Вы здесь
Главные вкладки
Обзор катастрофических рисков ИИ: 4. Организационные риски
4. Организационные риски
В январе 1986 года десятки миллионов человек следили за запуском шаттла Челленджер. Примерно через 73 секунды после взлёта шаттл взорвался и все на борту погибли. Это трагично само по себе, но вдобавок одним из членов экипажа была школьная учительница Криста Маколифф. Она была выбрана проектом НАСА «Учитель в космосе» из более чем десяти тысяч претендентов, чтобы стать первым учителем в космосе. В результате, миллионы из зрителей были школьниками. У НАСА были лучшие учёные и инженеры в мире, и если была миссия, которую НАСА особенно хотели не провалить, то эта [75].
Крушение Челленджера, подобно другим катастрофам, служит жутким напоминанием, что даже лучшие профессионалы и лучшие намерения не могут полностью защитить от происшествий. Когда мы будем разрабатывать продвинутые ИИ-системы, важно будет помнить, что они не иммунны к катастрофическим случаям. Ключевой фактор их предотвращения и поддержания риска на низком уровне – ответственная за эти технологии организация. Сначала мы обсудим, как происшествия могут случиться (и неизбежно случаются) даже без конкурентного давления или злонамеренных лиц. Затем мы обсудим, как улучшить организационные факторы, чтобы снизить вероятность связанной с ИИ катастрофы.
Катастрофы случаются даже при низком конкурентном давлении. Даже без конкурентного давления и злонамеренных лиц, к катастрофе могут привести факторы человеческой ошибки и непредвиденных обстоятельств. Крушение Челленджера показывает, что организационная небрежность может привести к гибели людей, даже если нет острой нужды не отставать или превзойти соперников. К январю 1986 года космическая гонка между СССР и США сильно сбавила обороты, но трагедия всё равно произошла из-за неправильных решений и недостаточных предосторожностей.
Аналогично, авария на Чернобыльской АЭС в апреле 1986 года показывает, как катастрофа может произойти и без внешнего давления. Авария произошла на государственном проекте без особого участия в международной конкуренции. Неадекватно подготовленная ночная смена неправильно провела тестирование, затрагивавшее систему охлаждения реактора. В результате ядро реактора стало нестабильным, произошли взрывы и выброс радиоактивных частиц, разлетевшихся на приличную часть Европы [76]. Семью годами ранее у Америки чуть не случился свой Чернобыль, когда в марте 1979 года произошла авария на АЭС Три-Майл-Айленд. Она была не такой ужасной, но всё равно оба события показывают, как катастрофы могут произойти даже при мощных мерах предосторожности и без особых внешних воздействий.
Другой пример доставшегося дорогой ценой урока о важности организационной безопасности – всего через месяц после аварии на Три-Майл-Айленд, в апреле 1979 года, с советского военного исследовательского центра в Свердловске произошла утечка Bacillus anthracis, или, попросту, сибирской язвы. Это привело к вспышке болезни, из-за которой погибло как минимум 66 человек [77]. Расследование происшествия обнаружило, что причиной утечки стали ошибка в соблюдении необходимых процедур и плохое обслуживание систем безопасности центра. Это произошло несмотря на то, что лаборатория принадлежала государству и не была особо подвержена конкурентному давлению.
Пугающим фактом остаётся то, что мы куда хуже понимаем ИИ, чем атомные или ракетные технологии, и в то же время стандарты безопасности в ИИ-индустрии куда менее требовательны, чем в этих областях. Атомные реакторы основаны на твёрдых, хорошо выясненных и полностью понимаемых теоретических принципах. Стоящая за ними инженерия использует эту теорию. Все компоненты максимально тщательно тестируются. И аварии всё равно происходят. Область ИИ, напротив, лишена нормального теоретического понимания. Внутреннее устройство моделей остаётся загадкой даже для тех, кто их создаёт. Эта необходимость контролировать и обеспечивать безопасность технологии, которую мы не вполне понимаем, дополнительно усложняет дело.
Происшествия с ИИ могут быть катастрофичными. Происшествия в разработке ИИ могут иметь ужасающие последствия. К примеру, представьте, что организация случайно допустит критический баг в ИИ-системе, спроектированной для исполнения определённой задачи, вроде «помогать компании улучшать свои сервисы». Этот баг может радикально изменить поведение ИИ. Это может привести к ненамеренным и вредным результатам. Исторический пример такого случая – исследователи OpenAI однажды пытались обучить ИИ-систему генерировать полезные и позитивные ответы. При рефакторинге кода исследователи случайно перепутали знак функции вознаграждения, при помощи которой обучался ИИ [78].
