Вы здесь
Главные вкладки
Встроенная Агентность. Встроенные агенты
Примечание переводчика - из-за отсутствия на сайте нужного класса для того, чтобы покрасить текст в оранжевый цвет, я заменил его фиолетовым. Фиолетовый в тексте соответствует оранжевому на картинках.
Предположим, вы хотите создать робота, чтобы он для вас достиг некоей цели в реальном мире – цели, которая требует у робота обучаться самостоятельно и выяснить много того, чего вы пока не знаете.
Это запутанная инженерная задача. Но есть ещё и задача выяснения того, что вообще означает создать такого обучающегося агента. Что такое – оптимизировать реалистичные цели в физическом окружении? Говоря обобщённо – как это работает?
В этой серии постов я покажу четыре стороны нашего непонимания того, как это работает, и четыре области активного исследования, направленных на выяснение этого.
Вот Алексей, он играет в компьютерную игру.
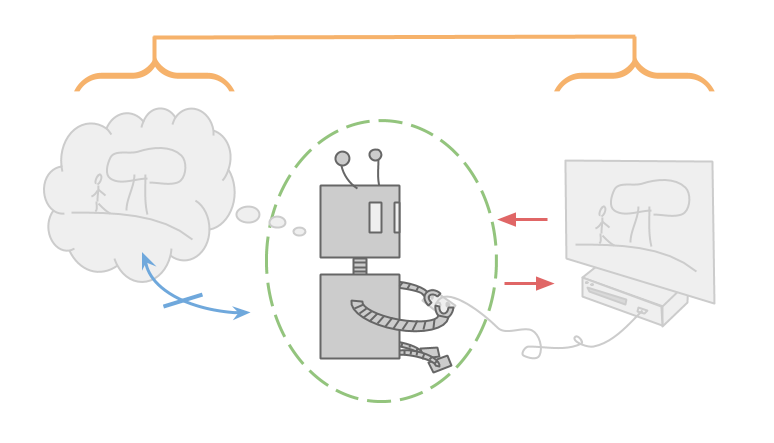
Как в большинстве игр, в этой есть явные потоки ввода и вывода. Алексей наблюдает игру только посредством экрана компьютера и манипулирует игрой только посредством контроллера.
Игру можно считать функцией, которая принимает последовательность нажатия кнопок и выводит последовательность пикселей на экране.
Ещё Алексей очень умён и способен удерживать в своей голове всю компьютерную игру. Если у Алексея и есть неуверенность, то она касается только эмпирических фактов вроде того, в какую игру он играет, а не логических фактов вроде того, какой ввод (для данной детерминированной игры) приведёт к какому выводу. Это означает, что Алексей должен хранить в своей голове ещё и каждую возможную игру, в которую он может быть играет.
Алексею, однако, нет нужды думать о самом себе. Он оптимизирует только игру, в которую он играет, и не оптимизирует мозг, который он использует, чтобы думать об игре. Он всё ещё может выбирать действия, основываясь на ценности информации, но только чтобы помочь себе сузить набор возможных игр, а не чтобы изменить то, как он думает.
На самом деле, Алексей может считать себя неизменяемым неделимым атомом. Раз он не существует в окружении, о котором он думает, Алексей не беспокоится о том, изменится ли он со временем или о подпроцессах, которые ему может понадобиться запустить.
Заметим, что все свойства, о которых я говорил, становятся возможны в частности благодаря тому, что Алексей чётко отделён от окружения, которое он оптимизирует.
Вот Эмми, она играет в реальность.
