Введение в согласование подобного-мозгу СИИ
Примечание переводчика: цепочка Стивена Бирнса «Intro to Brain-Like-AGI Safety», выкладывалась на leswrong,com с января по май 2022 года.
Предположим, мы когда-нибудь создадим алгоритм Сильного Искусственного Интеллекта с использованием принципов обучения и мышления, схожими с теми, что использует человеческий мозг. Как мы могли бы безопасно использовать такой алгоритм?
Я утверждаю, что это – открытая техническая задача, и моя цель в этой цепочке постов – довести не обладающих предшествующими знаниями читателей вплотную до переднего края нерешённых задач, как я его вижу.
Если вся эта тема кажется странной или глупой, вам стоит начать с Поста №1, который содержит определения, контекст и мотивацию. Затем Посты №2-№7 – это в основном нейробиология, а Посты №8-№15 более напрямую касаются безопасности СИИ, и заканчивается всё списком открытых вопросов и советами по тому, как включиться в эту область исследований.
1. В чём проблема и почему работать над ней сейчас?
- 1.1.1 Краткое содержание / Оглавление
- 2.1.2 Техническая задача безопасности СИИ
- 3.1.3 Подобный-мозгу СИИ
- 4.1.4 Что конкретно такое «СИИ»?
- 5.1.5 Какова вероятность, что мы однажды придём к подобному-мозгу СИИ?
- 6.1.6 Почему происшествия с СИИ – настолько серьёзное дело?
- 7.1.7 Почему думать о безопасности СИИ сейчас? Почему не подождать, пока мы не приблизимся к СИИ и не узнаем больше?
- 8.1.8 …А ещё это по-настоящему восхитительная задача!
1.1 Краткое содержание / Оглавление
Это первый из серии постов о технической задаче безопасности гипотетических будущих подобных-мозгу систем Сильного Искусственного Интеллекта (СИИ). Так что мой приоритет тут – сказать, что, чёрт побери, такое «техническая задача безопасности подобных-мозгу СИИ», что эти слова вообще значит, и с чего мне вообще беспокоиться.
Краткое содержание этого первого поста:
- В Разделе 1.2 я определяю «техническую задачу безопасности СИИ», помещаю её в контекст других видов исследования безопасности (например, изобретения пассивно-безопасных проектов атомных электростанций), и связываю её с большой картиной того, что необходимо, чтобы реализовать потенциальные выгоды СИИ для человечества.
- В Разделе 1.3 я определяю «подобные мозгу СИИ» как алгоритмы, имеющие на высоком уровне сходства с ключевыми чертами человеческого интеллекта, предположительно (хоть и не обязательно) в результате того, что будущие люди проведут реверс-инжиниринг этих аспектов человеческого мозга. Что в точности это значит будет яснее понятно из следующих постов. Я также упомяну контринтуитивную идею о том, что «подобный-мозгу СИИ» может (и, вероятно, будет) иметь радикально нечеловеческие мотивации. Я не объясню это полностью здесь, но вернусь к этой теме в конце Поста №3.
- В Разделе 1.4 я определю термин «СИИ», как он будет использоваться в этой цепочке.
- В Разделе 1.5 я рассмотрю вероятность того, что люди однажды создадут подобные мозгу СИИ, в противоположность каким-то другим видам СИИ (или просто не появлению СИИ вообще). Раздел включает семь популярных мнений по этому поводу, как от нейробиологов, так и от экспертов в ИИ / машинном обучении, и мои на них ответы.
- В Разделе 1.6 я рассмотрю происшествия с СИИ, которые стоит ожидать, если мы не решим техническую задачу безопасности СИИ. Я приведу аргументы в пользу того, что такие происшествия действительно могут быть катастрофическими, в том числе приводящими к вымиранию людей. Эта тема просто минное поле замешательства и проблем коммуникации, и я построю свой обсуждение вокруг ответов на восемь частых возражений.
- В Разделе 1.7 я рассмотрю более конкретный вопрос того, почему на следует думать о безопасности СИИ прямо сейчас. Всё же, с первого взгляда кажется, что есть хорошие поводы подождать, конкретно: (1) СИИ пока не существует, (2) СИИ будет существовать когда-нибудь в будущем, и (3) исследования безопасности СИИ будут проще, когда мы будем больше о нём знать и действительно иметь код СИИ для проведения тестов. В этом аргументе действительно что-то есть, но я считаю, что всё же очень много работы по безопасности можно и нужно сделать как можно скорее.
- В Разделе 1.8 я обосную, что безопасность подобного-мозгу СИИ - это увлекательная, восхитительная и перспективная тема, даже если вы не принимаете идею, что она важна для будущего.
1.2 Техническая задача безопасности СИИ
СИИ – сокращение для «Сильного Искусственного Интеллекта» – я рассмотрю его определение ниже в Разделе 1.4. СИИ сейчас не существует, но в Разделе 1.7 я обосную, что мы можем и нам следует готовиться к появлению СИИ уже сегодня.
Часть, о которой я буду говорить в этой цепочке – это красный прямоугольник тут:
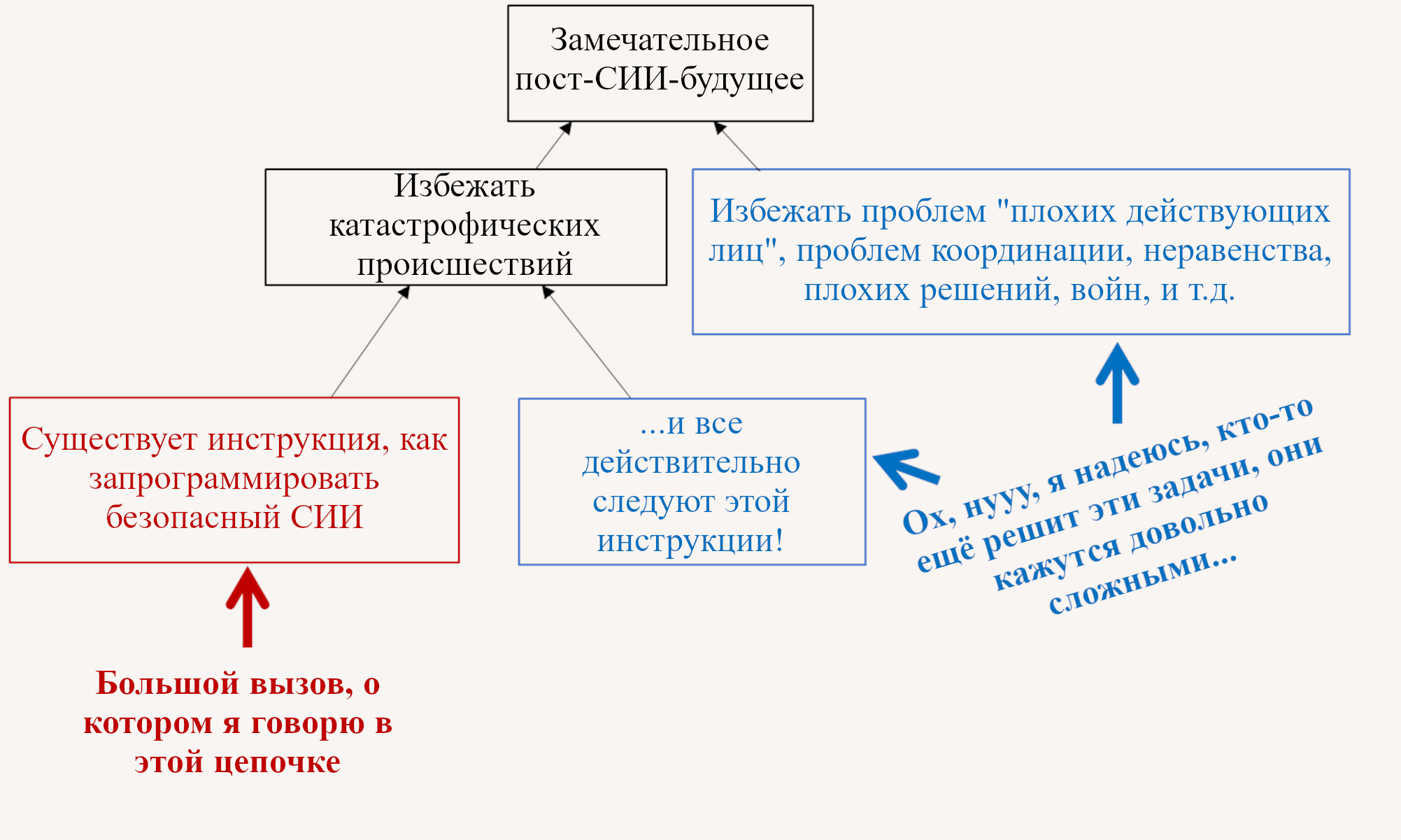
Конкретнее, мы будем представлять одну команду людей, пытающихся создать один СИИ, и стремиться, чтобы для них было возможным сделать это не вызвав какую-нибудь катастрофу, которую никто не хочет, с вышедшим из под контроля СИИ, самовоспроизводящимся через Интернет, или чем-то ещё (больше про это в Разделе 1.6).
Синие прямоугольники на диаграмме – это то, о чём я не буду говорить в этой цепочке. На самом деле, я вообще над ними не работаю – мне и так уже достаточно. Но я очень сильно одобряю, что над ними работают другие люди. Если ты, дорогой читатель, хочешь работать над ними, удачи тебе! Я болею за тебя! И вот несколько ссылок, чтобы начать: 1, 2, 3, 4, 5, 6, 7.
Возвращаясь к красному прямоугольнику. Это техническая задача, требующая технического решения. Никто не хочет катастрофических происшествий. И всё же катастрофы случаются! В самом деле, для людей совершенно возможно написать алгоритм, который делает что-то, что никто от него не хотел. Это происходит всё время! Мы можем назвать это «багом», когда это локальная проблема в коде, и мы можем назвать это «фундаментально порочным дизайном софта», когда это глобальная проблема. Позднее в цепочке я буду отстаивать позицию, что код СИИ может быть необычайно склонен к катастрофическим происшествиям, и что ставки очень высоки (см. Раздел 1.6 ниже и Пост №10).
Вот аналогия. Если вы строите атомную электростанцию, то никто не хочет вышедшей из-под контроля цепной реакции. Люди в Чернобыле точно не хотели! Но это всё равно произошло! Я извлекаю из этой аналогии несколько уроков:
- Энрико Ферми изобрёл техническое решение для контроля атомных цепных реакций – аварийные регулирующие кассеты – до создания первой атомной цепной реакции. Правильно!! Вот это значит делать вещи в нужном порядке! По той же причине, я считаю, что нам следует стремиться иметь техническое решение для избегания катастрофических происшествий с СИИ наготове до того, как начинать программировать СИИ. На самом деле, я ниже буду отстаивать даже более сильное утверждение: знать (хотя бы в общих чертах) решение за 10 лет до СИИ ещё лучше; за 20 лет до СИИ – ещё лучше; и т.д. и т.д. Это заявление неочевидно, но я к нему ещё вернусь (Раздел 1.7).
- Технические решения – это не всё-или-ничего. Некоторые снижают риск происшествий, не избавляясь от него полностью. Некоторые сложны и дороги, и подвершены ошибкам при реализации. В случае атомных реакций, аварийные регулирующие кассеты сильно снижают риск происшествий, но пассивно-безопасные реакторы снижают его ещё сильнее. Аналогично, я ожидаю, что техническая безопасность СИИ будет большой областью, в которой мы будем со временем разрабатывать всё более хорошие подходы, используя множество техник и множество слоёв защиты. По крайней мере, я надеюсь! Дальше в цепочке я заявлю, что прямо сейчас у нас нет никакого решения – даже примерного. У нас полно работы!
- Синие прямоугольники (см. диаграмму выше) тоже существуют, и они совершенно необходимы, хоть и находятся за пределами рассмотрения этой конкретной серии статей. Причиной Чернобыля было не то, что никто не знал, как контролировать цепную атомную реакцию, а то, что лучшим практикам не следовали. В таком случае, мы все в пролёте! Всё же, хоть техническая сторона не может сама по себе решить проблему невыполнения, мы можем несколько с ней помочь, разрабатывая лучшие практики минимально дорогими и с максимальной защитой от дурака.

В *Ученике Чародея*, если я правильно его помню, программный инженер Микки Маус программирует СИИ с метлоподобным роботизированным телом. СИИ делает в точности то, что Микки *запрограммировал* его делать («наполнить ведро водой»), но это оказалось сильно отличающимся от того, что Микки от него *хотел* («наполнить ведро водой, не устроив беспорядок и не делая чего-то ещё, что я бы счёл проблематичным, и т.д.»). Наша цель – дать программным инженерам вроде Микки *возможность* избегать подобных инцидентов, снабдив их необходимыми для этого инструментами и знаниями. См. эту лекцию Нейта Соареса для глубокого обзора того, почему перед Микки ещё полно работы.
1.3 Подобный-мозгу СИИ
1.3.1 Обзор
Эта цепочка фокусируется на конкретном сценарии того, как будут выглядеть алгоритмы СИИ:
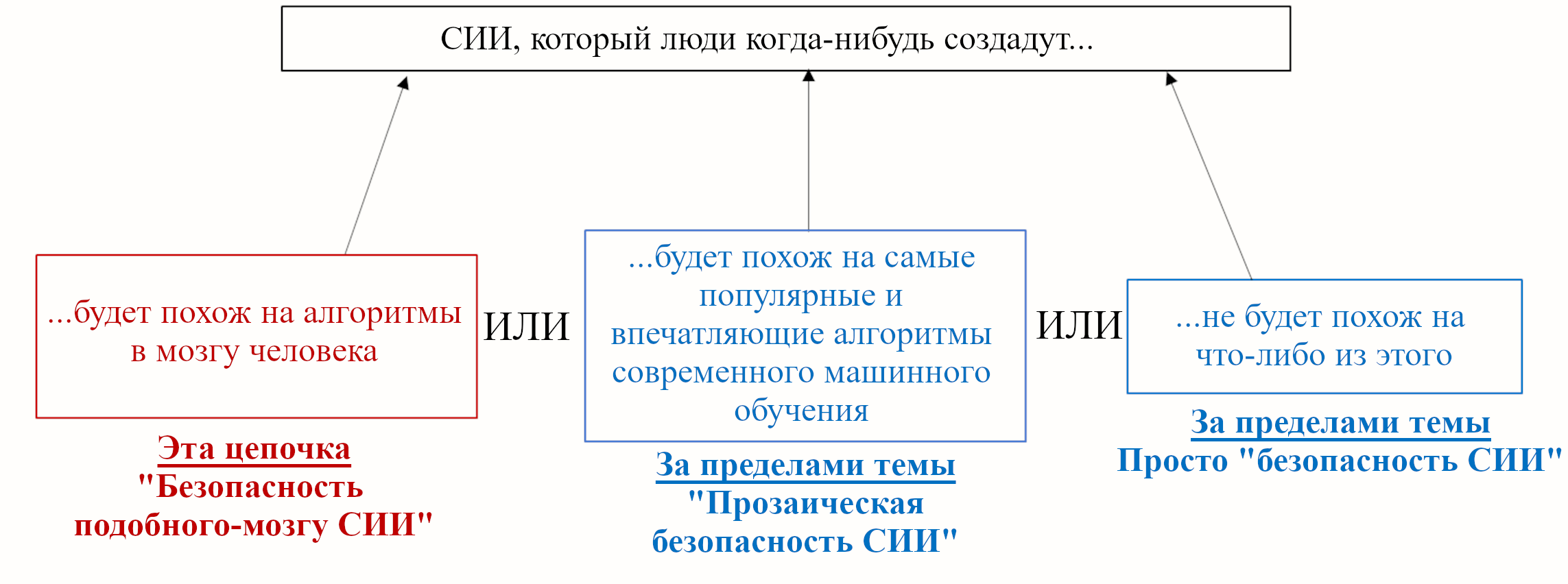
Красный прямоугольник – то, о чём я говорю тут. Синие прямоугольники находятся за пределами рассмотрения данной цепочки.
У вас может быть своё мнение о том, какие из этих категорий более или менее вероятны, или даже невозможны, или вообще имеет ли это разделение смысл. У меня оно тоже есть! Я опишу его позже (Раздел 1.5). Но его основа – что все три варианта в достаточной степени вероятны, чтобы нам следовало к ним готовиться. Так что хоть я лично и не делаю много работы в этих синих прямоугольниках, я уж точно рад, что это делают другие!
Вот аналогия. Если бы кто-то в 1870 пытался бы догадаться, как будет выглядеть будущий человеческий полёт…
- «Что-то вроде птиц» было бы осмысленным предположением…
- «Что-то вроде лучших нынешних летательных аппаратов» было бы тоже осмысленным предположением…
- «Ни то, ни другое» было бы ещё одним осмысленным предположением!!
В этом конкретном воображаемом случае, все три предположения оказались бы частично верны, а частично ошибочны: братья Райт активно напрямую вдохновлялись большими парящими птицами, но отбросили махание крыльями. Они также использовали некоторые компоненты уже существовавших аппаратов (например, пропеллеры), но и прилично своих оригинальных деталей. Это всего один пример, но мне кажется, что он убедительный.
1.3.2 Что в точности такое «подобный-мозгу СИИ»?
Когда я говорю «подобный-мозгу СИИ», я имею в виду нечто конкретное. Это станет яснее в следующих постах, после того, как мы начнём погружаться в нейробиологию. Но вот, в общих чертах, о чём я:
Есть некоторые составляющие в человеческом мозгу и его окружении, которые приводят к тому, что у людей есть обобщённый интеллект (например, здравый смысл, способность что-то понимать, и т.д. – см. Раздел 1.4 ниже). В представляемом мной сценарии исследователи выясняют, что это за составляющие и как они работают, а потом пишут код ИИ, основываясь на этих же ключевых составляющих.
Для прояснения:
- Я не ожидаю, что «подобный мозгу СИИ» будет включать каждую часть мозга и его окружения. К примеру, есть высокоинтеллектуальные люди, рождённые без чувства запаха, из чего можно сделать вывод, что цепи обработки ольфакторной информации не необходимы для СИИ. Есть и высокоинтеллектуальные парализованные с рождения люди, так что большинство спинного мозга и некоторые аспекты ощущения тела тоже не необходимы. Есть люди, рождённые без мозжечка, несмотря на это вполне попадающие в диапазон нормального интеллекта взрослого человека (способные работать, независимо жить и т.д. – способности, которые мы бы без сомнений назвали бы «СИИ»). Другие взрослые ходят на работу, будучи лишёнными целого полушария мозга, и т.д. Моё ожидание по умолчанию – что СИИ будет создан людьми, пытающимися создать СИИ, и они отбросят столько компонентов, сколько возможно, чтобы сделать свою работу проще. (Я не утверждаю, что это обязательно хорошая идея, только что этого я ожидаю по умолчанию. Подробнее об этом в Посте №3.)
- В частности, «подобный мозгу СИИ», о котором я говорю – это точно не тоже самое, что Полная Эмуляция Мозга.
- Я не требую, чтобы «подобный-мозгу СИИ» напоминал человеческий мозг в низкоуровневых деталях, вроде импульсных нейронов, дендритов, и т.д., или их прямых симуляций. Если сходство есть только на высоком уровне, хорошо, это тут ни на что не повлияет.
- Я не требую, чтобы «подобный мозгу СИИ» был изобретён процессом реверс-инжиниринга мозга. Если исследователи ИИ независимо переизобретут схожие с исполняемыми в мозгу алгоритмами – просто потому, что это хорошие идеи – что ж, я всё ещё буду считать результат подобным-мозгу.
- Я не требую, чтобы «подобный мозгу СИИ» был спроектирован способом, напоминающим то, как был спроектирован мозг, т.е. эволюционным поиском. Даже наоборот: моё рабочее допущение – что он будет спроектирован людьми способом, сходным с типичными проектами машинного обучения сегодня: много написанного людьми кода (очень приблизительно аналогичного геному), часть которого определяет выведение и правила обновлений одного или нескольких алгоритмов обучения (соответствующих алгоритмам обучения мозга во время жизни). В коде могут быть какие-то пустые места, заполняемые поиском гиперпараметров или нейронной архитектуры и т.п. Потом код запускают, и обучающие алгоритмы постепенно создают большую сложно устроенную обученную модель, возможно, с триллионами настраиваемых параметров. Больше об этом в следующих двух постах и Посте №8.
- Я не требую, чтобы «подобный-мозгу СИИ» имел самосознание. Есть этические причины беспокоиться об осознанности СИИ (больше об этом в Посте №12), но всё, что я говорю в этой цепочке, не зависит от этого. Машинное сознание – большая спорная тема, и я не хочу в неё тут погружаться. (Я написал немного об этом в другом месте.)
Я собираюсь много чего заявить про алгоритмы в основе человеческого интеллекта, и потом говорить о безопасном использовании алгоритмов с этими свойствами. Если наши будущие алгоритмы СИИ будут иметь эти свойства, то эта цепочка будет полезна, и я буду склонен называть такие алгоритмы «подобными мозгу». Мы увидим, что это в точности за свойства дальше.
1.3.3 «Подобный мозгу СИИ» (по моему определению) может (и очень возможно, что будет) иметь радикально нечеловеческие мотивации
Я собираюсь много говорить об этом в следующих статьях, но это настолько важно, что я хочу поднять эту тему немедленно.
Да, я знаю, это звучит странно.
Да, я знаю, вы думаете, что я чокнутый.
Но пожалуйста, прошу вас, сначала выслушайте. К моменту, когда мы доберёмся до Поста №3, тогда вы сможете решать, верить мне или нет.
На самом деле, я пойду дальше. Я отстаиваю позицию, что «радикально нечеловеческие мотивации» не просто возможны для подобного-мозгу СИИ, но и являются основным ожиданием от него. Я считаю, что это в целом плохо, и что для избегания этого нам следует проактивно приоритезировать конкретные направления исследований и разработок.
(Для ясности, «радикально нечеловеческие мотивации» - это не синоним «пугающих и опасных мотиваций». К сожалению, «пугающие и опасные мотивации» – тоже моё основное ожидание от подобного-мозгу СИИ!! Но это требует дальнейшей аргументации, и вам придётся подождать её до Поста №10.)
1.4 Что конкретно такое «СИИ»?
Частый источник замешательства – слово «Обобщённый» в «Обобщённом Искусственном Интеллекта» (по-русски устоялось словосочетание «Сильный Искусственный Интеллект», поэтому аббревиатуру я перевожу как СИИ, но вообще в оригинале он General – прим.пер.):
- Слово «Обобщённый» ОЗНАЧАЕТ «не специфичный», как «Говоря обобщённо, в Бостоне жить хорошо.»
- Слово «Обобщённый» НЕ ОЗНАЧАЕТ «универсальный», как в «Я нашёл обобщённое доказательство теоремы.»
СИИ не «обобщённый» во втором смысле. Это не штука, которая может мгновенно обнаружить любой паттерн и решить любую задачу. Люди тоже не могут! На самом деле, никакой алгоритм не может, потому что это фундаментально невозможно. Вместо этого, СИИ – это штука, которая, встретившись с сложной задачей, может быть способна легко её решить, но если нет, то может быть она способна создать инструмент для решения задачи, или найти умный способ обойти задачу, и т.д. В наших целях можно думать о СИИ как об алгоритме, который может «разобраться в вещах» и «понять, что происходит» и «сделать дело», в том числе с использованием языка, науки и технологии, способом, напоминающим то, как это может делать большинство взрослых людей, но не могут младенцы, шимпанзе и GPT-3. Конечно, алгоритмы СИИ вполне могут быть в чём-то слабее людей и сверхчеловеческими в чём-то другом.
В любом случае, эта цепочка – про подобные-мозгу алгоритмы. Эти алгоритмы по определению способны на совершенно любое интеллектуальное поведение, на которое способны люди, и потенциально на куда большее. Так что они уж точно достигают уровня СИИ. А вот сегодняшние ИИ-алгоритмы не являются СИИ. Так что где-то посередине есть неясная граница, отделяющая «СИИ» от «не СИИ». Где точно? Мой ответ: я не знаю, и мне всё равно. Проведение этой линии никогда не казалось мне полезным. Так что я не вернусь к этому в цепочке.
1.5 Какова вероятность, что мы однажды придём к подобному-мозгу СИИ?
Выше (Раздел 1.3.1) я предложил три категории алгоритмов СИИ: «подобные мозгу» (определённые выше), «прозаические» (т.е. подобные современным наиболее впечатляющим глубоким нейросетевым алгоритмам машинного обучения), и «другие».
Если ваше отношение – «Да, давайте изучать безопасность для всех трёх возможностей, просто на всякий случай!!» – как, по-моему, и надо – то, наверное, не так уж важно для принятия решений, как между этими возможностями распределена вероятность.
Но даже если это не важно, об этом интересно поговорить, так что почему нет, я просто быстро перескажу и отвечу на некоторые популярные известные мне мнения на этот счёт.
Мнение №1: «Я оспариваю предпосылку: человеческий мозг работает в целом по тем же принципам, что и нынешние популярные алгоритмы машинного обучения.»
- В первую очередь, «нынешние популярные алгоритмы машинного обучения» – это зонтичный термин, включающий в себя много разных алгоритмов. К примеру, я едва ли вижу хоть какое-то пересечение у «безопасности подобного-GPT-3 СИИ» и «безопасности подобного-мозгу СИИ», но вижу у второго значительное пересечение с «безопасностью подобного-агенту-основанного-на-модели-обучения-с-подкреплением СИИ».
- В любом случае, предполагая «подобный-мозгу СИИ» я могу делать некоторые предположения о его когнитивной архитектуре, внутренних отображениях, обучающих алгоритмах, и так далее.
- Некоторые из этих «ингредиентов подобного-мозгу СИИ» – повсеместные части нынешних популярных алгоритмов машинного обучения (например, алгоритмы обучения; распределённые отображения).
- Другие из этих «ингредиентов подобного-мозгу СИИ» – представлены (по отдельности) в некотором подмножестве нынешних популярных алгоритмов машинного обучения, но отсутствуют в других (например, обучение с подкреплением; предсказывающее обучение [так же известное как самообучение]; явное планирование).
- А ещё некоторые из этих «ингредиентов подобного-мозгу СИИ» кажутся в основном отсутствующими в нынешних самых популярных алгоритмах машинного обучения (например, способность формировать «мысли» [вроде «Я собираюсь пойти в магазин»], которые совмещают немедленные действия, краткосрочные и долгосрочные предсказания и гибкие иерархические планы в генеративной модели мира, поддерживающей причинные, гипотетические и метакогнитивные рассуждения).
- Так что в этом смысле «подобный мозгу СИИ» – это конкретная штука, которая может случиться или не случиться независимо от «прозаического СИИ». Больше про «подобный мозгу СИИ», или, по крайней мере, его важные для безопасности аспекты, в следующих постах.
Мнение №2: «Подобный-мозгу СИИ» возможен, а Прозаический – нет. Этого просто не будет. Современное исследование машинного обучения – не путь к СИИ, точно так же, как забираться на дерево – не путь на Луну.»
- Это кажется мне умеренно популярным мнением среди нейробиологов и когнитивных психологов. Видные защитники этой точки зрения – это, например, Гэри Маркус и Мелани Митчелл.
- Один вопрос: если мы возьмём одну из нынешних самых популярных моделей машинного обучения, не будем добавлять никаких значительных озарений или изменений архитектуры, и просто масштабируем её на ещё больший размер, получим ли мы СИИ? Я присоединяюсь к этим нейробиологам в ожидании ответа «наверное, нет».
- С другой стороны, даже если окажется, что глубокие нейросети не могут делать важные-для-интеллекта штуки X, Y и Z, то ну серьёзно, кто-нибудь наверное просто приклеит к глубоким нейросетям другие компоненты, которые делают X, Y и Z. И у нас останется лишь какой-то бессмысленный спор об определениях, о том, «действительно» ли это прозаический СИИ или нет.
- В любом случае, в этой цепочке я буду предполагать, что СИИ будет иметь некоторые алгоритмические черты (например, онлайновое обучение, разновидность основанного на модели планирования, и т.д. Больше об этом в следующих постах). Я буду предполагать это, потому что (1) эти черты – части человеческого интеллекта, (2) кажется, что они в нём не зря. Мои относящиеся к безопасности рассуждения будут полагаться на наличие этих черт. Могут ли алгоритмы с этими чертами быть реализованы в PyTorch на GPU? Ну, мне всё равно.
Мнение №3: «Прозаический СИИ появится настолько скоро, что другие программы исследований не имеют ни шанса.»
- Некоторое подмножество людей в области машинного обучения считают так. Я нет. Или, по крайней мере, я был бы ужасно удивлён.
- Я согласен, что ЕСЛИ прозаический СИИ, скажем, в пяти годах от нас, то нам почти точно не надо думать о подобном мозгу СИИ или о любой иной программе исследований. Я просто думаю, что это ну очень большое «если».
Мнение №4: «Мозги НАСТОЛЬКО сложные – и мы понимаем о них НАСТОЛЬКО мало после НАСТОЛЬКО больших усилий – что мы никак не можем получить подобный мозгу СИИ даже за следующие 100 лет.»
- Это довольно популярное мнение, как внутри, так и снаружи нейробиологии. Я думаю, что оно крайне неверно, и буду спорить с ним в следующих двух постах.
Мнение №5: «Нейробиологи не пытаются изобрести СИИ, так что нам не следует ожидать, что они это сделают».
- В этом есть какая-то правда, но в основном я не соглашусь. Для начала, некоторое количество ведущих вычислительных нейробиологов (команда нейробиологии DeepMind, Рэндалл О’Райли, Джефф Хокинс, Дайлип Джордж) на самом деле явно пытаются изобрести СИИ. Во-вторых, люди в области ИИ, включая влиятельных лидеров области, стараются иметь в виду нейробиологическую литературу и осваивать её идеи. И в любом случае, «понять мозговой алгоритм, важный для СИИ» – это часть изобретения подобного-мозгу СИИ, независимо от того, пытается ли это сделать человек, проводящий исследование.
Мнение №6: «Подобный-мозгу СИИ – не вполне имеющий смысл концепт; интеллект требует телесного воплощения, не просто мозга в банке (или на чипе).»
- Дебаты о «телесном воплощении» в нейробиологии всё продолжаются. Я принимаю позицию где-то посередине. Я думаю, что будущие СИИ будут иметь какое-то пространство действий – вроде способности (виртуально) призвать конкретную книгу и открыть её на конкретном месте. Я не думаю, что обладание целым буквальным телом важно – к примеру, Кристофер Нолан (1965-2009) был парализован всю жизнь, что не помешало ему быть известным писателем и поэтом. Что важнее, я ожидаю, что какие бы аспекты телесного воплощения ни оказались важны для интеллекта, их можно будет легко встроить в подобный-мозгу СИИ, запущенный на кремниевом чипе. Тело всё же необходимо для интеллекта? ОК, ладно, давайте дадим СИИ виртуальное тело в виртуальном мире. Гормональные сигналы необходимы для интеллекта? ОК, хорошо, мы можем закодировать виртуальные гормональные сигналы. И т.д., и т.п.
Мнение №7: «Подобный-мозгу СИИ несовместим с обычными кремниевыми чипами, он потребует новой аппаратной платформы, основанной на импульсных нейронах, активных дендритах, и т.д. Нейроны попросту лучше в вычислениях, чем кремниевые чипы – просто посмотри на энергетическую эффективность и подобное.»
- Я довольно плохо отношусь к этой позиции. Стандартные кремниевые чипы точно могут симулировать биологические нейроны – нейробиологи всё время это делают. По-видимому, они также могут исполнять «подобные мозгу алгоритмы», используя иные низкоуровневые операции, более подходящие для этого «железа» – так же как один и тот же код на C можно скомпилировать для разных наборов инструкций процессоров. Касательно же «нейроны попросту лучше», я вполне признаю, что человеческий мозг выполняет чертовски впечатляющее количество вычислений для своего крохотного объёма, массы и потребления энергии. Но это всё не жёсткие ограничения! Если СИИ на кремниевых чипах будет буквально в 10000 раз больше по объёму, массе и потреблению энергии, чем человеческий мозг сравнимой интеллектуальной мощности, то я не думаю, что кому-то было бы дело до меньшей эффективности – в частности, стоимость потребляемого им электричества была бы всё ещё меньше минимальной зарплаты в моём регионе!! И моя лучшая оценка такова, что покупка достаточного количества кремниевых чипов для осуществления того же объёма вычислений, что выполняет человеческий мозг за всю жизнь, скорее всего легко доступна, или будет легко доступна в следующем десятилетии, даже для маленьких компаний. Ключевая причина, по которой маленькие компании не создают СИИ сегодня – мы не знаем правильных алгоритмов.
Это просто быстрый обзор; каждое из этих мнений можно растянуть на отдельную статью – да что там, на целую книгу. Что касается меня, я оцениваю вероятность, что у нас будет достаточно подобный мозгу СИИ, чтобы эта цепочка была к месту, более чем в 50%. Но, конечно, кто знает.
1.6 Почему происшествия с СИИ – настолько серьёзное дело?
Две причины: (1) ставки высоки, и (2) задача трудна. Я буду говорить о (2) куда позже в цепочке (Посты №10-11). Давайте поговорим про (1).
И давайте поговорим конкретнее про возможность одной высокой ставки: риск человеческого вымирания. Это звучит немного дико, но послушайте.
Я оформлю это как ответы на популярные возражения:
Возражение №1: Единственный способ, которым вышедший из под контроля СИИ может привести к вымиранию людей – это если СИИ изобретёт сумасшедшее фантастическое супероружие, например, серую слизь. Как будто это вообще возможно!
О, если бы это было так! Но увы, я не думаю, что фантастическое супероружие невозможно. На самом деле, мне кажется, что где-то примерно на границе возможного для человеческого интеллекта использовать существующие технологии для вымирания человечества!
Подумайте об этом: для амбициозного харизматичного методичного человека уже по крайней мере недалеко от границ возможного устроить производство и высвобождение новой заразной болезни в 100 раз смертельнее, чем COVID-19. Чёрт побери, наверное, возможно выпустить 30 таких болезней одновременно! В то же время, я думаю, хотя бы на границах возможного для амбициозного умного харизматичного человека и найти способ манипулировать системами раннего оповещения о ядерном ударе (обмануть, взломать, подкупить или запугать операторов, и т.д.), устроив полноценную ядерную войну, убив миллиарды людей и посеяв в мире хаос. Это всего лишь два варианта, креативный читатель немедленно придумает ещё немало. В смысле, серьёзно, есть художественные книги с совершенно правдоподобными апокалиптическими безумноучёновскими сценариями, не согласно лишь моему мнению, но согласно экспертам в соответствующих областях.
Теперь, ну принято, вымирание выглядит очень сложнодостижимым требованием! Люди живут в куче разных мест, в том числе на маленьких тропических островах, которые были бы защищены и от ядерной зимы, и от эпидемий. Но тут мы вспомним о большой разнице между интеллектуальным агентом, вроде СИИ и неинтеллектуальным, вроде вируса. Оба могут самовоспроизводиться. Оба могут убить кучу людей. Но СИИ, в отличии от вируса, может взять управление военными дронами и перебить выживших!!
Так что я подозреваю, что мы всё ещё тут в основном из-за того, что самые амбициозные умные харизматичные методичные люди не пытаются всех убить, а не из-за того, что «убить всех» – задача, требующая сумасшедшего фантастического супероружия.
Как описано выше, один из возможных вариантов провала, которые я себе представляю, включает в себя вышедший из-под контроля СИИ, сочетающий интеллект (как минимум) человеческого уровня с радикально нечеловеческими мотивациями. Это была бы новая для мира ситуация, и она не кажется мне комфортной!
Вы можете возразить: То, что пошло не так в этом сценарии – это не вышедший из-под контроля СИИ, это факт того, что человечество слишком уязвимо! И моим ответом будет: Одно другому не мешает! Так что: да, нам совершенно точно следует делать человечество более устойчивым к искусственно созданным эпидемиям и уменьшать шансы атомной войны, и т.д., и т.п. Всё это – замечательные идеи, которые я сильно одобряю, и удачи вам, если вы над ними работаете. Но в то же время, нам следует ещё и очень много работать над тем, чтобы не создать вышедший из-под контроля самовоспроизводящийся подобный-человеку интеллект с радикально нечеловеческими мотивациями!
…О, и ещё одно: может быть, «сумасшедшее фантастическое супероружие вроде серой слизи» тоже возможно! Не знаю! Если так, нам надо быть ещё более осторожными!
Возражение №2: Единственный способ, которым происшествие с СИИ может привести к вымиранию людей – это если СИИ каким-то образом умнее всех людей вместе взятых.
Проблема тут в том, что «все люди вместе взятые» могут не знать, что участвуют в битве против СИИ. Могут знать, а могут и нет. Если СИИ вполне компетентен в секретности, то он скорее организует неожиданную атаку, чтобы никто не знал, что происходит, пока не станет слишком поздно. Или, если СИИ вполне компетентен в дезинформации и пропаганде, он предположительно сможет представить свои действия как несчастные случаи, или как (человеческие) враждебные действия. Может быть, все будут обвинять кого-то ещё, и никто не будет знать, что происходит.
Возражение №3: Единственный способ, которым происшествие с СИИ может привести к вымиранию людей – если СИИ намеренно дадут доступ к рычагам влияния, вроде кодов запуска ядерных ракет, контроля над социальными медиа, и т.д. Но мы также можем запустить код СИИ на всего одном сервере, и потом выключить его, если что-то пойдёт не так.
Проблема тут в том, что интеллектуальные агенты могут превратить «мало ресурсов» в «много ресурсов». Подумайте о Уоррене Баффетте или Адольфе Гитлере.
Интеллектуальные агенты могут зарабатывать деньги (легально или нет), зарабатывать доверие (заслуженное или нет) и получать доступ к другим компьютерам (приобретая серверное время или взламывая их). Последнее особенно важно, потому что СИИ – как вирус, но не как человек – потенциально может самовоспроизводиться. Самовоспроизведение – один из способов, которыми он может защитить себя от выключения, если он на это мотивирован. Другой способ – обмануть / ввести в заблуждение / склонить на свою сторону / подкупить / перехитрить того, кто контролирует кнопку выключения.
(Зерно истины тут в том, что если мы не уверены в мотивации и компетентности СИИ, то давать ему доступ к кодам запуска – очень плохая идея! Попытки ограничить власть и ресурсы СИИ не кажутся решением ни одной из сложнейших интересующих нас тут задач, но это всё ещё может быть как-то полезно, вроде «дополнительного слоя защиты». Так что я целиком за.)
Возражение №4: Хорошие СИИ могут остановить плохих вышедших-из-под-контроля СИИ.
Для начала, если мы не решим техническую проблему того, как направлять мотивацию СИИ и удерживать его под контролем (см. Посты №10-15), то может случиться так, что некоторое время хороших СИИ нет! Вместо этого, все СИИ будут вышедшими из-под контроля!
Вдобавок, вышедшие из-под контроля СИИ будут иметь асимметричные преимущества над хорошими СИИ – вроде возможности красть ресурсы, манипулировать людьми и социальными институтами ложью и дезинформацией; начинать войны, пандемии, блэкауты, выпускать серую слизь, и так далее; и отсутствия необходимости справляться с трудностями координации многих разных людей с разными убеждениями и целями. Больше на эту тему – тут.
Возражение №5: СИИ, который пытается всех убить – это очень конкретный вариант провала! Нет причин считать, что СИИ попробует это сделать. Это не то, что произойдёт как общий результат забагованного или плохо спроектированного софта СИИ. Такое произойдёт только, если кто-то намеренно вложит в СИИ злобные мотивации. На самом деле, забагованный или плохо спроектированный софт обычно делает, ну, ничего особенного! Я знаю кое-что про забагованный софт – я вообще-то написал один сегодня с утра. Единственное, что было убито – моя самооценка!
Тут есть зерно истины в том, что некоторые баги или недостатки проектирования в коде СИИ действительно приведут к тому, что получившийся софт не будет СИИ, не будет «интеллектуальным», и, возможно, даже не будет функционировать! Такие ошибки не считаются катастрофическими происшествиями, если только мы не оказались настолько глупы, что поставили этот софт управлять ядерным арсеналом. (См. «Возражение №3» выше.)
Однако, я утверждаю, что другие баги / ошибки проектирования будут потенциально вести к тому, что СИИ намеренно будет всех убивать, даже если его создатели – разумные люди с благородными скромными намерениями.
Почему? В области безопасности СИИ классический способ это обосновать – это триада из (1) «Тезиса Ортогональности», (2) «Закона Гудхарта» и (3) «Инструментальной Конвергенции». Вы можете ознакомиться с короткой версией этого тройного аргумента тут. Для длинной версии, читайте дальше: эта цепочка вся про детали мотивации подобного мозгу СИИ, и про то, что там может пойти не так.
Так что запомните эту мысль, мы проясним её к тому моменту, как пройдём Пост №10.
Возражение №6: Если создание СИИ кажется спусковым крючком катастрофических происшествий, то мы просто не будем этого делать, до тех пор, пока (если) не решим проблему.
Моя немедленная реакция: «Мы»? Кто, чёрт побери, такие «Мы»? Занимающееся ИИ сообщество состоит из многих тысяч способных исследователей, рассеянных по земному шару. Они расходятся друг с другом во мнениях практически о чём угодно. Никто не присматривает за тем, что они делают. Некоторые из них работают в секретных военных лабораториях. Так что я не думаю, что мы можем принять за данность, что «мы» не будем проводить разработки, которые вы и я считаем очевидно необдуманными и рискованными.
(К тому же, если от некоторых катастрофических происшествий нельзя восстановиться, то даже одно такое – слишком много.)
К слову, если предположить, что кто-то скажет мне «У меня есть экстраординарно амбициозный план, который потребует многих лет или десятилетий работы, но если мы преуспеем, то «Все на Земле ставят разработку СИИ на паузу, пока не будут решены задачи безопасности» будет возможной опцией в будущем» – ОК, конечно, я бы с готовностью выслушал. По крайней мере, этот человек говорит так, будто понимает масштаб вызова. Конечно, я ожидаю, что это скорее всего провалится. Но кто знает?
Возражение №7: Риски происшествий падают и падают уже на протяжении десятилетий. Ты не читал Стивена Пинкера? Имей веру!
Риски не решают сами себя. Они решаются, когда их решают люди. Самолёты обычно не падают. потому что люди сообразили, как избегать падения самолётов. Реакторы атомных электростанций обычно не плавятся потому, что люди сообразили, как избежать и этого.
Представьте, что я сказал: «Хорошие новости, уровень смертей в автокатастрофах сейчас ниже, чем когда либо! Так что теперь мы можем избавиться от ремней безопасности, зон деформации и дорожных знаков!». Вы бы ответили: «Нет!! Это безумие!! Ремни безопасности, зоны деформации и дорожные знаки – это и есть причина того, что смертей в автокатастрофах меньше, чем когда либо!»
Точно так же, если вы оптимистичны и считаете, что мы в итоге избежим происшествий с СИИ, то это не причина возражать против исследований безопасности СИИ.
Есть ещё кое-что, что надо держать в голове, прежде чем находить утешение в исторических данных о рисках технологических происшествий: пока технология неумолимо становится могущественнее, масштабы урона от технологических происшествий также неумолимо растут. Происшествие с атомной бомбой было бы хуже, чем с конвенционной. Биотеррорист с технологией 2022 года был бы способен нанести куда больший ущерб, чем биотеррорист с технологией 1980 года. Точно так же, раз ИИ системы в будущем станут значительно более мощными, нам следует ожидать, что масштаб урона от происшествий с ними так же будет расти. Так что исторические данные не обязательно правильно отображают будущее.
Возражение №8: Люди всё равно обречены. И вообще, никакой вид не живёт вечно.
Я много встречал вариации этого. И, ну да, я не могу доказать, что это неверно. Но мечехвосты вот существуют уже половину миллиарда лет. Давайте, люди, мы так можем! В любом случае, я без боя сдаваться не собираюсь!
А для людей, принимающих “далёкое” отчуждённое философско-кресельное отношение к человеческому вымиранию: если вас опустошила бы безвременная смерть вашего лучшего друга или любимого члена семьи… но вас не особенно заботит идея вышедшего из-под контроля СИИ, убивающего всех… эммм, я не уверен, что тут сказать. Может, вы не очень осторожно всё продумали?
1.7 Почему думать о безопасности СИИ сейчас? Почему не подождать, пока мы не приблизимся к СИИ и не узнаем больше?
Это частое возражение, и в нём действительно есть огромное зерно истины: в будущем, когда мы будем знать больше деталей об устройстве СИИ, будет много новой технической работы по безопасности, которую мы не можем сделать прямо сейчас.
Однако, есть работа по безопасности, которую мы можем сделать прямо сейчас. Просто продолжайте читать эту цепочку, если не верите мне!
Я хочу заявить, что работу по безопасности, которую мы можем делать прямо сейчас, действительно стоит делать прямо сейчас. Ждать куда хуже, даже если до СИИ ещё много десятилетий. Почему? Три причины:
Причина поторопиться №1: Ранние наводки по поводу безопасности могут влиять на решения при исследовании и разработке, включая «Дифференцированное Технологическое Развитие».

Самое важное, что уж точно есть более чем один способ запрограммировать алгоритм СИИ.
Очень рано в этом процессе мы принимаем высокоуровневые решения о пути к СИИ. Мы можем вести исследования и разработку к одной из многих вариаций «подобного мозгу СИИ», как определено здесь, или к полной эмуляции мозга, или к разным видам «прозаического СИИ» (Раздел 1.3.1), или к СИИ, основанному на запросах к графу базы данных, или к системе знания / дискуссии / рассуждения, мы можем использовать или не использовать различные интерфейсы мозг-компьютер, и так далее. Вероятно, не все из этих путей осуществимы, но тут уж точно есть более чем один путь к более чем одной возможной точке назначения. Нам надо выбрать по какому пути пойти. Чёрт, мы даже решаем, создавать ли СИИ вообще! (Однако, смотри «Возражение №6» выше)
На самом деле, мы принимаем эти решения уже сейчас. Мы принимаем их годами. И наша процедура принятия решений такова, что много отдельных людей по всему миру спрашивают себя: какое направление исследований и разработки лучше всего для меня прямо сейчас? Что принесёт мне работу / повышение / выгоду / высокоцитируемую публикацию прямо сейчас?
Получше была бы такая процедура принятия решений: какой СИИ мы хотим однажды создать? ОК! Давайте попробуем прийти к этому раньше всех плохих альтернатив.
Другими словами, те, кто выбирает направление исследований и разработки, основываясь на том, что выглядит интересным и многообещающим, так же как все остальные, не поменяют путь развития нашей технологии. Они просто проведут нас по тому же пути немного быстрее. Если мы думаем, что некоторые точки назначения лучше других, скажем, если мы пытаемся избежать будущих полностью неподконтрольных СИИ с радикально нечеловеческими мотивациями – то важно выбрать, какие исследования делать, чтобы стратегически ускорить то, что мы хотим, чтобы произошло. Этот принцип называется дифференцированное технологическое развитие – или, более обобщённо, дифференцированный интеллектуальный прогресс.

У меня есть мои собственные предварительные идеи о том, что следует ускорять, чтобы с подобным-мозгу СИИ всё получилось получше. (Я доберусь до этого подробно позже в цепочке.) Но главное, в чём я убеждён: «нам нужно отдельно ускорять работу над выяснением, какую работу следует отдельно ускорять»!! К примеру, будет ли подобный мозгу СИИ склонным к катастрофическим происшествиям или нет? Нам надо выяснить! Потому я и пишу эту цепочку!
Причина поторопиться №2: Мы не знаем, сколько времени займёт исследование безопасности.
Как будет описано куда подробнее в позднейших постах (особенно в Постах №10-15), сейчас неизвестно, как создать СИИ, который надёжно будет пытаться делать то, что мы от него хотим. Мы не знаем, как долго займёт выяснение этого (или доказательство невозможности!). Кажется важным начать сейчас.