Рис. 11: Примеры из многих областей должны напоминать нам о рисках, которые несёт управление сложными системами, как биологическими и атомными, так, теперь, и ИИ-системами. Организационная безопасность жизненно важна для снижения рисков катастрофических случаев.
В результате, после обучения в течении одной ночи ИИ вместо генерации полезного контента начал выдавать наполненный ненавистью и сексуально откровенный текст. Подобные случаи могут привести к ненамеренному появлению опасной, возможно даже смертельно опасной, ИИ-системы. Так как ИИ можно легко копировать, утечка или взлом может быстро вывести такую систему за пределы контроля её создателей. Когда ИИ-система выходит в открытый доступ, загнать джинна обратно в бутылку становится практически невозможно.
Исследователи могут намеренно обучать ИИ-систему быть вредной и опасной, чтобы понять пределы её способностей и оценить потенциальные риски. Но такие продвигающие разрушительные способности систем исследования опасных ИИ, аналогично исследованиям опасных патогенов, тоже могут привести к проблемам. Да, они могут выдавать полезные результаты и улучшать наше понимание рисков той или иной ИИ-системы. Но в будущем такие исследования смогут приводить к обнаружению значительно худших, чем предполагалось, способностей и нести серьёзную угрозу, которую сложно будет смягчить и взять под контроль. Как в случае вирусов, такие исследования стоит проводить только при условии очень строгих процедур безопасности и ответственном подходе к распространению информации. Надеемся, эти примеры показали, как происшествия с ИИ-системами могут оказаться катастрофичными, и насколько для их предотвращения важны внутренние факторы организации, которая эти системы разрабатывает.
4.1 Избежать происшествий сложно
В случае сложных систем надо сосредотачиваться на том, чтобы происшествия не могли перерасти в катастрофы. В своей книге «Обычные происшествия: как жить с рискованными технологиями» социолог Чарльс Перроу заявляет, что в сложных системах происшествия неизбежны и даже «нормальны», потому что вызваны не только лишь ошибками людей, но и сложностью самих систем [79]. В частности, происшествия вероятны, когда компоненты системы взаимодействуют друг с другом запутанным образом, который нельзя было полностью предвидеть и на случай которого нельзя было заранее составить план. Например, к аварии на Три-Майл-Айленд в частности привело то, что операторы не знали, что важный вентиль был закрыт, потому что соответствующий ему индикатор был скрыт от взгляда жёлтым ярлычком «находится на обслуживании» [80]. Это крохотное взаимодействие внутри сложной системы привело к большим непредвиденным последствиям.
Ядерные реакторы, несмотря на их сложность, мы понимаем хорошо. Большинство сложных систем не такие – их полного технического понимания часто нет. Системы глубинного обучения – случай, для которого это особенно верно. Невероятно сложно понять их внутреннее устройство. Зачастую даже знание задним числом не особо помогает понять, почему работает то или иное решение. Более того, в отличие от надёжных компонентов, которые используются в других индустриях (например, топливных баков), системы глубинного обучения и не идеально точны, и не особо надёжны. Так что организациям, которые имеют дело с системами глубинного обучения, следует сосредоточиться в первую очередь не на том, чтобы происшествий не было, а на том, чтобы они не перерастали в катастрофы.

Рис. 12: При обучении новые способности могут возникнуть быстро и без предупреждения. Так что мы можем пройти опасную веху, сами того не зная.
Внезапные и непредсказуемые прорывы мешают избегать происшествий. Учёные, изобретатели, и прочие эксперты часто значительно переоценивают время, которое потребуется на прорывное совершенствование технологии. Широко известно, как братья Райт заявляли, что до летательных аппаратов тяжелее воздуха с двигателем ещё пятьдесят лет. Всего через два года они сами такой создали. Лорд Резерфорд, отец ядерной физики, отбросил идею извлечения энергии из ядерного распада как пустые мечты. Лео Силард изобрёл цепную реакцию ядерного распада меньше чем через сутки. Энрико Ферми утверждал, что с вероятностью в 90% невозможно использовать уран для поддержания реакции распада, но сам работал с первым реактором всего через четыре года [81].
Развитие ИИ тоже может застать нас врасплох. Это уже происходит. В 2016 году многие эксперты были удивлены победой AlphaGo над Ли Седолем, ведь тогда считалось, что для такого потребуется ещё много лет. Потом были внезапные эмерджентные способности больших языковых моделей, вроде GPT-4 [82]. Сложно заранее предсказать, насколько хорошо они справляются с разными задачами. Это ещё и часто резко меняется, стоит лишь потратить на обучение побольше ресурсов. Более того, нередко они демонстрируют поразительные новые способности, которым их никто намеренно не обучал и которые никто не предсказывал, вроде рассуждений из нескольких шагов и обучения на лету. Эта быстрая и непредсказуемая эволюция способностей ИИ значительно усложняет предотвращение происшествий. Сложно контролировать то, про что мы не знаем, на что оно способно, и насколько оно может превзойти наши ожидания.
