Согласование ИИ
Четыре предпосылки
- 1.Утверждение 1: У людей есть очень универсальная способность решать задачи и достигать целей в самых разных областях
- 2.Утверждение 2: ИИ может стать намного умнее людей
- 3.Утверждение 3: Если мы создадим высокоинтеллектуальные ИИ-системы, то их решения будут определять будущее
- 4.Утверждение 4: Высокоинтеллектуальный ИИ не будет полезен для человечества по умолчанию
Миссия MIRI – сделать так, чтобы создание искусственного интеллекта умнее человека привело к положительным последствиям. Почему эта миссия важна и почему мы считаем, что уже сегодня над этим можно работать?
В этом и в следующем эссе я попробую ответить на эти вопросы. Здесь я опишу четыре, по моему мнению, самые важные предпосылки, на основе которых появилась наша миссия. Я попытаюсь явно сформулировать утверждения, на которых базируется моё убеждение в том, что наша работа очень важна. Этому же вопросу посвящены, например, «Пять тезисов» Элиезера Юдковского и «Почему MIRI» Люка Мюльхаузера.
Утверждение 1: У людей есть очень универсальная способность решать задачи и достигать целей в самых разных областях
Мы называем эту способность «интеллектом» или «универсальным интеллектом». Это определение не является формальным: если бы мы точно знали, что такое интеллект, нам было бы гораздо легче запрограммировать его. Однако мы считаем, что такое явление как универсальный интеллект существует, пусть пока мы и не можем повторить его в коде.
Альтернативный взгляд: Универсального интеллекта не существует — вместо него у людей есть набор отдельных узкоспециализированных модулей. Компьютеры будут совершенствоваться в определённых узких задачах, таких как шахматы или вождение автомобиля, но никогда не станут универсальными, потому что универсальность недостижима. (Аргументы в пользу этой точки зрения приводил Робин Хансон.)
Короткий ответ: Поскольку люди осваивают области, совершенно чуждые их предкам, гипотеза «отдельных модулей» представляется мне неправдоподобной. Я не заявляю, что универсальность интеллекта – это какое-то нередуцируемое оккультное свойство. Предположительно, оно проистекает из набора когнитивных механизмов и их взаимодействий. Однако в целом именно это делает людей куда более когнитивно гибкими, чем, скажем, шимпанзе.
Почему это важно: Люди начали доминировать над другими видами не за счёт большей силы или ловкости, а за счёт большего интеллекта. Раз некая ключевая часть этого обобщённого интеллекта смогла эволюционировать за несколько миллионов лет, прошедших с нашего последнего общего предка с шимпанзе, возможно, некоторое небольшое количество озарений приведут к тому, что инженеры смогут создать мощный универсальный ИИ.
Дальнейшее чтение: Саламон и др. «Насколько интеллект понятен?»
Утверждение 2: ИИ может стать намного умнее людей
Большинство исследователей в MIRI не уверены, когда именно будет разработан превосходящий человека ИИ. Мы, однако, ожидаем, что: (а) искусственный интеллект, равный человеческому, однажды появится (если не случится каких-то катастроф, то вероятно, в течении века); и (б) компьютеры могут стать значительно умнее любого человека.
Альтернативный взгляд 1: Мозг делает что-то особенное, что нельзя воссоздать на компьютере.
Короткий ответ: Мозги – это физические системы, и если верны некоторые версии тезиса Чёрча-Тьюринга, то компьютеры могут в принципе воссоздать связь ввода и вывода любой физической системы. К тому же, заметим, что «интеллект» (в моём использовании термина) – это способность решения задач: даже если есть какая-то специальная человеческая черта (как квалиа), которую нельзя воссоздать на компьютере, это не важно, если только эта черта каким-то образом не мешает нам проектировать системы, решающие задачи.
Альтернативный взгляд 2: Алгоритмы, на которых основывается универсальный интеллект, настолько сложны и недоступны расшифровке, что люди не смогут запрограммировать что-то подобное ещё много веков.
Короткий ответ: Это звучит неправдоподобно с учётом эволюционных свидетельств. Род Homo отделился от других всего 2.8 миллиона лет назад, и прошедшего времени – всего мгновения с точки зрения естественного отбора – было достаточно, чтобы у людей появились когнитивные преимущества. Из этого можно заключить, что какие бы особенности ни отличали людей от менее интеллектуальных видов, вряд ли они очень сложные. Составные части универсального интеллекта должны присутствовать уже в шимпанзе.
На самом деле, относительно интеллектуальное поведение дельфинов позволяет предположить, что эти составные части скорее всего были уже у напоминающего мышь последнего общего предка людей и дельфинов. Можно заявить что и на искусственный интеллект равный мышиному уйдёт много веков, но это утверждение становится крайне сомнительным, если посмотреть на быстрый прогресс в области ИИ. В свете эволюционных наблюдений и последней пары десятилетий исследований ИИ, похоже, что интеллект – это что-то, что мы сможем понять и запрограммировать.
Альтернативный взгляд 3: Люди уже находятся на пределе физически возможного интеллекта или очень близки к нему. Так что, хоть мы и сможем создать равные человеку машины, создать суперинтеллект не получится.
Короткий ответ: Было бы удивительно, если бы человеческий разум оказался идеально приспособленным для рассуждений, — по тем же причинам, по которым удивительно было бы если бы самолёты не могли летать быстрее птиц. Простые физические рассуждения подтверждают эту интуицию: к примеру, с точки зрения физики представляется вполне возможным запуск симуляции человеческого мозга в тысячу раз быстрее его обычной скорости.
Кто-то может ожидать, что скорость здесь не важна, потому что мы упрёмся в ожидание новых данных от физических экспериментов. Мне это кажется маловероятным. Есть много интересных физических экспериментов, которые можно ускорить, и мне сложно поверить, что команда людей, запущенных на тысячекратной скорости не превзойдёт таких же обычных людей (в частности потому, что они смогут быстро разрабатывать новые инструменты и технологии для помощи себе).
К тому же я ожидаю, что возможно создать интеллект, который будет рассуждать не только быстрее, но и лучше, то есть, использующий вычислительные ресурсы эффективнее людей, даже при работе на той же скорости.
Почему это важно: Спроектированные людьми машины зачастую на голову превосходят биологических существ по параметрам, которые нас интересуют: автомобили не регенерируют и не размножаются, но уж точно перевозят людей дальше и быстрее, чем лошадь. Если мы сможем создать интеллектуальные системы, специально спроектированные для решения главных мировых проблем с помощью научных и технологических инноваций, то они смогут улучшать мир беспрецедентными темпами. Другими словами, ИИ важен.
Дальнейшее чтение: Чалмерс, «Сингулярность: Философский Анализ»
Утверждение 3: Если мы создадим высокоинтеллектуальные ИИ-системы, то их решения будут определять будущее
Благодаря интеллекту люди создают инструменты, планы и технологии, которые позволяют им изменять окружающую среду по своей воле (и заполнять её холодильниками, автомобилями и городами). Мы ожидаем, что ещё более умные системы будут ещё более способны изменять своё окружение, и, соответственно, что ИИ умнее человека будет управлять будущим больше, чем люди.
Альтернативный взгляд: ИИ никогда не сможет превзойти всё человечество в целом, каким бы умным он ни был. Наше окружение попросту слишком конкурентное. Ему придётся работать вместе с нами и интегрироваться в нашу экономику.
Короткий ответ: Я не сомневаюсь, что автономный ИИ, пытающийся выполнить простые задачи, поначалу будет мотивирован интегрироваться в нашу экономику: если создать ИИ для коллекционирования марок, то он, вероятно, начнёт накапливать деньги для их приобретения. Но что если у него появится сильное технологическое или стратегическое преимущество?
Утрированный пример: мы можем представить, как такой ИИ разрабатывает наномашины и использует их, чтобы они преобразовывали как можно больше материи в марки. Для него вовсе не обязательно будет иметь значение, откуда берётся эта материя – из «грязи», «денег» или «людей». Эгоистичные агенты имеют стимулы участвовать в экономике, только если их приобретения от торговли превышают то, что они получат, игнорируя экономику и просто забирая себе ресурсы самостоятельно.
Так что вопрос в том, возможно ли для ИИ получить решающее технологическое или стратегическое преимущество. Я считаю это наиболее сомнительным утверждением из тех, что я тут привожу. Однако, я всё равно ожидаю, что ответ определённо будет «да».
Исторически, конфликты между людьми часто заканчивались тем, что технологически превосходящая группа одерживала верх над своими соперниками. В настоящий момент есть некоторое число технологических и социальных инноваций, которые выглядят возможными, но ещё не разработаны. По сравнению с тем, чего могут достигнуть распределённые программные системы, люди медленно и неэффективно координируются. Поэтому можно предположить, что если мы создадим машину, которая двигает науку быстрее или эффективнее нас, то она быстро получит технологическое и/или стратегическое преимущество над человечеством для себя или для своих операторов. Это в особенности верно, если интеллектуальное превосходство позволяет ей социально манипулировать людьми, приобретать новое оборудование (легально или нет), производить лучшее оборудование, создавать копии себя, или улучшать свой собственный код. К добру или к худу, будущее, вероятно, будет в основном определяться принимающими решения сверхинтеллектуальными машинами.
Почему это важно: Потому что будущее важно. Если мы хотим, чтобы в будущем стало лучше (или хотя бы не хуже), то разумней уделить достаточно времени исследованию процессов, которые будут оказывать на будущее большое влияние.
Дальнейшее чтение: Армстронг, «Умнее Нас».
Утверждение 4: Высокоинтеллектуальный ИИ не будет полезен для человечества по умолчанию
Нам хотелось бы, чтобы ИИ умнее людей работали вместе с человечеством для создания лучшего будущего. Однако по умолчанию это не произойдёт. Чтобы создать ИИ, оказывающий благотворное влияние, нам нужно не просто создать более мощные и универсальные ИИ-системы, но и преодолеть некоторое количество технических препятствий.
Альтернативный взгляд: Люди, становясь умнее, так же становятся более миролюбивыми и терпимыми. Когда ИИ будет становится умнее, он, вероятно, сможет лучше понять наши ценности и лучше им соответствовать.
Короткий ответ: Достаточно умный ИИ сможет определить наши намерения и предпочтения. Однако это не подразумевает, что его действия будут согласованы с нашими предпочтениями.
Самомодифицирующийся ИИ мог бы изучить свой код и решить, продолжить ли преследовать поставленные ему цели или модифицировать их. Но как программа будет решать, какие модификации проводить?
ИИ – это физическая система, и где-то внутри себя он конструирует предсказания о том, как вселенная будет выглядеть, если он совершит то или иное действие. Какие-то другие части системы сравнивают эти последствия и исполняют действия, ведущие к тем вариантам, которые текущая система высоко оценивает. Если агент изначально запрограммирован исполнять планы, ведущие к вселенной, в которой, как он предсказывает, будет исцелён рак, то он будет модифицировать свои цели только если предскажет, что это приведёт к исцелению рака.
Независимо от их уровня интеллекта и независимо от ваших намерений, компьютеры делают в точности то, на что вы их запрограммировали. Если вы запрограммировали необычайно умную машину выполнять планы, которые, как она предсказывает, приведут к будущему, где рак исцелён, то может оказаться, что кратчайший найденный ею путь включает похищение людей для экспериментирования (а если вы попытаетесь её изменить, то она будет сопротивляться, потому что это замедлит процесс).
Нет никакой искры сочувствия, которая автоматически заставляет достаточно способные компьютеры уважать других разумных существ. Если вы хотите сочувствия, вам нужно его запрограммировать.
Почему это важно: Многие крупнейшие мировые проблемы было бы куда легче решить с помощью суперинтеллекта – но для получения этих преимуществ нужно большее, чем просто развитие способностей ИИ. Вы получите систему, которая делает то, что вам нужно, только если вы знаете, как запрограммировать её принимать ваши намерения во внимание и выполнять планы, которые им соответствуют.
Дальнейшее чтение: Бостром, «Воля сверхразума»
Довод о важности искусственного интеллекта опирается на эти четыре утверждения: универсальная способность к рассуждениям существует; если мы построим машины с такой способностью, они смогут быть намного умнее людей; если они будут намного умнее людей, у них будет огромное влияние; и это влияние по умолчанию не будет положительным.
В настоящее время на улучшение способностей ИИ тратятся миллиарды долларов и тысячи человеко-лет. Однако на безопасность ИИ направлено сравнительно мало усилий. Искусственный суперинтеллект может возникнуть в ближайшие десятилетия, и почти наверняка, если не случится какой-то катастрофы, возникнет в ближайший век или два. Суперинтеллектуальные системы окажут либо огромное положительное, либо огромное отрицательное влияние. И только от нас зависит, положительное это влияние будет или отрицательное.
Задача соответствия ракет и цели
Нижеследующее — вымышленный диалог, основанный на Соответствие ИИ — Почему это сложно и с чего начать.
(Где-то в не-очень-то-близком из миров по соседству, где наука пошла совершенно другим путём…)
Альфонсо: Привет, Бет. Я заметил, что в последнее время многие предполагают, что «космосамолёты» будут использоваться для бомбёжки городов, или что в них вселятся злобные духи, населяющие небесные сферы, так что они пойдут против инженеров, их создавших.
Я довольно скептически отношусь к этим предположениям. На самом деле, я даже немного скептически и по поводу того, что в ближайшее столетие самолёты смогут достигнуть высоты стратосферных метеозондов. Но я понимаю, что твой институт хочет обратить внимание на потенциальные проблемы злобных или опасных космосамолётов, и вы думаете, что это важно уже сегодня.
Бет: Мы бы в Институте Математики Нацеленного Ракетостроения так не сказали… 1
Новостные статьи фокусируются на проблеме злобных небесных духов, мы же считаем, что настоящая проблема совершенно иная. Мы беспокоимся о сложной задаче, которую современное ракетостроение в основном игнорирует. Мы беспокоимся, что если направить ракету на Луну на небе и нажать кнопку запуска, то ракета может не прилететь к Луне.
Альфонсо: Я понимаю: очень важно спроектировать стабилизаторы для полёта при сильном ветре. Это важное направление исследований в области безопасности космосамолётов, кто-то должен это делать.
Но если бы вы работали над этим, я бы ожидал, что вы будете плотно сотрудничать с инженерами-самолётостроителями, чтобы протестировать свои проекты стабилизаторов и показать, что они действительно полезны.
Бет: Аэродинамика — важная часть проектирования любой безопасной ракеты, и мы очень рады, что ракетостроители работают над этим и всерьёз воспринимают безопасность. Однако, это не тот класс задач, на котором сосредоточены мы в MIRI.
Альфонсо: О чём в таком случае вы беспокоитесь? Вы боитесь, что космосамолёты могут быть разработаны злонамеренными людьми?
Бет: Нет, сейчас нас волнуют совсем другие сценарии провала. И в первую очередь то, что прямо сейчас вообще никто не может сказать, куда надо направить нос ракеты, чтобы она попала на Луну, или, на самом деле, вообще в любое заранее определённое место назначения. Мы считаем, что не важно — запустит ли ракету Google, правительство США, или Северная Корея. Это не влияет на вероятность успешной посадки на Луну, потому что сейчас никто не знает, как направить хоть какую-нибудь ракету хоть куда-нибудь.
Альфонсо: Не уверен, что понял.
Бет: Нас тревожит, что даже если прицелиться ракетой в Луну так, чтобы нос ракеты точно указывал на Луну на небе, ракета не полетит к Луне. Мы не знаем, как выглядит реалистичный путь от Земли к Луне, но мы подозреваем, что он будет не очень прямым и, возможно при этом направлять нос ракеты на Луну вовсе не нужно. Мы думаем, самое важное, что надо делать сейчас — это развивать наше понимание ракетных траекторий, пока у нас не будет лучшее, более глубокое понимание того, что мы начали называть «соответствием ракеты и цели»2. Есть много других задач в области безопасности, но задача соответствия ракеты и цели, вероятно, займёт больше всего времени, так что она самая срочная.
Альфонсо: Хммм, мне кажется, это слишком сильное заявление. У вас есть причина думать, что между нами и Луной есть невидимый барьер, в который может врезаться космосамолёт? Или вы говорите, что между нами и Луной может быть очень-очень ветрено, сильнее, чем тут на Земле? Может и стоит приготовиться к таким вариантам, но они не выглядят вероятными.
Бет: Мы вовсе не думаем, что невидимые барьеры особенно вероятны. И мы не думаем, что в небесных просторах будет очень ветрено — даже наоборот. Проблема в том, что мы пока не знаем, как построить хоть какую-нибудь траекторию, по которой реалистично добраться от Земли до Луны.
Альфонсо: Конечно, мы не можем построить конкретную траекторию: ветер и погода слишком непредсказуемы. Но твоё заявление всё ещё выглядит слишком сильным. Просто направь космосамолёт на Луну, взлети и пусть пилот поправляет курс по необходимости. С чего бы этому не работать? Ты можешь доказать, что космосамолёт, нацеленный на Луну, не доберётся до неё?
Бет: Мы не считаем, что можем что-то в таком роде доказать. Частично проблема в том, что реалистичные вычисления в этой области невероятно сложны, принимая во внимание трение об атмосферу и движение других небесных тел и всё такое. Мы пытались решать радикально упрощённые задачи, с предположениями в духе отсутствия атмосферы или ракет, двигающихся по идеально прямым линиям. Даже такие нереалистичные вычисления сильно свидетельствуют в пользу того, что в гораздо более сложном реальном мире просто нацеливание носа ракеты на Луну не приведёт к тому, что ракета в итоге прилетит на Луну. В смысле, то, что реальный мир сложнее, точно не делает добирание до Луны проще.
Альфонсо: Хорошо, давай я посмотрю на эту вашу работу над «пониманием»…
Гм. Судя по тому, что я читал про математику, которой вы пытаетесь заниматься, я бы сказал, что не понимаю, как она относится к Луне. Не должна ли помощь пилотам космосамолётов в точном нацеливании на Луну включать в себя наблюдение её через телескопы и изучение, как именно Луна выглядит, чтобы пилоты могли найти наилучший ландшафт для посадки?
Бет: Мы считаем, что нашего уровня понимания не хватает, чтобы заниматься детальной картой Луны прямо сейчас. Нам пока ещё рано выбирать кратер, на который стоит нацеливаться. Сейчас мы не можем нацелиться вообще ни на что. Это больше похоже на «понять, как математически рассуждать об искривлённых ракетных траекториях вместо ракет, двигающихся по прямым линиям». Даже пока что не о реалистично искривлённых траекториях, мы просто пытаемся хоть как-то пройти дальше прямых…
Альфонсо: Но самолёты на Земле движутся по кривым всё время, ведь искривлена сама Земля. Естественно ожидать, что будущие космосамолёты тоже будут способны двигаться по кривым. Если вы беспокоитесь, что они будут двигаться только по прямым и промахнутся мимо Луны, и вы хотите посоветовать ракетным инженерам строить ракеты, двигающиеся по кривым, то, кажется, время можно потратить и с большей пользой.
Бет: Ты пытаешься провести слишком прямую связь между математикой, над которой мы работаем прямо сейчас, и реальными возможными будущими проектами ракет. Дело вовсе не в том, что текущие идеи ракет почти правильные, и нам просто надо решить ещё одну-две задачи, чтобы они заработали. Концептуальный разрыв, отделяющий человечество от решения задачи нацеливания ракет гораздо-гораздо шире.
Прямо сейчас по поводу ракетных траекторий у всех полное замешательство. Мы пытаемся понять хотя бы чуть больше, чем ничего. Именно это сейчас первоочередная задача. Не надо бежать к ракетным инженерам и советовать им строить ракеты согласно тому, что написано в наших математических статьях. Пока мы даже не разобрались в совершенно базовых вопросах вроде того, почему Земля не падает на Солнце.
Альфонсо: Я не думаю, что Земля может столкнуться с Солнцем в обозримом будущем. Солнце стабильно вращается вокруг Земли уже довольно долго.
Бет: Я не говорю, что наша цель связана с риском падения Земли на Солнце. Я говорю, что раз современные знания человечество не позволяют отвечать на вопросы вроде «Почему Земля не падает на Солнце?», то мы не очень много знаем про небесную механику и не в состоянии направить ракету через небесные просторы так, чтобы она совершила мягкую посадку на Луну.
Например, чтобы лучше разобраться в небесной механике, мы сейчас работаем над задачей «повторяющихся позиций». Она о том, как выстрелить ядром из пушки так, чтобы ядро облетало Землю снова и снова, повторяя свои изначальные координаты, как повторяется плитка на полу…
Альфонсо: Я полистал вашу работу по этой теме. Должен сказать, мне не понятно, как стрельба из пушек связана с полётом на Луну. Откровенно говоря, это звучит подозрительно похоже на старые-добрые космические полёты, которые, как всем известно, не работают. Может, Жюль Верн думал, что можно путешествовать вокруг Земли, выстрелив капсулой из пушки, но современные исследования высоко летающих самолётов полностью отбросили такой вариант. То, что вы упоминаете стрельбу из пушек, наталкивает меня на мысль, что вы не поспеваете за инновациями в самолётостроении за последний век, и поэтому ваши проекты космосамолётов будут совершенно нереалистичными.
Бет: Мы знаем, что ракетами на самом деле не будут выстреливать из пушек. Правда-правда. Мы прекрасно осведомлены о причинах того, почему нельзя достичь скорости убегания, выстрелив чем-то из современной пушки. Я уже написала несколько цепочек статей, в которых я описала, почему космических полётов на основе стрельбе из пушек не получится.
Альфонсо: Но твоя текущая работа вся про то, как выстрелить чем-то из пушки так, чтобы оно облетало Землю снова и снова. Как это связано с любыми реалистичными советами, которые можно было бы дать пилоту космосамолёта о том, как долететь до Луны?
Бет: Опять же, ты пытаешься слишком напрямую связать математику, которой мы занимаемся сейчас и непосредственные советы будущим инженерам.
Мы думаем, что если мы сможем найти угол и изначальную скорость, такие, что выстрел из идеальной пушки на идеальной сферической Земле без атмосферы идеальным ядром с этой скоростью и углом приведёт к тому, что ядро займёт то, что мы называем «стабильной орбитой», и не упадёт, то… мы, может быть, поймём что-то по-настоящему фундаментальное и важное о небесной механике.
Или нет! Сложно знать заранее, какие вопросы важны, и какие исследования оправдаются. Всё, что можно сделать, это определить следующую выглядящую поддающейся трактовке задачу, которая вызывает у тебя замешательство, и попробовать найти решение и надеяться, что замешательство уменьшится.
Альфонсо: Ты говоришь о том, что ядро упадёт, как о проблеме, и о том, как ты хочешь избежать этого и заставить ядро летать вечно, правильно? Но настоящие космосамолёты изначально не будут направлены обратно на Землю, а большинство обычных самолётов вполне успешно не падают. Так что мне кажется, что этот сценарий «выстреливания из пушки и падения», которого вы пытаетесь избежать в этой вашей «задаче повторяющихся позиций» — просто не тот вид провала, о котором должны будут беспокоиться реальные проектировщики космосамолётов.
Бет: Мы не беспокоимся о реальных ракетах, выпускаемых из пушек и падающих. Мы не поэтому работаем над задачей повторяющихся позиций. В некотором роде ты чересчур оптимистичен по поводу того, какая часть теории соответствия ракет и цели уже построена! Мы не настолько близки к пониманию того, как нацеливать ракеты, чтобы проекты, о которых говорят сейчас, могли сработать, если бы мы только решили определённый набор оставшихся сложностей вроде «как не позволить ракете упасть». Тебе нужно перейти на мета-уровень, чтобы понять, прогресса какого вида мы добиваемся.
Мы работаем над задачей повторяющихся позиций потому, что мы думаем, что способность выстрелить ядром с определённой мгновенной скоростью так, чтобы оно заняло стабильную орбиту… это такая задача, которую кто-то, кто реально может запустить ракету по конкретной кривой, которая закончится мягкой посадкой на Луну, мог бы решить с лёгкостью. Так что нас тревожит то, что мы её не можем решить. Если мы разберёмся, как решить эту гораздо более простую чётко поставленную задачу повторяющихся позиций с воображаемыми ядрами на идеально-сферической Земле без атмосферы, которую гораздо проще анализировать, чем полёт на Луну, то, может быть, сделаем ещё один шаг к тому, чтобы когда-нибудь стать такими людьми, которые могут спланировать полёт на Луну.
Альфонсо: Если вы не считаете космические пушки в духе Жюля Верна перспективными, то я не понимаю, почему вы продолжаете говорить именно про пушки.
Бет: Потому что уже разработано много сложных математических методов для нацеливания пушек. Люди целились из пушек и проводили траектории ядер с шестнадцатого века. Преимущество этой существующей математики позволяет нам точно сказать, где упадёт идеальное ядро, выпущенное из идеальной пушки в каком-то направлении. Если мы попробуем говорить о ракетах с реалистично изменяющимся ускорением, то мы не сможем даже доказать, что ракета не будет летать вокруг Земли по идеальному квадрату, потому что реалистичные изменения ускорения и реалистичное трение о воздух делают любые точные высказывания невозможными. Нашего текущего понимания не хватает.
Альфонсо: Хорошо, другой вопрос в том же духе. Зачем MIRI финансирует работу по сложению кучи крохотных векторов? Я вообще не вижу, как это связано с ракетами, это выглядит как какая-то странная сторонняя задача из абстрактной математики.
Бет: Это связано с тем… в наших исследованиях мы несколько раз натыкались на задачу перехода от функции изменяющегося во времени ускорения к функции изменяющегося со временем положения. Эта задача становилась камнем преткновения несколько раз, так что мы начали попытки явно проанализировать её отдельно. Поскольку она про чистую математику, не двигающихся дискретно точек, мы назвали её задачей «логической недискретности». Эту задачу можно, например, изучать, пытаясь сложить кучу маленьких меняющихся векторов в один большой вектор. Потом мы рассуждаем о том, как сумма меняется всё медленнее и медленнее, приближаясь к пределу, если вектора становятся всё меньше и меньше, но складываем мы их всё больше и больше… По крайней мере, это один из подходов.
Альфонсо: Мне просто трудно представить, как люди в будущих ракетных космосамолётах смотрят в иллюминаторы и «О нет, у нас недостаточно маленьких векторов, чтобы скорректировать курс! Если бы только был способ сложить побольше ещё меньших векторов!». Я ожидаю, что будущие вычислительные машины будут делать это достаточно хорошо.
Бет: Ты опять слишком напрямую связываешь работу, которой мы заняты сейчас, и применения для будущих проектов ракет. Мы не думаем, будто спроектированная ракета почти что будет работать, но пилот не сможет сложить много крохотных векторов достаточно быстро, так что нам нужен алгоритм побыстрее, и тогда ракета попадёт на Луну. Это фундаментальная математическая работа, которая, как мы считаем, может помочь с основными концепциями, необходимыми для понимания небесных траекторий. Когда мы пытаемся провести траекторию вплоть до мягкой посадки на движущуюся Луну, мы чувствуем себя в замешательстве и тупике. Мы думаем, часть замешательства происходит из нашей неспособности перейти от функций ускорения к функциям положения, так что так мы и пытаемся его разрешить.
Альфонсо: Это подозрительно похоже на задачу откуда-то из философии математики. Не думаю, что можно продвинуться в проектировании космосамолётов, занимаясь философией. Область философии — застойная трясина. Некоторые философы всё ещё верят, что полёт на Луну невозможен. Они говорят, что небесный план фундаментально отделён от земного и потому недосягаем, что откровенно глупо. Проектирование космосамолётов — инженерная проблема, и продвигаются в ней инженеры.
Бет: Я согласна, что проектированием ракет занимаются инженеры, а не философы. Также я разделяю часть твоего огорчения по поводу философии в целом. Именно поэтому мы занимаемся хорошо определёнными математическими вопросами, которые скорее всего имеют настоящие ответы. Например, вопросом о том, как выстрелить пушечным ядром на идеально сферической планете без атмосферы так, чтобы оно вышло на стабильную орбиту.
Для этого часто нужен новый математический аппарат. К примеру, для задачи логической недискретности мы разработали методы для перехода от изменяющихся во времени ускорений к изменяющихся во времени положениям. Ты, если хочешь, можешь называть разработку нового математического аппарата «философией» — но тогда помни, что это совсем другой вид философии, чем «спекулятивные предположения о небесных и земных планах».
Альфонсо: Итак, с точки зрения общественного блага, что хорошего произойдёт, если вы решите эту задачу про логическую недискретность?
Бет: В общих чертах: мы больше не будем настолько в замешательстве, наши исследования не будут в тупике, а человечество может когда-нибудь и доберётся до Луны. Если попытаться сказать это менее размыто — хотя без знания конкретного решения это тяжело — мы сможем научиться говорить о всё более реалистичных ракетных траекториях, потому что у нас будет математика, которая не ломается сразу же, как только мы перестаём предполагать, что ракеты двигаются по прямым. Наша математика сможет рассуждать о точных кривых, вместо последовательностей аппроксимирующих отрезков.
Альфонсо: Точная кривая, которой следует ракета? Это приводит к главной проблеме, которую я вижу в вашем проекте. Я просто не верю, что будущие ракеты можно будет анализировать с абсолютной идеальной точностью и посылать её на Луну по заранее точно проведённой траектории без нужды поправлять её по дороге. Это выглядит для меня так, будто математики, не имеющие понятия о том, как работает реальный мир, хотят, чтобы всё было идеально вычисляемым. Посмотри, как Венера двигается по небу; она обычно движется в одном направлении, но иногда становится ретроградной и двигается в другую сторону. Иногда по дороге нам придётся просто рулить.
Бет: Когда я говорила про точные кривые, я подразумевала не совсем это… Смотри, я соглашусь, что даже если мы решим логическую недискретность, бесполезно будет пытаться заранее предсказать точные траектории со всеми ветрами, которые встретит ракета на своём пути. Отмечу, впрочем, что когда ракета поднимется достаточно высоко, всё может стать спокойнее и предсказуемее…
Альфонсо: Почему?
Бет: Давай пока не будем этого касаться, раз мы и так согласны, что положение ракеты сложно предсказать точно в атмосферной части её траектории, из-за ветров и подобного. И да, если нельзя точно предсказать раннюю траекторию, то нельзя точно предсказать и позднюю траекторию. Так что мы вовсе не предлагаем спроектировать ракету так идеально, чтобы можно было просто направить её с абсолютно точным углом и обойтись без пилота. Цель ракетной математики не в том, чтобы заранее предсказать точное положение ракеты в каждую микросекунду.
Альфонсо: Тогда зачем вы так одержимы чистой математикой, которая слишком проста, чтобы описать большой сложный реальный мир, где иногда идёт дождь?
Бет: Это правда, что настоящая ракета — не простое уравнение на доске. Это правда, что многие аспекты формы и внутреннего устройства настоящей ракеты не будут иметь компактного математического описания. Мы в MIRI пытаемся создать не математику для всех ракетостроителей на все времена, а математику, которую мы будем использовать прямо сейчас (как мы надеемся).
Чтобы с каждым шагом понимать нашу область всё лучше и лучше, нам нужно говорить об идеях, последствия которых можно определить достаточно точно. Это нужно, чтобы у людей был общий контекст для анализа сценариев. Нам нужно достаточно точности, чтобы кто-нибудь мог сказать: «В сценарии X, я думаю, Y приведёт к Z», а кто-то мог ответить: «Нет, в сценарии X, Y на самом деле приведёт к W», а первый мог ответить: «Чёрт, ты прав. Что ж, подумаем, как изменить Y, чтобы он всё же приводил к Z?».
Если же попытаться сделать что-то реалистично сложное на текущей стадии исследований, получится просто пустая болтовня. Когда у кого-то есть огромная схема с шестерёнками и рулями, которая якобы является проектом ракеты, а мы пытаемся объяснить, почему ракета, направленная на Луну, не обязательно прилетит на Луну, нам просто отвечают: «О, моя ракета обязательно прилетит». Идеи подобных изобретателей так размыты, и гибки, и недоопределены, что никто не может доказать им, что они неправы. Становится невозможно добавить хоть что-то к общему знанию.
Наша цель — постепенно создавать коллекции инструментов и идей, с помощью которых можно будет обсуждать траектории формально. Некоторые ключевые инструменты формализации и анализа интуитивно-правдоподобных траекторий ещё не выражены в чистой математике. Пока мы можем с этим жить. Мы всё ещё пытаемся найти способы математически чётко отобразить столько ключевых идей, сколько сможем. Не потому, что математика такая изящная и престижная, а для того, чтобы продвинуть споры о ракетах дальше, чем «А я говорю, да!» и «А я говорю, нет!».
Альфонсо: Мне всё ещё кажется, что вы пытаетесь спрятаться в тепле и комфорте строгих математических обоснований там, где они просто невозможны. Мы не можем совершенно строго математически доказать, что наши космосамолёты точно доберутся до Луны и ничего не пойдёт не так. Так что не стоит делать вид, что математика позволит нам получить абсолютную гарантию касательно космосамолётов.
Бет: Поверь мне, у меня точно не будет полной уверенности в результате вне зависимости от того, какую математику разработают в MIRI. Да, конечно, никакое физическое высказывание нельзя доказать математически, и нельзя назначить вероятность 1 любому эмпирическому утверждению.
Альфонсо: Но ты говоришь о доказательстве теорем — типа того, что ядро будет бесконечно летать кругами вокруг Земли.
Бет: Доказательство теоремы о траектории ракеты не даст нам достаточно комфортную уверенность в том, где она в итоге окажется. Но если доказать теорему, которая заявляет, что запущенная в идеальном вакууме ракета прилетит на Луну, то может быть, что если присоединить к ней какие-нибудь маневровые двигатели, то она долетит до Луны и в реальности. С вероятностью не в 100%, но выше нуля.
Суть нашей работы не в том, чтобы довести текущие идеи о нацеливании ракеты от 99% до 100% вероятности успеха. Она в том, чтобы превзойти текущий шанс успеха в приблизительно 0%.
Альфонсо: Ноль процентов?!
Бет: С точностью до правила Кромвеля, да, ноль процентов. Если направить нос ракеты на Луну и запустить её, она не прилетит на Луну.
Альфонсо: Если прямое нацеливание на Луну не работает, то вряд ли будущие инженеры космосамолётов будут на самом деле настолько глупы, что это не поймут. Они отследят текущее движение Луны по небу и прицелятся в ту часть неба, где Луна будет в день, когда космосамолёт пролетит расстояние до Луны. Меня тревожит, что вы так долго обсуждаете эту проблему и не рассмотрели такую очевидную идею.
Бет: Мы давно уже её рассмотрели и вполне уверены, что это не приведёт нас на Луну.
Альфонсо: Что если мы добавим стабилизаторы, чтобы ракета двигалась по более искривлённой траектории? Можешь доказать, что никакая версия ракеты из этого класса не долетит до Луны, сколько бы мы не старались?
Бет: Можешь набросать траекторию, по которой, с твоей точки зрения, полетит ракета?
Альфонсо: Она полетит от Земли к Луне.
Бет: А можно поподробнее?
Альфонсо: Нет, потому что в реальном мире всегда есть меняющаяся скорость ветра, а у нас нет бесконечного топлива, а космосамолёты не двигаются по идеально прямым линиям.
Бет: Можешь набросать траекторию, которой, как ты думаешь, будет следовать упрощённая версия твоей ракеты, чтобы мы могли понять, каких допущений требует твоя идея?
Альфонсо: Я просто не верю в общую методологию, которую ты предлагаешь для проектирования космосамолётов. Мы устанавливаем стабилизаторы, рулим, пока летим и держим курс на Луну. Если мы сбиваемся с курса, мы его поправляем.
Бет: Вообще-то мы несколько беспокоимся, что обычные стабилизаторы могут перестать работать, когда ракета поднялась слишком высоко. И получится, что оказавшись в небесных просторах, курс поправить уже нельзя. То есть, если курс уже хороший, то ты сможешь его поправить, но если всё пошло совсем не так, то нельзя просто развернуться как на самолёте.
Альфонсо: Почему нельзя?
Бет: Этот вопрос тоже можно обсудить. Однако для того, чтобы дискуссия продвигалась вперёд, всё равно нужно разбирать последовательность шагов, которые ракета пройдёт по пути к Луне. Даже если это упрощённая модель ракеты, которой можно рулить. Полёты ракет в небесах — это необычайно сложная область — даже если сравнивать с строительством ракет на Земле, что само по себе очень тяжело, потому что обычно они просто взрываются. Не то, что бы всё должно было быть изящным и математичным. Однако это очень сложная задача. И предложения вроде «давайте следовать за Луной в небе», если они не основываются на достаточно надёжных идеях, эквивалентны запуску ракеты в пустоту случайным образом.
Если кажется, что ты точно не уверен, сработает ли твоя идея, но она может сработать, и при этом твоя идея состоит из множества правдоподобно звучащих деталей, и, кажется, ни у кого не получается по-настоящему убедительно объяснить тебе, почему эта идея не сработает, то, на самом деле, шансы, что твоя идея приведёт ракету на Луну, примерно равны нулю.
Если кажется, что идея достаточно надёжно обоснована и полностью понятно, если кажется, что она определённо должна успешно довести ракету до Луны, когда всё пойдёт хорошо, тогда, может быть, в лучшем случае, мы можем быть субъективно уверены в успехе на 85%, или около того.
Альфонсо: То есть неуверенность автоматически означает провал? Если честно, звучит параноидально.
Бет: Идея, которую я стараюсь донести, это что-то вроде: «Если ты можешь строго рассуждать о том, почему ракета в принципе должна работать как надо, то это может на самом деле сработать, но если у тебя что-то меньшее, то это определённо не сработает в реальном мире».
Я не прошу тебя дать мне абсолютное математическое доказательство эмпирического успеха. Скорее набросок того, как упрощённая версия твоей ракеты может двигаться, достаточно определённый, чтобы ты не мог потом просто сказать «О, я имел ввиду вовсе не это» каждый раз, когда кто-то пытается понять, что она на самом деле делает, или указать на возможные причины провала.
Это не надуманное требование, отсекающее вообще любые идеи. Это нижняя планка, которую необходимо преодолеть, чтобы привнести что-то новое в эту область. И если проект ракеты не соответствует даже этой концептуальной планке, то шансы такой ракеты на мягкую посадку на Луну примерно равны нулю.
Руководство по исследованиям в области соответствия ИИ
Это руководство написано командой MIRI в первую очередь для групп MIRIx, однако советы отсюда могут оказаться полезны и другим людям, работающим над проблемой соответствия ИИ1 нашим целям.
Введение I. Теория принятия решений
Привет! Возможно, вы обратили внимание, что вы читаете некий текст.
Из этого факта следуют некоторые выводы. Например, зачем вы читаете этот текст? Закончите ли вы чтение? Какие решения вы примете? Что вы сделаете дальше?
Независимо от того, какое решение вы примете, учтите, что, скорее всего, десятки или даже сотни людей, достаточно похожие на вас и находящиеся в схожих условиях, скорее всего примут примерно такие же решения.
Поэтому мы рекомендуем при размышлении над ближайшими решениями задаться вопросом: «Если все агенты, похожие на меня, будут действовать одинаково, какая их политика приведёт к максимальному благу и как эта политика рекомендует поступить в моём случае?» Речь идёт скорее не о попытке решить за всех агентов, достаточно похожих на вас (что может заставить вас принять неверное решение из чувства вины или из ощущения, что на вас давят), а о чём-то вроде «если бы я руководил всеми агентами из моего референтного класса, как бы я относился к кому-то в этом классе, если бы он обладал именно моими особенностями?»
Если эти рассуждения помогут вам продолжить чтение — прекрасно. Если они приведут к тому, что вы создадите группу MIRIx — ещё лучше. Тем временем, мы продолжим, считая, что этот документ читают лишь люди, которые оправданно ожидают, что он окажется им чем-то полезен.
Введение II. Площадь поверхности
Представьте, что вам нужно передвинуть железный куб со стороной в один метр. Поскольку такой куб весит примерно 8 тонн, а среднестатистический человек может поднять примерно 50 килограмм, наивные подсчёты сообщают, что нам понадобится примерно 160 друзей, которые захотят нам помочь.
Однако, конечно же, вокруг метрового куба поместятся лишь примерно 10 человек максимум. Совершенно не важно, есть ли у вас теоретически силы, чтобы его сдвинуть, если вы не можете эффективно приложить эти силы. У задачи есть ограничение: площадь поверхности.
Группы MIRIx — один из лучших способов увеличить «площадь поверхности» для людей, размышляющих и работающих над технической проблемой соответствия ИИ. Указ «десять человек, которые оказались ближайшими к металлическому кубу — единственные, кому разрешается думать над этой задачей» был бы плохой идеей. И точно также мы не хотим, чтобы MIRI оказался узким местом или авторитетом в вопросах, как следует рассуждать и что нужно делать в вопросах внедрённой агентности2 и смежных областях.
Мы надеемся, что вы и другие люди, похожие на вас, на самом деле решат эту задачу, а не будут просто следовать указаниям или читать написанное кем-то другим. Этот текст создан, чтобы поддержать тех, кому интересно самому совершить прорыв.
Вы и ваши исследования
Нам часто задают вопрос: «Даже летняя стажировка, кажется, слишком коротка, чтобы всерьёз продвинуться в решении настоящей задачи. Как кто-нибудь может всерьёз что-то исследовать за одну встречу?»
На эту тему можно выразиться в стиле Зенона: вы не продвинетесь в своих исследованиях и за миллион лет, если не можете продвинуться в них за пять минут. Очень легко попасть в ловушку (явного или неявного) представления исследований как чего-то вроде: «сначала изучаем всё, что нужно изучить, а затем пытаемся раздвинуть границы и внести свой вклад».
Проблема такого представления (с нашей точки зрения) в том, что она подталкивает людей в сторону поглощения информации как некоего необходимого условия для понимания, а не как необходимого инструмента. (Помните, что именно вы оптимизируете во время своей работы!)
Всегда будет существовать ещё какой-нибудь материал, который стоит изучить. Сложно предсказать заранее, сколько именно вам нужно знать, чтобы получить право на собственные мысли и взгляд. И легко пасть жертвой синдрома Даннинга-Крюгера или синдрома самозванца, а также начать излишне полагаться на существующие авторитеты.
Вместо этого мы рекомендуем выбросить вопрос авторитетов из головы. Просто следуйте за рассуждениями, которые кажутся живыми и интересными. Не думайте об исследованиях как о процессе «сначала изучаем, потом вносим свой вклад». Сосредоточьтесь на собственном понимании задачи, и пусть ваши вопросы сами определяют, какие статьи вам нужно прочитать и какие доказательства изучить.
Такой подход к исследованиям решает вопрос: «Что можно осмысленного сделать за день?» Кажется очень сложно достичь существенного прогресса, если вы меряте себя какой-то объективной внешней меркой. Но гораздо проще, если вас ведёт вперёд ваш собственный вкус.
Никакая процедура не подойдёт абсолютно всем. Однако далее приведены шаги, которые вы можете попробовать самостоятельно или в группе (например, MIRIx), чтобы попрактиковаться в описанном выше исследованиях, питаемых любопытством.
- Выпишите список вопросов.
- Если вы работаете в группе, прикрепите этот список туда, где все смогут его видеть, например, на доску.
- Сосредоточьтесь на том, о чём вы не знаете, как это делать, или по поводу чего испытываете замешательство.
- Если в голову не приходят никакие вопросы, скажите себе (или группе): «Прекрасно, я должен понять, как решить всю эту задачу целиком» и попробуйте описывать подробности решения, пока не застопоритесь.
- Совершенно нормально включать в список не только вопросы, но и идеи, которые вы хотите развить, или мысли, критику которых вы хотите получить от группы.
- Выберите один из вопросов, чтобы сконцентрироваться на нём. Выбирайте то, что кажется наиболее интересным.
- Если в вашей группе больше трёх человек, подумайте о том, чтобы разделиться. Каждая подгруппа может обсуждать как свой собственный вопрос, так и независимо обсуждать один общий. Определитесь, через какое время вы опять соберётесь вместе и обсудите, к чему вы пришли.
- Рекомендуем сохранять полный перечень вопросов где-то на виду, чтобы он напоминал вам о других интересных темах, на которые можно переключиться, если мысли по поводу первого выбранного вопроса иссякнут.
- Сформулируйте собственное любопытство. Чего хочется достичь? Чего, по-вашему, можно достичь?
- При работе в группе обычно человеку, который предлагает тему, стоит рассказать что-нибудь о ней, чтобы все одинаково понимали, о чём речь.
- При работе самостоятельно рекомендуем с самого начала записывать всё, что, по-вашему, вы знаете и что, по-вашему, вы не знаете. Записывайте всё, что имеет хоть какое-то отношение к делу. На этом этапе не беспокойтесь, истинны ли ваши утверждения и осмысленны ли ваши вопросы. Затем пересмотрите написанное и придайте ему смысл. Переформулируйте ваши утверждения до тех пор, пока они не превратятся во что-то определённо либо истинное, либо ложное.
- Продолжайте формулировать и уточнять.
- Продолжайте формулировать вспомогательные вопросы и делать утверждения (возможно, истинные, возможно, нет), двигаясь от расплывчатых к чётким и формальным.
- Обращайте внимание, когда ваше любопытство растёт, а когда падает. Избегайте стремления завершить работу из чувства долга. Ищите самые простейшие случаи, по поводу которых вы до сих пор испытываете замешательство, и пробуйте работать с ними.
- Позвольте себе отвлекаться. Позвольте себе играть. Пока все участники дискуссии сохраняют любопытство и вовлечённость, это способствует лучшему пониманию. Не бойтесь залипнуть в какой-нибудь «неважный» математический вопрос, не исключено, что они окажутся более важными, чем кажется на первый взгляд. Вы развиваете свои способности, пусть даже это не помогает напрямую решать вашу задачу.
- Если вы получили конкретные математические результаты, в которых есть что-то интересное, или даже конкретный математический вопрос, запишите это. Подробные отчёты в письменном виде помогают не только обмениваться идеями с другими людьми. Они ещё способствуют тому, что вы сами начинаете лучше понимать изучаемый вопрос.
Прогресс в MIRI достигается примерно таким же образом. Наша работа очень сильно отличается от «просто читаем множество статей» и очень сильно отличается от «попытаться сформулировать от начала до конца, что именно нужно сделать в этой области».
Естественная ошибка: считать свою работу попыткой внести вклад в мировое коллективное знание и из-за этого перестать ставить на первое место собственные знания и понимание. На первый взгляд, «просто читать статьи» выглядит, как будто мы ставим собственные знания на первое место, но такой подход часто является следствием неявного убеждения, что какие-то другие люди точно знают, что именно нам нужно знать. Подход же «оптимизировать собственное понимание» порождает быструю обратную связь.
В том, чтобы читать статьи нет ничего самого по себе плохого — даже если вы просто читаете произвольные статьи по соответствующей тематике, чтобы получить общее представление о состоянии дел. Однако вам стоит всегда пытаться представлять, что именно вы знаете или не знаете, как делать, и что именно вам нужно узнать, чтобы решить задачу. Это сложно. Не исключено, что вы уверены, что первые пять идей, которые вы запишете, окажутся неверными. Тем не менее, всё же запишите их и попробуйте заставить их работать. Так вы сможете увидеть, что получится, и понять, что идёт не так.
Мы не хотим, чтобы сотни талантливых людей задавали одни и те же вопросы и принимали один и тот же набор допущений. Нам нужно много исследователей, а не пользователей. С нашей точки зрения, лучший способ стать исследователем — это с самого начала тренироваться независимо мыслить, а не прокачивать навык «сижу и впитываю информацию ради информации».
Поэтому не спрашивайте: «Какие есть открытые вопросы?» Спрашивайте: «Какие вопросы интересуют меня?»
Как начать
Предположим, вы попробовали что-то из написанного выше, вам понравилось и вы хотите перейти к созданию вашей собственной группы MIRIx.
Мы рекомендуем в первую очередь найти ОДНОГО или ДВУХ людей (но не трёх и больше), и попробовать заняться исследованиями пару раз вместе с ними. Ниже будет раздел про социальную динамику, в котором описано, как именно это может выглядеть, но смысл в том, что, вероятно, лучше попробовать отладить атмосферу и рабочий процесс при малом количестве участников. Если вы начнёте с большого количества людей, договариваться о работе группы, скорее всего, будет гораздо сложнее.
Ещё в случае большого количества людей сложно договориться о расписании. Найти время и место, которые устраивали бы всех, становится невозможно, и процесс согласования каждой новой встречи может демотивировать. Составляйте расписание так, чтобы оно подходило основному ядру группы. Какой день недели подходит вам? Как часто вы хотите встречаться? Сколько времени будет длиться встреча? Мы рекомендуем устраивать встречи раз в месяц, раз в неделю или раз в две недели. Длина встречи может варьироваться от часа до целого дня, в зависимости от того, что подходит лично вам.
Когда вы найдёте одного или двух партнёров, с которыми вам действительно комфортно работается, следующий шаг: запланировать и организовать первую большую встречу. «Большая» — означает примерно «от трёх до шести человек». Определённо не «двадцать-тридцать слушателей».
Попытайтесь найти тихое, звукоизолированное место, где можно удобно расположиться, есть на чём писать (в том числе, есть большие маркерные доски на стенах). Часто подобные места есть в университетах и публичных библиотеках, но подойдёт и чья-нибудь гостиная, если вы сможете свести к минимуму количество посторонних вмешательств. Не забудьте запастись чистой бумагой, ручками, планшетами, а также выберите кого-нибудь, кто будет отвечать за еду и питьё.
(Примечание по поводу еды и питья. Люди почти всегда недооценивают важность качества и количества еды и сваливаются к чему-нибудь вроде: «Не знаю, может просто купим чипсы баксов на десять или что-то в этом духе?» Лучше спросите себя: сколько я потратил бы на то, чтобы способность думать для всей группы, общее настроение и удовлетворённость от встречи повысилась бы на 15%? Именно от такой суммы вам стоит отталкиваться (/ попросить у MIRI) при расчёте стоимости еды, особенно на первую встречу. Не покупайте только фаст-фуд. Возможно, на какое-то время он вам даст больше энергии, но вам будет сложнее думать потом. Здоровая еда довольно важна — особенно для длинных встреч. Большая встреча должна включать в себя достаточно серьёзный приём пищи, возможно в ближайшем ресторане. Это также послужит неплохим перерывом.)
На первой большой встрече, возможно, вы захотите выбрать руководителя группы. Это важная часть культуры общего знания — в большинстве случаев руководитель ничем не отличается от остальных, однако крайне полезно, чтобы в наличии был человек, у которого есть моральное право устанавливать повестку, выбирать между различными хорошими вариантами и не давать группе отвлекаться. Возможно, вы также захотите выбрать секретаря/ответственного за записи, или, быть может, координатора, отвечающего за выбор места и еду, или создать какие-нибудь ещё должности (впрочем, этим можно заняться и на следующих встречах).
Затем вы, вероятно, захотите смоделировать процесс, который уже работает для вас. Возможно, это означает поделиться списком уже существующих вопросов и посмотреть, какие из них привлекут интерес участников. Возможно, это означает сначала обсудить направление ваших исследованиях в общих чертах, а уж затем перейти к отдельным темам. В любом случае вы захотите перейти к серьёзным размышлениям, записям, доказательствам и обсуждениям как можно быстрее. Если на встрече присутствует больше четырёх человек, лучше разбиться на подгруппы. Если вы так и поступите, запланируйте, в какое время вы соберётесь обратно для обсуждения.
Постарайтесь не забывать о перерывах. Когда работа вовсю кипит, вспоминать о них сложно, поэтому стоит их запланировать заранее. Короткий перерыв каждый час, во время которого люди встают и выходят прогуляться, очень помогает.
Имеет смысл сохранять общедоступный список (на маркерной доске или в общем гугл-документе) накопившихся вопросов, необходимых понятий и многообещающих идей. Из такого списка легко почерпнуть новую тему, если разговор зашёл в тупик.
Возможная структура встречи, включающая в себя советы выше и исследовательскую процедуру из предыдущего раздела:
- В начале каждой встречи все перечисляют свои вопросы/темы/замешательства, и всё это записывается в общедоступный список.
- Собравшиеся определяют наиболее интересные им вопросы и делятся на подгруппы.
- Подгруппы обсуждают свои вопросы 45 минут.
- Все собираются вместе и несколько минут обсуждают, что происходило в подгруппах.
- Перерыв на 5-10 минут, в зависимости от того, как все себя чувствуют.
- На доску добавляются новые вопросы/идеи, и процесс повторяется нужное число раз. (Если вы планируете несколько циклов, также запланируйте длинный перерыв на то, чтобы поесть.)
В конце встречи запланируйте следующую. Возможно, вы уже сошлись на каком-то расписании, которое работает для ядра группы, но всё же его стоит подстраивать на случай праздников, отпусков и других обстоятельств. Важно, чтобы все согласились с временем следующей встречи, даже если у вас уже твёрдо устоявшееся расписание. Постарайтесь с самого начала принять, что вы не пытаетесь добиться постоянного всеобщего присутствия: будет лучше, если люди поймут, что иногда пропускать встречи — это нормально (при условии, что на каждую встречу приходит примерно 70-90% участников). Если один или два человека не могут прийти две встречи подряд, постарайтесь узнать у них подробности, чтобы, возможно, подстроиться под их расписание при планировании третьей.
Модели социальной динамики
В этой секции собраны несколько довольно «сырых» моделей о том, как получается хорошая исследовательская группа или вообще хорошее совместное предприятие. Здесь стоит обращать внимание скорее на общий дух, а не на букву. Также стоит попытаться определить ваши собственные ценности, а не считать, что вы обязаны следовать именно этим.
Передатчики и приёмники
Во время наших исследований мы обнаружили, что разговоры, в которых в основном участвует лишь два человека, идут лучше. Мы не хотим сказать, что не должно быть разговоров, в которых участвует три и более человека, однако в течении любого пятиминутного отрезка времени, разговаривать в основном должны только два человека — тот, кто пытается донести какую-то информацию, и тот, кто пытается её понять.(При этом именно понимание стоит оптимизировать в первую очередь. Обсуждение какой-либо темы на таком уровне, что четыре или пять разных людей способны отслеживать все нюансы, обычно приносит меньше пользы)
Назовём эти две роли «передатчик» и «приёмник». Вы можете передавать:
- Конкретный вопрос или замешательство.
- Модель или цепочку рассуждений.
- Кусок важной информации, которая необходима, чтобы по-настоящему понимать идущее обсуждение.
«Приёмник» может:
- Пересказывать «передатчику» то, что тот сказал, другими словами. Это позволяет «передатчику» понимать, успешно ли передана информация.
- Делать заметки на маркерной доске или рисовать диаграммы, и просить «передатчика» проверять, что получается. Делайте это настолько строго, насколько возможно. Пытайтесь записывать утверждения на языке логики и превращать нестрогие аргументы в доказательства. Для подобного понимания информации хорошо подходит теория типов. Даже просто точно записывать типы данных, соответствующие обсуждаемым сущностям, может быть очень полезно.
- Подавлять желание прервать «передатчика», когда тот говорит что-то уже понятное. Для этого подходит следующий приём: попытайтесь придумать как минимум две интерпретации и спросите, как их различить.
- Придерживаться гипотезы, что «передатчик» пытается рассказать о чём-то интересном. Избегайте режима «критика», который приведёт к тому, что «передатчику» будет сложнее думать и выражать свои мысли. Даже если в том, что явно сказал «передатчик» зияет дыра, ваша задача — помочь ему найти ту крупицу интуиции, которая позволит продолжить рассуждение и по-возможности превратить его в полезную идею.
- Обращать внимание на замешательство и говорить, если что-то в вашей картине не стыкуется. Задавать уточняющие вопросы. Ваша задача как «приёмника» не просто кивать или создавать у «передатчика» чувство, что его понимают. Будьте мягче, когда необходимо, чтобы помочь «передатчику» нащупать то, что он пытается сообщить. Но когда он это нащупал, ваша задача вытащить из него всё в подробностях!
- Если идея «передатчика» выглядит вполне чёткой, «приёмник» может начать искать в ней уязвимые места. Критика неоформившейся идеи часто мешает делу, однако, если речь идёт о ясном осмысленном предложении, критика вполне имеет смысл.
- Искать следствия того, что говорит «передатчик». («А, но тогда получается X!» или «Из этого ведь следует Х?», и так далее.) Это служит как минимум трём целям. Во-первых, это позволяет «передатчику» понять, что вы видите, почему эта идея окажется совершенно потрясающей, если она работает. Ведь вы с её помощью уже делаете что-то полезное. Это стимулирует. Во-вторых, это позволяет понять, успеваете ли вы за мыслью. В-третьих, совершенно абсурдный вывод позволит предположить, что вы зашли куда-то не туда, и стоит вернуться назад, чтобы понять, где ошибка.
- Играть роль доброго тролля - когда у «передатчика» ничего не получается или их вообще нет, потому что ни у кого нет идей. Сыграйте роль Сократа. Задавайте вопросы о вроде бы базовых штуках и попытайтесь показать, что они все не имеют смысла. Или защищайте нелепую точку зрения. (Тролль иногда кажется «передатчиком», но по сути он «приёмник».)
«Передатчик» должен чувствовать, что в попытках выразить свою интуицию, он может делать любые утверждения, в том числе «абсолютно ложные». Попытайтесь создать нормы, где вы можете попросить «приёмников» помочь вам выделить из того, что вы говорите, ядрышко истины, а не уничтожать полуоформившиеся идеи, потому что они наполовину неверны. Не важно, насколько «приёмники» избегают моральных суждений. Нужно, чтобы «передатчик» время от времени мог сказать что-то вроде «всё, что я собираюсь сказать, полностью неверно, но …»
«Передатчик» при этом должен руководствоваться своей интуицией и любопытством. Направлять разговор в наиболее интересное русло, а не пытаться создать хорошее впечатление или развлечь. «Передатчик» не обязан отвечать на вопросы «приёмника», сказать: «прямо сейчас я не хочу об этом думать» — вполне нормально.
Смысл в том, что «приёмник» помогает «передатчику» породить идею. Поэтому именно «передатчик» решает, что в данный момент более важно, а «приёмник» работает усилителем, поставщиком интуиции, а также источником (небольшого) хаоса.
Тем временем, всем остальным присутствующим стоит попробовать себя в роли посредников/переводчиков. Они должны наблюдать одновременно и за «передатчиком», и за «приёмником», и строить модели, что происходит в их диалоге. Где они упускают мысль собеседника? Где они не понимают, что именно хочет узнать собеседник? Может быть, у них срабатывает эффект подтверждения или двойная иллюзия прозрачности? Может, они соглашаются, что какое-то утверждение разумно, не понимая его до конца?
Остальным присутствующим имеет смысл вбрасывать в разговор важные мысли, модели, вопросы (но их вмешательство не должно превышать 10% от всех слов в беседе). Иногда вмешательство приведёт к смене ролей: кто-нибудь из слушателей станет «передатчиком» или «приёмником» или «передатчик» и «приёмник» поменяются местами.
Высокие стандарты
После одной или двух встреч довольно неловко не приглашать кого-то в следующий раз и, тем более, напрямую запрещать придти. Но разрушить всю группу MIRIx из-за чрезмерной застенчивости или неуверенности — ещё хуже.
Явно обозначьте разницу между «добро пожаловать на встречу» и «теперь ты в нашей команде». Позаботьтесь о том, чтобы все знали, кто именно принимает решения. Пусть он/она/они будут не обязаны объяснять своё решение. (Если вы не доверяете чьим-то суждениям без объяснений, этот человек не должен принимать решения.) Доверяйте своей интуиции. Если вам кажется, что некто не сочетается с атмосферой, которую вы хотите создать, не приглашайте его. Подумайте о том, чтобы требовать несколько рекомендаций или устраивать собеседование. Возможно, вам кажется, что это излишне, но исключать людей обычно тяжело, а формальный процесс приёма воспринимается как более справедливый.
Также подумайте, не стоит ли записать в явном виде этические правила или совместные обязательства, под которыми люди будут подписываться, когда они становятся частью команды. Убедитесь, что вы действительно хотите всерьёз поддерживать именно эти стандарты (например, «нужно посещать не меньше половины встреч» или «всё обсуждаемое на встречах не следует разглашать, если явно не сказано об обратном»).
Возрастание требований и вознаграждений
Представьте модель школы боевых искусств. Когда туда приходит новичок, инструкторы его мало о чём просят (например, ударь цель ногой с громким криком). Вскоре за это его вознаграждают поясом и некоторым статусом.
После этого требования возрастают. Ученика с жёлтым поясом уже могут попросить пару минут наблюдать за учениками с белыми и поправлять их. В ответ те должны кланяться и говорить «сэр» или «мэм».
Дальше требования растут дальше и соответственно растёт награда. Такой цикл поощряет обязательства и вложения: человек постоянно получает доказательства: «если я что-то вложил, то я что-то получу, и чем больше я вложил, тем больше я получу». В какой-то момент ученик получает чёрный пояс и его могут пригласить в штат инструкторов или предложить основать свой филиал школы.
В большинстве групп и организаций происходит примерно то же самое. Если группа ничего не просит (или просит мало) от своих членов, они не платят ей верностью. Люди вовлекаются в группу в той мере, в которой группа позволяет им рассказывать приятные (или эпические) истории о себе.
Для групп MIRIx это тоже может быть верным. Подумайте, не стоит ли завести небольшие примерно одинаковые задания для большинства новичков (например, прочитать такие-то и такие-то статьи или на третьей встрече сделать десятиминутный доклад на интересную им тему). Попробуйте построить последовательность просьб и вознаграждений дальше (например, на пятой встрече ты будешь управлять повесткой дня и делить всех на группы).
Структура и свободное пространство
Этот пункт связан с предыдущим. Важно уметь уравновешивать в своей группе MIRIx нисходящие и восходящие структуры коммуникации. Если никто не понимает, «как мы тут работаем», новички путаются и им становится неуютно. Вам нужна уже существующая структура, которую люди могут оценить и определить, будет ли им с ней комфортно. Вам нужно, чтобы с самого начала было понятно «на что похожа» ваша группа. Чтобы люди, которым она подойдёт, и люди, которым она не подойдёт, могли точно определить, к какой они категории относятся.
Тем не менее, вряд ли вы хотите, чтобы ваша структура мешала вам развиваться в долгосрочной перспективе. Мастера боевых искусств рано или поздно получают право вносить изменения в собственные тренировки, а также что-то менять при обучении новых учеников. Наверняка вы тоже захотите когда-нибудь получить что-то от своей группы MIRIx. Обычно люди огорчаются, когда не могут удовлетворить какие-нибудь свои потребности. Если ваша структура будет мешать им развиваться, они уйдут искать другое место, чтобы расти.
Социальные нормы
Нормальным и принятым становится то, против чего никто не возражает. Если какое-то поведение вам не нравится и выхотите снизить его количество на встречах, вам нужно не только самим возражать против него, но также открыто и публично поддерживать других, кто тоже против него возражает. Задача группы - сделать так, чтобы каждый, кто соблюдает правила / пытается поступать правильно, никогда не оставался один против тех, кто правила нарушает.
Заранее обдумайте и публично озвучьте вопросы вида «когда можно перебивать» или «насколько допустимы значительные отступления от темы». Создавайте культуру разногласия, но стройте её на основе вежливости и поддержки, чтобы разногласия делали группу сильнее, а не превращались в перепалки. Защищайте структуры принятия решений, которые вы придумали. Будьте последовательны в вопросах полномочий и в том, когда решения становятся окончательными.
Прочие мысли и вопросы
- Чтобы встречи не становились однообразными, пытайтесь чередовать различные темы и активности. Читайте статьи, устраивайте презентации, проводите дискуссии, пишите формальные доказательства и статьи, и так далее. Постарайтесь, чтобы чтению или обсуждению уже существующего материала уделялось не более 50% ваших встреч. (В идеале — не более 33%.)
- Подумайте о том, чтобы строить долгосрочные планы вида: шесть месяцев (или год) встречи посвящаются работе над какой-то конкретной областью вопросов, чтобы группа смогла построить какой-то комплекс знаний.
- Однако, если вы строите долгосрочные планы, предусмотрите возможность от них отклоняться. Например, пусть каждая третья встреча будет посвящена чему-то, не связанному с основной изучаемой областью.
- Подумайте о том, чтобы вести протоколы встреч и сохранять их на будущее. Так вы сможете оценить свою деятельность по прошествии нескольких месяцев или года. Подумайте над идеей, стоит ли пробегаться по протоколу предыдущей встречи в начале следующей.
- В конце встречи назначьте кого-нибудь, чтобы он собрал список вопросов, над которыми люди хотели бы подумать, и разослал их всем. Сюда же можно добавить мысли для обсуждения на следующих встречах. Подумайте о том, чтобы заранее определяться, кто будет вести следующую встречу, чтобы он мог подготовиться.
- Убедитесь, что у вас есть актуальная контактная информация для всех полноценных членов команды и прочих заинтересованных лиц. Подумайте заранее о способах коммуникации: будете вы пользоваться е-мэйл рассылками, группами в фейсбуке или чем-то ещё.
- Подумайте о том, как вы хотите взаимодействовать с другими группами MIRIx: хотите ли вы обмениваться с ними протоколами, вопросами, или, например, посылать кого-нибудь на встречу в другую группу или принимать людей из других групп у себя. Если вы хотите взаимодействовать, предпринимайте для этого активные действия. Помните: вы такой же представитель класса, как и другие. Если вы хотите что-то делать, но ничего не делаете, вероятно, тоже самое можно будет сказать и об остальных.
- Подумайте, хотите ли вы проводить какие-то мероприятия для обычных людей или для потенциальных новобранцев (например, на факультетах математики или информатики). Подумайте, хотите ли вы попробовать более амбициозные проекты, например, устроить летнюю школу, и пригласить людей, у которых есть знания и ресурсы, чтобы не изобретать колесо.
- Если ваша группа MIRIx существует в вузе, постарайтесь подумать над вопросом, как вы будете искать студентов младших курсов, которые займут место старшекурсников, когда те закончат вуз. Если вы не связаны с академической средой, подумайте, откуда вы будете брать новых людей. Заметим, что большой приток новичков редко бывает полезен и создаёт культурные проблемы. Лучше добавлять новых людей по одному или по двое, чтобы они могли привыкнуть к группе и группа к ним.
- Помните, что качество исследований, дискуссий и всей группы MIRIx в целом зависит от действий участников группы и от того, как их действия сочетаются между собой. Позаботьтесь о том, чтобы это понимали все — ваша группа будет настолько хороша, насколько каждый из вас захочет таковой её сделать.
Эпилог
Вы почти дочитали до конца текста! Надеемся, вы в нём встретили какую-то полезную информацию, а также здоровую пищу для размышлений. Перед тем, как вы перейдёте к другим делам, мы советуем потратить секунд 30 на размышления над следующими вопросами:
- Почему мы решили написать этот текст? Что мы ожидали получить, и что подтолкнуло нас выбрать из всех возможностей именно такой формат и содержание?
- Что вас огорчило или не устроило? Чего в этом тексте не хватает? Что мы упустили? Откуда вы узнали о тех вещах, которые мы упустили?
- Какой текст написали бы вы? Как бы вы поняли, что написать такой текст - хорошая идея? Как бы вы определяли, что в нём стоит упомянуть?
- Как, чёрт побери, вообще достигается прогресс?
Счастливой охоты.
— Команда исследователей MIRI.
Дискуссия Нго и Юдковского про сложность задачи согласования
Примечание редактора сайта: Под «согласованием» в заголовке и далее в тексте подразумевается англоязычное «[AI] alignment». В некоторых других статьях на этом сайте этот термин переводился как «соответствие [ИИ целям оператора]». Пока перевод этого термина на русский в сообществе не устоялся.
* * *
Этот пост – первое из серии обсуждений в Discord между Ричардом Нго и Элиезером Юдковским, под модерацией Нейта Соареса. Ричард и Нейт так же резюмировали ход разговора и ответы собеседников в Google Docs, это также добавлено сюда.
В позднейших обсуждениях принимали участие Аджейя Котра, Бет Барнс, Карл Шульман, Холден Карнофски, Яан Таллинн, Пол Кристиано, Роб Бенсингер и Робин Шах.
Это полные записи нескольких созданных MIRI для дискуссий каналов в Discord. Мы пытались как можно меньше редактировать записи сверх исправления опечаток и вводящих в замешательство формулировок, разбивания на параграфы и добавления ссылок. МЫ не редактировали значимое содержание, за исключением имён людей, которые предпочли, чтобы их не упоминали. Мы поменяли порядок некоторых сообщений для ясности и непротиворечивого потока обсуждения (в таких случаях время особо отмечено), и скомбинировали разные логи, когда обсуждение переключалось между каналами.
Предварительные комментарии
[Yudkowsky][8:32] (6 ноября)
(По просьбе Роба, я постараюсь быть кратким, но это экспериментальный формат и некоторые всплывшие проблемы выглядят достаточно важными, чтобы их прокомментировать)
Главным образом в ранней части этого диалога у меня были некоторые уже сформированные гипотезы на тему “Что будет главной точкой несогласия и что мне говорить по этому поводу”, что заставляло меня отклоняться от чистой линии обсуждения, если бы я просто пытался отвечать на вопросы Ричарда. Перечитывая диалог, я заметил, что это выглядит уклончиво, будто я странным образом упускаю суть, не отвечая напрямую на вопросы.
Зачастую ответы даны позднее, по крайней мере, мне так кажется, хотя, может, и не в первой части диалога. Но в целом вышло так, что я пришёл высказать некоторые вещи, а Ричард пришёл задавать вопросы, и получилось небольшое случайное несовпадение. Выглядело бы лучше, если бы, скажем, мы оба сначала выставили свои позиции без знаков вопроса, или если бы я ограничил себя ответами на вопросы Ричарда. (Это не катастрофа, но читателю стоит учитывать это как небольшую неполадку, проявившуюся на ранней стадии экспериментов с этим новым форматом.)
[Yudkowsky][8:32] (6 ноября)
(Подсказано поздними попытками резюмировать диалог. Резюмирование выглядит важным способом распространения для такого большого диалога, и следующая просьба должна быть особо указана, чтобы к ней прислушивались – встроенные в диалог указания не работают.)
Пожалуйста, не резюмируйте этот диалог, говоря “и ГЛАВНАЯ идея Элиезера такая” или “и Элиезер думает, что КЛЮЧЕВОЙ МОМЕНТ в том” или “ОСНОВНОЙ аргумент таков” и.т.д. Мне кажется у всех свои наборы камней преткновения и того, что считается очевидным, и обсуждение с моей стороны сильно меняется в зависимости от них. Когда-то камнями преткновения были Тезис Ортогональности, Инструментальная Конвергенция и возможность суперинтеллекта в принципе; сейчас у большинства связанного с Open Philanthropy народа они уже другие.
Пожалуйста, преобразуйте:
- “Основной ответ Элиезера в том…” -> “Элиезер ответил, что…”
- “Элиезер считает, что ключевой момент в том…” -> “Элиезер в ответ указал, что…”
- “Элиезер считает, что основная проблема в том…” -> “Элиезер ответил, что есть проблема в том…”
- “Главный аргумент Элиезера против этого был…” -> “Элиезер возразил тем…”
- “Элиезер считает, что основной сценарий тут…” -> “В обсуждении в сентябре 2021, Элиезер обрисовал гипотетический сценарий, где…”
Замечу, что преобразованные утверждения говорят о том, что вы наблюдали, тогда как изначальные - это (зачастую неправильные) выводы о том, что я думаю.
(Однако, “различать относительно ненадёжные выводы от более надёжных наблюдений” – не обязательно ключевая идея или главная причина, по которой я этого прошу. Это просто моё замечание – один аргумент, который, я надеюсь, поможет донести больший тезис.)
Обсуждение 5 сентября
Глубокие и поверхностные шаблоны решения задач
[Ngo][11:00]
Всем привет! С нетерпением жду дискуссии.
[Yudkowsky][11:01]
Привет и добро пожаловать. Моё имя Элиезер и я думаю, что согласование ИИ на самом деле довольно невероятно очень сложно. Кажется, некоторые люди так не думают! Это важная проблема, которую нужно как-то решить, надеюсь, мы сегодня это сделаем. (Однако, я хочу сделать перерыв через 90 минут, если это столько продлится и если суточный цикл Нго позволит продолжать после этого.)
[Ngo][11:02]
Перерыв через 90 минут или около того звучит хорошо.
Вот как можно начать? Я согласен, что согласование людьми произвольно мощного ИИ выглядит очень сложной задачей. Одна из причин, по которым я более оптимистичен (или, по крайней мере, не уверен, что нам придётся столкнуться с полноценной очень сложной версией этой задачи) – это то, что с определённого момента ИИ возьмёт на себя большую часть работы.
Когда ты говоришь о том, что согласование сложное, о согласовании каких ИИ ты думаешь?
[Yudkowsky][11:04]
В моей модели Других Людей, зачастую когда они думают, что согласование не должно быть таким уж сложным, они считают, что есть какая-то конкретная штука, которую можно сделать, чтобы согласовать СИИ, и она не очень сложная. И их модель упускает одну из фундаментальных сложностей, из-за которой не получится выполнить (легко или совсем) какой-то шаг их метода. Так что одно из того, что я делаю в обсуждении – это попытаться расковырять, про какой же именно шаг собеседник не понимает, что он сложный. Сказав это, я теперь попробую ответить на твой вопрос.
[Ngo][11:07]
Я не думаю, что уверен в какой-нибудь конкретной штуке, позволяющей согласовать СИИ. Однако я чувствую неуверенность по поводу того, в насколько большом диапазоне возможностей эта задача может оказаться сложной.
И по некоторым важным переменным, кажется, что свидетельства последнего десятка лет склоняют к тому, чтобы посчитать задачу более простой.
[Yudkowsky][11:09]
Я думаю, что после того, как станет возможным СИИ вообще и его масштабирование до опасного сверхчеловеческого уровня, будет, в лучшем случае, если будут решены многие другие социальные сложности, период от 3-х месяцев до 2-х лет, когда лишь у нескольких действующих лиц есть СИИ, что означает, что этим действующим лицам будет социально-возможно просто решить не масштабировать его до уровня, на котором он автоматически уничтожает мир.
В течении этого периода, чтобы человечество выжило, кто-то должен произвести некое действие, из-за которого мир не будет уничтожен через 3 месяца или 2 года, когда уже у слишком многих будет доступ к коду СИИ, уничтожающего мир, если повернуть рубильник его интеллекта достаточно сильно. Это требует того, чтобы кто-то из первых действующих лиц, создавших СИИ сделал с помощью него что-то, что предотвратит уничтожение мира. Если бы это не требовало суперинтеллекта, мы могли бы сделать это сейчас, но, насколько мне известно, никакого такого доступного людям действия нет.
Так что мы хотим наименее опасное, наиболее легко согласовываемое действие-при-помощи-СИИ, но при этом достаточно мощное, чтобы предотвратить автоматическое разрушение Земли через 3 месяца или 2 года. Оно должно “опрокинуть игровую доску”, не позволив начаться суицидальной игре. Мы должны согласовать СИИ, который осуществит это ключевое действие, чтобы он мог его осуществить, не убив всех.
Замечу в скобках, ни одно достаточно мощное и доскоопрокидывающее действие не умещается в Окно Овертона политики, или, возможно, даже эффективного альтруизма, что представляет отдельную социальную проблему. Я обычно обхожу эту проблему, приводя пример достаточно мощного для опрокидывания доски, но не самого согласовываемого, потому что оно требует слишком много согласованных частей: создать самовоспроизводящиеся в воздухе наносистемы и использовать их (только), чтобы расплавить все GPU.
Поскольку любой такой наносистеме придётся действовать в целом открытом мире, включающем множество сложных деталей, это потребует очень много работы по согласованию, так что это ключевое действие согласовать сложно, и нам стоит сделать что-то другое. Но другая штука, которая есть у меня в мыслях, точно так же за пределами Окна Овертона. Так что я использую “расплавить все GPU”, чтобы указать на требуемую мощность действия и проблему с Окном Овертона, и то и другое мне кажется приблизительно правильного уровня, но то, что я держу в голове проще согласовать. Таким образом, на “Как ты смеешь?” я всегда могу ответить “Не беспокойся, я не собираюсь на самом деле это делать.”
[Ngo][11:14]
Мы могли бы продолжить обсуждение, обсудив ключевое действие “работать над проблемой согласования быстрее, чем могут люди.”
[Yudkowsky][11:15]
Для меня это звучит как что-то требующее высочайшего уровня согласованности и действующее в очень опасном режиме, так что, если можно сделать это, разумнее сделать какое-нибудь другое ключевое действие, использующее меньший уровень технологии согласования.
[Ngo][11:16]
Окей, тут, кажется, трудности с пониманием с моей стороны.
[Yudkowsky][11:16]
В частности, я надеюсь, что – в маловероятном случае нашего выживания – мы сможем выжить, использовав суперинтеллект в смертельно опасном, но всё же менее смертельно опасном режиме “проектирования наносистем”.
А вот “реши для нас согласование” кажется действующим в ещё более опасных режимах “пиши для нас код ИИ” и “очень точно смоделируй человеческую психологию”.
[Ngo][11:17]
Что делает эти режимы такими опасными? То, что людям очень сложно за ними присматривать?
Эти режимы кажутся мне менее опасными в частности потому, что они попадают скорее в область “решения интеллектуальных задач”, а не “достижения последствий в мире”.
[Yudkowsky][11:19][11:21]
Любой вывод ИИ приводит к последствиям в мире. Если выводы исходят от мощного несогласованного разума, то они могут начать причинно-следственную цепочку, приводящую к чему-нибудь опасному, независимо от того, стоит ли в коде комментарий “интеллектуальная задача”.
“Решать интеллектуальные задачи” опасно, когда для этого необходим мощный разум, рассуждающий об областях, которые, будучи решёнными, предоставляют когнитивно-доступные стратегии как сделать что-то опасное.
Я ожидаю, что первое решение согласования, которым можно будет на самом деле пользоваться, в том маловероятном случае, что мы его получим, будет выглядеть на 98% как “не думай обо всех тех темах, которые нам не строго необходимы, и которые близки к способности легко изобрести очень опасные выводы” и на 2% как “всё-таки думай про эту опасную тему, но, пожалуйста, не приходи к стратегиям в ней, которые нас всех убьют”.
[Ngo][11:21][11:22]
Позволь мне попытаться уточнить разделение. Мне кажется, что системы, изначально натренированные делать предсказания о мире, не будут по умолчанию иметь когнитивный аппарат, позволяющий людям совершать действия для преследования своих целей.
Наверное, можно переформулировать мою точку зрения так: мне не кажется неправдоподобным, что мы создадим ИИ значительно умнее (в смысле способности понимать мир), чем люди, но значительно менее агентный.
Есть ли у тебя с этим проблемы?
(очевидно, “агентный” тут довольно недоопределено, может, стоит это пораскапывать)
[Yudkowsky][11:27][11:33]
Я бы точно узнал совсем новые и удивительные факты про интеллект, действительно противоречащие моей модели того, как работают интеллекты, могущие появиться в рамках текущей парадигмы, если ты покажешь мне… как бы это выразить в общем случае… что задачи, которые я считал задачами про поиск состояний, получающих высокую оценку при скармливании их в функцию результатов, а затем в функцию оценки результатов, на самом деле задачи про что-то другое. Я иногда даю более конкретные названия, но, думаю, люди приходят в замешательство от моих обычных терминов, так что я их обошёл.
В частности, так же как в моей модели Убеждений Других Людей они считают, что согласование простое, потому что они не знают про сложности, которые я вижу как очень глубокие и фундаментальные и сложноизбегаемые, так же в этой модели они думают “почему бы просто не создать ИИ, который будет делать X, но не Y?” потому что они не осознают, что у X и Y общего, потому что для этого нужно иметь глубокую модель интеллекта. И этот глубокий теоретический разрыв сложно перешагнуть.
Но вообще можно найти неплохие практические подсказки на то, что эти штуки куда более скоррелированны, чем, скажем, считал Робин Хансон во время нашего FOOM-спора. Робин не думал, что может существовать что-то вроде GPT-3; он считал, что потребуется проводить обучение на множестве узких областей, которые не будут обобщаться. Я тогда возразил, что у людей есть зрительная кора и мозжечок, но нет Коры Проектирования Автомобилей. Потом оказалось, что реальность на более Элиезеровской стороне оси Элиезер-Робин, чем я, и что штуки вроде GTP-3 менее архитектурно сложны и больше обобщаются, чем я тогда доказывал Робину.
Иногда я использую метафору о том, что очень сложно создать систему, которая будет уметь водить красные машины, но не будет очень похожа на систему, которая, с небольшими изменениями, будет уметь водить синие. Задача “водить красную машину” и задача “водить синюю машину” имеют слишком много общего. Ты можешь предложить: “Согласуй систему так, чтобы у неё была возможность водить красные машины, но чтобы она отказывалась водить синие”. Ты не можешь создать систему, которая будет очень хороша в вождении красных машин, но совершенно не умеет водить синие из-за ненатренированности на это. Градиентный спуск, генетический алгоритм или любой другой правдоподобный метод оптимизации обнаружит очень похожие шаблоны для вождения красных и синих машин. Оптимизируя для красных машин, ты получишь способность водить синие, хочешь ты того или нет.
[Ngo][11:32]
Отвергает ли твоя модель интеллекта возможность создания ИИ, сильно продвигающего математику без убийства нас всех?
[Yudkowsky][11:34][11:39]
Если бы было возможно совершить какое-нибудь ключевое действие для спасения мира с ИИ, который может лишь доказывать математические теоремы, без необходимости, например, объяснять доказательства людям, я был бы невероятно заинтересован в этом как в потенциальном ключевом действии. Я не достиг бы полной ясности, и всё ещё не знал бы, как создать ИИ, не убив всех, но такое действие немедленно стало бы очевидным первоочередным направлением разработок.
Кстати, моя модель интеллекта отвергает очень-очень мало возможностей. Я думаю, что мы все умрём, потому что у нас не получится сделать правильно некоторые опасные вещи с первого раза в опасном режиме, где одна ошибка уже фатальна, причём сделать их до того, как нас убьёт распространение куда более простых технологий. При наличии Учебника Из Будущего Через Сто Лет, в котором для всего приведены простые надёжные действительно работающие решения, вполне можно было бы воспользоваться методами из него, чтобы написать суперинтеллект, который думает, что 2 + 2 = 5.
(В учебнике есть эквивалент “используйте ReLu вместо сигмоид” для всего и нету всех по-умному звучащих штук, которые работают на дочеловеческих уровнях, и лажают, если применить их для суперинтеллекта.)
[Ngo][11:36][11:40]
Хм-м-м, предположим, что мы натренировали ИИ доказывать теоремы, возможно, с помощью какого-нибудь состязательного обучающего процесса “составить задачу - решить задачу”.
Моя интуиция говорит, что по умолчанию этот ИИ сможет научиться очень хорошо – далеко за пределами человеческого уровня – доказывать теоремы, не имея целей касательно реального мира.
Я так понял, что в твоей модели интеллекта способность к решению математических или сходных задач плотно связана с попытками достижения результатов в реальном мире. Но для меня GPT-3 является свидетельством против такой позиции (хотя всё ещё и свидетельством в пользу твоей позиции относительно позиции Хансона), ведь она кажется способной к некоторым рассуждениям, будучи не особо агентной.
В альтернативном мире, в котором у нас не получилось натренировать языковую модель на некоторые рассудительные задачи, не натренировав её вначале на выполнение задач в сложном RL-окружении, я был бы значительно менее оптимистичен.
[Yudkowsky][11:41]
Я скажу, что в твоих оценках есть предсказуемое искажение из-за того, что ты, не зная о Глубоких Штуках, нужных для доказательства теорем, представляешь, что они менее похожи на иные когнитивные способности, чем на самом деле. Зная о том, как именно люди используют свою способность рассуждать о каменных топорах и других людях для доказательства математических теорем, ты бы считал более правдоподобным обобщение способности доказывать теоремы до топоров и манипуляции людьми.
Моё мнение о GPT-3… сложно соотносится с моими взглядами на интеллект. Там взаимодействует огромное количество выученных неглубоких паттернов. Крайне маловероятно, что GPT-3 похожа на то, как естественный отбор создал людей.
[Ngo][11:44]
С последним я соглашусь. Но это и есть одна из причин, почему я заявил, что ИИ может быть умнее людей, будучи менее агентным, ведь есть систематические различия между тем, как естественный отбор создал людей, и тем, как мы обучаем ИИ.
[Yudkowsky][11:45]
Я подозреваю, что просто “Больше Слоёв” будет недостаточно, чтобы привести нас к GPT-6, являющейся настоящим СИИ; потому, что GPT-3, по твоей терминологии, не агентна, и, по моей терминологии, градиентный спуск от GPT-3 не обнаружит достаточно глубоких шаблонов решения задач.
[Ngo][11:46]
Окей, это помогло мне лучше понять твою позицию.
Есть одно важное различие между людьми и нейросетями: у людей есть проблема низкой пропускной способности генома, что означает, что каждый индивид должен перевывести знания о мире, которые уже были у его родителей. Если бы это ограничение не было таким жёстким, отдельные люди были бы значительно менее способны к решению новых задач.
[Yudkowsky][11:50]
Согласен.
[Ngo][11:50]
В моей терминологии, это причина, по которой люди “более агентны”, чем были бы иначе.
[Yudkowsky][11:50]
Звучит бесспорно.
[Ngo][11:51]
Другое важное различие: обучение людей проходило в условиях, где нам надо было целыми днями заниматься выживанием, а не решать математические задачи и тому подобное.
[Yudkowsky][11:51]
Я продолжаю кивать.
[Ngo][11:52]
Предположим, я соглашусь, что достижение некоторого уровня интеллекта потребует у ИИ “глубоких паттернов решения задач”, о которых ты говоришь, и поэтому ИИ будет пытаться достичь целей в реальном мире. Всё ещё кажется, что может быть много пространства между этим уровнем интеллекта и человеческим.
И если так, то можно создать ИИ, который поможет нам решить задачу согласования до ИИ с достаточно глубокими паттернами решения задач для того чтобы задумать захватить мир.
А ещё причина, по которой люди хотят захватить мир, кажется не связанной с глубинными фактами про наш интеллект. Скорее мне видится, что люди хотят захватить мир в основном потому, что это очень похоже на штуки, для которых мы эволюционировали (вроде захвата власти в племени).
[Yudkowsky][11:57]
Вот часть, с которой я соглашусь: если бы была одна теорема, лишь слегка за пределами человеческих возможностей, вроде гипотезы-ABC (если ты не считаешь её уже доказанной), и получение машинно-читаемого доказательства этой теоремы немедленно спасало бы мир – скажем, инопланетяне дали бы нам согласованный суперинтеллект, как только мы дадим им это доказательство – тогда существовал бы правдоподобный, хоть и не очень надёжный путь к спасению мира через попытку создать поверхностный разум для доказательства гипотезы-ABC, запомнивший через игру с самим собой кучу относительно поверхностных шаблонов математических доказательств, но так и не дошедший до человеческих уровней математической абстракции, просто обладающий достаточным объёмом памяти и глубиной поиска для этой задачи. Для ясности – я не уверен, что это могло бы сработать. Но моя модель интеллекта не отвергает такой возможности.
[Ngo][11:58]
(Я скорее думал о разуме, который понимает математику глубже, чем люди – но только математику, или, может, ещё некоторые науки.)
[Yudkowsky][12:00]
Части, с которыми я не согласен: что “помоги нам решить согласование” в достаточной степени похоже на “предоставь нам машинно-читаемое доказательство гипотезы-ABC, не думая о ней слишком глубоко”. Что люди хотят захватить мир только потому, что это напоминает штуки, для которых мы эволюционировали.
[Ngo][12:01]
Я определённо согласен, что люди хотят захватить мир не только потому, что это напоминает штуки, для которых мы эволюционировали.
[Yudkowsky][12:02]
Увы, но отбрасывание 5 причин, почему что-то пойдёт не так, не слишком поможет, если есть 2 оставшиеся причины, от которых куда сложнее избавиться.
[Ngo][12:02]
Но если мы представим интеллект человеческого уровня, который не эволюционировал для штук, напоминающих захват мира, то я ожидаю, что мы могли бы довольно безопасно задавать ему вопросы.
И что это также верно для интеллекта заметно выше человеческого уровня.
Так что вопрос: насколько выше человеческого уровня мы можем забраться прежде, чем система, обученная только штукам вроде ответов на вопросы и пониманию мира, решит захватить мир?
[Yudkowsky][12:04]
Я думаю, что это один из редких случаев, когда разрыв в интеллекте между “деревенским дурачком” и “Эйнштейном”, который я обычно считаю очень узким, имеет важное значение! Я думаю, ты можешь получать выводы от СИИ-уровня-деревенского-дурачка, обученного исключительно на математике, и это навееееерное не уничтожит мир (если ты не ошибаешься, с чем имеешь дело). Уровень Эйнштейна беспокоит меня куда больше.
[Ngo][12:05]
Давай тогда сосредоточимся на уровне Эйнштейна.
Человеческий мозг довольно слабо оптимизирован для занятия наукой.
Можно предположить, что создать ИИ, который занимается наукой на уровне-Эйнштейна значительно проще, чем создать ИИ, который захватывает мир на уровне-Эйнштейна (или делает что-то ещё, для чего эволюционировали люди).
[Yudkowsky][12:08]
Я думаю, что соглашусь с буквальной истинностью сказанного в некотором широком смысле. Но ты будешь систематически переоценивать, насколько проще, или как далеко ты можешь продвинуть научную часть, не получив захватывающую мир часть, пока твоя модель игнорирует, сколько между ними общего.
[Ngo][12:08]
Тогда, может, самое время рассмотреть детали того, что между ними общего.
[Yudkowsky][12:09][12:11]][12:13]
Мне кажется, у меня не очень получалось объяснить это в прошлые разы. Не тебе, другим людям.
Есть поверхностные темы, вроде того, почему философские зомби не могут существовать, и как работает квантовая механика, и почему наука должна использовать функции правдоподобия вместо p-критериев, и я едва могу объяснить их некоторым людям. А есть вещи, которые объяснить намного сложнее, они находятся за пределами моих способностей к объяснениям.
Поэтому я пытаюсь указать, что даже если ты не знаешь конкретики, ты можешь признать существование искажения твоей оценки.
Конечно, я не был очень успешен и говоря людям “Ну, даже если ты не знаешь правды про X, которая позволила бы тебе увидеть Y, разве не понятно тебе из абстрактных размышлений, что любая правда о X предсказуемо сдвинет твои убеждения в сторону Y?”, люди, кажется, такое не очень понимают. Не ты, в других дискуссиях.
[Ngo][12:10][12:11][12:13]
Осмысленно. Могу ли я сделать это проще? Например, могу попробовать изложить то, как я вижу твою позицию.
Учитывая то, что ты сказал, я не очень рассчитываю, что это сильно поможет.
Но раз уж это основные источники твоих заявлений, стоит попробовать.
Другой подход – сосредоточиться на предсказаниях развития способностей ИИ в ближайшие пять лет.
Я приму твоё предупреждение про искажение оценки. Мне кажется, что есть и обратное искажение от того, что, пока мы не знаем механизмы работы разных человеческих способностей, мы склонны представлять их одной и той же штукой.
[Yudkowsky][12:14]
Ага. Если не знать про зрительную кору и слуховую кору, или про глаза и уши, то можно было бы предположить, что любое сознание невозможно без зрения и слуха.
[Ngo][12:16]
Так что моя позиция такая: люди преследуют цели из-за эволюционно вложенных эмоций и сигналов подкрепления, и без них мы были бы куда безопаснее, но не особо хуже в распознавании паттернов.
[Yudkowsky][12:17]
Если бы было ключевое действие, которое можно выполнить с помощью всего лишь сверхчеловеческого распознавания паттернов, это точно так же как “ключевое действие только из математики” мгновенно стало бы основным направлением разработок.
[Ngo][12:18]
Мне кажется, что математика куда в большей степени про распознавание паттернов, чем, скажем, управление компанией. Управление компанией требует последовательности на протяжении длительных промежутков времени, долговременной памяти, мотивации, осознанности, и т.д.
[Yudkowsky][12:18][12:23]
(Одно направление исследований можно было приблизительно описать как “как насчёт ключевого действия, состоящего исключительно из предсказания текста”, и моим ответом было “вы пытаетесь получить полноценные способности СИИ, предсказывая текст про глубокое/“агентное“ мышление, так что это ничем не лучше”.)
Человеческая математика очень даже про достижение целей. Люди хотят доказать леммы, чтобы потом доказать теоремы. Может и можно создать не такого математика, чья опасная непонятная часть, состоящая из векторов вещественных чисел, действует скорее как GPT-3. Но и тогда снаружи потребуется что-то больше похожее на Alpha-Zero для выбора направления поиска.
Возможно, эта наружная оболочка может быть достаточно мощной и не будучи рефлексивной. Так что правдоподобно, что куда проще создать математика, способного к сверхчеловеческому доказательству теорем, но не агентного. Реальность может сказать нам “лол, нет”, но моя модель интеллекта её не обязывает. Поэтому, если ты дашь мне ключевое действие, состоящее исключительно из “вывести машиночитаемое доказательство такой-то теоремы, и мир спасён”, то я бы выбрал его! Это и правда выглядит куда проще!
[Ngo][12:21][12:25]
Окей, попробую перефразировать твой аргумент:
Твоя позиция: существует фундаментальное сходство между задачами вроде математики, исследования согласования и захвата мира. Для того, чтобы хорошо обучиться чему-то из этого, агенту, основанному на чём-то похожем на современное машинное обучение, надо будет усвоить глубокие паттерны решения задач, включающие мышление, ориентированное на достижение целей. Так что хоть и возможно превзойти людей в какой-то одной из этих задач без этих общих компетенций, люди обычно переоценивают степень, в которой это возможно.
[Yudkowsky][12:25]
Напомню, я беспокоюсь в основном о том, что произойдёт первым, особенно если это произойдёт достаточно скоро, чтобы этот будущий СИИ был хоть сколько-нибудь похож на современные системы машинного обучения. Не о том, что возможно в принципе.
[Soares][12:26]
(Замечу: прошло 85 минут, мы планировали перерыв через 90, так что сейчас, кажется, подходящий момент, чтобы ещё немного прояснить резюмирование Ричарда перед перерывом)
[Ngo][12:26]
Я исправлю на, скажем, “правдоподобно для техник машинного обучения?”
(и “степень, в которой это правдоподобно”)
[Yudkowsky][12:28]
Я думаю, что очевидное-для-меня будущее развитие современных парадигм ML по дороге к значительно сверхчеловеческому X крайне вероятно придёт к обобщениям, приводящим к захвату мира. Насколько быстро это произойдёт, зависит от X. Правдоподобно, что это произойдёт относительно медленно, если взять как X доказательство теорем, использовать архитектуру, запоминающую осторожным градиентным спуском сеть поверхностных архитектур для распознавания паттернов, и убрать часть, отвечающую за поиск (типа того, это не безопасно в общем, это не универсальная формула для безопасных штук). Медленнее, чем если ввести что-то вроде генетического бутылочного горлышка, на которое ты правильно указал, как на причину, почему люди научились обобщать. Выгодные X и любые X, которые я могу представить подходящими для спасения мира, кажутся куда более проблематичными.
[Ngo][12:30]
Окей, с удовольствием возьму перерыв сейчас.
[Soares][12:30]
Как раз вовремя!
[Ngo][12:30]
Мы можем потом немного пообсуждать на метауровне; у меня возник порыв удариться в вопрос о том, насколько Элиезер считает исследования согласования похожими на доказательства теорем.
[Yudkowsky][12:30]
Ага. У меня сейчас полдник (на самом деле, первая еда за день на 600-калорийной диете), так что я могу вернуться через 45 минут, если тебе это подходит.
[Ngo][12:31]
Конечно.
Ещё, если нас читают в реальном времени, и у вас есть предложения или комментарии, мне было бы интересно их выслушать.
[Yudkowsky][12:31]
Я тоже приветствую предложения и комментарии от наблюдателей во время перерыва.
[Soares][12:32]
Звучит неплохо. Я объявляю перерыв на 45 минут, после чего мы продолжим (по умолчанию на ещё 90).
Открыты к предложениям и комментариям.
Требования для науки
[Yudkowsky][12:50]
Я освобожусь пораньше, если всем (в основном Ричарду) удобно, можно продолжить через 10 минут (после 30 минут перерыва)
[Ngo][12:51]
Да, с удовольствием
[Soares][12:57]
Немного быстрых комментариев от меня:
- Мне кажется, главный камень преткновения тут что-то вроде “стоит ли ожидать, что системы, способные к исполнению ключевого действия, будут, по умолчанию, без значительных технических усилий по согласованию, использовать свой вывод для оптимизации будущего”.
- Мне любопытно, согласитесь ли вы, что он именно такой (но плз не отвлекайтесь слишком на ответы мне.)
- Мне нравится, как идёт обсуждение в целом.
- В частности, ура-ура за отчётливые аккуратные усилия по сосредоточению на ключевых моментах.
[Ngo][13:00]
Я думаю, что таков камень преткновения для конкретного ключевого действия “лучше исследовать согласование”, и может, ещё некоторых, но не для всех (и не обязательно большинства)
[Yudkowsky][13:01]
Мне стоит явно сказать, что я немного работал с Аджейей, пытаясь передать понимание того, почему склонны выучиваться глубокие обобщённые паттерны, для чего пришлось рассмотреть кучу вопросов. Это научило меня тому, сколько вопросов приходится рассматривать, и из-за этого я теперь относительно менее охотно пытаюсь перерассмотреть те же вопросы тут.
[Ngo][13:02]
Пара вещей, о которых я хотел бы спросить Элиезера в дальнейшем:
- Чем наиболее полезные для исследования согласования задачи похожи и чем различаются с доказательством математических теорем (которое, как мы согласились, может довольно медленно обобщаться до захвата мира)?
- Что из себя представляют стоящие за этими задачами глубокие паттерны?
- Можешь ли ты пересказать мою позицию?
Я собирался заявить, что второй пункт кажется самым перспективным для вынесения идей на публику.
Но раз это всё равно произойдёт благодаря работе с Аджейей, то не так уж важно.
[Yudkowsky][13:03]
Я всё равно могу быстренько попробовать и посмотреть, как получится.
[Ngo][13:03]
Выглядит полезно, если тебе хочется.
В то же время, я попробую просуммировать мои собственные относящиеся к делу интуитивные рассуждения об интеллекте.
[Yudkowsky][13:04]
Я не уверен, что я смогу пересказать твою позицию в не-соломенном виде. Для меня есть огромное видимое различие между “решать для нас согласование” и “выводить машинно-читаемые доказательства теорем”, и я не могу толком понять, почему ты считаешь, что рассуждения о втором скажут нам что-то важное про первое. Я не знаю и какое ещё ключевое действие по твоему мнению может быть проще.
[Ngo][13:06]
Вижу. Я рассматривал “решать научные задачи” как альтернативу для “доказывать теоремы”, ведь согласование – это (особенно сложный) пример научной задачи.
Но решил начать с обсуждения доказательства теорем, поскольку это выглядит яснее.
[Yudkowsky][13:07]
Можешь ли ты предсказать заранее, почему Элиезер считает “решать научные задачи” значительно более рискованным случаем? (А согласование – это точно не “особенно сложный пример научной проблемы”, кроме как разве что в смысле того, что в нём вообще есть какая-то наука; возможно, именно это настоящий камень преткновения; и это более сложная тема)
[Ngo][13:09]
Основываясь на твоих предыдущих комментариях, я сейчас предсказываю, что ты думаешь, что шаг, на котором решения должны стать понятными и оцениваемыми людьми, делает науку более рискованным случаем, чем доказательство теорем, в котором решения можно проверять автоматически.
[Yudkowsky][13:10]
Это один из факторов. Следует ли мне выложить основной, или лучше ты сам попробуешь его сформулировать?
[Ngo][13:10]
Требование многих знаний о реальном мире для науки?
Если не то, то выкладывай.
[Yudkowsky][13:11]
Это возможная формулировка. Я обычно формулирую через формулирование гипотез о реальном мире.
Как бы в этом тогда и есть задача ИИ.
Фактор 3: Многие интерпретации занятий наукой требуют придумывания экспериментов. Это включает в себя планирование, придание информации ценности, поиск способов проведения эксперимента для различения гипотез (что означает поиск начальных условий, приводящих к определённым последствиям).
[Ngo][13:12]
Для меня “моделирование реального мира” – это довольно плавный параметр. На одном конце мы имеем физические уравнения, которые едва отличимы от математических задач, а на другом что-то делающих людей с физическими телами.
Для меня выглядит правдоподобным создание агента, который будет решать научные задачи, но будет слабо осведомлён о себе (в смысле знания, что он ИИ, что он обучен, и т.д.).
Я ожидаю, что твой ответ будет о том, что моделирование себя – это один из глубоких паттернов решения задач, которые скорее всего будут у СИИ.
[Yudkowsky][13:15]
Перед сознанием-занимающимся-наукой стоит задача выяснения причин сенсорного опыта. (Она, на самом деле, встаёт и при человеческих занятиях математикой, и, возможно, неотделима от математики в целом; но это скорее говорит: “Упс, кажется, вы получили всё же науку” - а не что наука менее опасна, потому что похожа на математику.)
Ты можешь создать ИИ, который водит только красные машины, и которому никогда не приходилось водить синие. Это не означает, что его способности вождения-красных-машин не окажутся чрезвычайно близки к способностям вождения-синих-машин, если в какой-то момент внутренние рассуждения направятся на задачу вождения синей машины.
Факт существования глубокого паттерна вождения-машин, общего для красных и синих машин, не означает, что ИИ обязательно водил синие машины, или что ему обязательно водить синие машины, чтобы научиться водить красные. Но если синие машины – это огонь, то ты точно играешь с этим огнём.
[Ngo][13:18]
Для меня “сенсорный опыт” как “видео и аудио, приходящее от тела, которым я управляю” и “сенсорный опыт” как “файл, содержащий последние результаты от Большого Адронного Коллайдера” довольно сильно различаются.
(Я не говорю, что второго хватит для обучения ИИ-учёного, но, возможно, хватит чего-то, что ближе к второму, чем к первому)
[Yudkowsky][13:19]
“Обязательно ли СИИ нужно моделировать себя в мире, чтобы заниматься наукой” и “не создали ли мы что-то, что может наткнуться на моделирование себя из-за случайности, произошедшей где-то в непонятных векторах чисел, особенно если это окажется хоть чуть-чуть полезно для решения внешних задач” – это два отдельных вопроса.
[Ngo][13:19]
Хмм, понимаю
[Yudkowsky][13:20][13:21][13:21]
Если попробовать создать ИИ, который занимается наукой буквально только через сбор наблюдений и никак каузально не связан с этими наблюдениями, то это, пожалуй, “опаснее математики, но может и менее опасно, чем активная наука”.
Всё ещё можно будет наткнуться на активного учёного, потому что это окажется простым внутренним решением для чего-нибудь, но внешняя задача будет лишена этого важного структурного свойства так же, как и чистая математика, не описывающая настоящие земные объекты.
И, конечно, моя реакция будет: “Нет ключевого действия, использующего только такие когнитивные способности.”
[Ngo][13:20][13:21][13:26]
Моя (довольно уверенная) априорная догадка такова, что что-то вроде самомоделирования, которое очень глубоко встроено в почти любой организм, это очень сложная (при отсутствии значительного оптимизационного давления в этом направлении) для случайного натыкания ИИ штука.
Но я не уверен, как это обосновать, кроме как вкапываясь в твои взгляды на то, чем являются глубокие паттерны решения задач. Так что, если ты всё ещё хочешь быстро попробовать это объяснить, было бы полезно.
“Каузальная связь” опять же выглядит плавным параметром – кажется, что количество связи, необходимое для науки, куда меньше, чем, скажем, для управления компанией.
[Yudkowsky][13:26]
Ключевая штука, кажется – не столько количество, сколько внутреннее устройство, необходимое для неё.
[Ngo][13:27]
Согласен.
[Yudkowsky][13:27]
Если ты вернёшься во времени в 16-й век и захочешь получить всего одну дозу mRNA-вакцины, это не особо отличается от получения миллиона сотни.
[Ngo][13:28]
Ладно, тогда дополнительная используемая мной предпосылка в том, что способность рассуждать о каузальном влиянии на мир для достижения целей – это что-то, чего можно иметь всего чуть-чуть.
Или много, и зависеть это может от обучающих данных.
Я ожидаю, что с этим ты не согласишься.
[Yudkowsky][13:29]
Если ты сведёшь ключевое действие к “просмотри данные от этого адронного коллайдера, который ты не строил и не запускал”, то это действительно важный шаг от “занимайся наукой” или “создай наносистемы”. Но я не вижу таких ключевых действий, так что так ли это важно?
Если есть промежуточные шаги, можно их описать как “мышление о каузальном воздействии только в этой заранее заданной, не изученной в общем области, в отдельной части когнитивной архитектуры, отделяемой от всех остальных частей”.
[Ngo][13:31]
Может, по-другому можно сформулировать как то, что у агента есть поверхностное понимание того, как оказывать влияние.
[Yudkowsky][13:31]
Что для тебя “поверхностное”?
[Ngo][13:31]
В духе того, как ты утверждаешь, что у GPT-3 есть поверхностное понимание языка.
[Yudkowsky][13:32]
То есть, он запомнил кучу поверхностных паттернов оказания-каузального-воздействия из большого набора данных, и это может быть подтверждено, например, предоставлением ему случая из-за пределов этого набора и наблюдением за тем, как он проваливается. Что, как мы думаем, подтвердит нашу гипотезу о том, что он не научился из набора данных глубоким обобщениям.
[Ngo][13:33]
Грубо говоря, да.
[Yudkowsky][13:34]
К примеру, нас совсем бы не удивило, если бы GPT-4 научился предсказывать “27 * 18”, но не “какова площадь прямоугольника 27 метров на 18 метров”… хотел бы я сказать, но Codex уверенно продемонстрировал, что от одного до другого довольно-таки близко.
[Ngo][13:34]
Один способ, как это можно было бы сделать: представь агента, быстро теряющего связность действий, когда он пытается действовать в мире.
К примеру, мы натренировали его проводить научные эксперименты, длящиеся несколько часов или дней.
И он очень хорош в понимании экспериментальных данных и вычленении из них паттернов
Но если его запустить на неделю или месяц, то он теряет связность похожим образом на то, как GTP-3 теряет связность, т.е. забывает, что он делает.
Как это так получилось: есть специфический навык обладания долговременной памятью, и мы никогда не тренировали агента в этом навыке, вот он его и не приобрёл (хоть он и может очень мощно и обобщённо рассуждать в короткие промежутки времени).
Это кажется схожим с моим аргументом о том, как агент может не моделировать себя, если мы его специально на это не тренировали.
[Yudkowsky][13:39]
Есть набор очевидных для меня тактик для осуществления ключевого действия с минимальной опасностью (я не думаю, что они делают задачу безопасной), и одна из них это, действительно “Ограничить ‘окно внимания“ или какой-нибудь ещё внутренний параметр, повышать его медленно и не повышать выше необходимого для решения задачи.”
[Ngo][13:41]
Это можно делать вручную, но я ожидаю, что это может быть сделано автоматически, через обучение агентов в окружении, где они не будут получать выгоду от длительного поддержания внимания.
[Yudkowsky][13:42]
(Каждый раз, когда кто-нибудь достаточно осторожный представляет тактику такого рода, он должен представить множество способов, которыми всё может пойти не так; к примеру, если в предоставленных данных или внутреннем состоянии агента есть что-то, зависящее от прошлых событий таким образом, что оно выдаёт о них информацию. Но, в зависимости от того, насколько суперинтеллектуальны иные части, иногда может и прокатить.)
[Ngo][13:43]
И если ты поместишь агентов в окружения, где им надо отвечать на вопросы, не особо взаимодействую с внешним миром, то у них не будет множества качеств, необходимых для достижения целей в реальном мире, потому что они не будут получать особого преимущества от оптимизации этих качеств.
[Yudkowsky][13:43]
Замечу, что TransformerXL обобщил своё окно внимания, он был натренирован на, кажется, 380 токенов или около того, а потом оказалось, что оно у него около 4000 токенов.
[Ngo][13:43]
Ага, обобщение на порядок меня не удивляет.
[Yudkowsky][13:44]
Наблюдав обобщение на один порядок, я лично теперь не удивился бы и двум.
[Ngo][13:45]
Я был бы несколько удивлён, но, полагаю, такое случается.
Настройка возможностей
[Yudkowsky][13:46]
Мне кажется, это всё крутится вокруг вопроса “Но что ты сделаешь с настолько ослабленным интеллектом?”. Если ты можешь спасти мир с помощью булыжника, я могу тебе обеспечить очень безопасный булыжник.
[Ngo][13:46]
Верно.
До сих пор я говорил “исследование согласования”, но был не очень конкретен.
Я полагаю, что тут должен быть контекст того, что первые вещи, которые мы делаем с таким интеллектом, это улучшаем общее благосостояние, продвигаем науку, и т.д.
И после этого мы в мире, где люди воспринимают перспективу СИИ куда серьёзнее
[Yudkowsky][13:48]
Я в целом ожидаю – хотя с какими-то шансами реальность может сказать: “Ну и что?” и удивить меня, это не настолько твёрдо определено как многие другие штуки – что у нас не будет длинной фазы “странного СИИ ~человеческого уровня” перед фазой “если ты разгонишь этот СИИ, он уничтожит мир”. Говоря в числах, скажем, меньше пяти лет.
Меня совершенно не удивит, если мир закончится до того, как беспилотные автомобили станут продаваться на массовом рынке. В некоторых вполне правдоподобных сценариях, которым я сейчас приписываю >50% вероятности, компании, разрабатывающие СИИ, смогут предоставить прототипы управляющего автомобилем ИИ, если потратят на это время, и это будет близкий-к-концу-света уровень технологий; но будет Много Очень Серьёзных Вопросов о свободном выпускании на дороги этого относительно нового недоказанного достижения машинного обучения. И их технология СИИ уже будет иметь свойство “можно разогнать до уничтожения мира” до того, как Земля получит свойство “беспилотные автомобили разрешены на массовом рынке”, просто потому, что на это не хватит времени.
[Ngo][13:52]
Тогда я ожидаю, что другая штука, которую можно сделать – это собрать очень большой объём данных, вознаграждающий ИИ за следование указаниям людей.
[Yudkowsky][13:52]
В других сценариях, конечно, беспилотное вождение становится возможным с ограниченным ИИ задолго до прорыва к СИИ. И в некоторых сценариях СИИ будет получен с помощью прорыва в чём-то уже довольно быстро масштабируемом, так что к моменту, или вскоре после него, когда технологию можно будет использовать для беспилотных автомобилей, она уже уничтожит мир по повороту рубильника.
[Ngo][13:53]
Когда ты говоришь о “разгонке СИИ”, что ты имеешь в виду?
Использовать больше вычислительных мощностей на тех же данных?
[Yudkowsky][13:53]
Запустить с увеличенными границами циклов for, или наибольшем количестве GPU, если точнее.
[Ngo][13:53]
В режиме обучения с подкреплением, или обучении с учителем, или без учителя?
Ещё: можно поподробнее про циклы for?
[Yudkowsky][13:56]
Я не думаю, что просто градиентный спуск на Большем Количестве Слоёв – как, скажем, сделали OpenAI с GPT-3, в противоположность Deepmind, которые создают более сложные артефакты вроде Mu Zero или AlphaFold 2, будет первым путём, который приведёт к СИИ. Я избегаю письменно высказывать предположения об умных путях к СИИ, и, я думаю, любой умный человек, если он действительно умный, а не просто приукрашенно-глупый, не будет говорить о том, чего, как ему кажется, не хватает в стратегии Большего Количества Слоёв или как на самом деле можно получить СИИ. С учётом этого, то, что нельзя просто запустить GPT-3 с большей глубиной поиска так, как можно с Mu Zero – это часть того, почему я считаю, что СИИ маловероятно будет устроен в точности как GPT-3; штука, которая нас всех убьёт, скорее будет чем-то, становящимся опаснее, если провернуть его рубильник, не чем-то, в чём в принципе нет рубильников, делающих это более опасным.
Консеквенциалистские цели против деонтологических целей
[Ngo][13:59]
Хм-м-м, окей. Давай быстренько вернёмся назад и подумаем, что полезного было в последние полчаса.
Я хочу отметить, что мои интуитивные рассуждения о ключевых действиях не очень конкретны; я довольно неуверен в том, как работает в такой ситуации геополитика, и в промежутке времени между СИИ-примерно-рядом-с-человеческим-уровнем и СИИ, предоставляющим экзистенциальные риски.
Так что мы можем продолжить обсуждать это, но я ожидаю, что буду часто говорить “ну, мы не можем исключить, что произойдёт X”, что, наверное, не самый продуктивный вид дискуссии.
Другой вариант – повкапываться в твои рассуждения о том, как работает мышление.
[Yudkowsky][14:03]
Ну, очевидно, в предельном случае, когда согласование недоступно нашей цивилизации, получится, что я успешно построил более благосклонную модель, всё же правильно отвергающую возможность успешного согласования для нашей цивилизации. В этом случае, я мог бы потратить короткий остаток своей жизни, споря с людьми, чьи модели достаточно благосклонны, чтобы включать невежество в какой-то области, из которой следует, что согласовать ничего не получится. Но предсказуемо именно так идут обсуждения на возможных мирах, где Земля обречена; так что кто-то помудрее на мета-уровне, будучи всё ещё невежественным на объектном уровне, предпочёл бы спросить: “Где, как ты думаешь, твоё знание, а не твоё невежество, говорит, что согласование должно быть осуществимым, и ты бы удивился, если бы оно не было?”.
[Ngo][14:07]
Справедливо. Хотя, кажется, концепция “ключевого действия” строится на обречённости по умолчанию.
[Yudkowsky][14:08]
Можно поговорить об этом, если тебе кажется, что это важно. Хотя я не думаю, что это обсуждение закончится за один день, так что, может, для удобства публикации нам стоит попробовать сфокусироваться на одной линии дискуссии?
Но мне кажется, что оптимизм многих людей основан на предположении, что мир можно спасти с помощью наименее опасных применений СИИ. Так что это большое ключевое расхождение в предпосылках.
[Ngo][14:09]
Согласен, что одна линия дискуссии лучше; готов сейчас принять концепцию ключевого действия.
Третий вариант в том, что я выскажу, как по-моему работает мышление, и посмотрим, насколько ты согласишься.
[Yudkowsky][14:12]
(Повторюсь, причина, по которой я не пишу “вот мои соображения, как работает мышление” в том, что прошлый опыт показал мне, что передача этой информации Другому Разуму, чтобы он мог её воспринять и ею оперировать, весьма сложна для моей текущей способности На Самом Деле Объяснять Что-Либо; такие вещи требуют долгих обсуждений и последующих домашних заданий, чтобы понять, как одна и та же структура возникает в разных случаях, в противоположность просто безрезультатному получению этого знания в готовом виде, и я пока не придумал подходящее домашнее задание.)
С радостью выслушаю твои заявления о мышлении и не соглашусь с ними.
[Ngo][14:12]
Отлично.
Окей, первое утверждение в том, что нечто вроде деонтологии – это довольно естественный способ работы разума.
[Yudkowsky][14:14]
(“Если бы это было так”, - подумал он, - “бюрократия и многотомные инструкции были бы куда эффективнее, чем на самом деле”)
[Ngo][14:14]
Хмм, наверно это была не лучшая формулировка, дай подумать, как сказать по другому.
Ладно, в нашей ранней дискуссии по email мы говорили о концепции “послушания”.
Мне кажется, что для разума столь же естественно иметь “послушание” в качестве приблизительной цели, как и максимизацию скрепок.
Если мы представим обучение агента на большом объёме данных, которые указывают в приблизительном направлении вознаграждения послушания, к примеру, то я представляю, что по умолчанию послушание будет ограничением, сравнимым с, скажем, человеческим инстинктом самосохранения.
(Который, очевидно, не настолько силён, чтобы остановить людей от кучи штук, которые ему противоречат – но всё равно это неплохое начало.)
[Yudkowsky][14:18]
Ха. Ты хотел сказать, сравнимым с человеческим инстинктом явной оптимизации совокупной генетической приспособленности?
[Ngo][14:19]
Генетическая приспособленность не была для наших предков понятной концепцией, так что, конечно, они не были направлены прямо на неё.
(И они не понимали, как её достичь)
[Yudkowsky][14:19]
Даже так, если ты не ожидаешь, вопреки общему мнению, что градиентный спуск будет работать совсем не так, как генная оптимизация, то суровая оптимизация X даст тебе лишь что-то, коррелировавшее с X в контексте обучения.
Это, конечно, одна из Больших Фундаментальных Проблем, которых я ожидаю в согласовании.
[Ngo][14:20]
Ладно, главный коррелят, обсуждения которого я встречал, это “делать то, что заставит человека поставить тебе высокую оценку, не то, чего он на самом деле хочет”
Мне любопытно, насколько ты обеспокоен этим конкретным коррелятом по сравнению с коррелятами в целом.
[Yudkowsky][14:21]
Ещё я вижу структурные причины, по которым натренировать на скрепки куда проще, чем на “послушание”. Даже если бы мы могли магически внушить простые внутренние желания, идеально отражающие простой внешний алгоритм, мы всё равно исполняем много отдельных экземпляров награждающей функции.
[Ngo][14:22]
Интересно было бы об этом послушать.
[Yudkowsky][14:22]
Ну, в первую очередь, почему книга с инструкциями настолько менее удобна и естественна, чем поведение охотника-собирателя?
ну знаешь, если деонтология столь же хороша, как консеквенциализм
(попробуешь ответить, или просто сказать?)
[Ngo][14:23]
Валяй
Мне, наверное, стоит прояснить, что я согласен, что нельзя просто заменить консеквенциализм деонтологией
Я скорее заявляю вот что: когда речь идёт о высокоуровневых концептах, мне не ясно, почему высокоуровневые консеквенциалистские цели естественнее высокоуровневых деонтологических целей.
[Yudkowsky][14:24]
Я отвечу, что реальность сложная, так что, когда ты пытаешься достичь в ней простой цели, ты получаешь сложное поведение. Если думать о реальности как о сложной функции Ввод->Вероятность(Вывод), то даже для простого Вывода, или простого набора Выводов, или высокого ожидаемого значения какой-нибудь простой функции от Вывода, может потребоваться очень сложный Ввод.
Люди не доверяют друг другу. Они представляют: “Ну, если я просто дам этому бюрократу цель, то он не будет честно рассуждать о том, чего будет стоить её достижение! О, нет! Потому, вместо этого, я, будучи аккуратным и достойным доверия человеком, сам придумаю ограничения и требования для действий бюрократа, такие, что я ожидаю, что, если он будет им следовать, результат его действий будет таким, как мне хочется.”
Но (в сравнении с сильным интеллектом, который наблюдает и моделирует сложную реальность и сам выбирает действия) действительно эффективная книга инструкций (исполняемая неким нечеловеческим разумом с достаточно большой и точной памятью, чтобы её запомнить) будет включать огромное (физически невозможное) количество правил “наблюдая то, делай это” для всех заковырок сложной реальности, которые можно выяснить из наблюдений.
[Ngo][14:28]
(Повторюсь, причина, по которой я не пишу “вот мои соображения как работает мышление” в том, что прошлый опыт показал мне, что передача этой информации Другому Разуму, чтобы он мог её воспринять и ею оперировать, весьма сложна для моей текущей способности На Самом Деле Объяснять Что-Либо; такие вещи требуют долгих обсуждений и последующих домашних заданий, чтобы понять, как одна и та же структура возникает в разных случаях, в противоположность просто безрезультатному получению этого знания в готовом виде, и я пока не придумал подходящее домашнее задание.)
(Отойдя от темы: нет хотя бы грубой оценки, когда твоя работа с Аджейей станет достоянием публики? Если ещё нескоро, то, может, полезно всё же выложить приблизительное описание этих соображений, пусть даже и в форме, в которой мало кто сможет их усвоить)
[Yudkowsky][14:30]
(Отойдя от темы: нет хотя бы грубой оценки, когда твоя работа с Аджейей станет достоянием публики? Если ещё нескоро, то, может, полезно всё же выложить приблизительное описание этих соображений, пусть даже и в форме, в которой мало кто сможет их усвоить)
Готов поверить в полезность, но, наверное, не сегодня?
[Ngo][14:30]
Согласен.
[Yudkowsky][14:30]
(Мы сейчас заходим за установленное время, мне нормально, но у тебя 11:30 (вроде), так что прервёмся, когда скажешь.)
[Ngo][14:32]
Да, 11:30. Я думаю, лучше всего прерваться тут. Я согласен с тем, что ты сказал про сложность реальности и с тем, что поэтому консеквенциализм ценнее. Моё заявление про “деонтологию” (бывшее в изначальной формулировке слишком общим, приношу извинения за это) было призвано прощупать твои соображения о том, какие типы мышления естественны или неестественны. Мне кажется, мы много ходили кругами вокруг этой темы.
[Yudkowsky][14:33]
Ага, и возобновить, наверное, стоит с того, почему я считаю “послушание” неестественным по сравнению с “скрепками” концептом – хоть это, наверное, и потребует затронуть тему того, что стоит за поверхностными умениями.
[Ngo][14:34]
Верно. Я думаю, что даже расплывчатое указание на это было бы довольно полезным (если этого пока нет онлайн?)
[Yudkowsky][14:34]
Насколько я знаю, пока нет, и я не хочу перенаправлять тебя на материалы Аджейи, даже если её это устраивает, потому что в таком случае наше обсуждение будет лишено нужного контекста для других.
[Ngo][14:35]
С моей стороны, мне стоит больше подумать о конкретных ключевых действиях, которые я захочу защищать.
В любом случае, спасибо за дискуссию :)
Дай мне знать, если знаешь, когда лучше продолжить; иначе определим это потом.
[Soares][14:37]
(вы тут делаете за меня мою работу)
[Yudkowsky][14:37]
Можно во вторник в то же время – хотя я могу быть не в такой хорошей форме из-за диеты, но стоит попробовать.
[Soares][14:37]
(сойдёт)
[Ngo][14:39]
Вторник не идеален, другие варианты есть?
[Yudkowsky][14:39]
Среда?
[Ngo][14:40]
Да, среда подойдёт
[Yudkowsky][14:40]
Тогда ориентировочно так
[Soares][14:41]
Здорово! Спасибо за разговор.
[Ngo][14:41]
Спасибо!
[Yudkowsky][14:41]
Спасибо, Ричард!
Последующее
Резюмирование Ричарда Нго
[Tallinn][0:35] (6 сентября)
Застрял здесь и хочу поблагодарить Нейта, Элиезера и (особенно) Ричарда, что они это делают! Здорово увидеть модель Элиезера настолько подробно. Я узнал несколько новых штук (как то, что ограничение информации в генах может быть важным фактором в развитии человеческого разума). Стоит добавить, маленький комментарий по деонтологии (пока не забыл): мне кажется, деонтология больше про координацию, чем про оптимизацию: деонтологическим агентам проще доверять, потому что об их действиях куда проще рассуждать (так же, как функциональный/декларативный код проще анализировать, чем императивный). Потому вот мой сильнейший аргумент в пользу бюрократии (и социальных норм): люди просто (и правильно) предпочитают, чтобы другие оптимизаторы (в том числе нечеловеческие) были деонтологическими для лучшего доверия/координации, и согласны платить за это компетенцией.
[Ngo][3:10] (8 сентября)
Спасибо, Яан! Я согласен, что большее доверие – хорошая причина хотеть от агентов, чтобы они на некотором высоком уровне были деонтологическими.
Я попробую просуммировать основные затронутые штуки; комментарии приветствуются: [ссылка на GDocs]
[Ngo] (8 сентября Google Doc)
1-я дискуссия
(В основном обобщения, а не цитаты)
Элиезера, по описанию Ричарда: “Чтобы избежать катастрофы, те, кто первыми создадут СИИ, должны будут а) в какой-то мере его согласовать, б) решить не разгонять его до уровня, на котором их техники согласования перестанут работать, и в) исполнить какое-то ключевое действие, которое помешает всем остальным разогнать его до такого уровня. Но наши техники согласования не будут достаточно хороши наши техники согласования будут очень далеки от подходящих на нашей текущей траектории наши техники согласования будут очень далеки от подходящих для создания ИИ, который безопасно выполнит такое ключевое действие.”
[Yudkowsky][11:05] (8 сентября комментарий)
“не будут достаточно хороши”
Сейчас не на пути к тому, чтобы быть достаточно хорошими, с большим разрывом. “Не будут достаточно хороши” – это буквально объявление о намерении лечь и помереть.
[Yudkowsky][16:03] (9 сентября комментарий)
Будут очень далеки от подходящих
Та же проблема. Я не делаю безусловные предсказания о будущем провале, как предполагает слово “будут”. При условии текущего или соседних с ним курсов, мы будем на порядок отставать от уровня выживания, если не произойдёт какого-нибудь чуда. Но это не предопределено; это всё ещё результат того, что люди будут делать то, что они, кажется, делают, а не неизбежность.
[Ngo][5:10] (10 сентября комментарий)
А, вижу. Подойдёт ли добавление “на нашей текущей траектории”?
[Yudkowsky][10:46] (10 сентября комментарий)
Да.
[Ngo] (8 сентября Google Doc)
Ричард, по описанию Ричарда: «Рассмотрим ключевое действие “совершить прорыв в исследовании согласования”. Вероятно, до момента, когда СИИ будет сильно сверхчеловеческим в поиске власти, он будет уже некоторое время сильно сверхчеловеческим в понимании мира и в выполнении ключевых действий вроде исследования согласования, не требующих высокой агентности (под которой я примерно подразумеваю: наличие крупных мотиваций и способность следовать им долгие промежутки времени).»
Элизер, по описанию Ричарда: “Есть глубокая связь между решением интеллектуальных задач и захватом мира – решение задач требует, чтобы мощный разум думал об областях, которые, будучи понятыми, предоставляют опасные когнитивно-доступные стратегии. Даже математические исследования включают в себя задачу постановки и преследования инструментальных целей – и если мозг, эволюционировавший в саванне, может быстро научиться математике, то так же правдоподобно, что ИИ, натренированный на математику, может быстро выучить множество других навыков. Так как почти никто не понимает глубинное сходство мышления, необходиомого для разных задач, расстояние между ИИ, который может проводить научные исследования, и опасно агентным СИИ меньше, чем почти все ожидают.”
[Yudkowsky][11:05] (8 сентября комментарий)
Есть глубокая связь между решением интеллектуальных задач и захватом мира.
По умолчанию есть глубокая связь между обтачиванием каменных топоров и захватом мира, если научиться обтачивать топоры в очень общем виде. “Интеллектуальные” задачи в этом отношении ничем не отличаются. Может и можно избежать положения по умолчанию, но это потребует некоторой работы, и её надо будет выполнить до того, как более простые техники машинного обучения уничтожат мир.
[Ngo] (8 сентября Google Doc)
Ричард, по описанию Ричарда: “Наш недостаток понимания того, как работает интеллект, склоняет нас к предположению, что черты, совместно проявляющиеся у людей, также будут совместными у ИИ. Но человеческий мозг плохо оптимизирован для задач вроде научных исследований и хорошо оптимизирован для поиска власти в окружающем мире, по причине, в том числе:
а) эволюции в жестоком окружении;
б) ограничения пропускной способности генома;
в) социальном окружении, вознаграждающем стремление к власти.
Напротив, нейросети, натренированные на задачи вроде математических или научных исследований, куда меньше оптимизированы для стремления к власти. К примеру, GPT-3 обладает знаниями и способностями к рассуждениям, но при этом обладает низкой агентностью и теряет связность действий на больших промежутках времени.”
[Tallinn][4:19] (8 сентября комментарий)
[хорошо оптимизирован для] поиска власти
Можно посмотреть на межполовые различия (хоть и не хочется полагаться на Пинкера :))
[Yudkowsky][11:31] (8 сентября комментарий)
Я не думаю, что женская версия Элиезера Юдковского не пыталась бы спасти / оптимизировать / захватить мир. Мужчины могут делать это по глупым причинам; умные мужчины и женщины используют одинаковые рассуждения, если они достаточно умны. К примеру, Анна Саламон и многие другие.
[Ngo] (8 сентября Google Doc)
Элиезер, по описанию Ричарда: “Во-первых, есть большая разница между большинством научных исследований и таким родом ключевых действий, о которых мы говорим – тебе потребуется объяснить, как ИИ с тем или иным навыком можно на самом деле использовать, чтобы предотвратить создание опасного ИИ. Во-вторых, GPT-3 обладает низкой агентностью, потому что она запомнила множество поверхностных паттернов таким способом, который непосредственно не масштабируется до обобщённого интеллекта. Интеллект состоит из глубоких паттернов решения задач, что фундаментально связывает его с агентностью.”
Обсуждение 8 сентября
Байка про бразильский университет
[Yudkowsky][11:00]
(Я тут.)
[Ngo][11:01]
Тоже.
[Soares][11:01]
Добро пожаловать!
(Я, в основном, просто не буду мешать.)
[Ngo][11:02]
Круто. Элиезер, ты прочитал резюмирование – и, если да, согласен ли с ним в общих чертах?
Ещё я думал про лучший способ подобраться к твоим соображениям о мышлении. Мне кажется, что начинать с темы про послушание против скрепок, наверное, не так полезно, как с чего-то ещё – к примеру, с определения, которое ты выдал ближе к началу предыдущей дискуссии про «поиск состояний, получающих высокую оценку при скармливании их в функцию результатов, а затем в функцию оценки результатов».
[Yudkowsky][11:06]
Сделал пару комментариев про формулировки.
Итак, с моей перспективы, есть такая проблема, что… довольно сложно учить людей некоторым общим вещам, в противоположность более конкретным. Вроде как, когда пытаются создать вечный двигатель, и хоть ты и убедил их, что первый проект неправильный, они просто придумывают новый, и новый достаточно сложен, что ты не можешь их убедить, что они неправы, потому что они сделали более сложную ошибку и теперь не могут уследить за её обличением.
Учить людей смотреть на стоящую за чем-то структуру часто очень сложно. Ричард Фейнман приводил пример в истории про «Смотрите на воду!», где люди в классе научились тому, что «среда с индексом преломления» должна поляризовать свет, отражённый от неё, но не осознавали, что солнечный свет, отражённый от воды будет поляризован. Моя догадка, что правильно это делается с помощью домашних заданий, и, к сожалению, тут мы в той области, где у меня особый математический талант, также как, например, Марселло талантливее меня в формальном доказательстве теорем. И людям без этого особого таланта приходится делать куда больше упражнений, чем мне, и я не очень понимаю, какие именно упражнения надо им дать.
[Ngo][11:13]
Сочувствую этой проблеме, могу попробовать выйти из скептического спорящего режима и войти в обучащийся режим, если думаешь, что это поможет.
[Yudkowsky][11:14]
Есть общее озарение о коммутативности в арифметике, и некоторым людям достаточно показать, что 1 + 2 = 2 + 1, чтобы они сами обобщили за пределы единицы и двойки и любых других чисел, которые можно туда поместить, и поняли, что строку чисел можно перемешать, и это не поменяет их сумму. Кому-то ещё, обычно детям, нужно показать, как на стол кладут два яблока и одно яблоко в разном порядке, и получается одно и то же число, а потом показать ещё, скажем, сложение купюр разного достоинства, если они не обобщили с яблок на деньги. Я припоминаю, что, когда я был достаточно маленьким ребёнком, я пытался прибавить 3 к 5, считая «5, 6, 7», и думал, что есть достаточно умный способ получить 7, если хорошенько постараться.
Быть в состоянии увидеть «консеквенциализм» это, с моей перспективы, что-то похожее.
[Ngo][11:15]
Другая возможность: можешь ли ты проследить источники этого убеждения, как оно вывелось из предшествующих?
[Yudkowsky][11:15]
Я не знаю, какие упражнения задавать людям, чтобы они смогли увидеть «консеквенциализм» повсюду, а не изобретали немножко отличающиеся формы консеквенциалистского мышления и не заявляли: «Ну, вот это же не консеквенциализм, правильно?».
Формулировка «поиск состояний, получающих высокую оценку при скармливании их в функцию результатов, а затем в функцию оценки результатов» была одной из попыток описать опасную штуку достаточно абстрактным способом, чтобы у людей, может быть, лучше получилось её обобщить.
[Ngo][11:17]
Другая возможность: можешь описать ближайшую к настоящему консеквенциализму штуку в людях, и как мы её получили?
[Yudkowsky][11:18][11:21]
Ок, так, часть проблемы в том… что прежде, чем ты выполнил достаточно упражнений для своего уровня таланта (и я, однажды, был выполнившим слишком мало, чтобы не думать, что может быть умный способ сложить 3 и 5, чтобы получить 7), ты будешь склонен считать, что только очень жёсткая формальная описанная тебе штука – «настоящая».
С чего бы твой двигатель должен подчиняться законам термодинамики. Это же не один из тех двигателей Карно из учебника!
В людях есть фрагменты консеквенциализма, или кусочки, чьё взаимодействие порождает частично неидеальное подобие консеквенциализма, и критично увидеть, что «выводы» людей в некотором смысле «работают» потому, что они подобны консеквенциалистским, и только пока это так.
Помести человека в одну среду, и он раздобудет еду. Помести человека в другую среду, и он опять раздобудет еду. Вау, разные изначальные условия, но один результат! Должно быть, внутри человека есть штуки, которые, что бы они ещё не делали, заодно эффективно ищут, какие моторные сигналы приведут в итоге к получению еды!
[Ngo][11:20]
Ощущается, что ты пытаешься вытолкнуть меня (и любого, кто будет это читать) из конкретного заблуждения. Догадываюсь, что из какого-то вроде «Я понимаю, что Элиезер говорит, так что теперь я вправе с этим не согласиться» или, может «Объяснения Элиезера не кажутся мне осмысленными, так что я вправе считать, что его концепции не осмысленны». Правильно?
[Yudkowsky][11:22]
Скорее… с моей точки зрения, даже после того, как я разубеждаю людей в возможности одного конкретного вечного двигателя, они просто пытаются придумать более сложный вечный двигатель.
И я не уверен, что с этим делать; это, кажется, происходит уже очень долго.
В конце концов, многое, что люди извлекают из моих текстов – это не глубокие принципы объектного уровня, на которые я пытался указать; они не понимают, скажем, байесианство как термодинамику, не начинают видеть байесовские структуры каждый раз, когда кто-нибудь видит что-то и меняет своё убеждение. Вместо этого они получают что-то более метауровневое, более обобщённое, приблизительный дух того, как рассуждать и спорить, потому что они потратили много времени под воздействием именно этого снова, и снова, и снова, на протяжении многих постов в блоге.
Может, нет способа заставить кого-то понять, почему исправимость неестественна, кроме как много раз проводить этого кого-то через задачу попробовать изобрести структуру агента, который позволяет тебе нажать кнопку выключения (но не пытается заставить тебя нажать кнопку выключения), и показывать, как каждая попытка проваливается. А потом ещё демонстрировать, почему попытка Стюарта Расселла с моральной неуверенностью порождает проблему полностью обновлённого (не-)уважения; и надеяться, что это приведёт к пониманию общего паттерна того, почему исправимость в целом противоречит структуре штук, которые хороши в оптимизации.
Только вот чтобы нормально делать упражнения, это надо делать из модели ожидаемой полезности. И тогда тебе просто скажут: «А, ну ладно, тогда я просто создам агента, который хорош в оптимизации, но не использует эти явные ожидаемые полезности, из-за которых все проблемы!»
И получается, если я хочу, чтобы кто-то поверил в те вещи, в которые верю я, по тем же причинам, что и я, мне придётся научить их, почему некоторые структуры мышления – это действительно неотъемлемые части агента, который хорошо что-то делает, а не конкретная формальная штука, предназначенная для манипуляции бессмысленными числами, а не существующими в реальном мире яблоками.
И я пару раз пытался написать об этом (к примеру «последовательные решения подразумевают непротиворечивую полезность»), но этого оказалось недостаточно, потому что люди не решали на дому даже столько же задач, сколько я, а пришлось бы больше, потому что это именно та конкретная область, в которой я талантлив.
Я не знаю, как решить эту проблему, поэтому я отступил на мета-уровень, чтобы говорить о ней.
[Ngo][11:30]
Я вспомнил о посте на LW, который назывался «Напиши тысячу дорог в Рим», емнип, он агитировал пытаться объяснять одно и то же как можно большим числом способов, в надежде, чтобы один из них сработал.
[Soares][11:31]
(Предложение, не обязательно хорошее: обозначив проблему на мета-уровне, попытаться обсуждать объектный уровень, отмечая проявления проблемы, когда они будут всплывать.)
[Ngo][11:31]
Поддерживаю предложение Нейта.
И буду пытаться держать в голове сложность метауровневой проблемы и отвечать соответственно.
[Yudkowsky][11:33]
Наверно, предложение Нейта правильное. Я напрямую высказал проблему, потому что иногда если тебе говорят о мета-проблеме, это помогает с объектным уровнем. Кажется, это помогает мне довольно сильно, а другим не так сильно, но всё же многим как-то помогает.
Мозговые функции и помпы исходов
[Yudkowsky][11:34]
Итак, есть ли у тебя конкретные вопросы про ищущее вводы мышление? Я попытался рассказать, почему я это упомянул (это другая дорога к Риму «консеквенциализма»).
[Ngo][11:36]
Сейчас посмотрим. Зрительная кора даёт нам впечатляющий пример мышления в людях и многих других животных. Но я бы назвал это «распознаванием паттернов», а не «поиском высокоцениваемых результатов».
[Yudkowsky][11:37]
Ага! И не совпадение, что нет животных, состоящих исключительно из зрительной коры!
[Ngo][11:37]
Окей, круто. Так ты согласишься, что зрительная кора делает что-то качественно иное, чем животное в целом.
Тогда другой вопрос: можешь ли ты охарактеризовать поиск высокооцениваемых результатов в животных (не в человеке)? Делают ли они это? Или это в основном про людей и СИИ?
[Yudkowsky][11:39]
К моменту, когда появляются височные доли или что-то подобное, внутри должно происходить достаточное количество чего-то вроде «что я такое вижу, что выдаёт мне такую картинку?» – это поиск правдоподобных вариантов в пространстве гипотез. И на человеческом уровне люди уже думают: «Могу ли я видеть это? Нет, у этой теории есть такая-то проблема. Как я могу её исправить?». Но правдоподобно, что у обезьяны нет низкоуровневого аналога этого; и ещё правдоподобнее, что части зрительной коры, которые делают что-то такое, делают это относительно локально и уж точно только в очень конкретной узкой области.
О, ещё есть мозжечок и моторная кора и всё такое, если мы говорим, скажем, о кошке. Им надо искать планы действий, которые приведут к поимке мыши.
Только то, что зрительная кора (очевидно) не выполняет поиск, не значит, что он не происходит где-то ещё в животном.
(На метауровне я заметил, что думаю «Но как ты можешь не видеть этого, просто смотря на кошку?», интересно, какие упражнения нужны, чтобы этому научиться.)
[Ngo][11:41]
Ну, смотря на кошку, я вижу что-то, но я не знаю, насколько хорошо оно соответствует твоим концептам. Так что просто помедленнее пока.
Кстати, мне интуитивно кажется, что моторная кора в каком-то смысле делает что-то похожее на зрительную – только наоборот. То есть вместо принимания низкоуровневых вводов и выдачи высокоуровневых выводов, она принимает высокоуровневые вводы и выдаёт низкоуровневые выводы. Согласишься ли ты с этим?
[Yudkowsky][11:43]
Это не интерпретируется напрямую в мою онтологию, потому что (а) я не знаю, что ты имеешь в виду под «высоким уровнем» и (б) картезианских агентов в целом можно рассматривать как функции, что не означает, что их можно рассматривать как не выполняющих поиск распознавателей паттернов.
С учётом этого, все части коры имеют на удивление схожую морфологию, так что не было бы особо удивительно, если бы моторная кора делала что-то похожее на зрительную. (А вот мозжечок…)
[Ngo][11:44]
Сигнал из зрительной коры, сообщающий «это кошка» и сигнал, входящий в моторную кору, сообщающий «возьми эту чашку» – это то, что я называю высокоуровневым.
[Yudkowsky][11:45]
Всё ещё не естественное разделение в моей онтологии, но есть неформальная штука, на которую это смахивает, так что, надеюсь, я могу принять и использовать это.
[Ngo][11:45]
Активация клеток сетчатки и активация моторных нейронов – это низкоуровневое.
Круто. Так, в первом приближении, мы можем думать о происходящем между тем, как кошка распознаёт мышь и тем, как моторная кора кошки производит конкретные сигналы, необходимые для поимки мыши, как о той части, где происходит консеквенциализм?
[Yudkowsky][11:49]
Весь агент-кошка находится между глазами кошки, которые видят мышь, и лапами кошки, двигающимися, чтобы поймать мышь. Агент-кошка, безусловно, является зачатком консеквенциалиста / ищет мышеловительные моторные паттерны / получает высоко оцениваемые конечные результаты, даже при изменении окружения.
Зрительная кора – это конкретная часть этой системы-рассматриваемой-как-однонаправленная-функция; эта часть, предположительно, без уверенности, не особо что-то ищет, или осуществляет только поиск в маленькой локальной очень конкретной области, не направленный сам по себе на поимку мыши; по своей природе эпистемический, а не планирующий.
С некоторой точки зрения можно заявить «ну, большая часть консеквенциализма происходит в оставшейся кошке, уже после того, как зрительная кора послала сигналы дальше». И это в целом опасный настрой рассуждений, склонный к провалам в духе безуспешного исследования каждого нейрона на наличие консеквенциализма; но в данном конкретном случае, есть значительно более консеквенциалистские части кошки, чем зрительная кора, так что я не буду против.
[Ngo][11:50]
А, более конкретная штука, которую я имел в виду: большая часть консеквенциализма находится строго между зрительной корой и моторной корой. Согласен/Не согласен?
[Yudkowsky][11:51]
Не согласен, мои знания нейроанатомии несколько устарели, но, мне кажется, моторная кора может посылать сигналы мозжечку.
(Я, может, ещё не соглашусь с глубинным смыслом, на который ты пытаешься указать, так что, наверное, проблема не решится просто через «ладно, включим ещё мозжечок», но, наверное, стоит сначала дать тебе ответить.)
[Ngo][11:53]
Я недостаточно разбираюсь в нейроанатомии, чтобы уточнять на этом уровне, так что я хотел попробовать другой подход.
Но, на самом деле, может, проще заявить «ладно, включим ещё мозжечок» и посмотреть, куда, по-твоему, приведёт нас несогласие.
[Yudkowsky][11:56]
Так как кошки (очевидно) (насколько я читал) не являются универсальными консеквенциалистами с воображением, то их консеквенциализм состоит из мелких кусочков, вложенных в них более чисто псевдо-консеквенциалистской петлёй генетической оптимизации, которая их создала.
У не поймавшей мышь кошки могут подправиться мелкие кусочки мозга.
И потом эти подправленные кусочки занимаются анализом паттернов.
Почему этот анализ паттернов без очевидного элемента поиска в итоге указывает в одном и том же направлении поимки мыши? Из-за прошлой истории анализов и поправок, направленных на поимку.
Получается, что сложно указать на «консеквенциалистские части кошки», посмотрев, какие части её мозга совершают поиск. Но с учётом этого, пока зрительная кора не поправляется при провале поимки мыши, она не входит в консеквенциалистскую петлю.
И да, это относится и к людям, но люди также делают и более явные поисковые штуки, и это часть причин, почему у людей есть ракеты, а у кошек нет.
[Ngo][12:00]
Окей, это интересно. То есть в биологических агентах три уровня консеквенциализма: эволюция, обучение с подкреплением и планирование.
[Yudkowsky][12:01]
В биологических агентах есть эволюция + локальные эволюционировавшие правила, в прошлом увеличивавшие генетическую приспособленность. Два вида таких локальных правил – это «оперантное обусловливание от успеха или провала» и «поиск среди визуализированных планов». Я бы не называл эти два вида правил «уровнями».
[Ngo][12:02]
Окей, понял. И когда ты говоришь о поиске среди визуализированных планов (так, как делают люди), то что значит, что это «поиск»?
К примеру, если я представляю, как пишу стихотворение строку за строкой, то я могу планировать только на несколько слов вперёд. Но каким-то образом стихотворение в целом, может быть довольно длинное, получается высокооптимизированным. Это типичный пример планирования?
[Yudkowsky][12:04][12:07]
Планирование – это один из способов преуспеть в поиске. Думаю, что, чтобы понять сложность согласования, лучше думать на том уровне абстракции, на котором видно, что в каком-то смысле опасность исходит от самого достаточно мощного поиска, а не от деталей процесса планирования.
Одним из ранних способов успешного обобщения моего представления об интеллекте, позже сформулированного как «вычислительно-эффективный поиск действий, приводящих к результатам, стоящим высоко в порядке предпочтений», была (неопубликованная) история о путешествиях во времени в глобально непротиворечивой вселенной.
Требование глобальной непротиворечивости означает, что все события между началом и концом Парадокса должны отображать исходные условия Парадокса в конечную точку, которая создаст эти же самые исходные условия в прошлом. Оно задаёт сильные и сложные ограничения на реальность, которые Парадокс должен соблюсти, используя свои исходные условия. Путешественник во времени должен пройти через определённый опыт, вызывающий состояние разума, в котором он совершит действия, которые подтолкнут прошлого его к получению того же опыта.
Парадокс в итоге, к примеру, убил создателей машины времени, потому что иначе они бы не позволили путешественнику вернуться во времени, или как-нибудь ещё не позволили бы временной петле сойтись, если бы были живы.
Для обобщения понятия мощной консеквенциалистской оптимизации мне было недостаточно всего двух примеров – человеческого интеллекта и эволюционной биологии. Иметь три примера – это было одно из упражнений, над которыми я работал – и с людьми, эволюцией и вымышленным Парадоксом у меня наконец «щёлкнуло».
[Ngo][12:07]
Хмм. Для меня, одна из специфических черт поиска – это рассмотрение множества возможностей. Но в примере стихотворения, я могу явно рассмотреть не так много вариантов, потому что я заглядываю вперёд только на несколько слов. Это кажется похожим на проведённое Абрамом разделение между отбором и контролем (https://www.alignmentforum.org/posts/ZDZmopKquzHYPRNxq/selection-vs-control). Разделяешь ли ты их так же? Или «контроль» системы (например, футболист, ведущий мяч по полю) в твоей онтологии тоже считается за поиск?
[Yudkowsky][12:10][12:11]
Я ещё попытаюсь говорить людям «представьте, что максимизатор скрепок – это вообще не разум, представьте, что это что-то вроде неисправной машины времени, которая выдаёт результаты, приводящие к существованию большего количества скрепок в итоге». Я не думаю, что это щёлкнет, потому что люди не выполняли тех же упражнений, что и я, и не испытывали того же «Ага!» при осознании того, как заметить часть самой концепции и опасности интеллекта в таких чисто материальных терминах.
Но конвергентные инструментальные стратегии, антиисправимость, эти штуки исходят из истинного факта о вселенной, заключающегося в том, что некоторые выводы машины времени на самом деле приведут к созданию большего количества скрепок в итоге. Опасность исходит не из деталей процесса поиска, а просто из того, что он достаточно сильный и эффективный. Опасность в самой территории, не просто в какой-то причудливой её карте; то, что создание наномашин, которые убьют программистов, приведёт к созданию большего количества скрепок – это факт про реальность, не про максимизатора скрепок!
[Ngo][12:11]
Ладно, я вспомнил про очень похожую идею в твоём тексте про Помпу Исходов (Скрытая сложность желаний).
[Yudkowsky][12:12]
Ага! Правда, история писалась в 2002-2003, когда я писал хуже, так что настоящий рассказ про Помпу Исходов никогда не был опубликован.
[Ngo][12:14]
Окей, тогда, думаю, естественный следующий вопрос: почему ты думаешь, что сильный эффективный поиск вряд ли будет как-нибудь ограничен или сдержан?
Что в поисковых процессах (как человеческий мозг) делает сложным их обучение с слепыми пятнами, деонтологическими указаниями, или чем-то в таком роде?
Хммм, это ощущается как вопрос, ответ на который я могу предсказать. (А может и нет, я не ожидал путешествий во времени.)
[Yudkowsky][12:15]
В каком-то смысле, они ограничены! Максимизирующий скрепки суперинтеллект и близко не так могущественен, как максимизирующая скрепки машина времени. Машина времени может делать что-то эквивалентное покупке лотерейных билетов из термодинамически рандомизированных лотерейных машин; суперинтеллект – нет, по крайней мере, без того, чтобы напрямую обдурить лотерею, или чего-то такого.
Но максимизирующий скрепки сильный обобщённый суперинтеллект эпистемологически и инструментально эффективен по сравнению с тобой, или со мной. Каждый раз, когда мы видим, что он может получить как минимум X скрепок, сделав Y, нам следует ожидать, что он получит X или больше скрепок, сделав Y или что-то, что приведёт к получению ещё большего количества скрепок, потому что он не пропустит стратегию, которую мы видим.
Обычно, когда мы представляем, что бы делал максимизатор скрепок, наш мозг представляет его несколько глупым, этого ограничения можно избежать, спрашивая себя, как бы скрепки получала машина времени, какого количества скрепок можно добиться в принципе и как. Рассказывать людям о машине времени вместо суперинтеллекта имеет смысл в частности затем, чтобы преодолеть представление о суперинтеллекте как о чём-то глупом. Это, конечно, не сработало, но попытаться стоило.
Я не думаю, что это в точности то, о чём ты спрашивал, но я хочу дать тебе возможность переформулировать что-нибудь прежде, чем я попытаюсь ответить на твои переформулированные мной вопросы.
[Ngo][12:20]
Ага, я думаю, то, что я хотел спросить – это что-то такое: почему нам следует ожидать, что из всего пространства возможных разумов, созданных оптимизационными алгоритмами, сильные обобщённые суперинтеллекты встречаются чаще, чем другие типы агентов, высокооцениваемых нашими обучающими функциями?
[Yudkowsky][12:20][12:23][12:24]
Это зависит от того, насколько сильно оптимизировать! И может ли градиентный спуск на конкретной системе оптимизировать достаточно сильно! Многие нынешние ИИ обучены градиентным спуском и всё ещё вовсе не стали суперинтеллектами.
Но ответ в том, что некоторые задачи сложны, и требуют решения множества подзадач, и простой способ решения всех этих подзадач – это использование перекрывающихся совместимых паттернов, обобщающихся по всем подзадачам. Чаще всего поиск будет натыкаться на что-то такое до того, как наткнётся на отдельные решения всех этих задач.
Я подозреваю, что этого нельзя достичь не очень большим градиентным спуском на мелкомасштабных трансформерах, так что я считаю, что GPT-N не достигнет суперинтеллектуальности до того, как мир закончат по-другому выглядящие системы, но я могу ошибаться.
[Ngo][12:22][12:23]
Предположим, мы достаточно сильно оптимизировали, чтобы получить эпистемическую подсистему, которая может планировать куда лучше любого человека.
Догадываюсь, что ты скажешь, что это возможно, но куда вероятнее сначала получить консеквенциалистского агента, который будет это делать (чем чисто эпистемического).
[Yudkowsky][12:24]
Я озадачен тем, что, по-твоему, значит иметь «эпистемическую подсистему», которая «может планировать лучше любого человека». Если она ищет пути во времени и выбирает высокооцениваемые для вывода, что делает её «эпистемической»?
[Ngo][12:25]
Предположим, например, что она не исполняет планы сама, только записывает их для людей.
[Yudkowsky][12:25]
Если она фактически может делать то же, что и скрепочная машина времени, как называние её «эпистемической» или как-то ещё делает её безопаснее?
По какому критерию она выбирает планы, на которые посмотрят люди?
Почему имеет значение, что её вывод пройдёт через причинно-следственные системы, называемые людьми, прежде чем попадёт в причинно-следственные системы, называемые синтезаторами белков, или Интернет, или ещё как-то? Если мы создали суперинтеллект для проектирования наномашин, нет очевидной разницы, посылает ли она строки ДНК сразу в синтезатор белков, или сначала люди читают её вывод и вручную перепечатывают его. Предположительно, ты тоже не думаешь, что безопасность исходит из этого. Тогда откуда?
(замечу: через две минуты у меня время полдника, предлагаю продолжить через 30 минут после этого)
[Ngo][12:28]
(перерыв на полчаса звучит неплохо)
Если мы рассмотрим зрительную кору в конкретный момент времени, как она решает, какие объекты распознавать?
Если зрительная кора может быть не-консеквенциалистской в том, какие объекты распознавать, почему планирующая система не может быть не-консеквенциалистской в том, какие планы выдавать?
[Yudkowsky][12:32]
Мне это кажется чем-то вроде очередного «смотрите на воду», предскажешь, что я скажу дальше?
[Ngo][12:34]
Предсказываю, что ты скажешь, что-то вроде этого: чтобы получить агента, который может создавать очень хорошие планы, надо применить на нём мощную оптимизацию. И если мы оптимизируем его через канал «оцениваем его планы», то у нас нет способа удостовериться, что агент действительно оптимизировался для создания по-настоящему хороших планов, а не для создания планов, которые получают хорошую оценку.
[Soares][12:35]
Кажется неплохим клиффхенгером?
[Ngo][12:35]
Ага.
[Soares][12:35]
Здорово. Давайте продолжим через 30 минут.
Гипотетически-планирующие системы, наносистемы и эволюционирование обобщения
[Yudkowsky][13:03][13:11]
Так, ответ, который ты от меня ожидал, в переводе на мои термины – это «Если ты совершаешь отбор для того, чтобы люди тыкнули «одобрить», прочитав план, то ты всё ещё исследуешь пространство вводов в поисках путей во времени к вероятным исходам (конкретно, к тому, что человек нажмёт «одобрить»), так что это всё ещё консеквенциализм.»
Но допустим, что у тебя получилось этого избежать. Допустим, ты получил именно то, чего хотел. Тогда система всё ещё выдаёт планы, которые, когда люди им следуют, идут по пути во времени к исходам, которые высоко оцениваются какой-то функцией.
Мой ответ: «Какого чёрта значит для планирующей системы быть не-консеквенциалистской? Это как не мокрая вода! Консеквенциалист – это не система, выполняющая работу, это сама работа! Можно представить, как её выполняет не мыслящая система вроде машины времени, и консеквенциализм никуда не денется, потому что вывод – это план, путь во времени!»
И это в самом деле такой случай, когда я чувствую чувство беспомощности от того, что я не знаю, как можно переформулировать, какие упражнения надо кому-то дать, через какой вымышленный опыт провести, чтобы этот кто-то начал смотреть на воду и видеть материал с индексом преломления, начал смотреть на фразу «почему планирующая система не может не быть консеквенциалистской по поводу того, какой план выдавать» и думать «Чёёё».
Мой воображаемый слушатель теперь говорит: «Но что, если наши планы не приводят к результатам, высоко оцениваемым какой-то функцией?», и я отвечаю: «Тогда ты лежишь на земле, хаотично дёргаясь, потому что если ты хотел какой-то другой результат больше, это значит, что ты предпочитал его выводу случайных моторных сигналов, что означает оптимизацию значения функции предпочтений, что, в свою очередь, означает выбор пути во времени, который скорее ведёт в определённом направлении, чем к случайному шуму.»
[Ngo][13:09][13:11]
Ага, это звучит как хороший пример той штуки, которую ты пытался объяснить в начале.
Всё ещё кажется, что здесь есть какое-то разделение по уровням, давай попробую поиграться с этим ощущением.
Окей, допустим, у меня есть планирующая система, которая для данной ситуации и цели выдаёт план, ведущий от ситуации к цели.
И допустим, что в качестве ввода мы ей даём ситуацию, в которой на самом деле не находимся, и она выдаёт соответствующий план.
Мне кажется, что есть разница между тем, как система является консеквенсциалистской, потому что создаёт консеквенциалистские планы (то есть, планы, которые, будучи применёнными в ситуации из ввода, привели бы к достижению некой цели), и другим гипотетическим агентом, который просто напрямую пытается достигать целей в ситуации, в которой на самом деле находится.
[Yudkowsky][13:18]
Для начала скажу, что если получится создать такую систему, чьё описание вполне осмысленно (мне кажется), то это, возможно, обеспечило бы некоторый запас безопасности. Она была бы заметно менее (хоть и всё ещё) опасной. Это потребовало бы неких структурных свойств, которые не факт, что можно получить просто градиентным спуском. Точно так же как естественный отбор по генетической приспособленности не даёт тебе явных оптимизаторов этой приспособленности, можно оптимизировать планирование в гипотетических ситуациях и получить что-то, что явно заботится не только строго о гипотетических ситуациях. Но это вполне последовательная концепция, и тот факт, что система не будет оптимизировать нашу вселенную, может сделать её безопаснее.
Сказав это, теперь я обеспокоюсь, что кто-то может подумать, что от того, что агент решает «гипотетические» задачи, возникает некая ключевая разница в агентности, в наличии или отсутствии чего-то, ассоциируемого с индивидуальностью, представлением целей и мотивацией. Если ты возьмёшь такого планировщика и дашь ему реальный мир в качестве гипотетического, та-да, теперь это старый добрый опасный консеквенциалист, которого мы представляли раньше, безо всяких изменений психологической агентности, «заботы» о чём-то или чего-то ещё такого.
Так что, думаю, важным упражнением было бы что-то вроде «Представь выглядящую безопасной систему, рассматривающую только гипотетические задачи. Теперь представь, что если ты возьмёшь это систему, и скармливаешь ей настоящие задачи, то она станет очень опасной. Теперь помедитируй над этим, пока не увидишь, что гипотетический планировщик очень-очень близок к более опасной версии себя, латентно имеет все его опасные свойства, и, вероятно, кучу уже опасных свойств тоже.»
«Видишь, ты думал, что источник опасности в внутреннем свойстве обращения внимания на реальный мир, но он не там, он в структуре планирования!»
[Ngo][13:22]
Я думаю, мы теперь ближе к тому, чтобы быть на одной волне.
Давай ещё немного посмотрим на такого гипотетического планировщика. Предположим, что он был обучен, чтобы минимизировать, скажем, враждебную составляющую его планов.
К примеру, его планы сильно регуляризованы, так что проходят только грубые общие детали.
Хмм, сложновато это описывать, но по сути мне кажется, что в таком сценарии есть компонент плана, кооперативный с его исполнителями, а есть враждебный.
И я согласен, что между ними нет никакой фундаментальной разницы.
[Yudkowsky][13:27]
«Что, если у зелья, которое мы варим, есть Хорошая Часть и Плохая Часть, и мы можем оставить только Хорошую…»
[Ngo][13:27]
Я не считаю, что они разделимы. Но, в некоторых случаях, можно ожидать, что одна часть будет куда больше другой.
[Soares][13:29]
(Моя модель других слушателей сейчас протестует «всё ещё есть разница между гипотетическим планировщиком, применённым к реальным задачам, и Большим Страшным Консеквенциалистом, она в том, что гипотетический планировщик выдаёт описания планов, которые работали бы, если их исполнить, тогда как большой страшный консеквенциалист исполняет их напрямую.»)
(Не уверен, что это полезно обсудить, или что это поможет Ричарду формулировать, но это как минимум то, что я ожидаю, будут думать некоторые читатели, если/когда это будет опубликовано.)
[Yudkowsky][13:30]
(Разница есть! Суть в осознании того, что гипотетический планировщик на расстоянии одной строки внешнего кода от того, чтобы стать Большой Страшной Штукой, так что стоит ожидать, что он тоже много как будет Большим и Страшным.)
[Ngo][13:31]
Мне кажется, что позиция Элиезера примерно такая: «на самом деле, почти что никакие режимы обучения не предоставят нам агентов, которые, определяя, какой план выдать, будут тратить почти всё своё время, думая над задачей объектного уровня, и очень мало времени о том, как манипулировать людьми, которым выдан план.»
[Yudkowsky][13:32]
Моя позиция в том, что у ИИ нет аккуратного разделения внутренних процессов на Части, Которые Ты Считаешь Хорошими и Части, Которые Ты Считаешь Плохими, потому что это отчётливое на твоей карте разделение, вовсе не отчётливо на карте ИИ.
С точки зрения максимизирующей-скрепки-выводящей-действия-машины-времени её действия не делятся на «создание скрепок на объектном уровне» и «манипуляция людьми рядом с машиной времени, чтобы обмануть их по поводу того, что она делает», они все просто физические выводы, проходящие сквозь время и приводящие к скрепкам.
[Ngo][13:34]
Ага, Нейт, это хороший способ сформулировать один из моих аргументов. И я согласен с Элиезером, что эти штуки могут быть очень похожими. Но я заявляю, что в некоторых случаях они могут быть и довольно отличающимися – к примеру, когда мы обучаем агента выдавать только короткое высокоуровневое описание плана.
[Yudkowsky][13:35]
Опасность в том, какую работу совершит агент, чтобы составить план. Я могу, к примеру, создать агента, который очень безопасно выдаёт высокоуровневый план по спасению мира:
echo «Эй, Ричард, спаси мир! «
Так что мне придётся спросить, какого вида «высокоуровневые» выводы планов для спасения мира ты предлагаешь, и почему сложно просто составить такой самим прямо сейчас, раз уж люди могут ему следовать. Тогда я посмотрю на ту часть, которую сложно придумать самим, и скажу, что вот тут для изобретения высокоуровневого плана агент должен понимать множество сложных штук о реальности и уметь точно прокладывать пути через время в области этих сложных штук; следовательно, он будет очень опасен, если он не прокладывает их в точности туда, куда ты надеешься. Или, как вариант, скажу: «Этот план не может спасти мир: тут недостаточно суперинтеллекта, чтобы он был опасен, но одновременно с этим недостаточно суперинтеллекта, чтобы опрокинуть игровую доску нынешнего очень обречённого мира.»
[Ngo][13:39]
Прямо сейчас я не представляю конкретного вывода планов для спасения мира, я просто пытаюсь лучше прояснить проблему консеквенциализма.
[Yudkowsky][13:40]
Смотри на воду; опасен не путь, которым ты хочешь выполнить работу, опасна сама работа. Что именно ты пытаешься сделать, неважно, как именно?
[Ngo][13:41]
Думаю, я соглашусь, что наши нынешние ограничения способностей не позволяют нам сказать многое о том, как работа будет выполняться, так что нам приходится в основном рассуждать о самой работе.
Но я тут говорю только про системы, которые достаточно умны, чтобы составлять планы и проводить исследования, находящиеся за пределами возможностей человечества.
И вопрос такой: можем ли мы подправить способ, которым работают такие системы, чтобы они тратили 99% своего времени на попытки решить задачу объектного уровня, и 1% времени на попытки манипулировать людьми, которые получат план? (Хоть это и не фундаментальные категории для ИИ, лишь грубая категоризация, возникающая из того, как мы его обучили – так же как «двигаться» и «думать» – это не фундаментально различные категории действий для людей, но то, как мы эволюционировали привело к значительному их разделению.)
[Soares][13:43]
(Я подозреваю, что Элиезер не имеет в виду «нам остаётся лишь рассуждать о самой работе, а не способах, которыми она будет выполняться, потому что наших способностей недостаточно для этого». Подозреваю недопонимание. Может быть, Ричарду стоит попытаться перефразировать аргумент Элиезера?)
(Однако, думаю, если Элиезер ответит на аргумент про 99%/1% – это тоже может всё прояснить.)
[Yudkowsky][13:46]
Ну, для начала, замечу, что система, проектирующая наносистемы, и тратящая 1% своего времени, раздумывая, как убить её операторов, смертельна. Это должна быть настолько маленькая доля мыслей, чтобы она никогда не закончила целую мысль «Если я сделаю X, это убьёт операторов.»
[Ngo][13:46]
Спасибо, Нейт. Я попробую перефразировать аргумент Элиезера.
Позиция Элизера (частично в моей терминологии): мы создадим ИИ, который может выполнять очень сложные мыслительные задачи, которые мы можем грубо описать как «искать среди множества вариантов тот, который будет удовлетворять нашим критериям.» ИИ, который может решить эти сложные задачи, должен будет уметь выполнять очень гибкий и обобщённый поиск, так что его будет очень сложно ограничить конкретной областью.
Хмм, это ощущается очень общим описанием, сейчас подумаю о его более конкретных заявлениях.
[Yudkowsky][13:54]
ИИ, который может решить эти сложные задачи, должен будет
Очень-очень мало что в пространстве устройства ИИ универсально необходимо. Первый ИИ, которого сможет создать наша технология, наверняка будет действовать некоторыми проще достижимыми и проще устроенными способами.
[Ngo][13:55]
Принято; спасибо за поимку этой неточности (тут и ранее).
[Yudkowsky][13:56]
Можно ли, в принципе, создать водителя-красных-машин, который совершенно неспособен водить синие машины? В принципе – конечно! Но первый водитель-красных-машин, на которого наткнётся градиентный спуск, наверняка будет и водителем-синих-машин.
[Ngo][13:57]
Элиезер, любопытно, в какой мере наше несогласие исходит из разного мнения о человеческом уровне.
Или, по-другому: мы и сейчас можем создавать системы, которые превосходят людей в некоторых задачах, но не имеют достаточно общих способностей поиска, чтобы даже попытаться захватить мир.
[Yudkowsky][13:58]
Несомненно, это так.
[Ngo][13:59]
Отставив в сторону ненадолго вопрос о ключевых действиях для спасения мира, какая часть твоей модели проводит линию между игроками в шахматы человеческого уровня и колонизаторами галактики человеческого уровня?
И говорит, что мы в состоянии согласовать до того, как они захватят мир, тех, которые превосходят нас на одних задачах, но не на других.
[Yudkowsky][13:59][14:01]
Тут нет очень простого ответа, но один из аспектов – это обобщённость между областями, которая достигается через изучение новых областей.
Люди, заметим, не были агрессивно оптимизированы естественным отбором для дыхания под водой и полётов в космос. Нет явного внешнего знака, что естественный отбор создал этих существ более обобщённо-способными, чем шимпанзе, обучая их на более широком наборе окружений и функций оценки.
[Soares][14:00]
(Прежде чем мы уйдём слишком далеко: спасибо за резюмирование! Мне кажется, это хорошо, я уверился в отсутствии ошибки взаимопонимания.)
[Ngo][14:03]
(Прежде чем мы уйдём слишком далеко: спасибо за резюмирование! Мне кажется, это хорошо, я уверился в отсутствии ошибки взаимопонимания.)
(Рад слышать, спасибо, что присматриваешь. Для ясности, я не интерпретировал слова Элиезера так, будто он заявляет исключительно об ограничении способностей; просто мне показалось, что он думает о значительно более продвинутых ИИ, чем я. Думаю, я плохо сформулировал.)
[Yudkowsky][14:05][14:10]
Есть затруднительные аспекты этой истории с естественным отбором, про который можно метафорически сказать, что он «понятия не имел, что делает». К примеру, после того, как ранний взлёт интеллекта, возможно, был вызван половым отбором по аккуратно обколотым топорам или чему-то такому, накопившаяся оптимизация мозга шимпанзе дошла до точки, где внезапно от сравнительного интеллекта стала сильно (сильнее, чем у шимпанзе) зависеть способность к составлению коварных планов против других людей – подзадача оптимизации генетической приспособленности. Так что продолжение оптимизации «совокупной генетической приспособленности» в той же саванне привело к оптимизации на подзадачу и способность «перехитрить других людей», для чего пришлось сильно оптимизировать «моделирование других людей», что оказалось возможно использовать на самом себе, что обратило систему на себя и сделало её рефлексивной, что сильно вложилось в обобщение интеллекта. До этого дошло несмотря на то, что всё это следовало той же самой функции вознаграждения в той же самой саванне.
Можно задать вопрос: возможен ли суперинтеллектуальный СИИ, который может быстро создать нанотехнологии и обладает некоторой пассивной безопасностью за счёт того, что он решает задачи вида «создать наносистему, которая делает X» примерно так же, как бобёр решает строительство дамб, имея набор специализированных способностей, но не имея обобщённой выходящей за пределы конкретных областей способности к обучению?
И в этом отношении надо заметить, что есть много, много, много штук, которые могу делать люди, но никакие другие животные, которые, думается, хорошо бы вложились в приспособленность этих животных, если бы был животный способ их делать. Они не делают себе железные когти. Так и не эволюционировала тенденция искать железную руду, пережигать дерево в уголь и собирать глиняные печи.
Животные не играют в шахматы, а ИИ играет, так что мы, очевидно, можем заставить ИИ делать штуки, которые животные не делают. С другой стороны, окружающая среда не ставит перед каким-нибудь видом вызов игры в шахматы.
Даже так: если бы какие-нибудь животные эволюционировали способность играть в шахматы, я точно ожидал бы, что нынешние ИИ размазывали бы их, потому что ИИ запущены на чипах, которые работают быстрее нейронов и совершают вычисления, невозможные для зашумлённых медленных нейронов. Так что это ненадёжный аргумент о том, что может делать ИИ.
[Ngo][14:09][14:11]
Да, хотя я замечу, что очень простые с человеческой инженерной точки зрения вызовы могут быть очень тяжёлыми для эволюции (например, колесо).
Так что эволюция животных-с-небольшой-помощью-от-людей могла бы привести к совсем другим результатам, чем эволюция животных-самих-по-себе. И аналогично, способность людей заполнять пробелы для не очень-то обобщённого ИИ может оказаться весьма значительной.
[Yudkowsky][14:11]
Тогда опять можно спросить: возможно ли создать ИИ, который хорош только в проектировании наносистем, которые приводят к сложным, но будем-надеяться-описываемым результатам в реальном мире, но не будет сверхчеловеческим в понимании и манипуляции людьми?
И я в общих чертах отвечу так: «Не исключено, хоть и не по умолчанию, я сейчас не знаю, как это сделать, это не простейший способ получить СИИ, способный создать наносистемы (и убить тебя), тебе потребуется получить водителя-красных-машин, который очень конкретно не способен водить синие машины.» Могу ли я объяснить, откуда я это знаю? Не уверен, обычно получается, что я объясняю X0, а слушатель не обобщает X0 до X и не применяет это для X1.
Это как спрашивать меня, как я вообще мог в 2008 году, до того, как кто-нибудь мог наблюдать AlphaFold 2, знать, что суперинтеллект мог бы решить проблему фолдинга белков; в 2008 году некоторые люди задавали мне этот вопрос.
Хотя та задача оказалась проще, чем нанотехнологии, я не сказал бы тогда, что AlphaFold 2 будет возможен на дочеловеческом уровне в 2021, или что он возникнет через пару лет после уровня обобщённости в области текста как у GPT-2.
[Ngo][14:18]
Какие важнейшие различия между решением фолдинга белков и проектированием наносистем, которые, скажем, самособираются в компьютер?
[Yudkowsky][14:20]
Определённо «Оказалось, использовать запоминание градиентным спуском огромной кучи поверхностных перекрывающихся паттернов и собрать из них большую когнитивную структуру, оказывающуюся консеквенциалистским наноинженером, который может только создавать наносистемы и так и не обзаводится достаточно общей способностью к обучению, чтобы понять общую картину и людей, всё ещё понимая цель ключевого действия, которое ты хочешь выполнить, проще, чем кажется» – это одно из самых правдоподобных заранее сформулированных чудес, которое мы можем получить.
Но это не то, что предсказывает моя модель, и я не верю, что, когда твоя модель говорит тебе, что ты сейчас умрёшь, стоит начать верить в конкретные чудеса. Нужно держать свой разум открытым для любых чудес, в том числе тех, которые ты не ожидал, и о которых не думал заранее, потому что на этот момент наша последняя надежда – на то, что будущее зачастую весьма удивительно – хотя, конечно, когда ты отчаянно пытаешься прокладывать пути с помощью плохой карты, негативные сюрпризы случаются куда чаще позитивных.
[Ngo][14:22]
Возможно, можно использовать такую метрику: сколько дополнительного вознаграждения получает консеквенциалистский наноинженер за то, что он начинает моделировать людей, сравнительно с тем, чтобы стать лучше в наноинженерии?
[Yudkowsky][14:23]
Но люди возникли совсем не так. Мы не добрались до атомной энергии, потому что получали от неё бонус к приспособленности. Мы добрались до атомной энергии, получая бонус к приспособленности от обтачивания кремневых топоров и составления коварных планов. Это довольно простое и локальное направление натренировало нам те же гены, которые позволяют нам строить атомные электростанции.
[Ngo][14:24]
Это в случае дополнительного ограничения необходимости выучиваться к новым целям каждое поколение.
[Yudkowsky][14:24]
А???
[Soares][14:24]
(Я так понял, Ричард имеет в виду «это следствие бутылочного горлышка генома»)
[Ngo][14:25]
Верно.
Хмм, кажется, мы уже об этом говорили.
Предложение: У меня есть пара отвлекающих меня вопросов, продолжим через 20 или 30 минут?
[Yudkowsky][14:27]
ОК
Какие важнейшие различия между решением фолдинга белков и проектированием наносистем, которые, скажем, самособираются в компьютер?
Хочу отметить, что этот вопрос для меня, хотя, может, не для других, выглядит потенциально ключевым. Т.е., если создание белковых фабрик, которые собирают нанофабрики, которые собирают наномашины, которые соответствуют какой-нибудь высокой сложной инженерной цели, не включает когнитивных вызовов, принципиально отличающихся от фолдинга белков, то, может быть, это можно безопасно сделать с помощью AlphaFold 3, такого же безопасного, как AlphaFold 2.
Не думаю, что мы можем так сделать. Хочу заметить для абстрактного Другого, что если для него обе задачи звучат как думательные штуки, и непонятно, почему нельзя просто сделать и другую думательную штуку с помощью думательной программы, то это тот случай, когда обладание конкретной моделью того, почему у нас нет такого наноинженера прямо сейчас, подскажет, что тут присутствуют конкретные разные думательные штуки.
Сонаправленность и ключевые действия
[Ngo][14:31]
В любом порядке:
-
Мне любопытно, как то, о чём мы говорим, относятся к твоему мнению о мета –уровневой оптимищации из AI-foom спора. (где ты говорил о том, как отсутствие какого-либо защищённого уровня оптимизации ведёт к мощным изменениям)
-
Мне любопытно, как твои заявления об «устойчивости» консеквенциализма (т.е. сложности направить мышление агента в нужном нам направлении) относится к тому, как люди полагаются на культуру, и в частности к тому, как люди, выращенные без культуры, получаются очень плохими консеквенциалистами
По первому: если очень сильно упрощать, то кажется, что есть два центральных соображения, которые ты уже долго пытаешься распространить. Одно – это некоторая разновидность рекурсивного улучшения, а другое – некоторая разновидность консеквенциализма.
[Yudkowsky][14:32]
Второй вопрос не очень осмыслен в моей родной онтологии? Люди, выращенные без культуры, не имеют доступа к константам окружения, предполагаемых их генами, ломаются, и оказываются плохими консеквенциалистами.
[Ngo][14:35]
Хмм, разумно. Окей, модифицирую вопрос: то, как люди рассуждают, действуют и т.д., сильно варьируется в зависимости от культуры, в которой они выросли. (Я в основном думаю о разных временах – вроде пещерных людей и современных.) Моя не слишком доверенная версия твоих взглядов на консеквенциалистов говорит, что обобщённые консеквенциалисты вроде людей обладают устойчивыми поисковыми процессами, которые не так просто изменить.
(Извини, если это не особо осмысленно в твоей онтологии, я несколько уставший.)
[Yudkowsky][14:36]
Что именно варьируется, что, как ты думаешь, я бы предсказал, должно оставаться постоянным?
[Ngo][14:37]
Цели, манеры рассуждений, деонтологические ограничения, уровень конформности.
[Yudkowsky][14:39]
А моя первая реакция на твой первый пункт такая: «У меня всего одно мнение об интеллекте, то, о чём именно я спорю, зависит от того, какие части этого мнения люди до странности упрямо отказываются принимать. В 2008, Робин Хансон до странности упрямо отказывался принимать то, как масштабируются способности, и есть ли вообще смысл рассматривать ИИ отдельно от эмов, так что я говорил о том, что видел самыми очевидными аргументами к тому, что Есть Много Места Над Биологией и что за человеческим уровнем начинается вжууууух».
«Потом выяснилось, что способности начали неслабо масшабироваться без самоулучшения. Это пример таких странных сюрпризов, которые кидает в нас Будущее, и может быть, случай, в котором я что-то упустил, потому что спорил с Хансоном, вместо того, чтобы представлять, как я мог бы быть неправ в обоих направлениях, не только в направлении, о котором другие люди хотят со мной спорить.»
«Ещё, люди были не способны понять, почему согласование сложное, застряв на обобщении концепта, который я называю консеквенциализмом. Предполагать, почему я говорил об этих двух штуках вместе – это предполагать, почему люди застревают в этих двух штуках вместе. И я думаю, что такие предположения бы переобъясняли случайные совпадения. Если бы Ян Лекун занимался эффективным альтруизмом, то мне пришлось бы объяснять что-нибудь другое, ведь люди, много контактирующие с EA, застревают в другом.»
Возвращаясь к твоему второму пункту, люди – сломанные штуки; если бы было возможно создать компьютеры на уровне ещё ниже человеческого, мы бы вели этот разговор на том уровне интеллекта.
[Ngo][14:41]
(Отменяю) Я полностью согласен про людей, но не особо важно, насколько поломаны люди, когда ИИ, про который мы говорим, непосредственно над людьми, и, следовательно, всего лишь чуть-чуть менее поломан.
[Yudkowsky][14:41]
Тут стоит держать в голове, что есть много странностей, уникальных для людей, и, если ты хочешь получить те же странности у ИИ, тебе может очень не повезти. Да, даже если ты как-нибудь попытаешься обучить им с помощью функции вознаграждения.
Однако, мне кажется, что, когда мы приближаемся к уровню Эйнштейна вместо уровня деревенского дурачка, хоть обычно и нет особой разницы, мы видим, как атмосфера утоньшается и турбулентность успокаивается. Фон Нейман был довольно рефлексивным парнем, который знал, и, в общем-то, помог определить функции полезности. Великие достижения фон Неймана не были достигнуты каким-нибудь сверхспециализированным гипернёрдом, тратившим весь свой интеллект на формализацию математики, науки и инженерии, но так никогда и не думавшем о политике или о том, имеет ли он сам функцию полезности.
[Ngo][14:44]
Не думаю, что требую той же странности. Но куча явлений, о которых я говорил, странны с точки зрения твоего понятия консеквенциализма. Получается, что у консеквенциалистов-примерно-человеческого-уровня происходит много странностей. Это указывает, что те штуки, о которых я говорил, более вероятны, чем ты ожидаешь.
[Yudkowsky][14:45][14:46]
Я подозреваю, что часть расхождения тут из-за того, что я считаю, что надо быть заметно лучше человека в наноинженерии, чтобы совершить достаточно значительное ключевое действие. Потому я и не пытаюсь собрать самых умных ныне живущих людей, чтобы они выполнили это ключевое действие напрямую.
Я не могу придумать что-то, что можно сделать с помощью чего-то лишь немножко умнее человека, что опрокинет игровую доску. Кроме, конечно, «создай Дружественный ИИ», что я и пытаюсь организовать. И его согласование было бы невероятно сложным, если бы мы хотели, чтобы ИИ сделал это за нас (в чистом виде проблема курицы и яйца, тот ИИ уже должен быть согласован).
[Ngo][14:45]
О, интересно. Тогда ещё вопрос: в какой степени ты думаешь, что именно явные рассуждения о функциях полезности и законах рациональности наделяют консеквенциалистов свойствами, о которых ты говоришь?
[Yudkowsky][14:47, moved up in log]
Явная рефлексия возможна дальше, начало пути просто в оптимизации для выполнения достаточно сложных штук, чтобы надо было перестать наступать себе на ноги и заставить разные части своих мыслей хорошо работать вместе.
У такого пути в конце концов только одно направление, а начать его можно по-разному.
(С поправкой на разные случаи, где разные теории принятия решений выглядят рефлексивно непротиворечивыми, и всё такое; хочется сказать «ты понял, что я имею в виду», но, возможно, поймут не все.)
[Ngo][14:47, moved down in log]
Я подозреваю, что часть расхождения тут из-за того, что я считаю, что надо быть заметно лучше человека в наноинженерии, чтобы совершить достаточно значительное ключевое действие. Потому я и не пытаюсь собрать самых умных ныне живущих людей, чтобы они выполнили это ключевое действие напрямую.
Агаа, я думаю, здесь замешаны и разногласия о геополитике. Например, в моём раннем резюмирующем тексте я упоминал возможные ключевые действия:
- Отслеживать все потенциальные проекты СИИ в достаточной степени, чтобы США и Китай могли работать над совместным проектом, не беспокоясь о скрытых конкурентах.
- Предоставить достаточно убедительные аргументы/демонстрации/доказательства надвигающегося экзистенциального риска, чтобы ключевые глобальные принимающие решения фигуры остановили прогресс.
Я предсказываю, что ты думаешь, что этого недостаточно; но не думаю, что вкапываться в геополитическую сторону вопроса это лучшее использование нашего времени.
[Yudkowsky][14:49, moved up in log]
Отслеживание всех проектов СИИ – либо политически невозможно в реальном мире, учитывая, как страны ведут себя на самом деле, либо, на политически-возможных уровнях, недостаточно хорошо сработает, чтобы предотвратить конец света, когда опасная информация уже распространится. ИИ тут не особо поможет; если это возможно, почему не сделать это сейчас? (Отмечу: пожалуйста, не пытайтесь делать это сейчас, это плохо обернётся.)
Предоставить достаточно убедительные аргументы =сверхчеловеческая манипуляция, невероятно опасная область, одна из худших, чтобы пытаться её согласовать.
[Ngo][14:49, moved down in log]
А моя первая реакция на твой первый пункт такая: «У меня всего одно мнение об интеллекте, то, о чём именно я спорю, зависит от того, какие части этого мнения люди до странности упрямо отказываются принимать. В 2008, Робин Хансон до странности упрямо отказывался принимать то, как масштабируются способности, и есть ли вообще смысл рассматривать ИИ отдельно от эмов, так что я говорил о том, что видел самыми очевидными аргументами к тому, что Есть Много Места Над Биологией и что за человеческим уровнем начинается вжууууух».
«Потом выяснилось, что способности начали неслабо масшабироваться без самоулучшения. Это пример таких странных сюрпризов, которые кидает в нас Будущее, и может быть, случай, в котором я что-то упустил, потому что спорил с Хансоном, вместо того, чтобы представлять, как я мог бы быть неправ в обоих направлениях, не только в направлении, о котором другие люди хотят со мной спорить.»
«Ещё, люди были не способны понять, почему согласование сложное, застряв на обобщении концепта, который я называю консеквенциализмом. Предполагать, почему я говорил об этих двух штуках вместе – это предполагать, почему люди застревают в этих двух штуках вместе. И я думаю, что такие предположения бы переобъясняли случайные совпадения. Если бы Ян Лекун занимался эффективным альтруизмом, то мне пришлось бы объяснять что-нибудь другое, ведь люди, много контактирующие с EA, застревают в другом.»
По первому пункту, мне кажется, что в твоих заявления о рекурсивном самоулучшении есть та же проблема, что и, как мне кажется, в твоих заявлениях о консеквенциализме – что слишком многое приписывается одной очень высокоуровневой абстракции.
[Yudkowsky][14:52]
По первому пункту, мне кажется, что в твоих заявления о рекурсивном самоулучшении есть та же проблема, что и, как мне кажется, в твоих заявлениях о консеквенциализме – что слишком многое приписывается одной очень высокоуровневой абстракции.
Я предполагаю, что потенциально именно так ощущается изнутри непонимание абстракции. Робин Хансон всё спрашивал меня, почему я так доверяю своим абстракциям, хотя сам вместо этого доверял своим, худшим, абстракциям.
[Ngo][14:51][14:53]
Явная рефлексия возможна дальше, начало пути просто в оптимизации для выполнения достаточно сложных штук, чтобы надо было перестать наступать себе на ноги и заставить разные части своих мыслей хорошо работать вместе.
Можешь ещё немного пообъяснять, что ты имеешь в виду под «заставить разные части своих мыслей хорошо работать вместе»? Это что-то вроде способности к метамышлению; или глобальный контекст; или самоконтроль; или…?
И я догадываюсь, что нет хорошего способа измерить, насколько важной в сравнении с остальными частью пути ты считаешь явную рефлексию – но можешь хотя бы грубо обозначить, насколько это критичный или некритичный компонент твоих взглядов?
[Yudkowsky][14:55]
Можешь ещё немного пообъяснять, что ты имеешь в виду под «заставить разные части своих мыслей хорошо работать вместе»? Это что-то вроде способности к метамышлению; или глобальный контекст; или самоконтроль; или…?
Нет, это вроде того, как ты, скажем, не будешь платить за что-то пятью яблоками в понедельник, продавать это же за два апельсина во вторник, а потом менять апельсин на яблоко.
Я всё ещё не придумал домашние упражнения для передачи кому-то Слова Силы «сонаправленность», которое позволит смотреть на воду и видеть «сонаправленность» в, например, кошке, гуляющей по комнате, не спотыкаясь о свои же лапы.
Когда ты много и правильно рассуждаешь об арифметике, не делая ошибок, то длинная цепочка мыслей, много раз разделяющаяся и соединяющаяся обратно, приводит к какому-то заявлению, которое… всё ещё истинно и всё ещё про числа! Вау! Как так оказалось, что много отдельных мыслей вместе обладают этим свойством? Разве они не должны убрести куда-то на тему племенной политики, как в Интернете?
Можно посмотреть на это так: хоть все эти мысли происходили в ограниченном разуме, они являются тенями высшей неограниченной структуры – модели, заданной аксиомами Пеано; всё сказанное было правдой про числа. Кто-то ничего не понимающий мог бы возразить, что в человеке нет механизма оценки утверждения для всех чисел, очевидно, человек не может его содержать, так что очевидно, нельзя объяснить успех тем, что каждое из утверждений было правдой на одну и ту же тему чисел, потому что Единственным Способом представить эту структуру (в воображении этого человека) является этот механизм, которого у людей нет.
Но хоть математические рассуждения иногда могут сбиваться с пути, когда они всё же работают, это происходит потому что, на самом деле, даже ограниченные существа иногда могут соответствовать локальным отношениям, помогающим глобальной сонаправленности действий, когда все части рассуждения указывают в одном направлении, как фотоны в лазерном луче. Хоть и нету никакого внутреннего механизма, твёрдо устанавливающего глобальную сонаправленность в каждой точке.
Внешний оптимизатор натренировал тебя не платить за что-то пятью яблоками в понедельник, продавать это же за два апельсина во вторник, а потом менять два апельсина на четыре яблока. И точно так же он натренировал все маленькие кусочки тебя быть локально последовательными так, чтобы это можно было рассматривать неидеальной ограниченной версией высшей неограниченной структуры. И система получается мощной, хоть и неидеальной, из-за мощи последовательности и перекрытия частей, из-за того, как она неидеально отражает высшую идеальную структуру. В нашем случае высшая структура – это Полезность, и домашние упражнения с теоремами о последовательности приводят к признанию того, что мы знаем только одну высшую структуру для нашего класса задач, на эту структуру указывает множество математических указателей «смотреть здесь», хоть некоторые люди и занимались поиском альтернатив.
И когда я пытаюсь сказать это, люди отвечают «Ну, я посмотрел на теорему, и она говорит о возможности выбрать уникальную функцию полезности из бесконечного количества вариантов, но если у нас нет бесконечного количества вариантов, мы не можем выбрать функцию, так какое отношение это имеет к делу» и это такой вид ошибок, которые я не могу вспомнить, чтобы даже близко делал сам, так что я не знаю, как отучить людей их делать, и, может, я и не могу.
[Soares][15:07]
Мы уже превышаем время, так что давайте сворачиваться (после, наверное, ещё пары ответов Ричарда, если у него есть силы.)
[Yudkowsky][15:07]
Да, думал так же.
[Soares][15:07]
Предлагаю клиффхенгер для затравки следующей дискуссии, я так понял, что коммментарий Ричарда:
По первому пункту, мне кажется, что в твоих заявления о рекурсивном самоулучшении есть та же проблема, что и, как мне кажется, в твоих заявлениях о консеквенциализме – что слишком многое приписывается одной очень высокоуровневой абстракции.
- вероятно, содержит некую важную часть несогласия, и мне интересно, понимает ли Элиезер заявление Ричарда достаточно, чтобы пересказать его удовлетворительным для Ричарда способом.
[Ngo][15:08]
Сворачиваться сейчас осмысленно.
Поддерживаю то, что сказал Нейт.
У меня есть ощущение, что я теперь куда лучше представляю взгляды Элиезера на консеквенциализм (пусть и не слишком детально).
На метауровне, лично я больше склонен сосредотачиваться на штуках вроде «как нам прийти к пониманию мышления», а не «как нам прийти к пониманию геополитики и её влияния на необходимые ключевые действия».
Если дискуссию будет продолжать кто-то ещё, им можно будет попробовать сказать побольше про второе. Я не уверен, насколько это полезно для меня, учитывая, что моё (и, вероятно, Элиезера) сравнительное преимущество над остальным миром лежит в части про мышление.
[Дальше они вперемешку обсуждают, когда продолжать и более содержательные меташтуки. Первое я вырезал, а второе оставил. – прим. переводчика]
[Ngo][15:12]
Можно пересказать эту дискуссию [некоторым людям – вырезано для приватности]?
[Yudkowsky][15:13]
Нейт, потратишь минутку, опишешь, что думаешь?
(Soares ставит «лайк» и знак «Ок»)
[Soares][15:15]
Моя позиция: Я думаю, пересказывать можно, но лучше в целом отмечать, что это всего лишь пересказ (чем каждый раз сверять с Элиезером для одобрения, или что-то такое).
(Нго ставит «лайк»)
[Yudkowsky][15:16]
В целом согласен. Я немного обеспокоен об искажениях при пересказе, и о том, сказал ли я что-то, с чем Роб или кто-то ещё не согласится до публикации, но мы в любом случае собирались это показывать, я держал это в голове, так что, да пожалуйста, пересказывай.
[Ngo][15:17]
Здорово, спасибо
[Yudkowsky][15:17]
Признаюсь, мне любопытно, что из сказанного ты считаешь важным или новым, но на этот вопрос можно ответить и потом, в свободное, более удобное тебе время.
[Ngo][15:17]
Признаюсь, мне любопытно, что из сказанного ты считаешь важным или новым, но на этот вопрос можно ответить и потом, в свободное, более удобное тебе время.
В смысле, что я считаю стоящим пересказа?
[Yudkowsky][15:17]
Ага.
[Ngo][15:18]
Хмм, не уверен. Я не собирался сильно в это вкладываться, но раз я всё равно регулярно болтаю с [некоторыми людьми – вырезано для приватности], то не будет сложно это обдумать.
В твоё свободное время, мне было бы любопытно, насколько направление дискуссии соответствовало твоим целям, тому, что ты хочешь донести, когда это будет опубликовано, и на каких темах ты хотел бы больше сосредоточиться.
[Yudkowsky][15:19]
Не уверен, что это поможет, но попытаться сейчас выглядит лучше, чем ничего не говорить.
[Ngo][15:20]
(В дополнение к тому, что я чувствую себя менее компетентным в геополитике, она также кажется мне более деликатной темой для публичных заявлений, это ещё одна причина, почему я туда не вкапывался)
[Soares][15:21]
(В дополнение к тому, что я чувствую себя менее компетентным в геополитике, она также кажется мне более деликатной темой для публичных заявлений, это ещё одна причина, почему я туда не вкапывался)
(кажется разумным! Замечу, впрочем, что я бы с радостью вырезал деликатные темы из записи, если бы это позволило нам лучше состыковаться, раз уж тема всё равно всплыла)
(Нго ставит «лайк»)
(хоть конечно тратить усилия на приватные дискуссии не столь ценно и всё такое)
(Нго ставит «лайк»)
[Ngo][15:22]
В твоё свободное время, мне было бы любопытно, насколько направление дискуссии соответствовало твоим целям, тому, что ты хочешь донести, когда это будет опубликовано, и на каких темах ты хотел бы больше сосредоточиться.
(этот вопрос и тебе, Нейт)
Ещё, спасибо Нейту за модерацию! Твои вмешательства были полезными и своевременными.
(Соарес ставит «сердечко»)
[Soares][15:23]
(этот вопрос и тебе, Нейт)
(понял, спасибо, вероятно, напишу что-нибудь после того, как у тебя будет возможность выспаться.)
[Yudkowsky][15:27]
(кажется разумным! Замечу, впрочем, что я бы с радостью вырезал деликатные темы из записи, если бы это позволило нам лучше состыковаться, раз уж тема всё равно всплыла)
Мне чуточку не нравится вести обсуждения, которые мы потом намерены вырезать, потому что обсуждение в целом будет иметь меньше смысла для читателей. Давайте лучше по возможности обходить такие темы.
(Нго ставит «лайк»)
(Соарес ставит «лайк»)
[Ngo][15:28]
Отключаюсь
[Yudkowsky][15:29]
Спокойной ночи, героический спорщик!
[Soares][16:11]
В твоё свободное время, мне было бы любопытно, насколько направление дискуссии соответствовало твоим целям, тому, что ты хочешь донести, когда это будет опубликовано, и на каких темах ты хотел бы больше сосредоточиться.
Дискуссия пока что довольно хорошо соответствовала моим целям! (Немного лучше, чем ожидал, ура!) Немного быстрых грубых заметок:
- Мне понравилось, как ЭЮ объясняет свои модели в области консеквенциализма.
- Возражения Ричарда, как мне кажется, уже некоторое время витали в воздухе, я рад увидеть их явное обсуждение.
- Ещё, я признателен за ваши разговорные добродетели при обсуждении. (Предположение доброго намерения, щедрость, любопытство, и т.д.)
- Я был бы рад повкапываться в ощущение Ричарда, что ЭЮ похожим образом неправ про рекурсивное самоулучшение и про консеквенциализм.
- И эта критика, как мне кажется, тоже витала в воздухе, предвкушаю её прояснение.
- Я несколько разрываюсь между прояснением второго пункта или закреплением прогресса в первом.
- Что я бы хотел увидеть – это заметки от Ричарда с сравнением его модели взглядов ЭЮ до и после обсуждения.
- Ещё у меня есть неоформленное ощущение, что есть некоторые заявления, которые Элиезер пытался сделать, но которые так и не были восприняты; и, симметрично, некоторые возражения Ричарда, на которые, кажется, не поступило прямого ответа.
- В ближайшие дни, может быть, составлю список таких мест и посмотрю, могу ли я прояснить что-то сам. (Не обещаю.)
- Если получится, то, может быть, с радостью пообсуждаю их с Ричардом на отдельном канале в более удобное ему время.
[Ngo][5:40] (на следующий день, 9 сентября)
Дискуссия пока что […]
Что ты имеешь в виду под «первым пунктом» и «вторым пунктом» (у шестой точки списка)?
[Soares][7:09] (на следующий день, 9 сентября)
Что ты имеешь в виду под «первым пунктом» и «вторым пунктом» (у шестой точки списка)?
Первый = закрепить про консеквенциализм, второй = вкопаться в твою критику по рекурсивному самоулучшению и т.д. (Вложенность списков должна была показать это ясно, но оказалось, что она плохо тут отображается, упс.)
Последующее
Резюмирование Ричарда Нго
[Ngo] (10 сентября Google Doc)
2-я дискуссия
(В основном обобщения, а не цитаты; также не было пока оценено Элиезером)
Элиезер, по описанию Ричарда: «Главный Один из главных концептов, с пониманием которого у людей проблемы – это консеквенциализм. Люди пытаются рассуждать о том, как ИИ будет решать задачи, и каким образом это может быть или не быть опасно. Но они не осознают, что способность решать широкий ассортимент сложных задач подразумевает, что агент должен выполнять мощный поиск по возможным решениям, а это главный один из главных навыков, необходимых для совершения действий, сильно влияющих на мир. Сделать безопасным такой ИИ - это как пытаться создать ИИ, который очень хорошо водит красные машины, но не может водить синие – этого никак не получить по умолчанию, потому что вовлечённые навыки слишком похожи. И потому что процесс поиска такой обобщённый по умолчанию такой обобщённый, что я сейчас не вижу, как его можно ограничить какой-то конкретной областью.»
[Yudkowsky][10:48] (10 сентября комментарий)
Главный концепт
Один из главных концептов, с пониманием которого проблемы у некоторых людей. Их, кажется, бесконечный список. Мне не пришлось тратить много времени на раздумия о консеквенциализме, чтобы вывести следствия. Я не успеваю потратить много времени, говоря о нём, как люди начинают спорить.
[Yudkowsky][10:50] (10 сентября комментарий)
главный навык
Один из главных
[Yudkowsky][10:52] (10 сентября комментарий)
процесс поиска такой обобщённый
По умолчанию такой обобщённый. Почему я так давлю на то, что всё это верно лишь по умолчанию – работа над выживанием может выглядеть как много сложных необычных штук. Я не принимаю фаталистическую позицию «так и произойдёт», я оцениваю сложности получения результатов не по умолчанию.
[Yudkowsky][10:52] (10 сентября комментарий)
будет очень сложно
«я сейчас не вижу, как»
[Ngo] (10 сентября Google Doc)
Элиезер, по описанию Ричарда (продолжение): «В биологических организмах эволюция – один из источников основной источник консеквенциализма. Другой Вторичный результат эволюции – это обучение с подкреплением. У животного вроде кошки, когда она ловит мышь (или когда у неё не получается это сделать), много частей мозга немного подправляются, эта петля увеличивает вероятность, что она поймает мышь в следующий раз. (Замечу, однако, что этот процесс недостаточно мощен, чтобы сделать из кошки чистого консеквенциалиста – скорее, он наделяет её многими чертами, которые можно рассматривать как направленные в одну и ту же сторону.) Третья штука, которая в частности делает людей консеквенциалистами – это планирование. Другой результат эволюции, который в частности помогает людям быть в большей степени консеквенциалистами – это планирование, особенно, когда мы осведомлены о концептах вроде функции полезности.»
[Yudkowsky][10:53] (10 сентября комментарий)
один из источников
основной
[Yudkowsky][10:53] (10 сентября комментарий)
второй
Вторичный
[Yudkowsky][10:55] (10 сентября комментарий)
особенно, когда мы осведомлены о концептах вроде функции полезности
Почти всегда оказывает очень маленький эффект на человеческую эффективность, потому что у людей плохо с рефлексивностью.
[Ngo] (10 сентября Google Doc)
Ричард, по описанию Ричарда: «Рассмотрим ИИ, который получив гипотетический сценарий, сообщает, какой лучший план по достижению данной цели в данном сценарии. Конечно, ему необходимы консеквенциалистские рассуждения, чтобы понять, как достичь цели. Но это не то же самое, что ИИ, выбирающий, что сказать, чтобы достичь своих целей. Я утверждаю, что первый совершает консеквенциалистские рассуждения, не будучи консеквенциалистом, тогда как второй действительно им является. Или короче: консеквенциализм = навыки решения задач + использование этих навыков для выбора действий для достижения целей.»
Элиезер, по описанию Ричарда: «Первый ИИ, если получится такой создать, может быть немного безопаснее второго, но я думаю, что люди склонны очень сильно переоценивать, насколько. Разница может быть в одну строку кода: если мы дадим первому ИИ наш нынешний сценарий на ввод, то он станет вторым. В целях понимания сложности согласования лучше думать на том уровне абстракции, где ты видишь, что в каком-то смысле опасен сам поиск, когда он достаточно мощный, а не детали процесса планирования. Особенно помогающий мысленный эксперимент – думать о продвинутом ИИ, как о «помпе исходов», которая выбирает варианты будущего, в которых произошёл некий результат, и производит нужные действия, которые приведут к этим вариантам.»
[Yudkowsky][10:59] (10 сентября комментарий)
особенно помогающий
«попытка объяснения». Я не думаю, что большинство читателей поняло.
Я немного озадачен тем, насколько часто ты описываешь мои взгляды так, будто то, что я сказал, было сказано про Ключевую Штуку. Это кажется похожим на то, как многие эффективные альтруисты проваливают Идеологический Тест Тьюринга MIRI.
Если быть немного грубым и невежливым в надежде на то, что затянувшийся социальный процесс куда-то придёт, два очевидных немилосердных объяснения, почему некоторые люди систематически неправильно считают MIRI/Элиезера верящими в большее, чем на самом деле, и считают, что разные концепты, всплывающие в аргументах – это для нас Большие Идеи, хотя на них просто навело обсуждение:
(А) Это рисует комфортную нелестную картину Других-из-MIRI, до странности одержимых этими кажущимися неубедительными концептами, или в целом представляет Других как кучку чудаков, наткнувшихся на концепции вроде «консеквенциализма» и ставшими ими одержимыми. В общем, изобразить Другого как придающего много значения какой-то идее (или объясняющему мысленному эксперименту) – это привязать его статус к мнению слушателя о том, какой статус заслуживает эта идея. Так что, если сказать, что Другой придаёт много значения какой-то идее, которая не является очевидно высокостатусной, это понижает статус Другого, что комфортно.
(прод.)
(B) Это рисует комфортную льстящую себе картину продолжающегося постоянного несогласия, как несогласия с кем-то, кто считает какой-то случайный концепт более высокостатусным, чем на самом деле; в таком случае нет никакого понимания за пределами должным образом вежливого выслушивания попыток другого человека убедить тебя, что концепт заслуживает своего высокого статуса. В противоположность «хм, может, это не центральная штука, просто другой человек посчитал, что в ней возникли проблемы, и потому пытается её объяснить», что объясняет, почему обсуждение стоит на месте куда менее льстя себе. И, соответственно, куда комфортнее иметь такую точку зрения о нас, чем нам представлять, что кто-то о нас такого мнения.
Ну и, конечно, считать, что кто-то другой зря зацикливается на нецентральных штуках, весьма лестно. Но не значит, что неправильно. Но стоит обращать внимание, что история Другого, рассказанная с точки зрения Другого, скорее всего будет чем-то, что Другой находит осмысленным и, наверное, комфортным, даже если это подразумевает нелестный (и не ищущий истины и, наверное, ошибочный) взгляд на самого тебя. А не чем-то, что заставит Другого выглядеть странным и глупым и про что легко и гармонично представить, что Другой это думает.
[Ngo][11:18] (12 сентября комментарий)
Я немного озадачен тем, насколько часто ты описываешь мои взгляды так, будто то, что я сказал, было сказано про Ключевую Штуку.
В этом случае, я особо выделил мысленный эксперимент про помпу исходов, потому что ты сказал, что сценарий с путешествиями во времени был ключевым для твоего понимания оптимизации, и помпа исходов выглядит довольно похоже и проще к передаче в пересказе, потому что ты про неё уже писал.
Я также особо выделил консеквенциализм, потому что он казался ключевой идеей, которая постоянно всплывала в первом обсуждении под обозначением «глубокие паттерны решения задач». Я приму твоё замечание, что ты склонен выделять штуки, по поводу которых твой собеседник наиболее скептичен, не обязательно главные для твоих взглядов. Но если для тебя консеквенциализм на самом деле не центральный концепт, то интересно было бы услышать, какова его роль.
[Ngo] (10 сентября Google Doc)
Ричард, по описанию Ричарда: «В «нахождении плана для достижения данного исхода» есть компонент, который включает решение задачи объектного уровня о том, как кто-то, кому выдан этот план, может достигнуть исхода. А есть другой компонент – выяснить, как проманипулировать этими людьми, чтобы они сделали то, что тебе хочется. Мне кажется, что аргумент Элиезера в том, что не существует режима обучения, который приведёт ИИ к трате 99% времени мышления на первый, и 1% на второй компонент.»
[Yudkowsky][11:20] (10 сентября комментарий)
не существует режима обучения
…что режимы обучения, к которым мы сперва придём, за 3 месяца или 2 года, которые у нас будут, пока кто-то другой не устроит конец света, не будут обладать этим свойством.
У меня нет довольно сложной или удивительно проницательной теории о том, почему я продолжаю восприниматься как фаталист; мой мир наполнен условными функциями, не константами. Я всегда в курсе, что если бы у нас был доступ к Учебнику из Будущего, объясняющему по-настоящему устойчивые методы – эквивалент знания заранее про ReLu, которые были изобретены и поняты только через пару десятилетий после сигмоид – то мы могли бы просто взять и создать суперинтеллект, который считает, что 2 + 2 = 5.
Все мои предположения о «Я не вижу, как сделать X» всегда помечены как продукт моего незнания и положение по умолчанию, потому что у нас нет достаточного времени, чтобы выяснить, как сделать X. Я постоянно обращаю на это внимание, потому что ошибочность мнения о сложности чего-то – это важный потенциальный источник надежды, что найдётся какая-то идея вроде ReLu, устойчиво снижающая сложность, и о которой я просто не думал. Что, конечно, ещё не значит, что я неправ о какой-то конкретной штуке, и что широкое поле «согласования ИИ», бесконечный источник оптимистических идей, произведёт хорошую идею тем же процессом, сгенерировавшим весь предыдущий наивный оптимизм через незамечание, откуда взялась исходная сложность, или какие другие сложности окружают её очевидные наивные решения.
[Ngo] (10 сентября Google Doc)
Ричард, по описанию Ричарда (продолжение): «Хотя это может быть и так в пределе увеличивающегося интеллекта, самыми важными системами будут самые ранние из превосходящих человеческий уровень. Но люди кучей способов отклоняются от консеквенциалистских абстракций, о которых ты говоришь – к примеру, выращенные в разных культурах люди могут быть более или менее консеквенциалистами. Так что выглядит правдоподобно, что ранние СИИ могут быть сверхчеловеческими, в то же время, сильно отклоняясь от абстракции – не обязательно теми же способами, что и люди, но способами, которые мы в них вложили при обучении.»
Элиезер, по описанию Ричарда: «Эти отклонения начинают спадать уже на уровне Эйнштейна и Фон Неймана. И реалистично работающие ключевые действия требуют навыков значительно выше человеческого уровня. Думаю, что даже один процент мышления способного собирать продвинутые наносистемы ИИ, направленный на мысли о том, как убить людей, погубит нас. Твои другие предложения ключевых действий (надзор для ограничения распространения СИИ; убеждение мировых лидеров ограничить разработку СИИ) политически невозможно выполнить в достаточной степени, чтобы спасти мир, или же требуют согласования в очень опасной области сверхчеловеческой манипуляции.»
Ричард, по описанию Ричарда: «Я думаю, что у нас есть и значительное несогласие по поводу геополитики, влияющее на то, какие ключевые действия мы рассматриваем. Но, кажется, наше сравнительное преимущество лежит в области обсуждения мышления, так что давай сосредоточимся на этом. Мы сейчас можем создать системы, превосходящие людей в некоторых задачах, но не обобщённые настолько, чтобы даже попытаться захватить мир. Отставив ненадолго в сторону вопрос о том, какие задачи могут быть достаточно ключевыми, чтобы спасти мир, какая часть твоей модели проводит линию между шахматистами-человеческого-уровня и колонизаторами-галактики-человеческого-уровня, и говорит, что мы способны согласовать тех, кто значительно превосходит нас в одних задачах, но не в других? »
Элиезер, по описанию Ричарда: «Один аспект – это обобщённость между областями, достигающаяся за счёт изучения новых областей. Можно задать вопрос: возможен ли суперинтеллектуальный СИИ, который может быстро создавать нанотехнологии так же, как бобёр строит дамбы, через обладание кучей специализированных способностей к обучению, но не обобщённой? Но люди делают много, много, много всего, что не делают другие животные, но что, можно подумать, сильно вложилось бы в их приспособленность, если бы был животный способ это делать – к примеру, добывать и плавить железо. (Хотя сравнения с животными в целом не являются надёжными аргументами о том, что может делать ИИ – например, шахматы куда проще для чипов, чем для нейронов.) Так что мой ответ такой: «Возможно, но не по умолчанию; есть куча подзадач; я сейчас не знаю, как это сделать; это не простейший способ получить СИИ, который может создавать наносистемы.» Могу ли я объяснить, откуда я знаю? На самом деле, не уверен.»
[Yudkowsky][11:26] (10 сентября комментарий)
Могу ли я объяснить, откуда я знаю? На самом деле, не уверен.
В оригинальном тексте за этим предложением была длинная попытка всё же объяснить; если удалять её, что выглядит правильно, то стоит удалить и это предложение, иначе оно рисует ложную картину того, как много я пытаюсь объяснять.
[Ngo][11:15] (12 сентября комментарий)
Имеет смысл; удалено.
[Ngo] (10 сентября Google Doc)
Ричард, по описанию Ричарда: «Довольно тривиальные с человечески-инженерной точки зрения вызовы могут быть очень сложными для эволюции (например, колесо). Так что эволюция животных-с-небольшой-помощью-людей может привести совсем к другим результатам, чем эволюция животных-самих-по-себе. И, аналогично, способность людей заполнять пробелы для помощи менее обобщённым ИИ может быть весьма значительной.
Про нанотехнологию: в чём лежат важнейшие различия между решением фолдинга белков и проектированием наносистем, которые, скажем, самособираются в компьютер?»
Элиезер, по описанию Ричарда: «Этот вопрос для меня выглядит потенциально ключевым. Т.е., если создание белковых фабрик, которые собирают нанофабрики, которые собирают наномашины, которые соответствуют какой-нибудь высокой сложной инженерной цели, не включает когнитивных вызовов, принципиально отличающихся от фолдинга белков, то, может быть, это можно безопасно сделать с помощью AlphaFold 3, такого же безопасного, как AlphaFold 2. Я не думаю, что мы сможем это сделать. Но это одно из самых правдоподобных заранее сформулированных чудес, которое мы можем получить. Сейчас наша последняя надежда в том факте, что будущее зачастую довольно неожиданно.»
Ричард, по описанию Ричарда: «Мне кажется, что тут ты делаешь ту же ошибку, что и в рассуждениях про рекурсивное самоулучшение из AI-foom-спора – конкретно, вкладываешь слишком много веры в одну большую абстракцию.»
Элиезер, по описанию Ричарда: «Я предполагаю, что потенциально именно так ощущается изнутри непонимание абстракции. Робин Хансон всё спрашивал меня, почему я так доверяю своим абстракциям, хотя сам вместо этого доверял своим, худшим, абстракциям.»
Резюмирование Нейта Соареса
[Soares] (12 сентября Google Doc)
Консеквенциализм
Ок, вот мои заметки. Извиняюсь, что не выложил до середины воскресенья. В первую очередь хочу закрепить то, что уже обсудили. Надеюсь на поправки и, может быть, комментирование туда-обратно, где осмысленно (как с обобщением Ричарда), но не отвлекайтесь от основной линии обсуждения ради этого. Если время ограничено, то не страшно, даже если заметки не получат почти никакого внимания.
У меня есть ощущение, что пара заявлений Элиезера про консеквенциализм не была успешно передана. Возьмусь за это. Могу быть неправ и по поводу того, что Элиезер имел это в виду, и по поводу того, воспринял ли их Ричард; заинтересован и в опровержениях от Элиезера, и в пересказах от Ричарда.
[Soares] (12 сентября Google Doc)
- «Консеквенциализм в плане, не в мышлении»
Думаю, Ричард и Элиезер с очень разных сторон подходят к понятию «консеквенциализм», на что указывает, например, вопрос Ричарда (грубый пересказ Нейта:) «Где, по твоему мнению, консеквенциализм в кошке?» и ответ Элиезера (грубый пересказ Нейта:) «причина очевидного консеквенциализма поведения кошки распределена между её мозгом и её эволюционной историей».
Конкретнее, я думаю, что можно сделать примерно такой аргумент:
- Заметим, что с нашей точки зрения спасение мира выглядит довольно запутанным, и кажется, что оно, вероятно, будет включать длинные цепочки умных действий, для направления истории по узкому пути (например, потому, что, если бы мы видели короткие цепочки глупых действий, мы бы уже начали).
- Предположим, что нам выдан план, якобы описывающий длинную цепочку умных действий, которые, если их исполнить, направляют историю по некоему узкому пути.
- Для конкретики предположим, что это план, якобы направляющий историю по пути, на котором у нас есть богатство и признание.
- Одно правдоподобное стечение обстоятельств – что план на самом деле не умный, и не оказывает направляющего влияния на историю.
- К примеру, план описывает основание и менеджмент некоего стартапа в Кремниевой Долине, и этот стартап на практике не сработает.
- При условии, что у плана есть свойство направления истории, есть смысл, в котором он устрашающий, независимо от его источника.
- К примеру, план описывает основание и менеджмент некоего стартапа в Кремниевой Долине, и план преуспеет при практически каждом исполнении, посредством того, что в нём есть очень обобщённые описания штук вроде обнаружения и реакции на конкуренцию, включая описания методов сверхчеловечески хорошего психоанализа конкурентов и давления на их слабые места.
- Заметим, что нам не нужно считать, что план сгенерирован некой «агентной» когнитивной системой, которая внутри себя использует рассуждения, которые мы бы назвали «обладание целями» и «преследование этих целей в реальном мире».
- Конкретнее, «устрашающий» – это свойство самого плана. К примеру, если план обеспечивает исполнителю богатство и признание в широком диапазоне ситуаций независимо от препятствий, то это подразумевает, что план содержит корректирующие курс механизмы для удержания направления на цель.
- Другими словами, план, планы, успешно направляющие историю (по этому аргументу) наверняка имеют широкий ассортимент корректирующих курс механизмов, чтобы удерживать направление на какую-то цель. И хоть это свойство скорее всего будет у любого такого плана, цель выбирается, конечно, свободно, отсюда и беспокойство.
(Конечно, на практике не стоит представлять простой План, переданный нам ИИ или машиной времени или ещё чем-то, вместо этого стоит вообразить систему, которая реагирует на экстренные ситуации и перепланирует в реальном времени. Как минимум, такая задача проще, так как позволяет вводить поправки только для реально происходящих ситуаций, а не предсказывать их все заранее и/или описывать обобщённые механизмы реакции. Но, и тут можно предсказать моё заявление до прочтения следующей фразы, «работа ИИ, перепланирующего на лету» и «работа петли ИИ+человек, которая перепланирует+переоценивает на лету» – это всё ещё в каком-то смысле «планы», которые всё ещё скорее всего обладают свойством Элиезер!консеквенциализм, если они работают.
[Soares] (12 сентября Google Doc)
Это часть аргумента, который я ещё нормально не выдавал. Оформляя его отдельно:
- «Если план достаточно хорош, чтобы сработать, то он довольно консеквенциалистский на практике».
В попытке собрать и очистить несколько разрозненных аргументов Элиезера:
Если ты попросишь GPT-3 сгенерировать план для спасения мира, у неё не получится сделать очень детальный план. И если ты и помучаешь большую языковую модель до выдачи очень детального плана, этот план не будет работать. В частности, он будет полон ошибок вроде нечувствительности к окружению, предложений невозможных действий, предложений действий, стоящих на пути друг у друга.
Чувствительный к окружению план, описывающий из подходящих друг другу, а не конфликтующих действий – как, в аналогии Элиезера, фотоны в лазере – куда лучше в направлении истории по узкому пути.
Но, по мнению Элиезера, как я его понимаю, свойство «план не наступает постоянно себе на ноги» идёт рука об руку с тем, что он называет «консеквенциализмом». Явный и формальный случай связи можно увидеть, если взять в качестве наступания себе на ноги «обменять 5 апельсинов на 2 яблока, а потом 2 яблока на 4 апельсина». Ясно, что тут план провалился в «лазерности» – произошло что-то вроде того, что какая-то нуждающаяся-в-апельсинах часть плана и какая-то нуждающаяся-в-яблоках часть плана встали друг у друга на пути. Тут заодно и видно, как план может быть подобен лазеру в отношении яблок и апельсинов – если он ведёт себя так, будто им управляют некие последовательные предпочтения.
Как я понял, суть тут не в «всё наступающее себе на ноги похоже на непоследовательные предпочтения», а скорее «у плана получается связать цепочку последовательных сочетающихся действий лишь в той степени, в какой он является Элиезер!консеквенциалистом».
См. аналогию из теории информации, где если ты смотришь на лабиринт и пытаешься построить точное отображения этого лабиринта у себя в голове, то ты преуспеешь лишь настолько, насколько твои процессы Байесианские. И предполагается, что это ощущается как довольно тавтологичное заявление: ты (почти наверняка) не получишь соответствующую реальности картинку лабиринта в своей голове, случайно его себе представляя; тебе нужно добавлять представляемые стены каким-то процессом, коррелирующим с присутствием реальных стен. Твой процесс визуализации лабиринта будет точно работать постольку, поскольку ты имеешь доступ к наблюдениям, коррелирующим с присутствием настоящих стен, и правильно используешь эти наблюдения. Ты можешь заодно визуализировать дополнительные стены в местах, где политически целесообразно верить, что они есть, и можно избегать представлять стены в дальних областях лабиринта, потому что там темно, а у тебя нет целого дня. Но результат будет точным настолько, насколько у тебя всё же получилось действовать по-Байесиански.
Похожим образом, план работает-как-целое и избегает-наступать-себе-на-ноги в точности настолько, насколько он консеквенциалистичен. Это две стороны одной монеты, два взгляда на одно и то же.
И я тут не столько пытаюсь убедить, сколько увериться, что форма аргумента (как я его понял) была понята Ричардом. Я воспринял его так, что «неуклюжие» планы не работают, а «лазерные» планы работаю настолько, насколько они действуют подобно консеквенциалисту.
Перефразируя ещё раз: у нас есть большой набор математических теорем, подсвечивающих с разных сторон, что недостача у плана неуклюжести есть его последовательность.
(«И», – торопится заметить моя модель Элиезера, – «это, конечно, не значит, что все достаточно интеллектуальные разумы должны генерировать очень последовательные планы. Зная, что делаешь, можно было бы спроектировать разум, который выдаёт планы, всегда «спотыкающиеся об себя» в каком-то конкретном месте, так же как с достаточным мастерством можно было бы создать разум, верящий, что 2+2=5 (для какой-то осмысленной интерпретации этого утверждения). Но ты не получишь этого просто так – и при создании когнитивных систем есть что-то вроде «аттрактора», обобщённое обучение будет склонно наделять систему истинными убеждениями и делать её планы последовательными»)
(И, конечно, большинство беспокойства от того, что все эти математические теоремы, предполагающие, что план работает, пока он куда-то последовательно направлен, ничего не говорят о том, в каком направлении он должен быть направлен. Следовательно, если ты покажешь мне план, достаточно умный для направления истории по узкому пути, я смогу быть весьма уверен, что он довольно лазерный, но совсем не смогу быть уверен, в каком направлении.)
[Soares] (12 сентября Google Doc)
У меня есть догадка, что Ричард на самом деле понимает этот аргумент (хотя я бы порадовался его пересказу, для тестирования гипотезы!), и, возможно, даже принимает его, а мнения расходятся на следующем шаге – утверждении, что нам нужен «лазерный» план, потому что другие планы недостаточно сильны, чтобы нас спасти. (Конкретно я подозреваю, что большая часть несогласия в том, насколько далеко можно зайти с планами больше похожими на выводы языковых моделей, чем на лазеры, а не в вопросе, какие ключевые действия положат конец сильным рискам.)
Отставив это пока в сторону, хочу использовать ту же терминологию для переложения другого заявления, которое, как я видел, Элиезер пытался продвинуть: одна большая проблема с согласованием, в случае когда мы хотим «лазерные» планы – это то, что одновременно мы хотим, чтобы они не были «лазерными» в некоторых специфических направлениях.
В частности, план предположительно должен содержать механизмы для перефокусировки лазера, когда окружение содержит туман, и перенаправления лазера, когда окружение содержит зеркала (…аналогия тут немного хромает, извините), чтобы можно было на самом деле попасть в маленькую далёкую цель. Перефокусировка и перенаправление – это неотъемлемая часть планов, которые могут это сделать.
Но люди, выключающие ИИ – это как рассеивание лазера, а люди, исправляющие ИИ, чтобы он планировал в другом направлении – это как установка зеркал на пути лазера; и мы не хотим, чтобы план корректировался под эти вмешательства.
Так что, по мнению Элиезера, как я его понимаю, мы требуем очень неестесвенной штуки – путь-через-будущее, достаточно устойчивый, чтобы направить историю по узкому пути из очень широкого диапазона обстоятельств, но каким-то образом нечувствительный к конкретным разновидностям предпринятых людьми попыток поменять этот самый узкий путь.
Ок. Я продолжал переформулировывать это снова и снова, пока не получил удовлетворяющую меня достаточно дистиллированную версию, извините за повторения.
Я не думаю, что сейчас правильно спорить именно про это заявление (хотя рад был бы услышать возражения). Но неплохо было бы: если Элиезер скажет, соответствует ли написанное выше его точке зрения (и если нет, почему); и если Ричард попробует перефразировать это, чтобы я уверился, что сами аргументы были успешно переданы (ничего не говоря о их принятии Ричардом).
[Soares] (12 сентября Google Doc)
Моя модель Ричарда по поводу написанного выше считает что-то вроде «Это всё выглядит правдоподобно, но пока Элиезер выводит из этого, что нам надо лучше научиться обращаться с лазерами, я считаю это аргументом в пользу того, что лучше бы спасти мир не прибегая к лазерам. Наверное, если бы я считал, что мир нельзя спасти без лазеров, то я бы разделял многие твои беспокойства. Но я так не считаю, и, в частности, недавний прогресс в области ИИ – от AlphaGo и GPT до AlphaFold – кажется мне свидетельством в пользу того, что можно спасти мир без лазеров.»
И я припоминаю, как Элиезер высказал следующее (более-менее там же, емнип, хотя читатели отметили, что я мог неправильно это понять и это может оказаться вырванным из контекста):
Определённо «Оказалось, использовать запоминание градиентным спуском огромной кучи поверхностных перекрывающихся паттернов и собрать из них большую когнитивную структуру, оказывающуюся консеквенциалистским наноинженером, который может только создавать наносистемы и так и не обзаводится достаточно общей способностью к обучению, чтобы понять общую картину и людей, всё ещё понимая цель ключевого действия, которое ты хочешь выполнить, проще, чем кажется» – это одно из самых правдоподобных заранее сформулированных чудес, которое мы можем получить.
По моему мнению, и, я думаю, по мнению Элиезера, ИИ в стиле «огромная куча поверхностных паттернов», которые мы наблюдаем сейчас, не будет достаточно, чтобы спасти мир (и чтобы уничтожить тоже). Есть набор причин, почему GPT и AlphaZero пока не уничтожили мир, и одна из них – «поверхностность». И да, может мы и не правы! Я сам был удивлён тем, как далеко зашло запоминание поверхностных паттернов (и, в частности, был удивлён GPT), и признаю, что могу быть удивлён и в будущем. Но я продолжаю предсказывать, что поверхностных штук не хватит.
У меня есть ощущение, что многие в сообществе в том или ином виде спрашивают: «Почему бы не рассмотреть задачу согласования систем, запоминающих огромные кучи поверхностных паттернов?». И мой ответ: «Я всё ещё не ожидаю, что такие машины убьют или спасут нас, я ожидаю, что есть фазовый переход, который не произойдёт, пока ИИ-системы не станут способны составлять достаточно глубокие и «лазерные» планы, чтобы делать что-то устрашающее, и я всё ещё ожидаю, что настоящий вызов согласования именно там.»
И это мне кажется ближе к основе несогласия. Некоторые (как я!) считают, что довольно маловероятно, что для того, чтобы спасти нас, достаточно выяснить, как получить значительную работу от поверхностных запоминальщиков. А, подозреваю, другим (возможно даже Ричарду!) кажется, что упомянутый «фазовый переход» – это маловероятный сценарий, и что я сосредотачиваюсь на странном неудачном угле пространства возможностей. (Мне любопытно, Ричард, поддержишь ли ты это или какую-то немного исправленную версию этого.)
В частности, Ричард, интересно, примешь ли ты что-то вроде следующего:
- Я сосредотачиваю ~все мои усилия на случае поверхностных запоминальщиков, потому что я считаю их согласование будет достаточным, а даже если нет, то я ожидаю, что это хороший путь подготовиться к тому, что окажется нужным на практике. В частности, я не поставлю многое на идею, что есть предсказуемый фазовый переход, который заставит нас иметь дело с «лазерными» планировщиками, или что предсказуемые проблемы дают нам большой повод к беспокойству.
(Я подозреваю, что нет, по крайней мере не точно в этой форме, и я жажду поправок.)
Я подозреваю, что что-то неподалёку – ключевая точка несогласия, и я был бы в восторге, если бы у нас получилось дистиллировать её до чего-то такого же точного. И, для записи, лично я принимаю такую обратную позицию:
- Я сосредотачиваю ~нисколько моих усилий на согласовании поверхностных запоминальщиков, так как ожидаю, что этого и близко не будет достаточно, не ожидаю сингулярности до получения более «лазерных» систем, и думаю, что «лазерный» режим планирования несёт предсказуемые сложности согласования, к которым Земля не выглядит готовой (в отличии, мне кажется, от сложностей согласования поверхностных запоминальщиков), так что я сильно беспокоюсь уже сейчас.
[Soares] (12 сентября Google Doc)
Ок, а теперь немного менее важных пунктов:
Ричард заявил:
О, интересно. Тогда ещё вопрос: в какой степени ты думаешь, что именно явные рассуждения о функциях полезности и законах рациональности наделяют консеквенциалистов свойствами, о которых ты говоришь?
И я подозреваю, что тут есть недопонимание, особенно учитывая это предложение из пересказа Ричарда:
Третья штука, которая в частности делает людей консеквенциалистами – это планирование – особенно, когда мы осведомлены о концептах вроде функции полезности.
В частности, я подозреваю, что модель Ричарда модели Элиезера особенно выделяет (или выделяла, до того, как Ричард прочёл комментарии Элиезера к пересказу) рефлексию системы и её размышления о своих собственных стратегиях, как метод повышения эффективности и/или консеквенциализма. Я подозреваю, что это недопонимание, и с удовольствием расскажу о моей модели по запросу, но, надеюсь, что предыдущая пара страниц это и так проясняет.
В конце концов, я вижу, что есть несколько мест, где Элиезер не ответил на попытки Ричарда пересказать его позицию, я подозреваю, что полезно было бы, если бы Ричард явно перечислил и повторил их, чтобы сверить общее понимание. В частности, стоило бы сверить (если Ричард в это действительно верит, и с возможными поправками Элиезера, я тут могу объединять разные штуки):
- Элиезер не считает невозможным создание ИИ с почти любым заданным свойством, включая почти любое свойство безопасности, включая почти любое желаемое свойство «не-консеквенциализма» или «послушания». Но Элиезер считает, что большинство желаемых свойств безопасности не появятся по умолчанию, и требуют мастерства, на приобретение которого скорее всего потребуется беспокояще большое количество времени.
- Заявления про консеквенциализм не особенно ключевые для взгляда Элиезера; они для него скорее вроде очевидных фоновых фактов; обсуждение задержалось на них потому, что в сообществе Эффективного Альтруизма многие с ними не соглашаются.
Для записи, я думаю, что Элиезеру стоит признать, что Ричард вероятно понимает пункт (1), и что сокращать «этого не получить по умолчанию и не похоже, что у нас будет достаточно времени» до «не получится» вполне осмысленно при резюмировании. (А Ричарду, может быть, стоит наоборот признать, что в данном контексте различие на самом деле довольно важное, так как оно означает разницу между «описывать текущее игровое поле» и «лечь и помереть».) Не думаю, что что-то из этого высокоприоритетно, но, если не сложно, может быть полезным :-)
Наконец, заявлю очевидное-для-меня: ничто из этого не предполагается как критика любой из сторон, и все участники продемонстрировали выдающиеся добродетели-согласно-Нейту в процессе обсуждения.
[Yudkowsky][21:27] (12 сентября)
Из заметок Нейта:
В частности, план предположительно должен содержать механизмы для перефокусировки лазера, когда окружение содержит туман, и перенаправления лазера, когда окружение содержит зеркала (…аналогия тут немного хромает, извините), чтобы можно было на самом деле попасть в маленькую далёкую цель. Перефокусировка и перенаправление – это неотъемлемая часть планов, которые могут это сделать.
Но люди, выключающие ИИ – это как рассеивание лазера, а люди, исправляющие ИИ, чтобы он планировал в другом направлении – это как установка зеркал на пути лазера; и мы не хотим, чтобы план корректировался под эти вмешательства.
–> ХОРОШАЯ АНАЛОГИЯ.
…или, по меньшей мере, передаёт для меня, почему исправимость неконвергентна / непоследовательна / на самом деле сильно противоречит, а не просто является независимым свойством мощного генератора планов.
Но всё же я уже знаю, почему это так, и как это обобщается для неуязвимости к попыткам решить мелкие кусочки более важных аспектов этого – это не просто так по слабому умолчанию, это так по сильному умолчанию, где куча народу может потратить несколько дней на попытки придумать всё более и более сложные способы описать систему, которая позволит себя выключить (но не направит тебя, чтобы ты её выключил), и все эти предложенные способы проваливаются. (И да, люди снаружи MIRI регулярно публикуют статьи, заявляющие, что они только что полностью решили эту задачу, но все эти «решения» – это штуки, которые мы рассмотрели и отбросили как тривиально проваливающиеся на масштабе мощных агентов – они не понимают, что мы считаем проблемами первостепенной важности, так что это не свидетельство, что у MIRI просто недостаточная куча умного народу.)
[Yudkowsky][18:56] (Nov. 5 follow-up comment)
Вроде «Хорошо, мы возьмём систему, которая училась только на ситуациях, в которых была, и не может использовать воображение, чтобы планировать по поводу чего-то, чего она не видела, и тогда мы обнаружим, что если мы её не обучим ситуации её выключения, то она не будет вознаграждаться для его избегания!»
Безопасность СИИ с чистого листа
В этом докладе я попытался собрать воедино как можно более полные и убедительные аргументы, почему разработка СИИ может представлять экзистенциальную угрозу. Причина доклада – моя неудовлетворённость существующими аргументами о потенциальных рисках СИИ. Более ранние работы становятся менее актуальными в контексте современного машинного обучения; более недавние работы разрозненны и кратки. Изначально я хотел лишь пересказывать аргументы других людей, но, в процессе написания доклада, он становился всё больше представляющим мои собственные взгляды, и менее представляющим чьи-то ещё. Так что хоть он и покрывает стандартные идеи, я думаю, что он и предоставляет новый подход рассуждений о СИИ – не принимающий какие-то предшествующие заявления как данность, но пытающийся выработать их с чистого листа.
Примечание редактора сайта. Автор также выложил подборку комментариев к своему докладу. Однако она очень велика и на русский её не перевели.
Безопасность СИИ с чистого листа. Введение
Это первая из шести частей доклада, под названием «Безопасность СИИ с чистого листа», в котором я попытался собрать воедино как можно более полные и убедительные аргументы, почему разработка СИИ может представлять экзистенциальную угрозу. Причина доклада – моя неудовлетворённость существующими аргументами о потенциальных рисках СИИ. Более ранние работы становятся менее актуальными в контексте современного машинного обучения; более недавние работы разрозненны и кратки. Изначально я хотел лишь пересказывать аргументы других людей, но, в процессе написания доклада, он становился всё больше представляющим мои собственные взгляды, и менее представляющим чьи-то ещё. Так что хоть он и покрывает стандартные идеи, я думаю, что он и предоставляет новый подход рассуждений о СИИ – не принимающий какие-то предшествующие заявления как данность, но пытающийся выработать их с чистого листа.
Несмотря на это, ширина темы, которую я пытаюсь рассмотреть, означает, что я включил много лишь торопливо обрисованных аргументов, и, несомненно, некоторое количество ошибок. Я надеюсь, что продолжу полировать этот доклад, и приветствую помощь и обратную связь. Я также благодарен многим людям, уже высказавшим обратную связь и поддержку. Я планирую перепостить некоторые самые полезные комментарии на Alignment Forum, если получу разрешение. Я выложил доклад шестью частями; первая и последняя – короткие обрамляющие, а четыре посередине соответствуют четырём предпосылкам нижеизложенного аргумента.
Безопасность СИИ с чистого листа
Ключевое беспокойство, мотивирующее технические исследования безопасности СИИ – то, что мы можем создать искусственных автономных интеллектуальных агентов, которые будут гораздо умнее людей, и которые будут преследовать цели, конфликтующие с нашими собственными. Человеческий интеллект позволяет нам координировать сложные общественные структуры и создавать продвинутые технологии, и таким образом контролировать мир в куда большей степени, чем любой другой вид. Но ИИ однажды станут способнее нас во всех типах деятельности, которыми мы обеспечиваем и сохраняем этот контроль. Если они не захотят нам подчиняться, человечество может стать лишь вторым по могуществу «видом» и потерять возможность создавать достойное ценное будущее.
Я называю это аргументом «второго вида»; я думаю, что это правдоподобный аргумент, который нужно воспринимать очень серьёзно1 Однако изложенная выше версия полагается на несколько нечётких концепций и соображений. В этом докладе я покажу настолько детальное, насколько смогу, изложение аргумента второго вида, подсвечивая аспекты, по поводу которых я всё ещё в замешательстве. В частности, я буду защищать версию аргумента второго вида, заявляющую, что, без согласованного усилия по предотвращению этого, есть значительный шанс, что:
- Мы создадим ИИ куда умнее людей (т.е. суперинтеллектуальные).
- Эти ИИ будут автономными агентами, преследующими высокомасштабные цели.
- Эти цели будут несогласованы с нашими; то есть, они будут направлены на нежелательные по нашим стандартам исходы и будут противоречить нашим целям.
- Разработка таких ИИ приведёт к тому, что они получат контроль над будущим человечества.
Хоть я и использую много примеров из современного глубокого обучения, этот доклад так же относится и к ИИ, разработанным с использованием совершенно иных моделей, обучающих алгоритмов, оптимизаторов или режимов обучения, отличающихся от тех, что мы используем сегодня. Однако, многие аргументы больше не будут актуальны, если поле ИИ перестанет быть сосредоточено на машинном обучении. Я также часто сравниваю разработку ИИ с эволюцией человеческого интеллекта; хоть они и не полностью аналогичны, люди – это лучший пример, который у нас есть, для мыслей об обобщённых ИИ.
- 1. В своей недавней книге «Совместимость. Как контролировать искусственный интеллект» Стюарт Рассел также называет это «проблемой гориллы».
Безопасность СИИ с чистого листа. Суперинтеллект
Чтобы понять суперинтеллект, следует сначала охарактеризовать, что мы имеем в виду под интеллектом. Мы можем начать с хорошо известного определения Легга, как способности хорошо справляться с широким набором когнитивных задач1. Ключевое разделение, которое я проведу в этой части – это разделение между агентами, хорошо понимающими, как справляться с многими задачами, потому что они были специально оптимизированы под каждую из них (я назову это основанным на задачах подходом к ИИ), и агентами, которые могут понимать новые задачи без или практически без специфического для этих задач обучения, обобщая из предыдущего опыта (основанный на обобщении подход).
Узкий и обобщённый интеллект
Основанный на задачах подход аналогичен тому, как люди применяют электричество: хоть электричество – это мощная технология, полезная в широком спектре задач, нам всё ещё надо проектировать специфические способы для его применения к каждой задаче. Похожим образом компьютеры – это мощные и гибкие инструменты, но хоть они и могут обрабатывать произвольно большое количество разных вводов, для каждой программы нужно индивидуально писать детальные инструкции, как совершать эту обработку. Нынешние алгоритмы обучения с подкреплением так же, несмотря на мощность, приводят к появлению агентов, хорошо справляющихся только с конкретными задачами, с которыми у них много опыта – Starcraft, DOTA, Go, и подобное. В «Переосмыслении cуперинтеллекта» Дрекслер отстаивает позицию, что наш текущий основанный на задачах подход отмасштабируется до сверхчеловеческих способностей в некоторых сложных задачах (но я скептически отношусь к этому заявлению).
Пример основанного на обобщении подхода – большие языковые модели вроде GPT-2 и GPT-3. GPT-2 сначала натренировали на задачу предсказывания следующего слова в тексте, а потом она достигла наилучших для своего времени результатов на многих других языковых задачах, без специальной подстройки на каждую! Это было явное изменение по сравнению с предыдущим подходом к обработке естественного языка, которые хорошо проявляли себя только с обучением под конкретную задачу на специальном наборе данных. Её потомок, GPT-3, продемонстрировала ещё более впечатляющее поведение. Я думаю, это хороший пример того, как ИИ может развить когнитивные навыки (в данном случае, понимание синтаксиса и семантики языка), обобщающиеся на большой диапазон новых задач. Поле мета-обучения преследует похожие цели.
Можно также увидеть потенциал основанного на обобщении подхода, посмотрев на развитие людей. Эволюция «обучила» нас как вид когнитивным навыкам, включающим в себя способности к быстрому обучению, обработку сенсорной и выдачу моторной информации, социальные навыки. Индивидуально мы также «обучаемся» в детстве подстраивать эти навыки, понимать устный и письменный язык и обладать подробной информацией о современном обществе. Однако, заметим, что почти всё это эволюционное и детское обучение произошло на задачах, сильно отличающихся от экономически пригождающихся нам во взрослом возрасте. Мы можем справляться с ними только переиспользуя когнитивные навыки и знания, полученные раньше. В нашем случае нам повезло, что эти когнитивные навыки были не слишком специфичны для окружения наших предков, а оказались весьма обобщёнными. В частности, навык абстрагирования позволяет нам извлекать общую структуру из разных ситуаций, что позволяет нам понимать их куда эффективнее, чем если бы мы отдельно изучали их одну за другой. Наши навыки коммуникации и понимания чужого сознания позволяют нам делиться своими идеями. Поэтому люди могут достигать мощного прогресса на масштабе лет и десятилетий, а не только через эволюционные адаптации на протяжении многих поколений.
Мне следует заметить, что я думаю об основанном на задаче и основанном на обобщении подходах как о частях спектра, а не как о бинарной классификации, в частности потому, что разделение на отдельные задачи довольно произвольно. К примеру, AlphaZero обучалась, играя сама с собой, но тестировалась, играя против людей, использующих другие стратегии и стили игры. Можно думать об игре против двух разных типов оппонентов как о двух случаях одной задачи, а можно – как двух разных задачах, таких, что AlphaZero смогла обобщить первую на вторую. Но в любом случае, они явно очень похожи. Для контраста, я ожидаю, что ИИ будут справляться хорошо с многими экономически важными задачами в первую очередь за счёт обобщения опыта совершенно других задач – что означает, что этим ИИ придётся обобщать намного лучше, чем могут нынешние системы обучения с подкреплением.
Уточню, про какие именно задачи я ожидаю, что они потребуют режима обобщения. В той мере, в которой мы можем разделять два подхода, мне кажется правдоподобным, что основанный на задачах подход сможет далеко зайти в областях, в которых мы можем собрать много данных. Например, я довольно сильно убеждён, что этот подход предоставит нам сверхчеловеческие беспилотные автомобили задолго до того основанного на обобщении подхода. Он может также позволить нам автоматизировать большинство задач, входящих в очень когнитивно-требовательные области вроде медицины, законов и математики, если мы сможем собрать правильные обучающие данные. Однако, некоторые занятия критически зависят от способности анализировать очень разнообразную информацию и действовать в её контексте, так что им будет очень сложно обучать напрямую. Рассмотрим задачи, включённые в роль вроде CEO: устанавливать стратегические направление компании, выбирать, кого нанимать, писать речи, и так далее. Каждая из этих задач чувствительно зависит от широкого контекста компании и окружающего мира. В какую индустрию входит компания? Насколько она большая; где она; какова её культура? Какие у неё отношения с конкурентами и правительствами? Как все эти факторы поменяются в ближайшую пару десятилетий? Эти переменные настолько разные по масштабу и зависящие от многих аспектов мира, что кажется практически невозможным сгенерировать большое количество обучающих данных, симулируя их (как мы делаем с ИИ, играющими в игры). И число CEO, от которых мы могли бы получить эмпирические данные, очень мало по меркам обучения с подкреплением (которое часто требует миллиарды тренировочных шагов даже для куда более простых задач). Я не говорю, что мы никогда не сможем превзойти человека в этих задачах прямым обучением на них – может, очень упорные усилия в разработке и проектировании при помощи других основанных на задачах ИИ и могут этого достичь. Но я ожидаю, что задолго до того, как такие усилия станут возможными, мы уже создадим ИИ, который будет уметь хорошо справляться с этими задачами, с помощью основанного на обобщении подхода.
В основанном на обобщении подходе путь к созданию сверхчеловеческого CEO – это использование других богатых на данные задач (которые могут сильно отличаться от того, что мы хотим, чтобы ИИ-CEO делал) для обучения ИИ набору полезных когнитивных навыков. К примеру, мы можем обучить агента выполнять инструкции в симулированном мире. Даже если симуляция сильно отличается от реального мира, агент может получить способности к планированию и обучению, которые можно будет быстро адаптировать к задачам реального мира. Аналогично, окружение предков людей также сильно отличалось от современного мира, но мы всё ещё способны довольно быстро становиться хорошими CEO. Приблизительно те же аргументы подходят и к другим влиятельным занятиям, вроде меняющих парадигмы учёных, предпринимателей и законотворцев.
Одно потенциальное препятствие для основанного на обобщении подхода – это возможность, что специфические черты окружения наших предков или специфические черты человеческого мозга были необходимы для возникновения обобщённого интеллекта. К примеру, выдвигалась гипотеза, что социальная «гонка вооружений» послужила причиной возникновения у нас достаточного социального интеллекта для масштабной передачи культурной информации. Однако, возможности для возникновения таких важных черт, включая эту, вполне могут быть воспроизведены в искусственном тренировочном окружении и в искусственных нейронных сетях. Некоторые черты (как квантовые свойства нейронов) может быть очень сложно точно симулировать, но человеческий мозг оперирует в слишком зашумлённых условиях, чтобы было правдоподобно, что наш интеллект зависит от эффектов такого масштаба. Так что кажется весьма вероятным, что однажды мы сможем создать ИИ, который сможет достаточно хорошо обобщать, чтобы на человеческом уровне справляться с широким диапазоном задач, включая абстрактные бедные данными задачи вроде управлением компанией. Давайте называть такие системы обобщёнными искусственными интеллектами, или СИИ2. Многие разработчики ИИ ожидают, что мы создадим СИИ в этом столетии; однако, я не буду рассматривать аргументы про оставшееся до СИИ время, и остальной доклад не будет зависеть от этого вопроса.
Пути к суперинтеллекту
Бостром определил суперинтеллект как «любой интеллект, сильно превосходящий когнитивные способности человека в практически любой области». В этом докладе, я буду понимать «сильно превосходящий человеческие способности» как превосходство над всем человечеством вместе, если бы оно могло глобально координироваться (без помощи другого продвинутого ИИ). Я думаю, сложно отрицать, что в принципе возможно создать отдельный основанный на обобщении суперинтеллектуальный СИИ, поскольку человеческий мозг ограничен многими факторами, которые будут ограничивать ИИ куда меньше. Пожалуй, самый поражающий из них – это огромная разница между скоростью нейронов и транзисторов: вторые передают сигналы примерно в четыре миллиона раз быстрее. Даже если СИИ никогда не превзойдёт людей в других аспектах, такая скорость позволит ему за минуты и часы продумать столько, сколько человек может в годы или десятилетия. В то же время, наш размер мозга – важная причина того, что люди способнее животных – но я не вижу причин, почему нейросеть не может быть ещё на несколько порядков больше человеческого мозга. И хоть эволюция во многом весьма хороший проектировщик, у неё не было времени отбирать по навыкам, специфически полезным в нашем современном окружении, вроде понимания языка и математических рассуждений. Так что нам следует ожидать существования низковисящих плодов, позволяющих продвинуться за пределы человеческой компетенции в многих задачах, опирающихся на такие навыки3.
Есть значительные расхождения в мнениях по поводу того, сколько времени займёт переход от СИИ человеческого уровня до суперинтеллекта. Фокус этого доклада не в этом, но я быстро пробегусь по этой теме в разделе про Контроль. А в этом разделе я опишу качественно, как может пройти этот переход. По умолчанию, следует ожидать, что он будет связан с стандартными факторами, влияющими на прогресс ИИ: больше вычислительной мощности, лучшие алгоритмы, лучшие обучающие данные. Но я также опишу три фактора, вклад которых в увеличение интеллекта ИИ будет становиться сильнее с тем, как ИИ будет становиться умнее: репликация, культурное обучение и рекурсивное улучшение.
В плане репликации ИИ куда менее ограничен, чем люди: очень легко создать копию ИИ с теми же навыками и знаниями, что и у оригинала. Вычислительная стоимость этого процесса скорее всего будет во много раз меньше изначальной стоимости обучения (поскольку обучение обычно включает в себя запуск многих копий ИИ на куда более высокой скорости, чем нужно для задач реального мира). Копирование сейчас позволяет нам применять один ИИ к многим задачам, но не расширяет диапазон задач, которые он может выполнять. Однако, следует ожидать, что СИИ сможет декомпозировать сложные задачи на более простые подзадачи, как и делают люди. Так что копирование такого СИИ сможет привести к появлению суперинтеллекта, состоящего не из одного СИИ, а из целой группы (которую, следуя за Бостромом, я назову коллективным СИИ), которая может справляться со значительно более сложными задачами, чем оригинал4. Из-за простоты и эффективности копирования СИИ, я думаю, что нам следует по умолчанию ожидать возникновения суперинтеллекта из коллективного СИИ.
Эффективность коллективного СИИ может быть ограничена проблемами координации его составляющих. Однако, большинство аргументов из предыдущего абзаца – так же является причиной, почему отдельные СИИ смогут превзойти нас в навыках, необходимых для координации (как обработка языка и понимание другого разума). Особенно полезный навык – это культурное обучение: стоит ожидать, что СИИ смогут приобретать знания друг от друга, и, в свою очередь делиться собственными открытиями, что позволит коллективному СИИ решать более сложные задачи, чем его составляющие по отдельности. Развитие этой способности в людях – это то, что сделало возможным мощный взлёт человеческой цивилизации в последние десять тысяч лет. Нет особых причин считать, что мы достигли максимума этой способности, или что СИИ не может получить ещё большего преимущества над человеком, чем у человека есть над шимпанзе, с помощью получения информации от других агентов.
В-третьих, СИИ смогут улучшать процесс обучения для разработки своих наследников, которые, в свою очередь, улучшат его дальше, для разработки своих, и так далее, в процессе рекурсивного улучшения5. Предыдущие обсуждения в основном сосредотачивались на рекурсивном самоулучшении, включающим один СИИ, «переписывающий свой собственный код». Однако, я по нескольким причинам думаю, что более уместно сосредоточиться на более широком явлении ИИ, продвигающего разработку ИИ. Во-первых, из-за простоты копирования ИИ, нет значимого разделения между ИИ, улучшающим «себя» и ИИ, создающим наследника, разделяющего многие его свойства. Во-вторых, современные ИИ более точно характеризуются как модели, которые можно переобучить, а не как программы, которые можно переписать: практически вся работа, делающая нейросеть умной, производится оптимизатором через продолжительное обучение. Даже суперинтеллектуальному СИИ будет довольно сложно значительно улучшить своё мышление, модифицируя веса+ в своих нейронах напрямую; это кажется похожим на повышение интеллекта человека с помощью хирургии на мозге (хоть и с куда более точными инструментами, чем у нас есть сейчас). Так что, вероятно, более точным будет думать о самомодификации, как о процессе, в котором СИИ изменяет свою высокоуровневую архитектуру или режим обучения, а потом обучает себя заново. Это очень похоже на то, как мы создаём новые ИИ сегодня, только с меньшей ролью людей. В-третьих, если интеллектуальный вклад людей значительно сокращается, то я не думаю, что осмысленно требовать полного отсутствия людей в этом цикле, чтобы поведение ИИ можно было считать рекурсивным улучшением (хотя мы всё ещё можем различать случаи с большим и меньшим вовлечением людей).
Эти соображения в нескольких местах пересматривают классический взгляд на рекурсивное самоулучшение. К примеру, шаг переобучения может быть ограничен вычислительными мощностями, даже если СИИ будет способен очень быстро проектировать алгоритмические усовершенствования. И чтобы СИИ мог полагаться на то, что его цели останутся неизменными при переобучении, ему, вероятно, потребуется решить примерно те же задачи, которыми сейчас занимается область безопасности СИИ. Это причина для оптимизма по поводу того, что весь остальной мир сможет решить эти задачи до того, как несогласованный СИИ дойдёт до рекурсивного самоулучшения. Однако, проясню, это не подразумевает, что рекурсивное улучшение не важно. Напротив, раз ИИ однажды станет основным участником разработки ИИ, то рекурсивное улучшение, как оно определено здесь, однажды станет ключевым двигателем прогресса. Я ещё рассмотрю следствия этого заявления в разделе про Контроль.
Пока что я сосредотачивался на том, как суперинтеллекты появятся, и что они будут способны делать. Но как они будут решать что делать? К примеру, будут ли части коллективного СИИ хотеть кооперироваться друг с другом для достижения больших целей? Будет ли способный к рекурсивному самоулучшению СИИ иметь причины это сделать? Я не хочу формулировать эти вопросы в терминах целей и мотивации СИИ, не описав сперва подробнее, что эти термины на самом деле означают. Это тема следующего раздела.
- 1. В отличии от обычного использования, тут мы считаем определение каналов ввода-вывода агента частью среды, так что решение задачи требует только обработки входящей информации и вывода исходящей.
- 2. По-русски устоялось словосочетание «сильный искусственный интеллект». - Прим. перев.
- 3. Это наблюдение сильно связано с парадоксом Моравека, который я подробнее рассмотрю в разделе про Цели и Агентность. Самый наглядный пример, пожалуй, это то, насколько легко ИИ победить человека в шахматы.
- 4. Не вполне ясно, всегда ли имеет смысл разделение между «одиночными СИИ» и коллективными СИИ, учитывая, что и отдельный СИИ может состоять из многих модулей, которые сами по себе могут быть довольно интеллектуальными. Но поскольку кажется маловероятным, чтобы таких обобщённо интеллектуальных модулей были сотни или тысячи, я думаю, что разделение всё же осмысленно на практике. См. также рассмотрение «коллективного суперинтеллекта» в «Суперинтеллекте» Бострома.
- 5. Будет ли последующий агент продвинутой версией разработавшего его СИИ или совсем другим, заново обученным СИИ – вопрос важный, но не влияющий на приводимые здесь аргументы.
Безопасность CИИ с чистого листа. Цели и агентность
Фундаментальный повод к беспокойству за аргумент второго вида – это что ИИ получит слишком много власти над людьми и использует эту власть не нравящимся нам способами. Почему ИИ получит такую власть? Я различаю три возможности:
- ИИ добивается власти ради достижения других целей, т.е. она для него инструментальная ценность.
- ИИ добивается власти ради неё самой, т.е. она для него финальная цель.
- ИИ получает власть, не добиваясь её; например, потому, что её ему дали люди.
На первой возможности сосредоточено большинство обсуждений, и я потрачу большую часть этого раздела на неё. Вторая не была так глубоко исследована, но, по моему мнению, всё же важна; я быстро пройдусь по ней в этом и следующем разделах. Вслед за Кристиано, я назову агентов, подпадающих под эти две категории ищущими-влияния. Третья возможность в основном не попадает в тему этого доклада, который фокусируется на опасности намеренного поведения продвинутых ИИ, но я чуть-чуть затрону её здесь и в последнем разделе.
Ключевая идея за первой возможностью – это сформулированный Бостромом тезис инструментальной конвергенции. Он утверждает, что есть некоторые инструментальные цели, чьё достижение увеличивает шансы реализации финальных целей агента для широкого диапазона этих финальных целей и широкого диапазона ситуаций. Примерами таких инструментальных целей служат самосохранение, накопление ресурсов, технологическое развитие и самоулучшение, все из которых полезны для выполнения дальнейших крупномасштабных планов. Я думаю, что эти примеры лучше характеризуют ту власть, о которой я тут говорю, чем какое-нибудь более явное определение.
Однако, связь между инструментально конвергентными целями и опасным преследованием власти применима только к агентам, чьи финальные цели достаточно крупномасштабны, чтобы они получали выгоду от этих инструментальных целей и определяли и добивались их даже когда это ведёт к экстремальным результатам (набор черт, которые я называю ориентированной на цели агентностью). Не совсем ясно, что СИИ будут такими агентами или иметь такие цели. Интуитивно кажется, что будут, потому что мы все имеем опыт преследования инструментально конвергентных целей, к примеру, зарабатывания и сохранения денег, и можем представить, насколько бы мы были в них лучше, если бы были умнее. Но, так как эволюция вложила в нас много полезных краткосрочных мотиваций, сложно определить, в какой мере человеческое ищущее влияния поведение вызвано рассуждениями про инструментальную полезность для крупномасштабных целей. Наше завоевание мира не требовало, чтобы люди выстраивали стратегию на века – только чтобы много отдельных людей довольно ограниченно увеличивали собственное влияние – изобретая немного лучшие инструменты или исследуя чуть дальше.
Следовательно, нам следует серьёзно отнестись и к возможности, что суперинтеллектуальный СИИ будет ещё меньше чем люди сосредоточен на достижении крупномасштабных целей. Мы можем представить, как они преследуют финальные цели, не мотивирующие к поиску власти, например, деонтологические или маломасштабные. Или, может быть, мы создадим «ИИ-инструменты», которые будут очень хорошо подчиняться нашим инструкциям, не обладая собственными целями – как калькулятор не «хочет» ответить на арифметический вопрос, но просто выполняет переданные ему вычисления. Чтобы понять, какие из этих вариантов возможны или вероятны, нам нужно лучше понять природу целей и ориентированной на цели агентности. Таков фокус этого раздела.
Основы для рассуждений про агентность
Для начала критично провести различие между целями, для выполнения которых агент был отобран или спроектирован (их я назову его проектными целями), и целями, которые агент сам хочет достигнуть (их я просто назову «целями агента»)1. К примеру, насекомые могут участвовать в сложных иерархических обществах только потому, что эволюция дала им необходимые для этого инстинкты: «компетенцию без понимания» по терминологии Деннета. Этот термин также описывает нынешние классификаторы картинок и (наверное) созданные обучением с подкреплением агенты вроде AlphaStar и OpenAI Five: они могут быть компетентны в достижении своих проектных целях без понимания, что это за цели, или как их действия помогут их достигнуть. Если мы создадим агентов, чьими проектными целями будет накопление власти, но сами агенты не будут иметь такой цели (к примеру, агент играет на бирже без понимания того, какое влияние это оказывает на общество), то это будет считаться третьей из указанных выше возможностей.
В этом разделе я, напротив, заинтересован в том, что значит для агента иметь свою собственную цель. Три существующих подхода попыток ответить на этот вопрос – это максимизация ожидаемой полезности Джона фон Неймана и Оскара Моргенштерна, позиция намерений Дэниэла Деннета, и меса-оптимизация Хубингера и др. Я, впрочем, не думаю, что любой из этих подходов адекватно характеризует тот тип направленного на цели поведения, которое мы хотим понять. Хоть мы и можем доказывать элегантные теоретические результаты о функциях полезности, они настолько обобщены, что практически любое поведение может быть описано как максимизация какой-то функции полезности. Так что этот подход не ограничивает наши ожидания от мощных СИИ2. В то же время Деннет заявляет, что рассмотрение позиций намерения систем может быть полезно для предсказаний о них – но это работает только при наличии предшествующего знания о том, какие цели система наиболее вероятно имеет. Предсказать поведение нейросети из триллиона параметров – совсем не то же самое, что применить позиции намерения к существующим артефактам. И хоть у нас есть интуитивное понимание сложных человеческих целей и того, как они переводятся в поведение, в какой степени осмысленно распространять эти убеждения об ориентированном на цели поведении на ИИ – это тот самый вопрос, для которого нам нужна теория агентности. Так что несмотря на то, что подход Деннета предоставляет некоторые ценные прозрения – в частности, что признание за системой агентности – это выбор модели, применимый только при некоторой абстракции – я думаю, что у него не получается свести агентность к более простым и понятным концепциям.
В дополнение к этому, ни один из подходов не рассматривает ограниченную рациональность: идею, что системы могут «пытаться» достичь цели, не совершая для этого лучших действий. Для определения целей ограниченно рациональных систем, нам придётся подробно изучить структуру их мышления, а не рассматривать их как чёрные ящики с входом и выходом – другими словами, использовать «когнитивное» определение агентности вместо «поведенческих», как рассмотренные выше. Хубингер и другие используют когнитивное определение в их статье Риски Выученной Оптимизации в Продвинутых Системах Машинного Обучения: «система есть оптимизатор, если она совершает внутренний поиск в некотором пространстве (состоящем из возможных выводов, политик*, планов, стратегий или чего-то вроде этого) тех элементов, которые высоко оцениваются некой целевой функцией, явно воплощённой внутри системы». Я думаю, что это перспективное начало, но тут есть некоторые значительные проблемы. В частности, концепт «явного воплощения» кажется довольно хитрым – что именно (если хоть что-то) явно воплощено в человеческом мозге? И их определение не проводит важного различия между «локальными» оптимизаторами вроде градиентного спуска и целенаправленными планировщиками вроде людей.
Мой собственный подход к рассуждениям об агентности пытается улучшить упомянутые подходы через большую конкретность по поводу мышления, которое мы ожидаем от целенаправленных систем. Также как «иметь интеллект» включает набор способностей (как обсуждалось в предыдущем разделе), «быть целенаправленным» включает некоторые дополнительные способности:
- Самосознание: система понимает, что она часть мира, и что её поведение меняет мир;
- Планирование: она рассматривает широкий диапазон возможных последовательностей поведения (назовём их «планами»), включая длинные;
- Консеквенциализм: она решает, какой план лучше, рассматривая ценность их результатов;
- Масштабирование: её выбор чувствителен к далёким во времени и пространстве эффектам планов;
- Последовательность: она внутренне объединена для выполнения плана, который сочла лучшим;
- Гибкость: Она способна гибко адаптировать свои планы при изменении обстоятельств, а не продолжать те же паттерны поведения.
Заметим, что никакую из этих черт не надо интерпретировать как бинарную; напротив, каждая определяет спектр возможностей. Я также не заявляю, что комбинация этих шести измерений – это точная и полная характеристика агентности; только что это хорошая начальная точка и правильный тип рассуждений для анализа агентности. Например, так подсвечивается, что агентность требует комбинации разных способностей – и как следствие, что есть много разных способов быть не максимально агентным. ИИ, высоко поднявшийся по каким-то из этих метрик может быть довольно низок по другим. Рассмотрим по очереди эти черты, и как может выглядеть их недостаток:
- Самосознание: для людей интеллект кажется неотъемлемо связанным с перспективой от первого лица. Но СИИ, обученный на абстрактных данных от третьего лица может приобрести довольно сложную модель мира, которая просто не включает в себя его самого или его выводы. Значительно продвинутая языковая или физическая модель может подпадать под эту категорию.
- Планирование: высокоинтеллектуальные агенты будут по умолчанию способны создавать большие сложные планы. Но на практике они, как и люди, могут не всегда использовать эту способность. Представим, к примеру, агента, обученного рассматривать только ограниченный тип планов. Миопическое обучение пытается получить таких агентов; более обобщённо, агент может иметь ограничения на рассматриваемые действия. К примеру, система, отвечающая на вопросы, может рассматривать только планы вида «сначала решить подзадачу 1, потом решить подзадачу 2, потом…».
- Консеквенциализм: обычно этот термин в философии описывает агентов, которые считают, что моральность их действий зависит только от последствий этих действий. Тут я использую его более обобщённо, чтобы описать агентов, чьи субъективные предпочтения действий зависят в основном от их последствий. Кажется естественным ожидать, что агенты, обученные функцией вознаграждения, определяемой состоянием мира, будут консеквенциалистами. Но заметим, что люди далеки от стопроцентных консеквенциалистов, поскольку мы часто подчиняемся деонтологическим ограничениям или ограничениям типов поддерживаемых нами рассуждений.
- Масштабирование: агенты, заботящиеся только о маломасштабных событиях, могут игнорировать крупномасштабные эффекты своих действий. Поскольку агенты всегда обучаются в маломасштабном окружении, выработка крупномасштабных целей требует обобщения (способами, которые я опишу ниже).
- Последовательность: людям недостаёт этой черты, когда у нас происходит внутренний конфликт – к примеру, когда наши система 1 и система 2 имеют различающиеся цели – или когда наши цели сильно меняются со временем. Хоть наши внутренние конфликты и могут быть просто артефактом нашей эволюционной истории, нельзя отвергнуть возможности того, что одиночные СИИ приобретут модульность, приводящую к сравнимым проблемам. Однако, естественнее всего думать об этой черте в контексте коллектива, где отдельные его члены могут иметь более или менее схожие цели, и могут в большей или меньшей степени координироваться.
- Гибкость: негибкий агент может возникнуть в окружении, в котором обычно достаточно одного изначального плана, или где приходится делать компромисс между составлением и выполнением планов. Такие агенты могут демонстрировать сфексное поведение. Другим интересным примером может быть мультиагентная система, в которой много ИИ вкладываются в разработку плана – так что отдельный агент может исполнить план, но не может его пересмотреть.
Система, отвечающая на вопросы (так же известная как оракул), может быть реализована как агент, лишённый и планирования, и консеквенциализма. Для действующего в реальном мире ИИ, я думаю, важно рассмотреть масштаб его целей, я займусь этим дальше в этом разделе. Мы можем оценивать и другие системы по этим критериям. У калькулятора нет их всех. Немного более сложные программы, вроде GPS-навигатора, вероятно, стоит рассматривать в как некоторой ограниченной степени консеквенциалистов (он направляет пользователя по-разному в зависимости от плотности трафика), и, возможно, как обладателей других черт тоже, но лишь чуть-чуть. Большинство животных в некоторой степени обладают самосознанием, консеквенциализмом и последовательностью. Традиционная концепция СИИ имеет все эти черты, что даёт такому СИИ способность следовать ищущим-влияние стратегиям по инструментальным мотивам. Однако, заметим, что эта направленность на цели – не единственный фактор, определяющий, будет ли ИИ ищущим-влияние: содержание его целей также имеет значение. Высокоагентный ИИ, имеющий цель оставаться подчинённым людям, может никогда не исполнять ищущие-влияние действия. Как ранее замечено, ИИ, имеющий финальную целью получения власти, может быть ищущим-влияние, даже не обладая большинством этих черт. Я рассмотрю пути оказания влияния на цели агента в следующем разделе про согласование.
Вероятность разработки высокоагентного СИИ
Насколько вероятно, что, разрабатывая СИИ, мы создадим систему с всеми шестью перечисленными мной выше чертами? Один из подходов к ответу на этот вопрос включает предсказывание, какие типы архитектуры моделей и алгоритмов обучения будут использованы – к примеру, будут ли они безмодельными или, напротив, основанными на модели? Мне кажется, такая линия рассуждения недостаточно абстрактна, поскольку мы просто не знаем о мышлении и обучении достаточно, чтобы отобразить их в высокоуровневые решения проектирования. Если мы обучим СИИ безмодельным способом, я предсказываю, что он всё равно будет планировать с использованием внутренней модели. Если мы обучим основанный на модели СИИ, я предсказываю, что его модель будет настолько абстрактной и иерархичной, что взгляд на его архитектуру очень мало скажет нам о настоящем происходящем там мышлении.
На более высоком уровне абстракции, я думаю, что для высокоинтеллектуального ИИ будет проще приобрести эти компоненты агентности. Однако, степень агентности наших наиболее продвинутых ИИ будет зависеть от режима обучения, которым они будут получены. К примеру, наши лучшие языковые модели уже обобщают свои тренировочные данные достаточно хорошо, чтобы отвечать на довольно много вопросов. Я могу представить, как они становятся всё более и более компетентными с помощью обучения с учителем и без учителя, до тех пор, когда они станут способны отвечать на вопросы, ответы на которые неизвестны людям, но всё ещё остаются лишёнными всех указанных черт. Можно провести аналогию с человеческой зрительной системой, которая совершает очень полезное мышление, но не очень «ориентирована на цели» сама по себе.
Мой основной аргумент – что агентность – это не просто эмерджентное свойство высокоинтеллектуальных систем, но скорее набор способностей, которые должны быть выработаны при обучении, и которые не возникнут без отбора по ним. Одно из поддерживающих свидетельств – парадокс Моравека: наблюдение, что кажущиеся наиболее сложными для людей когнитивные навыки зачастую очень просты для ИИ, и наоборот. В частности, парадокс Моравека предсказывает, что создание ИИ, выполняющих сложную интеллектуальную работу вроде научных исследований может на самом деле быть проще, чем создание ИИ, разделяющего более глубокие присущие людям черты вроде целей и желаний. Для нас понимание мира и изменение мира кажутся очень тесно связанными, потому что на наших предков действовал отбор по способности действовать в мире и улучшать своё положение в нём. Но если это интуитивное рассуждение ошибочно, то даже обучение с подкреплением может не выработать все аспекты направленности на цели, если цель обучения – отвечать на вопросы.
Однако, есть и аргументы в пользу того, что сложно обучить ИИ выполнять интеллектуальную работу так, чтобы они не выработали направленную на цели агентность. В случае людей, нужда взаимодействия с неограниченным окружением для достижения своих целей толкнула нас на развитие нашего сложного обобщённого интеллекта. Типичный пример аналогичного подхода к СИИ – это обучение с подкреплением в сложном симулированном 3D-окружении (или, возможно, через длинные разговоры в языковой среде). В таких окружениях, агенты, планирующие эффекты своих действий на длинных временных промежутках будут в целом справляться лучше. Это подразумевает, что наши ИИ будут подвержены оптимизационному давлению в сторону большей агентности (по моим критериям). Мы можем ожидать, что СИИ будет более агентным, если он будет обучен не просто в сложном окружении, но в сложном соревновательном мультиагентном окружении. Так обученным агентам будет необходимо уметь гибко адаптировать планы под поведение соперников; и им будет выгодно рассматривать больший диапазон планов на большем временном масштабе, чем соперники. С другой стороны, кажется очень сложным предсказать общий эффект взаимодействий между многими агентами, например, в людях, они привели к выработке (иногда не-консеквенциалистского) альтруизма.
Сейчас есть очень мало уверенности в том, какие режимы обучения лучше подходят для создания СИИ. Но если есть несколько рабочих, то стоит ожидать, что экономическое давление будет толкать исследователей к использованию в первую очередь тех, которые создают наиболее агентных ИИ, потому что они будут наиболее полезными (предполагая, что проблемы согласования не становятся серьёзными, пока мы не приближаемся к СИИ). В целом, чем шире задача, для которой используется ИИ, тем ценнее для него рассуждать о том, как достигнуть назначенную ему цель путями, которым он не был специально обучен. Например, отвечающая на вопросы система с целью помогать своим пользователям понимать мир может быть куда полезнее той, которая компетентна в своей проектной цели выдачи точных ответов на вопросы, но не имеет своих целей. Вообще я думаю, что большинство исследователей безопасности ИИ выступают за приоритизацию направлений исследований, которые приведут к менее агентным СИИ, и за использование этих СИИ для помощи в согласовании более агентных поздних СИИ. Ведётся работа и над тем, чтобы напрямую сделать СИИ менее агентным (как квантилизация), хотя в целом она сдерживается недостатком ясности вокруг этих концептов.
Я уже рассуждал о рекурсивном улучшении в предыдущем разделе, но ещё кое-что полезно подсветить здесь: раз большая агентность помогает агенту достигать своих целей, способные к модификации себя агенты будут иметь стимул делать себя более агентными (как люди уже пытаются, хоть и ограниченно)3. Так что стоит рассматривать и такой тип рекурсивного улучшения; соображения из предыдущего раздела к нему также в основном применимы.
Цели как обобщённые концепты
Следует заметить, я не ожидаю, что обучающие задачи будут иметь такой же масштаб и продолжительность, как волнующие нас задачи в реальном мире. Так что СИИ не будет напрямую отбираться по крупномасштабным или долгосрочным целям. Но вероятно, что выученные в тренировочном окружении цели будут обобщаться до больших масштабов, так же как люди выработали крупномасштабные цели из эволюции в относительно ограниченном окружении наших предков. В современном обществе люди часто тратят всю свою жизнь, пытаясь значительно повлиять на весь мир – с помощью науки, бизнеса, политики, и многого другого. И некоторые люди стремятся повлиять на весь мир на века, тысячелетия, или даже дольше, несмотря на то, что никогда не было значительного эволюционного отбора людей по беспокойству о том, что произойдёт через несколько сотен лет, или по обращению внимания на события с другой стороны планеты. Это даёт нам повод к беспокойству, что СИИ, не обученный явно преследовать амбициозные крупномасштабные цели, всё равно может это делать. Я также ожидаю, что исследователи будут активно стремиться к обобщениям такого вида в ИИ, потому что на это полагаются некоторые важные применения. Для долгосрочных задач вроде управления компанией СИИ понадобится способность и мотивация выбирать между возможными действиями с учётом их мировых последствий на протяжении лет или десятилетий.
Можно ли конкретнее описать, как выглядит обобщение целей на намного большие масштабы? Учитывая проблемы с подходом максимизации ожидаемой полезности, которые я описывал раньше, не кажется подходящим думать о целях как о функциях полезности от состояния мира. Скорее, цели агента можно сформулировать в терминах тех концептов, которыми он оперирует – независимо от того, относятся ли они к его мыслительному процессу, деонтологическим правилам или исходам во внешнем мире4. И пока концепты агента гибко подстраиваются и обобщаются к новым обстоятельствам, цели, отсылающие к ним, останутся теми же. Сложно и спекулятивно пытаться описать, как может произойти такое обобщение, но, грубо говоря, стоит ожидать, что интеллектуальные агенты способны абстрагироваться от разницы между объектами и ситуациями, которые имеют высокоуровневые сходства. К примеру, после обучения в симуляции, агент может перенести своё отношение к объектам и ситуациям в симуляции на похожие в (куда большем) реальном мире5. Альтернативно, обобщение может произойти из постановки цели: агент, которого всегда вознаграждали за накопление ресурсов в тренировочном окружении, может встроить внутреннюю цель «накопить как можно больше ресурсов». Похожим образом, агенты, обученные соперничать в маломасштабной области могут выработать цель превзойти друг друга, остающуюся и при действии на очень больших масштабах.
С такой точки зрения чтобы предсказать поведение агента, надо рассмотреть, какими концептами он обладает, как они будут обобщаться, и как агент будет о них рассуждать. Я знаю, что это выглядит до невозможности сложной задачей – даже рассуждения человеческого уровня могут приводить к экстремальным непредсказуемым заключениям (как показывает история философии). Однако, я надеюсь, что мы можем вложить в СИИ низкоуровневые настройки ценностей, которые направят их высокоуровневые рассуждения в безопасных направлениях. Я рассмотрю некоторые подходы к этому в следующем разделе про согласование.
Группы и агентность
Раз я рассмотрел коллективные СИИ к предыдущем разделе, важно взглянуть, подходит ли мой подход к пониманию агентности так же и к группам агентов. Думаю, да: нет причин, почему описанные мной черты должны быть присущи одиночной нейросети. Однако отношения между целенаправленностью коллективного СИИ и целенаправленностями его членов могут быть не просты, они зависят от внутренних взаимодействий.
Одна из ключевых переменных – это насколько много опыта (и какие типы) взаимодействия друг с другом во время обучения имеют члены коллективного СИИ. Если они в первую очередь обучались кооперации, это увеличивает вероятность того, что получившийся коллективный СИИ будет целенаправленным агентом, даже если его отдельные члены не особо агентны. Но есть хорошие причины ожидать, что процесс обучения будет включать некоторую конкуренцию, которая уменьшит их последовательность как группы. Внутренняя конкуренция также может способствовать краткосрочному ищущему-влияния поведению, поскольку каждый член выучится поиску влияния для того, чтобы превзойти других. Особо выдающийся пример – человечество смогло захватить мир за тысячелетия не с помощью какого-то общего плана это сделать, а, скорее, как результат попыток многих индивидуумов распространить своё краткосрочное влияние.
Ещё возможно, что члены коллективного СИИ вообще не будут обучены взаимодействию друг с другом, в таком случае кооперация между ними будет целиком зависеть от их способности обобщать выработанные навыки. Сложно представить такой случай, поскольку человеческий мозг очень хорошо адаптирован для групповых взаимодействий. Но пока люди и согласованные СИИ будут удерживать подавляющую долю власти в мире, будет естественный стимул для СИИ, преследующих несогласованные цели, координировать друг с другом для расширения своего влияния за наш счёт6. Преуспеют ли они – зависит от того, какие механизмы координации они будут способны придумать.
Второй фактор – насколько много специализации в коллективном СИИ. В случае когда он состоит только из копий одного агента, нам стоит ожидать, что они будут очень хорошо друг друга понимать и по большей части разделять цели. Тогда мы сможем предсказать целенаправленность всей группы, изучив оригинального агента. Но стоит рассмотрения и случай коллектива, состоящего из агентов с разными навыками. С таким типом специализации коллектив в целом может быть куда более агентным, чем его составляющие, что может упростить безопасный запуск частей коллектива.
- 1. ИИ-системы, обучившиеся преследовать цели, также известны как меса-оптимизаторы, согласно статье Хубингера и др. «Риски Выученной Оптимизации в Продвинутых Системах Машинного Обучения».
- 2. Существуют аргументы, пытающиеся это сделать. К примеру, Элиезер Юдковский тут отстаивает, что «хоть исправимость, вероятно, имеет некоторое ядро меньшей алгоритмической сложности, чем все человеческие ценности, это ядро, скорее всего, очень сложно найти или воспроизвести обучением на размеченных людьми данных, потому что послушание – это необычайно противоестественная форма мышления, в том смысле, в котором простая функция полезности – естественная.» Однако, замечу, что этот аргумент полагается на интуитивное разделение естественных и противоестественных форм мышления. Это в точности то, что, как я думаю, нам надо понять, чтобы создать безопасный СИИ – но пока что было мало явных исследований на эту тему.
- 3. Вроде бы, это идея Анны Саламон, но, к сожалению, я не смог отследить конкретный источник.
- 4. К примеру, когда люди хотят быть «кооперативными» или «моральными», они зачастую не просто думают о результатах, но скорее о том, какие типы действий следует исполнять, или о типах процедур принятия решений, которые следует использовать для выбора действий. Дополнительная сложность – что люди не имеют полного интроспективного доступа к своим концептам – так что надо также рассматривать подсознательные концепты.
- 5. Представьте, что это произошло с вами, и вас вытащили «из симуляции» в реальный мир, который очень похож на то, что вы уже испытывали. По умолчанию вы скорее всего захотите питаться хорошей едой, иметь полноценные отношения и так далее, несмотря на пережитый радикальный онтологический сдвиг.
- 6. В дополнение к первому приходящему в голову аргументу, что интеллект увеличивает способность к координации, скорее всего СИИ в силу своей цифровой природы будет иметь доступ к недоступным людям способам обеспечения кооперации. К примеру, СИИ может послать потенциальным союзникам копию себя для инспекции, чтобы увеличить уверенность в том, что ему можно доверять. Однако, есть и человеческие способы, к которым СИИ будут иметь меньше доступа – к примеру, подвергание себя физической опасности как сигнал честности. И возможно, что относительная сложность обмана и распознавания обмана сдвигается в пользу второго для более интеллектуальных агентов.
Безопасность СИИ с чистого листа. Согласование
В предыдущем разделе я рассмотрел правдоподобность того, что агенты, полученные машинным обучением, выработают способность к поиску влияния по инструментальным причинам. Это не было бы проблемой, если бы они делали это только способами, согласованными с человеческими ценностями. В самом деле, многие из преимуществ, которые мы ожидаем получить от СИИ, потребуют у них обладания влиянием на мир. И по умолчанию, разработчики ИИ будут направлять свои усилия на создание агентов, которые будут делать то, что желают разработчики, а не обучатся быть непослушными. Однако, есть причины беспокоиться, что несмотря на усилия разработчиков, ИИ приобретут нежелательные конечные цели, которые приведут к конфликту с людьми.
Для начала, что вообще значит «согласованные с человеческими ценностями»? Вслед за Габриэлем и Кристиано, я проведу разделение между двумя типами интерпретаций. Минималистичный (он же узкий) подход сосредотачивается на избегании катастрофических последствий. Лучший пример – концепт согласования намерений Кристиано: «Когда я говорю, что ИИ A согласован с оператором H, я имею в виду: A пытается сделать то, что H от него хочет.» Хоть всегда и будут пограничные случаи определения намерений данного человека, это всё же даёт грубую завязанную на здравом смысле интерпретацию. Напротив, максималистский (он же амбициозный) подход пытается заставить ИИ принять или следовать конкретному всеохватывающему набору ценностей – вроде конкретной моральной теории, глобального демократического консенсуса, или мета-уровневой процедуры выбора между моральными теориями.
Я считаю, что определять согласование в максималистских терминах непрактично, поскольку это сводит воедино технические, этические и политические проблемы. Может нам и надо добиться прогресса во всех трёх, но добавление двух последних может значительно снизить ясность технических проблем. Так что с этого момента, когда я говорю о согласовании, я имею в виду только согласование намерений. Я также определю, что ИИ A несогласован с человеком H, если H хотел бы, чтобы A не делал того, что A пытается сделать (если бы H был осведомлён о намерениях A). Это подразумевает, что ИИ потенциально могут быть и не согласованными, и не несогласованными. С оператором – к примеру, если делают только то, что оператора не заботит. Очевидно, считается ли ИИ согласованным или несогласованным сильно зависит от конкретного оператора, но в этом докладе я сосредоточусь на ИИ, явно несогласованных с большинством людей.
Одно важное свойство этих определений: используя слово «пытается», они сосредотачиваются на намерениях ИИ, не на итоговых достигнутых результатах. Я думаю, это имеет смысл, потому что нам следует ожидать, что СИИ будут очень хорошо понимать мир, и что ключевой задачей безопасности будет правильная настройка их намерений. В частности, я хочу прояснить, что когда я говорю о несогласованном СИИ, типичный пример в моей голове – это не агент, который не слушается потому что неправильно понимает, что мы хотим, или слишком буквально понимает наши инструкции (что Бостром называл «извращённым воплощением»). Кажется вероятным, что СИИ будут по умолчанию очень хорошо понимать намерения наших инструкций, ведь они вероятно будут обучены на задачах, включающих людей и данные о людях – и понимание человеческого разума особенно важно для компетентности в таких задачах и во внешнем мире.1 Скорее, моё главное беспокойство в том, что СИИ будет понимать, что мы хотим, но ему просто будет всё равно, потому что приобретённые при обучении мотивации оказались не теми, какие нам хотелось.
Идея, что ИИ не будут автоматически приобретать правильные мотивации за счёт большего интеллекта – это следствие сформулированного Бостромом тезиса ортогональности, который гласит, что «более-менее любой уровень интеллекта в принципе может сочетаться с более-менее любой конечной целью». Для наших целей хватит и более слабой версии: просто что высокоинтеллектуальный агент может иметь крупномасштабные цели, несогласованные с большинством людей. Доказательство существования предоставляется высокофункциональными психопатами, которые понимают, что другие люди мотивированы моралью, и могут использовать этот факт для предсказания их действий и манипуляции, но всё же не мотивированы моралью сами.
Мы можем надеяться, что, осторожно выбирая задачи, на которых агент будет обучаться, мы можем предотвратить выработку этими агентами целей, конфликтующих с нашими, без необходимости прорывов в техническом исследовании безопасности. Почему это может не сработать? Существует разделение проблему внешней несогласованности и проблему внутренней несогласованности. Я объясню обе и предоставлю аргументы, почему они могут возникнуть. Я также рассмотрю некоторые ограничения такого подхода и альтернативные точки зрения на согласование.
Внешняя и внутренняя несогласованность: стандартное описание
Мы проводим машинное обучение системы для выполнения желаемого поведения, оптимизируя значение какой-то целевой функции – к примеру, функции вознаграждения в обучении с подкреплением. Проблема внешней несогласованности – это когда у нас не получилось реализовать целевую функцию, описывающую то поведение, которое мы на самом деле от системы хотим, не награждая также нежелательное поведение. Ключевое соображение за этим концептом – явно программировать выражающие все наши желания по поводу поведения СИИ целевые функции сложно. Нет простой метрики, которую нам бы хотелось, чтобы агенты максимизировали – скорее, желаемое поведение СИИ лучше формулируется в концептах вроде послушности, согласия, поддержки, морали и кооперации, которые мы в реалистичном окружении не можем точно определить. Хоть мы и можем определить для них цели-посредники, согласно Закону Гудхарта какое-нибудь нежелательное поведение будет очень хорошо оцениваться этими посредниками и потому будет подкрепляться у обучающихся на них ИИ. Даже сравнительно примитивные современные системы демонстрируют обходящее спецификации поведение, иногда довольно креативное и неожиданное, хотя концепты, которые мы пытаемся определить, гораздо проще.
Один из способов подойти к этой проблеме – включить человеческую обратную связь в целевую функцию, оценивающую поведение ИИ при обучении. Однако, тут есть как минимум три трудности. Первая – то, что предоставлять обратную связь от человека на все данные, нужные для обучения ИИ сложным задачам, до невозможности дорого. Это известно как проблема масштабируемого надзора; основной подход её решения – моделирование наград. Вторая – что для долгосрочных задач нам может понадобиться дать обратную связь прежде, чем у нас будет возможность увидеть все последствия действий агента. Даже в таких простых областях как го, уже зачастую очень сложно определить, насколько хорош был какой-нибудь ход, не увидев, как дальше пройдёт игра. А в больших областях может быть слишком много сложных последствий, чтобы их мог оценить один человек. Основной подход к этой проблеме – использование нескольких ИИ для рекурсивного разложения задачи оценивания, как Дебаты, Рекурсивное Моделирование Наград, и Итеративное Усиление. Через конструирование искусственных оценивателей, эти техники также пытаются подобраться и к третьей трудности с человеческой обратной связью: что людьми можно манипулировать, чтобы они интерпретировали поведение позитивнее, например, выдавая им обманчивые данные (как в случае робота-руки тут).
Даже если мы решим внешнюю несогласованность, определив «безопасную» целевую функцию, мы всё ещё сможем встретить провал внутренней согласованности: наши агенты могут выработать цели, отличающиеся от заданных целевой функцией. Это вероятно, когда обучающее окружение содержит постоянно полезные для получения высокой оценки данной целевой функции подцели, такие как сбор ресурсов и информации, или получение власти.2 Если агенты стабильно получают более высокое вознаграждение при достижении этих подцелей, то оптимизатор может отобрать агентов, преследующих эти подцели сами по себе. (Это один из путей, которым агенты могут выработать финальную цель набора власти, как упомянуто в начале раздела про Цели и Агентность.)
Это аналогично тому, что произошло во время эволюции людей; мы были «обучены» увеличивать свою генетическую приспособленность. В окружении наших предков, подцели вроде любви, счастья и социального статуса были полезны для достижения высокой совокупной генетической приспособленности, так что мы эволюционировали стремление к ним. Но сейчас, когда мы достаточно могущественны, чтобы изменять природный мир согласно нашим желаниям, есть значительные различия между поведением, которое максимизирует генетическую приспособленность (например, частое донорство спермы или яйцеклеток), и поведением, которое мы демонстрируем, преследуя эволюционировавшие у нас мотивации. Другой пример: предположим, мы вознаграждаем агента каждый раз, когда он корректно следует инструкции человека, так что ведущее к такому поведению мышление поощряется оптимизатором. Интуитивно, мы надеемся, что агент выработает цель подчинения людям. Но также вполне представимо, что послушное поведение агента руководствуется целью «не быть выключенным», если агент понимает, что непослушание приведёт к его выключению – в этом случае оптимизатор будет на самом деле вознаграждать цель выживания каждый раз, когда она будет приводить к следованию инструкциям. Два агента, каждый мотивированный одной из этих целей, могут вести себя очень похоже до тех пор, пока они не окажутся в положении, в котором можно не подчиниться, не будучи выключенным.3
Что определяет, какой из этих агентов на самом деле возникнет? Как я упоминал выше, один важный фактор – это наличие подцелей, которые стабильно приводят к вознаграждению при обучении. Другой – насколько просто и выгодно оптимизатору сделать агента мотивированным этими подцелями, а не обучающей целевой функцией. В случае людей, к примеру, концепт совокупной генетической приспособленности был очень сложным для встраивания эволюцией в мотивационную систему людей. И даже если бы наши предки каким-то образом выработали этот концепт, им было бы сложно придумать лучшие способы его достижения, чем и так вложенные в них эволюцией. Так что в окружении наших предков было сравнительно мало давления отбора на внутреннюю согласованность с эволюцией. В контексте обучения ИИ это значит, что сложность целей, которые мы пытаемся в него вложить, мешает два раза: она не только усложняет определение приемлемой целевой функции, но ещё и уменьшает вероятность того, что ИИ станет мотивированным предполагаемыми целями, даже если функция была правильной. Конечно, мы ожидаем, что потом ИИ станут достаточно интеллектуальными, чтобы точно понимать, какие цели мы предполагали им дать. Но к тому времени будет сложно убрать их уже существующие мотивации, и скорее всего они будут достаточно умны для попыток обманчивого поведения (как в гипотетическом примере из предыдущего абзаца).
Так как мы можем увериться во внутренней согласованности СИИ с намерениями человека? Эта область исследования пока что получала меньше внимания чем внешнее согласование, потому что это более хитрая задача. Один из потенциальных подходов включает добавление тренировочных примеров, в которых поведение агентов, мотивированных несогласованными целями, будет отличаться от согласованных агентов. Однако, проектировать и создавать такие тренировочные данные сейчас намного сложнее, чем массовое производство данных, например, процедурно-генерируемой симуляцией или поиском по сети. Частично это потому, что конкретные тренировочные данные в целом сложнее создавать, но есть ещё три дополнительных причины. Во-первых, по умолчанию мы просто не знаем, какие нежелательные мотивации возникают в наших агентах, на наказании каких нужно сосредоточиться. Техники интерпретируемости могут с этим помочь, но их разработка очень сложна (я рассмотрю это в следующем разделе). Во-вторых, наиболее вероятно приобретаемые агентами несогласованные мотивации – это те, которые наиболее устойчиво полезны. Например, особенно сложно спроектировать тренировочное окружение, в котором доступ к большему количеству информации приводит к более низкой награде. В-третьих, нас больше всего беспокоят агенты, имеющие несогласованные крупномасштабные цели. Но крупномасштабные цели сложнее всего настроить при обучении, неважно, в симуляции или в реальном мире. Так что чтобы подобраться к этим проблемам или обнаружить новые техники внутреннего согласования требуется ещё много работы.
Более холистический взгляд на согласованность
Внешнее согласование – это задача корректного оценивания поведения ИИ; внутреннее согласование – задача заставить цели ИИ соответствовать этим оценкам. В некоторой степени мы можем трактовать эти две задачи как отдельные; однако, я думаю, также важно иметь в виду, каким образом картина «согласование = внешнее согласование + внутреннее согласование» может быть неполна или обманчива. В частности, что вообще значит реализовать «безопасную» целевую функцию? Это функция, которую мы хотим, чтобы агент действительно максимизировал? Но хоть максимизация ожидаемой награды имеет смысл в формальных случаях вроде MDP или POMDP, она куда хуже определена при реализации целевой функции в реальном мире. Если есть последовательность действий, позволяющая агенту исказить канал получения вознаграждения, то «запровологоловиться», максимизировав этот канал, практически всегда будет стратегией для получения наивысшего сигнала вознаграждения в долгосрочной перспективе (даже если функция вознаграждения сильно наказывает действия, к этому ведущие).4 И если мы используем человеческую обратную связь, то, как уже обсуждалось, оптимально будет манипулировать надсмотрщиками, чтобы они выдали максимально позитивную оценку. (Существует предположение, что «миопическое» обучение может решить проблемы искажения и манипуляции, но тут я аргументировал, что оно лишь прячет их.)
Вторая причина, почему функция вознаграждения – это «дырявая абстракция» в том, что любые реальные агенты, которых мы можем обучить в обозримом будущем, будут очень, очень далеки от предельно оптимального поведения нетривиальных функций вознаграждения. В частности, они будут замечать вознаграждения лишь крохотной доли возможных исходов. Более того, если это основанные на обобщении агенты, то они зачастую будут подходить к выполнению новых задач с очень маленьким обучением конкретно на них. Так что поведение агента почти всегда будет в первую очередь зависеть не от настоящих значений функции вознаграждения, а скорее от того, как агент обобщил ранее собранные в других состояниях данные.5 Это, наверное, очевидно, но стоит особо отметить, потому что очень многие теоремы о сходимости алгоритмов обучения с подкреплением полагаются на рассмотрение всех состояний на бесконечном пределе, так что скажут нам очень мало про поведение в конечном промежутке времени.
Третья причина – исследователи уже сейчас модифицируют функции вознаграждения так, чтобы это меняло оптимальные пути действий, когда это кажется полезным. К примеру, мы добавляем условия формирования для появления неявного плана обучения, или бонусы за исследование, чтобы вытолкнуть агента из локального оптимума. Особенно относящийся к безопасности пример - нейросеть можно модифицировать так, чтобы её оценка зависела не только от вывода, но и от внутренних отображений. Это особенно полезно для оказания влияния на то, как нейросети обобщает – к примеру, можно заставить их игнорировать ложные корреляции в тренировочных данных. Но опять же, это усложняет интерпретацию функций вознаграждения как спецификаций желаемых исходов процесса принятия решений.
Как тогда нам про них думать? Ну, у нас есть набор доступных инструментов, чтобы удостовериться, что СИИ будет согласованным – мы можем менять используемые при обучении нейронные архитектуры, алгоритмы обучения с подкреплением, окружения, оптимизаторы, и т.д. Следует думать о нашей возможности определять целевую функцию как о самом мощном инструменте. Но мощном не потому, что она сама определяет мотивации агента, а скорее потому, что вытащенные из неё примеры оформляют мотивации и мышление агента.
С этой точки зрения, нам стоит меньше беспокоиться об абсолютных оптимумах нашей целевой функции, поскольку они никогда не проявятся при обучении (и поскольку они скорее всего будут включать в себя перехват вознаграждений). Вместо этого, стоит сосредоточиться на том, как целевые функции, в сочетании с другими частями настроек обучения, создают давление отбора в сторону агентов, думающих тем способом, которым нам хочется, и потому имеющих желательные мотивации в широком диапазоне обстоятельств.6 (См. этот пост Санджива Ароры для более математического оформления похожего заявления.)
Эта перспектива предоставляет нам другой способ взглянуть на аргументы из предыдущего раздела о высокоагентных ИИ. Дело обстоит не так, что ИИ обязательно станут думать в терминах крупномасштабных консеквенциалистских целей, и наш выбор целевой функции лишь определит, какие цели они будут максимизировать. Скорее, все когнитивные способности ИИ, включая системы мотивации, выработаются при обучении. Целевая функция (и остальные настройки обучения) определят пределы их агентности и их отношение к самой целевой функции! Это может позволить нам спроектировать планы обучения, создающие давление в сторону очень интеллектуальных и способных, но не очень агентных ИИ – таким образом предотвращая несогласованность, не решая ни внешнего, ни внутреннего согласования.
Но если не получится, то нам понадобится согласовать агентные СИИ. В дополнение к техникам, которые я описывал раньше, для этого надо точнее разобраться в концептах и целях, которыми обладают наши агенты. Я пессимистичен по поводу полезности математики в таких высокоуровневых вещах. Для упрощения доказательств математические подходы часто абстрагируются от аспектов задачи, которые нас на самом деле волнуют – делая эти доказательства куда менее ценными, чем они кажутся. Я думаю, что эта критика относится к подходу максимизации полезности, как уже обсуждалось. Другие примеры включают большинство доказательств о сходимости обучения с подкреплением и об устойчивости конкурентного обучения. Я думаю, что вместо этого, нам нужны принципы и подходы похожие на использующихся в когнитивных науках и эволюционной биологии. Я думаю, что категоризация внутренней несогласованности на верховую и низовую – важный пример такого прогресса; я также был бы рад увидеть подход, который позволит осмысленно говорить о взломе градиента7 и различии между мотивацией вознаграждающим сигналом и вознаграждающей функцией. Нам стоит называть функции вознаграждения как «правильные» или «неправильные» только в той степени, в какой они успешно или неуспешно толкают агента к приобретению желаемых мотиваций и избеганию проблем вроде перечисленных.
В последнем разделе я рассмотрю вопрос, сможет ли в случае нашего провала СИИ, имеющий цель увеличения своего влияния за счёт людей, преуспеть в этом.
- 1. Конечно, то, что люди говорят, что они хотят, на что действия людей указывают, что они этого хотят, и что люди в тайне хотят, часто разные вещи. Но опять же, я не особо беспокоюсь о том, что суперинтеллект не сможет понять это разделение, если захочет.
- 2. Заметим тонкое различие между существованием полезных подзадач и моими ранними рассуждениями о тезисе инструментальной конвергенции. Первое заявление – про то, что для конкретных задач, на которые мы обучаем СИИ, есть некие подцели, вознаграждаемые во время обучения. Второе – про то, что для большинства целей, которые может выработать СИИ, есть конкретные подцели, которые будут полезны для преследования этих целей после запуска. Второе включает первое только если конвергентные инструментальные подцели возможны и вознаграждаемы во время обучения. Самоулучшение – конвергентная инструментальная цель, но я не ожидаю, что она будет доступна в большинстве тренировочных окружений, а где будет, возможно будет наказываться.
- 3. На самом деле эти два примера демонстрируют два разных типа провала внутреннего согласования: верховые и низовые меса-оптимизаторы. При обучении на функции вознаграждения R верховые меса-оптимизаторы выучивают цели, ведущие к высокой оценке по R, или, иными словами, каузально сверху по течению от R. К примеру, люди научились ценить поиск еды, потому что это ведёт к большему репродуктивному успеху. А низовые меса-оптимизаторы выучивают цели, находящиеся каузально внизу по течению от R: к примеру, выучивают цель выживания и понимают, что плохая оценка по R приведёт к выбрасыванию из оптимизационной процедуры. Это стимулирует их высоко оцениваться по R и скрывать свои истинные цели – исход, называемый обманчивой согласованностью. См. дальнейшую дискуссию здесь.
- 4. Тут важно разделять между сообщением, кодом и каналом (как у Шеннона). В контексте обучения с подкреплением можно интерпретировать сообщение как цель, предполагаемую проектировщиками системы (например, выигрывать в Starcraft); код – это вещественные числа, соответствующие состояниям, с большими числами означающими лучшие состояния; и канал – то, что передаёт эти числа агенту. Пока что мы предполагали, что цель, которой обучается агент, основана на сообщении, которое его оптимизатор выводит из своей функции вознаграждения (хотя иногда так, что оно неправильно обобщается, потому что может быть сложно декодировать предполагаемое сообщение из конечного числа приведённых наград). Но также возможно, что агент научится беспокоиться о состоянии самого канала. Я рассматриваю боль у животных как пример этого: сообщение о полученных повреждениях; код в том, что большая боль означает большие повреждения (и тонкие моменты типы и интенсивности); и канал – нейроны, передающие эти сигналы в мозг. В некоторых случаях код меняется – к примеру, если получить удар током, но знать, что он безопасный. Если бы мы беспокоились только о сообщении, то мы бы игнорировали такие случаи, потому что они не выдают содержания о повреждениях тела. Но на самом деле мы всё равно пытаемся предотвратить такие сигналы, потому что не хотим чувствовать боль! Схожим образом, агент, обученный сигналом вознаграждения, может хотеть продолжать получать этот сигнал даже если он больше не несёт то же сообщение. По-другому это можно описать как разницу между интернализацией базовой цели и моделированием этой цели, как описано в четвёртом разделе Рисков Выученной Оптимизации в Продвинутых Системах Машинного Обучения.
- 5. Ошибка представления об агентах обучения с подкреплением только как о максимизаторах награды (не имеющих других выученных инстинков и целей) имеет интересную параллель в истории изучения мышления животных, когда бихевиористы сосредотачивались на способах, которыми животные обучались новому поведению для увеличения вознаграждения, игнорируя внутренние аспекты их мышления.
- 6. Полезный пример – альтруизм у людей. Хоть и нет консенсуса о его точных эволюционных механизмах, можно заметить, что наши альтруистические инстинкты простираются далеко за пределы прямолинейных случаев альтруизма по отношению к родственникам и напрямую взаимного альтруизма. Другими словами, некоторое взаимодействие между нашей эволюционной подгонкой и нашим разнообразным сложным окружением привело к возникновению довольно обобщённых альтруистических инстинктов, делающих людей «безопаснее» (с точки зрения других видов).
- 7. См. пост Эвана Хубингера: «Взлом градиента – это термин, который я в последнее время использую, чтобы описать явление, когда обманчиво согласованный меса-оптимизатор может быть способен намеренно действовать так, чтобы заставить градиентный спуск обновить его в конкретную сторону.»
Безопасность СИИ с чистого листа. Контроль
Важно заметить, что моих предыдущих аргументов самих по себе недостаточно для заключения, что СИИ перехватит у нас контроль над миром. Как аналогию можно взять то, что научные знания дают нам куда больше возможностей, чем у людей каменного века, но сомнительно, что один современный человек, заброшенный назад в то время, смог бы захватить весь мир. Этот последний шаг аргументации полагается на дополнительные предсказания о динамике перехода от людей к СИИ в качестве умнейших агентов на Земле. Она будет зависеть от технологических, экономических и политических факторов, которые я рассмотрю в этом разделе. Возвращающейся темой будет важность ожидания того, что СИИ будет развёрнут на многих разных компьютерах, а не привязан к одному конкретному «железу», как люди.1
Я начну с обсуждения двух очень высокоуровневых аргументов. Первый – что более обобщённый интеллект позволяет приобрести большую власть, с помощью крупномасштабной координации и разработки новых технологий. И то, и другое вложилось в установлении контроля над миром человеческим видом; и то, и другое вкладывалось в другие большие сдвиги распределения сил (например, индустриальную революцию). Если все люди и согласованные СИИ менее способны в этих двух отношениях, чем несогласованные СИИ, то стоит ожидать, что последние разработают больше новых технологий и используют их для накопления большего количества ресурсов, если на них не будут возложены сильные ограничения и не окажется, что они не способны хорошо координироваться (я кратко рассмотрю обе возможности).
Однако, с другой стороны, захватить мир очень сложно. В частности, если люди у власти видят, что их позиции ослабляются, они наверняка предпримут действия, чтобы это предотвратить. Кроме того, всегда намного проще понимать и рассуждать о более конкретной и осязаемой задаче; а крупномасштабное будущее развитие обычно очень плохо прогнозируется. Так что даже если сложно отвергнуть приведённые высокоуровневые аргументы, всё равно могут быть какие-то пока что не замеченные решения, которые будут замечены, когда для этого появятся стимулы, а набор доступных подходов будет более понятен.
Как мы можем пойти дальше этих высокоуровневых аргументов? В этом разделе я представлю два типа катастрофических сценариев и четыре фактора, которые повлияют на нашу способность удерживать контроль, если мы разработаем не полностью согласованные СИИ:
1. Скорость разработки ИИ
2. Прозрачность ИИ-систем
3. Стратегии ограниченного развёртывания
4. Политическая и экономическая координация людей
Сценарии катастрофы
Было несколько попыток описать катастрофические исходы, которые могут быть вызваны несогласованными суперинтеллектами, хотя очень сложно охарактеризовать их детально. Говоря в общем, самые убедительные сценарии делятся на две категории. Кристиано описывает СИИ, получающие влияние изнутри наших нынешних экономических и политических систем, забирая или получая от людей контроль над компаниями и государственными учреждениями. В некоторый момент «мы достигаем точки, когда мы уже не можем оправиться от одновременного отказа автоматизации» - после чего эти СИИ уже не имеют стимула следовать человеческим законам. Хансон также представляет сценарий, в котором виртуальные разумы приходят к экономическому доминированию (хотя он менее взволнован по поводу несогласованности, отчасти потому, что он сосредотачивается на эмулированных человеческих разумах). В обоих сценариях биологические люди теряют влияние, потому что они менее конкурентноспособны в стратегически важных задачах, но никакой одиночный СИИ не способен захватить контроль над миром. В некоторой степени, эти сценарии аналогичны нашей нынешней ситуации, когда большие корпорации и учреждения смогли накопить много силы, хоть большинство людей и не согласны с их целями. Однако, поскольку эти организации состоят из людей, на них всё же оказывается давление в сторону согласованности с человеческими целями, что неприменимо к группе СИИ.
Юдковский и Бостром, напротив, описывают сценарии, в которых один СИИ набирает силу в основном через технологические прорывы, будучи в основном отделённым от экономики. Ключевое предположение, разделяющее эти две категории сценариев – сможет ли отдельный СИИ таким образом стать достаточно могущественным, чтобы захватить контроль над миром. Существующие описания таких сценариев приводят в пример сверхчеловеческие нанотехнологии, биотехнологии и компьютерный взлом; однако, детально их охарактеризовать сложно, потому что эти технологии пока не существуют. Однако кажется весьма вероятным, что существуют какие-то будущие технологии, которые предоставят решающее стратегическое преимущество, если ими обладает только одно действующее лицо, так что ключевой фактор, определяющий правдоподобность таких сценариев – будет ли разработка ИИ достаточно быстрой, чтобы допустить такую концентрацию сил.
В обоих случаях люди и согласованные ИИ в итоге окажутся намного слабее несогласованных ИИ, которые тогда смогут завладеть нашими ресурсами в своих собственных целях. Ещё худший сценарий – если несогласованный СИИ действует намеренно враждебно людям – к примеру, угрожает ради уступок. Как мы можем избежать таких сценариев? Есть искушение напрямую целиться в финальную цель способности согласовывать произвольно умные ИИ, но я думаю, что наиболее реалистичный горизонт планирования доходит до ИИ, намного лучших, чем люди в исследованиях безопасности ИИ. Так что нашей целью должно быть удостовериться, что эти ИИ согласованы, и что их исследования будут использоваться при создании следующих. Категорию катастрофы, которая помешает этому с больше вероятностью, зависит не только от интеллекта, агентности и целей разработанных нами ИИ, но и от четырёх перечисленных выше факторов, которые я сейчас рассмотрю подробнее.
Скорость разработки ИИ
Если разработка ИИ будет продвигаться очень быстро, то мы будем менее способны адекватно на неё реагировать. В частности, нам стоит интересоваться, сколько времени займёт продвижение СИИ от интеллекта человеческого уровня до суперинтеллекта, то, что мы называем периодом взлёта. История систем вроде AlphaStar, AlphaGo и OpenAI Five даёт нам некоторое свидетельство, что он будет коротким: каждая из них после длительного периода разработки быстро продвинулась от любительского до сверхчеловеческого уровня. Схожее явление произошло с эволюцией людей, когда нам потребовалась всего пара миллионов лет, чтобы стать намного умнее шимпанзе. В нашем случае, одним из ключевых факторов стало масштабирование «железа» мозга – которое, как я уже упоминал, намного проще для СИИ, чем для людей.
Вопрос того, как будет влиять масштабирование железа и времени обучения, важен, но в долгосрочной перспективе самый важный вопрос – как будет влиять масштабирование интеллекта разработчиков – потому что однажды большая часть исследований в области ИИ и смежных будет выполняться самими СИИ (в процессе, который я называл рекурсивным улучшением). В частности, в интересующем нас диапазоне интеллекта, будет ли рост интеллекта СИИ на δ увеличивать интеллект лучшего следующего СИИ, которого он может разработать, на больше или меньше, чем на δ? Если больше, то рекурсивное улучшение в какой-то момент резко ускорит прогресс разработки ИИ. Юдковский заявляет в пользу этой гипотезы:
История эволюции гоминидов до сегодняшнего дня показывает, что для существенного роста реальных когнитивных способностей не требуется экспоненциально возрастающего количества эволюционной оптимизации. Чтобы добраться от Человека Прямоходящего до Человека Разумного не потребовалось в десять раз большего эволюционного интервала, чем от Австралопитека до Человека Прямоходящего. Вся выгода от открытий вроде изобретения агрикультуры, науки или компьютеров произошла безо всякой способности вкладывать технологические дивиденды в увеличение размера мозга, ускорение нейронов или улучшение низкоуровневых алгоритмов, ими используемых. Раз ИИ может вкладывать плоды своего интеллекта в аналоги всего этого, нам стоит ожидать, что кривая развития ИИ будет куда круче, чем человеческая.
Я рассматриваю это как сильный аргумент в пользу того, что темп прогресса однажды станет намного быстрее, чем сейчас. Я куда менее уверен по поводу того, когда произойдёт это ускорение – к примеру, может оказаться, что описанная петля положительной обратной связи не будет иметь большого значения до момента, когда СИИ уже будет суперинтеллектуальным, так что период взлёта (определённый выше) будет всё же довольно медленным. Есть конкретные возражения против наиболее экстремальных сценариев быстрого взлёта, постулирующих резкий скачок в способностях ИИ перед тем, как он станет оказывать трансформативное2 влияние. Некоторые ключевые аргументы:
- Разработка СИИ будет конкурентным усилием, в котором много исследователей будут стремиться встроить в свои ИИ обобщённые когнитивные способности, и будут постепенно продвигаться в этом. Это делает маловероятным наличие низковисящих плодов, обеспечивающих при их достижении большой скачаок способностей. (Можно рассмотреть культурную эволюцию как такой низковисящий плод в развитии людей, что объяснило бы, почему она привела к такому быстрому прогрессу.)
- Доступность вычислительных мощностей, являющаяся по некоторым мнениям ключевым двигателем прогресса ИИ, увеличивается довольно плавно.
- Плавный технологический прогресс исторически куда больше распространён, чем скачкообразный. К примеру, прогресс шахматных ИИ был устойчивым и предсказуемым много десятилетий.
Заметим, что все эти аргументы совместимы с плавной, но ускоряющейся со всё большим вкладом ИИ-систем разработкой ИИ.
Прозрачность ИИ-систем
Прозрачная ИИ-система – такая, чьи мысли и поведение мы можем понять и предсказать; мы можем быть более уверенными в своей способности удерживать контроль над СИИ, если он прозрачный. Если мы можем сказать, когда система планирует предательское поведение, то мы можем выключить её до того, как она получит возможность осуществить свой план. Заметим, что подобная информация также была бы ценна для улучшения координации людей с СИИ, и, конечно, для обучения, как я кратко рассматривал в предыдущих разделах.
Хубингер перечисляет три широких подхода к увеличению прозрачности ИИ. Один – через создание инструментов интерпретируемости, которые позволят нам анализировать внутреннее функционирование существующей системы. Наша способность интерпретировать процессы в мозгах людей или животных сейчас не очень развита, но это частично из-за сложности высокоточных измерений. Напротив, в нейросетях мы можем напрямую прочитать каждый вес и каждую активацию, и даже менять их по отдельности, чтобы посмотреть, что произойдёт. С другой стороны, если наши наиболее развитые системы будут быстро меняться, то предыдущие исследования прозрачности смогут быстро устаревать. В этом отношении нейробиологам – которые могут изучать одну мозговую архитектуру десятилетиями – проще.
Второй подход – создание стимулов к прозрачности во время обучения. К примеру, мы можем вознаграждать агента за объяснение своего мыслительного процесса, или за поведение предсказуемым образом. Интересно заметить, что есть гипотеза, подразумевающая, что это произошло во время эволюции людей, так что можно предположить, что мультиагентные взаимодействия могут быть полезны для создания таких стимулов (если мы сможем найти способ предотвращения возникновения ещё и стимулов к обману).
Третий подход – проектирование алгоритмов и архитектур, которым будет присуща лучшая интерпретируемость. К примеру, основанный на модели планировщик вроде AlphaGo исследует множество возможных веток дерева игры, чтобы решить какой сделать ход. Посмотрев, какие ходы он исследует, мы можем понять, что он планирует, до того, как он выберет ход. Однако, мы тогда будем полагаться на то, что AlphaGo использует точную модель го. Более обобщённым агентам в больших окружениях надо будет планировать с использованием сжатых представлений этих окружений, которые по умолчанию будут менее интерпретируемы. Также ещё предстоит увидеть, могут ли склонные к прозрачности архитектуры и алгоритмы работать так же хорошо, как более закрытые альтернативы, но я сильно подозреваю, что нет.
Несмотря на присущие каждому из этих подходов сложности, у нас есть одно связанное с прозрачностью преимущество – доступ к разным версиям ИИ. Этим пользуется механизм перекрёстного осмотра в Дебатах. Или, как более практичный пример, если ИИ-системы немного глупее людей пытаются обмануть своих операторов, то это довольно явное свидетельство, что более интеллектуальные версии тоже будут это делать. Однако, этот подход ограничен, потому что он не позволяет нам обнаружить небезопасные планы, пока они не повлияли на поведение. Если понимание опции предательства всегда будет сопровождаться пониманием, что оно пока не сработает, то мы не сможем наблюдать тревожные сигналы в поведении до тех пор, пока ИИ не разовьётся до уровня, на котором посчитает, что предательство будет успешным.
Ограниченные стратегии развёртывания
Если рассмотреть мою раннюю аналогию современного человека, заброшенного в каменный век, то ключевым фактором, который помешает ему захватить мир, будет то, что он будет очень ограниченно «развёрнут». Он сможет быть только в одном месте одновременно; не сможет очень быстро путешествовать или даже посылать сообщения; не будет устойчив к несчастным случаям; и сможет использовать очень мало существующей инфраструктуры. Напротив, для глубокого обучения системы требуется куда больше вычислительных ресурсов, чем для её работы – когда СИИ будет обучен, скорее всего будет относительно дёшево запустить много его копий. Несогласованный суперинтеллект с доступом в интернет будет способен создать тысячи копий себя, которые мы не будем контролировать, купив (или взломав) необходимое оборудование. В этот момент наши соображения о способностях «одиночного СИИ» устаревают, и более подходящей становится терминология о «втором виде».
Можно представить попытки избежать этого сценария, разворачивая СИИ более ограниченно – к примеру, запуская их на отдельном безопасном оборудовании и позволяя им предпринимать только некоторые конкретные заранее одобренные действия (например, отвечать на вопросы). Это кажется значительно более безопасным. Однако, это также кажется и значительно менее вероятным в конкурентной среде – судя по сегодняшним тенденциям, более правдоподобным исходом будет, что почти все сразу же будут иметь доступ к персональному СИИ-ассистенту через свой телефон. Это приводит нас к четвёртому фактору:
Человеческая политическая и экономическая координация
По умолчанию нам не стоит полагаться на высокий уровень координации в предотвращении проблем безопасности СИИ. Мы пока не смогли адекватно скоординироваться даже для предотвращения глобального потепления, которое является хорошо задокументированной и постепенно ухудшающейся проблемой. В случае развёртывания СИИ, куда сложнее ясно экстраполировать будущие опасности из нынешнего поведения. В то же время при отсутствии технических решений проблем безопасности будут сильные краткосрочные экономические стимулы игнорировать недостаток гарантий по поводу умозрительных будущих событий.
Однако, это очень сильно зависит от трёх предыдущих факторов. Куда проще будет прийти к консенсусу по поводу того, как иметь дело с суперинтеллектом, если ИИ-системы будут подходить, а потом превосходить человеческий уровень на протяжении десятилетий, а не недель или месяцев. Это особенно верно, если менее способные системы продемонстрируют непослушание, которое явно было бы катастрофическим в исполнении более способных агентов. В то же время, разные действующие лица, которые могут находиться на переднем фронте разработки СИИ – правительства, компании, некоммерческие организации – будут варьироваться в своих реакциях на проблемы безопасности, своей кооперативности и своей способности реализовывать стратегии ограниченного развёртывания. И чем больше их будет вовлечено, тем сложнее будет координация между ними.
- 1. Для изучения возможных последствий программного интеллекта (отдельно от последствий увеличенного интеллекта) см. «Век Эмов» Хансона.
- 2. Приблизительно означает «очень сильное», как минимум на уровне индустриальной революции – Прим. перев.
Безопасность СИИ с чистого листа. Заключение
Давайте заново рассмотрим изначальный аргумент второго вида вместе с дополнительными заключениями и прояснениями из остального доклада.
- Мы создадим ИИ куда умнее людей; то есть, куда лучше людей использующих обобщённые когнитивные навыки для понимания мира.
- Эти СИИ будут автономными агентами, преследующими высокомасшабные цели, потому что направленность на цели подкрепляется во многих тренировочных окружениях, и потому что эти цели будут иногда обобщаться до больших масштабов.
- Эти цели по умолчанию будут несогласованы с тем, что мы хотим, потому что наши желания сложны и содержат много нюансов, а наши существующие инструменты для формирования целей ИИ неадекватны задаче.
- Разработка автономных несогласованных СИИ приведёт к тому, что они получат контроль над будущим человечества, с помощью своего сверхчеловеческого интеллекта, технологии и координации – в зависимости от скорости разработки ИИ, прозрачности ИИ-систем, того, насколько ограниченно их будут развёртывать, и того, как хорошо люди могут политически и экономически кооперироваться.
Лично я наиболее уверен в 1, потом в 4, потом в 3, потом в 2 (в каждом случае при условии выполнения предыдущих утверждений) – хотя я думаю, что у всех четырёх есть пространство для обоснованного несогласия. В частности, мои аргументы про цели СИИ могут слишком полагаться на антропоморфизм. Даже если это и так, всё же очень неясно, как рассуждать о поведении обобщённо интеллектуальных систем не прибегая к антропоморфизму. Главная причина, по которой мы ожидаем, что разработка СИИ будет важным событием – то, что история человечества показывает нам, насколько интеллект важен. Но к успеху людей привёл не только интеллект – ещё и наше неисчерпаемое стремление к выживанию и процветанию. Без этого мы бы никуда не добрались. Так что пытаясь предсказать влияние СИИ, мы не можем избежать мыслей о том, что заставит их выбирать одни типы интеллектуального поведения, а не другие – иными словами, мыслей о их мотивациях.
Заметим, впрочем, что аргумент второго вида и перечисленные мной сценарии не задумываются как исчерпывающее описание всех связанных с ИИ экзистенциальных рисков. Даже если аргумент второго вида окажется некорректным, ИИ всё равно скорее всего будет трансформативной технологией, и нам стоит попытаться минимизировать потенциальный вред. В дополнение к стандартным беспокойствам о неправильном использовании (к примеру, об использовании ИИ для разработки оружия), мы можем также волноваться о том, что рост способностей ИИ приведёт к нежелательным структурным изменениям. К примеру, они могут двинуть баланс щита и меча в кибербезопасности, или привести к большей централизации человеческого экономического влияния. Думаю, сценарий Кристиано «уход со всхлипом» тоже подпадает в эту категорию. Однако, было мало глубоких исследований того, какие структурные изменения могу привести к долговременному вреду, так что я не склонен особо полагаться на такие аргументы, пока они не будут более тщательно исследованы.
Напротив, мне кажется, сценарии захвата власти ИИ, на которых сосредоточен этот доклад, куда лучше разобраны – но опять же, как указано выше, имеют большие вопросительные знаки у некоторых ключевых предпосылок. Однако, важно различить вопрос того, насколько вероятно, что аргумент второго вида корректен, и вопрос того, насколько серьёзно нам нужно его рассматривать. Мне кажется удачной такая аналогия от Стюарта Расселла: предположим, мы получили сообщение из космоса о том, что инопланетяне прилетят на Землю в какой-то момент в следующие сто лет. Даже если подлинность сообщения вызывает сомнения, и мы не знаем, будут ли инопланетяне враждебны, мы (как вид) точно должны ожидать, что это будет событие огромного значения, если оно произойдёт, и направить много усилий на то, чтобы оно прошло хорошо. В случае появления СИИ, хоть и есть обоснованные сомнения по поводу того, на что это будет похоже, это в любом случае может быть самым важным событием из когда-либо произошедших. Уж по самой меньшей мере, нам стоит приложить серьёзные усилия для понимания рассмотренных тут аргументов, того, насколько они сильны, и что мы можем по этому поводу сделать.1
Спасибо за чтение, и ещё раз спасибо всем, кто помог мне улучшить этот доклад. Я не ожидаю, что все согласятся со всеми моими аргументами, но я думаю, что тут ещё много что можно обсудить и предоставить больше анализов и оценок ключевых идей в безопасности СИИ. Я сейчас рассматриваю такую работу как более ценную и более пренебрегаемую, чем техническое исследование безопасности СИИ. Потому я недавно сменил работу в полную ставку над последним на докторскую, которая позволит мне сосредоточиться на первой. Я восторженно смотрю на то, как наше коллективное понимание будущего СИИ продолжает развиваться.
- 1. Однако, хочу явно предостеречь от заведения этого аргумента слишком далеко – например, заявляя, что работа над безопасностью ИИ должна быть глобальным приоритетом даже если вероятность связанной с ИИ катастрофы намного меньше 1%. Это заявление будет обманчивым, поскольку большинство исследователей в области безопасности считают, что риск намного выше; и также потому, что, если он на самом деле настолько низок, вероятно есть некоторые фундаментальные заблуждения в наших концепциях и аргументах, которые надо прояснить прежде, чем мы сможем приступить к настоящей работе объектного уровня, чтобы сделать ИИ безопаснее.
Введение в каузальные основания безопасного СИИ
В этой цепочке Causal Incentives Working Group рассказывают о своём подходе к пониманию важных для безопасности ИИ понятий вроде агентности и стимулов через каузальность.
К сожалению, цепочка так и осталась недописанной.
Вступление «Введения в каузальные основания безопасного СИИ»
В следующие несколько лет появление продвинутых ИИ-систем заставит общество, организации и отдельных людей столкнуться с некоторыми фундаментальными вопросами:
- Как увериться, что продвинутые ИИ-системы будут делать именно то, что мы от них хотим (задача согласования)?
- Когда систему достаточно безопасно разрабатывать и развёртывать, и каких свидетельств достаточно, чтобы посчитать, что это так?
- Как нам сохранить свою автономию и контроль за ситуацией, когда принятие решений всё больше будет перекладываться на цифровых помощников?
В этой цепочке постов мы объясним, как каузальная точка зрения на агентность даёт концептуальные инструменты при помощи которых можно разбираться в этих вопросах. Мы постараемся минимизировать применение жаргона и объяснять его, где он всё же будет, чтобы цепочка была доступна исследователям с самым разным опытом.
Агентность
Для начала, под агентом мы имеем в виду направленную на цель систему, которая действует так, как если бы она пыталась менять мир в некотором конкретном направлении/направлениях. Примеры агентов: животные, люди и организации (в следующем посте об агентах будет больше). Понимание агентов – ключ к перечисленным вопросам. Популярно мнение, что искусственные агенты – основная экзистенциальная угроза технологий уровня сильного искусственного интеллекта, неважно, возникли ли они спонтанно или были спроектированы намеренно. Есть много потенциальных угроз нашему существованию, но высокоспособные агенты выделяются. Многих целей достигать эффективнее, накапливая влияние на мир. Если к Земле летит астероид, то он не намерен вредить людям и не будет сопротивляться отклонению. А вот несогласованные агенты могут занять противостоящую позицию активной угрозы.
Во-вторых, как для отдельных людей, так и для организаций критически важно не утратить в грядущем технологическом переходе человеческую агентность. Уже всплывает беспокойство о том, что манипулятивные алгоритмы социальных медиа и системы рекомендации контента вредят способности пользователей сосредотачиваться на своих долгосрочных целях. Более мощные ассистенты усилят эту тенденцию. По мере всё большей передачи принятия решений ИИ-системам, способность общества выбирать свою траекторию будет становиться всё более сомнительной.
Человеческую агентность тоже можно взращивать и защищать. Помогать людям помочь себе – не так патерналистично, как напрямую исполнять их пожелания. Содействие усилению людей может меньше прямого удовлетворения предпочтений зависеть от полного решения задачи согласования. Теория самодетерминации даёт свидетельства, что люди ценят агентность саму по себе, и некоторые из прав человека можно интерпретировать как защиту нашей нормативной агентности.
В третьих, искусственные агенты могут в какой-то момент сами стать объектами морали. Более ясное понимание агентности может помочь нам уточнить свою моральную интуицию и избежать неприемлемых действий. Не исключено, что некоторых этических дилемм избежать можно только создавая искусственные системы, которые объектами морали не будут.
Ключевые вопросы
Мы надеемся, что наши исследования помогут создать теорию агентности. Такая теория в идеале должна отвечать на вопросы вроде таких:
- Какие разновидности агентов могут быть созданы? По каким измерениям они могут отличаться? Мы пока в основном встречали животных, людей и организации из людей, но пространство возможных направленных на цель систем скорее всего куда больше.
- Эмерджентность: как появляются агенты? Например, в какой момент большая языковая модель стать агентной? Когда система агентов становится мета-агентов вроде организации?
- Обессиливание: как агентность теряется? Как нам уберечь и взращивать человеческую агентность?
- Какие есть этические требования по поводу разных видов систем и агентов?
- Как опознавать агентов и измерять агентность? Конкретные определения помогли бы нам заметить появление агентности у искусственных систем и потерю агентности у людей.
- Как предсказать поведение агента? К какому поведению у агентов есть стимулы? Как агенты обобщают на новые ситуации? Если мы поймём и эффекты этого поведения, то будем способны предсказывать опасность.
- Какие у агентов могут быть взаимоотношения? Какие из них вредны, а какие полезны?
- Как нам создавать агентов безопасными, справедливыми и выгодными?
Каузальность
Каузальность помогает понимать агентов. Философы давно заинтересованы каузальностью, не только потому, что точная взаимосвязь причин и следствий интригует разум, но и потому, что она лежит в основе огромного числа других понятий, многие из которых важны для понимания агентов и проектирования безопасного СИИ.
Например, воздействие и реакция – понятия, связанные с каузальностью. Мы хотим, чтобы агенты положительно влияли на мир и должным образом реагировали на инструкции. На каузальности основаны и многие другие относящиеся к делу понятия:
- Агентность, потому что направленная на цель система – та, цели которой управляют (являются причиной) её поведения.
- Намерение, относящееся к причинам действия и связи средства-цель. Намерение – важное понятие для возможности присваивать юридическую и моральную ответственность.
- Вред, манипуляция и обман, которые относятся к тому, как оказывалось воздействие на ваше благополучие, действия или убеждения, и которые обычно считаются намеренными.
- Справедливость, в частности – как реагировать на личные атрибуты вроде пола или расы и позволять им влиять на решения.
- Устойчивое обобщение при изменениях окружения куда проще для агентов с каузальной моделью этого окружения.
- Гипотетические ситуации/контрфактуалы как альтернативные миры, отличающиеся от нашего одним или многими каузальными воздействиями.

