3. Две Подсистемы: Обучающаяся и Направляющая
- 1.3.1 Краткое содержание / Оглавление
- 2.3.2 Большая картина
- 3.3.3 «Теория Триединого Мозга» неверна, но давайте не выплёскивать ребёнка вместе с водой
- 4.3.4 Три типа составных частей Направляющей Подсистемы
- 4.1.3.4.1 Общая таблица
- 4.2.3.4.2 В сторону: что я имею в виду под «стремлениями»?
- 4.3.3.4.3 Категория A: Штуки, которая Направляющая Подсистема должна делать для достижения обобщённого интеллекта (например, стремление к любопытству)
- 4.4.3.4.4 Категория B: Всё остальное из человеческой Направляющей Системы (например, стремления, связанные с альтруизмом)
- 4.5.3.4.5 Категория C: Любые другие возможности (например, стремление увеличить баланс на банковском счёте)
- 5.3.5 Подобные-мозгу СИИ будут по умолчанию иметь радикально нечеловеческие (и опасные) мотивации
- 6.3.6 Ответ на аргументы Джеффа Хокинса против риска происшествий с СИИ
- 7.3.7 Сроки-до-подобного-мозгу-СИИ, часть 2 из 3: насколько сложен достаточный для СИИ реверс-инжиниринг Направляющей Подсистемы??
- 8.3.8 Сроки-до-подобного-мозгу-СИИ, часть 3 из 3: масштабирование, отладка, обучение, и т.д.
- 9.3.9 Сроки-до-подобного-мозгу-СИИ, ещё: Что мне чувствовать по поводу вероятностей?
3.1 Краткое содержание / Оглавление
В предыдущем посте я определил понятие «обучающихся с чистого листа» алгоритмов – широкую категорию, включающую, помимо прочего, любой алгоритм машинного обучения (неважно, насколько сложный) с случайной инициализацией и любую систему изначально пустой памяти. Я затем предложил разделение мозга на две части по признаку наличия или отсутствия обучения с чистого листа. Теперь я даю им имена:
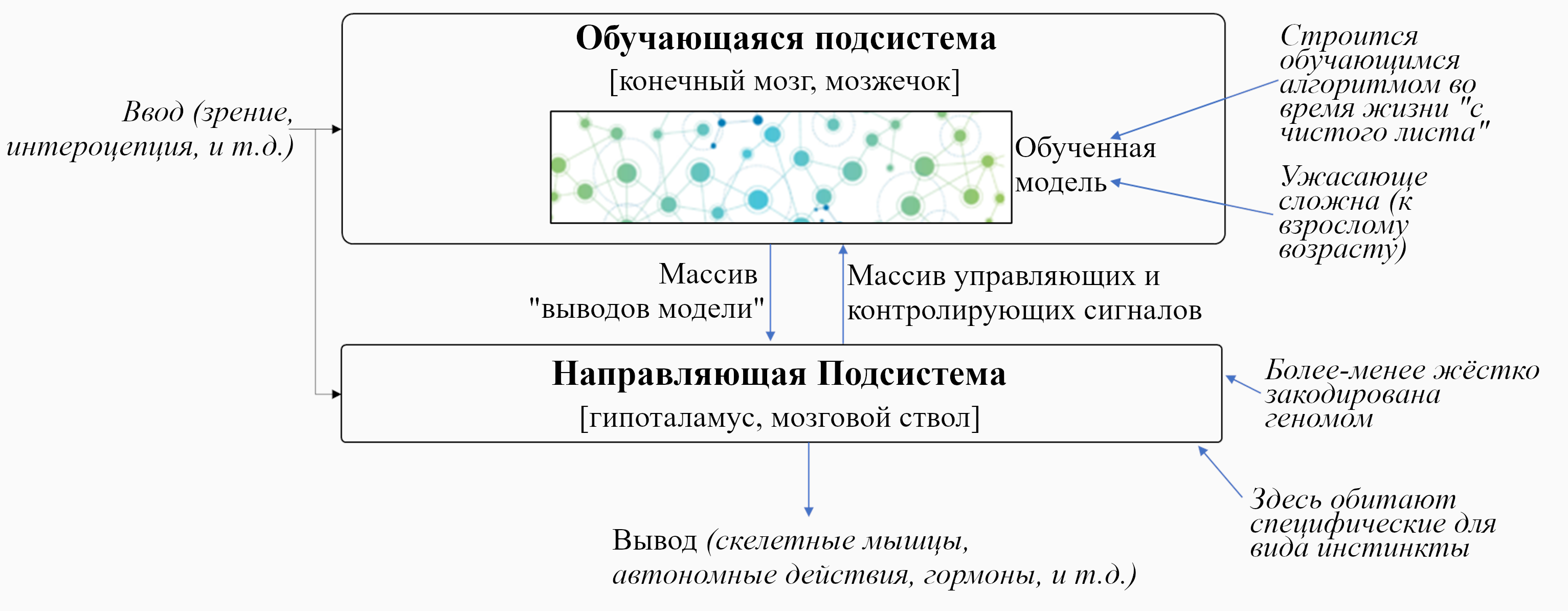
Обучающаяся Подсистема – это 96% мозга, «обучающиеся с чистого листа» – по сути – конечный мозг и мозжечок.
Направляющая Подсистема – это 4% мозга, не «обучающиеся с чистого листа» – по сути – гипоталамус и мозговой ствол.
(См. Предыдущий пост за более подробным анатомическим разделением.)
Этот пост будет обсуждением этой картины двух подсистем в целом и Направляющей Подсистемы в частности.
- В Разделе 3.2 я поговорю о большой картине того, что эти подсистемы делают и как они взаимодействуют. Как пример, я объясню, почему каждая подсистема нуждается в своей собственной обработке сенсорных сигналов – к примеру, почему визуальный ввод обрабатывается и в зрительной коре в Обучающейся Подсистеме, и в верхнем двухолмии в Направляющей Подсистеме.
- В Разделе 3.3 я признаю, что эта картина двух подсистем имеет некоторые сходства с дискредитированной «теорией триединого мозга». Но я буду утверждать, что проблемы теории триединого мозга не относятся к моей картине двух подсистем.
- В Разделе 3.4 я опишу три категории того, что может относиться к Направляющей Подсистеме:
- Категория A: Штуки, правдоподобно необходимые для обобщённого интеллекта (например, встроенная склонность к любопытству),
- Категория B: Иные штуки в человеческой направляющей подсистеме (например, встроенная склонность быть добрым к своим друзьям),
- Категория C: Всё, что может представить программист СИИ, даже если это радикально отличается от того, что встречается у людей и животных (например, встроенная склонность корректно предсказывать цены акций).
