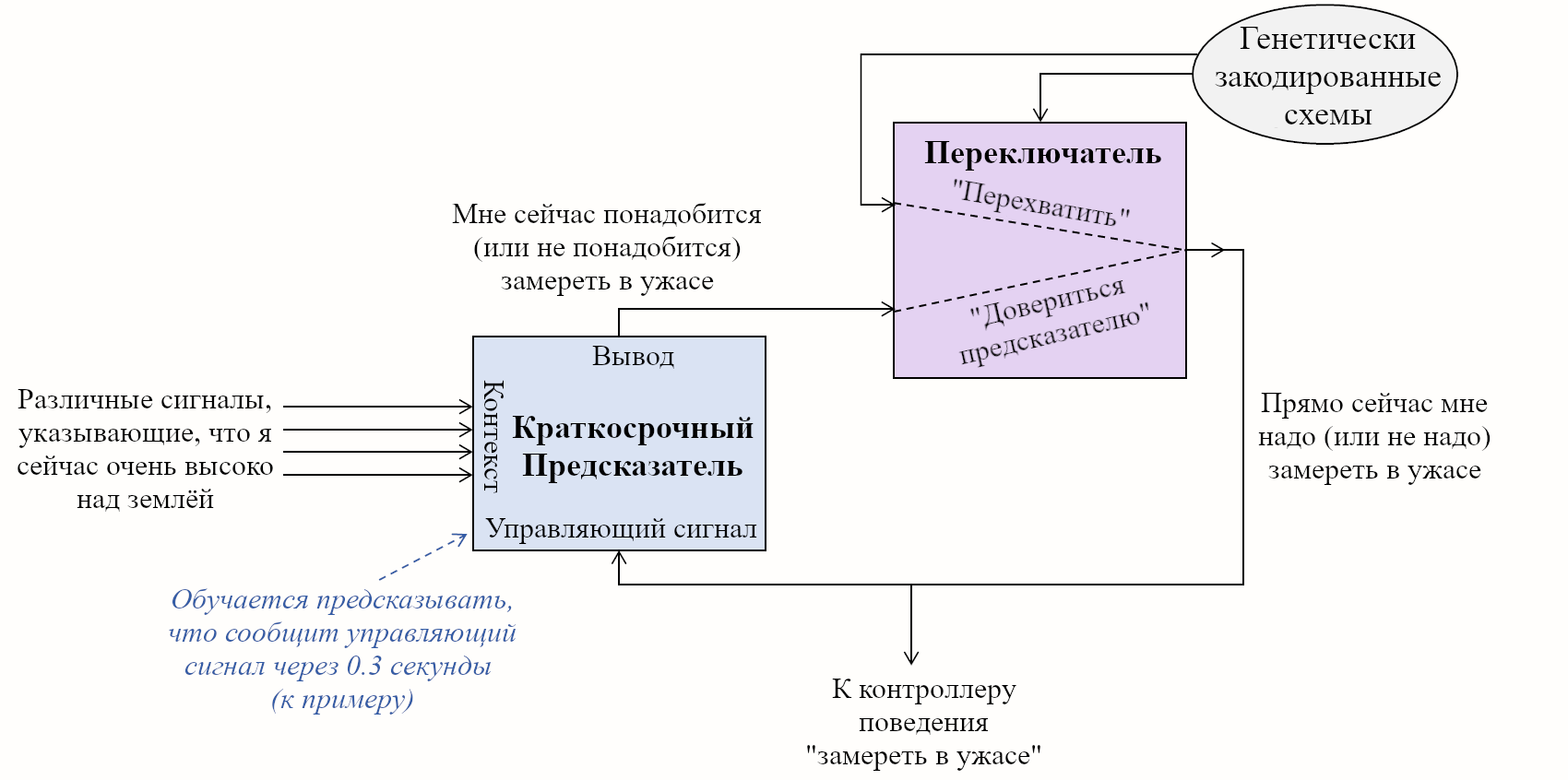
Эта история кажется прекрасно совместимой с моей игрушечной моделью. Дэвид начал день в состоянии, когда его краткосрочные предсказатели выдавали очень сильную реакцию страха, когда он забирался на высоту. Пока Дэвид оставался на лестнице, эти краткосрочные предсказатели продолжали получать одни и те же контекстные данные, и продолжали выдавать всё такой же вывод. И Дэвид продолжал быть в ужасе.
Потом, после 15 скучных-но-ужасающих минут на лестнице, какая-то внутренняя схема в мозговом стволе Дэвида произвела *перехват* – как будто сказала «Слушай, ничего не меняется, ничего не происходит, мы не можем просто весь день продолжать сжигать на это калории». Краткосрочный предсказатель продолжил посылать всё тот же вывод, но мозговой ствол применил своё право вето и насильно «перезагрузил» Дэвиду уровень кортизола, пульс, и т.д., вернув их обратно на базовое значение. Это состояние «перехвата» немедленно привело к получению краткосрочным предсказателем в миндалевидном теле Дэвида *сигналов об ошибке*! Эти сигналы, в свою очередь, привели к обновлению модели! Краткосрочные предсказатели оказались обновлены, и с тех пор Дэвид больше не боялся высоты.
Конечно эта история выглядит спекуляцией на спекуляции, но я всё равно думаю, что она верна. По крайней мере, это хороший пример! Вот диаграмма для этой ситуации, удостоверьтесь, что не упускаете шагов.
5.2.2 Разбор игрушечной модели, предполагая изменяющийся контекст
Предыдущий подраздел предполагал статичные потоки контекстных данных (постоянная сенсорная информация об окружении, постоянное поведение, постоянные мысли и планы, и т.д.). Что происходит, если контекст не статичен?
При изменениях в потоках контекстных данных обучение происходит не только при «перехватах». Если контекст меняется без «перехватов», то это приводит к изменениям вывода, и новый вывод будет трактоваться как эмпирическая истина о том, каким должен был быть старый вывод. Опять же, это кажется в точности тем, что нам надо? Если мы обучаемся чему-то новому и оказавшемуся важным в последнюю секунду, то наше текущее ожидание должно быть точнее, чем раннее, так что у нас есть основание для обновления нашей модели.
5.3 Вычисление функции ценности (обучение методом Временных Разниц) как особый случай долгосрочного предсказания
К этому моменту эксперты в машинном обучении должны распознать сходство с обучением методом Временных Разниц. Однако, это не совсем одно и то же. Различия:
Первое, обучение методом Временных Разниц обычно используется в обучении с подкреплением как метод перехода от функции вознаграждения к функции ценности. Я, напротив, говорю о штуках вроде «производства пищеварительных энзимов», которые не являются ни вознаграждениями, ни ценностями.