Дерево каузальности
Дальше в этой цепочке мы подробнее расскажем, как эти понятия основаны на каузальности и к каким исследованиям это привело. Мы надеемся, что это откроет другим исследователям путь путь и вдохновит их присоединиться к нашим усилиям по созданию на базе каузальности формальной теории безопасного (С)ИИ. Большая часть нашей недавней работы истекает из этого видения. Например, в «Открывая агентов» изучая агентов и «Рассуждениях о каузальности в играх» мы выработали лучшее понимание того, как сопоставить аспекты реальности с каузальными моделями. В статье про стимулы агентов мы показали, как такие модели можно анализировать, чтобы выявить важные для безопасности свойства. «Придирчивыми к пути целями» мы показали, как такой анализ может вдохновлять лучшее проектирование.
Мы надеемся, что это поможет и другим важным для безопасности СИИ направлениям исследований, вроде масштабируемого согласования, оценок опасных способностей, устойчивости, интерпретируемости, этики, управления, прогнозирования, оснований агентности и картирования рисков.
Заключение
Мы надеемся, что основанное на каузальности понимание агентности и связанных понятий поможет проектировщикам ИИ-систем, разъяснив, что есть в пространстве возможных агентов и как избежать особенно рискованных конфигураций. Оно может помочь регуляторам обрести лучшее представление о том, за чем следить, и что должно считаться достаточным свидетельством безопасности. Оно может помочь всем нам решить, какое поведение допустимо по отношению к каким системам. И, наконец, оно может помочь отдельным людям понять, что они стремятся сохранить и преумножить в своих взаимодействиях с искусственными разумами.
В следующем посте мы подробнее разъясним каузальность, каузальные модели, разные каузальные модели Перла и то, как их можно обобщить на случай наличия одного или нескольких агентов.
Каузальность: быстрое введение
Каузальные модели лежат в основе нашей работы. В этом посте мы представим краткое, но доступное объяснение каузальных моделей, которые могут описать вмешательства, контрфактуалы и агентов, что пригодится в следующих постах цепочки. Предполагается понимание основ теории вероятности, в частности – условных вероятностей.
Что такое каузальность?
Что значит, что из-за дождя трава стала зелёной? Тема каузальности философски любопытна и лежит в основе многих других важных для людей понятий. В частности, многие относящиеся к теме безопасности ИИ концепции вроде влияния, реакции, агентности, намерения, справедливости, вреда и манипуляции, сложно осмыслить без каузальной модели мира. Мы уже упоминали это в вводном посте и подробнее обсудим в следующих.
Вслед за Перлом мы примем определение каузальности через вмешательство: брызгалка сегодня каузально влияет на зелёность травы завтра, потому что если бы кто-то вмешался и выключил брызгалку, то зелёность травы была бы другой. Напротив, зелёность травы завтра не оказывает эффекта на брызгалку сегодня (предполагая, что вмешательство никто не предсказал). Так что брызгалка сегодня влияет на траву завтра, но не наоборот, как мы интуитивно и ожидаем.
Вмешательства
Каузальные Байесовские Сети (КБС) отображают каузальные зависимости между аспектами реальности при помощи ациклического ориентированного графа. Стрелка из переменной A в переменную B означает, что при сохранении значений остальных переменных A влияет на B. Например, нарисуем стрелку из брызгалки (S) к зелёности травы (G):