- В Разделе 3.5 я свяжу эти категории с тем, как я ожидаю будет выглядеть создание людьми подобного-мозгу СИИ, и обосную, что «подобный-мозгу СИИ с радикально нечеловеческими (и опасными) мотивациями» – не оксюморон, а, напротив, ожидаемый по умолчанию исход, если мы не потрудимся, чтобы его предотвратить.
- В Разделе 3.6 я рассмотрю тот факт, что у Джеффа Хокинса есть мнение о двух подсистемах, похожее на мою картину, но он спорит с тем, что катастрофические происшествия с СИИ представляют риск. Я скажу, где, как я считаю, он неправ.
- Разделы 3.7 и 3.8 будут последними двумя частями моего обсуждения «сроков до подобного-мозгу СИИ». Первой частью был Раздел 2.8 предыдущего поста, где я заявил, что реверс-инжиниринг Обучающейся Подсистемы (достаточный для подобного-мозгу СИИ) может правдоподобно произойти довольно скоро, в следующие два десятилетия, хотя это может и занять больше времени. Тут я дополню это заявлением, что-то же верно и для реверс-инжиниринга Направляющей Подсистемы, и для усовершенствования и масштабирования алгоритмов, проведения обучения модели, и т.д.
- Раздел 3.9 – быстрое не-техническое обсуждение того, как невероятно расходятся мнения разных людей по поводу сроков до СИИ, даже когда они согласны по поводу вероятностей. К примеру, можно найти двух людей, которые согласятся, что с шансами 3 к 1 СИИ не будет до 2042 года, но один может подчёркивать, как вероятность низка («Видишь? СИИ скорее всего не будет ещё десятилетия»), тогда как другой – как высока эта вероятность. Я поговорю немного о факторах, скрывающихся за этими отношениями.
3.2 Большая картина
В предыдущем посте я заявил, что 96% объёма мозга – грубо говоря, конечный мозг (неокортекс, гиппокампус, миндалевидное тело, большая часть базальных ганглиев, и ещё кое-что) и мозжечок – «обучаются с чистого листа» в том смысле, что на ранних этапах жизни их выводы – случайный мусор, но со временем они становятся невероятно полезны благодаря прижизненному обучению. (См. там больше подробностей) Я сейчас называю эту часть мозга Обучающейся Подсистемой.
Остальной мозг – в основном мозговой ствол и гипоталамус – я называю Направляющей Подсистемой.
Как нам об этом думать?
Давайте начнём с Обучающейся Подсистемы. Как я описывал в предыдущем посте, эта подсистема имеет некоторое количество взаимосвязанных встроенных алгоритмов обучения, встроенную нейронную архитектуру и встроенные гиперпараметры. Она имеет также много (миллиарды или триллионы) подстраиваемых параметров (обычно предполагается, что это сила синаптических связей, но это спорный момент, и я не буду в него погружаться), и значения этих параметров изначально случайны. Так что изначально Обучающаяся Подсистема выдаёт случайные бесполезные для организма выводы – например, может быть, они могут заставить организм дёргаться. Но со временем различные управляющие сигналы и соответствующие правила обновления подправляют настраиваемые параметры системы, что позволяет её за время жизни животного научиться делать сложные биологически-адаптивные штуки.
Дальше: Направляющая Подсистема. Как нам её интуитивно представлять?
Для начала, представьте хранилище с кучей специфичных для вида инстинктов и поведений, жёстко закодированных в геноме:
- «Чтобы блевануть, сжать мышцы A,B,C, и выпустить гормоны D,E,F.”
- «Если сенсорный ввод удовлетворяет таким-то эвристикам, то вероятно я ем что-то здоровое и энергоёмкое; это хорошо, и надо отреагировать сигналами G,H,I.”
- «Если сенсорный ввод удовлетворяет таким-то эвристикам, то наверное я склоняюсь над пропастью, это плохо, и надо отреагировать сигналами J,K,L.”
- «Если я замёрз, поднять волоски на теле.»
- «Если я недоедаю, выполнить: (1) запустить ощущение голода, (2) начать вознаграждать неокортекс за получение еды, (3) снизить фертильность и рост, (4) уменьшить чувствительность к боли, и т.д.» (ссылка).
Особенно важная задача Направляющей Подсистемы – посылать управляющие и контролирующие сигналы Обучающейся Подсистеме. Отсюда название: Направляющая Подсистема направляет обучающиеся алгоритмы к адаптивным штукам.
Пример: почему человеческий неокортекс обучается адаптивным-для-человека штукам, а беличий неокортекс обучается адаптивным-для-белки штукам, если они оба исполняют примерно одинаковые алгоритмы обучения с чистого листа?
Я заявляю, что главная часть ответа – то, что обучающиеся алгоритмы в этих двух случаях по-разному «направляются». Особенно важный аспект тут – сигнал «вознаграждения» обучения с подкреплением. Можно представить, что человеческий мозговой ствол посылает «награду» за достижение высокого социального статуса, а беличий мозговой ствол – за запасание орехов осенью. (Это упрощение, я ещё буду к этому возвращаться.)
Аналогично, в машинном обучении один и тот же обучающийся алгоритм может стать очень хорош в шахматах (при условии определённого сигнала вознаграждения и сенсорных данных) или может стать очень хорош в го (при условии других сигналов вознаграждения и сенсорных данных).
Для ясности, несмотря на название, «направление» Обучающейся Подсистемы – не всё, что делает Направляющая Подсистема. Она может и просто что-то делать самостоятельно, без вовлечения Обучающейся Подсистемы! Это хорошо подходит для того, что делать важно прямо с рождения, или для того, в чём даже один провал фатален. Пример, который я упоминал в предыдущем посте – мыши, оказывается, имеют цепь-обнаружения-приближающихся-птиц в мозговом стволе, напрямую соединённую с цепью-убегания-прочь в нём же.
Важно держать в голове, что Направляющая Подсистема мозга не имеет прямого доступа к нашему здравому смыслу и пониманию мира. К примеру, Направляющая Подсистема может исполнять реакции вроде «во время еды выделять пищеварительные энзимы». Но когда мы переходим к абстрактным концептам, которые мы используем для действий в мире – оценки, долги, популярность, соевый соус, и так далее – надо предполагать, что Направляющая Подсистема не имеет о них ни малейшего понятия, если мы не можем объяснить, откуда она могла о них узнать. И иногда такое объяснение есть! Мы ещё рассмотрим много таких случаев, в частности в Посте №7 (для простого примера желания съесть пирог) и Посте №13 (для более хитрого случая социальных инстинктов).
