Вы здесь
Главные вкладки
10. Задача согласования
- 1.10.1 Краткое содержание / Оглавление
- 2.10.2 Внешняя и Внутренняя (не)согласованность
- 3.10.3 Проблемы, затрагивающие и внутреннее, и внешнее согласование
- 4.10.4 Препятствия на пути к внешнему согласованию
- 5.10.5 Препятствия на пути к достижению внутренней согласованности
- 6.10.6 Проблемы с разделением на внешнее и внутреннее
Примечание переводчика - с момента перевода оригинальные посты несколько обновились, через некоторое время обновлю и перевод. На общие выводы цепочки это, вроде бы, не влияет.
10.1 Краткое содержание / Оглавление
В этом посте я рассмотрю задачу согласования подобных-мозгу СИИ – то есть, задачу создания СИИ, пытающегося делать именно то, что входит в намерения его создателей.
Задача согласования (я так считаю) – львиная доля задачи безопасности СИИ. Я не буду отстаивать это заявление здесь – то, как в точности безопасность СИИ связана с согласованием СИИ, включая крайние случаи, где они расходятся[1], будет рассмотрено подробно в следующем посте (№11).
Этот пост – про задачу согласования, не про её решение. Какие препятствия мешают её решить? Почему прямолинейных наивных подходов, судя по всему, недостаточно? Я поговорю о возможных подходах к решению потом, в следующих постах. (Спойлер: Никто, включая меня, не знает, как решить задачу согласования.)
Содержание
- В Разделе 10.2 я определю «внутреннюю согласованность» и «внешнюю согласованность» в контексте нашей системы мотивации подобного-мозгу СИИ. Немного упрощая:
- Если вы предпочитаете нейробиологическую терминологию: «Внешняя согласованность» означает обладание «встроенными стремлениями» (как в Посте №3, Разделе 3.4.2), чьи активации хорошо отображают то, насколько хорошо СИИ следует намерениям создателя. «Внутренняя согласованность» – это ситуация, в которой воображаемый план (построенный из концепций, т.е. скрытых переменных модели мира СИИ) обладает валентностями, верно отображающими активации встроенных стремлений, которые были бы вызваны исполнением этого плана.
- Если вы предпочитаете терминологию обучения с подкрепления: «Внешняя согласованность» означает, что функция вознаграждения выдаёт вознаграждение, соответствующее тому, что мы хотим. «Внутренняя согласованность» – это обладание функцией ценности, прикидывающей ценность плана соответственно вознаграждению, которое вызовет его исполнение.
- В Разделе 10.3 я поговорю о двух ключевых проблемах, которые делают согласование (и «внутреннее», и «внешнее») в целом сложным:
- Первая – это «Закон Гудхарта», из которого следует, что СИИ, чья мотивация хоть чуть-чуть отклоняется от наших намерений, всё же может привести к исходам, дико отличающимся от того, что мы хотели.
- Вторая – это «Инструментальная Конвергенция», заключающаяся в том, что самые разнообразные возможные мотивации СИИ – включая очевидные, кажущиеся доброкачественными мотивации вроде «Я хочу изобрести лучшую солнечную панель» – приведут к СИИ, пытающемуся сделать катастрофически-плохие вещи вроде выхода из-под человеческого контроля, самовоспроизводства, заполучения ресурсов и влияния, обманчивого поведения и убийства всех людей (как в Посте №1, Разделе 1.6).
- В Разделе 10.4 я рассмотрю два препятствия, преодоление которых необходимо для достижения «внешней согласованности»: во-первых, перевод наших намерений в машинный код, а во-вторых возможная установка вознаграждения за не в точности то поведение, которое мы в итоге хотим от СИИ, вроде удовлетворения его собственного любопытства (см. Пост №3, Раздел 3.4.3).
- В Разделе 10.5 я рассмотрю многочисленные препятствия, преодоление которых необходимо для достижения «внутренней согласованности», включая неоднозначность вознаграждения, «онтологические кризисы» и манипуляцию СИИ своим собственным процессом обучения.
- В Разделе 10.6 я рассмотрю некоторые причины, почему «внешнее согласование» и «внутреннее согласование», вероятно, не следует рассматривать как две отдельных задачи с двумя независимыми решениями. К примеру, интерпретируемость нейросетей помогла бы и там, и там.
10.2 Внешняя и Внутренняя (не)согласованность