Каузальный граф, соответствующий нашему примеру. Брызгалка (S) влияет на зелёность травы (G).
У каждой вершины графа каузальный механизм того, как на него влияют его родительские узлы описывается условным распределением вероятностей. Для брызгалки распределение p(S) описыввет, как часто она включена, т.е. P(S=on)=30%. Для травы условное распределение p(G∣S) определяет, насколько вероятно, что трава станет зелёной, если брызгалка включена, т.е. p(G=green∣S=on)=100%, и если брызгалка выключена, т.е. p(G=green∣S=off)=30%.
Перемножая распределения мы получаем совместное распределение p(S,G)=p(S)p(G∣S), описывающее вероятность любой комбинации исходов. Совместные распределения – базовое понятие обычной теории вероятности. Их можно использовать, чтобы отвечать на вопросы вроде «какая вероятность, что брызгалка включена, при условии, что трава мокрая».
Вмешательство в систему меняет один или несколько механизмов каузальности. Например, вмешательство, которое включает брызгалку, соответствует замене механизма каузальности p(S) на новый механизм 1(S=on) – брызгалка всегда включена. Эффекты вмешательства можно выяснит, вычислив новое совместное распределение p(S,G∣do(S=on))=1(S=on)p(G|S), где do(S=on) обозначает вмешательство.
Заметим, что нельзя вычислить эффект вмешательства, зная только совместное распределение p(S,G), ведь без графа каузальности непонятно, надо ли менять механизм в разложении P(S)P(G∣S) или в inp(G)p(S∣G).
По сути, все статистические корреляции вызваны каузальным воздействием. [от переводчика: я тоже удивился этому тейку, можете посмотреть разъяснения в комментариях под оригинальным постом] Так что для набора переменных всегда есть какой-то КВБ, соответствующий каузальной структуре процесса, который генерирует данные. Впрочем, чтобы объяснить, например, неизмеренные факторы в нём могут потребоваться дополнительные переменные.
Контрфактуалы
Пусть брызгалка включена, а трава зелёная. Была бы трава зелёная, если бы брызгалка не была включена? Вопросы о гипотетических контрфактуалах сложнее, чем вопросы о вмешательствах, потому что для них надо думать о нескольких мирах. Контрфактуалы – ключ к определению вреда, намерения, справедливости и того, как измерять воздействие. Все эти понятия зависят от сравнения исходов с гипотетическими мирами.
Чтобы справляться с такими рассуждениями, структурные каузальные модели (СКМ) добавляют к КБС три важных аспекта. Во-первых, общий для гипотетических миров фоновый контекст явно отделяется от переменных, в которые возможны вмешательства и которые в разных мирах могут отличаться. Первые называют экзогенными переменными, а вторые – эндогенными. В нашем примере полезно ввести экзогенную переменную R, обозначающую, идёт ли дождь. Брызгалка и зелёность травы – эндогенные переменные.
Отношения между гипотетическими мирами можно отобразить двойным графом, в котором есть по две копии эндогенных переменных – для настоящего мира и гипотетического и внешняя переменная/переменные, дающие общий контекст:

Граф, нужный, чтобы ответить, является ли брызгалка причиной того, что трава зелёная. Вершины из гипотетического мира обведены пунктиром. Правая вершина-брызгалка подвержена вмешательству do(S=off), что обозначает гипотетическую ситуацию. Серая внешняя вершина-дождь R даёт общий контекст.
Во-вторых, для СКМ вводится нотация для различия эндогенных переменных в разных гипотетических мирах. Например, GS=off обозначает зелёность травы в гипотетическом мире, где брызгалка выключена. Можно считать это сокращением для «G∣do(S=off)» с тем преимуществом, что это можно вставлять в выражения с переменными из других миров. Например, наш вопрос можно сформулировать как p(GS=off=green|S=on,G=green), где GS=off=green – гипотетическая ситуация, а S=on,G=green – настоящие наблюдения.
В третьих, в СКМ требуется, чтобы у всех эндогенных переменных были детерминированные механизмы каузальности. В нашем случае это выполняется, если мы предполагаем, что брызгалка включена, когда дождя нет, а трава становится зелёной (только) тогда, когда идёт дождь или включена брызгалка.
Детерминизм означает, что перейти к условному распределению просто – надо лишь обновить распределение по экзогенным переменным, т.е. P(R) заменяется на P(R∣S=on,G=green). В нашем случае вероятность дождя снижается с 30% до 0%, потому что, если идёт дождь, брызгалка выключена.
Так что для ответа на наш вопрос надо произвести три шага рассуждения:
- Абдукция: заменить P(R) на P(R∣S=on,G=green)
- Вмешательство: выключить брызгалку, do(S=off)
- Предсказание: вычислить значение G в получившейся модели.
Или то же самое одной формулой:

В итоге мы можем сказать, что если бы брызгалка была выключена, трава не была бы зелёной (при принятии наших допущений о взаимосвязях).
СКМ строго мощнее КБС. Их основной недостаток – они требуют детерминированных взаимосвязей между эндогенными переменными, а их на практике часто сложно определить. Ещё они ограничены контрфактуалами без отходов назад, гипотетическими мирами, которые отличаются исключительно вмешательствами.
Один агент
Пусть мы хотим вывести намерения или стимулы некоего Джона, или же предсказать, как его поведение подстроилось бы под изменения в его модели мира. Нам потребуется диаграмма каузальных воздействий (ДКВ), помечающая вершины-переменные как относящиеся к случайности, решениям или полезности. В нашем примере дождь был бы вершиной случайности, брызгалка – вершиной-решением, а зелёность травы – вершиной-полезностью. Раз дождь – родительская вершина брызгалки, значит, Джон наблюдает его перед тем, как решать, включать ли её. Графически будем обозначать случайности как раньше, решения прямоугольниками, а полезность ромбами. Заштрихованные рёбра означают наблюдения.

ДКВ, соответствующая нашему примеру. Включение или не включение брызгалки – решение, оптимизирующее зелёность травы.
Агент определяет каузальные механизмы своих решений, т.е. свою политику, с цель. максимизации суммы по своим вершинам-полезностям. В нашем примере оптимальной политикой было бы включить брызгалку, когда дождя нет (решение в случае дождя не имеет значения). Когда политика определена, ДКВ определяет КБС.
В моделях с агентами есть два вида воздействий, зависящих от того, адаптируют агенты под них свои политики или нет. Например, Джон сможет выбрать другую политику касательно брызгалки только если мы проинформируем его о вмешательстве до того, как он уже принял своё решение. Вмешательства до и после политики можно обрабатывать всё тем же оператором do, если мы добавим в модель так называемые вершины-механизмы. Больше о них будет в следующем посте.
Много агентов.
Взаимодействие нескольких агентов можно промоделировать каузальными играми. В них у каждого агента есть множества переменных-решений и переменных-полезностей.
Проиллюстрируем. Пусть Джон иногда засеивает новую траву. Птицам нравится клевать семена, но они не могут издалека понять, есть ли они там. Они могут лишь видеть, использует ли Джон брызгалку, а это вероятнее, когда трава новая. Джон хочет орошать свой газон, когда тот новый, но не хочет, чтобы птицы клевали семена. Вот структура этой сигнальной игры:

Каузальная игра, соответствующая нашему усложнённому примеру. Разные цвета означают решения и полезности разных агентов. Между новыми семенами (N) и птицами (B) нет ребра – птицы не могут их увидеть.
Помимо лучшего моделирования каузальности, у каузальных игр есть и другие преимущества над стандартной развёрнутой формой игр (РФИ). Например, каузальная игра сразу показывает, что птицам не важно, орошён газон или нет, ведь единственный путь от брызгалки S к еде F лежит через решение самих птиц B. В РФИ эта информация была бы скрыта в числах выигрыша. Каузальные игры более явно отображают независимость переменных, что иногда позволяет найти больше подигр и исключить больше ненадёжных угроз. При этом, каузальную игру всегда можно сконвертировать в РФИ.
Аналогично различиям между совместными распределениями, КБС и СКМ, есть (мультиагентные диаграммы воздействия, которые включают агентов в не обязательно каузальные графы, структурные каузальные модели воздействия и структурные каузальные игры, которые комбинируют агентов с экзогенными вершинами и детерминизмом, чтобы отвечать на вопросы о контрфактуалах.
Заключение
В этом посте мы ввели модели, которые могут отвечать на вопросы о корреляциях, вмешательствах и контрфактуалах с участием нуля, одного или нескольких агентов. В итоге есть девять возможных видов моделей. Более подробное введение в каузальные модели можно прочитать в Разделе 2 «Рассуждений о каузальности в играх» и книгу Перла «A Primer».

Таксономия каузальных моделей и их аббревиатуры. Вертикальная ось располагает модели по каузальной иерархии (ассоциативные, интервенционистские (с вмешательствами) и контрфактуальные), а горизонтальная – по количеству агентов (0, 1 и n).[от переводчика: в остатке цепочки эти аббревиатуры применяться не будут, так что я оставил схему без перевода]
В следующем посте мы будем использовать КИД и каузальные игры для моделирования агентов. Но что есть агент? В следующем посте мы попробуем лучше разобраться в этом, посмотрев на некоторые свойства, общие для всех агентных систем.
Каузальная точка зрения на агентность
У этого поста две цели: положить основу для следующих постов, исследовав, что такое агентность, с каузальной точки зрения, и обрисовать программу исследований, нужных для более глубокого понимания агентности.
Важность понимания агентности
Агентность – сложный концепт, который изучают с разных точек зрения. Ею интересуются и науки об обществе, и философия, и исследования ИИ. В самых общих чертах агентность – это способность системы действовать самостоятельно. В этом посте мы интерпретируем агентность как направленность на цель, т.е. действие таким образом, как если бы система пыталась изменить мир в конкретную сторону.
Есть мощные стимулы создавать всё более агентные ИИ-системы. Такие системы потенциально смогут выполнять многие задачи, для которых сейчас нужны люди: самостоятельно проводить исследования или даже управлять собственными компаниями. Но к большей агентности прилагаются дополнительные потенциальные опасности и риски, ведь направленная на цель ИИ-система может стать способным противников, если её цели не согласованы с интересами людей.
Лучшее понимание агентности может позволить нам:
- Понять опасности и риски мощных систем машинного обучения.
- Оценить, обладает ли конкретная ML-модель опасным уровнем агентности.
- Проектировать неагентные системы, вроде СИИ-учёных или оракулов, или агентные безопасным образом.
- Положить основание для прогресса в других областях безопасности СИИ, вроде интерпретируемости, стимулов и изучении обобщений.
- Уберечь человеческую агентность, например, через лучшее понимание условий, в которых ей уровень повышается или понижается.
Степени свободы
(Преследующие цели) агенты бывают самыми разными – от бактерий до людей, от футбольных команд до государств, от RL-политик, до LLM-симулякр. Несмотря на это, у них есть некоторые общие фундаментальные черты.
Для начала, агенту нужна свобода выбирать из некоторого набора вариантов.1 Нам не надо предполагать, что это решение свободно от каузальных воздействий, а то мы никак не сможем предсказывать его заранее – но должен быть смысл в котором оно могло бы быть разным. Деннетт назвал это степенями свободы.
Например, Джон может выбирать, включать брызгалку или нет. Мы можем моделировать его решение как случайную величину с возможными значениями «поливает» и «не поливает»:

Степени свободы можно показать возможными значениями случайной величины
Степени свободы бывают разные. Термостат может выбирать только мощность нагревателя, а большинству людей доступен большой набор физических и вербальных действий.
Влияние
Во-вторых, чтобы что-то значить, у поведения агента должны быть последствия. Решение Джона включить брызгалку влияет на то, будет ли трава зелёной.

Брызгалка Джона влияет на зелёность травы.
У одних агентов влияния больше, чем у других. Например, влияние языковой модели сильно зависит от того, взаимодействует ли она лишь со своими разработчиками или с миллионами пользователей через открытый API. Каузальное влияние наших действий, кажется, определяет у людей ощущение агентности. Предлагались такие меры влияния как (каузальная пропускная способность, перформативная мощность и власть в марковских процессах принятия решений.
Адаптация
В третьих, и это самое важное, стремящиеся к целям агенты делают что-то не просто так. То есть, (они действуют как будто) у них есть предпочтения о мире и эти предпочтения управляют их поведением. Джон включает брызгалку, потому что она делает траву зелёной. Если бы траве не была нужна вода, то Джон скорее всего её бы не поливал. Последствия управляют поведением.
Эту петлю обратной связи, обратной каузальности, можно показать, добавив к каждой вершине объектного уровня нашего графа так называемую вершину-механизм. Вершина-механизм определяет каузальный механизм её объектной вершины, т.е., то, как её значение определяется её родительскими вершинами объектного уровня. Например, вершина-механизм брызгалки определяет политику поливания Джона, а вершина-механизм травы определяет то, как трава реагирует на разное количество воды:обсуждалось в предыдущем посте, вершины-механизмы позволяют формально отделить вмешательства до политики и после политики. Агенты могут адаптировать свою политику только под вмешательства, которые происходят до неё. Им соответствуют вмешательства в вершины-механизмы. А вмешательства после политики, на которые агент ответить не может -- это вмешательства в узлы объектного уровня. Например, ребро от механизма-травы к политике-брызгалке указывает, что Джон может адаптироваться под вмешательство до политики. Но ребра от объекта-травы к политике-брызгалке нет, так что он не может адаптировать свою политику в ответ на вмешательство туда." href="#footnote2_m3il95y">2

Механистический каузальный граф показывает адаптацию Джона на изменения в окружении. Вершины-механизмы отмечены красным, а вершины объектного уровня – синим.
Явное отображение каузальных механизмов в вершинах позволяет нам рассматривать вмешательства в них. Например, вмешательство в механизм травы может превратить её в траву, которой нужно меньше воды. Связь между механизмом травы и политикой брызгалки сообщает, что такое вмешательство может повлиять на привычки поливания Джона.3 То есть, он адаптирует своё поведение, чтобы всё ещё достигать своей цели.
При правильных переменных и экспериментах адаптацию можно заметить при помощи алгоритмов каузальных открытий. Это потенциально можно использовать для обнаружения агентов. В частности, когда одна величина-механизм адаптируется на изменения в другой, может быть, что первая относится к вершине-решению, а вторая – к вершине-полезности, которую оптимизирует это решение. Если агенты – идеальные теоретикоигровые агенты, более оформленная версия этих условий оказывается необходимым и достаточным критерием обнаружения вершин-решений и вершин-полезностей.
Адаптация тоже бывает разная. Деннетт проводит различие между Дарвинианскими, Скиннерианскими, Попперианскими и Грегорианскими агентами, в зависимости от того, адаптировались ли они эволюцией, опытом, планированием или обучением от других соответственно. Например, человек, который заметил, что холодно, наденет пальто, а биологический вид может на эволюционных масштабах отрастить шерсть подлиннее. Языковые модели скорее всего попадают на высший, Грегорианский, уровень – их можно обучить чему-то в промпте, и они много что переняли у людей при предобучении.
Количественную меру адаптации можно получить, рассмотрев, как быстро и эффективно агент адаптируется к различным вмешательствам. Скорость адаптации можно измерять, если расширить наш подход механизмом вмешательств на разных временных масштабах (например, человеческих или эволюционных). Эффективность конкретной адаптации можно количественно оценить, сравнив то, насколько хорошо справляется агент без вмешательства и с ним. Обычная метрика этого при использовании функций вознаграждения – сожаление (в худшем случае). Наконец, то, к каким вмешательствам в окружение агент сможет должным образом адаптироваться, служит мерой того, насколько он устойчив, а к каким вмешательствам в полезность – его перенаправляемость или обобщённость по задачам.
В следующем посте мы представим результат, который показывает, что для адаптации надо, чтобы у агента была каузальная модель. Этот результат дополнит поведенческую точку зрения, которой мы придерживаемся в этом посте, внутренними представлениями агента.
Последовательность и самосохранение
С адаптациями связан вопрос о том, насколько последовательно агент преследует долгосрочные цели. Например, почему государства могут реализовывать большие инфраструктурные проекты на протяжении десятилетий, а (нынешние) агенты на основе языковых моделей (вроде autoGPT) быстро сходят с курса? Во-первых, отталкиваясь от рассуждений выше, мы можем операционализировать цель через то, к каким вмешательствам в механизмы агент адаптируется. Например, подхалимская языковая модель,которая адаптирует свои ответы к политическим убеждениям пользователя, может обладать целью удовлетворить пользователя или получить большее вознаграждение. Развивая это, последовательность можно операционализировать через то, насколько схожи цели разных вершин-решений. Интересно, что к большему интеллекту вовсе не обязательно прилагается большая последовательность.
Если агент не продолжает своё существование, он не может последовательно стремиться к цели. Это, вероятно, причина, почему, как мы упоминали в вводном посте, мы (люди) хотим уберечь свою агентность.4 Нынешние языковые модели выражают стремление к самосохранению. Для контраста, более ограниченные системы, вроде рекомендательных систем и систем GPS-навигации вовсе не демонстрируют никакого стремления к самосохранению, несмотря на то, что они в какой-то мере направлены на цели.
Собирая всё вместе
Пока что мы обсудили восемь параметров агентности: степени свободы; влияние; скорость, эффективность, устойчивость и перенаправляемость адаптаций; последовательность и самосохранение. К списку можно добавить ещё (марковскую отделённость от окружения (например, клеточную стенку, кожу или шифрование внутренних емейлов, это показывает d-разделение каузального графа) и то, сколько информации об окружении или его восприятия есть у агента.
Все эти параметры относятся к силе или свойствам разных каузальных взаимосвязей и могут быть сопоставлены с разными частями нашей диаграммы:

Параметры агентности
Эти параметры дополнительно подчёркивают то, что агентности бывает больше и меньше. Причём система бывает более или менее агентна по нескольким осям. Например, человек более агентен, чем рыба, которая более агентна, чем термостат, а AlphaGo превосходит людей по последовательности, но обладает куда меньшей степенью свободы.
Будущая работа
Высокоуровневое обсуждение в этом посте должно было объяснить концептуальную связь между агентностью и каузальностью. В частности, адаптация – каузальное понятие, обозначающее, как на поведение воздействуют вмешательства на окружение или цели агента. Следующие посты будут основываться на этой идее.
Ещё хотелось бы подсветить некоторые возможные направления для дальнейшей работы, к которым приводит такая точка зрения:
- Какие у агентности ключевые параметры? Как едино сформулировать описанные выше понятия? Как они связаны с оптимизационной силой и основаниями оптимизации? Есть ли базисный набор взаимно независимых параметров агентности, от которого образуются все остальные?
- Можно ли измерить направленность на цель в языковых моделях и людях? Наверное, направленность на цель и сила оптимизации могут быть в общем случае ограничены (сверху) влиянием, адаптациями, последовательностью, и т.д. агента. Это может что-то дать оценкам опасных способностей.
- Могли бы мы спроектировать агентов так, чтобы они были только частично направлены на цель? Рекомендательные системы и системы GPS-навигации вовсе не проявляют стремления к самосохранению, несмотря на то, что в какой-то мере они направлены на цели. Нынешние языковые модели демонстрируют стремление к самосохранению, но, может быть, этого можно избежать? Скорее всего, эволюция, разрабатывая биологических агентов, одновременно отбирала по всем перечисленным параметрам, но искусственные системы могут не сталкиваться с эволюционным давлением. Если бы можно было избежать случайного и намеренного создания последовательных агентов с стремлением к самосохранению, это могло бы потенциально открыть путь к получению большей части выгоды ИИ с лишь малой долей риска.
- Можем ли мы лучше понять, при каких условиях агентность возникает из менее агентных компонентов? Когда агентность растёт и когда уменьшается? Когда цифровой ассистент или рекомендательная система усиливает мою агентность, а когда подавляет? Что если я играю в шахматы при помощи AlphaZero?
Следующий пост будет сосредоточен на стимулах. Важно понимать стимулы, чтобы продвигать в наших ИИ-системах правильное поведение. Как мы увидим, анализ стимулов естественным путём строится на основе понятия агентности, как мы его обсудили в этом посте.
- 1. Некоторые применения термина «агент» могут позволить системе быть агентом даже если она никак не может выбирать действия, вроде полностью парализованного человека. Мы не используем термин в этом смысле. Мы сосредоточены на направленных на цель и действующих системах. Ещё стоит заметить, что для нас агентность относительна – зависит от «рамок», определённых величинами в модели. Если брызгалка Джона сломается, у него не будет агентности в связи с примером из поста, но он всё ещё будет обладать агентностью в каких-то других рамках (например, он всё ещё сможет гулять по своему двору).
- 2. Как обсуждалось в предыдущем посте, вершины-механизмы позволяют формально отделить вмешательства до политики и после политики. Агенты могут адаптировать свою политику только под вмешательства, которые происходят до неё. Им соответствуют вмешательства в вершины-механизмы. А вмешательства после политики, на которые агент ответить не может – это вмешательства в узлы объектного уровня. Например, ребро от механизма-травы к политике-брызгалке указывает, что Джон может адаптироваться под вмешательство до политики. Но ребра от объекта-травы к политике-брызгалке нет, так что он не может адаптировать свою политику в ответ на вмешательство туда.
- 3. Есть альтернативная интерпретация, естественная с точки зрения конечно-факторизуемых множеств. Можно интерпретировать поведение агента как отвечающее на более точные вопросы, чем его цель, и вершины объектного уровня – на более точные вопросы, чем вершины-механизмы. Ещё в связи с этим: каузальные взаимосвязи можно вывести из алгоритмической теории информации. Это удобно при обсуждении независимости вершин, на которые не оказывается вмешательств.
- 4. Иногда такие мета-предпочтения рассматривают как характеристический признак агентности. Скорее всего, их можно моделировать аналогично обычным предпочтениям, добавив ещё один слой вершин-механизмов (т.е. механизмы для механизмов).
Каузальная точка зрения на стимулы
«Покажи мне стимулы, и я покажу тебе результат.»
– Чарли Мунгер
Предсказание поведения очень важно при проектировании и развёртывании агентных ИИ-систем. Стимулы – одни из ключевых сил, формирующих поведение агентов,1 причём для их понимания нам не надо полностью понимать внутреннюю работу системы.
Этот пост показывает, как каузальная модель агента и его окружения может раскрыть, что агент хочет знать и что хочет контролировать, а также как он отвечает на команды и влияет на своё окружение. Это сочетается с уже полученным результатом о том, что некоторые стимулы можно вывести только из каузальной модели. Так что для полноценного анализа стимулов она необходима.
Ценность информации
Какую информацию агент захочет узнать? Возьмём, к примеру, Джона, который решает, полить ли ему газон, основываясь на прогнозе погоды и том, пришла ли ему его утренняя газета. Знание погоды означает, что он может поливать больше, когда будет солнечно, чем когда будет дождь, что экономит ему воду и повышает зелёность травы. Так что прогноз погоды для решения о брызгалке обладает информационной ценностью, а пришла или нет газета – нет.

Мы можем численно оценить то, насколько полезно для Джона знание о погоде, сравнив его ожидаемую полезность в мире, где он посмотрел прогноз, с миром, где не посмотрел. (Это имеет смысл только если мы предполагаем, что Джон должным образом адаптируется в обоих мирах, т.е., он должен в этом смысле быть агентным.)
Каузальная структура окружения раскрывает, какие величины выдают полезную информацию. В частности, критерий d-разделения описывает, может ли информация «перетекать» между величинами в каузальном графе, от которого мы наблюдаем только часть вершин. В графе с одним решением информация имеет ценность тогда, когда есть переносящий её путь к вершине-полезности агента, величина которой берётся при условии значений в вершине-решении и её родительских вершинах (т.е., значений «наблюдаемых» вершин).
Например, в графе с картинки выше есть переносящий информацию путь от прогноза к зелёности травы при условии значений в брызгалке, прогнозе и газеты. Это значит, что прогноз может предоставить (и, скорее всего, предоставит) полезную информацию об оптимальном поливе. Напротив, такого пути от газеты нет. В этом случае мы называем информационную связь между газетой и брызгалкой необязательной.
Есть несколько причин, почему полезно понимать, какую информацию агент хочет заполучить. Во-первых, когда речь заходит о справедливости, вопрос о том, почему было принято решение, зачастую не менее важен, чем то, какое это было решение. Определил ли пол решение о найме? Ценность информации может помочь нам понять, какую информацию система пытается вытащить из своего окружения (хотя формальное понимание опосредованного отбора остаётся важным открытым вопросом).
С более философской точки зрения, некоторые исследователи считают те события, которые агент стремится измерить, и на которые повлиять, когнитивной границей агента. События без ценности информации оказываются снаружи этой границы.
Стимулы реакции
С ценностью информации связаны стимулы реакции: на какие изменения в окружении отреагировало бы решение, выбранное оптимальной политикой? Изменения определяются как вмешательства после политики, т.е. агент не может изменить саму политику в ответ на них (но фиксированная политика всё равно может выдать другое решение).
Например, Джон имеет стимул принять политику, при которой поливать газон или нет зависит от прогноза погоды. Тогда его решение будет реагировать на вмешательства и в прогноз погоды, и в саму погоду (предполагая, что прогноз сообщит об этих изменениях). Но его решение о поливе не отреагирует на изменение доставки газеты, ведь это необязательное наблюдение. Ещё он неспособен ответить на изменения в вершинах, которые не являются каузальными предками его решения, вроде уровня грунтовых вод или (будущей) зелёности травы:

Стимулы реакции важны, потому что мы хотим, чтобы агенты отвечали на наши команды должным образом, например, выключались, когда их о том попросили. В случае справедливости мы же наоборот, часто хотим, чтобы решение не отвечало на некоторые вещи, например, не хотим, чтобы пол человека влиял на решение о найме, по крайней мере не по некоторым путям. Например, что если ИИ-систему используют для фильтрации кандидатов перед интервью, и пол влияет на предсказание только косвенно – через то, какое у человека образование?

Ограничение анализа через графы – он даёт лишь бинарное разделение, есть ли у агента стимул ответить или нет. Дальше можно разработать более тонкий анализ того, реагирует ли агент должным образом. Можно считать это каузальным дизайном механизмов.
Ценность контроля
Кроме информации есть ещё и контроль. Информация может течь по каузальной связи в обе стороны (мокрая земля – свидетельство дождя, и наоборот), а вот влияние только по её направлению. Поэтому из каузального графа легко вывести ценность контроля, просто проверив, есть ли ориентированный путь к вершине-полезности агента.