3.2.1 Каждая подсистема в общем случае нуждается в своей собственной сенсорной обработке
К примеру, в случае зрения, у Направляющей Подсистемы есть верхнее двухолмие, а к Обучающейся Подсистемы есть зрительная кора. Для вкуса у Направляющей Подсистемы есть вкусовое ядро в продолговатом мозге, а у Обучающейся Подсистемы – вкусовая кора. И т. д.
Не избыточно ли это? Некоторые так и думают! Книга Дэвида Линдена «Случайный Разум» упоминает существование двух систем сенсорной обработки как замечательный пример корявого проектирования мозга в результате отсутствия у эволюции планирования наперёд. Но я не соглашусь. Они не избыточны. Если бы я делал СИИ, я бы точно сделал ему две системы сенсорной обработки!
Почему? Предположим, что Эволюция хочет создать цепочку реакции, чтобы жёстко генетически закодированные сенсорные условия запускали генетически закодированный ответ. К примеру, как упоминалось выше, если вы мышь, то увеличивающееся тёмное пятно сверху области видимости часто означает приближающуюся птицу, поэтому геном мыши жёстко связал детектор-увеличивающегося-тёмного-пятна с поведенческой-цепью-убегания-прочь.
И я скажу, что создавая эту реакцию геном не может использовать зрительную кору для детектора. Почему? Вспомните предыдущий пост: зрительная кора обучается с чистого листа! Она принимает неструктурированные визуальные данные и строит из них предсказывающую модель. Вы можете (приближённо) думать о зрительной коре как о тщательном каталогизаторе паттернов из ввода, и паттернов из паттернов из ввода, и т.д. Один из этих паттернов может соответствовать увеличивающемуся тёмному пятну в верхней части поля зрения. Или нет! И даже если такой есть, геном не знает заранее, какие в точности нейроны будут хранить этот конкретный паттерн. Так что геном не может жёстко привязать эти нейроны к поведенческому-контроллеру-убегания-прочь.
В итоге:
- Встроить обработку сенсорных данных в Направляющую Подсистему – хорошая идея, потому что есть много областей, где сильно выгодно для приспособленности связать жёстко генетически заданное сенсорное условие с соответствующей реакцией. В случае людей, подумайте о страхе высоты, страхе змей, эстетике потенциального жилища, эстетике потенциальных партнёров, вкусе сытной еды, звуке вопля, чувстве боли, и так далее.
- Встроить обработку сенсорных данных в Обучающуюся Подсистему – ТОЖЕ хорошая идея, потому что использование обучающихся с чистого листа алгоритмов для выучивания произвольных паттернов из сенсорного ввода – это, ну, прямо очень хорошая идея. В конце концов, многие полезные сенсорные паттерны супер-специфичны – к примеру, «запах этого одного конкретного дерева» – так что соответствующий жёстко генетически заданный детектор никак не мог эволюционировать.
Так что две системы обработки сенсорной информации – не пример корявого проектирования. Это пример Второго Правила Орджела: «эволюция умнее тебя»!
3.3 «Теория Триединого Мозга» неверна, но давайте не выплёскивать ребёнка вместе с водой
В 1960-х и 70-х Пол Маклейн и Карл Саган изобрели и популяризировали идею Триединого Мозга. Согласно этой теории, мозг состоит из трёх слоёв, сложенных вместе как мороженое в рожке, и они эволюционировали по очереди: сначала «мозг ящерицы» (он же «древний мозг» или «рептильный мозг»), ближайший к спинному; потом «лимбическая система», обёрнутая вокруг него (состоящая из миндалевидного тела, гиппокампуса и гипоталамуса), и, наконец, наружным слоем, неокортекс (он же «новый мозг») – гвоздь программы, вершина эволюции, жилище человеческого интеллекта!!!
(Плохая!) модель триединого мозга (источник картинки)
{kind=link}
Ну, сейчас хорошо известно, что Теория Тройственного Мозга – чепуха. Она разделяет мозг на части способом, не имеющим ни функционального ни эмбриологического смысла, и эволюционная история просто откровенно неверна. К примеру, половину миллиарда лет назад самые ранние позвоночные имели предшественников всех трёх слоёв триединого мозга – включая «плащ», который потом (в нашей линии) разделился на неокортекс, гиппокампус, часть миндалевидного тела, и т.д. (ссылка).
Так что да, Теория Тройственного Мозга – чепуха. Но я вполне признаю: нравящаяся мне история (предыдущий раздел) несколько напоминает её. Моя Направляющая Подсистема выглядит подозрительно похожей на маклейновский «рептильный мозг». Моя Обучающаяся Подсистема выглядит подозрительно похожей на маклейновские «лимбическую систему и неокортекс». Мы с Маклейном не вполне согласны по поводу того, что в точности к чему относится, и два там слоя или три. Но сходство несомненно есть.
Моя история про две подсистемы не оригинальна. Вы услышите похожие от Джеффа Хокинса, Дайлипа Джорджа, Илона Маска, и других.
Но эти другие люди делают это придерживаясь традиции теории триединого мозга, и, в частности, сохраняя её проблематичные аспекты, вроде терминологии «древнего мозга» и «нового мозга».
Нет нужды так делать!!! Мы можем сохранить модель двух подсистем, избавившись от унаследованных у тройственного мозга ошибок.
Так что вот моя версия: я думаю, что пол миллиарда лет назад у ранних позвоночные уже был (простой!) алгоритм обучения с чистого листа в их (прото-) конечном мозге, и он «направлялся» сигналами из их (простого, прото-) мозгового ствола и гипоталамуса.
На самом деле, мы можем пойти даже дальше позвоночных! Оказывается, существует сходство между обучающейся с чистого листа корой у людей и обучающимся с чистого листа «грибовидным телом» у плодовых мух! (Подробное обсуждение здесь.) Замечу, к примеру, что у плодовых мух, сигналы запахов отправляются и в грибовидное тело, и в боковой рог, что замечательно сходится с общим принципом того, что сенсорный ввод должен отправляться и в Обучающуюся Подсистему, и в Направляющую Подсистему (Раздел 3.2.1 выше).
В любом случае, за 700 миллионов лет прошедших с нашего последнего общего предка с насекомыми в нашей линии очень сильно увеличились и усложнились и Обучающаяся Подсистема, и Направляющая Подсистема.