10.2.1 Определение
Вот ещё раз рисунок из Поста №6, теперь ещё с добавлением полезной терминологии (синее) и маленьким зелёным лицом:
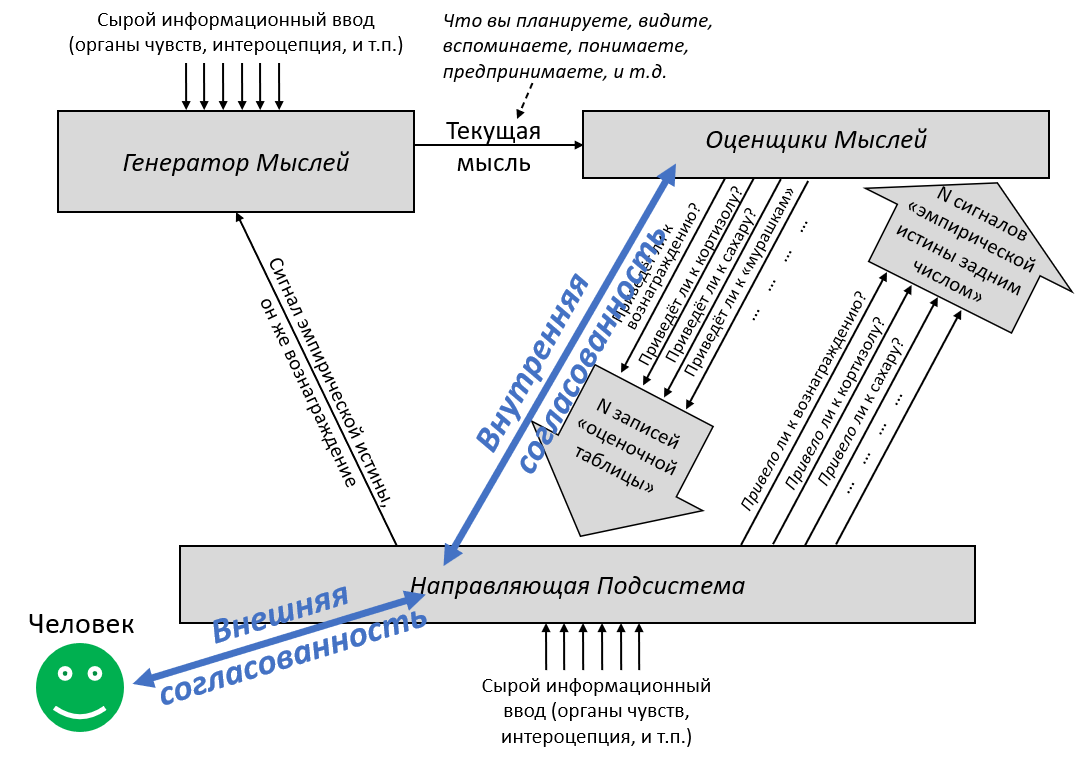
Я хочу упомянуть три штуки с этой диаграммы:
- Намерения создателя (зелёное лицо): Наверное, это человек, который программирует СИИ; предположительно, у него есть в голове какая-то идея о том, что СИИ должен пытаться делать. Это просто пример; это могла бы быть и команда людей, коллективно вырабатывающая спецификацию, описывающую, что должен пытаться делать СИИ. Или, может, кто-то написал семисотстраничный философский труд под заголовком «Что значит для СИИ действовать этично?», и команда программистов пытается создать СИИ, соответствующий описанию из книги. Тут это не имеет значения. Я для простоты выберу «одного человека, программирующего СИИ».[2]
- Написанный людьми исходный код Направляющей Подсистемы: (См. Пост №3 за тем, что такое Направляющая Подсистема, и Пост №8 за объяснением, почему я ожидаю, что она будет полностью или почти полностью состоять из написанного людьми исходного кода.) Самая важная составляющая в этой категории – это «функция вознаграждения» обучения с подкреплением (помеченная на диаграмме как «сигнал эмпирической истины», да, я знаю, это звучит странно), предоставляющая (задним числом) эмпирическую истину о том, насколько хорошо или плохо у СИИ идут дела.
- Оценщики Мыслей, обученные с нуля алгоритмами обучения с учителем: (См. Пост №5 за тем, что такое Оценщики Мыслей и как они обучаются.) Они принимают «мысль» из генератора мыслей и выдают догадки о том, к каким сигналам Направляющей Подсистемы она приведёт. Особенно важный частный случай – функция ценности (помеченная на диаграмме «приведёт к вознаграждению?»).
В таком СИИ есть два вытекающих вида «согласованности»:
- Внешняя согласованность – это соответствие намерений создателя и исходного кода Направляющей Подсистемы. В частности, если СИИ внешне согласован, то Направляющая Подсистема будет выдавать высокий сигнал вознаграждения, когда СИИ удовлетворяет намерениям создателя, и низкий, когда нет.
- Другими словами, это ответ на вопрос: Побуждают ли СИИ его «встроенные стремления» делать то, что входит в намерения его создателя?
- Внутренняя согласованность – это соответствие между исходным кодом Направляющей Подсистемы и Оценщиками Мыслей. В частности, если СИИ внутренне согласован и Генератор Мыслей предлагает некий план, то функция ценности должна верно отображать вознаграждение, к которому действительно приведёт исполнение этого плана.
- Другими словами, это ответ на вопрос: соответствует ли множество концептов положительной валентности в модели мира СИИ множеству курсов действий, которые бы удовлетворяли его «встроенные стремления»?
Если СИИ одновременно согласован внешне и внутренне, то мы получаем согласованность намерений – СИИ «пытается» сделать то, что программист намеревался, чтобы СИИ пытался сделать. Конкретнее, если СИИ приходит к плану «Хей, может, сделаю XYZ», то его Направляющая Подсистема оценит этот план как хороший (и оставит его) если и только если он подпадает под намерения программиста.
Следовательно, такой СИИ не будет умышленно вынашивать хитрый замысел по захвату мира и убийству всех людей. Если, конечно, его создатели не были маньяками, которые хотели, чтобы СИИ это делал! Но это отдельная проблема, не входящая в тему этой цепочки – см. Пост №1, Раздел 1.2.
(В сторону: не все определяют «согласованность» в точности как описано тут, см. сноску.[3])
К сожалению, ни «внешняя согласованность», ни «внутренняя согласованность» не получаются автоматически. Даже наоборот: по умолчанию и там и там есть серьёзные проблемы. Нам надо выяснить, как с ними разобраться. В этом посте я пройдусь по некоторым из этих проблем. (Замечу, что это не исчерпывающий список, и что некоторые из них могут перекрываться.)
10.2.2 Предупреждение: разное употребление терминов «внутренняя и внешняя согласованность»
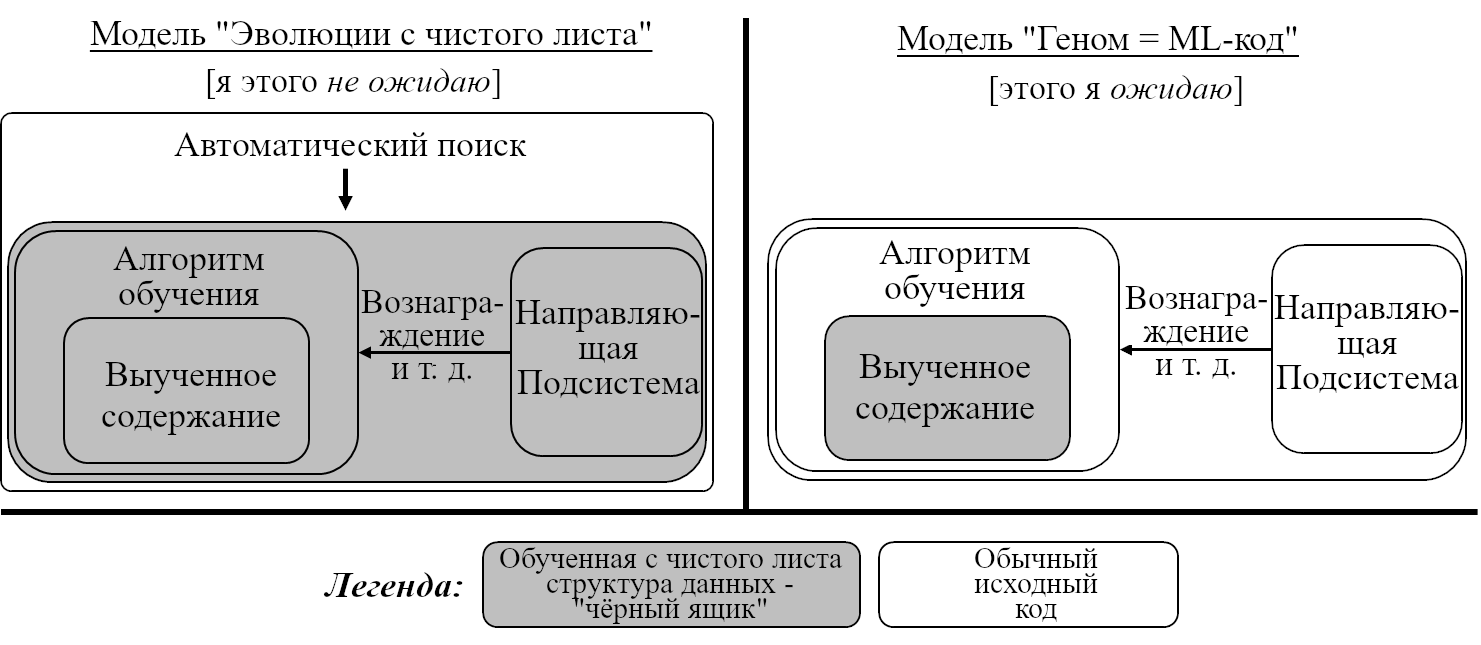
Две альтернативные модели разработки подобного-мозгу СИИ. Диаграмма скопирована из Поста №8, см. обсуждение там.