Часто на обнаружение рисков или проблем уходят годы. История полна примерами веществ или технологий, которые сначала считали безопасными, только чтобы обнаружить вред через много лет, или даже десятилетий. К примеру, свинец широко использовали в продуктах вроде краски и бензина, пока не стало известно, что он нейротоксичен [83]. Было время, когда асбест очень ценили за его термоустойчивость и прочность. Потом его связали с серьёзными заболеваниями – раком лёгких и мезотелиомой [84]. Здоровье «радиевых девушек» сильно пострадало от контактов с радием, который считалось безопасным помещать в рот [85]. Табак изначально рекламировался как безвредное развлечение, а оказался главной причиной рака лёгких и других проблем со здоровьем [86]. Хлорфторуглероды считались безвредными. Их использовали в аэрозолях и холодильниках, а оказалось, что они разрушают озоновый слой [87]. Талидомид, лекарство, которое должно было помогать беременным от утренней тошноты, как оказалось, приводил к серьёзным врождённым дефектам [88]. А совсем недавно распространение социальных медиа связали с учащением депрессии и тревожности, особенно среди молодёжи [89].
Это всё подчёркивает, насколько важно не только проводить экспертное тестирование, но и внедрять технологии медленно, позволяя проверке временем выявить потенциальные проблемы до того, как они повлияют на большое количество людей. Скрытые уязвимости могут быть даже в технологиях, для которых действуют жёсткие стандарты безопасности и надёжности. Например, баг «Heartbleed» – серьёзная уязвимость в популярной криптографической библиотеке OpenSSL – оставался неизвестным многие годы [90].
Даже самые совершенные ИИ-системы, которые, казалось бы, уверенно решают свои задачи, могут нести в себе уязвимости, на раскрытие которых потребуются годы. К примеру, прорывной успех AlphaGo заставил многих поверить, что ИИ покорили игру в го, но успешная состязательная атака на другой очень продвинутый ИИ для игры в го, KataGo, выявил ранее неизвестную слабость [91]. Эта уязвимость позволила людям-новичкам стабильно обыгрывать ИИ, несмотря на его значительное преимущество над неосведомлёнными о ней людьми. Если обобщить, этот пример напоминает, что нам надо оставаться бдительными. Казалось бы сверхнадёжные ИИ-системы могут таить в себе нераскрытые проблемы. Подведём итоги: происшествия непредсказуемы, избежать их сложно, а понимание и смягчение рисков требуют комбинации проактивных мер, медленного внедрения и незаменимой мудрости, полученной через упорное тестирование.
4.2 Организационные факторы могут снизить вероятность катастрофы
Некоторые организации работают с сложными и опасными системами вроде атомных реакторов, авианосцев или систем контроля воздушного трафика, но успешно избегают катастроф [92, 93]. Эти организации признают, что недостаточно обращать внимание только на угрозы самой технологии. Надо иметь в виду и организационные факторы, которые могут повлиять на происшествия. К ним относятся человеческий фактор, принятые процедуры и структура организации. Это особенно важно в случае ИИ – плохо понимаемой и ненадёжной технологии.
Человеческие факторы вроде культуры безопасности критически важны для избегания ИИ-катастроф. Один из важнейших для предотвращения катастроф организационных факторов – культура безопасности [94, 95]. Сильная культура безопасности создаётся не только установкой правил и процедур, но и их должным усвоением всеми членами организации. Они должны считать безопасность ключевой целью, а не ограничением, наложенным на их работу. Характерные черты таких организаций: лидеры явно обязываются поддерживать безопасность; все сотрудники берут на себя личную ответственность за безопасность; культура открытой коммуникации позволяет свободно и безбоязненно обсуждать риски и проблемы [96]. Ещё организациям надо предпринимать меры, чтобы избегать десенситизации по отношению к тревожным сигналам, когда люди перестают обращать на них внимание, потому что те слишком часты. Катастрофа Челленджера, когда культура быстрых запусков увела безопасность на второй план, показала страшные последствия игнорирования этих факторов. Миссию не затормозили несмотря на свидетельства потенциально фатальных проблем, и этого хватило, чтобы привести к трагедии безо всякого конкурентного давления [97].