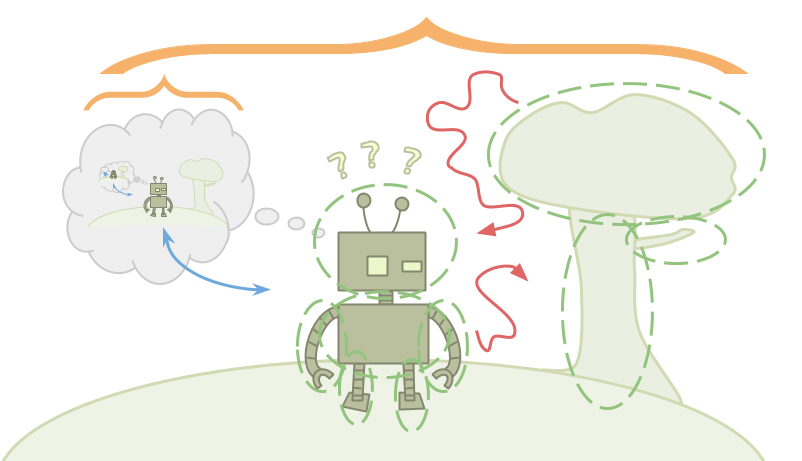
Реальность не похожа на компьютерную игру. Разница в основном вызвана тем, что Эмми находится в окружении, которое пытается оптимизировать.
Алексей видит вселенную как функцию и оптимизирует, выбирая для этой функции ввод, приводящий к более высокому вознаграждению, чем иные возможные вводы, которые он мог бы выбрать. У Эмми, напротив, нет функции. У неё есть лишь окружение, и оно её содержит.
Эмми хочет выбрать лучшее возможное действие, но то, какое действие Эмми выберет – это просто ещё один факт об окружении. Эмми может рассуждать о той части окружения, которая является её решением, но раз Эмми в итоге на самом деле выберет только одно действие, неясно, что вообще значит для Эмми «выбирать» действие, лучшее, чем остальные.
Алексей может потыкать в вселенную и посмотреть, что произойдёт. Эмми – это вселенная, тыкающая себя. Как нам в случае Эмми вообще формализовать идею «выбора»?
Мало того, раз Эмми содержится в окружении, Эмми ещё и должна быть меньше, чем окружение. Это означает, что Эмми не способна хранить в своей голове детальные точные модели окружения.
Это приводит к проблеме: Байесовские рассуждения работают, начиная с большого набора возможных окружений, и, когда вы наблюдаете факты, несовместимые с некоторыми из этих окружений, вы эти окружения отвергаете. На что похожи рассуждения, когда вы неспособны хранить даже одну обоснованную гипотезу о том, как работает мир? Эмми придётся использовать иной вид рассуждений, и совершать поправки, не вписывающиеся в стандартный Байесовский подход.
Раз Эмми находится внутри окружения, которым она манипулирует, она также будет способна на самоулучшение. Но как Эмми может быть уверена, что пока она находит и выучивает всё больше способов улучшить себя, она будет менять себя только действительно полезными способами? Как она может быть уверена, что она не модифицирует свои изначальные цели нежелательным образом?
Наконец, раз Эмми содержится в окружении, она не может считать себя подобной атому. Она состоит из тех же частей, что и остальное окружение, из-за чего она и способна думать о самой себе.
В дополнение к угрозам внешнего окружения, Эмми будет беспокоиться и об угрозах, исходящих изнутри. В процессе оптимизации Эмми может запускать другие оптимизаторы как подпроцессы, намеренно или ненамеренно. Эти подсистемы могут вызывать проблемы, если они становятся слишком мощными и не согласованными с целями Эмми. Эмми должна разобраться, как рассуждать, не запуская разумные подсистемы, или разобраться, как удерживать их слабыми, контролируемыми или полностью согласованными с её целями.
Эмми в замешательстве, так что давайте вернёмся к Алексею. Подход AIXI Маркуса Хаттера предоставляет хорошую теоретическую модель того, как работают агенты вроде Алексея:
$$a_{k}:=argmax_{a_{k}}\sum_{o_{k}r_{k}}…max_{a_{m}}\sum_{o_{m}r_{m}}[r_{k}+…+r{m}]\sum_{q:U(1,a_{1}…a_{m})=o_{1}r_{1}…o_{m}r_{m}}2^{-l(q)}$$
В этой модели есть агент и окружение, взаимодействующие посредством действий, наблюдений и вознаграждений. Агент посылает действие a, а потом окружение посылает наружу и наблюдение o, и вознаграждение r. Этот процесс повторяется в каждый момент k…m.