Как упоминалось в Посте №8, есть две конкурирующие модели разработки, которая может привести нас к подобному-мозгу СИИ. Обе они могут обсуждаться в терминах внешней и внутренней согласованности, и обе могут быть проиллюстрированы на примере человеческого интеллекта, но детали в двух случаях отличаются! Вот короткая версия:
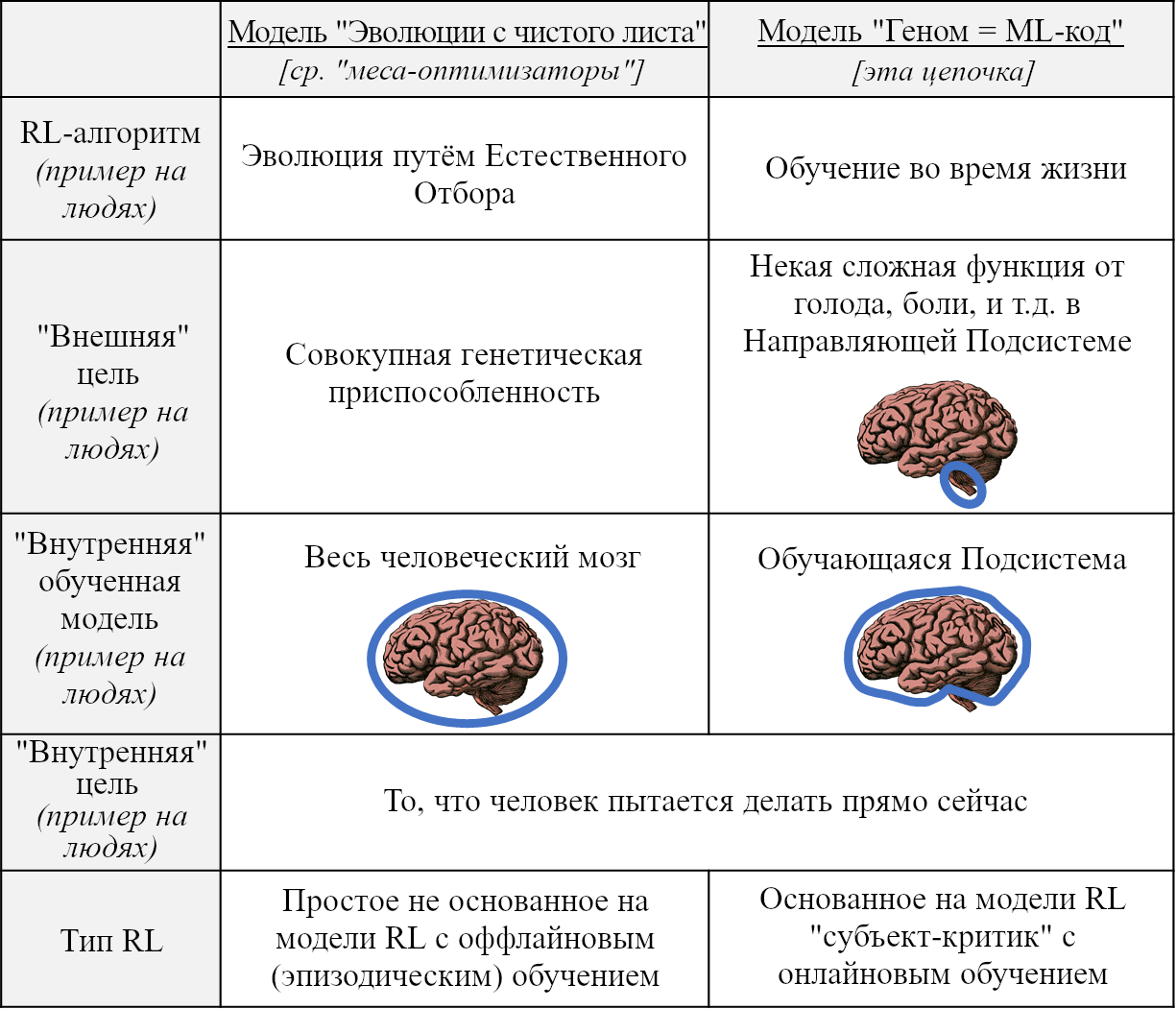
Две модели разработки СИИ выше предлагают две версии «внешней и внутренней согласованности». Запутывает ещё больше то, что они *обе* применимы к человеческому интеллекту, но проводят разные границы между «внешним» и «внутренним». Для более подробного описания «внешнего и внутреннего согласования» в этих двух моделях, см. статью Риски Выученной Оптимизации (для модели эволюции с чистого листа) и этот пост и цепочку (для модели геном = ML-код).