Культура безопасности зачастую далека от идеала даже в областях, где она особенно важна. Взять, к примеру, Брюса Блэра, старшего научного сотрудника Брукингского института, а ранее – офицера по запуску ядерного оружия. Он как-то рассказал, что до 1977 года ВВС США упорно устанавливали код разблокировки межконтинентальных баллистических ракет на «00000000» [98]. Так механизмы безопасности вроде блокировки могут оказаться бесполезными из-за человеческого фактора.
Более драматичный пример показывает нам, как исследователи иногда принимают непренебрежимый шанс вымирания. До первого теста ядерного оружия один из знаменитых учёных Манхэттенского Проекта вычислил, что бомба может вызвать экзистенциальную катастрофу: взрыв может воспламенить атмосферу Земли. Оппенгеймер считал, что вычисления, вероятно, неверны, но он всё равно оставался сильно обеспокоен. Команда перепроверяла и обсуждала это вплоть до дня взрыва [99]. Такие случаи подчёркивают нужду в устойчивой культуре безопасности.
Критический подход может помочь выявить потенциальные проблемы. Неожиданное поведение системы может привести к уязвимости или происшествию. Чтобы этому противостоять, организации могут взращивать критический подход. Сотрудники могут постоянно ставить под сомнение совершаемые действия и действующие условия в поисках несостыковок, которые могут привести к ошибкам и неуместным выборам [100]. Этот подход помогает поощрять плюрализм мысли и любопытство, и предотвращает ловушки единообразия мнений и допущений. Чернобыльская авария показывает важность критического подхода – меры безопасности оказались недостаточными для компенсации недостатков реактора и плохо составленных процедур. Критический подход к безопасности реактора при тестировании мог предотвратить взрыв, который привёл к бесчисленным смертям и заболеваниям.
Мышление безопасника критически важно для избегания худших случаев. Мышление безопасника (security mindset), особо ценящееся среди профессионалов по кибербезопасности, также применимо и для организаций, которые разрабатывают ИИ. Оно идёт дальше критического подхода, требуя принять перспективу атакующего и рассмотреть худшие, а не только типичные случаи. Такой настрой требует бдительного поиска уязвимостей и рассуждений о том, как систему можно сломать специально, а не только о том, как заставить её работать. Он напоминает нам не делать допущения, что система безопасна только потому, что быстрый брейншторм не выявил никаких потенциальных угроз. Культивирование и применение мышления безопасника требуют времени и усилий. Неудача в этом может быть внезапной и контринтуитивной. Мышление безопасника подчёркивает важность внимательности к казалось бы мелким проблемам, или «безвредным ошибкам», которые могут привести к катастрофическим исходам, если их использует умный противник или если они произойдут синхронно [101]. Такое внимание к потенциальным угрозам напоминает о законе Мёрфи – «Всё, что может пойти не так, пойдёт» – он может быть вполне верен в случае враждебной оптимизации или непредвиденных событий.
Организации с сильной культурой безопасности могут успешно избегать катастроф. Высоконадёжные организации (ВНО) – организации, которые стабильно поддерживают высокий уровень безопасности и надёжности в сложных сильно рискованных окружениях [92]. Ключевая характеристика ВНО – их сосредоточенность на возможности провала. Это требует рассматривать худшие возможные сценарии и даже те риски, которые кажутся очень маловероятными. Эти организации остро осознают, что существуют новые, ранее не встречавшиеся варианты провала. Они тщательно изучают все известные неудачи, аномалии и едва не произошедшие катастрофы, чтобы на них учиться. В ВНО поощряется докладывать о всех ошибках и аномалиях, чтобы поддерживать бдительное выявление проблем. Они регулярно «осматривают горизонт» в поисках возможных рискованных сценариев, и оценивают их вероятность заранее. Они практикуют менеджмент внезапностей и вырабатывают навыки быстрого и эффективного ответа на непредвиденные ситуации, что помогает им не допускать катастроф. Эта комбинация критического мышления, планирования заранее и постоянного обучения может сделать организации более готовыми работать с катастрофическими рисками ИИ. Однако, практики ВНО – не панацея. Для организаций очень важно развивать свои меры безопасности, чтобы эффективно смягчать новые риски происшествий с ИИ. Не следует ограничиваться лучшими практиками ВНО.