Но это не значит, что они одинаково вкладываются в «человеческий интеллект». Опять же, обе необходимы, но, я думаю, факт того, что 96% объёма человеческого мозга занимает Обучающаяся Подсистема, довольно убедителен. Сосредоточимся ещё конкретнее на конечном мозге (который у млекопитающих включает неокортекс), его доля объёма мозга – 87% у людей (ссылка), 79% у шимпанзе (ссылка), 77% у некоторых попугаев, 51% у куриц, 45% у крокодилов, и лишь 22% у лягушек (ссылка). Тут есть очевидная закономерность, и думаю, что для получения способности к распознаваемому интеллектуальному и гибкому поведению действительно необходима большая Обучающаяся Подсистема.
Видите? Я могу описать свою модель двух подсистем без всей этой чепухи про «древний мозг, новый мозг».
3.4 Три типа составных частей Направляющей Подсистемы
Я начну с общей таблицы, а потом рассмотрю всё подробнее в следующих подразделах.
3.4.1 Общая таблица
| Категория составных частей Направляющей Подсистемы | Возможные примеры | Присутствуют в (компетентных) людях? | Ожидаются в будущих СИИ? |
| (A) Штуки, которая Направляющая Подсистема должна делать для достижения обобщённого интеллекта | Стремление к любопытству (?) Стремление обращать внимание на некоторые категории вещей в окружении (люди, язык, технология, и т.д.) (?) Общая вовлечённость в настройку нейронной архитектуры Обучающейся Подсистемы (?) | Да, по определению | Да |
| (B) Всё остальное из Направляющей Подсистемы нейротипичного человека | Социальные инстинкты (лежащие в основе альтруизма, любви, сожаления, вину, чувства справедливости, верности, и т. д.) Стремления в основе отвращения, эстетики, спокойствия, восхищения, голода, боли, боязни пауков, и т. д. | Обычно, но не всегда – к примеру, высокофункциональные социопаты лишены некоторых обычных социальных инстинктов. | Нет «по умолчанию», но *возможно*, если мы: (1)поймём, как в точности они работают, и (2)убедим разработчиков СИИ заложить их в него |
| (C) Любые другие возможности, большинство из которых *совершенно непохожи на всё*, что можно обнаружить в Направляющей Подсистеме человека или любого другого животного | Стремление увеличить баланс на банковском счёте компании? Стремление изобрести более хорошую солнечную панель? Стремление делать то, что хочет от меня человек-оператор? *(Тут ловушка: никто не знает, как реализовать это!)* | Нет | Да «по умолчанию». Если что-то – плохая идея, мы можем попробовать убедить разработчиков СИИ это не делать. |
3.4.2 В сторону: что я имею в виду под «стремлениями»?
Я подробнее разберу это в следующих постах, но сейчас давайте просто скажем, что Обучающаяся Подсистема (помимо всего прочего) проводит обучение с подкреплением, и Направляющая Подсистема присылает ей вознаграждение. Компоненты функции вознаграждения соответствуют тому, что я называю «встроенными стремлениями» - это корень того, почему некоторые штуки по своей сути мотивирующие / привлекающие, а другие – демотивирующие / отталкивающие.
Явные цели вроде «я хочу избавиться от долгов» отличаются от встроенных стремлений. Явные цели возникают из сложного взаимодействия «встроенных стремлений Направляющей Подсистемы» и «выученного содержания Обучающейся Подсистемы». Опять же, куда больше про это в будущих постах.
Напомню, встроенные стремления находятся в Направляющей Подсистеме, а абстрактные концепции, составляющие ваш осознанный мир – в Обучающейся. К примеру, если я говорю что-то вроде «встроенные стремления, связанные с альтруизмом», то надо понимать, что я говорю не про «абстрактную концепцию альтруизма, как он определён в словаре», а про «некая встроенная в Направляющую Подсистему схема, являющаяся причиной того, что нейротипичные люди иногда считают альтруистические действия по своей сути мотивирующими». Абстрактные концепции имеют какое-то отношение к встроенным схемам, но оно может быть сложным – никто не ожидает взаимно-однозначного соответствия N отдельных встроенных схем и N отдельных слов, описывающих эмоции и стремления.[1]
Разобравшись с этим, давайте подробнее рассмотрим таблицу.
3.4.3 Категория A: Штуки, которая Направляющая Подсистема должна делать для достижения обобщённого интеллекта (например, стремление к любопытству)
Давайте начнём с «стремления к любопытству». Если вы не знакомы с понятием «любопытства» в контексте машинного обучения, я рекомендую Задачу Согласования Брайана Кристиана, главу 6, содержащую занимательную историю того, как исследователи смогли научить агентов обучения с подкреплением выигрывать в игре с Atari Montezuma’s Revenge. Стремление к любопытству кажется необходимым для хорошей работы системы машинного обучения, и, кажется, оно встроено и в людей. Я предполагаю, что будущие СИИ тоже будут в нём нуждаться, а иначе просто не будут работать.
Для большей конкретности – я думаю, что оно важно для начального развития – думаю, стремление к любопытству необходимо на ранних этапах обучения, а потом его, вероятно, можно в какой-то момент отключить. Скажем, представим СИИ, обладающего общими знаниями о мире и самом себе, способного доводить дела до конца, и сейчас пытающегося изобрести новую солнечную панель. Я утверждаю, что ему скорее всего не нужно встроенное стремление к любопытству. Он может искать информацию и жаждать сюрпризов как будто у него оно есть, потому что из опыта он уже выучил, что это зачастую хорошая стратегия для, в частности, изобретения солнечных панелей. Другими словами, что-то вроде любопытства может быть мотивирующим как средство для достижения цели, даже если оно не мотивирует как цель – любопытство может быть выученной метакогнитивной эвристикой. См. инструментальная конвергенция. Но этот аргумент неприменим на ранних этапах обучения, когда СИИ начинает с чистого листа, ничего не зная о мире и о себе. Так что, если мы хотим получить СИИ, то поначалу, я думаю, Направляющая Подсистема действительно должна указывать Обучающейся Подсистеме правильное направление.
Другой возможный элемент в Категории A – это встроенное стремление обращать внимание на конкретные вещи в окружении, например, человеческую деятельность, человеческий язык или технологию. Я не совсем уверен, что это необходимо, но мне кажется, что стремления к любопытству самого по себе не хватит для того, что мы от него хотим. Оно было бы совершенно ненаправленным. Может, СИИ мог бы провести вечность, прокручивая в своей голове Правило 110, находя всё более и более глубокие паттерны, полностью игнорируя физическую вселенную. Или„ может быть, он мог бы находить всё более и более глубокие паттерны в формах облаков, полностью игнорируя всё, связанное с людьми и технологией. В случае человеческого мозга, мозговой ствол определённо обладает механизмами, заставляющими обращать внимание на человеческие лица (ссылка), и я сильно подозреваю, что там есть и система обращения внимания на человеческую речь. Я могу быть неправ, но, думаю, что-то вроде этого понадобиться и для СИИ. И точно также, может оказаться, что это необходимо только в начале обучения.