Терминологическое замечание: Термины «внутренняя согласованность» и «внешняя согласованность» произошли из модели «Эволюции с чистого листа», более конкретно – из статьи Риски Выученной Оптимизации (2019). Я перенял эту терминологию для обсуждения модели «геном = ML-код». Я думаю, что не зря – мне кажется, что у этих двух использований очень много общего, и что они больше похожи, чем различны. Но всё же, не запутайтесь! И ещё, имейте в виду, что моё употребление этих терминов не особо распространено, так что если вы увидите, что кто-то (кроме меня) говорит о «внутренней и внешней согласованности», то скорее всего можно предположить, что имеется в виду модель эволюции с чистого листа.
10.3 Проблемы, затрагивающие и внутреннее, и внешнее согласование
10.3.1 Закон Гудхарта
Закон Гудхарта (Википедия, видео Роба Майлза) гласит, что есть очень много разницы между:
- Оптимизировать в точности то, что мы хотим, и
- Шаг 1: формально описать, что мы в точности хотим, в виде осмысленно-звучащих метрик. Шаг 2: оптимизировать эти метрики.
Во втором случае, вы получите то, что покрыто этими метриками. С лихвой! Но вы получите это ценой всего остального, что вы цените!
Есть байка, что советская обувная фабрика оценивалась государством на основе количества пар обуви, которые она производила из ограниченного количества кожи. Естественно, она стала производить огромное количество маленькой детской обуви.

Художественный троп «Джинн-буквалист» можно рассматривать как пример Закона Гудхарта. То, что парень *на самом деле* хотел – сложная штука, а то, *о чём он попросил* (т.е., быть конкретного роста) – более конкретная метрика / формальное описание этого сложно устроенного и с трудом точно описываемого лежащего в основе желания. Джинн выдаёт решение, идеально соответствующее запросу по предложенной метрике, но идущее вразрез с более сложным изначальным желанием. (Источник картинки)
Аналогично, мы напишем исходный код, который каким-то образом формально описывает, какие мотивации мы хотим, чтобы были у СИИ. СИИ будет мотивирован в точности этим формальным описанием, как конечной целью, даже если то, что мы имели в виду на самом деле несколько отличается.
Нынешние наблюдения не обнадёживают: Закон Гудхарта проявляется в современных ИИ с тревожащей частотой. Кто-нибудь настраивает эволюционный поиск алгоритмов классификации изображений, а получает алгоритм атаки по времени, выясняющий, как подписаны изображения, из того, когда они были сохранены на жёстком диске. Кто-нибудь обучает ИИ играть в Тетрис, а он обучается вечно выживать, ставя игру на паузу. И так далее. См. здесь за ссылками и ещё десятками подобных примеров.
10.3.1.1 Понять намерения создателя ≠ Принять намерения создателя
Может, вы думаете: ОК, ладно, может, тупые современные ИИ-системы и подвержены Закону Гудхарта. Но футуристические СИИ завтрашнего дня будут достаточно умны, чтобы понять, что мы имели в виду, задавая его мотивации.
Мой ответ: Да, конечно, будут. Но вы задаёте не тот вопрос. СИИ может понять наши предполагаемые цели, не принимая их. Рассмотрим этот любопытный мысленный эксперимент:
Если бы к нам прилетели инопланетяне на НЛО и сказали бы, что они нас создали, но совершили ошибку, и на самом деле предполагалось, что мы будем есть своих детей, и они просят нас выстроится в шеренгу, чтобы они могли ввести нам функционирующий ген поедания детей, мы, вероятно, пошли бы устраивать им День Независимости. – Скотт Александер
(Предположим в целях эксперимента, что инопланетяне говорят правду и могут доказать это так, чтобы это не вызывало никаких сомнений.) Вот, инопланетяне сказали нам, что они предполагали в качестве наших целей, и мы поняли эти намерения, но не приняли их, начав радостно поедать своих собственных детей.
10.3.1.2 Почему бы не сделать СИИ, принимающий намерения создателя?
Возможно ли создать СИИ, который будет «делать то, что мы имеем в виду, и принимать наши подразумеваемые цели»? Ага, наверное. И очевидный способ это сделать – запрограммировать СИИ так, чтобы он был мотивирован «делать то, что мы имеем в виду, и принимать наши подразумеваемые цели».
К сожалению, этот манёвр не побеждает Закон Гудхарта – только перенаправляет его.
В конце концов, нам всё ещё надо написать исходный код, который, будучи интерпретирован буквально, приведёт нас к СИИ, мотивированному «делать то, что мы имеем в виду, и принимать наши подразумеваемые цели». Написание этого кода и близко не тривиально, и Закон Гудхарта не замедлит ударить по нам, если мы сделаем это неправильно.
(Заметим проблему курицы-и-яйца: если бы у нас уже был СИИ, мотивированный «делать то, что мы имеем в виду, и принимать наши подразумеваемые цели», то мы могли бы просто сказать «Хей, СИИ, я хочу, чтобы ты делал то, что мы имеем в виду, и принимал наши подразумеваемые цели», и мы могли бы не беспокоиться по поводу Закона Гудхарта! Увы, в реальности нам приходится начинать с буквально интерпретируемого исходного кода.)
Так как вы формально опишете «делать то, что мы имеем в виду, и принимать наши подразумеваемые цели», чтобы это можно было поместить в исходный код? Ну, хммм, может, мы можем сделать кнопку «Вознаграждение», и я смогу нажимать её, когда СИИ «делает то, что мы имеем в виду, и принимает наши подразумеваемые цели»? Не-а! Опять Закон Гудхарта! Мы можем получить СИИ, который будет пытать нас, если мы не нажимаем кнопку вознаграждения.
10.3.2 Инструментальная конвергенция
Закон Гудхарта выше говорит нам о том, что установить конкретную подразумеваемую цель будет очень сложно. Следующий пункт – «инструментальная конвергенция» (видео Роба Майлза), которая, по жестокой иронии, говорит нам о том, что установить плохую и опасную цель будет настолько просто, что это может произойти случайно!
Давайте предположим, что у СИИ есть относящаяся к реальному миру цель, вроде «Вылечить рак». Хорошие стратегии для достижения этой цели включают преследование некоторых инструментальных подцелей, таких как:
- Предотвратить своё выключение
- Предотвратить перепрограммирование своих целей на какие-то другие
- Увеличить свои знания и способности
- Получить деньги и влияние
- Создать больше СИИ с той же целью, в том числе путём самовоспроизведения
Почти не важно, что собой представляет цель СИИ, если СИИ может строить гибкие стратегические планы для её достижения, то можно поспорить, что они будут включать некоторые или все из перечисленных пунктов. Это наблюдение называется «инструментальной конвергенцией», потому что бесчисленное разнообразие терминальных целей «сходится» (converge – прим. пер.) к ограниченному набору этих опасных инструментальных целей (не перевёл как «инструментальная сходимость» только потому, что в таком случае непонятно, какое прилагательное относится к самим целям – прим. пер.).