Другими словами, есть в целом полезный мотив перехода от некого немедленного значения X к «долгосрочному ожиданию X». Вычисление функции ценности из функции вознаграждения – пример этого мотива, но не исчерпывающий.
(В плане терминологии, мне кажется вполне общепринятым, что термин «обучение методом Временных Разниц» на самом деле может относиться к чему-то, не являющемуся функцией ценности обучения с подкреплением.[4] Однако, по моему собственному эмпирическому опыту, как только я упоминаю этот метод, мои собеседники немедленно начинают подразумевать, что я говорю о функциях ценности обучения с подкреплением. Так что мне приходится тут прояснять.)
Второе, чтобы получить что-то более похожее на традиционное обучение методом Временных Разниц, нам потребовалось бы заменить переключатель между двумя вариантами сумматором – и тогда «перехваты» были бы аналогичны наградам. Куда больше о «переключении против суммирования» – в следующем подразделе.

Вот схема обучения методом Временных Разниц, которая вела бы себя похоже на то, что вы можете найти в учебных пособиях по ИИ. Обратите внимание на фиолетовый прямоугольник справа: в отличии от предыдущей диаграммы, тут не *переключатель*, а *сумматор*. Куда больше о «переключении против суммирования» – в следующем подразделе.
Третье, есть много дополнительных способов поправить эту схему, которые часто используют в литературе по ИИ, и некоторые из них могут встречаться и в схемах в мозгу. К примеру, мы можем добавить обесценивание со временем, или разные реакции на ложно-положительные и ложно-отрицательные сигналы (см. моё рассмотрение обучения распределениям в Разделе 5.5.6.1 ниже), и т.д.
Чтобы всё не становилось слишком сложным, я буду игнорировать эти возможности (включая обесценивание со временем) ниже.
5.3.1 Переключатель (т.е. ценность = ожидаемая следующая награда) или сумматор (т.е. ценность = ожидаемая сумма будущих наград)?
Диаграммы выше показывают два варианта нашей игрушечной модели. В одном фиолетовый прямоугольник – переключатель между состоянием «доверия краткосрочному предсказателю» и некой независимой «эмпирической истиной». В другом в фиолетовом прямоугольнике вместо этого происходит суммирование.
В версии с переключателем краткосрочный предсказатель обучается предсказывать следующие эмпирические данные, когда бы они ни поступили.
В версии с сумматором, краткосрочный предсказатель обучается предсказывать сумму будущих эмпирических сигналов.
Правильным ответом может быть ещё «что-то промежуточное между переключением и суммированием». Или даже «ничто из этого».
Статьи по обучению с подкреплением повсеместно используют версию суммирования – т.е. «ценность – это ожидаемая сумма будущих наград». Что про биологию? И что на самом деле лучше?
Это не всегда вообще имеет значение! Рассмотрим AlphaGo. Как и повсюду в AlphaGo изначально использовалась парадигма суммирования. Но получилось так, что за каждую игру он получает только один ненулевой сигнал вознаграждения, если конкретно, +1 в конце игры, если он выигрывает, или -1 – если проигрывает. В таком случае, переключатель и сумматор ничем друг от друга не отличаются. Разница только в терминологии:
- В случае суммирования можно сказать «каждый не-последний ход в го приносит вознаграждение = 0».
- В случае переключения, можно сказать «каждый не-последний ход в го приносит вознаграждение (null) / не приносит вознаграждения».
(Видите, почему?)
Но в других случаях это важно. Так что вернёмся к вопросу: это должно быть переключение или суммирование?
Давайте сделаем шаг назад. Чего мы пытаемся добиться?
Одна из штук, которые должен делать мозг – это принимать решения, взвешивая при этом выгоды из разных областей. Если вы человек, то вам надо решать, посмотреть телевизор или пойти в спортзал. Если вы некое древнее червеподобное существо, то вам надо «решать» – копать или плавать. В любом случае, это «решение» затрагивает энергетический баланс, солевой баланс, вероятность травм, вероятность размножения – и много чего ещё. Проектная цель алгоритма принятия решений – принимать такие решения, которые будут максимизировать совокупную генетическую приспособленность. Как это может быть лучше всего реализовано?
Один из методов включает создание функции ценности, которая оценивает совокупную генетическую приспособленность организма (сравнительно с некой произвольной, и может, меняющейся со временем точкой отсчёта), при условии продолжения выполнения данного курса действий. Конечно, это не идеальная оценка – настоящая совокупная генетическая приспособленность может быть вычислена только задним числом, ещё через много поколений. Но когда у нас есть такая функция ценности, сколь бы неидеальной она ни была, мы можем подключить её к алгоритму, принимающему решения, максимизирующие ценность (больше про это в следующем посте), и таким образом получить приблизительно-максимизирующее-приспособленность поведение.
Так что обладание функцией ценности – ключ к принятию хороших решений, учитывающих выгоду в разных областях. Но тут нигде не сказано «ценность – это ожидаемая сумма будущих вознаграждений»! Это конкретный способ настройки этого алгоритма; метод, который может подходить, а может и не подходить к конкретной ситуации.
Я думаю, что мозг использует что-то более похожее на схему с переключателем, а не на схему с сумматором, причём не только для предсказаний гомеостаза (как в примере пищеварительных энзимов выше), но и для функции ценности, вопреки мейнстримным статьям об обучении с подкреплением. Опять же, я считаю, что на самом деле это «ничто из этого» во всех этих случаях; просто это ближе к переключателю.
Почему я отдаю предпочтение «переключателю», а не «сумматору»?
Пример: иногда я стукаюсь пальцем и он болит 20 секунд; в другой раз я стукаюсь пальцем и он болит 40 секунд. Но я не думаю о втором событии как о вдвое худшем, чем первое. На самом деле, уже через пять минут, я не вспомню, какая из двух ситуаций это была. (см. правило пика-и-конца.) Это то, чего я бы ожидал от переключателя, но довольно плохо подходит для сумматора. Это не строго несовместимо с суммированием; просто требует более сложной и зависящей от ценности функции вознаграждения. На самом деле, если мы это позволяем, то переключатель и сумматор могут имитировать друг друга.
В любом случае, в следующих постах я буду подразумевать переключатели, не сумматоры. Я не думаю, что это на большом масштабе очень важно, и я точно не думаю, что это часть «секретного ингредиента» интеллекта животных, или что-то такое. Но это влияет на некоторые детальные описания.