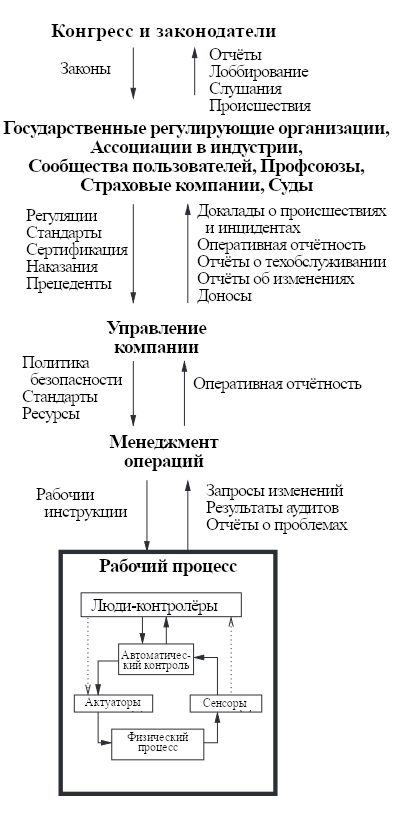
Рис. 13: Смягчение рисков требует работы с более широкой социотехнической системой, например, корпорацией (заимствовано и адаптировано из [94]).
Большая часть исследователей ИИ не понимает, как снизить общий риск ИИ В большинстве организаций, которые создают передовые ИИ-системы, слабо понимают, как устроены технические исследования безопасности. Это понятно, ведь безопасность и способности ИИ тесно переплетены, и способности могут помогать или вредить безопасности. Более умные ИИ-системы могут быть надёжнее и избегать ошибок, но они же могут нести большие риски злонамеренного использования и потери контроля. Общее улучшение способностей может способствовать некоторым аспектам безопасности, но оно же может ускорить пришествие экзистенциальных рисков. Интеллект – обоюдоострый меч [102].
Действия, направленные на улучшение безопасности, могут случайно повысить риски. К примеру, типичная практика в организациях, которые создают продвинутые ИИ – настраивать их так, чтобы они удовлетворяли предпочтениям пользователей. Тогда ИИ меньше склонны к генерации токсичных высказываний, а это типичная метрика безопасности. Но кроме этого пользователи склонны предпочитать более умных ассистентов, так что это повышает и общие способности ИИ, вроде навыков классификации, оценки, рассуждений, планирования, программирования, и так далее. Эти более мощные ИИ в самом деле более полезны для пользователей, но они же и более опасны. Так что недостаточно проводить исследования, которые помогают повысить метрику безопасности или достигнуть конкретной связанной с безопасностью цели. Исследования безопасности ИИ должны повышать соотношение безопасности к общим способностям.
Для проверки, действительно ли мера безопасности снижает риски, нужны методы эмпирического измерения как безопасности, так и способностей ИИ. Совершенствование того или иного аспекта безопасности ИИ часто не снижает риски в целом, потому что улучшение метрик безопасности может быть вызвано и прогрессом способностей. Для снижения рисков метрика безопасности должна улучшаться относительно способностей. И то, и другое должно быть измерено эмпирически, чтобы их можно было сравнить. Сейчас большинство организаций определяют, помогут ли меры безопасности, полагаясь на чутьё, интуицию и апелляцию к авторитетам. Объективная оценка эффектов как на метрики безопасности, так и на метрики способностей, позволит организациям лучше понимать, добиваются ли они прогресса первых относительно вторых.
К счастью, общие способности и способности, связанные с безопасностью, не идентичны. Более умные ИИ могут быть эрудированнее, сообразительнее, аккуратнее и быстрее, но это не обязательно делает их более справедливыми, честными и лишёнными амбиций. Умный ИИ – не обязательно доброжелательный ИИ. Несколько областей исследований, которые мы уже упоминали, улучшают безопасность относительно общих способностей. К примеру, улучшение методов детектирования скрытого опасного или просто нежелательного поведения ИИ-систем не улучшает их общие способности, вроде способности программировать, но может сильно улучшить их безопасность. Исследования, которые эмпирически показывают относительный прогресс безопасности, могут снизить общий риск и помочь избежать ненамеренного продвижения прогресса ИИ, подпитывания конкурентного давления и сокращения времени до появления экзистенциальных рисков.
«Театр безопасности» может обесценивать искренние усилия по улучшению безопасности ИИ. Организациям стоит опасаться «театра безопасности» (safetywashing) – преувеличивания своей сосредоточенности на «безопасности» и эффективности мер, технических методов, метрик «безопасности», и подобного. Это явление принимает разные формы и мешает осмысленному прогрессу в исследованиях безопасности. К примеру, организация может публично объявлять о своей приверженности безопасности, имея при этом минимальное число исследователей, которые бы работали над проектами, действительно безопасности помогающими.