Каждое действие – функция всех предыдущих троек действие-наблюдение-вознаграждение. И каждое наблюдение и каждое вознаграждение аналогично является функцией этих троек и последнего действия.
Вы можете представить, что при этом подходе агент обладает полным знанием окружения, с которым он взаимодействует. Однако, AIXI используется, чтобы смоделировать оптимизацию в условиях неуверенности в окружении. AIXI обладает распределением по всем возможным вычислимым окружениям q, и выбирает действия, ведущие к высокому ожидаемому вознаграждению согласно этому распределению. Так как его интересует и будущее вознаграждение, это может привести к исследованию из-за ценности информации.
При некоторых допущениях можно показать, что AIXI довольно хорошо работает во всех вычислимых окружениях несмотря на неуверенность. Однако, хоть окружения, с которыми взаимодействует AIXI, вычислимы, сам AIXI невычислим. Агент состоит из чего-то другого рода, чего-то более мощного, чем окружение.
Мы можем назвать агентов вроде AIXI и Алексея «дуалистичными». Они существуют снаружи своего окружения и составляющие агента взаимодействуют с составляющими окружения исключительно ограниченным множеством установленных способов. Они требуют, чтобы агент был больше окружения, и не склонны к самореферентным рассуждениям, потому что агент состоит из чего-то совсем другого, чем то, о чём он рассуждает.
AIXI не одинок. Эти дуалистические допущения показываются во всех наших нынешних лучших теориях рациональной агентности.
Я выставил AIXI как что-то вроде фона, из AIXI можно и черпать вдохновение. Когда я смотрю на AIXI, я чувствую, что я действительно понимаю, как работает Алексей. Таким же пониманием я хочу обладать и об Эмми.
К сожалению, Эмми вводит в замешательство. Когда я говорю о желании получить теорию «встроенной агентности», я имею в виду, что я хочу быть способен теоретически понимать, как работают такие агенты, как Эмми. То есть, агенты, встроенные внутрь своего окружения, а следовательно:
- Не имеющие хорошо определённых каналов ввода/вывода;
- меньшие, чем своё окружение;
- способные рассуждать о себе и самоулучшаться;
- и состоящие из примерно того-же, что и окружение.
Не стоит думать об этих четырёх трудностях как об отдельных. Они очень сильно переплетены друг с другом.
К примеру, причина, по которой агент способен на самоулучшение – то, что он состоит из частей. И если окружение значительно больше агента, оно может содержать другие его копии, что отнимает у нас хорошо определённые каналы ввода/вывода.