Следующий пост будет включать больше деталей обучения с подкреплением в мозгу, включая то, как работает сигнал «ошибки предсказания вознаграждения». Я готовлюсь к тому, что много читателей будут в замешательстве от того, что я подразумеваю не такую связь ценности с вознаграждением, к которой все привыкли. К примеру, в моей картине «вознаграждение» синонимично «эмпирическим данным о том, какой сейчас следует быть функции ценности» – и то, и другое должно учитывать не только текущие обстоятельства организма, но и будущие перспективы. Заранее прошу прощения за замешательство! Я изо всех сил попробую быть яснее.
5.4 Массив долгосрочных предсказателей с участием конечного мозга и мозгового ствола
Вот наша схема долгосрочного предсказателя:
Скопировано с схемы выше.
Я могу соединить переключатель с остальной генетически-прошитой схемой и немного переместить прямоугольники, тогда получится это:
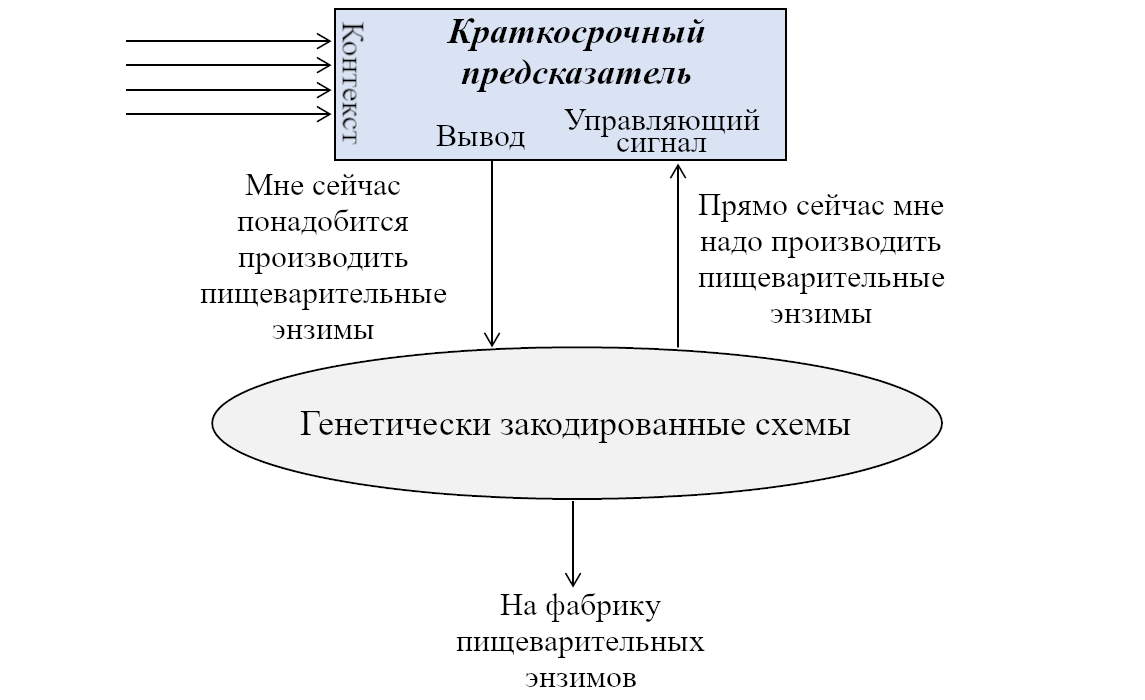
То же, что и выше, но нарисованное по-другому.
Очевидно, пищеварительные энзимы – лишь один пример. Давайте дорисуем ещё примеров, добавим гипотетическую нейронанатомию и ещё немного терминов. Вот, что получится:
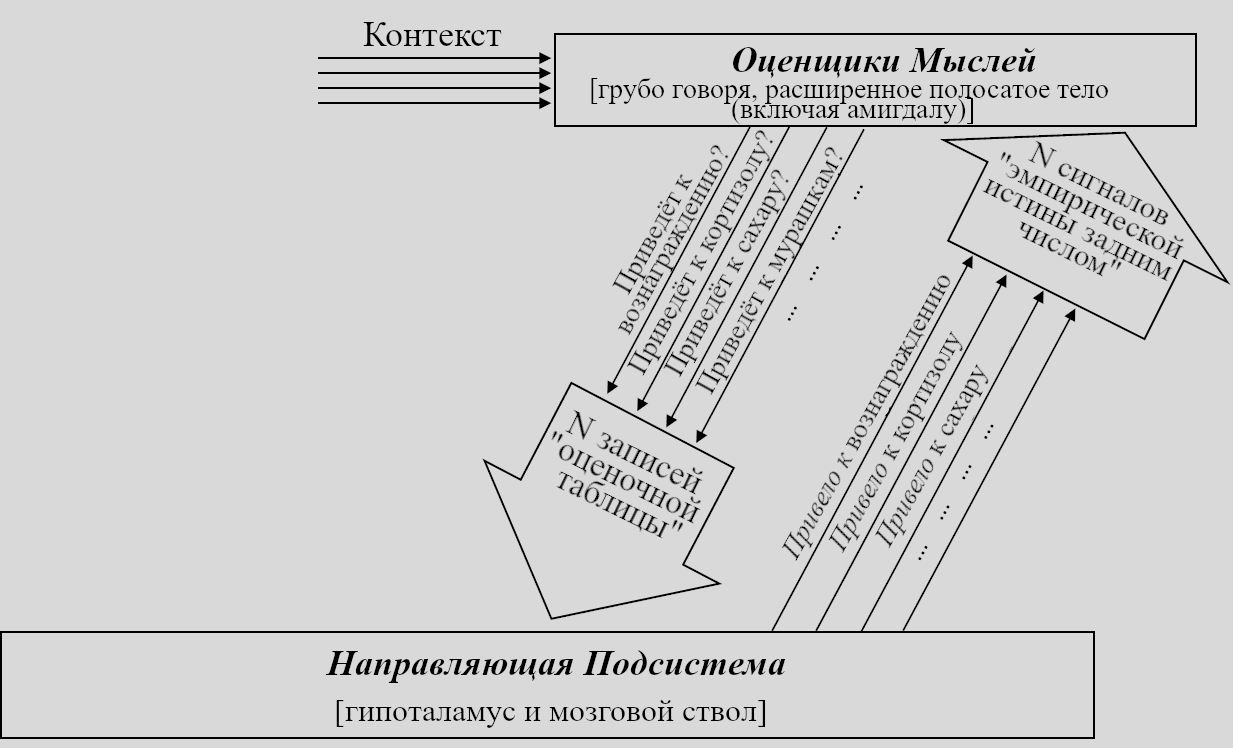
Я заявляю, что в мозгу есть целый набор долгосрочных предсказателей, состоящий из краткосрочных предсказателей в конечном мозге, каждый из которых петлёй связан с соответствующей схеме в Направляющей Подсистеме. По причинам, описанным ниже в Разделе 5.5.4, я называю первую часть (в конечном мозге) «Оценщиками Мыслей».