Ещё театр безопасности может проявиться через неверную оценку развития способностей. Например, методы, которые улучшают мышление ИИ-систем, могут рекламироваться как будто они улучшают их приверженность человеческим ценностям. Люди ведь предпочитают, чтобы ИИ выдавал правильные ответы. Но в основном такие методы служат на пользу как раз способностям. Подавая такие совершенствования как ориентированные на безопасность, организация может вводить в заблуждение, убеждая, что она добивается прогресса в снижении рисков, когда это не так. Для организации очень важно верно описывать свои исследования, чтобы продвигалась настоящая безопасность, и театр безопасности не способствовал росту рисков.
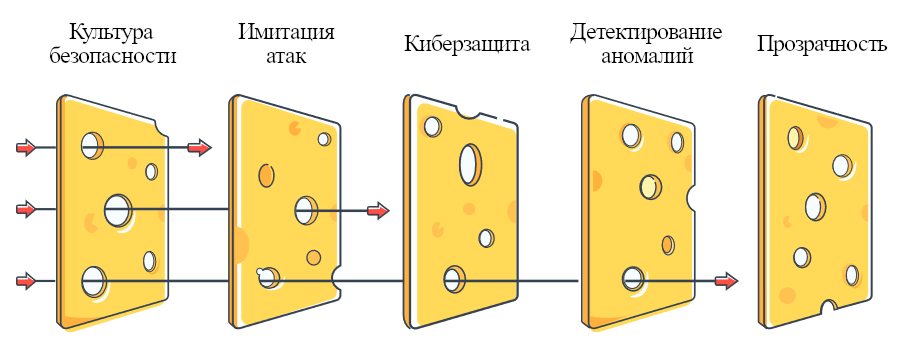
Рис. 14: модель швейцарского сыра показывает нам, как технические факторы могут улучшить организационную безопасность. Много слоёв защиты компенсируют слабости друг друга, снижая итоговый риск.
Вдобавок к человеческому фактору, организационная безопасность сильно зависит ещё и от принципов безопасного проектирования.. Пример такого принципа в организационной безопасности – модель швейцарского сыра (см. Рис. 14). Она применима в многих областях, в том числе и в ИИ. Это многослойный подход к улучшению итоговой безопасности системы. Такая стратегия «глубокой защиты» подразумевает использование многих разнообразных мер безопасности с разными сильными и слабыми сторонами, чтобы в итоге получилась стабильно безопасная система. Некоторыми из этих слоёв могут быть культура безопасности, имитация атак (red teaming), детектирование аномалий, информационная безопасность и прозрачность. К примеру, имитация атак оценивает уязвимости и потенциальные провалы системы, а детектирование аномалий позволяет обнаружить неожиданное и странное поведение системы или её пользователей. Прозрачность позволяет удостовериться, что внутренняя работа ИИ-систем доступна пониманию и присмотру, обеспечивая доверия и более эффективный надзор. Модель швейцарского сыра стремится использовать эти и другие меры безопасности для построения полноценно безопасной системы, в которой слабости каждого из слоёв компенсированы другими. В рамках этой модели безопасности достигается не одним сверхнадёжным решением, а разнообразием мер.
Подведём итоги. Слабая организационная безопасность у разработчиков ИИ приводит к многим рискам. Если безопасность у них просто для галочки, то они не вырабатывают хорошего понимания рисков ИИ и не борются с театром безопасности – выдачей не относящихся к делу исследований за полезные для безопасности. Их нормы могут быть унаследованы от академии («публикуйся или пропадай») или стартапов («иди быстро и ломай»), и их сотрудники часто не переживают по поводу безопасности. Эти нормы сложно менять, и с ними надо работать проактивно.
История: слабая культура безопасности
В ИИ-компании обдумывают, обучать ли новую модель. Эта компания наняла своего директора по рискам только чтобы соответствовать регуляциям. Он указал, что предыдущая ИИ-система, разработанная этой компанией, продемонстрировала тревожащие способности к взлому. Он заявил, что хоть подход, который компания использует для предотвращения злонамеренного использования, многообещающ, но он недостаточно надёжен, чтобы использовать его для более способных ИИ. Он предупредил, что, если основываться на предварительных оценках, следующая ИИ-система сильно упростит для злонамеренных лиц взлом критически важных систем. Другие руководители компании не обеспокоены, они считают, что процедуры безопасности компании достаточно хорошо предотвращают злоупотребления. Один из них упоминает, что у конкурентов всё куда хуже, так что их усилия по этому направлению и так сверх нормы. Другой указывает, что исследования по этим мерам ещё идут, и, когда модель будет выпущена, всё будет ещё лучше. Директор по рискам оказывается в меньшинстве, и нехотя подписывает план.