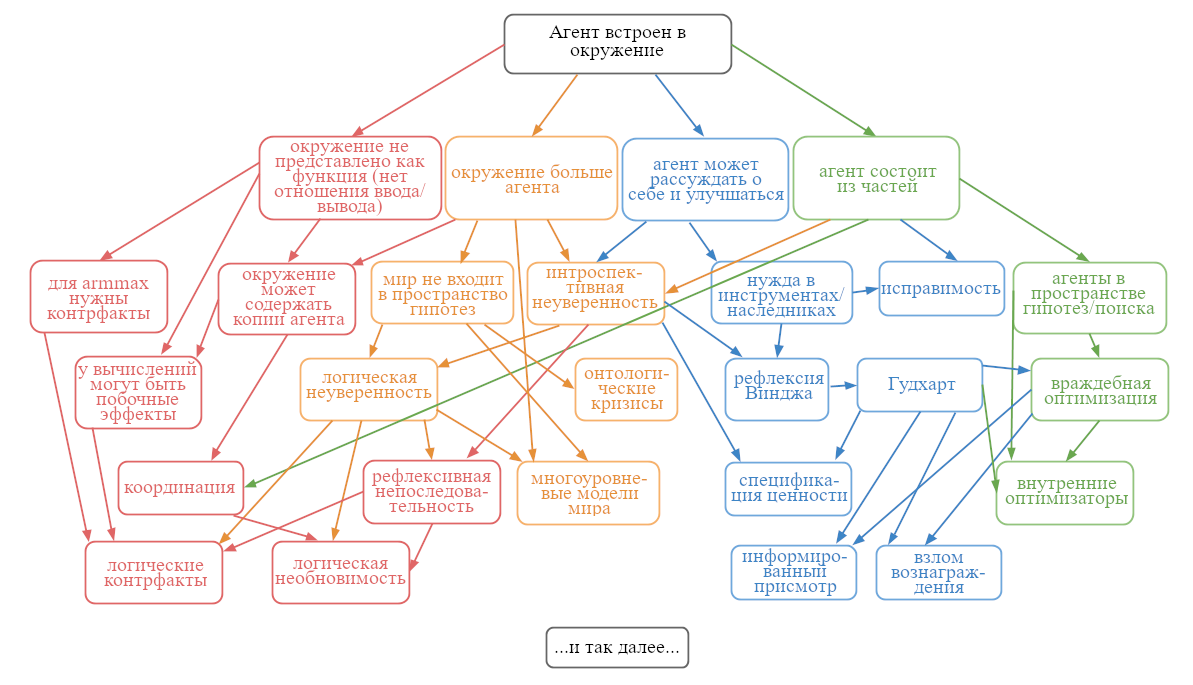
Однако, я буду использовать эти четыре трудности как мотивацию разделения темы встроенной агентности на четыре подзадачи. Это: теория принятия решений, встроенные модели мира, устойчивое делегирование, и согласование подсистем.
Теория принятия решений вся про встроенную оптимизацию.
Простейшая модель дуалистичной оптимизации - это argmax. argmax принимает функцию из действий в вознаграждения, и возвращает действие, ведущее к самому высокому вознаграждению согласно этой функции. Большую часть оптимизации можно рассматривать как вариацию этого. У вас есть некое пространство; у вас есть функция из этого пространства на некую шкалу, вроде вознаграждения или полезности; и вы хотите выбрать ввод, который высоко оценивается этой функцией.
Но мы только что сказали, что большая часть того, что значит быть встроенным агентом – это что у вас нет функционального окружения. Так что нам делать? Оптимизация явно является важной частью агентности, но мы пока даже теоретически не можем сказать, что это такое, не совершая серьёзных ошибок типизации.
Некоторые крупные открытые задачи в теории принятия решений:
- Логические контрфакты: как вам рассуждать о том, что бы произошло, если бы вы совершили действие B, при условии, что вы можете доказать, что вы вместо этого совершите действие A?
- Окружения, включающие множественные копии агента, или достоверные предсказания об агенте.
- Логическая необновимость, о том, как совместить очень изящный, но очень Байесовский мир необновимой теории принятия решений, с куда менее Байесовским миром логической неуверенности.
Встроенные модели мира о том, как вы можете составлять хорошие модели мира, способные поместиться внутри агента, который куда меньше мира.
Известно, что это очень сложно – во-первых, потому что это означает, что настоящая вселенная не находится в вашем пространстве гипотез, что разрушает многие теоретические гарантии; а во-вторых, потому что это означает, что, обучаясь, мы будем совершать не-Байесовские поправки, что тоже рушит кучу теоретических гарантий.
Ещё это о том, как создавать модели мира с точки зрения находящегося внутри него наблюдателя, и вытекающих проблем вроде антропного принципа. Некоторые крупные открытые задачи о встроенных моделях мира:
- Логическая неуверенность, о том, как совместить мир логики с миром вероятностей.