Что ещё может быть в Категории A? В таблице я написал расплывчатое «Общая вовлечённость в настройку нейронной архитектуры Обучающейся Подсистемы». Это включает посылание сигналов вознаграждения, и сигналов об ошибке, и гиперпараметры и т. д. для конкретных частей нейронной архитектуры Обучающейся Подсистемы. К примеру, в Посте №6 я поговорю о том, как только часть нейронной архитектуры становится получателем главного сигнала вознаграждения обучения с подкреплением. Я думаю об этих вещах, как о (одном аспекте) настоящей реализации нейронной архитектуры Обучающейся Подсистемы. У СИИ тоже будет какая-то нейронная архитектура, хотя, возможно, не в точности такая же, как у людей. Следовательно, СИИ тоже могут понадобится такие сигналы. Я немного говорил о нейронной архитектуре в Разделе 2.8 предыдущего поста, но в основном она не важна для этой цепочки, так что я не буду рассматривать её ещё подробнее.
В Категории A могут быть и другие штуки, о которых я не подумал.
3.4.4 Категория B: Всё остальное из человеческой Направляющей Системы (например, стремления, связанные с альтруизмом)
Я сразу перепрыгну к тому, что мне кажется наиболее важным: социальные инстинкты, включающие различные стремления, связанные с альтруизмом, симпатией, любовью, виной, завистью, чувством справедливости, и т. д. Ключевой вопрос: Откуда я знаю, что социальные инстинкты попадают в Категорию B, то есть, что они не в Категории A вещей, необходимых для обобщённого интеллекта?
Ну, для начала, посмотрите на высокофункциональных социопатов. У меня в своё время был опыт очень хорошего знакомства с парочкой. Они хорошо понимают мир, себя, язык, математику, науку, могут разрабатывать сложные планы и успешно достигать впечатляющих вещей. ИИ, умеющий всё, что может делать высокофункциональный социопат, мы бы без колебаний назвали «СИИ». Конечно, я думаю, высокофункциональные социопаты имеют какие-то социальные инстинкты – они более заинтересованы в манипуляциях людьми, а не игрушками – но их социальные инстинкты кажутся очень сильно отличающимися от социальных инстинктов нейротипичного человека.
Сверх этого, мы можем рассмотреть людей с аутизмом, людей с шизофренией, и S.M. (лишённую миндалевидного тела, и более-менее – негативных социальных эмоций), и так далее, и так далее. Все эти люди имеют «обобщённый интеллект», но их социальные инстинкты / стремления очень разнятся.[2]
С учётом всего этого, мне сложно поверить, что какие-то аспекты социальных инстинктов строго необходимы для обобщённого интеллекта. Я думаю, как минимум открытый вопрос – даже способствуют ли они обобщённому интеллекту!! К примеру, если вы посмотрите на самых гениальных в мире учёных, то я предположу, что люди с нейротипичными социальными инстинктами там будут несколько недопредставлены.
Причина, по которой это важно – я заявляю, что социальные инстинкты лежат в основе «желания поступать этично». Опять же, рассмотрим высокофункциональных социопатов. Они могут понять честь и справедливость и этику, если захотят, понять в смысле правильных ответов на тестовые вопросы о том, что справедливо, а что нет и т.д., они просто всем этим не мотивированы.[3]
Если подумать, это имеет смысл. Предположим, я скажу вам «Тебе следует запихнуть камушки себе в уши». Вы скажете «Почему?». И я скажу «Потому что, ну знаете, в ваших ушах нет камушков, но надо, чтобы были». И вы опять скажете «Почему?» …В какой-то момент этому разговору придётся свестись к тому, что вы и я считаем по своей сути, независимо от всего остального, мотивирующим или демотивирующим. И я утверждаю, что социальные инстинкты – различные встроенные стремления, связанные с чувством честности, симпатией, верностью, и так далее – и являются основанием для этих интуитивных заключений.
(Я тут не решаю дилемму морального реализма против морального релятивизма – то есть вопрос о том, есть ли «материальные факты» о том, что этично, а что неэтично. Вместо этого, я говорю, что если агент полностью лишён встроенных стремлений, которые могу разжечь в нём желание поступать этично, то нельзя ожидать от него этичного поведения, неважно, насколько он интеллектуален. С чего ему? Ладно, он может поступать этично как средство для достижения цели – например, чтобы привлечь на свою сторону союзников – но это не считается. Больше обсуждения и оснований интуиции в моём комментарии тут.)
Пока что это всё, что я хочу сказать о социальных инстинктах; я ещё вернусь к ним позже в этой цепочке.
Что ещё попадает в Категорию B? Много штук!! Отвращение, эстетика, спокойствие, восхищение, голод, боль, страх пауков, и т. д.
3.4.5 Категория C: Любые другие возможности (например, стремление увеличить баланс на банковском счёте)
Люди, создающие СИИ, могут поместить в функцию вознаграждения что им захочется! Они смогут создавать совершенно новые встроенные стремления. И эти стремления будут радикально непохожи на что-либо присущее людям или животным.
Зачем будущим программистам СИИ изобретать новые, ранее не встречавшиеся встроенные стремления? Потому что это естественно!! Если похитить случайного разработчика машинного обучения из холла NeurIPS, запереть его в заброшенном складе и заставить создавать ИИ-для-зарабатывания-денег-на-банковском-счёте с использованием обучения с подкреплением[4], то спорю на что угодно, в его исходном коде будет функция вознаграждения, использующая баланс на банковском счёте. Вы не найдёте ничего похожего в генетически прошитых схемах в мозговом стволе человека! Это новое для мира встроенное стремление.
«Поместить встроенное стремление для увеличения баланса на банковском счёте» – не только очевидный вариант, но, думаю, и в самом деле работающий! Некоторое время! А потом он катастрофически провалится! Он провалится как только ИИ станет достаточно компетентным, чтобы найти нестандартные стратегии увеличения баланса на банковском счёте – занять денег, взломать сайт банка, и так далее. (Смешной и ужасающий список исторических примеров того, как ИИ находили нестандартные не предполагавшиеся стратегии максимизации награды, больше об этом в следующих постах.) На самом деле, этот пример с балансом банковского счёте – только одно из многих-многих возможных стремлений, которые правдоподобно могут привести СИИ к вынашиванию тайной мотивации сбежать из под человеческого контроля и всех убить (см. Пост №1).