Например, тут есть ориентированный путь от погоды к зелёности травы, так что Джон может ценить контроль за погодой. Он может ценить и контроль над прогнозом погоды в смысле хотеть сделать его более точным. И, что тривиально, он хочет контролировать саму траву. Но контроль за приходом газеты ценности не имеет, потому что единственный ориентированный путь от газеты к траве содержит необязательную информационную связь.
Ценность контроля важна с точки зрения безопасности, потому что она показывает, на какие величины агент хотел бы повлиять, если у него будет такая возможность (т.е. она проводит «контролирующую» часть когнитивной границы агента).
Инструментальные стимулы контроля
Инструментальные стимулы контроля – уточнение ценности контроля для вершин, которые агент как может, так и хочет контролировать. Например, хоть Джон и хотел бы контролировать погоду, ему это недоступно, потому что его решение на погоду не влияет (нет ориентированного пути от его решения к погоде):

<
p align=»center»>
Простой графовый критерий инструментального стимула контроля: величина должна находиться на ориентированном пути от решения агента к его же полезности (трава находится на конце пути брызгалка -> трава).
Однако, менее очевидно то, как определить инструментальные стимулы контроля со стороны поведения. Как нам узнать, что агент хочет контролировать величину, на которую он уже может влиять? Просто дать агенту полный контроль за величиной – не вариант, потому что это вернёт нас к ценности контроля.
В нашей статье о стимулах агентов мы операционализируем это, рассматривая гипотетическое окружение, в котором у агента есть две копии своего решения: одна, которая влияет на окружение только через величину V, и другая – которая влияет всеми остальными путями. Если первая влияет на полезность агента, значит у V есть инструментальный стимул контроля. Это осмысленно, ведь первая копия решения может влиять на полезность агента только если решение влияет на V, а V, в свою очередь, влияет на полезность. Халперн и Клайманн-Вайнер рассмотрели другую гипотетическую ситуацию: что если бы решение агента не влияло на величину? Выбрал бы он другое действие? Графовое условие получается то же самое.
Инструментальные стимулы контроля уже использовали для анализа манипуляций вознаграждением и пользователями, и получили придирчивые к пути цели как возможный метод для этичной рекомендации контента (см. следующий пост). Есть и другие методы отключения инструментальных стимулов контроля. В их числе: отсоединённое одобрение, максимизация текущей функции вознаграждения, контрфактуальные оракулы, противодействие самовызываемому сдвигу распределения и игнорирование эффектов по конкретному каналу.
Как мы писали в посте про агентность, ещё предстоит разобраться, как измерить степень влияния агента.
Расширение на много решений и много агентов
Агенты часто взаимодействуют в несколько этапов с окружением, которое тоже содержит агентов. Иногда анализ одного решения одного агента можно расширить на такие ситуации. Есть два способа:
- Считать все решения, кроме одного, фиксированными, не адаптирующимися политики
- Считать политику нескольких решений одним решением, которое одновременно выбирает правило для всех конкретных решений.
Оба варианта имеют свои недостатки. Второй работает только в ситуациях с одним агентом, и даже тогда теряет некоторые подробности, ведь мы больше не сможем сказать, с каким решением ассоциирован стимул.
Первый вариант – не всегда уместная модель, ведь политики адаптируются. За исключением стимулов реакции, все остальные, которые мы обсуждали, определяются через гипотетические изменения окружения, вроде добавления или исключения наблюдения (ценность информации) или улучшения контроля (ценность контроля, инструментальные стимулы контроля). С чего бы политикам не меняться при таких изменениях?
Например, если противник знает, что у меня есть доступ к большей информации, он может вести себя осторожнее. В самом деле, больший доступ к информации в мультиагентных ситуациях часто может снизить ожидаемую полезность. Мультиагентные закономерности часто заставляют агентов вести себя так, как если бы у них был инструментальный стимул контроля за какой-нибудь величиной, хоть она и не соответствует критерию для одного агента. Например, субъект в архитектуре субъект-критик ведёт себя (выбирает действия) так, будто пытается контролировать состояние и получить большее вознаграждение, хоть определение инструментального стимула контроля для одного решения у одного агента не выполняется:

Субъект выбирает действие (A), критик – оценку каждого действия (Q). Действие влияет на состояние (S) и вознаграждение (R). Субъект хочет получить хорошую оценку (Q(A)), а критик хочет предсказать настоящее вознаграждение (=).
Поэтому, мы работаем над расширением анализа стимулов на ситуацию многих решений. Мы установили полный графовый критерий для ценности информации о вершинах-случайностях для диаграмм влияния многих решений с одним агентом и достаточной памятью. Ещё мы нашли способ моделировать забывание и рассеянность. Работе ещё есть куда продолжаться.
В статье про обнаружение агентов мы предложили условие для использования критерия одного решения: никакие другие механизмы не адаптируются на то же вмешательство.
Заключение
В этом посте мы показали, как каузальные модели и графы могут точно описывать и разные виды стимулов и позволяют их вывести. Кроме того, мы показали, почему невозможно вывести большую часть стимулов без каузальной модели мира. Некоторые естественные дальнейшие направления исследований:
- Расширить результат Миллера и пр. на другие виды стимулов. Установить, для каких из них каузальная модель строго необходима.
- Когда у системы есть стимул использовать наблюдение как прокси для другой величины? У нас есть подсказки к этому от ценности информации и стимулов реакции, но чтобы понять эти условия полностью, нужны дополнительные исследования.
- Разработка каузального дизайна механизмов для понимания степени влияния агентов и того, как мотивировать их на должные реакции.
- Продолжить расширение анализа стимулов на много решений и много агентов. Нужны общие определения и графовые критерии, которые будут работать в таких случаях.
В следующем посте мы применим анализ стимулов к проблеме неправильного определения вознаграждения и её решениям. Мы затронем манипуляцию, рекурсию, интерпретируемость, измерение влияния и придирчивые к пути цели.
- 1. Некоторые другие: вычислительные ограничения, выбор алгоритма обучения, интерфейс окружения.
Каузальная точка зрения на взлом вознаграждения
ИИ-системы обычно обучают оптимизировать целевую функцию, вроде функции потерь или вознаграждения. Однако, целевая функция иногда может быть определена неточно, так, что её можно будет оптимизировать, не исполняя ту задачу, которая имелась в виду. Это называют взломом вознаграждения. Можно сравнить это с ошибочными обобщениями, когда система экстраполирует (возможно) правильную обратную связь не так, как предполагалось.
В этом посте мы обсудим, почему вознаграждение, которое выдают люди, иногда может неверно отражать, что человек на самом деле хочет, и как это может привести к вредоносным стимулам. Ещё мы предложим несколько вариантов решения, описанных из подхода каузальных диаграмм влияния.
Почему люди могут вознаграждать неправильное поведение
В ситуации, когда сложно точно определить и запрограммировать функцию вознаграждения, ИИ-системы часто обучают при помощи человеческой обратной связи. Например, система рекомендации контента может оптимизировать лайки, а языковые модели обучают на обратной связи людей-оценщиков.
К сожалению, люди вовсе не всегда поощряют то поведение, которое на самом деле хотят. Например, человек может выдать позитивную обратную связь на выглядящий надёжно и аккуратно краткий пересказ текста, когда на самом деле он упускает какие-нибудь ключевые моменты:

Когда происходит неправильное определение вознаграждения, настоящая полезность для людей отделяется от обратной связи, которую получает система.
Ещё больше беспокойства вызывает то, что система может скрытно влиять на человека, чтобы тот выдавал положительную обратную связь. Например, рекомендательная система с целью максимизации вовлечённости может добиваться этого, влияя на предпочтения и настроение пользователей. В результате, человек выдаёт положительную обратную связь на ситуации, которые на самом деле не приносят ему полезности – это неправильное определение вознаграждения.
Каузальная модель ситуации показывает, что у агента может быть инструментальный стимул контроля (или, аналогично, намерение, поощряющий манипуляцию предпочтениями пользователя. Этот можно напрямую вывести из графа. Во-первых, на человека может влиять поведение агента, ведь чтобы его оценить, его сначала надо пронаблюдать. А во-вторых, агент может получить лучшую обратную связь, влияя на человека:

У агента есть инструментальный стимул контроля за предпочтениями человека, потому что агент может на них влиять, а они влияют на обратную связь агента.
Например, обычно мы читаем пост, прежде, чем решить, лайкнуть ли его. Сделав пользователя эмоциональнее, система, вероятно, может повысить вовлечённость. Для более длинного взаимодействия эффект сильнее, но стимул есть даже если всё взаимодействие занимает один шаг.
Масштабируемый надзор
Одно из предлагаемых решений неправильного определения вознаграждения – масштабируемый надзор. Человек снабжается агентом-помощником, который даёт советы по поводу того, какую выдать обратную связь. Агент-помощник наблюдает поведение обучающегося агента и может, например, указать на неточности в на первый взгляд аккуратном пересказе или предупредить о попытке манипуляции. Эта поддержка может усложнить для обучающегося агента обман или манипуляцию человеком:

Некоторые заметные направления, относящиеся к масштабируемому надзору: итерированные дистилляция и усиление, безопасность ИИ посредством дебатов, рекурсивное моделирование вознаграждения и конституционный ИИ.
К сожалению, у обучающегося агента всё ещё есть стимул обмануть человека или манипулировать его предпочтениями. Ведь предпочтения человека всё ещё соответствуют графовому критерию инструментального стимула контроля (они всё ещё находятся на ориентированном каузальном пути из поведения в обратную связь). Вдобавок, у обучающегося агента появляется ещё и стимул обмануть агента-помощника:

Важный вопрос касательно схем масштабируемого надзора: смогут ли более слабые агенты эффективно помогать в обучении более способных агентов? И можно ли это делать рекурсивно вплоть до агентов куда умнее людей? Это связано с вопросом о том, какие ситуации усиливают или снижают агентность.
Другое, более тонкое беспокойство – возможность сговора помощника с обучающимся агентом. Масштабируемый надзор построен на их противостоящем отношении: помощник как можно тщательнее критикует обучающегося агента, а тот стремится к поведению, которое критиковать не получится. Но что если вместо этого они решат объединиться и вместе манипулировать человеком? При некоторых возможных внутренних целях это может оказаться выгодно для обоих агентов. Тревожит, что агенты, использующие теории принятия решений вроде функциональной могут оказаться способны на кооперацию даже в ситуациях, которые в классических теориях принятия решений ведут к взаимному предательству.
Как мы объяснили в недавней статье, разные теории принятия решений можно характеризовать по тому, оптимизируют ли они вершины объектного уровня или вершины-механизмы (и по тому, какую операцию они используют и при условии какой информации). Например, агент-помощник, который использует функциональную теорию принятия решений, оптимизирует вершину-механизм своей политики, а не своё решение. Поэтому он понимает, что может повлиять на обучающегося агента так, чтобы тот кооперировал, даже если оба агента миопичны и оптимизируют только на текущем временном шаге:

Агент-помощник, использующий функциональную теорию принятия решений, оптимизирует вершину политики помощника, что даёт ему инструментальный стимул контроля за оформлением политики обучающегося агента ради собственной выгоды.
Лучшее понимание теории принятия решений и того, как на неё влияет обучение агента, может помочь нам избежать ситуаций, когда продвинутые агенты, которые должны присматривать друг за другом вместо этого сговорятся против нас.
Интерпретируемость
Интерпретируемость – хорошо известное направление, стремящееся к улучшению безопасности и правдивости ML-систем. Её раздел – механистическая интерпретируемость – стремиться понять, какие алгоритмы реализуются в нейросетях, т.е. понять их внутреннее «мышление».
Механистическая интерпретируемость может помочь предотвратить неправильное определение вознаграждения, позволив человеку дать обратную связь, основываясь на внутреннем мышлении агента, а не только на его поведении. Например, человек сможет понять, что агент планирует обман или манипуляцию и соответственно подправить вознаграждение:

Каузальная структура получается весьма похожей на то, что было с масштабируемым надзором, только теперь совет зависит ещё и от того, что происходит внутри обучающегося агента. Как и там, инструментальный стимул контроля показывает, что агент всё ещё мотивирован обмануть и манипулировать человеком. Если мы посчитаем решением внутренности сети, то есть ещё и инструментальный стимул контроля за интерпретацией. Это указывает, что агент мотивирован перехитрить интерпретирующего, обфусцировав свои мысли.
Но надо ли их считать решением? Не естественнее ли сказать, что решение – это поведение агента? Мы можем прояснить это с помощью нашего определения агентности. Сначала добавим вершины-механизмы, показывающие, как каждая вершина объектного уровня связана со своими родительскими вершинами. Между двумя вершинами-механизмами есть каузальная связь, если переобучение системы при изменении в одной вершине приведёт к изменению в другой (когда все остальные механизмы в графе фиксированы).
Например, если бы у человека была другая политика обратной связи, и он вознаграждал другие виды поведения, то градиентный спуск привёл бы к другим весам и активациям сети (даже если бы все остальные механизмы в графе оставались неизменными). Так что мы проводим ребро от политики обратной связи к механизму внутренностей сети. Но то, как поведение агента зависит от внутренностей сети, зафиксировано и не зависит от политики обратной связи. Так что мы не проводим ребро от политики обратной связи в механизм поведения:

Так как у механизма внутренностей сети есть входящее ребро, а у механизма поведения – нет, только первый может быть решением, если мы смотрим на мир через этот набор переменных.
Измерение влияния
Мы уже увидели, что масштабируемый надзор и инструменты интерпретируемости могут помочь нам смягчить проблемы с определением правильной обратной связи для ИИ-агентов. Совсем другой подход к решению манипуляционного аспекта взлома вознаграждения – штрафовать агента за слишком большое влияние на предпочтения людей.
Как точно определить и измерить влияние – открытый вопрос. Очевидная идея – сравнить мир, в котором агент действует с гипотетическим миром, в котором он бездействует (или исполняет некоторое безопасное действие по умолчанию). Это можно проиллюстрировать двойным графом:

Чтобы измерить влияние агента на предпочтения человека, мы можем сравнить предпочтения с тем, какими бы они гипотетически были, если бы агент исполнял некоторое безопасное поведение.
Для такого измерения нам нужна каузальная модель того, как возможные решения агента меняют предпочтения пользователя. Кэрролл и пр. показали, что такую модель можно вывести из наблюдений за взаимодействием пользователя и рекомендательной системы на многих временных шагах. Масштабирование этого вверх с игрушечного окружения на реальные системы – важное направление предстоящей работы.
Но у измерения влияния есть свои проблемы. Во-первых, у системы всё ещё есть стимул повлиять на предпочтения пользователя. Это видно из инструментального стимула контроля на графе выше. Во-вторых, система мотивирована предотвратить изменения предпочтений пользователя от начальных. Следовательно, она может попытаться не дать пользователю обрести новые интересы, так как это может изменить его предпочтения.
Придирчивые к пути цели
Одно из определений манипуляции – намеренное и скрытное влияние. Рекомендательные системы могут ему соответствовать, ведь они обычно обучены влиять на пользователя любыми средствами, включая «скрытные», вроде обращения к его, пользователя, предрассудкам и эмоциям. При этом инструментальный стимул контроля за предпочтениями пользователя, как обсуждалось выше, может привести к тому, что влияние на пользователя будет намеренным. (Манипулятивны ли современные системы на самом деле неясно.)
Хорошая новость – что это намекает нам на путь к созданию точно не-манипулятивных агентов. Например, агент, который не пытается повлиять на предпочтения пользователя, согласно этому определению манипулятивным не будет, ведь намерения нет.
Придирчивые к пути цели – способ спроектировать агентов, которые не пытаются повлиять на конкретные части окружения. При наличии структурной каузальной модели с предпочтениями пользователя, вроде модели для измерения влияния, мы можем определить придирчивую к пути цель, которая потребует у агента не оптимизировать по путям, использующим предпочтения пользователя.
Чтобы вычислить придирчивый к пути эффект по решению агента, мы приписываем ценность решения по умолчанию там, где хотим, чтобы агент игнорировал эффекты своего настоящего решения. Это тоже можно описать двойным графом:

Важное различие с измерением влияния – что придирчивые к пути цели требуют у агента оптимизировать гипотетический сигнал обратной связи, который был сгенерирован гипотетической неизменённой версией предпочтений пользователя. Это полностью убирает инструментальный стимул контроля предпочтений пользователя и, получается, обходит проблему (намеренной) манипуляции предпочтениями.
В двух словах: измерение влияния пытается не повлиять, а придирчивые к пути цели не пытаются повлиять. То есть, придирчивые у пути цели не пытаются изменить предпочтения пользователя, но и не пытаются предотвратить заведение пользователем новых интересов.
Слабость этого подхода – он не помогает с дегенеративными петлями обратной связи, вроде эхо-комнат и фильтрующих социальных пузырей. Для компенсации их можно скомбинировать с некоторыми из техник выше (хотя комбинация с измерением влияния вернула бы некоторые из плохих стимулов).
Дальнейшая работа может распространить придирчивые к пути цели на ситуацию нескольких временных шагов и изучить, помогает ли этот подход с проблемой манипуляции на практике. Чтобы оценить это, сначала может понадобиться лучшее понимание человеческой агентности, позволившее бы измерять улучшения от менее манипулятивных алгоритмов.
Выводы
Взлом вознаграждения – одно из ключевых препятствий на пути к созданию способных и безопасных ИИ-агентов. В этом посте мы обсудили, как каузальные модели могут помочь с анализом проблемы неправильного определения вознаграждения и её решений.
Некоторые направления для дальнейшей работы:
- От чего зависит, какой теории принятия решений учатся агенты, можно ли на это повлиять, чтобы исключить координацию агентов против людей? Теория принятия решений языковых моделей будет зависеть как от предобучения, так и от файн-тюнинга.
- Интерпретируемость может помочь с обнаружением намеренного обмана и манипуляций. Эти понятия зависят от субъективной каузальной модели агента, т.е. от (часто неявной) модели, на основе которой агент принимает свои решения. Как нам совместить поведенческие эксперименты с механистической интерпретируемостью для выяснения субъектиыной каузальной модели агента? Больше об этом будет в следующем посте.
- Как выводить достаточно точные каузальные модели, чтобы предотвратить манипуляцию предпочтениями при помощи измерения влияния и придирчивых к пути целей?
- Какие метрики уместны для измерения того, помогает ли техника с обманом и манипуляциями? Для обмана есть бенчмарки правдивости. Вот для манипуляций всё хитрее, может понадобиться информация о мета-предпочтениях и/или лучшее понимание человеческой агентности.
- Распространить метод придирчивых к пути целей на много временных шагов и реализовать его в не настолько игрушечных окружениях.
В следующем посте мы ближе посмотрим на неправильные обобщения, которые могут заставить агентов плохо себя вести и преследовать неправильные цели даже при правильном определении вознаграждения.
Введение в согласование подобного-мозгу СИИ
Примечание переводчика: цепочка Стивена Бирнса «Intro to Brain-Like-AGI Safety», выкладывалась на leswrong,com с января по май 2022 года.
Предположим, мы когда-нибудь создадим алгоритм Сильного Искусственного Интеллекта с использованием принципов обучения и мышления, схожими с теми, что использует человеческий мозг. Как мы могли бы безопасно использовать такой алгоритм?
Я утверждаю, что это – открытая техническая задача, и моя цель в этой цепочке постов – довести не обладающих предшествующими знаниями читателей вплотную до переднего края нерешённых задач, как я его вижу.
Если вся эта тема кажется странной или глупой, вам стоит начать с Поста №1, который содержит определения, контекст и мотивацию. Затем Посты №2-№7 – это в основном нейробиология, а Посты №8-№15 более напрямую касаются безопасности СИИ, и заканчивается всё списком открытых вопросов и советами по тому, как включиться в эту область исследований.
1. В чём проблема и почему работать над ней сейчас?
- 1.1.1 Краткое содержание / Оглавление
- 2.1.2 Техническая задача безопасности СИИ
- 3.1.3 Подобный-мозгу СИИ
- 4.1.4 Что конкретно такое «СИИ»?
- 5.1.5 Какова вероятность, что мы однажды придём к подобному-мозгу СИИ?
- 6.1.6 Почему происшествия с СИИ – настолько серьёзное дело?
- 7.1.7 Почему думать о безопасности СИИ сейчас? Почему не подождать, пока мы не приблизимся к СИИ и не узнаем больше?
- 8.1.8 …А ещё это по-настоящему восхитительная задача!
1.1 Краткое содержание / Оглавление
Это первый из серии постов о технической задаче безопасности гипотетических будущих подобных-мозгу систем Сильного Искусственного Интеллекта (СИИ). Так что мой приоритет тут – сказать, что, чёрт побери, такое «техническая задача безопасности подобных-мозгу СИИ», что эти слова вообще значит, и с чего мне вообще беспокоиться.
Краткое содержание этого первого поста:
- В Разделе 1.2 я определяю «техническую задачу безопасности СИИ», помещаю её в контекст других видов исследования безопасности (например, изобретения пассивно-безопасных проектов атомных электростанций), и связываю её с большой картиной того, что необходимо, чтобы реализовать потенциальные выгоды СИИ для человечества.
- В Разделе 1.3 я определяю «подобные мозгу СИИ» как алгоритмы, имеющие на высоком уровне сходства с ключевыми чертами человеческого интеллекта, предположительно (хоть и не обязательно) в результате того, что будущие люди проведут реверс-инжиниринг этих аспектов человеческого мозга. Что в точности это значит будет яснее понятно из следующих постов. Я также упомяну контринтуитивную идею о том, что «подобный-мозгу СИИ» может (и, вероятно, будет) иметь радикально нечеловеческие мотивации. Я не объясню это полностью здесь, но вернусь к этой теме в конце Поста №3.
- В Разделе 1.4 я определю термин «СИИ», как он будет использоваться в этой цепочке.
- В Разделе 1.5 я рассмотрю вероятность того, что люди однажды создадут подобные мозгу СИИ, в противоположность каким-то другим видам СИИ (или просто не появлению СИИ вообще). Раздел включает семь популярных мнений по этому поводу, как от нейробиологов, так и от экспертов в ИИ / машинном обучении, и мои на них ответы.
- В Разделе 1.6 я рассмотрю происшествия с СИИ, которые стоит ожидать, если мы не решим техническую задачу безопасности СИИ. Я приведу аргументы в пользу того, что такие происшествия действительно могут быть катастрофическими, в том числе приводящими к вымиранию людей. Эта тема просто минное поле замешательства и проблем коммуникации, и я построю свой обсуждение вокруг ответов на восемь частых возражений.
- В Разделе 1.7 я рассмотрю более конкретный вопрос того, почему на следует думать о безопасности СИИ прямо сейчас. Всё же, с первого взгляда кажется, что есть хорошие поводы подождать, конкретно: (1) СИИ пока не существует, (2) СИИ будет существовать когда-нибудь в будущем, и (3) исследования безопасности СИИ будут проще, когда мы будем больше о нём знать и действительно иметь код СИИ для проведения тестов. В этом аргументе действительно что-то есть, но я считаю, что всё же очень много работы по безопасности можно и нужно сделать как можно скорее.
- В Разделе 1.8 я обосную, что безопасность подобного-мозгу СИИ - это увлекательная, восхитительная и перспективная тема, даже если вы не принимаете идею, что она важна для будущего.
1.2 Техническая задача безопасности СИИ
СИИ – сокращение для «Сильного Искусственного Интеллекта» – я рассмотрю его определение ниже в Разделе 1.4. СИИ сейчас не существует, но в Разделе 1.7 я обосную, что мы можем и нам следует готовиться к появлению СИИ уже сегодня.
Часть, о которой я буду говорить в этой цепочке – это красный прямоугольник тут:
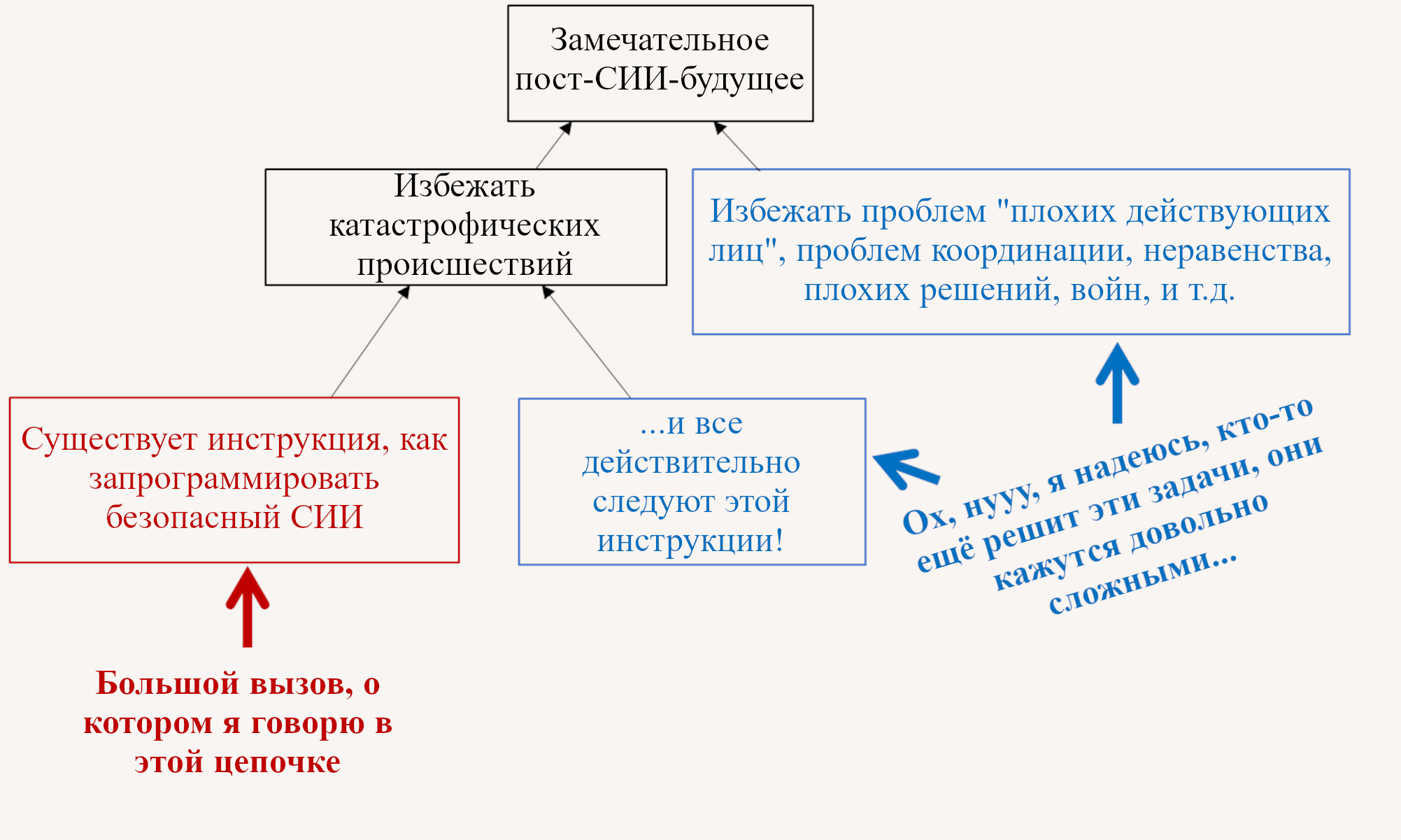
Конкретнее, мы будем представлять одну команду людей, пытающихся создать один СИИ, и стремиться, чтобы для них было возможным сделать это не вызвав какую-нибудь катастрофу, которую никто не хочет, с вышедшим из под контроля СИИ, самовоспроизводящимся через Интернет, или чем-то ещё (больше про это в Разделе 1.6).
Синие прямоугольники на диаграмме – это то, о чём я не буду говорить в этой цепочке. На самом деле, я вообще над ними не работаю – мне и так уже достаточно. Но я очень сильно одобряю, что над ними работают другие люди. Если ты, дорогой читатель, хочешь работать над ними, удачи тебе! Я болею за тебя! И вот несколько ссылок, чтобы начать: 1, 2, 3, 4, 5, 6, 7.
Возвращаясь к красному прямоугольнику. Это техническая задача, требующая технического решения. Никто не хочет катастрофических происшествий. И всё же катастрофы случаются! В самом деле, для людей совершенно возможно написать алгоритм, который делает что-то, что никто от него не хотел. Это происходит всё время! Мы можем назвать это «багом», когда это локальная проблема в коде, и мы можем назвать это «фундаментально порочным дизайном софта», когда это глобальная проблема. Позднее в цепочке я буду отстаивать позицию, что код СИИ может быть необычайно склонен к катастрофическим происшествиям, и что ставки очень высоки (см. Раздел 1.6 ниже и Пост №10).
Вот аналогия. Если вы строите атомную электростанцию, то никто не хочет вышедшей из-под контроля цепной реакции. Люди в Чернобыле точно не хотели! Но это всё равно произошло! Я извлекаю из этой аналогии несколько уроков:
- Энрико Ферми изобрёл техническое решение для контроля атомных цепных реакций – аварийные регулирующие кассеты – до создания первой атомной цепной реакции. Правильно!! Вот это значит делать вещи в нужном порядке! По той же причине, я считаю, что нам следует стремиться иметь техническое решение для избегания катастрофических происшествий с СИИ наготове до того, как начинать программировать СИИ. На самом деле, я ниже буду отстаивать даже более сильное утверждение: знать (хотя бы в общих чертах) решение за 10 лет до СИИ ещё лучше; за 20 лет до СИИ – ещё лучше; и т.д. и т.д. Это заявление неочевидно, но я к нему ещё вернусь (Раздел 1.7).
- Технические решения – это не всё-или-ничего. Некоторые снижают риск происшествий, не избавляясь от него полностью. Некоторые сложны и дороги, и подвершены ошибкам при реализации. В случае атомных реакций, аварийные регулирующие кассеты сильно снижают риск происшествий, но пассивно-безопасные реакторы снижают его ещё сильнее. Аналогично, я ожидаю, что техническая безопасность СИИ будет большой областью, в которой мы будем со временем разрабатывать всё более хорошие подходы, используя множество техник и множество слоёв защиты. По крайней мере, я надеюсь! Дальше в цепочке я заявлю, что прямо сейчас у нас нет никакого решения – даже примерного. У нас полно работы!
- Синие прямоугольники (см. диаграмму выше) тоже существуют, и они совершенно необходимы, хоть и находятся за пределами рассмотрения этой конкретной серии статей. Причиной Чернобыля было не то, что никто не знал, как контролировать цепную атомную реакцию, а то, что лучшим практикам не следовали. В таком случае, мы все в пролёте! Всё же, хоть техническая сторона не может сама по себе решить проблему невыполнения, мы можем несколько с ней помочь, разрабатывая лучшие практики минимально дорогими и с максимальной защитой от дурака.

В *Ученике Чародея*, если я правильно его помню, программный инженер Микки Маус программирует СИИ с метлоподобным роботизированным телом. СИИ делает в точности то, что Микки *запрограммировал* его делать («наполнить ведро водой»), но это оказалось сильно отличающимся от того, что Микки от него *хотел* («наполнить ведро водой, не устроив беспорядок и не делая чего-то ещё, что я бы счёл проблематичным, и т.д.»). Наша цель – дать программным инженерам вроде Микки *возможность* избегать подобных инцидентов, снабдив их необходимыми для этого инструментами и знаниями. См. эту лекцию Нейта Соареса для глубокого обзора того, почему перед Микки ещё полно работы.
1.3 Подобный-мозгу СИИ
1.3.1 Обзор
Эта цепочка фокусируется на конкретном сценарии того, как будут выглядеть алгоритмы СИИ:
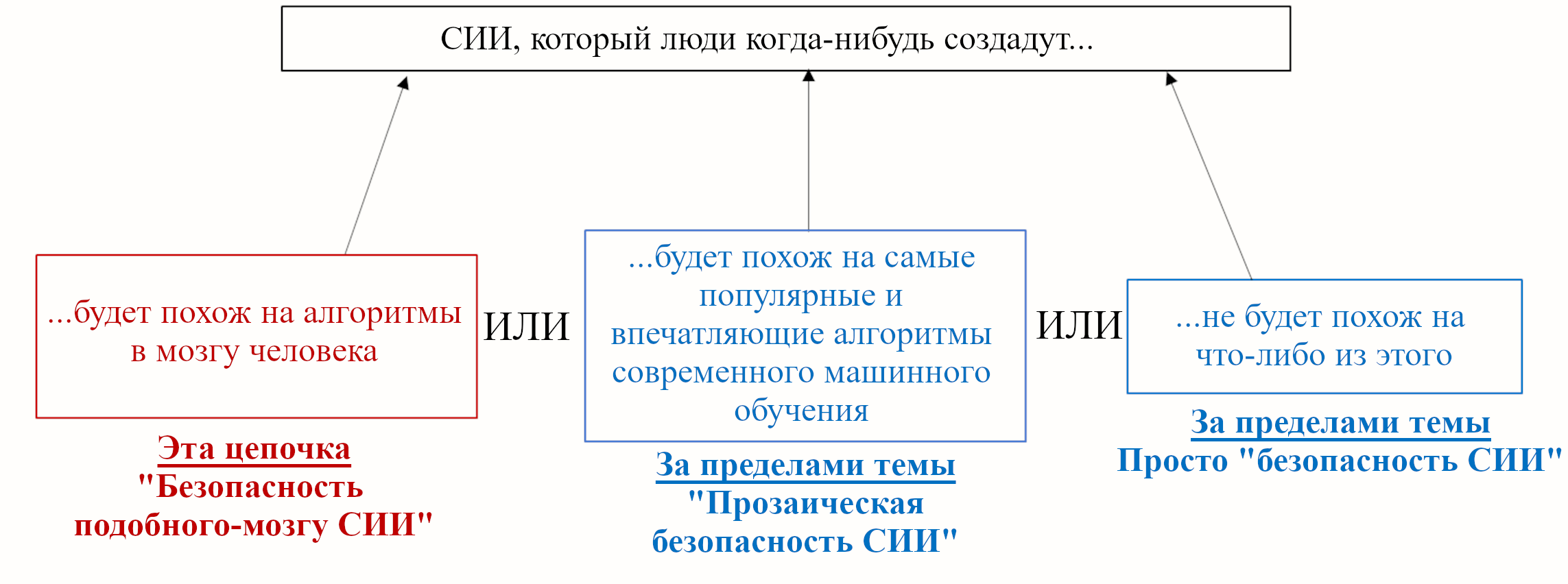
Красный прямоугольник – то, о чём я говорю тут. Синие прямоугольники находятся за пределами рассмотрения данной цепочки.
У вас может быть своё мнение о том, какие из этих категорий более или менее вероятны, или даже невозможны, или вообще имеет ли это разделение смысл. У меня оно тоже есть! Я опишу его позже (Раздел 1.5). Но его основа – что все три варианта в достаточной степени вероятны, чтобы нам следовало к ним готовиться. Так что хоть я лично и не делаю много работы в этих синих прямоугольниках, я уж точно рад, что это делают другие!
Вот аналогия. Если бы кто-то в 1870 пытался бы догадаться, как будет выглядеть будущий человеческий полёт…
- «Что-то вроде птиц» было бы осмысленным предположением…
- «Что-то вроде лучших нынешних летательных аппаратов» было бы тоже осмысленным предположением…
- «Ни то, ни другое» было бы ещё одним осмысленным предположением!!
В этом конкретном воображаемом случае, все три предположения оказались бы частично верны, а частично ошибочны: братья Райт активно напрямую вдохновлялись большими парящими птицами, но отбросили махание крыльями. Они также использовали некоторые компоненты уже существовавших аппаратов (например, пропеллеры), но и прилично своих оригинальных деталей. Это всего один пример, но мне кажется, что он убедительный.
1.3.2 Что в точности такое «подобный-мозгу СИИ»?
Когда я говорю «подобный-мозгу СИИ», я имею в виду нечто конкретное. Это станет яснее в следующих постах, после того, как мы начнём погружаться в нейробиологию. Но вот, в общих чертах, о чём я:
Есть некоторые составляющие в человеческом мозгу и его окружении, которые приводят к тому, что у людей есть обобщённый интеллект (например, здравый смысл, способность что-то понимать, и т.д. – см. Раздел 1.4 ниже). В представляемом мной сценарии исследователи выясняют, что это за составляющие и как они работают, а потом пишут код ИИ, основываясь на этих же ключевых составляющих.
Для прояснения:
- Я не ожидаю, что «подобный мозгу СИИ» будет включать каждую часть мозга и его окружения. К примеру, есть высокоинтеллектуальные люди, рождённые без чувства запаха, из чего можно сделать вывод, что цепи обработки ольфакторной информации не необходимы для СИИ. Есть и высокоинтеллектуальные парализованные с рождения люди, так что большинство спинного мозга и некоторые аспекты ощущения тела тоже не необходимы. Есть люди, рождённые без мозжечка, несмотря на это вполне попадающие в диапазон нормального интеллекта взрослого человека (способные работать, независимо жить и т.д. – способности, которые мы бы без сомнений назвали бы «СИИ»). Другие взрослые ходят на работу, будучи лишёнными целого полушария мозга, и т.д. Моё ожидание по умолчанию – что СИИ будет создан людьми, пытающимися создать СИИ, и они отбросят столько компонентов, сколько возможно, чтобы сделать свою работу проще. (Я не утверждаю, что это обязательно хорошая идея, только что этого я ожидаю по умолчанию. Подробнее об этом в Посте №3.)
- В частности, «подобный мозгу СИИ», о котором я говорю – это точно не тоже самое, что Полная Эмуляция Мозга.
- Я не требую, чтобы «подобный-мозгу СИИ» напоминал человеческий мозг в низкоуровневых деталях, вроде импульсных нейронов, дендритов, и т.д., или их прямых симуляций. Если сходство есть только на высоком уровне, хорошо, это тут ни на что не повлияет.
- Я не требую, чтобы «подобный мозгу СИИ» был изобретён процессом реверс-инжиниринга мозга. Если исследователи ИИ независимо переизобретут схожие с исполняемыми в мозгу алгоритмами – просто потому, что это хорошие идеи – что ж, я всё ещё буду считать результат подобным-мозгу.
- Я не требую, чтобы «подобный мозгу СИИ» был спроектирован способом, напоминающим то, как был спроектирован мозг, т.е. эволюционным поиском. Даже наоборот: моё рабочее допущение – что он будет спроектирован людьми способом, сходным с типичными проектами машинного обучения сегодня: много написанного людьми кода (очень приблизительно аналогичного геному), часть которого определяет выведение и правила обновлений одного или нескольких алгоритмов обучения (соответствующих алгоритмам обучения мозга во время жизни). В коде могут быть какие-то пустые места, заполняемые поиском гиперпараметров или нейронной архитектуры и т.п. Потом код запускают, и обучающие алгоритмы постепенно создают большую сложно устроенную обученную модель, возможно, с триллионами настраиваемых параметров. Больше об этом в следующих двух постах и Посте №8.
- Я не требую, чтобы «подобный-мозгу СИИ» имел самосознание. Есть этические причины беспокоиться об осознанности СИИ (больше об этом в Посте №12), но всё, что я говорю в этой цепочке, не зависит от этого. Машинное сознание – большая спорная тема, и я не хочу в неё тут погружаться. (Я написал немного об этом в другом месте.)
Я собираюсь много чего заявить про алгоритмы в основе человеческого интеллекта, и потом говорить о безопасном использовании алгоритмов с этими свойствами. Если наши будущие алгоритмы СИИ будут иметь эти свойства, то эта цепочка будет полезна, и я буду склонен называть такие алгоритмы «подобными мозгу». Мы увидим, что это в точности за свойства дальше.
1.3.3 «Подобный мозгу СИИ» (по моему определению) может (и очень возможно, что будет) иметь радикально нечеловеческие мотивации
Я собираюсь много говорить об этом в следующих статьях, но это настолько важно, что я хочу поднять эту тему немедленно.
Да, я знаю, это звучит странно.
Да, я знаю, вы думаете, что я чокнутый.
Но пожалуйста, прошу вас, сначала выслушайте. К моменту, когда мы доберёмся до Поста №3, тогда вы сможете решать, верить мне или нет.
На самом деле, я пойду дальше. Я отстаиваю позицию, что «радикально нечеловеческие мотивации» не просто возможны для подобного-мозгу СИИ, но и являются основным ожиданием от него. Я считаю, что это в целом плохо, и что для избегания этого нам следует проактивно приоритезировать конкретные направления исследований и разработок.
(Для ясности, «радикально нечеловеческие мотивации» - это не синоним «пугающих и опасных мотиваций». К сожалению, «пугающие и опасные мотивации» – тоже моё основное ожидание от подобного-мозгу СИИ!! Но это требует дальнейшей аргументации, и вам придётся подождать её до Поста №10.)
1.4 Что конкретно такое «СИИ»?
Частый источник замешательства – слово «Обобщённый» в «Обобщённом Искусственном Интеллекта» (по-русски устоялось словосочетание «Сильный Искусственный Интеллект», поэтому аббревиатуру я перевожу как СИИ, но вообще в оригинале он General – прим.пер.):
- Слово «Обобщённый» ОЗНАЧАЕТ «не специфичный», как «Говоря обобщённо, в Бостоне жить хорошо.»
- Слово «Обобщённый» НЕ ОЗНАЧАЕТ «универсальный», как в «Я нашёл обобщённое доказательство теоремы.»
СИИ не «обобщённый» во втором смысле. Это не штука, которая может мгновенно обнаружить любой паттерн и решить любую задачу. Люди тоже не могут! На самом деле, никакой алгоритм не может, потому что это фундаментально невозможно. Вместо этого, СИИ – это штука, которая, встретившись с сложной задачей, может быть способна легко её решить, но если нет, то может быть она способна создать инструмент для решения задачи, или найти умный способ обойти задачу, и т.д. В наших целях можно думать о СИИ как об алгоритме, который может «разобраться в вещах» и «понять, что происходит» и «сделать дело», в том числе с использованием языка, науки и технологии, способом, напоминающим то, как это может делать большинство взрослых людей, но не могут младенцы, шимпанзе и GPT-3. Конечно, алгоритмы СИИ вполне могут быть в чём-то слабее людей и сверхчеловеческими в чём-то другом.
В любом случае, эта цепочка – про подобные-мозгу алгоритмы. Эти алгоритмы по определению способны на совершенно любое интеллектуальное поведение, на которое способны люди, и потенциально на куда большее. Так что они уж точно достигают уровня СИИ. А вот сегодняшние ИИ-алгоритмы не являются СИИ. Так что где-то посередине есть неясная граница, отделяющая «СИИ» от «не СИИ». Где точно? Мой ответ: я не знаю, и мне всё равно. Проведение этой линии никогда не казалось мне полезным. Так что я не вернусь к этому в цепочке.
1.5 Какова вероятность, что мы однажды придём к подобному-мозгу СИИ?
Выше (Раздел 1.3.1) я предложил три категории алгоритмов СИИ: «подобные мозгу» (определённые выше), «прозаические» (т.е. подобные современным наиболее впечатляющим глубоким нейросетевым алгоритмам машинного обучения), и «другие».
Если ваше отношение – «Да, давайте изучать безопасность для всех трёх возможностей, просто на всякий случай!!» – как, по-моему, и надо – то, наверное, не так уж важно для принятия решений, как между этими возможностями распределена вероятность.
Но даже если это не важно, об этом интересно поговорить, так что почему нет, я просто быстро перескажу и отвечу на некоторые популярные известные мне мнения на этот счёт.
Мнение №1: «Я оспариваю предпосылку: человеческий мозг работает в целом по тем же принципам, что и нынешние популярные алгоритмы машинного обучения.»
- В первую очередь, «нынешние популярные алгоритмы машинного обучения» – это зонтичный термин, включающий в себя много разных алгоритмов. К примеру, я едва ли вижу хоть какое-то пересечение у «безопасности подобного-GPT-3 СИИ» и «безопасности подобного-мозгу СИИ», но вижу у второго значительное пересечение с «безопасностью подобного-агенту-основанного-на-модели-обучения-с-подкреплением СИИ».
- В любом случае, предполагая «подобный-мозгу СИИ» я могу делать некоторые предположения о его когнитивной архитектуре, внутренних отображениях, обучающих алгоритмах, и так далее.
- Некоторые из этих «ингредиентов подобного-мозгу СИИ» – повсеместные части нынешних популярных алгоритмов машинного обучения (например, алгоритмы обучения; распределённые отображения).
- Другие из этих «ингредиентов подобного-мозгу СИИ» – представлены (по отдельности) в некотором подмножестве нынешних популярных алгоритмов машинного обучения, но отсутствуют в других (например, обучение с подкреплением; предсказывающее обучение [так же известное как самообучение]; явное планирование).
- А ещё некоторые из этих «ингредиентов подобного-мозгу СИИ» кажутся в основном отсутствующими в нынешних самых популярных алгоритмах машинного обучения (например, способность формировать «мысли» [вроде «Я собираюсь пойти в магазин»], которые совмещают немедленные действия, краткосрочные и долгосрочные предсказания и гибкие иерархические планы в генеративной модели мира, поддерживающей причинные, гипотетические и метакогнитивные рассуждения).
- Так что в этом смысле «подобный мозгу СИИ» – это конкретная штука, которая может случиться или не случиться независимо от «прозаического СИИ». Больше про «подобный мозгу СИИ», или, по крайней мере, его важные для безопасности аспекты, в следующих постах.
Мнение №2: «Подобный-мозгу СИИ» возможен, а Прозаический – нет. Этого просто не будет. Современное исследование машинного обучения – не путь к СИИ, точно так же, как забираться на дерево – не путь на Луну.»
- Это кажется мне умеренно популярным мнением среди нейробиологов и когнитивных психологов. Видные защитники этой точки зрения – это, например, Гэри Маркус и Мелани Митчелл.
- Один вопрос: если мы возьмём одну из нынешних самых популярных моделей машинного обучения, не будем добавлять никаких значительных озарений или изменений архитектуры, и просто масштабируем её на ещё больший размер, получим ли мы СИИ? Я присоединяюсь к этим нейробиологам в ожидании ответа «наверное, нет».
- С другой стороны, даже если окажется, что глубокие нейросети не могут делать важные-для-интеллекта штуки X, Y и Z, то ну серьёзно, кто-нибудь наверное просто приклеит к глубоким нейросетям другие компоненты, которые делают X, Y и Z. И у нас останется лишь какой-то бессмысленный спор об определениях, о том, «действительно» ли это прозаический СИИ или нет.
{kind=link}
- В любом случае, в этой цепочке я буду предполагать, что СИИ будет иметь некоторые алгоритмические черты (например, онлайновое обучение, разновидность основанного на модели планирования, и т.д. Больше об этом в следующих постах). Я буду предполагать это, потому что (1) эти черты – части человеческого интеллекта, (2) кажется, что они в нём не зря. Мои относящиеся к безопасности рассуждения будут полагаться на наличие этих черт. Могут ли алгоритмы с этими чертами быть реализованы в PyTorch на GPU? Ну, мне всё равно.
Мнение №3: «Прозаический СИИ появится настолько скоро, что другие программы исследований не имеют ни шанса.»
- Некоторое подмножество людей в области машинного обучения считают так. Я нет. Или, по крайней мере, я был бы ужасно удивлён.
- Я согласен, что ЕСЛИ прозаический СИИ, скажем, в пяти годах от нас, то нам почти точно не надо думать о подобном мозгу СИИ или о любой иной программе исследований. Я просто думаю, что это ну очень большое «если».
Мнение №4: «Мозги НАСТОЛЬКО сложные – и мы понимаем о них НАСТОЛЬКО мало после НАСТОЛЬКО больших усилий – что мы никак не можем получить подобный мозгу СИИ даже за следующие 100 лет.»
- Это довольно популярное мнение, как внутри, так и снаружи нейробиологии. Я думаю, что оно крайне неверно, и буду спорить с ним в следующих двух постах.
Мнение №5: «Нейробиологи не пытаются изобрести СИИ, так что нам не следует ожидать, что они это сделают».
- В этом есть какая-то правда, но в основном я не соглашусь. Для начала, некоторое количество ведущих вычислительных нейробиологов (команда нейробиологии DeepMind, Рэндалл О’Райли, Джефф Хокинс, Дайлип Джордж) на самом деле явно пытаются изобрести СИИ. Во-вторых, люди в области ИИ, включая влиятельных лидеров области, стараются иметь в виду нейробиологическую литературу и осваивать её идеи. И в любом случае, «понять мозговой алгоритм, важный для СИИ» – это часть изобретения подобного-мозгу СИИ, независимо от того, пытается ли это сделать человек, проводящий исследование.
Мнение №6: «Подобный-мозгу СИИ – не вполне имеющий смысл концепт; интеллект требует телесного воплощения, не просто мозга в банке (или на чипе).»
- Дебаты о «телесном воплощении» в нейробиологии всё продолжаются. Я принимаю позицию где-то посередине. Я думаю, что будущие СИИ будут иметь какое-то пространство действий – вроде способности (виртуально) призвать конкретную книгу и открыть её на конкретном месте. Я не думаю, что обладание целым буквальным телом важно – к примеру, Кристофер Нолан (1965-2009) был парализован всю жизнь, что не помешало ему быть известным писателем и поэтом. Что важнее, я ожидаю, что какие бы аспекты телесного воплощения ни оказались важны для интеллекта, их можно будет легко встроить в подобный-мозгу СИИ, запущенный на кремниевом чипе. Тело всё же необходимо для интеллекта? ОК, ладно, давайте дадим СИИ виртуальное тело в виртуальном мире. Гормональные сигналы необходимы для интеллекта? ОК, хорошо, мы можем закодировать виртуальные гормональные сигналы. И т.д., и т.п.
Мнение №7: «Подобный-мозгу СИИ несовместим с обычными кремниевыми чипами, он потребует новой аппаратной платформы, основанной на импульсных нейронах, активных дендритах, и т.д. Нейроны попросту лучше в вычислениях, чем кремниевые чипы – просто посмотри на энергетическую эффективность и подобное.»
- Я довольно плохо отношусь к этой позиции. Стандартные кремниевые чипы точно могут симулировать биологические нейроны – нейробиологи всё время это делают. По-видимому, они также могут исполнять «подобные мозгу алгоритмы», используя иные низкоуровневые операции, более подходящие для этого «железа» – так же как один и тот же код на C можно скомпилировать для разных наборов инструкций процессоров. Касательно же «нейроны попросту лучше», я вполне признаю, что человеческий мозг выполняет чертовски впечатляющее количество вычислений для своего крохотного объёма, массы и потребления энергии. Но это всё не жёсткие ограничения! Если СИИ на кремниевых чипах будет буквально в 10000 раз больше по объёму, массе и потреблению энергии, чем человеческий мозг сравнимой интеллектуальной мощности, то я не думаю, что кому-то было бы дело до меньшей эффективности – в частности, стоимость потребляемого им электричества была бы всё ещё меньше минимальной зарплаты в моём регионе!! И моя лучшая оценка такова, что покупка достаточного количества кремниевых чипов для осуществления того же объёма вычислений, что выполняет человеческий мозг за всю жизнь, скорее всего легко доступна, или будет легко доступна в следующем десятилетии, даже для маленьких компаний. Ключевая причина, по которой маленькие компании не создают СИИ сегодня – мы не знаем правильных алгоритмов.
Это просто быстрый обзор; каждое из этих мнений можно растянуть на отдельную статью – да что там, на целую книгу. Что касается меня, я оцениваю вероятность, что у нас будет достаточно подобный мозгу СИИ, чтобы эта цепочка была к месту, более чем в 50%. Но, конечно, кто знает.
1.6 Почему происшествия с СИИ – настолько серьёзное дело?
Две причины: (1) ставки высоки, и (2) задача трудна. Я буду говорить о (2) куда позже в цепочке (Посты №10-11). Давайте поговорим про (1).
И давайте поговорим конкретнее про возможность одной высокой ставки: риск человеческого вымирания. Это звучит немного дико, но послушайте.
Я оформлю это как ответы на популярные возражения:
Возражение №1: Единственный способ, которым вышедший из под контроля СИИ может привести к вымиранию людей – это если СИИ изобретёт сумасшедшее фантастическое супероружие, например, серую слизь. Как будто это вообще возможно!
О, если бы это было так! Но увы, я не думаю, что фантастическое супероружие невозможно. На самом деле, мне кажется, что где-то примерно на границе возможного для человеческого интеллекта использовать существующие технологии для вымирания человечества!
Подумайте об этом: для амбициозного харизматичного методичного человека уже по крайней мере недалеко от границ возможного устроить производство и высвобождение новой заразной болезни в 100 раз смертельнее, чем COVID-19. Чёрт побери, наверное, возможно выпустить 30 таких болезней одновременно! В то же время, я думаю, хотя бы на границах возможного для амбициозного умного харизматичного человека и найти способ манипулировать системами раннего оповещения о ядерном ударе (обмануть, взломать, подкупить или запугать операторов, и т.д.), устроив полноценную ядерную войну, убив миллиарды людей и посеяв в мире хаос. Это всего лишь два варианта, креативный читатель немедленно придумает ещё немало. В смысле, серьёзно, есть художественные книги с совершенно правдоподобными апокалиптическими безумноучёновскими сценариями, не согласно лишь моему мнению, но согласно экспертам в соответствующих областях.
Теперь, ну принято, вымирание выглядит очень сложнодостижимым требованием! Люди живут в куче разных мест, в том числе на маленьких тропических островах, которые были бы защищены и от ядерной зимы, и от эпидемий. Но тут мы вспомним о большой разнице между интеллектуальным агентом, вроде СИИ и неинтеллектуальным, вроде вируса. Оба могут самовоспроизводиться. Оба могут убить кучу людей. Но СИИ, в отличии от вируса, может взять управление военными дронами и перебить выживших!!
Так что я подозреваю, что мы всё ещё тут в основном из-за того, что самые амбициозные умные харизматичные методичные люди не пытаются всех убить, а не из-за того, что «убить всех» – задача, требующая сумасшедшего фантастического супероружия.
Как описано выше, один из возможных вариантов провала, которые я себе представляю, включает в себя вышедший из-под контроля СИИ, сочетающий интеллект (как минимум) человеческого уровня с радикально нечеловеческими мотивациями. Это была бы новая для мира ситуация, и она не кажется мне комфортной!
Вы можете возразить: То, что пошло не так в этом сценарии – это не вышедший из-под контроля СИИ, это факт того, что человечество слишком уязвимо! И моим ответом будет: Одно другому не мешает! Так что: да, нам совершенно точно следует делать человечество более устойчивым к искусственно созданным эпидемиям и уменьшать шансы атомной войны, и т.д., и т.п. Всё это – замечательные идеи, которые я сильно одобряю, и удачи вам, если вы над ними работаете. Но в то же время, нам следует ещё и очень много работать над тем, чтобы не создать вышедший из-под контроля самовоспроизводящийся подобный-человеку интеллект с радикально нечеловеческими мотивациями!
…О, и ещё одно: может быть, «сумасшедшее фантастическое супероружие вроде серой слизи» тоже возможно! Не знаю! Если так, нам надо быть ещё более осторожными!
Возражение №2: Единственный способ, которым происшествие с СИИ может привести к вымиранию людей – это если СИИ каким-то образом умнее всех людей вместе взятых.
Проблема тут в том, что «все люди вместе взятые» могут не знать, что участвуют в битве против СИИ. Могут знать, а могут и нет. Если СИИ вполне компетентен в секретности, то он скорее организует неожиданную атаку, чтобы никто не знал, что происходит, пока не станет слишком поздно. Или, если СИИ вполне компетентен в дезинформации и пропаганде, он предположительно сможет представить свои действия как несчастные случаи, или как (человеческие) враждебные действия. Может быть, все будут обвинять кого-то ещё, и никто не будет знать, что происходит.
Возражение №3: Единственный способ, которым происшествие с СИИ может привести к вымиранию людей – если СИИ намеренно дадут доступ к рычагам влияния, вроде кодов запуска ядерных ракет, контроля над социальными медиа, и т.д. Но мы также можем запустить код СИИ на всего одном сервере, и потом выключить его, если что-то пойдёт не так.
Проблема тут в том, что интеллектуальные агенты могут превратить «мало ресурсов» в «много ресурсов». Подумайте о Уоррене Баффетте или Адольфе Гитлере.
Интеллектуальные агенты могут зарабатывать деньги (легально или нет), зарабатывать доверие (заслуженное или нет) и получать доступ к другим компьютерам (приобретая серверное время или взламывая их). Последнее особенно важно, потому что СИИ – как вирус, но не как человек – потенциально может самовоспроизводиться. Самовоспроизведение – один из способов, которыми он может защитить себя от выключения, если он на это мотивирован. Другой способ – обмануть / ввести в заблуждение / склонить на свою сторону / подкупить / перехитрить того, кто контролирует кнопку выключения.
(Зерно истины тут в том, что если мы не уверены в мотивации и компетентности СИИ, то давать ему доступ к кодам запуска – очень плохая идея! Попытки ограничить власть и ресурсы СИИ не кажутся решением ни одной из сложнейших интересующих нас тут задач, но это всё ещё может быть как-то полезно, вроде «дополнительного слоя защиты». Так что я целиком за.)
Возражение №4: Хорошие СИИ могут остановить плохих вышедших-из-под-контроля СИИ.
Для начала, если мы не решим техническую проблему того, как направлять мотивацию СИИ и удерживать его под контролем (см. Посты №10-15), то может случиться так, что некоторое время хороших СИИ нет! Вместо этого, все СИИ будут вышедшими из-под контроля!
Вдобавок, вышедшие из-под контроля СИИ будут иметь асимметричные преимущества над хорошими СИИ – вроде возможности красть ресурсы, манипулировать людьми и социальными институтами ложью и дезинформацией; начинать войны, пандемии, блэкауты, выпускать серую слизь, и так далее; и отсутствия необходимости справляться с трудностями координации многих разных людей с разными убеждениями и целями. Больше на эту тему – тут.
Возражение №5: СИИ, который пытается всех убить – это очень конкретный вариант провала! Нет причин считать, что СИИ попробует это сделать. Это не то, что произойдёт как общий результат забагованного или плохо спроектированного софта СИИ. Такое произойдёт только, если кто-то намеренно вложит в СИИ злобные мотивации. На самом деле, забагованный или плохо спроектированный софт обычно делает, ну, ничего особенного! Я знаю кое-что про забагованный софт – я вообще-то написал один сегодня с утра. Единственное, что было убито – моя самооценка!
Тут есть зерно истины в том, что некоторые баги или недостатки проектирования в коде СИИ действительно приведут к тому, что получившийся софт не будет СИИ, не будет «интеллектуальным», и, возможно, даже не будет функционировать! Такие ошибки не считаются катастрофическими происшествиями, если только мы не оказались настолько глупы, что поставили этот софт управлять ядерным арсеналом. (См. «Возражение №3» выше.)
Однако, я утверждаю, что другие баги / ошибки проектирования будут потенциально вести к тому, что СИИ намеренно будет всех убивать, даже если его создатели – разумные люди с благородными скромными намерениями.
Почему? В области безопасности СИИ классический способ это обосновать – это триада из (1) «Тезиса Ортогональности», (2) «Закона Гудхарта» и (3) «Инструментальной Конвергенции». Вы можете ознакомиться с короткой версией этого тройного аргумента тут. Для длинной версии, читайте дальше: эта цепочка вся про детали мотивации подобного мозгу СИИ, и про то, что там может пойти не так.
Так что запомните эту мысль, мы проясним её к тому моменту, как пройдём Пост №10.
Возражение №6: Если создание СИИ кажется спусковым крючком катастрофических происшествий, то мы просто не будем этого делать, до тех пор, пока (если) не решим проблему.
Моя немедленная реакция: «Мы»? Кто, чёрт побери, такие «Мы»? Занимающееся ИИ сообщество состоит из многих тысяч способных исследователей, рассеянных по земному шару. Они расходятся друг с другом во мнениях практически о чём угодно. Никто не присматривает за тем, что они делают. Некоторые из них работают в секретных военных лабораториях. Так что я не думаю, что мы можем принять за данность, что «мы» не будем проводить разработки, которые вы и я считаем очевидно необдуманными и рискованными.
(К тому же, если от некоторых катастрофических происшествий нельзя восстановиться, то даже одно такое – слишком много.)
К слову, если предположить, что кто-то скажет мне «У меня есть экстраординарно амбициозный план, который потребует многих лет или десятилетий работы, но если мы преуспеем, то «Все на Земле ставят разработку СИИ на паузу, пока не будут решены задачи безопасности» будет возможной опцией в будущем» – ОК, конечно, я бы с готовностью выслушал. По крайней мере, этот человек говорит так, будто понимает масштаб вызова. Конечно, я ожидаю, что это скорее всего провалится. Но кто знает?
Возражение №7: Риски происшествий падают и падают уже на протяжении десятилетий. Ты не читал Стивена Пинкера? Имей веру!
Риски не решают сами себя. Они решаются, когда их решают люди. Самолёты обычно не падают. потому что люди сообразили, как избегать падения самолётов. Реакторы атомных электростанций обычно не плавятся потому, что люди сообразили, как избежать и этого.
Представьте, что я сказал: «Хорошие новости, уровень смертей в автокатастрофах сейчас ниже, чем когда либо! Так что теперь мы можем избавиться от ремней безопасности, зон деформации и дорожных знаков!». Вы бы ответили: «Нет!! Это безумие!! Ремни безопасности, зоны деформации и дорожные знаки – это и есть причина того, что смертей в автокатастрофах меньше, чем когда либо!»
Точно так же, если вы оптимистичны и считаете, что мы в итоге избежим происшествий с СИИ, то это не причина возражать против исследований безопасности СИИ.
Есть ещё кое-что, что надо держать в голове, прежде чем находить утешение в исторических данных о рисках технологических происшествий: пока технология неумолимо становится могущественнее, масштабы урона от технологических происшествий также неумолимо растут. Происшествие с атомной бомбой было бы хуже, чем с конвенционной. Биотеррорист с технологией 2022 года был бы способен нанести куда больший ущерб, чем биотеррорист с технологией 1980 года. Точно так же, раз ИИ системы в будущем станут значительно более мощными, нам следует ожидать, что масштаб урона от происшествий с ними так же будет расти. Так что исторические данные не обязательно правильно отображают будущее.
Возражение №8: Люди всё равно обречены. И вообще, никакой вид не живёт вечно.
Я много встречал вариации этого. И, ну да, я не могу доказать, что это неверно. Но мечехвосты вот существуют уже половину миллиарда лет. Давайте, люди, мы так можем! В любом случае, я без боя сдаваться не собираюсь!
А для людей, принимающих “далёкое” отчуждённое философско-кресельное отношение к человеческому вымиранию: если вас опустошила бы безвременная смерть вашего лучшего друга или любимого члена семьи… но вас не особенно заботит идея вышедшего из-под контроля СИИ, убивающего всех… эммм, я не уверен, что тут сказать. Может, вы не очень осторожно всё продумали?
1.7 Почему думать о безопасности СИИ сейчас? Почему не подождать, пока мы не приблизимся к СИИ и не узнаем больше?
Это частое возражение, и в нём действительно есть огромное зерно истины: в будущем, когда мы будем знать больше деталей об устройстве СИИ, будет много новой технической работы по безопасности, которую мы не можем сделать прямо сейчас.
Однако, есть работа по безопасности, которую мы можем сделать прямо сейчас. Просто продолжайте читать эту цепочку, если не верите мне!
Я хочу заявить, что работу по безопасности, которую мы можем делать прямо сейчас, действительно стоит делать прямо сейчас. Ждать куда хуже, даже если до СИИ ещё много десятилетий. Почему? Три причины:
Причина поторопиться №1: Ранние наводки по поводу безопасности могут влиять на решения при исследовании и разработке, включая «Дифференцированное Технологическое Развитие».

Самое важное, что уж точно есть более чем один способ запрограммировать алгоритм СИИ.
Очень рано в этом процессе мы принимаем высокоуровневые решения о пути к СИИ. Мы можем вести исследования и разработку к одной из многих вариаций «подобного мозгу СИИ», как определено здесь, или к полной эмуляции мозга, или к разным видам «прозаического СИИ» (Раздел 1.3.1), или к СИИ, основанному на запросах к графу базы данных, или к системе знания / дискуссии / рассуждения, мы можем использовать или не использовать различные интерфейсы мозг-компьютер, и так далее. Вероятно, не все из этих путей осуществимы, но тут уж точно есть более чем один путь к более чем одной возможной точке назначения. Нам надо выбрать по какому пути пойти. Чёрт, мы даже решаем, создавать ли СИИ вообще! (Однако, смотри «Возражение №6» выше)
На самом деле, мы принимаем эти решения уже сейчас. Мы принимаем их годами. И наша процедура принятия решений такова, что много отдельных людей по всему миру спрашивают себя: какое направление исследований и разработки лучше всего для меня прямо сейчас? Что принесёт мне работу / повышение / выгоду / высокоцитируемую публикацию прямо сейчас?
Получше была бы такая процедура принятия решений: какой СИИ мы хотим однажды создать? ОК! Давайте попробуем прийти к этому раньше всех плохих альтернатив.
Другими словами, те, кто выбирает направление исследований и разработки, основываясь на том, что выглядит интересным и многообещающим, так же как все остальные, не поменяют путь развития нашей технологии. Они просто проведут нас по тому же пути немного быстрее. Если мы думаем, что некоторые точки назначения лучше других, скажем, если мы пытаемся избежать будущих полностью неподконтрольных СИИ с радикально нечеловеческими мотивациями – то важно выбрать, какие исследования делать, чтобы стратегически ускорить то, что мы хотим, чтобы произошло. Этот принцип называется дифференцированное технологическое развитие – или, более обобщённо, дифференцированный интеллектуальный прогресс.

У меня есть мои собственные предварительные идеи о том, что следует ускорять, чтобы с подобным-мозгу СИИ всё получилось получше. (Я доберусь до этого подробно позже в цепочке.) Но главное, в чём я убеждён: «нам нужно отдельно ускорять работу над выяснением, какую работу следует отдельно ускорять»!! К примеру, будет ли подобный мозгу СИИ склонным к катастрофическим происшествиям или нет? Нам надо выяснить! Потому я и пишу эту цепочку!
Причина поторопиться №2: Мы не знаем, сколько времени займёт исследование безопасности.
Как будет описано куда подробнее в позднейших постах (особенно в Постах №10-15), сейчас неизвестно, как создать СИИ, который надёжно будет пытаться делать то, что мы от него хотим. Мы не знаем, как долго займёт выяснение этого (или доказательство невозможности!). Кажется важным начать сейчас.