Как будет описано позже в цепочке (особенно в Постах №10-15), Безопасность СИИ выглядит очень заковыристой технической задачей. Мы сейчас не знаем, как её решить – на самом деле, мы даже не знаем, решаема ли она. Так что кажется мудрым заточить свои карандаши и приняться за работу прямо сейчас, а не ждать до последнего. Концепт мема украден отсюда
Запомнившаяся аналогия Стюарта Расселла: представьте, что мы получили сообщение от инопланетян «Мы летим к вам на наших космических кораблях, и прибудем через 50 лет. Когда мы доберёмся, мы радикально преобразуем весь ваш мир до неузнавания.» И мы в самом деле видим их корабли в телескопы. Они становятся ближе с каждым годом. Что нам делать?
Если мы будем относиться к приближающемуся инопланетному вторжению так же, как мы на самом деле сейчас относимся к СИИ, то мы коллективно пожмём плечами и скажем «А, 50 лет, это ещё совсем нескоро. Нам не надо думать об этом сейчас! Если 100 человек на Земле пытаются подготовиться к надвигающемуся вторжению, этого достаточно. Может, слишком много! Знаете, спросите меня, этим 100 людям стоит перестать смотреть на звёзды и посмотреть на их собственное общество. Тогда они увидят, что РЕАЛЬНОЕ «надвигающееся инопланетное вторжение» – это кардиоваскулярные заболевания. Вот что убивает людей прямо сейчас!»
…Ну вы поняли. (Не язвлю, ничего такого.)
Причина поторопиться №3: Создание близкого к универсальному консенсуса о чём угодно может быть ужасающе медленным процессом.
Представим, что у меня есть по-настоящему хороший и корректный аргумент о том, что некая архитектура или некий подход к СИИ – просто ужасная идея – непоправимо небезопасная. Я публикую аргумент. Поверят ли мне немедленно и изменят ли направление исследований все вовлечённые в разработку СИИ, включая тех, кто вложил всю свою карьеру в этот подход? Вероятно, нет!!
Бывает, что такое происходит, особенно в зрелых областях вроде математики. Но у некоторых идей широкое (не говоря уж об универсальном) принятие занимает десятки лет: известные примеры включают эволюцию и тектонику плит. Доработка аргументов занимает время. Приведение в порядок свидетельств занимает время. Написание новых учебных пособий занимает время. И да, чтобы несогласные упрямцы умерли и их заменило следующее поколение, тоже занимает время.
Почему почти-универсальный консенсус настолько важен? См. Раздел 1.2 выше. Хорошие идеи о том, как создать СИИ, бесполезны, если люди, создающие СИИ, им не следуют. Если мы хотим добровольного сотрудничества, то нам надо, чтобы создатели СИИ поверили идеям. Если мы хотим принудительного сотрудничества, то нам надо, чтобы люди, обладающие политической властью, поверили идеям. И чтобы создатели СИИ поверили тоже, потому что идеальное принуждение – несбыточная мечта (особенно учитывая секретные лаборатории и т.п.).
1.8 …А ещё это по-настоящему восхитительная задача!
Эй, нейробиологи, слушайте. Некоторые из вас хотят лечить болезни. Хорошо. Давайте. Остальные, вы говорите, что хотите лечить болезни, в своих заявках на гранты, но ну серьёзно, это не ваша настоящая цель, все это знают. На самом деле вы тут, чтобы решать восхитительные нерешённые задачи. Ну, позвольте мне вам сказать, безопасность подобного-мозгу СИИ – это восхитительная нерешённая задача!
Это даже богатый источник озарений о нейробиологии! Когда я целыми днями думаю о штуках из безопасности СИИ (вайрхединг, принятие желаемого за действительное, основания символов, онтологический кризис, интерпретируемость, бла-бла-бла), я задаю вопросы, отличающиеся от обычно задаваемых большинством нейробиологов, а значит наталкиваюсь на другие идеи. (…Мне нравится так думать. Ну, читайте дальше, и сами для себя решите, есть ли в них что-то хорошее.)
Так что даже если я не убедил вас, что техническая задача безопасности СИИ супер-пупер-важная, всё равно читайте. Вы можете работать над ней, потому что она офигенная. ;-)
2. "Обучение с чистого листа" в мозгу
- 1.2.1 Краткое содержание / Оглавление
- 2.2.2 Что такое «обучение с чистого листа»?
- 3.2.3 Три вещи, которыми «обучение с чистого листа» НЕ ЯВЛЯЕТСЯ
- 4.2.4 Моя гипотеза: конечный мозг и мозжечок обучаются с чистого листа, гипоталамус и мозговой ствол – нет
- 5.2.5 Свидетельства того, что конечный мозг и мозжечок обучаются с чистого листа
2.1 Краткое содержание / Оглавление
В предыдущем посте я представил задачу «безопасности подобного-мозгу СИИ». Следующие 6 постов (№2-№7) будут в основном про нейробиологию, в них я буду выстраивать более детальное понимание того, как может выглядеть подобный-мозгу СИИ (или, по крайней мере, его относящиеся к безопасности аспекты).
Этот пост сосредоточен на концепции, которую я называю «обучением с чистого листа», я выдвину гипотезу разделения, в котором 96% человеческого мозга (включая неокортекс) «обучается с чистого листа», а остальные 4% (включая ствол головного мозга) – нет. Эта гипотеза – центральная часть моего представления о том, как работает мозг, так что она требуется для дальнейших рассуждений в этой цепочке.
- В Разделе 2.2 я определю концепцию «обучения с чистого листа». Например, заявляя, что неокортекс «обучается с чистого листа», я имею в виду, что он изначально совершенно бесполезен для организма – выводит улучшающие приспособленность сигналы не чаще, чем случайно – пока не начинает обучаться (во время жизни индивида). Вот пара повседневных примеров штук, которые «обучаются с чистого листа»:
- В большинстве статей по глубинному обучению модель «учится с чистого листа» – она инициализирована случайными весами, так что поначалу её вывод – случайный мусор. Но по ходу обучения её веса обновляются и вывод модели со временем становится весьма полезным.
- Пустой жёсткий диск тоже «учится с чистого листа» – нельзя вытащить оттуда полезную информацию, пока её туда не запихнули.
- В Разделе 2.3 я проясню некоторые частые поводы к замешательству:
- «Обучение с чистого листа» – не то же самое, что «с нуля», потому что существуют встроенные алгоритм обучения, нейронная архитектура, гиперпараметры и т.д.
- «Обучение с чистого листа» – не то же самое, что «воспитание превыше природы», потому что (1) только некоторые части мозга обучаются с чистого листа, а другие – нет, и (2) алгоритмы обучения вовсе не обязательно обучаются внешнему окружению – они так же могут обучаться, например, как контролировать собственное тело.
- «Обучение с чистого листа» – не то же самое (и конкретнее), чем «пластичность мозга», потому что последняя также включает (например) жёстко генетически заданную цепь с всего одним конкретным подстраиваемым параметром, полу-перманентно изменяющимся в некоторых условиях.
- В Разделе 2.4 я опишу свою гипотезу о том, что две большие части мозга существуют исключительно для того, чтобы исполнять алгоритмы обучения с чистого листа – конкретно, конечный мозг (неокортекс, гиппокампус, миндалевидное тело, большая часть базальных ганглиев) и мозжечок. Вместе они составляют 96% от объёма человеческого мозга.
- В Разделе 2.5 я коснусь четырёх источников свидетельств, относящихся к моей гипотезе о том, что конечный мозг и мозжечок обучаются с нуля: (1) размышления о том, как мозг работает на высоком уровне, (2) неонатальные данные, (3) связь с гипотезой «однородности коры» и относящимися к ней проблемами, и (4) возможность, что некоторое свойство предварительной обработки в мозгу – так называемое «разделение паттернов» – включает рандомизацию, заставляющую последующие алгоритмы обучаться с чистого листа.
- В Разделе 2.6 я немного поговорю о том, является ли моя гипотеза мэйнстримной или выделяющейся. (Ответ: я не уверен.)
- В Разделе 2.7 я выдам намёки на то, почему обучение с чистого листа важно для безопасности СИИ – мы попадаем в ситуацию, где то, что мы хотим, чтобы пытался сделать СИИ (например, вылечить болезнь Альцгеймера) – концепт, погребённый в большой и сложной-для-интерпретации структуре данных. Поэтому написание относящегося к мотивации кода весьма не прямолинейно. Подробнее об этом будет в будущих постах.
- Раздел 2.8 будет первой из трёх частей моего обсуждения «сроков до подобного-мозгу СИИ», сосредоточенной на том, сколько времени займёт у учёных реверс-инжиниринг ключевых управляющих принципов обучающейся с чистого листа части мозга. (Остальное обсуждение сроков будет в следующем посте.)
2.2 Что такое «обучение с чистого листа»?
Как указано в введении выше, я предлагаю гипотезу, утверждающую, что большие части мозга – конечный мозг и мозжечок (см. Раздел 2.4 ниже) – «обучаются с чистого листа», в том смысле, что изначально они выдают не вкладывающиеся в эволюционно-адаптивное поведение случайные мусорные сигналы, но со временем становятся всё более полезными благодаря работающему во время жизни алгоритму обучения.
Вот два способа думать о гипотезе обучения с чистого листа:
- Как вам следует думать об обучении с чистого листа (если вы из машинного обучения): Представьте глубокую нейросеть, инициализированную случайными весами. Её нейронная архитектура может быть простой или невероятно сложной, это не важно. У неё точно есть склонности, из-за которых выучить одни виды паттернов для нее легче чем другие. Но их в любом случае надо выучить! Если её веса изначально случайны, то она изначально бесполезна и становится более полезной по мере получения обучающих данных. Идея в том, что эти части мозга (неокортекс и т.д.) схожим образом «инициализированы случайными весами» или обладают каким-то эквивалентным свойством.
- Как вам следует думать об обучении с чистого листа (если вы из нейробиологии): Представьте о связанной с памятью системе, вроде гиппокампуса. Способность формировать воспоминания – очень полезная для организма! …Но она не помогает от рождения!![1] Вам нужно накопить воспоминания перед тем, как их использовать! Моё предположение – что всё в конечном мозге и мозжечке попадает в ту же категорию – это всё разновидности модулей памяти. Они могут быть очень особыми разновидностями модулей памяти! Неокортекс, например, может обучиться и запомнить суперсложную сеть взаимосвязанных паттернов, к нему прилагаются мощные возможности составления запросов, он даже может делать запросы самому себе рекуррентными петлями, и т.д. Но всё равно, это форма памяти, и она изначально бесполезна, и становится всё более полезной для организма, накапливая выученное содержание.
2.3 Три вещи, которыми «обучение с чистого листа» НЕ ЯВЛЯЕТСЯ
2.3.1 Обучение с чистого листа – это НЕ «с нуля»
Я уже упомянул это, но я хочу быть максимально ясным: если неокортекс (к примеру) обучается с чистого листа, это не означает, что в нём нет жёстко генетически закодированного информационного содержания. Это означает, что жёстко генетически закодированное информационное содержание скорее всего что-то в этом духе:
- Обучающий(е) алгоритм(ы) – т.е. встроенные правила полу-перманентных изменений нейронов или их связей в зависимости от ситуации.
- Алгоритм(ы) вывода – т.е. встроенные правила того, какие выходные сигналы следует послать прямо сейчас, чтобы помочь выжить и преуспеть. Сами выходные сигналы, конечно, также зависят от ранее выученной информации.
- Архитектура нейронной сети – т.е. встроенная высокоуровневая диаграмма связей, определяющая, как разные части обучающегося модуля соединены друг с другом, входными и выходными сигналами.
- Гиперпараметры – т.е. разные части архитектуры могут иметь разные встроенные скорости обучения. Эти гиперпараметры тоже могут меняться при развитии (см. сенситивные периоды). Также может быть и встроенная способность изменять гиперпараметры от момента к моменту в ответ на специальные управляющие сигналы (в виде нейромодуляторов вроде ацетилхолина).
При наличии всех этих встроенных составляющих алгоритм обучения с чистого листа готов принимать снаружи входные данные и управляющие сигналы[2], и постепенно обучается делать что-то полезное.
Эта встроенная информация не обязательно проста. Может быть 50000 совершенно разных алгоритмов обучения в 50000 разных частях неокортекса, и это всё ещё будет с моей точки зрения считаться обучением с чистого листа! (Впрочем, я не думаю, что это так – см. Раздел 2.5.3 про «однородность».)
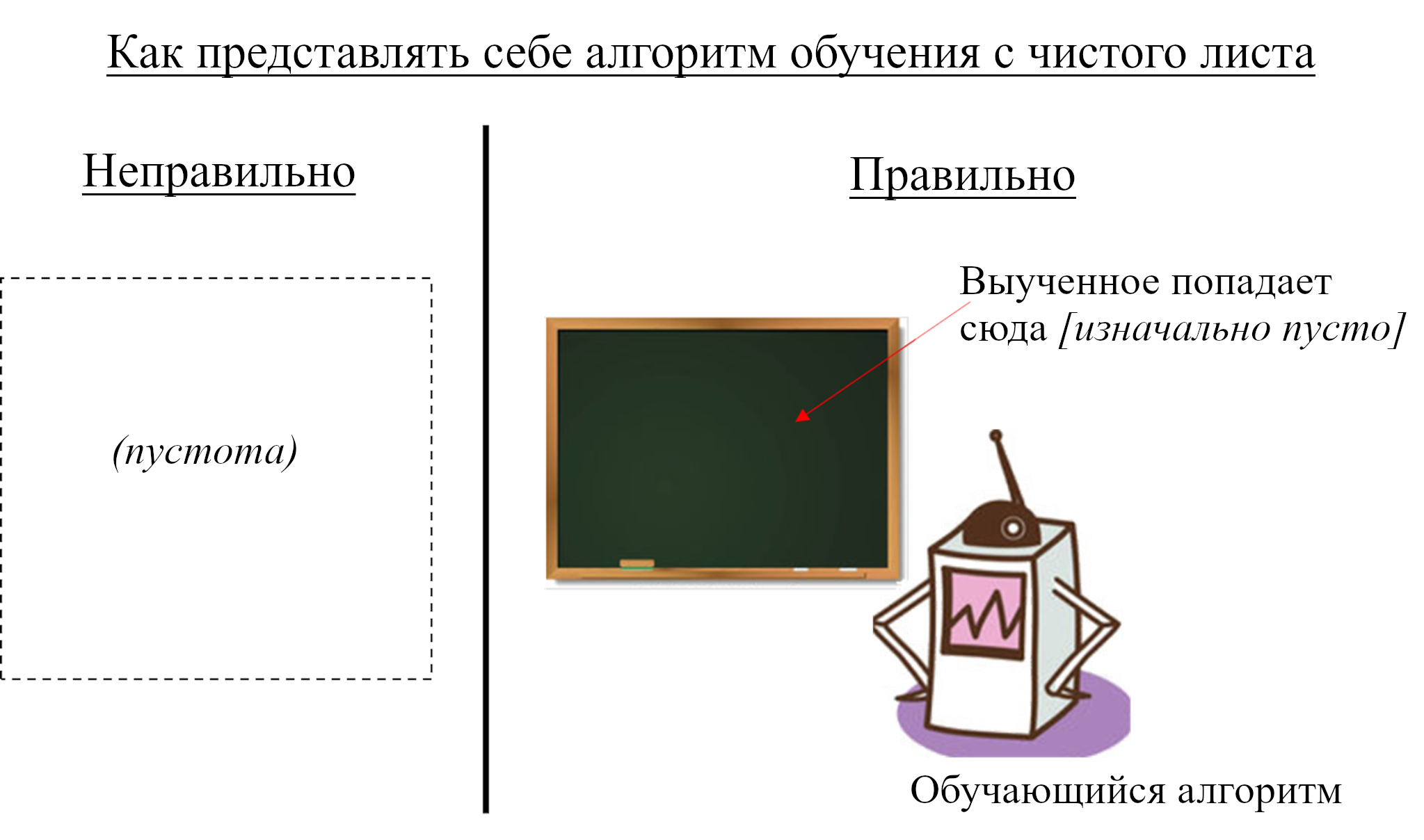
Представляя себе обучающийся с чистого листа алгоритм, *не* следует представлять пустоту, наполняемую данными. Стоит представлять *механизм*, который постоянно (1) записывает информацию в хранилище памяти, и (2) выполняет запросы к текущему содержанию хранилища памяти. «С чистого листа» просто означает, что хранилище памяти изначально пусто. Таких механизмов *много*, они следуют разным процедурам того, что записывать и как запрашивать. К примеру «справочная таблица» соответствует простому механизму, который просто записывает то, что видит. Другим механизмам соответствуют алгоритмы обучения с учителем, алгоритмы обучения с подкреплением, автокодировщики, и т.д., и т.п.
2.3.2 Обучение с чистого листа НЕ означает «воспитание превыше природы»
Есть тенденция ассоциировать «алгоритмы обучения с чистого листа» с стороной «воспитания» споров «природа против воспитания». Я думаю, это неверно. Даже напротив. Я думаю, что гипотеза обучения с чистого листа полностью совместима с возможностью того, что эволюционировавшее встроенное поведение играет большую роль.
Две причины:
Во-первых, некоторые части мозга совершенно точно НЕ выполняют алгоритмы обучения с чистого листа! Это в основном мозговой ствол и гипоталамус (больше про это ниже и в следующем посте). Эти не-обучающиеся-с-чистого-листа части мозга должны быть полностью ответственны за любое адаптивное поведение при рождении.[1] Правдоподобно ли это? Думаю, да, учитывая впечатляющий диапазон функциональности мозгового ствола. К примеру, в неокортексе есть цепи обработки визуальных и других сенсорных данных – но в мозговом стволе тоже! В неокортексе есть цепи моторного контроля – и в мозговом стволе тоже! В по крайней мере некоторых случаях полностью адаптивное поведение кажется исполняемым целиком в мозговом стволе: к примеру, у мышей есть цепь-обнаружения-приближающихся-птиц в мозговом стволе, напрямую соединённая с цепью-убегания-прочь в нём же. Так что моя гипотеза обучения с чистого листа не делает никаких общих заявлений о том, какие алгоритмы или функциональности присутствуют или отсутствуют в мозгу. Только заявления о том, что некоторые виды алгоритмов есть только в некоторых конкретных частях мозга.
Во-вторых, «обучение с чистого листа» - не то же самое, что «обучение из окружения». Вот искусственный пример.[3] Представьте, что мозговой ствол птицы имеет встроенную способность судить о том, как должно звучать хорошее птичье пение, но не инструкцию, как произвести хорошее птичье пение. Ну, алгоритм обучения с чистого листа может заполнить эту дыру – методом проб и ошибок вывести вторую способность из первой. Этот пример показывает, что алгоритмы обучения с чистого листа могут управлять поведением, которое мы естественно и корректно описываем как встроенное / «природное, а не воспитанное».
2.3.3 Обучение с чистого листа – это НЕ более общее понятие «пластичности»
«Пластичность» - это термин, означающий, что мозг полу-перманентно изменяет себя, обычно изменяя присутствие / отсутствие / силу синаптических связей нейронов, но иногда и другими механизмами, вроде изменений в экспрессии генов в нейронах.
Любой алгоритм обучения с чистого листа обязательно включает пластичность. Но не вся пластичность мозга – часть алгоритмов обучения с чистого листа. Другая возможность – то, что я называю «отдельными встроенными настраиваемыми параметрами». Вот таблица с примерами и того, и другого и тем, чем они отличаются:
| Алгоритмы обучения с чистого листа | Отдельные встроенные настраиваемые параметры | |
| Стереотипный пример | Любая статья о глубоком обучении: есть *обучающий алгоритм*, который постепенно создаёт *обученную модель*, настраивая много её параметров. | Некоторые связи в крысином мозгу усиливаются, когда крыса выигрывает драку – по сути, считают, сколько драк крыса выиграла за свою жизнь. Потом такая связь используется для выполнения поведения «Выиграв много драк за свою жизнь – будь агрессивнее.» (ссылка) |
| Количество параметров, изменяемых на основании входных данных (т.е. как много измерений в пространстве всех возможных обученных моделей?) | Может быть много – сотни, тысячи, миллионы, и т.д. | Скорее всего мало, может даже один |
| Если масштабировать это вверх, будет ли это работать лучше после обучения? | Да, наверное. | А?? Что, чёрт побери, вообще значит «масштабировать»? |
Я не думаю, что между этими штуками есть чёткая граница; наверное, есть спорная область, где одна перетекает в другую. По крайней мере, я думаю, что в теории она есть. На практике, мне кажется, существует довольно явное разделение – всегда, когда я узнаю о конкретном примере пластичности мозга, она явным образом попадает в одну или другую категорию.
К слову, как мне кажется, моя категоризация для нейробиологии несколько необычна. Нейробиологи чаще сосредотачиваются на низкоуровневых деталях реализации: «Источник пластичности – синаптические изменения или изменения экспрессии генов?», «Каков биохимический механизм?» и т.д. Это совсем другая тема. К примеру, готов поспорить, что один и то же низкоуровневый биохимический механизм синаптической пластичности может быть вовлечён и в алгоритмы обучения с чистого листа и в изменение отдельного встроенного настраиваемого параметра.
Почему я подымаю эту тему? Потому что я планирую заявить, что гипоталамус и мозговой ствол не выполняют или почти не выполняют алгоритмы обучения с чистого листа. Но они точно имеют отдельные встроенные настраиваемые параметры.
Для конкретики, вот три примера «отдельных встроенных настраиваемых параметров» в гипоталамусе и мозговом стволе:
- Уже упомянутая цепь в крысином гипоталамусе «если ты продолжаешь выигрывать драки, становись агрессивнее» – ссылка.
- Вот цепь в крысином гипоталамусе «если тебе опасно не хватает соли, увеличь базовое желание соли».
- Верхнее двухолмие в мозговом стволе содержит зрительную, слуховую и саккадную моторную область, и механизм, связывающий все три – так что, когда ты видишь вспышку или слышишь шум, ты немедленно направляешь взгляд в точности в правильном направлении. В этом механизме есть пластичность – к примеру, он может самокорректироваться у животного, носящего призматические очки. Я не знаю точных деталей, но полагаю, что это что-то вроде: Если видишь движение и переводишь на него взгляд, но движение не центрировано даже после саккады, то это генерирует сигнал об ошибке, сдвигающий соответствие областей. Может, вся эта система включает 8 настраиваемых параметров (масштаб и смещение, горизонталь и вертикаль, три области для выравнивания), а может она сложнее – опять же, я не знаю деталей.
Видна разница? Вернитесь к таблице, если всё ещё в замешательстве.
2.4 Моя гипотеза: конечный мозг и мозжечок обучаются с чистого листа, гипоталамус и мозговой ствол – нет
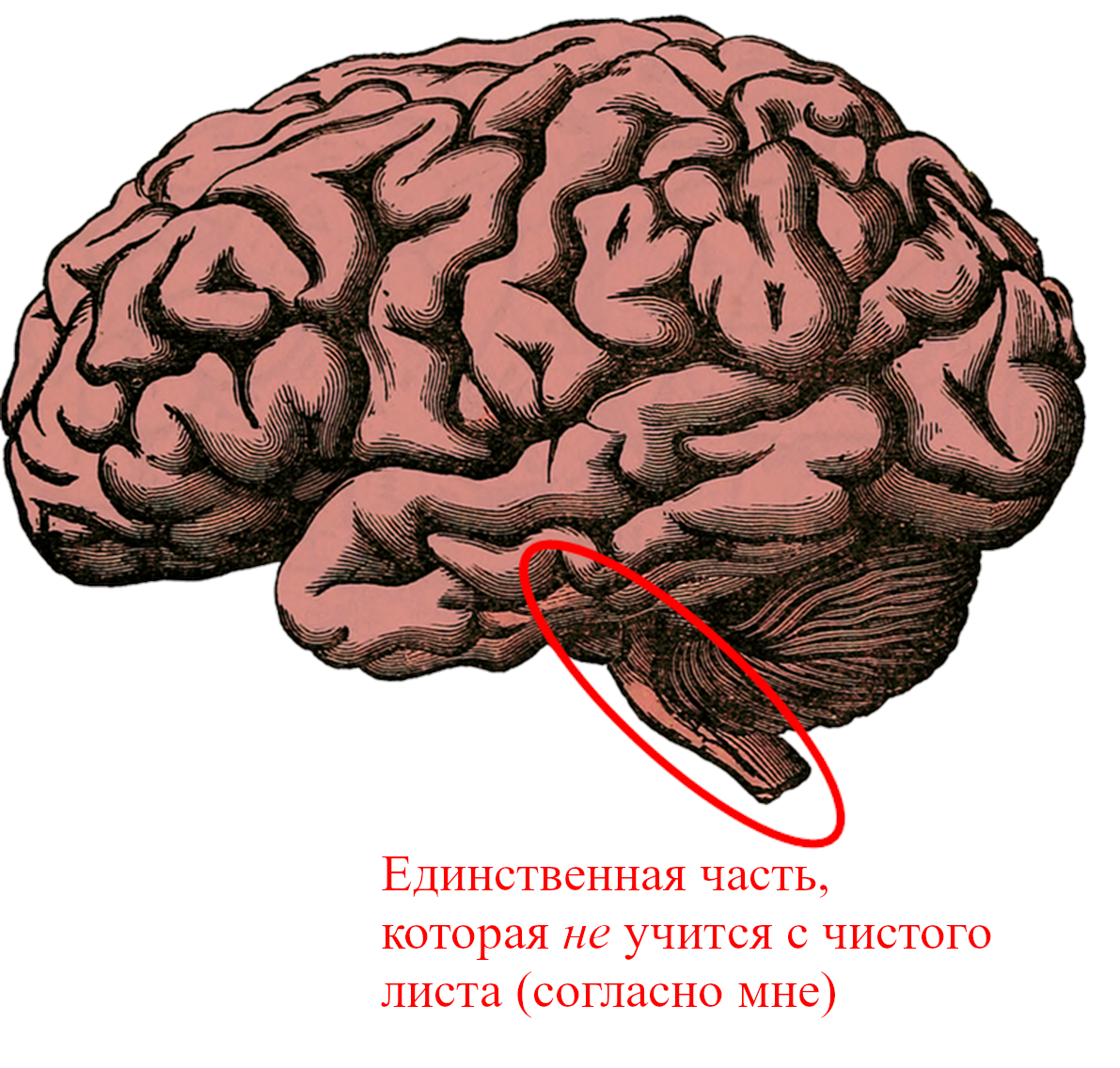
Моя гипотеза заключается в том, что ~96% человеческого мозга выполняет алгоритмы обучения с чистого листа. Главные исключения – мозговой ствол и гипоталамус, общим размером с большой палец. Источник картинки.
Вот моя гипотеза в трёх утверждениях:
Во-первых, я думаю, что весь конечный мозг обучается с чистого листа (и бесполезен при рождении[1]). Конечный мозг (также известный как «большой мозг») у людей – это в основном неокортекс, плюс гиппокампус, миндалевидное тело, большая часть базальных ганглиев и разнообразные более загадочные кусочки.
Несмотря на внешний вид, нравящаяся мне модель (изначально принадлежащая гениальному Ларри Свансону) заявляет, что весь конечный мозг организован в трёхслойную структуру (кора, полосатое тело, паллидум), и эта структура согласуется относительно маленьким количеством взаимосвязанных алгоритмов обучения. См. мой (довольно длинный и технический) пост Большая Картина Фазового Дофамина за подробностями.
(ОБНОВЛЕНИЕ: Узнав больше, я хочу это пересмотреть. Я думаю, что вся «кортикальная мантия» и всё «расширенное полосатое тело» обучаются с чистого листа. (Это включает штуки вроде гиппокампуса, миндалевидного тела, боковой перегородки, и т.д. - которые эмбриологически и/или цитоархитектурно развиваются вместе с корой и/или полосатым телом). Кто касается паллидума, я думаю, некоторые его части по сути являются расширением RAS мозгового ствола, так что им точно не место в этом списке. Про другие его части может оказаться и так, и так, в зависимости от того, как определить поверхность ввода/вывода некоторых алгоритмов обучения. Паллидум довольно маленький, так что мне не надо менять оценки объёма, включая число 96%. Я не буду проходить по всей цепочке и менять «конечный мозг» на «кортикальная мантия и расширенное полосатое тело» в миллионе мест, извините, придётся просто запомнить.)
Таламус технически не входит в конечный мозг, но по крайней мере его часть тесно связана с корой – некоторые исследователи описывают его функциональность как «дополнительный слой» коры. Так что я буду считать и его частью обучающегося с чистого листа конечного мозга.
Конечный мозг и таламус вместе составляют ~86% объёма человеческого мозга (ссылка).
Во-вторых, я думаю, что мозжечок тоже обучается с чистого листа (и тоже бесполезен при рождении). Мозжечок – это ~10% объёма взрослого мозга (ссылка). Больше про мозжечок будет в Посте №4.
В третьих, я думаю, что гипоталамус и мозговой ствол совершенно точно НЕ обучаются с чистого листа (и они очень активны и полезны прямо с рождения). Думаю, другие части промежуточного мозга – например, хабенула и шишковидное тело – тоже попадают в эту категорию.
Я не буду удивлён, если обнаружатся мелкие исключения из этой картины. Может, где-то в конечном мозге есть маленькое ядро, управляющее биологически-активным поведением, не обучаясь ему с чистого листа. Конечно, почему нет. Но сейчас я считаю, что такая картина по крайней мере приблизительно верна.
В следующих двух разделах я расскажу о свидетельствах, относящихся к моей гипотезе, и о том, что о ней думают другие люди из этой области.
2.5 Свидетельства того, что конечный мозг и мозжечок обучаются с чистого листа
2.5.1 Свидетельства общей картины
Из чтения и разговоров с людьми я вижу, что самые большие преграды к тому, чтобы поверить, что конечный мозг и мозжечок обучаются с чистого листа – это в подавляющем большинстве случаев не детализированные аргументы о данных нейробиологии, а скорее:
- Нерассмотрение этой гипотезы как возможности вовсе
- Замешательство касательно следствий гипотезы, в частности – как она встраивается в одну осмысленную картину мозга и поведения.
Раз вы досюда дочитали, №1 уже не должно быть проблемой.
Что по поводу №2? Типичный тип вопросов – это «Если конечный мозг и мозжечок обучаются с чистого листа, то как они делают X?» – для разных X. Если есть X, для которого мы совсем не можем ответить на этот вопрос, то это подразумевает, что гипотеза обучения с чистого листа неверна. Напротив, если мы можем найти действительно хорошие ответы на этот вопрос для многих X, то это свидетельство (хоть и не доказательство), того что гипотеза обучения с чистого листа верна. Следующие посты, я надеюсь, обеспечат вам такие свидетельства.
2.5.2 Неонатальное свидетельство
Если конечный мозг и мозжечок не могут производить биологически-адаптивный вывод, не научившись этому со временем, то из этого следует, что любое биологически-адаптивное поведение новорожденных[1] должно управляться мозговым стволом и гипоталамусом. Так ли это? Кажется, такие вещи должны быть экспериментально измеримы, верно? И в этой статье 1991 года действительно говорится «накопившиеся свидетельства приводят к выводу, что перцептомоторная активность новорожденных в основном контролируется подкорковыми механизмами». Но не знаю, изменилось ли что за прошедшие 30 лет – дайте мне знать, если видели другие упоминания этого.
На самом деле, этот вопрос сложнее, чем кажется. Представьте, что младенец совершает что-то биологически-адаптивное…
- Первый вопрос, который надо задать: в самом деле? Может, это плохой (или неверно интерпретированный) эксперимент. К примеру, если взрослый покажет младенцу язык, высунет ли младенец язык тоже, имитируя? Кажется простым вопросом, верно? Не-а, это источник споров уже десятилетия. Конкурирующая теория строится вокруг орального исследования: «высовывание языка кажется общим ответом на заметные стимулы и зависит от интереса ребёнка к стимулу»; показывающий язык взрослый просто активирует этот ответ, но так же делают мелькающие огоньки и звуки музыки. Я уверен, кто-то знает, каким экспериментам с новорожденными можно доверять, но я, по крайней мере пока не знаю. И я очень параноидально отношусь к тому, что две уважаемые книги в этой области (Учёный в кроватке,Происхождение Концептов) повторяют заявление об имитации будто это твёрдый как скала факт.
- Второй вопрос, который надо задать: результат ли это прижизненного обучения? Помните, даже у трёхмесячного ребёнка есть 4 миллиона секунд «обучающих данных». На самом деле, даже только что рождённый ребёнок возможно выполнял алгоритмы обучения с чистого листа в утробе.[1]
- Третий вопрос, который надо задать: какая часть мозга управляет этим поведением? Моя гипотеза заявляет, что не-выученное адаптивное поведение не может управляться конечным мозгом или мозжечком. Но моя гипотеза позволяет мозговому стволу управление таким поведением! И выяснение, какая часть мозга новорожденного в ответе за некоторое поведение может быть экспериментально сложным.
2.5.3 Свидетельство «однородности»
Гипотеза «однородности коры» заявляет, что все части неокортекса выполняют более-менее похожие алгоритмы. (…С некоторыми нюансами, особенно связанными с неоднородной нейронной архитектурой и гиперпараметрами). Мнения по поводу того, верна ли эта гипотеза (и в какой степени) расходятся – я кратко обсуждал свидетельства и аргументы тут. Я считаю, что весьма вероятно, что она верна, по крайней мере в слабом смысле, что будущий исследователь, имеющий очень хорошее детальное понимание того, как работает Область Неокортекса №147 будет очень хорошо продвинут в понимании того, как работает буквально любая другая часть неокортекса. Я не буду тут погружаться в это подробнее; мне кажется, это не совсем укладывается в тему этой цепочки.
Я упоминаю это потому, что если вы верите в однородность коры, то вам, наверное, следует верить и в то, что она обучается с чистого листа. Аргументация такая:
Неокортекс взрослого делает много явно различающихся вещей: обрабатывает зрительную информацию, слуховую информацию, занимается моторным контролем, языком, планированием и т.д. Как это совместимо с однородностью коры?
Обучение с чистого листа предоставляет правдоподобный способ. В конце концов, мы знаем, что один и тот же алгоритм обучения с чистого листа, если ему скормить очень разные входные данные и управляющие сигналы, может начать делать очень разные вещи: посмотрите как глубокие нейросети-трансформеры можно обучить генерировать текст на естественном языке, или картинки, или музыку, или сигналы моторного контроля робота, и т.д.
Если мы, напротив, примем однородность коры, но отвергнем обучение с чистого листа, то, эм-м-м, я не вижу осмысленных вариантов того, как это может работать.
Аналогично (но куда реже обсуждаемо, чем случай неокортекса), стоит ли нам верить в «однородность аллокортекса»? Для справки, аллокортекс – что-то вроде упрощённой версии неокортекса с тремя слоями вместо шести; считается, что до того, как эволюционировал неокортекс, ранние амниоты имели только аллокортекс. Он, как и неокортекс, делает много всякого разного: у взрослых людей гиппокампус вовлечён в ориентирование в пространстве и эпизодическую память, а грушевидная кора – в обработку запахов. Так что тут можно сделать аналогичный аргумент про обучение с чистого листа.
Двигаясь дальше, я уже упоминал выше (и больше в Большой Картине Фазового Дофамина, а ещё в Посте №5, Разделе 5.4.1) идею (Ларри Свансона), что весь конечный мозг кажется организованным в три слоя – «кору», «полосатое тело» и «паллидум». Я пока говорил только про кору; что насчёт «однородности полосатого тела» и «однородности паллидума»? Не ожидайте найти посвящённый этому обзор – на самом деле, предыдущее предложение судя по всему первое, где встречаются эти словосочетания. Но в каждом из этих слоёв есть как минимум некоторые общие черты: например, средние шиповатые нейроны вроде бы есть по всему полосатому телу. И я продолжаю считать, что описанная мной в Большой Картине Фазового Дофамина (и Постах №5-№6) модель – осмысленное первое приближение того, как может сочетаться «всё, что мы знаем о полосатом теле и паллидуме» с «несколькими вариациями конкретных алгоритмов обучения с чистого листа».
В случае мозжечка, есть по крайней мере какая-то литература по гипотезе однородности (ищите термин «universal cerebellar transform»), но, опять же, нет консенсуса. Мозжечок взрослого так же вовлечён в явно разные функции вроде моторной координации, языка, сознания и эмоций. Я лично считаю, что там тоже есть однородность, подробнее будут в Посте №4.
2.5.4 Локально-случайное разделение паттернов
Это другая причина, по которой лично я готов многое поставить на то, что конечный мозг и мозжечок обучаются с нуля. Она несколько специфична, но для меня довольно заметна; посмотрим, примете ли вы её.
2.5.4.1 Что такое разделение паттернов?
В мозгу есть частый мотив, называемый «разделением паттернов». Давайте я объясню, что это и откуда берётся.
Представьте, что вы инженер машинного обучения, работающий на сеть ресторанов. Ваш начальник даёт вам задание предсказать продажи для разных локаций, куда можно распространить франшизу.
Первое, что вы можете сделать – это собрать кучу потоков данных – местные уровни безработицы, местные рейтинги ресторанов, местные цены в магазинах, распространяется ли по миру сейчас новый коронавирус, и т.д. Я называю это «контекстные данные». Вы можете использовать контекстные данные как ввод нейросети. Выводом сети должно быть предсказание уровня продаж. Вы подправляете веса нейросети (используя обучения с учителем, собрав данные от существующих ресторанов), чтобы всё получилось. Никаких проблем!
Разделение паттернов – это когда вы добавляете в начало ещё один шаг. Вы берёте различные потоки контекстных данных и случайно комбинируете их многими разными способами. Затем вы добавляете немного нелинейности, и вуаля! Теперь у вас есть куда больше потоков контекстных данных, чем было изначально! Теперь они могут быть вводом для обучаемой нейросети.[4]
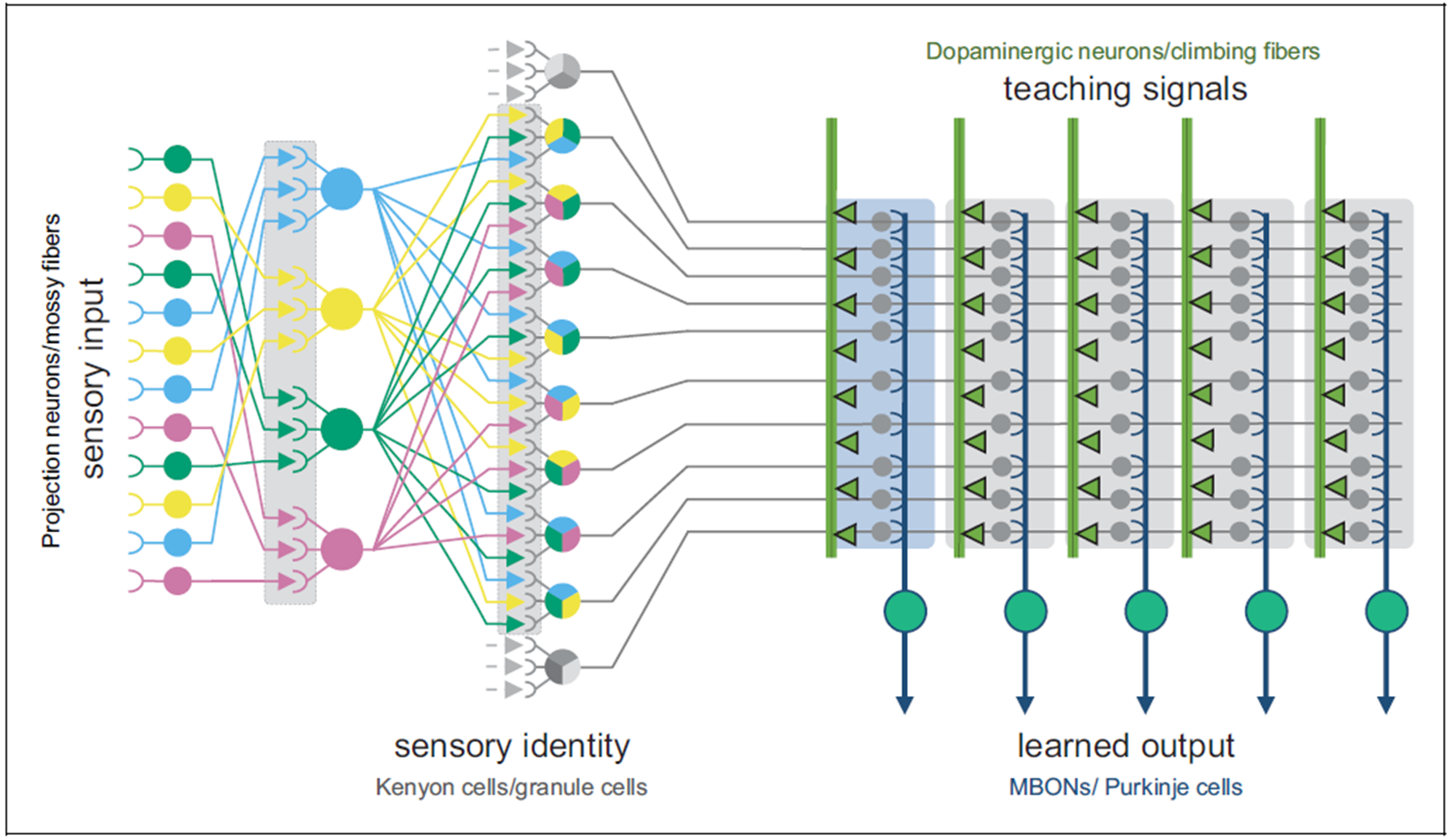
Иллюстрация (части) обработки сенсорных данных плодовой мухи. Высокий вертикальный серый прямоугольник чуть левее центра – это слой «разделения паттернов»; он принимает организованные сенсорные сигналы слева и перемешивает их большим количеством разных (локально) случайных комбинаций. Потом они посылаются направо, чтобы служить «контекстными» вводами модуля обучения с учителем. Источник картинки: Ли и пр..
3. Две Подсистемы: Обучающаяся и Направляющая
- 1.3.1 Краткое содержание / Оглавление
- 2.3.2 Большая картина
- 3.3.3 «Теория Триединого Мозга» неверна, но давайте не выплёскивать ребёнка вместе с водой
- 4.3.4 Три типа составных частей Направляющей Подсистемы
- 4.1.3.4.1 Общая таблица
- 4.2.3.4.2 В сторону: что я имею в виду под «стремлениями»?
- 4.3.3.4.3 Категория A: Штуки, которая Направляющая Подсистема должна делать для достижения обобщённого интеллекта (например, стремление к любопытству)
- 4.4.3.4.4 Категория B: Всё остальное из человеческой Направляющей Системы (например, стремления, связанные с альтруизмом)
- 4.5.3.4.5 Категория C: Любые другие возможности (например, стремление увеличить баланс на банковском счёте)
- 5.3.5 Подобные-мозгу СИИ будут по умолчанию иметь радикально нечеловеческие (и опасные) мотивации
- 6.3.6 Ответ на аргументы Джеффа Хокинса против риска происшествий с СИИ
- 7.3.7 Сроки-до-подобного-мозгу-СИИ, часть 2 из 3: насколько сложен достаточный для СИИ реверс-инжиниринг Направляющей Подсистемы??
- 8.3.8 Сроки-до-подобного-мозгу-СИИ, часть 3 из 3: масштабирование, отладка, обучение, и т.д.
- 9.3.9 Сроки-до-подобного-мозгу-СИИ, ещё: Что мне чувствовать по поводу вероятностей?
3.1 Краткое содержание / Оглавление
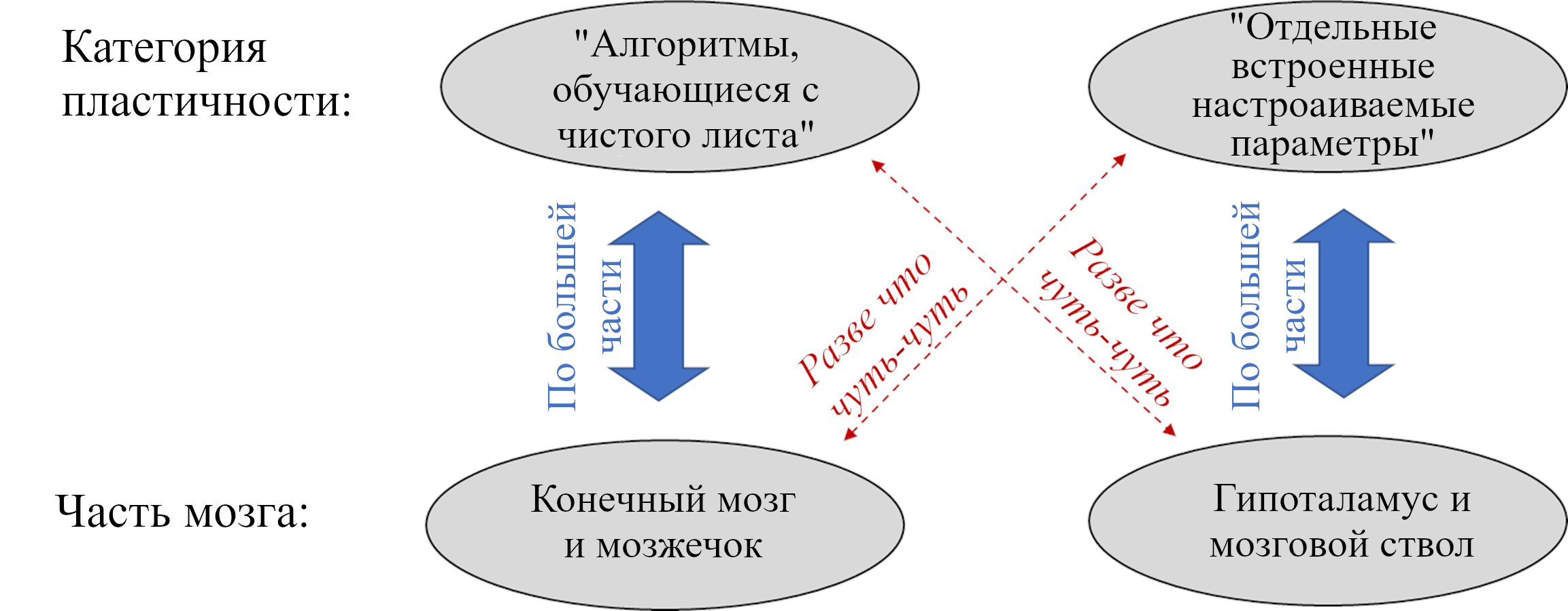
В предыдущем посте я определил понятие «обучающихся с чистого листа» алгоритмов – широкую категорию, включающую, помимо прочего, любой алгоритм машинного обучения (неважно, насколько сложный) с случайной инициализацией и любую систему изначально пустой памяти. Я затем предложил разделение мозга на две части по признаку наличия или отсутствия обучения с чистого листа. Теперь я даю им имена:
Обучающаяся Подсистема – это 96% мозга, «обучающиеся с чистого листа» – по сути – конечный мозг и мозжечок.
Направляющая Подсистема – это 4% мозга, не «обучающиеся с чистого листа» – по сути – гипоталамус и мозговой ствол.
(См. Предыдущий пост за более подробным анатомическим разделением.)
Этот пост будет обсуждением этой картины двух подсистем в целом и Направляющей Подсистемы в частности.
- В Разделе 3.2 я поговорю о большой картине того, что эти подсистемы делают и как они взаимодействуют. Как пример, я объясню, почему каждая подсистема нуждается в своей собственной обработке сенсорных сигналов – к примеру, почему визуальный ввод обрабатывается и в зрительной коре в Обучающейся Подсистеме, и в верхнем двухолмии в Направляющей Подсистеме.
- В Разделе 3.3 я признаю, что эта картина двух подсистем имеет некоторые сходства с дискредитированной «теорией триединого мозга». Но я буду утверждать, что проблемы теории триединого мозга не относятся к моей картине двух подсистем.
- В Разделе 3.4 я опишу три категории того, что может относиться к Направляющей Подсистеме:
- Категория A: Штуки, правдоподобно необходимые для обобщённого интеллекта (например, встроенная склонность к любопытству),
- Категория B: Иные штуки в человеческой направляющей подсистеме (например, встроенная склонность быть добрым к своим друзьям),
- Категория C: Всё, что может представить программист СИИ, даже если это радикально отличается от того, что встречается у людей и животных (например, встроенная склонность корректно предсказывать цены акций).
- В Разделе 3.5 я свяжу эти категории с тем, как я ожидаю будет выглядеть создание людьми подобного-мозгу СИИ, и обосную, что «подобный-мозгу СИИ с радикально нечеловеческими (и опасными) мотивациями» – не оксюморон, а, напротив, ожидаемый по умолчанию исход, если мы не потрудимся, чтобы его предотвратить.
- В Разделе 3.6 я рассмотрю тот факт, что у Джеффа Хокинса есть мнение о двух подсистемах, похожее на мою картину, но он спорит с тем, что катастрофические происшествия с СИИ представляют риск. Я скажу, где, как я считаю, он неправ.
- Разделы 3.7 и 3.8 будут последними двумя частями моего обсуждения «сроков до подобного-мозгу СИИ». Первой частью был Раздел 2.8 предыдущего поста, где я заявил, что реверс-инжиниринг Обучающейся Подсистемы (достаточный для подобного-мозгу СИИ) может правдоподобно произойти довольно скоро, в следующие два десятилетия, хотя это может и занять больше времени. Тут я дополню это заявлением, что-то же верно и для реверс-инжиниринга Направляющей Подсистемы, и для усовершенствования и масштабирования алгоритмов, проведения обучения модели, и т.д.
- Раздел 3.9 – быстрое не-техническое обсуждение того, как невероятно расходятся мнения разных людей по поводу сроков до СИИ, даже когда они согласны по поводу вероятностей. К примеру, можно найти двух людей, которые согласятся, что с шансами 3 к 1 СИИ не будет до 2042 года, но один может подчёркивать, как вероятность низка («Видишь? СИИ скорее всего не будет ещё десятилетия»), тогда как другой – как высока эта вероятность. Я поговорю немного о факторах, скрывающихся за этими отношениями.
3.2 Большая картина
В предыдущем посте я заявил, что 96% объёма мозга – грубо говоря, конечный мозг (неокортекс, гиппокампус, миндалевидное тело, большая часть базальных ганглиев, и ещё кое-что) и мозжечок – «обучаются с чистого листа» в том смысле, что на ранних этапах жизни их выводы – случайный мусор, но со временем они становятся невероятно полезны благодаря прижизненному обучению. (См. там больше подробностей) Я сейчас называю эту часть мозга Обучающейся Подсистемой.
Остальной мозг – в основном мозговой ствол и гипоталамус – я называю Направляющей Подсистемой.
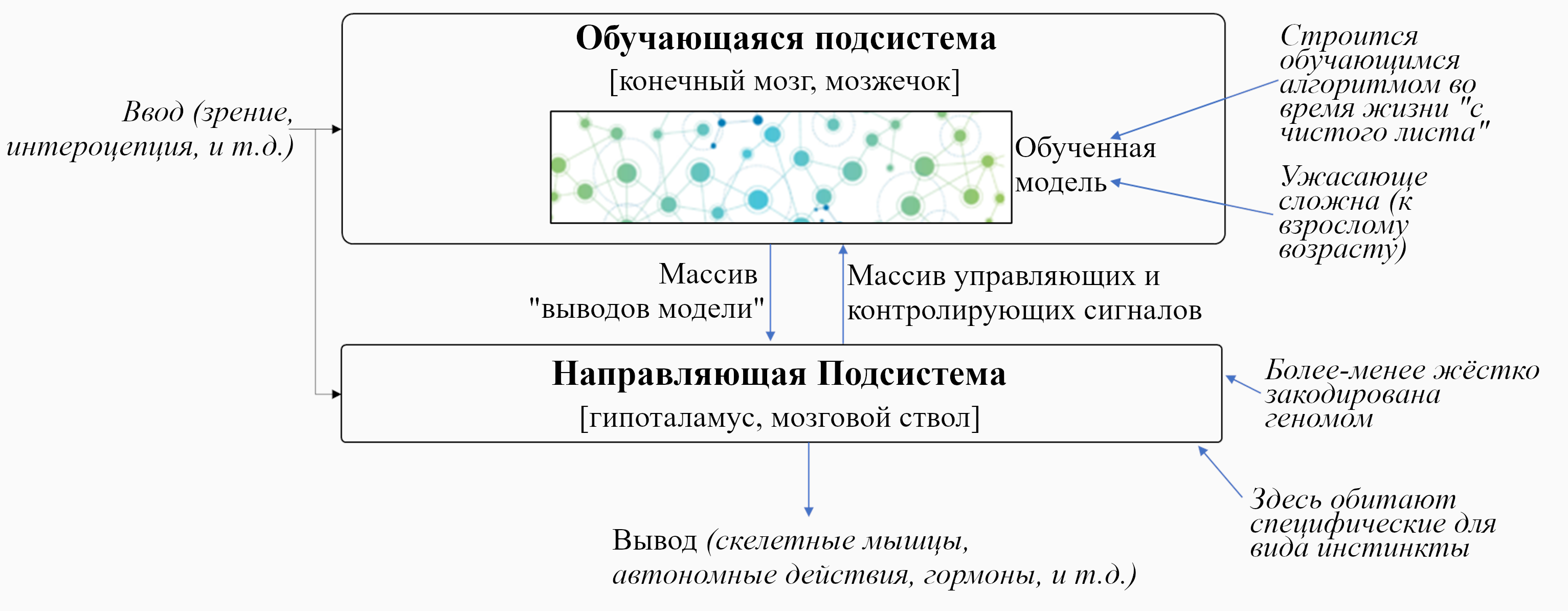
Как нам об этом думать?
Давайте начнём с Обучающейся Подсистемы. Как я описывал в предыдущем посте, эта подсистема имеет некоторое количество взаимосвязанных встроенных алгоритмов обучения, встроенную нейронную архитектуру и встроенные гиперпараметры. Она имеет также много (миллиарды или триллионы) подстраиваемых параметров (обычно предполагается, что это сила синаптических связей, но это спорный момент, и я не буду в него погружаться), и значения этих параметров изначально случайны. Так что изначально Обучающаяся Подсистема выдаёт случайные бесполезные для организма выводы – например, может быть, они могут заставить организм дёргаться. Но со временем различные управляющие сигналы и соответствующие правила обновления подправляют настраиваемые параметры системы, что позволяет её за время жизни животного научиться делать сложные биологически-адаптивные штуки.
Дальше: Направляющая Подсистема. Как нам её интуитивно представлять?
Для начала, представьте хранилище с кучей специфичных для вида инстинктов и поведений, жёстко закодированных в геноме:
- «Чтобы блевануть, сжать мышцы A,B,C, и выпустить гормоны D,E,F.”
- «Если сенсорный ввод удовлетворяет таким-то эвристикам, то вероятно я ем что-то здоровое и энергоёмкое; это хорошо, и надо отреагировать сигналами G,H,I.”
- «Если сенсорный ввод удовлетворяет таким-то эвристикам, то наверное я склоняюсь над пропастью, это плохо, и надо отреагировать сигналами J,K,L.”
- «Если я замёрз, поднять волоски на теле.»
- «Если я недоедаю, выполнить: (1) запустить ощущение голода, (2) начать вознаграждать неокортекс за получение еды, (3) снизить фертильность и рост, (4) уменьшить чувствительность к боли, и т.д.» (ссылка).
Особенно важная задача Направляющей Подсистемы – посылать управляющие и контролирующие сигналы Обучающейся Подсистеме. Отсюда название: Направляющая Подсистема направляет обучающиеся алгоритмы к адаптивным штукам.
Пример: почему человеческий неокортекс обучается адаптивным-для-человека штукам, а беличий неокортекс обучается адаптивным-для-белки штукам, если они оба исполняют примерно одинаковые алгоритмы обучения с чистого листа?
Я заявляю, что главная часть ответа – то, что обучающиеся алгоритмы в этих двух случаях по-разному «направляются». Особенно важный аспект тут – сигнал «вознаграждения» обучения с подкреплением. Можно представить, что человеческий мозговой ствол посылает «награду» за достижение высокого социального статуса, а беличий мозговой ствол – за запасание орехов осенью. (Это упрощение, я ещё буду к этому возвращаться.)
Аналогично, в машинном обучении один и тот же обучающийся алгоритм может стать очень хорош в шахматах (при условии определённого сигнала вознаграждения и сенсорных данных) или может стать очень хорош в го (при условии других сигналов вознаграждения и сенсорных данных).
Для ясности, несмотря на название, «направление» Обучающейся Подсистемы – не всё, что делает Направляющая Подсистема. Она может и просто что-то делать самостоятельно, без вовлечения Обучающейся Подсистемы! Это хорошо подходит для того, что делать важно прямо с рождения, или для того, в чём даже один провал фатален. Пример, который я упоминал в предыдущем посте – мыши, оказывается, имеют цепь-обнаружения-приближающихся-птиц в мозговом стволе, напрямую соединённую с цепью-убегания-прочь в нём же.
Важно держать в голове, что Направляющая Подсистема мозга не имеет прямого доступа к нашему здравому смыслу и пониманию мира. К примеру, Направляющая Подсистема может исполнять реакции вроде «во время еды выделять пищеварительные энзимы». Но когда мы переходим к абстрактным концептам, которые мы используем для действий в мире – оценки, долги, популярность, соевый соус, и так далее – надо предполагать, что Направляющая Подсистема не имеет о них ни малейшего понятия, если мы не можем объяснить, откуда она могла о них узнать. И иногда такое объяснение есть! Мы ещё рассмотрим много таких случаев, в частности в Посте №7 (для простого примера желания съесть пирог) и Посте №13 (для более хитрого случая социальных инстинктов).
3.2.1 Каждая подсистема в общем случае нуждается в своей собственной сенсорной обработке
К примеру, в случае зрения, у Направляющей Подсистемы есть верхнее двухолмие, а к Обучающейся Подсистемы есть зрительная кора. Для вкуса у Направляющей Подсистемы есть вкусовое ядро в продолговатом мозге, а у Обучающейся Подсистемы – вкусовая кора. И т. д.
Не избыточно ли это? Некоторые так и думают! Книга Дэвида Линдена «Случайный Разум» упоминает существование двух систем сенсорной обработки как замечательный пример корявого проектирования мозга в результате отсутствия у эволюции планирования наперёд. Но я не соглашусь. Они не избыточны. Если бы я делал СИИ, я бы точно сделал ему две системы сенсорной обработки!
Почему? Предположим, что Эволюция хочет создать цепочку реакции, чтобы жёстко генетически закодированные сенсорные условия запускали генетически закодированный ответ. К примеру, как упоминалось выше, если вы мышь, то увеличивающееся тёмное пятно сверху области видимости часто означает приближающуюся птицу, поэтому геном мыши жёстко связал детектор-увеличивающегося-тёмного-пятна с поведенческой-цепью-убегания-прочь.
И я скажу, что создавая эту реакцию геном не может использовать зрительную кору для детектора. Почему? Вспомните предыдущий пост: зрительная кора обучается с чистого листа! Она принимает неструктурированные визуальные данные и строит из них предсказывающую модель. Вы можете (приближённо) думать о зрительной коре как о тщательном каталогизаторе паттернов из ввода, и паттернов из паттернов из ввода, и т.д. Один из этих паттернов может соответствовать увеличивающемуся тёмному пятну в верхней части поля зрения. Или нет! И даже если такой есть, геном не знает заранее, какие в точности нейроны будут хранить этот конкретный паттерн. Так что геном не может жёстко привязать эти нейроны к поведенческому-контроллеру-убегания-прочь.
В итоге:
- Встроить обработку сенсорных данных в Направляющую Подсистему – хорошая идея, потому что есть много областей, где сильно выгодно для приспособленности связать жёстко генетически заданное сенсорное условие с соответствующей реакцией. В случае людей, подумайте о страхе высоты, страхе змей, эстетике потенциального жилища, эстетике потенциальных партнёров, вкусе сытной еды, звуке вопля, чувстве боли, и так далее.
- Встроить обработку сенсорных данных в Обучающуюся Подсистему – ТОЖЕ хорошая идея, потому что использование обучающихся с чистого листа алгоритмов для выучивания произвольных паттернов из сенсорного ввода – это, ну, прямо очень хорошая идея. В конце концов, многие полезные сенсорные паттерны супер-специфичны – к примеру, «запах этого одного конкретного дерева» – так что соответствующий жёстко генетически заданный детектор никак не мог эволюционировать.
Так что две системы обработки сенсорной информации – не пример корявого проектирования. Это пример Второго Правила Орджела: «эволюция умнее тебя»!
3.3 «Теория Триединого Мозга» неверна, но давайте не выплёскивать ребёнка вместе с водой
В 1960-х и 70-х Пол Маклейн и Карл Саган изобрели и популяризировали идею Триединого Мозга. Согласно этой теории, мозг состоит из трёх слоёв, сложенных вместе как мороженое в рожке, и они эволюционировали по очереди: сначала «мозг ящерицы» (он же «древний мозг» или «рептильный мозг»), ближайший к спинному; потом «лимбическая система», обёрнутая вокруг него (состоящая из миндалевидного тела, гиппокампуса и гипоталамуса), и, наконец, наружным слоем, неокортекс (он же «новый мозг») – гвоздь программы, вершина эволюции, жилище человеческого интеллекта!!!
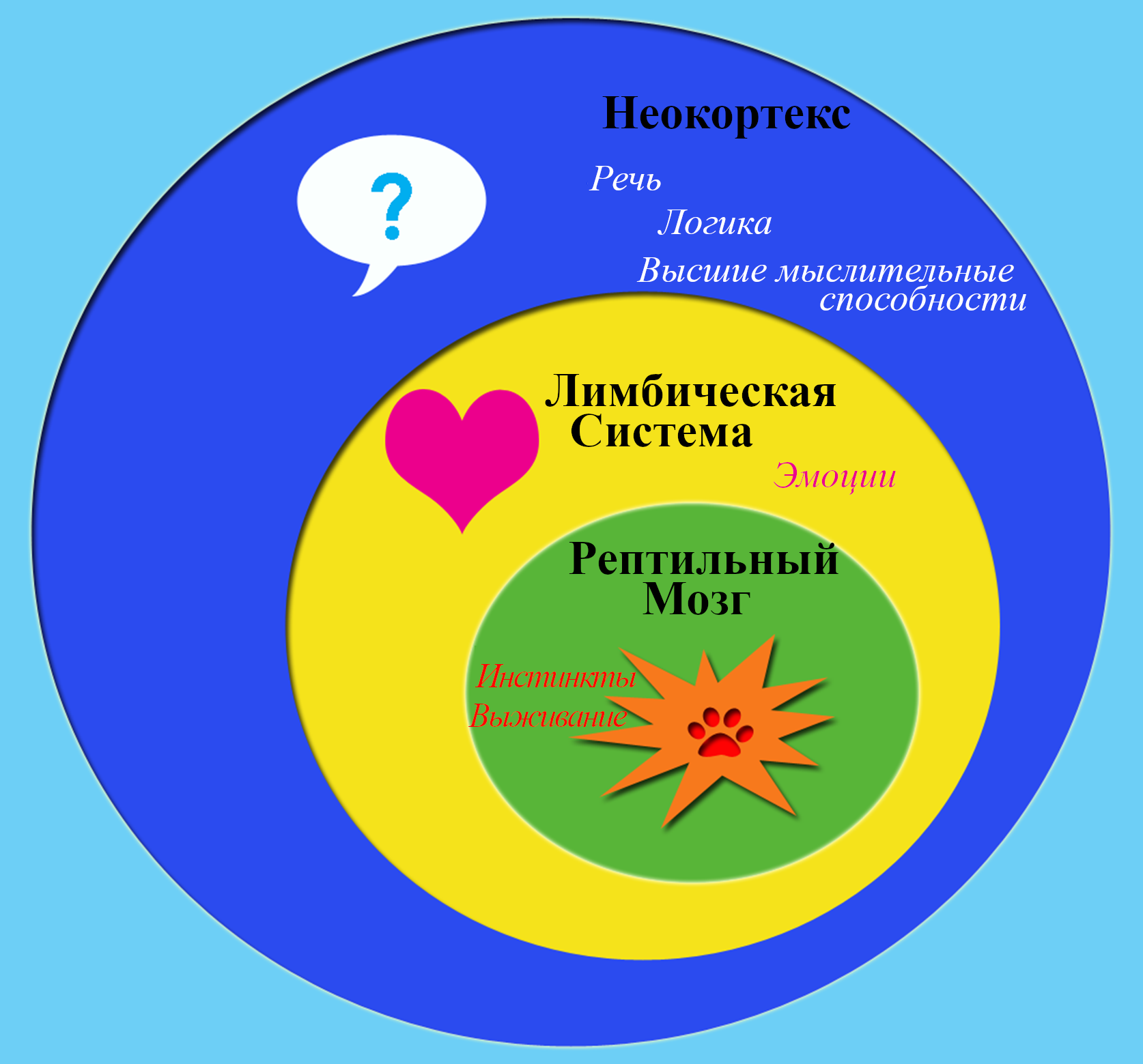
(Плохая!) модель триединого мозга (источник картинки)
{kind=link}
Ну, сейчас хорошо известно, что Теория Тройственного Мозга – чепуха. Она разделяет мозг на части способом, не имеющим ни функционального ни эмбриологического смысла, и эволюционная история просто откровенно неверна. К примеру, половину миллиарда лет назад самые ранние позвоночные имели предшественников всех трёх слоёв триединого мозга – включая «плащ», который потом (в нашей линии) разделился на неокортекс, гиппокампус, часть миндалевидного тела, и т.д. (ссылка).
Так что да, Теория Тройственного Мозга – чепуха. Но я вполне признаю: нравящаяся мне история (предыдущий раздел) несколько напоминает её. Моя Направляющая Подсистема выглядит подозрительно похожей на маклейновский «рептильный мозг». Моя Обучающаяся Подсистема выглядит подозрительно похожей на маклейновские «лимбическую систему и неокортекс». Мы с Маклейном не вполне согласны по поводу того, что в точности к чему относится, и два там слоя или три. Но сходство несомненно есть.
Моя история про две подсистемы не оригинальна. Вы услышите похожие от Джеффа Хокинса, Дайлипа Джорджа, Илона Маска, и других.
Но эти другие люди делают это придерживаясь традиции теории триединого мозга, и, в частности, сохраняя её проблематичные аспекты, вроде терминологии «древнего мозга» и «нового мозга».
Нет нужды так делать!!! Мы можем сохранить модель двух подсистем, избавившись от унаследованных у тройственного мозга ошибок.
Так что вот моя версия: я думаю, что пол миллиарда лет назад у ранних позвоночные уже был (простой!) алгоритм обучения с чистого листа в их (прото-) конечном мозге, и он «направлялся» сигналами из их (простого, прото-) мозгового ствола и гипоталамуса.
На самом деле, мы можем пойти даже дальше позвоночных! Оказывается, существует сходство между обучающейся с чистого листа корой у людей и обучающимся с чистого листа «грибовидным телом» у плодовых мух! (Подробное обсуждение здесь.) Замечу, к примеру, что у плодовых мух, сигналы запахов отправляются и в грибовидное тело, и в боковой рог, что замечательно сходится с общим принципом того, что сенсорный ввод должен отправляться и в Обучающуюся Подсистему, и в Направляющую Подсистему (Раздел 3.2.1 выше).
В любом случае, за 700 миллионов лет прошедших с нашего последнего общего предка с насекомыми в нашей линии очень сильно увеличились и усложнились и Обучающаяся Подсистема, и Направляющая Подсистема.
Но это не значит, что они одинаково вкладываются в «человеческий интеллект». Опять же, обе необходимы, но, я думаю, факт того, что 96% объёма человеческого мозга занимает Обучающаяся Подсистема, довольно убедителен. Сосредоточимся ещё конкретнее на конечном мозге (который у млекопитающих включает неокортекс), его доля объёма мозга – 87% у людей (ссылка), 79% у шимпанзе (ссылка), 77% у некоторых попугаев, 51% у куриц, 45% у крокодилов, и лишь 22% у лягушек (ссылка). Тут есть очевидная закономерность, и думаю, что для получения способности к распознаваемому интеллектуальному и гибкому поведению действительно необходима большая Обучающаяся Подсистема.
Видите? Я могу описать свою модель двух подсистем без всей этой чепухи про «древний мозг, новый мозг».
3.4 Три типа составных частей Направляющей Подсистемы
Я начну с общей таблицы, а потом рассмотрю всё подробнее в следующих подразделах.
3.4.1 Общая таблица
| Категория составных частей Направляющей Подсистемы | Возможные примеры | Присутствуют в (компетентных) людях? | Ожидаются в будущих СИИ? |
| (A) Штуки, которая Направляющая Подсистема должна делать для достижения обобщённого интеллекта | Стремление к любопытству (?) Стремление обращать внимание на некоторые категории вещей в окружении (люди, язык, технология, и т.д.) (?) Общая вовлечённость в настройку нейронной архитектуры Обучающейся Подсистемы (?) | Да, по определению | Да |
| (B) Всё остальное из Направляющей Подсистемы нейротипичного человека | Социальные инстинкты (лежащие в основе альтруизма, любви, сожаления, вину, чувства справедливости, верности, и т. д.) Стремления в основе отвращения, эстетики, спокойствия, восхищения, голода, боли, боязни пауков, и т. д. | Обычно, но не всегда – к примеру, высокофункциональные социопаты лишены некоторых обычных социальных инстинктов. | Нет «по умолчанию», но *возможно*, если мы: (1)поймём, как в точности они работают, и (2)убедим разработчиков СИИ заложить их в него |
| (C) Любые другие возможности, большинство из которых *совершенно непохожи на всё*, что можно обнаружить в Направляющей Подсистеме человека или любого другого животного | Стремление увеличить баланс на банковском счёте компании? Стремление изобрести более хорошую солнечную панель? Стремление делать то, что хочет от меня человек-оператор? *(Тут ловушка: никто не знает, как реализовать это!)* | Нет | Да «по умолчанию». Если что-то – плохая идея, мы можем попробовать убедить разработчиков СИИ это не делать. |
3.4.2 В сторону: что я имею в виду под «стремлениями»?
Я подробнее разберу это в следующих постах, но сейчас давайте просто скажем, что Обучающаяся Подсистема (помимо всего прочего) проводит обучение с подкреплением, и Направляющая Подсистема присылает ей вознаграждение. Компоненты функции вознаграждения соответствуют тому, что я называю «встроенными стремлениями» - это корень того, почему некоторые штуки по своей сути мотивирующие / привлекающие, а другие – демотивирующие / отталкивающие.
Явные цели вроде «я хочу избавиться от долгов» отличаются от встроенных стремлений. Явные цели возникают из сложного взаимодействия «встроенных стремлений Направляющей Подсистемы» и «выученного содержания Обучающейся Подсистемы». Опять же, куда больше про это в будущих постах.
Напомню, встроенные стремления находятся в Направляющей Подсистеме, а абстрактные концепции, составляющие ваш осознанный мир – в Обучающейся. К примеру, если я говорю что-то вроде «встроенные стремления, связанные с альтруизмом», то надо понимать, что я говорю не про «абстрактную концепцию альтруизма, как он определён в словаре», а про «некая встроенная в Направляющую Подсистему схема, являющаяся причиной того, что нейротипичные люди иногда считают альтруистические действия по своей сути мотивирующими». Абстрактные концепции имеют какое-то отношение к встроенным схемам, но оно может быть сложным – никто не ожидает взаимно-однозначного соответствия N отдельных встроенных схем и N отдельных слов, описывающих эмоции и стремления.[1]
Разобравшись с этим, давайте подробнее рассмотрим таблицу.
3.4.3 Категория A: Штуки, которая Направляющая Подсистема должна делать для достижения обобщённого интеллекта (например, стремление к любопытству)
Давайте начнём с «стремления к любопытству». Если вы не знакомы с понятием «любопытства» в контексте машинного обучения, я рекомендую Задачу Согласования Брайана Кристиана, главу 6, содержащую занимательную историю того, как исследователи смогли научить агентов обучения с подкреплением выигрывать в игре с Atari Montezuma’s Revenge. Стремление к любопытству кажется необходимым для хорошей работы системы машинного обучения, и, кажется, оно встроено и в людей. Я предполагаю, что будущие СИИ тоже будут в нём нуждаться, а иначе просто не будут работать.
Для большей конкретности – я думаю, что оно важно для начального развития – думаю, стремление к любопытству необходимо на ранних этапах обучения, а потом его, вероятно, можно в какой-то момент отключить. Скажем, представим СИИ, обладающего общими знаниями о мире и самом себе, способного доводить дела до конца, и сейчас пытающегося изобрести новую солнечную панель. Я утверждаю, что ему скорее всего не нужно встроенное стремление к любопытству. Он может искать информацию и жаждать сюрпризов как будто у него оно есть, потому что из опыта он уже выучил, что это зачастую хорошая стратегия для, в частности, изобретения солнечных панелей. Другими словами, что-то вроде любопытства может быть мотивирующим как средство для достижения цели, даже если оно не мотивирует как цель – любопытство может быть выученной метакогнитивной эвристикой. См. инструментальная конвергенция. Но этот аргумент неприменим на ранних этапах обучения, когда СИИ начинает с чистого листа, ничего не зная о мире и о себе. Так что, если мы хотим получить СИИ, то поначалу, я думаю, Направляющая Подсистема действительно должна указывать Обучающейся Подсистеме правильное направление.
Другой возможный элемент в Категории A – это встроенное стремление обращать внимание на конкретные вещи в окружении, например, человеческую деятельность, человеческий язык или технологию. Я не совсем уверен, что это необходимо, но мне кажется, что стремления к любопытству самого по себе не хватит для того, что мы от него хотим. Оно было бы совершенно ненаправленным. Может, СИИ мог бы провести вечность, прокручивая в своей голове Правило 110, находя всё более и более глубокие паттерны, полностью игнорируя физическую вселенную. Или„ может быть, он мог бы находить всё более и более глубокие паттерны в формах облаков, полностью игнорируя всё, связанное с людьми и технологией. В случае человеческого мозга, мозговой ствол определённо обладает механизмами, заставляющими обращать внимание на человеческие лица (ссылка), и я сильно подозреваю, что там есть и система обращения внимания на человеческую речь. Я могу быть неправ, но, думаю, что-то вроде этого понадобиться и для СИИ. И точно также, может оказаться, что это необходимо только в начале обучения.
Что ещё может быть в Категории A? В таблице я написал расплывчатое «Общая вовлечённость в настройку нейронной архитектуры Обучающейся Подсистемы». Это включает посылание сигналов вознаграждения, и сигналов об ошибке, и гиперпараметры и т. д. для конкретных частей нейронной архитектуры Обучающейся Подсистемы. К примеру, в Посте №6 я поговорю о том, как только часть нейронной архитектуры становится получателем главного сигнала вознаграждения обучения с подкреплением. Я думаю об этих вещах, как о (одном аспекте) настоящей реализации нейронной архитектуры Обучающейся Подсистемы. У СИИ тоже будет какая-то нейронная архитектура, хотя, возможно, не в точности такая же, как у людей. Следовательно, СИИ тоже могут понадобится такие сигналы. Я немного говорил о нейронной архитектуре в Разделе 2.8 предыдущего поста, но в основном она не важна для этой цепочки, так что я не буду рассматривать её ещё подробнее.
В Категории A могут быть и другие штуки, о которых я не подумал.
3.4.4 Категория B: Всё остальное из человеческой Направляющей Системы (например, стремления, связанные с альтруизмом)
Я сразу перепрыгну к тому, что мне кажется наиболее важным: социальные инстинкты, включающие различные стремления, связанные с альтруизмом, симпатией, любовью, виной, завистью, чувством справедливости, и т. д. Ключевой вопрос: Откуда я знаю, что социальные инстинкты попадают в Категорию B, то есть, что они не в Категории A вещей, необходимых для обобщённого интеллекта?
Ну, для начала, посмотрите на высокофункциональных социопатов. У меня в своё время был опыт очень хорошего знакомства с парочкой. Они хорошо понимают мир, себя, язык, математику, науку, могут разрабатывать сложные планы и успешно достигать впечатляющих вещей. ИИ, умеющий всё, что может делать высокофункциональный социопат, мы бы без колебаний назвали «СИИ». Конечно, я думаю, высокофункциональные социопаты имеют какие-то социальные инстинкты – они более заинтересованы в манипуляциях людьми, а не игрушками – но их социальные инстинкты кажутся очень сильно отличающимися от социальных инстинктов нейротипичного человека.
Сверх этого, мы можем рассмотреть людей с аутизмом, людей с шизофренией, и S.M. (лишённую миндалевидного тела, и более-менее – негативных социальных эмоций), и так далее, и так далее. Все эти люди имеют «обобщённый интеллект», но их социальные инстинкты / стремления очень разнятся.[2]
С учётом всего этого, мне сложно поверить, что какие-то аспекты социальных инстинктов строго необходимы для обобщённого интеллекта. Я думаю, как минимум открытый вопрос – даже способствуют ли они обобщённому интеллекту!! К примеру, если вы посмотрите на самых гениальных в мире учёных, то я предположу, что люди с нейротипичными социальными инстинктами там будут несколько недопредставлены.
Причина, по которой это важно – я заявляю, что социальные инстинкты лежат в основе «желания поступать этично». Опять же, рассмотрим высокофункциональных социопатов. Они могут понять честь и справедливость и этику, если захотят, понять в смысле правильных ответов на тестовые вопросы о том, что справедливо, а что нет и т.д., они просто всем этим не мотивированы.[3]
Если подумать, это имеет смысл. Предположим, я скажу вам «Тебе следует запихнуть камушки себе в уши». Вы скажете «Почему?». И я скажу «Потому что, ну знаете, в ваших ушах нет камушков, но надо, чтобы были». И вы опять скажете «Почему?» …В какой-то момент этому разговору придётся свестись к тому, что вы и я считаем по своей сути, независимо от всего остального, мотивирующим или демотивирующим. И я утверждаю, что социальные инстинкты – различные встроенные стремления, связанные с чувством честности, симпатией, верностью, и так далее – и являются основанием для этих интуитивных заключений.
(Я тут не решаю дилемму морального реализма против морального релятивизма – то есть вопрос о том, есть ли «материальные факты» о том, что этично, а что неэтично. Вместо этого, я говорю, что если агент полностью лишён встроенных стремлений, которые могу разжечь в нём желание поступать этично, то нельзя ожидать от него этичного поведения, неважно, насколько он интеллектуален. С чего ему? Ладно, он может поступать этично как средство для достижения цели – например, чтобы привлечь на свою сторону союзников – но это не считается. Больше обсуждения и оснований интуиции в моём комментарии тут.)
Пока что это всё, что я хочу сказать о социальных инстинктах; я ещё вернусь к ним позже в этой цепочке.
Что ещё попадает в Категорию B? Много штук!! Отвращение, эстетика, спокойствие, восхищение, голод, боль, страх пауков, и т. д.
3.4.5 Категория C: Любые другие возможности (например, стремление увеличить баланс на банковском счёте)
Люди, создающие СИИ, могут поместить в функцию вознаграждения что им захочется! Они смогут создавать совершенно новые встроенные стремления. И эти стремления будут радикально непохожи на что-либо присущее людям или животным.
Зачем будущим программистам СИИ изобретать новые, ранее не встречавшиеся встроенные стремления? Потому что это естественно!! Если похитить случайного разработчика машинного обучения из холла NeurIPS, запереть его в заброшенном складе и заставить создавать ИИ-для-зарабатывания-денег-на-банковском-счёте с использованием обучения с подкреплением[4], то спорю на что угодно, в его исходном коде будет функция вознаграждения, использующая баланс на банковском счёте. Вы не найдёте ничего похожего в генетически прошитых схемах в мозговом стволе человека! Это новое для мира встроенное стремление.
«Поместить встроенное стремление для увеличения баланса на банковском счёте» – не только очевидный вариант, но, думаю, и в самом деле работающий! Некоторое время! А потом он катастрофически провалится! Он провалится как только ИИ станет достаточно компетентным, чтобы найти нестандартные стратегии увеличения баланса на банковском счёте – занять денег, взломать сайт банка, и так далее. (Смешной и ужасающий список исторических примеров того, как ИИ находили нестандартные не предполагавшиеся стратегии максимизации награды, больше об этом в следующих постах.) На самом деле, этот пример с балансом банковского счёте – только одно из многих-многих возможных стремлений, которые правдоподобно могут привести СИИ к вынашиванию тайной мотивации сбежать из под человеческого контроля и всех убить (см. Пост №1).
Так что такие мотивации худшие: они прямо у всех под носом, они – лучший способ достигать целей, публиковать статьи и побивать рекорды показателей, пока СИИ не слишком умный, а потом, когда СИИ становится достаточно компетентным, они приводят к катастрофическим происшествиям.
Вы можете подумать: «Это же совсем очевидно, что СИИ с всепоглощающим стремлением повысить баланс конкретного банковского счёта – это СИИ, который попытается сбежать из-под человеческого контроля, самовоспроизводиться и т.д. Ты реально веришь, что будущие программисты СИИ буду настолько беспечны, чтобы поместить в него что-то в таком роде??»
Ну, эммм, да. Да, так и думаю. Но даже отложив это пока в сторону, есть проблема побольше: мы пока не знаем, как закодировать хоть какое-нибудь встроенное стремление так, чтобы получившийся СИИ точно остался под контролем. Даже стремления, которые на первый взгляд кажутся благоприятными, скорее всего не такие, по крайней мере при нашем нынешнем уровне понимания. Куда больше про это в будущих постах (особенно №10).
Безусловно, Категория C – очень широкая. Я совсем не буду удивлён, если в ней существуют встроенные стремления, которые очень хороши для безопасности СИИ! Нам просто надо их найти! Я поисследую это пространство возможностей дальше в цепочке.
3.5 Подобные-мозгу СИИ будут по умолчанию иметь радикально нечеловеческие (и опасные) мотивации
Я упоминал это уже в первом посте (Раздел 1.3.3), но сейчас у нас есть объяснение.
Предыдущий подраздел предложил разделение на три типа возможного содержания Направляющей Подсистемы: (A) Необходимые для СИИ, (B) Всё остальное, что есть в людях, (C) Всё, чего нет в людях.
Мои заявления:
- Люди хотят создавать мощные ИИ с прорывными способностями в сложных областях – они знают, что это хорошо для публикаций, производит впечатление на коллег, помогает получить работу, повышения и гранты, и т.д. В смысле, ну просто посмотрите на ИИ и машинное обучение сейчас. Поэтому, по умолчанию, я ожидаю, что разработчики СИИ будут нестись прямиком по самому короткому к нему пути: реверс-инжиниринг Обучающейся Подсистемы и комбинирование её с стремлениями из Категории A.
- Категория B содержит некоторые стремления, которые, вполне возможно, могут быть полезны для безопасности СИИ: связанные с альтруизмом, симпатией, щедростью, скромностью, и т.д. К сожалению, мы сейчас не знаем, как они реализованы в мозге. И выяснение этого необязательно для создания СИИ. Так что я думаю, что по умолчанию следует ожидать, что разработчики СИИ будут игнорировать Категорию B до тех пор, пока у них не будет работающего СИИ, и только затем они начнут попытки разобраться, как встроить стремление к альтруизму и т.п. И у них может просто не получиться – вполне возможно, что соответствующие схемы в мозговом стволе и гипоталамусе ужасающе сложны и запутаны, а у нас будет только некоторое ограниченное время между «СИИ работает» и «кто-то случайно создаёт вышедший из под контроля СИИ, который всех убивает» (см. Пост №1).
- В Категории C есть штуки вроде «низкоуровневое встроенное стремление увеличить баланс конкретного банковского счёта», которые немедленно очевидны для кого угодно, легко реализуются, и будут хорошо справляться с достижением целей программистов, пока их прото-СИИ не слишком способен. Следовательно, по умолчанию, я ожидаю, что будущие исследователи будут использовать такие «очевидные» (но опасные и радикально нечеловеческие) стремления в своей работе по разработке СИИ. И, как и обсуждалось выше (и больше в следующих постах), даже если исследователи начнут добросовестные попытки дать своему СИИ встроенное стремление к услужливости / послушности / чему-то ещё, они могут обнаружить, что не знают, как это сделать.
Обобщая, если исследователи пойдут по самому простому и естественному пути – вытекающему из того, что сообщества ИИ и нейробиологии продолжат вести себя похоже на то, как они ведут себя сейчас – то мы получим СИИ, способные на впечатляющие вещи, поначалу на те, которые хотят их программисты, но ими будут управлять радикально чужеродные системы мотивации, фундаментально безразличные к человеческому благополучию, и эти СИИ попытаются сбежать из-под человеческого контроля как только станут достаточно способными для этого.
Давайте попробуем это изменить! В частности, если мы заранее разберёмся, как написать код, задающий встроенное стремление к альтруизму / услужливости / послушности / чему-то подобному, то это будет очень полезно. Это большая тема этой цепочки. Но не ожидайте финальных ответов. Это нерешённая задача: впереди ещё много работы.
3.6 Ответ на аргументы Джеффа Хокинса против риска происшествий с СИИ
Недавно вышла книга Джеффа Хокинса «Тысяча мозгов». Я написал подробный её обзор тут. Джефф Хокинс продвигает очень похожую на мою точку зрения о двух подсистемах. Это не совпадение – его работы подтолкнули меня в этом направлении!
К чести Хокинса, он признаёт, что его работа по нейробиологии / ИИ продвигает (неизвестной длины) путь в сторону СИИ, и он попытался осторожно обдумать о последствиях такого проекта – в противоположность более типичной точке зрения, объявляющей СИИ чьей-то чужой проблемой.
Так что я восхищён тем, что Хокинс посвятил большой раздел своей книги аргументам о катастрофических рисках СИИ. Но его аргументы – против катастрофического риска!! Что такое? Как он и я, начав с похожих точек зрения на две подсистемы, пришли к диаметрально противоположным заключениям?
Хокинс приводит много аргументов, и, опять же, я более подробно их рассмотрел в моём обзоре. Но тут я хочу подчеркнуть две самые большие проблемы, касающиеся этого поста.
Вот мой пересказ некоторых аргументов Хокинса. (Я перевожу их в используемую мной в этой цепочке терминологию, например, где он говорит «древний мозг», я говорю «Направляющая Подсистема». И, может быть, я немного груб. Вы можете прочитать книгу и решить для себя, насколько я справедлив.)
- Обучающаяся Подсистема (неокортекс и т.п.) сама по себе не имеет целей и мотиваций. Она не сделает ничего. Она точно не сделает ничего опасного. Это как карта, лежащая на столе.
- В той степени, в какой у людей есть проблематичные стремления (жадность, самосохранение, и т.д.), они происходят из Направляющей Подсистемы (мозговой ствол и т.д.).
- То, что я, Джефф Хокинс, предлагаю, и делаю – это попытки реверс-инжиниринга Обучающейся Подсистемы, не Направляющей. Так какого чёрта все так взволнованы?
- …
- …
- О, кстати, совершенно не связанное замечание, мы когда-нибудь в будущем сделаем СИИ, и у них будет не только Обучающаяся Подсистема, но ещё и подключённая к ней Направляющая Подсистема. Я не собираюсь говорить о том, как мы спроектируем Направляющую Подсистему. Это на самом деле не то, о чём я много думаю.
Каждый пункт по отдельности кажется вполне осмысленным. Но если сложить их вместе, тут зияющая дыра! Кого волнует, что неокортекс сам по себе безопасен? План вовсе не в неокортексе самом по себе! Вопрос, который надо задавать – будет ли безопасен СИИ, состоящий из обеих подсистем. И это критически зависит от того, как мы создадим Направляющую Подсистему. Хокинсу это неинтересно. А мне да! Дальше в цепочке будет куда больше на эту тему. В Посте №10 я особенно погружусь в тему того, почему чертовски сложнее, чем кажется создать Направляющую Подсистему, способствующую тому, чтобы СИИ делал что-то конкретное, что нам надо, не вложив в него также случайно опасные антисоциальные мотивации, которые мы не намеревались в него вкладывать.
Ещё одна (имеющая значение) проблема, которую я не упоминал в своём обзоре: я думаю, что Хокинс частично руководствуется интуитивным соображением, против которого я выступал в (Мозговой ствол, Неокртекс) ≠ (Базовые Мотивации, Благородные Мотивации) (и больше на эту тему будет в Посте №6): тенденцией необоснованно приписывать эгосинтонические мотивации вроде «раскрытия тайн вселенной» неокортексу (Обучающейся Подсистеме), а эгодистонические мотивации вроде голода и сексуального желания – мозговому стволу (Направляющей Подсистеме). Я заявляю, что все мотивации без исключения изначально исходят из Направляющей Подсистемы. Надеюсь, это станет очевидно, если вы продолжите читать эту цепочку.
На самом деле, мое заявление даже подразумевается в лучших частях книги самого Хокинса! К примеру:
- Хокинс в Главе 10: «Неокортекс обучается модели мира, которая сама по себе не содержит целей и ценностей.»
- Хокинс в Главе 16: «Мы – разумная модель нас, обитающая в неокортексе – заперты. Мы заперты в теле, которое … в основном находится под контролем невежественной скотины, древнего мозга. Мы можем использовать интеллект, чтобы представить лучшее будущее… Но древний мозг может всё испортить…»
Проговорю противоречие: если «мы» = модель в неокортексе, и модель в неокортексе не имеет целей и ценностей, то «мы» точно не жаждем лучшего будущего и не вынашиваем планы, чтобы обойти контроль мозгового ствола.
3.7 Сроки-до-подобного-мозгу-СИИ, часть 2 из 3: насколько сложен достаточный для СИИ реверс-инжиниринг Направляющей Подсистемы??
(Напомню: Часть 1 из 3 – Раздел 2.8 предыдущего поста.)
Выше (Раздел 3.4.3) я рассмотрел «Категорию A», минимальный набор составляющих для создания Направляющей Системы СИИ (не обязательно безопасного, только способного).
Я на самом деле не знаю, что в этом наборе. Я предположил, что вероятно нам понадобится какая-то разновидность стремления к любопытству, и может быть какое-то стремление обращать внимание на человеческие языки и прочую человеческую деятельность, и, может быть, какие-то сигналы для помощи в образовании нейронной архитектуры Обучающейся Подсистемы.
Если это так, ну, это не поражает меня как что-то очень сложное! Это уж точно намного проще, чем реверс-инжиниринг всего, что есть в человеческом гипоталамусе и мозговом стволе! Держите в голове, что есть довольно обширная литература по любопытству, как в машинном обучении (1, 2), так и в психологии. «Стремление обращать внимание на человеческий язык» не требует ничего сверх классификатора, который (с осмысленной точностью, он не обязан быть идеальным) сообщает, является ли данный звуковой ввод человеческой речью или нет; это уже тривиально с нынешними инструментами, может уже залито на GitHub.
Я думаю, нам стоит быть открытыми к возможности что не так уж сложно создать Направляющую Подсистему, которая (вместе с получившейся в результате реверс-инжиниринга Обучающейся Подсистемой, см. Раздел 2.8 предыдущего поста) может развиться в СИИ после обучения. Может, это не десятилетия исследований и разработки; может даже не годы! Может, компетентный исследователь может сделать это всего с нескольких попыток. С другой стороны – может и нет! Может, это супер сложно! Я думаю, сейчас очень сложно предсказать, сколько времени это займёт, так что нам стоит оставаться неуверенными.
3.8 Сроки-до-подобного-мозгу-СИИ, часть 3 из 3: масштабирование, отладка, обучение, и т.д.
Обладание полностью определённым алгоритмом с способностями СИИ – ещё не конец истории; его всё ещё надо реализовать, отполировать, аппаратно ускорить и распараллелить, исправить причуды, провести обучение, и т.д. Не стоит игнорировать эту часть, но не стоит и её переоценивать. Я не буду описывать это тут, потому что я недавно написал целый отдельный пост на эту тему:
Вдохновлённый-мозгом СИИ и «прижизненные якоря»
Суть поста: я думаю, что всё это точно можно сделать меньше, чем за 10 лет. Может, меньше чем за 5. Или это может занять дольше. Я думаю, нам стоит быть очень неуверенными.
Это заканчивает моё обсуждение сроков-до-подобного-мозгу-СИИ, что, опять же, не главная тема этой цепочки. Вы можете прочитать три его части (2.8, 3.7, и эта), согласиться или не согласиться, и прийти к своим собственным выводам.
3.9 Сроки-до-подобного-мозгу-СИИ, ещё: Что мне чувствовать по поводу вероятностей?
Моё обсуждение «сроков» (Разделы 2.8, 3.7, 3.8) касалось вопроса прогнозирования «какое распределение вероятностей мне приписывать времени появления СИИ (если он вообще будет)?»
Полу-независимым от этого вопроса является вопрос отношения: «Что мне чувствовать по поводу этого распределения вероятностей?»
Например, два человека могут соглашаться с (допустим) «35% шансом СИИ к 2042», но иметь невероятно разное отношение к этому:
- Один из них закатывает глаза, смеётся и говорит: «Видишь, я же говорил! СИИ скорее всего не появится ещё десятилетия!»
- У другого глаза расширяются, челюсть отпадает, и он говорит: «О. Боже. Извините, дайте минутку, пока я переобдумываю всё о своей жизни.»
Есть много факторов, лежащих в основе таких разных отношений к одному и тому же убеждению о мире. Во-первых, некоторые факторы – больше про психологию, а не про фактические вопросы:
- «Какое отношение лучше подходит моему восприятию себя и моей психике?» - о-о-о, блин, это в нас глубоко засело. Людей, думающих о себе как о хладнокровных серьёзных скептических величавых приземлённых учёных, может непреодолимо тянуть к мнению, что СИИ – не такое уж большое дело. Людей, думающих о себе как о радикальных трансгуманистических технологических первопроходцах, может так же непреодолимо тянуть к противоположному мнению, что СИИ радикально изменит всё. Я говорю это, чтобы вы могли пообдумывать свои собственные искажения. О, да кого я обманываю; на самом деле, я просто дал вам удобный способ самодовольно насмехаться над всеми, кто с вами не согласен, и отбрасывать их мнение. (Можете не благодарить!) С моей стороны, я заявляю, что я несколько иммунен к отбрасыванию-мнения-через-психоанализ: Когда я впервые пришёл к убеждению, что СИИ – очень серьёзное дело, я полностью идентифицировал себя как хладнокровного серьёзного скептического величавого приземлённого учёного средних лет, не интересующегося и не связанного с научной фантастикой, трансгуманизмом, технологической индустрией, ИИ, Кремниевой долиной, и т.д. Вот так-то! Ха! Но на самом деле, это глупая игра: отбрасывать убеждения людей через психоанализ их скрытых мотивов – всегда было ужасной идеей. Это слишком просто. Правда или неправда, вы всегда можете найти хороший повод самодовольно усомниться в мотивах любого, кто с вами не согласен. Это просто дешёвый трюк для избегания тяжёлой работы выяснения, не могут ли они на самом деле оказаться правы. И про психологию в целом: принять всерьёз возможность будущего с СИИ (настолько серьёзно, насколько, как я думаю, она того заслуживает) может быть, ну, довольно мучительно! Довольно сложно было привыкнуть к идее, что Изменение Климата реально происходит, верно?? См. этот пост за большими подробностями.
- Как мне следует думать о возможных-но-не-гарантированных будущих событиях? Я предлагаю прочитать этот пост Скотта Александера. Или, если вы предпочитаете в виде мема:

Источник картинки: Скотт Александер
Ещё, тут есть ощущение, выраженное в известном эссе «Заметив Дым», и этом меме:

Примерно основано на меме @Linch, если не ошибаюсь
Говоря явно, правильная идея – взвешивать риски и выгоды и вероятности переподготовки и недоподготовки к возможному будущему риску. Неправильная идея – добавлять в это уравнение дополнительный элемент – «риск глупо выглядеть перед моими друзьями из-за переподготовки к чему-то странному, что оказалось не таким уж важным» – и трактовать этот элемент как подавляюще более важный, чем все остальные, и затем через какое-то безумное странное выворачивание Пари Паскаля выводить, что нам не следует пытаться избежать потенциальной будущей катастрофы до тех пор, пока мы не будем уверены на >99.9%, что катастрофа действительно произойдёт. К счастью, это становится всё более и более обсуждаемой темой; ваши друзья всё с меньшей и меньшей вероятностью подумают, что вы странный, потому что безопасность СИИ стала куда более мейнстримной в последние годы – особенно благодаря агитации и педагогике Стюарта Расселла, Брайана Кристиана, Роба Майлза, и многих других. Вы можете поспособствовать этому процессу, поделившись этой цепочкой! ;-) (рад помочь – прим. пер.)
Отложив это в сторону, другие более вещественные причины разного отношения к срокам до СИИ включают вопросы:
- Насколько сильно СИИ преобразует мир? Что касается меня, я нахожусь далеко на конце спектра «сильно». Я одобряю цитату Элиезера Юдковского: «Спрашивать о воздействии [сверхчеловеческого СИИ] на [безработицу] – это как спрашивать, как на торговлю США с Китаем повлияет падение Луны на Землю. Воздействие будет, но вы упускаете суть.» Для более трезвого обсуждения, попробуйте Цифровые Люди Были Бы Ещё Большим Делом Холдена Карнофского, и, может быть, ещё и Так не Может Продолжаться для фона, и, почему бы и нет, всю остальную серию постов тоже. Также смотрите здесь некоторые числа, предполагающие, что подобный-мозгу СИИ скорее всего не потребует ни такого количества компьютерных чипов, ни такого количества электричества, что он не мог бы широко использоваться.
- Насколько многое нам надо сделать, чтобы подготовиться к СИИ? См. в Посте №1, Разделе 1.7 мои аргументы в пользу того, что мы сильно отстаём от расписания, а позже в этой цепочке я затрону много всё ещё нерешённых задач.
- Ну, может быть кто-то и ожидает, что есть взаимно-однозначное соответствие между абстрактными языковыми концепциями вроде «печали» и соответствующими внутренними реакциями. Если прочитать книгу Как Рождаются Эмоции, Лиза Фельдман Барретт тратит там сотни страниц, избивая эту позицию. Она, наверное, отвечает кому-то, верно? В смысле, мне бы показалось каким-то абсурдным очучеливанием мнение: «Каждая ситуация, которую мы бы описали как «грустная» соответствует в точности одной и той же внутренней реакции с одним и тем же выражением лица.» Я буду удивлён, если окажется, что Пол Экман (которого, вроде бы, Барретт опровергала) на самом деле в это верит, но я не знаю…
- Я не предполагаю, что схемы Направляющей Подсистемы, лежащие в основе социальных инстинктов, устроены у этих разных групп совершенно по-разному – это было бы эволюционно неправдоподобно. Скорее, я думаю, что там есть много настраиваемых параметров того, насколько сильны разные стремления, и они могут принимать широкие диапазоны значений, включая такие, что стремление будет таким слабым, что на практике можно считать его отсутствующим. См. мои спекулятивные рассуждения про аутизм и психопатию тут.
- См. Тест Психопата Джона Ронсона за забавными обсуждениями попыток научить психопатов эмпатии. Студенты лишь стали лучше способны подделывать эмпатию для манипуляции людьми. Цитата одного человека, учившего такой класс: «Думаю, мы случайно создали для них пансион благородных девиц.»
- Предполагаю, можно было бы просто нанять исследователя в области машинного обучения. Но кто будет ему платить?
4. "Краткосрочный предсказатель"
- 1.4.1 Краткое содержание / Оглавление
- 2.4.2 Иллюстративный пример: вздрагивание перед получением удара в лицо
- 3.4.3 Терминология: Контекст, Вывод, Управление
- 4.4.4 Очень упрощённый игрушечный пример того, как это могло бы работать в биологических нейронах
- 5.4.5 Сравнение с другими алгоритмическими подходами
- 6.4.6 Пример «краткосрочных предсказателей» №1: Мозжечок
- 7.4.7 Пример «краткосрочных предсказателей» №2: Предсказательное обучение сенсорных вводов в коре
- 8.4.8 Другие примеры приложений «краткосрочных предсказателей»
Примечание переводчика - с момента перевода оригинальные посты несколько обновились, через некоторое время обновлю и перевод. На общие выводы цепочки это, вроде бы, не влияет.
4.1 Краткое содержание / Оглавление
Предыдущие два поста (№2 и №3) представили общую картину мозга, состоящего из Направляющей Подсистемы (мозговой ствол и гипоталамус) и Обучающейся Подсистемы (всё остальное), где последняя «обучается с чистого листа» в конкретном смысле, определённом в Посте №2.
Я предположил, что наши явные цели (например, «Хочу быть космонавтом!») возникают из взаимодействия этих двух подсистем, и понимание этого критически важно, если мы хотим научиться формировать мотивацию подобного-мозгу СИИ так, чтобы он пытался делать то, что мы хотим, чтобы он пытался делать, и избежать катастрофических происшествий, описанных в Посте №1.
Следующие три поста (№4-6) прорабатывают это дальше. Этот пост предоставляет необходимый нам ингредиент: «краткосрочный предсказатель».
Краткосрочное предсказание – одна из вещей, которые делает Обучающаяся Подсистема, я поговорю о других в следующих постах. Краткосрочный предсказатель получает управляющий сигнал («эмпирическую истину») извне и использует обучающийся алгоритм для построения модели, предсказывающей, каким будет этот сигнал через короткий промежуток времени (например, долю секунды) в будущем.
Этот пост содержит общее обсуждение того, как краткосрочные предсказатели работают, и почему они важны. Как мы увидим в следующих двух постах, они окажутся ключевым строительным элементом мотивации и обучения с подкреплением.
Тизер следующей пары постов: Следующий пост (№5) опишет, как определённый вид замкнутой схемы, обёрнутой вокруг краткосрочного предсказателя, превращает его в «долгосрочный предсказатель», связанный с обучением методом временных разниц (TD). Я заявлю, что в мозгу много таких долгосрочных предсказателей, созданных петлями «конечный мозг – мозговой ствол», одна из которых сродни «критику» из модели «субъект-критик» обучения с подкреплением. «Субъект» - это тема поста №6.
Содержание:
- Раздел 4.2 описывает иллюстративный пример вздрагивания перед получением удара в лицо. Это можно сформулировать как задачу обучения с учителем, в том смысле, что тут есть эмпирический сигнал, на котором можно обучаться. (Если вам только что прилетело в лицо, надо было вздрогнуть!) Получившаяся схема – то, что я называю «краткосрочным предсказателем».
- В Разделе 4.3 я определяю терминологию: «контекстные сигналы», «сигналы вывода» и «управляющие сигналы». (В терминологии машинного обучения они соответствуют «вводу обученной модели», «выводу обученной модели» и «маркировке данных».)
- Раздел 4.4 предлагает набросок очень простого краткосрочного предсказателя, который можно создать из биологических нейронов, просто чтобы можно было представлять что-то конкретное.
- Раздел 4.5 описывает преимущества краткосрочных предсказателей в сравнении с альтернативными подходами, включающими (в примере вздрагивания) жёстко прошитую схему, определяющую, когда вздрогнуть, и агента обучения с подкреплением, вознаграждаемого за уместное вздрагивание. В последнем случае краткосрочный предсказатель обучается быстрее, потому что получает «бесплатный» градиент ошибки каждый раз – или, выражаясь проще, когда он облажался, он получает указание, что именно он сделал не так, в духе того, была ли ошибка недолётом или перелётом.
- Разделы 4.6-4.8 покрывают разные примеры краткосрочных предсказателей в человеческом мозге. Все они не слишком важны для безопасности СИИ – по-настоящему важна тема следующего поста – но они выплывают довольно часто, так что заслуживают быстрого рассмотрения:
- Раздел 4.6 описывает мозжечок, который согласно моей теории представляет из себя коллекцию из ≈300,000 краткосрочных предсказателей, используемых для сокращения задержки ≈300,000 сигналов, проходящих через мозг и тело.
- Раздел 4.7 покрывает предсказательное обучение на сенсорных вводах в коре – к примеру, то, как вы постоянно предсказываете, что вы сейчас увидите, услышите, почувствуете, и т.д., и ошибки предсказания используются для обновления ваших внутренних моделей.
- Раздел 4.8 быстро описывает ещё несколько случайных интересных штук, которые краткосрочные предсказатели могут делать у животных.
4.2 Иллюстративный пример: вздрагивание перед получением удара в лицо
Представьте, что у вас есть работа или хобби, где есть конкретный распознаваемый сенсорный намёк (например, кто-то орёт «FORE!!!» в гольфе), а потом через пол секунды после этого намёка вам очень часто прилетает удар в лицо. Ваш мозг научится (непроизвольно) вздрагивать в ответ на этот намёк. В мозгу есть обучающийся алгоритм, управляющий этим вздрагиванием; вероятно, он эволюционировал для защиты лица. Об этом обучающемся алгоритме я и хочу поговорить в этом посте.
Я называю это «краткосрочным предсказателем». Это «предсказатель», потому что цель алгоритма – предсказать что-то заранее (например, приближающийся удар в лицо). Он «краткосрочный», потому что он должен предсказывать, что произойдёт, только на долю секунды в будущее. Это разновидность обучения с учителем, потому что есть «эмпирический» сигнал, задним числом показывающий, какой вывод алгоритму следовало произвести.
4.3 Терминология: Контекст, Вывод, Управление
Наш «краткосрочный предсказатель» имеет «API» («программный интерфейс приложения» – т.е. каналы, через которые другие части мозга взаимодействуют с модулем «краткосрочного предсказателя») из трёх составляющих:
- Сигнал вывода – это предсказание алгоритма.
- В нашем примере выше это был бы сигнал, вызывающий вздрагивание.
- Управляющий сигнал предоставляет (задним числом) «эмпирическую истину» о том, каким должен был быть вывод алгоритма.
- В нашем примере выше, это был бы сигнал, указывающий, что я только что получил в лицо (и, соответственно, подразумевающий, что мне надо было вздрогнуть).
- В терминологии машинного обучения «управляющие сигналы» часто называются «ярлыками» или «маркировкой данных».
- На самом деле управляющий ввод краткосрочного предсказателя не обязан быть эмпирической истиной. Он может быть сигналом ошибки, или отрицательным сигналом ошибки, или ещё чем-то. С моей точки зрения, это маловажные низкоуровневые детали реализации.
- Контекстные сигналы несут информацию о том, что происходит.
- В нашем примере выше это может быть случайный набор сигналов (соответствующих скрытым переменным), поступающих из зрительной и слуховой коры. Если повезёт, некоторые из этих сигналов могут нести полезную-для-предсказания информацию: может, один из них сообщает, что я нахожусь на поле для гольфа, а другой – что кто-то недалеко от меня только что заорал «FORE!».
- В терминологии машинного обучения «контекстные сигналы» можно было бы назвать «ввод обученной модели».
Контекстные сигналы не обязаны все иметь отношение к задаче предсказания. Мы можем просто закинуть туда целую кучу мусора, и обучающийся алгоритм автоматически отыщет контекстные данные, полезные для задачи предсказания, и будет игнорировать всё остальное.
4.4 Очень упрощённый игрушечный пример того, как это могло бы работать в биологических нейронах
Как краткосрочный предсказатель может работать на низком уровне?
Ну, предположим, что мы хотим получить сигнал вывода, предшествующий управляющему сигналу на 0.3 секунды – как выше, к примеру, мы хотели бы научиться вздрагивать до удара. Мы хватаем кучу контекстных данных, которые могут иметь отношение к делу – к примеру, нейроны, несущие частично обработанную сенсорную информацию. Мы отслеживаем, какие из этих контекстных потоков особенно вероятно срабатывают за 0.3 секунды до управляющего сигнала. И мы связываем эти потоки с выводом.
И готово! Легкотня.
В биологии это может выглядеть как что-то вроде синаптической пластичности с «трёхфакторным правилом обучения» - т.е. синапс становится сильнее или слабее в зависимости от активности трёх других нейронов (контекст, управление, вывод) и их относительного времени срабатывания.
Чёрные точки обозначают синапсы настраиваемой силы
Для ясности – краткосрочный предсказатель может быть намного, намного сложнее этого. Большая сложность может обеспечить лучшую работу. Приведу интересный пример, про который я совсем недавно узнал – оказывается, в краткосрочных предсказателях в мозжечке (Раздел 4.6 ниже) есть нейроны, которые каким-то образом могут хранить настраиваемый параметр временной задержки внутри самого нейрона(!!) (ссылка – это всплыло на этом подкасте). Другие возможные прибамбасы включают разделение паттернов (Пост №2, Раздел 2.5.4) и обучение одним и тем же управляющим сигналом большого количества выводов и их объединение (ссылка), или, ещё лучше – обучение большого количества выводов с одним и тем же управляющим сигналом, но разными гиперпараметрами, чтобы получить распределение вероятностей (оригинальная статья, дальнейшее обсуждение), и так далее.
Так что этот подраздел – сильное упрощение. Но я не буду извиняться, я думаю, что такие грубо упрощённые игрушечные модели важно рассказывать и держать в голове. С концептуальной точки зрения, мы получили ощущение правдоподобной истории того, как ранние животные могут начать с очень простой (но уже полезной) схемы, которая может затем стать более сложной по прошествии многих поколений. Так что привыкайте – в будущих постах вас ждёт ещё много грубо упрощённых игрушечных моделей!
4.5 Сравнение с другими алгоритмическими подходами
4.5.1 «Краткосрочный предсказатель» против жёстко прошитой схемы
Давайте вернёмся к примеру выше: вздрагиванию перед получением удара в лицо. Я предположил, что хороший способ решить, когда вздрогнуть – это обучающийся алгоритм «краткосрочного предсказателя». Вот альтернатива: мы можем жёстко прошить схему, определяющую, когда вздрогнуть. К примеру, если в поле зрения есть быстро увеличивающееся пятно, но, вероятно, это хороший момент, чтобы вздрогнуть. Такой детектор правдоподобно может быть прошит в мозгу.
Как сравнить эти два решения? Какое лучше? Ответ: нет нужды выбирать! Они взаимодополняющие. Можно иметь оба. Но всё же, педагогически полезно обговорить их сравнительные преимущества и недостатки.
Главное (единственное?) преимущество жёстко прошитой системы вздрагивания – она работает с рождения. В идеале, не надо получать удар в лицо ни разу. Напротив, краткосрочный предсказатель – обучающийся алгоритм, так что ему в общем случае надо «учиться на своих ошибках».
С другой стороны, у краткосрочного предсказателя есть два мощных преимущества над жёстко прошитым решением – одно очевидное, другое не столь очевидное.
Очевидное преимущество – краткосрочный предсказатель работает на прижизненном, а не эволюционном обучении, так что он может выучивать намёки на то, что надо вздрогнуть, которые редко или вовсе никогда не встречались у предыдущих поколений. Если я часто ударяюсь головой, когда вхожу в конкретную пещеру, я научусь вздрагивать. Нет никакого шанса, чтобы у моих предков эволюционировал рефлекс вздрагивать в этой конкретной части этой конкретной пещеры. Мои предки вообще могли никогда не заходить в эту пещеру. Сама пещера могла не существовать до прошлой недели!
Менее очевидное, но всё же важное преимущество – краткосрочный предсказатель может использовать как ввод выученные с чистого листа паттерны (Пост №2), а жёстко прошитая система вздрагивания – нет. Обоснование тут такое же, как в Разделе 3.2.1 предыдущего поста: геном не может точно знать, какие именно (если вообще какие-то) нейроны будут хранить информацию о конкретном выученном с чистого листа паттерне, так что геном не может жёстко прошить связи с этими нейронами.
Способность использовать выученные с чистого листа паттерны очень выгодна. К примеру, хороший намёк на вздрагивание может зависеть от выученных с чистого листа семантических паттернов (вроде знания «Я сейчас играю в гольф»), выученных с чистого листа зрительных паттернов (например, образ замахивающегося клюшкой человека) или выученных с чистого листа указаний на место (вроде «эта конкретная комната с низким потолком»), и т.д.
4.5.2 «Краткосрочный предсказатель» против агента обучения с подкреплением: Более быстрое обучение благодаря градиентам ошибки
Схема краткосрочного предсказывания – особый случай обучения с учителем.
Обучение с учителем – это когда обучающийся алгоритм получает сигнал такого рода:
«Хе-хей, обучающийся алгоритм, ты облажался – тебе вместо этого следовало сделать то-то и то-то.»
Сравните это с обучением с подкреплением, при котором обучающийся алгоритм получает куда менее помогающий сигнал:
«Хе-хей, обучающийся алгоритм, ты облажался.»
(также известный как отрицательное вознаграждение). Очевидно, обучение с учителем может быть куда быстрее обучения с подкреплением. Управляющие сигналы, по крайней мере в принципе, говорят тебе точно, какие параметры менять и как, если ты хочешь лучше справиться в следующий раз в схожей ситуации. Обучение с подкреплением так не делает; вместо этого приходится учиться методом проб и ошибок.
В технических терминах машинного обучения, обучение с учителем «бесплатно» предоставляет полный градиент ошибки на каждом запросе, а обучение с подкреплением – нет.
Эволюция не всегда может использовать обучение с учителем. К примеру, если вы – профессиональный математик, пытающийся доказать теорему, и ваше последнее доказательство не работает, то нет никакого сигнала «эмпирической истины», сообщающего вам, что в следующий раз надо сделать по-другому – ни в вашем мозгу, ни где-то ещё в мире. Извините! Ваше пространство того, что можно сделать, имеет очень высокую размерность и никаких явных указателей. На каком-то уровне метод проб и ошибок – ваш единственный вариант. Не повезло.
Но эволюция может иногда использовать обучение с учителем, как в примерах в этом посте. И суть такова: если она может, скорее всего она использует.
4.6 Пример «краткосрочных предсказателей» №1: Мозжечок
Я сразу перескочу к тому, для чего, как я думаю, нужен мозжечок, а потом поговорю о том, как моя теория соотносится с другими предложениями в литературе.
4.6.1 Моя теория мозжечка
Я утверждаю, что мозжечок – место обитания большого количества схем краткосрочного предсказывания.
Связи нейроанатомии мозжечка (красным) с нашей диаграммой выше. Как обычно (см. выше), я опускаю множество прибамбасов, которые делают краткосрочный предсказатель точнее, вроде ещё одного дополнительного слоя, который я не показываю, плюс разделение паттернов (Пост №2, Раздел 2.5.4), и т.д.
Насколько много краткосрочных предсказателей: Моя лучшая оценка: около 300000.[1]
Какого чёрта?? Зачем мозгу может понадобиться 300000 краткосрочных предсказателей?
У меня есть версия! Я думаю, что мозжечок смотрит на много сигнал в мозге и обучается сам посылать эти сигналы заранее.
Вот так. Это вся моя теория мозжечка.
Другими словами, мозжечок может открыть правило «С учётом нынешней контекстной информации, я предсказываю, что выходной нейрон коры №218502 активируется через 0.3 секунды». Тогда мозжечок просто берёт и посылает сигнал туда же прямо сейчас. Или наоборот, мозжечок может открыть правило «Учитывая нынешнюю контекстную информацию, я предсказываю, что проприоцептивный нерв №218502 активируется через 0.3 секунды». Опять же, мозжечок идёт на опережение и посылает сигнал туда же прямо сейчас.
Некоторые примерно-аналогичные концепции:
- Когда мозжечок предсказывает-и-предвосхищает конечный мозг, мы можем думать об этом примерно как о «мемоизации»(sic!) в программной инженерии или как о «дистилляции знаний» в машинном обучении, или как о предложенных этой недавней статьёй «нейронных суррогатах».
- Когда мозжечок предсказывает-и-предвосхищает периферийные нервы, мы можем думать об этом как о составлении кучи предсказывающих моделей тела, каждая из которых узко настроена, чтобы предсказывать свой периферийный сигнал. Тогда, когда конечный мозг занимается моторным контролем и нуждается в периферийных сигналах обратной связи, он может использовать вместо настоящих сигналов эти предсказывающие модели.
По сути, я думаю, что у мозга есть проблемы такого вида, что пропускная способность некой подсистемы вполне адекватная, но её время ожидания слишком высоко. В случае периферийных нервов время ожидания высоко, потому что сигналам надо пройти большое расстояние. В случае конечного мозга задержка высока потому что сигналам надо пройти не-такое-длинное-но-всё-же-существенное расстояние, а кроме этого им надо пройти через много последовательных шагов обработки. В любом случае, мозжечок может чудесным образом уменьшить время ожидания, заплатив за это периодическими ошибками. Мозжечок находится в центре событий, постоянно спрашивая себя «что за сигнал сейчас появится?» и предвосхищает его сам. И потом через долю секунды он видит, было ли предсказание корректным и обновляет свою модель, если не было. Это как маленькая волшебная коробочка путешествий во времени – линия задержки, чья задержка отрицательна.
И теперь у нас есть ответ: зачем нам надо ≈300000 краткосрочных предсказателей? Потому что периферийных нервов и потоков вывода конечного мозга и может ещё чего много. И многие из этих сигналов выгодно предсказывать-и-предвосхищать! Чёрт, если я понимаю правильно, то мозжечок может даже предсказать-и-предвосхитить сигнал, который конечный мозг посылает сам себе!
Вот моя теория. Я не запускал никаких симуляций; это просто идея. См. здесь и здесь два примера, где я использовал эту модель, чтобы попытаться понять наблюдения из нейробиологии и психологии. Всё остальное, что я знаю про мозжечок – нейроанатомия, как он соединён с другими частями мозга, исследования повреждений и визуализации, и т.д. – всё, насколько я могу сказать, кажется хорошо соответствующим моей теории. Но на самом деле, этот маленький раздел – это почти что сумма всего, что я знаю на эту тему.
4.6.2 Как моя теория о мозжечке связана с другими теориями в литературе
(Я тут не эксперт и открыт для поправок.)
Я думаю, широко признано, что мозжечок вовлечён в обучении с учителем. Вроде бы, эта идея называется моделью Марра-Альбуса-Ито, см. Марр 1969 или Альбус 1971, или занимательный YouTube канал Brains Explained.
Напомню, что краткосрочный предсказатель – это случай алгоритма обучения с учителем как более широкой категории. Так что часть про обучение с учителем – не отличительная черта моего предложения, и, например, диаграмма выше (с указанием анатомических деталей мозжечка красным) совместима с обычной картиной Марра-Альбуса-Ито. Отличительный аспект моей теории – чем являются эмпирические сигналы (или чем являются сигналы ошибки – всё равно).
В Посте №2 я упоминал, что когда я вижу прижизненный обучающийся алгоритм, у меня возникает немедленный вопрос: «На каких эмпирических данных он учится?» Я также упоминал, что обычно поиски ответа на этот вопрос в литературе приводят к замешательству и неудовлетворённости. Литература о мозжечке – идеальный тому пример.
К примеру, я часто слышу что-то вроде «синапсы мозжечка обновляются при моторных ошибках». Но кто говорит, что считается моторной ошибкой?
- Если вы пытаетесь идти в школу, то поскользнуться на банановой кожуре – моторная ошибка.
- Если вы пытаетесь поскользнуться на банановой кожуре, то поскользнуться на банановой кожуре – это успех!
Откуда мозжечку знать? Непонятно.
Я читал несколько вычислительных теорий по поводу мозжечка. Они обычно куда сложнее моей. И они всё ещё оставляют ощущение непонимания, откуда берутся эмпирические данные. Для ясности, я не читал тщательно каждую такую статью, и вполне возможно, что я что-то упустил.
Ну, в любом случае, это не сильно влияет на эту цепочку. Как я упоминал ранее, вы можете быть функционирующим взрослым человеком, способным жить независимо, работать и т.д., вовсе без мозжечка. Так что даже если я полностью неправ по его поводу, это не должно сильно влиять на общую картину.
4.7 Пример «краткосрочных предсказателей» №2: Предсказательное обучение сенсорных вводов в коре
В вашей коре находится богатая генеративная модель мира, включающего вас самих. Много раз в секунду ваш мозг использует эту модель, чтобы предсказать поступающие сенсорные вводы (зрение, звук, прикосновение, проприоцепция, интероцепция, и т.д.), и, когда его предсказания неверны, модель обновляется в результате ошибки. Так, к примеру, вы можете открыть дверцу вашего шкафа и немедленно понять, что кто-то смазал петли. Вы предсказывали, что это будет звучать и ощущаться определённым образом, и это предсказание было опровергнуто.
С моей точки зрения, предсказательное обучение сенсорных вводов – это главный двигатель запихивания информации из мира в нашу модель мира в коре. Я поддерживаю цитату Яна Лекуна: «Если бы интеллект был тортом, то его основой было бы [предсказательное обучение сенсорных вводов], глазурью – [остальные виды] обучение с учителем, а вишенкой на торте – обучение с подкреплением». Просто количество битов информации, которые мы получаем предсказательным обучением сенсорных вводов подавляюще превосходит все остальные источники.
Предсказательное обучение сенсорных вводов – в том конкретном смысле, в котором я это тут использую – не большая общая теория мышления. Большая проблема возникает, когда оно сталкивается с «решениями» (какие мышцы двигать, на что обращать внимание, и т.д.). Рассмотрим следующее: я могу предсказать, что я буду петь, а потом петь, и предсказание получится правильным. Или я могу предсказать, что я буду танцевать, а потом танцевать, и тогда это предсказание было правильным. Так что у предсказательного обучения есть недостаток; оно не может помочь мне сделать правильное действие. Потому нам нужна ещё и Направляющая Подсистема (Пост №3), посылающая управляющие сигналы и сигналы вознаграждения обучения с подкреплением. Эти сигналы могут продвинуть хорошие решения ток, как предсказательное обучение сенсорных вводов не может.
Всё же, предсказательное обучение сенсорных вводов – это очень важная штука для мозга, и о ней можно много чего сказать. Однако, я рассматриваю её как одну из многих тем, которые очень напрямую важны для создания подобного–мозгу СИИ, но лишь немного относятся к его безопасности. Так что я буду упоминать её время от времени, но если вы ищете точных деталей, вы сами по себе.
4.8 Другие примеры приложений «краткосрочных предсказателей»
Эти примеры тоже не будут важны для этой цепочки, так что я не буду много о них говорить, но просто для интереса вот ещё три случайные штуки, которые, как я думаю, Эволюция может делать с помощью краткосрочных предсказателей.
- Фильтрация – к примеру, мой мозг может иметь краткосрочный предсказатель входящей звуковой информации, с ограничением, что его контекстный ввод несёт информацию только о моём движении челюсти и активности голосовых связок. Предсказатель должен выдавать модель моего собственного вклада в входящий звуковой поток. Это очень полезно, потому что мозг может её вычесть, оставив только пришедшие извне звуки.
- Сжатие входных данных – это вроде экстремальной версии фильтрации. Вместо всего лишь отфильтровывания предсказываемой из собственных действий информации, можно фильтровать всю информацию, предсказуемую из чего угодно, что мы уже знаем. Кстати, это то, что я ориентировочно думаю о дорсальном кохлеарном ядре, маленькой структуре в цепи обработки звукового ввода, которая подозрительно похожа на мозжечок. См. здесь. Предупреждаю: возможно, что эта идея не имеет смысла, я сам колеблюсь.
- Отмечание новизны – см. обсуждение здесь.
———
- Клеток Пуркинье 15 миллионов (ссылка), а эта статья заявляет, что один предсказатель состоит из «горстки» клеток Пуркинье с одним управляющим сигналом и одним (совмещённым) выводом. Что значит «горстка»? В статье указано «около 50». Ну, 50 у мышей. Я не смог быстро найти соответствующее число у людей. Я предположил, что это всё ещё 50, но это просто догадка. В любом случае, из этого я вывел предположение о 300,000 предсказателей.
5. "Долгосрочный предсказатель" и TD-обучение
- 1.5.1 Краткое содержание / Оглавление
- 2.5.2 Игрушечная модель схемы «долгосрочного предсказателя»
- 3.5.3 Вычисление функции ценности (обучение методом Временных Разниц) как особый случай долгосрочного предсказания
- 4.5.4 Массив долгосрочных предсказателей с участием конечного мозга и мозгового ствола
- 5.5.5 Шесть причин, почему мне нравится эта картина «массива долгосрочных предсказателей»
- 5.1.5.5.1 Это разумный способ реализовать биологически-полезные способности
- 5.2.5.5.2 Это интроспективно правдоподобно
- 5.3.5.5.3 Это эволюционно правдоподобно
- 5.4.5.5.4 Это позволяет согласовать «висцемоторный» и «мотивационный» способы описания медиальной префронтальной коры (mPFC)
- 5.5.5.5.5 Это объясняет эксперимент с Солью Мёртвого Моря
- 5.6.5.5.6 Это предлагает хорошее объяснение разнообразию активности дофаминовых нейронов
- 6.5.6 Заключение
Примечание переводчика - с момента перевода оригинальные посты несколько обновились, через некоторое время обновлю и перевод. На общие выводы цепочки это, вроде бы, не влияет.
5.1 Краткое содержание / Оглавление
В предыдущем посте я описал «краткосрочные предсказатели» – схемы, которые благодаря обучающемуся алгоритму выводят предсказание управляющего сигнала, который прибудет через некоторое небольшое время (например, долю секунды).
В этом посте я выдвигаю идею, что можно взять краткосрочный предсказатель, обернуть его замкнутой петлёй, включающей ещё некоторые схемы, и получить новый модуль, который я называю «долгосрочным предсказателем». Как и кажется по названию, такая схема может делать долгосрочные предсказания, например, «Я скорее всего поем в следующие 10 минут». Как мы увидим, эта схема тесно связана с обучением методом Временных Разниц (TD).
Я считаю, что в мозгу есть большой набор расположенных рядом долгосрочных предсказателей, каждый из которых состоит из краткосрочного предсказателя в конечном мозге (включая специфические его области вроде полосатого тела, медиальной префронтальной коры и миндалевидного тела), образующим петлю с Направляющей Подсистемой (гипоталамус и мозговой ствол) с помощью дофаминовых нейронов. Эти долгосрочные предсказатели прогнозируют биологически-важные вводы и выводы – к примеру, один из них может предсказывать, почувствую ли я боль в своей руке, другой – произойдёт ли выброс кортизола, третий – поем ли я, и так далее. Более того, один из этих долгосрочных предсказателей – по сути, функция ценности для обучения с подкреплением.
Все эти предсказатели будут играть большую роль в мотивации – об этом я закончу рассказывать в следующем посте.
Содержание:
- Раздел 5.2 начинается с игрушечной модели схемы «долгосрочного предсказателя», состоящей из «краткосрочного предсказателя» из предыдущего поста и ещё некоторых частей, соединённых в замкнутую петлю. Хорошее интуитивное понимание этой модели будет важно в дальнейшем, и я пройдусь по тому, как это модель будет себя вести в разных обстоятельствах.
- Раздел 5.3 связывает эту модель с обучением методом Временных Разниц (TD), близким родственником «долгосрочного предсказателя». Я покажу два варианта схемы долгосрочного предсказателя, «суммирующую» (приводящую к функции ценности, приближённо суммирующей будущие награды) и «переключающуюся» (приводящую к функции ценности, приближённо оценивающей следующую награду, когда бы она ни пришла, даже если до неё ещё долго). «Суммирующая» версия повсеместна в связанной с ИИ литературе, но я предполагаю, что «переключающаяся» версия скорее всего ближе к тому, что происходит в мозге. По совпадению, эти две модели эквивалентны в случаях вроде AlphaGo, который получает всю награду сразу в конце каждого эпизода (= игры в го).
- Раздел 5.4 свяжет долгосрочные предсказатели с нейроанатомией (частей) конечного мозга и мозгового ствола.
- По «вертикальной» нейроанатомии,[1] я опишу как в мозге размещается огромное количество параллельных «петель кора-базальные ганглии-таламус-кора», и предположу, что некоторые их этих петель функционируют как краткосрочные предсказатели с управляющим дофаминовым сигналом.
- По «горизонтальной» нейроанатомии, я предложу, что в обучении с учителем, о котором я говорю, участвуют (к примеру) медиальная префронтальная кора, полосатое тело, внешняя островковая кора и миндалевидное тело.
- Раздел 5.5 предложит шесть источников свидетельств, которые привели меня к убеждённости в этой модели: (1) это разумный способ реализовать биологически-полезные способности; (2) это интроспективно правдоподобно; (3) это эволюционно правдоподобно; (4) это позволяет согласовать «висцемоторный» и «мотивационный» способы описания медиальной префронтальной коры; (5) это объясняет эксперимент с Солью Мёртвого Моря; и (6) это предлагает хорошее объяснение разнообразию активности дофаминовых нейронов.
5.2 Игрушечная модель схемы «долгосрочного предсказателя»
«Долгосрочный предсказатель» – это, по сути, краткосрочный предсказатель, чей выходной сигнал помогает определить его собственный управляющий сигнал. Вот игрушечная модель того, как это может выглядеть:
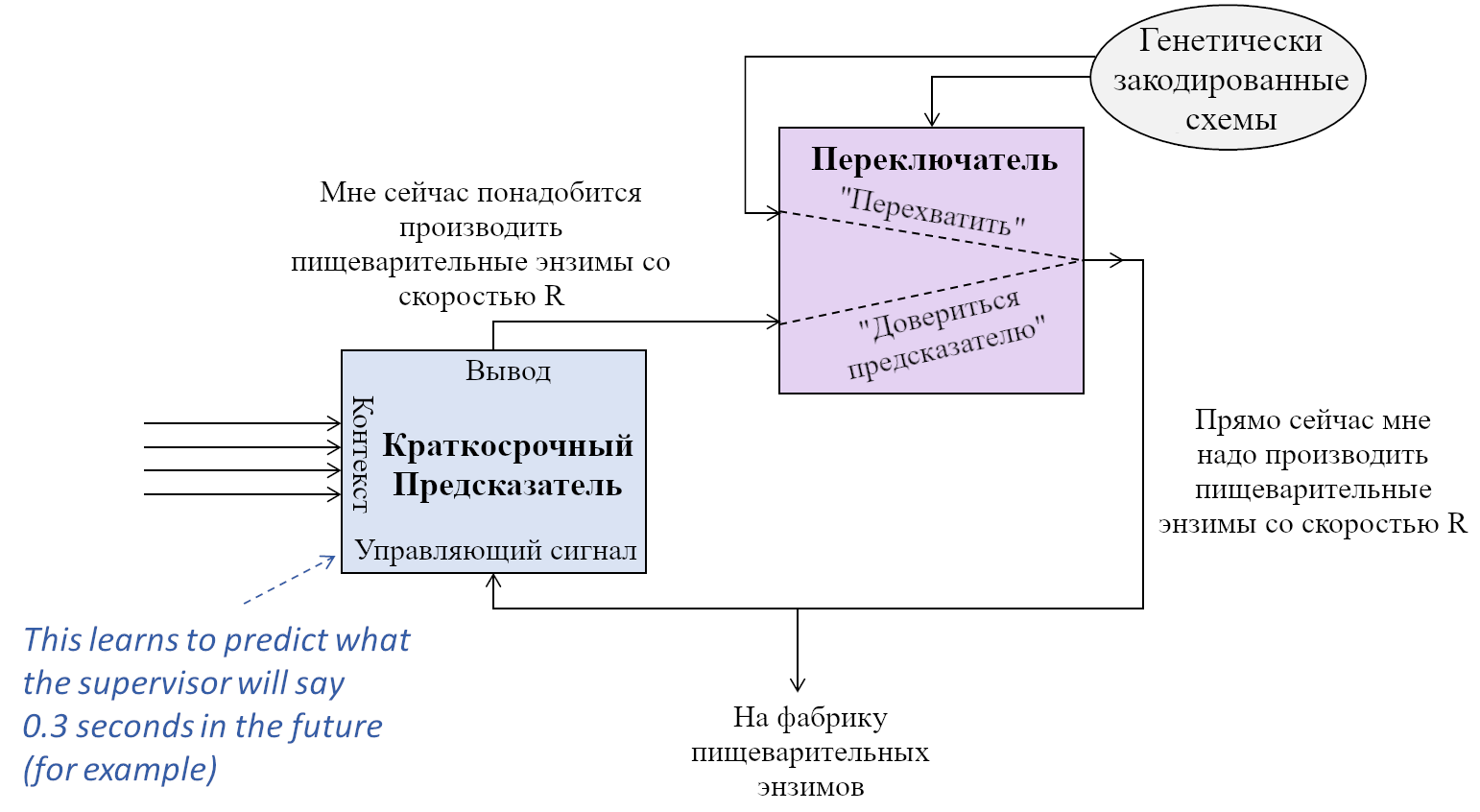
Игрушечная модель схемы долгосрочного предсказателя. Следующую пару подразделов я буду описывать, как это работает. На этой и похожих диаграммах в этом посте, все блоки в каждый момент времени работают параллельно, и, аналогично, каждая стрелка в каждый момент времени несёт числовое значение. Так что это НЕ диаграмма потока выполнения последовательного кода, это скорее похоже на, например, диаграммы, которые можно увидеть в описании FPGA.
- Синий прямоугольник – краткосрочный предсказатель из предыдущего поста. Он оптимизирует выходной сигнал, приближая его к тому, каким будет управляющий сигнал через 0.3 секунды (в этом примере).
- Фиолетовый прямоугольник – переключатель между двумя вариантами. Его контролирует генетически закодированная схема (серый овал) согласно следующим правилам:
- В основном переключатель находится в нижнем положении (довериться предсказателю). Это сродни тому, что генетически закодированная схема «доверяет» тому, что вывод краткосрочного предсказателя осмысленен, и, в этом примере, производит предложенное количество пищеварительных энзимов.
- Если генетически закодированная схема получает сигнал, что я что-то ем прямо сейчас, и у меня нет адекватного количества пищеварительных энзимов, то она переводит переключатель в вариант «перехватить», и посылает сигнал начать производство пищеварительных энзимов независимо от того, что говорит краткосрочный предсказатель.
- Если генетически-прошитая схема долгое время получала запросы на производство пищеварительных энзимов, но всё ещё ничего не было съедено, то она опять же переключает на вариант «перехватить» и посылает сигнал прекратить производство энзимов, независимо от того, что говорит краткосрочный предсказатель.
Замечу: Вы можете считать, что все сигналы на диаграмме могут непрерывно изменяться по диапазону значений (в противоположность дискретным сигналам вкл/выкл), за исключением сигнала управления переключателем.[2] В мозгу плавно-настраиваемые сигналы могут создаваться, к примеру, кодированием через частоту активаций нейрона.
5.2.1 Разбор игрушечной модели, часть 1: статичный контекст
Давайте пройдёмся по тому, что происходит в этой игрушечной модели.[3] Для начала, предположим, что на протяжении некоторого протяжённого периода времени «контекст» статичен. К примеру, представьте, как какое-нибудь древнее червеподобное существо много последовательных минут копается в песчаном дне океана. Правдоподобно, что пока оно копает, его сенсорное окружение будет оставаться довольно постоянным, и также постоянными будут оставаться его мысли и планы (в той мере, в которой у древнего червеподобного существа вообще есть «мысли и планы»). Или, если хотите другой пример (приблизительно) статичного контекста – с участием человека, а не червя – подождите следующего подраздела.
В этом случае, давайте посмотрим, что происходит, когда переключатель находится в положении «довериться-предсказателю»: поскольку вывод связан с управляющим сигналом, обучающийся модуль не получит сигнала об ошибке. Предсказание верно. Синапсы не меняются. Эта ситуация, сколь бы ни была частой, не повлияет на поведение краткосрочного предсказателя.
Что на него повлияет – те редкие случаи, когда переключатель переходит в режим «перехватить». Можно думать об этом как о периодическом «впрыскивании эмпирической истины». В этих случаях обучающийся алгоритм краткосрочного предсказания получает сигнал об ошибке, что меняет его настраиваемые параметры (например, силу синапсов).
Набрав достаточно жизненного опыта (или, что то же самое, после достаточного обучения), краткосрочный предсказатель должен получить свойство балансирования перехватов. Перехваты всё ещё могут увеличивать производство энзимов, а иногда могут его снижать, но эти два типа перехватов должны происходить с примерно одинаковой частотой. Ведь если бы они не были сбалансированы, то алгоритм обучения краткосрочного предсказания постепенно изменил бы его параметры, чтобы перехваты всё же были сбалансированы.
И это как раз то, что нам надо! Мы получаем подходящее производство энзимов в подходящее время, способом, в нужной мере учитывающим доступную контекстную информацию – что животное сейчас делает, что планирует делать, его сенсорные вводы, и т.д.
5.2.1.1 Экспозиционная терапия в стиле Дэвида Бернса – возможный реальный пример игрушечной модели с статичным контекстом?
Так вышло, что я недавно прочёл книгу Дэвида Бернса Терапия Настроения (мой обзор). У Дэвида Бернса очень интересный подход к экспозиционной терапии – служащий отличным примером того, как моя игрушечная модель работает в ситуации статичного контекста!
Вот короткая версия. (Предупреждение: если вы думаете самостоятельно заниматься экспозиционной терапией в домашних условиях, по меньшей мере сначала прочитайте всю книгу!) Отрывок из книги:
Во время обучения в старшей школе я хотел попасть в команду технических помощников сцены для постановки мюзикла «Бригадун». Учитель драмы, мистер Крэнстон, сказал мне, что помощники сцены должны забираться на высокие лестницы и ползать по балкам под потолком, чтобы регулировать свет. Я ответил, что для меня это может оказаться проблемой, ведь я боюсь высоты. Он объяснил, что я не смогу стать частью команды помощников сцены, пока не захочу преодолеть свой страх. Я спросил, как это сделать.
Мистер Крэнстон ответил, что это довольно просто. Он установил 18-футовую лестницу по центру сцены, сказал мне забраться на нее и встать на верхнюю перекладину. Я доверял ему, поэтому поднимался по лестнице, перекладина за перекладиной, пока не оказался наверху. Вдруг я увидел, что там не за что держаться, и пришел в ужас! Я спросил, что мне делать дальше. Мистер Крэнстон ответил, что не нужно ничего делать, просто стоять там, пока не уйдет страх. Он ждал меня внизу лестницы и подбадривал, чтобы я продолжал стоять.
В течение 15 минут я пребывал в полном оцепенении. Затем мой страх вдруг начал уходить. Через минуту или две он полностью исчез. Я с гордостью объявил: «Мистер Крэнстон, думаю, я исцелился. Я больше не боюсь высоты».
Он сказал: «Прекрасно, Дэвид! Ты можешь спускаться. Будет здорово, если ты присоединишься к команде помощников сцены для мюзикла «Бригадун»».
Я гордился тем, что стал помощником сцены. Мне понравилось ползать по балкам под потолком, закрепляя занавес и свет. Я удивлялся, что прежний источник моих страхов может приносить столько восторга.
Эта история кажется прекрасно совместимой с моей игрушечной моделью. Дэвид начал день в состоянии, когда его краткосрочные предсказатели выдавали очень сильную реакцию страха, когда он забирался на высоту. Пока Дэвид оставался на лестнице, эти краткосрочные предсказатели продолжали получать одни и те же контекстные данные, и продолжали выдавать всё такой же вывод. И Дэвид продолжал быть в ужасе.
Потом, после 15 скучных-но-ужасающих минут на лестнице, какая-то внутренняя схема в мозговом стволе Дэвида произвела *перехват* – как будто сказала «Слушай, ничего не меняется, ничего не происходит, мы не можем просто весь день продолжать сжигать на это калории». Краткосрочный предсказатель продолжил посылать всё тот же вывод, но мозговой ствол применил своё право вето и насильно «перезагрузил» Дэвиду уровень кортизола, пульс, и т.д., вернув их обратно на базовое значение. Это состояние «перехвата» немедленно привело к получению краткосрочным предсказателем в миндалевидном теле Дэвида *сигналов об ошибке*! Эти сигналы, в свою очередь, привели к обновлению модели! Краткосрочные предсказатели оказались обновлены, и с тех пор Дэвид больше не боялся высоты.
Конечно эта история выглядит спекуляцией на спекуляции, но я всё равно думаю, что она верна. По крайней мере, это хороший пример! Вот диаграмма для этой ситуации, удостоверьтесь, что не упускаете шагов.
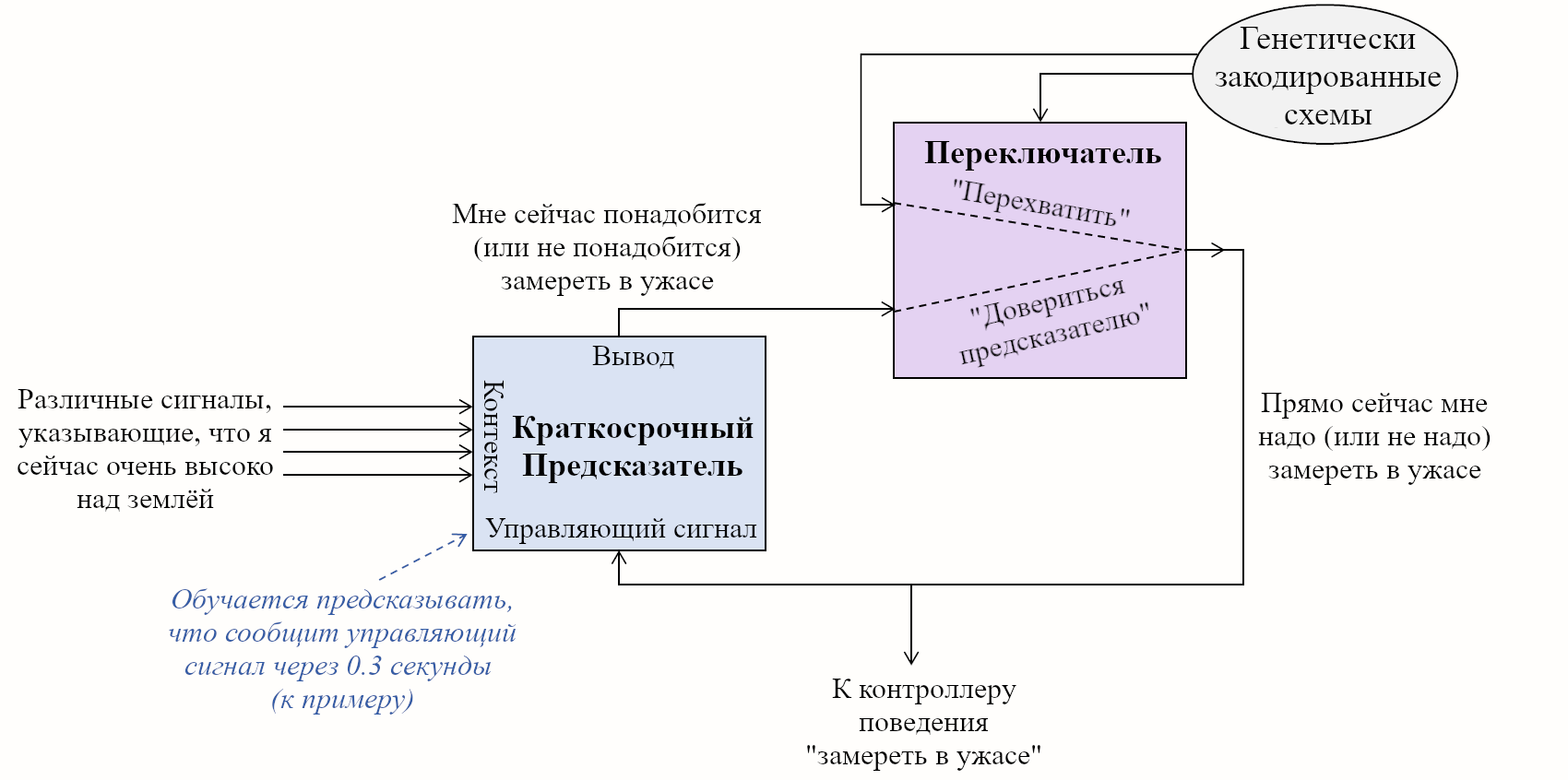
5.2.2 Разбор игрушечной модели, предполагая изменяющийся контекст
Предыдущий подраздел предполагал статичные потоки контекстных данных (постоянная сенсорная информация об окружении, постоянное поведение, постоянные мысли и планы, и т.д.). Что происходит, если контекст не статичен?
При изменениях в потоках контекстных данных обучение происходит не только при «перехватах». Если контекст меняется без «перехватов», то это приводит к изменениям вывода, и новый вывод будет трактоваться как эмпирическая истина о том, каким должен был быть старый вывод. Опять же, это кажется в точности тем, что нам надо? Если мы обучаемся чему-то новому и оказавшемуся важным в последнюю секунду, то наше текущее ожидание должно быть точнее, чем раннее, так что у нас есть основание для обновления нашей модели.
5.3 Вычисление функции ценности (обучение методом Временных Разниц) как особый случай долгосрочного предсказания
К этому моменту эксперты в машинном обучении должны распознать сходство с обучением методом Временных Разниц. Однако, это не совсем одно и то же. Различия:
Первое, обучение методом Временных Разниц обычно используется в обучении с подкреплением как метод перехода от функции вознаграждения к функции ценности. Я, напротив, говорю о штуках вроде «производства пищеварительных энзимов», которые не являются ни вознаграждениями, ни ценностями.
Другими словами, есть в целом полезный мотив перехода от некого немедленного значения X к «долгосрочному ожиданию X». Вычисление функции ценности из функции вознаграждения – пример этого мотива, но не исчерпывающий.
(В плане терминологии, мне кажется вполне общепринятым, что термин «обучение методом Временных Разниц» на самом деле может относиться к чему-то, не являющемуся функцией ценности обучения с подкреплением.[4] Однако, по моему собственному эмпирическому опыту, как только я упоминаю этот метод, мои собеседники немедленно начинают подразумевать, что я говорю о функциях ценности обучения с подкреплением. Так что мне приходится тут прояснять.)
Второе, чтобы получить что-то более похожее на традиционное обучение методом Временных Разниц, нам потребовалось бы заменить переключатель между двумя вариантами сумматором – и тогда «перехваты» были бы аналогичны наградам. Куда больше о «переключении против суммирования» – в следующем подразделе.