Так что такие мотивации худшие: они прямо у всех под носом, они – лучший способ достигать целей, публиковать статьи и побивать рекорды показателей, пока СИИ не слишком умный, а потом, когда СИИ становится достаточно компетентным, они приводят к катастрофическим происшествиям.
Вы можете подумать: «Это же совсем очевидно, что СИИ с всепоглощающим стремлением повысить баланс конкретного банковского счёта – это СИИ, который попытается сбежать из-под человеческого контроля, самовоспроизводиться и т.д. Ты реально веришь, что будущие программисты СИИ буду настолько беспечны, чтобы поместить в него что-то в таком роде??»
Ну, эммм, да. Да, так и думаю. Но даже отложив это пока в сторону, есть проблема побольше: мы пока не знаем, как закодировать хоть какое-нибудь встроенное стремление так, чтобы получившийся СИИ точно остался под контролем. Даже стремления, которые на первый взгляд кажутся благоприятными, скорее всего не такие, по крайней мере при нашем нынешнем уровне понимания. Куда больше про это в будущих постах (особенно №10).
Безусловно, Категория C – очень широкая. Я совсем не буду удивлён, если в ней существуют встроенные стремления, которые очень хороши для безопасности СИИ! Нам просто надо их найти! Я поисследую это пространство возможностей дальше в цепочке.
3.5 Подобные-мозгу СИИ будут по умолчанию иметь радикально нечеловеческие (и опасные) мотивации
Я упоминал это уже в первом посте (Раздел 1.3.3), но сейчас у нас есть объяснение.
Предыдущий подраздел предложил разделение на три типа возможного содержания Направляющей Подсистемы: (A) Необходимые для СИИ, (B) Всё остальное, что есть в людях, (C) Всё, чего нет в людях.
Мои заявления:
- Люди хотят создавать мощные ИИ с прорывными способностями в сложных областях – они знают, что это хорошо для публикаций, производит впечатление на коллег, помогает получить работу, повышения и гранты, и т.д. В смысле, ну просто посмотрите на ИИ и машинное обучение сейчас. Поэтому, по умолчанию, я ожидаю, что разработчики СИИ будут нестись прямиком по самому короткому к нему пути: реверс-инжиниринг Обучающейся Подсистемы и комбинирование её с стремлениями из Категории A.
- Категория B содержит некоторые стремления, которые, вполне возможно, могут быть полезны для безопасности СИИ: связанные с альтруизмом, симпатией, щедростью, скромностью, и т.д. К сожалению, мы сейчас не знаем, как они реализованы в мозге. И выяснение этого необязательно для создания СИИ. Так что я думаю, что по умолчанию следует ожидать, что разработчики СИИ будут игнорировать Категорию B до тех пор, пока у них не будет работающего СИИ, и только затем они начнут попытки разобраться, как встроить стремление к альтруизму и т.п. И у них может просто не получиться – вполне возможно, что соответствующие схемы в мозговом стволе и гипоталамусе ужасающе сложны и запутаны, а у нас будет только некоторое ограниченное время между «СИИ работает» и «кто-то случайно создаёт вышедший из под контроля СИИ, который всех убивает» (см. Пост №1).
- В Категории C есть штуки вроде «низкоуровневое встроенное стремление увеличить баланс конкретного банковского счёта», которые немедленно очевидны для кого угодно, легко реализуются, и будут хорошо справляться с достижением целей программистов, пока их прото-СИИ не слишком способен. Следовательно, по умолчанию, я ожидаю, что будущие исследователи будут использовать такие «очевидные» (но опасные и радикально нечеловеческие) стремления в своей работе по разработке СИИ. И, как и обсуждалось выше (и больше в следующих постах), даже если исследователи начнут добросовестные попытки дать своему СИИ встроенное стремление к услужливости / послушности / чему-то ещё, они могут обнаружить, что не знают, как это сделать.
Обобщая, если исследователи пойдут по самому простому и естественному пути – вытекающему из того, что сообщества ИИ и нейробиологии продолжат вести себя похоже на то, как они ведут себя сейчас – то мы получим СИИ, способные на впечатляющие вещи, поначалу на те, которые хотят их программисты, но ими будут управлять радикально чужеродные системы мотивации, фундаментально безразличные к человеческому благополучию, и эти СИИ попытаются сбежать из-под человеческого контроля как только станут достаточно способными для этого.
Давайте попробуем это изменить! В частности, если мы заранее разберёмся, как написать код, задающий встроенное стремление к альтруизму / услужливости / послушности / чему-то подобному, то это будет очень полезно. Это большая тема этой цепочки. Но не ожидайте финальных ответов. Это нерешённая задача: впереди ещё много работы.
3.6 Ответ на аргументы Джеффа Хокинса против риска происшествий с СИИ
Недавно вышла книга Джеффа Хокинса «Тысяча мозгов». Я написал подробный её обзор тут. Джефф Хокинс продвигает очень похожую на мою точку зрения о двух подсистемах. Это не совпадение – его работы подтолкнули меня в этом направлении!
К чести Хокинса, он признаёт, что его работа по нейробиологии / ИИ продвигает (неизвестной длины) путь в сторону СИИ, и он попытался осторожно обдумать о последствиях такого проекта – в противоположность более типичной точке зрения, объявляющей СИИ чьей-то чужой проблемой.
Так что я восхищён тем, что Хокинс посвятил большой раздел своей книги аргументам о катастрофических рисках СИИ. Но его аргументы – против катастрофического риска!! Что такое? Как он и я, начав с похожих точек зрения на две подсистемы, пришли к диаметрально противоположным заключениям?
Хокинс приводит много аргументов, и, опять же, я более подробно их рассмотрел в моём обзоре. Но тут я хочу подчеркнуть две самые большие проблемы, касающиеся этого поста.
Вот мой пересказ некоторых аргументов Хокинса. (Я перевожу их в используемую мной в этой цепочке терминологию, например, где он говорит «древний мозг», я говорю «Направляющая Подсистема». И, может быть, я немного груб. Вы можете прочитать книгу и решить для себя, насколько я справедлив.)
- Обучающаяся Подсистема (неокортекс и т.п.) сама по себе не имеет целей и мотиваций. Она не сделает ничего. Она точно не сделает ничего опасного. Это как карта, лежащая на столе.
- В той степени, в какой у людей есть проблематичные стремления (жадность, самосохранение, и т.д.), они происходят из Направляющей Подсистемы (мозговой ствол и т.д.).