Замечательно! Мы на полпути к моей большой картине принятия решений и мотивации. Остаток – включая «субъекта» из обучения с подкреплением «субъект-критик» – будет в следующем посте, он заполнит дыру в верхней-левой части диаграммы.
Вот ещё одна диаграмма с педагогическими пометками.
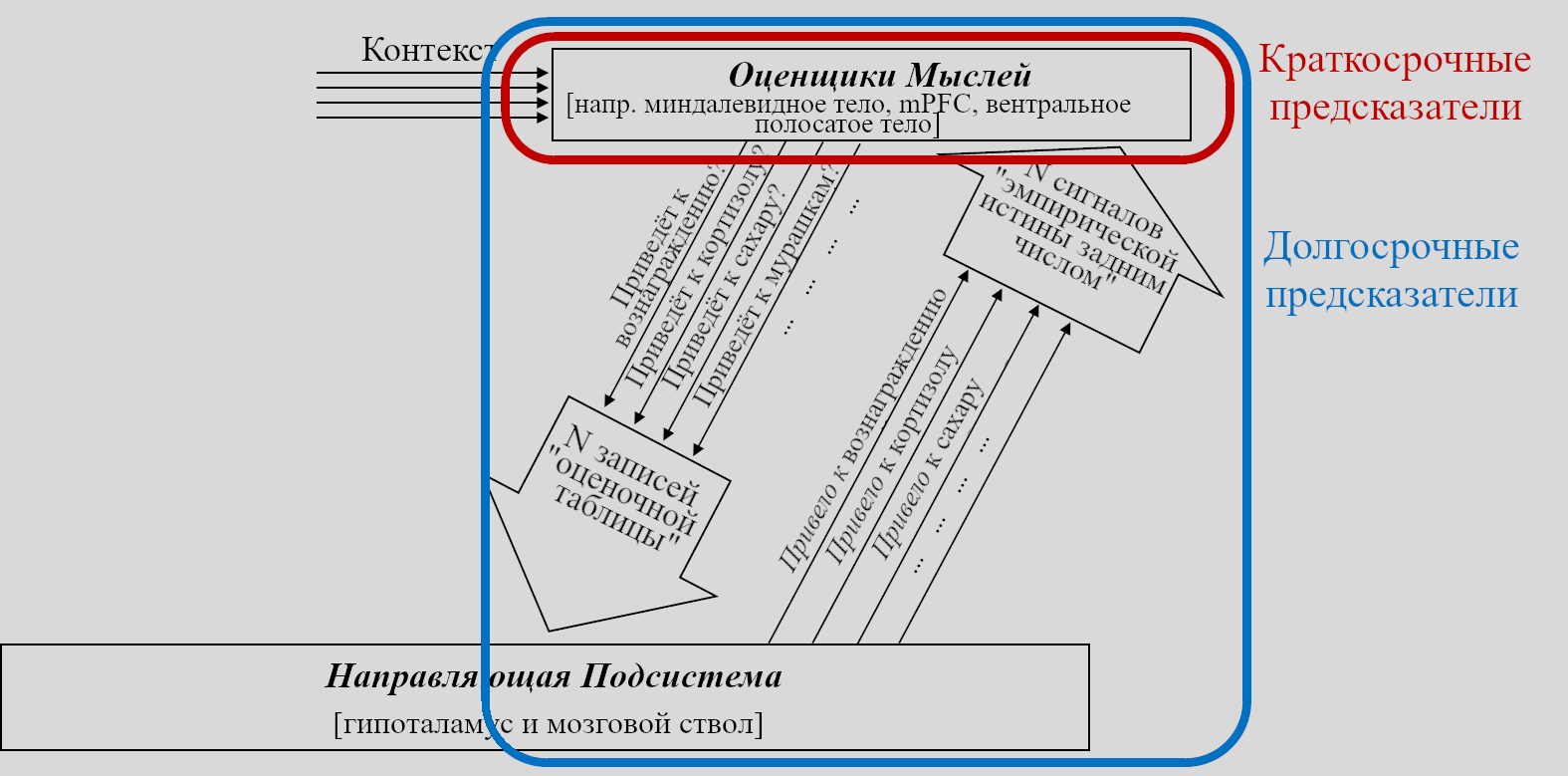
Напоминание: «краткосрочный предсказатель» - это *один из компонентов* «долгосрочного предсказателя». Тут показано, как они оба располагаются на предыдущей диаграмме. Долгосрочный предсказатель обеспечивается режимом «довериться предсказателю» - т.е. Направляющая Подсистема может посылать сигнал «эмпирической истины задним числом», который является не «эмпирической истиной» в нормальном смысле, но скорее копией соответствующего элемента «оценочной таблицы». Другими словами, режим «довериться предсказателю» можно описать как то, что Направляющая Подсистема говорит краткосрочному предсказателю «ОК, конечно, принято, верю тому, что ты говоришь». Если Направляющая Подсистема регулярно придерживается сигнала «довериться предсказателю» 10 минут подряд, то мы может получать прогнозирование будущего на 10 минут. Напротив, если Направляющая Подсистема *никогда* не использует для какого-то сигнала режим «довериться предсказателю», то получившуюся конструкцию вовсе нельзя назвать «долгосрочным предсказателем».
В следующих двух подразделах, я подробнее опишу нейроанатомию, на которую я даю намёки на этой диаграмме, и поговорю о том, почему вам стоит мне поверить.
5.4.1 «Вертикальная» нейроанатомия[1]: Петли «кора-базальные ганглии-таламус-кора»
В моём посте Большая Картина Фазового Дофамина, я рассказывал о теории (за авторством Ларри Свансона), что весь конечный мозг изящно организован в три слоя (кора, полосатое тело, паллидум):
| **Подобная-коре часть петли** | Гиппокампус | Миндалевидное тело [базолатеральная часть] | Грушевидная кора | Медиальная префронтальная кора | Моторная и «планирующая» кора |
| **Подобная-полосатому-телу часть петли** | Латеральная перегородочная зона | Миндалевидное тело [центральная часть] | Обонятельный бугорок | Вентральное полосатое тело | Дорсальное полосатое тело |
| **Подобная-паллидуму часть петли** | Медиальная перегородочная зона | BNST | Безымянная субстанция | Вентральный паллидум | Дорсальный паллидум |
Весь конечный мозг – неокортекс, гиппокампус, миндалевидное тело, всё остальное – может быть разделён на подобные-коре, подобные-полосатому-телу и подобные-паллидуму структуры. Если две структуры в таблице в одном столбце, это значит, что они связаны вместе в петлю «кора-базальные ганглии-таламус-кора» (см. следующий параграф). Эта таблица неполна и упрощена; для версии получше см. Рис. 4 здесь.