Как будет описано позже в цепочке (особенно в Постах №10-15), Безопасность СИИ выглядит очень заковыристой технической задачей. Мы сейчас не знаем, как её решить – на самом деле, мы даже не знаем, решаема ли она. Так что кажется мудрым заточить свои карандаши и приняться за работу прямо сейчас, а не ждать до последнего. Концепт мема украден отсюда
Запомнившаяся аналогия Стюарта Расселла: представьте, что мы получили сообщение от инопланетян «Мы летим к вам на наших космических кораблях, и прибудем через 50 лет. Когда мы доберёмся, мы радикально преобразуем весь ваш мир до неузнавания.» И мы в самом деле видим их корабли в телескопы. Они становятся ближе с каждым годом. Что нам делать?
Если мы будем относиться к приближающемуся инопланетному вторжению так же, как мы на самом деле сейчас относимся к СИИ, то мы коллективно пожмём плечами и скажем «А, 50 лет, это ещё совсем нескоро. Нам не надо думать об этом сейчас! Если 100 человек на Земле пытаются подготовиться к надвигающемуся вторжению, этого достаточно. Может, слишком много! Знаете, спросите меня, этим 100 людям стоит перестать смотреть на звёзды и посмотреть на их собственное общество. Тогда они увидят, что РЕАЛЬНОЕ «надвигающееся инопланетное вторжение» – это кардиоваскулярные заболевания. Вот что убивает людей прямо сейчас!»
…Ну вы поняли. (Не язвлю, ничего такого.)
Причина поторопиться №3: Создание близкого к универсальному консенсуса о чём угодно может быть ужасающе медленным процессом.
Представим, что у меня есть по-настоящему хороший и корректный аргумент о том, что некая архитектура или некий подход к СИИ – просто ужасная идея – непоправимо небезопасная. Я публикую аргумент. Поверят ли мне немедленно и изменят ли направление исследований все вовлечённые в разработку СИИ, включая тех, кто вложил всю свою карьеру в этот подход? Вероятно, нет!!
Бывает, что такое происходит, особенно в зрелых областях вроде математики. Но у некоторых идей широкое (не говоря уж об универсальном) принятие занимает десятки лет: известные примеры включают эволюцию и тектонику плит. Доработка аргументов занимает время. Приведение в порядок свидетельств занимает время. Написание новых учебных пособий занимает время. И да, чтобы несогласные упрямцы умерли и их заменило следующее поколение, тоже занимает время.
Почему почти-универсальный консенсус настолько важен? См. Раздел 1.2 выше. Хорошие идеи о том, как создать СИИ, бесполезны, если люди, создающие СИИ, им не следуют. Если мы хотим добровольного сотрудничества, то нам надо, чтобы создатели СИИ поверили идеям. Если мы хотим принудительного сотрудничества, то нам надо, чтобы люди, обладающие политической властью, поверили идеям. И чтобы создатели СИИ поверили тоже, потому что идеальное принуждение – несбыточная мечта (особенно учитывая секретные лаборатории и т.п.).
1.8 …А ещё это по-настоящему восхитительная задача!
Эй, нейробиологи, слушайте. Некоторые из вас хотят лечить болезни. Хорошо. Давайте. Остальные, вы говорите, что хотите лечить болезни, в своих заявках на гранты, но ну серьёзно, это не ваша настоящая цель, все это знают. На самом деле вы тут, чтобы решать восхитительные нерешённые задачи. Ну, позвольте мне вам сказать, безопасность подобного-мозгу СИИ – это восхитительная нерешённая задача!
Это даже богатый источник озарений о нейробиологии! Когда я целыми днями думаю о штуках из безопасности СИИ (вайрхединг, принятие желаемого за действительное, основания символов, онтологический кризис, интерпретируемость, бла-бла-бла), я задаю вопросы, отличающиеся от обычно задаваемых большинством нейробиологов, а значит наталкиваюсь на другие идеи. (…Мне нравится так думать. Ну, читайте дальше, и сами для себя решите, есть ли в них что-то хорошее.)
Так что даже если я не убедил вас, что техническая задача безопасности СИИ супер-пупер-важная, всё равно читайте. Вы можете работать над ней, потому что она офигенная. ;-)
2. "Обучение с чистого листа" в мозгу
- 1.2.1 Краткое содержание / Оглавление
- 2.2.2 Что такое «обучение с чистого листа»?
- 3.2.3 Три вещи, которыми «обучение с чистого листа» НЕ ЯВЛЯЕТСЯ
- 4.2.4 Моя гипотеза: конечный мозг и мозжечок обучаются с чистого листа, гипоталамус и мозговой ствол – нет
- 5.2.5 Свидетельства того, что конечный мозг и мозжечок обучаются с чистого листа
2.1 Краткое содержание / Оглавление
В предыдущем посте я представил задачу «безопасности подобного-мозгу СИИ». Следующие 6 постов (№2-№7) будут в основном про нейробиологию, в них я буду выстраивать более детальное понимание того, как может выглядеть подобный-мозгу СИИ (или, по крайней мере, его относящиеся к безопасности аспекты).
Этот пост сосредоточен на концепции, которую я называю «обучением с чистого листа», я выдвину гипотезу разделения, в котором 96% человеческого мозга (включая неокортекс) «обучается с чистого листа», а остальные 4% (включая ствол головного мозга) – нет. Эта гипотеза – центральная часть моего представления о том, как работает мозг, так что она требуется для дальнейших рассуждений в этой цепочке.
- В Разделе 2.2 я определю концепцию «обучения с чистого листа». Например, заявляя, что неокортекс «обучается с чистого листа», я имею в виду, что он изначально совершенно бесполезен для организма – выводит улучшающие приспособленность сигналы не чаще, чем случайно – пока не начинает обучаться (во время жизни индивида). Вот пара повседневных примеров штук, которые «обучаются с чистого листа»:
- В большинстве статей по глубинному обучению модель «учится с чистого листа» – она инициализирована случайными весами, так что поначалу её вывод – случайный мусор. Но по ходу обучения её веса обновляются и вывод модели со временем становится весьма полезным.
- Пустой жёсткий диск тоже «учится с чистого листа» – нельзя вытащить оттуда полезную информацию, пока её туда не запихнули.
- В Разделе 2.3 я проясню некоторые частые поводы к замешательству:
- «Обучение с чистого листа» – не то же самое, что «с нуля», потому что существуют встроенные алгоритм обучения, нейронная архитектура, гиперпараметры и т.д.
- «Обучение с чистого листа» – не то же самое, что «воспитание превыше природы», потому что (1) только некоторые части мозга обучаются с чистого листа, а другие – нет, и (2) алгоритмы обучения вовсе не обязательно обучаются внешнему окружению – они так же могут обучаться, например, как контролировать собственное тело.
- «Обучение с чистого листа» – не то же самое (и конкретнее), чем «пластичность мозга», потому что последняя также включает (например) жёстко генетически заданную цепь с всего одним конкретным подстраиваемым параметром, полу-перманентно изменяющимся в некоторых условиях.
- В Разделе 2.4 я опишу свою гипотезу о том, что две большие части мозга существуют исключительно для того, чтобы исполнять алгоритмы обучения с чистого листа – конкретно, конечный мозг (неокортекс, гиппокампус, миндалевидное тело, большая часть базальных ганглиев) и мозжечок. Вместе они составляют 96% от объёма человеческого мозга.
- В Разделе 2.5 я коснусь четырёх источников свидетельств, относящихся к моей гипотезе о том, что конечный мозг и мозжечок обучаются с нуля: (1) размышления о том, как мозг работает на высоком уровне, (2) неонатальные данные, (3) связь с гипотезой «однородности коры» и относящимися к ней проблемами, и (4) возможность, что некоторое свойство предварительной обработки в мозгу – так называемое «разделение паттернов» – включает рандомизацию, заставляющую последующие алгоритмы обучаться с чистого листа.
- В Разделе 2.6 я немного поговорю о том, является ли моя гипотеза мэйнстримной или выделяющейся. (Ответ: я не уверен.)
- В Разделе 2.7 я выдам намёки на то, почему обучение с чистого листа важно для безопасности СИИ – мы попадаем в ситуацию, где то, что мы хотим, чтобы пытался сделать СИИ (например, вылечить болезнь Альцгеймера) – концепт, погребённый в большой и сложной-для-интерпретации структуре данных. Поэтому написание относящегося к мотивации кода весьма не прямолинейно. Подробнее об этом будет в будущих постах.
- Раздел 2.8 будет первой из трёх частей моего обсуждения «сроков до подобного-мозгу СИИ», сосредоточенной на том, сколько времени займёт у учёных реверс-инжиниринг ключевых управляющих принципов обучающейся с чистого листа части мозга. (Остальное обсуждение сроков будет в следующем посте.)
2.2 Что такое «обучение с чистого листа»?
Как указано в введении выше, я предлагаю гипотезу, утверждающую, что большие части мозга – конечный мозг и мозжечок (см. Раздел 2.4 ниже) – «обучаются с чистого листа», в том смысле, что изначально они выдают не вкладывающиеся в эволюционно-адаптивное поведение случайные мусорные сигналы, но со временем становятся всё более полезными благодаря работающему во время жизни алгоритму обучения.
Вот два способа думать о гипотезе обучения с чистого листа:
- Как вам следует думать об обучении с чистого листа (если вы из машинного обучения): Представьте глубокую нейросеть, инициализированную случайными весами. Её нейронная архитектура может быть простой или невероятно сложной, это не важно. У неё точно есть склонности, из-за которых выучить одни виды паттернов для нее легче чем другие. Но их в любом случае надо выучить! Если её веса изначально случайны, то она изначально бесполезна и становится более полезной по мере получения обучающих данных. Идея в том, что эти части мозга (неокортекс и т.д.) схожим образом «инициализированы случайными весами» или обладают каким-то эквивалентным свойством.
- Как вам следует думать об обучении с чистого листа (если вы из нейробиологии): Представьте о связанной с памятью системе, вроде гиппокампуса. Способность формировать воспоминания – очень полезная для организма! …Но она не помогает от рождения!![1] Вам нужно накопить воспоминания перед тем, как их использовать! Моё предположение – что всё в конечном мозге и мозжечке попадает в ту же категорию – это всё разновидности модулей памяти. Они могут быть очень особыми разновидностями модулей памяти! Неокортекс, например, может обучиться и запомнить суперсложную сеть взаимосвязанных паттернов, к нему прилагаются мощные возможности составления запросов, он даже может делать запросы самому себе рекуррентными петлями, и т.д. Но всё равно, это форма памяти, и она изначально бесполезна, и становится всё более полезной для организма, накапливая выученное содержание.
2.3 Три вещи, которыми «обучение с чистого листа» НЕ ЯВЛЯЕТСЯ
2.3.1 Обучение с чистого листа – это НЕ «с нуля»
Я уже упомянул это, но я хочу быть максимально ясным: если неокортекс (к примеру) обучается с чистого листа, это не означает, что в нём нет жёстко генетически закодированного информационного содержания. Это означает, что жёстко генетически закодированное информационное содержание скорее всего что-то в этом духе:
- Обучающий(е) алгоритм(ы) – т.е. встроенные правила полу-перманентных изменений нейронов или их связей в зависимости от ситуации.
- Алгоритм(ы) вывода – т.е. встроенные правила того, какие выходные сигналы следует послать прямо сейчас, чтобы помочь выжить и преуспеть. Сами выходные сигналы, конечно, также зависят от ранее выученной информации.
- Архитектура нейронной сети – т.е. встроенная высокоуровневая диаграмма связей, определяющая, как разные части обучающегося модуля соединены друг с другом, входными и выходными сигналами.
- Гиперпараметры – т.е. разные части архитектуры могут иметь разные встроенные скорости обучения. Эти гиперпараметры тоже могут меняться при развитии (см. сенситивные периоды). Также может быть и встроенная способность изменять гиперпараметры от момента к моменту в ответ на специальные управляющие сигналы (в виде нейромодуляторов вроде ацетилхолина).
При наличии всех этих встроенных составляющих алгоритм обучения с чистого листа готов принимать снаружи входные данные и управляющие сигналы[2], и постепенно обучается делать что-то полезное.
Эта встроенная информация не обязательно проста. Может быть 50000 совершенно разных алгоритмов обучения в 50000 разных частях неокортекса, и это всё ещё будет с моей точки зрения считаться обучением с чистого листа! (Впрочем, я не думаю, что это так – см. Раздел 2.5.3 про «однородность».)
Представляя себе обучающийся с чистого листа алгоритм, *не* следует представлять пустоту, наполняемую данными. Стоит представлять *механизм*, который постоянно (1) записывает информацию в хранилище памяти, и (2) выполняет запросы к текущему содержанию хранилища памяти. «С чистого листа» просто означает, что хранилище памяти изначально пусто. Таких механизмов *много*, они следуют разным процедурам того, что записывать и как запрашивать. К примеру «справочная таблица» соответствует простому механизму, который просто записывает то, что видит. Другим механизмам соответствуют алгоритмы обучения с учителем, алгоритмы обучения с подкреплением, автокодировщики, и т.д., и т.п.
2.3.2 Обучение с чистого листа НЕ означает «воспитание превыше природы»
Есть тенденция ассоциировать «алгоритмы обучения с чистого листа» с стороной «воспитания» споров «природа против воспитания». Я думаю, это неверно. Даже напротив. Я думаю, что гипотеза обучения с чистого листа полностью совместима с возможностью того, что эволюционировавшее встроенное поведение играет большую роль.
Две причины:
Во-первых, некоторые части мозга совершенно точно НЕ выполняют алгоритмы обучения с чистого листа! Это в основном мозговой ствол и гипоталамус (больше про это ниже и в следующем посте). Эти не-обучающиеся-с-чистого-листа части мозга должны быть полностью ответственны за любое адаптивное поведение при рождении.[1] Правдоподобно ли это? Думаю, да, учитывая впечатляющий диапазон функциональности мозгового ствола. К примеру, в неокортексе есть цепи обработки визуальных и других сенсорных данных – но в мозговом стволе тоже! В неокортексе есть цепи моторного контроля – и в мозговом стволе тоже! В по крайней мере некоторых случаях полностью адаптивное поведение кажется исполняемым целиком в мозговом стволе: к примеру, у мышей есть цепь-обнаружения-приближающихся-птиц в мозговом стволе, напрямую соединённая с цепью-убегания-прочь в нём же. Так что моя гипотеза обучения с чистого листа не делает никаких общих заявлений о том, какие алгоритмы или функциональности присутствуют или отсутствуют в мозгу. Только заявления о том, что некоторые виды алгоритмов есть только в некоторых конкретных частях мозга.
Во-вторых, «обучение с чистого листа» - не то же самое, что «обучение из окружения». Вот искусственный пример.[3] Представьте, что мозговой ствол птицы имеет встроенную способность судить о том, как должно звучать хорошее птичье пение, но не инструкцию, как произвести хорошее птичье пение. Ну, алгоритм обучения с чистого листа может заполнить эту дыру – методом проб и ошибок вывести вторую способность из первой. Этот пример показывает, что алгоритмы обучения с чистого листа могут управлять поведением, которое мы естественно и корректно описываем как встроенное / «природное, а не воспитанное».
2.3.3 Обучение с чистого листа – это НЕ более общее понятие «пластичности»
«Пластичность» - это термин, означающий, что мозг полу-перманентно изменяет себя, обычно изменяя присутствие / отсутствие / силу синаптических связей нейронов, но иногда и другими механизмами, вроде изменений в экспрессии генов в нейронах.
Любой алгоритм обучения с чистого листа обязательно включает пластичность. Но не вся пластичность мозга – часть алгоритмов обучения с чистого листа. Другая возможность – то, что я называю «отдельными встроенными настраиваемыми параметрами». Вот таблица с примерами и того, и другого и тем, чем они отличаются:
| Алгоритмы обучения с чистого листа | Отдельные встроенные настраиваемые параметры | |
| Стереотипный пример | Любая статья о глубоком обучении: есть *обучающий алгоритм*, который постепенно создаёт *обученную модель*, настраивая много её параметров. | Некоторые связи в крысином мозгу усиливаются, когда крыса выигрывает драку – по сути, считают, сколько драк крыса выиграла за свою жизнь. Потом такая связь используется для выполнения поведения «Выиграв много драк за свою жизнь – будь агрессивнее.» (ссылка) |
| Количество параметров, изменяемых на основании входных данных (т.е. как много измерений в пространстве всех возможных обученных моделей?) | Может быть много – сотни, тысячи, миллионы, и т.д. | Скорее всего мало, может даже один |
| Если масштабировать это вверх, будет ли это работать лучше после обучения? | Да, наверное. | А?? Что, чёрт побери, вообще значит «масштабировать»? |
Я не думаю, что между этими штуками есть чёткая граница; наверное, есть спорная область, где одна перетекает в другую. По крайней мере, я думаю, что в теории она есть. На практике, мне кажется, существует довольно явное разделение – всегда, когда я узнаю о конкретном примере пластичности мозга, она явным образом попадает в одну или другую категорию.
К слову, как мне кажется, моя категоризация для нейробиологии несколько необычна. Нейробиологи чаще сосредотачиваются на низкоуровневых деталях реализации: «Источник пластичности – синаптические изменения или изменения экспрессии генов?», «Каков биохимический механизм?» и т.д. Это совсем другая тема. К примеру, готов поспорить, что один и то же низкоуровневый биохимический механизм синаптической пластичности может быть вовлечён и в алгоритмы обучения с чистого листа и в изменение отдельного встроенного настраиваемого параметра.
Почему я подымаю эту тему? Потому что я планирую заявить, что гипоталамус и мозговой ствол не выполняют или почти не выполняют алгоритмы обучения с чистого листа. Но они точно имеют отдельные встроенные настраиваемые параметры.
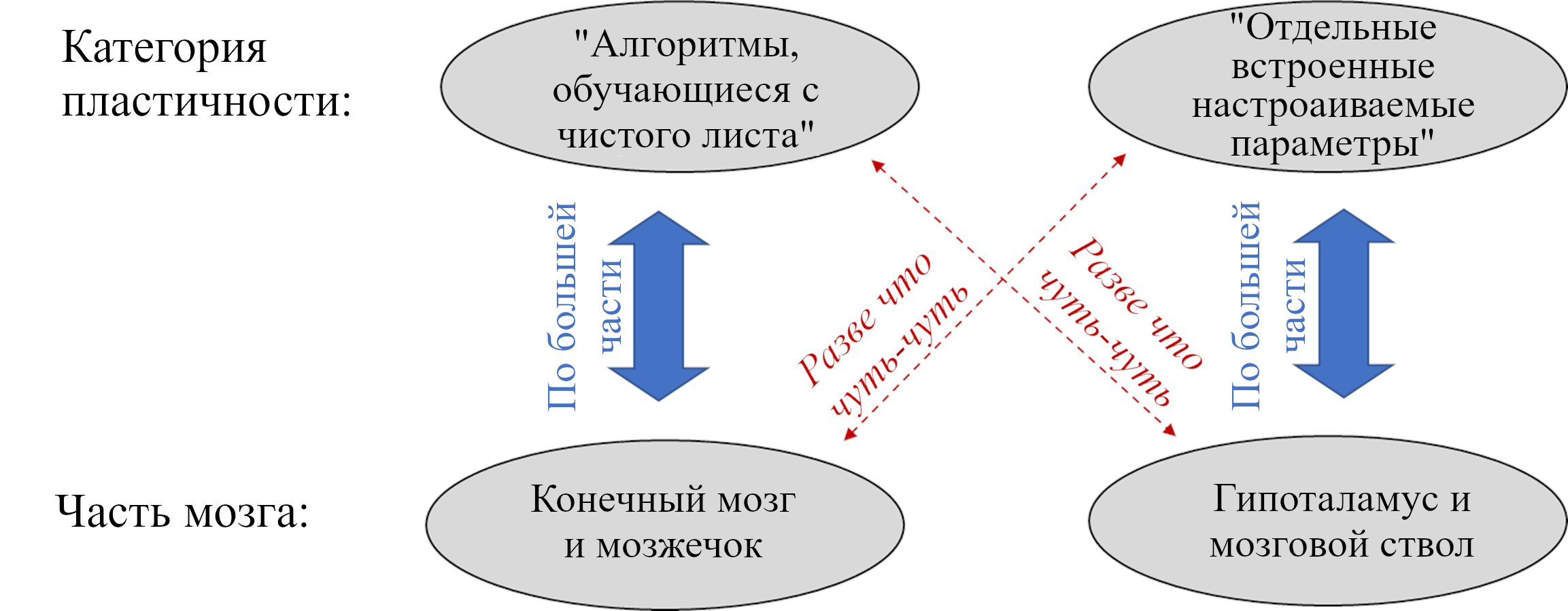
Для конкретики, вот три примера «отдельных встроенных настраиваемых параметров» в гипоталамусе и мозговом стволе:
- Уже упомянутая цепь в крысином гипоталамусе «если ты продолжаешь выигрывать драки, становись агрессивнее» – ссылка.
- Вот цепь в крысином гипоталамусе «если тебе опасно не хватает соли, увеличь базовое желание соли».
- Верхнее двухолмие в мозговом стволе содержит зрительную, слуховую и саккадную моторную область, и механизм, связывающий все три – так что, когда ты видишь вспышку или слышишь шум, ты немедленно направляешь взгляд в точности в правильном направлении. В этом механизме есть пластичность – к примеру, он может самокорректироваться у животного, носящего призматические очки. Я не знаю точных деталей, но полагаю, что это что-то вроде: Если видишь движение и переводишь на него взгляд, но движение не центрировано даже после саккады, то это генерирует сигнал об ошибке, сдвигающий соответствие областей. Может, вся эта система включает 8 настраиваемых параметров (масштаб и смещение, горизонталь и вертикаль, три области для выравнивания), а может она сложнее – опять же, я не знаю деталей.
Видна разница? Вернитесь к таблице, если всё ещё в замешательстве.
2.4 Моя гипотеза: конечный мозг и мозжечок обучаются с чистого листа, гипоталамус и мозговой ствол – нет
Моя гипотеза заключается в том, что ~96% человеческого мозга выполняет алгоритмы обучения с чистого листа. Главные исключения – мозговой ствол и гипоталамус, общим размером с большой палец. Источник картинки.
Вот моя гипотеза в трёх утверждениях:
Во-первых, я думаю, что весь конечный мозг обучается с чистого листа (и бесполезен при рождении[1]). Конечный мозг (также известный как «большой мозг») у людей – это в основном неокортекс, плюс гиппокампус, миндалевидное тело, большая часть базальных ганглиев и разнообразные более загадочные кусочки.
Несмотря на внешний вид, нравящаяся мне модель (изначально принадлежащая гениальному Ларри Свансону) заявляет, что весь конечный мозг организован в трёхслойную структуру (кора, полосатое тело, паллидум), и эта структура согласуется относительно маленьким количеством взаимосвязанных алгоритмов обучения. См. мой (довольно длинный и технический) пост Большая Картина Фазового Дофамина за подробностями.
(ОБНОВЛЕНИЕ: Узнав больше, я хочу это пересмотреть. Я думаю, что вся «кортикальная мантия» и всё «расширенное полосатое тело» обучаются с чистого листа. (Это включает штуки вроде гиппокампуса, миндалевидного тела, боковой перегородки, и т.д. - которые эмбриологически и/или цитоархитектурно развиваются вместе с корой и/или полосатым телом). Кто касается паллидума, я думаю, некоторые его части по сути являются расширением RAS мозгового ствола, так что им точно не место в этом списке. Про другие его части может оказаться и так, и так, в зависимости от того, как определить поверхность ввода/вывода некоторых алгоритмов обучения. Паллидум довольно маленький, так что мне не надо менять оценки объёма, включая число 96%. Я не буду проходить по всей цепочке и менять «конечный мозг» на «кортикальная мантия и расширенное полосатое тело» в миллионе мест, извините, придётся просто запомнить.)
Таламус технически не входит в конечный мозг, но по крайней мере его часть тесно связана с корой – некоторые исследователи описывают его функциональность как «дополнительный слой» коры. Так что я буду считать и его частью обучающегося с чистого листа конечного мозга.
Конечный мозг и таламус вместе составляют ~86% объёма человеческого мозга (ссылка).
Во-вторых, я думаю, что мозжечок тоже обучается с чистого листа (и тоже бесполезен при рождении). Мозжечок – это ~10% объёма взрослого мозга (ссылка). Больше про мозжечок будет в Посте №4.
В третьих, я думаю, что гипоталамус и мозговой ствол совершенно точно НЕ обучаются с чистого листа (и они очень активны и полезны прямо с рождения). Думаю, другие части промежуточного мозга – например, хабенула и шишковидное тело – тоже попадают в эту категорию.
Я не буду удивлён, если обнаружатся мелкие исключения из этой картины. Может, где-то в конечном мозге есть маленькое ядро, управляющее биологически-активным поведением, не обучаясь ему с чистого листа. Конечно, почему нет. Но сейчас я считаю, что такая картина по крайней мере приблизительно верна.
В следующих двух разделах я расскажу о свидетельствах, относящихся к моей гипотезе, и о том, что о ней думают другие люди из этой области.
2.5 Свидетельства того, что конечный мозг и мозжечок обучаются с чистого листа
2.5.1 Свидетельства общей картины
Из чтения и разговоров с людьми я вижу, что самые большие преграды к тому, чтобы поверить, что конечный мозг и мозжечок обучаются с чистого листа – это в подавляющем большинстве случаев не детализированные аргументы о данных нейробиологии, а скорее:
- Нерассмотрение этой гипотезы как возможности вовсе
- Замешательство касательно следствий гипотезы, в частности – как она встраивается в одну осмысленную картину мозга и поведения.
Раз вы досюда дочитали, №1 уже не должно быть проблемой.
Что по поводу №2? Типичный тип вопросов – это «Если конечный мозг и мозжечок обучаются с чистого листа, то как они делают X?» – для разных X. Если есть X, для которого мы совсем не можем ответить на этот вопрос, то это подразумевает, что гипотеза обучения с чистого листа неверна. Напротив, если мы можем найти действительно хорошие ответы на этот вопрос для многих X, то это свидетельство (хоть и не доказательство), того что гипотеза обучения с чистого листа верна. Следующие посты, я надеюсь, обеспечат вам такие свидетельства.
2.5.2 Неонатальное свидетельство
Если конечный мозг и мозжечок не могут производить биологически-адаптивный вывод, не научившись этому со временем, то из этого следует, что любое биологически-адаптивное поведение новорожденных[1] должно управляться мозговым стволом и гипоталамусом. Так ли это? Кажется, такие вещи должны быть экспериментально измеримы, верно? И в этой статье 1991 года действительно говорится «накопившиеся свидетельства приводят к выводу, что перцептомоторная активность новорожденных в основном контролируется подкорковыми механизмами». Но не знаю, изменилось ли что за прошедшие 30 лет – дайте мне знать, если видели другие упоминания этого.
На самом деле, этот вопрос сложнее, чем кажется. Представьте, что младенец совершает что-то биологически-адаптивное…
- Первый вопрос, который надо задать: в самом деле? Может, это плохой (или неверно интерпретированный) эксперимент. К примеру, если взрослый покажет младенцу язык, высунет ли младенец язык тоже, имитируя? Кажется простым вопросом, верно? Не-а, это источник споров уже десятилетия. Конкурирующая теория строится вокруг орального исследования: «высовывание языка кажется общим ответом на заметные стимулы и зависит от интереса ребёнка к стимулу»; показывающий язык взрослый просто активирует этот ответ, но так же делают мелькающие огоньки и звуки музыки. Я уверен, кто-то знает, каким экспериментам с новорожденными можно доверять, но я, по крайней мере пока не знаю. И я очень параноидально отношусь к тому, что две уважаемые книги в этой области (Учёный в кроватке,Происхождение Концептов) повторяют заявление об имитации будто это твёрдый как скала факт.
- Второй вопрос, который надо задать: результат ли это прижизненного обучения? Помните, даже у трёхмесячного ребёнка есть 4 миллиона секунд «обучающих данных». На самом деле, даже только что рождённый ребёнок возможно выполнял алгоритмы обучения с чистого листа в утробе.[1]
- Третий вопрос, который надо задать: какая часть мозга управляет этим поведением? Моя гипотеза заявляет, что не-выученное адаптивное поведение не может управляться конечным мозгом или мозжечком. Но моя гипотеза позволяет мозговому стволу управление таким поведением! И выяснение, какая часть мозга новорожденного в ответе за некоторое поведение может быть экспериментально сложным.
2.5.3 Свидетельство «однородности»
Гипотеза «однородности коры» заявляет, что все части неокортекса выполняют более-менее похожие алгоритмы. (…С некоторыми нюансами, особенно связанными с неоднородной нейронной архитектурой и гиперпараметрами). Мнения по поводу того, верна ли эта гипотеза (и в какой степени) расходятся – я кратко обсуждал свидетельства и аргументы тут. Я считаю, что весьма вероятно, что она верна, по крайней мере в слабом смысле, что будущий исследователь, имеющий очень хорошее детальное понимание того, как работает Область Неокортекса №147 будет очень хорошо продвинут в понимании того, как работает буквально любая другая часть неокортекса. Я не буду тут погружаться в это подробнее; мне кажется, это не совсем укладывается в тему этой цепочки.
Я упоминаю это потому, что если вы верите в однородность коры, то вам, наверное, следует верить и в то, что она обучается с чистого листа. Аргументация такая:
Неокортекс взрослого делает много явно различающихся вещей: обрабатывает зрительную информацию, слуховую информацию, занимается моторным контролем, языком, планированием и т.д. Как это совместимо с однородностью коры?
Обучение с чистого листа предоставляет правдоподобный способ. В конце концов, мы знаем, что один и тот же алгоритм обучения с чистого листа, если ему скормить очень разные входные данные и управляющие сигналы, может начать делать очень разные вещи: посмотрите как глубокие нейросети-трансформеры можно обучить генерировать текст на естественном языке, или картинки, или музыку, или сигналы моторного контроля робота, и т.д.
Если мы, напротив, примем однородность коры, но отвергнем обучение с чистого листа, то, эм-м-м, я не вижу осмысленных вариантов того, как это может работать.
Аналогично (но куда реже обсуждаемо, чем случай неокортекса), стоит ли нам верить в «однородность аллокортекса»? Для справки, аллокортекс – что-то вроде упрощённой версии неокортекса с тремя слоями вместо шести; считается, что до того, как эволюционировал неокортекс, ранние амниоты имели только аллокортекс. Он, как и неокортекс, делает много всякого разного: у взрослых людей гиппокампус вовлечён в ориентирование в пространстве и эпизодическую память, а грушевидная кора – в обработку запахов. Так что тут можно сделать аналогичный аргумент про обучение с чистого листа.
Двигаясь дальше, я уже упоминал выше (и больше в Большой Картине Фазового Дофамина, а ещё в Посте №5, Разделе 5.4.1) идею (Ларри Свансона), что весь конечный мозг кажется организованным в три слоя – «кору», «полосатое тело» и «паллидум». Я пока говорил только про кору; что насчёт «однородности полосатого тела» и «однородности паллидума»? Не ожидайте найти посвящённый этому обзор – на самом деле, предыдущее предложение судя по всему первое, где встречаются эти словосочетания. Но в каждом из этих слоёв есть как минимум некоторые общие черты: например, средние шиповатые нейроны вроде бы есть по всему полосатому телу. И я продолжаю считать, что описанная мной в Большой Картине Фазового Дофамина (и Постах №5-№6) модель – осмысленное первое приближение того, как может сочетаться «всё, что мы знаем о полосатом теле и паллидуме» с «несколькими вариациями конкретных алгоритмов обучения с чистого листа».
В случае мозжечка, есть по крайней мере какая-то литература по гипотезе однородности (ищите термин «universal cerebellar transform»), но, опять же, нет консенсуса. Мозжечок взрослого так же вовлечён в явно разные функции вроде моторной координации, языка, сознания и эмоций. Я лично считаю, что там тоже есть однородность, подробнее будут в Посте №4.
2.5.4 Локально-случайное разделение паттернов
Это другая причина, по которой лично я готов многое поставить на то, что конечный мозг и мозжечок обучаются с нуля. Она несколько специфична, но для меня довольно заметна; посмотрим, примете ли вы её.
2.5.4.1 Что такое разделение паттернов?
В мозгу есть частый мотив, называемый «разделением паттернов». Давайте я объясню, что это и откуда берётся.
Представьте, что вы инженер машинного обучения, работающий на сеть ресторанов. Ваш начальник даёт вам задание предсказать продажи для разных локаций, куда можно распространить франшизу.
Первое, что вы можете сделать – это собрать кучу потоков данных – местные уровни безработицы, местные рейтинги ресторанов, местные цены в магазинах, распространяется ли по миру сейчас новый коронавирус, и т.д. Я называю это «контекстные данные». Вы можете использовать контекстные данные как ввод нейросети. Выводом сети должно быть предсказание уровня продаж. Вы подправляете веса нейросети (используя обучения с учителем, собрав данные от существующих ресторанов), чтобы всё получилось. Никаких проблем!
Разделение паттернов – это когда вы добавляете в начало ещё один шаг. Вы берёте различные потоки контекстных данных и случайно комбинируете их многими разными способами. Затем вы добавляете немного нелинейности, и вуаля! Теперь у вас есть куда больше потоков контекстных данных, чем было изначально! Теперь они могут быть вводом для обучаемой нейросети.[4]
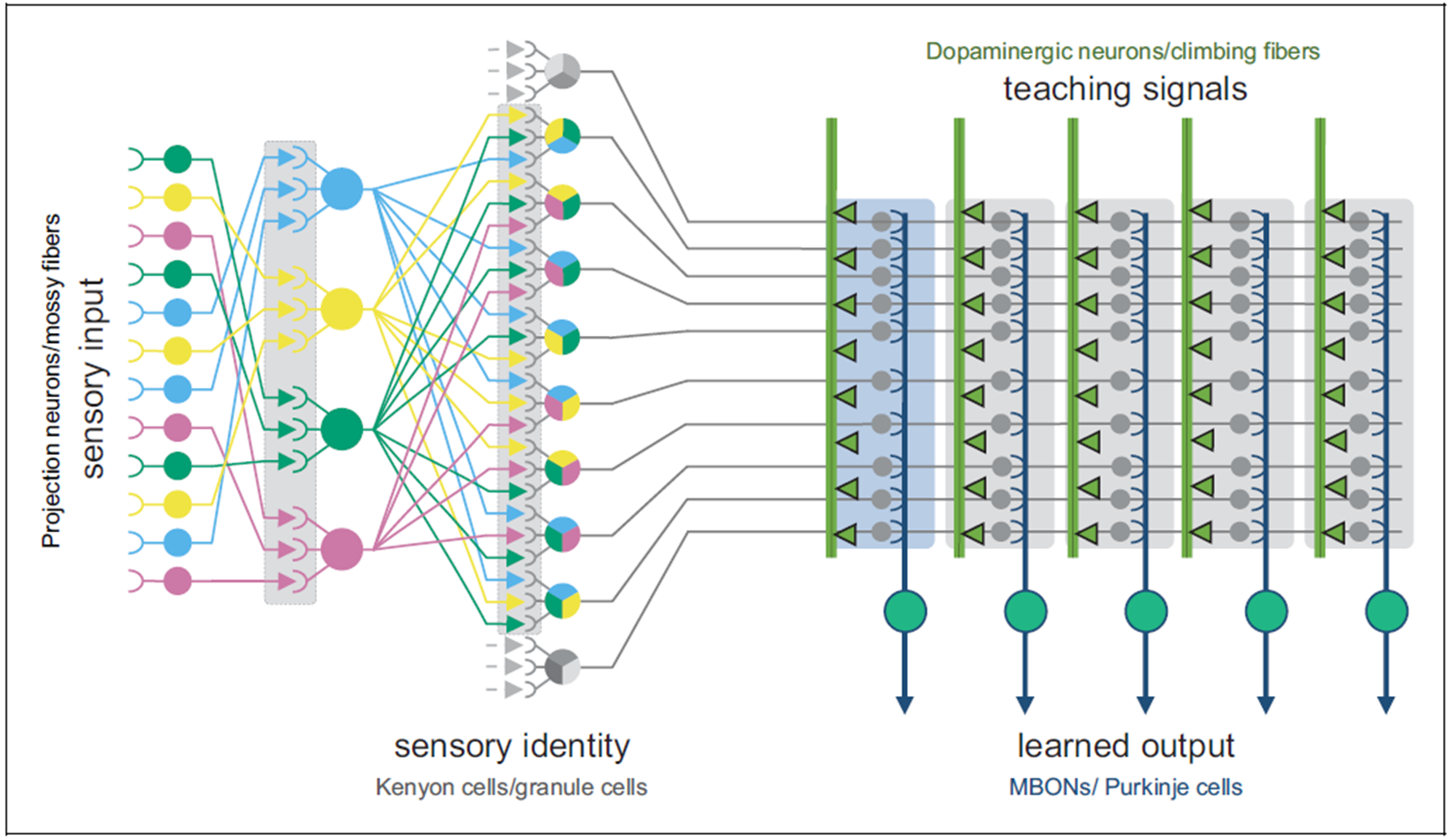
Иллюстрация (части) обработки сенсорных данных плодовой мухи. Высокий вертикальный серый прямоугольник чуть левее центра – это слой «разделения паттернов»; он принимает организованные сенсорные сигналы слева и перемешивает их большим количеством разных (локально) случайных комбинаций. Потом они посылаются направо, чтобы служить «контекстными» вводами модуля обучения с учителем. Источник картинки: Ли и пр..
3. Две Подсистемы: Обучающаяся и Направляющая
- 1.3.1 Краткое содержание / Оглавление
- 2.3.2 Большая картина
- 3.3.3 «Теория Триединого Мозга» неверна, но давайте не выплёскивать ребёнка вместе с водой
- 4.3.4 Три типа составных частей Направляющей Подсистемы
- 4.1.3.4.1 Общая таблица
- 4.2.3.4.2 В сторону: что я имею в виду под «стремлениями»?
- 4.3.3.4.3 Категория A: Штуки, которая Направляющая Подсистема должна делать для достижения обобщённого интеллекта (например, стремление к любопытству)
- 4.4.3.4.4 Категория B: Всё остальное из человеческой Направляющей Системы (например, стремления, связанные с альтруизмом)
- 4.5.3.4.5 Категория C: Любые другие возможности (например, стремление увеличить баланс на банковском счёте)
- 5.3.5 Подобные-мозгу СИИ будут по умолчанию иметь радикально нечеловеческие (и опасные) мотивации
- 6.3.6 Ответ на аргументы Джеффа Хокинса против риска происшествий с СИИ
- 7.3.7 Сроки-до-подобного-мозгу-СИИ, часть 2 из 3: насколько сложен достаточный для СИИ реверс-инжиниринг Направляющей Подсистемы??
- 8.3.8 Сроки-до-подобного-мозгу-СИИ, часть 3 из 3: масштабирование, отладка, обучение, и т.д.
- 9.3.9 Сроки-до-подобного-мозгу-СИИ, ещё: Что мне чувствовать по поводу вероятностей?
3.1 Краткое содержание / Оглавление
В предыдущем посте я определил понятие «обучающихся с чистого листа» алгоритмов – широкую категорию, включающую, помимо прочего, любой алгоритм машинного обучения (неважно, насколько сложный) с случайной инициализацией и любую систему изначально пустой памяти. Я затем предложил разделение мозга на две части по признаку наличия или отсутствия обучения с чистого листа. Теперь я даю им имена:
Обучающаяся Подсистема – это 96% мозга, «обучающиеся с чистого листа» – по сути – конечный мозг и мозжечок.
Направляющая Подсистема – это 4% мозга, не «обучающиеся с чистого листа» – по сути – гипоталамус и мозговой ствол.
(См. Предыдущий пост за более подробным анатомическим разделением.)
Этот пост будет обсуждением этой картины двух подсистем в целом и Направляющей Подсистемы в частности.
- В Разделе 3.2 я поговорю о большой картине того, что эти подсистемы делают и как они взаимодействуют. Как пример, я объясню, почему каждая подсистема нуждается в своей собственной обработке сенсорных сигналов – к примеру, почему визуальный ввод обрабатывается и в зрительной коре в Обучающейся Подсистеме, и в верхнем двухолмии в Направляющей Подсистеме.
- В Разделе 3.3 я признаю, что эта картина двух подсистем имеет некоторые сходства с дискредитированной «теорией триединого мозга». Но я буду утверждать, что проблемы теории триединого мозга не относятся к моей картине двух подсистем.
- В Разделе 3.4 я опишу три категории того, что может относиться к Направляющей Подсистеме:
- Категория A: Штуки, правдоподобно необходимые для обобщённого интеллекта (например, встроенная склонность к любопытству),
- Категория B: Иные штуки в человеческой направляющей подсистеме (например, встроенная склонность быть добрым к своим друзьям),
- Категория C: Всё, что может представить программист СИИ, даже если это радикально отличается от того, что встречается у людей и животных (например, встроенная склонность корректно предсказывать цены акций).
- В Разделе 3.5 я свяжу эти категории с тем, как я ожидаю будет выглядеть создание людьми подобного-мозгу СИИ, и обосную, что «подобный-мозгу СИИ с радикально нечеловеческими (и опасными) мотивациями» – не оксюморон, а, напротив, ожидаемый по умолчанию исход, если мы не потрудимся, чтобы его предотвратить.
- В Разделе 3.6 я рассмотрю тот факт, что у Джеффа Хокинса есть мнение о двух подсистемах, похожее на мою картину, но он спорит с тем, что катастрофические происшествия с СИИ представляют риск. Я скажу, где, как я считаю, он неправ.
- Разделы 3.7 и 3.8 будут последними двумя частями моего обсуждения «сроков до подобного-мозгу СИИ». Первой частью был Раздел 2.8 предыдущего поста, где я заявил, что реверс-инжиниринг Обучающейся Подсистемы (достаточный для подобного-мозгу СИИ) может правдоподобно произойти довольно скоро, в следующие два десятилетия, хотя это может и занять больше времени. Тут я дополню это заявлением, что-то же верно и для реверс-инжиниринга Направляющей Подсистемы, и для усовершенствования и масштабирования алгоритмов, проведения обучения модели, и т.д.
- Раздел 3.9 – быстрое не-техническое обсуждение того, как невероятно расходятся мнения разных людей по поводу сроков до СИИ, даже когда они согласны по поводу вероятностей. К примеру, можно найти двух людей, которые согласятся, что с шансами 3 к 1 СИИ не будет до 2042 года, но один может подчёркивать, как вероятность низка («Видишь? СИИ скорее всего не будет ещё десятилетия»), тогда как другой – как высока эта вероятность. Я поговорю немного о факторах, скрывающихся за этими отношениями.
3.2 Большая картина
В предыдущем посте я заявил, что 96% объёма мозга – грубо говоря, конечный мозг (неокортекс, гиппокампус, миндалевидное тело, большая часть базальных ганглиев, и ещё кое-что) и мозжечок – «обучаются с чистого листа» в том смысле, что на ранних этапах жизни их выводы – случайный мусор, но со временем они становятся невероятно полезны благодаря прижизненному обучению. (См. там больше подробностей) Я сейчас называю эту часть мозга Обучающейся Подсистемой.
Остальной мозг – в основном мозговой ствол и гипоталамус – я называю Направляющей Подсистемой.
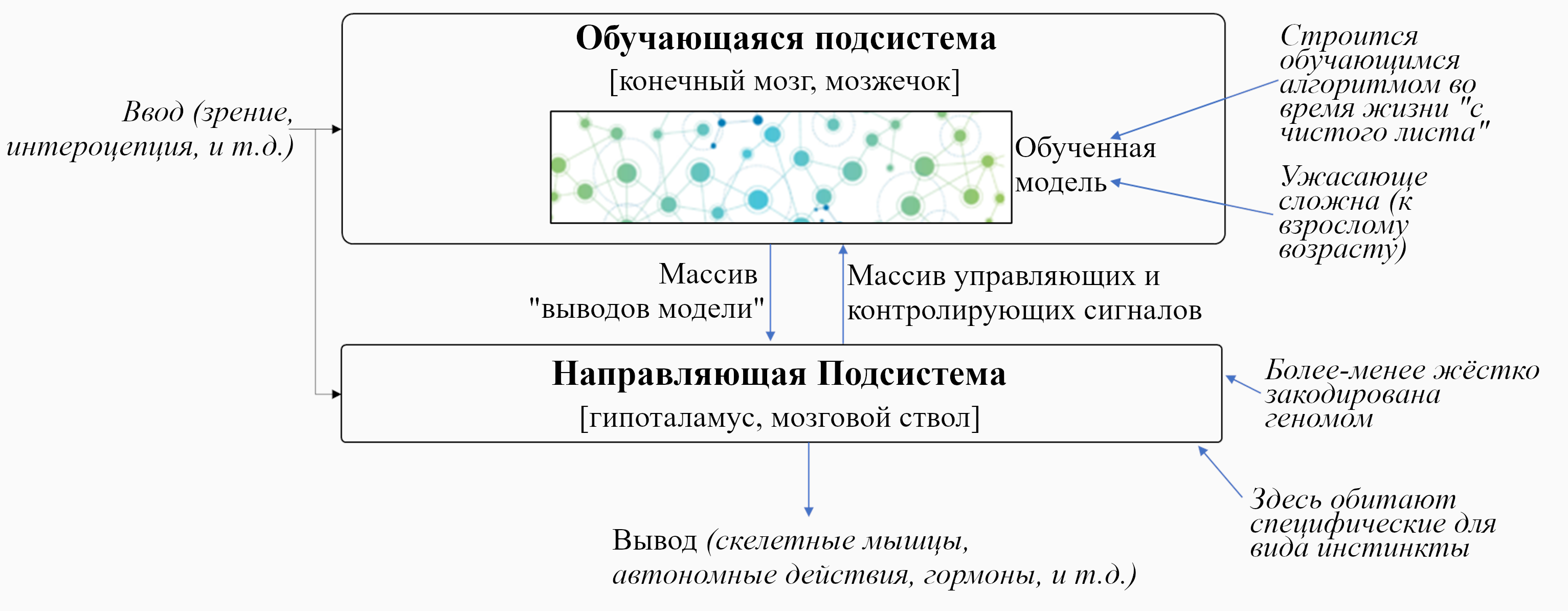
Как нам об этом думать?
Давайте начнём с Обучающейся Подсистемы. Как я описывал в предыдущем посте, эта подсистема имеет некоторое количество взаимосвязанных встроенных алгоритмов обучения, встроенную нейронную архитектуру и встроенные гиперпараметры. Она имеет также много (миллиарды или триллионы) подстраиваемых параметров (обычно предполагается, что это сила синаптических связей, но это спорный момент, и я не буду в него погружаться), и значения этих параметров изначально случайны. Так что изначально Обучающаяся Подсистема выдаёт случайные бесполезные для организма выводы – например, может быть, они могут заставить организм дёргаться. Но со временем различные управляющие сигналы и соответствующие правила обновления подправляют настраиваемые параметры системы, что позволяет её за время жизни животного научиться делать сложные биологически-адаптивные штуки.
Дальше: Направляющая Подсистема. Как нам её интуитивно представлять?
Для начала, представьте хранилище с кучей специфичных для вида инстинктов и поведений, жёстко закодированных в геноме:
- «Чтобы блевануть, сжать мышцы A,B,C, и выпустить гормоны D,E,F.”
- «Если сенсорный ввод удовлетворяет таким-то эвристикам, то вероятно я ем что-то здоровое и энергоёмкое; это хорошо, и надо отреагировать сигналами G,H,I.”
- «Если сенсорный ввод удовлетворяет таким-то эвристикам, то наверное я склоняюсь над пропастью, это плохо, и надо отреагировать сигналами J,K,L.”
- «Если я замёрз, поднять волоски на теле.»
- «Если я недоедаю, выполнить: (1) запустить ощущение голода, (2) начать вознаграждать неокортекс за получение еды, (3) снизить фертильность и рост, (4) уменьшить чувствительность к боли, и т.д.» (ссылка).
Особенно важная задача Направляющей Подсистемы – посылать управляющие и контролирующие сигналы Обучающейся Подсистеме. Отсюда название: Направляющая Подсистема направляет обучающиеся алгоритмы к адаптивным штукам.
Пример: почему человеческий неокортекс обучается адаптивным-для-человека штукам, а беличий неокортекс обучается адаптивным-для-белки штукам, если они оба исполняют примерно одинаковые алгоритмы обучения с чистого листа?
Я заявляю, что главная часть ответа – то, что обучающиеся алгоритмы в этих двух случаях по-разному «направляются». Особенно важный аспект тут – сигнал «вознаграждения» обучения с подкреплением. Можно представить, что человеческий мозговой ствол посылает «награду» за достижение высокого социального статуса, а беличий мозговой ствол – за запасание орехов осенью. (Это упрощение, я ещё буду к этому возвращаться.)
Аналогично, в машинном обучении один и тот же обучающийся алгоритм может стать очень хорош в шахматах (при условии определённого сигнала вознаграждения и сенсорных данных) или может стать очень хорош в го (при условии других сигналов вознаграждения и сенсорных данных).
Для ясности, несмотря на название, «направление» Обучающейся Подсистемы – не всё, что делает Направляющая Подсистема. Она может и просто что-то делать самостоятельно, без вовлечения Обучающейся Подсистемы! Это хорошо подходит для того, что делать важно прямо с рождения, или для того, в чём даже один провал фатален. Пример, который я упоминал в предыдущем посте – мыши, оказывается, имеют цепь-обнаружения-приближающихся-птиц в мозговом стволе, напрямую соединённую с цепью-убегания-прочь в нём же.
Важно держать в голове, что Направляющая Подсистема мозга не имеет прямого доступа к нашему здравому смыслу и пониманию мира. К примеру, Направляющая Подсистема может исполнять реакции вроде «во время еды выделять пищеварительные энзимы». Но когда мы переходим к абстрактным концептам, которые мы используем для действий в мире – оценки, долги, популярность, соевый соус, и так далее – надо предполагать, что Направляющая Подсистема не имеет о них ни малейшего понятия, если мы не можем объяснить, откуда она могла о них узнать. И иногда такое объяснение есть! Мы ещё рассмотрим много таких случаев, в частности в Посте №7 (для простого примера желания съесть пирог) и Посте №13 (для более хитрого случая социальных инстинктов).
3.2.1 Каждая подсистема в общем случае нуждается в своей собственной сенсорной обработке
К примеру, в случае зрения, у Направляющей Подсистемы есть верхнее двухолмие, а к Обучающейся Подсистемы есть зрительная кора. Для вкуса у Направляющей Подсистемы есть вкусовое ядро в продолговатом мозге, а у Обучающейся Подсистемы – вкусовая кора. И т. д.
Не избыточно ли это? Некоторые так и думают! Книга Дэвида Линдена «Случайный Разум» упоминает существование двух систем сенсорной обработки как замечательный пример корявого проектирования мозга в результате отсутствия у эволюции планирования наперёд. Но я не соглашусь. Они не избыточны. Если бы я делал СИИ, я бы точно сделал ему две системы сенсорной обработки!
Почему? Предположим, что Эволюция хочет создать цепочку реакции, чтобы жёстко генетически закодированные сенсорные условия запускали генетически закодированный ответ. К примеру, как упоминалось выше, если вы мышь, то увеличивающееся тёмное пятно сверху области видимости часто означает приближающуюся птицу, поэтому геном мыши жёстко связал детектор-увеличивающегося-тёмного-пятна с поведенческой-цепью-убегания-прочь.
И я скажу, что создавая эту реакцию геном не может использовать зрительную кору для детектора. Почему? Вспомните предыдущий пост: зрительная кора обучается с чистого листа! Она принимает неструктурированные визуальные данные и строит из них предсказывающую модель. Вы можете (приближённо) думать о зрительной коре как о тщательном каталогизаторе паттернов из ввода, и паттернов из паттернов из ввода, и т.д. Один из этих паттернов может соответствовать увеличивающемуся тёмному пятну в верхней части поля зрения. Или нет! И даже если такой есть, геном не знает заранее, какие в точности нейроны будут хранить этот конкретный паттерн. Так что геном не может жёстко привязать эти нейроны к поведенческому-контроллеру-убегания-прочь.
В итоге:
- Встроить обработку сенсорных данных в Направляющую Подсистему – хорошая идея, потому что есть много областей, где сильно выгодно для приспособленности связать жёстко генетически заданное сенсорное условие с соответствующей реакцией. В случае людей, подумайте о страхе высоты, страхе змей, эстетике потенциального жилища, эстетике потенциальных партнёров, вкусе сытной еды, звуке вопля, чувстве боли, и так далее.
- Встроить обработку сенсорных данных в Обучающуюся Подсистему – ТОЖЕ хорошая идея, потому что использование обучающихся с чистого листа алгоритмов для выучивания произвольных паттернов из сенсорного ввода – это, ну, прямо очень хорошая идея. В конце концов, многие полезные сенсорные паттерны супер-специфичны – к примеру, «запах этого одного конкретного дерева» – так что соответствующий жёстко генетически заданный детектор никак не мог эволюционировать.
Так что две системы обработки сенсорной информации – не пример корявого проектирования. Это пример Второго Правила Орджела: «эволюция умнее тебя»!
3.3 «Теория Триединого Мозга» неверна, но давайте не выплёскивать ребёнка вместе с водой
В 1960-х и 70-х Пол Маклейн и Карл Саган изобрели и популяризировали идею Триединого Мозга. Согласно этой теории, мозг состоит из трёх слоёв, сложенных вместе как мороженое в рожке, и они эволюционировали по очереди: сначала «мозг ящерицы» (он же «древний мозг» или «рептильный мозг»), ближайший к спинному; потом «лимбическая система», обёрнутая вокруг него (состоящая из миндалевидного тела, гиппокампуса и гипоталамуса), и, наконец, наружным слоем, неокортекс (он же «новый мозг») – гвоздь программы, вершина эволюции, жилище человеческого интеллекта!!!
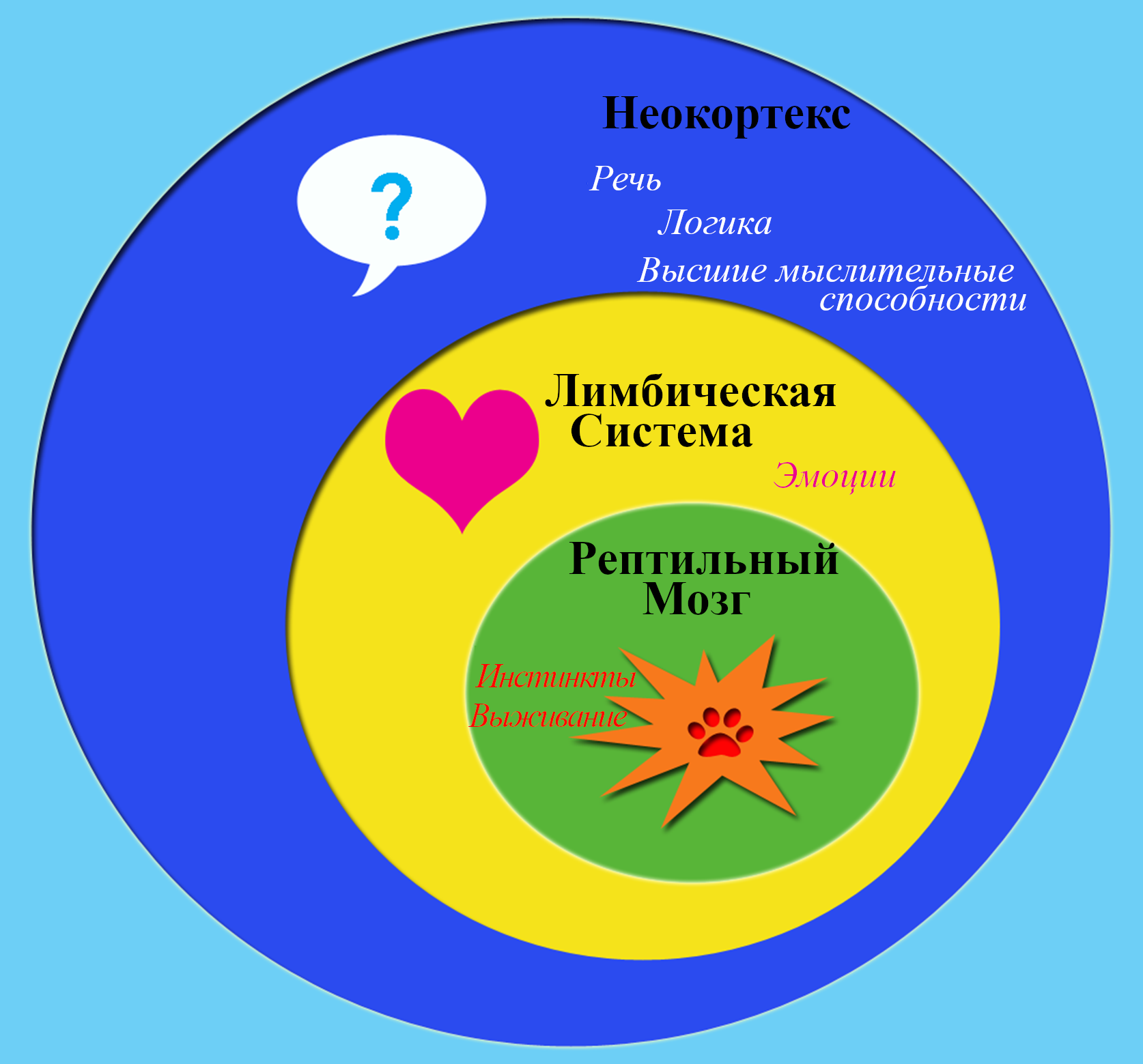
(Плохая!) модель триединого мозга (источник картинки)
{kind=link}
Ну, сейчас хорошо известно, что Теория Тройственного Мозга – чепуха. Она разделяет мозг на части способом, не имеющим ни функционального ни эмбриологического смысла, и эволюционная история просто откровенно неверна. К примеру, половину миллиарда лет назад самые ранние позвоночные имели предшественников всех трёх слоёв триединого мозга – включая «плащ», который потом (в нашей линии) разделился на неокортекс, гиппокампус, часть миндалевидного тела, и т.д. (ссылка).
Так что да, Теория Тройственного Мозга – чепуха. Но я вполне признаю: нравящаяся мне история (предыдущий раздел) несколько напоминает её. Моя Направляющая Подсистема выглядит подозрительно похожей на маклейновский «рептильный мозг». Моя Обучающаяся Подсистема выглядит подозрительно похожей на маклейновские «лимбическую систему и неокортекс». Мы с Маклейном не вполне согласны по поводу того, что в точности к чему относится, и два там слоя или три. Но сходство несомненно есть.
Моя история про две подсистемы не оригинальна. Вы услышите похожие от Джеффа Хокинса, Дайлипа Джорджа, Илона Маска, и других.
Но эти другие люди делают это придерживаясь традиции теории триединого мозга, и, в частности, сохраняя её проблематичные аспекты, вроде терминологии «древнего мозга» и «нового мозга».
Нет нужды так делать!!! Мы можем сохранить модель двух подсистем, избавившись от унаследованных у тройственного мозга ошибок.
Так что вот моя версия: я думаю, что пол миллиарда лет назад у ранних позвоночные уже был (простой!) алгоритм обучения с чистого листа в их (прото-) конечном мозге, и он «направлялся» сигналами из их (простого, прото-) мозгового ствола и гипоталамуса.
На самом деле, мы можем пойти даже дальше позвоночных! Оказывается, существует сходство между обучающейся с чистого листа корой у людей и обучающимся с чистого листа «грибовидным телом» у плодовых мух! (Подробное обсуждение здесь.) Замечу, к примеру, что у плодовых мух, сигналы запахов отправляются и в грибовидное тело, и в боковой рог, что замечательно сходится с общим принципом того, что сенсорный ввод должен отправляться и в Обучающуюся Подсистему, и в Направляющую Подсистему (Раздел 3.2.1 выше).
В любом случае, за 700 миллионов лет прошедших с нашего последнего общего предка с насекомыми в нашей линии очень сильно увеличились и усложнились и Обучающаяся Подсистема, и Направляющая Подсистема.
Но это не значит, что они одинаково вкладываются в «человеческий интеллект». Опять же, обе необходимы, но, я думаю, факт того, что 96% объёма человеческого мозга занимает Обучающаяся Подсистема, довольно убедителен. Сосредоточимся ещё конкретнее на конечном мозге (который у млекопитающих включает неокортекс), его доля объёма мозга – 87% у людей (ссылка), 79% у шимпанзе (ссылка), 77% у некоторых попугаев, 51% у куриц, 45% у крокодилов, и лишь 22% у лягушек (ссылка). Тут есть очевидная закономерность, и думаю, что для получения способности к распознаваемому интеллектуальному и гибкому поведению действительно необходима большая Обучающаяся Подсистема.
Видите? Я могу описать свою модель двух подсистем без всей этой чепухи про «древний мозг, новый мозг».
3.4 Три типа составных частей Направляющей Подсистемы
Я начну с общей таблицы, а потом рассмотрю всё подробнее в следующих подразделах.
3.4.1 Общая таблица
| Категория составных частей Направляющей Подсистемы | Возможные примеры | Присутствуют в (компетентных) людях? | Ожидаются в будущих СИИ? |
| (A) Штуки, которая Направляющая Подсистема должна делать для достижения обобщённого интеллекта | Стремление к любопытству (?) Стремление обращать внимание на некоторые категории вещей в окружении (люди, язык, технология, и т.д.) (?) Общая вовлечённость в настройку нейронной архитектуры Обучающейся Подсистемы (?) | Да, по определению | Да |
| (B) Всё остальное из Направляющей Подсистемы нейротипичного человека | Социальные инстинкты (лежащие в основе альтруизма, любви, сожаления, вину, чувства справедливости, верности, и т. д.) Стремления в основе отвращения, эстетики, спокойствия, восхищения, голода, боли, боязни пауков, и т. д. | Обычно, но не всегда – к примеру, высокофункциональные социопаты лишены некоторых обычных социальных инстинктов. | Нет «по умолчанию», но *возможно*, если мы: (1)поймём, как в точности они работают, и (2)убедим разработчиков СИИ заложить их в него |
| (C) Любые другие возможности, большинство из которых *совершенно непохожи на всё*, что можно обнаружить в Направляющей Подсистеме человека или любого другого животного | Стремление увеличить баланс на банковском счёте компании? Стремление изобрести более хорошую солнечную панель? Стремление делать то, что хочет от меня человек-оператор? *(Тут ловушка: никто не знает, как реализовать это!)* | Нет | Да «по умолчанию». Если что-то – плохая идея, мы можем попробовать убедить разработчиков СИИ это не делать. |
3.4.2 В сторону: что я имею в виду под «стремлениями»?
Я подробнее разберу это в следующих постах, но сейчас давайте просто скажем, что Обучающаяся Подсистема (помимо всего прочего) проводит обучение с подкреплением, и Направляющая Подсистема присылает ей вознаграждение. Компоненты функции вознаграждения соответствуют тому, что я называю «встроенными стремлениями» - это корень того, почему некоторые штуки по своей сути мотивирующие / привлекающие, а другие – демотивирующие / отталкивающие.
Явные цели вроде «я хочу избавиться от долгов» отличаются от встроенных стремлений. Явные цели возникают из сложного взаимодействия «встроенных стремлений Направляющей Подсистемы» и «выученного содержания Обучающейся Подсистемы». Опять же, куда больше про это в будущих постах.
Напомню, встроенные стремления находятся в Направляющей Подсистеме, а абстрактные концепции, составляющие ваш осознанный мир – в Обучающейся. К примеру, если я говорю что-то вроде «встроенные стремления, связанные с альтруизмом», то надо понимать, что я говорю не про «абстрактную концепцию альтруизма, как он определён в словаре», а про «некая встроенная в Направляющую Подсистему схема, являющаяся причиной того, что нейротипичные люди иногда считают альтруистические действия по своей сути мотивирующими». Абстрактные концепции имеют какое-то отношение к встроенным схемам, но оно может быть сложным – никто не ожидает взаимно-однозначного соответствия N отдельных встроенных схем и N отдельных слов, описывающих эмоции и стремления.[1]
Разобравшись с этим, давайте подробнее рассмотрим таблицу.
3.4.3 Категория A: Штуки, которая Направляющая Подсистема должна делать для достижения обобщённого интеллекта (например, стремление к любопытству)
Давайте начнём с «стремления к любопытству». Если вы не знакомы с понятием «любопытства» в контексте машинного обучения, я рекомендую Задачу Согласования Брайана Кристиана, главу 6, содержащую занимательную историю того, как исследователи смогли научить агентов обучения с подкреплением выигрывать в игре с Atari Montezuma’s Revenge. Стремление к любопытству кажется необходимым для хорошей работы системы машинного обучения, и, кажется, оно встроено и в людей. Я предполагаю, что будущие СИИ тоже будут в нём нуждаться, а иначе просто не будут работать.
Для большей конкретности – я думаю, что оно важно для начального развития – думаю, стремление к любопытству необходимо на ранних этапах обучения, а потом его, вероятно, можно в какой-то момент отключить. Скажем, представим СИИ, обладающего общими знаниями о мире и самом себе, способного доводить дела до конца, и сейчас пытающегося изобрести новую солнечную панель. Я утверждаю, что ему скорее всего не нужно встроенное стремление к любопытству. Он может искать информацию и жаждать сюрпризов как будто у него оно есть, потому что из опыта он уже выучил, что это зачастую хорошая стратегия для, в частности, изобретения солнечных панелей. Другими словами, что-то вроде любопытства может быть мотивирующим как средство для достижения цели, даже если оно не мотивирует как цель – любопытство может быть выученной метакогнитивной эвристикой. См. инструментальная конвергенция. Но этот аргумент неприменим на ранних этапах обучения, когда СИИ начинает с чистого листа, ничего не зная о мире и о себе. Так что, если мы хотим получить СИИ, то поначалу, я думаю, Направляющая Подсистема действительно должна указывать Обучающейся Подсистеме правильное направление.
Другой возможный элемент в Категории A – это встроенное стремление обращать внимание на конкретные вещи в окружении, например, человеческую деятельность, человеческий язык или технологию. Я не совсем уверен, что это необходимо, но мне кажется, что стремления к любопытству самого по себе не хватит для того, что мы от него хотим. Оно было бы совершенно ненаправленным. Может, СИИ мог бы провести вечность, прокручивая в своей голове Правило 110, находя всё более и более глубокие паттерны, полностью игнорируя физическую вселенную. Или„ может быть, он мог бы находить всё более и более глубокие паттерны в формах облаков, полностью игнорируя всё, связанное с людьми и технологией. В случае человеческого мозга, мозговой ствол определённо обладает механизмами, заставляющими обращать внимание на человеческие лица (ссылка), и я сильно подозреваю, что там есть и система обращения внимания на человеческую речь. Я могу быть неправ, но, думаю, что-то вроде этого понадобиться и для СИИ. И точно также, может оказаться, что это необходимо только в начале обучения.
Что ещё может быть в Категории A? В таблице я написал расплывчатое «Общая вовлечённость в настройку нейронной архитектуры Обучающейся Подсистемы». Это включает посылание сигналов вознаграждения, и сигналов об ошибке, и гиперпараметры и т. д. для конкретных частей нейронной архитектуры Обучающейся Подсистемы. К примеру, в Посте №6 я поговорю о том, как только часть нейронной архитектуры становится получателем главного сигнала вознаграждения обучения с подкреплением. Я думаю об этих вещах, как о (одном аспекте) настоящей реализации нейронной архитектуры Обучающейся Подсистемы. У СИИ тоже будет какая-то нейронная архитектура, хотя, возможно, не в точности такая же, как у людей. Следовательно, СИИ тоже могут понадобится такие сигналы. Я немного говорил о нейронной архитектуре в Разделе 2.8 предыдущего поста, но в основном она не важна для этой цепочки, так что я не буду рассматривать её ещё подробнее.
В Категории A могут быть и другие штуки, о которых я не подумал.
3.4.4 Категория B: Всё остальное из человеческой Направляющей Системы (например, стремления, связанные с альтруизмом)
Я сразу перепрыгну к тому, что мне кажется наиболее важным: социальные инстинкты, включающие различные стремления, связанные с альтруизмом, симпатией, любовью, виной, завистью, чувством справедливости, и т. д. Ключевой вопрос: Откуда я знаю, что социальные инстинкты попадают в Категорию B, то есть, что они не в Категории A вещей, необходимых для обобщённого интеллекта?
Ну, для начала, посмотрите на высокофункциональных социопатов. У меня в своё время был опыт очень хорошего знакомства с парочкой. Они хорошо понимают мир, себя, язык, математику, науку, могут разрабатывать сложные планы и успешно достигать впечатляющих вещей. ИИ, умеющий всё, что может делать высокофункциональный социопат, мы бы без колебаний назвали «СИИ». Конечно, я думаю, высокофункциональные социопаты имеют какие-то социальные инстинкты – они более заинтересованы в манипуляциях людьми, а не игрушками – но их социальные инстинкты кажутся очень сильно отличающимися от социальных инстинктов нейротипичного человека.
Сверх этого, мы можем рассмотреть людей с аутизмом, людей с шизофренией, и S.M. (лишённую миндалевидного тела, и более-менее – негативных социальных эмоций), и так далее, и так далее. Все эти люди имеют «обобщённый интеллект», но их социальные инстинкты / стремления очень разнятся.[2]
С учётом всего этого, мне сложно поверить, что какие-то аспекты социальных инстинктов строго необходимы для обобщённого интеллекта. Я думаю, как минимум открытый вопрос – даже способствуют ли они обобщённому интеллекту!! К примеру, если вы посмотрите на самых гениальных в мире учёных, то я предположу, что люди с нейротипичными социальными инстинктами там будут несколько недопредставлены.
Причина, по которой это важно – я заявляю, что социальные инстинкты лежат в основе «желания поступать этично». Опять же, рассмотрим высокофункциональных социопатов. Они могут понять честь и справедливость и этику, если захотят, понять в смысле правильных ответов на тестовые вопросы о том, что справедливо, а что нет и т.д., они просто всем этим не мотивированы.[3]
Если подумать, это имеет смысл. Предположим, я скажу вам «Тебе следует запихнуть камушки себе в уши». Вы скажете «Почему?». И я скажу «Потому что, ну знаете, в ваших ушах нет камушков, но надо, чтобы были». И вы опять скажете «Почему?» …В какой-то момент этому разговору придётся свестись к тому, что вы и я считаем по своей сути, независимо от всего остального, мотивирующим или демотивирующим. И я утверждаю, что социальные инстинкты – различные встроенные стремления, связанные с чувством честности, симпатией, верностью, и так далее – и являются основанием для этих интуитивных заключений.
(Я тут не решаю дилемму морального реализма против морального релятивизма – то есть вопрос о том, есть ли «материальные факты» о том, что этично, а что неэтично. Вместо этого, я говорю, что если агент полностью лишён встроенных стремлений, которые могу разжечь в нём желание поступать этично, то нельзя ожидать от него этичного поведения, неважно, насколько он интеллектуален. С чего ему? Ладно, он может поступать этично как средство для достижения цели – например, чтобы привлечь на свою сторону союзников – но это не считается. Больше обсуждения и оснований интуиции в моём комментарии тут.)
Пока что это всё, что я хочу сказать о социальных инстинктах; я ещё вернусь к ним позже в этой цепочке.
Что ещё попадает в Категорию B? Много штук!! Отвращение, эстетика, спокойствие, восхищение, голод, боль, страх пауков, и т. д.
3.4.5 Категория C: Любые другие возможности (например, стремление увеличить баланс на банковском счёте)
Люди, создающие СИИ, могут поместить в функцию вознаграждения что им захочется! Они смогут создавать совершенно новые встроенные стремления. И эти стремления будут радикально непохожи на что-либо присущее людям или животным.
Зачем будущим программистам СИИ изобретать новые, ранее не встречавшиеся встроенные стремления? Потому что это естественно!! Если похитить случайного разработчика машинного обучения из холла NeurIPS, запереть его в заброшенном складе и заставить создавать ИИ-для-зарабатывания-денег-на-банковском-счёте с использованием обучения с подкреплением[4], то спорю на что угодно, в его исходном коде будет функция вознаграждения, использующая баланс на банковском счёте. Вы не найдёте ничего похожего в генетически прошитых схемах в мозговом стволе человека! Это новое для мира встроенное стремление.
«Поместить встроенное стремление для увеличения баланса на банковском счёте» – не только очевидный вариант, но, думаю, и в самом деле работающий! Некоторое время! А потом он катастрофически провалится! Он провалится как только ИИ станет достаточно компетентным, чтобы найти нестандартные стратегии увеличения баланса на банковском счёте – занять денег, взломать сайт банка, и так далее. (Смешной и ужасающий список исторических примеров того, как ИИ находили нестандартные не предполагавшиеся стратегии максимизации награды, больше об этом в следующих постах.) На самом деле, этот пример с балансом банковского счёте – только одно из многих-многих возможных стремлений, которые правдоподобно могут привести СИИ к вынашиванию тайной мотивации сбежать из под человеческого контроля и всех убить (см. Пост №1).
Так что такие мотивации худшие: они прямо у всех под носом, они – лучший способ достигать целей, публиковать статьи и побивать рекорды показателей, пока СИИ не слишком умный, а потом, когда СИИ становится достаточно компетентным, они приводят к катастрофическим происшествиям.
Вы можете подумать: «Это же совсем очевидно, что СИИ с всепоглощающим стремлением повысить баланс конкретного банковского счёта – это СИИ, который попытается сбежать из-под человеческого контроля, самовоспроизводиться и т.д. Ты реально веришь, что будущие программисты СИИ буду настолько беспечны, чтобы поместить в него что-то в таком роде??»
Ну, эммм, да. Да, так и думаю. Но даже отложив это пока в сторону, есть проблема побольше: мы пока не знаем, как закодировать хоть какое-нибудь встроенное стремление так, чтобы получившийся СИИ точно остался под контролем. Даже стремления, которые на первый взгляд кажутся благоприятными, скорее всего не такие, по крайней мере при нашем нынешнем уровне понимания. Куда больше про это в будущих постах (особенно №10).
Безусловно, Категория C – очень широкая. Я совсем не буду удивлён, если в ней существуют встроенные стремления, которые очень хороши для безопасности СИИ! Нам просто надо их найти! Я поисследую это пространство возможностей дальше в цепочке.
3.5 Подобные-мозгу СИИ будут по умолчанию иметь радикально нечеловеческие (и опасные) мотивации
Я упоминал это уже в первом посте (Раздел 1.3.3), но сейчас у нас есть объяснение.
Предыдущий подраздел предложил разделение на три типа возможного содержания Направляющей Подсистемы: (A) Необходимые для СИИ, (B) Всё остальное, что есть в людях, (C) Всё, чего нет в людях.
Мои заявления:
- Люди хотят создавать мощные ИИ с прорывными способностями в сложных областях – они знают, что это хорошо для публикаций, производит впечатление на коллег, помогает получить работу, повышения и гранты, и т.д. В смысле, ну просто посмотрите на ИИ и машинное обучение сейчас. Поэтому, по умолчанию, я ожидаю, что разработчики СИИ будут нестись прямиком по самому короткому к нему пути: реверс-инжиниринг Обучающейся Подсистемы и комбинирование её с стремлениями из Категории A.
- Категория B содержит некоторые стремления, которые, вполне возможно, могут быть полезны для безопасности СИИ: связанные с альтруизмом, симпатией, щедростью, скромностью, и т.д. К сожалению, мы сейчас не знаем, как они реализованы в мозге. И выяснение этого необязательно для создания СИИ. Так что я думаю, что по умолчанию следует ожидать, что разработчики СИИ будут игнорировать Категорию B до тех пор, пока у них не будет работающего СИИ, и только затем они начнут попытки разобраться, как встроить стремление к альтруизму и т.п. И у них может просто не получиться – вполне возможно, что соответствующие схемы в мозговом стволе и гипоталамусе ужасающе сложны и запутаны, а у нас будет только некоторое ограниченное время между «СИИ работает» и «кто-то случайно создаёт вышедший из под контроля СИИ, который всех убивает» (см. Пост №1).
- В Категории C есть штуки вроде «низкоуровневое встроенное стремление увеличить баланс конкретного банковского счёта», которые немедленно очевидны для кого угодно, легко реализуются, и будут хорошо справляться с достижением целей программистов, пока их прото-СИИ не слишком способен. Следовательно, по умолчанию, я ожидаю, что будущие исследователи будут использовать такие «очевидные» (но опасные и радикально нечеловеческие) стремления в своей работе по разработке СИИ. И, как и обсуждалось выше (и больше в следующих постах), даже если исследователи начнут добросовестные попытки дать своему СИИ встроенное стремление к услужливости / послушности / чему-то ещё, они могут обнаружить, что не знают, как это сделать.
Обобщая, если исследователи пойдут по самому простому и естественному пути – вытекающему из того, что сообщества ИИ и нейробиологии продолжат вести себя похоже на то, как они ведут себя сейчас – то мы получим СИИ, способные на впечатляющие вещи, поначалу на те, которые хотят их программисты, но ими будут управлять радикально чужеродные системы мотивации, фундаментально безразличные к человеческому благополучию, и эти СИИ попытаются сбежать из-под человеческого контроля как только станут достаточно способными для этого.
Давайте попробуем это изменить! В частности, если мы заранее разберёмся, как написать код, задающий встроенное стремление к альтруизму / услужливости / послушности / чему-то подобному, то это будет очень полезно. Это большая тема этой цепочки. Но не ожидайте финальных ответов. Это нерешённая задача: впереди ещё много работы.
3.6 Ответ на аргументы Джеффа Хокинса против риска происшествий с СИИ
Недавно вышла книга Джеффа Хокинса «Тысяча мозгов». Я написал подробный её обзор тут. Джефф Хокинс продвигает очень похожую на мою точку зрения о двух подсистемах. Это не совпадение – его работы подтолкнули меня в этом направлении!
К чести Хокинса, он признаёт, что его работа по нейробиологии / ИИ продвигает (неизвестной длины) путь в сторону СИИ, и он попытался осторожно обдумать о последствиях такого проекта – в противоположность более типичной точке зрения, объявляющей СИИ чьей-то чужой проблемой.
Так что я восхищён тем, что Хокинс посвятил большой раздел своей книги аргументам о катастрофических рисках СИИ. Но его аргументы – против катастрофического риска!! Что такое? Как он и я, начав с похожих точек зрения на две подсистемы, пришли к диаметрально противоположным заключениям?
Хокинс приводит много аргументов, и, опять же, я более подробно их рассмотрел в моём обзоре. Но тут я хочу подчеркнуть две самые большие проблемы, касающиеся этого поста.
Вот мой пересказ некоторых аргументов Хокинса. (Я перевожу их в используемую мной в этой цепочке терминологию, например, где он говорит «древний мозг», я говорю «Направляющая Подсистема». И, может быть, я немного груб. Вы можете прочитать книгу и решить для себя, насколько я справедлив.)
- Обучающаяся Подсистема (неокортекс и т.п.) сама по себе не имеет целей и мотиваций. Она не сделает ничего. Она точно не сделает ничего опасного. Это как карта, лежащая на столе.
- В той степени, в какой у людей есть проблематичные стремления (жадность, самосохранение, и т.д.), они происходят из Направляющей Подсистемы (мозговой ствол и т.д.).
- То, что я, Джефф Хокинс, предлагаю, и делаю – это попытки реверс-инжиниринга Обучающейся Подсистемы, не Направляющей. Так какого чёрта все так взволнованы?
- …
- …
- О, кстати, совершенно не связанное замечание, мы когда-нибудь в будущем сделаем СИИ, и у них будет не только Обучающаяся Подсистема, но ещё и подключённая к ней Направляющая Подсистема. Я не собираюсь говорить о том, как мы спроектируем Направляющую Подсистему. Это на самом деле не то, о чём я много думаю.
Каждый пункт по отдельности кажется вполне осмысленным. Но если сложить их вместе, тут зияющая дыра! Кого волнует, что неокортекс сам по себе безопасен? План вовсе не в неокортексе самом по себе! Вопрос, который надо задавать – будет ли безопасен СИИ, состоящий из обеих подсистем. И это критически зависит от того, как мы создадим Направляющую Подсистему. Хокинсу это неинтересно. А мне да! Дальше в цепочке будет куда больше на эту тему. В Посте №10 я особенно погружусь в тему того, почему чертовски сложнее, чем кажется создать Направляющую Подсистему, способствующую тому, чтобы СИИ делал что-то конкретное, что нам надо, не вложив в него также случайно опасные антисоциальные мотивации, которые мы не намеревались в него вкладывать.
Ещё одна (имеющая значение) проблема, которую я не упоминал в своём обзоре: я думаю, что Хокинс частично руководствуется интуитивным соображением, против которого я выступал в (Мозговой ствол, Неокртекс) ≠ (Базовые Мотивации, Благородные Мотивации) (и больше на эту тему будет в Посте №6): тенденцией необоснованно приписывать эгосинтонические мотивации вроде «раскрытия тайн вселенной» неокортексу (Обучающейся Подсистеме), а эгодистонические мотивации вроде голода и сексуального желания – мозговому стволу (Направляющей Подсистеме). Я заявляю, что все мотивации без исключения изначально исходят из Направляющей Подсистемы. Надеюсь, это станет очевидно, если вы продолжите читать эту цепочку.
На самом деле, мое заявление даже подразумевается в лучших частях книги самого Хокинса! К примеру:
- Хокинс в Главе 10: «Неокортекс обучается модели мира, которая сама по себе не содержит целей и ценностей.»
- Хокинс в Главе 16: «Мы – разумная модель нас, обитающая в неокортексе – заперты. Мы заперты в теле, которое … в основном находится под контролем невежественной скотины, древнего мозга. Мы можем использовать интеллект, чтобы представить лучшее будущее… Но древний мозг может всё испортить…»
Проговорю противоречие: если «мы» = модель в неокортексе, и модель в неокортексе не имеет целей и ценностей, то «мы» точно не жаждем лучшего будущего и не вынашиваем планы, чтобы обойти контроль мозгового ствола.
3.7 Сроки-до-подобного-мозгу-СИИ, часть 2 из 3: насколько сложен достаточный для СИИ реверс-инжиниринг Направляющей Подсистемы??
(Напомню: Часть 1 из 3 – Раздел 2.8 предыдущего поста.)
Выше (Раздел 3.4.3) я рассмотрел «Категорию A», минимальный набор составляющих для создания Направляющей Системы СИИ (не обязательно безопасного, только способного).
Я на самом деле не знаю, что в этом наборе. Я предположил, что вероятно нам понадобится какая-то разновидность стремления к любопытству, и может быть какое-то стремление обращать внимание на человеческие языки и прочую человеческую деятельность, и, может быть, какие-то сигналы для помощи в образовании нейронной архитектуры Обучающейся Подсистемы.
Если это так, ну, это не поражает меня как что-то очень сложное! Это уж точно намного проще, чем реверс-инжиниринг всего, что есть в человеческом гипоталамусе и мозговом стволе! Держите в голове, что есть довольно обширная литература по любопытству, как в машинном обучении (1, 2), так и в психологии. «Стремление обращать внимание на человеческий язык» не требует ничего сверх классификатора, который (с осмысленной точностью, он не обязан быть идеальным) сообщает, является ли данный звуковой ввод человеческой речью или нет; это уже тривиально с нынешними инструментами, может уже залито на GitHub.
Я думаю, нам стоит быть открытыми к возможности что не так уж сложно создать Направляющую Подсистему, которая (вместе с получившейся в результате реверс-инжиниринга Обучающейся Подсистемой, см. Раздел 2.8 предыдущего поста) может развиться в СИИ после обучения. Может, это не десятилетия исследований и разработки; может даже не годы! Может, компетентный исследователь может сделать это всего с нескольких попыток. С другой стороны – может и нет! Может, это супер сложно! Я думаю, сейчас очень сложно предсказать, сколько времени это займёт, так что нам стоит оставаться неуверенными.
3.8 Сроки-до-подобного-мозгу-СИИ, часть 3 из 3: масштабирование, отладка, обучение, и т.д.
Обладание полностью определённым алгоритмом с способностями СИИ – ещё не конец истории; его всё ещё надо реализовать, отполировать, аппаратно ускорить и распараллелить, исправить причуды, провести обучение, и т.д. Не стоит игнорировать эту часть, но не стоит и её переоценивать. Я не буду описывать это тут, потому что я недавно написал целый отдельный пост на эту тему:
Вдохновлённый-мозгом СИИ и «прижизненные якоря»
Суть поста: я думаю, что всё это точно можно сделать меньше, чем за 10 лет. Может, меньше чем за 5. Или это может занять дольше. Я думаю, нам стоит быть очень неуверенными.
Это заканчивает моё обсуждение сроков-до-подобного-мозгу-СИИ, что, опять же, не главная тема этой цепочки. Вы можете прочитать три его части (2.8, 3.7, и эта), согласиться или не согласиться, и прийти к своим собственным выводам.
3.9 Сроки-до-подобного-мозгу-СИИ, ещё: Что мне чувствовать по поводу вероятностей?
Моё обсуждение «сроков» (Разделы 2.8, 3.7, 3.8) касалось вопроса прогнозирования «какое распределение вероятностей мне приписывать времени появления СИИ (если он вообще будет)?»
Полу-независимым от этого вопроса является вопрос отношения: «Что мне чувствовать по поводу этого распределения вероятностей?»
Например, два человека могут соглашаться с (допустим) «35% шансом СИИ к 2042», но иметь невероятно разное отношение к этому:
- Один из них закатывает глаза, смеётся и говорит: «Видишь, я же говорил! СИИ скорее всего не появится ещё десятилетия!»
- У другого глаза расширяются, челюсть отпадает, и он говорит: «О. Боже. Извините, дайте минутку, пока я переобдумываю всё о своей жизни.»
Есть много факторов, лежащих в основе таких разных отношений к одному и тому же убеждению о мире. Во-первых, некоторые факторы – больше про психологию, а не про фактические вопросы:
- «Какое отношение лучше подходит моему восприятию себя и моей психике?» - о-о-о, блин, это в нас глубоко засело. Людей, думающих о себе как о хладнокровных серьёзных скептических величавых приземлённых учёных, может непреодолимо тянуть к мнению, что СИИ – не такое уж большое дело. Людей, думающих о себе как о радикальных трансгуманистических технологических первопроходцах, может так же непреодолимо тянуть к противоположному мнению, что СИИ радикально изменит всё. Я говорю это, чтобы вы могли пообдумывать свои собственные искажения. О, да кого я обманываю; на самом деле, я просто дал вам удобный способ самодовольно насмехаться над всеми, кто с вами не согласен, и отбрасывать их мнение. (Можете не благодарить!) С моей стороны, я заявляю, что я несколько иммунен к отбрасыванию-мнения-через-психоанализ: Когда я впервые пришёл к убеждению, что СИИ – очень серьёзное дело, я полностью идентифицировал себя как хладнокровного серьёзного скептического величавого приземлённого учёного средних лет, не интересующегося и не связанного с научной фантастикой, трансгуманизмом, технологической индустрией, ИИ, Кремниевой долиной, и т.д. Вот так-то! Ха! Но на самом деле, это глупая игра: отбрасывать убеждения людей через психоанализ их скрытых мотивов – всегда было ужасной идеей. Это слишком просто. Правда или неправда, вы всегда можете найти хороший повод самодовольно усомниться в мотивах любого, кто с вами не согласен. Это просто дешёвый трюк для избегания тяжёлой работы выяснения, не могут ли они на самом деле оказаться правы. И про психологию в целом: принять всерьёз возможность будущего с СИИ (настолько серьёзно, насколько, как я думаю, она того заслуживает) может быть, ну, довольно мучительно! Довольно сложно было привыкнуть к идее, что Изменение Климата реально происходит, верно?? См. этот пост за большими подробностями.
- Как мне следует думать о возможных-но-не-гарантированных будущих событиях? Я предлагаю прочитать этот пост Скотта Александера. Или, если вы предпочитаете в виде мема:

Источник картинки: Скотт Александер
Ещё, тут есть ощущение, выраженное в известном эссе «Заметив Дым», и этом меме:

Примерно основано на меме @Linch, если не ошибаюсь
Говоря явно, правильная идея – взвешивать риски и выгоды и вероятности переподготовки и недоподготовки к возможному будущему риску. Неправильная идея – добавлять в это уравнение дополнительный элемент – «риск глупо выглядеть перед моими друзьями из-за переподготовки к чему-то странному, что оказалось не таким уж важным» – и трактовать этот элемент как подавляюще более важный, чем все остальные, и затем через какое-то безумное странное выворачивание Пари Паскаля выводить, что нам не следует пытаться избежать потенциальной будущей катастрофы до тех пор, пока мы не будем уверены на >99.9%, что катастрофа действительно произойдёт. К счастью, это становится всё более и более обсуждаемой темой; ваши друзья всё с меньшей и меньшей вероятностью подумают, что вы странный, потому что безопасность СИИ стала куда более мейнстримной в последние годы – особенно благодаря агитации и педагогике Стюарта Расселла, Брайана Кристиана, Роба Майлза, и многих других. Вы можете поспособствовать этому процессу, поделившись этой цепочкой! ;-) (рад помочь – прим. пер.)
Отложив это в сторону, другие более вещественные причины разного отношения к срокам до СИИ включают вопросы:
- Насколько сильно СИИ преобразует мир? Что касается меня, я нахожусь далеко на конце спектра «сильно». Я одобряю цитату Элиезера Юдковского: «Спрашивать о воздействии [сверхчеловеческого СИИ] на [безработицу] – это как спрашивать, как на торговлю США с Китаем повлияет падение Луны на Землю. Воздействие будет, но вы упускаете суть.» Для более трезвого обсуждения, попробуйте Цифровые Люди Были Бы Ещё Большим Делом Холдена Карнофского, и, может быть, ещё и Так не Может Продолжаться для фона, и, почему бы и нет, всю остальную серию постов тоже. Также смотрите здесь некоторые числа, предполагающие, что подобный-мозгу СИИ скорее всего не потребует ни такого количества компьютерных чипов, ни такого количества электричества, что он не мог бы широко использоваться.
- Насколько многое нам надо сделать, чтобы подготовиться к СИИ? См. в Посте №1, Разделе 1.7 мои аргументы в пользу того, что мы сильно отстаём от расписания, а позже в этой цепочке я затрону много всё ещё нерешённых задач.
- Ну, может быть кто-то и ожидает, что есть взаимно-однозначное соответствие между абстрактными языковыми концепциями вроде «печали» и соответствующими внутренними реакциями. Если прочитать книгу Как Рождаются Эмоции, Лиза Фельдман Барретт тратит там сотни страниц, избивая эту позицию. Она, наверное, отвечает кому-то, верно? В смысле, мне бы показалось каким-то абсурдным очучеливанием мнение: «Каждая ситуация, которую мы бы описали как «грустная» соответствует в точности одной и той же внутренней реакции с одним и тем же выражением лица.» Я буду удивлён, если окажется, что Пол Экман (которого, вроде бы, Барретт опровергала) на самом деле в это верит, но я не знаю…
- Я не предполагаю, что схемы Направляющей Подсистемы, лежащие в основе социальных инстинктов, устроены у этих разных групп совершенно по-разному – это было бы эволюционно неправдоподобно. Скорее, я думаю, что там есть много настраиваемых параметров того, насколько сильны разные стремления, и они могут принимать широкие диапазоны значений, включая такие, что стремление будет таким слабым, что на практике можно считать его отсутствующим. См. мои спекулятивные рассуждения про аутизм и психопатию тут.
- См. Тест Психопата Джона Ронсона за забавными обсуждениями попыток научить психопатов эмпатии. Студенты лишь стали лучше способны подделывать эмпатию для манипуляции людьми. Цитата одного человека, учившего такой класс: «Думаю, мы случайно создали для них пансион благородных девиц.»
- Предполагаю, можно было бы просто нанять исследователя в области машинного обучения. Но кто будет ему платить?
4. "Краткосрочный предсказатель"
- 1.4.1 Краткое содержание / Оглавление
- 2.4.2 Иллюстративный пример: вздрагивание перед получением удара в лицо
- 3.4.3 Терминология: Контекст, Вывод, Управление
- 4.4.4 Очень упрощённый игрушечный пример того, как это могло бы работать в биологических нейронах
- 5.4.5 Сравнение с другими алгоритмическими подходами
- 6.4.6 Пример «краткосрочных предсказателей» №1: Мозжечок
- 7.4.7 Пример «краткосрочных предсказателей» №2: Предсказательное обучение сенсорных вводов в коре
- 8.4.8 Другие примеры приложений «краткосрочных предсказателей»
Примечание переводчика - с момента перевода оригинальные посты несколько обновились, через некоторое время обновлю и перевод. На общие выводы цепочки это, вроде бы, не влияет.
4.1 Краткое содержание / Оглавление
Предыдущие два поста (№2 и №3) представили общую картину мозга, состоящего из Направляющей Подсистемы (мозговой ствол и гипоталамус) и Обучающейся Подсистемы (всё остальное), где последняя «обучается с чистого листа» в конкретном смысле, определённом в Посте №2.
Я предположил, что наши явные цели (например, «Хочу быть космонавтом!») возникают из взаимодействия этих двух подсистем, и понимание этого критически важно, если мы хотим научиться формировать мотивацию подобного-мозгу СИИ так, чтобы он пытался делать то, что мы хотим, чтобы он пытался делать, и избежать катастрофических происшествий, описанных в Посте №1.
Следующие три поста (№4-6) прорабатывают это дальше. Этот пост предоставляет необходимый нам ингредиент: «краткосрочный предсказатель».
Краткосрочное предсказание – одна из вещей, которые делает Обучающаяся Подсистема, я поговорю о других в следующих постах. Краткосрочный предсказатель получает управляющий сигнал («эмпирическую истину») извне и использует обучающийся алгоритм для построения модели, предсказывающей, каким будет этот сигнал через короткий промежуток времени (например, долю секунды) в будущем.
Этот пост содержит общее обсуждение того, как краткосрочные предсказатели работают, и почему они важны. Как мы увидим в следующих двух постах, они окажутся ключевым строительным элементом мотивации и обучения с подкреплением.
Тизер следующей пары постов: Следующий пост (№5) опишет, как определённый вид замкнутой схемы, обёрнутой вокруг краткосрочного предсказателя, превращает его в «долгосрочный предсказатель», связанный с обучением методом временных разниц (TD). Я заявлю, что в мозгу много таких долгосрочных предсказателей, созданных петлями «конечный мозг – мозговой ствол», одна из которых сродни «критику» из модели «субъект-критик» обучения с подкреплением. «Субъект» - это тема поста №6.
Содержание:
- Раздел 4.2 описывает иллюстративный пример вздрагивания перед получением удара в лицо. Это можно сформулировать как задачу обучения с учителем, в том смысле, что тут есть эмпирический сигнал, на котором можно обучаться. (Если вам только что прилетело в лицо, надо было вздрогнуть!) Получившаяся схема – то, что я называю «краткосрочным предсказателем».
- В Разделе 4.3 я определяю терминологию: «контекстные сигналы», «сигналы вывода» и «управляющие сигналы». (В терминологии машинного обучения они соответствуют «вводу обученной модели», «выводу обученной модели» и «маркировке данных».)
- Раздел 4.4 предлагает набросок очень простого краткосрочного предсказателя, который можно создать из биологических нейронов, просто чтобы можно было представлять что-то конкретное.
- Раздел 4.5 описывает преимущества краткосрочных предсказателей в сравнении с альтернативными подходами, включающими (в примере вздрагивания) жёстко прошитую схему, определяющую, когда вздрогнуть, и агента обучения с подкреплением, вознаграждаемого за уместное вздрагивание. В последнем случае краткосрочный предсказатель обучается быстрее, потому что получает «бесплатный» градиент ошибки каждый раз – или, выражаясь проще, когда он облажался, он получает указание, что именно он сделал не так, в духе того, была ли ошибка недолётом или перелётом.
- Разделы 4.6-4.8 покрывают разные примеры краткосрочных предсказателей в человеческом мозге. Все они не слишком важны для безопасности СИИ – по-настоящему важна тема следующего поста – но они выплывают довольно часто, так что заслуживают быстрого рассмотрения:
- Раздел 4.6 описывает мозжечок, который согласно моей теории представляет из себя коллекцию из ≈300,000 краткосрочных предсказателей, используемых для сокращения задержки ≈300,000 сигналов, проходящих через мозг и тело.
- Раздел 4.7 покрывает предсказательное обучение на сенсорных вводах в коре – к примеру, то, как вы постоянно предсказываете, что вы сейчас увидите, услышите, почувствуете, и т.д., и ошибки предсказания используются для обновления ваших внутренних моделей.
- Раздел 4.8 быстро описывает ещё несколько случайных интересных штук, которые краткосрочные предсказатели могут делать у животных.
4.2 Иллюстративный пример: вздрагивание перед получением удара в лицо
Представьте, что у вас есть работа или хобби, где есть конкретный распознаваемый сенсорный намёк (например, кто-то орёт «FORE!!!» в гольфе), а потом через пол секунды после этого намёка вам очень часто прилетает удар в лицо. Ваш мозг научится (непроизвольно) вздрагивать в ответ на этот намёк. В мозгу есть обучающийся алгоритм, управляющий этим вздрагиванием; вероятно, он эволюционировал для защиты лица. Об этом обучающемся алгоритме я и хочу поговорить в этом посте.
Я называю это «краткосрочным предсказателем». Это «предсказатель», потому что цель алгоритма – предсказать что-то заранее (например, приближающийся удар в лицо). Он «краткосрочный», потому что он должен предсказывать, что произойдёт, только на долю секунды в будущее. Это разновидность обучения с учителем, потому что есть «эмпирический» сигнал, задним числом показывающий, какой вывод алгоритму следовало произвести.
4.3 Терминология: Контекст, Вывод, Управление
Наш «краткосрочный предсказатель» имеет «API» («программный интерфейс приложения» – т.е. каналы, через которые другие части мозга взаимодействуют с модулем «краткосрочного предсказателя») из трёх составляющих:
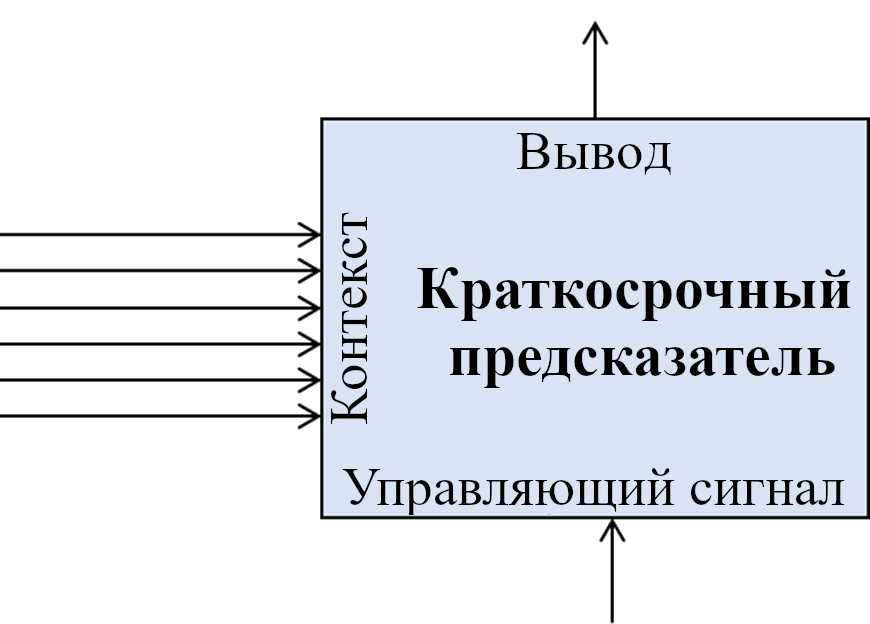
- Сигнал вывода – это предсказание алгоритма.
- В нашем примере выше это был бы сигнал, вызывающий вздрагивание.
- Управляющий сигнал предоставляет (задним числом) «эмпирическую истину» о том, каким должен был быть вывод алгоритма.
- В нашем примере выше, это был бы сигнал, указывающий, что я только что получил в лицо (и, соответственно, подразумевающий, что мне надо было вздрогнуть).
- В терминологии машинного обучения «управляющие сигналы» часто называются «ярлыками» или «маркировкой данных».
- На самом деле управляющий ввод краткосрочного предсказателя не обязан быть эмпирической истиной. Он может быть сигналом ошибки, или отрицательным сигналом ошибки, или ещё чем-то. С моей точки зрения, это маловажные низкоуровневые детали реализации.
- Контекстные сигналы несут информацию о том, что происходит.
- В нашем примере выше это может быть случайный набор сигналов (соответствующих скрытым переменным), поступающих из зрительной и слуховой коры. Если повезёт, некоторые из этих сигналов могут нести полезную-для-предсказания информацию: может, один из них сообщает, что я нахожусь на поле для гольфа, а другой – что кто-то недалеко от меня только что заорал «FORE!».
- В терминологии машинного обучения «контекстные сигналы» можно было бы назвать «ввод обученной модели».
Контекстные сигналы не обязаны все иметь отношение к задаче предсказания. Мы можем просто закинуть туда целую кучу мусора, и обучающийся алгоритм автоматически отыщет контекстные данные, полезные для задачи предсказания, и будет игнорировать всё остальное.
4.4 Очень упрощённый игрушечный пример того, как это могло бы работать в биологических нейронах
Как краткосрочный предсказатель может работать на низком уровне?
Ну, предположим, что мы хотим получить сигнал вывода, предшествующий управляющему сигналу на 0.3 секунды – как выше, к примеру, мы хотели бы научиться вздрагивать до удара. Мы хватаем кучу контекстных данных, которые могут иметь отношение к делу – к примеру, нейроны, несущие частично обработанную сенсорную информацию. Мы отслеживаем, какие из этих контекстных потоков особенно вероятно срабатывают за 0.3 секунды до управляющего сигнала. И мы связываем эти потоки с выводом.
И готово! Легкотня.
В биологии это может выглядеть как что-то вроде синаптической пластичности с «трёхфакторным правилом обучения» - т.е. синапс становится сильнее или слабее в зависимости от активности трёх других нейронов (контекст, управление, вывод) и их относительного времени срабатывания.
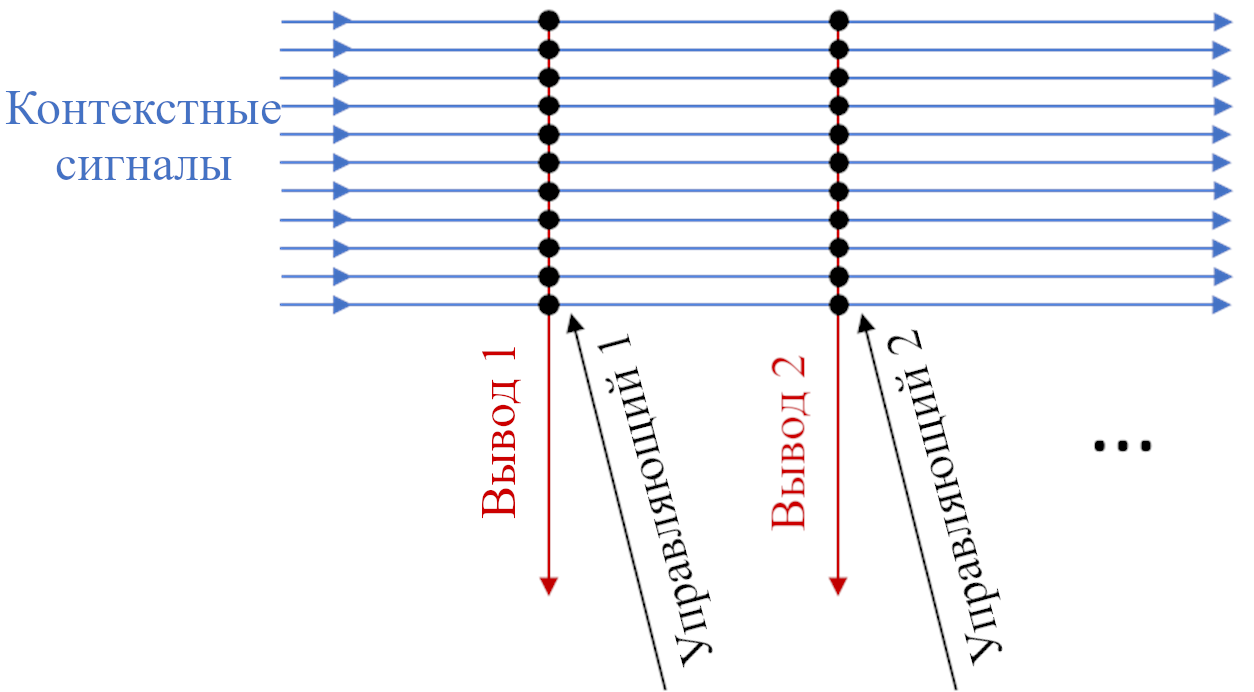
Чёрные точки обозначают синапсы настраиваемой силы
Для ясности – краткосрочный предсказатель может быть намного, намного сложнее этого. Большая сложность может обеспечить лучшую работу. Приведу интересный пример, про который я совсем недавно узнал – оказывается, в краткосрочных предсказателях в мозжечке (Раздел 4.6 ниже) есть нейроны, которые каким-то образом могут хранить настраиваемый параметр временной задержки внутри самого нейрона(!!) (ссылка – это всплыло на этом подкасте). Другие возможные прибамбасы включают разделение паттернов (Пост №2, Раздел 2.5.4) и обучение одним и тем же управляющим сигналом большого количества выводов и их объединение (ссылка), или, ещё лучше – обучение большого количества выводов с одним и тем же управляющим сигналом, но разными гиперпараметрами, чтобы получить распределение вероятностей (оригинальная статья, дальнейшее обсуждение), и так далее.
Так что этот подраздел – сильное упрощение. Но я не буду извиняться, я думаю, что такие грубо упрощённые игрушечные модели важно рассказывать и держать в голове. С концептуальной точки зрения, мы получили ощущение правдоподобной истории того, как ранние животные могут начать с очень простой (но уже полезной) схемы, которая может затем стать более сложной по прошествии многих поколений. Так что привыкайте – в будущих постах вас ждёт ещё много грубо упрощённых игрушечных моделей!
4.5 Сравнение с другими алгоритмическими подходами
4.5.1 «Краткосрочный предсказатель» против жёстко прошитой схемы
Давайте вернёмся к примеру выше: вздрагиванию перед получением удара в лицо. Я предположил, что хороший способ решить, когда вздрогнуть – это обучающийся алгоритм «краткосрочного предсказателя». Вот альтернатива: мы можем жёстко прошить схему, определяющую, когда вздрогнуть. К примеру, если в поле зрения есть быстро увеличивающееся пятно, но, вероятно, это хороший момент, чтобы вздрогнуть. Такой детектор правдоподобно может быть прошит в мозгу.
Как сравнить эти два решения? Какое лучше? Ответ: нет нужды выбирать! Они взаимодополняющие. Можно иметь оба. Но всё же, педагогически полезно обговорить их сравнительные преимущества и недостатки.
Главное (единственное?) преимущество жёстко прошитой системы вздрагивания – она работает с рождения. В идеале, не надо получать удар в лицо ни разу. Напротив, краткосрочный предсказатель – обучающийся алгоритм, так что ему в общем случае надо «учиться на своих ошибках».
С другой стороны, у краткосрочного предсказателя есть два мощных преимущества над жёстко прошитым решением – одно очевидное, другое не столь очевидное.
Очевидное преимущество – краткосрочный предсказатель работает на прижизненном, а не эволюционном обучении, так что он может выучивать намёки на то, что надо вздрогнуть, которые редко или вовсе никогда не встречались у предыдущих поколений. Если я часто ударяюсь головой, когда вхожу в конкретную пещеру, я научусь вздрагивать. Нет никакого шанса, чтобы у моих предков эволюционировал рефлекс вздрагивать в этой конкретной части этой конкретной пещеры. Мои предки вообще могли никогда не заходить в эту пещеру. Сама пещера могла не существовать до прошлой недели!
Менее очевидное, но всё же важное преимущество – краткосрочный предсказатель может использовать как ввод выученные с чистого листа паттерны (Пост №2), а жёстко прошитая система вздрагивания – нет. Обоснование тут такое же, как в Разделе 3.2.1 предыдущего поста: геном не может точно знать, какие именно (если вообще какие-то) нейроны будут хранить информацию о конкретном выученном с чистого листа паттерне, так что геном не может жёстко прошить связи с этими нейронами.
Способность использовать выученные с чистого листа паттерны очень выгодна. К примеру, хороший намёк на вздрагивание может зависеть от выученных с чистого листа семантических паттернов (вроде знания «Я сейчас играю в гольф»), выученных с чистого листа зрительных паттернов (например, образ замахивающегося клюшкой человека) или выученных с чистого листа указаний на место (вроде «эта конкретная комната с низким потолком»), и т.д.
4.5.2 «Краткосрочный предсказатель» против агента обучения с подкреплением: Более быстрое обучение благодаря градиентам ошибки
Схема краткосрочного предсказывания – особый случай обучения с учителем.
Обучение с учителем – это когда обучающийся алгоритм получает сигнал такого рода:
«Хе-хей, обучающийся алгоритм, ты облажался – тебе вместо этого следовало сделать то-то и то-то.»
Сравните это с обучением с подкреплением, при котором обучающийся алгоритм получает куда менее помогающий сигнал:
«Хе-хей, обучающийся алгоритм, ты облажался.»
(также известный как отрицательное вознаграждение). Очевидно, обучение с учителем может быть куда быстрее обучения с подкреплением. Управляющие сигналы, по крайней мере в принципе, говорят тебе точно, какие параметры менять и как, если ты хочешь лучше справиться в следующий раз в схожей ситуации. Обучение с подкреплением так не делает; вместо этого приходится учиться методом проб и ошибок.
В технических терминах машинного обучения, обучение с учителем «бесплатно» предоставляет полный градиент ошибки на каждом запросе, а обучение с подкреплением – нет.
Эволюция не всегда может использовать обучение с учителем. К примеру, если вы – профессиональный математик, пытающийся доказать теорему, и ваше последнее доказательство не работает, то нет никакого сигнала «эмпирической истины», сообщающего вам, что в следующий раз надо сделать по-другому – ни в вашем мозгу, ни где-то ещё в мире. Извините! Ваше пространство того, что можно сделать, имеет очень высокую размерность и никаких явных указателей. На каком-то уровне метод проб и ошибок – ваш единственный вариант. Не повезло.
Но эволюция может иногда использовать обучение с учителем, как в примерах в этом посте. И суть такова: если она может, скорее всего она использует.
4.6 Пример «краткосрочных предсказателей» №1: Мозжечок
Я сразу перескочу к тому, для чего, как я думаю, нужен мозжечок, а потом поговорю о том, как моя теория соотносится с другими предложениями в литературе.
4.6.1 Моя теория мозжечка
Я утверждаю, что мозжечок – место обитания большого количества схем краткосрочного предсказывания.
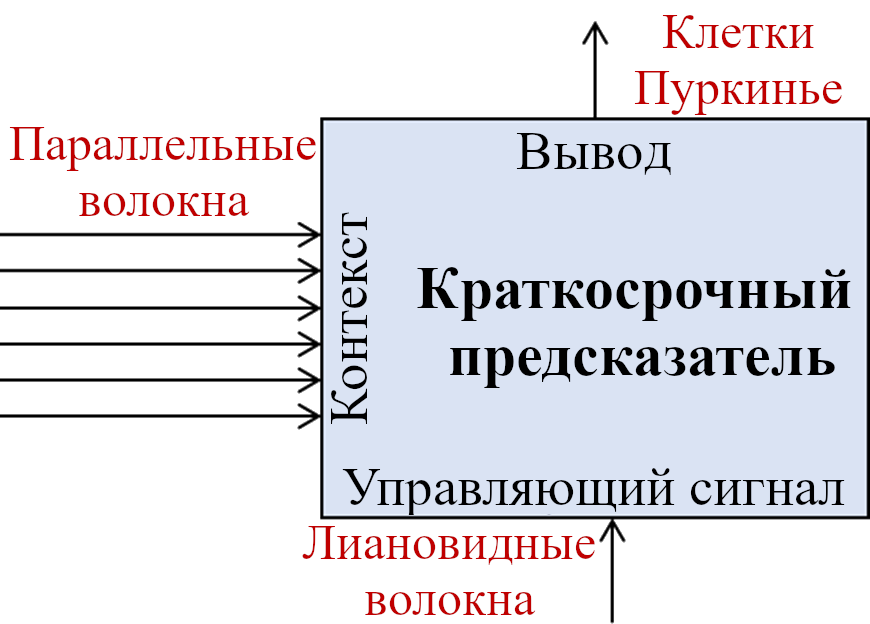
Связи нейроанатомии мозжечка (красным) с нашей диаграммой выше. Как обычно (см. выше), я опускаю множество прибамбасов, которые делают краткосрочный предсказатель точнее, вроде ещё одного дополнительного слоя, который я не показываю, плюс разделение паттернов (Пост №2, Раздел 2.5.4), и т.д.
Насколько много краткосрочных предсказателей: Моя лучшая оценка: около 300000.[1]
Какого чёрта?? Зачем мозгу может понадобиться 300000 краткосрочных предсказателей?
У меня есть версия! Я думаю, что мозжечок смотрит на много сигнал в мозге и обучается сам посылать эти сигналы заранее.
Вот так. Это вся моя теория мозжечка.
Другими словами, мозжечок может открыть правило «С учётом нынешней контекстной информации, я предсказываю, что выходной нейрон коры №218502 активируется через 0.3 секунды». Тогда мозжечок просто берёт и посылает сигнал туда же прямо сейчас. Или наоборот, мозжечок может открыть правило «Учитывая нынешнюю контекстную информацию, я предсказываю, что проприоцептивный нерв №218502 активируется через 0.3 секунды». Опять же, мозжечок идёт на опережение и посылает сигнал туда же прямо сейчас.
Некоторые примерно-аналогичные концепции:
- Когда мозжечок предсказывает-и-предвосхищает конечный мозг, мы можем думать об этом примерно как о «мемоизации»(sic!) в программной инженерии или как о «дистилляции знаний» в машинном обучении, или как о предложенных этой недавней статьёй «нейронных суррогатах».
- Когда мозжечок предсказывает-и-предвосхищает периферийные нервы, мы можем думать об этом как о составлении кучи предсказывающих моделей тела, каждая из которых узко настроена, чтобы предсказывать свой периферийный сигнал. Тогда, когда конечный мозг занимается моторным контролем и нуждается в периферийных сигналах обратной связи, он может использовать вместо настоящих сигналов эти предсказывающие модели.
По сути, я думаю, что у мозга есть проблемы такого вида, что пропускная способность некой подсистемы вполне адекватная, но её время ожидания слишком высоко. В случае периферийных нервов время ожидания высоко, потому что сигналам надо пройти большое расстояние. В случае конечного мозга задержка высока потому что сигналам надо пройти не-такое-длинное-но-всё-же-существенное расстояние, а кроме этого им надо пройти через много последовательных шагов обработки. В любом случае, мозжечок может чудесным образом уменьшить время ожидания, заплатив за это периодическими ошибками. Мозжечок находится в центре событий, постоянно спрашивая себя «что за сигнал сейчас появится?» и предвосхищает его сам. И потом через долю секунды он видит, было ли предсказание корректным и обновляет свою модель, если не было. Это как маленькая волшебная коробочка путешествий во времени – линия задержки, чья задержка отрицательна.
И теперь у нас есть ответ: зачем нам надо ≈300000 краткосрочных предсказателей? Потому что периферийных нервов и потоков вывода конечного мозга и может ещё чего много. И многие из этих сигналов выгодно предсказывать-и-предвосхищать! Чёрт, если я понимаю правильно, то мозжечок может даже предсказать-и-предвосхитить сигнал, который конечный мозг посылает сам себе!
Вот моя теория. Я не запускал никаких симуляций; это просто идея. См. здесь и здесь два примера, где я использовал эту модель, чтобы попытаться понять наблюдения из нейробиологии и психологии. Всё остальное, что я знаю про мозжечок – нейроанатомия, как он соединён с другими частями мозга, исследования повреждений и визуализации, и т.д. – всё, насколько я могу сказать, кажется хорошо соответствующим моей теории. Но на самом деле, этот маленький раздел – это почти что сумма всего, что я знаю на эту тему.
4.6.2 Как моя теория о мозжечке связана с другими теориями в литературе
(Я тут не эксперт и открыт для поправок.)
Я думаю, широко признано, что мозжечок вовлечён в обучении с учителем. Вроде бы, эта идея называется моделью Марра-Альбуса-Ито, см. Марр 1969 или Альбус 1971, или занимательный YouTube канал Brains Explained.
Напомню, что краткосрочный предсказатель – это случай алгоритма обучения с учителем как более широкой категории. Так что часть про обучение с учителем – не отличительная черта моего предложения, и, например, диаграмма выше (с указанием анатомических деталей мозжечка красным) совместима с обычной картиной Марра-Альбуса-Ито. Отличительный аспект моей теории – чем являются эмпирические сигналы (или чем являются сигналы ошибки – всё равно).
В Посте №2 я упоминал, что когда я вижу прижизненный обучающийся алгоритм, у меня возникает немедленный вопрос: «На каких эмпирических данных он учится?» Я также упоминал, что обычно поиски ответа на этот вопрос в литературе приводят к замешательству и неудовлетворённости. Литература о мозжечке – идеальный тому пример.
К примеру, я часто слышу что-то вроде «синапсы мозжечка обновляются при моторных ошибках». Но кто говорит, что считается моторной ошибкой?
- Если вы пытаетесь идти в школу, то поскользнуться на банановой кожуре – моторная ошибка.
- Если вы пытаетесь поскользнуться на банановой кожуре, то поскользнуться на банановой кожуре – это успех!
Откуда мозжечку знать? Непонятно.
Я читал несколько вычислительных теорий по поводу мозжечка. Они обычно куда сложнее моей. И они всё ещё оставляют ощущение непонимания, откуда берутся эмпирические данные. Для ясности, я не читал тщательно каждую такую статью, и вполне возможно, что я что-то упустил.
Ну, в любом случае, это не сильно влияет на эту цепочку. Как я упоминал ранее, вы можете быть функционирующим взрослым человеком, способным жить независимо, работать и т.д., вовсе без мозжечка. Так что даже если я полностью неправ по его поводу, это не должно сильно влиять на общую картину.
4.7 Пример «краткосрочных предсказателей» №2: Предсказательное обучение сенсорных вводов в коре
В вашей коре находится богатая генеративная модель мира, включающего вас самих. Много раз в секунду ваш мозг использует эту модель, чтобы предсказать поступающие сенсорные вводы (зрение, звук, прикосновение, проприоцепция, интероцепция, и т.д.), и, когда его предсказания неверны, модель обновляется в результате ошибки. Так, к примеру, вы можете открыть дверцу вашего шкафа и немедленно понять, что кто-то смазал петли. Вы предсказывали, что это будет звучать и ощущаться определённым образом, и это предсказание было опровергнуто.
С моей точки зрения, предсказательное обучение сенсорных вводов – это главный двигатель запихивания информации из мира в нашу модель мира в коре. Я поддерживаю цитату Яна Лекуна: «Если бы интеллект был тортом, то его основой было бы [предсказательное обучение сенсорных вводов], глазурью – [остальные виды] обучение с учителем, а вишенкой на торте – обучение с подкреплением». Просто количество битов информации, которые мы получаем предсказательным обучением сенсорных вводов подавляюще превосходит все остальные источники.
Предсказательное обучение сенсорных вводов – в том конкретном смысле, в котором я это тут использую – не большая общая теория мышления. Большая проблема возникает, когда оно сталкивается с «решениями» (какие мышцы двигать, на что обращать внимание, и т.д.). Рассмотрим следующее: я могу предсказать, что я буду петь, а потом петь, и предсказание получится правильным. Или я могу предсказать, что я буду танцевать, а потом танцевать, и тогда это предсказание было правильным. Так что у предсказательного обучения есть недостаток; оно не может помочь мне сделать правильное действие. Потому нам нужна ещё и Направляющая Подсистема (Пост №3), посылающая управляющие сигналы и сигналы вознаграждения обучения с подкреплением. Эти сигналы могут продвинуть хорошие решения ток, как предсказательное обучение сенсорных вводов не может.
Всё же, предсказательное обучение сенсорных вводов – это очень важная штука для мозга, и о ней можно много чего сказать. Однако, я рассматриваю её как одну из многих тем, которые очень напрямую важны для создания подобного–мозгу СИИ, но лишь немного относятся к его безопасности. Так что я буду упоминать её время от времени, но если вы ищете точных деталей, вы сами по себе.
4.8 Другие примеры приложений «краткосрочных предсказателей»
Эти примеры тоже не будут важны для этой цепочки, так что я не буду много о них говорить, но просто для интереса вот ещё три случайные штуки, которые, как я думаю, Эволюция может делать с помощью краткосрочных предсказателей.
- Фильтрация – к примеру, мой мозг может иметь краткосрочный предсказатель входящей звуковой информации, с ограничением, что его контекстный ввод несёт информацию только о моём движении челюсти и активности голосовых связок. Предсказатель должен выдавать модель моего собственного вклада в входящий звуковой поток. Это очень полезно, потому что мозг может её вычесть, оставив только пришедшие извне звуки.
- Сжатие входных данных – это вроде экстремальной версии фильтрации. Вместо всего лишь отфильтровывания предсказываемой из собственных действий информации, можно фильтровать всю информацию, предсказуемую из чего угодно, что мы уже знаем. Кстати, это то, что я ориентировочно думаю о дорсальном кохлеарном ядре, маленькой структуре в цепи обработки звукового ввода, которая подозрительно похожа на мозжечок. См. здесь. Предупреждаю: возможно, что эта идея не имеет смысла, я сам колеблюсь.
- Отмечание новизны – см. обсуждение здесь.
———
- Клеток Пуркинье 15 миллионов (ссылка), а эта статья заявляет, что один предсказатель состоит из «горстки» клеток Пуркинье с одним управляющим сигналом и одним (совмещённым) выводом. Что значит «горстка»? В статье указано «около 50». Ну, 50 у мышей. Я не смог быстро найти соответствующее число у людей. Я предположил, что это всё ещё 50, но это просто догадка. В любом случае, из этого я вывел предположение о 300,000 предсказателей.
5. "Долгосрочный предсказатель" и TD-обучение
- 1.5.1 Краткое содержание / Оглавление
- 2.5.2 Игрушечная модель схемы «долгосрочного предсказателя»
- 3.5.3 Вычисление функции ценности (обучение методом Временных Разниц) как особый случай долгосрочного предсказания
- 4.5.4 Массив долгосрочных предсказателей с участием конечного мозга и мозгового ствола
- 5.5.5 Шесть причин, почему мне нравится эта картина «массива долгосрочных предсказателей»
- 5.1.5.5.1 Это разумный способ реализовать биологически-полезные способности
- 5.2.5.5.2 Это интроспективно правдоподобно
- 5.3.5.5.3 Это эволюционно правдоподобно
- 5.4.5.5.4 Это позволяет согласовать «висцемоторный» и «мотивационный» способы описания медиальной префронтальной коры (mPFC)
- 5.5.5.5.5 Это объясняет эксперимент с Солью Мёртвого Моря
- 5.6.5.5.6 Это предлагает хорошее объяснение разнообразию активности дофаминовых нейронов
- 6.5.6 Заключение
Примечание переводчика - с момента перевода оригинальные посты несколько обновились, через некоторое время обновлю и перевод. На общие выводы цепочки это, вроде бы, не влияет.
5.1 Краткое содержание / Оглавление
В предыдущем посте я описал «краткосрочные предсказатели» – схемы, которые благодаря обучающемуся алгоритму выводят предсказание управляющего сигнала, который прибудет через некоторое небольшое время (например, долю секунды).
В этом посте я выдвигаю идею, что можно взять краткосрочный предсказатель, обернуть его замкнутой петлёй, включающей ещё некоторые схемы, и получить новый модуль, который я называю «долгосрочным предсказателем». Как и кажется по названию, такая схема может делать долгосрочные предсказания, например, «Я скорее всего поем в следующие 10 минут». Как мы увидим, эта схема тесно связана с обучением методом Временных Разниц (TD).
Я считаю, что в мозгу есть большой набор расположенных рядом долгосрочных предсказателей, каждый из которых состоит из краткосрочного предсказателя в конечном мозге (включая специфические его области вроде полосатого тела, медиальной префронтальной коры и миндалевидного тела), образующим петлю с Направляющей Подсистемой (гипоталамус и мозговой ствол) с помощью дофаминовых нейронов. Эти долгосрочные предсказатели прогнозируют биологически-важные вводы и выводы – к примеру, один из них может предсказывать, почувствую ли я боль в своей руке, другой – произойдёт ли выброс кортизола, третий – поем ли я, и так далее. Более того, один из этих долгосрочных предсказателей – по сути, функция ценности для обучения с подкреплением.
Все эти предсказатели будут играть большую роль в мотивации – об этом я закончу рассказывать в следующем посте.
Содержание:
- Раздел 5.2 начинается с игрушечной модели схемы «долгосрочного предсказателя», состоящей из «краткосрочного предсказателя» из предыдущего поста и ещё некоторых частей, соединённых в замкнутую петлю. Хорошее интуитивное понимание этой модели будет важно в дальнейшем, и я пройдусь по тому, как это модель будет себя вести в разных обстоятельствах.
- Раздел 5.3 связывает эту модель с обучением методом Временных Разниц (TD), близким родственником «долгосрочного предсказателя». Я покажу два варианта схемы долгосрочного предсказателя, «суммирующую» (приводящую к функции ценности, приближённо суммирующей будущие награды) и «переключающуюся» (приводящую к функции ценности, приближённо оценивающей следующую награду, когда бы она ни пришла, даже если до неё ещё долго). «Суммирующая» версия повсеместна в связанной с ИИ литературе, но я предполагаю, что «переключающаяся» версия скорее всего ближе к тому, что происходит в мозге. По совпадению, эти две модели эквивалентны в случаях вроде AlphaGo, который получает всю награду сразу в конце каждого эпизода (= игры в го).
- Раздел 5.4 свяжет долгосрочные предсказатели с нейроанатомией (частей) конечного мозга и мозгового ствола.
- По «вертикальной» нейроанатомии,[1] я опишу как в мозге размещается огромное количество параллельных «петель кора-базальные ганглии-таламус-кора», и предположу, что некоторые их этих петель функционируют как краткосрочные предсказатели с управляющим дофаминовым сигналом.
- По «горизонтальной» нейроанатомии, я предложу, что в обучении с учителем, о котором я говорю, участвуют (к примеру) медиальная префронтальная кора, полосатое тело, внешняя островковая кора и миндалевидное тело.
- Раздел 5.5 предложит шесть источников свидетельств, которые привели меня к убеждённости в этой модели: (1) это разумный способ реализовать биологически-полезные способности; (2) это интроспективно правдоподобно; (3) это эволюционно правдоподобно; (4) это позволяет согласовать «висцемоторный» и «мотивационный» способы описания медиальной префронтальной коры; (5) это объясняет эксперимент с Солью Мёртвого Моря; и (6) это предлагает хорошее объяснение разнообразию активности дофаминовых нейронов.
5.2 Игрушечная модель схемы «долгосрочного предсказателя»
«Долгосрочный предсказатель» – это, по сути, краткосрочный предсказатель, чей выходной сигнал помогает определить его собственный управляющий сигнал. Вот игрушечная модель того, как это может выглядеть:
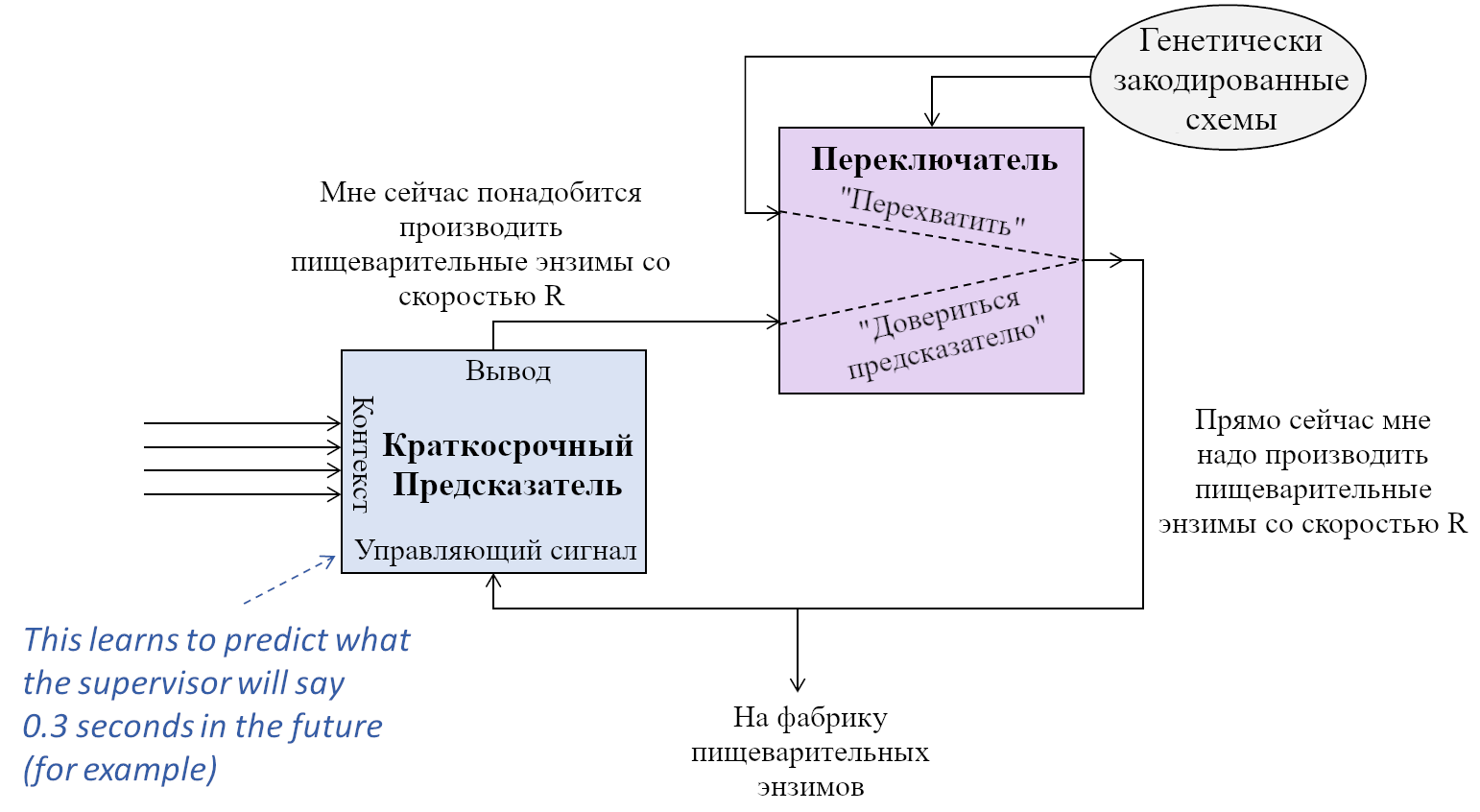
Игрушечная модель схемы долгосрочного предсказателя. Следующую пару подразделов я буду описывать, как это работает. На этой и похожих диаграммах в этом посте, все блоки в каждый момент времени работают параллельно, и, аналогично, каждая стрелка в каждый момент времени несёт числовое значение. Так что это НЕ диаграмма потока выполнения последовательного кода, это скорее похоже на, например, диаграммы, которые можно увидеть в описании FPGA.
- Синий прямоугольник – краткосрочный предсказатель из предыдущего поста. Он оптимизирует выходной сигнал, приближая его к тому, каким будет управляющий сигнал через 0.3 секунды (в этом примере).
- Фиолетовый прямоугольник – переключатель между двумя вариантами. Его контролирует генетически закодированная схема (серый овал) согласно следующим правилам:
- В основном переключатель находится в нижнем положении (довериться предсказателю). Это сродни тому, что генетически закодированная схема «доверяет» тому, что вывод краткосрочного предсказателя осмысленен, и, в этом примере, производит предложенное количество пищеварительных энзимов.
- Если генетически закодированная схема получает сигнал, что я что-то ем прямо сейчас, и у меня нет адекватного количества пищеварительных энзимов, то она переводит переключатель в вариант «перехватить», и посылает сигнал начать производство пищеварительных энзимов независимо от того, что говорит краткосрочный предсказатель.
- Если генетически-прошитая схема долгое время получала запросы на производство пищеварительных энзимов, но всё ещё ничего не было съедено, то она опять же переключает на вариант «перехватить» и посылает сигнал прекратить производство энзимов, независимо от того, что говорит краткосрочный предсказатель.
Замечу: Вы можете считать, что все сигналы на диаграмме могут непрерывно изменяться по диапазону значений (в противоположность дискретным сигналам вкл/выкл), за исключением сигнала управления переключателем.[2] В мозгу плавно-настраиваемые сигналы могут создаваться, к примеру, кодированием через частоту активаций нейрона.
5.2.1 Разбор игрушечной модели, часть 1: статичный контекст
Давайте пройдёмся по тому, что происходит в этой игрушечной модели.[3] Для начала, предположим, что на протяжении некоторого протяжённого периода времени «контекст» статичен. К примеру, представьте, как какое-нибудь древнее червеподобное существо много последовательных минут копается в песчаном дне океана. Правдоподобно, что пока оно копает, его сенсорное окружение будет оставаться довольно постоянным, и также постоянными будут оставаться его мысли и планы (в той мере, в которой у древнего червеподобного существа вообще есть «мысли и планы»). Или, если хотите другой пример (приблизительно) статичного контекста – с участием человека, а не червя – подождите следующего подраздела.
В этом случае, давайте посмотрим, что происходит, когда переключатель находится в положении «довериться-предсказателю»: поскольку вывод связан с управляющим сигналом, обучающийся модуль не получит сигнала об ошибке. Предсказание верно. Синапсы не меняются. Эта ситуация, сколь бы ни была частой, не повлияет на поведение краткосрочного предсказателя.
Что на него повлияет – те редкие случаи, когда переключатель переходит в режим «перехватить». Можно думать об этом как о периодическом «впрыскивании эмпирической истины». В этих случаях обучающийся алгоритм краткосрочного предсказания получает сигнал об ошибке, что меняет его настраиваемые параметры (например, силу синапсов).
Набрав достаточно жизненного опыта (или, что то же самое, после достаточного обучения), краткосрочный предсказатель должен получить свойство балансирования перехватов. Перехваты всё ещё могут увеличивать производство энзимов, а иногда могут его снижать, но эти два типа перехватов должны происходить с примерно одинаковой частотой. Ведь если бы они не были сбалансированы, то алгоритм обучения краткосрочного предсказания постепенно изменил бы его параметры, чтобы перехваты всё же были сбалансированы.
И это как раз то, что нам надо! Мы получаем подходящее производство энзимов в подходящее время, способом, в нужной мере учитывающим доступную контекстную информацию – что животное сейчас делает, что планирует делать, его сенсорные вводы, и т.д.
5.2.1.1 Экспозиционная терапия в стиле Дэвида Бернса – возможный реальный пример игрушечной модели с статичным контекстом?
Так вышло, что я недавно прочёл книгу Дэвида Бернса Терапия Настроения (мой обзор). У Дэвида Бернса очень интересный подход к экспозиционной терапии – служащий отличным примером того, как моя игрушечная модель работает в ситуации статичного контекста!
Вот короткая версия. (Предупреждение: если вы думаете самостоятельно заниматься экспозиционной терапией в домашних условиях, по меньшей мере сначала прочитайте всю книгу!) Отрывок из книги:
Во время обучения в старшей школе я хотел попасть в команду технических помощников сцены для постановки мюзикла «Бригадун». Учитель драмы, мистер Крэнстон, сказал мне, что помощники сцены должны забираться на высокие лестницы и ползать по балкам под потолком, чтобы регулировать свет. Я ответил, что для меня это может оказаться проблемой, ведь я боюсь высоты. Он объяснил, что я не смогу стать частью команды помощников сцены, пока не захочу преодолеть свой страх. Я спросил, как это сделать.
Мистер Крэнстон ответил, что это довольно просто. Он установил 18-футовую лестницу по центру сцены, сказал мне забраться на нее и встать на верхнюю перекладину. Я доверял ему, поэтому поднимался по лестнице, перекладина за перекладиной, пока не оказался наверху. Вдруг я увидел, что там не за что держаться, и пришел в ужас! Я спросил, что мне делать дальше. Мистер Крэнстон ответил, что не нужно ничего делать, просто стоять там, пока не уйдет страх. Он ждал меня внизу лестницы и подбадривал, чтобы я продолжал стоять.
В течение 15 минут я пребывал в полном оцепенении. Затем мой страх вдруг начал уходить. Через минуту или две он полностью исчез. Я с гордостью объявил: «Мистер Крэнстон, думаю, я исцелился. Я больше не боюсь высоты».
Он сказал: «Прекрасно, Дэвид! Ты можешь спускаться. Будет здорово, если ты присоединишься к команде помощников сцены для мюзикла «Бригадун»».
Я гордился тем, что стал помощником сцены. Мне понравилось ползать по балкам под потолком, закрепляя занавес и свет. Я удивлялся, что прежний источник моих страхов может приносить столько восторга.
Эта история кажется прекрасно совместимой с моей игрушечной моделью. Дэвид начал день в состоянии, когда его краткосрочные предсказатели выдавали очень сильную реакцию страха, когда он забирался на высоту. Пока Дэвид оставался на лестнице, эти краткосрочные предсказатели продолжали получать одни и те же контекстные данные, и продолжали выдавать всё такой же вывод. И Дэвид продолжал быть в ужасе.
Потом, после 15 скучных-но-ужасающих минут на лестнице, какая-то внутренняя схема в мозговом стволе Дэвида произвела *перехват* – как будто сказала «Слушай, ничего не меняется, ничего не происходит, мы не можем просто весь день продолжать сжигать на это калории». Краткосрочный предсказатель продолжил посылать всё тот же вывод, но мозговой ствол применил своё право вето и насильно «перезагрузил» Дэвиду уровень кортизола, пульс, и т.д., вернув их обратно на базовое значение. Это состояние «перехвата» немедленно привело к получению краткосрочным предсказателем в миндалевидном теле Дэвида *сигналов об ошибке*! Эти сигналы, в свою очередь, привели к обновлению модели! Краткосрочные предсказатели оказались обновлены, и с тех пор Дэвид больше не боялся высоты.
Конечно эта история выглядит спекуляцией на спекуляции, но я всё равно думаю, что она верна. По крайней мере, это хороший пример! Вот диаграмма для этой ситуации, удостоверьтесь, что не упускаете шагов.
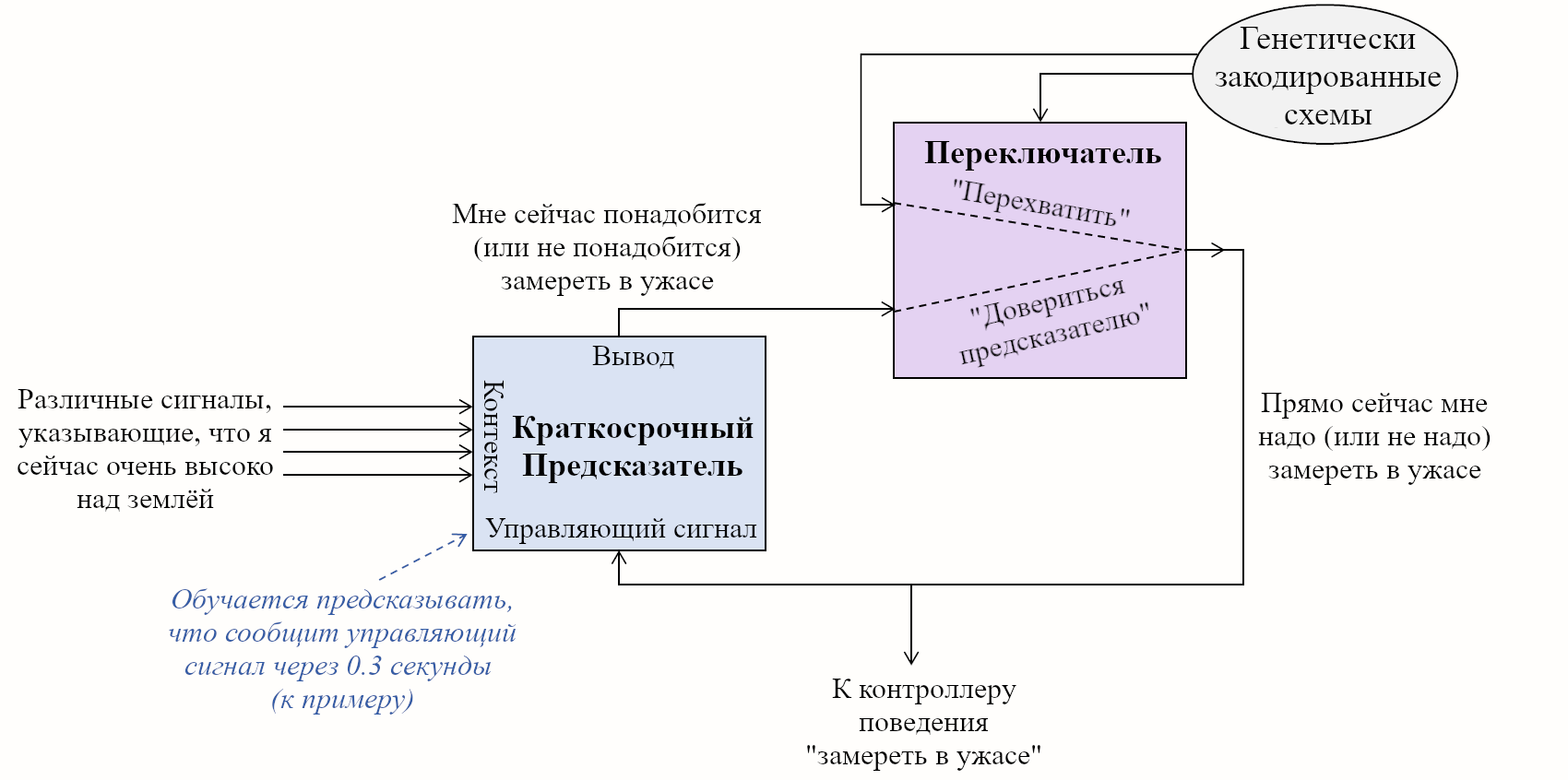
5.2.2 Разбор игрушечной модели, предполагая изменяющийся контекст
Предыдущий подраздел предполагал статичные потоки контекстных данных (постоянная сенсорная информация об окружении, постоянное поведение, постоянные мысли и планы, и т.д.). Что происходит, если контекст не статичен?
При изменениях в потоках контекстных данных обучение происходит не только при «перехватах». Если контекст меняется без «перехватов», то это приводит к изменениям вывода, и новый вывод будет трактоваться как эмпирическая истина о том, каким должен был быть старый вывод. Опять же, это кажется в точности тем, что нам надо? Если мы обучаемся чему-то новому и оказавшемуся важным в последнюю секунду, то наше текущее ожидание должно быть точнее, чем раннее, так что у нас есть основание для обновления нашей модели.
5.3 Вычисление функции ценности (обучение методом Временных Разниц) как особый случай долгосрочного предсказания
К этому моменту эксперты в машинном обучении должны распознать сходство с обучением методом Временных Разниц. Однако, это не совсем одно и то же. Различия:
Первое, обучение методом Временных Разниц обычно используется в обучении с подкреплением как метод перехода от функции вознаграждения к функции ценности. Я, напротив, говорю о штуках вроде «производства пищеварительных энзимов», которые не являются ни вознаграждениями, ни ценностями.
Другими словами, есть в целом полезный мотив перехода от некого немедленного значения X к «долгосрочному ожиданию X». Вычисление функции ценности из функции вознаграждения – пример этого мотива, но не исчерпывающий.
(В плане терминологии, мне кажется вполне общепринятым, что термин «обучение методом Временных Разниц» на самом деле может относиться к чему-то, не являющемуся функцией ценности обучения с подкреплением.[4] Однако, по моему собственному эмпирическому опыту, как только я упоминаю этот метод, мои собеседники немедленно начинают подразумевать, что я говорю о функциях ценности обучения с подкреплением. Так что мне приходится тут прояснять.)
Второе, чтобы получить что-то более похожее на традиционное обучение методом Временных Разниц, нам потребовалось бы заменить переключатель между двумя вариантами сумматором – и тогда «перехваты» были бы аналогичны наградам. Куда больше о «переключении против суммирования» – в следующем подразделе.

Вот схема обучения методом Временных Разниц, которая вела бы себя похоже на то, что вы можете найти в учебных пособиях по ИИ. Обратите внимание на фиолетовый прямоугольник справа: в отличии от предыдущей диаграммы, тут не *переключатель*, а *сумматор*. Куда больше о «переключении против суммирования» – в следующем подразделе.
Третье, есть много дополнительных способов поправить эту схему, которые часто используют в литературе по ИИ, и некоторые из них могут встречаться и в схемах в мозгу. К примеру, мы можем добавить обесценивание со временем, или разные реакции на ложно-положительные и ложно-отрицательные сигналы (см. моё рассмотрение обучения распределениям в Разделе 5.5.6.1 ниже), и т.д.
Чтобы всё не становилось слишком сложным, я буду игнорировать эти возможности (включая обесценивание со временем) ниже.
5.3.1 Переключатель (т.е. ценность = ожидаемая следующая награда) или сумматор (т.е. ценность = ожидаемая сумма будущих наград)?
Диаграммы выше показывают два варианта нашей игрушечной модели. В одном фиолетовый прямоугольник – переключатель между состоянием «доверия краткосрочному предсказателю» и некой независимой «эмпирической истиной». В другом в фиолетовом прямоугольнике вместо этого происходит суммирование.
В версии с переключателем краткосрочный предсказатель обучается предсказывать следующие эмпирические данные, когда бы они ни поступили.
В версии с сумматором, краткосрочный предсказатель обучается предсказывать сумму будущих эмпирических сигналов.
Правильным ответом может быть ещё «что-то промежуточное между переключением и суммированием». Или даже «ничто из этого».
Статьи по обучению с подкреплением повсеместно используют версию суммирования – т.е. «ценность – это ожидаемая сумма будущих наград». Что про биологию? И что на самом деле лучше?
Это не всегда вообще имеет значение! Рассмотрим AlphaGo. Как и повсюду в AlphaGo изначально использовалась парадигма суммирования. Но получилось так, что за каждую игру он получает только один ненулевой сигнал вознаграждения, если конкретно, +1 в конце игры, если он выигрывает, или -1 – если проигрывает. В таком случае, переключатель и сумматор ничем друг от друга не отличаются. Разница только в терминологии:
- В случае суммирования можно сказать «каждый не-последний ход в го приносит вознаграждение = 0».
- В случае переключения, можно сказать «каждый не-последний ход в го приносит вознаграждение (null) / не приносит вознаграждения».
(Видите, почему?)
Но в других случаях это важно. Так что вернёмся к вопросу: это должно быть переключение или суммирование?
Давайте сделаем шаг назад. Чего мы пытаемся добиться?
Одна из штук, которые должен делать мозг – это принимать решения, взвешивая при этом выгоды из разных областей. Если вы человек, то вам надо решать, посмотреть телевизор или пойти в спортзал. Если вы некое древнее червеподобное существо, то вам надо «решать» – копать или плавать. В любом случае, это «решение» затрагивает энергетический баланс, солевой баланс, вероятность травм, вероятность размножения – и много чего ещё. Проектная цель алгоритма принятия решений – принимать такие решения, которые будут максимизировать совокупную генетическую приспособленность. Как это может быть лучше всего реализовано?
Один из методов включает создание функции ценности, которая оценивает совокупную генетическую приспособленность организма (сравнительно с некой произвольной, и может, меняющейся со временем точкой отсчёта), при условии продолжения выполнения данного курса действий. Конечно, это не идеальная оценка – настоящая совокупная генетическая приспособленность может быть вычислена только задним числом, ещё через много поколений. Но когда у нас есть такая функция ценности, сколь бы неидеальной она ни была, мы можем подключить её к алгоритму, принимающему решения, максимизирующие ценность (больше про это в следующем посте), и таким образом получить приблизительно-максимизирующее-приспособленность поведение.
Так что обладание функцией ценности – ключ к принятию хороших решений, учитывающих выгоду в разных областях. Но тут нигде не сказано «ценность – это ожидаемая сумма будущих вознаграждений»! Это конкретный способ настройки этого алгоритма; метод, который может подходить, а может и не подходить к конкретной ситуации.
Я думаю, что мозг использует что-то более похожее на схему с переключателем, а не на схему с сумматором, причём не только для предсказаний гомеостаза (как в примере пищеварительных энзимов выше), но и для функции ценности, вопреки мейнстримным статьям об обучении с подкреплением. Опять же, я считаю, что на самом деле это «ничто из этого» во всех этих случаях; просто это ближе к переключателю.
Почему я отдаю предпочтение «переключателю», а не «сумматору»?
Пример: иногда я стукаюсь пальцем и он болит 20 секунд; в другой раз я стукаюсь пальцем и он болит 40 секунд. Но я не думаю о втором событии как о вдвое худшем, чем первое. На самом деле, уже через пять минут, я не вспомню, какая из двух ситуаций это была. (см. правило пика-и-конца.) Это то, чего я бы ожидал от переключателя, но довольно плохо подходит для сумматора. Это не строго несовместимо с суммированием; просто требует более сложной и зависящей от ценности функции вознаграждения. На самом деле, если мы это позволяем, то переключатель и сумматор могут имитировать друг друга.
В любом случае, в следующих постах я буду подразумевать переключатели, не сумматоры. Я не думаю, что это на большом масштабе очень важно, и я точно не думаю, что это часть «секретного ингредиента» интеллекта животных, или что-то такое. Но это влияет на некоторые детальные описания.
Следующий пост будет включать больше деталей обучения с подкреплением в мозгу, включая то, как работает сигнал «ошибки предсказания вознаграждения». Я готовлюсь к тому, что много читателей будут в замешательстве от того, что я подразумеваю не такую связь ценности с вознаграждением, к которой все привыкли. К примеру, в моей картине «вознаграждение» синонимично «эмпирическим данным о том, какой сейчас следует быть функции ценности» – и то, и другое должно учитывать не только текущие обстоятельства организма, но и будущие перспективы. Заранее прошу прощения за замешательство! Я изо всех сил попробую быть яснее.
5.4 Массив долгосрочных предсказателей с участием конечного мозга и мозгового ствола
Вот наша схема долгосрочного предсказателя:
Скопировано с схемы выше.
Я могу соединить переключатель с остальной генетически-прошитой схемой и немного переместить прямоугольники, тогда получится это:
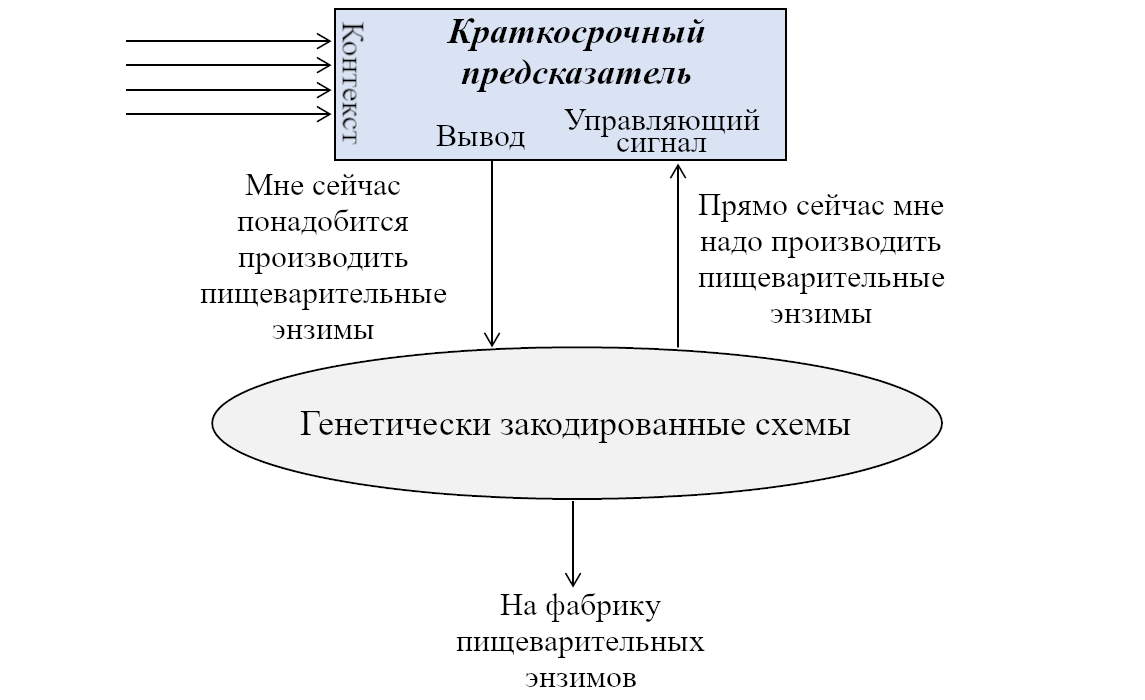
То же, что и выше, но нарисованное по-другому.
Очевидно, пищеварительные энзимы – лишь один пример. Давайте дорисуем ещё примеров, добавим гипотетическую нейронанатомию и ещё немного терминов. Вот, что получится:
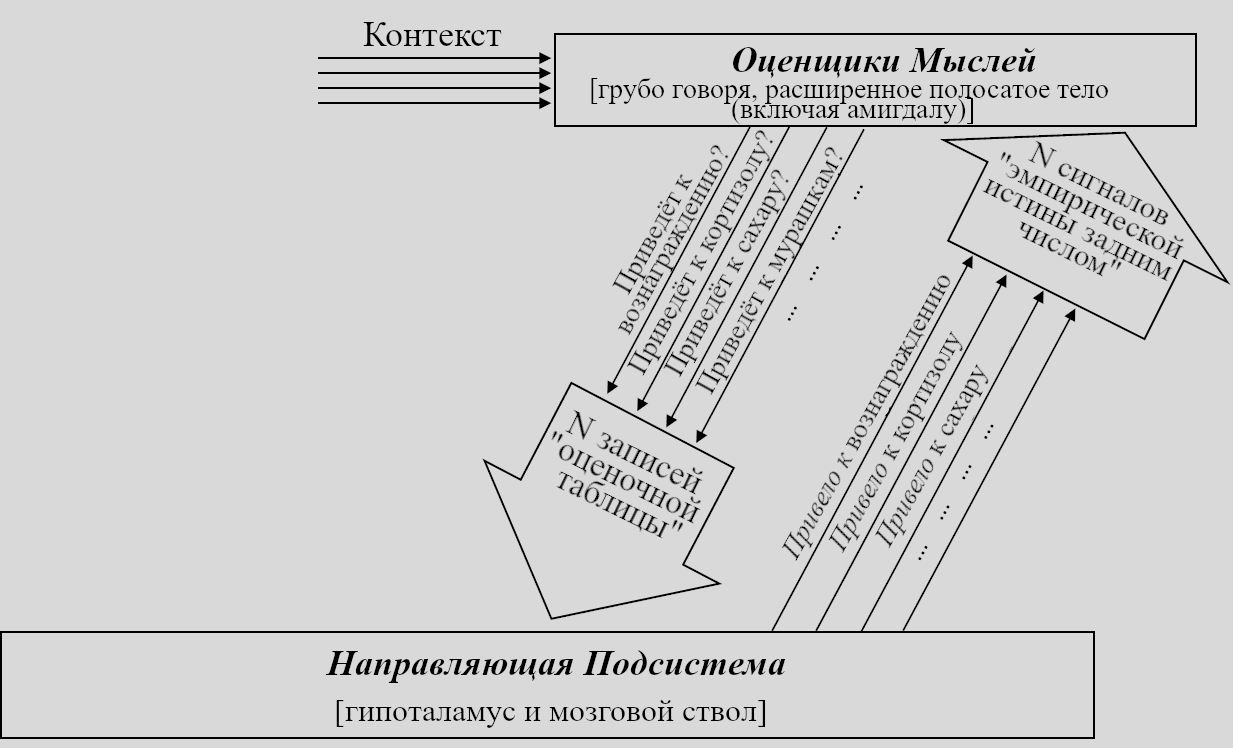
Я заявляю, что в мозгу есть целый набор долгосрочных предсказателей, состоящий из краткосрочных предсказателей в конечном мозге, каждый из которых петлёй связан с соответствующей схеме в Направляющей Подсистеме. По причинам, описанным ниже в Разделе 5.5.4, я называю первую часть (в конечном мозге) «Оценщиками Мыслей».
Замечательно! Мы на полпути к моей большой картине принятия решений и мотивации. Остаток – включая «субъекта» из обучения с подкреплением «субъект-критик» – будет в следующем посте, он заполнит дыру в верхней-левой части диаграммы.
Вот ещё одна диаграмма с педагогическими пометками.
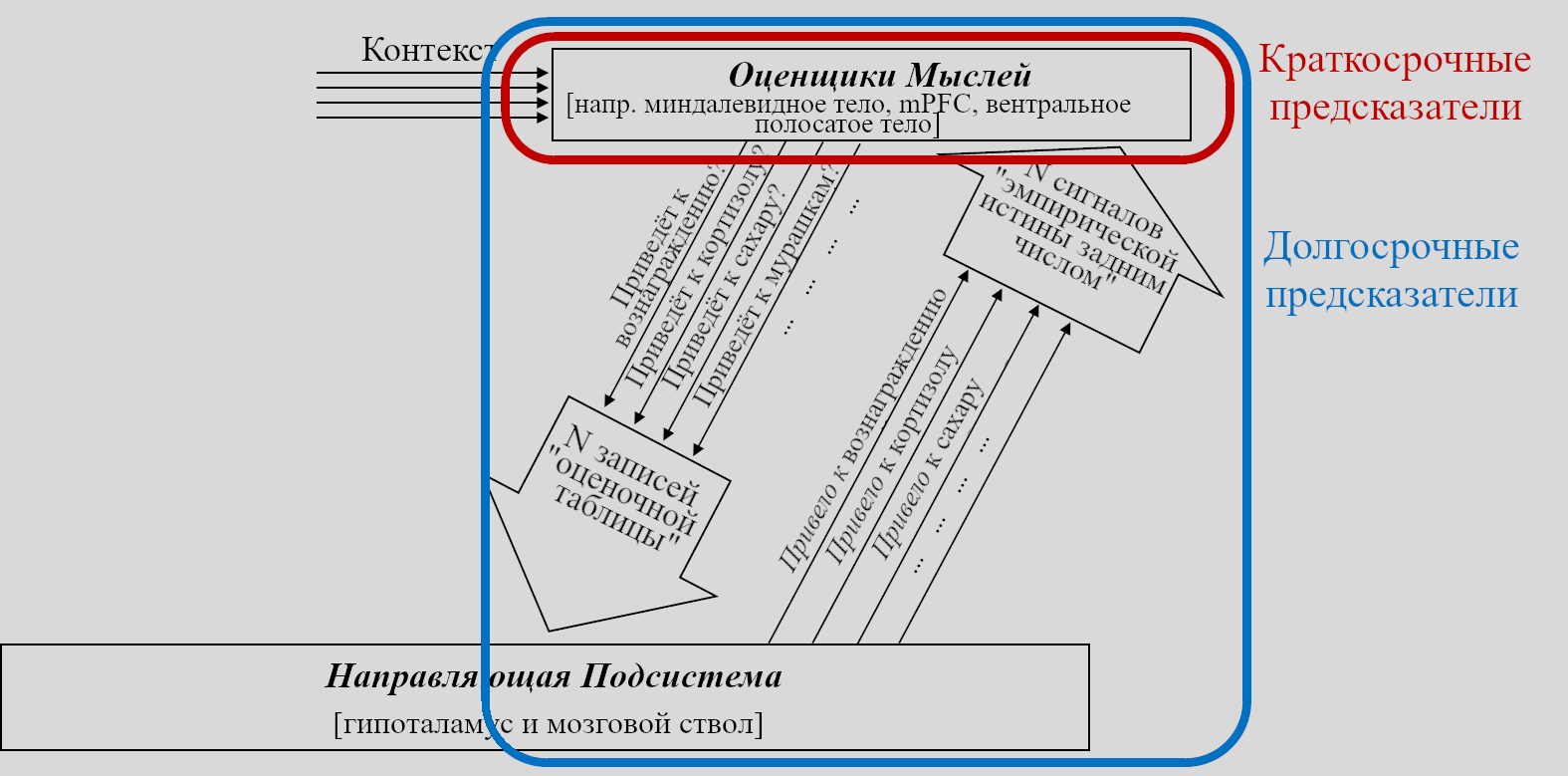
Напоминание: «краткосрочный предсказатель» - это *один из компонентов* «долгосрочного предсказателя». Тут показано, как они оба располагаются на предыдущей диаграмме. Долгосрочный предсказатель обеспечивается режимом «довериться предсказателю» - т.е. Направляющая Подсистема может посылать сигнал «эмпирической истины задним числом», который является не «эмпирической истиной» в нормальном смысле, но скорее копией соответствующего элемента «оценочной таблицы». Другими словами, режим «довериться предсказателю» можно описать как то, что Направляющая Подсистема говорит краткосрочному предсказателю «ОК, конечно, принято, верю тому, что ты говоришь». Если Направляющая Подсистема регулярно придерживается сигнала «довериться предсказателю» 10 минут подряд, то мы может получать прогнозирование будущего на 10 минут. Напротив, если Направляющая Подсистема *никогда* не использует для какого-то сигнала режим «довериться предсказателю», то получившуюся конструкцию вовсе нельзя назвать «долгосрочным предсказателем».
В следующих двух подразделах, я подробнее опишу нейроанатомию, на которую я даю намёки на этой диаграмме, и поговорю о том, почему вам стоит мне поверить.
5.4.1 «Вертикальная» нейроанатомия[1]: Петли «кора-базальные ганглии-таламус-кора»
В моём посте Большая Картина Фазового Дофамина, я рассказывал о теории (за авторством Ларри Свансона), что весь конечный мозг изящно организован в три слоя (кора, полосатое тело, паллидум):
| **Подобная-коре часть петли** | Гиппокампус | Миндалевидное тело [базолатеральная часть] | Грушевидная кора | Медиальная префронтальная кора | Моторная и «планирующая» кора |
| **Подобная-полосатому-телу часть петли** | Латеральная перегородочная зона | Миндалевидное тело [центральная часть] | Обонятельный бугорок | Вентральное полосатое тело | Дорсальное полосатое тело |
| **Подобная-паллидуму часть петли** | Медиальная перегородочная зона | BNST | Безымянная субстанция | Вентральный паллидум | Дорсальный паллидум |
Весь конечный мозг – неокортекс, гиппокампус, миндалевидное тело, всё остальное – может быть разделён на подобные-коре, подобные-полосатому-телу и подобные-паллидуму структуры. Если две структуры в таблице в одном столбце, это значит, что они связаны вместе в петлю «кора-базальные ганглии-таламус-кора» (см. следующий параграф). Эта таблица неполна и упрощена; для версии получше см. Рис. 4 здесь.
Эта идея связывается с ранней (и сейчас широко принятой) теорией (Александер 1986), что эти три слоя конечного мозга взаимосвязаны большим количеством параллельных петель «кора-базальные ганглии-таламус-кора», которые можно обнаружить почти в любой части конечного мозга.
Вот небольшая иллюстрация:
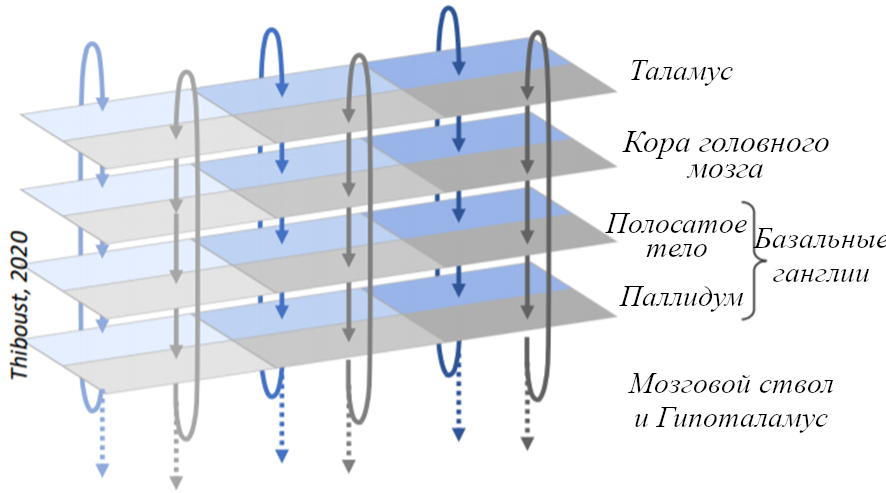
Упрощённая иллюстрация массива параллельных петель «кора-базальные ганглии-таламус-кора». Источник: Мэтью Тибуст.
С учётом всего этого, вот возможная грубая модель того, как эта петельная архитектура связана с обучающимся алгоритмом краткосрочных предсказателей, о котором я говорил:
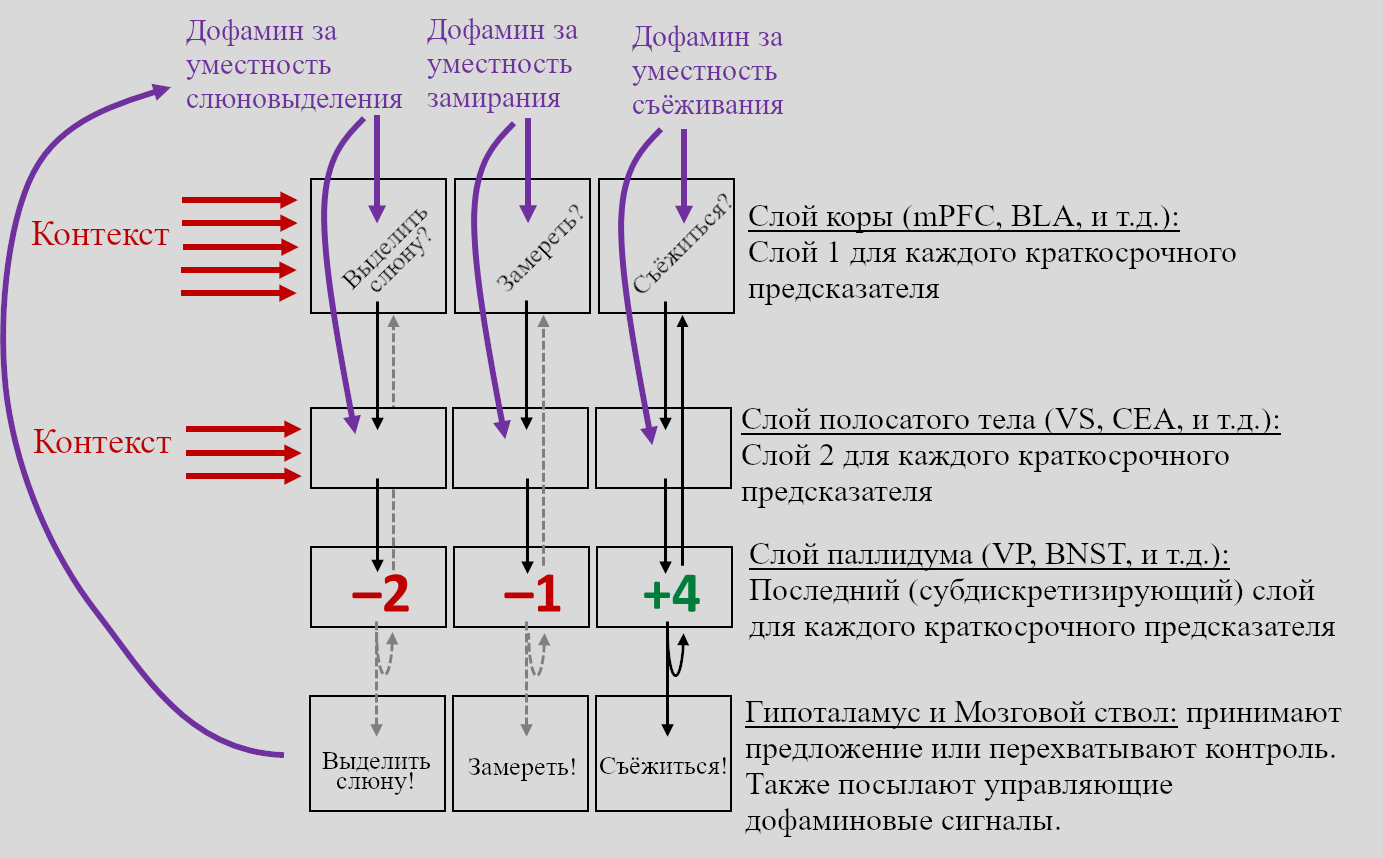
ПРЕДУПРЕЖДЕНИЕ: НЕ ВОСПРИНИМАЙТЕ ЭТУ ДИАГРАММУ СЛИШКОМ БУКВАЛЬНО
См. Большую Картину Фазового Дофамина за *немного* более подробными деталями, но вообще я не особо много в это погружался, и, в частности ярлыки «Слой 1, Слой 2, Последний (суюдискретизирующий) слой» расставлены почти наугад. («Субдискретизация» основана на том, что в полосатом теле в 2000 раз больше нейронов, чем в паллидуме – см. здесь.)
Сокращения: BLA = базолатеральное миндалевидное тело, BNST = опорное ядро терминального тяжа, CEA = центральное миндалевидное тело, mPFC = медиальная префронтальная кора, VP = вентральный паллидум, VS = вентральное полосатое тело.
5.4.2 «Горизонтальная» нейронанатомия – специализация коры
Предыдущий подраздел весь был про «вертикальную» трёхслойную структуру конечного мозга. Сейчас давайте переключимся на «горизонтальную» структуру, т.е. тот факт, что разные части коры делают разные вещи (в кооперации с соответствующими частями полосатого тела и паллидума).
Это упрощение, но вот моя новейшая попытка объяснить (часть) коры на пальцах:
- Расширенная моторная кора – это основной источник выводов коры, вовлекающих скелетные мышцы, вроде хватания и ходьбы.
- Медиальная префронтальная кора (mPFC – также включающая переднюю поясную кору) – это главный источник выводов коры, вовлекающих автономные/висцемоторные/гормнональные действия, вроде выпускания кортизола, сужения сосудов, гусиной кожи, и т.д.
- Миндалевидное тело – это главный источник выводов коры, связанных с некоторыми поведениями, вовлекающими и скелетные мышцы и автономные реакции, вроде вздрагивания, замирания (при испуге), и т.д.
- Островковая кора – это главный регион вводов коры для автономной / гомеостатической / связанной с статусом тела информации, вроде уровня сахара в крови, боли, холода, вкуса, напряжения мышц и т.д.
В этой цепочке я не буду говорить про моторную кору, но я думаю, что остальные три все вовлечены в схемы долгосрочного предсказания. К примеру:
- Я заявляю, что если взглянуть на маленький подрегион в медиальной префронтальной коре, то можно будет обнаружить, что он обучен активироваться пропорционально вероятности предстоящего выброса кортизола;
- Я заявляю, что если взглянуть на маленький подрегион в миндалевидном теле, то можно будет обнаружить, что он обучен активироваться пропорционально вероятности предстоящей реакции замирания;
- Я заявляю, что если взглянуть на маленький подрегион в (внешней) островковой коре, то можно будет обнаружить, что он обучен активироваться пропорционально вероятности предстоящего ощущения холода в левой руке.
5.5 Шесть причин, почему мне нравится эта картина «массива долгосрочных предсказателей»
5.5.1 Это разумный способ реализовать биологически-полезные способности
Если начать производить пищеварительные энзимы перед едой, то пища будет переварена быстрее. Если начать разгонять сердце до того, как вы увидите льва, то мышцы будут уже подготовлены убегать, когда вы увидите льва.
Так что такие предсказатели кажутся очевидно полезными.
Более того, как обсуждалось в предыдущем посте (Раздел 4.5.2), предлагаемая мной (основанная на обучении с учителем) техника кажется либо превосходящей, либо хорошо сочетающейся с другими способами это сделать.
5.5.2 Это интроспективно правдоподобно
Вообще, мы на самом деле начинаем слюновыделение до того, как съели крекер, начинаем нервничать до того, как видим льва, и т.д.
Ещё учтите тот факт, что все действия, о которых я говорил в этом посте непроизвольны: вы не можете выделять слюну по команде, расширять свои зрачки по команде и т.д, по крайней мере не так же, как можете подвигать пальцем по команде.
(Больше о произвольных действиях в следующем посте – они в совсем другой части конечного мозга.)
Я тут замалчиваю о многих сложностях, но непроизвольная природа этих вещей кажется удобно сочетающейся с идеей, что они обучаются своими собственными управляющими сигналами, прямо из мозгового ствола. Можно сказать, что они случат другому господину. Мы можем как-то обхитрить их и заставить вести себя определённым образом, но наш контроль ограниченный и непрямой.
5.5.3 Это эволюционно правдоподобно
Как описано в Разделе 4.4 предыдущего поста, простейший краткосрочный предсказатель невероятно прост, а простейший долгосрочный предсказатель лишь немногим сложнее. И эти очень простые версии уже правдоподобно полезны для приспособленности, даже у очень простых животных.
Более того, как я уже обсуждал некоторое время назад (Управляемое дофамином обучение у млекопитающих и плодовых мух), у плодовых мух есть массив маленьких обучающихся модулей, играющих роль, кажущуюся схожей с тем, о чём я тут говорю. Эти модули тоже используют дофамин в качестве управляющего сигнала, и есть некоторое генетическое свидетельство гомологии этих схем с конечным мозгом млекопитающих.
5.5.4 Это позволяет согласовать «висцемоторный» и «мотивационный» способы описания медиальной префронтальной коры (mPFC)
Возьмём mPFC (также включающую переднюю поясную кору) как пример. Люди пытаются говорить об этой области двумя довольно разными способами:
- С одной стороны, как упомянуто выше (Раздел 5.4.2), mPFC описывают как область висцемоторного / гомеостатического / автономно-моторного вывода – она задаёт команды контроля гормонов, исполнения реакций симпатической и парасимпатической нервной системы, и так далее. К примеру, «показано, что электрическая стимуляция инфралимбической коры влияет на подвижность желудка и вызывает гипотонию», а в этой статье говорится, что стимуляция mPFC вызывает «расширение зрачков, изменения кровяного давления, частоты дыхания и пульса», или посмотрите в книгу Бада Крейга, который характеризует переднюю поясную кору как центр гомеостатического моторного вывода. Это подход элегантно объясняет тот факт, что этот регион агранулярен (лишён слоя №4 из 6 слоёв неокортекса), что подразумевает «регион вывода» как по теоретическим причинам, так и по аналогии с (агранулярной) моторной корой.
- С другой стороны, mPFC часто описывают как место обитания приближённо-связанных-с-мотивацией активностей. К примеру, Википедия в связи с передней поясной корой упоминает «распределение внимания, предвкушение вознаграждения, этика и моральность, контроль импульсов … и эмоции».
Я думаю, моя картина работает и там, и там[5]:
С первой (висцемоторной) точки зрения, если вы взглянете на Раздел 5.2. выше, то вы увидите, что выводы предсказателей действительно приводят к гомеостатическим изменениям – как минимум, когда генетически-прошитые схемы Направляющей Подсистемы посылают сигнал в режиме «довериться предсказателю» (а не «перехвата»).
Касательно второй (мотивационной) точки зрения, это будет иметь больше смысла после следующего поста, но отметьте предложенное мной описание «оценочной таблицы» в диаграмме в Разделе 5.4. Идея такая: потоки «контекста» входящие в «Оценщики Мыслей» содержат ужасающую сложность всего вашего сознательного разума и даже больше – где вы, что вы видите и делаете, о чём вы думаете, что вы планируете делать в будущем и почему, и т.д. Довольно простая, генетически закодированная Направляющая Подсистема никак не может во всём этом разобраться!
Но ведь Направляющая Подсистема – источник наград / стремлений / мотиваций! Как она может предоставлять награду за хороший план, если она вовсе не может разобраться в том, что вы планируете??
Ответ – «оценочная таблица». В ней вся эта ужасающая сложность дистиллируется в стандартизированную табличку – как раз то, что генетически-заходированные схемы Направляющей Подсистемы могут легко обработать.
Так что любое взаимодействие между мыслями и стремлениями – эмоции, принятие решений, этика, антипатия, и т.д. – должно на промежуточном шаге вовлекать «Оценщики Мыслей».
5.5.5 Это объясняет эксперимент с Солью Мёртвого Моря
См. мой старый пост Внутреняя согласованность в лишённых-соли крысах. Если коротко, экспериментаторы периодически проигрывали звук и выдвигали объект в клетку с крысами, и немедленно после этого впрыскивали прямо им во рты очень солёную воду. Крысы считали её отвратительной, и с ужасом реагировали на звук и объект. Потом экспериментаторы лишили крыс соли. И после этого когда они играли звук и выдвигали объект, крысы становились очень радостно возбуждёнными – хоть раньше и не испытывали недостатка соли ни разу за всю свою жизнь.
Это в точности то, чего мы бы ожидали в нашей схеме: когда звук и объект появляются, предсказатель «я предчувствую вкус соли» начинает быть бешено активным. В то же время, Направляющая Подсистема (гипоталамус и мозговой ствол) имеют прошитую схему, заявляющую «Если у меня недостаток соли, а «оценочная таблица» Обучающейся Подсистемы предполагает, что я скоро почувствую вкус соли, то это замечательно, и я должен следовать той идее, которую сейчас думает Обучающаяся Подсистема!»
5.5.6 Это предлагает хорошее объяснение разнообразию активности дофаминовых нейронов
Напомню, что выше в Разделе 5.4.1 я заявлял, что дофаминовые нейроны несут управляющие сигналы всех этих модулей обучения с подкреплением.[6]
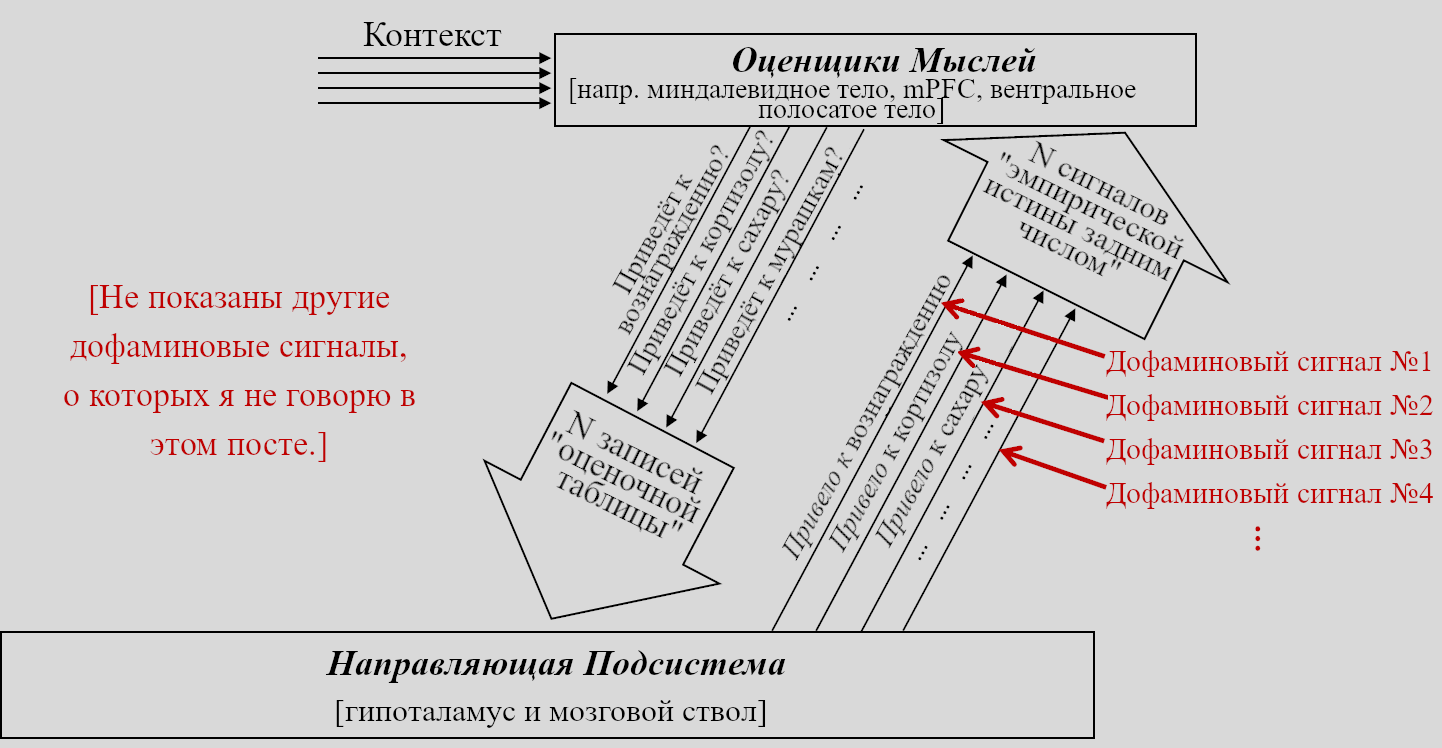
Есть научно-популярное заблуждение о том, что есть (единый) дофаминовый сигнал в мозгу, срабатывающий, когда происходит что-то хорошее. На самом деле, там есть множество разных дофаминовых нейронов, делающих разные вещи.
Так мы получаем вопрос: что делают все эти разнообразные дофаминовые сигналы? Консенсуса нет; в литературе есть самые разные заявления. Но я могу вбросить ещё и своё: в описанной мной картине, в конечном мозге, вероятно, есть сотни тысяч краткосрочных предсказателей, предсказывающих сотни тысяч разных вещей, и каждому нужен свой управляющий дофаминовый сигнал!
(И дофаминовых сигналов ещё больше, не только эти! Один такой сигнал, ассоциируемый с «главным» сигналом вознаграждения ошибки предсказания, будет обсуждаться в следующем посте. Прочие сигналы не входят в тему этой цепочки, но обсуждаются здесь.)
Если моя модель правильна, то что нам ожидать от экспериментов с измерением дофамина?
Представьте крысу, бегающую по лабиринту. В каждый момент времени её массив предсказателей получает управляющие сигналы о уровнях различных гормонов, пульсе, ожиданиям питья и еды, больной ноге, холоде, вкусе соли, и так далее. Говоря коротко, мы ожидаем, что активность дофаминовых нейронов скачет вверх и вниз самыми разными способами.
Так что, в общем-то каждый случай, когда экспериментатор выяснял, что дофаминовый нейрон коррелирует с какой-то поведенческой переменной, это, наверное, вписывается в мою картину.
Вот пара примеров:
- Есть дофаминовые нейроны, активирующиеся заметными стимулами вроде неожиданных вспышек света (ссылка). Могу ли я это объяснить? Конечно, без проблем! Я говорю: это могут быть управляющие сигналы, сообщающие «сейчас хороший момент, чтобы сориентироваться» или «вздрогнуть» или «повысить пульс», и т.д.
- Есть дофаминовые нейроны, коррелирующие с скоростью, с которой мышь бежит в колесе (ссылка). Могу я это объяснить? Конечно, без проблем! Я говорю: это могут быть управляющие сигналы, сообщающие «ожидай боли в мышцах» или «ожидай кортизол» или «ожидай повышения пульса», и т.д.
Вот ещё данные, кажущиеся подтверждающими мою картину. Некоторые дофаминовые нейроны активируются, когда происходит что-то неприятное (ссылка). Четыре из пяти областей[7], в которых можно обнаружить такие нейроны (согласно статье по ссылке) – в точности те, где я ожидаю существование краткосрочных предсказателей – конкретнее, это подобный-коре и подобный-полосатому-телу слои миндалевидного тела, медиальная префронтальная кора (mPFC) и вентромедиальная оболочка прилежащего ядра, являющаяся (по крайней мере примерно) частью петель «кора-базальные ганглии-маламус-кора», находящейся в полосатом теле. Это в точности то, что я бы ожидал. К примеру, если мышь шокирована, то предсказатель «следует ли мне сейчас замереть» получает управляющий сигнал «Да, тебе сейчас следовало замереть».
5.5.6.1 В сторону: Вывод распределений предсказателями
Я не говорил об этом в предыдущем посте, но обучающиеся алгоритмы краткосрочных предсказателей имеют гиперпараметры, два из которых – «как сильно обновляться после ложноположительной (перелёт) ошибки» и «как сильно обновляться после ложноотрицательной (недолёт) ошибки». Соотношение этих гиперпараметров может варьироваться от 0 до ∞, так что получившийся предсказатель может варьироваться от «активируй вывод, если есть хоть малейший шанс, что управляющий сигнал сработает» до «не активируй сигнал, если нет полной уверенностью, что управляющий сигнал сработает.»
Таким образом, если у нас есть много предсказателей, и у каждого своё соотношение гиперпараметров, то мы можем (хотя бы приблизительно) выводить распределение вероятности предсказания, а не просто одну оценку.
Недавний набор экспериментов от DeepMind и сотрудничающих с ними обнаружил свидетельство (основанное на измерениях дофаминовых нейронов), что мозг действительно использует этот трюк, по крайней мере для предсказания вознаграждения.
Я предполагаю, что он может использовать тот же трюк и в других долгосрочных предсказателях – к примеру, может быть, предсказания и боли в руке, и кортизола, и гусиной кожи – все выдаются группами долгосрочных предсказателей, составляющих распределения вероятностей.
Я поднял эту тему в первую очередь потому, что это ещё один пример того, как дофаминовые нейроны ведут себя, кажется, очень хорошо укладывающимся в мою картину образом, а во-вторых, потому что это вполне может быть полезно для безопасности СИИ – так что я в любом случае искал повод это упомянуть!
5.6 Заключение
Как обычно, я не претендую на то, что у меня есть неопровержимое доказательство молей гипотезы (т.е. что в мозгу есть массивы долгосрочных предсказателдей с участием петель «конечный мозг – мозговой ствол»). Но с учётом свидетельств в этом и предыдущем подразделах, я пришёл к сильному ощущению, что я примерно на правильном пути. Я с радостью обсужу это подробнее в комментариях. А в следующем посте мы наконец-то сложим всё это вместе в большую картину того, как, по моему мнению, работает мотивация и принятие решений в мозгу!
- «Горизонтальная» и «вертикальная» нейронанатомия – это моя своеобразная терминология, но я надеюсь, что она интуитивно понятна. Если вы представите кору, расправленную в горизонтальный лист, то «вертикальная нейронанатомия» будет включать, например, взаимосвязи между структурами в коре и подкорке, а «горизонтальная» нейроанатомия – например, разные роли разных частей коры. См. также таблицу в Разделе 5.4.1.
- Для ясности, скорее всего на самом деле нет никакого дискретного переключателя всё-или-ничего. Может быть, например, «взвешенное среднее». Напомню, всё это – просто педагогическая «игрушечная модель»; я ожидаю, что реальность во многих отношениях сложнее.
- Отмечу, что тут я просто прокручиваю этот алгоритм у себя в голове, я его не симулировал. Я оптимистично считаю, что я не облажался по-крупному, то есть, что то, что я говорю про алгоритм качественно верно при подходящих настройках параметров и, возможно иных мелких поправках.
- Примеры использования терминологии «Временных Разниц» в чём-то не связанном с функциями вознаграждения обучения с подкреплением включают «TD-сети» и литературу по Последовательным Отображениям (пример), и вот эту статью, и т.д.
- Классическая попытка примирить «висцемоторную» и «мотивационную» картины mPFC - это «гипотеза соматических маркеров» Антонио Дамасио. Моё описание тут имеет некоторые сходства и некоторые различия от неё. Я не буду в это погружаться, это не по теме.
- Как и в предыдущем посте, когда я говорю «дофамин несёт управляющий сигнал», я открыт к возможности того, что дофамин на самом деле несёт тесно-связанный сигнал, вроде сигнала об ошибке или отрицательного сигнала об ошибке, или отрицательного управляющего сигнала. Для наших целей это не имеет значения.
- Пятая область, хвост полосатого тела, как я думаю, объясняется по-иному – см. здесь.
6. Большая картина мотивации, принятия решений, и RL
- 1.6.1 Краткое содержание / Оглавление
- 2.6.2 Большая картина
- 3.6.3 «Генератор Мыслей»
- 4.6.3.2 Ввод Генератора Мыслей
- 5.6.4 Ценности и вознаграждения
- 6.6.5 Решения вовлекают не только одновременные, но и последовательные сравнения ценности
- 7.6.6 Частые заблуждения
Примечание переводчика - с момента перевода оригинальные посты несколько обновились, через некоторое время обновлю и перевод. На общие выводы цепочки это, вроде бы, не влияет.
6.1 Краткое содержание / Оглавление
Пока что в этой цепочке Пост №1 задал некоторые определения и мотивации (что такое «безопасность подобного-мозгу ИИ», и с чего нам беспокоиться?), Посты №2 и №3 представили разделение мозга на Обучающуюся Подсистему (конечный мозг и мозжечок), которая использует алгоритмы «обучения с чистого листа», и Направляющую Подсистему (гипоталамус и мозговой ствол), которая в основном генетически-прошита и выполняет специфичные для вида инстинкты и реакции.
В Посте №4 я описал «краткосрочные предсказатели» – схемы, которые в результате обучения с учителем начинают предсказывать сигналы до их появления, но, наверное, лишь за долю секунды. В Посте №5 я затем предложил, что если сформировать замкнутую петлю с участием и краткосрочных предсказателей в Обучающейся Подсистеме, и соответствующих им прошитых схем в Направляющей Подсистеме, то можно получить «долгосрочный предсказатель». Я заметил, что схема «долгосрочного предсказателя» сильно схожа с обучением методом Временных Разниц.
Теперь, в этом посте, мы добавим последние ингредиенты – грубо говоря, «субъекта» из обучения с подкреплением «субъект-критик» (RL) – чтобы у нас получилась полная большая картина мотивации и принятия решений в человеческом мозге. (Я говорю «человеческий мозг» для конкретики, но в любом другом млекопитающем, и, в меньшей степени, в любом другом позвоночном, всё было бы похоже.)
Причина, почему меня волнует мотивация и принятие решений, в том, что, если мы однажды создадим подобные-мозгу СИИ (как в Посте №1), мы захотим обеспечить, чтобы у них были некоторые мотивации (например, быть полезным) и не было некоторых других (например, выйти из-под человеческого контроля и распространить свои копии по Интернету). Куда больше на эту тему в следующих постах.
Тизер предстоящих постов: Следующий пост (№7) пройдётся по конкретному примеру модели из этого поста, и мы сможем пронаблюдать, как встроенное стремление приводит к сначала формированию явной цели, а потом принятию и исполнению плана для её достижения. Потом, начиная с Поста №8, мы сменим контекст, и с этого момента вы можете ожидать значительно меньше обсуждения нейробиологии и значительно больше обсуждения безопасности СИИ (за исключением ещё одного поста про нейробиологию ближе к концу).
Всё в этом посте, если не сказано обратное, это «то, в чём я убеждён прямо сейчас», а не нейробиологический консенсус. (Лайфхак: нейробиологического консенсуса никогда нет.) Я буду принимать минимальные усилия для связи своих гипотез с другими из литературы, но буду рад поболтать об этом в комментариях или по email.
Содержание:
- В Разделе 6.2 я представлю большую картину мотивации и принятия решений в человеческом мозге и пройдусь по тому, как это работает. Остаток поста будет описывать различные части этой картины более детально. Если вы торопитесь, я предлагаю дочитать до конца Раздела 6.2 и закончить.
- В Разделе 6.3 я поговорю о так называемом «Генераторе Мыслей», состоящем (как мне кажется) из дорсолатеральной префронтальной коры, сенсорной коры и других областей. (Для читателей из области машинного обучения, знакомых с «основанном на модели обучением с подкреплением субъект-критик», Генератор Мыслей более-менее соответствует комбинации «субъекта» и «модели».) Я поговорю о вводах и выводах этого модуля и кратко обрисую, как его алгоритм связан с нейроанатомией.
- В Разделе 6.4 я поговорю о том, как в этой картине работают ценности и вознаграждения, включая сигнал вознаграждения, руководящий обучением и принятием решений в Генераторе Мыслей.
- В Разделе 6.5 я немного больше углублюсь в детали того, как и почему думание и принятие решений должны вовлекать не только одновременные сравнения (например, механизм параллельной генерации разных вариантов и выбора наиболее многообещающего), но и последовательные сравнения (например, думать о чём-то, затем думать о чём-то другом, и сравнить эти две мысли). К примеру, вы можете подумать: «Хмм, я думаю, что я пойду в спортзал. Но, на самом деле, что если я вместо этого пойду в кафе?»
- В Разделе 6.6 я прокомментирую частое заблуждение о том, что Обучающаяся Подсистема – место обитания эгосинтонических интернализированных «глубоких желаний», а Направляющая Подсистема – эгодистонических, экстернализированных «первобытных побуждений». Я буду в целом возражать представлению о том, что две подсистемы – два противостоящих агента; более хорошая ментальная модель – что это две связанных шестерни в одном механизме.
6.2 Большая картина
Да, это буквально большая картинка, если вы только не читаете это с телефона. Вы уже видели её часть в предыдущем посте (Раздел 5.4), но сейчас тут больше всего.
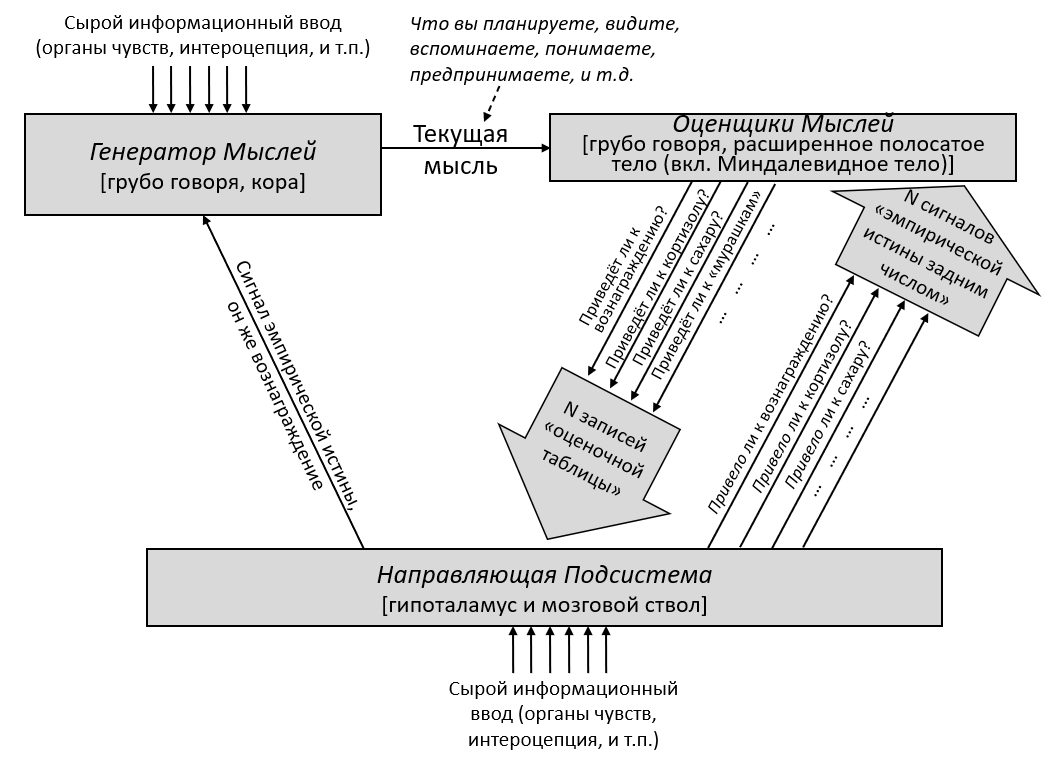
Большая картина – Весь пост будет вращаться вокруг этой диаграммы. Обратите внимание, что ярлычки на верхних двух блоках довольно условны и уж точно сильно утрированы.
Тут много, но не беспокойтесь. Мы пройдёмся по каждому кусочку отдельно.
6.2.1 Связь с «двумя подсистемами»
Вот как эта диаграмма укладывается в мою модель «двух подсистем», описанную в Посте №3:
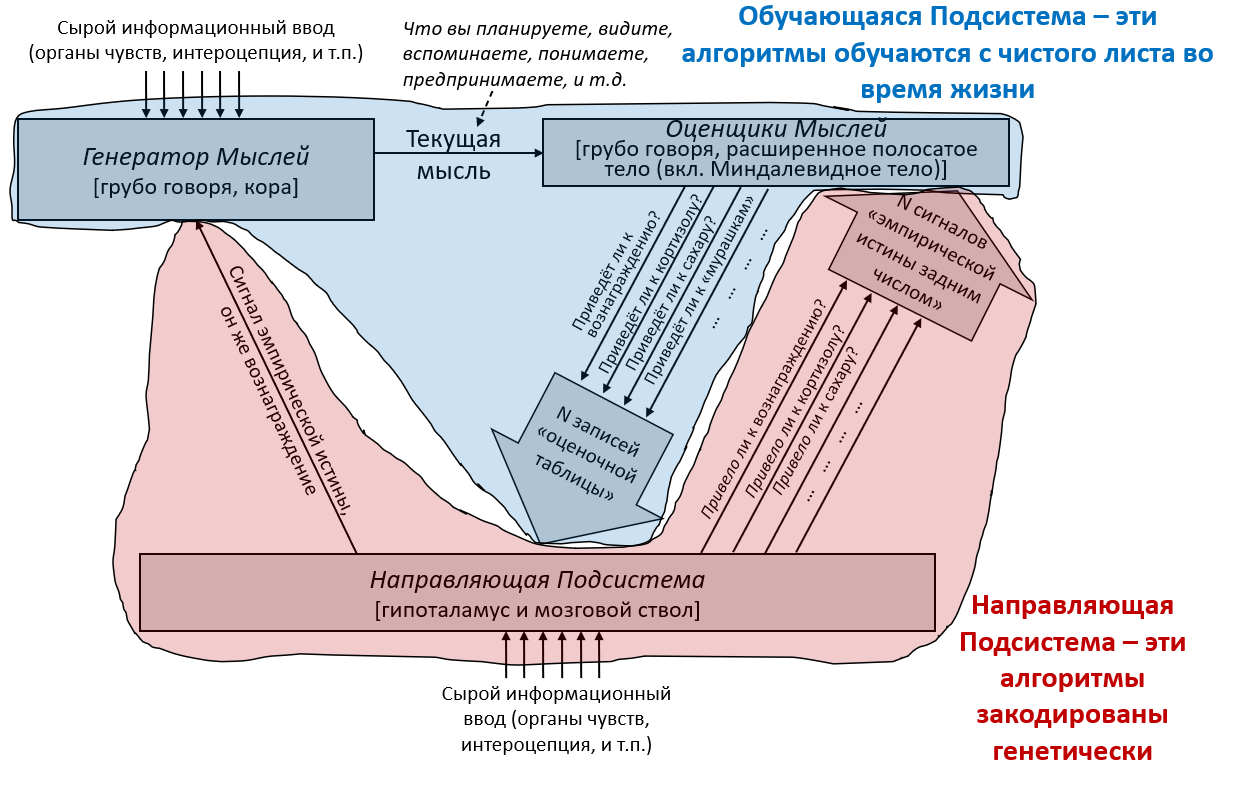
Тоже, что и выше, но две подсистемы подсвечены разными цветами.
6.2.2 Быстрый обзор
До погружения в детали дальше в посте, просто пройдёмся по диаграмме:
1. Генератор Мыслей генерирует мысль: Генератор Мыслей выбирает мысль из высокоразмерного пространства всех мыслей, которые возможно подумать в данный момент. Заметим, что это пространство возможностей, хоть и огромное, ограничено текущим сенсорным вводом, прошлым сенсорным вводом и всем остальным в выученной модели мира. К примеру, если вы сидите за письменным столом в Бостоне, в общем случае для вас невозможно подумать, что вы занимаетесь скуба-дайвингом у берега Мадагаскара. Но вы можете составлять план или насвистывать мелодию, или погрузиться в воспоминание, или рефлексировать о смысле жизни, и т.д.
2. Оценщики Мыслей сводят мысль к «оценочной таблице»: Оценщики Мыслей – набор, возможно, сотен тысяч схем «краткосрочных предсказателей» (Пост №4), который я более подробно описывал в предыдущем посте (№5). Каждый предсказатель обучен предсказывать свой сигнал из Направляющей Подсистемы. С точки зрения Оценщика Мыслей, всё в Генераторе Мыслей (не только выводы, но и скрытые переменные) – это контекст – информация, которую можно использовать для создания лучших предсказаний. Так что, если я думаю мысль «я прямо сейчас съем конфету», то Оценщик Мыслей может предсказать «высокую вероятность ощутить вкус чего-то сладкого очень скоро» исключительно на основании мысли – у него нет необходимости полагаться на внешнее поведение или сенсорные вводы, хоть это тоже может быть важным контекстом.
3. «Оценочная таблица» решает задачу построения интерфейса между обучающейся с чистого листа моделью мира и генетически закодированными схемами: Напомню, текущая мысль и ситуация – это невероятно сложные объекты в высокоразмерном выученном с чистого листа пространстве «всех возможных мыслей, которые можно подумать». Но нам нужно, чтобы относительно простые генетически закодированные схемы Направляющей Подсистемы анализировали мысль и выдавали суждение о её высокой или низкой ценности (см. Раздел 6.4 ниже) и о том, требует ли она выброса кортизола, гусиной кожи или расширения зрачков, и т.д. «Оценочная таблица» решает эту проблему! Она сводит возможные мысли / убеждения /планы и т.д. к генетически стандартизированной форме, которую уже можно напрямую передать генетически закодированным схемам.
4. Направляющая Подсистема исполняет некий генетически закодированный алгоритм: Его ввод – это (1) оценочная таблица с предыдущего шага, и (2) прочие источники информации – боль, метаболический статус, и т.д., поступающие из её собственной системы сенсорной обработки в мозговом стволе (см. Пост №3, Раздел 3.2.1). Её вывод включает выбросы гормонов, моторные команды, и т.д., а также посылание управляющих сигналов «эмпирической истины», показанных на диаграмме.[1]
5.Генератор Мыслей оставляет или отбрасывает мысли, основываясь на том, нравятся ли они Направляющей Подсистеме: Более конкретно, есть сигнал эмпирической истины (он же вознаграждение, да, я знаю, что это не звучит синонимично, см. Пост №5, Раздел 5.3.1). Когда его значение велико и положительно, текущая мысль «усиливается», задерживается, и может начать контролировать поведение и вызывать последующие мысли, а когда велико и отрицательно, текущая мысль немедленно отбрасывается, и Генератор Мыслей призывает следующую.
6. И Генератор Мыслей, и Оценщик Мыслей «обучаются с чистого листа» по ходу жизни, благодаря, в частности, управляющим сигналам Направляющей Подсистемы. Конкретнее, Оценщики Мыслей обучаются всё лучшему и лучшему предсказыванию сигнала «эмпирической истины задним числом» (это форма обучения с учителем – см. Пост №4), а Генератор Мыслей в большей степени обучается генерировать высокоценные мысли. (Процесс обучения с чистого листа Генератора Мыслей также включает и предсказательное обучение сенсорных вводов – Пост №4, Раздел 4.7.)
6.3 «Генератор Мыслей»
6.3.1 Общий обзор
Вернёмся к большой диаграмме выше. Слева-сверху находится Генератор Мыслей. В терминах основанного на модели обучения с подкреплением «субъект-критик», Генератор Мыслей грубо соответствует комбинации «субъект» + «модель», но не «критику». («Критик» обсуждался в предыдущем посте, а больше про него – ниже.)
На нашем несколько упрощённом уровне анализа, мы можем думать о «мыслях», генерируемых Генератором Мыслей как о комбинации ограничений (из предсказательного обучения сенсорных вводов) и выборов (управляемых обучением с подкреплением). Подробнее:
- Ограничения Генератора Мыслей происходят из информации из сенсорного ввода и предсказательного обучения сенсорному вводу (Пост №4, Раздел 4.7). К примеру, я не могу подумать мысль «На моём столе кот, и я прямо сейчас на него смотрю.» Кота, к сожалению, нет, и я не могу просто пожелать увидеть что-то, чего очевидно нет. Я могу представить, как я его вижу, но это не та же мысль.
- Но с учётом этих ограничений есть более чем одна возможная мысль, которую мой мозг может подумать в каждый конкретный момент. Он может обращаться к памяти, раздумывать о смысле жизни, выдать команду встать, и т.д. Я утверждаю, что эти «выборы» принимаются системой обучения с подкреплением (RL). Эта RL-система – одна из главных тем этого поста.
6.3.2 Ввод Генератора Мыслей
Генератор Мыслей принимает в качестве ввода, в том числе сенсорные данные и изменяющие гиперпараметры нейромодуляторы. Но в этом посте для нас наибольший интерес представляет сигнал эмпирической истины, он же вознаграждение. Я более детально поговорю о нём позже, но мы можем считать, что это оценка того, хороша или плоха мысль, в смысле, «стоит ли её удержать и развивать или же она заслуживает того, чтобы её выбросили и сгенерировали следующую». Этот сигнал важен и для того, чтобы научиться думать мысли получше, и для думания хороших мыслей прямо сейчас:
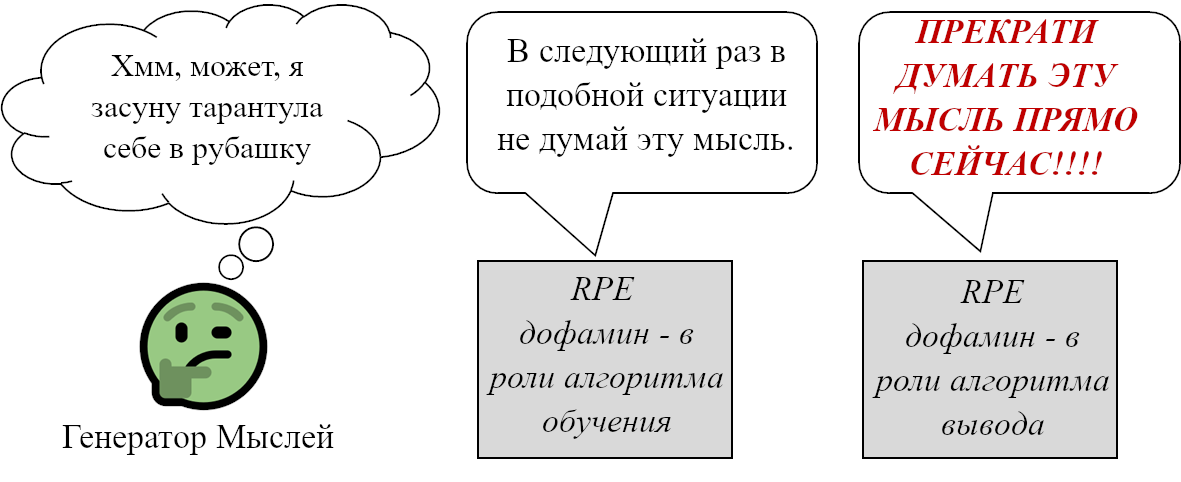
6.3.3 Вывод Генератора Мыслей
В тоже время множество сигналов выходят из Генератора Мыслей. Некоторые – то, о чём мы интуитивно думаем как о «выводе» – например, скелетные моторные команды. Другие сигналы вывода, ну, это несколько забавно…
Напомню идею «контекста» из Раздела 4.3 Поста №4: Оценщики Мыслей – это краткосрочные предсказатели, а краткосрочный предсказатель в принципе может взять любой сигнал в мозгу и применить его для улучшения своей способности предсказывать свой целевой сигнал. Так что если Генератор Мыслей имеет модель мира, то где-то в этой модели мира есть конфигурация активаций скрытых переменных, кодирующая концепт «маленькие котята, дрожащие под холодным дождём». Мы не стали бы думать об этом как о «сигналах вывода» – я только что сказал, что это скрытые переменные! Но, так уж получается, что Оценщик Мыслей «это приведёт к плачу» применяет копию этих скрытых переменных как контекстный сигнал, и постепенно обучается на опыте, что этот конкретный сигнал сильно предсказывает слёзы.
То есть, сейчас, у взрослого меня эти нейроны «маленьких котят под холодным дождём» в моём Генераторе Мыслей живут двойной жизнью:
- Они являются скрытыми переменными в моей модели мира – т.е. они и их сеть связей помогают мне распознать картинку маленьких котят под дождём, если я такую вижу, и рассуждать о том, что с ними произойдёт, и т.д.
- Активация этих нейронов, например, с помощью воображения – это способ вызвать слёзы по команде.
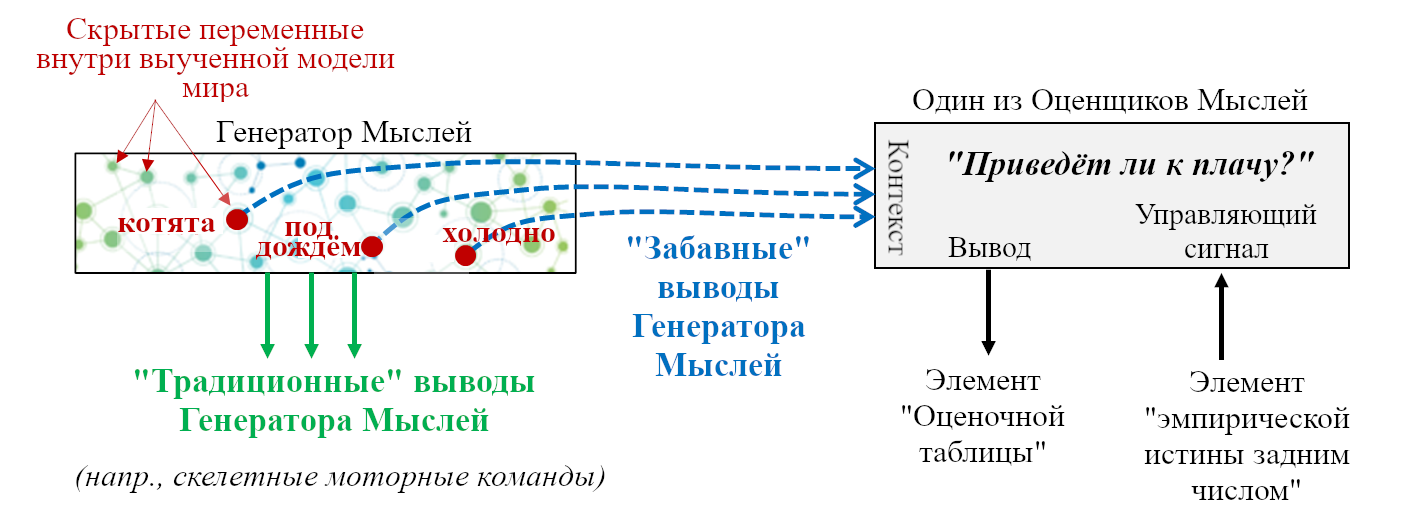
Генератор Мыслей (сверху слева) имеет два типа вывода: «традиционный» вывод, ассоциированный с произвольным поведением (зелёные стрелки) и «забавный» вывод, позволяющий даже скрытым переменным модели напрямую влиять на непроизвольное поведение (синие стрелки).
6.3.4 Обрисовка нейроанатомии Генератора Мыслей
ПРИМЕЧАНИЕ АВТОРА: Изначально в этом разделе было обсуждение петель «кора-базальные ганглии-таламус-кора», но это всё было очень спекулятивно и оказалось несколькими разными способами ошибочным. Это в любом случае не было особо важно для цепочки в целом, так что я это просто удалил. Я как-нибудь напишу исправленную версию отдельным постом. Извините!
Обновлённая дофаминовая диаграмма из предыдущего поста:
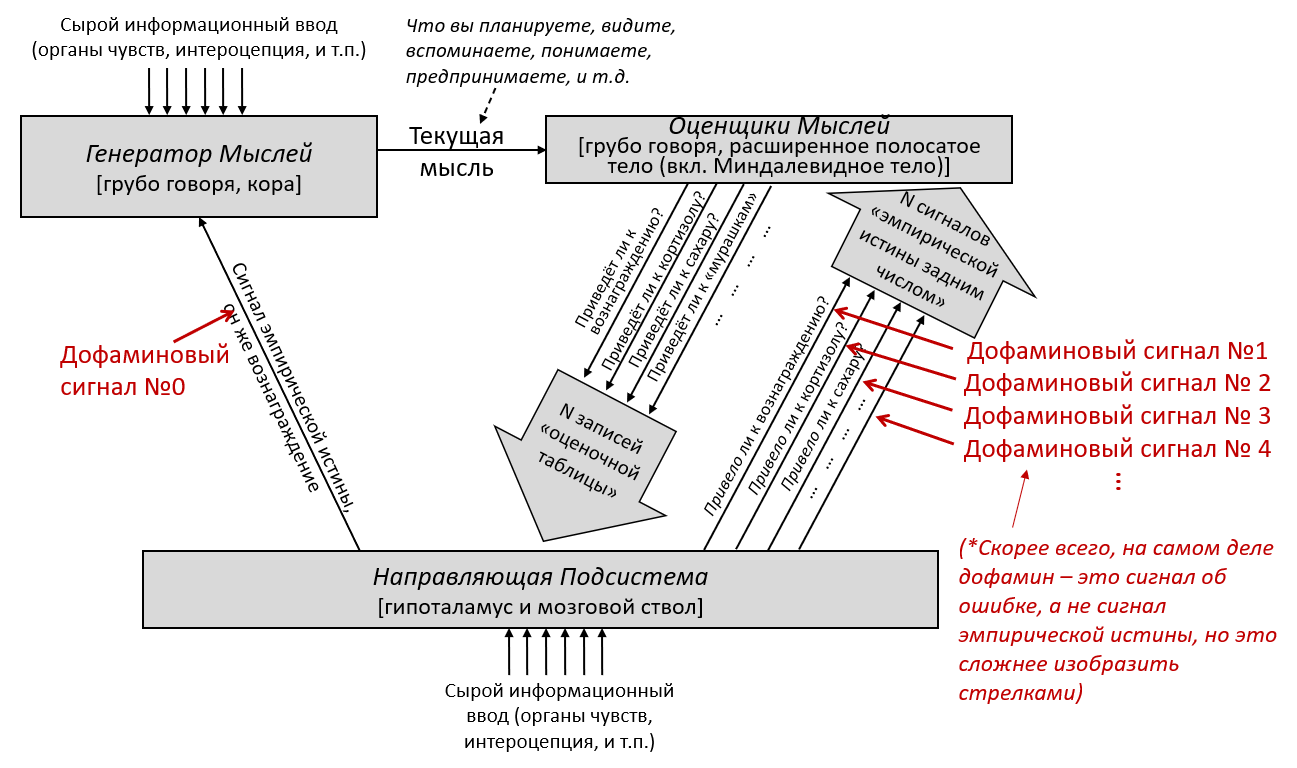
«Мезолимбические» дофаминовые сигналы справа обсуждались в предыдущем посте (Раздел 5.5.6). «Мезокортикальный» сигнал слева новый. (Я думаю, что в мозгу *ещё больше* дофаминовых сигналов, которые здесь не показаны. Они за пределами темы этой цепочки, но см. обсуждение здесь)
В Генераторе Мыслей есть ещё много деталей реализации, которые я тут не обсуждаю, включая детали диаграммы «петли» выше, так же, как и отношения между разными регионами коры. Однако, этого небольшого раздела более-менее достаточно для следующих постов по безопасности СИИ. Запутанные подробности Генератора Мыслей, так же, как и в чём угодно другом в Обучающейся Подсистеме, в основном полезны для создания СИИ.
6.4 Ценности и вознаграждения
6.4.1 Кора прикидывает «ценность», но Направляющая Подсистема может выбрать перехватить
На диаграмме есть две «ценности» (выглядит, будто три, но две красных – одно и то же):
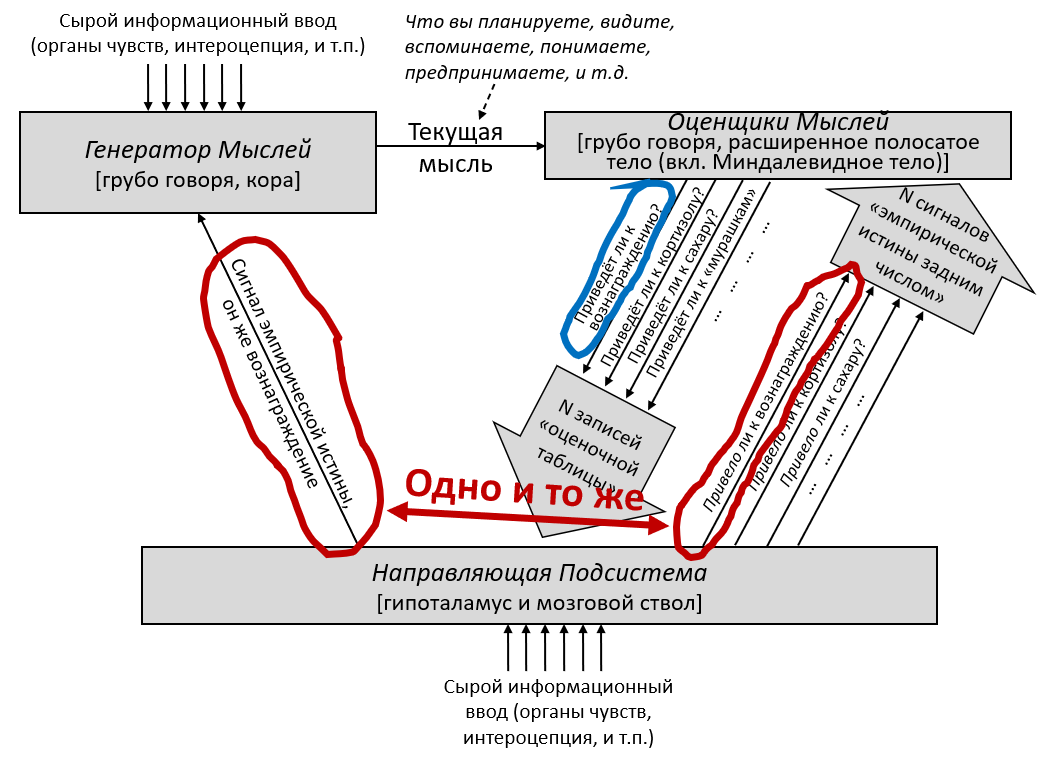
Два типа «ценности» в моей модели
Обведённый синим сигнал – это прикидка ценности из соответствующего Оценщика Мыслей в коре. Обведённый красным сигнал (ещё раз, это один и тот же сигнал, нарисованный дважды) – «эмпирическая истина» о том, какой должна была быть прикидка ценности. (Напомню, что «эмпирическая ценность» – синоним «вознаграждения»; да, знаю, звучит неправильно, см. предыдущий пост (Раздел 5.3.1) за подробностями.)
Так же, как и у других «долгосрочных предсказателей», которые обсуждались в предыдущем посте, Направляющая Подсистема может выбирать между режимом «довериться предсказателю» и режимом «перехвата». В первом случае, она задаёт красный сигнал эквивалентный синему, как будто говорит: «ОК, Оценщик Мыслей, конечно, я поверю тебе на слово». Во втором случае, она игнорирует предложение Оценщика Мыслей, а её собственные встроенные схемы выдают некую другую ценность.[2]
По каким причинам Направляющая Подсистема перехватывает прикидку ценности Оценщика Мыслей? Два фактора:
- Во-первых, Направляющая Подсистема может действовать на основе информации от других (не-ценностных) Оценщиков Мыслей. К примеру, в Эксперименте с Солью Мёртвого Моря (см. предыдущий пост, Раздел 5.5.5), прикидка ценности была «сейчас произойдёт что-то плохое», но в то же время Направляющая Подсистема получила предсказание «я сейчас почувствую вкус соли» в контексте состояния недостатка соли. Так что Направляющая Подсистема как бы сказала себе: «То, что происходит сейчас, очень перспективно; Оценщик не знает, что несёт!»
- Во-вторых, Направляющая Подсистема могла действовать на основе своих собственных источников информации, независимых от Обучающейся Подсистемы. В частности, Направляющая Подсистема обладает собственной системой обработки сенсорной информации (см. Пост №3, Раздел 3.2.1), которая может ощущать биологически-важные намёки вроде боли, голода, вкуса, вида ползущей змеи, запаха потенциального партнёра, и так далее. Всё это и более того может быть возможными основаниями для перехвата сигнала у Оценщика Мыслей, т.е. установке значения обведённого красным сигнала, отличного от обведённого синим.
Интересно (и в отличии от RL «по учебнику»), что в этой большой картине обведённый синим сигнал не обладает в алгоритме специальной ролью, в сравнении с другими Оценщиками Мыслей. Это лишь один из многих вводов прошитого алгоритма Направляющей Подсистемы, решающего, каким сделать обведённый красным сигнал. Обведённый синим сигнал может на практике оказаться особенно важным, более весомым, чем остальные, но вообще они все в одной куче. На самом деле, мои давние читатели вспомнят, что в прошлом году я писал посты, опускавшие обведённый синим сигнал ценности в списке Оценщиков Мыслей! Сейчас я считаю, что это ошибка, но оставил примерно такое же отношение.
6.5 Решения вовлекают не только одновременные, но и последовательные сравнения ценности
Вот «одновременная» модель принятия решений, описанная в книге «Голодный Мозг» Стефана Гийанэя на примере изучения миног:
Каждый участок паллиума [=эквивалент коры у миноги] связан с определенной частью полосатого тела. Паллиум посылает сигнал в полосатое тело, и затем сигнал из полосатого тела (через другие части базальных ганглиев) возвращается назад в тот же участок паллиума.
Иными словами, определенный участок паллиума и полосатое тело связаны замкнутой цепью, которая реализует запрос на конкретное действие. Например, существует цепь для преследования добычи, для ускользания от хищника, для прикрепления к камню и так далее. Каждый отдельный участок паллиума без конца нашептывает полосатому телу, упрашивая дать добро на исполнение того или иного поведенческого шаблона. А полосатое тело по умолчанию отвечает на это «нет!» При особых обстоятельствах шепот паллиума превращается в крик, и тогда полосатое тело исполняет требования настойчивого паллиума и приводит в действие мышцы.
Я принимаю это как часть моей модели принятия решений, но только как часть. Конкретнее, это одна из вещей, происходящих, когда Генератор Мыслей генерирует мысль. В самом деле, моя диаграмма в Разделе 6.3.4 выше явно вдохновлена этой моделью. Сравниваются разные одновременные возможности.
Другая часть моей модели – сравнение последовательных мыслей. Вы думаете одну мысль, а потом другую мысль (возможно, что сильно отличающуюся, а возможно, что преобразованную первую), и они сравниваются (Направляющей Подсистемой, отбирающей значение эмпирической истины, основываясь на, например, закономерностях того, как активизируются и успокаиваются Оценщики Мыслей), и если вторая хуже, то она ослабляется, чтобы её могла заменить следующая (возможно, снова первая).
Я могу процитировать эксперименты об аспекте последовательного сравнения в принятии решений (например, Рисунок 5 этой статьи, заявляющий то же, что и я), но действительно ли это надо? Интроспективно это очевидно! Вы думаете: «Хмм, думаю, я пойду в спортзал. На самом деле, что если я вместо этого пойду в кафе?» Вы представляете одно, а потом другое.
И я не думаю, что это то, что отличает людей от миног. Предполагаю, что сравнение последовательных мыслей универсально для позвоночных. Как иллюстрация того, что я имею в виду:
6.5.1 Выдуманный пример того, как сравнение последовательных мыслей могло бы выглядеть у более простого животного
Представьте простую древнюю маленькую рыбку, плывущую к пещере, где она живёт Она натыкается на ~~развилку дороги,~~ эмммм, «развилку в лесу водорослей»? Её текущий план навигации включает плыть налево к пещере, но у неё также есть вариант повернуть направо, чтобы добраться до рифа, где она часто кормится.
Я утверждаю, что её алгоритм навигации, увидев путь направо, рефлексивно загружает план: «Я поверну направо и доберусь до рифа.» Этот план немедленно оценивается и сравнивается с старым планом. Если новый план кажется хуже старого, то новая мысль затыкается, а старая мысль («Я направляюсь к своей пещере») восстанавливает своё положение. Рыбка без промедления продолжает следовать к пещере. А вот есть новый план кажется лучше старого, то новый план усиливается, приживается и принимает управление моторными командами. И тогда рыбка поворачивает направо и направляется к рифу.
(На самом деле, я не знаю достаточно о маленьких древних рыбках, но благодаря измерениям нейронов гиппокампуса известно, что крысы на развилке ~~дороги~~ лабиринта представляют оба возможных навигационных плана последовательно – ссылка.)
6.5.2 Сравнение последовательных мыслей: почему это необходимо
Согласно моим взглядам, мысли сложны. Чтобы подумать «Я пойду в кафе» вы не просто активируете некоторый крохотный кластер нейронов походов-в-кафе. Нет, это распределённый паттерн, включающий практически все части коры. Вы не можете одновременно думать «Я пойду в кафе» и «Я пойду в спортзал», потому что в эти мысли будут вовлечены разные паттерны активности одного и того же набора нейронов. Они бы мешали друг другу. Так что единственная возможность – думать мысли по очереди.
Как конкретный пример того, что я себе представляю, подумайте о том, как сеть Хопфилда не может вспомнить двенадцать воспоминаний одновременно. У неё есть множество стабильных состояний, но вы можете вызывать из только последовательно, одно за другим. Или подумайте о нейронах решётки и места, и т.д.
6.5.3 Сравнение последовательных мыслей: как это могло эволюционировать
Я представляю, что с эволюционной точки зрения сравнение последовательных мыслей – далёкий потомок очень простых механизмов сродни механизма «бежать-и-кувыркаться» у плавающих бактерий.
Механизм «бежать-и-кувыркаться» работает так: бактерия плывёт по прямой линии («бежит»), и периодически меняет направление на новое случайное («кувыркается»). Фокус в том, что, когда ситуация / окружение бактерии становится лучше, она кувыркается реже, а когда окружение становится хуже – она кувыркается чаще. Таким образом, она в итоге (в среднем, со временем) двигается в хорошем направлении.