- То, что я, Джефф Хокинс, предлагаю, и делаю – это попытки реверс-инжиниринга Обучающейся Подсистемы, не Направляющей. Так какого чёрта все так взволнованы?
- …
- …
- О, кстати, совершенно не связанное замечание, мы когда-нибудь в будущем сделаем СИИ, и у них будет не только Обучающаяся Подсистема, но ещё и подключённая к ней Направляющая Подсистема. Я не собираюсь говорить о том, как мы спроектируем Направляющую Подсистему. Это на самом деле не то, о чём я много думаю.
Каждый пункт по отдельности кажется вполне осмысленным. Но если сложить их вместе, тут зияющая дыра! Кого волнует, что неокортекс сам по себе безопасен? План вовсе не в неокортексе самом по себе! Вопрос, который надо задавать – будет ли безопасен СИИ, состоящий из обеих подсистем. И это критически зависит от того, как мы создадим Направляющую Подсистему. Хокинсу это неинтересно. А мне да! Дальше в цепочке будет куда больше на эту тему. В Посте №10 я особенно погружусь в тему того, почему чертовски сложнее, чем кажется создать Направляющую Подсистему, способствующую тому, чтобы СИИ делал что-то конкретное, что нам надо, не вложив в него также случайно опасные антисоциальные мотивации, которые мы не намеревались в него вкладывать.
Ещё одна (имеющая значение) проблема, которую я не упоминал в своём обзоре: я думаю, что Хокинс частично руководствуется интуитивным соображением, против которого я выступал в (Мозговой ствол, Неокртекс) ≠ (Базовые Мотивации, Благородные Мотивации) (и больше на эту тему будет в Посте №6): тенденцией необоснованно приписывать эгосинтонические мотивации вроде «раскрытия тайн вселенной» неокортексу (Обучающейся Подсистеме), а эгодистонические мотивации вроде голода и сексуального желания – мозговому стволу (Направляющей Подсистеме). Я заявляю, что все мотивации без исключения изначально исходят из Направляющей Подсистемы. Надеюсь, это станет очевидно, если вы продолжите читать эту цепочку.
На самом деле, мое заявление даже подразумевается в лучших частях книги самого Хокинса! К примеру:
- Хокинс в Главе 10: «Неокортекс обучается модели мира, которая сама по себе не содержит целей и ценностей.»
- Хокинс в Главе 16: «Мы – разумная модель нас, обитающая в неокортексе – заперты. Мы заперты в теле, которое … в основном находится под контролем невежественной скотины, древнего мозга. Мы можем использовать интеллект, чтобы представить лучшее будущее… Но древний мозг может всё испортить…»
Проговорю противоречие: если «мы» = модель в неокортексе, и модель в неокортексе не имеет целей и ценностей, то «мы» точно не жаждем лучшего будущего и не вынашиваем планы, чтобы обойти контроль мозгового ствола.
3.7 Сроки-до-подобного-мозгу-СИИ, часть 2 из 3: насколько сложен достаточный для СИИ реверс-инжиниринг Направляющей Подсистемы??
(Напомню: Часть 1 из 3 – Раздел 2.8 предыдущего поста.)
Выше (Раздел 3.4.3) я рассмотрел «Категорию A», минимальный набор составляющих для создания Направляющей Системы СИИ (не обязательно безопасного, только способного).
Я на самом деле не знаю, что в этом наборе. Я предположил, что вероятно нам понадобится какая-то разновидность стремления к любопытству, и может быть какое-то стремление обращать внимание на человеческие языки и прочую человеческую деятельность, и, может быть, какие-то сигналы для помощи в образовании нейронной архитектуры Обучающейся Подсистемы.
Если это так, ну, это не поражает меня как что-то очень сложное! Это уж точно намного проще, чем реверс-инжиниринг всего, что есть в человеческом гипоталамусе и мозговом стволе! Держите в голове, что есть довольно обширная литература по любопытству, как в машинном обучении (1, 2), так и в психологии. «Стремление обращать внимание на человеческий язык» не требует ничего сверх классификатора, который (с осмысленной точностью, он не обязан быть идеальным) сообщает, является ли данный звуковой ввод человеческой речью или нет; это уже тривиально с нынешними инструментами, может уже залито на GitHub.
Я думаю, нам стоит быть открытыми к возможности что не так уж сложно создать Направляющую Подсистему, которая (вместе с получившейся в результате реверс-инжиниринга Обучающейся Подсистемой, см. Раздел 2.8 предыдущего поста) может развиться в СИИ после обучения. Может, это не десятилетия исследований и разработки; может даже не годы! Может, компетентный исследователь может сделать это всего с нескольких попыток. С другой стороны – может и нет! Может, это супер сложно! Я думаю, сейчас очень сложно предсказать, сколько времени это займёт, так что нам стоит оставаться неуверенными.
3.8 Сроки-до-подобного-мозгу-СИИ, часть 3 из 3: масштабирование, отладка, обучение, и т.д.
Обладание полностью определённым алгоритмом с способностями СИИ – ещё не конец истории; его всё ещё надо реализовать, отполировать, аппаратно ускорить и распараллелить, исправить причуды, провести обучение, и т.д. Не стоит игнорировать эту часть, но не стоит и её переоценивать. Я не буду описывать это тут, потому что я недавно написал целый отдельный пост на эту тему:
Вдохновлённый-мозгом СИИ и «прижизненные якоря»
Суть поста: я думаю, что всё это точно можно сделать меньше, чем за 10 лет. Может, меньше чем за 5. Или это может занять дольше. Я думаю, нам стоит быть очень неуверенными.
Это заканчивает моё обсуждение сроков-до-подобного-мозгу-СИИ, что, опять же, не главная тема этой цепочки. Вы можете прочитать три его части (2.8, 3.7, и эта), согласиться или не согласиться, и прийти к своим собственным выводам.
3.9 Сроки-до-подобного-мозгу-СИИ, ещё: Что мне чувствовать по поводу вероятностей?
Моё обсуждение «сроков» (Разделы 2.8, 3.7, 3.8) касалось вопроса прогнозирования «какое распределение вероятностей мне приписывать времени появления СИИ (если он вообще будет)?»
Полу-независимым от этого вопроса является вопрос отношения: «Что мне чувствовать по поводу этого распределения вероятностей?»
Например, два человека могут соглашаться с (допустим) «35% шансом СИИ к 2042», но иметь невероятно разное отношение к этому:
- Один из них закатывает глаза, смеётся и говорит: «Видишь, я же говорил! СИИ скорее всего не появится ещё десятилетия!»