Эта идея связывается с ранней (и сейчас широко принятой) теорией (Александер 1986), что эти три слоя конечного мозга взаимосвязаны большим количеством параллельных петель «кора-базальные ганглии-таламус-кора», которые можно обнаружить почти в любой части конечного мозга.
Вот небольшая иллюстрация:
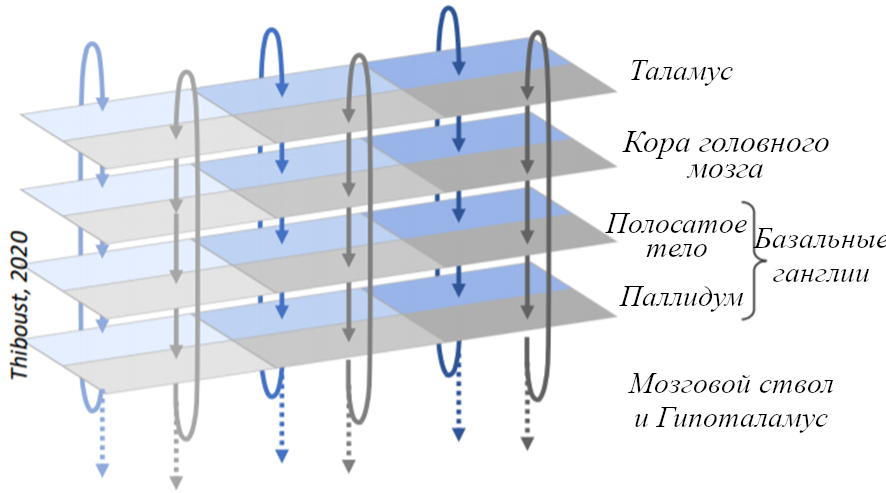
Упрощённая иллюстрация массива параллельных петель «кора-базальные ганглии-таламус-кора». Источник: Мэтью Тибуст.
С учётом всего этого, вот возможная грубая модель того, как эта петельная архитектура связана с обучающимся алгоритмом краткосрочных предсказателей, о котором я говорил:
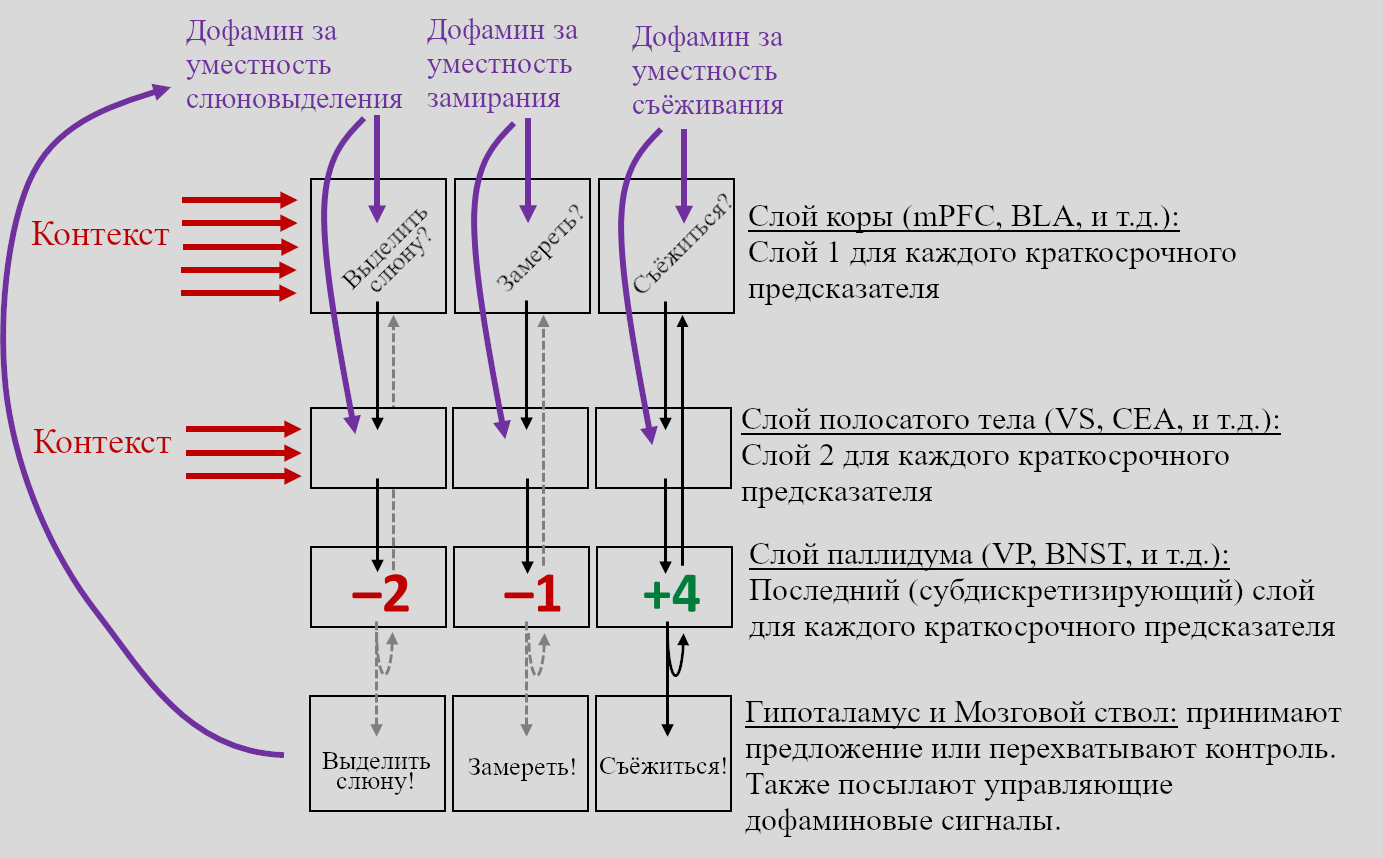
ПРЕДУПРЕЖДЕНИЕ: НЕ ВОСПРИНИМАЙТЕ ЭТУ ДИАГРАММУ СЛИШКОМ БУКВАЛЬНО
См. Большую Картину Фазового Дофамина за *немного* более подробными деталями, но вообще я не особо много в это погружался, и, в частности ярлыки «Слой 1, Слой 2, Последний (суюдискретизирующий) слой» расставлены почти наугад. («Субдискретизация» основана на том, что в полосатом теле в 2000 раз больше нейронов, чем в паллидуме – см. здесь.)