Через несколько месяцев после того, как компания выпустила модель, новости сообщают, об аресте хакера, который использовал ИИ-систему при попытке взлома сети большого банка. Взлом был неудачен, но хакер прошёл дальше, чем все его предшественники, несмотря на то, что был довольно неопытен. Компания быстро обновила модель, чтобы та не предоставляла той конкретной поддержки, которую использовал хакер, но принципиально ничего не меняет.
Ещё через несколько месяцев компания решает, обучать ли ещё большую систему. Директор по рискам заявляет, что процедуры компании явно не оказались достаточными, чтобы не дать злонамеренным лицам использовать модели в опасных целях, и что компании нужно что-то большее, чем простая заплатка. Другие директора говорят, что вовсе наоборот, хакер потерпел неудачу, а проблему быстро исправили. Один из них заявляет, что до развёртывания некоторые проблемы просто нельзя предвидеть в достаточной степени, чтобы их можно было исправить. Директор по рискам соглашается, но замечает, что, если следующую модель хотя бы задержат, уже ведущиеся исследования позволят справиться лучше. Генеральный директор не согласен: «Ты так и говорил в прошлый раз, а всё закончилось хорошо. Я уверен, и сейчас будет так.»
После собрания директор по рискам увольняется, но потом не критикует компанию, ведь все сотрудники подписали соглашение, которое это запрещает. Общество понятия не имеет о принятых компанией решениях, а директора по рискам заменяют новым, более сговорчивым. Он быстро подписывает все планы.
Компания обучает, тестирует и развёртывает свою новую, самую способную модель. Для предотвращения злоупотреблений используются всё те же процедуры. Проходит месяц, и становится известно, что террористы использовали модель, чтобы взломать государственные системы и похитить секретную информацию о ядерных и биологических проектах. Взлом заметили, но к тому моменту было поздно – информация уже утекла и распространилась.
4.3 Предложения
Мы обсудили, что при работе с сложными системами происшествия неизбежны, что они могут распространяться по системе и привести к полномасштабному бедствию, и что организационные факторы могут сильно снижать риск катастрофы. Теперь опишем некоторые практические шаги, следуя которым организации могут поспособствовать безопасности.
Имитация атак. Имитация атак (red teaming) – процесс оценки безопасности, надёжности и эффективности систем, в котором «красная команда» отыгрывает противника и пытается обнаружить проблемы [103]. ИИ-лабораториям следует работать с внешними красными командами, чтобы находить угрозы, которые могут нести их ИИ-системы, и отталкиваться от этой информации, принимая решения о развёртывании. Красные команды могут показывать опасное поведение модели или уязвимости в системе мониторинга, которая должна предотвращать недозволенное использование. Ещё они могут предоставлять косвенные свидетельства об опасности ИИ-систем. Например, если продемонстрировано, что меньшие ИИ ведут себя обманчиво, это может значить, что большие ИИ тоже так делают, но лучше это скрывают.
Положительная демонстрация безопасности. Компаниям следует обладать положительными свидетельствами того, что их план разработки и развёртывания безопасен, до того, как они будут воплощать его в жизнь. Внешняя имитация атак полезна, но некоторые проблемы может найти только сама компания, так что её недостаточно [104]. Угрозы могут возникнуть уже на этапе обучения системы, так что аргументы за безопасность надо приводить до его начала. Это, например, обоснованные предсказания того, что, скорее всего, новая система будет уметь, подробные планы мониторинга, развёртывания и обеспечения инфобезопасности, а также демонстрация того, что процедуры принятия компанией решений адекватны. Чтобы не играть в русскую рулетку не нужно свидетельство, что револьвер заряжен. Чтобы запереть дверь не нужно свидетельство, что неподалёку вор [105]. Точно также и тут бремя доказательства должно быть на разработчиках продвинутых ИИ.
Процедуры развёртывания. ИИ-лабораториям надо собирать информацию о безопасности ИИ-систем перед тем, как сделать их доступными для широкого использования. Можно давать «красным командам» выискивать угрозы до выпуска систем; ещё можно сначала проводить «ограниченный релиз»: постепенно расширять доступ к системе, чтобы исправить проблемы безопасности до того, как они смогут привести к масштабным последствиям [106]. Наконец, ИИ-лаборатории могут не обучать более мощные ИИ, пока на достаточно долгом опыте не будет установлено, что уже развёрнутые ИИ безопасны.