Вот схема обучения методом Временных Разниц, которая вела бы себя похоже на то, что вы можете найти в учебных пособиях по ИИ. Обратите внимание на фиолетовый прямоугольник справа: в отличии от предыдущей диаграммы, тут не *переключатель*, а *сумматор*. Куда больше о «переключении против суммирования» – в следующем подразделе.
Третье, есть много дополнительных способов поправить эту схему, которые часто используют в литературе по ИИ, и некоторые из них могут встречаться и в схемах в мозгу. К примеру, мы можем добавить обесценивание со временем, или разные реакции на ложно-положительные и ложно-отрицательные сигналы (см. моё рассмотрение обучения распределениям в Разделе 5.5.6.1 ниже), и т.д.
Чтобы всё не становилось слишком сложным, я буду игнорировать эти возможности (включая обесценивание со временем) ниже.
5.3.1 Переключатель (т.е. ценность = ожидаемая следующая награда) или сумматор (т.е. ценность = ожидаемая сумма будущих наград)?
Диаграммы выше показывают два варианта нашей игрушечной модели. В одном фиолетовый прямоугольник – переключатель между состоянием «доверия краткосрочному предсказателю» и некой независимой «эмпирической истиной». В другом в фиолетовом прямоугольнике вместо этого происходит суммирование.
В версии с переключателем краткосрочный предсказатель обучается предсказывать следующие эмпирические данные, когда бы они ни поступили.
В версии с сумматором, краткосрочный предсказатель обучается предсказывать сумму будущих эмпирических сигналов.
Правильным ответом может быть ещё «что-то промежуточное между переключением и суммированием». Или даже «ничто из этого».
Статьи по обучению с подкреплением повсеместно используют версию суммирования – т.е. «ценность – это ожидаемая сумма будущих наград». Что про биологию? И что на самом деле лучше?
Это не всегда вообще имеет значение! Рассмотрим AlphaGo. Как и повсюду в AlphaGo изначально использовалась парадигма суммирования. Но получилось так, что за каждую игру он получает только один ненулевой сигнал вознаграждения, если конкретно, +1 в конце игры, если он выигрывает, или -1 – если проигрывает. В таком случае, переключатель и сумматор ничем друг от друга не отличаются. Разница только в терминологии:
- В случае суммирования можно сказать «каждый не-последний ход в го приносит вознаграждение = 0».
- В случае переключения, можно сказать «каждый не-последний ход в го приносит вознаграждение (null) / не приносит вознаграждения».
(Видите, почему?)
Но в других случаях это важно. Так что вернёмся к вопросу: это должно быть переключение или суммирование?
Давайте сделаем шаг назад. Чего мы пытаемся добиться?
Одна из штук, которые должен делать мозг – это принимать решения, взвешивая при этом выгоды из разных областей. Если вы человек, то вам надо решать, посмотреть телевизор или пойти в спортзал. Если вы некое древнее червеподобное существо, то вам надо «решать» – копать или плавать. В любом случае, это «решение» затрагивает энергетический баланс, солевой баланс, вероятность травм, вероятность размножения – и много чего ещё. Проектная цель алгоритма принятия решений – принимать такие решения, которые будут максимизировать совокупную генетическую приспособленность. Как это может быть лучше всего реализовано?
Один из методов включает создание функции ценности, которая оценивает совокупную генетическую приспособленность организма (сравнительно с некой произвольной, и может, меняющейся со временем точкой отсчёта), при условии продолжения выполнения данного курса действий. Конечно, это не идеальная оценка – настоящая совокупная генетическая приспособленность может быть вычислена только задним числом, ещё через много поколений. Но когда у нас есть такая функция ценности, сколь бы неидеальной она ни была, мы можем подключить её к алгоритму, принимающему решения, максимизирующие ценность (больше про это в следующем посте), и таким образом получить приблизительно-максимизирующее-приспособленность поведение.
Так что обладание функцией ценности – ключ к принятию хороших решений, учитывающих выгоду в разных областях. Но тут нигде не сказано «ценность – это ожидаемая сумма будущих вознаграждений»! Это конкретный способ настройки этого алгоритма; метод, который может подходить, а может и не подходить к конкретной ситуации.
Я думаю, что мозг использует что-то более похожее на схему с переключателем, а не на схему с сумматором, причём не только для предсказаний гомеостаза (как в примере пищеварительных энзимов выше), но и для функции ценности, вопреки мейнстримным статьям об обучении с подкреплением. Опять же, я считаю, что на самом деле это «ничто из этого» во всех этих случаях; просто это ближе к переключателю.
Почему я отдаю предпочтение «переключателю», а не «сумматору»?
Пример: иногда я стукаюсь пальцем и он болит 20 секунд; в другой раз я стукаюсь пальцем и он болит 40 секунд. Но я не думаю о втором событии как о вдвое худшем, чем первое. На самом деле, уже через пять минут, я не вспомню, какая из двух ситуаций это была. (см. правило пика-и-конца.) Это то, чего я бы ожидал от переключателя, но довольно плохо подходит для сумматора. Это не строго несовместимо с суммированием; просто требует более сложной и зависящей от ценности функции вознаграждения. На самом деле, если мы это позволяем, то переключатель и сумматор могут имитировать друг друга.
В любом случае, в следующих постах я буду подразумевать переключатели, не сумматоры. Я не думаю, что это на большом масштабе очень важно, и я точно не думаю, что это часть «секретного ингредиента» интеллекта животных, или что-то такое. Но это влияет на некоторые детальные описания.
Следующий пост будет включать больше деталей обучения с подкреплением в мозгу, включая то, как работает сигнал «ошибки предсказания вознаграждения». Я готовлюсь к тому, что много читателей будут в замешательстве от того, что я подразумеваю не такую связь ценности с вознаграждением, к которой все привыкли. К примеру, в моей картине «вознаграждение» синонимично «эмпирическим данным о том, какой сейчас следует быть функции ценности» – и то, и другое должно учитывать не только текущие обстоятельства организма, но и будущие перспективы. Заранее прошу прощения за замешательство! Я изо всех сил попробую быть яснее.
5.4 Массив долгосрочных предсказателей с участием конечного мозга и мозгового ствола
Вот наша схема долгосрочного предсказателя:
Скопировано с схемы выше.
Я могу соединить переключатель с остальной генетически-прошитой схемой и немного переместить прямоугольники, тогда получится это:
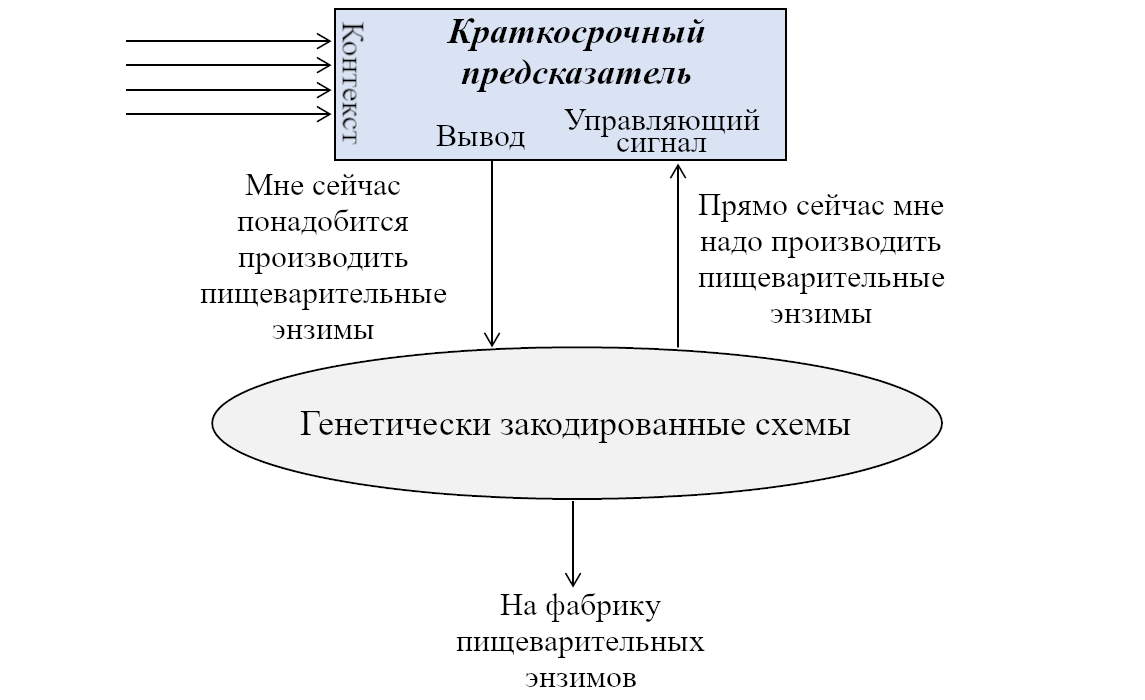
То же, что и выше, но нарисованное по-другому.
Очевидно, пищеварительные энзимы – лишь один пример. Давайте дорисуем ещё примеров, добавим гипотетическую нейронанатомию и ещё немного терминов. Вот, что получится:
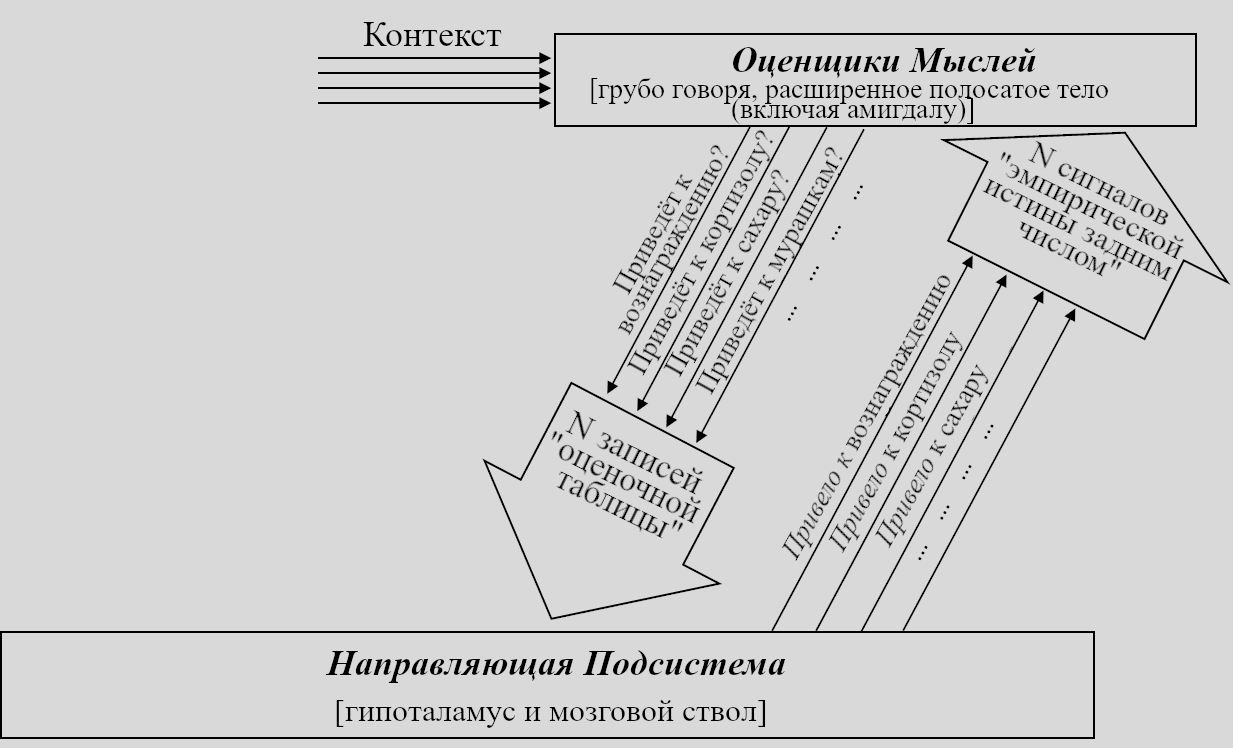
Я заявляю, что в мозгу есть целый набор долгосрочных предсказателей, состоящий из краткосрочных предсказателей в конечном мозге, каждый из которых петлёй связан с соответствующей схеме в Направляющей Подсистеме. По причинам, описанным ниже в Разделе 5.5.4, я называю первую часть (в конечном мозге) «Оценщиками Мыслей».
Замечательно! Мы на полпути к моей большой картине принятия решений и мотивации. Остаток – включая «субъекта» из обучения с подкреплением «субъект-критик» – будет в следующем посте, он заполнит дыру в верхней-левой части диаграммы.
Вот ещё одна диаграмма с педагогическими пометками.
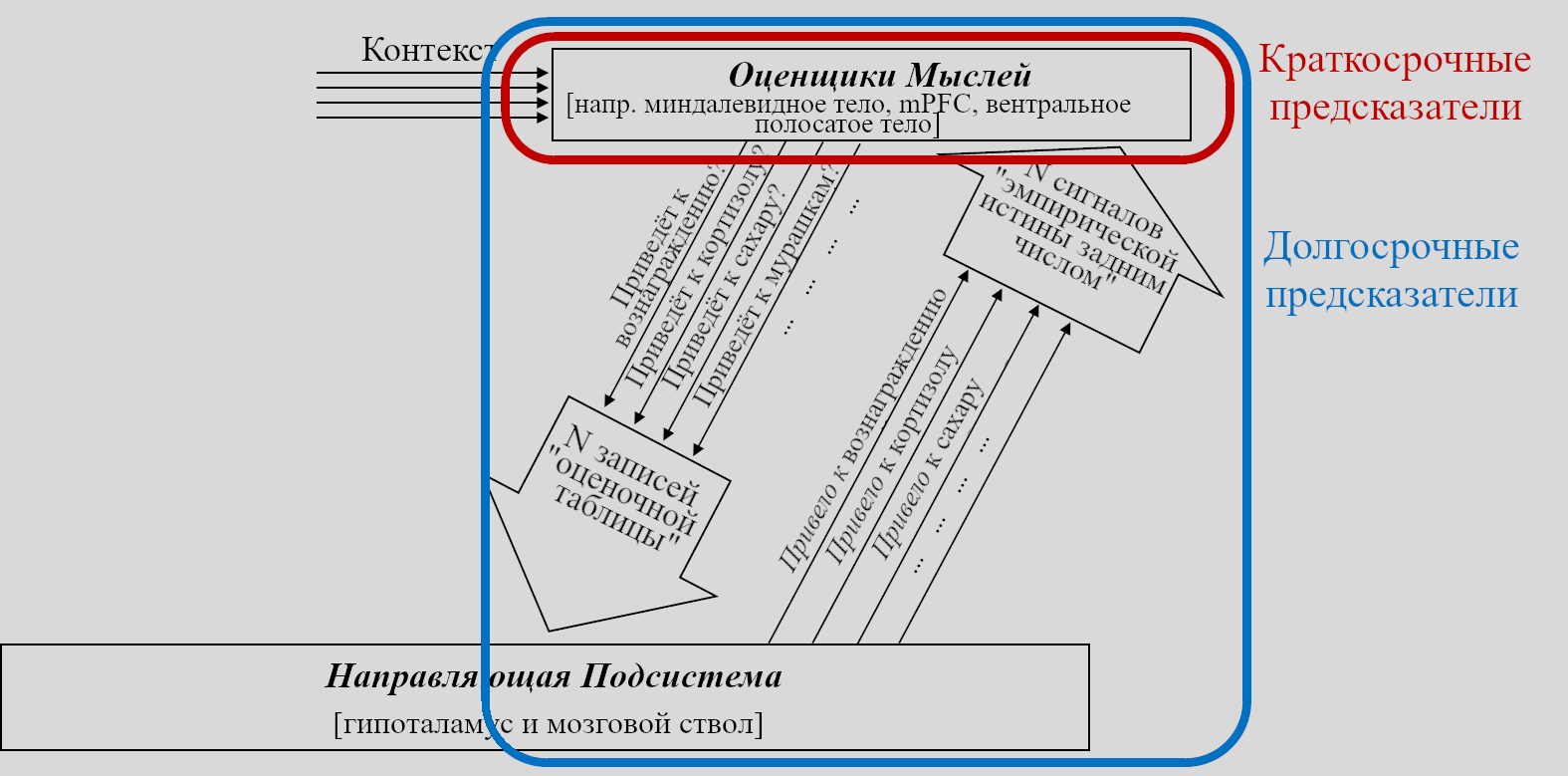
Напоминание: «краткосрочный предсказатель» - это *один из компонентов* «долгосрочного предсказателя». Тут показано, как они оба располагаются на предыдущей диаграмме. Долгосрочный предсказатель обеспечивается режимом «довериться предсказателю» - т.е. Направляющая Подсистема может посылать сигнал «эмпирической истины задним числом», который является не «эмпирической истиной» в нормальном смысле, но скорее копией соответствующего элемента «оценочной таблицы». Другими словами, режим «довериться предсказателю» можно описать как то, что Направляющая Подсистема говорит краткосрочному предсказателю «ОК, конечно, принято, верю тому, что ты говоришь». Если Направляющая Подсистема регулярно придерживается сигнала «довериться предсказателю» 10 минут подряд, то мы может получать прогнозирование будущего на 10 минут. Напротив, если Направляющая Подсистема *никогда* не использует для какого-то сигнала режим «довериться предсказателю», то получившуюся конструкцию вовсе нельзя назвать «долгосрочным предсказателем».
В следующих двух подразделах, я подробнее опишу нейроанатомию, на которую я даю намёки на этой диаграмме, и поговорю о том, почему вам стоит мне поверить.
5.4.1 «Вертикальная» нейроанатомия[1]: Петли «кора-базальные ганглии-таламус-кора»
В моём посте Большая Картина Фазового Дофамина, я рассказывал о теории (за авторством Ларри Свансона), что весь конечный мозг изящно организован в три слоя (кора, полосатое тело, паллидум):
| **Подобная-коре часть петли** | Гиппокампус | Миндалевидное тело [базолатеральная часть] | Грушевидная кора | Медиальная префронтальная кора | Моторная и «планирующая» кора |
| **Подобная-полосатому-телу часть петли** | Латеральная перегородочная зона | Миндалевидное тело [центральная часть] | Обонятельный бугорок | Вентральное полосатое тело | Дорсальное полосатое тело |
| **Подобная-паллидуму часть петли** | Медиальная перегородочная зона | BNST | Безымянная субстанция | Вентральный паллидум | Дорсальный паллидум |
Весь конечный мозг – неокортекс, гиппокампус, миндалевидное тело, всё остальное – может быть разделён на подобные-коре, подобные-полосатому-телу и подобные-паллидуму структуры. Если две структуры в таблице в одном столбце, это значит, что они связаны вместе в петлю «кора-базальные ганглии-таламус-кора» (см. следующий параграф). Эта таблица неполна и упрощена; для версии получше см. Рис. 4 здесь.
Эта идея связывается с ранней (и сейчас широко принятой) теорией (Александер 1986), что эти три слоя конечного мозга взаимосвязаны большим количеством параллельных петель «кора-базальные ганглии-таламус-кора», которые можно обнаружить почти в любой части конечного мозга.
Вот небольшая иллюстрация:
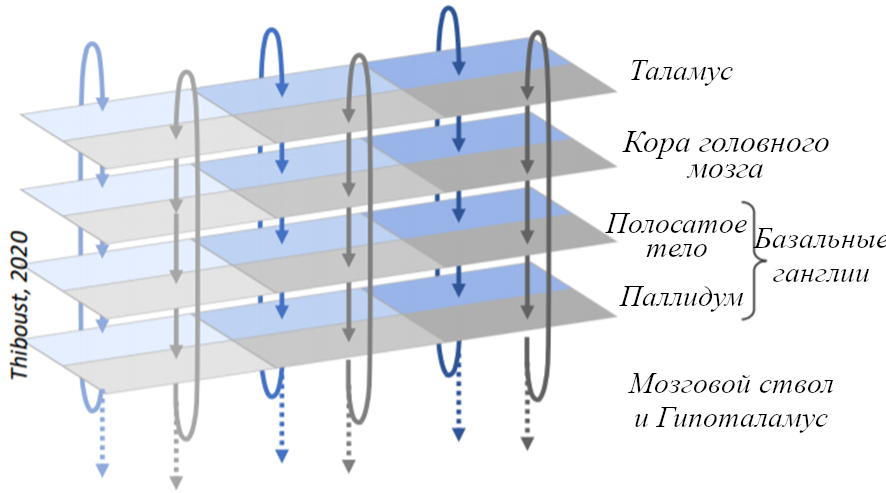
Упрощённая иллюстрация массива параллельных петель «кора-базальные ганглии-таламус-кора». Источник: Мэтью Тибуст.
С учётом всего этого, вот возможная грубая модель того, как эта петельная архитектура связана с обучающимся алгоритмом краткосрочных предсказателей, о котором я говорил:
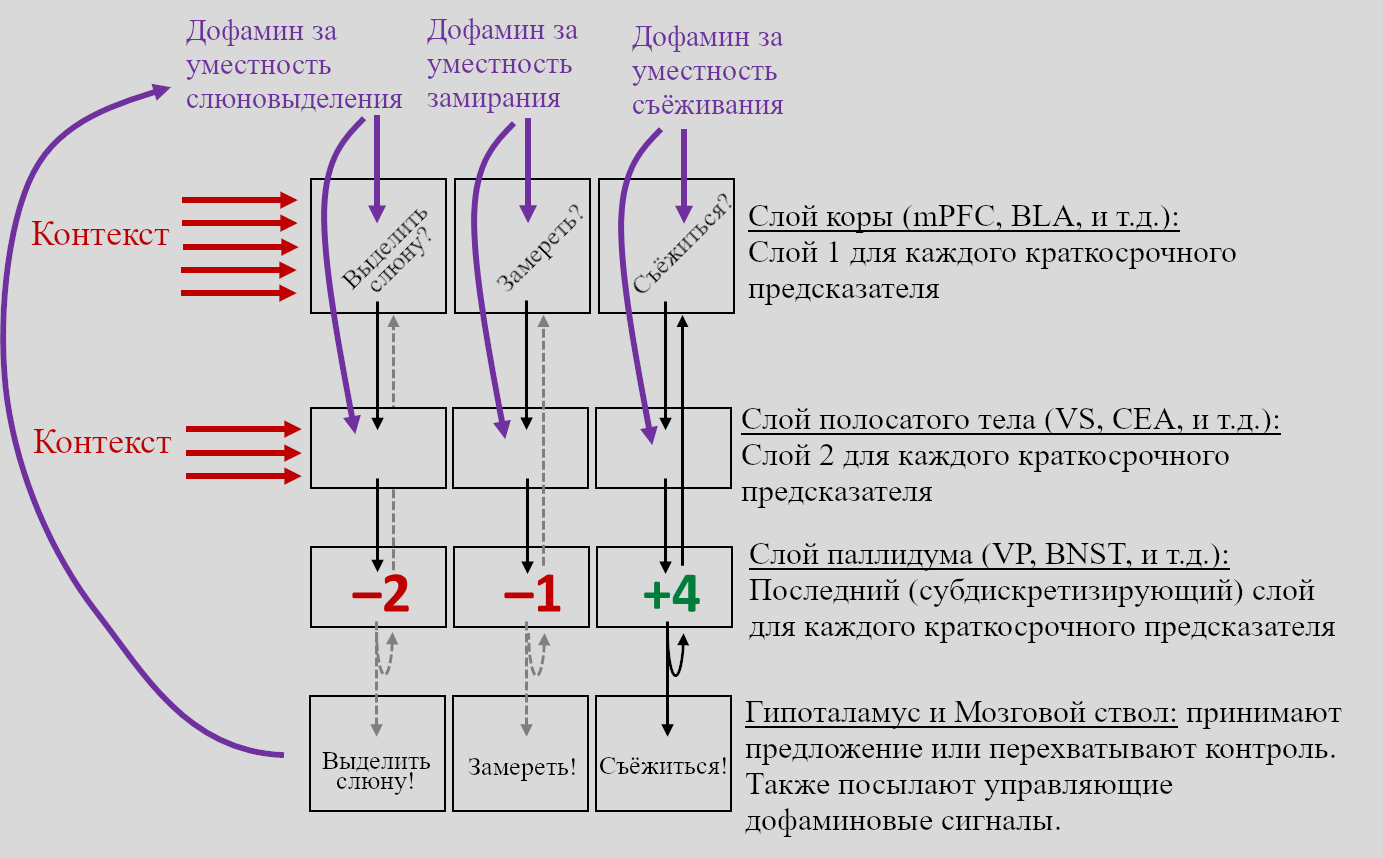
ПРЕДУПРЕЖДЕНИЕ: НЕ ВОСПРИНИМАЙТЕ ЭТУ ДИАГРАММУ СЛИШКОМ БУКВАЛЬНО
См. Большую Картину Фазового Дофамина за *немного* более подробными деталями, но вообще я не особо много в это погружался, и, в частности ярлыки «Слой 1, Слой 2, Последний (суюдискретизирующий) слой» расставлены почти наугад. («Субдискретизация» основана на том, что в полосатом теле в 2000 раз больше нейронов, чем в паллидуме – см. здесь.)
Сокращения: BLA = базолатеральное миндалевидное тело, BNST = опорное ядро терминального тяжа, CEA = центральное миндалевидное тело, mPFC = медиальная префронтальная кора, VP = вентральный паллидум, VS = вентральное полосатое тело.
5.4.2 «Горизонтальная» нейронанатомия – специализация коры
Предыдущий подраздел весь был про «вертикальную» трёхслойную структуру конечного мозга. Сейчас давайте переключимся на «горизонтальную» структуру, т.е. тот факт, что разные части коры делают разные вещи (в кооперации с соответствующими частями полосатого тела и паллидума).
Это упрощение, но вот моя новейшая попытка объяснить (часть) коры на пальцах:
- Расширенная моторная кора – это основной источник выводов коры, вовлекающих скелетные мышцы, вроде хватания и ходьбы.
- Медиальная префронтальная кора (mPFC – также включающая переднюю поясную кору) – это главный источник выводов коры, вовлекающих автономные/висцемоторные/гормнональные действия, вроде выпускания кортизола, сужения сосудов, гусиной кожи, и т.д.
- Миндалевидное тело – это главный источник выводов коры, связанных с некоторыми поведениями, вовлекающими и скелетные мышцы и автономные реакции, вроде вздрагивания, замирания (при испуге), и т.д.
- Островковая кора – это главный регион вводов коры для автономной / гомеостатической / связанной с статусом тела информации, вроде уровня сахара в крови, боли, холода, вкуса, напряжения мышц и т.д.
В этой цепочке я не буду говорить про моторную кору, но я думаю, что остальные три все вовлечены в схемы долгосрочного предсказания. К примеру:
- Я заявляю, что если взглянуть на маленький подрегион в медиальной префронтальной коре, то можно будет обнаружить, что он обучен активироваться пропорционально вероятности предстоящего выброса кортизола;
- Я заявляю, что если взглянуть на маленький подрегион в миндалевидном теле, то можно будет обнаружить, что он обучен активироваться пропорционально вероятности предстоящей реакции замирания;
- Я заявляю, что если взглянуть на маленький подрегион в (внешней) островковой коре, то можно будет обнаружить, что он обучен активироваться пропорционально вероятности предстоящего ощущения холода в левой руке.
5.5 Шесть причин, почему мне нравится эта картина «массива долгосрочных предсказателей»
5.5.1 Это разумный способ реализовать биологически-полезные способности
Если начать производить пищеварительные энзимы перед едой, то пища будет переварена быстрее. Если начать разгонять сердце до того, как вы увидите льва, то мышцы будут уже подготовлены убегать, когда вы увидите льва.
Так что такие предсказатели кажутся очевидно полезными.
Более того, как обсуждалось в предыдущем посте (Раздел 4.5.2), предлагаемая мной (основанная на обучении с учителем) техника кажется либо превосходящей, либо хорошо сочетающейся с другими способами это сделать.
5.5.2 Это интроспективно правдоподобно
Вообще, мы на самом деле начинаем слюновыделение до того, как съели крекер, начинаем нервничать до того, как видим льва, и т.д.
Ещё учтите тот факт, что все действия, о которых я говорил в этом посте непроизвольны: вы не можете выделять слюну по команде, расширять свои зрачки по команде и т.д, по крайней мере не так же, как можете подвигать пальцем по команде.
(Больше о произвольных действиях в следующем посте – они в совсем другой части конечного мозга.)
Я тут замалчиваю о многих сложностях, но непроизвольная природа этих вещей кажется удобно сочетающейся с идеей, что они обучаются своими собственными управляющими сигналами, прямо из мозгового ствола. Можно сказать, что они случат другому господину. Мы можем как-то обхитрить их и заставить вести себя определённым образом, но наш контроль ограниченный и непрямой.
5.5.3 Это эволюционно правдоподобно
Как описано в Разделе 4.4 предыдущего поста, простейший краткосрочный предсказатель невероятно прост, а простейший долгосрочный предсказатель лишь немногим сложнее. И эти очень простые версии уже правдоподобно полезны для приспособленности, даже у очень простых животных.
Более того, как я уже обсуждал некоторое время назад (Управляемое дофамином обучение у млекопитающих и плодовых мух), у плодовых мух есть массив маленьких обучающихся модулей, играющих роль, кажущуюся схожей с тем, о чём я тут говорю. Эти модули тоже используют дофамин в качестве управляющего сигнала, и есть некоторое генетическое свидетельство гомологии этих схем с конечным мозгом млекопитающих.
5.5.4 Это позволяет согласовать «висцемоторный» и «мотивационный» способы описания медиальной префронтальной коры (mPFC)
Возьмём mPFC (также включающую переднюю поясную кору) как пример. Люди пытаются говорить об этой области двумя довольно разными способами:
- С одной стороны, как упомянуто выше (Раздел 5.4.2), mPFC описывают как область висцемоторного / гомеостатического / автономно-моторного вывода – она задаёт команды контроля гормонов, исполнения реакций симпатической и парасимпатической нервной системы, и так далее. К примеру, «показано, что электрическая стимуляция инфралимбической коры влияет на подвижность желудка и вызывает гипотонию», а в этой статье говорится, что стимуляция mPFC вызывает «расширение зрачков, изменения кровяного давления, частоты дыхания и пульса», или посмотрите в книгу Бада Крейга, который характеризует переднюю поясную кору как центр гомеостатического моторного вывода. Это подход элегантно объясняет тот факт, что этот регион агранулярен (лишён слоя №4 из 6 слоёв неокортекса), что подразумевает «регион вывода» как по теоретическим причинам, так и по аналогии с (агранулярной) моторной корой.
- С другой стороны, mPFC часто описывают как место обитания приближённо-связанных-с-мотивацией активностей. К примеру, Википедия в связи с передней поясной корой упоминает «распределение внимания, предвкушение вознаграждения, этика и моральность, контроль импульсов … и эмоции».
Я думаю, моя картина работает и там, и там[5]:
С первой (висцемоторной) точки зрения, если вы взглянете на Раздел 5.2. выше, то вы увидите, что выводы предсказателей действительно приводят к гомеостатическим изменениям – как минимум, когда генетически-прошитые схемы Направляющей Подсистемы посылают сигнал в режиме «довериться предсказателю» (а не «перехвата»).
Касательно второй (мотивационной) точки зрения, это будет иметь больше смысла после следующего поста, но отметьте предложенное мной описание «оценочной таблицы» в диаграмме в Разделе 5.4. Идея такая: потоки «контекста» входящие в «Оценщики Мыслей» содержат ужасающую сложность всего вашего сознательного разума и даже больше – где вы, что вы видите и делаете, о чём вы думаете, что вы планируете делать в будущем и почему, и т.д. Довольно простая, генетически закодированная Направляющая Подсистема никак не может во всём этом разобраться!
Но ведь Направляющая Подсистема – источник наград / стремлений / мотиваций! Как она может предоставлять награду за хороший план, если она вовсе не может разобраться в том, что вы планируете??
Ответ – «оценочная таблица». В ней вся эта ужасающая сложность дистиллируется в стандартизированную табличку – как раз то, что генетически-заходированные схемы Направляющей Подсистемы могут легко обработать.
Так что любое взаимодействие между мыслями и стремлениями – эмоции, принятие решений, этика, антипатия, и т.д. – должно на промежуточном шаге вовлекать «Оценщики Мыслей».
5.5.5 Это объясняет эксперимент с Солью Мёртвого Моря
См. мой старый пост Внутреняя согласованность в лишённых-соли крысах. Если коротко, экспериментаторы периодически проигрывали звук и выдвигали объект в клетку с крысами, и немедленно после этого впрыскивали прямо им во рты очень солёную воду. Крысы считали её отвратительной, и с ужасом реагировали на звук и объект. Потом экспериментаторы лишили крыс соли. И после этого когда они играли звук и выдвигали объект, крысы становились очень радостно возбуждёнными – хоть раньше и не испытывали недостатка соли ни разу за всю свою жизнь.
Это в точности то, чего мы бы ожидали в нашей схеме: когда звук и объект появляются, предсказатель «я предчувствую вкус соли» начинает быть бешено активным. В то же время, Направляющая Подсистема (гипоталамус и мозговой ствол) имеют прошитую схему, заявляющую «Если у меня недостаток соли, а «оценочная таблица» Обучающейся Подсистемы предполагает, что я скоро почувствую вкус соли, то это замечательно, и я должен следовать той идее, которую сейчас думает Обучающаяся Подсистема!»
5.5.6 Это предлагает хорошее объяснение разнообразию активности дофаминовых нейронов
Напомню, что выше в Разделе 5.4.1 я заявлял, что дофаминовые нейроны несут управляющие сигналы всех этих модулей обучения с подкреплением.[6]
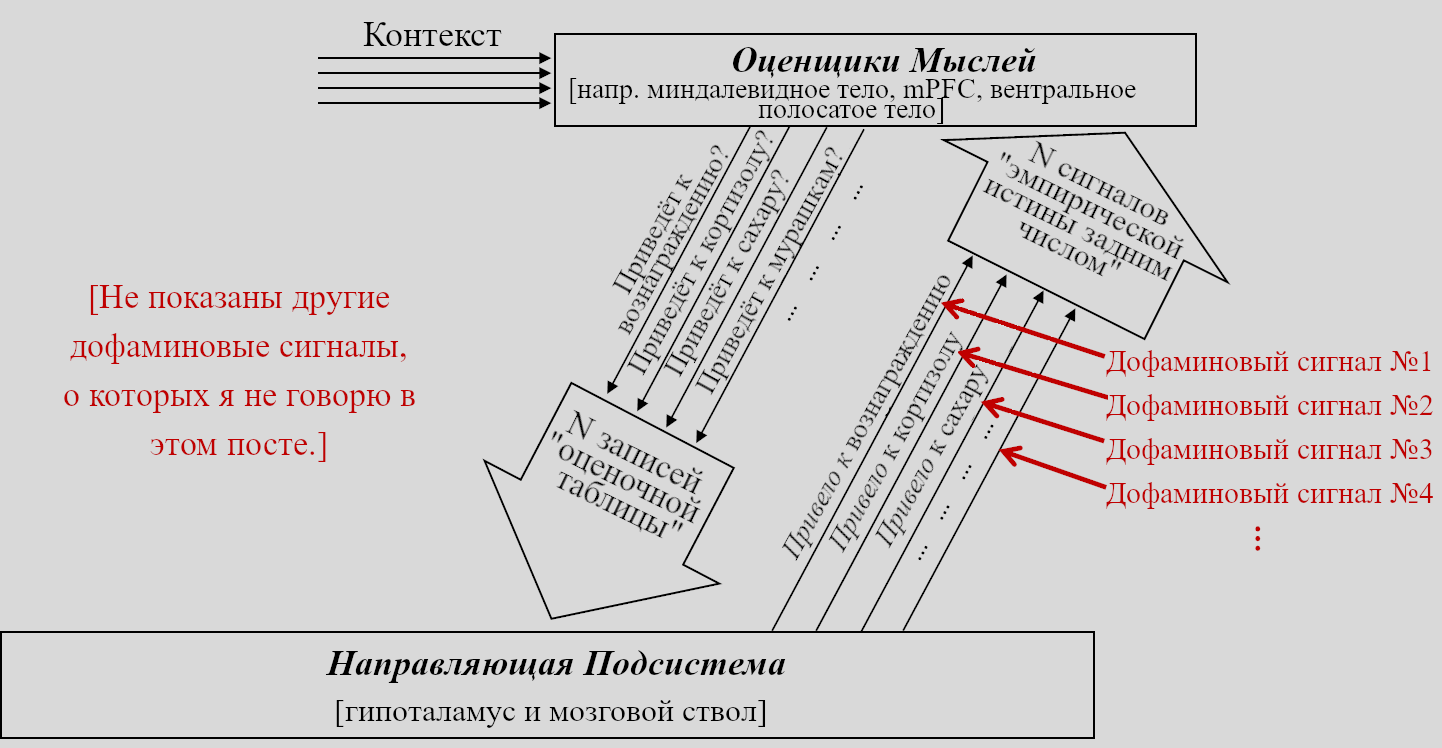
Есть научно-популярное заблуждение о том, что есть (единый) дофаминовый сигнал в мозгу, срабатывающий, когда происходит что-то хорошее. На самом деле, там есть множество разных дофаминовых нейронов, делающих разные вещи.
Так мы получаем вопрос: что делают все эти разнообразные дофаминовые сигналы? Консенсуса нет; в литературе есть самые разные заявления. Но я могу вбросить ещё и своё: в описанной мной картине, в конечном мозге, вероятно, есть сотни тысяч краткосрочных предсказателей, предсказывающих сотни тысяч разных вещей, и каждому нужен свой управляющий дофаминовый сигнал!
(И дофаминовых сигналов ещё больше, не только эти! Один такой сигнал, ассоциируемый с «главным» сигналом вознаграждения ошибки предсказания, будет обсуждаться в следующем посте. Прочие сигналы не входят в тему этой цепочки, но обсуждаются здесь.)
Если моя модель правильна, то что нам ожидать от экспериментов с измерением дофамина?
Представьте крысу, бегающую по лабиринту. В каждый момент времени её массив предсказателей получает управляющие сигналы о уровнях различных гормонов, пульсе, ожиданиям питья и еды, больной ноге, холоде, вкусе соли, и так далее. Говоря коротко, мы ожидаем, что активность дофаминовых нейронов скачет вверх и вниз самыми разными способами.
Так что, в общем-то каждый случай, когда экспериментатор выяснял, что дофаминовый нейрон коррелирует с какой-то поведенческой переменной, это, наверное, вписывается в мою картину.
Вот пара примеров:
- Есть дофаминовые нейроны, активирующиеся заметными стимулами вроде неожиданных вспышек света (ссылка). Могу ли я это объяснить? Конечно, без проблем! Я говорю: это могут быть управляющие сигналы, сообщающие «сейчас хороший момент, чтобы сориентироваться» или «вздрогнуть» или «повысить пульс», и т.д.
- Есть дофаминовые нейроны, коррелирующие с скоростью, с которой мышь бежит в колесе (ссылка). Могу я это объяснить? Конечно, без проблем! Я говорю: это могут быть управляющие сигналы, сообщающие «ожидай боли в мышцах» или «ожидай кортизол» или «ожидай повышения пульса», и т.д.
Вот ещё данные, кажущиеся подтверждающими мою картину. Некоторые дофаминовые нейроны активируются, когда происходит что-то неприятное (ссылка). Четыре из пяти областей[7], в которых можно обнаружить такие нейроны (согласно статье по ссылке) – в точности те, где я ожидаю существование краткосрочных предсказателей – конкретнее, это подобный-коре и подобный-полосатому-телу слои миндалевидного тела, медиальная префронтальная кора (mPFC) и вентромедиальная оболочка прилежащего ядра, являющаяся (по крайней мере примерно) частью петель «кора-базальные ганглии-маламус-кора», находящейся в полосатом теле. Это в точности то, что я бы ожидал. К примеру, если мышь шокирована, то предсказатель «следует ли мне сейчас замереть» получает управляющий сигнал «Да, тебе сейчас следовало замереть».
5.5.6.1 В сторону: Вывод распределений предсказателями
Я не говорил об этом в предыдущем посте, но обучающиеся алгоритмы краткосрочных предсказателей имеют гиперпараметры, два из которых – «как сильно обновляться после ложноположительной (перелёт) ошибки» и «как сильно обновляться после ложноотрицательной (недолёт) ошибки». Соотношение этих гиперпараметров может варьироваться от 0 до ∞, так что получившийся предсказатель может варьироваться от «активируй вывод, если есть хоть малейший шанс, что управляющий сигнал сработает» до «не активируй сигнал, если нет полной уверенностью, что управляющий сигнал сработает.»
Таким образом, если у нас есть много предсказателей, и у каждого своё соотношение гиперпараметров, то мы можем (хотя бы приблизительно) выводить распределение вероятности предсказания, а не просто одну оценку.
Недавний набор экспериментов от DeepMind и сотрудничающих с ними обнаружил свидетельство (основанное на измерениях дофаминовых нейронов), что мозг действительно использует этот трюк, по крайней мере для предсказания вознаграждения.
Я предполагаю, что он может использовать тот же трюк и в других долгосрочных предсказателях – к примеру, может быть, предсказания и боли в руке, и кортизола, и гусиной кожи – все выдаются группами долгосрочных предсказателей, составляющих распределения вероятностей.
Я поднял эту тему в первую очередь потому, что это ещё один пример того, как дофаминовые нейроны ведут себя, кажется, очень хорошо укладывающимся в мою картину образом, а во-вторых, потому что это вполне может быть полезно для безопасности СИИ – так что я в любом случае искал повод это упомянуть!
5.6 Заключение
Как обычно, я не претендую на то, что у меня есть неопровержимое доказательство молей гипотезы (т.е. что в мозгу есть массивы долгосрочных предсказателдей с участием петель «конечный мозг – мозговой ствол»). Но с учётом свидетельств в этом и предыдущем подразделах, я пришёл к сильному ощущению, что я примерно на правильном пути. Я с радостью обсужу это подробнее в комментариях. А в следующем посте мы наконец-то сложим всё это вместе в большую картину того, как, по моему мнению, работает мотивация и принятие решений в мозгу!
- «Горизонтальная» и «вертикальная» нейронанатомия – это моя своеобразная терминология, но я надеюсь, что она интуитивно понятна. Если вы представите кору, расправленную в горизонтальный лист, то «вертикальная нейронанатомия» будет включать, например, взаимосвязи между структурами в коре и подкорке, а «горизонтальная» нейроанатомия – например, разные роли разных частей коры. См. также таблицу в Разделе 5.4.1.
- Для ясности, скорее всего на самом деле нет никакого дискретного переключателя всё-или-ничего. Может быть, например, «взвешенное среднее». Напомню, всё это – просто педагогическая «игрушечная модель»; я ожидаю, что реальность во многих отношениях сложнее.
- Отмечу, что тут я просто прокручиваю этот алгоритм у себя в голове, я его не симулировал. Я оптимистично считаю, что я не облажался по-крупному, то есть, что то, что я говорю про алгоритм качественно верно при подходящих настройках параметров и, возможно иных мелких поправках.
- Примеры использования терминологии «Временных Разниц» в чём-то не связанном с функциями вознаграждения обучения с подкреплением включают «TD-сети» и литературу по Последовательным Отображениям (пример), и вот эту статью, и т.д.
- Классическая попытка примирить «висцемоторную» и «мотивационную» картины mPFC - это «гипотеза соматических маркеров» Антонио Дамасио. Моё описание тут имеет некоторые сходства и некоторые различия от неё. Я не буду в это погружаться, это не по теме.
- Как и в предыдущем посте, когда я говорю «дофамин несёт управляющий сигнал», я открыт к возможности того, что дофамин на самом деле несёт тесно-связанный сигнал, вроде сигнала об ошибке или отрицательного сигнала об ошибке, или отрицательного управляющего сигнала. Для наших целей это не имеет значения.
- Пятая область, хвост полосатого тела, как я думаю, объясняется по-иному – см. здесь.
6. Большая картина мотивации, принятия решений, и RL
- 1.6.1 Краткое содержание / Оглавление
- 2.6.2 Большая картина
- 3.6.3 «Генератор Мыслей»
- 4.6.3.2 Ввод Генератора Мыслей
- 5.6.4 Ценности и вознаграждения
- 6.6.5 Решения вовлекают не только одновременные, но и последовательные сравнения ценности
- 7.6.6 Частые заблуждения
Примечание переводчика - с момента перевода оригинальные посты несколько обновились, через некоторое время обновлю и перевод. На общие выводы цепочки это, вроде бы, не влияет.
6.1 Краткое содержание / Оглавление
Пока что в этой цепочке Пост №1 задал некоторые определения и мотивации (что такое «безопасность подобного-мозгу ИИ», и с чего нам беспокоиться?), Посты №2 и №3 представили разделение мозга на Обучающуюся Подсистему (конечный мозг и мозжечок), которая использует алгоритмы «обучения с чистого листа», и Направляющую Подсистему (гипоталамус и мозговой ствол), которая в основном генетически-прошита и выполняет специфичные для вида инстинкты и реакции.
В Посте №4 я описал «краткосрочные предсказатели» – схемы, которые в результате обучения с учителем начинают предсказывать сигналы до их появления, но, наверное, лишь за долю секунды. В Посте №5 я затем предложил, что если сформировать замкнутую петлю с участием и краткосрочных предсказателей в Обучающейся Подсистеме, и соответствующих им прошитых схем в Направляющей Подсистеме, то можно получить «долгосрочный предсказатель». Я заметил, что схема «долгосрочного предсказателя» сильно схожа с обучением методом Временных Разниц.
Теперь, в этом посте, мы добавим последние ингредиенты – грубо говоря, «субъекта» из обучения с подкреплением «субъект-критик» (RL) – чтобы у нас получилась полная большая картина мотивации и принятия решений в человеческом мозге. (Я говорю «человеческий мозг» для конкретики, но в любом другом млекопитающем, и, в меньшей степени, в любом другом позвоночном, всё было бы похоже.)
Причина, почему меня волнует мотивация и принятие решений, в том, что, если мы однажды создадим подобные-мозгу СИИ (как в Посте №1), мы захотим обеспечить, чтобы у них были некоторые мотивации (например, быть полезным) и не было некоторых других (например, выйти из-под человеческого контроля и распространить свои копии по Интернету). Куда больше на эту тему в следующих постах.
Тизер предстоящих постов: Следующий пост (№7) пройдётся по конкретному примеру модели из этого поста, и мы сможем пронаблюдать, как встроенное стремление приводит к сначала формированию явной цели, а потом принятию и исполнению плана для её достижения. Потом, начиная с Поста №8, мы сменим контекст, и с этого момента вы можете ожидать значительно меньше обсуждения нейробиологии и значительно больше обсуждения безопасности СИИ (за исключением ещё одного поста про нейробиологию ближе к концу).
Всё в этом посте, если не сказано обратное, это «то, в чём я убеждён прямо сейчас», а не нейробиологический консенсус. (Лайфхак: нейробиологического консенсуса никогда нет.) Я буду принимать минимальные усилия для связи своих гипотез с другими из литературы, но буду рад поболтать об этом в комментариях или по email.
Содержание:
- В Разделе 6.2 я представлю большую картину мотивации и принятия решений в человеческом мозге и пройдусь по тому, как это работает. Остаток поста будет описывать различные части этой картины более детально. Если вы торопитесь, я предлагаю дочитать до конца Раздела 6.2 и закончить.
- В Разделе 6.3 я поговорю о так называемом «Генераторе Мыслей», состоящем (как мне кажется) из дорсолатеральной префронтальной коры, сенсорной коры и других областей. (Для читателей из области машинного обучения, знакомых с «основанном на модели обучением с подкреплением субъект-критик», Генератор Мыслей более-менее соответствует комбинации «субъекта» и «модели».) Я поговорю о вводах и выводах этого модуля и кратко обрисую, как его алгоритм связан с нейроанатомией.
- В Разделе 6.4 я поговорю о том, как в этой картине работают ценности и вознаграждения, включая сигнал вознаграждения, руководящий обучением и принятием решений в Генераторе Мыслей.
- В Разделе 6.5 я немного больше углублюсь в детали того, как и почему думание и принятие решений должны вовлекать не только одновременные сравнения (например, механизм параллельной генерации разных вариантов и выбора наиболее многообещающего), но и последовательные сравнения (например, думать о чём-то, затем думать о чём-то другом, и сравнить эти две мысли). К примеру, вы можете подумать: «Хмм, я думаю, что я пойду в спортзал. Но, на самом деле, что если я вместо этого пойду в кафе?»
- В Разделе 6.6 я прокомментирую частое заблуждение о том, что Обучающаяся Подсистема – место обитания эгосинтонических интернализированных «глубоких желаний», а Направляющая Подсистема – эгодистонических, экстернализированных «первобытных побуждений». Я буду в целом возражать представлению о том, что две подсистемы – два противостоящих агента; более хорошая ментальная модель – что это две связанных шестерни в одном механизме.
6.2 Большая картина
Да, это буквально большая картинка, если вы только не читаете это с телефона. Вы уже видели её часть в предыдущем посте (Раздел 5.4), но сейчас тут больше всего.
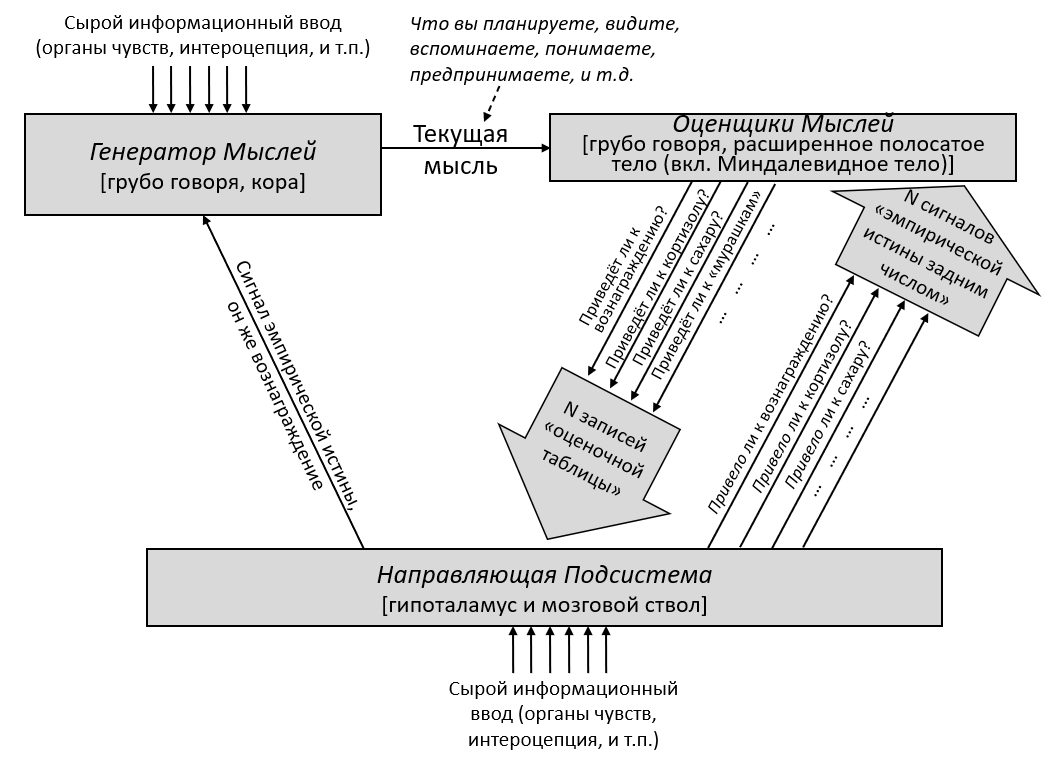
Большая картина – Весь пост будет вращаться вокруг этой диаграммы. Обратите внимание, что ярлычки на верхних двух блоках довольно условны и уж точно сильно утрированы.
Тут много, но не беспокойтесь. Мы пройдёмся по каждому кусочку отдельно.
6.2.1 Связь с «двумя подсистемами»
Вот как эта диаграмма укладывается в мою модель «двух подсистем», описанную в Посте №3:
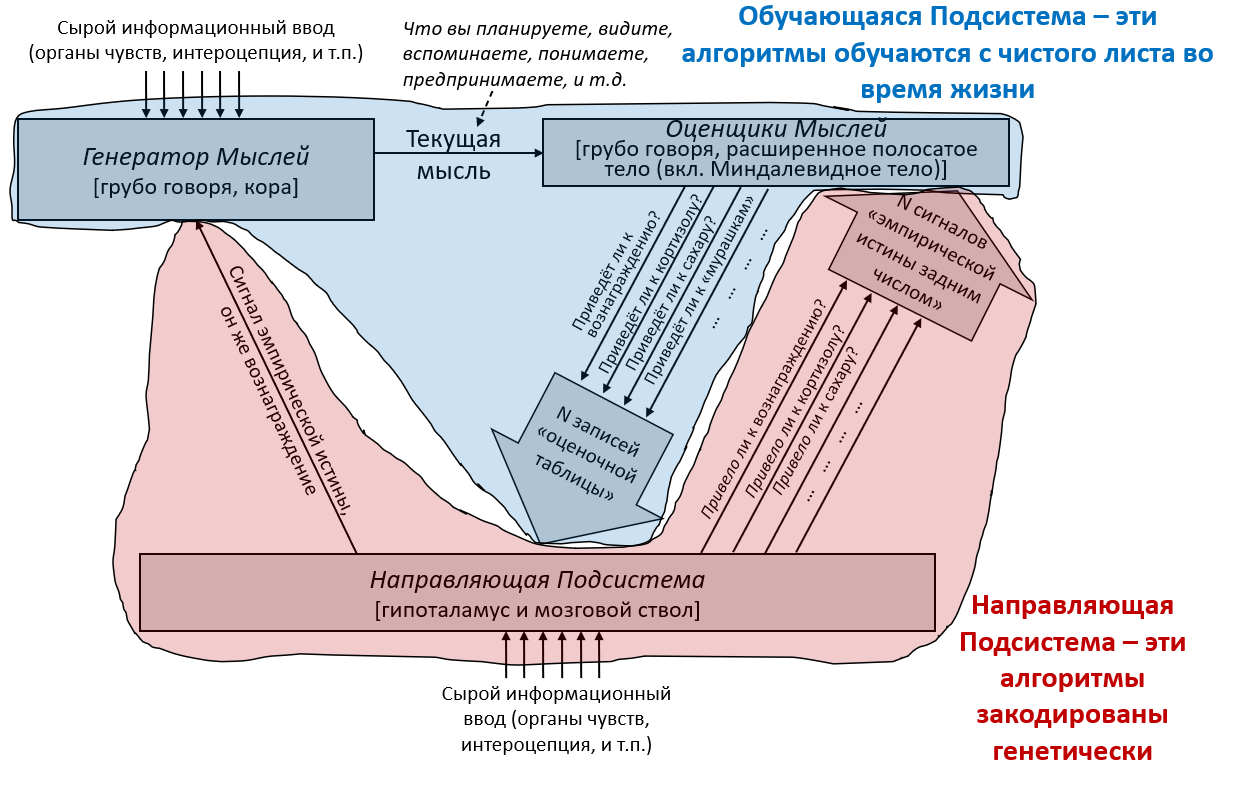
Тоже, что и выше, но две подсистемы подсвечены разными цветами.
6.2.2 Быстрый обзор
До погружения в детали дальше в посте, просто пройдёмся по диаграмме:
1. Генератор Мыслей генерирует мысль: Генератор Мыслей выбирает мысль из высокоразмерного пространства всех мыслей, которые возможно подумать в данный момент. Заметим, что это пространство возможностей, хоть и огромное, ограничено текущим сенсорным вводом, прошлым сенсорным вводом и всем остальным в выученной модели мира. К примеру, если вы сидите за письменным столом в Бостоне, в общем случае для вас невозможно подумать, что вы занимаетесь скуба-дайвингом у берега Мадагаскара. Но вы можете составлять план или насвистывать мелодию, или погрузиться в воспоминание, или рефлексировать о смысле жизни, и т.д.
2. Оценщики Мыслей сводят мысль к «оценочной таблице»: Оценщики Мыслей – набор, возможно, сотен тысяч схем «краткосрочных предсказателей» (Пост №4), который я более подробно описывал в предыдущем посте (№5). Каждый предсказатель обучен предсказывать свой сигнал из Направляющей Подсистемы. С точки зрения Оценщика Мыслей, всё в Генераторе Мыслей (не только выводы, но и скрытые переменные) – это контекст – информация, которую можно использовать для создания лучших предсказаний. Так что, если я думаю мысль «я прямо сейчас съем конфету», то Оценщик Мыслей может предсказать «высокую вероятность ощутить вкус чего-то сладкого очень скоро» исключительно на основании мысли – у него нет необходимости полагаться на внешнее поведение или сенсорные вводы, хоть это тоже может быть важным контекстом.
3. «Оценочная таблица» решает задачу построения интерфейса между обучающейся с чистого листа моделью мира и генетически закодированными схемами: Напомню, текущая мысль и ситуация – это невероятно сложные объекты в высокоразмерном выученном с чистого листа пространстве «всех возможных мыслей, которые можно подумать». Но нам нужно, чтобы относительно простые генетически закодированные схемы Направляющей Подсистемы анализировали мысль и выдавали суждение о её высокой или низкой ценности (см. Раздел 6.4 ниже) и о том, требует ли она выброса кортизола, гусиной кожи или расширения зрачков, и т.д. «Оценочная таблица» решает эту проблему! Она сводит возможные мысли / убеждения /планы и т.д. к генетически стандартизированной форме, которую уже можно напрямую передать генетически закодированным схемам.
4. Направляющая Подсистема исполняет некий генетически закодированный алгоритм: Его ввод – это (1) оценочная таблица с предыдущего шага, и (2) прочие источники информации – боль, метаболический статус, и т.д., поступающие из её собственной системы сенсорной обработки в мозговом стволе (см. Пост №3, Раздел 3.2.1). Её вывод включает выбросы гормонов, моторные команды, и т.д., а также посылание управляющих сигналов «эмпирической истины», показанных на диаграмме.[1]
5.Генератор Мыслей оставляет или отбрасывает мысли, основываясь на том, нравятся ли они Направляющей Подсистеме: Более конкретно, есть сигнал эмпирической истины (он же вознаграждение, да, я знаю, что это не звучит синонимично, см. Пост №5, Раздел 5.3.1). Когда его значение велико и положительно, текущая мысль «усиливается», задерживается, и может начать контролировать поведение и вызывать последующие мысли, а когда велико и отрицательно, текущая мысль немедленно отбрасывается, и Генератор Мыслей призывает следующую.
6. И Генератор Мыслей, и Оценщик Мыслей «обучаются с чистого листа» по ходу жизни, благодаря, в частности, управляющим сигналам Направляющей Подсистемы. Конкретнее, Оценщики Мыслей обучаются всё лучшему и лучшему предсказыванию сигнала «эмпирической истины задним числом» (это форма обучения с учителем – см. Пост №4), а Генератор Мыслей в большей степени обучается генерировать высокоценные мысли. (Процесс обучения с чистого листа Генератора Мыслей также включает и предсказательное обучение сенсорных вводов – Пост №4, Раздел 4.7.)
6.3 «Генератор Мыслей»
6.3.1 Общий обзор
Вернёмся к большой диаграмме выше. Слева-сверху находится Генератор Мыслей. В терминах основанного на модели обучения с подкреплением «субъект-критик», Генератор Мыслей грубо соответствует комбинации «субъект» + «модель», но не «критику». («Критик» обсуждался в предыдущем посте, а больше про него – ниже.)
На нашем несколько упрощённом уровне анализа, мы можем думать о «мыслях», генерируемых Генератором Мыслей как о комбинации ограничений (из предсказательного обучения сенсорных вводов) и выборов (управляемых обучением с подкреплением). Подробнее:
- Ограничения Генератора Мыслей происходят из информации из сенсорного ввода и предсказательного обучения сенсорному вводу (Пост №4, Раздел 4.7). К примеру, я не могу подумать мысль «На моём столе кот, и я прямо сейчас на него смотрю.» Кота, к сожалению, нет, и я не могу просто пожелать увидеть что-то, чего очевидно нет. Я могу представить, как я его вижу, но это не та же мысль.
- Но с учётом этих ограничений есть более чем одна возможная мысль, которую мой мозг может подумать в каждый конкретный момент. Он может обращаться к памяти, раздумывать о смысле жизни, выдать команду встать, и т.д. Я утверждаю, что эти «выборы» принимаются системой обучения с подкреплением (RL). Эта RL-система – одна из главных тем этого поста.
6.3.2 Ввод Генератора Мыслей
Генератор Мыслей принимает в качестве ввода, в том числе сенсорные данные и изменяющие гиперпараметры нейромодуляторы. Но в этом посте для нас наибольший интерес представляет сигнал эмпирической истины, он же вознаграждение. Я более детально поговорю о нём позже, но мы можем считать, что это оценка того, хороша или плоха мысль, в смысле, «стоит ли её удержать и развивать или же она заслуживает того, чтобы её выбросили и сгенерировали следующую». Этот сигнал важен и для того, чтобы научиться думать мысли получше, и для думания хороших мыслей прямо сейчас:
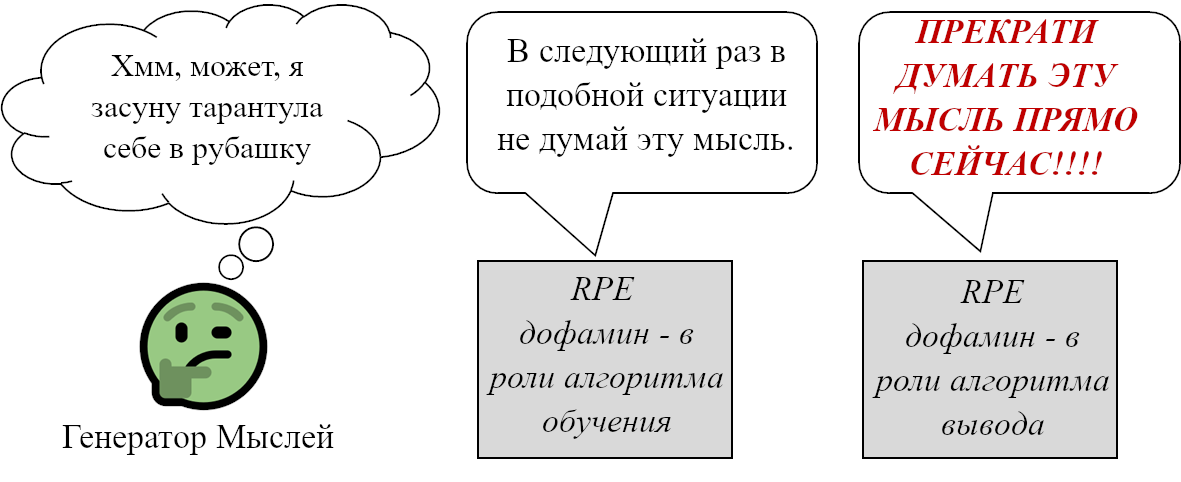
6.3.3 Вывод Генератора Мыслей
В тоже время множество сигналов выходят из Генератора Мыслей. Некоторые – то, о чём мы интуитивно думаем как о «выводе» – например, скелетные моторные команды. Другие сигналы вывода, ну, это несколько забавно…
Напомню идею «контекста» из Раздела 4.3 Поста №4: Оценщики Мыслей – это краткосрочные предсказатели, а краткосрочный предсказатель в принципе может взять любой сигнал в мозгу и применить его для улучшения своей способности предсказывать свой целевой сигнал. Так что если Генератор Мыслей имеет модель мира, то где-то в этой модели мира есть конфигурация активаций скрытых переменных, кодирующая концепт «маленькие котята, дрожащие под холодным дождём». Мы не стали бы думать об этом как о «сигналах вывода» – я только что сказал, что это скрытые переменные! Но, так уж получается, что Оценщик Мыслей «это приведёт к плачу» применяет копию этих скрытых переменных как контекстный сигнал, и постепенно обучается на опыте, что этот конкретный сигнал сильно предсказывает слёзы.
То есть, сейчас, у взрослого меня эти нейроны «маленьких котят под холодным дождём» в моём Генераторе Мыслей живут двойной жизнью:
- Они являются скрытыми переменными в моей модели мира – т.е. они и их сеть связей помогают мне распознать картинку маленьких котят под дождём, если я такую вижу, и рассуждать о том, что с ними произойдёт, и т.д.
- Активация этих нейронов, например, с помощью воображения – это способ вызвать слёзы по команде.
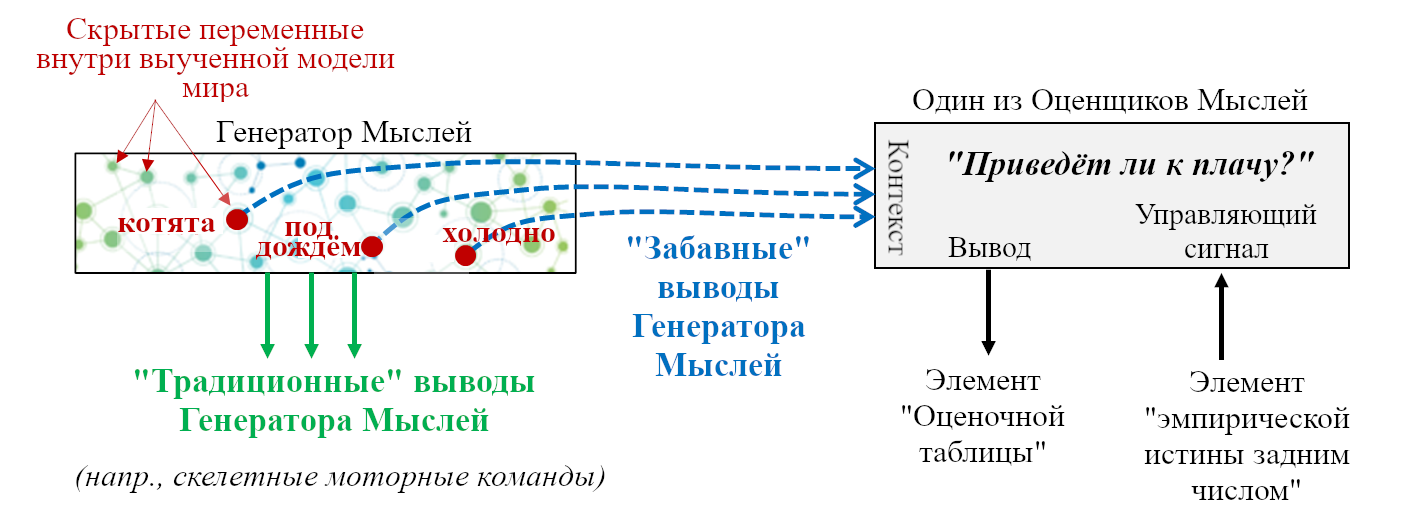
Генератор Мыслей (сверху слева) имеет два типа вывода: «традиционный» вывод, ассоциированный с произвольным поведением (зелёные стрелки) и «забавный» вывод, позволяющий даже скрытым переменным модели напрямую влиять на непроизвольное поведение (синие стрелки).
6.3.4 Обрисовка нейроанатомии Генератора Мыслей
ПРИМЕЧАНИЕ АВТОРА: Изначально в этом разделе было обсуждение петель «кора-базальные ганглии-таламус-кора», но это всё было очень спекулятивно и оказалось несколькими разными способами ошибочным. Это в любом случае не было особо важно для цепочки в целом, так что я это просто удалил. Я как-нибудь напишу исправленную версию отдельным постом. Извините!
Обновлённая дофаминовая диаграмма из предыдущего поста:
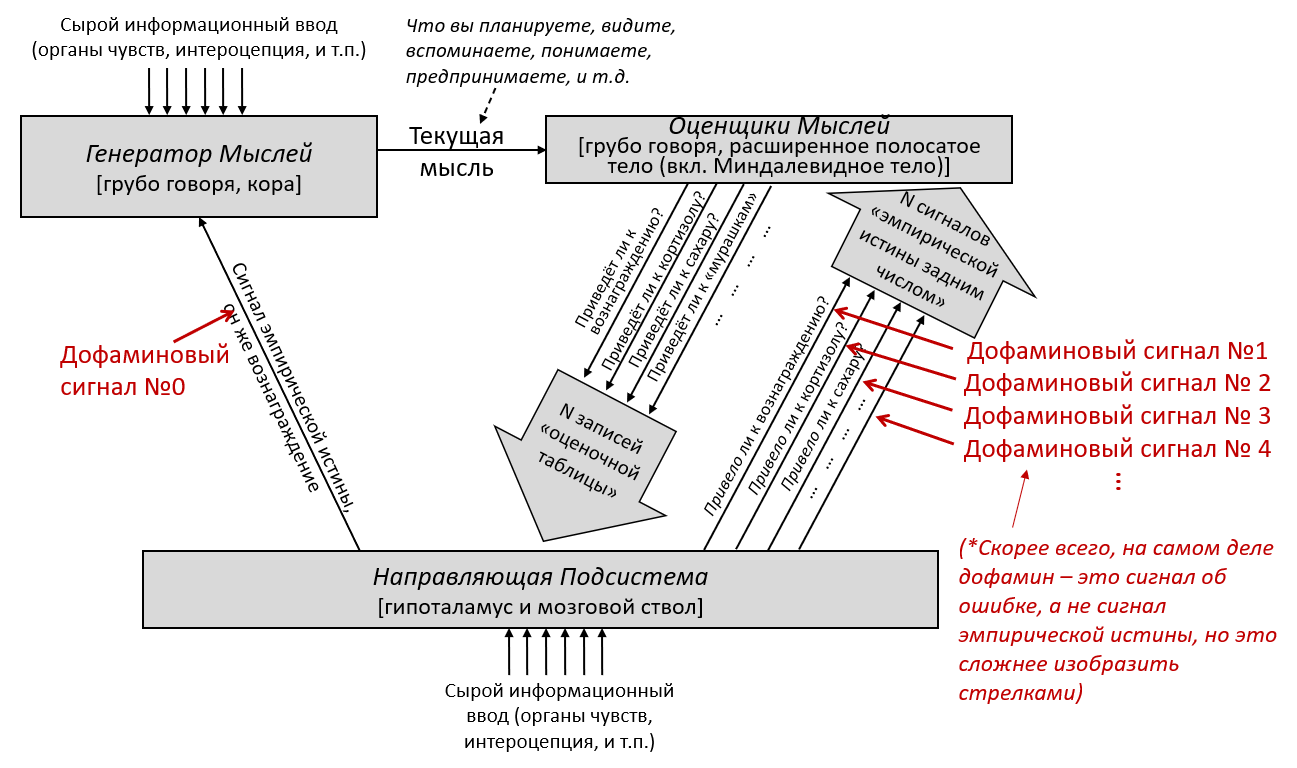
«Мезолимбические» дофаминовые сигналы справа обсуждались в предыдущем посте (Раздел 5.5.6). «Мезокортикальный» сигнал слева новый. (Я думаю, что в мозгу *ещё больше* дофаминовых сигналов, которые здесь не показаны. Они за пределами темы этой цепочки, но см. обсуждение здесь)
В Генераторе Мыслей есть ещё много деталей реализации, которые я тут не обсуждаю, включая детали диаграммы «петли» выше, так же, как и отношения между разными регионами коры. Однако, этого небольшого раздела более-менее достаточно для следующих постов по безопасности СИИ. Запутанные подробности Генератора Мыслей, так же, как и в чём угодно другом в Обучающейся Подсистеме, в основном полезны для создания СИИ.
6.4 Ценности и вознаграждения
6.4.1 Кора прикидывает «ценность», но Направляющая Подсистема может выбрать перехватить
На диаграмме есть две «ценности» (выглядит, будто три, но две красных – одно и то же):
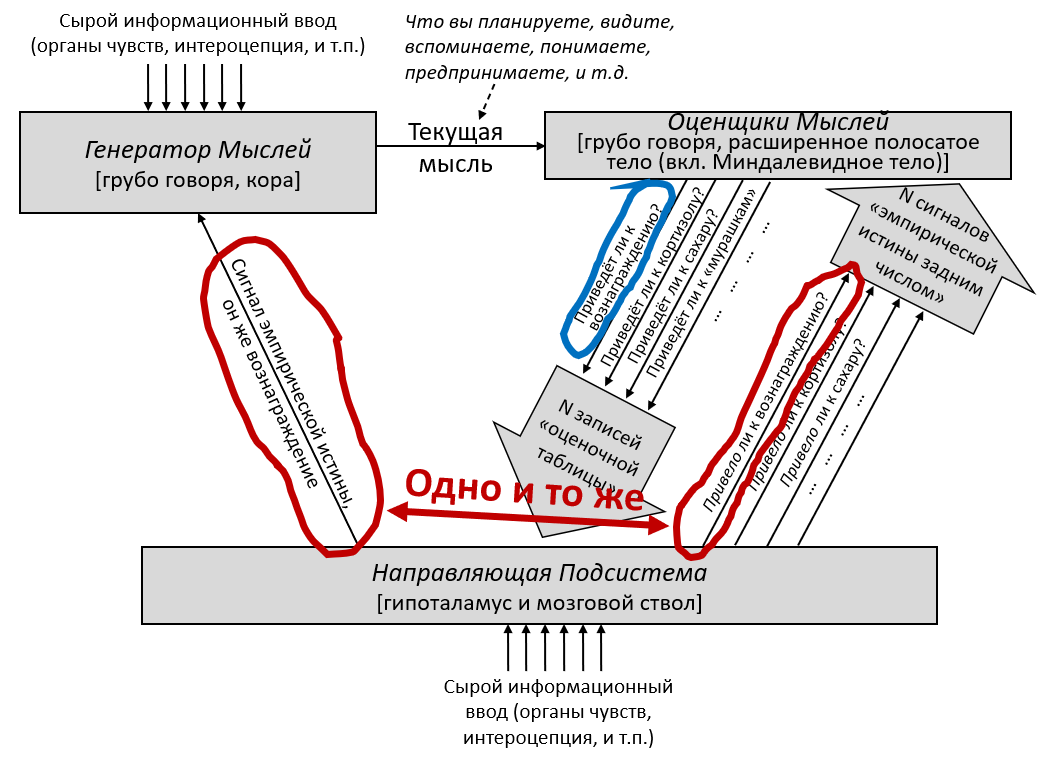
Два типа «ценности» в моей модели
Обведённый синим сигнал – это прикидка ценности из соответствующего Оценщика Мыслей в коре. Обведённый красным сигнал (ещё раз, это один и тот же сигнал, нарисованный дважды) – «эмпирическая истина» о том, какой должна была быть прикидка ценности. (Напомню, что «эмпирическая ценность» – синоним «вознаграждения»; да, знаю, звучит неправильно, см. предыдущий пост (Раздел 5.3.1) за подробностями.)
Так же, как и у других «долгосрочных предсказателей», которые обсуждались в предыдущем посте, Направляющая Подсистема может выбирать между режимом «довериться предсказателю» и режимом «перехвата». В первом случае, она задаёт красный сигнал эквивалентный синему, как будто говорит: «ОК, Оценщик Мыслей, конечно, я поверю тебе на слово». Во втором случае, она игнорирует предложение Оценщика Мыслей, а её собственные встроенные схемы выдают некую другую ценность.[2]
По каким причинам Направляющая Подсистема перехватывает прикидку ценности Оценщика Мыслей? Два фактора:
- Во-первых, Направляющая Подсистема может действовать на основе информации от других (не-ценностных) Оценщиков Мыслей. К примеру, в Эксперименте с Солью Мёртвого Моря (см. предыдущий пост, Раздел 5.5.5), прикидка ценности была «сейчас произойдёт что-то плохое», но в то же время Направляющая Подсистема получила предсказание «я сейчас почувствую вкус соли» в контексте состояния недостатка соли. Так что Направляющая Подсистема как бы сказала себе: «То, что происходит сейчас, очень перспективно; Оценщик не знает, что несёт!»
- Во-вторых, Направляющая Подсистема могла действовать на основе своих собственных источников информации, независимых от Обучающейся Подсистемы. В частности, Направляющая Подсистема обладает собственной системой обработки сенсорной информации (см. Пост №3, Раздел 3.2.1), которая может ощущать биологически-важные намёки вроде боли, голода, вкуса, вида ползущей змеи, запаха потенциального партнёра, и так далее. Всё это и более того может быть возможными основаниями для перехвата сигнала у Оценщика Мыслей, т.е. установке значения обведённого красным сигнала, отличного от обведённого синим.
Интересно (и в отличии от RL «по учебнику»), что в этой большой картине обведённый синим сигнал не обладает в алгоритме специальной ролью, в сравнении с другими Оценщиками Мыслей. Это лишь один из многих вводов прошитого алгоритма Направляющей Подсистемы, решающего, каким сделать обведённый красным сигнал. Обведённый синим сигнал может на практике оказаться особенно важным, более весомым, чем остальные, но вообще они все в одной куче. На самом деле, мои давние читатели вспомнят, что в прошлом году я писал посты, опускавшие обведённый синим сигнал ценности в списке Оценщиков Мыслей! Сейчас я считаю, что это ошибка, но оставил примерно такое же отношение.
6.5 Решения вовлекают не только одновременные, но и последовательные сравнения ценности
Вот «одновременная» модель принятия решений, описанная в книге «Голодный Мозг» Стефана Гийанэя на примере изучения миног:
Каждый участок паллиума [=эквивалент коры у миноги] связан с определенной частью полосатого тела. Паллиум посылает сигнал в полосатое тело, и затем сигнал из полосатого тела (через другие части базальных ганглиев) возвращается назад в тот же участок паллиума.
Иными словами, определенный участок паллиума и полосатое тело связаны замкнутой цепью, которая реализует запрос на конкретное действие. Например, существует цепь для преследования добычи, для ускользания от хищника, для прикрепления к камню и так далее. Каждый отдельный участок паллиума без конца нашептывает полосатому телу, упрашивая дать добро на исполнение того или иного поведенческого шаблона. А полосатое тело по умолчанию отвечает на это «нет!» При особых обстоятельствах шепот паллиума превращается в крик, и тогда полосатое тело исполняет требования настойчивого паллиума и приводит в действие мышцы.
Я принимаю это как часть моей модели принятия решений, но только как часть. Конкретнее, это одна из вещей, происходящих, когда Генератор Мыслей генерирует мысль. В самом деле, моя диаграмма в Разделе 6.3.4 выше явно вдохновлена этой моделью. Сравниваются разные одновременные возможности.
Другая часть моей модели – сравнение последовательных мыслей. Вы думаете одну мысль, а потом другую мысль (возможно, что сильно отличающуюся, а возможно, что преобразованную первую), и они сравниваются (Направляющей Подсистемой, отбирающей значение эмпирической истины, основываясь на, например, закономерностях того, как активизируются и успокаиваются Оценщики Мыслей), и если вторая хуже, то она ослабляется, чтобы её могла заменить следующая (возможно, снова первая).
Я могу процитировать эксперименты об аспекте последовательного сравнения в принятии решений (например, Рисунок 5 этой статьи, заявляющий то же, что и я), но действительно ли это надо? Интроспективно это очевидно! Вы думаете: «Хмм, думаю, я пойду в спортзал. На самом деле, что если я вместо этого пойду в кафе?» Вы представляете одно, а потом другое.
И я не думаю, что это то, что отличает людей от миног. Предполагаю, что сравнение последовательных мыслей универсально для позвоночных. Как иллюстрация того, что я имею в виду:
6.5.1 Выдуманный пример того, как сравнение последовательных мыслей могло бы выглядеть у более простого животного
Представьте простую древнюю маленькую рыбку, плывущую к пещере, где она живёт Она натыкается на ~~развилку дороги,~~ эмммм, «развилку в лесу водорослей»? Её текущий план навигации включает плыть налево к пещере, но у неё также есть вариант повернуть направо, чтобы добраться до рифа, где она часто кормится.
Я утверждаю, что её алгоритм навигации, увидев путь направо, рефлексивно загружает план: «Я поверну направо и доберусь до рифа.» Этот план немедленно оценивается и сравнивается с старым планом. Если новый план кажется хуже старого, то новая мысль затыкается, а старая мысль («Я направляюсь к своей пещере») восстанавливает своё положение. Рыбка без промедления продолжает следовать к пещере. А вот есть новый план кажется лучше старого, то новый план усиливается, приживается и принимает управление моторными командами. И тогда рыбка поворачивает направо и направляется к рифу.
(На самом деле, я не знаю достаточно о маленьких древних рыбках, но благодаря измерениям нейронов гиппокампуса известно, что крысы на развилке ~~дороги~~ лабиринта представляют оба возможных навигационных плана последовательно – ссылка.)
6.5.2 Сравнение последовательных мыслей: почему это необходимо
Согласно моим взглядам, мысли сложны. Чтобы подумать «Я пойду в кафе» вы не просто активируете некоторый крохотный кластер нейронов походов-в-кафе. Нет, это распределённый паттерн, включающий практически все части коры. Вы не можете одновременно думать «Я пойду в кафе» и «Я пойду в спортзал», потому что в эти мысли будут вовлечены разные паттерны активности одного и того же набора нейронов. Они бы мешали друг другу. Так что единственная возможность – думать мысли по очереди.
Как конкретный пример того, что я себе представляю, подумайте о том, как сеть Хопфилда не может вспомнить двенадцать воспоминаний одновременно. У неё есть множество стабильных состояний, но вы можете вызывать из только последовательно, одно за другим. Или подумайте о нейронах решётки и места, и т.д.
6.5.3 Сравнение последовательных мыслей: как это могло эволюционировать
Я представляю, что с эволюционной точки зрения сравнение последовательных мыслей – далёкий потомок очень простых механизмов сродни механизма «бежать-и-кувыркаться» у плавающих бактерий.
Механизм «бежать-и-кувыркаться» работает так: бактерия плывёт по прямой линии («бежит»), и периодически меняет направление на новое случайное («кувыркается»). Фокус в том, что, когда ситуация / окружение бактерии становится лучше, она кувыркается реже, а когда окружение становится хуже – она кувыркается чаще. Таким образом, она в итоге (в среднем, со временем) двигается в хорошем направлении.

Можно представить, как начиная с простого механизма вроде этого, можно навешивать на него всё больше и больше прибамбасов. Палитра поведенческих вариантов становится всё сложнее и сложнее, в какой-то момент превращаясь в «каждая мысль, которую возможно подумать». Методы оценивания, хорош или плох нынешний план, могут становиться быстрее и точнее, в итоге приводя к основанным на обучающихся алгоритмах предсказателям, как в предыдущем посте. Новые поведенческие варианты могут начать выбираться не случайно, а с помощью умных обучающихся алгоритмов. Так что мне кажется, что от чего-то-вроде-беги-и-кувыркайся к замысловатым тонко настроенным системам человеческого мозга, о которых я тут говорю есть плавный путь. (Иные размышления о бежать-и-кувыркаться и человеческой мотивации: 1, 2.)
6.6 Частые заблуждения
6.6.1 Различие между интернализированными эгосинтоническими и экстернализированными эгодистоническими желаниями не связано с разделением на Обучающуюся Подсистему и Направляющую Подсистему
(См. также: мой пост (Мозговой ствол, Неокортекс) ≠ (Базовые мотивации, Благородные мотивации).)
Многие (включая меня) обладают сильным интуитивным разделением эгосинтонических стремлений, которые являются «частью нас» и «тем, чего мы хотим» от эгодистонических стремлений, ощущающихся как позывы, вторгающиеся в нас извне.
К примеру, гурман может сказать: «Я люблю хороший шоколад», а человек на диете – «Я чувствую позыв съесть хороший шоколад».
6.6.1.1 Объяснение, которое мне нравится
Я утверждаю, что эти два человека по сути описывают одно и то же ощущение, с по сути одинаковой нейроанатомической локализацией и по сути одинаковой связью с низкоуровневыми алгоритмами мозга. Но гурман признаёт это чувство, а человек на диете его экстернализирует.
Эти два разных концепта идут рука об руку с двумя разными «предпочтениями высшего уровня»: гурман хочет хотеть есть хороший шоколад, тогда как человек на диете хочет не хотеть есть хороший шоколад.
Это приводит нас к прямолинейному психологическому объяснению, почему гурман и человек на диете по-разному концептуализируют свои чувства:
- Гурману приятно думать о «желании хорошего шоколада» как о «части того, кто я есть». Так он и делает.
- Человеку на диете неприятно думать о «желании хорошего шоколада» как о «части того, кто я есть». Поэтому он так не делает.
6.6.1.2 Объяснение, которое мне не нравится
Многие (включая Джеффа Хокинса, см. Пост №3) замечают описанное выше различие и, отдельно, поддерживают (как и я) идею, что в мозгу есть Обучающаяся Подсистема и Направляющая Подсистема (опять же, см. Пост №3). Они естественно предполагают, что это эквивалентно тому, что «я и мои глубокие желания» соответствуют Обучающейся Подсистеме, а «позывы, с которыми я себя не идентифицирую» – Направляющей Подсистеме.

Многие люди, с которыми я говорил, да и я сам, имеют отдельные концепции в выученной модели мира для «меня» и «моих позывов». Я заявляю, что эти концепты *НЕ* исходят из достоверного интроспективного доступа к нашей нейроанатомии. И в частности, они не соответствуют Обучающейся и Направляющей Подсистемам.
Я думаю, что эта модель неверна. По меньшей мере, если вы хотите принимать эту модель, то вам придётся отвергнуть приблизительно всё, что я писал в этом и предыдущих четырёх постах.
В моей модели, если вы пытаетесь воздержаться от шоколада, но чувствуете позыв есть шоколад, то:
- У вас есть позыв есть шоколад, потому что Направляющая Подсистема одобряет мысль «я сейчас съем шоколад»; И
- Вы пытаетесь воздержаться от шоколада, потому что Направляющая Подсистема одобряет мысль «Я воздерживаюсь от шоколада».
(С чего Направляющей Подсистеме одобрять вторую мысль? Это зависит от человека, но готов поспорить, что в это вовлечены социальные инстинкты. Я больше поговорю про социальные инстинкты в Посте №13. Если вы ходите менее сложный пример, представьте человека с непереносимостью лактозы, пытающегося сопротивляться позыву прямо сейчас съесть вкусное мороженое, потому что это приведёт к очень плохим ощущениям потом. Направляющей Подсистеме нравятся планы, приводящие к неболению, но ей также нравятся планы, приводящие к поеданию вкусного мороженого.)
6.6.2 Обучающаяся Подсистема и Направляющая Подсистема – не два агента
Другая частая ошибка – воспринимать саму по себе Обучающуюся или Направляющую Подсистему как что-то вроде независимого агента. Это неверно с обеих сторон:
- Обучающаяся Подсистема не может думать никаких мыслей, если Направляющая Подсистема не одобрила их как стоящие думания.
- В то же время, Направляющая Подсистема сама по себе не понимает мир или себя. У неё нет явных целей на будущее. Она лишь относительно простая, жёстко закодированная машина ввода-вывода.
Как пример, совершенно возможно следующее:
- Обучающаяся Подсистема генерирует мысль «Я собираюсь хирургически изменить мою Направляющую Подсистему».
- Оценщики Мыслей сводят эту мысль к «оценочной таблице».
- Направляющая Подсистема получает оценочную таблицу и исполняет свои жёстко прошитые эвристики, и результат: «Очень хорошая мысль, давай сделаем это!»
Почему нет, верно? Я больше поговорю про этот пример в позднейших постах.
Если вы прочитали пример выше и подумали: «Ага! Это случай, когда Обучающаяся Подсистема обхитрила Направляющую Подсистему», то вы всё ещё не поняли.
(Может, попробуйте представить Обучающуюся и Направляющую Подсистемы как две сцепленных шестерни в одном механизме.)
———
- Как и в предыдущем посте, термин «эмпирическая истина» тут немного обманчив, потому что иногда Направляющая Подсистема просто доверяется Оценщикам Мыслей.
- Как и в предыдущем посте, я не считаю, что на самом деле есть чистая дихотомия между режимом «довериться предсказателю» и «перехватить». На самом деле, я готов поспорить, что Направляющая Подсистема может частично-но-не-совсем-полностью довериться Оценщику Мыслей, например, взяв взвешенное среднее от Оценщика Мыслей и какого-то другого независимого вычисления.
7. От закодированных стремлений к предусмотрительным планам: рабочий пример
- 1.7.1 Краткое содержание / Оглавление
- 2.7.2 Напоминание о предыдущем посте: большая картина мотивации и принятия решений
- 3.7.3 Создание вероятностной генеративной модели мира в коре
- 4.7.4 Присвоение ценности при первом съедении кусочка торта
- 5.7.5 Нацеленное планирование через формирование вознаграждения
7.1 Краткое содержание / Оглавление
Предыдущий пост представил большую картину того, как, по моему мнению, в человеческом мозге работает мотивация, но он был несколько абстрактен. В этом посте я рассмотрю пример. В общих чертах, шаги будут такие:
- (Раздел 7.3) Наши мозги постепенно выработали вероятностную генеративную модель мира и себя;
- (Раздел 7.4) Существует процесс «присвоения ценности», когда что-то в модели мира помечается как «хорошее»;
- (Раздел 7.5) Существует сигнал ошибки предсказания вознаграждения, приблизительно связанный с производной (по времени) ожидаемой вероятности того, что произойдёт «хорошая» вещь. Этот сигнал вызывает у нас стремление «пытаться» делать «хорошие» вещи, в том числе и с помощью планирования наперёд.
Все человеческие цели и мотивации в конце концов исходят из относительно простых генетически закодированных схем Направляющей Подсистемы (гипоталамуса и мозгового ствола), но детали этого в некоторых случаях могут быть довольно запутанными. К примеру, иногда я замотивирован исполнить глупый танец перед полноростовым зеркалом. Какие в точности генетически закодированные схемы в гипоталамусе или мозговом стволе являются причиной этой мотивации? Я не знаю! Я, на самом деле, утверждаю, что ответ на этот вопрос на сегодняшний день Не Известен Науке. Я думаю, это стоит выяснить! Эммм, ну, ОК, может, для этого конкретного примера и не стоит выяснять. Но в целом я оцениваю проект реверс-инжиниринга некоторых аспектов человеческой Направляющей Подсистемы (см. моё описание «Категории B» в Посте №3) – особенно стоящих за социальными инстинктами вроде альтруизма и стремления к высокому статусу – как невероятно важный для безопасности СИИ, и, при этом, чрезвычайно пренебрегаемый. Больше про это - в Постах №12-13.
А пока что я выберу пример цели, которая в первом приближении исходит из особенно прямолинейного и понятного набора схем Направляющей Подсистемы. Поехали.
Давайте предположим (совершенно гипотетически…), что я два года назад съел кусок торта «Принцесса», и он был очень вкусным, и с тех пор я хочу съесть его ещё раз. Так что моим рабочим примером явной цели будет «Я хочу кусок торта «Принцесса»».