Сокращения: BLA = базолатеральное миндалевидное тело, BNST = опорное ядро терминального тяжа, CEA = центральное миндалевидное тело, mPFC = медиальная префронтальная кора, VP = вентральный паллидум, VS = вентральное полосатое тело.
5.4.2 «Горизонтальная» нейронанатомия – специализация коры
Предыдущий подраздел весь был про «вертикальную» трёхслойную структуру конечного мозга. Сейчас давайте переключимся на «горизонтальную» структуру, т.е. тот факт, что разные части коры делают разные вещи (в кооперации с соответствующими частями полосатого тела и паллидума).
Это упрощение, но вот моя новейшая попытка объяснить (часть) коры на пальцах:
- Расширенная моторная кора – это основной источник выводов коры, вовлекающих скелетные мышцы, вроде хватания и ходьбы.
- Медиальная префронтальная кора (mPFC – также включающая переднюю поясную кору) – это главный источник выводов коры, вовлекающих автономные/висцемоторные/гормнональные действия, вроде выпускания кортизола, сужения сосудов, гусиной кожи, и т.д.
- Миндалевидное тело – это главный источник выводов коры, связанных с некоторыми поведениями, вовлекающими и скелетные мышцы и автономные реакции, вроде вздрагивания, замирания (при испуге), и т.д.
- Островковая кора – это главный регион вводов коры для автономной / гомеостатической / связанной с статусом тела информации, вроде уровня сахара в крови, боли, холода, вкуса, напряжения мышц и т.д.
В этой цепочке я не буду говорить про моторную кору, но я думаю, что остальные три все вовлечены в схемы долгосрочного предсказания. К примеру:
- Я заявляю, что если взглянуть на маленький подрегион в медиальной префронтальной коре, то можно будет обнаружить, что он обучен активироваться пропорционально вероятности предстоящего выброса кортизола;
- Я заявляю, что если взглянуть на маленький подрегион в миндалевидном теле, то можно будет обнаружить, что он обучен активироваться пропорционально вероятности предстоящей реакции замирания;
- Я заявляю, что если взглянуть на маленький подрегион в (внешней) островковой коре, то можно будет обнаружить, что он обучен активироваться пропорционально вероятности предстоящего ощущения холода в левой руке.
5.5 Шесть причин, почему мне нравится эта картина «массива долгосрочных предсказателей»
5.5.1 Это разумный способ реализовать биологически-полезные способности
Если начать производить пищеварительные энзимы перед едой, то пища будет переварена быстрее. Если начать разгонять сердце до того, как вы увидите льва, то мышцы будут уже подготовлены убегать, когда вы увидите льва.
Так что такие предсказатели кажутся очевидно полезными.
Более того, как обсуждалось в предыдущем посте (Раздел 4.5.2), предлагаемая мной (основанная на обучении с учителем) техника кажется либо превосходящей, либо хорошо сочетающейся с другими способами это сделать.
5.5.2 Это интроспективно правдоподобно
Вообще, мы на самом деле начинаем слюновыделение до того, как съели крекер, начинаем нервничать до того, как видим льва, и т.д.
Ещё учтите тот факт, что все действия, о которых я говорил в этом посте непроизвольны: вы не можете выделять слюну по команде, расширять свои зрачки по команде и т.д, по крайней мере не так же, как можете подвигать пальцем по команде.
(Больше о произвольных действиях в следующем посте – они в совсем другой части конечного мозга.)
Я тут замалчиваю о многих сложностях, но непроизвольная природа этих вещей кажется удобно сочетающейся с идеей, что они обучаются своими собственными управляющими сигналами, прямо из мозгового ствола. Можно сказать, что они случат другому господину. Мы можем как-то обхитрить их и заставить вести себя определённым образом, но наш контроль ограниченный и непрямой.
5.5.3 Это эволюционно правдоподобно
Как описано в Разделе 4.4 предыдущего поста, простейший краткосрочный предсказатель невероятно прост, а простейший долгосрочный предсказатель лишь немногим сложнее. И эти очень простые версии уже правдоподобно полезны для приспособленности, даже у очень простых животных.
Более того, как я уже обсуждал некоторое время назад (Управляемое дофамином обучение у млекопитающих и плодовых мух), у плодовых мух есть массив маленьких обучающихся модулей, играющих роль, кажущуюся схожей с тем, о чём я тут говорю. Эти модули тоже используют дофамин в качестве управляющего сигнала, и есть некоторое генетическое свидетельство гомологии этих схем с конечным мозгом млекопитающих.
5.5.4 Это позволяет согласовать «висцемоторный» и «мотивационный» способы описания медиальной префронтальной коры (mPFC)
Возьмём mPFC (также включающую переднюю поясную кору) как пример. Люди пытаются говорить об этой области двумя довольно разными способами:
- С одной стороны, как упомянуто выше (Раздел 5.4.2), mPFC описывают как область висцемоторного / гомеостатического / автономно-моторного вывода – она задаёт команды контроля гормонов, исполнения реакций симпатической и парасимпатической нервной системы, и так далее. К примеру, «показано, что электрическая стимуляция инфралимбической коры влияет на подвижность желудка и вызывает гипотонию», а в этой статье говорится, что стимуляция mPFC вызывает «расширение зрачков, изменения кровяного давления, частоты дыхания и пульса», или посмотрите в книгу Бада Крейга, который характеризует переднюю поясную кору как центр гомеостатического моторного вывода. Это подход элегантно объясняет тот факт, что этот регион агранулярен (лишён слоя №4 из 6 слоёв неокортекса), что подразумевает «регион вывода» как по теоретическим причинам, так и по аналогии с (агранулярной) моторной корой.
- С другой стороны, mPFC часто описывают как место обитания приближённо-связанных-с-мотивацией активностей. К примеру, Википедия в связи с передней поясной корой упоминает «распределение внимания, предвкушение вознаграждения, этика и моральность, контроль импульсов … и эмоции».
Я думаю, моя картина работает и там, и там[5]:
С первой (висцемоторной) точки зрения, если вы взглянете на Раздел 5.2. выше, то вы увидите, что выводы предсказателей действительно приводят к гомеостатическим изменениям – как минимум, когда генетически-прошитые схемы Направляющей Подсистемы посылают сигнал в режиме «довериться предсказателю» (а не «перехвата»).