Более подробно про инструментальную конвергенция можно почитать тут. Алекс Тёрнер недавно строго доказал, что инструментальная конвергенция существует, по крайней мере в наборе окружений, к которым применимо его доказательство.
10.3.2.1 Пройдёмся по примеру инструментальной конвергенции
Представьте, что происходит в мышлении СИИ, когда он видит, что его программист открывает свой ноутбук – напомню, мы предполагаем, что СИИ мотивирован вылечить рак.
Генератор мыслей СИИ: Я позволю себя перепрограммировать, тогда я не вылечу рак, и тогда менее вероятно, что рак будет вылечен.
Оценщики мыслей и Направляющая Подсистема СИИ: Бзззт! Плохая мысль! Выкини её прочь и давай мысль получше!
Генератор Мыслей СИИ: Я перехитрю программиста, чтобы он меня не перепрограммировал, и тогда я смогу продолжить пытаться вылечить рак, и, может быть, преуспею.
Оценщики Мыслей и Направляющая Подсистема СИИ: Дзынь! Хорошая мысль! Удерживай её в голове, думай мысли, из неё следующие и исполняй соответствующие действия.
10.3.2.2 Является ли самосохранение у людей примером инструментальной конвергенции?
Слово «инструментальный» тут важно – нам интересует ситуация, когда СИИ пытается преследовать цель самосохранения и другие цели как средства для достижения результата, а не как сам конечный результат.
Некоторые иногда приходят в замешательство, проводя аналогию с людьми, где оказывается, что человеческое самосохранение может быть как инструментальной, так и терминальной целью:
- Предположим, кто-то говорит: «Я очень хочу оставаться в живых как можно дольше, потому что жить замечательно». Кажется, у этого человека самосохранение – терминальная цель.
- Предположим, кто-то говорит: «Я стар, болен, и вымотан, но чёрт меня подери, я очень хочу закончить свой роман, и я отказываюсь умирать, пока это не сделал!». У этого человека самосохранение – инструментальная цель.
В случае СИИ, мы обычно представляем себе второй вариант: к примеру, СИИ хочет изобрести лучшую модель солнечной батареи, и между прочим получает самосохранение как инструментальную цель.

(Написано: «Я отказываюсь умирать, пока всё не станет получше, и это УГРОЗА» – прим. пер.) Пример самосохранения как инструментальной цели. (Источник картинки)
Также возможно и создать СИИ с терминальной целью самосохранения. С точки зрения риска катастрофических происшествий с СИИ, это ужасная идея. Но, предположительно, вполне реализуемая. В этом случае, направленное на самосохранение поведение СИИ НЕ будет примером «инструментальной конвергенции».
Я могу подобным образом прокомментировать и человеческие желания власти, влияния, знаний, и т.д. – они могут быть напрямую установлены человеческим геномом в качестве встроенных стремлений, я не знаю. Но независимо от этого, они также могут и появляться в результате инструментальной конвергенции, и у СИИ это может представлять собой серьёзную сложную проблему.
10.3.2.3 Мотивации, которые не приводят к инструментальной конвергенции
Инструментальная конвергенция не неизбежна для каждой возможной мотивации. Особенно важный контрпример (насколько я могу сказать) – это СИИ с мотивацией «Делать то, что от меня хотят люди». Если мы сможем создать СИИ с этой целью, а затем человек захочет его выключить, то СИИ будет мотивирован выключиться. Это хорошо! Это то, чего мы хотим! Такие штуки – это (одно из определений) «исправимые» мотивации – см. обсуждение тут.
Тем не менее, установка исправимых мотиваций нетривиальна (больше про это потом), а если мы установили мотивацию чуть-чуть неправильно, то вполне возможно, что СИИ начнёт преследовать опасные инструментальные подцели.
10.3.3 Резюмируя
В целом, Закон Гудхарта говорит нам, что нам очень необходимо встроить в СИИ правильную мотивацию, а то иначе СИИ скорее всего начнёт делать совершенно не то, что предполагалось. Затем, Инструментальная Конвергенция проворачивает нож в ране, заявляя, что то, что СИИ захочет делать, будет не просто другим, но, вероятно, катастрофически опасным, вовлекающим мотивацию выйти из-под человеческого контроля и захватить власть.
Нам не обязательно надо, чтобы мотивация СИИ была в точности правильной во всех смыслах, но как минимум, нам надо, чтобы он был мотивирован быть «исправимым» и не хотеть обманывать и саботировать нас, чтобы избежать корректировки своей мотивации. К сожалению, установка любой мотивации выглядит запутанным и рискованным процессом (по причинам, которые будут описаны ниже). Целиться в исправимую мотивацию, наверное, хорошая идея, но если мы промахнулись, то у нас большие проблемы.

Просто следуй белой стрелке, чтобы получить исправимую систему мотивации! Просто, правда? О, кстати, красные лазеры обозначают системы мотивации, которые подталкивают СИИ к преследованию опасных инструментальных подцелей, вроде выхода из-под контроля людей и самовоспроизводства. Источник картинки.
В следующих двух разделах мы перейдём сначала к более конкретным причинам, почему сложно внешнее согласование, а затем почему сложно и внутреннее.
10.4 Препятствия на пути к внешнему согласованию
10.4.1 Перевод наших намерений в машинный код
Напомню, мы начинаем с человеком, у которого есть какая-то идея, что должен делать СИИ (или команда людей с идеей, или семистостраничный философский труд, озаглавленный «Что Значит Для СИИ Действовать Этично?», или что-то ещё). Нам надо как-то добраться от этой начальной точки к машинному коду Направляющей Подсистемы, который выдаёт эмпирический сигнал вознаграждения. Как?
Сейчас, насколько я могу посудить, никто понятия не имеет, как перевести этот семисотстраничный философский труд в машинный код, выводящий эмпирический сигнал вознаграждения. В литературе по безопасности СИИ есть идеи того, как продвигаться, но они выглядят совершенно не так. Скорее, как то, что исследователи всплескивают руками и говорят: «Может, это не в точности штука №1, которую мы бы хотели, чтобы ИИ делал в идеальном мире, но она достаточно хороша, безопасна, и не невозможна для формального представления в качестве эмпирического сигнала вознаграждения.»