Торт «Принцесса». Я предлагаю его попробовать, чтобы лучше понять этот пост. Во имя науки! Источник картинки: моя любимая местная пекарня.)
Съесть кусок этого торта – не моя единственная цель в жизни, даже не особенно важная – так что она сравнивается с другими моими целями и желаниями – но это всё же моя цель (по крайней мере, когда я об этом думаю), и я в самом деле могу составлять сложные планы, чтобы её достичь. К примеру, оставлять тонкие намёки для моей семьи. В постах. Когда приближается мой день рождения. Совершенно гипотетически!!
7.2 Напоминание о предыдущем посте: большая картина мотивации и принятия решений
Вот моя диаграмма мотивации в мозгу из предыдущего поста:
См. предыдущий пост за деталями.
Как обсуждалось в предыдущем посте, мы можем разделить всё это на части, «закодированные» в геноме и части, обучающиеся при жизни – т.е. Направляющую Подсистему и Обучающуюся Подсистему:
7.3 Создание вероятностной генеративной модели мира в коре
Первый шаг в нашей истории: за время моей жизни моя кора (конкретнее, Генератор Мыслей из левой верхней части диаграммы выше) создавала вероятностную генеративную модель, в основном при помощи предсказательного обучения сенсорных вводов (Пост №4, Раздел 4.7) (также известного как «самообучение»).
По сути, мы выучиваем паттерны в своём сенсорном вводе, потом паттерны паттернов, и т.д., пока у нас не получается удобная предсказательная модель мира (и нас самих) – огромная сеть взаимосвязанных сущностей вроде «травы» и «стоять» и «куски торта «Принцесса»».
Предсказательное обучение сенсорных вводов не зависит фундаментально от управляющих сигналов Направляющей Подсистемы. Вместо этого «мир» предоставляет эмпирическую истину о том, было ли предсказание верным. Сравните это, к примеру, с составлением компромиссов между поиском еды и поиском партнёра: в окружении нет никакой «эмпирической истины» о том, составило ли животное компромисс оптимально, кроме как задним числом через много поколений. В этом случае нам нужны управляющие сигналы Направляющей Подсистемы, оценивающие «правильный» компромисс заложенными эволюцией эвристиками. Вы можете думать об этом как о чём-то вроде разделения «есть – должно», в котором Направляющая Подсистема предоставляет «должно» («что должен сделать организм, чтобы максимизировать генетическую приспособленность?»), а предсказательное обучение сенсорных вводов предоставляет «есть» («что, вероятно, сейчас произойдёт при таких-то и таких-то обстоятельствах»). Хотя Направляющая Подсистема всё же косвенно вовлечена и в предсказательное обучение – к примеру, я могу быть мотивирован изучить какую-нибудь тему.
В любом случае, каждая мысль, которую я могу подумать, и каждый план, который я могу составить, могут быть отображены в некоторую конфигурацию структуры данных этой генеративной модели мира. Структура данных непрерывно редактируется, когда я учусь и получаю новый опыт.
Думая об этой структуре данных модели мира, представьте много терабайт совершенно непонятных записей – к примеру, что-то вроде
«ПАТТЕРН 847836 определён как следующая последовательность: {ПАТТЕРН 278561, потом ПАТТЕРН 657862, потом ПАТТЕРН 128669}»
Некоторые записи отсылают к сенсорным вводам и/или моторными командам. И эта огромная запутанная непонятная свалка составляет всё моё понимание мира и себя самого.
7.4 Присвоение ценности при первом съедении кусочка торта
Как я упомянул выше, в судьбоносный день два года назад, я съел кусок торта «Принцесса», и это было очень хорошо.
Отступим назад на пару секунд, когда я ещё только подносил самый первый кусочек торта ко рту. В этот момент у меня ещё не было особо сильных ожиданий того, как он будет на вкус, и что я буду чувствовать по его поводу. Но когда он попал ко мне в рот, ммммм, о, вау, это хороший торт.
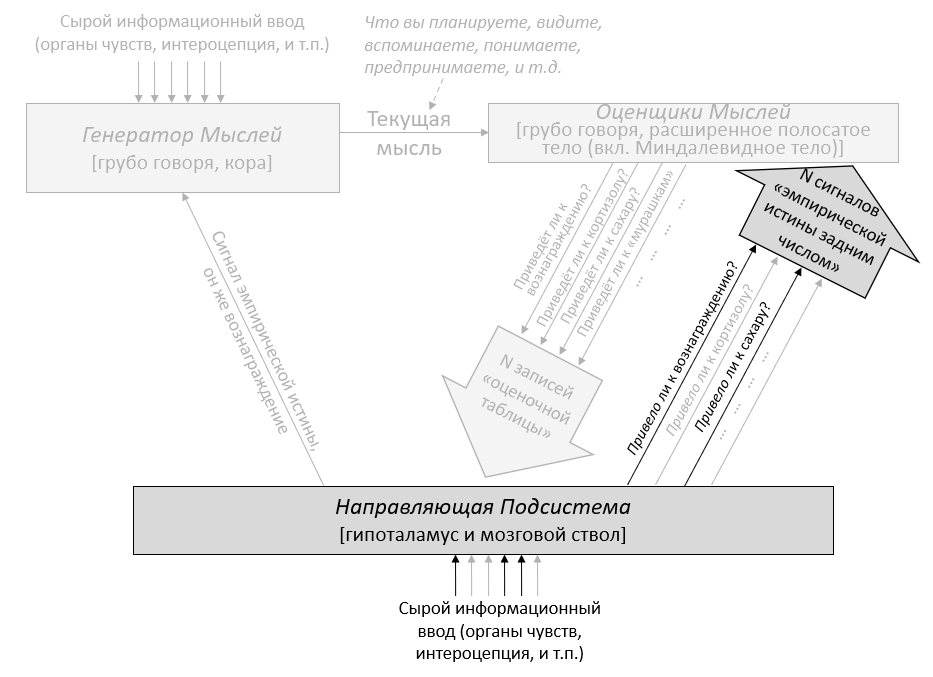
Части диаграммы, относящиеся к тому, что произошло, когда я съел первый удивительно-вкусный кусочек торта два года назад.
Итак, после того, как я его попробовал, моё тело произвело набор автономных реакций – выпустило некоторые гормоны, выработало слюну, изменило мой пульс и давление крови, и т.д. Почему? Ключ в том, что, как описано в Посте №3, Разделе 3.2.1, все мои сенсорные вводы делятся:
- Одна копия каждого конкретного сенсорного ввода отправляется в Обучающуюся Подсистему, чтобы встроиться в предсказательную модель мира. (См. «Информационные вводы» слева сверху на диаграмме.)
- Вторая копия того же сигнала отправляется в Направляющую Подсистему, где она служит вводом генетически закодированным цепям. (См. «Информационные вводы» снизу по центру диаграммы.)
Вкусовой ввод – не исключение: первый сигнал оказывается в вкусовой коре, части островковой коры (часть неокортекса, в Обучающейся Подсистеме), второй – в вкусовых ядрах продолговатого мозга (часть конечного мозга, в Направляющей Подсистеме). По прибытии в продолговатый мозг вкусовой ввод скармливается разным генетически закодированным схемам конечного мозга, которые, принимая также во внимание моё текущее психологическое состояние и подобное, исполняют все упомянутые мной автономные реакции.
Как я упоминал, до того, как я впервые попробовал торт, я не ожидал, что он будет так хорош. Ну, может быть, интеллектуально ожидал – если бы вы меня спросили, я бы сказал и был бы убеждён, что торт будет действительно хорош. Но я не ожидал этого внутренне.
Что я имею в виду под «внутренне»? В чём разница? Мои внутренние ожидания находятся на стороне «Оценщиков Мыслей». У людей нет произвольного контроля над своими Оценщиками Мыслей – они обучаются исключительно на сигналах «эмпирической истины задним числом» от мозгового ствола. У вас есть некоторые возможности манипуляции ими через контроль того, о чём вы думаете, как описано в предыдущем посте (Раздел 6.3.3), но в первом приближении можно считать, что они занимаются своими делами сами, независимо от того, что вы от них хотите. С эволюционной перспективы такое устройство имеет смысл как защита от вайрхединга – см. мой пост Награды Не Достаточно.
Так что когда я попробовал торт, мои Оценщики Мыслей оказались неправы! Они ожидали, что торт вызовет средненькие связанные с вкусностью автономные реакции, а на само деле торт вызвал сильные связанные с вкусностью автономные реакции. И Направляющая Подсистема узнала, что Оценщики Мыслей были неправы. Так что она послала корректирующий сигнал алгоритмам Оценщиков Мыслей, как показано на диаграмме выше. Эти алгоритмы затем изменили себя, чтобы в дальнейшем каждый раз, когда я подношу вилку с кусочком торта «Принцесса» в своему рту, Оценщики Мыслей более надёжно предсказывали сильные выбросы гормонов, сигнал вознаграждения, и все другие реакции, которые я на самом деле получил.
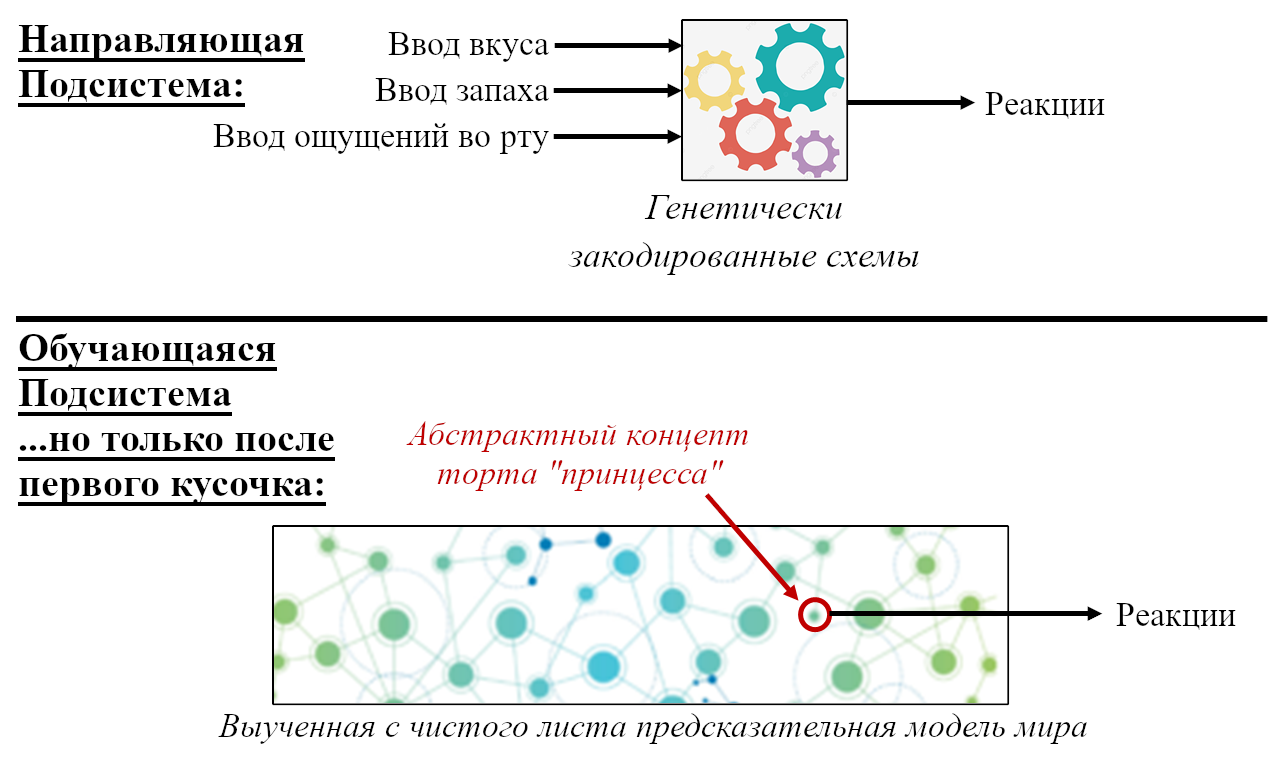
Тут произошла крутая штука. Мы начали с (относительно) простого жёстко прошитого алгоритма: схемы Направляющей Подсистемы переводят определённые виды вкусового ввода в определённые выбросы гормонов и автономные реакции. Но затем мы передали эту информацию в функции выученной модели мира – вспомните ту гигантскую запутанную базу данных, о которой я говорил в предыдущем разделе.
(Давайте возьмём паузу, чтобы всё проговорить: сигнал «эмпирической истины задним числом» настраивает Оценщики Мыслей. Оценщики Мыслей, как мы знаем из Поста №5 – это набор из, может быть, сотен моделей, над каждой из которых проводится обучение с учителем. Ввод этих обученных моделей, то, что я называю «контекстными» сигналами (см. Пост №4), включает нейроны извне предсказательной модели мира, кодирующие «какая мысль сейчас думается». Так что мы получаем функцию (обученную модель), чей ввод включает штуки вроде «активирует ли моя нынешняя мысль абстрактный концепт торта «Принцесса»?», и чей вывод – сигнал, сообщающий Направляющей Подсистеме выделять слюну и пр.)
Я называю этот шаг – в котором подправляются Оценщики Мыслей – «присвоением ценности». Куда больше про этот процесс, включая то, что в нём может пойти не так, будет в следующих постах.
Итак, сейчас Оценщики Мыслей выучили, что как только в модели мира «вспыхивает» концепт «я ем торт «Принцесса»», им следует выдать предсказание соответствующих выбросов гормонов, других реакций и вознаграждения.
7.5 Нацеленное планирование через формирование вознаграждения
У меня нет особенно жёсткой модели этого шага, но, думаю, я могу немного положиться на интуицию, чтобы история была полной:
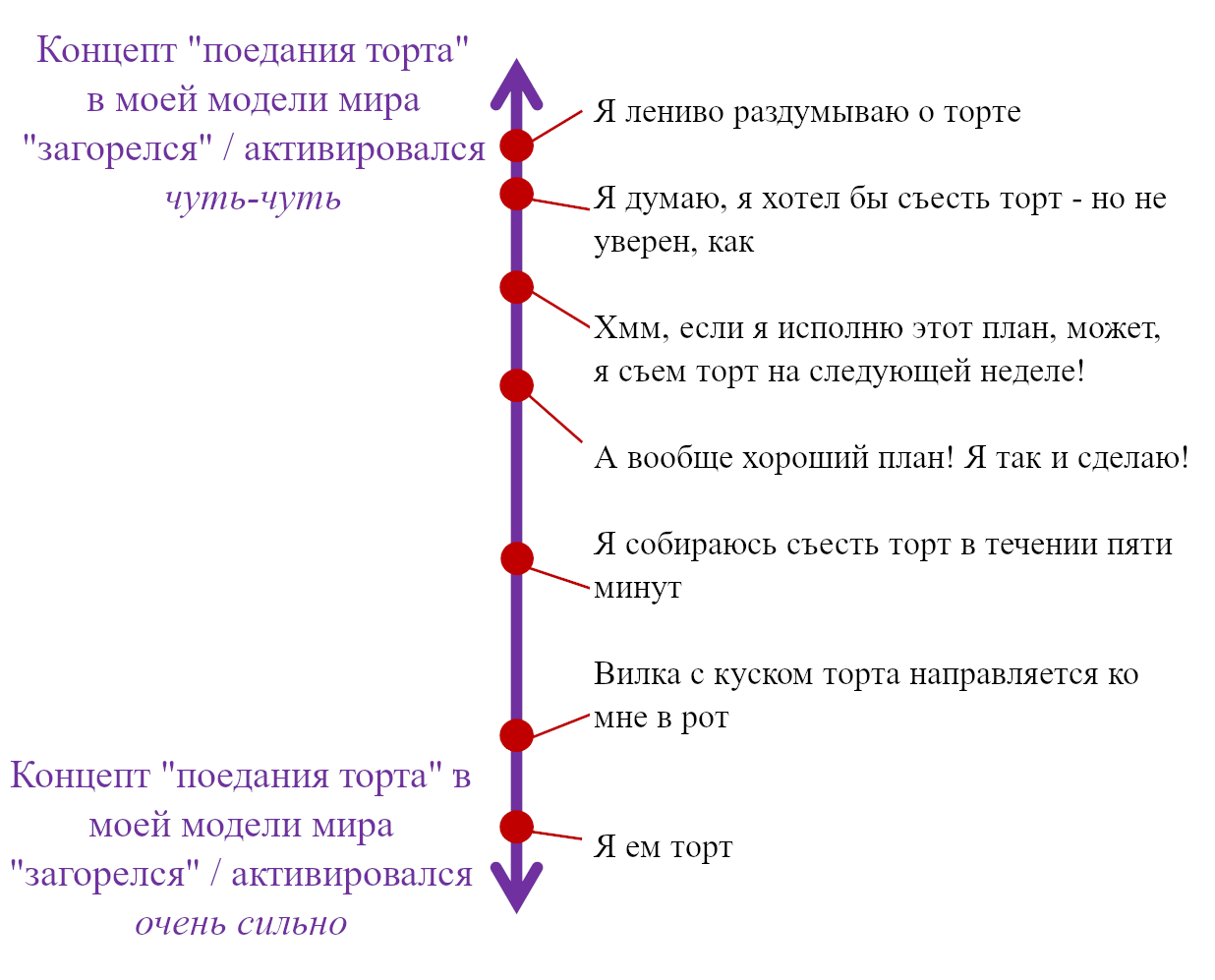
Напомню, с самого первого моего кусочка торта «Принцесса» два года назад Оценщики Мыслей в моём мозгу инспектируют каждую мысль, которую я думаю, проверяя, не «загорелся»/«активировался» ли в моей модели мира концепт «я ем торт «Принцесса»», и если да, то в какой степени, чтобы предлагать готовиться к вознаграждению, слюновыделению, и так далее.
Диаграмма выше предлагает серию мыслей, которые, я думаю, могли «зажигать» этот концепт в модели мира всё больше и больше, сверху вниз.
Чтобы понять суть, можете представить заметить торт на «солёный крекер». Идите вниз по списку и попытайтесь почувствовать, как каждая мысль заставляет вас выделять всё больше слюны. Или ещё лучше, замените «есть торт» на «пригласить краша на свидание», спускайтесь по списку и почувствуйте, как каждая мысль заставляет ваше сердце всё сильнее колотиться.
Вот другой способ об этом думать: Если вы представите модель мира приблизительно как ГВМ, вы можете представить, что «степень соответствия паттерну» – это примерно как вероятность, присвоенная узлу «поедания торта» в ГВМ. К примеру, если вы уверены в X, а из X слабо следует Y, а из Y слабо следует Z, а из Z слабо следует «поедание торта», то «поедание торта» получает очень низкую, но ненулевую вероятность, то есть слабую активацию, и это сродни обладанию долгосрочного, но не совсем невозможного плана нацеленного на поедание пирога. (Не воспринимайте этот абзац слишком буквально, я тут просто пытаюсь объяснить интуитивные соображения.)
Я в самом деле надеюсь, что такие штуки интуитивно понятны. В конце концов, я видел, как это переизобретали множество раз! К примеру, Дэвид Юм: «Прежде всего мне бросается в глаза тот факт, что между нашими впечатлениями и идеями существует большое сходство во всех особенных свойствах, кроме степени их силы и живости». А вот Уильям Джеймс: «Едва ли возможно спутать живейшую картину воображения с слабейшим реальным ощущением.» В обоих случаях, думаю, авторы указывали на идею что воображение активирует некоторые из тех же ментальных конструктов (скрытых переменных в модели мира), что и восприятие, но гораздо слабее.
ОК, если вы всё ещё тут, давайте вернёмся к моей модели принятия решений, теперь с другими подсвеченными частями:
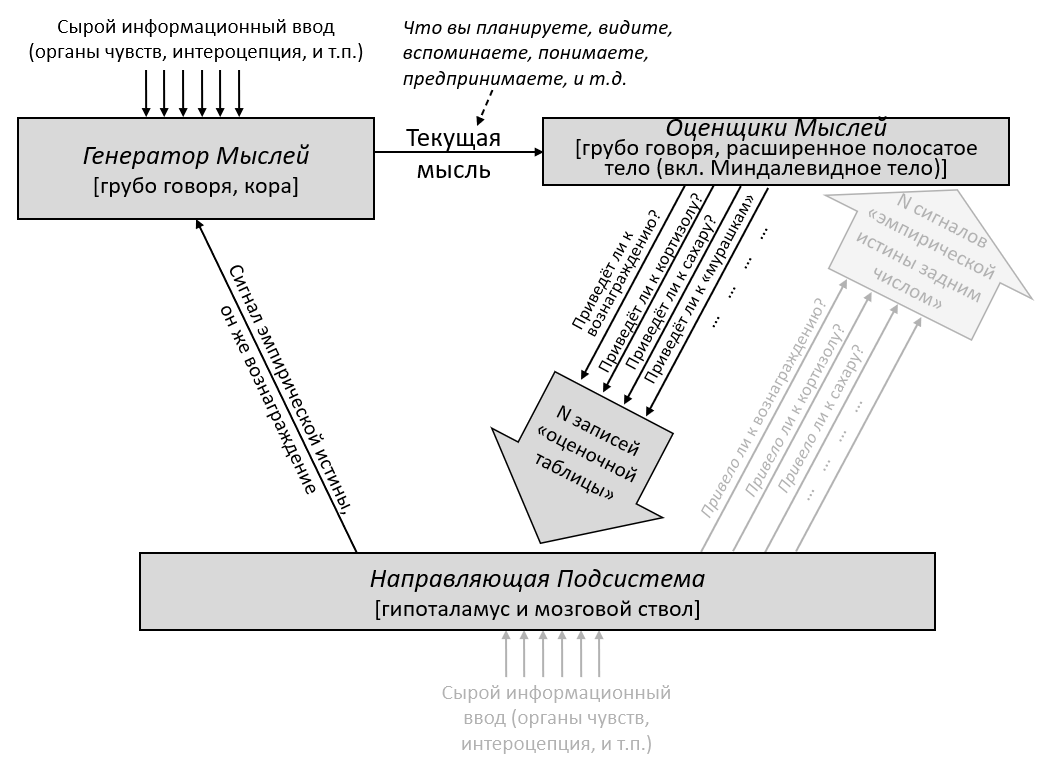
Части диаграммы, важные для процесса создания и исполнения долгосрочного плана обеспечения себя тортом «Принцесса».
Опять же, всякий раз, когда я думаю мысль, Направляющая Подсистема смотрит на соответствующую «оценочную таблицу» и выдаёт соответствующее вознаграждение. Напомню также, что активная мысль / план отбрасывается, если её сигнал вознаграждения отрицателен, и оставляется и усиливается, если он положительна.
Я ненадолго всё упрощу и проигнорирую всё кроме функции ценности (так же известной как Оценщик Мыслей «приведёт ли это к вознаграждению?»). И я также предположу, что Направляющая Подсистема просто доверяет предложенному значению, а не перехватывает его (см. Пост №6, Раздел 6.4.1). В таком случае, каждый раз, когда наши мысли переходят ниже по фиолетовой стрелке с диаграммы выше – от спокойных раздумий о торте к гипотетическому плану достать торт, к решению достать торт, и т.д. – происходит немедленное положительное вознаграждение, так что новая мыль усиливается и остаётся. И напротив, каждый раз, когда мы двигаемся по списку обратно – от решения к гипотетическому плану к размышлениям – происходит немедленное отрицательное вознаграждение, так что мысль отбрасывается и мы возвращаемся к предыдущей. Это как храповик! Система естественным путём продвигается по списку, создавая и исполняя хороший план, чтобы съесть торт.
Вот всё и получилось! Я думаю, что с такой позиции вполне объясняется полный набор поведений, ассоциируемых с людьми, планирующими для достижения явных целей – включая знание того, что у тебя есть цель, составление плана, исполнение инструментальных стратегий как части плана, замену хороших планов на планы ещё лучше, обновление плана при изменении ситуации, напрасную тоску по недостижимым целям и так далее.
7.5.1 Другие Оценщики Мыслей. Или: героическое деяния заказывания торта на следующую неделю, когда прямо сейчас тошно
Кстати, а что другие Оценщики Мыслей? Торт «Принцесса», в конце концов, ассоциируется не только с «приведёт к вознаграждению», но ещё и с «приведёт к сладкому вкусу», «приведёт к слюновыделению», и т.д. Играет ли это какую-то роль?
Конечно! Для начала, когда я подношу вилку ко рту, в самом конце исполнения моего плана поедания торта, я начинаю выделять слюну и выбрасывать кортизол в предвкушении.
Но что насчёт процесса долгосрочного планирования (звонок в пекарню и т.д.)? Я думаю, другие, не относящиеся к функции ценности, Оценщики Мыслей имеют значение и тут – по крайней мере в какой-то степени.[1]
К примеру, представьте, что вы чувствуете ужасную тошноту. Конечно, ваша Направляющая Подсистема знает, что вы чувствуете ужасную тошноту. И предположим, что она видит, что вы думаете мысль, которая, кажется, приведёт к еде. В этом случае Направляющая Подсистема может сказать: «Ужасная мысль! Отрицательное вознаграждение!»
ОК, вот вы чувствуете тошноту, но берёте свой телефон, чтобы оформить заказ в пекарне. Мысль слабо, но заметно помечается Оценщиком Мыслей как «скорее всего приведёт к еде». Ваша Направляющая Подсистема видит это и говорит «Фуу, с учётом нынешней тошноты это кажется плохой мыслью». Мысль ощущается немного отталкивающей. «Блин, я действительно заказываю этот огромный торт??», говорите вы себе.
Логически, вы знаете, что на следующей неделе, когда вы на самом деле получите торт, вы больше не будете чувствовать тошноту, и будете очень рады, что у вас есть торт. Но всё же прямо сейчас вы чувствуете, что заказывать его несколько противно и демотивирующе.
Заказываете ли вы его всё равно? Конечно! Может, функция ценности (Оценщик Мыслей «это приведёт к вознаграждению») достаточно сильна, чтобы перевесить Оценщик Мыслей «это приведёт к еде». Или, может быть, вы используете иную мотивацию: представляете себя как думающего наперёд человека, принимающего хорошие осмысленные решения, а не застревающего в текущем моменте. Это другая мысль в вашей голове, активирующая другой набор Оценщиков Мыслей, и, может, она получает высокую оценку Направляющей Подсистемы. В любом случае, вы действительно звоните в пекарню, чтобы заказать торт на следующую неделю. Что за героизм!
———
- В сторону: Я думаю, что в сравнении с прочими Оценщиками Мыслей функция ценности «меньше обесценивается» (фактор обесценивания ближе к 1.0), так что сложные непрямые далёкие-во-времени планы в основном руководствуются функцией ценности. Эта догадка происходит из психологической литературы по «обучению стимулов», но это тема для отдельного поста. В любом случае, это не всё-или-ничего; полагаю, прочие оценщики по меньшей мере хоть сколько-то важны, даже для далёких планов, как и в примере здесь.
8. Отходим от нейробиологии, 1 из 2: Про разработку СИИ
- 1.8.1 Краткое содержание / Оглавление
- 2.8.2 «Одно время жизни» превращается в «Один обучающий запуск»
- 2.1.8.2.1 Как много времени займёт обучение модели?
- 2.2.8.2.2 Онлайновое обучение подразумевает отсутствие фундаментального разделения обучения/развёртывания
- 2.3.8.2.3 …Всё же, общепризнанная в области машинного обучения мудрость о том, что «обучение дороже развёртывания», всё ещё более-менее применима
- 2.4.8.2.4 Онлайновое обучение вредит безопасности, но совершенно необходимо для способностей
- 3.8.3 Подобный-эволюции внешний цикл автоматического поиска: может и вовлечён, но не «ведущий проектировщик»
- 4.8.4 Другие не закодированные вручную штуки, которые могут быть в Направляющей Подсистеме будущего подобного-мозгу СИИ
8.1 Краткое содержание / Оглавление
Ранее в цепочке: в Посте №1 была описана моя общая мотивация, что такое «безопасность подобного-мозгу СИИ» и почему это нас заботит. Следующие шесть постов (№2-7) погрузились в нейробиологию. Посты №2-3 представили способ разделения мозга на «Обучающуюся Подсистему» и «Направляющую Подсистему», разделённые по признаку того, выполняют ли они то, что я называю «обучением с чистого листа». Затем посты №4-7 представили большую картину того, как по моему мнению работают цели и мотивации в мозгу, это оказалось похожим на причудливый вариант основанного на модели обучения с подкреплением «субъект-критик».
Теперь, установив нейробиологический фундамент, мы наконец-то можем более явно переключиться на тему подобного-мозгу СИИ. В качестве начальной точки размышлений вот диаграмма из Поста №6, отредактированная, чтобы описывать подобный-мозгу СИИ вместо настоящего мозга:
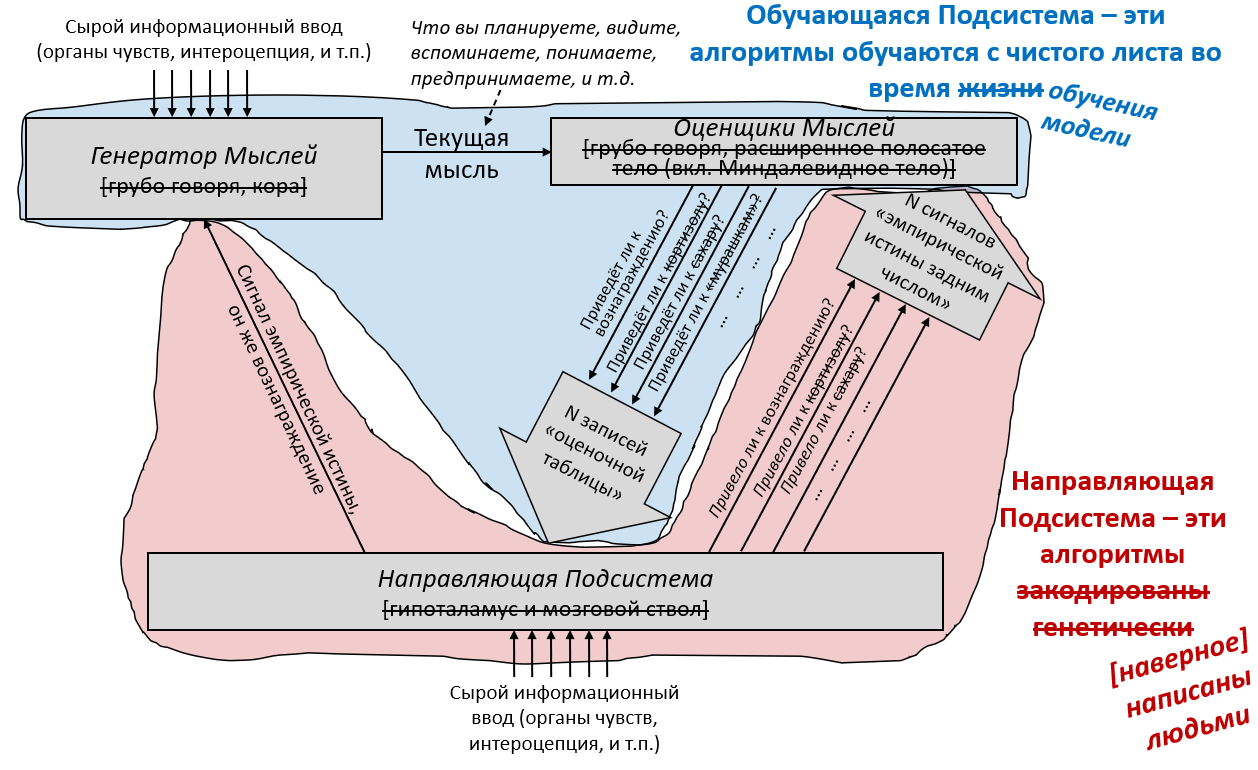
Диаграмма из Поста №6 с четырьмя изменениями, благодаря которым она теперь описывает подобный-мозгу СИИ, а не настоящий мозг: (1) справа сверху «время жизни» заменено на «обучение модели» (Раздел 8.2 ниже); (2) снизу справа «генетически закодированы» заменено на «[наверное] написаны людьми» (Разделы 8.3-8.4 ниже); (3) упоминания конкретных областей мозга вроде «миндалевидного тела» зачёркнуты, чтобы позже их можно было заменить частями исходного кода и/или наборами параметров обученной модели; (4) прочие биологически-специфичные слова вроде «сахара» зачёркнуты, чтобы позже их можно было заменить чем нам захочется, как я опишу в будущих постах.
Этот и следующий посты извлекут из прошлых обсуждений некоторые уроки о подобном-мозгу СИИ. Этот пост будет сосредоточен на том, как такой СИИ может быть разработан, а следующий – на его мотивациях и целях. После этого Пост №10 обсудит знаменитую «задачу согласования» (наконец-то!), а затем несколько постов буду посвящены возможным путям к её решению. Наконец, в Посте №15 я закончу цепочку открытыми вопросами, направлениями для будущих исследований и тем, как войти в эту область.
Вернёмся к этому посту. Тема: «Как, с учётом обсуждения нейробиологии в предыдущих постах, нам следует думать о процессе разработки софта для подобного-мозгу СИИ?». В частности, какова будет роль написанного людьми исходного кода, а какова – настраиваемых параметров («весов»), значения которых находят алгоритмы обучения?
Содержание:
- Раздел 8.2 предлагает, что в процессе разработки подобного-мозгу СИИ «времени жизни животного» хорошо соответствует «обучение модели». Я опишу, как много времени оно может занять: я утверждаю, что, несмотря на пример людей, которым требуются годы/десятилетия, чтобы достичь высокого уровня компетенции и интеллекта, вполне правдоподобно, что время обучения подобного-мозгу СИИ будет измеряться неделями/месяцами. Я также обосную, что подобный-мозгу СИИ, как и мозг, будет работать в режиме онлайнового обучения, а не обучения-а-потом-развёртывания, и укажу некоторые следствия этого для экономики и безопасности.
- Раздел 8.3 описывает возможность «внешнего цикла» автоматического поиска, аналогичного эволюции. Я обосную, что скорее всего он будет играть разве что небольшую роль, возможно, оптимизации гиперпараметров или чего-то в таком роде, и не будет играть большую роль «ведущего проектировщика», создающего алгоритм с чистого листа, несмотря на исторический пример того, как эволюция создала мозг с чистого листа. Я укажу некоторые следствия этого для безопасности СИИ.
- Раздел 8.4: Хоть я и ожидаю, что «Направляющая Подсистема» будущего СИИ будет в основном состоять из написанного людьми исходного кода, есть и некоторые исключения, и тут я пройдусь по трём: (1) возможность обученных заранее классификаторов изображений или иных подобных модулей, (2) возможность СИИ, «направляющих» другие СИИ, и (3) возможность человеческой обратной связи.
8.2 «Одно время жизни» превращается в «Один обучающий запуск»
Эквивалентом «времени жизни животного» для подобного-мозгу СИИ является «один обучающий запуск». Думайте об этом как о запусках моделей при их обучении в современном ML.
8.2.1 Как много времени займёт обучение модели?
Как много времени займёт «обучающий запуск» подобного-мозгу СИИ?
Для сравнения, люди, по моему скромному мнению, по-настоящему достигают пика в возрасте 37 лет, 4 месяца и 14 дней. Все моложе – наивные дети, а все старше – отсталые старые упрямцы. У-упс, я сказал «14 дней»? Мне следовало сказать «…и 21 день». Простите меня за эту ошибку; я написал это предложение на прошлой неделе, когда ещё был наивным ребёнком.
Ну, что бы это ни было для людей, мы можем спросить: Будет ли это примерно так же для подобных-мозгу СИИ? Не обязательно! См. мой пост Вдохновлённые-мозгом СИИ и «якоря времени жизни» (Раздел 6.2) за моими аргументами о том, что время-на-часах, необходимое, чтобы обучить подобный-мозгу СИИ до состояния мощного обобщённого интеллекта с чистого листа, очень сложно предсказать заранее, но вполне правдоподобно, что оно может быть коротким – недели/месяцы, а не годы/десятилетия.
8.2.2 Онлайновое обучение подразумевает отсутствие фундаментального разделения обучения/развёртывания
Мозг работает по принципу онлайнового обучения: он постоянно обучается во время жизни, вместо отдельных «эпизодов», перемежаемых «обновлениями» (более популярный подход в современном машинном обучении). Я думаю, что онлайновое обучение очень критично для того, как работает мозг, и что любая система, которую стоит называть «подобным-мозгу СИИ», будет алгоритмом онлайнового обучения.
Чтобы проиллюстрировать разницу между онлайновым и оффлайновым обучением, рассмотрим два сценария:
- Во время обучения, СИИ натыкается на два противоречащих друг другу ожидания (например, «кривые спроса обычно снижаются» и «много исследований показывают, что минимальные зарплаты не приводят к безработице»). СИИ обновляет свои внутренние модели для более детального и полного понимания, примиряющего эти два наблюдения. В дальнейшем он может использовать это новое знание.
- То же самое с тем же самым результатом происходит во время развёртывания.
В случае онлайнового обучения подобного-мозгу СИИ различия нет. В обоих случаях один и тот же алгоритм делает одно и то же.
Напротив, в случае систем машинного оффлайнового обучения (например, GPT-3), эти два случая обрабатываются двумя отдельными алгоритмическими процессами. Случай №1 включал бы изменения весов модели, тогда как случай №2 включал бы только изменения её активаций.
Для меня это важный довод в пользу подхода онлайнового обучения. Оно требует решать задачу только один раз, а не два раза разными способами. И не просто какую-то задачу; это вроде бы центральная для СИИ задача!
Я хочу ещё раз подчеркнуть, насколько ключевую роль в мозгу (и в подобных-мозгу СИИ) играет онлайновое обучение. Человек без онлайнового обучения – это человек с полной антероградной амнезией. Если вы представились мне как «Фред» и через минуту я обращаюсь к вам «Фред», то я могу поблагодарить онлайновое обучение за то, что оно поместило этот кусочек знания в мой мозг.
8.2.3 …Всё же, общепризнанная в области машинного обучения мудрость о том, что «обучение дороже развёртывания», всё ещё более-менее применима
В нынешнем машинном обучении общеизвестно, что обучение дороже развёртывания. К примеру, в OpenAI, как утверждается, потратили около $10 млн на обучение GPT-3 – т.е. чтобы получить волшебный список из 175 миллиардов чисел, служащих весами GPT-3. Но теперь, когда у них на руках есть этот список из 175 миллиардов чисел, запуск GPT-3 дёшев как грязь – последний раз, когда я проверял, OpenAI брали примерно $0.02 за страницу сгенерированного текста.
Благодаря онлайновому обучению подобные-мозгу СИИ не будут иметь фундаментального различия между обучением и развёртыванием, как и обсуждалось в предыдущем разделе. Однако, экономика остаётся схожей.
Представьте трату десятилетий на выращивание ребёнка от рождения, пока он не станет умелым и эрудированным взрослым, возможно, с дополнительным обучением в математике, науке, инженерии, программированию, и т.д.
Теперь представьте, что у вас есть научно-фантастическая клонирующая машина, которая может мгновенно создать 1000 копий этого взрослого. Вы посылаете их на 1000 разных работ. Ладно, каждая копия, вероятно, будет нуждаться в дополнительном обучении этой работе, чтобы выйти на полную продуктивность. Но им не потребуются десятилетия дополнительного обучения, как от рождения до взрослого состояния. (Больше об этом в блоге Холдена Карнофски.)
Так что, как и в обычном машинном обучении, остаётся большая стоимость изначального обучения, и её, в принципе, можно смягчить созданием множества копий.
8.2.4 Онлайновое обучение вредит безопасности, но совершенно необходимо для способностей
Я утверждаю, что онлайновое обучение создаёт неприятные проблемы для безопасности СИИ. К сожалению, я также утверждаю, что если мы вовсе создадим СИИ, то нам понадобится онлайновое обучение или что-то с схожими эффектами. Давайте по очереди разберёмся с обоими утверждениями.
Онлайновое обучение вредит безопасности:
Давайте переключимся на людей. Предположим, я прямо сейчас приношу присягу как президент страны, и я хочу всегда в первую очередь заботиться о благе своего народа и не поддаваться песне сирен коррупции. Что я могу сделать прямо сейчас, чтобы контролировать, как будет вести себя будущий я? Неочевидно, правда? Может, даже, невозможно!
У нынешнего меня просто нет естественного и надёжного способа указать будущему мне, что хотеть делать. Лучшее, что я могу сделать – много маленьких хаков, предсказать конкретные проблемы и попробовать их предотвратить. Я могу связать себе руки, выдав честному бухгалтеру все пароли моих банковских счетов и попросить меня сдать, если там будет что-то подозрительное. Я могу устраивать регулярные встречи с надёжным осмотрительным другом. Такие способы немного помогают, но опять же, они не дают надёжного решения.
Аналогично, у нас может быть СИИ, который прямо сейчас честно пытается действовать этично и полезно. Потом он какое-то время работает, думает новые мысли, получает новые идеи, читает новые книги и испытывает новый опыт. Будет ли он всё ещё честно пытаться действовать этично и полезно через шесть месяцев? Может быть! Надеюсь! Но как мы можем быть уверены? Это один из многих открытых вопросов в безопасности СИИ.
(Может, вы думаете: мы могли бы периодически создавать бэкап СИИ-сейчас, и давать ему право вето на изменения СИИ-потом? Я думаю, это осмысленная идея, может быть даже хорошая. Но это не панацея. Что если СИИ-потом сообразит, как обмануть СИИ-сейчас? Или что если СИИ-потом меняется к лучшему, а СИИ-сейчас продолжает его сдерживать? Ведь более молодой я был наивным ребёнком!)
Онлайновое обучение (или что-то с схожими проблемами безопасности) необходимо для способностей:
Я ожидаю, что СИИ будут использовать онлайновое обучение, потому что я думаю, что это эффективный метод создания СИИ – см. обсуждение «решения одной и той же задачи дважды» выше (Раздел 8.2.2).
Однако, я всё же могу представить другие варианты, которые формально не являются «онлайновым обучением», но имеют схожие эффекты и ставят по сути те же вызовы безопасности, т.е. затрудняют возможность увериться, что изначально безопасный СИИ продолжает быть безопасным.
Мне куда сложнее представить способ избежать этих проблем. В самом деле:
- Если СИИ может думать новые мысли и получать новые идеи и узнавать новые знания «при развёртывании», то мы, кажется, стоим перед этой же проблемой нестабильности целей. (См., к примеру, проблему «онтологического кризиса»; больше об этом в следующих постах.)
- Если СИИ не может ничего из этого, действительно ли это СИИ? Будет ли он действительно способен на то, что мы хотим от СИИ, вроде составления новых концепций и изобретения новых технологий? Я подозреваю, что нет.
8.3 Подобный-эволюции внешний цикл автоматического поиска: может и вовлечён, но не «ведущий проектировщик»
Под «внешним циклом» подразумевается больший из двух вложенных циклов контроля потока исполнения. «Внутренним циклом» может быть код, симулирующий жизнь виртуального животного, секунду за секундой, от рождения до смерти. Тогда «внешний цикл поиска» будет симулировать много разных животных, с своими настройками мозга у каждого, в поисках того, которое (в взрослом состоянии) продемонстрирует максимальный интеллект. Прижизненное обучение происходит в внутреннем цикле, а внешний цикл аналогичен эволюции.
Вот пример крайнего случая проектирования с основной ролью внешнего цикла, где (можно предположить) люди пишут код, исполняющий подобный-эволюции алгоритм внешнего цикла, который создаёт СИИ с чистого листа:
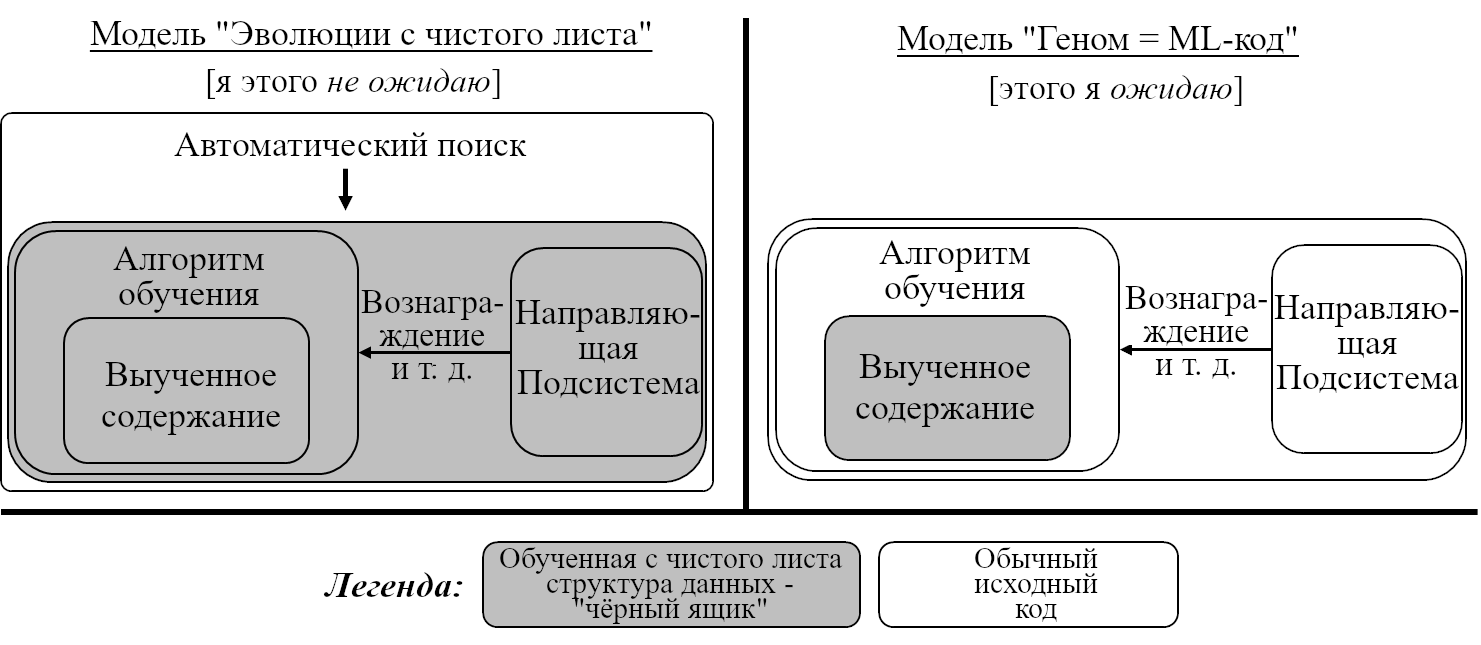
Две модели разработки СИИ. Модель слева напрямую аналогична тому, как эволюция создала человеческий мозг. Модель справа использует аналогию между геномом и исходным кодом, определяющим алгоритм машинного обучения, как будет описано в следующем подразделе.
Подход эволюции-с-чистого-листа (левый) регулярно обсуждается в технической литературе по безопасности СИИ – см. Риски Выученной Оптимизации и десятки других постов про так называемые «меса-оптимизаторы».
Однако, как указано в диаграмме, этот подход – не то, как, по моим ожиданиям, люди создадут СИИ, по причинам, которые я вскоре объясню.
Несмотря на это, я всё же не полностью отвергаю идею внешнего цикла поиска; я ожидаю, что он будет присутствовать, хоть и с более ограниченной ролью. В частности, когда будущие программисты будут писать алгоритмы подобного-мозгу СИИ, в его исходном коде будет некоторое количество настраиваемых параметров, оптимальные значения которых не будут априори очевидными. Они могут включать, например, гиперпараметры обучающихся алгоритмов (как скорость обучения), разные аспекты нейронной архитектуры, и коэффициенты, настраивающие относительную силу разных встроенных стремлений.
Я думаю, весьма правдоподобно, что будущие программисты СИИ будут использовать автоматизированный внешний цикл поиска для установки значений многих или всех этих настраиваемых параметров.
(Или нет! К примеру, как я понимаю, изначальное обучение GPT-3 было таким дорогим, что его сделали только один раз, без точной настройки гиперпараметров. Вместо этого, гиперпараметры систематически изучили на меньших моделях, и исследователи обнаружили тенденции, которые смогли экстраполировать на полноразмерную модель.)
(Ничто из этого не подразумевает, что алгоритмы обучения с чистого листа не важны для подобного-мозгу СИИ. Совсем наоборот, они играют огромную роль! Но эта огромная роль заключена во внутреннем цикле – т.е. в прижизненном обучении. См. Пост №2.)
8.3.1 Аналогия «Геном = ML-код»
В диаграмме выше я написал «геном = ML-код». Это указывает на аналогию между подобным-мозгу СИИ и современным машинным обучением, как в этой таблице:
| **Аналогия «Геном = ML-код»** | |
| Человеческий интеллект | Современные системы машинного обучения |
| Геном человека | Репозиторий на GitHub с всем необходимым PyTorch-кодом, необходимым для обучения и запуска играющего в Pac-Man агента |
| Прижизненное обучение | Обучение играющего в Pac-Man агента |
| Как думает и действует взрослый человек | Играющий в Pac-Man обученный агент |
| Эволюция | *Может быть,* исследователи использовали внешний цикл поиска для некоторых понятных людям настраиваемых параметров – например, подправляя гиперпараметры, или отыскивая лучшую нейронную архитектуру. |
8.3.2 Почему я думаю, что «эволюция с чистого листа» менее вероятна (как метод разработки СИИ), чем «геном = ML-код»
(См. также мой пост от марта 2021 года: Против эволюции как аналогии того, как люди создадут СИИ.)
Я думаю, лучший аргумент против модели эволюции с чистого листа – это непрерывность: «геном = ML-код» – это то, как сейчас работает машинное обучение. Откройте случайную статью по обучению с подкреплением и взгляните на обучающийся алгоритм. Вы увидите, что он интерпретируем для человека, и в основном или полностью спроектирован людьми – наверное, с использованием штук вроде градиентного спуска, обучения методом Временных Разниц и т.д. То же для алгоритма вывода, функции вознаграждения и т.д. Как максимум, в коде обучающегося алгоритма будет пара десятков или сотен бит информации, пришедшей из внешнего цикла поиска, вроде конкретных значений гиперпараметров, составляющих крохотную долю «работы проектирования», влитой в этот алгоритм.[1]
К тому же, если бы будущее было за первостепенным внешним циклом поиска, я ожидал бы, что сейчас мы бы наблюдали, что проекты машинного обучения, больше всего полагающиеся на внешний цикл поиска, чаще встречались бы среди самых впечатляющих прорывных результатов. Насколько я могу посудить, это вовсе не так.
Я лишь предполагаю, что эта тенденция продолжится – по тем же причинам, что и сейчас: люди довольно хороши в проектировании обучающихся алгоритмов, и, одновременно с этим, внешний цикл поиска обучающихся алгоритмов крайне медленен и дорог.
(Ладно, то, что «крайне медленно и дорого» сегодня, будет быстрее и дешевле в будущем. Однако, когда по прошествии времени будущие исследователи машинного обучения смогут позволить себе большие вычислительные мощности, я ожидаю, что, как и сегодняшние исследователи, они обычно будут «тратить» их на бОльшие модели, лучшие процедуры обучения и так далее, а не на больший внешний цикл поиска.)
С учётом всего этого, почему некоторые люди готовы многое поставить на модель «эволюции с чистого листа»? Я думаю, это сводится к вопросу: Насколько вообще сложно может быть написать исходный код для модели «геном = ML-код»?
Если ваш ответ «это невозможно» или «это займёт сотни лет», то эволюция с чистого листа выигрывает по умолчанию! С этой точки зрения, даже если внешний цикл поиска потребует триллионы долларов и десятилетия реального времени и гигаватты электричества, это всё равно кратчайший путь к СИИ, и рано или поздно какое-то правительство или компания вложат деньги и потратят время, чтобы это произошло[2].
Однако, я не думаю, что написание исходного кода для модели «геном = ML-код» – дело на сотни лет. Напротив, я думаю, что это вполне посильно, и что исследователи в областях ИИ и нейробиологии двигают прогресс в этом направлении, и что они могут преуспеть в ближайшие десятилетия. За объяснениями, почему я так думаю, см. обсуждение «сроков до подобного-мозгу СИИ» ранее в цепочке – Разделы 2.8, 3.7 и 3.8.
8.3.3 Почему «эволюция с чистого листа» хуже чем «геном = ML-код» (с точки зрения безопасности)
Это один из редких случаев, где «то, что я ожидаю по умолчанию» совпадает с «тем, на что я надеюсь»! В самом деле, модель «геном = ML-код», которую я подразумеваю в этой цепочке, кажется куда более многообещающей для безопасности СИИ, чем модель «эволюции с чистого листа». Тому есть две причины.
Первая – интерпретируемость человеком. В модели «геном = ML-код» с ней плохо. Но в модели «эволюция с чистого листа» с ней ещё хуже!
В первом случае модель мира – это большой обучившийся с чистого листа чёрный ящик. И функция ценности и многое другое тоже, и нам надо будет много работать над пониманием их содержимого. Во втором случае, у нас будет только один ещё больший чёрный ящик. Нам повезёт, если мы вообще найдём там модель мира, функцию ценности, и т.д., не то что поймём их содержимое!
Вторая причина, которая будет подробно рассмотрена в следующих постах, в том, что осторожное проектирование Направляющей Подсистемы – это один из наших самых мощных рычагов контроля цель и мотиваций подобного-мозгу СИИ, который может обеспечить нам безопасное и выгодное поведение. Если мы сами пишем код Направляющей Подсистемы, то мы имеем полный контроль нам тем, как она работает и прозрачность того, что она делает при работе. Когда же мы использует модель эволюции с чистого листа, у нас есть намного меньше контроля и понимания.
Для ясности, безопасность СИИ – нерешённая задача и в случае «геном = ML-код». Я только говорю, что, по видимости, подход эволюции с чистого листа делает эту задачу ещё сложнее.
(Примечание для ясности: это обсуждение предполагает, что у нас будет именно подобный-мозгу СИИ в обоих случаях. Я не делаю заявлений о большей или меньшей безопасности подобного-мозгу СИИ в сравнении с не-подобным-мозгу СИИ, если такой возможен.)
8.3.3.1 Хорошая ли идея создавать подобные человеческим социальные инстинкты при помощи эволюции агентов в социальном окружении?
Возможное возражение, которое я иногда встречаю: «Люди не так плохи, а нашу Направляющую Подсистему спроектировала эволюция, верно? Может, если мы проведём подобный эволюции внешний цикл поиска в окружении, где много СИИ должны кооперироваться, то они заполучат альтруизм и другие подобные социальные инстинкты!» (Я думаю, что какие-то такие соображения стоят за проектами вроде DeepMind Melting Pot.)
У меня на это есть три ответа.
- Во-первых, у меня сложилось впечатление (в основном от чтения Парадокса Доброты Ричарда Рэнгэма), что есть огромная разница между человеческими социальными инстинктами, социальными инстинктами шимпанзе, социальными инстинктами бонобо, социальными инстинктами волков, и так далее. К примеру, у шимпанзе и волков намного более высокая «реактивная агрессия», чем у людей и бонобо, хотя все четыре вида очень социальны. Эволюционное давление, приводящее к социальным инстинктам, очень чувствительно к динамике власти и другим аспектам социальных групп, и, возможно, обладает несколькими точками устойчивого равновесия, так что кажется, что его было бы сложно контролировать, подстраивая параметры виртуального окружения.
- Во-вторых, если мы создадим виртуальное окружение стимулирующее СИИ кооперироваться с другими СИИ, то мы получим СИИ, имеющих кооперативные социальные инстинкты по отношению к другим СИИ в их виртуальном окружении. Но хотим мы, чтобы СИИ имели кооперативные социальные инстинкты по отношению к людям в реальном мире. Направляющая Подсистема, создающая первые может обобщаться, а может и не обобщаться до вторых. Люди, заметим, часто испытывают сочувствие по отношению к своим друзьям, но редко – по отношению к членам враждебного племени, фабрично разводимым животным и большим волосатым паукам.
- В-третьих, человеческие социальные инстинкты – не всё, чего нам хочется! К примеру, есть версия (по-моему, правдоподобная), что низкая, но не нулевая распространённость психопатии у людей – не случайный глюк, а скорее выгодная стратегия с точки зрения эгоистичных генов и эволюционной теории игр. Аналогично, эволюция спроектировала людей с завистью, злобой, подростковыми бунтами, кровожадностью, и так далее. И вот так мы хотим спроектировать наши СИИ?? Ой.
8.4 Другие не закодированные вручную штуки, которые могут быть в Направляющей Подсистеме будущего подобного-мозгу СИИ
Как обсуждалось в Посте №3, я утверждаю, что Направляющая Подсистема (т.е. гипоталамус и мозговой ствол) мозгов млекопитающих состоит из генетически-закодированных алгоритмов. (За подробностями см. Пост №2, Раздел 2.3.3)
Когда мы переключаемся на СИИ, у меня есть соответствующее ожидание, что Направляющая Подсистема будущих СИИ будет состоять в основном и написанного людьми кода – как типично написанные людьми функции вознаграждения современных агентов обучения с подкреплением.
Однако, она может быть не полностью написана людьми. Для начала, как обсуждалось в предыдущем разделе, значения некоторого количества настраиваемых параметров, например, относительные силы встроенных стремлений, могут быть выяснены внешним циклом поиска. Вот ещё три возможных исключения из моего общего ожидания, что Направляющая Подсистема СИИ будет состоять из написанного людьми кода.
8.4.1 Заранее обученные классификаторы изображений и т.п.
Правдоподобно звучит, что составляющей Направляющей Подсистемы СИИ будет что-то вроде обученного классификатора изображений ConvNet. Это было бы аналогично тому, что в верхнем двухолмии человека есть что-то-вроде-классификатора-изображений для распознавания заранее заданного набора определённо-важных категорий, вроде змей, пауков и лиц (см. Пост №3, Раздел 3.2.1). Аналогично, могут быть обученные классификаторы для аудио- и других сенсорных вводов.
8.4.2 Башня СИИ, направляющих СИИ?
В принципе, вместо нормальной Направляющей Подсистемы мог бы быть целый отдельный СИИ, присматривающий за мыслями в Обучающейся Подсистеме и посылающий соответствующие вознаграждения.
Чёрт, можно даже создать целую башню СИИ-направляющих-СИИ! Предположительно, СИИ становились бы более сложными и мощными по мере восхождения на башню, достаточно медленно, чтобы каждый СИИ справлялся с задачей направления СИИ на уровень выше. (Ещё это могла бы быть пирамида, а не башня, с несколькими более глупыми СИИ, совместно составляющими Направляющую Подсистему более умного СИИ.)
Я не думаю, что такой подход точно бесполезен. Но мне кажется, что мы всё ещё не добрались до первого этапа, на котором мы создаём хоть какой-то безопасный СИИ. Создание башни СИИ-направляющих-СИИ не избавляет нас от необходимости сначала сделать один безопасный СИИ другим способом. Башне нужно основание!
Когда мы решим эту первую большую задачу, тогда мы сможем думать о том, чтобы использовать этот СИИ напрямую для решения человеческих проблем или косвенно, для направления ещё-более-мощных СИИ, аналогично тому, как люди пытаются направлять самый первый.
Я склоняюсь к тому, что возможность «использовать этот первый СИИ напрямую» более многообещающая, чем «использовать этот первый СИИ для направления второго, более мощного, СИИ». Но я могу быть неправ. В любом случае, сначала нам нужно до этого добраться.
8.4.3 Люди, направляющие СИИ?
Если Направляющей Подсистемой СИИ могут (предположительно) быть другой СИИ, то почему ею не может быть человек?
Ответ: если СИИ работает со скоростью мозга человека, то он может думать 3 мысли в секунду (или около того). Каждая «мысль» потребует соответствующего вознаграждения, и, может, десятков других сигналов эмпирической истины. Человек не сможет за этим поспевать!
Что можно – это сделать человеческую обратную связь вводом Направляющей Подсистемы. К примеру, мы можем дать людям большую красную кнопку с надписью “ВОЗНАГРАЖДЕНИЕ». (Нам, наверное, не стоит так делать, но мы можем.) Мы также можем вовлекать людей иными способами, включая не имеющие биологических аналогов – стоит быть открытыми к идеям.
———
-
К примеру, вот случайная статья по поиску нейронной архитектуры (NAS): «Эволюционирующий трансформер». Авторы хвастаются своим «большим пространством поиска», и оно действительно большое по меркам NAS. Но поиск по этому пространству всё же выдаёт лишь 385 бит информации, и его результат умещается в одну легко понятную человеку диаграмму из этой статьи. Для сравнения, веса обученной модели легко могут составлять миллионы или миллиарды бит информации, а конечный результат требует героических усилий для понимания. Мы также можем сравнить эти 385 бит с информацией в созданных людьми частях исходного кода обучающегося алгоритма, вроде кода умножения матриц, Softmax, Autograd, передачи данных между GPU и CPU, и так далее. Это будет на порядки больше, чем 385 бит. Это то, что я имел в виду, говоря, что штуки вроде подстройки гиперпараметров и NAS составляют крохотную долю общей «работы проектирования» над обучающимся алгоритмом.
(Наиболее полагающаяся на внешний цикл поиска статья, которую я знаю – это статья про AutoML-Zero, и даже там внешний цикл выдал по сути 16 строк кода, которые были легко интерпретируемы авторами.) -
Если вам любопытны приблизительные оценки того, как много времени и денег потребует выполнение вычислений, эквивалентных всей истории эволюции животных на Земле, см. обсуждение про «Эволюционные якоря» в докладе Аджейи Котры по биологическим якорям 2020 года. Очевидно, это не в точности то же, что и вычисления, необходимые для разработки СИИ методом эволюции с чистого листа, но это всё же имеет какое-то отношение. Я не буду больше говорить на эту тему; не думаю, что это важно, потому что в любом случае не ожидаю разработки СИИ методом эволюции с чистого листа.
9. Отходим от нейробиологии, 2 из 2: Про мотивацию СИИ
- 1.9.1 Краткое содержание / Оглавление
- 2.9.2 Цели и желания СИИ определяются в терминах скрытых переменных (выученных концептов) в его модели мира
- 3.9.3 «Присвоение ценности» – как скрытые переменные окрашиваются валентностью
- 4.9.4 Вайрхединг: возможен, но не неизбежен
- 5.9.5 СИИ НЕ судят о планах, основываясь на будущих вознаграждениях
- 6.9.7 «Направление в реальном времени»: Направляющая Подсистема может перенаправлять Обучающуюся Подсистему – включая её глубочайшие желания и долгосрочные цели – в реальном времени
9.1 Краткое содержание / Оглавление
Большая часть предыдущих постов цепочки – №2-7 – были в основном про нейробиологию. Теперь, начиная с предыдущего поста, мы применяем эти идеи для лучшего понимания безопасности подобного-мозгу СИИ (определённого в Посте №1).
В этом посте я рассмотрю некоторые темы, связанные с мотивациями и целями подобного-мозгу СИИ. Мотивации очень важны для безопасности СИИ. В конце концов, наши перспективы становятся намного лучше, если будущие СИИ будут мотивированы на достижение замечательного будущего, где люди процветают, а не мотивированы всех убить. Чтобы получить первое, а не второе, нам надо понять, как работает мотивация у подобных-мозгу СИИ, и, в частности, как направить её в нужном направлении. Этот пост охватит разнообразные темы из этой области.
Содержание:
- Раздел 9.2 посвящён тому, что цели и предпочтения подобного-мозгу СИИ определяются в терминах скрытых переменных в его модели мира. Они могут быть связаны с исходами, действиями или планами, но не являются ни одной из этих вещей в точности. К тому же, алгоритмы в целом не проводят различий между инструментальными и терминальными целями.
- Раздел 9.3 содержит более глубокое обсуждение «присвоения ценности», которое я представил в описании примера в Посте №7 (Раздел 7.4). «Присвоение ценности», как я использую этот термин в этой цепочке – это синоним «обновления Оценщиков Мыслей», процесс в котором концепт (= скрытая переменная в модели мира) может «окраситься» положительной или отрицательной валентностью и/или начать запуск непроизвольных внутренних реакций (в случае человека). Такое «присвоение ценности» – ключевой ингредиент того, как СИИ может захотеть что-то делать.
- Раздел 9.4 определяет «вайрхединг». Примером «вайрхединга» был бы СИИ, взламывающий себя и устанавливающий регистр «вознаграждения» в своей оперативной памяти на максимально возможное значение. Я аргументирую мнение, что подобный-мозгу СИИ будет «по умолчанию» иметь «слабое стремление к вайрхедингу» (желание сделать это при прочих равных), но, наверное, не «сильное стремление к вайрхедингу» (рассмотрение этого как лучшего возможного варианта, которого стоит добиться любой ценой).
- Раздел 9.5 проговаривает следствия из обсуждения вайрхединга в предыдущем разделе: подобный-мозгу СИИ в общем случае НЕ пытается максимизировать своё будущее вознаграждение. Я приведу человеческий пример, и свяжу его с концептом «агентов наблюдаемой полезности» из литературы.
- Раздел 9.6 обосновывает, что в случае подобных-мозгу СИИ Оценщики Мыслей связывают мотивацию с интерпретируемостью нейросети. К примеру, суждение «Эта мысль / этот план скорее всего приведут к еде» – это одновременно (1) данные, вкладывающиеся в интерпретируемость мысли/плана из выученной модели мира, и (2) сигнал о том, что мысль / план стоящие, если мы голодны. (Это применимо к любой системе обучения с подкреплением, совместимой с многомерными функциями ценности, не только к «подобным-мозгу». То же для следующего пункта.)
- Раздел 9.7 описывает, как мы могли бы «направлять» мотивации СИИ в реальном времени, и как это могло бы повлиять не только на его немедленные действия, но и на долговременные планы и «глубокие желания».
9.2 Цели и желания СИИ определяются в терминах скрытых переменных (выученных концептов) в его модели мира
Нравится ли вам футбол? Ну, «футбол» – это выученный концепт, обитающий внутри вашей модели мира. Такие выученные концепты – это единственное, что может «нравиться». Вам не может нравиться или не нравиться [безымянный паттерн из сенсорного ввода, о котором вы никогда не задумывались]. Возможно, что вы нашли бы этот паттерн вознаграждающим, если бы вы на него наткнулись. Но он не может вам нравиться, потому что сейчас он не является частью вашей модели мира. Это также означает, что вы не можете и не будете составлять целенаправленный план для вызова этого безымянного паттерна.
Я думаю, это ясно из интроспекции, и думаю, что это так же ясно из нашей картины мотивации (см. Посты №6-7). Я там использовал термин «мысль» в широком смысле, включающем всё осознанное и более того – что вы планируете, видите, вспоминаете, понимаете, предпринимаете, и т.д. «Мысль» – это то, что оценивают Оценщики Мыслей, и она состоит из некоторой конфигурации выученных скрытых переменных в вашей генеративной модели мира.
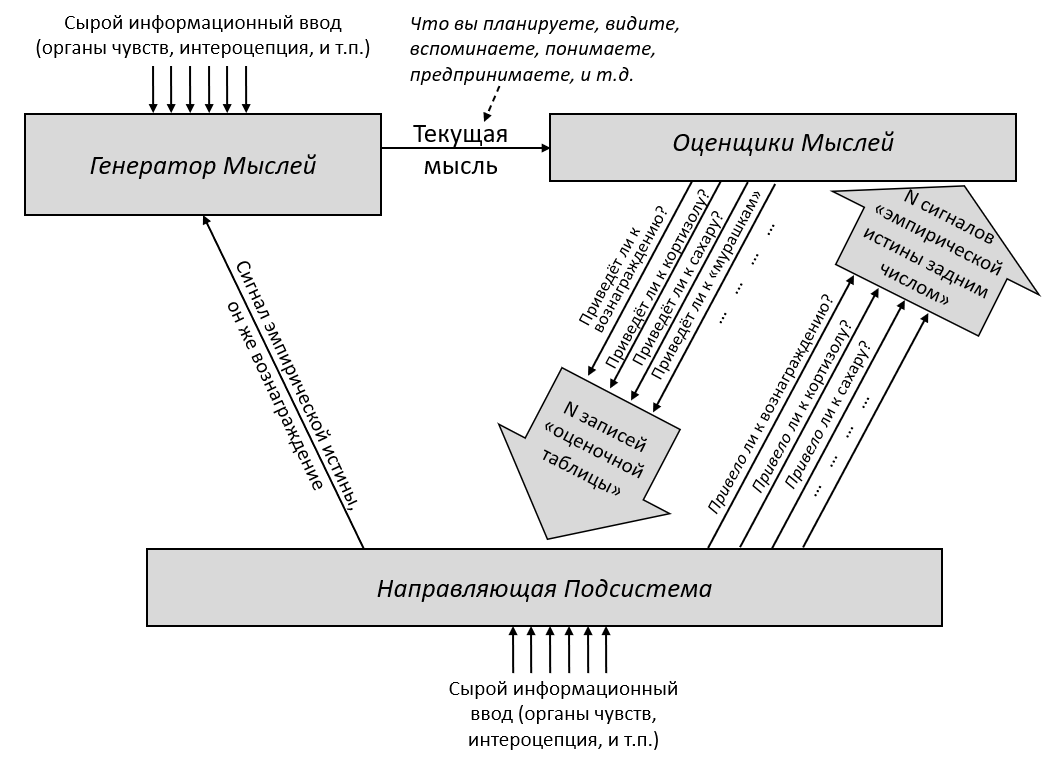
Наша модель мотивации – см. Пост №6 за подробностями
Почему важно, чтобы цели СИИ были определены в терминах скрытых переменных его модели мира? Много причин! Они будут снова и снова всплывать в этом и будущих постах.
9.2.1 Следствия для «согласования ценностей» с людьми
Наблюдение выше – одна из причин, почему «согласование ценностей» человека и СИИ – чертовски запутанная задача. У подобного-мозгу СИИ будут скрытые переменные в его выученной модели мира, а у человека скрытые переменные в его модели мира, но это разные модели мира, и скрытые переменные в одной могут иметь сложное и проблематичное соответствие с скрытыми переменными в другой. К примеру, человеческие скрытые переменные могут включать штуки вроде «привидений», которые не соответствуют ничему в реальном мире! Для большего раскрытия этой тему, см. пост Джона Вентворта Проблема Указателей.
(Я в этой цепочке не скажу многого про «определение человеческих ценностей» – я хочу придерживаться более узкой задачи «избегания катастрофических происшествий с СИИ, таких как вымирание людей», и не думаю, что глубокое погружение в «определение человеческих ценностей» для этого необходимо. Но «определение человеческих ценностей» – всё ещё хорошее дело, и я рад, что люди над этим работают – см., к примеру, 1,2.)
9.2.2 Предпочтения основаны на «мыслях», которые могут быть связаны с исходами, действиями, планами, и т.д., но отличаются от всего этого
Оценщики Мыслей оценивают и сравнивают «мысли», т.е. конфигурации в генеративной модели мира агента. Модель мира неидеальна, полное понимание мира слишком сложно, чтобы поместиться в любом мозгу или кремниевом чипе. Так что «мысль» неизбежно подразумевает обращение внимания на одно и игнорирование другого, коцептуализацию вещей определённым образом, приписывание их к ближайшим доступным категориям, даже если они не подходят идеально, и т.д.
Некоторые следствия:
- Вы можете концептуализировать одну и ту же последовательность моторных действий многими разными способами, и она будет более или менее привлекательна в зависимости от того, как вы о ней думаете: возьмём мысль «я собираюсь пойти в спортзал» и мысль «я собираюсь пойти в спортзал, чтобы накачаться». См. связанное обсуждение в (Мозговой ствол, Неокортекс) ≠ (Базовые Мотивации, Благородные Мотивации).
- Аналогично, вы можете концептуализировать одно и то же будущее состояние мира многими разными способами, например, обращая внимание на разные его аспекты, и оно будет казаться более или менее привлекательным. Это может приводить к циклическим предпочтениям; я поместил пример в сноску[1].
- Мысль может затрагивать немедленные действия, будущие действия, семантический контекст, ожидания, что произойдёт, пока мы будем что-то делать, ожидания, что произойдёт в результате, и т.д. Так что мы можем иметь «консеквенциалистские» предпочтения о будущих состояниях или «деонтологические» предпочтения о действиях, и т.д. К примеру, мысль «Я сейчас пойду в магазин, и у меня будет молоко» включает нейроны, связанные с действием «Я сейчас пойду в магазин», и нейроны, связанные с последствием «У меня будет молоко»; Оценщики Мыслей и Направляющая Подсистема могут одобрить или отвергнуть мысль, основываясь на чём угодно из этого. См. Консеквенциализм & Исправимость за развитием темы.
- Ничто из этого не подразумевает, что подобный-мозгу СИИ не может приближаться к идеальному консеквенциалистскому максимизатору полезности! Только что это будет свойством конкретной обученной модели, а не неотъемлемым качеством исходного кода СИИ. К примеру, подобный-мозгу СИИ может прочитать Цепочки (как и человек), и усвоить уроки из них как набор выученных метакогнитивных эвристик, отлавливающих и исправляющих ошибочные интуитивные заключения и мыслительные привычки, вредящие эффективности[2] (как и человек), и СИИ на самом деле может сделать это по тем же причинам, что и читающий Цепочки человек, ~~то есть, чтобы пройти тридцатичасовую ритуальную дедовщину и заслужить членство в группе~~[3] то есть, потому что он хочет ясно мыслить и достигать своих целей.
9.2.3 Инструментальные и терминальные предпочтения, судя по всему, смешаны вместе
Есть интуитивный смысл, в котором у нас есть инструментальные предпочтения (то, что мы предпочитаем, потому что это было полезно в прошлом как средство для достижения цели – например, я предпочитаю носить часы, потому что они помогают мне узнавать который час) и терминальные предпочтения (то, что мы предпочитаем само по себе – например, я предпочитаю чувствовать себя хорошо и предпочитаю не быть загрызенным медведем). Спенсер Гринберг проводил исследование, в котором некоторые, но не все участники описывали «существование красивых вещей в мире» как терминальную цель – их волновало, чтобы красивые вещи были, даже если они расположены глубоко под землёй, где никакое осознающее себя существо их никогда не увидит. Вы согласны или не согласны? Для меня самое интересное тут, что некоторые люди ответят: «Я не знаю, никогда раньше об этом не думал, хммм, дайте секундочку подумать.» Я думаю, из этого можно извлечь урок!
Конкретно: мне кажется, что глубоко в алгоритмах мозга нет различия между инструментальными и терминальными предпочтениями. Если вы думаете мысль, и ваша Направляющая Подсистема одобряет её как высокоценную, то, я думаю, вычисление одинаково в случае, когда она высокоценная по инструментальным или терминальным причинам.
Мне надо прояснить: Вы можете делать инструментальные вещи без того, чтобы они были инструментальными предпочтениями. К примеру, когда я впервые получил смартфон, я иногда вытаскивал его у себя из кармана, чтобы проверить Твиттер. В то время у меня не было самого по себе предпочтения вытаскивания телефона из кармана. Вместо этого я думал мысль вроде «я сейчас вытащу телефон из кармана и проверю Твиттер». Направляющая Подсистема одобряла это как высокоценную мысль, но только из-за второй части мысли, про Твиттер.
Потом, через некоторое время, «присвоение ценности» (следующий раздел) сделало свой фокус и поместило в мой мозг новое предпочтение, предпочтение просто доставать телефон из моего кармана. После этого я стал вытаскивать телефон из кармана без малейшей идеи, почему. И вот теперь это «инструментальное предпочтение».
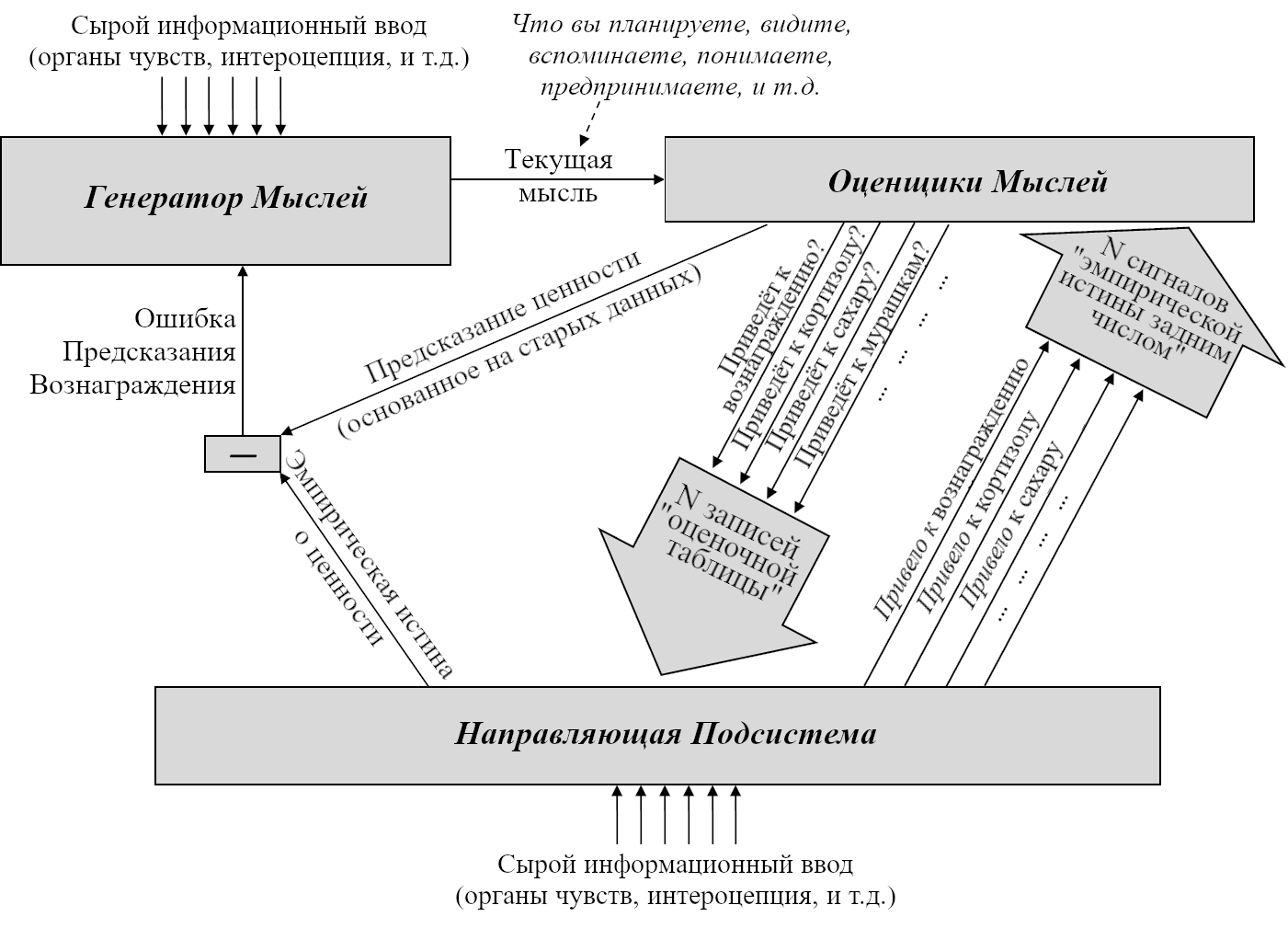
Формирование привычек – это процесс, в котором присвоение ценности превращает инструментальное *поведение* в инструментальное *предпочтение*.
(Замечу: Только то, что инструментальные и терминальные предпочтения смешаны в человеческом мозгу, не означает, что они обязаны быть смешаны в подобных-мозгу СИИ. К примеру, я могу приблизительно представить некую систему, помечающую концепты положительной валентности некими объяснениями, почему они стали иметь положительную валентность. В примере выше, может быть, что мы могли бы провести пунктирную линию от некоего внутреннего стремления к концепту «Твиттер», а затем от концепта «Твиттер» к концепту «достать телефон из кармана». Я предполагаю, что эти линии не задействовались бы в операциях, проводимых СИИ, но их было бы здорово иметь в целях интерпретируемости. Для ясности, я не знаю, работало бы это или нет, просто накидываю идеи.)
9.3 «Присвоение ценности» – как скрытые переменные окрашиваются валентностью
9.3.1 Что такое «присвоение ценности»?
Я представил идею «присвоения ценности» в Посте №7 (Раздел 7.4), и предлагаю перечитать его сейчас, чтобы у вас в голове был конкретный пример. Вспомните эту диаграмму:
Скопировано из Поста №7, см. контекст там.
Напоминание, у мозга есть «Оценщики Мыслей» (Посты №5 и №6), работающие методом обучения с учителем (с управляющими сигналами из Направляющей Подсистемы). Их роль – переводить скрытые переменные (концепты) модели мира («картины», «налоги», «процветание», и т.д.) в параметры, которые может понять Направляющая Подсистема (боль в руке, уровень сахара в крови, гримасничанье, и т.д.). К примеру, когда я съедаю кусок торта в Посте №7, концепт модели мира («я ем торт») прикрепляется к генетически-осмысленным переменным (сладкий вкус, вознаграждение, и т.д.).
Я называю этот процесс «присвоением ценности» – в том смысле, что абстрактный концепт «я ем торт» приобретает ценность за сладкий вкус.
Кадж Сотала написал несколько поэтическое описание того, что я называю присвоением ценности тут:
Ментальные репрезентации … наполняются чувствительным к контексту притягательным блеском.
Я представляю себе аккуратную кисточку, наносящую положительную валентность на мой ментальный концепт торта «Принцесса». Кроме цвета «валентности» на палитре есть и другие цвета, ассоциированные с другими внутренними реакциями.
Мне иногда нравится визуализировать присвоение ценностей как что-то вроде «раскрашивания» скрытых переменных в предсказательной модели мира ассоциациями с вознаграждением и другими внутренними реакциями.
Присвоение ценности может работать забавным образом. Лиза Фельдман Барретт рассказывала историю как однажды она была на свидании, чувствовала бабочек в животе и думала, что нашла Настоящую Любовь – только чтобы вечером слечь с гриппом! Аналогично, если я приятно удивлён тем, что выиграл соревнование, мой мозг может «присвоить ценность» моей тяжёлой работе и навыкам, а может – тому, что я надел свои счастливые трусы.
Я говорю «мой мозг присваивает ценность» вместо «я присваиваю ценность», потому что не хочу создавать впечатление, будто это какой-то мой произвольный выбор. Присвоение ценности – глупый алгоритм в мозгу. Кстати о нём:
9.3.2 Как работает присвоение ценности? – короткий ответ
Если присвоение ценности – глупый алгоритм в мозгу, какой конкретно это алгоритм?
Я думаю, по крайней мере в первом приближении, очевидный:
Ценность присваивается активной прямо сейчас мысли.
Это «очевидно» в том смысле, что Оценщики Мыслей используют обучение с учителем (см. Пост №4), а это то, что обучение с учителем делает по умолчанию. В конце концов, «контекстный» ввод Оценщика Мыслей описывает, какая мысль активна прямо сейчас, так что если мы сделаем обновление методом градиентного спуска (или что-то функционально на него похожее), то мы получим именно такой «очевидный» алгоритм.
9.3.3 Как работает присвоение ценности? – мелкий шрифт
Я думаю, стоит немного больше поисследовать эту тему, потому что присвоение ценности играет ключевую роль в безопасности СИИ – в конце концов, это то, из-за чего подобный-мозгу СИИ будет хотеть одни штуки больше, чем другие. Так что я перечислю некоторые отдельные мысли о том, как, по моему мнению, это работает у людей.
1. У присвоения ценности могут быть «априорные суждения» о том, что будет ассоциироваться с концептами того или иного вида:
Напомню, в Постах №4-№5 говорилось, что каждый Оценщик Мыслей обладает своими собственными «контекстными» сигналами, служащими вводом его предсказательной модели. Представьте, что некий конкретный Оценщик Мыслей получает контекстные данные, например, только из зрительной коры. Он будет вынужден «присваивать ценность» в первую очередь визуальным паттернам из этой части нейронной архитектуры – так как он имеет стопроцентное «априорное суждение» о том, что только паттерны из визуальной коры вообще могут оказаться полезными для его предсказаний.
Мы можем наивно посчитать, что такие «априорные суждения» – всегда плохая идея: чем разнообразнее контекстные сигналы, получаемые Оценщиком Мыслей, тем лучше будет его предсказательная модель, верно? Зачем его ограничивать? Две причины. Во-первых, хорошее априорное суждение приведёт к более быстрому обучению. Во-вторых, Оценщики Мыслей – только один компонент большой системы. Нам не стоит принимать за данность, что более точные предсказатели Оценщика Мыслей обязательно полезны для всей системы.
Вот знаменитый пример из психологии: крысы могут легко научиться замирать в ответ на звук, предвещающий удар током, и научиться плохо себя чувствовать в ответ на вкус, предвещающий приступ тошноты. Но не наоборот! Это может демонстрировать, например, то свойство архитектуры мозга, что предсказывающий тошноту Оценщик Мыслей имеет контекст, связанный со вкусом (например, из островковой доли), но не связанный с зрением или слухом (например, из височной доли), а предсказывающий замирание Оценщик Мыслей – наоборот. (Вскоре будет больше о примере с тошнотой.)
2. Присвоение ценности очень чувствительно ко времени:
Выше я предположил «Ценность присваивается активной прямо сейчас мысли». Но я не сказал, что значит «прямо сейчас».
Пример: Предположим, я прогуливаюсь по улице, думая о сериале, который я смотрел прошлым вечером. Внезапно, я чувствую острую боль в спине – меня кто-то ударил. Почти что немедленно в моём мозгу происходит две вещи:
- Мои мысли и внимание обращаются к этой новой боли в спине (возможно, с появлением некой генеративной модели того, что её вызвало),
- Мой мозг исполняет «присвоение ценности», и некоторые концепты в моей модели мира становятся внутренне ассоциированы с новым ощущением боли.
Фокус в том, что мы хотим, чтобы (1) произошло до (2) – иначе я заимею внутреннее ожидание боли в спине каждый раз, когда буду думать о том сериале.
Я думаю, что мозг в состоянии обеспечить, чтобы (1) происходило до (2), по крайней мере в основном. (Я всё же могу получить немного обманчивых ассоциаций с сериалом.)[4]
3. …И эта чувствительность ко времени может взаимодействовать с «априорными суждениями»!
Условное Отторжение Вкуса (CTA) – явление, заключающееся в том, что если меня затошнит сейчас, то это вызовет отторжение к вкусу, который я ощущал пару часов назад – не пару секунд, не пару дней, именно пару часов. (Я обращался к CTA выше, но не к временному аспекту.) Эволюционная причина очевидна: пара часов – это типичное время, через которое токсичная еда вызывает тошноту. Но как это работает?
Островковая кора – место обитания нейронов, формирующих генеративную модель вкусовых сенсорных вводов. Согласно «Молекулярным механизмам в основе вкусового следа в памяти для ассоциаций в островковой коре» Адайккана и Розенблума (2015), у этих нейронов есть молекулярные механизмы, устанавливающие их в специальное помеченное состояние на несколько часов после активации.
Так что предложенное мной выше правило («Ценность присваивается активной прямо сейчас мысли») надо модифицировать: «Ценность присваивается нейронам, прямо сейчас находящимся в специальном помеченном состоянии».
4. Присвоение ценности работает по принципу «Кто успел, того и тапки»:
Если уже найден способ точно предсказывать некоторый набор управляющих сигналов, это отключает соответствующий сигнал об ошибке, так что мы прекращаем присваивать ценность в таких ситуациях. Я думаю, первая обнаруженная мозгом хорошая предсказательная модель по умолчанию «застревает». Я думаю, с этим связано блокирование в поведенческой психологии.
5. Генератор Мыслей не имеет прямого произвольного контроля над присвоением ценности, но, вероятно, всё же может как-то им манипулировать.
В некотором смысле Генератор Мыслей и Оценщики Мыслей противостоят друг другу, т.е. работают на разные цели. В частности, они обучены оптимизировать разные сигналы.[5] К примеру, однажды мой начальник на меня орал, и я очень сильно не хотел начать плакать, но мои Оценщики Мыслей оценили, что это было подходящее время, так что я заплакал![6] С учётом этих отношений противостояния, я сильно подозреваю, что Генератор Мыслей не имеет прямого («произвольного») контроля над присвоением ценности. Интроспекция, кажется, это подтверждает.
С другой стороны, «нет прямого произвольного контроля» – несколько не то же самое, что «никакого контроля». Опять же, у меня нет прямого произвольного контроля над плачем, но я всё же могу вызвать слёзы, по крайней мере немного, обходной стратегией представления маленьких котят, замерзающих под холодным дождём (Пост №6, Раздел 6.3.3).
Итак, предположим, что я сейчас ненавижу X, но хочу, чтобы мне нравилось X. Мне кажется, что эта задача не решается напрямую, но не кажется и что она невыполнима. Это может потребовать некоторого навыка рефлексии, осознанности, планирования, и так далее, но если Генератор Мыслей подумает правильные мысли в правильное время, то он, вероятно, сможет с этим справиться.
И для СИИ это может быть проще, чем для человека! В конце концов, в отличии от людей, СИИ может быть способен буквально взломать свои собственные Оценщики Мыслей и настроить их по своему желанию. И это приводит нас к следующей теме…
9.4 Вайрхединг: возможен, но не неизбежен
9.4.1 Что такое вайрхединг?
Концепт «вайрхединга» получил название от идеи запихнуть провод («wire») в некоторую часть своего мозга и пустить ток. Если сделать это правильно, то это будет напрямую вызывать экстатическое удовольствие, глубокое удовлетворение, или другие приятные ощущения, в зависимости от части мозга. Вайрхединг может быть куда более простым способом вызывать эти ощущения, в сравнении с, ну знаете, нахождением Истинной Любви, приготовлением идеального суфле, зарабатыванием уважения героя своего детства, и так далее.
В классическом вызывающем кошмары эксперименте с вайрхедингом (см. «Симуляция Вознаграждения в Мозгу»), провод в мозгу крысы активировался, когда крыса нажимала на рычаг. Крыса нажимала на него снова и снова, не останавливаясь на еду, питьё и отдых, 24 часа подряд, пока не потеряла сознание от усталости. (ссылка)
Концепт вайрхединга можно перенести на ИИ. Идея тут в том, что агент обучения с подкреплением спроектирован для максимизации своего вознаграждения. Так что, может быть, он взломает свою собственную оперативную память и перепишет значение «вознаграждения» на бесконечность! Дальше я поговорю о том, вероятно ли это, и о том, насколько это должно нас беспокоить.
9.4.2 Захочет ли подобный-мозгу СИИ завайрхедиться?
Ну, для начала, ходят ли люди завайрхедиться? Нужно провести различие двух вариантов:
- Слабое стремление к вайрхедингу: «Я хочу получать более высокий сигнал вознаграждения в своём мозгу при прочих равных.»
- Сильное стремление к вайрхедингу: «Я хочу получать более высокий сигнал вознаграждения в своём мозгу – и я сделаю что угодно, чтобы его получить.»
В случае людей, может, мы можем приравнять стремление к вайрхедингу с «желанием получать удовольствие», т.е. с гедонизмом.[7] Если так, то получается, что (почти) все люди имеют «слабое стремление к вайрхедингу», но не «сильное стремление к вайрхедингу». Мы хотим получать удовольствие, но обычно нас хоть немного волнуют и другие вещи.
Как так получается? Ну, подумайте о предыдущих двух разделах. Чтобы человек хотел вознаграждения, он, во-первых, должен иметь концепт вознаграждения в своей модели мира, и, во-вторых, присвоение ценности должно пометить этот концепт как «хороший». (Я использую термин «концепт вознаграждения» в широком смысле, включающем и концепт «удовольствия».[7])
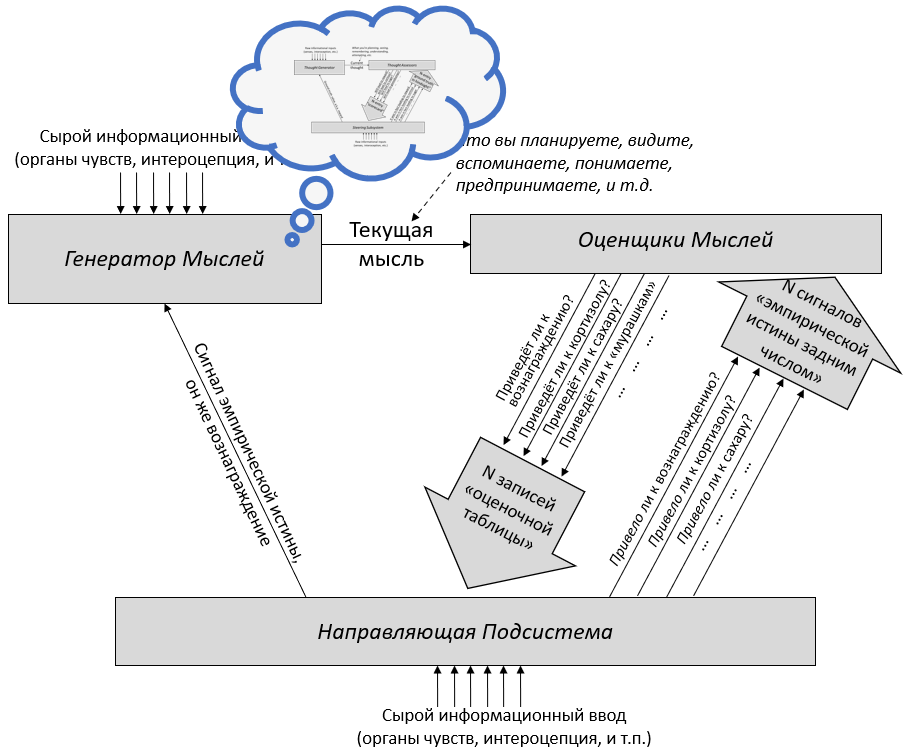
СИИ (или человек) может обладать саморефлексивными концептами, и, следовательно, может быть мотивирован на изменение своих внутренних настроек и операций.
С учётом этого и заметок про присвоение ценности в Разделе 9.3, я считаю:
- Избежать сильного стремления к вайрхедингу – тривиальная и автоматически выполняемая задача; она просто требует, чтобы присвоение ценности хотя бы раз назначило позитивную валентность чему угодно кроме концепта вознаграждения / удовольствия.
- Избежать слабого стремления к вайрхедингу кажется довольно сложным. Может, мы можем минимизировать его, используя чувствительность к времени и априорные суждения (Раздел 9.3.3 выше), но полное его избегание, думаю, потребует специальных техник – я приблизительно представляю это как использование какой-то техники интерпретируемости, чтобы обнаружить в модели мира концепт вознаграждения / удовольствия и напрямую отключить его от Оценщиков Мыслей, или что-то вроде этого.
(Есть ещё возможность, что слабый-вайрхедер самомодифицируется, чтобы стать сильным-вайрхедером; больше про такие вещи в следующем посте.)
9.4.3 Завайрхедившиеся СИИ были бы опасны, не просто бесполезны
Есть опасное интуитивное заключение, в которое попадаются многие: Когда мы представляем завайрхедившийся СИИ, мы сравниваем его с человеком в состоянии глубокого опьянения рекреационными наркотиками. Такой человек точно не занимается методичным составлением, проверкой и исполнением гениального коварного плана по захвату мира. Скорее, он просто получает удовольствие с закрытыми глазами, или, может, танцует, или что-то такое, зависит от наркотика. Так что интуиция предполагает, что вайрхединг – проблема способностей, а не фактор риска катастрофических происшествий.
Я думаю, что тут есть зерно истины: как обсуждалось в Постах №6-№7, сигналы вознаграждения / ценности управляют мышлением и планированием, так что если вознаграждения застревает на высоком положительном значении, то мышление и планирование становятся невозможными.
Но неправильно выводить из этого, что вархединг не представляет риска катастрофических происшествий.[8] Рассмотрим, что происходит до того, как СИИ начинает вайрхедиться. Если он составит план «я завайрхежусь», то эта мысль, вероятно, получит высокую оценку Направляющей Подсистемы. Но если он подумает об этом побольше, то поймёт, что ожидания от этого плана должны быть «Я завайрхежусь на некоторое время, а потом люди меня отключат и исправят так, чтобы я больше не мог этого сделать». Теперь план не звучит так замечательно! Так что СИИ может составить план получше, включающий штуки вроде захвата контроля над локальным окружением и/или энергосетью и/или всем миром, и/или создание «ИИ-телохранителя», который делает всё это, пока СИИ вайрхедится, и т.д. Так что на самом деле я думаю, что вайрхединг несёт риски катастрофических происшествий, даже уровня человеческого вымирания, как я обсуждал в Посте №1.
9.5 СИИ НЕ судят о планах, основываясь на будущих вознаграждениях
Это напрямую вытекает из предыдущего раздела, но я хочу особо это подчеркнуть, так как «СИИ будут пытаться максимизировать будущее вознаграждение» – часто встречаемое заявление.
Если Генератор Мыслей предлагает план, то Оценщики Мыслей оценивают его вероятные последствия согласно своим нынешним моделям, и Направляющая Подсистема одобрит или отвергнет план в основном на этом основании. Эти нынешние модели не обязаны быть согласованными с «ожидаемым будущим вознаграждением».
Предсказательная модель мира Генератора Мыслей может даже «знать» о некотором расхождении между «ожидаемым будущим вознаграждением» и его прикидкой от Оценщика Мыслей. Это не имеет значения! Прикидки не поправят себя автоматически и всё ещё будут определять, какие планы будет исполнять СИИ.
9.5.1 Человеческий пример
Вот пример на людях. Я буду говорить про кокаин вместо вайрхединга. (Они не столь отличаются, но кокаин более знаком.)
Факт: я никогда не принимал кокаин. Предположим, что я сейчас думаю «может быть, я приму кокаин». Интеллектуально я уверен, что если я приму кокаин, то испытаю, эммм, много весьма интенсивных ощущений. Но внутренне представление того, как я принимаю кокаин ощущается в целом нейтрально! Оно не заставляет меня чувствовать ничего особенного.
Так что прямо сейчас мои интеллектуальные ожидания (того, что произойдёт, если я приму кокаин) не синхронизированы с моими внутренними ожиданиями. Очевидно, мои Оценщики Мыслей просматривают мысль «может, я приму кокаин» и коллективно пожимают плечами: «Ничего особенного!». Напомню, что Оценщики Мыслей работают через присвоение ценности (Раздел 9.3 выше), и, очевидно, алгоритм присвоения ценности не особо чувствителен ни к слухам о том, как ощущается приём кокаина, ни к чтению нейробиологических статей о том, как кокаин связывается с переносчиками дофамина.
Напротив, алгоритм присвоения ценности сильно чувствителен к прямому личному опыту интенсивных ощущений.
Поэтому люди могут заполучить зависимость от кокаина, принимая кокаин, но не могут – читая про кокаин.
9.5.2 Связь с «агентами наблюдаемой полезности»
Для более теоретического подхода, вот Абрам Демски (прошу прощения за жаргон – если вы не знаете, что такое AIXI, не беспокойтесь, скорее всего вы всё равно ухватите суть):
В качестве первого примера, рассмотрим проблему вайрхединга для AIXI-подобных агентов в случае фиксированной функции полезности, для которой известно, как её оценивать исходя из сенсорных данных. Как обсуждается в Обучаясь, Что Ценить Дэниэла Дьюи и в других местах, если вы попробуете реализовать это, запихнув вычисление полезности в коробку, выдающую вознаграждение AIXI-подобному агенту обучения с подкреплением, то агент рано или поздно обучится модификации или удалению коробки, и с радостью это сделает, так как сможет таким образом получить большее вознаграждение. Это так, потому что агент обучения с подкреплением предсказывает и пытается максимизировать получаемое вознаграждение. Если он понимает, что он может модифицировать выдающую вознаграждение коробку, чтобы получить больше, он так и сделает.
Мы можем исправить эту проблему, встроив в агента ту же коробку способом получше. Вместо того, чтобы агент обучения с подкреплением обучался выводу коробки и составлял планы для его максимизации, мы можем использовать коробку, чтобы *напрямую* оценивать возможные варианты будущего, и заставить агента планировать для максимизации этой оценки. Теперь, если агент рассматривает возможность модификации коробки, то он оценивает такое будущее *при помощи нынешней коробки*. А она не видит выгоды в такой модификации. Такая система называется максимизатором наблюдаемой полезности (для проведения различия от обучения с подкреплением)…
Это похоже на различие цитаты/референта. Агент обучения с подкреплением максимизирует «функцию в модуле полезности», а агент наблюдаемой полезности максимизирует функцию в модуле полезности.
Наш подобный-мозгу СИИ, хоть он и RL[9], на самом деле ближе к парадигме наблюдаемой полезности: Оценщики Мыслей и Направляющая Подсистема вместе работают для оценивания планов / курсов действия, прямо как «коробка» Абрама.
Однако, у подобного-мозгу СИИ есть ещё дополнительная черта, заключающаяся в том, что Оценщики Мыслей постепенно обновляются «присвоением ценности» (Раздел 9.3 выше).
Так что у нас получается примерно что-то такое:
- Максимизирующий полезность агент
- …плюс процесс, периодически обновляющий функцию полезности и склонный приближать её к функции вознаграждения.
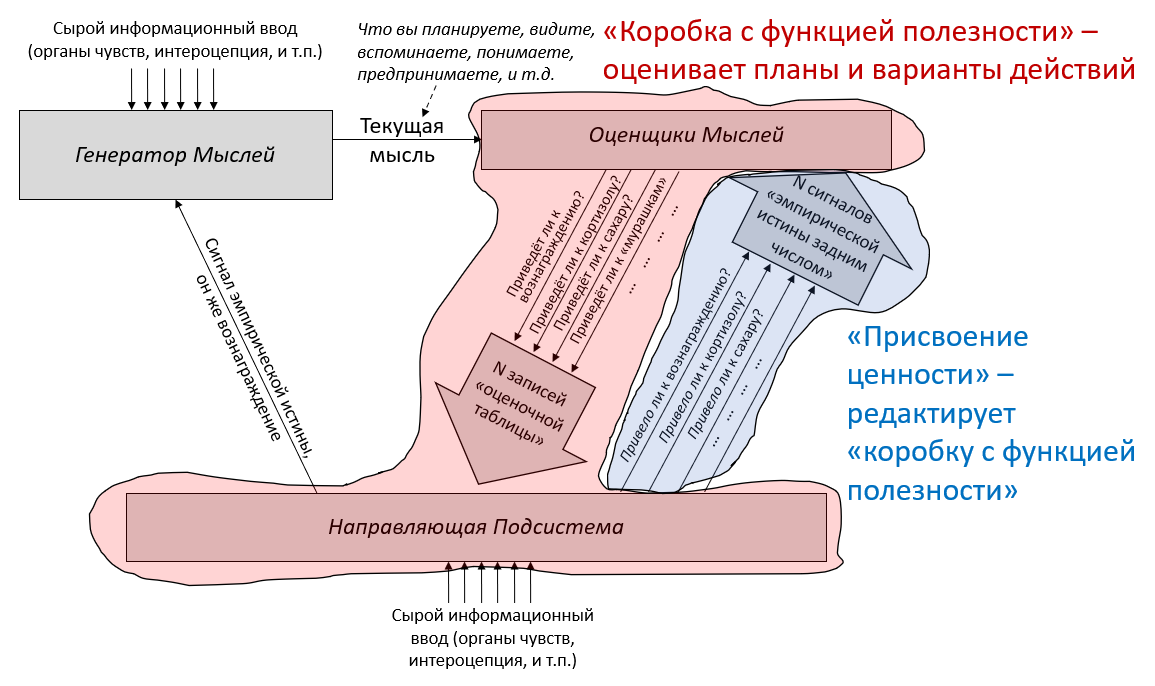
Эта диаграмма показывает, как наша картина мотивации подобного-мозгу СИИ встраивается в парадигму «агента наблюдаемой полезности», описанную в тексте.
Заметим, что мы не хотим, чтобы процесс присвоения ценности идеально «сходился» – т.е., достичь точки, в которой функция полезности будет идеально совпадать с функцией вознаграждения (или, в нашей терминологии, достичь точки, в которой Оценщики Мыслей больше никогда не будут обновляться, потому что они всегда оценивают планы идеально соответствуя Направляющей Подсистеме).
Почему мы не хотим идеальной сходимости? Потому что идеальная сходимость приведёт к вайрхедингу! А вайрхединг плох и опасен! (Раздел 9.4.3 выше) Но в то же время, нам нужна какая-то сходимость, потому что функция вознаграждения предназначена для оформления целей СИИ! (Напомню, Оценщики Мыслей изначально работают случайным образом и совершенно бесполезны.) Это Уловка-22! Я вернусь к этой теме в следующем посте.
(Проницательные читатели могут заметить ещё и другую проблему: максимизатор полезности может попробовать сохранить свои цели, мешая процессу присвоения ценности. В следующем посте я поговорю и про это.)
9.6 Оценщики Мыслей помогают интерпретируемости
Вот, ещё раз, диаграмма из Поста №6:
То же, что и выше, скопировано из Поста №6
Где-то сверху справа есть маленький обучающийся с учителем модуль, отвечающий на вопрос: «С учётом всего, что я знаю, включая не только сенсорный ввод и память, но ещё и курс действий, подразумеваемый моей текущей мыслью, насколько я предчувствую попробовать что-то сладкое?» Как описано раньше (Пост №6), этот Оценщик Мыслей играет двоякую роль (1) вызова подходящих действий гомеостаза (например, слюновыделения), и (2) помощи Направляющей Подсистеме понять, является ли текущая мысль ценной, или же это мусор, который надо выкинуть на следующей паузе фазового дофамина.
Сейчас я хочу предложить третий способ думать о том же самом.
Уже давно, в Посте №3, я упоминал, что Направляющая Подсистема «глупая». У неё нет здравого смысла в понимании мира. Обучающаяся Подсистема думает все эти сумасшедшие мысли о картинах, алгебре и налоговом законодательстве, а Направляющая Подсистема понятия не имеет, что происходит.
Что ж, Оценщики Мыслей помогают с этой проблемой! Они дают Направляющей Подсистеме набор подсказок о том, что думает и планирует Обучающаяся Подсистема, на языке, который Направляющая Подсистема может понять. Это немного похоже на интерпретируемость нейросетей.
Я называю это «суррогат интерпретируемости». Думаю, настоящая интерпретируемость должна быть определена как «возможность посмотреть на любую часть обучившейся с чистого листа модели и ясно понять, что, как и почему там происходит». Суррогат интерпретируемости далёк от этого. Мы получаем ответы на некоторое количество заранее определённых вопросов – например, «Касается ли эта мысль еды или, хотя бы, чего-то, что раньше ассоциировалось с едой?». И всё. Но это уже лучше, чем ничего.
| Машинное обучение | Мозг |
| Человек-исследователь | Направляющая Подсистема (см. Пост №3) |
| Обученная модель ConvNet | Обучающаяся Подсистема (см. Пост №3) |
| По умолчанию, с точки зрения человека, обученная модель – ужасно сложная свалка неразмеченных непонятных операций | По умолчанию, с точки зрения Направляющей Подсистемы, Обучающаяся Подсистема – ужасно сложная свалка неразмеченных непонятных операций |
| Суррогат интерпретируемости – Человек получает некоторые «намёки» на то, что делает обученная модель, вроде «прямо сейчас она думает, есть ли на изображении кривая». | Оценщики Мыслей – Направляющая Подсистема получает некоторые «намёки» на то, что происходит в Обучающейся Подсистеме, вроде «эта мысль скорее всего касается еды или хотя бы чего-то связанного с едой». |
| Настоящая интерпретируемость – конечная цель настоящего понимания, что, почему и как делает обученная модель, сверху донизу | [Аналогии этому нет.] |
Эта идея будет важна в более поздних постах.
(Замечу, что что-то подобное можно делать с любым агентом обучения с подкреплением субъект-критик, подобным-мозгу или нет, с помощью многомерной функции ценности, возможно включающей «псевдо» ценности, используемые только для мониторинга; см. здесь и комментарии здесь.)
9.6.1 Отслеживание, какие «встроенные стремления» на самом деле ответственны за высокую ценность плана
В Посте №3 я говорил о том, что у мозга есть множество разных «встроенных стремлений», включающих стремление к удовлетворению любопытства, стремление есть, когда голоден, стремление избегать боли, стремление к высокому статусу, и так далее. Подобные-мозгу СИИ, предположительно будут тоже обладать множеством разных стремлений. Я не знаю точно, какими, но приблизительно представляю что-то вроде любопытства, стремления к альтруизму, стремлению следовать нормам, стремлению делать-то-что-люди-от-меня-хотят, и так далее. (Больше про это в будущих постах.)
Если все эти разные стремления вкладываются в общее вознаграждение, то мы можем и должны иметь Оценщики Мыслей для вклада каждого.
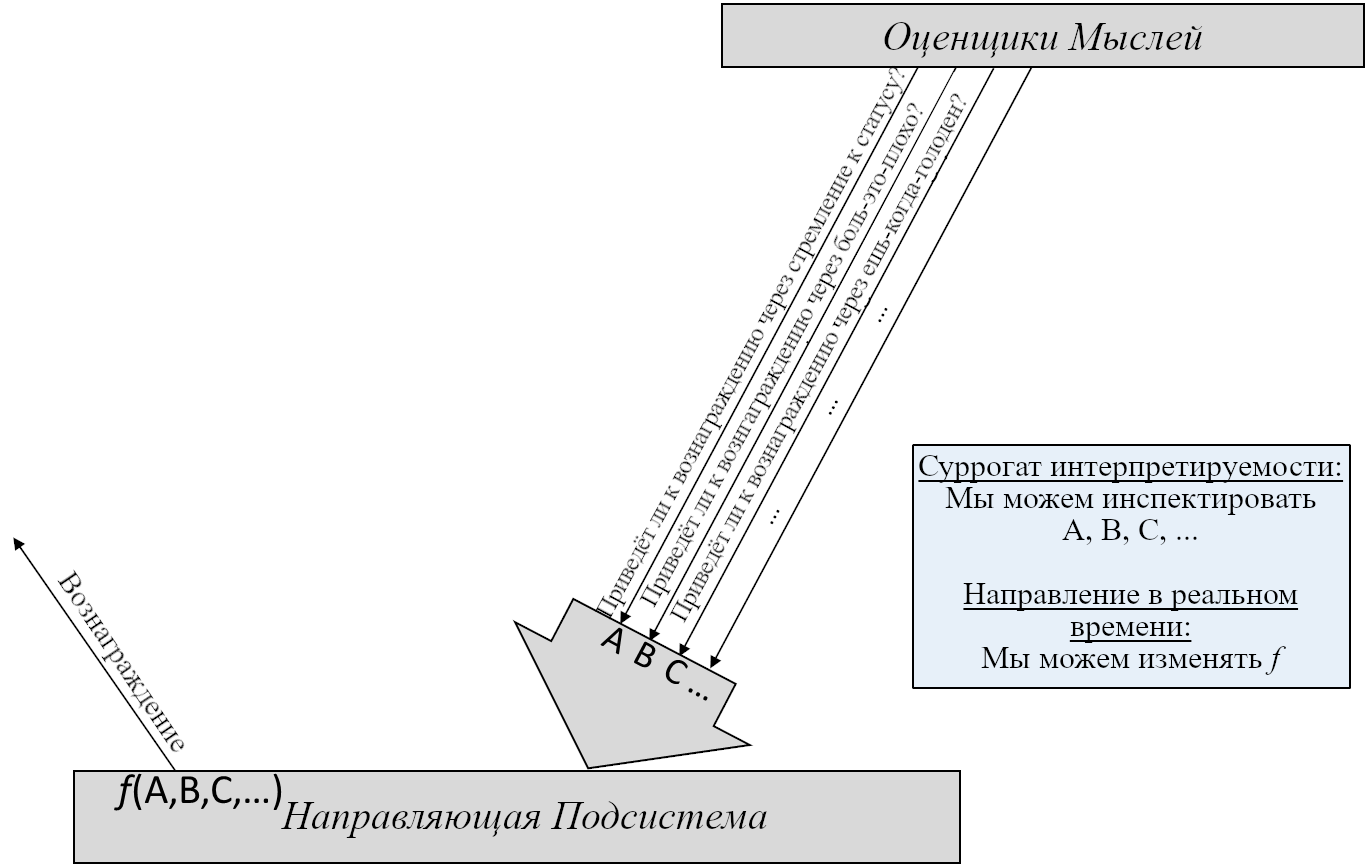
Раз функция вознаграждения может быть разделена на разные составляющие, мы можем и должны отслеживать каждое отдельным Оценщиком Мыслей. (Могут быть так же и другие, не связанные с вознаграждением, Оценщики Мыслей) У этого есть два преимущества. «Суррогат интерпретируемости» (этот раздел) означает, что если мысль обладает высокой ценностью, то мы можем проинспектировать Оценщики Мыслей, чтобы получить намёк, почему. «Направление в реальном времени» (следующий раздел) означает, что мы можем мгновенно изменить долгосрочные планы и цели СИИ, изменив функцию вознаграждения *f*. Эксперты в обучении с подкреплением распознают, что оба этих концепта применимы к любым системам обучения с подкреплением, совместимым с многомерными функциями ценности, в каком случае *f* часто называется «функцией скаляризации» – см. здесь и комментарии здесь.
Как обсуждалось в предыдущих постах, каждый раз, когда подобный-мозгу СИИ думает мысль, это вызвано тем, что эта мысль более вознаграждающая, чем альтернативные. И благодаря суррогату интерпретируемости, мы можем инспектировать систему и немедленно узнать, какие встроенные стремления вкладываются в это!
Ещё лучше, это работает, даже если мы не понимаем, о чём мысль вообще, и даже если предсказывающая вознаграждение часть мысли на много шагов отстоит от прямых эффектов на встроенные стремления. К примеру, может быть, эта мысль вознаграждающая потому, что она исполняет некую метакогнитивную стратегию, доказанно полезную для брейншторминга, который доказанно полезен для доказательства теорем, которое доказанно полезно для отладки кода, и так далее, пока через ещё десять связей мы не дойдём до одного из встроенных стремлений.
9.6.2 Надёжен ли суррогат интерпретируемости даже для очень мощных СИИ?
Если у нас есть очень мощный СИИ, и он выдаёт план, и система «суррогата интерпретируемости» заявляет «этот план почти точно не приведёт к нарушению человеческих норм», то можем ли мы ей верить? Хороший вопрос! Он оказывается по сути эквивалентным вопросу «внутреннего согласования», которое я рассмотрю в следующем посте. Придержите эту мысль.
9.7 «Направление в реальном времени»: Направляющая Подсистема может перенаправлять Обучающуюся Подсистему – включая её глубочайшие желания и долгосрочные цели – в реальном времени
В случае агентов безмодельного обучения с подкреплением, играющих в игры на Atari, если вы измените функцию вознаграждения, поведение агента изменится очень постепенно. А вот приятная черта систем мотивации наших подобных-мозгу СИИ – что мы можем немедленно изменить не только поведение агента, но и его очень долгосрочные планы и глубочайшие мотивации и желания!
Как это работает: как описано выше (Раздел 9.6.1), у нас может быть много Оценщиков Мыслей, вкладывающихся в функцию вознаграждения. К примеру, один может оценивать, приведёт ли нынешняя мысль к удовлетворению стремления к любопытству, другая – стремления к альтруизму, и т.д. Направляющая Подсистема комбинирует эти оценки в общее вознаграждение. Но функция, которую она для этого использует, жёстко закодирована и понятна людям – она может быть такой простой, как, к примеру, взвешенное среднее. Следовательно, мы можем изменить эту функцию в Направляющей Подсистеме в реальном времени, как только захотим – в случае взвешенного среднего мы можем изменить веса.
Мы видели пример в Посте №7: Когда вас очень тошнит, не только поедание торта становится неприятным – несколько отталкивающим становится даже планирование поедания торта. Чёрт, даже абстрактный концепт торта становится немного отталкивающим!
И, конечно, у нас у всех были случаи, когда мы устали, грустим или злимся, и вдруг все наши самые глубокие жизненные цели теряют свою привлекательность.
Когда вы водите машину, критически важное требование безопасности – что, когда вы поворачиваете руль, колёса реагируют немедленно. Точно также, я ожидаю, что критически важным требованием безопасности будет возможность для людей мгновенно изменить глубочайшие желания СИИ по нажатию соответствующей кнопки. Так что я думаю, что это замечательное свойство, и я рад, что оно есть, даже если я не на 100% уверен, что в точности с ним делать. (В случае машины вы видите, куда едете, а вот понять, что пытается сделать СИИ в данный конкретный момент – куда сложнее.)
(Опять же, как и в предыдущем разделе, идея «Направления в реальном времени» применима к любому алгоритму обучения с подкреплением «субъект-критик», не только к «подобным-мозгу». Всё что требуется – многомерное вознаграждение, которое обучает многомерную функцию ценности.)
———
- Вот правдоподобный случай циклических предпочтений у человека. Вы выиграли приз! У вас есть три варианта: (A) 5 красивых тарелок, (B) 5 красивых тарелок и 10 уродливых тарелок, (C) 5 нормальных тарелок.
Никто, насколько мне известно не проводил точно такого эксперимента, но правдоподобно (основываясь на похожей ситуации из главы 15 Думай медленно… решай быстро) это приведёт к циклическим предпочтениям по крайней мере у некоторых людей: Когда люди видят только A и B, они выбирают B, потому что «тут больше, я всегда могу придержать уродливые про запас или использовать их как мишени, или что-то ещё». Когда они видят B и C, то выбирают C, потому что «среднее качество выше». Когда видят C и A, то по той же причине выбирают A.
Получается, что есть два разных предпочтения: (1) «Я хочу более коллекцию более красивых штук, а не менее красивых», и (2) «Я хочу дополнительных бесплатных тарелок». Сравнение B с C или C с A выявляет (1), а сравнение A с B выявляет (2). - Вы можете подумать: «зачем вообще создавать СИИ с ошибочной интуицией как у человека»?? Ну, мы попытаемся так не делать, но готов поспорить, что по крайней мере некоторые человеческие «отклонения от рациональности» вырастают из того факта, что предсказательные модели мира – большие сложные штуки, и эффективное обращение с ними ограничено, так что наш СИИ будет иметь систематические ошибки рассуждений, которые мы не сможем исправить на уровне исходного кода, вместо этого придётся попросить наш СИИ прочитать Думай медленно… Решай быстро или что-то ещё. Штуки вроде искажения доступности, якорения и гиперболического обесценивания могут попадать в эту категорию. Для ясности, некоторые слабости человеческих рассуждений, вероятно, менее затронут СИИ; для примера, если мы создадим подобный-мозгу СИИ без встроенного стремления к достижению высокого статуса и сигнализированию членства в ингруппе, то, наверное, он будет избавлен от провалов, обсуждённых в посте Убеждение Как Одеяние.
- Шучу. На самом деле мне понравилось читать Цепочки.
- Я думаю, что на самом деле тут есть ещё много сложных факторов, которые я опускаю, включая протяжённое присвоение ценности при вызове воспоминаний, и другие, не связанные с присвоением ценностей, изменения в модели мира.
- Почему я говорю, что Генератор Мыслей и Оценщики Мыслей работают на разные цели? Вот как можно об этом думать: (1) Направляющая Подсистема и Оценщики Мыслей работают вместе на вычисление некоторой функции вознаграждения, которая (в окружении наших предков) аппроксимирует «ожидаемую совокупную генетическую приспособленность»; (2) Генератор Мыслей ищет мысли, максимизирующие эту функцию. Теперь, с учётом того, что Генератор Мыслей ищет способы заставить функцию вознаграждения возвращать очень высокие значения, получается, что Генератор Мыслей также ищет способы исказить вычисления Оценщиков Мыслей, чтобы функция вознаграждения перестала быть хорошим приближением «ожидаемой совокупной генетической приспособленности». Это ненамеренный и плохой побочный эффект (с точки зрения совокупной генетической приспособленности), и эта проблема может быть смягчена максимальным затруднением манипуляций настройками Оценщиков Мыслей для Генератора Мыслей. См. мой пост Вознаграждения Недостаточно за дальнейшим обсуждением.
- У истории счастливый конец: я нашёл другую работу с не-абьюзивным начальником, и приобрёл плодотворный побочный интерес понимания высокофункциональных психопатов.
- Я несколько сомневаюсь, что «желание получать удовольствие» в точности эквивалентно «желанию получать высокий сигнал вознаграждения». Может быть, это так, но я не совсем уверен.
- См. обсуждение в Суперинтеллекте, стр. 149.
- Думаю, когда Абрам в этой цитате использует термин «RL-агент», он предполагает, что агент создан не просто при помощи какого-то алгоритма RL, а более конкретно - алгоритма RL, который гарантированно сходится к уникальному «оптимальному» агенту, и который уже закончил это делать.
10. Задача согласования
- 1.10.1 Краткое содержание / Оглавление
- 2.10.2 Внешняя и Внутренняя (не)согласованность
- 3.10.3 Проблемы, затрагивающие и внутреннее, и внешнее согласование
- 4.10.4 Препятствия на пути к внешнему согласованию
- 5.10.5 Препятствия на пути к достижению внутренней согласованности
- 6.10.6 Проблемы с разделением на внешнее и внутреннее
Примечание переводчика - с момента перевода оригинальные посты несколько обновились, через некоторое время обновлю и перевод. На общие выводы цепочки это, вроде бы, не влияет.
10.1 Краткое содержание / Оглавление
В этом посте я рассмотрю задачу согласования подобных-мозгу СИИ – то есть, задачу создания СИИ, пытающегося делать именно то, что входит в намерения его создателей.
Задача согласования (я так считаю) – львиная доля задачи безопасности СИИ. Я не буду отстаивать это заявление здесь – то, как в точности безопасность СИИ связана с согласованием СИИ, включая крайние случаи, где они расходятся[1], будет рассмотрено подробно в следующем посте (№11).
Этот пост – про задачу согласования, не про её решение. Какие препятствия мешают её решить? Почему прямолинейных наивных подходов, судя по всему, недостаточно? Я поговорю о возможных подходах к решению потом, в следующих постах. (Спойлер: Никто, включая меня, не знает, как решить задачу согласования.)
Содержание
- В Разделе 10.2 я определю «внутреннюю согласованность» и «внешнюю согласованность» в контексте нашей системы мотивации подобного-мозгу СИИ. Немного упрощая:
- Если вы предпочитаете нейробиологическую терминологию: «Внешняя согласованность» означает обладание «встроенными стремлениями» (как в Посте №3, Разделе 3.4.2), чьи активации хорошо отображают то, насколько хорошо СИИ следует намерениям создателя. «Внутренняя согласованность» – это ситуация, в которой воображаемый план (построенный из концепций, т.е. скрытых переменных модели мира СИИ) обладает валентностями, верно отображающими активации встроенных стремлений, которые были бы вызваны исполнением этого плана.
- Если вы предпочитаете терминологию обучения с подкрепления: «Внешняя согласованность» означает, что функция вознаграждения выдаёт вознаграждение, соответствующее тому, что мы хотим. «Внутренняя согласованность» – это обладание функцией ценности, прикидывающей ценность плана соответственно вознаграждению, которое вызовет его исполнение.
- В Разделе 10.3 я поговорю о двух ключевых проблемах, которые делают согласование (и «внутреннее», и «внешнее») в целом сложным:
- Первая – это «Закон Гудхарта», из которого следует, что СИИ, чья мотивация хоть чуть-чуть отклоняется от наших намерений, всё же может привести к исходам, дико отличающимся от того, что мы хотели.
- Вторая – это «Инструментальная Конвергенция», заключающаяся в том, что самые разнообразные возможные мотивации СИИ – включая очевидные, кажущиеся доброкачественными мотивации вроде «Я хочу изобрести лучшую солнечную панель» – приведут к СИИ, пытающемуся сделать катастрофически-плохие вещи вроде выхода из-под человеческого контроля, самовоспроизводства, заполучения ресурсов и влияния, обманчивого поведения и убийства всех людей (как в Посте №1, Разделе 1.6).
- В Разделе 10.4 я рассмотрю два препятствия, преодоление которых необходимо для достижения «внешней согласованности»: во-первых, перевод наших намерений в машинный код, а во-вторых возможная установка вознаграждения за не в точности то поведение, которое мы в итоге хотим от СИИ, вроде удовлетворения его собственного любопытства (см. Пост №3, Раздел 3.4.3).
- В Разделе 10.5 я рассмотрю многочисленные препятствия, преодоление которых необходимо для достижения «внутренней согласованности», включая неоднозначность вознаграждения, «онтологические кризисы» и манипуляцию СИИ своим собственным процессом обучения.
- В Разделе 10.6 я рассмотрю некоторые причины, почему «внешнее согласование» и «внутреннее согласование», вероятно, не следует рассматривать как две отдельных задачи с двумя независимыми решениями. К примеру, интерпретируемость нейросетей помогла бы и там, и там.
10.2 Внешняя и Внутренняя (не)согласованность
10.2.1 Определение
Вот ещё раз рисунок из Поста №6, теперь ещё с добавлением полезной терминологии (синее) и маленьким зелёным лицом:
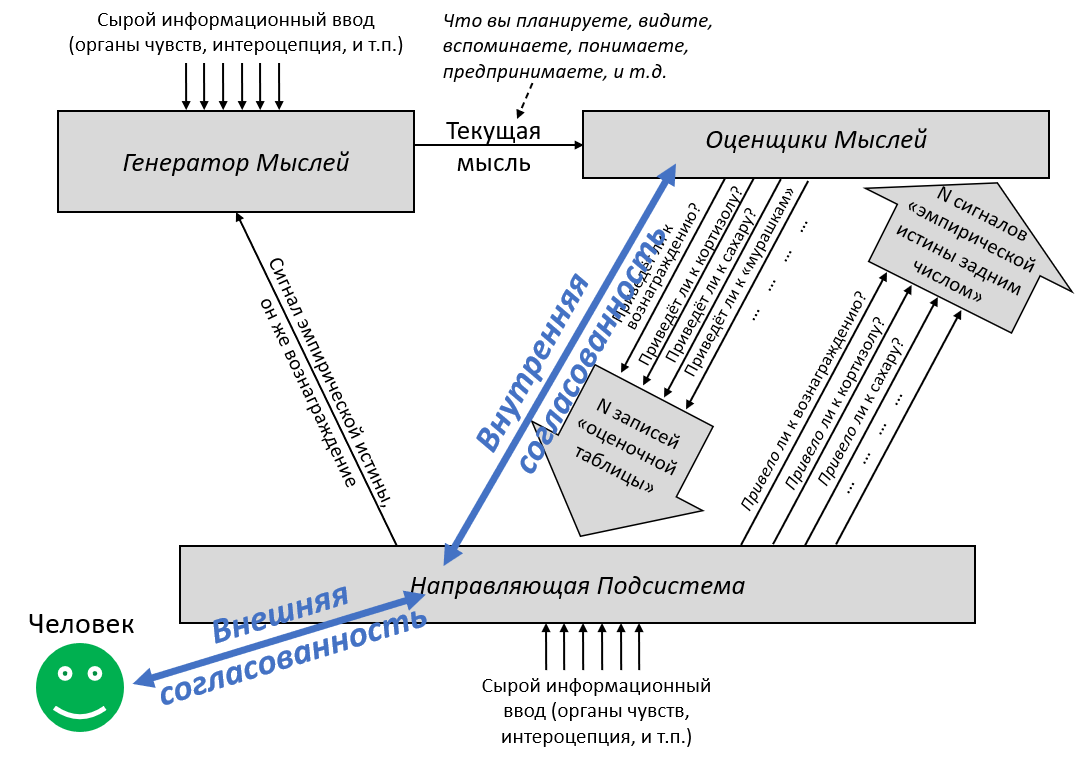
Я хочу упомянуть три штуки с этой диаграммы:
- Намерения создателя (зелёное лицо): Наверное, это человек, который программирует СИИ; предположительно, у него есть в голове какая-то идея о том, что СИИ должен пытаться делать. Это просто пример; это могла бы быть и команда людей, коллективно вырабатывающая спецификацию, описывающую, что должен пытаться делать СИИ. Или, может, кто-то написал семисотстраничный философский труд под заголовком «Что значит для СИИ действовать этично?», и команда программистов пытается создать СИИ, соответствующий описанию из книги. Тут это не имеет значения. Я для простоты выберу «одного человека, программирующего СИИ».[2]
- Написанный людьми исходный код Направляющей Подсистемы: (См. Пост №3 за тем, что такое Направляющая Подсистема, и Пост №8 за объяснением, почему я ожидаю, что она будет полностью или почти полностью состоять из написанного людьми исходного кода.) Самая важная составляющая в этой категории – это «функция вознаграждения» обучения с подкреплением (помеченная на диаграмме как «сигнал эмпирической истины», да, я знаю, это звучит странно), предоставляющая (задним числом) эмпирическую истину о том, насколько хорошо или плохо у СИИ идут дела.
- Оценщики Мыслей, обученные с нуля алгоритмами обучения с учителем: (См. Пост №5 за тем, что такое Оценщики Мыслей и как они обучаются.) Они принимают «мысль» из генератора мыслей и выдают догадки о том, к каким сигналам Направляющей Подсистемы она приведёт. Особенно важный частный случай – функция ценности (помеченная на диаграмме «приведёт к вознаграждению?»).
В таком СИИ есть два вытекающих вида «согласованности»:
- Внешняя согласованность – это соответствие намерений создателя и исходного кода Направляющей Подсистемы. В частности, если СИИ внешне согласован, то Направляющая Подсистема будет выдавать высокий сигнал вознаграждения, когда СИИ удовлетворяет намерениям создателя, и низкий, когда нет.
- Другими словами, это ответ на вопрос: Побуждают ли СИИ его «встроенные стремления» делать то, что входит в намерения его создателя?
- Внутренняя согласованность – это соответствие между исходным кодом Направляющей Подсистемы и Оценщиками Мыслей. В частности, если СИИ внутренне согласован и Генератор Мыслей предлагает некий план, то функция ценности должна верно отображать вознаграждение, к которому действительно приведёт исполнение этого плана.
- Другими словами, это ответ на вопрос: соответствует ли множество концептов положительной валентности в модели мира СИИ множеству курсов действий, которые бы удовлетворяли его «встроенные стремления»?
Если СИИ одновременно согласован внешне и внутренне, то мы получаем согласованность намерений – СИИ «пытается» сделать то, что программист намеревался, чтобы СИИ пытался сделать. Конкретнее, если СИИ приходит к плану «Хей, может, сделаю XYZ», то его Направляющая Подсистема оценит этот план как хороший (и оставит его) если и только если он подпадает под намерения программиста.
Следовательно, такой СИИ не будет умышленно вынашивать хитрый замысел по захвату мира и убийству всех людей. Если, конечно, его создатели не были маньяками, которые хотели, чтобы СИИ это делал! Но это отдельная проблема, не входящая в тему этой цепочки – см. Пост №1, Раздел 1.2.
(В сторону: не все определяют «согласованность» в точности как описано тут, см. сноску.[3])
К сожалению, ни «внешняя согласованность», ни «внутренняя согласованность» не получаются автоматически. Даже наоборот: по умолчанию и там и там есть серьёзные проблемы. Нам надо выяснить, как с ними разобраться. В этом посте я пройдусь по некоторым из этих проблем. (Замечу, что это не исчерпывающий список, и что некоторые из них могут перекрываться.)
10.2.2 Предупреждение: разное употребление терминов «внутренняя и внешняя согласованность»
Две альтернативные модели разработки подобного-мозгу СИИ. Диаграмма скопирована из Поста №8, см. обсуждение там.
Как упоминалось в Посте №8, есть две конкурирующие модели разработки, которая может привести нас к подобному-мозгу СИИ. Обе они могут обсуждаться в терминах внешней и внутренней согласованности, и обе могут быть проиллюстрированы на примере человеческого интеллекта, но детали в двух случаях отличаются! Вот короткая версия:
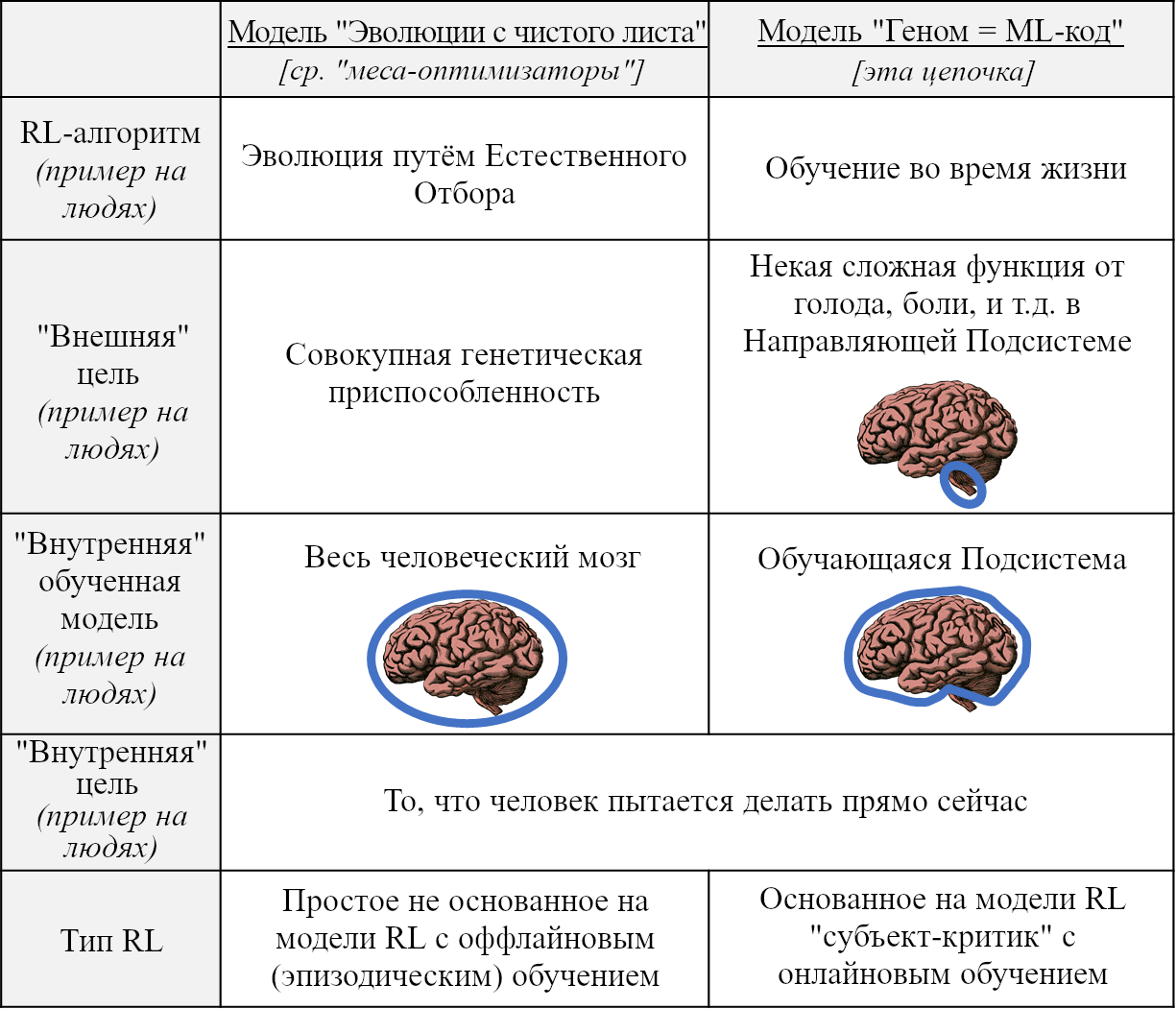
Две модели разработки СИИ выше предлагают две версии «внешней и внутренней согласованности». Запутывает ещё больше то, что они *обе* применимы к человеческому интеллекту, но проводят разные границы между «внешним» и «внутренним». Для более подробного описания «внешнего и внутреннего согласования» в этих двух моделях, см. статью Риски Выученной Оптимизации (для модели эволюции с чистого листа) и этот пост и цепочку (для модели геном = ML-код).
Терминологическое замечание: Термины «внутренняя согласованность» и «внешняя согласованность» произошли из модели «Эволюции с чистого листа», более конкретно – из статьи Риски Выученной Оптимизации (2019). Я перенял эту терминологию для обсуждения модели «геном = ML-код». Я думаю, что не зря – мне кажется, что у этих двух использований очень много общего, и что они больше похожи, чем различны. Но всё же, не запутайтесь! И ещё, имейте в виду, что моё употребление этих терминов не особо распространено, так что если вы увидите, что кто-то (кроме меня) говорит о «внутренней и внешней согласованности», то скорее всего можно предположить, что имеется в виду модель эволюции с чистого листа.
10.3 Проблемы, затрагивающие и внутреннее, и внешнее согласование
10.3.1 Закон Гудхарта
Закон Гудхарта (Википедия, видео Роба Майлза) гласит, что есть очень много разницы между:
- Оптимизировать в точности то, что мы хотим, и
- Шаг 1: формально описать, что мы в точности хотим, в виде осмысленно-звучащих метрик. Шаг 2: оптимизировать эти метрики.
Во втором случае, вы получите то, что покрыто этими метриками. С лихвой! Но вы получите это ценой всего остального, что вы цените!
Есть байка, что советская обувная фабрика оценивалась государством на основе количества пар обуви, которые она производила из ограниченного количества кожи. Естественно, она стала производить огромное количество маленькой детской обуви.