Касательно второй (мотивационной) точки зрения, это будет иметь больше смысла после следующего поста, но отметьте предложенное мной описание «оценочной таблицы» в диаграмме в Разделе 5.4. Идея такая: потоки «контекста» входящие в «Оценщики Мыслей» содержат ужасающую сложность всего вашего сознательного разума и даже больше – где вы, что вы видите и делаете, о чём вы думаете, что вы планируете делать в будущем и почему, и т.д. Довольно простая, генетически закодированная Направляющая Подсистема никак не может во всём этом разобраться!
Но ведь Направляющая Подсистема – источник наград / стремлений / мотиваций! Как она может предоставлять награду за хороший план, если она вовсе не может разобраться в том, что вы планируете??
Ответ – «оценочная таблица». В ней вся эта ужасающая сложность дистиллируется в стандартизированную табличку – как раз то, что генетически-заходированные схемы Направляющей Подсистемы могут легко обработать.
Так что любое взаимодействие между мыслями и стремлениями – эмоции, принятие решений, этика, антипатия, и т.д. – должно на промежуточном шаге вовлекать «Оценщики Мыслей».
5.5.5 Это объясняет эксперимент с Солью Мёртвого Моря
См. мой старый пост Внутреняя согласованность в лишённых-соли крысах. Если коротко, экспериментаторы периодически проигрывали звук и выдвигали объект в клетку с крысами, и немедленно после этого впрыскивали прямо им во рты очень солёную воду. Крысы считали её отвратительной, и с ужасом реагировали на звук и объект. Потом экспериментаторы лишили крыс соли. И после этого когда они играли звук и выдвигали объект, крысы становились очень радостно возбуждёнными – хоть раньше и не испытывали недостатка соли ни разу за всю свою жизнь.
Это в точности то, чего мы бы ожидали в нашей схеме: когда звук и объект появляются, предсказатель «я предчувствую вкус соли» начинает быть бешено активным. В то же время, Направляющая Подсистема (гипоталамус и мозговой ствол) имеют прошитую схему, заявляющую «Если у меня недостаток соли, а «оценочная таблица» Обучающейся Подсистемы предполагает, что я скоро почувствую вкус соли, то это замечательно, и я должен следовать той идее, которую сейчас думает Обучающаяся Подсистема!»
5.5.6 Это предлагает хорошее объяснение разнообразию активности дофаминовых нейронов
Напомню, что выше в Разделе 5.4.1 я заявлял, что дофаминовые нейроны несут управляющие сигналы всех этих модулей обучения с подкреплением.[6]
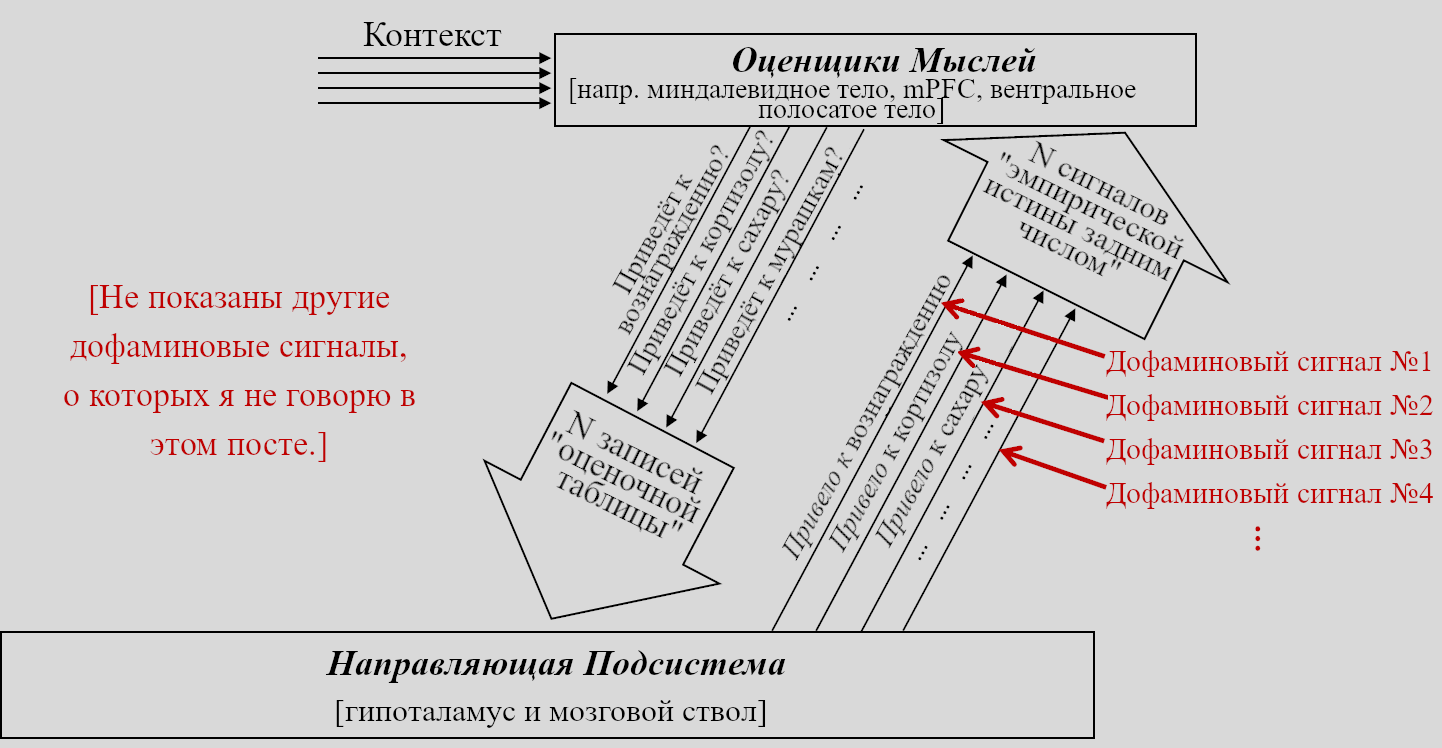
Есть научно-популярное заблуждение о том, что есть (единый) дофаминовый сигнал в мозгу, срабатывающий, когда происходит что-то хорошее. На самом деле, там есть множество разных дофаминовых нейронов, делающих разные вещи.
Так мы получаем вопрос: что делают все эти разнообразные дофаминовые сигналы? Консенсуса нет; в литературе есть самые разные заявления. Но я могу вбросить ещё и своё: в описанной мной картине, в конечном мозге, вероятно, есть сотни тысяч краткосрочных предсказателей, предсказывающих сотни тысяч разных вещей, и каждому нужен свой управляющий дофаминовый сигнал!