- Многоуровневое моделирование, о том, как обладать несколькими моделями одного и того же мира на разных уровнях описания и изящно переходить между ними.
- Онтологические кризисы, о том, что делать, поняв, что ваша модель, или даже ваша цель, определена не в той же онтологии, что реальный мир.
Устойчивое делегирование – про специальный вид задачи принципала-агента. У вас есть исходный агент, который хочет создать более умного наследника для помощи в оптимизации его целей. Исходный агент обладает всей властью, потому что он решает, что в точности агент-наследник будет делать. Но в другом смысле агент-наследник обладает всей властью, потому что он намного, намного умнее.
С точки зрения исходного агента, вопрос в создании наследника, который устойчиво не будет использовать свой интеллект против тебя. С точки зрения агента-наследника, вопрос в «Как тебе устойчиво выяснить и уважать цели чего-то тупого, легко манипулируемого и даже не использующего правильную онтологию?»
Ещё есть дополнительные проблемы, вытекающие из Лёбова препятствия, делающие невозможным постоянное доверие тому, что намного могущественнее тебя.
Можно думать об этих задачах в контексте агента, который просто обучается со временем, или в контексте агента, совершающего значительное самоулучшение, или в контексте агента, который просто пытается создать мощный инструмент.
Некоторые крупные открытые задачи устойчивого делегирования:
- Рефлексия Винджа – о том, как рассуждать об агентах и как доверять агентам, которые намного умнее тебя, несмотря на Лёбово препятствие доверию.
- Обучение ценностям – о том, как агент-наследник может выяснить цели исходного агента, несмотря на его глупость и непоследовательность.
- Исправимость – о том, как исходному агенту сделать так, чтобы агент-наследник допускал (или даже помогал производить) модификации себя, несмотря на инструментальную мотивацию этого не делать.
Согласование подсистем – о том, как быть одним объединённым агентом, не имеющим подсистем, сражающихся с тобой или друг с другом.
Когда у агента есть цель, вроде «спасти мир», он может потратить большое количество своего времени на мысли о подцели, вроде «заполучить денег». Если агент запускает субагента, который пытается лишь заполучить денег, то теперь есть два агента с разными целями, и это приводит к конфликту. Субагент может предлагать планы, которые выглядят так, будто они только приносят деньги, но на самом деле они уничтожают мир, чтобы заполучить ещё больше денег.
Проблема такова: вам не просто надо беспокоиться о субагентах, которых вы запускаете намеренно. Вам надо беспокоится и о ненамеренном запуске субагентов. Каждый раз, когда вы проводите поиск или оптимизацию по значительно большому пространству, которое может содержать агентов, вам надо беспокоится, что в самом пространстве тоже проводится оптимизация. Эта оптимизация может не в точности соответствовать оптимизации, которую пытается провести внешняя система, но у неё будет инструментальная мотивация выглядеть, будто она согласована.
Много оптимизации на практике использует передачу ответственности такого рода. Вы не просто находите решение, вы находите что-то, что само может искать решение.
В теории, я вовсе не понимаю, как оптимизировать иначе, кроме как методами, выглядящими вроде отыскивания кучи штук, которых я не понимаю, и наблюдения, не исполнят ли они мою цель. Но это в точности то, что наиболее склонно к запуску враждебных подсистем.
Большая открытая задача в согласовании подсистем – как сделать, чтобы оптимизатор базового уровня не запускал враждебные оптимизаторы. Можно разбить эту задачу на рассмотрение случаев, когда оптимизаторы получаются намеренно и ненамеренно, и рассмотреть ограниченные подклассы оптимизации, вроде индукции.
Но помните: теория принятия решений, встроенные модели мира, устойчивое делегирование и согласование подсистем – не четыре отдельных задачи. Они все разные подзадачи единого концепта встроенной агентности.
Вторая часть: Теория принятия решений.
- Короткая ссылка сюда: lesswrong.ru/3004