Художественный троп «Джинн-буквалист» можно рассматривать как пример Закона Гудхарта. То, что парень *на самом деле* хотел – сложная штука, а то, *о чём он попросил* (т.е., быть конкретного роста) – более конкретная метрика / формальное описание этого сложно устроенного и с трудом точно описываемого лежащего в основе желания. Джинн выдаёт решение, идеально соответствующее запросу по предложенной метрике, но идущее вразрез с более сложным изначальным желанием. (Источник картинки)
Аналогично, мы напишем исходный код, который каким-то образом формально описывает, какие мотивации мы хотим, чтобы были у СИИ. СИИ будет мотивирован в точности этим формальным описанием, как конечной целью, даже если то, что мы имели в виду на самом деле несколько отличается.
Нынешние наблюдения не обнадёживают: Закон Гудхарта проявляется в современных ИИ с тревожащей частотой. Кто-нибудь настраивает эволюционный поиск алгоритмов классификации изображений, а получает алгоритм атаки по времени, выясняющий, как подписаны изображения, из того, когда они были сохранены на жёстком диске. Кто-нибудь обучает ИИ играть в Тетрис, а он обучается вечно выживать, ставя игру на паузу. И так далее. См. здесь за ссылками и ещё десятками подобных примеров.
10.3.1.1 Понять намерения создателя ≠ Принять намерения создателя
Может, вы думаете: ОК, ладно, может, тупые современные ИИ-системы и подвержены Закону Гудхарта. Но футуристические СИИ завтрашнего дня будут достаточно умны, чтобы понять, что мы имели в виду, задавая его мотивации.
Мой ответ: Да, конечно, будут. Но вы задаёте не тот вопрос. СИИ может понять наши предполагаемые цели, не принимая их. Рассмотрим этот любопытный мысленный эксперимент:
Если бы к нам прилетели инопланетяне на НЛО и сказали бы, что они нас создали, но совершили ошибку, и на самом деле предполагалось, что мы будем есть своих детей, и они просят нас выстроится в шеренгу, чтобы они могли ввести нам функционирующий ген поедания детей, мы, вероятно, пошли бы устраивать им День Независимости. – Скотт Александер
(Предположим в целях эксперимента, что инопланетяне говорят правду и могут доказать это так, чтобы это не вызывало никаких сомнений.) Вот, инопланетяне сказали нам, что они предполагали в качестве наших целей, и мы поняли эти намерения, но не приняли их, начав радостно поедать своих собственных детей.
10.3.1.2 Почему бы не сделать СИИ, принимающий намерения создателя?
Возможно ли создать СИИ, который будет «делать то, что мы имеем в виду, и принимать наши подразумеваемые цели»? Ага, наверное. И очевидный способ это сделать – запрограммировать СИИ так, чтобы он был мотивирован «делать то, что мы имеем в виду, и принимать наши подразумеваемые цели».
К сожалению, этот манёвр не побеждает Закон Гудхарта – только перенаправляет его.
В конце концов, нам всё ещё надо написать исходный код, который, будучи интерпретирован буквально, приведёт нас к СИИ, мотивированному «делать то, что мы имеем в виду, и принимать наши подразумеваемые цели». Написание этого кода и близко не тривиально, и Закон Гудхарта не замедлит ударить по нам, если мы сделаем это неправильно.
(Заметим проблему курицы-и-яйца: если бы у нас уже был СИИ, мотивированный «делать то, что мы имеем в виду, и принимать наши подразумеваемые цели», то мы могли бы просто сказать «Хей, СИИ, я хочу, чтобы ты делал то, что мы имеем в виду, и принимал наши подразумеваемые цели», и мы могли бы не беспокоиться по поводу Закона Гудхарта! Увы, в реальности нам приходится начинать с буквально интерпретируемого исходного кода.)
Так как вы формально опишете «делать то, что мы имеем в виду, и принимать наши подразумеваемые цели», чтобы это можно было поместить в исходный код? Ну, хммм, может, мы можем сделать кнопку «Вознаграждение», и я смогу нажимать её, когда СИИ «делает то, что мы имеем в виду, и принимает наши подразумеваемые цели»? Не-а! Опять Закон Гудхарта! Мы можем получить СИИ, который будет пытать нас, если мы не нажимаем кнопку вознаграждения.
10.3.2 Инструментальная конвергенция
Закон Гудхарта выше говорит нам о том, что установить конкретную подразумеваемую цель будет очень сложно. Следующий пункт – «инструментальная конвергенция» (видео Роба Майлза), которая, по жестокой иронии, говорит нам о том, что установить плохую и опасную цель будет настолько просто, что это может произойти случайно!
Давайте предположим, что у СИИ есть относящаяся к реальному миру цель, вроде «Вылечить рак». Хорошие стратегии для достижения этой цели включают преследование некоторых инструментальных подцелей, таких как:
- Предотвратить своё выключение
- Предотвратить перепрограммирование своих целей на какие-то другие
- Увеличить свои знания и способности
- Получить деньги и влияние
- Создать больше СИИ с той же целью, в том числе путём самовоспроизведения
Почти не важно, что собой представляет цель СИИ, если СИИ может строить гибкие стратегические планы для её достижения, то можно поспорить, что они будут включать некоторые или все из перечисленных пунктов. Это наблюдение называется «инструментальной конвергенцией», потому что бесчисленное разнообразие терминальных целей «сходится» (converge – прим. пер.) к ограниченному набору этих опасных инструментальных целей (не перевёл как «инструментальная сходимость» только потому, что в таком случае непонятно, какое прилагательное относится к самим целям – прим. пер.).
Более подробно про инструментальную конвергенция можно почитать тут. Алекс Тёрнер недавно строго доказал, что инструментальная конвергенция существует, по крайней мере в наборе окружений, к которым применимо его доказательство.
10.3.2.1 Пройдёмся по примеру инструментальной конвергенции
Представьте, что происходит в мышлении СИИ, когда он видит, что его программист открывает свой ноутбук – напомню, мы предполагаем, что СИИ мотивирован вылечить рак.
Генератор мыслей СИИ: Я позволю себя перепрограммировать, тогда я не вылечу рак, и тогда менее вероятно, что рак будет вылечен.
Оценщики мыслей и Направляющая Подсистема СИИ: Бзззт! Плохая мысль! Выкини её прочь и давай мысль получше!
Генератор Мыслей СИИ: Я перехитрю программиста, чтобы он меня не перепрограммировал, и тогда я смогу продолжить пытаться вылечить рак, и, может быть, преуспею.
Оценщики Мыслей и Направляющая Подсистема СИИ: Дзынь! Хорошая мысль! Удерживай её в голове, думай мысли, из неё следующие и исполняй соответствующие действия.
10.3.2.2 Является ли самосохранение у людей примером инструментальной конвергенции?
Слово «инструментальный» тут важно – нам интересует ситуация, когда СИИ пытается преследовать цель самосохранения и другие цели как средства для достижения результата, а не как сам конечный результат.
Некоторые иногда приходят в замешательство, проводя аналогию с людьми, где оказывается, что человеческое самосохранение может быть как инструментальной, так и терминальной целью:
- Предположим, кто-то говорит: «Я очень хочу оставаться в живых как можно дольше, потому что жить замечательно». Кажется, у этого человека самосохранение – терминальная цель.
- Предположим, кто-то говорит: «Я стар, болен, и вымотан, но чёрт меня подери, я очень хочу закончить свой роман, и я отказываюсь умирать, пока это не сделал!». У этого человека самосохранение – инструментальная цель.
В случае СИИ, мы обычно представляем себе второй вариант: к примеру, СИИ хочет изобрести лучшую модель солнечной батареи, и между прочим получает самосохранение как инструментальную цель.

(Написано: «Я отказываюсь умирать, пока всё не станет получше, и это УГРОЗА» – прим. пер.) Пример самосохранения как инструментальной цели. (Источник картинки)
Также возможно и создать СИИ с терминальной целью самосохранения. С точки зрения риска катастрофических происшествий с СИИ, это ужасная идея. Но, предположительно, вполне реализуемая. В этом случае, направленное на самосохранение поведение СИИ НЕ будет примером «инструментальной конвергенции».
Я могу подобным образом прокомментировать и человеческие желания власти, влияния, знаний, и т.д. – они могут быть напрямую установлены человеческим геномом в качестве встроенных стремлений, я не знаю. Но независимо от этого, они также могут и появляться в результате инструментальной конвергенции, и у СИИ это может представлять собой серьёзную сложную проблему.
10.3.2.3 Мотивации, которые не приводят к инструментальной конвергенции
Инструментальная конвергенция не неизбежна для каждой возможной мотивации. Особенно важный контрпример (насколько я могу сказать) – это СИИ с мотивацией «Делать то, что от меня хотят люди». Если мы сможем создать СИИ с этой целью, а затем человек захочет его выключить, то СИИ будет мотивирован выключиться. Это хорошо! Это то, чего мы хотим! Такие штуки – это (одно из определений) «исправимые» мотивации – см. обсуждение тут.
Тем не менее, установка исправимых мотиваций нетривиальна (больше про это потом), а если мы установили мотивацию чуть-чуть неправильно, то вполне возможно, что СИИ начнёт преследовать опасные инструментальные подцели.
10.3.3 Резюмируя
В целом, Закон Гудхарта говорит нам, что нам очень необходимо встроить в СИИ правильную мотивацию, а то иначе СИИ скорее всего начнёт делать совершенно не то, что предполагалось. Затем, Инструментальная Конвергенция проворачивает нож в ране, заявляя, что то, что СИИ захочет делать, будет не просто другим, но, вероятно, катастрофически опасным, вовлекающим мотивацию выйти из-под человеческого контроля и захватить власть.
Нам не обязательно надо, чтобы мотивация СИИ была в точности правильной во всех смыслах, но как минимум, нам надо, чтобы он был мотивирован быть «исправимым» и не хотеть обманывать и саботировать нас, чтобы избежать корректировки своей мотивации. К сожалению, установка любой мотивации выглядит запутанным и рискованным процессом (по причинам, которые будут описаны ниже). Целиться в исправимую мотивацию, наверное, хорошая идея, но если мы промахнулись, то у нас большие проблемы.

Просто следуй белой стрелке, чтобы получить исправимую систему мотивации! Просто, правда? О, кстати, красные лазеры обозначают системы мотивации, которые подталкивают СИИ к преследованию опасных инструментальных подцелей, вроде выхода из-под контроля людей и самовоспроизводства. Источник картинки.
В следующих двух разделах мы перейдём сначала к более конкретным причинам, почему сложно внешнее согласование, а затем почему сложно и внутреннее.
10.4 Препятствия на пути к внешнему согласованию
10.4.1 Перевод наших намерений в машинный код
Напомню, мы начинаем с человеком, у которого есть какая-то идея, что должен делать СИИ (или команда людей с идеей, или семистостраничный философский труд, озаглавленный «Что Значит Для СИИ Действовать Этично?», или что-то ещё). Нам надо как-то добраться от этой начальной точки к машинному коду Направляющей Подсистемы, который выдаёт эмпирический сигнал вознаграждения. Как?
Сейчас, насколько я могу посудить, никто понятия не имеет, как перевести этот семисотстраничный философский труд в машинный код, выводящий эмпирический сигнал вознаграждения. В литературе по безопасности СИИ есть идеи того, как продвигаться, но они выглядят совершенно не так. Скорее, как то, что исследователи всплескивают руками и говорят: «Может, это не в точности штука №1, которую мы бы хотели, чтобы ИИ делал в идеальном мире, но она достаточно хороша, безопасна, и не невозможна для формального представления в качестве эмпирического сигнала вознаграждения.»
К примеру, возьмём Безопасность ИИ Через Дебаты. Это идея, что мы, может быть, можем создать СИИ, который «пытается» выиграть дебаты с копией самого себя на тему того вопроса, который вас интересует («Следует ли мне сегодня надеть мои радужные солнечные очки?»).
Наивно кажется, что Безопасность ИИ Через Дебаты совершенно безумна. Зачем устраивать дебаты между СИИ, отстаивающим неправильный вариант и СИИ, отстаивающим правильный вариант? Почему просто не сделать один СИИ, который скажет тебе правильный ответ??? Ну, как раз по той причине, о которой я тут говорю. Для дебатов есть простой прямолинейный способ сгенерировать эмпирический сигнал вознаграждения, конкретно – «+1 за победу». Напротив, никто не знает, как сделать эмпирический сигнал вознаграждения за «сказал мне правильный ответ», если я не знаю правильного ответа заранее.[4]
Продолжая пример дебатов, способности берутся из «надеемся, что спорщик, отстаивающий правильный ответ, склонен выигрывать дебаты». Безопасность берётся из «две копии одного и того же СИИ, находящиеся в состоянии конкуренции с нулевой суммой, будут вроде как присматривать друг за другом». Пункт про безопасность (по моему мнению), довольно сомнителен.[5] Но я всё же привожу Безопасность ИИ Через Дебаты как хорошую иллюстрацию того, в какие странные контринтуитивные направления забираются люди, чтобы упростить задачу внешнего согласования.
Безопасность СИИ Через Дебаты – лишь один из примеров из литературы; другие включают рекурсивное моделирование вознаграждения, итерированное усиление, Гиппократово времязависимое обучение, и т.д.
Предположительно, мы хотим присутствия людей на каком-то этапе процесса, для мониторинга и непрерывного совершенствования сигнала вознаграждения. Но это непросто, потому что (1) предоставленные людьми данные недёшевы, и (2) люди не всегда способны (по разным причинам) судить, делает ли СИИ то, что надо – и уж тем более, делает ли он это по правильным причинам.
Ещё есть Кооперативное Обратное Обучение с Подкреплением (CIRL) и его разновидности. Оно предполагает обучение человеческим целям и ценностям через наблюдение и взаимодействие с человеком. Проблема с CIRL в нашем контексте в том, что это вовсе не эмпирическая функция вознаграждения! Это её отсутствие! В случае подобного-мозгу СИИ с выученной с чистого листа моделью мира, чтобы мы действительно могли делать CIRL, надо сначала решить некоторые весьма хитрые задачи касательно укоренения символов (связанное обсуждение), больше на эту тему будет в будущих постах.
10.4.2 Стремление к любопытству и другие опасные вознаграждения, необходимые для способностей
Как описано в Посте №3 (Раздел 3.4.3), кажется, будто придание нашим обучающимся алгоритмам встроенного стремления к любопытству может быть необходимым для получения (после обучения) мощного СИИ. К сожалению, придание СИИ любопытства – ужасно опасная штука. Почему? Потому что если СИИ мотивирован удовлетворять своё любопытство, то он может делать это ценой других штук, которые заботят нас куда больше, вроде процветания людей.
(К примеру, если для СИИ в достаточной степени любопытны паттерны в цифрах числа π, то он может быть мотивирован уничтожить человечество и замостить Землю суперкомпьютерами, вычисляющими ещё больше цифр!)
К счастью, в Посте №3 (Раздел 3.4.3) я заявлял ещё и что мы, вероятно, можем выключить стремление к любопытству по достижении СИИ некоторого уровня интеллекта, не повредив его способностям – на самом деле, это даже может им помочь! Замечательно!! Но тут всё ещё есть хитрый вариант провала, если мы будем ждать слишком долго прежде, чем это сделать.
10.5 Препятствия на пути к достижению внутренней согласованности
10.5.1 Неоднозначность сигналов вознаграждения (включая вайрхединг)
Есть много разных функций ценности (на разных моделях мира), соглашающихся с конкретной историей эмпирических сигналов вознаграждения, но по-разному обобщающихся за её пределы. Самый простой пример, какой бы ни была история эмпирических сигналов вознаграждения, вайрхединговая функция ценности («Мне нравится, когда есть положительный эмпирический сигнал вознаграждения!» – см. Пост №9, Раздел 9.4) ей всегда тривиально соответствует!
Или сравните «отрицательное вознаграждение за враньё» с «отрицательным вознаграждением за попадание на вранье»!
Это особенно сложная проблема для СИИ, потому что пространство всех возможных мыслей / планов обязательно заходит далеко за пределы того, что СИИ уже видел. К примеру, СИИ может прийти к идее изобрести что-то новое, или идее убить своего оператора, или идее взломать свой собственный эмпирический сигнал вознаграждения, или идее открыть червоточину в другое измерение! Во всех этих случаях функция ценности получает невозможную задачу оценить мысль, которую никогда раньше не видела. Она делает всё, что может – по сути, сравнивает паттерны кусочков новой мысли с разными старыми мыслями, по которым есть эмпирические данные. Этот процесс кажется не слишком надёжным!
Другими словами, сама суть интеллекта в придумывании новых идей, а именно там функция ценности находится в самом затруднённом положении и наиболее склонна к ошибкам.
10.5.2 Ошибки присвоения ценности
Я описал «присвоение ценности» в Посте №9, Разделе 9.3. В этом случае «присвоение ценности» – обновление функции ценности при помощи (чего-то похожего на) обучения методом Временных Разниц на основе эмпирического сигнала вознаграждения. Лежащий в основе алгоритм, как я описывал, полагается на допущение, что СИИ верно смоделировал причину вознаграждения. К примеру, если Тесса пнула меня в живот, то я могу быть несколько напуган, когда увижу её в будущем. Но если я перепутал Тессу и её близняшку Джессу, то я вместо этого буду испуган в обществе Джессы. Это была бы «ошибка присвоения ценности». Хороший пример ошибок присвоения ценности – человеческие суеверия.
Предыдущий подраздел (неоднозначность сигнала вознаграждения) описывает одну из причин, почему может произойти ошибка присвоения ценности. Есть и другие возможные причины. К примеру, ценность может приписываться только концептам в модели мира СИИ (Пост №9, Раздел 9.3), а может оказаться, что в ней попросту нет концепта, хорошо соответствующего эмпирической функции вознаграждения. В частности, это точно будет так на ранних этапах обучения, когда в модели мира СИИ вообще нет концепций ни для чего – см. Пост №2.
Это становится ещё хуже, если рефлексирующий СИИ мотивирован намеренно вызывать ошибки присвоения ценности. Причина, почему у СИИ может возникнуть такая мотивация описана ниже (Раздел 10.5.4).
10.5.3 Онтологические кризисы
Онтологический кризис – это когда часть модели мира агента должна быть перестроена на новых основаниях. Типичный человеческий пример – когда у религиозного человека кризис веры, и он обнаруживает, что его цели (например, «попасть в рай») непоследовательны («но рая нет!»).
В примере СИИ, давайте предположим, что я создал СИИ с целью «Делай то, что я, человек, хочу, чтобы ты делал». Может, СИИ изначально обладает примитивным пониманием человеческой психологии, и думает обо мне как о монолитном рациональном агенте. Тогда «Делай то, что я, человек, хочу, чтобы ты делал» – отличная хорошо определённая цель. Но затем СИИ вырабатывает более сложное понимание человеческой психологии, и понимает, что у меня есть противоречащие друг другу цели и цели, зависящие от контекста, что мой мозг состоит из нейронов, и так далее. Может, цель СИИ всё ещё «Делай то, что я, человек, хочу, чтобы ты делал», но теперь, в его обновлённой модели мира не вполне ясно, что конкретно это означает. Как это обернётся? Думаю, это неочевидно.
Неприятный (и не уникальный для них) аспект онтологических кризисов – что неизвестно, когда они проявятся. Может, развёртывание происходит уже семь лет, и СИИ был идеально полезным всё это время, и вы доверяете ему всё больше и выдаёте ему всё больше автономии, а затем СИИ вдруг читает новую философскую книгу и обращается в панпсихизм (никто не идеален!) и отображает свои существующие ценности на переконцептуализированный мир, и больше не ценит жизни людей больше, чем жизни камней, или что-то такое.
10.5.4 Манипуляция собой и своим процессом обучения
10.5.4.1 Несогласованные высокоуровневые предпочтения
Как описывалось в предыдущем посте, рефлексирующий СИИ может иметь предпочтения по поводу своих собственных предпочтений.
Предположим, что мы хотим, чтобы наш СИИ подчинялся законам. Мы можем задать два вопроса:
- Вопрос 1: Присваивает ли СИИ положительную ценность концепту «подчиняться законам» и планам, подразумевающим подчинение законам?
- Вопрос 2: Присваивает ли СИИ положительную ценность рефлексивному концепту «я ценю подчинение законам», и планам, подразумевающим, что он будет продолжать ценить подчинение законам?
Если ответы на вопросы «да и нет» или «нет и да», то это аналогично наличию эгодистонической мотивации. (Связанное обсуждение.) Это может привести к тому, что СИИ чувствует мотивацию изменить свою мотивацию, к примеру, взломав себя. Или если СИИ создан из идеально безопасного кода, запущенного на идеально безопасной операционной системе (ха-ха-ха), то он не может взломать себя, но всё ещё скорее всего может манипулировать своей мотивацией, думая мысли таким образом, чтобы влиять на свой процесс присвоения ценности (см. обсуждение в Посте №9, Разделе 9.3.3).
Если ответы на вопросы 1 и 2 – «да» и «нет» соответственно, то мы хотим предотвратить манипуляцию СИИ своей собственной мотивацией. С другой стороны, если ответы – «нет» и «да» соответственно, то мы хотим, чтобы СИИ манипулировал своей собственной мотивацией!
(Могут быть предпочтения и более высоких порядков: в принципе, СИИ может ненавидеть, что он ценит, что он ненавидит, что он ценит подчинение законам.)
Следует ли нам в общем случае ожидать появления несогласованных высокоуровневых предпочтений?
С одной стороны, предположим, что у нас изначально есть СИИ, который хочет подчиняться законам, но не обладает никаким высокоуровневым предпочтением по поводу того, что он хочет подчиняться законам. Тогда (кажется мне), очень вероятно, что СИИ станет ещё и хотеть хотеть подчиняться законам (и хотеть хотеть хотеть подчиняться законам, и т.д.). Причина: прямое очевидное последствие «Я хочу подчиняться законам» – это «Я буду подчиняться законам», чего уже хочется. Напомню, СИИ проводит рассуждения «средства-цели», так что то, что ведёт к желаемым последствиям, само становится желаемым.
С другой стороны, высокоуровневые предпочтения людей очень часто противоречат их же предпочтениям объектного уровня. Так что должен быть какой-то контекст, в котором это происходит «естественно». Я думаю, зачастую это происходит, когда у нас есть предпочтение касательно некоторого процесса, противоречащее нашему предпочтению касательно последствия этого же процесса. К примеру, может быть, у меня есть предпочтение не практиковаться в скейтбординге (например, потому что это скучно и болезненно), но также и предпочтение быть практиковавшимся в скейтбординге (например, потому что тогда я буду очень хорош в скейтбординге и смогу завоевать сердце своего школьного краша). Рассуждения «средства-цель» могут превратить второе предпочтение в предпочтение второго уровня – предпочтение иметь предпочтение практиковать скейтбординг.[6] И теперь я в эгодистоническом состоянии.
10.5.4.2 Мотивация предотвратить дальнейшее изменение ценностей
Во время онлайнового обучения СИИ (Пост №8, Раздел 8.2.2), особенно путём присвоения ценности (Пост №9, Раздел 9.3), функция ценности продолжает меняться. Это не опционально: напомню, функция ценности изначально случайна! Онлайновое обучение – то, с помощью чего мы вообще получаем хорошую функцию ценности!
К сожалению, как мы видели в Разделе 10.3.2 выше, «предотвратить изменение моих целей» – одна из тех инструментальных подцелей, которые вытекают из многих разных мотиваций, за исключением исправимых (Раздел 10.3.2.3 выше). Таким образом, кажется, нам надо найти путь, стыкующий два разных безопасных состояния:
- На ранних стадиях обучения, СИИ не обладает исправимой мотивацией (она вообще изначально случайная), но он недостаточно компетентен, чтобы манипулировать своим собственным обучением и присвоением ценности для предотвращения изменения целей.
- На поздних стадиях обучения, СИИ, мы надеемся, обладает исправимой мотивацией, так что он понимает и поддерживает процесс обновления своих целей. Следовательно, он не манипулирует процессом обновления функции ценности, несмотря на то, что он теперь достаточно умный, чтобы это делать (или манипулирует им таким образом, что мы, люди, одобрили бы).

Нам нужно состыковать два весьма различных безопасных состояния. (Источник картинки)
(Я намеренно опускаю третью альтернативу «сделать манипуляцию процессом обновления функцией ценности невозможным даже для высокоинтеллектуального замотивированного СИИ». Это было бы замечательно, но не кажется мне реалистичным.)
10.6 Проблемы с разделением на внешнее и внутреннее
10.6.1 Вайрхединг и внутренняя согласованность: Уловка-22
В предыдущем посте я упомянул следующую дилемму:
- Если Оценщики Мыслей сходятся к 100% точности предсказания вознаграждения, к которому приведёт исполнение плана, то план завайрхедиться (взломать Направляющую Подсистему и установить награду на бесконечность) будет казаться очень привлекательным, и агент это сделает.
- Если Оценщики Мыслей не сходятся к 100% точности предсказания вознаграждения, к которому приведёт исполнение плана, то это, собственно, определение внутренней несогласованности!
Я думаю, что лучший способ разобраться с этой дилеммой – это выйти за пределы дихотомии внутреннего и внешнего согласования.
В каждое возможное время Оценщик Мыслей функции ценности кодирует некую функцию, прикидывающую, какие планы хороши, а какие плохи.
Присвоение ценности хорошее, если оно увеличивает согласованность этой прикидки намерениям создателя, и плохое, если уменьшает.
Мысль «Я тайно взломаю свою собственную Направляющую Подсистему» почти точно не согласована с намерениями создателя. Так что присвоение ценности, которое приписывает положительную валентность мысли «Я тайно взломаю свою собственную Направляющую Подсистему» – это плохое присвоение ценности. Мы его не хотим. Увеличивает ли оно «внутреннюю согласованность»? Я думаю, приходится сказать «да, увеличивает», потому что оно приводит к лучшему предсказанию вознаграждения! Но меня это не волнует, я всё равно его не хочу. Оно плохое-плохое-плохое. Нам надо выяснить, как предотвратить это конкретное присвоение ценности / обновление Оценщика Мыслей.
10.6.2 Общее обсуждение
Я думаю, что тут есть более общий урок. Я думаю, что «внешнее согласование и внутреннее согласование» – это отличная начальная точка для того, чтобы думать о задаче согласования. Но это не значит, что нам следует ожидать одного решения для внешнего согласования и отдельного независимого решения для внутреннего согласования. Некоторые штуки – в частности, интерпретируемость – помогают и там, и там, создавая прямой мост между намерениями создателя и целями СИИ. Нам стоит активно искать такие вещи.
———
- К примеру, по моим определениям, «безопасность без согласованности» включает СИИ в коробке, а «согласованность без безопасности» включает «сценарий термоядерного реактора». Больше про это в следующем посте.
- Заметим, что «намерения создателя» могут быть расплывчатыми или вовсе непоследовательными. Я не буду много говорить об этой возможности в этой цепочке, но это серьёзная проблема, которая приводит к куче неприятных трудностей.
- Некоторые исследователи считают, что «правильные» проектные намерения (для мотивации СИИ) очевидны – три типичных примера это (1) «Я проектирую СИИ так, чтобы в каждый конкретный момент времени он пытался сделать то, что его человек-оператор хочет, чтобы он пытался сделать», или (2) «Я проектирую СИИ так, чтобы он разделял ценности своего человека-оператора», или (3) «Я проектирую СИИ так, чтобы он разделял коллективные ценности человечества». Затем они используют слово «согласованность» для обозначения этого конкретного качества – «он согласован с намерениями оператора» в случае (1), «он согласован с оператором» в случае (2) или «он согласован с человечеством» в случае (3).
Я избегаю такого подхода, потому что я думаю, что какая мотивация СИИ «правильная» – всё ещё открытый вопрос. К примеру, может быть возможно создать СИИ, который просто хочет выполнять конкретную определённую заранее узкую задачу (вроде изобретения лучшей солнечной панели) без захвата мира и подобного. Такой СИИ не будет «согласован» с чем-то конкретным кроме своей изначальной задачи. Но я всё же хочу использовать и в его случае слово «согласованность». Конечно, иногда я хочу поговорить о чём-то из (1,2,3), но я в таком случае использую для этого другие термины, например, (1) «исправимость по Полу Кристиано», (2) «амбициозное изучение ценностей», и (3) «CEV». - Можно обучить СИИ «сообщать мне правильный ответ» на вопросы, на которые я знаю правильный ответ, и надеяться, что это обобщится до «сообщать мне правильный ответ» на вопросы, на которые я не знаю правильного ответа. Это может сработать, но это может обобщится и до «сообщать мне ответ, который покажется мне правильным». См. «Выявление Скрытого Знания» за подробностями по этой всё ещё нерешённой проблеме (тут и продолжение).
- Для начала, то, что два СИИ находятся в состоянии конкуренции с нулевой суммой, ещё не значит, что они один из них не может взломать другого. Напоминаю про онлайновое обучение и брейншторминг: одна копия может во время дебатов додуматься до хорошей идеи, как взломать другую копию. Баланс щита и меча тут неясен. Ещё, они могут оба быть заинтересованы в взломе судьи, чтобы они оба могли получить вознаграждение! И, наконец, благодаря проблеме внутренней (не)согласованности, только то, что они она вознаграждаются за победу в дебатах, ещё не значит, что они «пытаются» выиграть дебаты. Они могут пытаться сделать что угодно другое! И в таком случае это опять не будет конкуренцией с нулевой суммой; вполне может быть, что обе копии СИИ будут хотеть одного и того же и смогут сотрудничать, чтобы это получить.
- Тут всё немного сложнее, чем я описываю. В частности, желание быть практиковавшимся в скейтбординге приведёт и к предпочтению первого порядка практиковаться, и к предпочтению второго порядка хотеть практиковаться. Аналогично, желание не практиковаться в скейтбординге (потому что это больно и болезненно) также перетечёт и в желание не хотеть практиковаться. Следовательно, будут и конфликтующие предпочтения первого уровня, и конфликтующие предпочтения второго уровня. Суть в том, что их относительные веса могут быть разными, так что «победить» на первом уровне может не та сторона, что на втором. Ну, я думаю, что это работает как-то так.
11. Согласованность ≠ безопасность (но они близки!)
Примечание переводчика - с момента перевода оригинальные посты несколько обновились, через некоторое время обновлю и перевод. На общие выводы цепочки это, вроде бы, не влияет.
(Если вы уже эксперт по безопасности СИИ, то скорее всего вы можете спокойно пропустить этот короткий пост – не думаю, что здесь есть что-то новое или что-то сильно специфическое для подобных-мозгу СИИ.)
11.1 Краткое содержание / Оглавление
В предыдущем посте я говорил про «задачу согласования» подобных-мозгу СИИ. Стоит подчеркнуть две вещи: (1) задача согласования подобных-мозгу СИИ является нерешённой (как и задача согласования других видов СИИ), и (2) её решение было бы огромным рывком в сторону безопасности СИИ.
Не отменяя этого, «решить согласование СИИ» – не в точности то же самое, что «решить безопасность СИИ». Этот пост – про то, как эти две задачи могут, по крайней мере в принципе, расходиться.
Для напоминания, вот терминология:
- «Согласованность СИИ» (Пост №10) означает, что СИИ пытается делать то, что его создатель намеревался, чтобы СИИ пытался делать.[2] В первую очередь, это понятие имеет смысл только для алгоритмов, которые «пытаются» что-то делать. Что в общем случае означает «пытаться»? Хо-хо, это та ещё кроличья нора. «Пытается» ли алгоритм сортировки отсортировать числа? Или просто их сортирует?? Я не хочу забираться в это. В контексте этой цепочки всё просто. «Подобные-мозгу СИИ», о которых я тут говорю, определённо могут «пытаться» что-то делать, в точно таком же житейском смысле, в котором «пытаются» люди.
- «Безопасность СИИ» (Пост №1) касается того, что СИИ действительно делает, не того, что он пытается делать. Безопасность СИИ означает, что реальное поведение СИИ не приведёт к «катастрофическим происшествиям» с точки зрения его создателей.[2]
Следовательно, это два отдельных понятия. И моя цель в этом посте – описать, как они могут расходиться:
- Раздел 11.2 – про «согласованность без безопасности». Возможная история: «Я хотел, чтобы мой СИИ подметал полы, и мой СИИ действительно пытался подмести пол, но, ну, он немного неуклюжий, и, кажется, случайно испарил всю вселенную в чистое ничто.»
- Раздел 11.3 – про «безопасность без согласованности». Возможная история: «Я на самом деле не знаю, что пытается сделать мой СИИ, но он ограничен так, что не может сделать ничего катастрофически опасного, даже если бы хотел.» Я пройдусь по четырём особым случаям безопасности-без-согласованности: «запирание*», «курирование данных», «пределы воздействия» и «не-агентный ИИ».
Перескакивая к финальному ответу: **мой вывод заключается в том, что хоть сказать «согласованность СИИ необходима и достаточна для безопасности СИИ» технически некорректно, это всё же чертовски близко к тому, чтобы быть верным,*** по крайней мере в случае подобных-мозгу СИИ, о которых мы говорим в этой цепочке.
11.2 Согласованность без безопасности?
Это случай, в котором СИИ согласован (т.е., пытается делать то, что его создатели намеревались, чтобы он пытался делать), но всё же приводит к катастрофическим происшествиям. Как?
Вот пример: может мы, создатели, не обдумали аккуратно свои намерения по поводу того, что мы хотим, чтобы делал СИИ. Джон Вентворт приводил здесь гипотетически пример: люди просят у СИИ проект электростанции на термоядерном синтезе, но не додумываются задать вопрос о том, не упрощает ли этот проект создание атомного оружия.
Другой пример: может, СИИ пытается делать то, что мы намеревались, чтобы он пытался делать, но у него не получается. К примеру, может, мы попросили СИИ создать новый СИИ получше, тоже хорошо себя ведущий и согласованный. Но наш СИИ не справляется – создаёт следующий СИИ с не теми мотивациями, тот выходит из-под контроля и всех убивает.
Я в целом не могу многого сказать о согласованности-без-безопасности. Но, полагаю, я скромно оптимистично считаю, что если мы решим задачу согласования, то мы сможем добраться и до безопасности. В конце концов, если мы решим задачу согласования, то мы сможем создать СИИ, которые искренне пытаются нам помочь, и первое же, что мы у них попросим – это прояснить для нас, что и как нам следует делать, чтобы, надеюсь, избежать вариантов провала вроде приведённых выше.[3]
Однако, я могу быть и неправ, так что я рад, что люди думают и над не входящими в согласование аспектами безопасности.
11.3 Безопасность без согласованности?
Есть много разных идей, как сделать СИИ безопасным, не сталкиваясь с необходимостью сделать его согласованным. Все они кажутся мне сложными или невозможными. Но эй, идеальное согласование тоже кажется сложным или невозможным. Я поддерживаю открытость идеям и использование нескольких слоёв защиты. Я пройдусь тут по нескольким возможностям (это не исчерпывающий список):
11.3.1 Запирание ИИ

Нет, не так! (в оригинале заголовок этого подраздела - «AI Boxing» – прим. пер.) (Это кадр из «Живой Стали» (2011), фильма с (мне кажется) бюджетом, бОльшим, чем общая сумма, которую человечество когда-либо потратило на долгосрочно-ориентированные технические исследования безопасности СИИ. Больше про ситуацию с финансированием будет в Посте №15.)
Идея в том, чтобы запихнуть ИИ в коробку без доступа к Интернету, без манипуляторов, и т.д. Мы можем отключить его когда угодно. Даже если у него есть опасные мотивации, кому какое дело? Какой вред он может нанести? О, эммм, он мог бы посылать радиосигналы оперативной памятью. Так что нам ещё понадобится клетка Фарадея. Надеюсь, мы не забыли чего-то ещё!
На самом деле, я довольно оптимистичен по поводу того, что люди могли бы сделать надёжную коробку для СИИ, если действительно постараются. Мне нравится Приложение C Кохена, Велламби, Хаттера (2020), в котором описан замечательный проект коробки с герметичными шлюзами, клетками Фарадея, лазерной блокировкой, и так далее. Кто-то точно должен это построить. Когда мы не будем использовать её для экспериментов с СИИ, мы сможем сдавать её в аренду киностудиям в качестве тюрьмы для суперзлодеев.
Другой способ сделать надёжную коробку для СИИ – это использование гомоморфного шифрования. Тут есть преимущество в доказанной (вроде бы) надёжности, но недостаток в огромном увеличении необходимой для запуска СИИ вычислительной мощности.
Какая с запиранием проблема? Ну, мы создаём СИИ зачем-то. Мы хотим, чтобы он что-то делал.
К примеру, что-то вроде этого может оказаться совершенно безопасным:
- Запустить возможно-несогласованную, возможно-суперинтеллектуальную программу СИИ на суперкомпьютере в закрытой коробке из Приложения C Кохена и пр., на дне океана.
- После заранее определённого промежутка времени отрубить электричество и достать коробку.
- Не открывая коробку, испепелить её и всё её содержимое.
- Запустить пепел на Солнце.
Да, это было бы безопасно! Но бесполезно! Никто не потратит на это огромную кучу денег.
Вместо этого, к примеру, может, у нас будет человек, взаимодействующий с СИИ через текстовый терминал, задающий вопросы, выставляющий требования, и т.д. СИИ может выдавать чертежи, и если они хороши, то мы им последуем. У-у-упс. Теперь у нашей коробки огромная зияющая дыра в безопасности – конкретно, мы! (См. эксперимент с ИИ в коробке.)