(И дофаминовых сигналов ещё больше, не только эти! Один такой сигнал, ассоциируемый с «главным» сигналом вознаграждения ошибки предсказания, будет обсуждаться в следующем посте. Прочие сигналы не входят в тему этой цепочки, но обсуждаются здесь.)
Если моя модель правильна, то что нам ожидать от экспериментов с измерением дофамина?
Представьте крысу, бегающую по лабиринту. В каждый момент времени её массив предсказателей получает управляющие сигналы о уровнях различных гормонов, пульсе, ожиданиям питья и еды, больной ноге, холоде, вкусе соли, и так далее. Говоря коротко, мы ожидаем, что активность дофаминовых нейронов скачет вверх и вниз самыми разными способами.
Так что, в общем-то каждый случай, когда экспериментатор выяснял, что дофаминовый нейрон коррелирует с какой-то поведенческой переменной, это, наверное, вписывается в мою картину.
Вот пара примеров:
- Есть дофаминовые нейроны, активирующиеся заметными стимулами вроде неожиданных вспышек света (ссылка). Могу ли я это объяснить? Конечно, без проблем! Я говорю: это могут быть управляющие сигналы, сообщающие «сейчас хороший момент, чтобы сориентироваться» или «вздрогнуть» или «повысить пульс», и т.д.
- Есть дофаминовые нейроны, коррелирующие с скоростью, с которой мышь бежит в колесе (ссылка). Могу я это объяснить? Конечно, без проблем! Я говорю: это могут быть управляющие сигналы, сообщающие «ожидай боли в мышцах» или «ожидай кортизол» или «ожидай повышения пульса», и т.д.
Вот ещё данные, кажущиеся подтверждающими мою картину. Некоторые дофаминовые нейроны активируются, когда происходит что-то неприятное (ссылка). Четыре из пяти областей[7], в которых можно обнаружить такие нейроны (согласно статье по ссылке) – в точности те, где я ожидаю существование краткосрочных предсказателей – конкретнее, это подобный-коре и подобный-полосатому-телу слои миндалевидного тела, медиальная префронтальная кора (mPFC) и вентромедиальная оболочка прилежащего ядра, являющаяся (по крайней мере примерно) частью петель «кора-базальные ганглии-маламус-кора», находящейся в полосатом теле. Это в точности то, что я бы ожидал. К примеру, если мышь шокирована, то предсказатель «следует ли мне сейчас замереть» получает управляющий сигнал «Да, тебе сейчас следовало замереть».
5.5.6.1 В сторону: Вывод распределений предсказателями
Я не говорил об этом в предыдущем посте, но обучающиеся алгоритмы краткосрочных предсказателей имеют гиперпараметры, два из которых – «как сильно обновляться после ложноположительной (перелёт) ошибки» и «как сильно обновляться после ложноотрицательной (недолёт) ошибки». Соотношение этих гиперпараметров может варьироваться от 0 до ∞, так что получившийся предсказатель может варьироваться от «активируй вывод, если есть хоть малейший шанс, что управляющий сигнал сработает» до «не активируй сигнал, если нет полной уверенностью, что управляющий сигнал сработает.»
Таким образом, если у нас есть много предсказателей, и у каждого своё соотношение гиперпараметров, то мы можем (хотя бы приблизительно) выводить распределение вероятности предсказания, а не просто одну оценку.
Недавний набор экспериментов от DeepMind и сотрудничающих с ними обнаружил свидетельство (основанное на измерениях дофаминовых нейронов), что мозг действительно использует этот трюк, по крайней мере для предсказания вознаграждения.
Я предполагаю, что он может использовать тот же трюк и в других долгосрочных предсказателях – к примеру, может быть, предсказания и боли в руке, и кортизола, и гусиной кожи – все выдаются группами долгосрочных предсказателей, составляющих распределения вероятностей.
Я поднял эту тему в первую очередь потому, что это ещё один пример того, как дофаминовые нейроны ведут себя, кажется, очень хорошо укладывающимся в мою картину образом, а во-вторых, потому что это вполне может быть полезно для безопасности СИИ – так что я в любом случае искал повод это упомянуть!
5.6 Заключение
Как обычно, я не претендую на то, что у меня есть неопровержимое доказательство молей гипотезы (т.е. что в мозгу есть массивы долгосрочных предсказателдей с участием петель «конечный мозг – мозговой ствол»). Но с учётом свидетельств в этом и предыдущем подразделах, я пришёл к сильному ощущению, что я примерно на правильном пути. Я с радостью обсужу это подробнее в комментариях. А в следующем посте мы наконец-то сложим всё это вместе в большую картину того, как, по моему мнению, работает мотивация и принятие решений в мозгу!
- «Горизонтальная» и «вертикальная» нейронанатомия – это моя своеобразная терминология, но я надеюсь, что она интуитивно понятна. Если вы представите кору, расправленную в горизонтальный лист, то «вертикальная нейронанатомия» будет включать, например, взаимосвязи между структурами в коре и подкорке, а «горизонтальная» нейроанатомия – например, разные роли разных частей коры. См. также таблицу в Разделе 5.4.1.
- Для ясности, скорее всего на самом деле нет никакого дискретного переключателя всё-или-ничего. Может быть, например, «взвешенное среднее». Напомню, всё это – просто педагогическая «игрушечная модель»; я ожидаю, что реальность во многих отношениях сложнее.
- Отмечу, что тут я просто прокручиваю этот алгоритм у себя в голове, я его не симулировал. Я оптимистично считаю, что я не облажался по-крупному, то есть, что то, что я говорю про алгоритм качественно верно при подходящих настройках параметров и, возможно иных мелких поправках.
- Примеры использования терминологии «Временных Разниц» в чём-то не связанном с функциями вознаграждения обучения с подкреплением включают «TD-сети» и литературу по Последовательным Отображениям (пример), и вот эту статью, и т.д.
- Классическая попытка примирить «висцемоторную» и «мотивационную» картины mPFC - это «гипотеза соматических маркеров» Антонио Дамасио. Моё описание тут имеет некоторые сходства и некоторые различия от неё. Я не буду в это погружаться, это не по теме.
- Как и в предыдущем посте, когда я говорю «дофамин несёт управляющий сигнал», я открыт к возможности того, что дофамин на самом деле несёт тесно-связанный сигнал, вроде сигнала об ошибке или отрицательного сигнала об ошибке, или отрицательного управляющего сигнала. Для наших целей это не имеет значения.
- Пятая область, хвост полосатого тела, как я думаю, объясняется по-иному – см. здесь.
- Короткая ссылка сюда: lesswrong.ru/3022