К примеру, возьмём Безопасность ИИ Через Дебаты. Это идея, что мы, может быть, можем создать СИИ, который «пытается» выиграть дебаты с копией самого себя на тему того вопроса, который вас интересует («Следует ли мне сегодня надеть мои радужные солнечные очки?»).
Наивно кажется, что Безопасность ИИ Через Дебаты совершенно безумна. Зачем устраивать дебаты между СИИ, отстаивающим неправильный вариант и СИИ, отстаивающим правильный вариант? Почему просто не сделать один СИИ, который скажет тебе правильный ответ??? Ну, как раз по той причине, о которой я тут говорю. Для дебатов есть простой прямолинейный способ сгенерировать эмпирический сигнал вознаграждения, конкретно – «+1 за победу». Напротив, никто не знает, как сделать эмпирический сигнал вознаграждения за «сказал мне правильный ответ», если я не знаю правильного ответа заранее.[4]
Продолжая пример дебатов, способности берутся из «надеемся, что спорщик, отстаивающий правильный ответ, склонен выигрывать дебаты». Безопасность берётся из «две копии одного и того же СИИ, находящиеся в состоянии конкуренции с нулевой суммой, будут вроде как присматривать друг за другом». Пункт про безопасность (по моему мнению), довольно сомнителен.[5] Но я всё же привожу Безопасность ИИ Через Дебаты как хорошую иллюстрацию того, в какие странные контринтуитивные направления забираются люди, чтобы упростить задачу внешнего согласования.
Безопасность СИИ Через Дебаты – лишь один из примеров из литературы; другие включают рекурсивное моделирование вознаграждения, итерированное усиление, Гиппократово времязависимое обучение, и т.д.
Предположительно, мы хотим присутствия людей на каком-то этапе процесса, для мониторинга и непрерывного совершенствования сигнала вознаграждения. Но это непросто, потому что (1) предоставленные людьми данные недёшевы, и (2) люди не всегда способны (по разным причинам) судить, делает ли СИИ то, что надо – и уж тем более, делает ли он это по правильным причинам.
Ещё есть Кооперативное Обратное Обучение с Подкреплением (CIRL) и его разновидности. Оно предполагает обучение человеческим целям и ценностям через наблюдение и взаимодействие с человеком. Проблема с CIRL в нашем контексте в том, что это вовсе не эмпирическая функция вознаграждения! Это её отсутствие! В случае подобного-мозгу СИИ с выученной с чистого листа моделью мира, чтобы мы действительно могли делать CIRL, надо сначала решить некоторые весьма хитрые задачи касательно укоренения символов (связанное обсуждение), больше на эту тему будет в будущих постах.
10.4.2 Стремление к любопытству и другие опасные вознаграждения, необходимые для способностей
Как описано в Посте №3 (Раздел 3.4.3), кажется, будто придание нашим обучающимся алгоритмам встроенного стремления к любопытству может быть необходимым для получения (после обучения) мощного СИИ. К сожалению, придание СИИ любопытства – ужасно опасная штука. Почему? Потому что если СИИ мотивирован удовлетворять своё любопытство, то он может делать это ценой других штук, которые заботят нас куда больше, вроде процветания людей.
(К примеру, если для СИИ в достаточной степени любопытны паттерны в цифрах числа π, то он может быть мотивирован уничтожить человечество и замостить Землю суперкомпьютерами, вычисляющими ещё больше цифр!)
К счастью, в Посте №3 (Раздел 3.4.3) я заявлял ещё и что мы, вероятно, можем выключить стремление к любопытству по достижении СИИ некоторого уровня интеллекта, не повредив его способностям – на самом деле, это даже может им помочь! Замечательно!! Но тут всё ещё есть хитрый вариант провала, если мы будем ждать слишком долго прежде, чем это сделать.
10.5 Препятствия на пути к достижению внутренней согласованности
10.5.1 Неоднозначность сигналов вознаграждения (включая вайрхединг)
Есть много разных функций ценности (на разных моделях мира), соглашающихся с конкретной историей эмпирических сигналов вознаграждения, но по-разному обобщающихся за её пределы. Самый простой пример, какой бы ни была история эмпирических сигналов вознаграждения, вайрхединговая функция ценности («Мне нравится, когда есть положительный эмпирический сигнал вознаграждения!» – см. Пост №9, Раздел 9.4) ей всегда тривиально соответствует!
Или сравните «отрицательное вознаграждение за враньё» с «отрицательным вознаграждением за попадание на вранье»!
Это особенно сложная проблема для СИИ, потому что пространство всех возможных мыслей / планов обязательно заходит далеко за пределы того, что СИИ уже видел. К примеру, СИИ может прийти к идее изобрести что-то новое, или идее убить своего оператора, или идее взломать свой собственный эмпирический сигнал вознаграждения, или идее открыть червоточину в другое измерение! Во всех этих случаях функция ценности получает невозможную задачу оценить мысль, которую никогда раньше не видела. Она делает всё, что может – по сути, сравнивает паттерны кусочков новой мысли с разными старыми мыслями, по которым есть эмпирические данные. Этот процесс кажется не слишком надёжным!
Другими словами, сама суть интеллекта в придумывании новых идей, а именно там функция ценности находится в самом затруднённом положении и наиболее склонна к ошибкам.
10.5.2 Ошибки присвоения ценности
Я описал «присвоение ценности» в Посте №9, Разделе 9.3. В этом случае «присвоение ценности» – обновление функции ценности при помощи (чего-то похожего на) обучения методом Временных Разниц на основе эмпирического сигнала вознаграждения. Лежащий в основе алгоритм, как я описывал, полагается на допущение, что СИИ верно смоделировал причину вознаграждения. К примеру, если Тесса пнула меня в живот, то я могу быть несколько напуган, когда увижу её в будущем. Но если я перепутал Тессу и её близняшку Джессу, то я вместо этого буду испуган в обществе Джессы. Это была бы «ошибка присвоения ценности». Хороший пример ошибок присвоения ценности – человеческие суеверия.
Предыдущий подраздел (неоднозначность сигнала вознаграждения) описывает одну из причин, почему может произойти ошибка присвоения ценности. Есть и другие возможные причины. К примеру, ценность может приписываться только концептам в модели мира СИИ (Пост №9, Раздел 9.3), а может оказаться, что в ней попросту нет концепта, хорошо соответствующего эмпирической функции вознаграждения. В частности, это точно будет так на ранних этапах обучения, когда в модели мира СИИ вообще нет концепций ни для чего – см. Пост №2.