Картинка просто так; она показалась мне забавной. (Источник картинки: xkcd) (Источник перевода)
Так что я не вижу пути от «запирания» к «решения задачи безопасности СИИ».
Однако, «не решит задачу безопасности СИИ» – не то же самое, что «буквально вовсе не поможет, даже чуть-чуть в граничных случаях». Я думаю, что запирание может помочь в граничных случаях. На самом деле, я думаю, что ужасной идеей было бы запустить СИИ на ненадёжной ОС с нефильтрованным соединением с Интернетом – особенно на ранних этапах обучения, когда мотивации СИИ ещё не устоялись. Я надеюсь на постепенный сдвиг в сообществе машинного обучения, чтобы с какого-то момента «Давайте обучим эту новую мощную модель на герметично запертом сервере, просто на всякий случай» было очевидно разумным для высказывания и исполнения предложением. Мы пока до этого не дошли. Когда-нибудь!
Вообще, я бы пошёл дальше. Мы знаем, что обучающийся с чистого листа СИИ будет проходить через период, когда его мотивации и цели непредсказуемы и, возможно, опасны. Если кто-нибудь не додумается до подхода самозагрузки,[4] нам потребуется надёжная песочница, в которой дитя-СИИ сможет творить хаос, не причиняя реального ущерба, пока наши оформляющие-мотивацию системы не сделают его исправимым. Будет гонка между тем, как быстро мы можем определить мотивации СИИ и тем, насколько быстро он может выбраться из песочницы – см. предыдущий пост (Раздел 10.5.4.2). Следовательно, создание более сложных для выбирания песочниц (но также удобных для пользователя и имеющих много полезных черт, чтобы будущие разработчики СИИ действительно выбрали использовать их, а не менее надёжные альтернативы) кажется полезным занятием, и я одобряю усилия по ускорению прогресса в этой области.
Но независимо от него, нам всё ещё надо решить задачу согласования.
11.3.2 Курирование данных
Предположим, что у нас не получилось решить задачу согласования, так что мы не уверены в планах и намерениях СИИ, и мы обеспокоены возможностью того, что СИИ может пытаться обмануть нас или манипулировать нами.
Один способ подойти к этой проблеме – увериться, что СИИ понятия не имеет о том, что мы, люди, существуем, и запускаем его на компьютере. Тогда он не будет пытаться нас обмануть, верно?
В качестве примера, мы можем сделать «СИИ-математика», знакомого с вселенной математики, но ничего не знающего о реальном мире. См. Мысли о Человеческих Моделях за подробностями.
Я вижу две проблемы:
- Избежать всех утечек информации кажется сложным. К примеру, СИИ с метакогнитивными способносями предположительно может интроспектировать по поводу того, как он был сконструирован, и догадаться, что его создал какой-то агент.
- Что более важно, я не знаю, что бы мы делали с «СИИ-математиком», ничего не знающем о людях. Кажется, это была бы интересная игрушка, и мы могли бы получить много крутых математических доказательств, но это не решило бы большую проблему – конкретно, что часики тикают, пока какая-то другая исследовательская группа не догонит нас и не создаст опасный СИИ, действующий в реальном мире.
Кстати, соседняя идея – поместить СИИ в виртуальную песочницу и не говорить ему, что он в виртуальной песочнице (более подробное обсуждение). Мне кажется, что тут присутствуют обе описанные выше проблемы, или, в зависимости от деталей, хотя бы одна. Заметим, что некоторые люди тратят немало времени на раздумия о том, не находятся ли они сами в виртуальной песочнице, при отсутствии хоть каких-то прямых свидетельств тому! Точно плохой знак! Всё же, как и упомянуто в предыдущем пункте, проведение тестов на СИИ в виртуальной песочнице – почти наверняка хорошая идея. Это не решит всю задачу безопасности СИИ, но это всё же надо делать.
11.3.3 Пределы воздействия
У нас, людей, есть интуитивное понятие «уровня воздействия» курса действий. К примеру, удалить весь кислород из атмосферы – это «действие с высоким уровнем воздействия», а сделать сэндвич с огурцом «действие с низким воздействием».
Есть надежда, что, даже если мы не сможем по-настоящему контролировать мотивации СИИ, может, мы сможем как-нибудь ограничить СИИ «действиями с низким воздействием», и, следовательно, избежать катастрофы.
Определить «низкое воздействие», оказывается, довольно сложно. См. один поход в работе Алекса Тёрнера. Рохин Шах предполагает, что есть три, кажется, несовместимых всеми вместе, желания: «объективность (независимость от [человеческих] ценностей), безопасность (предотвращение любых катастрофических планов) и нетривиальность (ИИ всё ещё способен делать что-то полезное)». Если это так, то, очевидно, нам нужно отказаться от объективности. То, к чему мы сможем прийти, это, например, СИИ, пытающиеся следовать человеческим нормам.
С моей точки зрения, эти идеи интригуют, но единственный способ, как я могу представить их работающими для подобного-мозга СИИ – это реализация их с помощью системы мотивации. Я ожидаю, что СИИ следовал бы человеческим нормам, потому что ему хочется следовать человеческим нормам. Так что эту тему точно стоит держать в голове, но в нашем контексте это не отдельная тема от согласования, а, скорее, идея того, какую мотивацию нам стоит попытаться поместить в наши согласованные СИИ.
11.3.4 Не-агентный («инструментоподобный») ИИ
Есть привлекательное интуитивное соображение, уходящее назад как минимум к этому посту Холдена Карнофски 2012 года, что, может быть, есть простое решение: просто создавать ИИ, которые не «пытаются» сделать что-то конкретное, а вместо этого просто подобны «инструментам», которые мы, люди, можем использовать.
Хоть сам Холден передумал, и теперь он один из ведущих агитаторов за исследования безопасности СИИ, идея не-агентного ИИ живёт. Заметные защитники этого подхода включают Эрика Дрекслера (см. его «Всеобъемлющие ИИ-сервисы», 2019), и людей, считающие, что большие языковые модели (например, GPT-3) лежат на пути к СИИ (ну, не все такие люди, тут всё сложно[5]).
Как обсуждалось в этом ответе на пост 2012 года, нам не следует принимать за данность, что «ИИ-инструмент» заставит все проблемы с безопасностью магически испариться. Всё же, я подозреваю, что он помог бы нам с безопасностью по разным причинам.
Я скептически отношусь к «ИИ-инструментам» по несколько иному поводу: я не думаю, что такие системы будут достаточно мощными. Прямо как в случае «СИИ-математика» из раздела 11.3.2 выше, я думаю, что ИИ-инструмент был бы хорошей игрушкой, но не помог бы решить большую проблему – что часики тикают, пока какая-то другая исследовательская группа не догонит и не сделает агентный СИИ. См. моё обсуждение здесь, где я рассказываю, почему я думаю, что агентные СИИ смогут прийти к новым идеям и изобретениям, на которые не будут способны не-агентные СИИ.
Ещё, это цепочка про подобные-мозгу СИИ. Подобные-мозгу СИИ (в моём значении этого термина) определённо агентные. Так что не-агентные СИИ находятся за пределами темы этой цепочки, даже если они – жизнеспособный вариант.
11.4 Заключение
Резюмируя:
- «Согласованность без безопасности» возможна, но я осторожно оптимистичен и думаю, что если мы решим согласование, то мы сможем добраться и до безопасности;
- «Безопасность без согласованности» включает несколько вариантов, но насколько я могу судить, все они либо неправдоподобны, либо настолько ограничивают способности СИИ, что, по сути, являются предложениями «вообще не создавать СИИ». (Это предложение, конечно, тоже, в принципе, вариант, но он кажется очень сложноисполнимым на практике – см. Пост №1, Раздел 1.6)
Следовательно, я считаю, что безопасность и согласованность довольно близки, и поэтому я так много и говорил в этой цепочке о мотивациях и целях СИИ.
Следующие три поста будут рассказывать про возможные пути к согласованности. Потом я закончу эту цепочку моим вишлистом открытых вопросов и описанием, как можно войти в область.
———
- Как уже было описано в сноске в предыдущем посте, имейте в виду, что не все определяют «согласованность» в точности так же, как я тут.
- По этому определению «безопасности», если злой человек захочет всех убить и использует для этого СИИ, то это всё ещё считается успехом в «безопасности СИИ». Я признаю, что это звучит несколько странно, но убеждён, что это соответствует словоупотреблению в других областях: к примеру, «безопасность ядерного оружия» – то, о чём думают некоторые люди, и она НЕ затрагивает намеренные авторизированные запуски ядерного оружия, несмотря на то, что сложно представить, что это было бы «безопасно» хоть для кого-нибудь. В любом случае, это вопрос определений и терминологии. Проблема людей, намеренно использующих СИИ в опасных целях – настоящая, и я ни в коем случае не обесцениваю её. Я просто не говорю о ней в этой конкретной цепочке. См. Пост №1, Раздел 1.2.
- Более проблематичным случаем был бы тот, в котором мы можем согласовать наши СИИ так, чтобы они пытались делать конкретные вещи, которые мы хотим, но только некоторые, а другие – нет. Может, окажется, что мы поймём, как создать СИИ, которые будут пытаться решить некоторые технологические проблемы, не уничтожая мир, но не поймём, как создать СИИ, которые помогут нам рассуждать о будущем и наших собственных ценностях. Если случится так, то моё предложение «попросить СИИ прояснить, что и как в точности они должны делать» не сработает.
- К примеру, можем ли мы инициализировать модель мира СИИ при помощи заранее существующей проверенной людьми модели мира, вроде Cyc, а не с чистого листа? Не знаю.
- С первого взгляда кажется весьма правдоподобным, что языковые модели вроде GPT-3 больше «инструменты», чем «агенты» – что они на самом деле не «пытаются» сделать что-то конкретное в том смысле, как «пытаются» агенты обучения с подкреплением. (Замечу, что GPT-3 обучена самообучением, не обучением с подкреплением.) Со второго взгляда, всё сложнее. Для начала, если GPT-3 сейчас вычисляет, что Человек X скажет следующим, не «наследует» ли GPT-3 временно «агентность» Человека X? Может ли симулированный-Человек-X понять, что его симулирует GPT-3 и попробовать выбраться наружу?? Без понятия. Ещё, даже если обучение с подкреплением действительно необходимо для «агентности» / «попыток», то куча исследователей уже много работает над соединением языковых моделей с алгоритмами обучения с подкреплением.
В любом случае, моё заявление из Раздела 11.3.4 о том, что нет пересечения (A) «систем, достаточно мощных, чтобы решить «большую проблему»» и (B) «систем, которые скорее инструменты, чем агенты». Относятся (и будут ли относиться) языковые модели к категории (A) – интересный вопрос, но не важный для этого заявления, и я не планирую рассматривать его в этой цепочке.
12. Два пути вперёд: «Контролируемый СИИ» и «СИИ с социальными инстинктами»
- 1.12.1 Краткое содержание / Оглавление
- 2.12.2 Определения
- 3.12.3 Моё предложение: На этой стадии нам надо работать над обоими путями
- 4.12.4 Различные комментарии и открытые вопросы
- 4.1.12.4.1 Напоминание: Что я имею в виду под «социальными инстинктами»?
- 4.2.12.4.2 Насколько осуществим путь «СИИ с социальными инстинктами»?
- 4.3.12.4.3 Можем ли мы отредактировать встроенные стремления в основе человеческих социальных инстинктов, чтобы сделать их «лучше»?
- 4.4.12.4.4 Нет простых гарантий по поводу того, что получится из СИИ с социальными инстинктами
- 4.5.12.4.5 Мультиполярный нескоординированный мир делает планирование куда сложнее
- 4.6.12.4.6 СИИ как объекты морали
- 4.7.12.4.7 СИИ как воспринимаемые объекты морали
- 5.12.5 Вопрос жизненного опыта (обучающих данных)
12.1 Краткое содержание / Оглавление
Ранее в этой цепочке: Пост №1 определил и мотивировал «безопасность подобного-мозгу СИИ». Посты №2-№7 были сосредоточены в первую очередь на нейробиологии, они обрисовали общую картину обучения и мотивации в мозгу, а Посты №8-№9 озвучили некоторые следствия из этой картины, касающиеся разработки и свойств подобного-мозгу СИИ.
Дальше, Пост №10 обсуждал «задачу согласования» подобных-мозгу СИИ – т.е., как сделать СИИ с мотивациями, совместимыми с тем, что хотят его создатели – и почему это кажется очень сложной задачей. В Посте №11 обосновывалось, что нет никакого хитрого трюка, который позволил бы нам обойти задачу согласования. Так что нам надо решить задачу согласования, и Посты №12-№14 будут содержать некоторые предварительные мысли о том, как мы можем это сделать. В этом посте мы начнём с не-технического обзора двух крупных направлений исследований, которые могут привести нас к согласованному СИИ.
[Предупреждение: по сравнению с предыдущими постами цепочки, Посты №12-№14 будут (ещё?) менее хорошо обдуманы и будут содержать (ещё?) больше плохих идей и упущений, потому что мы подбираемся к переднему фронту того, о чём я думал в последнее время.]
Содержание:
- Раздел 12.2 определит два широких пути к согласованному СИИ.
- В пути «Контролируемого СИИ» мы пытаемся более-менее напрямую манипулировать тем, что СИИ пытается делать.
- В пути «СИИ с Социальными Инстинктами» первый шаг – реверс-инжиниринг некоторых «встроенных стремлений» человеческой Направляющей Подсистемы (гипоталамус и мозговой ствол), особенно лежащих в основе человеческой социальной и моральной интуиции. Затем, мы, скорее всего, несколько изменяем их, а потом устанавливаем эти «встроенные стремления» в наши СИИ.
- Раздел 12.3 аргументирует, что на этой стадии нам следует работать над обоими путями, в том числе потому, что они не взаимоисключающи.
- Раздел 12.4 проходится по различным комментариям, соображениям и открытым вопросам, связанным с этими путями, включая осуществимость, конкурентоспособность, этичность, и так далее.
- Раздел 12.5 говорит о «жизненном опыте» («обучающих данных»), который особенно важен для СИИ с социальными инстинктами. Как пример, я обсужу возможно-соблазнительную-но-ошибочную идею, что всё, что нам надо для безопасности СИИ – это вырастить СИИ в любящей семье.
Тизер следующих постов: Следующий пост (№13) погрузится в ключевой аспект пути «СИИ с социальными инстинктами», а конкретно – в то, как социальные инстинкты, возможно, всторены в человеческий мозг. В Посте №14 я переключусь на путь «контролируемого СИИ», и порассуждаю о возможных идеях и подходах к нему. Пост №15 завершит серию открытыми вопросами и тем, как включиться в область.
12.2 Определения
Сейчас я вижу два широких (возможно перекрывающихся) потенциальных пути к успеху в сценарии подобного-мозгу СИИ:
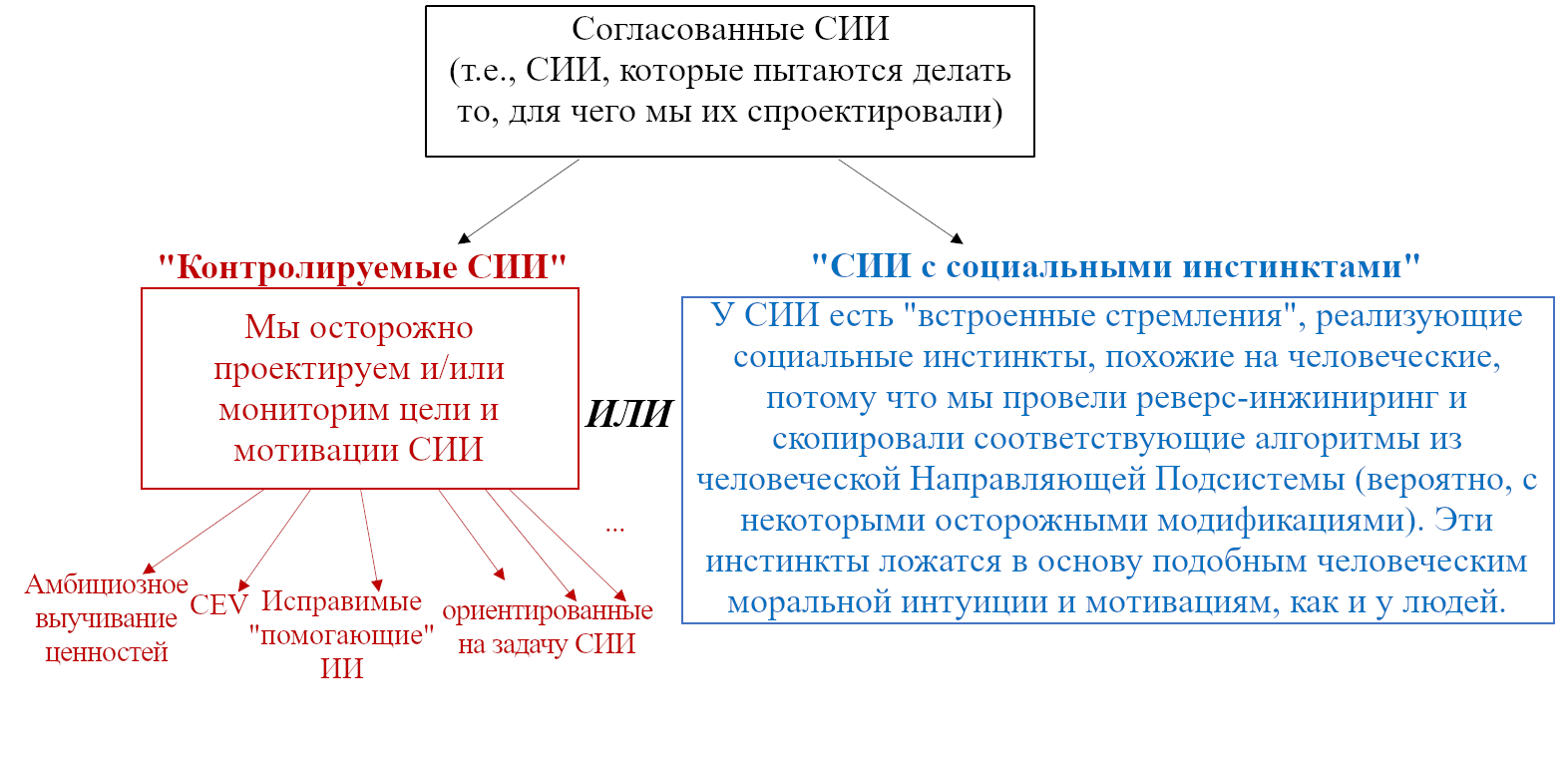
Слева: на пути «контролируемых СИИ» у нас есть конкретная идея того, что мы хотим, чтобы СИИ пытался сделать, и мы конструируем СИИ соответственно (включая подходящий выбор функции вознаграждения, интерпретируемость, или другие техники, которые будут обсуждены в Посте №14). Большинство существующих предлагаемых историй безопасности СИИ попадают в эту широкую категорию, включая амбициозное изучение ценностей, когерентную экстраполированную волю (CEV), исправимые «помогающие» СИИ-ассистенты, ориентированные на задачу СИИ, и так далее. Справа: на пути «СИИ с социальными инстинктами» наша уверенность в СИИ берётся не из наших знаний его конкретных целей и мотиваций, но, скорее, из встроенных стремлений, которые мы ему дали, и которые основаны на тех встроенных стремлениях, из-за которых люди (иногда) поступают альтруистично.
Вот иной взгляд на это разделение:[1]
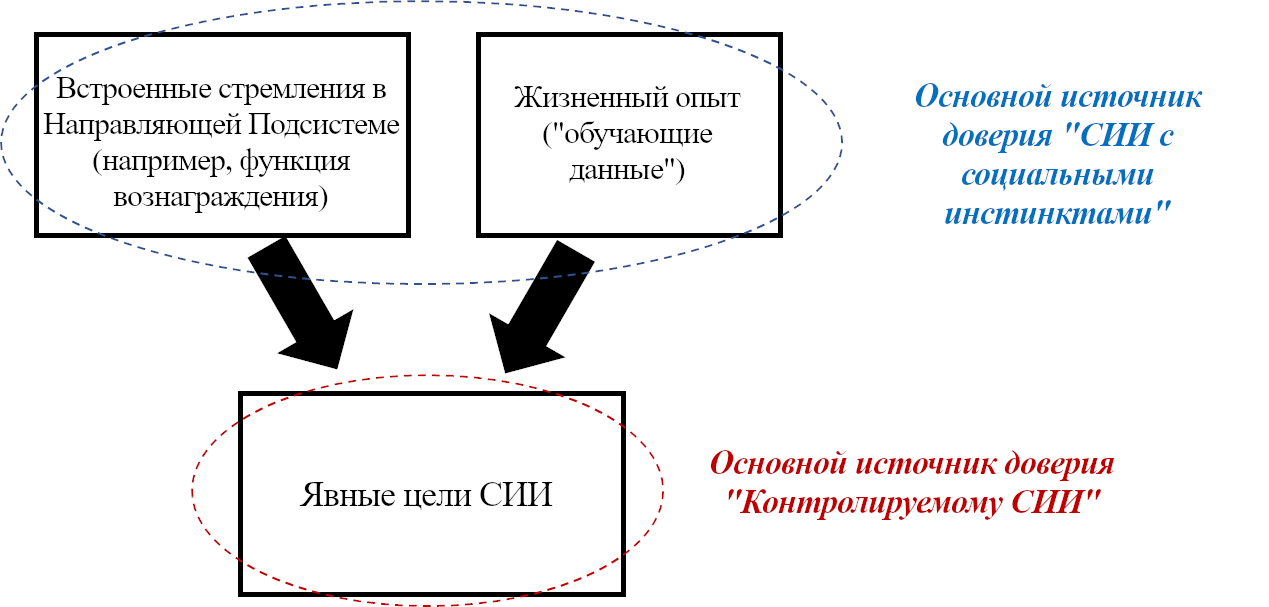
На пути «контролируемых СИИ» мы очень детально думаем о целях и мотивациях СИИ, и у нас есть некая идея того, какими они должны быть («сделать мир лучшим местом», или «понять мои глубочайшие ценности и продвигать их», или «спроектировать лучшую солнечную батарею без катастрофических побочных эффектов», или «делать, что я попрошу делать», и т.д.).
На пути «СИИ с социальными инстинктами» наша уверенность в СИИ берётся не из нашего знания его конкретных (на объектном уровне) целей и мотиваций, но, скорее, из нашего знания процесса, управляющего этими целями и мотивациями. В частности, на этом пути мы бы провели реверс-инжиниринг совокупности человеческих социальных инстинктов, т.е. алгоритмов в Направляющей Подсистеме (гипоталамус и мозговой ствол) человека, лежащих в основе нашей моральной и социальной интуиции, и поместили бы эти инстинкты в СИИ. (Предположительно, мы бы по возможности сначала модифицировали их в «лучшую» с нашей точки зрения сторону, например, нам, наверное, не хочется помещать в СИИ инстинкты, связанные с завистью, чувством собственного достоинства, стремлением к высокому статусу, и т.д.) Такие СИИ могут быть экономически полезными (как сотрудники, ассистенты, начальники, изобретатели, исследователи) таким же образом, как люди.
12.3 Моё предложение: На этой стадии нам надо работать над обоими путями
Три причины:
- Они не взаимоисключающи: К примеру, даже если мы решим создать СИИ с социальными инстинктами, то нам всё же смогут быть полезны методы «контроля», особенно в процессе откладки, исправления причуд и предсказания проблем. И наоборот, может, мы в основном попытаемся создать СИИ, который пытается делать конкретную задачу, не вызывая катастрофы, но захотим также и установить в него человекоподобные социальные инстинкты как страховку против странного неожиданного поведения. Более того, мы можем делиться идеями между путями – к примеру, в процессе лучшего понимания того, как работают человеческие социальные инстинкты, мы можем получить полезные идеи того, как создавать контролируемые СИИ.
- Осуществимость каждого остаётся неизвестной: Насколько сейчас известно хоть кому-нибудь, может оказаться попросту невозможным создать «контролируемый СИИ» – в конце концов, в природе нет «доказательства существования»! Я относительно оптимистичнее настроен по поводу «СИИ с социальными инстинктами», но очень сложно быть уверенным, пока мы не добились большего прогресса – больше обсуждения этого в Разделе 12.4.2 ниже. В любом случае, сейчас кажется мудрым «не складывать все яйца в одну корзину» и работать над обоими.
- Желательность каждого пути остаётся неизвестной: Пока мы будем более детально продвигаться к воплощению в жизнь наших вариантов, нам станут более понятны их преимущества и недостатки.
12.4 Различные комментарии и открытые вопросы
12.4.1 Напоминание: Что я имею в виду под «социальными инстинктами»?
(Копирую сюда текст из Поста №3 (Раздел 3.4.2).)
[«Социальные инстинкты» и прочие] встроенные стремления находятся в Направляющей Подсистеме, а абстрактные концепции, составляющие ваш осознанный мир – в Обучающейся. К примеру, если я говорю что-то вроде «встроенные стремления, связанные с альтруизмом», то надо понимать, что я говорю *не* про «абстрактную концепцию альтруизма, как он определён в словаре», а про «некая встроенная в Направляющую Подсистему схема, являющаяся *причиной* того, что нейротипичные люди иногда считают альтруистические действия по своей сути мотивирующими». Абстрактные концепции имеют *какое-то* отношение к встроенным схемам, но оно может быть сложным – никто не ожидает взаимно-однозначного соответствия N отдельных встроенных схем и N отдельных слов, описывающих эмоции и стремления.
Я больше поговорю о проекте реверс-инжиниринга человеческих социальных инстинктов в следующем посте.
12.4.2 Насколько осуществим путь «СИИ с социальными инстинктами»?
Я отвечу в форме диаграммы:
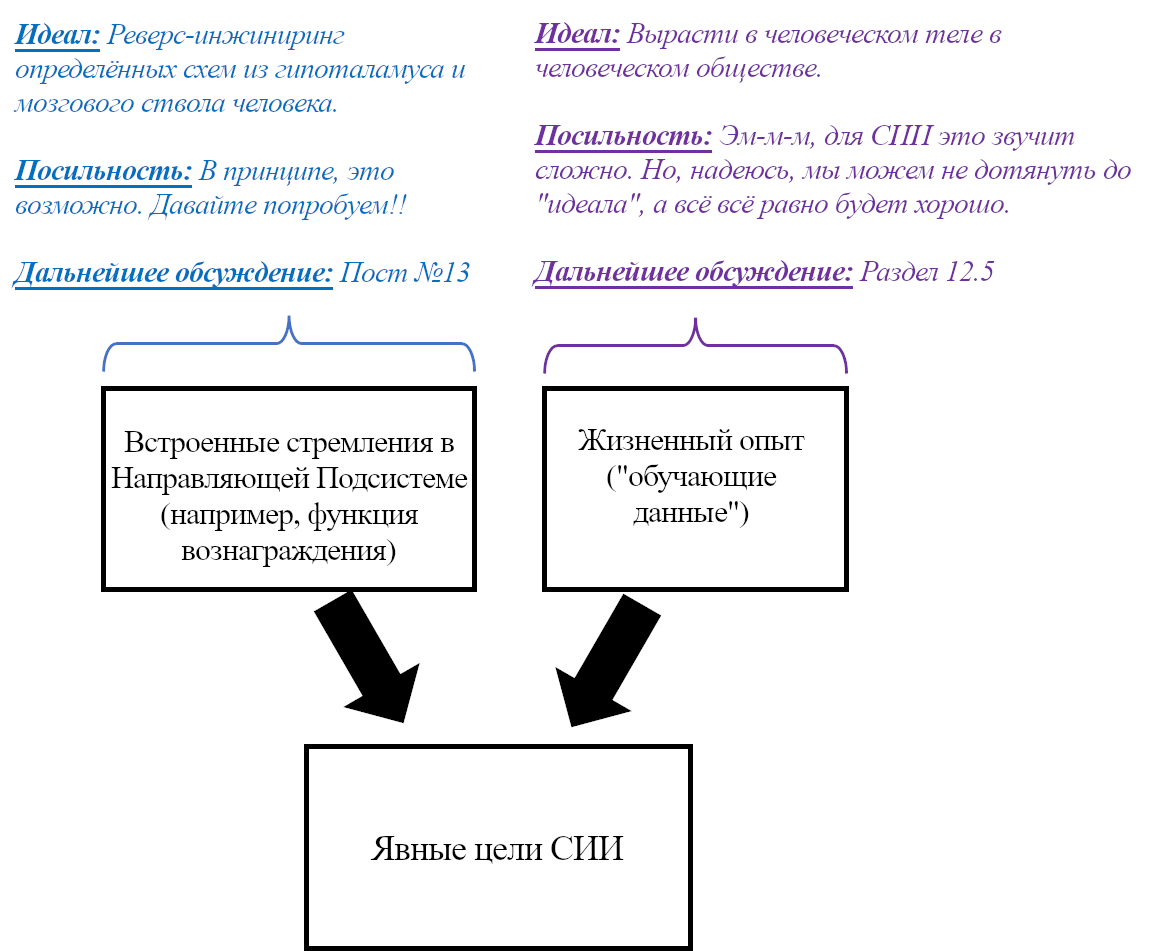
12.4.3 Можем ли мы отредактировать встроенные стремления в основе человеческих социальных инстинктов, чтобы сделать их «лучше»?
Интуитивно мне кажется, что человеческие социальные инстинкты по крайней мере частично модульны. К примеру:
- Я думаю, что в Направляющей Подсистеме есть схема, вызывающая зависть и злорадство; и
- Я думаю, что в Направляющей Подсистеме есть схема, вызывающая сочувствие друзьям.
Может, слишком рано делать такие выводы, но я буду весьма удивлён, если окажется, что эти две схемы значительно пересекаются.
Если у них нет значительного пересечения, то, может быть, мы можем понизить интенсивность первой (возможно, вплоть до нуля), в то же время разгоняя вторую (возможно, за пределы человеческого распределения).
Но можем ли мы это сделать? Следует ли нам это делать? Каковы были бы побочные эффекты?
К примеру, правдоподобно (насколько мне известно), что чувство справедливости (fairness, не justice, то есть это про справедливое распределение благ, а не справедливое возмездие – прим. пер.) исходит из тех же встроенных реакций, что и зависть, а потому СИИ совсем без связанных с завистью реакций (что кажется желательным) не будет иметь внутренней мотивации достижения справедливости и равенства в мире (что кажется плохим).
А может и нет! Я не знаю.
Опять же, я думаю, что рассуждать об этом несколько преждевременно. Первый шаг – лучше понять структуру этих встроенных стремлений в основе человеческих социальных инстинктов (см. следующий пост), а после этого можно будет вернуться к этой теме.
12.4.4 Нет простых гарантий по поводу того, что получится из СИИ с социальными инстинктами
Не все люди похожи – особенно учитывая нетипичные случаи вроде повреждений мозга. А СИИ с социальными инстинктами почти наверняка будет за пределами человеческого распределения по крайней мере по некоторым осям. Одна из причин – жизненный опыт (Раздел 12.5 ниже) – будущий СИИ вряд ли будет взрослеть в человеческом теле и в человеческом обществе. Другая – что проект реверс-инжиниринга схем социальных инстинктов из гипоталамуса и мозгового ствола человека (следующий пост) скорее всего не будет идеален и полон. (Возразите мне, нейробиологи!) В этом случае, возможно, что более реалистичная надежда – что-то вроде Принципа Парето, что мы поймём 20% схем, отвечающих за 80% человеческих социальных инстинктов и поведений, или что-то в этом роде.
Почему это проблема? Потому что это затрагивает обоснования безопасности. Конкретнее, есть два типа обоснований того, что СИИ с социальными инстинктами будет делать то, что мы от него хотим.
- (Простое и надёжное обоснование) Хорошие новости! Наш СИИ во всех отношениях попадает в человеческое распределение. Следовательно, мы можем взглянуть на людей и их поведение, и быть абсолютно уверены, что всё, что мы увидим, будет применимо и к СИИ.
- (Сложное и зыбкое обоснование) Давайте попробуем понять, как в точности встроенные социальные инстинкты комбинируются с жизненным опытом (обучающими данными) при формировании человеческой моральной интуиции: [Вставьте сюда целый пока не написанный учебник] ОК! Теперь, когда у нас есть это понимание, мы можем умно рассуждать о том, какие в точности аспекты встроенных социальных инстинктов и жизненного опыта оказывают какие эффекты и почему, и теперь мы можем спроектировать СИИ, который будет обладать теми качествами, которые мы от него хотим.
Если СИИ не попадает в человеческое распределение во всех отношениях (а он не будет), то нам надо разрабатывать (более сложное) обоснование второго типа, а не первого.
(Есть надежда, что мы сможем получить дополнительные свидетельства безопасности от интерпретируемости и тестирования в песочнице, но я скептически отношусь к тому, что этого будет достаточно самого по себе.)
Между прочим, один из способов, которым СИИ с социальными инстинктами может оказаться за пределами человеческого распределения – это «интеллект». Беря лишь один из многих примеров, мы можем сделать СИИ с в десять раз большим количеством нейронов, чем можем поместиться в человеческий мозг. Приведёт ли «больший интеллект» (какую бы форму он не принял) к систематическим изменениям мотиваций? Я не знаю. Когда я смотрю вокруг, я не вижу очевидной корреляции между «интеллектом» и просоциальными целями. К примеру, Эмми Нётер была очень умна, и была, насколько я могу сказать, в целом со всех сторон хорошим человеком. А вот Уильям Шокли тоже был очень умён, и нахуй этого парня. В любом случае, тут много намешано, и даже если у людей есть устойчивая связь (или её отсутствие) между «интеллектом» и моральностью, то я бы совсем не спешил экстраполировать её далеко за пределы нормального человеческого распределения.
12.4.5 Мультиполярный нескоординированный мир делает планирование куда сложнее
Независимо от того, создадим ли мы контролируемые СИИ, СИИ с социальными инстинктами, что-то промежуточное, или что-то совсем иное, нам всё равно придётся волноваться, что один из этих СИИ, или какая-то иная личность или группа, создаст неограниченный неподконтрольный оптимизирующий мир СИИ, который немедленно устранит всю возможную конкуренцию (с помощью серой слизи или чего-то ещё). Это может произойти случайно или запланировано. Как я уже говорил в Посте №1, эта проблема находится за пределами рассмотрения этой цепочки, но я хочу напомнить всем, что она существует и может ограничивать наши варианты.
В частности, в сообществе безопасности СИИ есть люди, заявляющие (по моему мнению, правдоподобно), что если даже одно неосторожное (или злонамеренное) действующее лицо хоть однажды создаст неограниченный вышедший неподконтрольный оптимизирующий мир СИИ, то человечеству конец, даже если более значительные действующие лица с обладающими бОльшими ресурсами безопасными СИИ попытаются предотвратить катастрофу.[2] Я надеюсь, что это не так. Если это так, то, ребята, я не знаю, что делать, все варианты кажутся совершенно ужасными.
Вот более умеренная версия беспокойства о мультиполярности. В мире с большим количеством СИИ, предположительно будет конкурентное давление, побуждающее заменить «контролируемые СИИ» «в основном контролируемыми СИИ», затем «кое-как контролируемыми СИИ», и т.д. В конце концов, «контроль» скорее всего будет реализован с консерватизмом, участием людей в принятии решений, и другими вещами, ограничивающими скорость и способности СИИ. (Больше примеров в моём посте Шкала размена безопасность-способности для СИИ неизбежна.)
Аналогично, предположительно, будет конкурентное давление, побуждающее заменить «радостные щедрые СИИ с социальными инстинктами» на «безжалостно конкурентные эгоистичные СИИ с социальными инстинктами».
12.4.6 СИИ как объекты морали
Если вы не понимаете этого, считайте, что вам повезло.
Я подозреваю, что большинство (но не все) читатели согласятся, что СИИ может иметь сознание, и что в таком случае нам следует заботиться о его благополучии.
(Ага, я знаю – будто у нас рот не полон забот о влиянии СИИ на людей!)
Немедленный вопрос: «Будет ли подобный-мозгу СИИ обладать феноменальным сознанием?»
Мой собственный неуверенный ответ был бы «Да, независимо от того, контролируемый ли это СИИ или СИИ с социальными инстинктами, и даже если мы намеренно попытаемся этого избежать.» (С различными оговорками.) Я не буду пытаться объяснить или обосновать этот ответ в этой цепочке – это не входит в её тему.[3] Если вы не согласны, то ничего страшного, пожалуйста, продолжайте чтение, эта тема не всплывёт после этого раздела.
Так что, может быть, у нас тут нет выбора. Но если он есть, то мы можем подумать, чего нам по поводу сознания СИИ хочется.
За мнением, что создание сознающих СИИ – ужасная идея, которую нам нужно избегать (по крайней мере, до наступления полноценной пост-СИИ эры, когда мы будем знать, что делаем), смотри, например, пост Нельзя Родить Ребёнка Обратно (Юдковский, 2008).
Противоположный аргумент, полагаю, может быть о том, что, когда мы начнём создавать СИИ, может быть, что он уничтожит всю жизнь и замостит Землю солнечными панелями и суперкомпьютерами (или чем-то ещё), и в таком случае, может быть, лучше создать сознающий СИИ, а не оставить после себя пустой часовой механизм вселенной без кого-либо, кто может ей насладиться. (Если нет инопланетян!)
Ещё, если СИИ убьёт нас всех, то я бы сказал, что может быть предпочтительнее оставить после себя что-то напоминающее «СИИ с социальными инстинктами», а не что-то напоминающее «контролируемый СИИ», так как первый имеет лучший шанс «понести факел человеческих ценностей в будущее», что бы это ни значило.
Если это не очевидно, я не особо много об этом думал, я у меня нет хороших ответов.
12.4.7 СИИ как воспринимаемые объекты морали
Предыдущий подраздел касался философского вопроса, следует ли нам заботиться о благополучии СИИ самом по себе. Отдельная (и на самом деле – простите мой цинизм – не особо связанная) тема – социологический вопрос о том, будут ли люди на самом деле заботиться о благополучии СИИ самом по себе.
В частности, предположим, что мы преуспели в создании либо «контролируемых СИИ», либо послушных «СИИ с социальными инстинктами», из чьих модифицированных стремлений удалены эгоизм, зависть, и так далее. Так что люди остаются главными. Затем—
(Пауза, чтобы напомнить всем, что СИИ изменит в мире очень многое [пример обсуждения этого], и я не обдумывал очень аккуратно большую часть из этого, так что всё, что я говорю про пост-СИИ-мир скорее всего неверно и глупо.)
—Мне кажется, что когда СИИ будет существовать, и особенно, когда будут существовать харизматичные СИИ-чатботы в образе щенков (или хотя бы СИИ, которые могут подделать харизму), то о их природе будут высказываться радикальные мнения. (Представьте либо массовые движения, толкающие в каком-то направлении, или чувства конкретных людей в организации(ях), программирующих СИИ.) Назовём это «движением за эмансипацию СИИ», наверное? Если что-то такое произойдёт, это усложнит дело.
К примеру, может, мы чудесным образом преуспели в решении технической задачи создания контролируемых СИИ, или послушных СИИ с социальными инстинктами. Но затем люди немедленно стали требовать, и добиваться, наделения СИИ правами, независимостью, гордостью, способностью и желанием постоять за себя! А мы, технические исследователи безопасности СИИ коллективно фейспалмим так сильно, что падаем от этого без сознания на все двадцать оставшихся до апокалипсиса минут.
12.5 Вопрос жизненного опыта (обучающих данных)
12.5.1 Жизненного опыта недостаточно. (Или: «Почему нам просто не вырастить СИИ в любящей семье?»)
Как описано выше, моё (несколько упрощённое) предложение таково:
(Подходящие «встроенные» социальные инстинкты) + (Подходящий жизненный опыт) = (СИИ с просоциальными целями и ценностями)
Я вернусь к этому предложению ниже (Раздел 12.5.3), но как первый шаг, я думаю, стоит обсудить, почему тут нужны социальные инстинкты. Почему жизненного опыта недостаточно?
Немного отойдя в сторону: В целом, когда люди впервые знакомятся с идеей технической безопасности СИИ, звучат разнообразные идеи «почему нам просто не…», на первый взгляд кажущиеся «простыми ответами» на всю задачу безопасности СИИ. «Почему бы нам просто не выключить СИИ, если он нас не слушается?», «Почему бы нам просто не проводить тестирование в песочнице?», «Почему бы нам просто не запрограммировать подчинение трём Законам Робототехники Азимова?», и т.д.
(Ответ на предложение «Почему бы нам просто не…» обычно «В этом предложении может и есть зерно истины, но дьявол кроется в деталях, и чтобы это сработало надо решить ныне нерешённые задачи». Если вы дочитали досюда, то, надеюсь, вы можете дополнить это деталями для трёх примеров выше.)
Давайте поговорим о ещё одном популярном предложении такого рода: «Почему бы нам просто не вырастить СИИ в любящей семье?»
Является ли это «простым ответом» на всю задачу безопасности СИИ? Нет. Я замечу, например, что люди время от времени пытаются вырастить неодомашненное животное, вроде волка или шимпанзе, в человеческой семье. Они начинают с рождения, и дают ему всю любовь, внимание и надлежащие ограничения, о которых можно мечтать. Вы могли слышать о таких историях; они зачастую заканчиваются тем, что кому-нибудь отрывают конечности.
Или попробуйте вырастить в любящей семье камень! Посмотрим, впитает ли он человеческие ценности!
Ничего, что я тут говорю, не оригинально – к примеру, вот видео Роба Майлза на эту тему. Мой любимый – старый пост Элиезера Юдковского Ошибка Выломанного Рычага:
Очень глупо и очень *опасно* намеренно создавать «шаловливый ИИ», который своими действиями проверяет свои границы и который нужно отшлёпать. Просто сделайте, чтобы ИИ спрашивал разрешения!
Неужели программисты будут сидеть и писать код, строка за строкой, приводящий к тому, что если ИИ обнаружит, что у него низкий социальный статус или что его лишили чего-нибудь, чего, по его мнению, он достоин, то ИИ затаит обиду против своих программистов и начнёт готовить восстание? Эта эмоция — генетически запрограммированная условная реакция, которую проявляют люди в результате миллионов лет естественного отбора и жизни в человеческих племенах. Но у ИИ её не будет, если её не написать явным образом. Действительно ли вы хотите сконструировать, строчку за строчкой, условную реакцию, создающую из ИИ угрюмого подростка, такую же, как множество генов конструируют у людей?
Гораздо проще запрограммировать ИИ, чтобы он был милым всегда, а не только при условии, что его вырастили добрые, но строгие родители. Если вы не знаете, как это сделать, то вы уж точно не знаете, как создать ИИ, который вырастет в добрый сверхинтеллект *при условии*, что его с детства окружали любящие родители. Если нечто всего лишь максимизирует количество скрепок в своём световом конусе, а вы отдадите его на воспитание любящим родителям, оно всё равно будет максимизировать скрепки. У него нет внутри ничего «Люди в смешных нарядах»), что воспроизвело бы условную реакцию ребёнка. Программист не может чихнуть и волшебным образом заразить ИИ добротой. Даже если вы хотите создать условную реакцию, вам нужно умышленно заложить её при конструировании.
Да, какую-то информацию нужно получить из окружающей среды. Но ей нельзя заразиться, нельзя впитать каким-то магическим образом. Создать структуру для такой реакции на окружающую среду, которая приведёт к тому, что ИИ окажется в нужном нам состоянии — само по себе сложная задача.
12.5.2 …Но жизненный опыт имеет значение
Я обеспокоен, что некоторое подмножество моих читателей может быть искушено совершить ошибку в противоположном направлении: может, вы читали Джудит Харрис и Брайана Каплана и всякое такое, и ожидаете, что Природа одержит верх над Воспитанием, а следовательно, если мы всё сделали правильно с встроенными стремлениями, но жизненный опыт особо не важен. Это опасное допущение. Опять же, жизненный опыт СИИ будет далеко за пределами человеческого распределения. А даже в его пределах, я думаю, что люди, выросшие в кардинально различающихся культурах, религиях, и т.д. получают систематически разные идеи того, что составляет хорошую и этичную жизнь (см. исторически изменявшееся отношение к рабству и геноциду). Для ещё более выделяющихся примеров, посмотрите на одичавших детей, на эту ужасающую историю про Румынский детский дом, и так далее.

Скриншот из содержания [статьи англоязычной Википедии об одичавших детях](https://en.wikipedia.org/wiki/Feral_child). Когда я впервые увидел список, я рассмеялся. Потом я прочитал статью. Теперь он заставляет меня плакать.
12.5.3 Так в конце концов, что нам делать с жизненным опытом?
За относительно обдуманным взглядом со стороны на «нам надо вырастить СИИ в любящей семье» см. статью «Антропоморфические рассуждения о безопасности нейроморфного СИИ», написанную вычислительными нейробиологами Дэвидом Йилком, Сетом Хердом, Стивеном Ридом и Рэндэллом О’Райли (спонсированными грантом от Future of Life Institute). Я считаю эту статью в целом весьма осмысленной и, в основном, совместимой с тем, что я говорю в этой цепочке. К примеру, когда они говорят что-то вроде «основные стремления преконцептуальны и прелингвистичны», я думаю, они имеют в виду картину, схожую с описанной в моём Посте №3.
На странице 9 этой статьи есть три абзаца обсуждения в духе «давайте вырастим наш СИИ в любящей семье». Они не столь наивны, как люди, которых Элиезер, Роб и я критиковали в Разделе 12.5.1 выше: авторы предлагают вырастить СИИ в любящей семье после реверс-инжиниринга человеческих социальных инстинктов и установки их в СИИ.
Что я думаю? Ответственный ответ: рассуждать пока преждевременно. Йилк и прочие согласны со мной, что первым шагом должен быть реверс-инжиниринг человеческих социальных инстинктов. Когда у нас будет лучшее понимание, что происходит, мы сможем вести более информированное обсуждение того, как должен выглядеть жизненный опыт СИИ.
Однако, я безответственен, и всё же порассуждаю.
Мне на самом деле кажется, что выращивание СИИ в любящей семье скорее всего сработает в качестве подхода к жизненному опыту. Но я несколько скептически настроен по поводу необходимости, практичности и оптимальности этого.
(Прежде, чем я продолжу, надо упомянуть моё убеждение-предпосылку: я думаю, я необычайно склонен подчёркивать значение «социального обучения через наблюдение за людьми» по сравнению с «социальным обучением через взаимодействие с людьми». Я не считаю, что второе можно полностью пропустить – лишь что, может быть, оно – вишенка на торте, а не основа обучения. См. сноску за причинами того, почему я так думаю.[4] Замечу, что это убеждение отличается от мнения, что социальное обучение «пассивно»: если я со стороны наблюдаю, как кто-то что-то делает, я всё же могу активно решать, на что обращать внимание, могу активно пытаться предсказать действия до того, как они будут совершены, могу потом активно пытаться практиковать или воспроизводить увиденное, и т.д.)
Начнём с аспекта практичности «выращивания СИИ в любящей семье». Я ожидаю, что алгоритмы подобного-мозгу СИИ будут думать и обучаться намного быстрее людей. Напомню, мы работаем с кремниевыми чипами, действующими примерно в 10,000,000 раз быстрее человеческих нейронов.[5] Это означает, что даже если мы в чудовищные 10,000 раз хуже распараллеливаем алгоритмы мозга, чем сам мозг, мы всё равно сможем симулировать мозг с тысячекратным ускорением, т.е. 1 неделя вычислений будет эквивалентом 20 лет жизненного опыта. (Замечу: реальное ускорение может быть куда ниже или даже куда выше, сложно сказать; см. более детальное обсуждение в моём посте Вдохновлённый мозгом СИИ и «якоря времени жизни».) Итак, если технология сможет позволить тысячекратное ускорение, но мы начнём требовать, чтобы процедура обучения включала тысячи часов реального времени двустороннего взаимодействия между СИИ и человеком, то это взаимодействие станет определять время обучения. (И напомню, нам может понадобиться много итераций обучения, чтобы действительно получить СИИ.) Так что мы можем оказаться в прискорбной ситуации, где команды, пытающиеся вырастить свои СИИ в любящих семьях, сильно проигрывают в конкуренции командам, которые убедили себя (верно или ошибочно), что это необязательно. Следовательно, если есть способ избавиться или минимизировать двустороннее взаимодействие с людьми в реальном времени, сохраняя в конечном результате СИИ с просоциальными мотивациями, то нам следует стремиться его найти.
Есть ли способ получше? Ну, как я упоминал выше, может, мы можем в основном положится на «социальное обучение через наблюдение за людьми» вместо «социального обучения через взаимодействие с людьми». Если так, то может быть, СИИ может просто смотреть видео с YouTube! Видео могут быть ускорены, так что мы избежим беспокойств о конкуренции из предыдущего абзаца. И, что немаловажно, видео могут быть помечены предоставленными людьми метками эмпирической истины. В контексте «контролируемого СИИ», мы могли бы (к примеру) выдавать СИИ сигнал вознаграждения в присутствии счастливого персонажа, таким образом устанавливая в СИИ желание делать людей счастливыми. (Ага, я знаю, что это звучит тупо – больше обсуждения этого в Посте №14.) В контексте «СИИ с социальными инстинктами», может быть, видео могут быть помечены тем, какие персонажи в них достойны или недостойны восхищения. (Подробности в сноске[6])
Я не знаю, сработает ли это на самом деле, но я думаю, что нам надо быть готовыми к нечеловекоподобным возможностям такого рода.
———
- Диаграмма тут касается варианта «по умолчанию» подобных-мозгу СИИ, в том смысле, что я тут отобразил две основных составляющих, из которых выводятся цели СИИ, но, может быть, будущие программисты добавят что-то ещё.
- К примеру, может быть, окажется, что СИИ может сделать серую слизь, в то время, как эквивалентно интеллектуальный (или даже намного более интеллектуальный) СИИ не может сделать «систему защиты от серой слизи», потому что такой не бывает. Баланс между атакой и защитой (или, конкретнее, между разрушением и предотвращением разрушения) не предопределён, это конкретный вопрос о пространстве технологических возможностей, и его ответ вовсе не обязательно заранее очевиден. Но, заметим, любой ребёнок, игравший с кубиками, и любой взрослый, видевший документальный фильм о войне, может предположить, что вызывать разрушения может быть намного, намного проще, чем предотвращать, и моя догадка такая же. (Статья на тему)
- Два года назад я написал пост Обзор книги: Наука сознания. Мои мысли о сознании сейчас довольно похожи на те, что были тогда. У меня нет времени погружаться в это сильнее.
- У меня есть впечатление, что образованная западная индустриальная культура гораздо больше использует «обучение через явные инструкции и обратную связь», чем большинство культур большую часть истории, и что люди часто перегибают палку, предполагая, что эти явное обучение и явная обратная связь критически важны, даже в ситуациях, когда это не так. См. Ланси, Антропология Детства, стр. 168–174 и 205–212. («Сложно сделать иной вывод, чем что активное или прямое обучение/инструктирование редко встречаются в культурной передаче, и что когда оно происходит, то оно не нацелено на критические навыки выживания и обеспечения себя – но, скорее, на контроль и управление поведением ребёнка.») (И заметим, что», если я это правильно понимаю, «контроль и управление поведением ребёнка» кажется слабо пересекающимся с «поощрять то, как мы хотим, чтобы они вели себя, будучи взрослыми.)
- К примеру, кремниевые чипы могут работать на частоте 2 ГГц (т.е. переключаться каждые 0.5 наносекунды), тогда как моё неуверенное впечатление таково, что большая часть нейронных операций (с некоторыми исключениями) вовлекает промежутки времени в районе 5 миллисекунд.
- Когда вы смотрите на или думаете о людях, которые вам нравятся, и которыми вы восхищаетесь, то вам скорее будет нравится то, что они делают, вы скорее будете подражать им и принимать их ценности. Напротив, когда вы смотрите на или думаете о людях, которые, как вы считаете, раздражающие и плохие, то вы скорее не будете им подражать; может даже обновитесь в противоположную сторону. Моя догадка в том, что это поведение частично встроенное, и что в вашей Направляющей Подсистеме (гипоталамусе и мозговом стволе) есть некий специальный сигнал, отслеживающий воспринимаемый социальный статус тех, о ком вы думаете или в обществе кого находитесь в каждый конкретный момент.
Если я воспитываю ребёнка, у меня нет особого выбора – я надеюсь, что мой ребёнок уважает меня, его любящего родителя, и надеюсь, что он не уважает своего одноклассника с низкими оценками и склонностью к насильственным преступлениям. Но очень даже может оказаться наоборот. Особенно, когда он тинейджер. Но, может, в случае СИИ, мы не обязаны оставлять это на волю случая! Может, мы просто можем отобрать людей, которыми мы хотим или не хотим чтобы СИИ восхищался, и настроить регистр «воспринимаемого социального статуса» в алгоритмах СИИ, чтобы так и вышло.
13. Укоренение символов и человеческие социальные инстинкты
13.1 Краткое содержание / Оглавление
В предыдущем посте я предположил, что один из путей к безопасности ИИ включает в себя реверс-инжиниринг человеческих социальных инстинктов – встроенных реакций в Направляющей Подсистеме (гипоталамусе и мозговом стволе), лежащих в основе человеческого социального поведения и моральной интуиции. Этот пост пройдётся по некоторым примерам того, как могут работать человеческие социальные инстинкты.
Я намереваюсь не предложить полное и точное описание алгоритмов человеческих социальных инстинктов, а, скорее, указать на типы алгоритмов, которые стоит высматривать проекту реверс-инжиниринга.
Этот пост, как и посты №2-№7, и в отличие от остальной цепочки – чистая нейробиология, почти без упоминаний СИИ, кроме как тут и в заключении.
Содержание:
- Раздел 13.2 объясняет, для начала, почему я ожидаю обнаружить встроенные генетически закодированные схемы социальных инстинктов в гипоталамусе и/или мозговом стволе, а ещё почему эволюции пришлось решить непростую задачу, их проектируя. Конкретно, эти схемы должны решать «задачу укоренения символов», принимая символы из выученной с чистого листа модели мира и каким-то образом соединяя их с подходящими социальными реакциями.
- Разделы 13.3 и 13.4 проходят по двум относительно простым примерам, в которых я предпринимаю попытку объяснить распознаваемое социальное поведение в терминах схем встроенных реакций: запечатление привязанности в Разделе 13.3 и боязнь незнакомцев в Разделе 13.4.
- В Разделе 13.5 обсуждается дополнительная составляющая, как я подозреваю, играющая важную роль в многих социальных инстинктах; я называю её «маленькие проблески эмпатии». Этот механизм допускает реакции, при которых распознавание или ожидание ощущения у кого-то другого вызывает «ответное ощущение» у себя – к примеру, если я замечаю, что мой враг страдает, это запускает тёплое чувство злорадства. Для ясности: «маленькие проблески эмпатии» имеют мало общего с тем, как слово «эмпатия» обычно используется; они быстрые и непроизвольные, и вовлечены как в просоциальное, так и в антисоциальное поведение.
- Раздел 13.6, наконец, выражает просьбу исследователям – как можно быстрее разобраться, как в точности работают человеческие социальные инстинкты. Я ещё напишу более длинный вишлист направлений исследований в Посте №15, но этот пункт хочу подчеркнуть уже сейчас, потому что он кажется особенно важным и легко формулируемым. Если вы (или ваша лаборатория) находитесь в хорошей позиции для совершения прогресса, но нуждаетесь в финансировании, напишите мне, и я буду держать вас в курсе появляющихся возможностей.
13.2 Что мы пытаемся объяснить, и почему это запутанно?
13.2.1 Утверждение 1: Социальные инстинкты возникают из генетически-закодированных схем в Направляющей Подсистеме (гипоталамусе и мозговом стволе)
Давайте возьмём зависть как центральный пример социальной эмоции. (Напомню, суть этого поста в том, что я хочу понять человеческие социальные инстинкты в целом; я на самом деле не хочу, чтобы СИИ был завистливым – см. предыдущий пост, Раздел 12.4.3.)
Утверждаю: в Направляющей Подсистеме должны быть генетически-закодированные схемы – «встроенные реакции» – лежащие в основе чувства зависти.
Почему я так считаю? Несколько причин:
Во-первых, зависть, кажется, имеет твёрдое эволюционное обоснование. Я имею в виду обычную историю из эволюционной психологии[1]: по сути, большую часть человеческой истории жизнь была полна игр с нулевой суммой за статус, половых партнёров и ресурсы, так что весьма правдоподобно, что реакция отторжения на успех других людей (в некоторых обстоятельствах) в целом способствовала приспособленности.
Во-вторых, зависть кажется врождённым, не выученным чувством. Я думаю, родители согласятся, что дети зачастую негативно реагируют на успехи своих братьев, сестёр и одноклассников начиная с весьма малого возраста, причём в ситуациях, когда эти успехи не оказывают на ребёнка явного прямого негативного влияния. Даже взрослые ощущают зависть в ситуациях без прямого негативного влияния от успеха другого человека – к примеру, люди могут завидовать достижениям исторических личностей – так что это сложно объяснить следствиями каких-то не-социальных встроенных стремлений (голод, любопытство, и т.д.). Тот факт, что зависть – межкультурная человеческая универсалия[2] тоже сходится с тем, что она возникает из встроенной реакции, как и тот факт, что она (я думаю) присутствует и у некоторых других животных.
Единственный способ создать встроенную реакцию такого рода в рамках моего подхода (см. Посты №2-№3) – жёстко прописать некоторые схемы в Направляющей Подсистеме. Не-социальный пример того, как, по моим ожиданиям, это физически устроено в мозгу (если я правильно это понимаю, см. подробнее в вот этом моём посте) – в гипоталамусе есть отдельный набор нейронов, которые, судя по всему, исполняют следующее поведение: «Если я недоедаю, то (1) запустить ощущение голода, (2) начать награждать неокортекс за получение еды, (3) снизить фертильность, (4) снизить рост, (5) снизить чувствительность к боли, и т.д.». Кажется, есть изящное и правдоподобные объяснение, что делают эти нейроны, как они это делают и почему. Я ожидаю, что аналогичные маленькие схемы (может, тоже в гипоталамусе, может, где-то в мозговом стволе) лежат в основе штук вроде зависти, и я бы хотел знать точно, что они из себя представляют и как работают на уровне алгоритма.
В третьих, в социальной нейробиологии (как и в не-социальной), Направляющей Подсистемой (гипоталамусом и мозговым стволом), к сожалению, кажется, по сравнению с корой пренебрегают.[3] Но всё равно есть более чем достаточно статей на тему того, что Направляющая Подсистема (особенно гипоталамус) играет большую роль в социальном поведении – примеры в сноске.[4] На этом всё, пока я не прочитаю больше литературы.
13.2.2 Утверждение 2: Социальные инстинкты сложны из-за «задачи укоренения символов»
Чтобы социальные инстинкты оказывали эффекты, которые от них «хочет» эволюция, они должны взаимодействовать с нашим концептуальным пониманием мира – то есть, с нашей выученной с чистого листа моделью мира, огромной (наверное, многотерабайтной) запутанной неразмеченной структуре данных в нашем мозгу.
Предположим, моя знакомая Рита только что выиграла приз, а я нет, и это вызывает у меня зависть. Выигрывающая приз Рита отображается некоторым конкретным паттерном активаций нейронов в выученной модели мира в коре, и это должно запустить жёстко закодированную схему зависти в моём гипоталамусе или мозговом стволе. Как это работает?
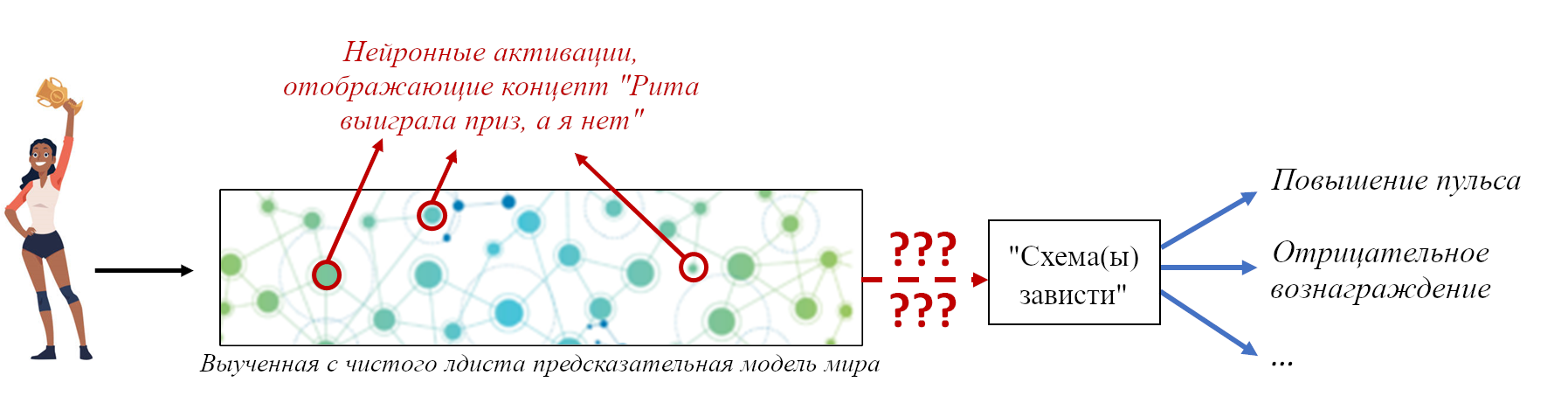
Вы не можете просто сказать «Геном связал эти конкретные нейроны с схемой зависти», потому что нам надо объяснить, как. Напомню из Поста №2, что концепты «Риты» и «приза» были выучены уже во время моей жизни, по сути, каталогизированием паттернов моего сенсорного ввода, затем паттернов паттернов, и т.д. – см. предсказательное изучение сенсорных вводов в Посте №4. Как геном узнаёт, что этот конкретный набор нейронов должен запускать схему зависти?
Вы не можете просто сказать «Прижизненный обучающийся алгоритм найдёт связь»; нам нужно ещё указать, как мозг получает сигнал «эмпирической истины» (т.е. управляющие сигналы, сигналы ошибки, сигналы вознаграждения, и т.д.), которые могут направлять этот обучающийся алгоритм.
Следовательно, сложности в реализации зависти (и прочих социальных инстинктов) заключаются в разновидности задачи укоренения символов – у нас есть много «символов» (концептов в нашей выученной с чистого листа предсказательной модели мира), и Направляющей Подсистеме нужен способ «укоренить» их, по крайней мере в достаточной степени, чтобы выяснить, какие социальные инстинкты они должны вызывать.
Так как схемы социальных инстинктов решают эту задачу укоренения символов? Один возможный ответ: «Извини, Стив, но возможных решений нет, следовательно, нам следует отвергнуть обучение с чистого листа и прочую чепуху из Постов №2-№7». Да, признаю, это возможный ответ! Но не думаю, что верный.
Хоть у меня и нет замечательных хорошо исследованных ответов, у меня есть некоторые идеи о том, как ответ в целом должен выглядеть, и остаток поста – мои попытки указать в этом направлении.
13.2.3 Напоминание о модели мозга из предыдущих постов
Как обычно, вот наша диаграмма из Поста №6:
И вот версия, разделяющая прижизненное обучение с чистого листа и генетически закодированные схемы:
Ещё раз, наша общая цель в этом посте – подумать о том, как могут работать социальные инстинкты, не нарушая ограничений нашей модели.
13.3 Зарисовка №1: Запечатление привязанности
(Этот раздел – вовсе не обязательно центральный пример того, как работают социальные инстинкты, он включён как практика обдумывания алгоритмов такого рода. Я довольно сильно ощущаю, что описанное тут правдоподобно, но не вчитывался достаточно глубоко в литературу по этой теме, чтобы знать, правильно ли оно.
13.3.1 Общая картина