- У другого глаза расширяются, челюсть отпадает, и он говорит: «О. Боже. Извините, дайте минутку, пока я переобдумываю всё о своей жизни.»
Есть много факторов, лежащих в основе таких разных отношений к одному и тому же убеждению о мире. Во-первых, некоторые факторы – больше про психологию, а не про фактические вопросы:
- «Какое отношение лучше подходит моему восприятию себя и моей психике?» - о-о-о, блин, это в нас глубоко засело. Людей, думающих о себе как о хладнокровных серьёзных скептических величавых приземлённых учёных, может непреодолимо тянуть к мнению, что СИИ – не такое уж большое дело. Людей, думающих о себе как о радикальных трансгуманистических технологических первопроходцах, может так же непреодолимо тянуть к противоположному мнению, что СИИ радикально изменит всё. Я говорю это, чтобы вы могли пообдумывать свои собственные искажения. О, да кого я обманываю; на самом деле, я просто дал вам удобный способ самодовольно насмехаться над всеми, кто с вами не согласен, и отбрасывать их мнение. (Можете не благодарить!) С моей стороны, я заявляю, что я несколько иммунен к отбрасыванию-мнения-через-психоанализ: Когда я впервые пришёл к убеждению, что СИИ – очень серьёзное дело, я полностью идентифицировал себя как хладнокровного серьёзного скептического величавого приземлённого учёного средних лет, не интересующегося и не связанного с научной фантастикой, трансгуманизмом, технологической индустрией, ИИ, Кремниевой долиной, и т.д. Вот так-то! Ха! Но на самом деле, это глупая игра: отбрасывать убеждения людей через психоанализ их скрытых мотивов – всегда было ужасной идеей. Это слишком просто. Правда или неправда, вы всегда можете найти хороший повод самодовольно усомниться в мотивах любого, кто с вами не согласен. Это просто дешёвый трюк для избегания тяжёлой работы выяснения, не могут ли они на самом деле оказаться правы. И про психологию в целом: принять всерьёз возможность будущего с СИИ (настолько серьёзно, насколько, как я думаю, она того заслуживает) может быть, ну, довольно мучительно! Довольно сложно было привыкнуть к идее, что Изменение Климата реально происходит, верно?? См. этот пост за большими подробностями.
- Как мне следует думать о возможных-но-не-гарантированных будущих событиях? Я предлагаю прочитать этот пост Скотта Александера. Или, если вы предпочитаете в виде мема:

Источник картинки: Скотт Александер
Ещё, тут есть ощущение, выраженное в известном эссе «Заметив Дым», и этом меме:

Примерно основано на меме @Linch, если не ошибаюсь
Говоря явно, правильная идея – взвешивать риски и выгоды и вероятности переподготовки и недоподготовки к возможному будущему риску. Неправильная идея – добавлять в это уравнение дополнительный элемент – «риск глупо выглядеть перед моими друзьями из-за переподготовки к чему-то странному, что оказалось не таким уж важным» – и трактовать этот элемент как подавляюще более важный, чем все остальные, и затем через какое-то безумное странное выворачивание Пари Паскаля выводить, что нам не следует пытаться избежать потенциальной будущей катастрофы до тех пор, пока мы не будем уверены на >99.9%, что катастрофа действительно произойдёт. К счастью, это становится всё более и более обсуждаемой темой; ваши друзья всё с меньшей и меньшей вероятностью подумают, что вы странный, потому что безопасность СИИ стала куда более мейнстримной в последние годы – особенно благодаря агитации и педагогике Стюарта Расселла, Брайана Кристиана, Роба Майлза, и многих других. Вы можете поспособствовать этому процессу, поделившись этой цепочкой! ;-) (рад помочь – прим. пер.)
Отложив это в сторону, другие более вещественные причины разного отношения к срокам до СИИ включают вопросы:
- Насколько сильно СИИ преобразует мир? Что касается меня, я нахожусь далеко на конце спектра «сильно». Я одобряю цитату Элиезера Юдковского: «Спрашивать о воздействии [сверхчеловеческого СИИ] на [безработицу] – это как спрашивать, как на торговлю США с Китаем повлияет падение Луны на Землю. Воздействие будет, но вы упускаете суть.» Для более трезвого обсуждения, попробуйте Цифровые Люди Были Бы Ещё Большим Делом Холдена Карнофского, и, может быть, ещё и Так не Может Продолжаться для фона, и, почему бы и нет, всю остальную серию постов тоже. Также смотрите здесь некоторые числа, предполагающие, что подобный-мозгу СИИ скорее всего не потребует ни такого количества компьютерных чипов, ни такого количества электричества, что он не мог бы широко использоваться.
- Насколько многое нам надо сделать, чтобы подготовиться к СИИ? См. в Посте №1, Разделе 1.7 мои аргументы в пользу того, что мы сильно отстаём от расписания, а позже в этой цепочке я затрону много всё ещё нерешённых задач.
- Ну, может быть кто-то и ожидает, что есть взаимно-однозначное соответствие между абстрактными языковыми концепциями вроде «печали» и соответствующими внутренними реакциями. Если прочитать книгу Как Рождаются Эмоции, Лиза Фельдман Барретт тратит там сотни страниц, избивая эту позицию. Она, наверное, отвечает кому-то, верно? В смысле, мне бы показалось каким-то абсурдным очучеливанием мнение: «Каждая ситуация, которую мы бы описали как «грустная» соответствует в точности одной и той же внутренней реакции с одним и тем же выражением лица.» Я буду удивлён, если окажется, что Пол Экман (которого, вроде бы, Барретт опровергала) на самом деле в это верит, но я не знаю…
- Я не предполагаю, что схемы Направляющей Подсистемы, лежащие в основе социальных инстинктов, устроены у этих разных групп совершенно по-разному – это было бы эволюционно неправдоподобно. Скорее, я думаю, что там есть много настраиваемых параметров того, насколько сильны разные стремления, и они могут принимать широкие диапазоны значений, включая такие, что стремление будет таким слабым, что на практике можно считать его отсутствующим. См. мои спекулятивные рассуждения про аутизм и психопатию тут.
- См. Тест Психопата Джона Ронсона за забавными обсуждениями попыток научить психопатов эмпатии. Студенты лишь стали лучше способны подделывать эмпатию для манипуляции людьми. Цитата одного человека, учившего такой класс: «Думаю, мы случайно создали для них пансион благородных девиц.»
- Предполагаю, можно было бы просто нанять исследователя в области машинного обучения. Но кто будет ему платить?