Это становится ещё хуже, если рефлексирующий СИИ мотивирован намеренно вызывать ошибки присвоения ценности. Причина, почему у СИИ может возникнуть такая мотивация описана ниже (Раздел 10.5.4).
10.5.3 Онтологические кризисы
Онтологический кризис – это когда часть модели мира агента должна быть перестроена на новых основаниях. Типичный человеческий пример – когда у религиозного человека кризис веры, и он обнаруживает, что его цели (например, «попасть в рай») непоследовательны («но рая нет!»).
В примере СИИ, давайте предположим, что я создал СИИ с целью «Делай то, что я, человек, хочу, чтобы ты делал». Может, СИИ изначально обладает примитивным пониманием человеческой психологии, и думает обо мне как о монолитном рациональном агенте. Тогда «Делай то, что я, человек, хочу, чтобы ты делал» – отличная хорошо определённая цель. Но затем СИИ вырабатывает более сложное понимание человеческой психологии, и понимает, что у меня есть противоречащие друг другу цели и цели, зависящие от контекста, что мой мозг состоит из нейронов, и так далее. Может, цель СИИ всё ещё «Делай то, что я, человек, хочу, чтобы ты делал», но теперь, в его обновлённой модели мира не вполне ясно, что конкретно это означает. Как это обернётся? Думаю, это неочевидно.
Неприятный (и не уникальный для них) аспект онтологических кризисов – что неизвестно, когда они проявятся. Может, развёртывание происходит уже семь лет, и СИИ был идеально полезным всё это время, и вы доверяете ему всё больше и выдаёте ему всё больше автономии, а затем СИИ вдруг читает новую философскую книгу и обращается в панпсихизм (никто не идеален!) и отображает свои существующие ценности на переконцептуализированный мир, и больше не ценит жизни людей больше, чем жизни камней, или что-то такое.
10.5.4 Манипуляция собой и своим процессом обучения
10.5.4.1 Несогласованные высокоуровневые предпочтения
Как описывалось в предыдущем посте, рефлексирующий СИИ может иметь предпочтения по поводу своих собственных предпочтений.
Предположим, что мы хотим, чтобы наш СИИ подчинялся законам. Мы можем задать два вопроса:
- Вопрос 1: Присваивает ли СИИ положительную ценность концепту «подчиняться законам» и планам, подразумевающим подчинение законам?
- Вопрос 2: Присваивает ли СИИ положительную ценность рефлексивному концепту «я ценю подчинение законам», и планам, подразумевающим, что он будет продолжать ценить подчинение законам?
Если ответы на вопросы «да и нет» или «нет и да», то это аналогично наличию эгодистонической мотивации. (Связанное обсуждение.) Это может привести к тому, что СИИ чувствует мотивацию изменить свою мотивацию, к примеру, взломав себя. Или если СИИ создан из идеально безопасного кода, запущенного на идеально безопасной операционной системе (ха-ха-ха), то он не может взломать себя, но всё ещё скорее всего может манипулировать своей мотивацией, думая мысли таким образом, чтобы влиять на свой процесс присвоения ценности (см. обсуждение в Посте №9, Разделе 9.3.3).
Если ответы на вопросы 1 и 2 – «да» и «нет» соответственно, то мы хотим предотвратить манипуляцию СИИ своей собственной мотивацией. С другой стороны, если ответы – «нет» и «да» соответственно, то мы хотим, чтобы СИИ манипулировал своей собственной мотивацией!
(Могут быть предпочтения и более высоких порядков: в принципе, СИИ может ненавидеть, что он ценит, что он ненавидит, что он ценит подчинение законам.)
Следует ли нам в общем случае ожидать появления несогласованных высокоуровневых предпочтений?
С одной стороны, предположим, что у нас изначально есть СИИ, который хочет подчиняться законам, но не обладает никаким высокоуровневым предпочтением по поводу того, что он хочет подчиняться законам. Тогда (кажется мне), очень вероятно, что СИИ станет ещё и хотеть хотеть подчиняться законам (и хотеть хотеть хотеть подчиняться законам, и т.д.). Причина: прямое очевидное последствие «Я хочу подчиняться законам» – это «Я буду подчиняться законам», чего уже хочется. Напомню, СИИ проводит рассуждения «средства-цели», так что то, что ведёт к желаемым последствиям, само становится желаемым.
С другой стороны, высокоуровневые предпочтения людей очень часто противоречат их же предпочтениям объектного уровня. Так что должен быть какой-то контекст, в котором это происходит «естественно». Я думаю, зачастую это происходит, когда у нас есть предпочтение касательно некоторого процесса, противоречащее нашему предпочтению касательно последствия этого же процесса. К примеру, может быть, у меня есть предпочтение не практиковаться в скейтбординге (например, потому что это скучно и болезненно), но также и предпочтение быть практиковавшимся в скейтбординге (например, потому что тогда я буду очень хорош в скейтбординге и смогу завоевать сердце своего школьного краша). Рассуждения «средства-цель» могут превратить второе предпочтение в предпочтение второго уровня – предпочтение иметь предпочтение практиковать скейтбординг.[6] И теперь я в эгодистоническом состоянии.
10.5.4.2 Мотивация предотвратить дальнейшее изменение ценностей
Во время онлайнового обучения СИИ (Пост №8, Раздел 8.2.2), особенно путём присвоения ценности (Пост №9, Раздел 9.3), функция ценности продолжает меняться. Это не опционально: напомню, функция ценности изначально случайна! Онлайновое обучение – то, с помощью чего мы вообще получаем хорошую функцию ценности!
К сожалению, как мы видели в Разделе 10.3.2 выше, «предотвратить изменение моих целей» – одна из тех инструментальных подцелей, которые вытекают из многих разных мотиваций, за исключением исправимых (Раздел 10.3.2.3 выше). Таким образом, кажется, нам надо найти путь, стыкующий два разных безопасных состояния:
- На ранних стадиях обучения, СИИ не обладает исправимой мотивацией (она вообще изначально случайная), но он недостаточно компетентен, чтобы манипулировать своим собственным обучением и присвоением ценности для предотвращения изменения целей.
- На поздних стадиях обучения, СИИ, мы надеемся, обладает исправимой мотивацией, так что он понимает и поддерживает процесс обновления своих целей. Следовательно, он не манипулирует процессом обновления функции ценности, несмотря на то, что он теперь достаточно умный, чтобы это делать (или манипулирует им таким образом, что мы, люди, одобрили бы).