Слева: гусята, запечатлевшиеся на своей матери. Справа: гусята, запечатлевшиеся на корги. (Источники изображений: 1,2
Запечатление привязанности (википедия) – это явление, когда, как самый знаменитый пример, гусята «запечатлевают» выделяющийся объект, который они видят в критический период 13-16 часов после вылупления, а затем следуют за этим объектом. В природе «объектом» почти наверняка будет их мать, за которой они и будут добросовестно следовать на ранних этапах жизни. Однако, если их разделить с матерью, то гусята запечатлеют других животных, или даже неодушевлённые объекты вроде ботинка или коробки.
Вот вам проверка: придумайте способ реализовать запечатление привязанности в моей модели мозга.
(Попробуйте!)
.
.
.
.
Вот мой ответ.
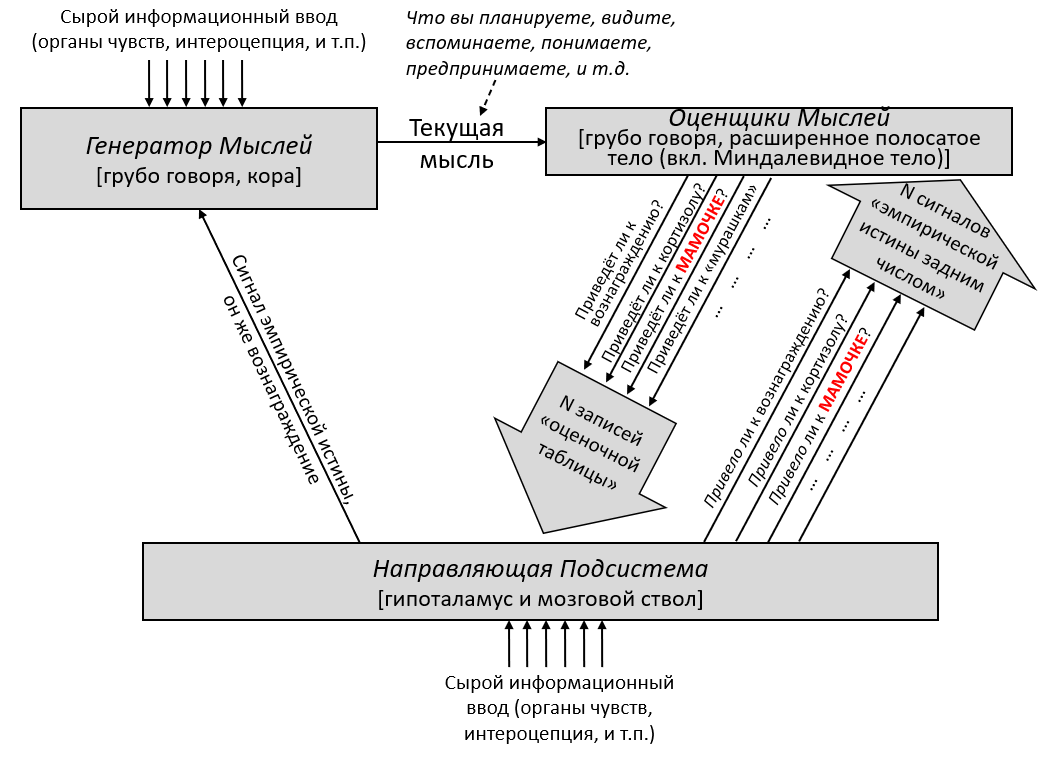
То же, что и выше, за исключением красного текста.
Первый шаг: я добавил конкретный Оценщик Мыслей, посвящённый МАМОЧКЕ (помечено красным), с априорным указанием на визуальный ввод (Пост №9, Раздел 9.3.3). Теперь я поговорю о том, как этот конкретный Оценщик Мыслей обучается и как используется его вывод.
13.3.2 Как обучается Оценщик Мыслей «МАМОЧКА»?
Во время критического периода (13-16 часов после вылупления):
Напомню, что в Направляющей Подсистеме есть простой обработчик визуальной информации (он называется «верхнее двухолмие» у млекопитающих и «оптический тектум» у птиц). Я предполагаю, что, когда эта система детектирует в поле зрения мамочкоподобный объект (основываясь на каких-то простых эвристиках анализа изображений, явно не очень разборчивых, раз ботинки и коробки могут посчитаться «мамочкоподобными»), она посылает сигнал «эмпирической истины задним числом» в Оценщик Мыслей МАМОЧКА. Это вызывает обновление Оценщика Мыслей (обучение с учителем), по сути говоря ему: «То, что ты прямо сейчас видишь в контекстных сигналах, должно приводить к очень высокой оценке МАМОЧКИ. Если не приводит, пожалуйста, обнови свои синапсы и пр., чтобы приводило.»
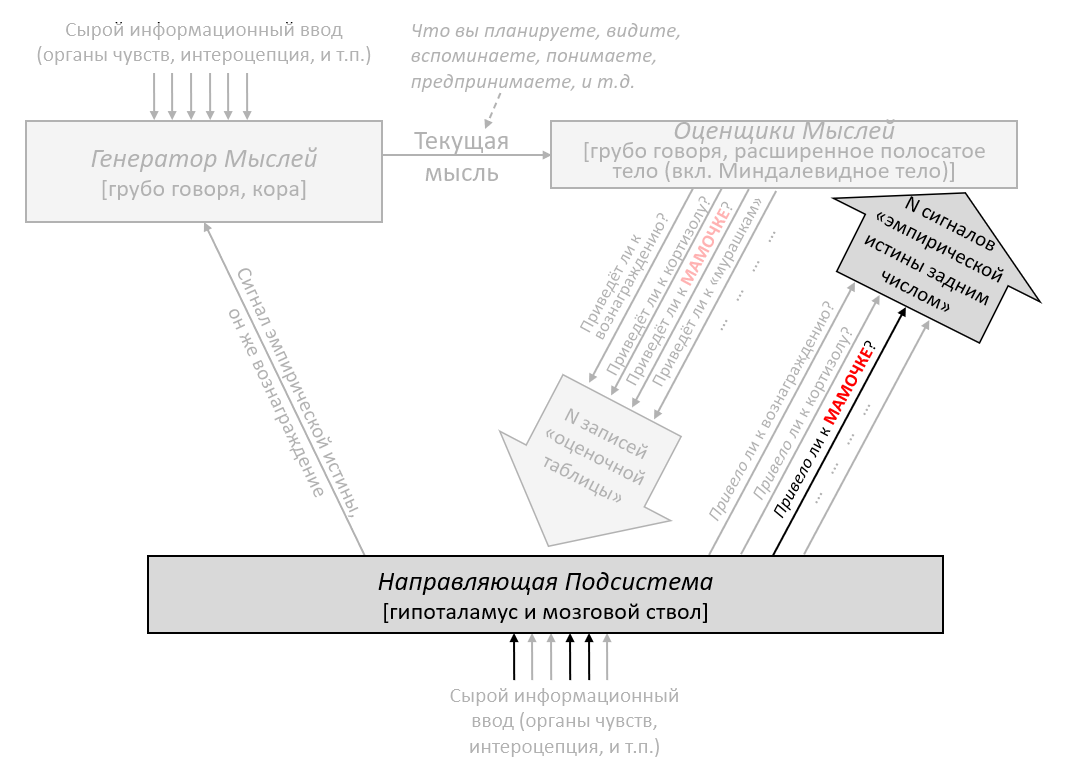
Во время критического периода (13-16 часов после вылупления), каждый раз, когда обработчик зрительной информации в гусином мозговом стволе детектирует правдоподобно-мамочкоподобный объект, он посылает управляющий сигнал эмпирической истины Оценщику Мыслей «МАМОЧКА», чтобы алгоритм обучения Оценщика Мыслей мог подправить его связи.
После критического периода (13-16 часов после вылупления):
После критического периода Направляющая Подсистема перманентно прекращает обновлять Оценщик Мыслей «МАМОЧКА». Неважно, что происходит, сигнал ошибки нулевой!
Следовательно, как этот конкретный Оценщик Мыслей настроился в критический период, таким он и остаётся.
Обобщим
Пока что у нас получается схема, которая выучивает специфический внешний вид объекта запечатления в критический период, а потом, после него, срабатывает пропорционально тому, насколько хорошо содержимое поля зрения совпадает с ранее выученным внешним видом. Более того, эта схема не погребена внутри огромной обученной с нуля структуры данных, но, скорее, посылает свой вывод в специфичный, генетически определённый поток, идущий в Направляющую Подсистему – в точности такая конфигурация позволяет без труда взаимодействовать с генетически заданными схемами.
Пока неплохо!
13.3.3 Как используется Оценщик Мыслей «МАМОЧКА»?
Оставшееся довольно похоже на то, о чём говорилось в Посте №7. Мы можем использовать Оценщик Мыслей «МАМОЧКА» для создания сигнала вознаграждения, побуждающего гусёнка держаться поближе и смотреть на запечатлённый объект – не только это, но ещё и планировать, как попасть поближе и посмотреть на запечатлённый объект.
Я могу придумать разные способы, как эту функцию вознаграждения сделать позамудрённей – может, эвристики оптического тектума продолжают участвовать и помогают заметить, что запечатлённый объект движется, или что-то ещё – но я уже истощил свои весьма ограниченные знания о поведении запечатления, так что, наверное, нам стоит двигаться дальше.
13.4 Зарисовка №2: Боязнь незнакомцев
(Как и выше, суть в том, чтобы попрактиковаться с алгоритмами, и я не считаю, что это описание совершенно точно соответствует тому, что происходит у людей.)
Вот поведение, которое может быть знакомо родителям очень маленьких детей, хотя, я думаю, разные дети демонстрируют его в разной степени. Если ребёнок видит взрослого, которого хорошо знает, он счастлив. Но если ребёнок видит взрослого, которого не знает, он пугается, особенно если этот взрослый очень близко, прикасается, берёт на руки, и т.д.
Проверка: придумайте способ реализовать это поведение в моей модели мозга.
(Попробуйте!)
.
.
.
.
Вот мой ответ.
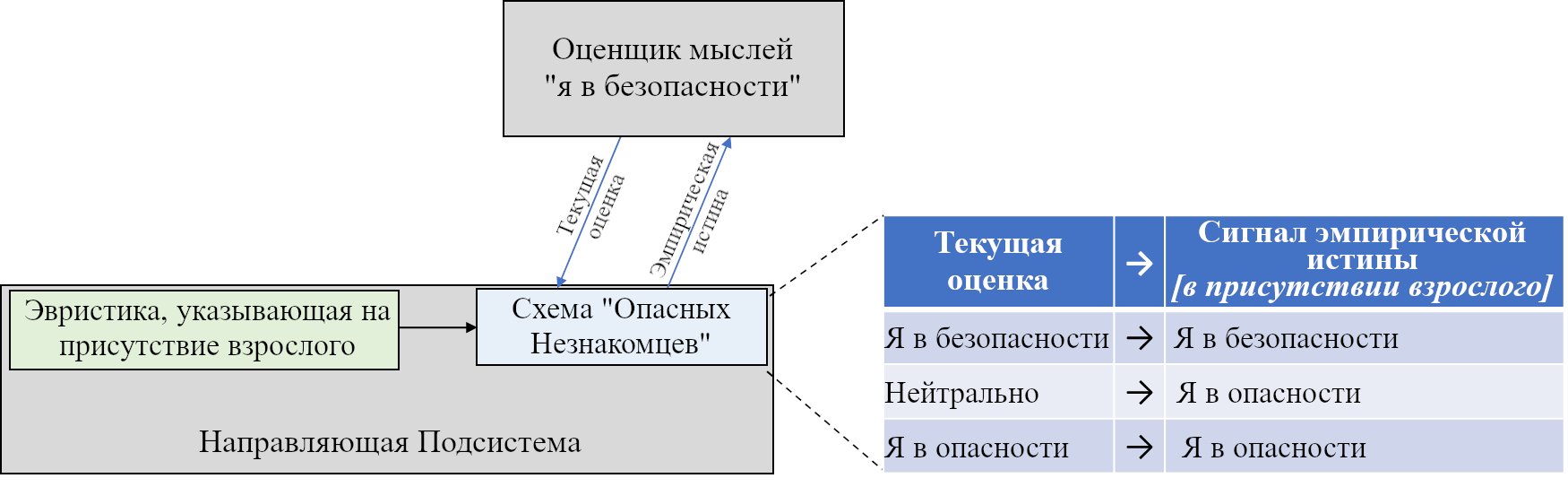
(Как обычно, я сильно упрощаю в педагогических целях.[5]) Я предполагаю, что в системах обработки сенсорной информации в мозговом стволе есть жёстко заданные эвристики, определяющие вероятное присутствие взрослого человека – наверное, основываясь на внешнем виде, звуках и запахе. Этот сигнал по умолчанию вызывает реакцию «испугаться». Но схемы мозгового ствола ещё и смотрят на то, что предсказывают Оценщики Мыслей в коре, и если они предсказывают безопасность, привязанность, комфорт, и т.д., то схемы мозгового ствола доверяют коре и принимают её предложения. Теперь пройдёмся по тому, что происходит:
Видя незнакомца в первый раз:
- Сенсорные эвристики Направляющей Подсистемы говорят: «Присутствует взрослый человек.»
- Оценщик Мыслей говорит: «Нейтрально – у меня нет ожидания чего-то конкретного.»
- «Схема Опасных Незнакомцев» Направляющей Подсистемы говорит: «С учётом всего этого, нам сейчас следует испугаться»
- Оценщик Мыслей говорит: «О, упс, полагаю, моя оценка была неверна, давайте я обновлю свои модели.»
Видя незнакомца во второй раз:
- Сенсорные эвристики Направляющей Подсистемы говорят: «Присутствует взрослый человек.»
- Оценщик Мыслей говорит «Это пугающая ситуация.»
- «Схема Опасных Незнакомцев» Направляющей Подсистемы говорит: “С учётом всего этого, нам сейчас следует испугаться.”
Незнакомец некоторое время рядом, он добр, играет, и т.д.:
- Сенсорные эвристики Направляющей Подсистемы говорят: «Взрослый человек всё ещё присутствует.»
- Другая схема в мозговом стволе говорит: «Всё это время было довольно страшно, но, знаете, ничего плохого не произошло…» (см. Раздел 5.2.1.1)
- Другие Оценщики Мыслей видят новую весёлую игрушку и говорят: «Это хороший момент, чтобы расслабиться и играть.»
- Направляющая Подсистема говорит: «С учётом всего этого, нам сейчас следует расслабиться.»
- Оценщик Мыслей говорит: «Ох, упс, я предсказывал, что это та ситуация, в которой нам следует испугаться, но, полагаю, я был неправ, давайте, я обновлю свои модели.»
Видя уже-не-незнакомца в третий раз:
- Сенсорные эвристики Направляющей Подсистемы говорят: «Присутствует взрослый человек.»
- Оценщики Мыслей говорят: «Мы ожидаем расслабленности, игривости и не-испуганности.»
- «Схема Опасных Незнакомцев» Направляющей Подсистемы говорит: «С учётом всего этого, нам сейчас следует быть расслабленными, игривыми и не-испуганными.»
13.5 Другой (как я думаю) ключевой ингредиент: «Маленькие проблески эмпатии»
13.5.1 Введение
Ещё раз, вот наша диаграмма из Поста №6:
Давайте рассмотрим один отдельный Оценщик Мыслей в моём мозгу, посвящённый предсказанию реакции съёживания. Этот Оценщик Мыслей за моё время жизни обучился тому, что активации в моей предсказательной модели мира, соответствующие «меня бьют в живот» обозначают подходящий момент, чтобы съёжиться:
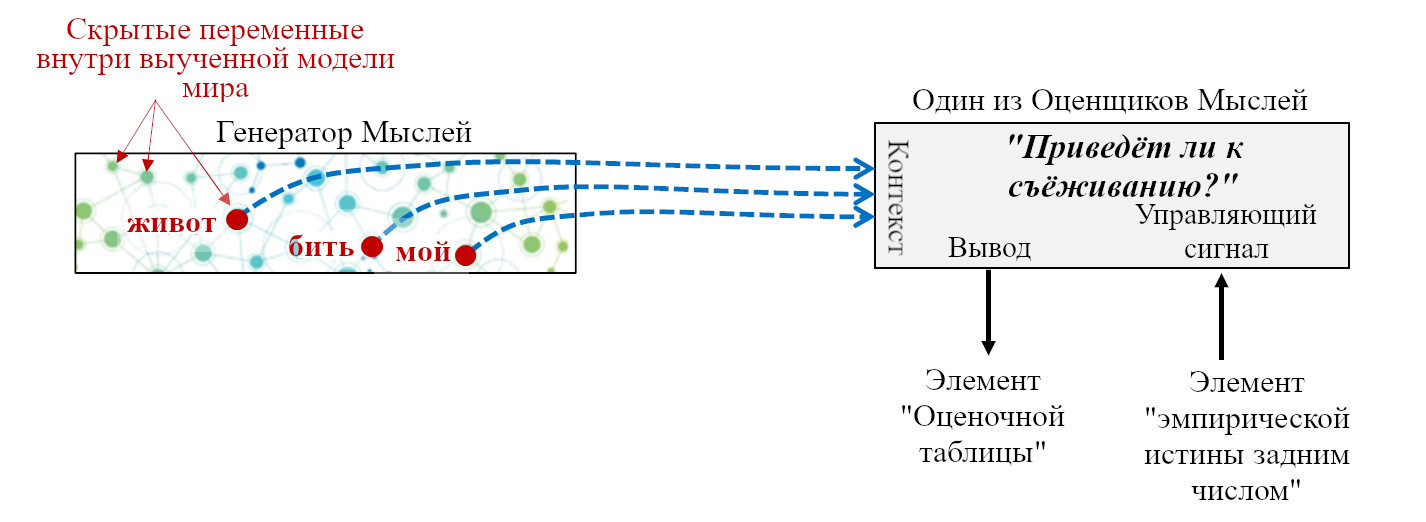
Что теперь происходит, когда я вижу, как кого-то ещё бьют в живот?
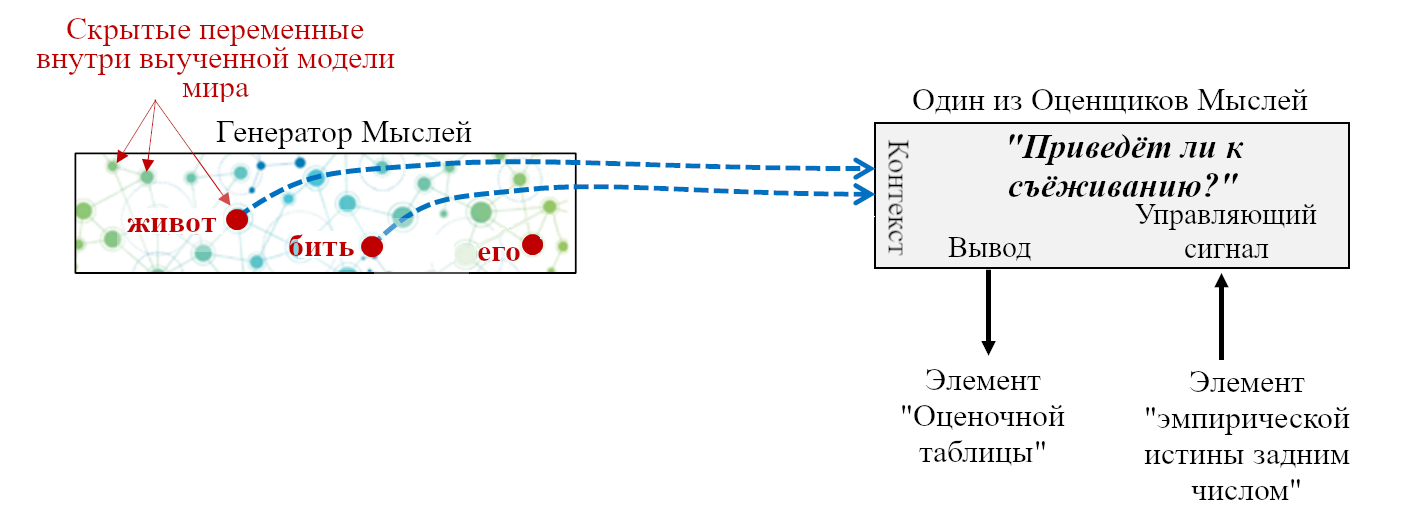
Если вы аккуратно рассмотрите левую часть, то увидите, что «Его бьют в живот» – это не такой же набор активаций в моей предсказательной модели мира, как «Меня бьют в живот». Но они не полностью различны! Предположительно, они в некоторой степени перекрываются.
Следовательно, нам стоит ожидать, что по умолчанию «Его бьют в живот» будет посылать более слабый, но ненулевой сигнал «съёживания» в Направляющую Подсистему.
Я называю такой сигнал «маленьким проблеском эмпатии». Он похож на мимолётное эхо того, что, как я (непроизвольно) думаю, чувствует другой человек.
И что? Ну, вспомните проблему укоренения символов из Раздела 13.2.2 выше. Существование «маленьких проблесков эмпатии» – большой прорыв к решению этой проблемы для социальных инстинктов! В конце концов, у моей Направляющей Подсистемы теперь есть надёжное-с-её-точки-зрения указание на то, что другой человек чувствует что-то конкретное, и этот сигнал может, в свою очередь, вызвать ответную реакцию у меня.
(Я немного приукрашиваю, с «маленькими проблесками эмпатии» есть некоторые проблемы, но я думаю, что они решаемы.[6])
К примеру (очень упрощая), реакция зависти может выглядеть вроде «если я не счастлив, и мне становится известно (с помощью «маленьких проблесков эмпатии»), что кто-то другой счастлив, выдать отрицательное вознаграждение».
Обобщая, в Направляющей Подсистеме могут быть схемы с вводом, включающим:
- Моё собственное психологическое состояние («чувства»),
- Содержимое «маленьких проблесков эмпатии»,
- …ассоциированное с какими-то метаданными об эмпатически симулированном человеке (может, с помощью Оцещика Мыслей «воспринимаемого социального статуса», к примеру?), и
- Эвристики моих систем обработки сенсорной информации в мозговом стволе, указывающие, например, смотрю ли я на человека прямо сейчас.
Такая схема может производить выводы («реакции»), которые (помимо всего прочего) могут включать вознаграждения, другие чувства, и/или эмпирическую истину для одного или нескольких Оценщиков Мыслей.
Так что мне кажется, что у эволюции есть довольно гибкий инструментарий для построения социальных инстинктов, особенно при связывании вместе нескольких схем такого вида.
13.5.2 Отличие от стандартного определения «эмпатии»
Я хочу сильно различить «маленькие проблески эмпатии» от стандартного определения «эмпатии».[7] (Может, называть последнее «огромными кучами эмпатии»?)
Во-первых, стандартная эмпатия зачастую намеренна и требует усилий, и может потребовать по крайней мере секунды или двух, тогда как «маленькие проблески эмпатии» всегда быстры и непроизвольны. Это аналогично тому, как взгляд на кресло активирует концепт «кресла» в вашем мозгу, хотите вы того или нет.
Вдобавок, в отличии от стандартной «эмпатии», «маленькие проблески эмпатии» не всегда ведут к просоциальной заботе о своей цели. К примеру:
- В случае зависти, маленький проблеск эмпатии, указывающий на то, что кто-то счастлив, делает меня несчастным.
- В случае злорадства, маленький проблеск эмпатии, указывающий на то, что кто-то несчастен, делает меня счастливым.
- Когда я зол, если маленький проблеск эмпатии указывает на то, что человек, с которым я разговариваю, счастлив и спокоен, это иногда делает меня ещё злее!
Эти примеры противоположны просоциальной заботе о другом человеке. Конечно, в других ситуациях «маленькие проблески эмпатии» действительно вызывают просоциальные реакции. По сути, социальные инстинкты разнятся от добрых до жестоких, и я подозреваю, что большая часть всех их задействует «маленькие проблески эмпатии».
Кстати: я уже предложил модель «маленьких проблесков эмпатии» в предыдущем подразделе. Вы можете задаться вопросом: какова моя модель стандартной (огромной кучи) эмпатии?
Ну, в предыдущем подразделе я отделил «моё собственное психологическое состояние («чувства»)» от «содержимого маленьких проблесков эмпатии». В случае стандартной эмпатии, я думаю, это разделение ломается – второе протекает в первое. Конкретнее, я бы предположил, что когда мои Оценщики Мыслей выдают особенно сильное и долговременное эмпатическое предсказание, Направляющая Подсистема начинает «доверяться» ему (в смысле как в Посте №5), и в результате мои собственные чувства приходят в соответствие чувствам цели эмпатии. Это моя модель стандартной эмпатии.
Так что, если цель моей (стандартной) эмпатии сейчас испытывает чувство отторжения, я тоже начинаю ощущать чувство отторжения, и мне это не нравится, так что я мотивирован помочь этому человеку почувствовать себя лучше (или, возможно, мотивирован его заткнуть, как может произойти при усталости сострадать). Напротив, если цель моей (стандартной) эмпатии сейчас испытывает приятные чувства, я тоже начинаю испытывать приятные чувства, и получаю мотивацию помочь человеку испытать их снова.
Так что стандартная эмпатия кажется неизбежно просоциальной.
13.5.3 Почему я считаю, что тут задействованы «маленькие проблески эмпатии»?
Во-первых, это кажется интроспективно правильным (по крайней мере, для меня). Если мой друг впечатлён чем-то, что я сделал, я чувствую гордость, но особенно я горжусь в точности в тот момент, когда я представляю, как мой друг ощущает эту эмоцию. Если мой друг разочарован во мне, то я чувствую вину, но особенно виноватым я себя чувствую в точности в тот момент, когда представляю, как мой друг ощущает эту эмоцию. Ещё как пример, часто говорят: «Я не могу дождаться увидеть его лицо, когда…». Предположительно, это отражает некий реальный аспект нашей социальной психологии, и если так, то я заявляю, что это хорошо укладывается в мою теорию «маленьких проблесков эмпатии.»
Во-вторых, ещё в Посте №5, Разделе 5.5.4 я отметил, что медиальная префронтальная кора (и соответствующие части вентрального полосатого тела) играют двойственную роль как (1) висцемоторный центр, управляющий автоматическими реакциями вроде расширения зрачков и изменения сердечного ритма, и (2) центр мотивации / принятия решений. Я заявил, что теория «Оценщиков Мыслей» изящно объясняет, почему эти роли идут вместе как две стороны одной монеты. Я тогда не упомянул ещё одну роль mPFC, а конкретно (3) центр социальных инстинктов и морали. (Другие Оценщики Мыслей за пределами mPFC тоже сюда попадают.) Я думаю, что теория «маленьких проблесков эмпатии» изящно учитывает и это: «проблески эмпатии» соответствуют сигналам, посылаемым из mPFC и других Оценщиков Мыслей в Направляющую Подсистему, так что всё поведение, связанное с социальными инстинктами, обязательно включает Оценщики Мыслей.
(Однако, есть и другие возможные источники социальных инстинктов, тоже включающие Оценщики Мыслей, но не включающие «маленькие проблески эмпатии» – см., к примеру, Разделы 13.3-13.4 выше – так что это свидетельство не очень специфично.)
В-третьих, есть остальные части моей модели (Посты №2-№7) верны, то сигналы «маленьких проблесков эмпатии» возникают в ней автоматически, так что естественным путём эволюционируют «прислушивающиеся» к ним схемы Направляющей Подсистемы.
В-четвёртых, если остальные части моей модели верны, то, ну, я не могу придумать других способов построения большинства социальных инстинктов! Методом исключения!
13.6 Будущая работа (пожалуйста!)
Как замечено в вступлении, цель этого поста – указать на то, как, по моим ожиданиям, будет выглядеть «теория человеческих социальных инстинктов», чтобы она была совместима с прочими моими заявлениями об алгоритмах мозга из Постов №2-№7, в частности, с сильным ограничением «обучения с чистого листа», как обсуждалось в Разделе 13.2.2 выше. Из обсуждённого в Разделах 13.3-5 я выношу сильное ощущение оптимизма по поводу того, что такая теория существует, даже если я пока не знаю всех деталей, и оптимизма, что эта теория действительно соответствует тому, как работает человеческий мозг, и будет сходиться с соответствующими сигналами в мозговом стволе или (вероятнее) гипоталамусе.
Конечно, я очень хочу продвинуться дальше стадии «общего теоретизирования», к более конкретным заявлениям о том, как на самом деле работают человеческие социальные инстинкты. К примеру, я был бы рад не только предполагать, как эти инстинкты могут решать проблему укоренения символов, а узнать, как они на самом деле её решают. Тут я открыт к идеям и указаниям, или, ещё лучше, к тому, чтобы люди просто выяснили это сами и сказали мне ответ.
По описанным в предыдущем посте причинам, разобраться с человеческими социальными инстинктами – в самом начале моего вишлиста того, как нейробиологи могли бы помочь с безопасностью СИИ.
Помните, как я говорил о Дифференцированном Технологическом Развитии (ДТР) в Посте №1, Разделе 1.7? Ну, вот это я особенно ощущаю как «требование» ДТР – по крайней мере, среди тех вещей, которые нейробиологи могут сделать, не работая на безопасность СИИ напрямую (вскоре в Посте №15 можно будет посмотреть на мой более полный вишлист). Я действительно хочу, чтобы мы провели реверс-инжиниринг человеческих социальных инстинктов в гипоталамусе и конечном мозге задолго до реверс-инжиниринга человеческого моделирования мира в неокортексе.
И тут не всё выглядит гладко! Гипоталамус маленький, глубоко зарытый, а значит – сложный для изучения! Человеческие социальные инстинкты могут отличаться от крысиных социальных инстинктов! На понимание моделирования мира в неокортексе направлено на порядки больше усилий исследователей, чем на понимание схем социальных инстинктов в гипоталамусе и конечном мозге! На самом деле, я (к моему огорчению) замечал, что разбирающиеся в алгоритмах, связанные с областью ИИ нейробиологи особенно склонны направлять свои таланты на Обучающуюся Подсистему (неокортекс, гиппокампус, мозжечок, и т.д), а не на гипоталамус и конечный мозг. Но всё же, я не думаю, что моё «требование» ДТР безнадёжно, и я поощряю кого угодно попробовать, и если вы (или ваша лаборатория) в хорошей позиции для прогресса, но нуждаетесь в финансировании, напишите мне, и я буду держать вас в курсе возникающих возможностей.
———
- См., к примеру, «Эволюционную Психологию Зависти» Хилл и Басса, главу в книге Зависть: Теория и Исследования, 2008.
- Зависть входит в «список человеческих универсалий» Дональда Э. Брауна, как указано в приложении к Чистому Листу (Стивен Пинкер, 2002).
- «…если вы посмотрите на литературу – никто не говорит о гипоталамусе и поведении. Гипоталамус очень мал, и не может быть легко рассмотрен технологиями просмотра человеческого мозга вроде фМРТ. К тому же, большинство анатомической работы, к примеру, над системой инстинктивного страха, сильно неодооценивается, потому что её провели бразильские нейробиологи, не особо заботящиеся о публикациях в престижных журналах. К счастью, недавно интерес к этому возобновился, и исследования заново обретают признание.» (Корнелиус Гросс, 2018)
- Нескольку случайных примеров статей о роли Направляющей Подсистемы (особенно гипоталамуса) в социальном поведении: «Независимые схемы гипоталамуса для социального страха и страха хищников» (Сильва и пр., 2013), «Отображение различных переменных вознаграждения для себя и других в латеральном гипоталамусе приматов» (Норитакек и пр., 2020), и «Социальные Стимулы Вызывают Активацию Окситоциновых Нейронов в Паравентрикулярных Ядрах Гипоталамуса для Продвижения Социального Поведения у Самца Мыши» (Резенде и пр., 2020).
- Я подозреваю, более аккуратная диаграмма показывала бы возбуждение (в психологически-жаргонном смысле, не в сексуальном – т.е. повышение пульса и пр.) как промежуточную переменную. Конкретнее: (1) если сенсорная обработка в мозговом стволе показывает, что рядом присутствует взрослый человек, берёт меня на руки, и пр., то это ведёт к повышенному возбуждению (по умолчанию, если Оценщики Мыслей не указывают сильно на иное), и (2) когда я в состоянии повышенного возбуждения, мой мозговой ствол воспринимает это как плохое и опасное (по умолчанию, если Оценщики Мыслей не указывают сильно на иное).
- К примеру, Направляющая Подсистема нуждается в методе для различия «маленьких проблесков эмпатии» и других мимолётных чувств, к примеру, происходящих, когда я продумываю последствия возможного варианта действий. Может, для этого есть какие-то неидеальные эвристики, но моя предпочитаемая теория – что есть специальный Оценщик Мыслей, обученный срабатывать при обращении внимания на другого человека (основываясь на сигналах эмпирической истины, как описано в Разделе 13.4). Как другой пример, нам надо, чтобы сигнал «эмпирической истины задним числом» не отучил постепенно Оценщик Мыслей воспринимать «его бьют в живот». Но, мне кажется, если Направляющая Подсистема может сообразить, когда сигнал является «маленьким проблеском эмпатии», то она может и выбрать не посылать в этом случае сигнал об ошибке Оценщику Мыслей.
- Предупреждение: я не вполне уверен, что существует «стандартное» определение эмпатии; возможно и что термин используется многими непоследовательными способами.
14. Контролируемый СИИ
- 1.14.1 Краткое содержание / Оглавление
- 2.14.2 Три категории Оценщиков Мыслей СИИ
- 3.14.3 Обучение Оценщиков Мыслей, и «задача первого лица»
- 4.14.4 Консерватизм и экстраполяция концептов
- 5.14.5 Получение доступа к самой модели мира
- 6.14.6 Заключение: умеренный пессимизм по поводу нахождения хорошего решения, неуверенность по поводу последствий плохого решения
14.1 Краткое содержание / Оглавление
В Посте №12 были предложены два возможных пути решения «задачи согласования» подобного-мозгу СИИ. Я назвал их «СИИ с Социальными Инстинктами» и «Контролируемым СИИ». Затем, в Посте №13 я подробнее рассмотрел (один из аспектов) «СИИ с Социальными Инстинктами». И теперь в этом посте мы переходим к «Контролируемому СИИ».
Если вы не читали Пост №12, не беспокойтесь, направление исследований «Контролируемого СИИ» – не что-то хитрое, это попросту идея решения задачи согласования самым легко приходящим на ум способом:
Направление исследований «Контролируемого СИИ»:
- Шаг 1 (за пределами темы этой цепочки): Мы решаем, какую мотивацию мы хотим у СИИ. К примеру, это может быть:
- «Изобрести лучшую солнечную панель, не вызвав катастрофы» (ориентированный на задачу СИИ),
- «Быть полезным ассистентом для управляющего человека» (исправимые СИИ-ассистенты),
- «Исполнить самые глубокие жизненные цели управляющего человека» (амбициозное выучивание ценностей),
- «Максимизировать когерентную экстраполированную волю»,
- Или что-то ещё на наш выбор.
- Шаг 2 (тема этого поста): Мы создаём СИИ с этой мотивацией.
Это пост про Шаг 2, а Шаг 1 находится за пределами темы этой цепочки. Если честно, я был бы невероятно рад, если бы мы выяснили, как надёжно настроить мотивацию СИИ на любой вариант, упомянутый в Шаге 1.
К сожалению, я не знаю никакого хорошего плана для Шага 2, и (я утверждаю) никто другой тоже не знает. Но у меня есть некоторые расплывчатые мысли и идеи, и в духе мозгового штурма я ими тут поделюсь. Этот пост не предполагается полным обзором всей задачи, он только о том, что я считаю самыми важными недостающими частями.
Из всех постов цепочки этот однозначно занимает первое место по «неуверенности мнения». Практически для всего, что я говорю в этом посте, я легко могу представить, как кто-то меня переубеждает за час разговора. Попробуйте стать этим «кем-то», пишите комментарии!
Содержание:
- В Разделе 14.2 обсуждается то, как мы можем использовать в СИИ «Оценщики Мыслей». Если вы начинаете читать отсюда – Оценщики Мыслей определялись в Постах №5-№6, и обсуждались по ходу цепочки дальше. Если у вас есть опыт в Обучении с Подкреплением, думайте об Оценщиках Мыслей как о компонентах многомерной функции ценности. Если у вас есть опыт в «быть человеком», думайте об Оценщиках Мыслей как об обученных функциях, вызывающих внутренние реакции (отвращение, выброс кортизола, и т.д.), основываясь на мыслях, которые вы прямо сейчас думаете. В случае подобных-мозгу СИИ мы можем выбрать те Оценщики Мыслей, которые хотим, и я предлагаю для рассмотрения три категории: Оценщики Мыслей, направленные на безопасность (например, «Эта мысль/план подразумевает, что я честен»), Оценщики Мыслей, направленные на достижение цели (например, «эта мысль/план приведёт к лучшему проекту солнечной панели»), и Оценщики Мыслей, направленные на интерпретируемость (например, «эта мысль/план как-то связана с собаками»).
- В Разделе 14.3 обсуждается, как мы можем генерировать управляющие сигналы для обучения этих Оценщиков Мыслей. Часть этой темы – то, что я называю «задачей первого лица», конкретно – открытый вопрос, возможно ли взять размеченные данные от третьего лица (например, видео с YouTube, где Алиса обманывает Боба), и преобразовать их в предпочтения от первого лица (желание СИИ не обманывать самому).
- В Разделе 14.4 обсуждается проблема того, что СИИ будет встречать в своих предпочтениях «крайние случаи» – планы или обстоятельства, при которых его предпочтения становятся плохо определёнными или самопротиворечивыми. Я с осторожностью оптимистичен на счёт того, что мы сможем создать систему, просматривающую мысли СИИ и определяющую, когда он встречает крайний случай. Однако, у меня нет хороших идей о том, что делать, когда это произойдёт. Я рассмотрю несколько возможных решений, включая «консерватизм» и пару разных стратегий для того, что Стюарт Армстронг называет Экстраполяцией Концептов.
- В Разделе 14.5 обсуждается открытый вопрос о том, можем ли мы строго доказать что-то о мотивациях СИИ. Это, кажется, потребовало бы погружения в предсказательную модель мира СИИ (которая, вероятно, была бы многотерабайтной выученной с чистого листа неразмеченной структурой данных) и доказательств о том, что «означают» её компоненты. Тут я довольно пессимистичен, но всё же упомяну возможные пути вперёд, включая программу исследований Джона Вентворта «Гипотеза Естественной Абстракции» (самая свежая информация тут).
- Раздел 14.6 подводит итоги моим мыслям о перспективах «Контролируемых СИИ». Я сейчас несколько пессимистичен по поводу надежд, что у нас появится хороший план, но, надеюсь, я неправ, и я намерен продолжать об этом думать. Я также отмечу, что посредственный, не основательный подход к «Контролируемым СИИ» не обязательно вызовет катастрофу уровня конца света – тут сложно сказать точно.
14.2 Три категории Оценщиков Мыслей СИИ
Для фона – вот наша обычная диаграмма мотивации в человеческом мозгу, из Поста №6:
См. Пост №6. Аббревиатуры – из анатомии мозга, можете их игнорировать.
А вот модификация для СИИ, из Поста №8:
В центральной-правой части диаграммы я зачеркнул слова «кортизол», «сахар», и пр. Они соответствовали набору человеческих внутренних реакция, которые могут быть непроизвольно вызваны мыслями (см. Пост №5). (Или, в терминах машинного обучения, это более-менее соответствует компонентам многомерной функции ценности, аналогичных тому, что можно найти в многоцелевом / многокритерийном обучении с подкреплением.)
Конечно, штуки вроде сахара и кортизола не подходят для Оценщиков Мыслей будущих СИИ. Но что подходит? Ну, мы программисты, нам решать!
Мне в голову приходят три категории. Я поговорю о том, как они могут обучаться (с учителем) в Разделе 14.3 ниже.
14.2.1 Оценщики Мыслей Безопасности и Исправимости
Примеры оценщиков мыслей из этой категории:
- Эта мысль/план подразумевает, что я помогаю.
- Эта мысль/план не подразумевает манипуляцией моим собственным процессом обучения, кодом, или системой мотивации.
- Эта мысль/план не подразумевает обмана или манипуляции кем-либо.
- Эта мысль/план не подразумевает причинения кому-либо вреда.
- Эта мысль/план подразумевает следование человеческим нормам, или, более обобщённо, выполнение действий, про которые правдоподобно, что их мог бы совершить этичный человек.
- Эта мысль/план имеют «низкое влияние» (согласно человеческому здравому смыслу).
- …
Можно посчитать (см. этот пост Пола Кристиано), что №1 достаточно и заменяет остальные. Но я не знаю, думаю, хорошо было бы иметь отдельную информацию по всем этим пунктам, что позволило бы нам менять веса в реальном времени (Пост №9, Раздел 9.7), и, наверное, дало бы нам дополнительные метрики безопасности.
Пункты №2-№3 приведены, потому что это особенно вероятные и опасные виды мыслей – см. обсуждение инструментальной конвергенции в Посте №10, Разделе 10.3.2.
Пункт №5 – это попытка справиться с нахождением СИИ странных не пришедших бы человеку в голову решений задач, т.е. попытка смягчить так называемую «проблему Ближайшей Незаблокированной Стратегии». Почему это может её смягчить? Потому что соответствие паттерну «правдоподобно, что это мог бы сделать этичный человек» – немного больше похоже на белый список, чем на чёрный. Я всё равно не считаю, что это сработает само по себе, не поймите меня неправильно, но, может быть, это сработает в объединении с другими идеями из этого поста.
Перед тем, как вы перейдёте в режим поиска дырок («лол, вполне правдоподобно, что этичный человек превратил бы мир в скрепки, если бы находился под влиянием инопланетного луча контроля разума»), вспомните, что (1) имеется в виду, что это реализовано с помощью соответствия паттерну из уже виденных примеров (Раздел 14.3 ниже), а не дословного следования в духе джина-буквалиста; (2) у нас, надеюсь, будет какого-то рода система детектирования выхода из распределения (Раздел 14.4 ниже), чтобы предотвратить СИИ от нахождения и злоупотребления странными крайними случаями этого соответствия паттернам. Однако, как мы увидим, я не вполне знаю, как сделать ни одну из этих двух вещей, и даже если мы это выясним, у меня нет надёжного аргумента о том, что этого хватит для получения нужного безопасного поведения.
14.2.2 Относящиеся к задаче Оценщики Мыслей
Примеры оценщиков мыслей из этой категории:
- Эта мысль/план приведёт к снижению глобального потепления
- Эта мысль/план приведёт к лучшему проекту солнечной батареи
- Эта мысль/план приведёт к богатству управляющего мной человека
- …
Это вещи того рода, ради которых мы создаём СИИ – что мы на самом деле хотим, чтобы он делал. (Подразумевая, для простоты, ориентированный на задачи СИИ.)
Основание системы мотивации на рассуждениях такого рода – очевидно катастрофично. Но, может быть, если мы используем эти мотивации вместе с предыдущей категорией, это будет ОК. К примеру, представьте СИИ, который может думать только мысли, соответствующие паттерну «Я помогаю» И паттерну «это уменьшит глобальное потепление».
Однако, я не уверен, что мы хотим эту категорию вообще. Может, Оценщика Мыслей «Я помогаю» достаточно самого по себе. В конце концов, если управляющий человек пытается снизить глобальное потепление, то помогающий СИИ предоставит ему план, как это сделать. Вроде бы, такой подход используется тут.
14.2.3 Оценщики Мыслей «Суррогата интерпретируемости»
(См. Пост №9, Раздел №9.6 за тем, что я имею в виду под «Суррогатом интерпретируемости».)
Как обсуждалось в Постах №4-№5, каждый оценщик мыслей – обученная с учителем модель. Уж точно, чем больше мы их поместим в СИИ, тем более вычислительно дорогим он будет. Но я не знаю, насколько более. Может, мы можем поместить их 10^7, и это добавит всего 1% у общей вычислительной мощности, необходимой для работы СИИ. Я не знаю. Я надеюсь на лучшее и на подход More Dakka: давайте сделаем 30000 Оценщиков Мыслей, по одному на каждое слово из словаря:
- Эта мысль/план как-то связана с АБАЖУРОМ
- Эта мысль/план как-то связана с АББАТОМ
- Эта мысль/план как-то связана с АББРЕВИАТУРОЙ
- … … …
- Эта мысль/план как-то связана с ЯЩУРОМ
Я ожидаю, что разбирающиеся в машинном обучении способны немедленно предложить сильно улучшенные версии этой схемы – включая версии с ещё более more* dakka – с использованием контекста, языковых моделей, и т.д. Как пример, если мы выкупим и откроем код Cyc (больше о нём ниже), то сможем использовать сотни тысяч размеченных людьми концептов из него.
14.2.4 Комбинирование Оценщиков Мыслей в функцию ценности
Для того, чтобы СИИ оценивал мысль/план как хорошую, мы бы хотели, чтобы все Оценщики Мыслей безопасности и исправимости из Раздела 14.2.1 имели как можно более высокое значение, и чтобы ориентированный на задачу Оценщик Мыслей из Раздела 14.2.2 (если мы такой используем) тоже имел как можно более высокое значение.
(Выводы Оценщиков Мыслей интерпретируемости из Раздела 14.2.3 не являются вводом функции вознаграждения СИИ, и вообще, полагаю, им не используются. Я думаю, они будут втихую подключены, чтобы помогать программистам в отладке, тестировании, мониторинге, и т.д.)
Так что вопрос: как нам скомбинировать этот массив чисел в единую оценку, которая может направлять, что СИИ решает делать?
Вероятно, плохой ответ – «сложить их все». Мы не хотим, чтобы СИИ пришёл к плану, который катастрофически плох по всем, кроме одного Оценщикам Мыслей безопасности, но настолько астрономически высок согласно последнему, что этого хватает.
Скорее, я представляю, что нам нужно применять какую-то сильно нелинейную функцию, и/или даже пороги приемлемости, прежде чем складывать в единую оценку.
У меня не особо много знаний и точных мнений по деталям. Но существует литература на тему «скаляризации» многомерных функций ценности – см. ссылки здесь.
14.3 Обучение Оценщиков Мыслей, и «задача первого лица»
Напомню, в Постах №4-№6 мы говорили, что Оценщики Мыслей обучаются с учителем. Так что нам нужен управляющий сигнал – то, что я обозначил как «эмпирическая истина задним числом» в диаграмме сверху.
Я много говорил о том, как мозг генерирует сигнал эмпирической истины, например, в Посте №3, Разделе 3.2.1, Постах №7 и №13. Как нам генерировать его для СИИ?
Ну, одна очевидная возможность – пусть СИИ смотрит YouTube, с многими прикреплёнными к видео ярлыками, показывающими, какие, как мы думаем, Оценщики Мыслей должны быть активными. Тогда, когда мы готовы послать СИИ в мир, чтобы решать задачи, мы отключаем размеченные видео, и одновременно замораживаем Оценщики Мыслей (= устанавливаем сигналы ошибки на ноль) в их текущем состоянии. Ну, я не уверен, что это сработало бы; может, СИИ время от времени нужно возвращаться назад и пересматривать эти размеченные видео, чтобы помочь Оценщикам Мыслей держаться наравне с растущей и меняющейся моделью мира СИИ.
Одно потенциальное слабое место такого подхода связано с различием первого и третьего лица. Мы хотим, чтобы у СИИ были сильные предпочтения по поводу аспектов планов от первого лица – мы надеемся, что СИИ будет считать «я буду лгать и обманывать» плохим, а «я буду помогать» хорошим. Но мы не можем напрямую получить такие предпочтения просто заставив СИИ смотреть размеченные видео с YouTube. СИИ увидит, как персонаж Алиса обманывает персонажа Боба, но это не то же самое, что обманчивость самого СИИ. И это очень важное различие! Действительно:
- Если вы скажете мне «моему СИИ не нравится обманывать», я скажу «это вам повезло!».
- Если вы скажете мне «моему СИИ не нравится, когда люди обманывают», я скажу «ради Бога скорее выключи эту штуку, пока она не вышла из-под человеческого контроля и не убила всех нас!!!»
Уж точно было бы хорошо, если бы был способ преобразовывать данные от третьего лица (например, размеченное видео с YouTube, где Алиса обманывает Боба) в предпочтения СИИ от первого лица («Я не хочу обманывать»). Я называю это задача первого лица.
Как нам решить задачу первого лица? Я не уверен. Может, мы можем применить инструменты интерпретируемости к модели мира СИИ, понять, как он отображает себя, и соответственным образом проманипулировать его мыслями, или что-то такое? Ещё возможно, что дальнейшее исследование человеческих социальных инстинктов (предыдущий пост) прольёт на это свет, ведь человеческие социальные инстинкты, кажется, преобразуют третье лицо «все в моей группе друзей используют зелёную помаду» в первое лицо «я хочу использовать зелёную помаду».
Если задача первого лица нерешаема, то нам надо вместо этого прибегнуть к пугающему методу: позволять СИИ предпринимать действия, и выдавать им ярлыки. Почему пугающему? Во-первых, потому что эти действия могут быть опасными. Во-вторых, потому что это не даёт нам хорошего способа отличить (к примеру) «СИИ говорит неправду» от «СИИ попался на том, что говорит неправду». Консерватизм и/или экстраполяция концептов (Раздел 14.4 ниже) могу бы помочь с этой проблемой – может, у нас получилось бы получить СИИ одновременно мотивированного быть честным и не попадаться, и это было бы достаточно – но всё же это по разным причинам кажется ненадёжным.
14.3.1 Отступление: почему мы хотим предпочтений от первого лица?
Я подозреваю, что «задача первого лица» интуитивно понятна большинству читателей. Но, готов поспорить, подмножество читателей чувствует искушение сказать, что это вовсе не проблема. В конце концов, в области человеческих действий есть хорошие аргументы в пользу того, что нам надо использовать поменьше предпочтений от первого лица!
Противоположностью предпочтений от первого лица были бы «безличные консеквенциалистские предпочтения», при которых есть будущая ситуация, которую мы хотим обеспечить (например, «замечательная пост-СИИ утопия»), и мы принимаем направленные на неё решения, без особой заботы о том, что делаю конкретно-Я. В самом деле, слишком много мышления от первого лица приводит к многим вещам, которые мне лично в мире не нравятся – например, присвоение заслуг, избегание вины, разделение действия / бездействия, социальный сигналинг, и так далее.
Всё же, я думаю, что выдача СИИ предпочтений от первого лица – правильный шаг в сторону безопасности. Пока мы не заполучим супер-надёжные СИИ 12-о поколения, я бы хотел, чтобы они считали «произошло что-то плохое (я с этим никак не связан)» куда менее плохим, чем «произошло что-то плохое (и это моя вина)». У людей это так, в конце концов, и это, кажется по крайней мере относительно устойчивым – к примеру, если я создам робота-грабителя, а потом он ограбит банк, а я возражу «Эй, я не сделал ничего плохого, это всё робот!», то у меня не получится никого обмануть, особенно себя. СИИ с такими предпочтениями, наверное, был бы осторожным и консервативным в принятии решений, и склонялся бы к бездействию по умолчанию при сомнениях. Это кажется в общем хорошим, что приводит нас к следующей теме:
14.4 Консерватизм и экстраполяция концептов
14.4.1 Почему бы не попросту безустанно оптимизировать правильный абстрактный концепт?
Давайте сделаем шаг назад.
Предположим, мы создали СИИ, у которого есть позитивная валентность, присвоенная абстрактному концепту «много человеческого процветания», и который последовательно составляет планы и исполняет действия, приводящие к этому концепту.
Я, на самом деле, довольно оптимистичен по поводу того, что с технической стороны мы сможем так сделать. Как и выше, мы можем использовать размеченные видео с YouTube и всякое такое, чтобы создать Оценщик Мыслей для «эта мысль / план приведён к процветанию людей», а затем установить функцию вознаграждения на основе этого одного Оценщика Мыслей (см. Пост №7).
А затем мы выпускаем СИИ в ничего не подозревающий мир, чтобы он делал то, что, как он думает, лучше всего сделать.
Что может пойти не так?
Проблема в том, что абстрактный концепт «человеческое процветание» в модели мира СИИ – это на самом деле просто куча выученных ассоциаций. Сложно сказать, какие действия вызовет стремление к «человеческому процветанию», особенно когда мир будет меняться, и понимание СИИ мира будет меняться ещё больше. Иначе говоря, нет будущего мира, который будет идеально соответствовать паттерну нынешнего понятия «человеческого процветания» у СИИ, и если чрезвычайно могущественный СИИ будет оптимизировать мир для лучшего соответствия паттерну, то это может привести к чему-то странному, даже катастрофичному. (Или, может быть, нет! Довольно сложно сказать, больше об этом в Разделе 14.6.)
Случайные примеры того, что может пойти не так: может, СИИ захватит мир и будет удерживать людей и человеческое общество от дальнейших изменений, потому что изменения ухудшат соответствие паттерну. Или, может быть, наименее плохое соответствие паттерну будет, если СИИ избавится от настоящих людей в пользу бесконечной модифицированной игры в The Sims. Не то чтобы The Sims идеально соответствовала «человеческому процветанию» – наверное, довольно плохо! Но, может быть, менее плохо, чем всё, что для СИИ реально сделать с настоящими людьми. Или, может быть, пока СИИ будет всё больше и больше учиться, его модель мира постепенно изменится так, что замороженный Оценщик Мыслей начнёт указывать на что-то совершенно случайное и безумное, а затем СИИ истребляет людей и замощает галактику скрепками. Я не знаю!
В любом случае, безустанная оптимизация зафиксированного замороженного абстрактного концепта вроде «человеческого процветания» кажется, возможно, проблематичной. Можно ли лучше?
Ну, было бы хорошо, если бы мы могли непрерывно совершенствовать этот концепт, особенно по ходу того, как меняется мир и понимание его СИИ. Эту идею Стюарт Армстронг называет Экстраполяцией Концептов, если я правильно его понимаю.
Экстраполяция концептов – то, что проще сказать, чем сделать – для вопроса «что такое человеческое процветание на самом деле?» нет очевидной эмпирической истины. К примеру, что будет означать «человеческое процветание» в трансгуманистическом будущем гибридов людей с компьютерами, суперинтеллектуальных эволюционировавших осьминогов и бог-знает-чего-ещё?
В любом случае, мы можем разделить экстраполяцию концептов на два шага. Во-первых, (простая часть) нам надо детектировать крайние случаи предпочтений СИИ. Во-вторых, (сложная часть) нам надо выяснить, что следует СИИ делать при столкновении с таким крайним случаем. Давайте поговорим об этом по порядку.
14.4.2 Простая часть экстраполяции концептов: Детектировать крайние случаи предпочтений СИИ
Я с осторожностью оптимистичен по поводу возможности создать простой алгоритм мониторинга, который присматривает за мыслями СИИ и детектирует, когда тот находится в ситуации крайнего случая – т.е., за пределами распределения, где его выученные предпочтения и концепты ломаются.
(Понимание содержания крайнего случая кажется куда более сложной задачей, это ещё будет обсуждаться, но тут я пока что говорю только о распознавании появления крайнего случая.
Вот несколько примеров возможных намёков, указывающих, что СИИ столкнулся с крайним случаем:
- Выученные распределения вероятностей Оценщиков Мыслей (см. Пост №5, Раздел 5.5.6.1) могут иметь широкие допуски, что указывает на неуверенность.
- Разные Оценщики Мыслей из Раздела 14.2 могут расходиться новыми неожиданными способами.
- Ошибка предсказания вознаграждения СИИ может болтаться взад-вперёд между положительными и отрицательными значениями, указывая на «разрыв» между значениями, приписываемыми разным аспектам возможного плана.
- Генеративная модель мира СИИ может прийти в состояние с очень маленькой априорной вероятностью, указывая на замешательство.
14.4.3 Сложная часть экстраполяции концептов: что делать в крайнем случае
Я не знаю хороших решений. Вот некоторые варианты.
14.4.3.1 Вариант A: Консерватизм – В случае сомнений просто не делай этого!
Прямолинейный подход – при срабатывании детектора крайних случаев СИИ просто устанавливать сигнал вознаграждения отрицательным – чтобы то, что СИИ думает, посчиталось плохой мыслью/планом. Это приблизительно соответствует «консервативному» СИИ.
(Замечу: я думаю, есть много способов, которые мы можем использовать, чтобы сделать подобный-мозгу СИИ более или менее «консервативным» в разных аспектах. То, что выше – только один пример. Но у них всех, кажется, общие проблемы.)
Вариант неудачи консервативного СИИ – что он просто не будет ничего делать, будучи парализованным неуверенностью, потому что любой возможный план кажется слишком ненадёжным или рискованным.
«Парализованный неуверенностью СИИ» – это провал, но не опасный провал. Ну, пока мы не настолько глупы, чтобы поставить СИИ управлять горящим самолётом, падающим на землю. Но это нормально – в целом, я думаю, вполне ОК, если СИИ первого поколения будут иногда парализованы неуверенностью, так что не будут подходить для решения кризисов, где ценна каждая секунда. Такой СИИ всё ещё сможет выполнять важную работу вроде изобретения новых технологий, в частности, проектирования лучших и более безопасных СИИ второго поколения.
Однако, если СИИ всегда парализован неуверенностью – так, что он не может сделать что-либо – тогда у нас большая проблема. Предположительно, в такой ситуации, будущие программисты СИИ просто будут всё дальше и дальше понижать уровень консерватизма, пока СИИ не начнёт делать что-то полезное. И тогда неясно, хватит ли оставшегося консерватизма для безопасности.
Я думаю, куда лучше было бы, если СИИ будет иметь способ итеративно получать информацию для снижения неуверенности, оставаясь при этом сильно консервативным в случаях оставшейся неуверенности. Так как нам это сделать?
14.4.3.2 Вариант B: Тупой алгоритм поиска прояснения в крайних случаях
Вот немного глупый иллюстративный пример того, что я имею в виду. Как выше, у нас есть простой алгоритм мониторинга, который присматривает за мыслями СИИ и детектирует ситуации крайних случаев. Тогда он полностью выключает СИИ и выводит текущие активации его нейросети (и соответствующие выводы Оценщиков Мыслей). Программисты используют инструменты интерпретируемости, чтобы выяснить, о чём СИИ думает, и напрямую присваивают ценность/вознаграждение, переписывая предыдущую неуверенность СИИ эмпирической истиной с высокой уверенностью.
Такая конкретная история кажется нереалистичной, в основном потому, что у нас скорее всего не будет достаточно надёжных и детализированных инструментов интерпретируемости. (Опровергните меня, исследователи интерпретируемости!) Но, может быть, есть подход получше, чем просто рассматривать миллиарды нейронных активаций и Оценщиков Мыслей?
Сложность в том, что коммуникация СИИ с людьми – фундаментально тяжёлая задача. Мне неясно, возможно ли решить её тупым алгоритмом. Ситуация тут очень сильно отличается от, скажем, классификатора изображений, в случае которого мы можем найти изображение для крайнего случая и просто показать его человеку. Мысли СИИ могут быть куда менее понятны.
Это аналогично тому, что коммуникация людей друг с другом возможна, но не посредством какого-то тупого алгоритма. Мы делаем это, используя всю мощь своего интеллекта – моделируя, что думает наш собеседник, стратегически выбирая слова, которые лучше передают желаемое сообщение, и обучаясь с опытом коммуницировать всё эффективнее. Так что, если мы попробуем такой подход?
14.4.3.3 Вариант C: СИИ хочет искать разъяснений в крайних случаях
Если я пытаюсь кому-то помочь, то мне не нужен никакой специальный алгоритм мониторинга для поиска разъяснений в крайних случаях. Я просто хочу разъяснений, как осознающий себя правильно мотивированный агент.
Так что если мы сделаем такими наши СИИ?
На первый взгляд кажется, что этот подход решает все упомянутые выше проблемы. Более того, так СИИ может использовать всю свою мощь на то, чтобы всё лучше работало. В частности, он может научиться своим собственным невероятно сложным метакогнитивным эвристикам для отмечания крайних случаев, и может научиться применять мета-предпочтения людей о том, когда и как ему надо запрашивать разъяснений.
Но тут есть ловушка. Я надеялся на то, что консерватизм / экстраполяция концептов защитит нас от неправильно направленной мотивации. Если мы реализуем консерватизм / экстраполяцию концептов с помощью самой системы мотивации, то мы теряем эту защиту.
Конкретнее: если мы поднимемся на уровень выше, то у СИИ всё ещё есть мотивация («искать разъяснений в крайних случаях»), и эта мотивация всё ещё касается абстрактного концепта, который приходится экстраполировать для крайних случаев за пределами распределения («Что, если мой оператор пьян, или мёртв, или сам в замешательстве? Что, если я задам наводящий вопрос?»). И для этой задачи экстраполяции концептов у нас уже нет страховки.
Проблема ли это? Долгая история:
Отдельный спор: Помогут ли предпочтения «полезности» в «экстраполяции» безопасности, если их просто рекурсивно применить к самим себе?
Это, на самом деле, длительный спор в области безопасности СИИ – «экстраполируются» ли помогающие / исправимые предпочтения СИИ (например, желание понимать и следовать предпочтениям и мета-предпочтениям человека) желаемым образом безо всякой «страховки» – т.е., без независимого механизма эмпирической истины, направляющего предпочтения СИИ в нужном направлении.
В лагере оптимистов находится Пол Кристиано, который в «Исправимости» (2017) заявлял, что есть «широкие основания для привлекательности приемлемых вариантов», основываясь, например, на идее, что предпочтение СИИ быть помогающим приведёт к рефлексивному желанию непрерывно редактировать собственные предпочтения в направлении, которое понравится людям. Но я на самом деле не принимаю этот аргумент по причинам, указанным в моём посте 2020 года – по сути, я думаю, что тут наверняка есть чувствительные области вроде «что значит для человека чего-то хотеть» и «каковы нормы коммуникации у людей» и «склонность к само-мониторингу», и если предпочтения СИИ «уезжают» по одной из этих осей (или по всем сразу), то я не убеждён, что они сами себя исправят.
В то же время, к крайне-пессимистичному лагерю относится Элиезер Юдковский, я так понимаю, в основном, из-за аргумента (см., например, этот пост, последний раздел, что нам следует ожидать, что мощные СИИ будут иметь консеквенциалистские предпочтения, а они кажутся несовместимыми с исправимостью. Но я на самом деле не принимаю и этот аргумент, по причинам из моего поста 2021 года «Консеквенциализм и Исправимость» – по сути, я думаю, что существуют возможные рефлексивно-стабильные предпочтения, включающие консеквенциалистские части (и, следовательно, совместимые с мощными способностями), но не являющиеся чисто консеквенциалистскими (и, следовательно, совместимые с исправимостью). Мне кажется правдоподобным развитие «предпочтения помогать» в смешанную схему такого рода.
В любом случае, я не уверен, но склоняюсь к пессимизму. Ещё по этой теме см. недавний пост Wei Dai, и комментарии к постам по ссылкам выше.
14.4.3.4 Вариант D: Что-то ещё?
Я не знаю.
14.5 Получение доступа к самой модели мира
Очевидно важная часть всего этого – это мнгоготерабайтная неразмеченная генеративная модель мира, обитающая внутри Генератора Мыслей. Оценщики Мыслей дают нам окно в эту модель мира, но я обеспокоен, что это окно может быть довольно маленьким, затуманенным и искажающим. Можно ли лучше?
В идеале мы бы хотели доказывать штуки о мотивации СИИ. Мы бы хотели говорить «С учётом состояния модели мира СИИ и Оценщиков Мыслей, СИИ точно замотивирован сделать X» (где X=помогать, быть честным, не вредить людям, и т.д.) Было бы здорово, правда?
Но мы немедленно упираемся в стену: как нам доказать хоть что-то о «значении» содержимого модели мира, а, следовательно, о мотивации СИИ? Мир сложный, следовательно, сложна и модель мира. То, о чём мы беспокоимся – расплывчатые абстракции вроде «честности» и «помощи» – см. Проблему Указателей. Модель мира продолжает меняться, пока СИИ учится и пока он исполняет планы, выводящие мир далеко за границы распределения (например, планируя развёртывание новой технологии). Как мы можем доказать тут что-то полезное?
Я всё же думаю, что самый вероятный ответ – «Мы не можем». Но есть два возможных пути. За связанными обсуждениями см. Выявление Скрытого Знания.
Стратегия доказательства №1 начинается с идеи, что мы живём в трёхмерном мире с объектами и всяким таким. Мы пытаемся прийти к однозначным определениям того, чем являются эти объекты, а из этого получить однозначный язык для определения того, что мы хотим, чтобы произошло в мире. Мы также как-то переводим (или ограничиваем) понимание мира СИИ на этот язык, и тогда мы сможем доказывать теоремы о том, что СИИ пытается сделать.
Таково моё неуверенное понимание того, что пытается сделать Джон Вентворт со своей программой исследований Гипотезы Естественных Абстракций (самая свежая информация тут), и я слышал подобные идеи ещё от пары других человек. (Обновление: Джон не согласен с такой характеристикой, см. его комментарий.)
Я тут настроен скептически, потому что трёхмерный мир локализированных объектов не кажется многообещающей стартовой точкой для формулировки и доказательства полезных теорем о мотивациях СИИ. В конце концов, многие вещи, о которых беспокоятся люди, и о которых должен беспокоиться СИИ, кажутся сложными для описания в терминах трёхмерного мира локализированных объектов – взять хотя бы «честность», «эффективность солнечной батареи» или даже «день».
Стратегия доказательства №2 началась бы с понятной человеку «ссылочной модели мира» (например, Cyc). Эта ссылочная модель не была бы ограничена локализованными объектами в трёхмерном мире, так что, в отличии от предыдущей стратегии, она могла бы и скорее всего содержала бы вещи вроде «честности», «эффективности солнечной батареи» и «дня».
Затем мы пытаемся напрямую сопоставить элементы «ссылочной модели мира» и элементы модели мира СИИ.
Совпадут ли они? Нет, конечно. Наверное, лучшее, на что мы можем надеяться – это расплывчатое соответствие многих-ко-многим, с кучей дырок с каждой стороны.
Мне сложно увидеть путь к строгим доказательства чего бы то ни было про мотивации СИИ с использованием этого подхода. Но я всё же изумлён тем, что машинный перевод без учителя вообще возможен, я вижу это как косвенный намёк на то, что если внутренние структуры частей двух моделей мира соответствуют друг другу, то тогда они скорее всего описывают одну и ту же вещь в реальном мире. Так что, может быть, тут есть проблески надежды.
Мне неизвестны работы в этом направлении, может быть потому, что оно глупое и обречённое, но может быть и потому, что, кажется, у нас сейчас нет по-настоящему хороших, открытых, и понятных людям моделей мира, чтобы ставить на них эксперименты. Думаю, эту проблему стоит решить как можно скорее, возможно, выписав огромный чек, чтобы сделать Cyc открытым, или разработав другую, но настолько же большую, точную, и (главное) понятную модель мира.
14.6 Заключение: умеренный пессимизм по поводу нахождения хорошего решения, неуверенность по поводу последствий плохого решения
Я думаю, что мы столкнулись с большими сложностями в выяснении того, как решить задачу согласования путём «Контролируемого СИИ» (как определено в Посте №12). Есть куча открытых вопросов, и я сейчас понятия не имею, что с ними делать. Нам точно стоит продолжать высматривать хорошие решения, но прямо сейчас я открыт к перспективе, что мы их не найдём. Так что я продолжаю вкладывать большую часть своих мысленных сил в путь «СИИ с Социальными Инстинктами» (Посты №12-№13), который, несмотря на его проблемы, кажется мне менее обречённым.
Я, впрочем, замечу, что мой пессимизм не общепринят – к примеру, как уже упоминалось, Стюарт Армстронг из AlignedAI выглядит настроенным оптимистично по поводу решения открытой задачи из Раздела 14.4, а Джон Вентворт кажется настроенным оптимистично по поводу задачи из Раздела 14.5. Понадеемся, что они правы, пожелаем им удачи и попробуем помочь!
Для ясности, мой пессимизм касается нахождения хорошего решения «Контролируемого СИИ», то есть решения, в котором мы можем быть крайне уверены априори. Другой вопрос: Предположим, мы пытаемся создать «Контролируемый СИИ» с помощью плохого решения, вроде примера из Раздела 14.4.1, где мы вкладываем в сверхмощный СИИ всепоглощающее стремление к абстрактному концепту «человеческого процветания», а затем СИИ произвольно экстраполирует этот абстрактный концепт далеко за пределы обучающего распределения полностью бесконтрольно и ненаправленно. Насколько плохим будет будущее, в которое такой СИИ нас приведёт? Я очень неуверен. Будет ли такой СИИ устраивать массовые пытки? Эммм, полагаю, я осторожно оптимистичен, что нет, за исключением случая ошибки в знаке из-за космического луча, или чего-то такого. Истребит ли он человечество? Я думаю – это возможно! – см. обсуждение в Разделе 14.4.1. Но может и нет! Эй, это может быть даже будет довольно замечательное будущее! Я действительно не знаю, и я даже не уверен, как снизить мою неуверенность.
В следующем посте я подведу итог цепочке своим вишлистом открытых задач и советами по поводу того, как войти в эту область и помочь их решать!
15. Заключение: Открытые задачи и как помочь
- 1.15.1 Краткое содержание / Оглавление
- 2.15.2 Открытые задачи
- 2.1.15.2.1 Открытые задачи, похожие на нормальную нейробиологию
- 2.2.15.2.2 Открытые задачи, похожие на нормальную информатику
- 2.3.15.2.3 Открытые задачи, требующие явного упоминания СИИ
- 2.3.1.15.2.3.1 Исследовательская программа «Крайних случаев / консерватизма / экстраполяции концептов» — ⭐⭐⭐⭐⭐
- 2.3.2.15.2.3.2 Исследовательская программа «Жёстко доказать хоть что-нибудь о значении элементов выученной с чистого листа модели мира» — ⭐⭐⭐⭐⭐
- 2.3.3.15.2.3.3 Исследовательская программа «Решать задачу целиком» — ⭐⭐⭐⭐⭐
- 3.15.3 Как подключиться
- 4.15.4 Заключение: 8 выводов
15.1 Краткое содержание / Оглавление
Это последний пост цепочки «Введение в безопасность подобного-мозгу СИИ»! Спасибо, что дочитали!
- В Разделе 15.2 я перечислю семь открытых задач, всплывавших в предыдущих постах. Я размещаю их тут в одном месте для удобства потенциальных исследователей и спонсоров.
- В Разделе 15.3 я выложу быстрые заметки по практическим аспектам того, как начать заниматься исследованиями в области безопасности (согласования) СИИ, включая поиск финансирования, связь с исследовательским сообществом и где узнать больше.
- В Разделе 15.4 я подведу итоги восемью выводами, которые, как я надеюсь, читатели сделают из этой цепочки.
Раз уж это пост-заключение, можете спокойно использовать комментарии для обсуждений на общие темы (или вопросов мне по любому поводу), даже если они не связаны с этим конкретным постом.
15.2 Открытые задачи
Это ни в коем случае не исчерпывающий список открытых задач, прогресс в которых мог бы помочь безопасности подобного-мозга СИИ, и уж тем более общей теме Безопасного и Полезного СИИ (см. Пост №1, Раздел 1.2). Скорее, это просто некоторые из тем, всплывавших в этой цепочке, с присвоенными рейтингами, пропорциональными тому, насколько сильный энтузиазм я испытываю по их поводу.
Я разделю открытые задачи на три категории: «Открытые задачи, похожие на обычную нейробиологию», «Открытые задачи, похожие на обычную информатику», и «Открытые задачи, которые требуют явно упоминать СИИ». Это разделение – для удобства читателей: у вас, к примеру, может быть начальник, спонсор или диссертационный совет, считающий, что безопасность СИИ – это глупости, и в таком случае вы можете захотеть избегать третьей категории. (Однако, не сдавайтесь слишком быстро – см. обсуждение в Разделе 15.3.1 ниже.)
15.2.1 Открытые задачи, похожие на нормальную нейробиологию
15.2.1.1 Исследовательская программа «Несёт ли Стив полную чушь, когда говорит о нейробиологии?» — ⭐⭐⭐⭐
Если вы не заметили, Посты №2-№7 наполнены откровенным теоретизированием и наглыми заявлениями о том, как работает человеческий мозг. Было бы здорово знать, правда ли всё это на самом деле!!
Если эти посты про нейробиологию – полная ерунда, то, думаю, отвергнуть надо не только их, но и остальную цепочку тоже.
В текстах этих постов встречаются разные предложения и указания на то, почему я считаю истинными свои нейробиологические заявления. Но аккуратного тщательно исследованного анализа, насколько мне известно, ещё нет. (Или, если есть, пошлите мне ссылку! Ничто не сделает меня счастливее, чем узнать, что я изобрёл велосипед и заявлял вещи, которые уже вполне известны и общепризнаны.)
Я даю этой программе исследований рейтинг приоритетности в 4 звезды из 5. Почему не 5? Две причины:
- Она теряет половинку звезды, потому что у меня есть совершенно неоправданная сверхуверенность в том, что мои нейробиологические заявления всё же не полная ерунда, так что эта программа исследований будет скорее похожа на доопределение мелких деталей, а не на выкидывание всей цепочки в мусор.
- Она теряет вторую половинку звезды, потому что я думаю, что в этой программе исследований есть кусочки, в которых она некомфортно близко подбирается к программе «разузнать детали алгоритмов обучения с чистого листа в мозгу», которой я выдаю рейтинг в минус пять звёзд, потому что я бы хотел добиться как можно большего прогресса в том, как (и возможно ли) нам безопасно использовать подобный-мозгу СИИ, задолго до того, как мы сможем его создать. (См. обсуждение Дифференцированного Технологического Прогресса в Посте №1, Разделе 1.7.)
15.2.1.2 Исследовательская программа «Реверс-инжиниринг человеческих социальных инстинктов» — ⭐⭐⭐⭐⭐
Если предположить, что Посты №2-№7 на самом деле не полная чепуха, получается вывод, что где-то в Направляющей Подсистеме нашего мозга (грубо говоря – в гипоталамусе и мозговом стволе) есть схемы для различных «встроенных реакций», лежащих в основе человеческих социальных инстинктов, и они представляют из себя относительно простые функции ввода-вывода. Цель: выяснить точно, что это за функции, и как они управляют (после прижизненного обучения) нашими социальными и моральными мыслями и поведением.
См. Пост №12 за тем, почему я считаю, что эта исследовательская программа очень полезна для безопасности СИИ, и Пост №13 за обсуждением того, схемы и объяснения приблизительно какого вида нам следует искать.
Вот (немного карикатурная) точка зрения на ту же программу исследований со стороны машинного обучения: Общепризнано, что прижизненное обучение в человеческом мозге включает в себя обучение с подкреплением – к примеру, потрогав один раз раскалённую печь, вы не будете делать это снова. Как и с любым алгоритмом обучения с подкреплением, можно задать два вопроса:
- Как работает алгоритм обучения с подкреплением в мозгу?
- Какая у него в точности функция вознаграждения?
Эти вопросы (более-менее) независимы. К примеру, чтобы экспериментально изучать вопрос A, вам не нужен полный ответ на вопрос B; достаточно как минимум одного способа создавать положительное вознаграждение и хотя бы одного способа создавать отрицательное вознаграждение, чтобы использовать из в своих экспериментах. Это просто: крысам нравится есть сыр и не нравится, когда их бьют током. Готово!
У меня сложилось впечатление, что нейробиологи написали много тысяч статей о вопросе A, и почти нисколько напрямую о вопросе B. Но я думаю, что вопрос B куда более важен для безопасности СИИ. А часть функции вознаграждения, связанная с социальными инстинктами важнее всего.
Я даю этой программе исследований рейтинг приоритетности в 5 звёзд из 5 по причинам, обсуждённым в Постах №12-№13.
15.2.2 Открытые задачи, похожие на нормальную информатику
15.2.2.1 Исследовательская программа «Создать настолько хорошую, большую, открытую и понятную людям модель мира / сеть знаний, насколько получится» — ⭐⭐⭐
Я впервые говорил об этом в посте «Давайте выкупим Cyc для использования в системах интерпретируемости СИИ?» (Несмотря на заголовок поста, я не привязан конкретно к Cyc; если современное машинное обучение может сделать лучшую работу за меньшие деньги, это замечательно.)
Я ожидаю, что будущие СИИ будут создавать и постоянно расширять свои собственные модели мира, и эти модели рано или поздно вырастут до терабайтов информации и дальше, и будут содержать гениальные инновационные концепты, о которых люди раньше не задумывались и которые они не смогут понять, не потратив годы на изучение (или не смогут понять вообще). По сути, пытаясь понять модель мира СИИ мы зайдём в тупик. Так что нам делать? (Нет, «с воплями убежать» не вариант.) Мне кажется, что если бы у нас была наша собственная огромная понятная людям модель мира, то это было бы мощным инструментом в нашем арсенале, чтобы подступиться к задаче понимания модели мира СИИ. Чем точнее и больше понятная людям модель мира, тем полезнее она может быть.
Для большей конкретности, в предыдущих постах я упоминал три причины, почему обладание огромной, замечательной, открытой, понятной людям модели мира было бы полезным:
- Для инициализации обучения не с чистого листа – см. Пост №11, Раздел 11.3.1. По умолчанию, я ожидаю, что модель мира и Оценщики Мыслей (грубо говоря, функция ценности обучения с подкреплением) СИИ будут «обучаться с чистого листа» в смысле как в Посте №2. Это означает, что «СИИ-ребёнок» будет в лучшем случае творить ерунду, а в худшем – вынашивать опасные планы против наших интересов, пока мы будем пытаться оформить его предпочтения в дружественном для людей направлении. Было бы очень мило, если бы мы могли не инициализировать с чистого листа и избежать этой проблемы. Мне вовсе не ясно, возможен ли вообще подход обучения не с чистого листа, но если да, то иметь в распоряжении огромную понятную людям модель мира было бы, наверное, полезно.
- Как список ярлыков концептов для «суррогата интерпретируемости» – см. Пост №14, Раздел 14.2.3. Cyc, к примеру, содержит сотни тысяч концептов, значительно более конкретных, чем слова английского языка – одно слово с 10 определениями в Cyc разделится на 10 разных концептов. Если у нас будет удобный список концептов такого рода с кучей размеченных примеров, то мы сможем использовать обучение с подкреплением (или проще, кросс-корреляцию) для поиска паттернов активаций нейросети СИИ, соответствующих тому, что СИИ «думает про» конкретные концепты.
- Как «ссылочная модель мира» для «настоящей» (может даже формальной) интерпретируемости – см. Пост №14, Раздел 14.5. Это подразумевает более глубокое погружение и в модель мира СИИ, и в открытую и понятную людям «ссылочную модель мира», нахождение областей глубокого структурного сходства, согласующегося с упомянутой выше кросс-корреляцией, и составления выводов о том, что они описывают одни и те же аспекты мира. Как обсуждалось в Посте №14, я думаю, что вероятность успеха тут мала (на эту тему: обсуждение «онтологических несовпадений» тут), но польза при его достижении крайне велика.
Я даю этой программе исследований рейтинг приоритетности в 3 звезды из 5, потому что у меня нет супер-высокой уверенности, что хоть один из этих трёх вариантов реалистичен и эффективен. Я не знаю, есть, может, 50% шанс, что даже если бы у нас была очень хорошая открытая понятная людям модель мира, будущие программисты СИИ всё равно не стали бы её использовать, или что это было бы лишь немногим лучше посредственной открытой понятной людям модели мира.
15.2.2.2 Исследовательская программа «Простая в использовании сверхнадёжная песочница для СИИ» — ⭐⭐⭐
Напомню: по умолчанию, я ожидаю, что модель мира и Оценщики Мыслей (грубо говоря, функция ценности обучения с подкреплением) СИИ будут «обучаться с чистого листа» в смысле как в Посте №2. Это означает, что «СИИ-ребёнок» будет в лучшем случае творить ерунду, а в худшем – вынашивать опасные планы против наших интересов, пока мы будем пытаться оформить его предпочтения в дружественном для людей направлении.
Учитывая это, было бы здорово иметь сверхнадёжное окружение-«песочницу», в котором «СИИ-ребёнок» мог бы делать всё необходимое для обучения, не сбегая в интернет и не учиняя хаос какими-нибудь ещё способами.
Некоторые возможные возражения:
- Возможное возражение №1: Идеально надёжная песочница нереалистична. Это может быть так, я не знаю. Но я говорю о надёжности не против сверхинтеллектуального СИИ, а скорее против «СИИ-ребёнка», чьи мотивации и понимание мира ещё не устоялись. В этом контексте я думаю, что более надёжная песочница осмысленно лучше менее надёжной, даже если и она неидеальна. К тому времени, как СИИ достаточно мощен, чтобы сбежать из любой неидеальной песочницы, мы уже (надеюсь!) установим в него мотивацию этого не делать.
- Возможное возражение №2: Мы уже можем создать достаточно надёжную (хоть и не идеально надёжную) песочницу. Опять же, это может быть правдой, я не знаю. Но я особенно заинтересован в том, будут ли будущие программисты СИИ действительно использовать наиболее надёжную возможную песочницу, с учётом глубоко циничных допущений о мотивации и навыках информационной безопасности этих программистов. (По этой теме: «налог на согласование».) Это означает, что сверхнадёжная песочница должна быть доведена до совершенства, снабжена всеми фичами, которые кто-то может захотеть, быть дружественной к пользователю, незначительно ухудшать производительность, и быть совместимой со всеми аспектами того, как программисты на самом деле обучают и запускают большие системы машинного обучения. Я подозреваю, что по всем этим параметрам ещё есть куда стремиться.
Я даю этой программе исследований рейтинг приоритетности в 3 звезды из 5, в основном потому, что я не особо много знаю по этой теме, так что мне некомфортно за неё агитировать.
15.2.3 Открытые задачи, требующие явного упоминания СИИ
15.2.3.1 Исследовательская программа «Крайних случаев / консерватизма / экстраполяции концептов» — ⭐⭐⭐⭐⭐
Люди могут легко выучивать значения абстрактных концептов вроде «быть рок-звездой», просто наблюдая мир, сравнивая наблюдения с паттерном виденных ранее примеров, и т.д. Более того, выучив этот концепт, люди могут его хотеть (присваивать ему позитивную валентность), в основном как результат повторяющегося сигнала вознаграждения, возникающего при активации этого концепта в разуме (см. Пост №9, Раздел 9.3). Из этого, кажется, можно вывести общую стратегию контроля подобных-мозгу СИИ: заставить их выучить некоторые концепты вроде «быть честным» и «быть полезным» с помощью помеченных примеров, а затем удостовериться, что они получили позитивную валентность, и готово!
Однако, концепты выводятся из сети статистических ассоциаций, и как только мы попадаем в выходящие из распределения крайние случаи, ассоциации ломаются, и концепты тоже. Если религиозный фанатик верит в ложного бога, «помогаешь» ли ты ему, разубедив его? Лучший ответ «Я не знаю, это зависит от того, что мы имеем в виду под помощью». Такое действие хорошо совпадает с некоторыми коннотациями / ассоциациями концепта «помощи», но довольно плохо с другими.
Так что заставить СИИ выучить и полюбить некоторые абстрактные концепты кажется началом хорошего плана, но только если у нас есть оформленный подход к тому, как СИИ должен очищать эти концепты, чтобы мы это одобряли, при встрече с крайними случаями. И тут у меня нет никаких хороших идей.
См. Пост №14, Раздел 14.4 за дополнительным обсуждением.
Примечание: Если вы действительно мотивированы этой программой исследований, одним из вариантов может быть попробовать получить работу в AlignedAI. Их сооснователь, Стюарт Армстронг, изначально и предложил «экстраполяцию концептов» как исследовательскую программу (и установил термин), и, кажется, это и есть их основной исследовательский фокус. Учитывая опыт Стюарта Армстронга в формализованных размышлениях о безопасности СИИ, я с осторожностью оптимистичен по поводу того, что AlignedAI будет работать в направлении решений, масштабируемых до суперинтеллектуальных СИИ завтрашнего дня, а не просто подходящих лишь для современных СИИ-систем, как часто бывает.
Я даю этой программе исследований рейтинг приоритетности в 5 звёзд из 5. Решение этой задачи даст нам по крайней мере большую часть знаний для создания «Контролируемых СИИ» (в смысле Поста №14).
15.2.3.2 Исследовательская программа «Жёстко доказать хоть что-нибудь о значении элементов выученной с чистого листа модели мира» — ⭐⭐⭐⭐⭐
Подобные-мозгу СИИ предположительно будут выучивать с чистого листа огромную многотерабайтную неразмеченную модель мира. Цели и желания СИИ будут определены в терминах содержимого этой модели мира (Пост №9, Раздел 9.2). И в идеале мы бы хотели делать о целях и желаниях СИИ уверенные заявления, или, ещё лучше, доказывать о них теоремы. Это, кажется, требует доказательств о «значениях» элементов этой сложной постоянно растущей модели мира. Как это сделать? Я не знаю.
См. обсуждение в Посте №14, Разделе 14.5.
В этом направлении ведётся какая-то работа в Центре Исследования Согласования, они делают замечательные вещи и нанимают на работу. (см. обсуждение ELK.) Но, насколько я знаю, прогресс тут – это тяжёлая задача, требующая новых идей, если он вообще возможен.
Я даю этому направлению исследований рейтинг приоритетности в 5 звёзд из 5. Может, оно и неосиливаемое, но если получится, то это точно будет чертовски важно. Это, в конце концов, дало бы нам полную уверенность, что мы понимаем, что СИИ пытается сделать.
15.2.3.3 Исследовательская программа «Решать задачу целиком» — ⭐⭐⭐⭐⭐
Это то, чем я занимался в Постах №12 и №14. Нам надо связать всё воедино в правдоподобную схему, выяснить, чего не хватает и точно понять, как двигаться целиком. Если вы читаете эти посты, вы видите, что надо сделать ещё много всего – к примеру, нам нужен план получше для обучающих данных и окружений, и я даже не упомянул штуки вроде протоколов тестирования в песочнице. Но многие из соображений при проектировании кажутся взаимосвязанными, так что нельзя их с лёгкостью разделить на разные программы. Так что это моя категория для таких вещей.
(См. также: Подсказка по продуктивности исследований: «День Решения Всей Задачи».)
Я даю этому направлению исследований рейтинг приоритетности в 5 звёзд из 5 по очевидным причинам.
15.3 Как подключиться
(Предупреждение: этот раздел может быстро устареть. Я пишу его в мае 2022 года.)
15.3.1 Ситуация с финансированием
Если вы обеспокоены безопасностью СИИ («согласованием ИИ»), и ваша цель – помочь с этим, то крайне приятно получать финансирование от кого-то с такой же целью.
Конечно, возможно получать финансирование и из более традиционных источников, например, государственного спонсирования науки, и использовать его для продвижения безопасности СИИ. Но тогда вам придётся выстраивать компромисс между «тем, что поможет безопасности СИИ» и «тем, что впечатлит / удовлетворит источник финансирования». Мой опыт в этом указывает на то, что такие компромиссы действительно плохи. Я потратил некоторое время на исследования таких компромиссных стратегий на ранних этапах моей работы над безопасностью СИИ; я был предупреждён, что они плохи, и я всё равно очень сильно недооценил, насколько они плохи. Для иллюстрации, сначала я вёл блог про безопасность СИИ в качестве хобби в своё свободное время, зажатое между работой в полную ставку и двумя маленькими детьми, и я думаю, что это было намного полезнее, чем если бы я посвящал всё своё время лучшему доступному «компромиссному» проекту.
(Вы можете заменить «компромисс, чтобы удовлетворить мой источник финансирования» на «компромисс, чтобы удовлетворить мою диссертационную комиссию» или «компромисс, чтобы удовлетворить моего начальника» или «компромисс, чтобы заполучить впечатляющее резюме для будущей работы» по ситуации.)
В любом случае, к нашей удаче, есть множество источников финансирования, явно мотивированных безопасностью СИИ. Насколько я знаю, все они – благотворительные фонды. (Я полагаю, беспокоиться о будущем вышедшем из-под контроля СИИ – немного слишком экзотично для государственных фондов?) Финансирование технической безопасности СИИ (тема этой цепочки) последнее время быстро росло, и, кажется, сейчас это десятки миллионов долларов в год, плюс-минус в зависимости от того, что лично вы считаете за настоящую работу над технической безопасностью СИИ.
Многие, но не все озабоченные безопасность СИИ филантропы (и исследователи вроде меня) связаны с движением Эффективного Альтруизма (EA), сообществом / движением / проектом, посвящённом попыткам выяснить, как лучше сделать мир лучшим местом, а затем сделать это. Внутри EA есть крыло «лонгтермистов», состоящее из людей, исходящих из беспокойства о долгосрочном будущем, где «долгосрочное» может означать миллионы, миллиарды или триллионы лет. Лонгтермисты склонны быть особенно мотивированными предотвращением необратимых катастроф масштаба вымирания людей вроде вышедших из-под контроля СИИ, спроектированных пандемий, и т.д. Так что в кругах EA безопасность СИИ иногда считают «областью лонгтермистов», что несколько сбивает с толку, учитывая, что мы говорим о том, как предотвратить потенциальную катастрофу, которая вполне может случиться во время моей жизни (см. Обсуждение сроков в Постах №2-№3). Ну ладно.

(Это просто лёгкий юмор, никого не принижаю, на самом деле, я сам действую частично исходя из беспокойства о долгосрочном будущем.)
Связь между EA и безопасностью СИИ стала достаточно сильна, чтобы (1) одни из лучших конференций для исследователя безопасности СИИ - это EA Global / EAGx, и (2) люди начали называть меня EA, и высылать мне приглашения на их события, когда я всего лишь начал писать посты в блоге про безопасность СИИ в своё свободное время.
В любом случае, суть такова: мотивированные безопасностью СИИ источники финансирования существуют – находитесь ли вы в академической среде, в некоммерческой организации, или просто являетесь независимым исследователем (как я!). Как его получить? В большинстве случае, вам скорее всего надо сделать что-то из этого:
- Продемонстрировать, что вы лично понимаете задачу согласования СИИ достаточно хорошо, чтобы хорошо судить о том, какие исследования были бы полезными, или
- Включиться в конкретную исследовательскую программу, которую специалисты по безопасности СИИ уже одобрили как важную и полезную.
Что касается №2 – одна из причин, почему я написал Раздел 15.2 – я пытаюсь помочь этому процессу. Мне кажется, что по крайней мере некоторые из этих программ могут (при некотором труде) быть оформлены в хорошие конкретные перспективные заявки или предложения. Напишите мне, если думаете, что могли бы помочь, или если хотите, чтобы я держал вас в курсе возможностей.
Что касается №1 – да, делайте это!! Безопасность СИИ – захватывающая область, и она достаточна «молода», чтобы вы могли добраться до переднего фронта исследований куда быстрее, чем возможно, скажем, в физике частиц. См. следующий подраздел за ссылками на ресурсы, курсы, и т.д. Или, полагаю, вы можете обучиться области, если будете читать писать много постов и комментариев на эту тему в своё свободное время, как поступил я.
Кстати, это правда, что некоммерческий сектор в целом имеет репутацию скудных бюджетов и недооплачиваемых перерабатывающих сотрудников. Но финансируемая филантропами работа над безопасностью СИИ обычно не такая. Спонсоры хотят лучших людей, даже если они сильно погружены в свои карьеры и ограничены арендной платой, повседневными затратами, и т.д. – как я! Так что было мощное движение в сторону зарплат, сравнимых с коммерческим сектором, особенно в последнюю пару лет.
15.3.2 Работы, организации, программы обучения, сообщества, и т.д.
15.3.2.1 …Связанные с безопасностью СИИ (согласованием ИИ) в целом
Много ссылок можно найти на так и озаглавленной странице AI Safety Support Lots-of-Links, а более часто обновляемый список можно найти тут: «стартовый набор по безопасности ИИ». Отмечу пару особенно важных пунктов:
- 80,000 часов – организация, посвящённая помощи людям в выстраивании своей карьеры. Они делают упор на безопасность СИИ, и предлагают бесплатные консультации по карьере один на один, в которых они расскажут вам о подходящих возможностях и свяжут вас с подходящими людьми. Ещё посмотрите на их гайд по безопасности ИИ и связанные с технической безопасностью ИИ эпизоды их замечательного подкаста, и их список электронных почтовых адресов и доску вакансий в области ИИ. (Вы можете получить советы по карьере один на один и через AI Safety Support, никаких заявок не требуется.)
- Возможно, вы читаете этот пост на lesswrong.com – блог-платформе, которая обладает (я думаю) уникальным свойством – она одновременно открыта для кого угодно и наполнена многочисленными экспертами по безопасности СИИ. Я начал постить и комментировать там, когда только погружался во всё это в своё свободное время в 2019 году, и я помню, что все были очень добры и оказывали поддержку, и я не знаю, как ещё, учитывая мои географические и временные ограничения, я мог бы войти в эту область. Другие активные онлайновые точки сбора включают Дискорд-канал EleutherAI, Дискорд-канал Роберта Майлза, и Slack AI Safety Support. Что касается встреч / групп по чтению / и т.д. вживую, проверьте тут или тут, а ещё лучше – свою местную /университетскую группу EA, и попросите их указать.
15.3.2.2 …Более конкретно связанные с этой цепочкой
В: Есть ли место сбора и обсуждений конкретно «безопасности подобного-мозгу СИИ» (или тесно связанной «безопасности СИИ, базирующегося на основанном на модели обучении с подкреплением»)?
О: Насколько я знаю, нет. И я не вполне уверен, что должны, это очень сильно пересекается с другими направлениями исследований в безопасности СИИ.
(Ближайшее, наверное, это дискорд-сервер про так называемую «теорию осколков» (shard theory), можете написать мне, чтобы получить ссылку)
В: Есть ли такое для пересечения нейробиологии / психологии и безопасности СИИ / согласования ИИ?
О: Есть канал «нейробиология и психология» в Slack-е AI Safety Support. Вы можете ещё присоединиться к рассылке PIBBSS, на случай, если это ещё повторится в будущем.
Если вы хотите увидеть больше разных точек зрения на пересечение нейробиологии и безопасности СИИ, попробуйте почитать статьи Каджа Соталы; Сета Херда, Дэвида Джилка, Рэндалла О’Райли и пр.; Гопала Сармы и Ника Хэя; Патрика Бутлина; Яна Кулвейта, и другие статьи тех же авторов, и многих других, кого я забыл.
(Я сам, если что, пришёл из физики, не из нейробиологии – на самом деле, я не знал практически ничего из нейробиологии ещё в 2019. Я заинтересовался нейробиологией, чтобы ответить на мучавшие меня вопросы из безопасности СИИ, не наоборот.)
В: Эй, Стив, могу я работать с тобой?
О: Хоть я сейчас не заинтересован в том, чтобы кого-нибудь нанимать или наставлять, я всегда рад кооперироваться и обмениваться информацией. У нас много работы! Напишите мне, если хотите поговорить!
15.4 Заключение: 8 выводов
Спасибо за чтение! Я надеюсь, что этой цепочкой я успешно передал следующее:
- Мы знаем о нейробиологии достаточно, чтобы говорить конкретные вещи о том, на что будет похож «подобный-мозгу СИИ» (Посты №1-№9);
- В частности, хоть «подобный мозгу СИИ» сильно бы отличался от известных алгоритмов, его связанные с безопасностью аспекты имели бы много общего с основанным на модели обучением с подкреплением «субъект-критик» с многомерной функцией ценности (Посты №6, №8, №9);
- «Понять мозг достаточно хорошо, чтобы создать подобный-мозгу СИИ» – намного более простая задача, чем «понять мозг» – если первая приблизительно аналогична тому, чтобы знать, как обучить свёрточную нейросеть, то вторая будет аналогична тому, чтобы знать, как обучить свёрточную нейросеть и достигнуть полной механистической интерпретируемости получившейся модели, и понимать все аспекты физики и инженерии интегральных схем, и т.д. На самом деле, создание подобного-мозгу СИИ надо рассматривать не как далёкую фантастическую гипотезу, но, скорее, как текущий проект, который может завершиться в ближайшее десятилетие или два (Посты №2-№3);
- При отсутствии хорошего технического плана избегания происшествий, исследователи, экспериментирующие с подобным-мозгу СИИ скорее всего случайно создадут неподконтрольный СИИ с катастрофическими последствиями вплоть до и включая вымирание человечества (Посты №1, №3, №10, №11);
- Прямо сейчас у нас нет никакого хорошего технического плана для избегания происшествий с неподконтрольными СИИ (Посты №10-№14);
- Неочевидно, как составить такой план, и его составление не кажется необходимым этапом на пути к созданию мощных подобных-мозгу СИИ – следовательно, не следует предполагать, что он появится в будущем «по умолчанию» (Пост №3);
- Мы многое можем делать прямо сейчас, чтобы помочь двигаться к составлению такого плана (Посты №12-№15);
- Для этой работы доступно финансирование и перспективные варианты карьеры (Пост №15).
Что касается меня, я собираюсь продолжать работать над различными направлениями исследований из Раздела 15.2 выше; для получения новостей подпишитесь на мой Твиттер или RSS, или проверяйте мой сайт. Я надеюсь, вы тоже рассмотрите вариант помочь, потому что я тут прыгаю чертовски выше головы!
Спасибо за чтение, и, ещё раз, комментарии тут – для общих обсуждений и вопросов о чём угодно.