Проверка публикаций. ИИ-лаборатории обладают доступом к потенциально опасной информации, вроде весов моделей и результатов исследований, которые могут нести риски, если попадут в широкий доступ. Внутренняя комиссия может оценивать, стоит ли публиковать то или иное исследование. Чтобы снизить риск злонамеренного и безответственного использования, разработчикам ИИ следует не выкладывать в открытый доступ код и веса своих самых мощных систем. Вместо этого лучше предоставлять доступ аккуратно и структурированно, как мы описывали выше.
Планы реакции. ИИ-лабораториям следует заранее иметь планы реакции как на внешние (например, кибератаки), так и на внутренние (например, ИИ ведёт себя ненамеренным и опасным образом) инциденты. Это обычная практика для высоконадёжных организаций. Обычно эти планы включают в себя определение потенциальных рисков, подробные шаги по работе с инцидентом, распределение ролей и ответственности, а также стратегии коммуникации [107].
Внутренний аудит и риск-менеджмент. Подобно тому, как это делается в прочих высокорискованных индустриях, ИИ-лабораториям следует нанимать директора по рискам – старшего ответственного за риск-менеджмент. Эта практика – обычное дело в финансовой и в медицинской индустрии, и может помочь снизить риск [108]. Директор по рискам был бы ответственен за оценку и смягчение рисков, связанных с мощными ИИ-системами. Ещё одна типичная практика – иметь внутреннюю команду по аудиту, которая оценивает эффективность практик работы с рисками [109]. Эта команда должна отвечать напрямую перед советом директоров.
Процедуры принятия важных решений. Решения по обучению или расширению развёртывания ИИ не должны зависеть от прихоти гендиректора компании. Они должны быть тщательно обдуманы директором по рискам. В то же время, должно быть ясно, кого конкретно следует считать ответственным за каждое решение. Подотчётность не должна нарушаться.
Принципы безопасного проектирования. ИИ-лабораториям следует внедрять принципы безопасного проектирования, чтобы снизить риск катастрофических происшествий. Встраивая их в свой подход к безопасности, ИИ-лаборатории могут повысить надёжность и устойчивость своих ИИ-систем [94, 110]. Эти принципы включают в себя:
- Глубокую защиту: наслаивание мер защиты друг на друга.
- Избыточность: не должно быть единой точки отказа системы. Надо избежать катастрофы даже если любой один компонент безопасности не сработает.
- Слабую связность: децентрализация компонентов системы так, чтобы маловероятна была ситуация, в которой неполадка в одной части провоцирует каскад проблем по всей системе.
- Разделение функций: распределение контроля по разным агентам, чтобы никто один не мог обладать излишним влиянием на всю систему.
- Отказобезопасность: проектирование систем так, чтобы неполадки проходили в наименее опасной манере.
Передовая информационная безопасность. У государств, компаний и преступников есть мотивация похитить веса моделей и результаты исследований. Чтобы обезопасить эту информацию, ИИ-лабораториям следует принимать меры, соответствующие её ценности и рискованности. Это может потребовать сравняться или даже превзойти уровень инфобезопасности лучших разведок, ведь атакующими могут быть и страны. Меры инфобезопасности включают в себя внешние аудиты, найм лучших специалистов-безопасников и тщательный скрининг потенциальных сотрудников. Компаниям следует координироваться с государственными организациями, чтобы удостовериться, что их практики инфобезопасности адекватны угрозам.
Большая доля исследований должна быть посвящена безопасности. Сейчас на каждую статью по безопасности ИИ приходится пятьдесят по общим способностям [111]. ИИ-лабораториям следует обеспечить, чтобы на минимизацию потенциальных рисков шла значительная доля их сотрудников и бюджета, скажем, 30% от исследовательских ресурсов. ИИ становятся мощнее и опаснее со временем, так что может потребоваться и больше.
Позитивное видение
В идеальном сценарии исследователи и руководители во всех ИИ-лабораториях обладали бы мышлением безопасника. У организаций была бы развитая культура безопасности и структурированный, прозрачный и обеспечивающий подотчётность подход к принятию важных для безопасности решений. Исследователи стремились бы повышать уровень безопасности относительно способностей, а не просто делать что-то, на что можно навесить ярлык «безопасность». Руководители не были бы априори оптимистичными и избегали бы принятия желаемого за действительное, когда дело касается безопасности. Исследователи явно и публично сообщали бы о своём понимании самых значительных рисков разработки ИИ, и своих усилиях по их смягчению. Неудачи ограничивались бы маломасштабными, показывая, что культура безопасности достаточно сильна. Наконец, разработчики ИИ не отбрасывали бы не-катастрофический вред и не-катастрофические неудачи как маловажные или как необходимую цену ведения дел, а активно стремились бы исправить вызвавшие их проблемы.
- Короткая ссылка сюда: lesswrong.ru/3546