Нам нужно состыковать два весьма различных безопасных состояния. (Источник картинки)
(Я намеренно опускаю третью альтернативу «сделать манипуляцию процессом обновления функцией ценности невозможным даже для высокоинтеллектуального замотивированного СИИ». Это было бы замечательно, но не кажется мне реалистичным.)
10.6 Проблемы с разделением на внешнее и внутреннее
10.6.1 Вайрхединг и внутренняя согласованность: Уловка-22
В предыдущем посте я упомянул следующую дилемму:
- Если Оценщики Мыслей сходятся к 100% точности предсказания вознаграждения, к которому приведёт исполнение плана, то план завайрхедиться (взломать Направляющую Подсистему и установить награду на бесконечность) будет казаться очень привлекательным, и агент это сделает.
- Если Оценщики Мыслей не сходятся к 100% точности предсказания вознаграждения, к которому приведёт исполнение плана, то это, собственно, определение внутренней несогласованности!
Я думаю, что лучший способ разобраться с этой дилеммой – это выйти за пределы дихотомии внутреннего и внешнего согласования.
В каждое возможное время Оценщик Мыслей функции ценности кодирует некую функцию, прикидывающую, какие планы хороши, а какие плохи.
Присвоение ценности хорошее, если оно увеличивает согласованность этой прикидки намерениям создателя, и плохое, если уменьшает.
Мысль «Я тайно взломаю свою собственную Направляющую Подсистему» почти точно не согласована с намерениями создателя. Так что присвоение ценности, которое приписывает положительную валентность мысли «Я тайно взломаю свою собственную Направляющую Подсистему» – это плохое присвоение ценности. Мы его не хотим. Увеличивает ли оно «внутреннюю согласованность»? Я думаю, приходится сказать «да, увеличивает», потому что оно приводит к лучшему предсказанию вознаграждения! Но меня это не волнует, я всё равно его не хочу. Оно плохое-плохое-плохое. Нам надо выяснить, как предотвратить это конкретное присвоение ценности / обновление Оценщика Мыслей.
10.6.2 Общее обсуждение
Я думаю, что тут есть более общий урок. Я думаю, что «внешнее согласование и внутреннее согласование» – это отличная начальная точка для того, чтобы думать о задаче согласования. Но это не значит, что нам следует ожидать одного решения для внешнего согласования и отдельного независимого решения для внутреннего согласования. Некоторые штуки – в частности, интерпретируемость – помогают и там, и там, создавая прямой мост между намерениями создателя и целями СИИ. Нам стоит активно искать такие вещи.
———
- К примеру, по моим определениям, «безопасность без согласованности» включает СИИ в коробке, а «согласованность без безопасности» включает «сценарий термоядерного реактора». Больше про это в следующем посте.
- Заметим, что «намерения создателя» могут быть расплывчатыми или вовсе непоследовательными. Я не буду много говорить об этой возможности в этой цепочке, но это серьёзная проблема, которая приводит к куче неприятных трудностей.
- Некоторые исследователи считают, что «правильные» проектные намерения (для мотивации СИИ) очевидны – три типичных примера это (1) «Я проектирую СИИ так, чтобы в каждый конкретный момент времени он пытался сделать то, что его человек-оператор хочет, чтобы он пытался сделать», или (2) «Я проектирую СИИ так, чтобы он разделял ценности своего человека-оператора», или (3) «Я проектирую СИИ так, чтобы он разделял коллективные ценности человечества». Затем они используют слово «согласованность» для обозначения этого конкретного качества – «он согласован с намерениями оператора» в случае (1), «он согласован с оператором» в случае (2) или «он согласован с человечеством» в случае (3).
Я избегаю такого подхода, потому что я думаю, что какая мотивация СИИ «правильная» – всё ещё открытый вопрос. К примеру, может быть возможно создать СИИ, который просто хочет выполнять конкретную определённую заранее узкую задачу (вроде изобретения лучшей солнечной панели) без захвата мира и подобного. Такой СИИ не будет «согласован» с чем-то конкретным кроме своей изначальной задачи. Но я всё же хочу использовать и в его случае слово «согласованность». Конечно, иногда я хочу поговорить о чём-то из (1,2,3), но я в таком случае использую для этого другие термины, например, (1) «исправимость по Полу Кристиано», (2) «амбициозное изучение ценностей», и (3) «CEV». - Можно обучить СИИ «сообщать мне правильный ответ» на вопросы, на которые я знаю правильный ответ, и надеяться, что это обобщится до «сообщать мне правильный ответ» на вопросы, на которые я не знаю правильного ответа. Это может сработать, но это может обобщится и до «сообщать мне ответ, который покажется мне правильным». См. «Выявление Скрытого Знания» за подробностями по этой всё ещё нерешённой проблеме (тут и продолжение).
- Для начала, то, что два СИИ находятся в состоянии конкуренции с нулевой суммой, ещё не значит, что они один из них не может взломать другого. Напоминаю про онлайновое обучение и брейншторминг: одна копия может во время дебатов додуматься до хорошей идеи, как взломать другую копию. Баланс щита и меча тут неясен. Ещё, они могут оба быть заинтересованы в взломе судьи, чтобы они оба могли получить вознаграждение! И, наконец, благодаря проблеме внутренней (не)согласованности, только то, что они она вознаграждаются за победу в дебатах, ещё не значит, что они «пытаются» выиграть дебаты. Они могут пытаться сделать что угодно другое! И в таком случае это опять не будет конкуренцией с нулевой суммой; вполне может быть, что обе копии СИИ будут хотеть одного и того же и смогут сотрудничать, чтобы это получить.
- Тут всё немного сложнее, чем я описываю. В частности, желание быть практиковавшимся в скейтбординге приведёт и к предпочтению первого порядка практиковаться, и к предпочтению второго порядка хотеть практиковаться. Аналогично, желание не практиковаться в скейтбординге (потому что это больно и болезненно) также перетечёт и в желание не хотеть практиковаться. Следовательно, будут и конфликтующие предпочтения первого уровня, и конфликтующие предпочтения второго уровня. Суть в том, что их относительные веса могут быть разными, так что «победить» на первом уровне может не та сторона, что на втором. Ну, я думаю, что это работает как-то так.
- Короткая ссылка сюда: lesswrong.ru/3031