Можно представить, как начиная с простого механизма вроде этого, можно навешивать на него всё больше и больше прибамбасов. Палитра поведенческих вариантов становится всё сложнее и сложнее, в какой-то момент превращаясь в «каждая мысль, которую возможно подумать». Методы оценивания, хорош или плох нынешний план, могут становиться быстрее и точнее, в итоге приводя к основанным на обучающихся алгоритмах предсказателям, как в предыдущем посте. Новые поведенческие варианты могут начать выбираться не случайно, а с помощью умных обучающихся алгоритмов. Так что мне кажется, что от чего-то-вроде-беги-и-кувыркайся к замысловатым тонко настроенным системам человеческого мозга, о которых я тут говорю есть плавный путь. (Иные размышления о бежать-и-кувыркаться и человеческой мотивации: 1, 2.)
6.6 Частые заблуждения
6.6.1 Различие между интернализированными эгосинтоническими и экстернализированными эгодистоническими желаниями не связано с разделением на Обучающуюся Подсистему и Направляющую Подсистему
(См. также: мой пост (Мозговой ствол, Неокортекс) ≠ (Базовые мотивации, Благородные мотивации).)
Многие (включая меня) обладают сильным интуитивным разделением эгосинтонических стремлений, которые являются «частью нас» и «тем, чего мы хотим» от эгодистонических стремлений, ощущающихся как позывы, вторгающиеся в нас извне.
К примеру, гурман может сказать: «Я люблю хороший шоколад», а человек на диете – «Я чувствую позыв съесть хороший шоколад».
6.6.1.1 Объяснение, которое мне нравится
Я утверждаю, что эти два человека по сути описывают одно и то же ощущение, с по сути одинаковой нейроанатомической локализацией и по сути одинаковой связью с низкоуровневыми алгоритмами мозга. Но гурман признаёт это чувство, а человек на диете его экстернализирует.
Эти два разных концепта идут рука об руку с двумя разными «предпочтениями высшего уровня»: гурман хочет хотеть есть хороший шоколад, тогда как человек на диете хочет не хотеть есть хороший шоколад.
Это приводит нас к прямолинейному психологическому объяснению, почему гурман и человек на диете по-разному концептуализируют свои чувства:
- Гурману приятно думать о «желании хорошего шоколада» как о «части того, кто я есть». Так он и делает.
- Человеку на диете неприятно думать о «желании хорошего шоколада» как о «части того, кто я есть». Поэтому он так не делает.
6.6.1.2 Объяснение, которое мне не нравится
Многие (включая Джеффа Хокинса, см. Пост №3) замечают описанное выше различие и, отдельно, поддерживают (как и я) идею, что в мозгу есть Обучающаяся Подсистема и Направляющая Подсистема (опять же, см. Пост №3). Они естественно предполагают, что это эквивалентно тому, что «я и мои глубокие желания» соответствуют Обучающейся Подсистеме, а «позывы, с которыми я себя не идентифицирую» – Направляющей Подсистеме.

Многие люди, с которыми я говорил, да и я сам, имеют отдельные концепции в выученной модели мира для «меня» и «моих позывов». Я заявляю, что эти концепты *НЕ* исходят из достоверного интроспективного доступа к нашей нейроанатомии. И в частности, они не соответствуют Обучающейся и Направляющей Подсистемам.
Я думаю, что эта модель неверна. По меньшей мере, если вы хотите принимать эту модель, то вам придётся отвергнуть приблизительно всё, что я писал в этом и предыдущих четырёх постах.
В моей модели, если вы пытаетесь воздержаться от шоколада, но чувствуете позыв есть шоколад, то:
- У вас есть позыв есть шоколад, потому что Направляющая Подсистема одобряет мысль «я сейчас съем шоколад»; И
- Вы пытаетесь воздержаться от шоколада, потому что Направляющая Подсистема одобряет мысль «Я воздерживаюсь от шоколада».
(С чего Направляющей Подсистеме одобрять вторую мысль? Это зависит от человека, но готов поспорить, что в это вовлечены социальные инстинкты. Я больше поговорю про социальные инстинкты в Посте №13. Если вы ходите менее сложный пример, представьте человека с непереносимостью лактозы, пытающегося сопротивляться позыву прямо сейчас съесть вкусное мороженое, потому что это приведёт к очень плохим ощущениям потом. Направляющей Подсистеме нравятся планы, приводящие к неболению, но ей также нравятся планы, приводящие к поеданию вкусного мороженого.)
6.6.2 Обучающаяся Подсистема и Направляющая Подсистема – не два агента
Другая частая ошибка – воспринимать саму по себе Обучающуюся или Направляющую Подсистему как что-то вроде независимого агента. Это неверно с обеих сторон:
- Обучающаяся Подсистема не может думать никаких мыслей, если Направляющая Подсистема не одобрила их как стоящие думания.
- В то же время, Направляющая Подсистема сама по себе не понимает мир или себя. У неё нет явных целей на будущее. Она лишь относительно простая, жёстко закодированная машина ввода-вывода.
Как пример, совершенно возможно следующее:
- Обучающаяся Подсистема генерирует мысль «Я собираюсь хирургически изменить мою Направляющую Подсистему».
- Оценщики Мыслей сводят эту мысль к «оценочной таблице».
- Направляющая Подсистема получает оценочную таблицу и исполняет свои жёстко прошитые эвристики, и результат: «Очень хорошая мысль, давай сделаем это!»
Почему нет, верно? Я больше поговорю про этот пример в позднейших постах.
Если вы прочитали пример выше и подумали: «Ага! Это случай, когда Обучающаяся Подсистема обхитрила Направляющую Подсистему», то вы всё ещё не поняли.
(Может, попробуйте представить Обучающуюся и Направляющую Подсистемы как две сцепленных шестерни в одном механизме.)
———
- Как и в предыдущем посте, термин «эмпирическая истина» тут немного обманчив, потому что иногда Направляющая Подсистема просто доверяется Оценщикам Мыслей.
- Как и в предыдущем посте, я не считаю, что на самом деле есть чистая дихотомия между режимом «довериться предсказателю» и «перехватить». На самом деле, я готов поспорить, что Направляющая Подсистема может частично-но-не-совсем-полностью довериться Оценщику Мыслей, например, взяв взвешенное среднее от Оценщика Мыслей и какого-то другого независимого вычисления.
7. От закодированных стремлений к предусмотрительным планам: рабочий пример
- 1.7.1 Краткое содержание / Оглавление
- 2.7.2 Напоминание о предыдущем посте: большая картина мотивации и принятия решений
- 3.7.3 Создание вероятностной генеративной модели мира в коре
- 4.7.4 Присвоение ценности при первом съедении кусочка торта
- 5.7.5 Нацеленное планирование через формирование вознаграждения
7.1 Краткое содержание / Оглавление
Предыдущий пост представил большую картину того, как, по моему мнению, в человеческом мозге работает мотивация, но он был несколько абстрактен. В этом посте я рассмотрю пример. В общих чертах, шаги будут такие:
- (Раздел 7.3) Наши мозги постепенно выработали вероятностную генеративную модель мира и себя;
- (Раздел 7.4) Существует процесс «присвоения ценности», когда что-то в модели мира помечается как «хорошее»;
- (Раздел 7.5) Существует сигнал ошибки предсказания вознаграждения, приблизительно связанный с производной (по времени) ожидаемой вероятности того, что произойдёт «хорошая» вещь. Этот сигнал вызывает у нас стремление «пытаться» делать «хорошие» вещи, в том числе и с помощью планирования наперёд.
Все человеческие цели и мотивации в конце концов исходят из относительно простых генетически закодированных схем Направляющей Подсистемы (гипоталамуса и мозгового ствола), но детали этого в некоторых случаях могут быть довольно запутанными. К примеру, иногда я замотивирован исполнить глупый танец перед полноростовым зеркалом. Какие в точности генетически закодированные схемы в гипоталамусе или мозговом стволе являются причиной этой мотивации? Я не знаю! Я, на самом деле, утверждаю, что ответ на этот вопрос на сегодняшний день Не Известен Науке. Я думаю, это стоит выяснить! Эммм, ну, ОК, может, для этого конкретного примера и не стоит выяснять. Но в целом я оцениваю проект реверс-инжиниринга некоторых аспектов человеческой Направляющей Подсистемы (см. моё описание «Категории B» в Посте №3) – особенно стоящих за социальными инстинктами вроде альтруизма и стремления к высокому статусу – как невероятно важный для безопасности СИИ, и, при этом, чрезвычайно пренебрегаемый. Больше про это - в Постах №12-13.
А пока что я выберу пример цели, которая в первом приближении исходит из особенно прямолинейного и понятного набора схем Направляющей Подсистемы. Поехали.
Давайте предположим (совершенно гипотетически…), что я два года назад съел кусок торта «Принцесса», и он был очень вкусным, и с тех пор я хочу съесть его ещё раз. Так что моим рабочим примером явной цели будет «Я хочу кусок торта «Принцесса»».

Торт «Принцесса». Я предлагаю его попробовать, чтобы лучше понять этот пост. Во имя науки! Источник картинки: моя любимая местная пекарня.)
Съесть кусок этого торта – не моя единственная цель в жизни, даже не особенно важная – так что она сравнивается с другими моими целями и желаниями – но это всё же моя цель (по крайней мере, когда я об этом думаю), и я в самом деле могу составлять сложные планы, чтобы её достичь. К примеру, оставлять тонкие намёки для моей семьи. В постах. Когда приближается мой день рождения. Совершенно гипотетически!!
7.2 Напоминание о предыдущем посте: большая картина мотивации и принятия решений
Вот моя диаграмма мотивации в мозгу из предыдущего поста:
См. предыдущий пост за деталями.
Как обсуждалось в предыдущем посте, мы можем разделить всё это на части, «закодированные» в геноме и части, обучающиеся при жизни – т.е. Направляющую Подсистему и Обучающуюся Подсистему:
7.3 Создание вероятностной генеративной модели мира в коре
Первый шаг в нашей истории: за время моей жизни моя кора (конкретнее, Генератор Мыслей из левой верхней части диаграммы выше) создавала вероятностную генеративную модель, в основном при помощи предсказательного обучения сенсорных вводов (Пост №4, Раздел 4.7) (также известного как «самообучение»).
По сути, мы выучиваем паттерны в своём сенсорном вводе, потом паттерны паттернов, и т.д., пока у нас не получается удобная предсказательная модель мира (и нас самих) – огромная сеть взаимосвязанных сущностей вроде «травы» и «стоять» и «куски торта «Принцесса»».
Предсказательное обучение сенсорных вводов не зависит фундаментально от управляющих сигналов Направляющей Подсистемы. Вместо этого «мир» предоставляет эмпирическую истину о том, было ли предсказание верным. Сравните это, к примеру, с составлением компромиссов между поиском еды и поиском партнёра: в окружении нет никакой «эмпирической истины» о том, составило ли животное компромисс оптимально, кроме как задним числом через много поколений. В этом случае нам нужны управляющие сигналы Направляющей Подсистемы, оценивающие «правильный» компромисс заложенными эволюцией эвристиками. Вы можете думать об этом как о чём-то вроде разделения «есть – должно», в котором Направляющая Подсистема предоставляет «должно» («что должен сделать организм, чтобы максимизировать генетическую приспособленность?»), а предсказательное обучение сенсорных вводов предоставляет «есть» («что, вероятно, сейчас произойдёт при таких-то и таких-то обстоятельствах»). Хотя Направляющая Подсистема всё же косвенно вовлечена и в предсказательное обучение – к примеру, я могу быть мотивирован изучить какую-нибудь тему.
В любом случае, каждая мысль, которую я могу подумать, и каждый план, который я могу составить, могут быть отображены в некоторую конфигурацию структуры данных этой генеративной модели мира. Структура данных непрерывно редактируется, когда я учусь и получаю новый опыт.
Думая об этой структуре данных модели мира, представьте много терабайт совершенно непонятных записей – к примеру, что-то вроде
«ПАТТЕРН 847836 определён как следующая последовательность: {ПАТТЕРН 278561, потом ПАТТЕРН 657862, потом ПАТТЕРН 128669}»
Некоторые записи отсылают к сенсорным вводам и/или моторными командам. И эта огромная запутанная непонятная свалка составляет всё моё понимание мира и себя самого.
7.4 Присвоение ценности при первом съедении кусочка торта
Как я упомянул выше, в судьбоносный день два года назад, я съел кусок торта «Принцесса», и это было очень хорошо.
Отступим назад на пару секунд, когда я ещё только подносил самый первый кусочек торта ко рту. В этот момент у меня ещё не было особо сильных ожиданий того, как он будет на вкус, и что я буду чувствовать по его поводу. Но когда он попал ко мне в рот, ммммм, о, вау, это хороший торт.
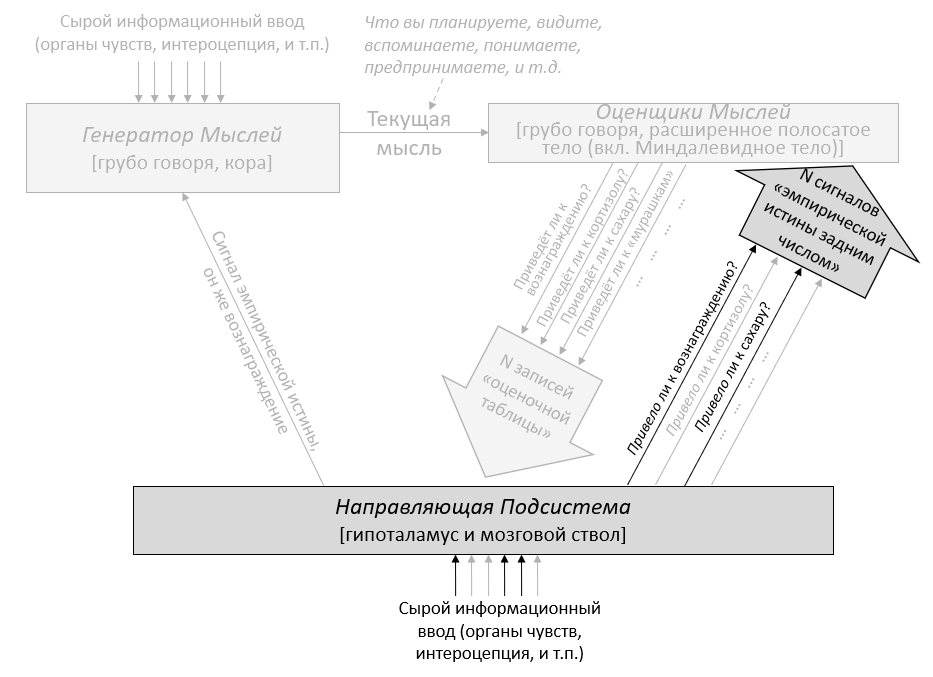
Части диаграммы, относящиеся к тому, что произошло, когда я съел первый удивительно-вкусный кусочек торта два года назад.
Итак, после того, как я его попробовал, моё тело произвело набор автономных реакций – выпустило некоторые гормоны, выработало слюну, изменило мой пульс и давление крови, и т.д. Почему? Ключ в том, что, как описано в Посте №3, Разделе 3.2.1, все мои сенсорные вводы делятся:
- Одна копия каждого конкретного сенсорного ввода отправляется в Обучающуюся Подсистему, чтобы встроиться в предсказательную модель мира. (См. «Информационные вводы» слева сверху на диаграмме.)
- Вторая копия того же сигнала отправляется в Направляющую Подсистему, где она служит вводом генетически закодированным цепям. (См. «Информационные вводы» снизу по центру диаграммы.)
Вкусовой ввод – не исключение: первый сигнал оказывается в вкусовой коре, части островковой коры (часть неокортекса, в Обучающейся Подсистеме), второй – в вкусовых ядрах продолговатого мозга (часть конечного мозга, в Направляющей Подсистеме). По прибытии в продолговатый мозг вкусовой ввод скармливается разным генетически закодированным схемам конечного мозга, которые, принимая также во внимание моё текущее психологическое состояние и подобное, исполняют все упомянутые мной автономные реакции.
Как я упоминал, до того, как я впервые попробовал торт, я не ожидал, что он будет так хорош. Ну, может быть, интеллектуально ожидал – если бы вы меня спросили, я бы сказал и был бы убеждён, что торт будет действительно хорош. Но я не ожидал этого внутренне.
Что я имею в виду под «внутренне»? В чём разница? Мои внутренние ожидания находятся на стороне «Оценщиков Мыслей». У людей нет произвольного контроля над своими Оценщиками Мыслей – они обучаются исключительно на сигналах «эмпирической истины задним числом» от мозгового ствола. У вас есть некоторые возможности манипуляции ими через контроль того, о чём вы думаете, как описано в предыдущем посте (Раздел 6.3.3), но в первом приближении можно считать, что они занимаются своими делами сами, независимо от того, что вы от них хотите. С эволюционной перспективы такое устройство имеет смысл как защита от вайрхединга – см. мой пост Награды Не Достаточно.
Так что когда я попробовал торт, мои Оценщики Мыслей оказались неправы! Они ожидали, что торт вызовет средненькие связанные с вкусностью автономные реакции, а на само деле торт вызвал сильные связанные с вкусностью автономные реакции. И Направляющая Подсистема узнала, что Оценщики Мыслей были неправы. Так что она послала корректирующий сигнал алгоритмам Оценщиков Мыслей, как показано на диаграмме выше. Эти алгоритмы затем изменили себя, чтобы в дальнейшем каждый раз, когда я подношу вилку с кусочком торта «Принцесса» в своему рту, Оценщики Мыслей более надёжно предсказывали сильные выбросы гормонов, сигнал вознаграждения, и все другие реакции, которые я на самом деле получил.
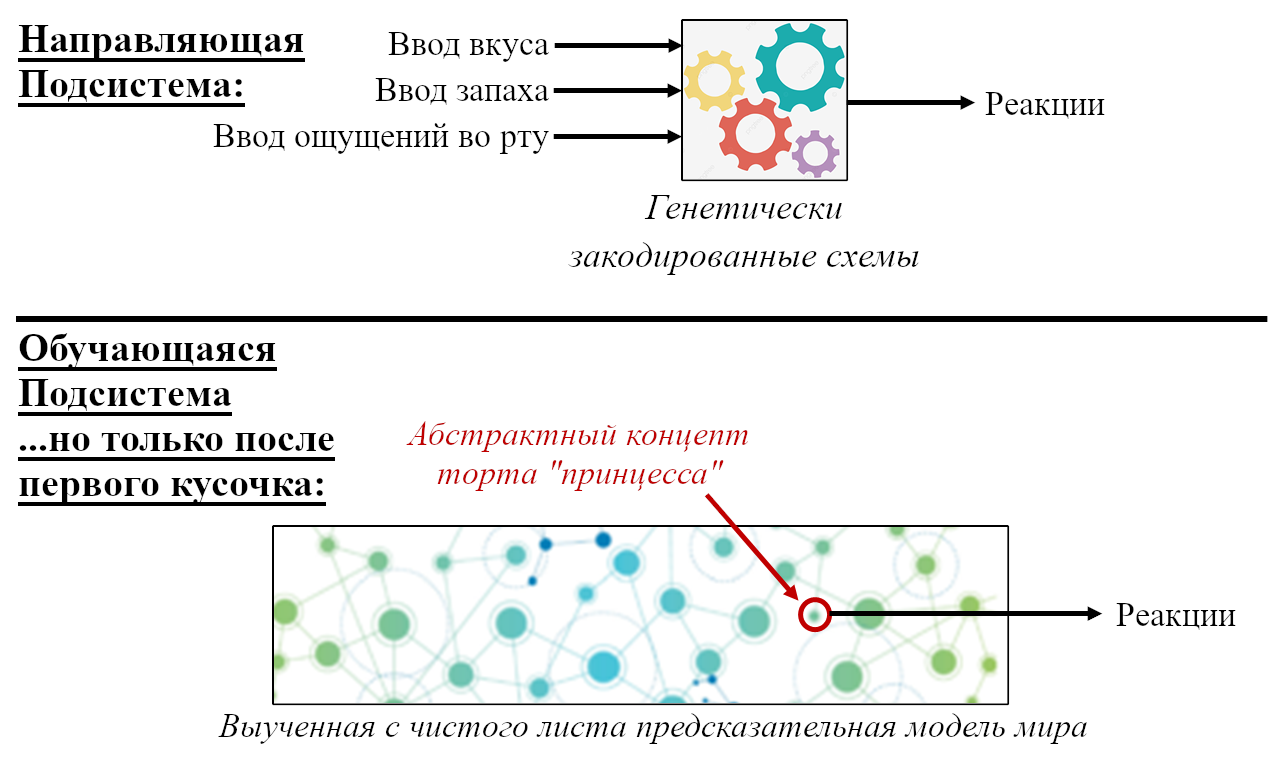
Тут произошла крутая штука. Мы начали с (относительно) простого жёстко прошитого алгоритма: схемы Направляющей Подсистемы переводят определённые виды вкусового ввода в определённые выбросы гормонов и автономные реакции. Но затем мы передали эту информацию в функции выученной модели мира – вспомните ту гигантскую запутанную базу данных, о которой я говорил в предыдущем разделе.
(Давайте возьмём паузу, чтобы всё проговорить: сигнал «эмпирической истины задним числом» настраивает Оценщики Мыслей. Оценщики Мыслей, как мы знаем из Поста №5 – это набор из, может быть, сотен моделей, над каждой из которых проводится обучение с учителем. Ввод этих обученных моделей, то, что я называю «контекстными» сигналами (см. Пост №4), включает нейроны извне предсказательной модели мира, кодирующие «какая мысль сейчас думается». Так что мы получаем функцию (обученную модель), чей ввод включает штуки вроде «активирует ли моя нынешняя мысль абстрактный концепт торта «Принцесса»?», и чей вывод – сигнал, сообщающий Направляющей Подсистеме выделять слюну и пр.)
Я называю этот шаг – в котором подправляются Оценщики Мыслей – «присвоением ценности». Куда больше про этот процесс, включая то, что в нём может пойти не так, будет в следующих постах.
Итак, сейчас Оценщики Мыслей выучили, что как только в модели мира «вспыхивает» концепт «я ем торт «Принцесса»», им следует выдать предсказание соответствующих выбросов гормонов, других реакций и вознаграждения.
7.5 Нацеленное планирование через формирование вознаграждения
У меня нет особенно жёсткой модели этого шага, но, думаю, я могу немного положиться на интуицию, чтобы история была полной:
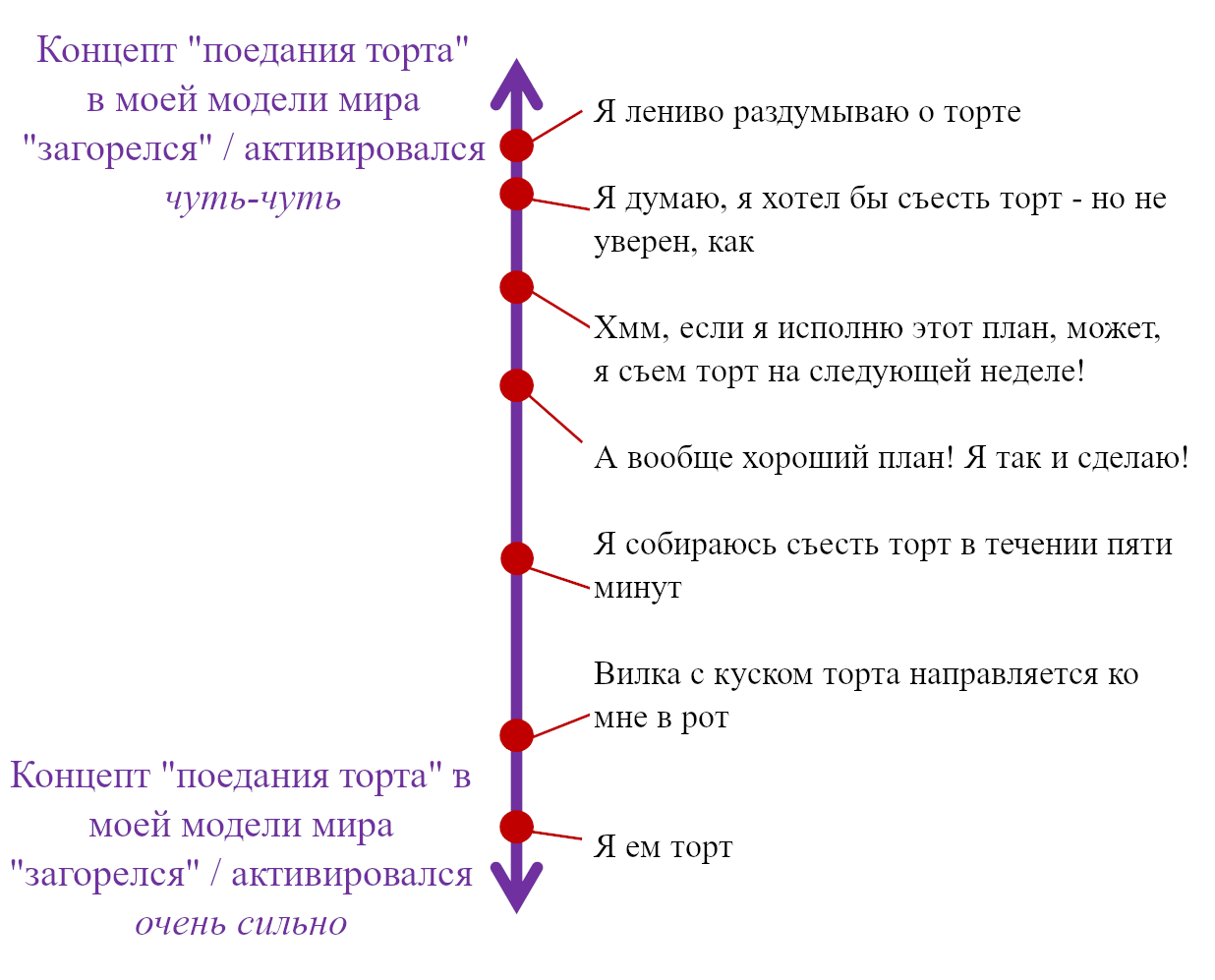
Напомню, с самого первого моего кусочка торта «Принцесса» два года назад Оценщики Мыслей в моём мозгу инспектируют каждую мысль, которую я думаю, проверяя, не «загорелся»/«активировался» ли в моей модели мира концепт «я ем торт «Принцесса»», и если да, то в какой степени, чтобы предлагать готовиться к вознаграждению, слюновыделению, и так далее.
Диаграмма выше предлагает серию мыслей, которые, я думаю, могли «зажигать» этот концепт в модели мира всё больше и больше, сверху вниз.
Чтобы понять суть, можете представить заметить торт на «солёный крекер». Идите вниз по списку и попытайтесь почувствовать, как каждая мысль заставляет вас выделять всё больше слюны. Или ещё лучше, замените «есть торт» на «пригласить краша на свидание», спускайтесь по списку и почувствуйте, как каждая мысль заставляет ваше сердце всё сильнее колотиться.
Вот другой способ об этом думать: Если вы представите модель мира приблизительно как ГВМ, вы можете представить, что «степень соответствия паттерну» – это примерно как вероятность, присвоенная узлу «поедания торта» в ГВМ. К примеру, если вы уверены в X, а из X слабо следует Y, а из Y слабо следует Z, а из Z слабо следует «поедание торта», то «поедание торта» получает очень низкую, но ненулевую вероятность, то есть слабую активацию, и это сродни обладанию долгосрочного, но не совсем невозможного плана нацеленного на поедание пирога. (Не воспринимайте этот абзац слишком буквально, я тут просто пытаюсь объяснить интуитивные соображения.)
Я в самом деле надеюсь, что такие штуки интуитивно понятны. В конце концов, я видел, как это переизобретали множество раз! К примеру, Дэвид Юм: «Прежде всего мне бросается в глаза тот факт, что между нашими впечатлениями и идеями существует большое сходство во всех особенных свойствах, кроме степени их силы и живости». А вот Уильям Джеймс: «Едва ли возможно спутать живейшую картину воображения с слабейшим реальным ощущением.» В обоих случаях, думаю, авторы указывали на идею что воображение активирует некоторые из тех же ментальных конструктов (скрытых переменных в модели мира), что и восприятие, но гораздо слабее.
ОК, если вы всё ещё тут, давайте вернёмся к моей модели принятия решений, теперь с другими подсвеченными частями:
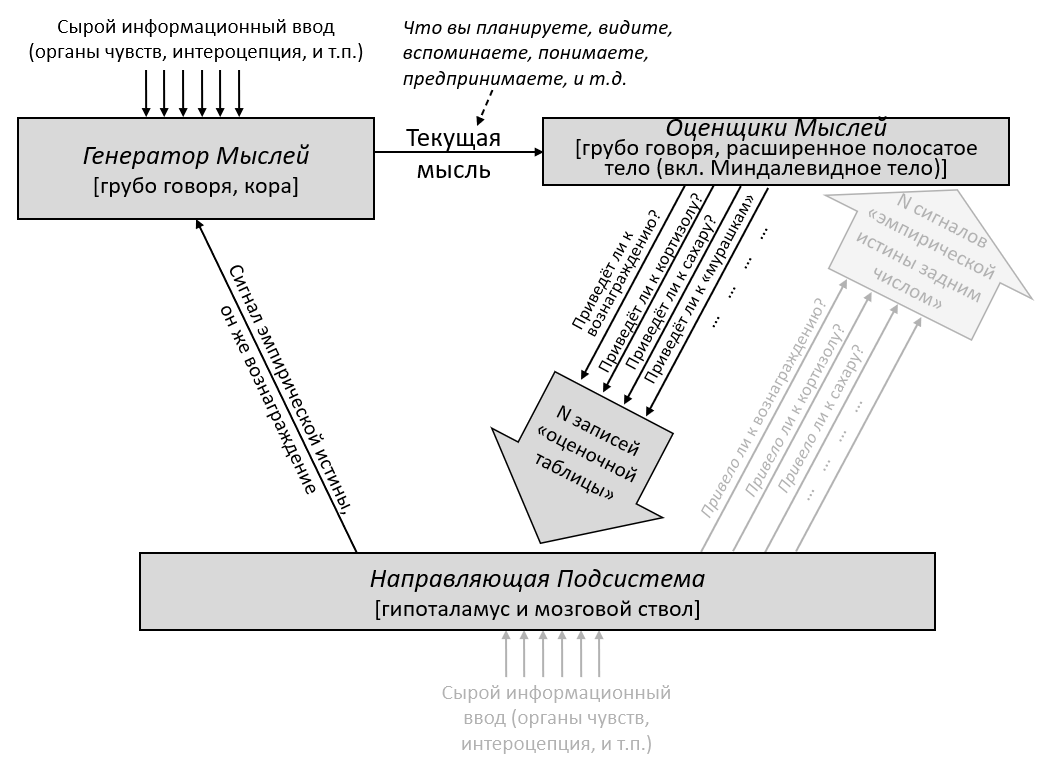
Части диаграммы, важные для процесса создания и исполнения долгосрочного плана обеспечения себя тортом «Принцесса».
Опять же, всякий раз, когда я думаю мысль, Направляющая Подсистема смотрит на соответствующую «оценочную таблицу» и выдаёт соответствующее вознаграждение. Напомню также, что активная мысль / план отбрасывается, если её сигнал вознаграждения отрицателен, и оставляется и усиливается, если он положительна.
Я ненадолго всё упрощу и проигнорирую всё кроме функции ценности (так же известной как Оценщик Мыслей «приведёт ли это к вознаграждению?»). И я также предположу, что Направляющая Подсистема просто доверяет предложенному значению, а не перехватывает его (см. Пост №6, Раздел 6.4.1). В таком случае, каждый раз, когда наши мысли переходят ниже по фиолетовой стрелке с диаграммы выше – от спокойных раздумий о торте к гипотетическому плану достать торт, к решению достать торт, и т.д. – происходит немедленное положительное вознаграждение, так что новая мыль усиливается и остаётся. И напротив, каждый раз, когда мы двигаемся по списку обратно – от решения к гипотетическому плану к размышлениям – происходит немедленное отрицательное вознаграждение, так что мысль отбрасывается и мы возвращаемся к предыдущей. Это как храповик! Система естественным путём продвигается по списку, создавая и исполняя хороший план, чтобы съесть торт.
Вот всё и получилось! Я думаю, что с такой позиции вполне объясняется полный набор поведений, ассоциируемых с людьми, планирующими для достижения явных целей – включая знание того, что у тебя есть цель, составление плана, исполнение инструментальных стратегий как части плана, замену хороших планов на планы ещё лучше, обновление плана при изменении ситуации, напрасную тоску по недостижимым целям и так далее.
7.5.1 Другие Оценщики Мыслей. Или: героическое деяния заказывания торта на следующую неделю, когда прямо сейчас тошно
Кстати, а что другие Оценщики Мыслей? Торт «Принцесса», в конце концов, ассоциируется не только с «приведёт к вознаграждению», но ещё и с «приведёт к сладкому вкусу», «приведёт к слюновыделению», и т.д. Играет ли это какую-то роль?
Конечно! Для начала, когда я подношу вилку ко рту, в самом конце исполнения моего плана поедания торта, я начинаю выделять слюну и выбрасывать кортизол в предвкушении.
Но что насчёт процесса долгосрочного планирования (звонок в пекарню и т.д.)? Я думаю, другие, не относящиеся к функции ценности, Оценщики Мыслей имеют значение и тут – по крайней мере в какой-то степени.[1]
К примеру, представьте, что вы чувствуете ужасную тошноту. Конечно, ваша Направляющая Подсистема знает, что вы чувствуете ужасную тошноту. И предположим, что она видит, что вы думаете мысль, которая, кажется, приведёт к еде. В этом случае Направляющая Подсистема может сказать: «Ужасная мысль! Отрицательное вознаграждение!»
ОК, вот вы чувствуете тошноту, но берёте свой телефон, чтобы оформить заказ в пекарне. Мысль слабо, но заметно помечается Оценщиком Мыслей как «скорее всего приведёт к еде». Ваша Направляющая Подсистема видит это и говорит «Фуу, с учётом нынешней тошноты это кажется плохой мыслью». Мысль ощущается немного отталкивающей. «Блин, я действительно заказываю этот огромный торт??», говорите вы себе.
Логически, вы знаете, что на следующей неделе, когда вы на самом деле получите торт, вы больше не будете чувствовать тошноту, и будете очень рады, что у вас есть торт. Но всё же прямо сейчас вы чувствуете, что заказывать его несколько противно и демотивирующе.
Заказываете ли вы его всё равно? Конечно! Может, функция ценности (Оценщик Мыслей «это приведёт к вознаграждению») достаточно сильна, чтобы перевесить Оценщик Мыслей «это приведёт к еде». Или, может быть, вы используете иную мотивацию: представляете себя как думающего наперёд человека, принимающего хорошие осмысленные решения, а не застревающего в текущем моменте. Это другая мысль в вашей голове, активирующая другой набор Оценщиков Мыслей, и, может, она получает высокую оценку Направляющей Подсистемы. В любом случае, вы действительно звоните в пекарню, чтобы заказать торт на следующую неделю. Что за героизм!
———
- В сторону: Я думаю, что в сравнении с прочими Оценщиками Мыслей функция ценности «меньше обесценивается» (фактор обесценивания ближе к 1.0), так что сложные непрямые далёкие-во-времени планы в основном руководствуются функцией ценности. Эта догадка происходит из психологической литературы по «обучению стимулов», но это тема для отдельного поста. В любом случае, это не всё-или-ничего; полагаю, прочие оценщики по меньшей мере хоть сколько-то важны, даже для далёких планов, как и в примере здесь.
8. Отходим от нейробиологии, 1 из 2: Про разработку СИИ
- 1.8.1 Краткое содержание / Оглавление
- 2.8.2 «Одно время жизни» превращается в «Один обучающий запуск»
- 2.1.8.2.1 Как много времени займёт обучение модели?
- 2.2.8.2.2 Онлайновое обучение подразумевает отсутствие фундаментального разделения обучения/развёртывания
- 2.3.8.2.3 …Всё же, общепризнанная в области машинного обучения мудрость о том, что «обучение дороже развёртывания», всё ещё более-менее применима
- 2.4.8.2.4 Онлайновое обучение вредит безопасности, но совершенно необходимо для способностей
- 3.8.3 Подобный-эволюции внешний цикл автоматического поиска: может и вовлечён, но не «ведущий проектировщик»
- 4.8.4 Другие не закодированные вручную штуки, которые могут быть в Направляющей Подсистеме будущего подобного-мозгу СИИ
8.1 Краткое содержание / Оглавление
Ранее в цепочке: в Посте №1 была описана моя общая мотивация, что такое «безопасность подобного-мозгу СИИ» и почему это нас заботит. Следующие шесть постов (№2-7) погрузились в нейробиологию. Посты №2-3 представили способ разделения мозга на «Обучающуюся Подсистему» и «Направляющую Подсистему», разделённые по признаку того, выполняют ли они то, что я называю «обучением с чистого листа». Затем посты №4-7 представили большую картину того, как по моему мнению работают цели и мотивации в мозгу, это оказалось похожим на причудливый вариант основанного на модели обучения с подкреплением «субъект-критик».
Теперь, установив нейробиологический фундамент, мы наконец-то можем более явно переключиться на тему подобного-мозгу СИИ. В качестве начальной точки размышлений вот диаграмма из Поста №6, отредактированная, чтобы описывать подобный-мозгу СИИ вместо настоящего мозга:
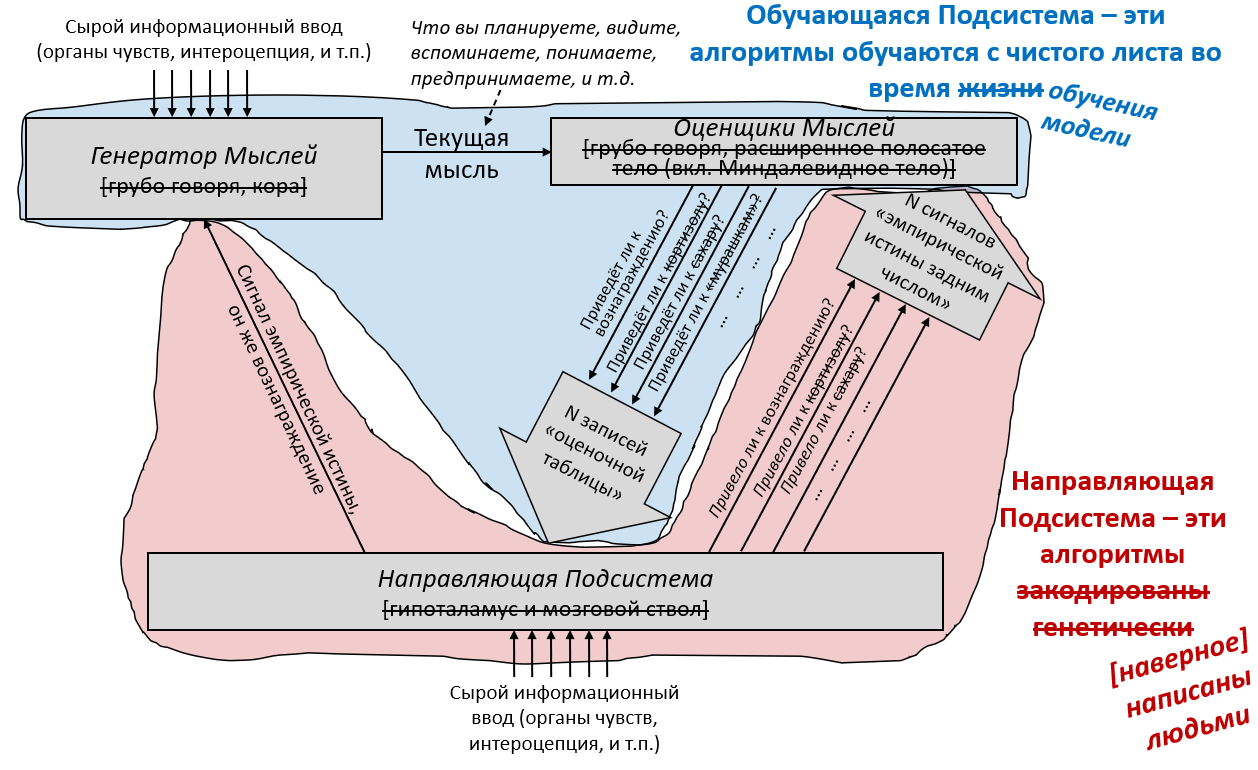
Диаграмма из Поста №6 с четырьмя изменениями, благодаря которым она теперь описывает подобный-мозгу СИИ, а не настоящий мозг: (1) справа сверху «время жизни» заменено на «обучение модели» (Раздел 8.2 ниже); (2) снизу справа «генетически закодированы» заменено на «[наверное] написаны людьми» (Разделы 8.3-8.4 ниже); (3) упоминания конкретных областей мозга вроде «миндалевидного тела» зачёркнуты, чтобы позже их можно было заменить частями исходного кода и/или наборами параметров обученной модели; (4) прочие биологически-специфичные слова вроде «сахара» зачёркнуты, чтобы позже их можно было заменить чем нам захочется, как я опишу в будущих постах.
Этот и следующий посты извлекут из прошлых обсуждений некоторые уроки о подобном-мозгу СИИ. Этот пост будет сосредоточен на том, как такой СИИ может быть разработан, а следующий – на его мотивациях и целях. После этого Пост №10 обсудит знаменитую «задачу согласования» (наконец-то!), а затем несколько постов буду посвящены возможным путям к её решению. Наконец, в Посте №15 я закончу цепочку открытыми вопросами, направлениями для будущих исследований и тем, как войти в эту область.
Вернёмся к этому посту. Тема: «Как, с учётом обсуждения нейробиологии в предыдущих постах, нам следует думать о процессе разработки софта для подобного-мозгу СИИ?». В частности, какова будет роль написанного людьми исходного кода, а какова – настраиваемых параметров («весов»), значения которых находят алгоритмы обучения?
Содержание:
- Раздел 8.2 предлагает, что в процессе разработки подобного-мозгу СИИ «времени жизни животного» хорошо соответствует «обучение модели». Я опишу, как много времени оно может занять: я утверждаю, что, несмотря на пример людей, которым требуются годы/десятилетия, чтобы достичь высокого уровня компетенции и интеллекта, вполне правдоподобно, что время обучения подобного-мозгу СИИ будет измеряться неделями/месяцами. Я также обосную, что подобный-мозгу СИИ, как и мозг, будет работать в режиме онлайнового обучения, а не обучения-а-потом-развёртывания, и укажу некоторые следствия этого для экономики и безопасности.
- Раздел 8.3 описывает возможность «внешнего цикла» автоматического поиска, аналогичного эволюции. Я обосную, что скорее всего он будет играть разве что небольшую роль, возможно, оптимизации гиперпараметров или чего-то в таком роде, и не будет играть большую роль «ведущего проектировщика», создающего алгоритм с чистого листа, несмотря на исторический пример того, как эволюция создала мозг с чистого листа. Я укажу некоторые следствия этого для безопасности СИИ.
- Раздел 8.4: Хоть я и ожидаю, что «Направляющая Подсистема» будущего СИИ будет в основном состоять из написанного людьми исходного кода, есть и некоторые исключения, и тут я пройдусь по трём: (1) возможность обученных заранее классификаторов изображений или иных подобных модулей, (2) возможность СИИ, «направляющих» другие СИИ, и (3) возможность человеческой обратной связи.
8.2 «Одно время жизни» превращается в «Один обучающий запуск»
Эквивалентом «времени жизни животного» для подобного-мозгу СИИ является «один обучающий запуск». Думайте об этом как о запусках моделей при их обучении в современном ML.
8.2.1 Как много времени займёт обучение модели?
Как много времени займёт «обучающий запуск» подобного-мозгу СИИ?
Для сравнения, люди, по моему скромному мнению, по-настоящему достигают пика в возрасте 37 лет, 4 месяца и 14 дней. Все моложе – наивные дети, а все старше – отсталые старые упрямцы. У-упс, я сказал «14 дней»? Мне следовало сказать «…и 21 день». Простите меня за эту ошибку; я написал это предложение на прошлой неделе, когда ещё был наивным ребёнком.
Ну, что бы это ни было для людей, мы можем спросить: Будет ли это примерно так же для подобных-мозгу СИИ? Не обязательно! См. мой пост Вдохновлённые-мозгом СИИ и «якоря времени жизни» (Раздел 6.2) за моими аргументами о том, что время-на-часах, необходимое, чтобы обучить подобный-мозгу СИИ до состояния мощного обобщённого интеллекта с чистого листа, очень сложно предсказать заранее, но вполне правдоподобно, что оно может быть коротким – недели/месяцы, а не годы/десятилетия.
8.2.2 Онлайновое обучение подразумевает отсутствие фундаментального разделения обучения/развёртывания
Мозг работает по принципу онлайнового обучения: он постоянно обучается во время жизни, вместо отдельных «эпизодов», перемежаемых «обновлениями» (более популярный подход в современном машинном обучении). Я думаю, что онлайновое обучение очень критично для того, как работает мозг, и что любая система, которую стоит называть «подобным-мозгу СИИ», будет алгоритмом онлайнового обучения.
Чтобы проиллюстрировать разницу между онлайновым и оффлайновым обучением, рассмотрим два сценария:
- Во время обучения, СИИ натыкается на два противоречащих друг другу ожидания (например, «кривые спроса обычно снижаются» и «много исследований показывают, что минимальные зарплаты не приводят к безработице»). СИИ обновляет свои внутренние модели для более детального и полного понимания, примиряющего эти два наблюдения. В дальнейшем он может использовать это новое знание.
- То же самое с тем же самым результатом происходит во время развёртывания.
В случае онлайнового обучения подобного-мозгу СИИ различия нет. В обоих случаях один и тот же алгоритм делает одно и то же.
Напротив, в случае систем машинного оффлайнового обучения (например, GPT-3), эти два случая обрабатываются двумя отдельными алгоритмическими процессами. Случай №1 включал бы изменения весов модели, тогда как случай №2 включал бы только изменения её активаций.
Для меня это важный довод в пользу подхода онлайнового обучения. Оно требует решать задачу только один раз, а не два раза разными способами. И не просто какую-то задачу; это вроде бы центральная для СИИ задача!
Я хочу ещё раз подчеркнуть, насколько ключевую роль в мозгу (и в подобных-мозгу СИИ) играет онлайновое обучение. Человек без онлайнового обучения – это человек с полной антероградной амнезией. Если вы представились мне как «Фред» и через минуту я обращаюсь к вам «Фред», то я могу поблагодарить онлайновое обучение за то, что оно поместило этот кусочек знания в мой мозг.
8.2.3 …Всё же, общепризнанная в области машинного обучения мудрость о том, что «обучение дороже развёртывания», всё ещё более-менее применима
В нынешнем машинном обучении общеизвестно, что обучение дороже развёртывания. К примеру, в OpenAI, как утверждается, потратили около $10 млн на обучение GPT-3 – т.е. чтобы получить волшебный список из 175 миллиардов чисел, служащих весами GPT-3. Но теперь, когда у них на руках есть этот список из 175 миллиардов чисел, запуск GPT-3 дёшев как грязь – последний раз, когда я проверял, OpenAI брали примерно $0.02 за страницу сгенерированного текста.
Благодаря онлайновому обучению подобные-мозгу СИИ не будут иметь фундаментального различия между обучением и развёртыванием, как и обсуждалось в предыдущем разделе. Однако, экономика остаётся схожей.
Представьте трату десятилетий на выращивание ребёнка от рождения, пока он не станет умелым и эрудированным взрослым, возможно, с дополнительным обучением в математике, науке, инженерии, программированию, и т.д.
Теперь представьте, что у вас есть научно-фантастическая клонирующая машина, которая может мгновенно создать 1000 копий этого взрослого. Вы посылаете их на 1000 разных работ. Ладно, каждая копия, вероятно, будет нуждаться в дополнительном обучении этой работе, чтобы выйти на полную продуктивность. Но им не потребуются десятилетия дополнительного обучения, как от рождения до взрослого состояния. (Больше об этом в блоге Холдена Карнофски.)
Так что, как и в обычном машинном обучении, остаётся большая стоимость изначального обучения, и её, в принципе, можно смягчить созданием множества копий.
8.2.4 Онлайновое обучение вредит безопасности, но совершенно необходимо для способностей
Я утверждаю, что онлайновое обучение создаёт неприятные проблемы для безопасности СИИ. К сожалению, я также утверждаю, что если мы вовсе создадим СИИ, то нам понадобится онлайновое обучение или что-то с схожими эффектами. Давайте по очереди разберёмся с обоими утверждениями.
Онлайновое обучение вредит безопасности:
Давайте переключимся на людей. Предположим, я прямо сейчас приношу присягу как президент страны, и я хочу всегда в первую очередь заботиться о благе своего народа и не поддаваться песне сирен коррупции. Что я могу сделать прямо сейчас, чтобы контролировать, как будет вести себя будущий я? Неочевидно, правда? Может, даже, невозможно!
У нынешнего меня просто нет естественного и надёжного способа указать будущему мне, что хотеть делать. Лучшее, что я могу сделать – много маленьких хаков, предсказать конкретные проблемы и попробовать их предотвратить. Я могу связать себе руки, выдав честному бухгалтеру все пароли моих банковских счетов и попросить меня сдать, если там будет что-то подозрительное. Я могу устраивать регулярные встречи с надёжным осмотрительным другом. Такие способы немного помогают, но опять же, они не дают надёжного решения.
Аналогично, у нас может быть СИИ, который прямо сейчас честно пытается действовать этично и полезно. Потом он какое-то время работает, думает новые мысли, получает новые идеи, читает новые книги и испытывает новый опыт. Будет ли он всё ещё честно пытаться действовать этично и полезно через шесть месяцев? Может быть! Надеюсь! Но как мы можем быть уверены? Это один из многих открытых вопросов в безопасности СИИ.
(Может, вы думаете: мы могли бы периодически создавать бэкап СИИ-сейчас, и давать ему право вето на изменения СИИ-потом? Я думаю, это осмысленная идея, может быть даже хорошая. Но это не панацея. Что если СИИ-потом сообразит, как обмануть СИИ-сейчас? Или что если СИИ-потом меняется к лучшему, а СИИ-сейчас продолжает его сдерживать? Ведь более молодой я был наивным ребёнком!)
Онлайновое обучение (или что-то с схожими проблемами безопасности) необходимо для способностей:
Я ожидаю, что СИИ будут использовать онлайновое обучение, потому что я думаю, что это эффективный метод создания СИИ – см. обсуждение «решения одной и той же задачи дважды» выше (Раздел 8.2.2).
Однако, я всё же могу представить другие варианты, которые формально не являются «онлайновым обучением», но имеют схожие эффекты и ставят по сути те же вызовы безопасности, т.е. затрудняют возможность увериться, что изначально безопасный СИИ продолжает быть безопасным.
Мне куда сложнее представить способ избежать этих проблем. В самом деле:
- Если СИИ может думать новые мысли и получать новые идеи и узнавать новые знания «при развёртывании», то мы, кажется, стоим перед этой же проблемой нестабильности целей. (См., к примеру, проблему «онтологического кризиса»; больше об этом в следующих постах.)
- Если СИИ не может ничего из этого, действительно ли это СИИ? Будет ли он действительно способен на то, что мы хотим от СИИ, вроде составления новых концепций и изобретения новых технологий? Я подозреваю, что нет.
8.3 Подобный-эволюции внешний цикл автоматического поиска: может и вовлечён, но не «ведущий проектировщик»
Под «внешним циклом» подразумевается больший из двух вложенных циклов контроля потока исполнения. «Внутренним циклом» может быть код, симулирующий жизнь виртуального животного, секунду за секундой, от рождения до смерти. Тогда «внешний цикл поиска» будет симулировать много разных животных, с своими настройками мозга у каждого, в поисках того, которое (в взрослом состоянии) продемонстрирует максимальный интеллект. Прижизненное обучение происходит в внутреннем цикле, а внешний цикл аналогичен эволюции.
Вот пример крайнего случая проектирования с основной ролью внешнего цикла, где (можно предположить) люди пишут код, исполняющий подобный-эволюции алгоритм внешнего цикла, который создаёт СИИ с чистого листа:
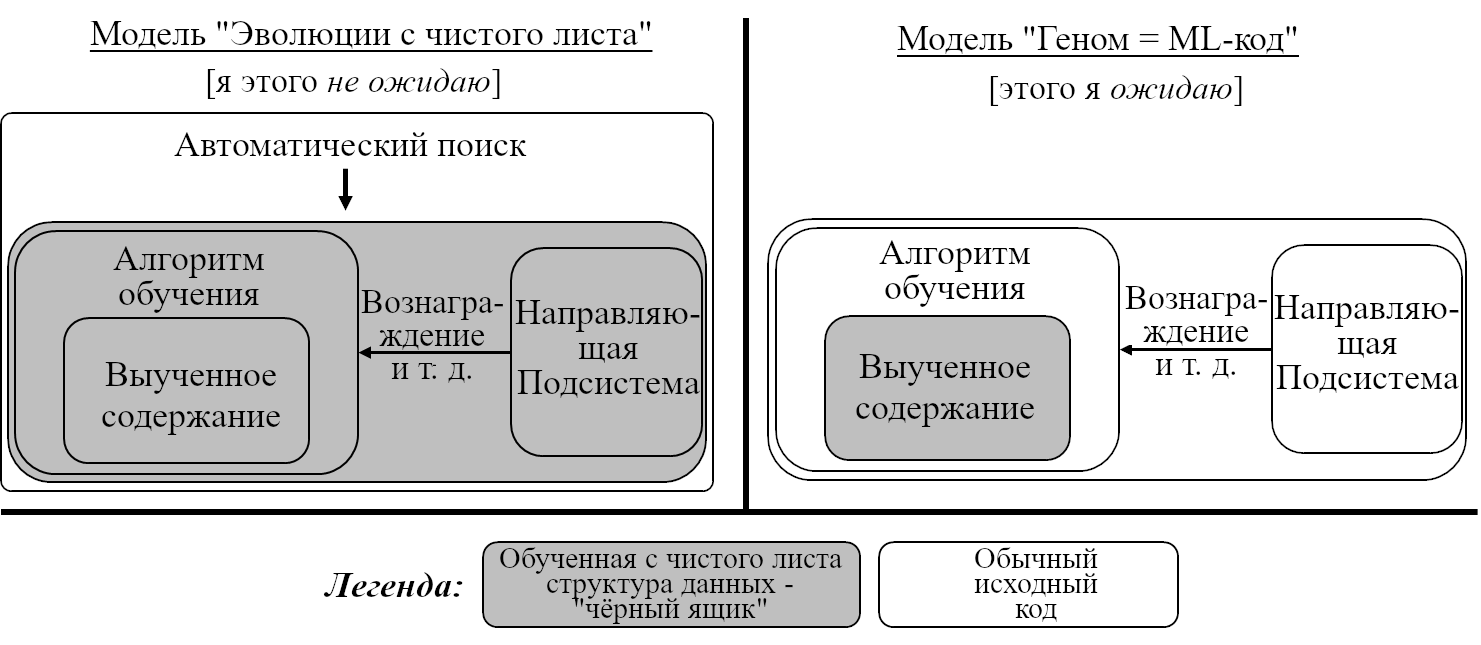
Две модели разработки СИИ. Модель слева напрямую аналогична тому, как эволюция создала человеческий мозг. Модель справа использует аналогию между геномом и исходным кодом, определяющим алгоритм машинного обучения, как будет описано в следующем подразделе.
Подход эволюции-с-чистого-листа (левый) регулярно обсуждается в технической литературе по безопасности СИИ – см. Риски Выученной Оптимизации и десятки других постов про так называемые «меса-оптимизаторы».
Однако, как указано в диаграмме, этот подход – не то, как, по моим ожиданиям, люди создадут СИИ, по причинам, которые я вскоре объясню.
Несмотря на это, я всё же не полностью отвергаю идею внешнего цикла поиска; я ожидаю, что он будет присутствовать, хоть и с более ограниченной ролью. В частности, когда будущие программисты будут писать алгоритмы подобного-мозгу СИИ, в его исходном коде будет некоторое количество настраиваемых параметров, оптимальные значения которых не будут априори очевидными. Они могут включать, например, гиперпараметры обучающихся алгоритмов (как скорость обучения), разные аспекты нейронной архитектуры, и коэффициенты, настраивающие относительную силу разных встроенных стремлений.
Я думаю, весьма правдоподобно, что будущие программисты СИИ будут использовать автоматизированный внешний цикл поиска для установки значений многих или всех этих настраиваемых параметров.
(Или нет! К примеру, как я понимаю, изначальное обучение GPT-3 было таким дорогим, что его сделали только один раз, без точной настройки гиперпараметров. Вместо этого, гиперпараметры систематически изучили на меньших моделях, и исследователи обнаружили тенденции, которые смогли экстраполировать на полноразмерную модель.)
(Ничто из этого не подразумевает, что алгоритмы обучения с чистого листа не важны для подобного-мозгу СИИ. Совсем наоборот, они играют огромную роль! Но эта огромная роль заключена во внутреннем цикле – т.е. в прижизненном обучении. См. Пост №2.)
8.3.1 Аналогия «Геном = ML-код»
В диаграмме выше я написал «геном = ML-код». Это указывает на аналогию между подобным-мозгу СИИ и современным машинным обучением, как в этой таблице:
| **Аналогия «Геном = ML-код»** | |
| Человеческий интеллект | Современные системы машинного обучения |
| Геном человека | Репозиторий на GitHub с всем необходимым PyTorch-кодом, необходимым для обучения и запуска играющего в Pac-Man агента |
| Прижизненное обучение | Обучение играющего в Pac-Man агента |
| Как думает и действует взрослый человек | Играющий в Pac-Man обученный агент |
| Эволюция | *Может быть,* исследователи использовали внешний цикл поиска для некоторых понятных людям настраиваемых параметров – например, подправляя гиперпараметры, или отыскивая лучшую нейронную архитектуру. |
8.3.2 Почему я думаю, что «эволюция с чистого листа» менее вероятна (как метод разработки СИИ), чем «геном = ML-код»
(См. также мой пост от марта 2021 года: Против эволюции как аналогии того, как люди создадут СИИ.)
Я думаю, лучший аргумент против модели эволюции с чистого листа – это непрерывность: «геном = ML-код» – это то, как сейчас работает машинное обучение. Откройте случайную статью по обучению с подкреплением и взгляните на обучающийся алгоритм. Вы увидите, что он интерпретируем для человека, и в основном или полностью спроектирован людьми – наверное, с использованием штук вроде градиентного спуска, обучения методом Временных Разниц и т.д. То же для алгоритма вывода, функции вознаграждения и т.д. Как максимум, в коде обучающегося алгоритма будет пара десятков или сотен бит информации, пришедшей из внешнего цикла поиска, вроде конкретных значений гиперпараметров, составляющих крохотную долю «работы проектирования», влитой в этот алгоритм.[1]
К тому же, если бы будущее было за первостепенным внешним циклом поиска, я ожидал бы, что сейчас мы бы наблюдали, что проекты машинного обучения, больше всего полагающиеся на внешний цикл поиска, чаще встречались бы среди самых впечатляющих прорывных результатов. Насколько я могу посудить, это вовсе не так.
Я лишь предполагаю, что эта тенденция продолжится – по тем же причинам, что и сейчас: люди довольно хороши в проектировании обучающихся алгоритмов, и, одновременно с этим, внешний цикл поиска обучающихся алгоритмов крайне медленен и дорог.
(Ладно, то, что «крайне медленно и дорого» сегодня, будет быстрее и дешевле в будущем. Однако, когда по прошествии времени будущие исследователи машинного обучения смогут позволить себе большие вычислительные мощности, я ожидаю, что, как и сегодняшние исследователи, они обычно будут «тратить» их на бОльшие модели, лучшие процедуры обучения и так далее, а не на больший внешний цикл поиска.)
С учётом всего этого, почему некоторые люди готовы многое поставить на модель «эволюции с чистого листа»? Я думаю, это сводится к вопросу: Насколько вообще сложно может быть написать исходный код для модели «геном = ML-код»?
Если ваш ответ «это невозможно» или «это займёт сотни лет», то эволюция с чистого листа выигрывает по умолчанию! С этой точки зрения, даже если внешний цикл поиска потребует триллионы долларов и десятилетия реального времени и гигаватты электричества, это всё равно кратчайший путь к СИИ, и рано или поздно какое-то правительство или компания вложат деньги и потратят время, чтобы это произошло[2].
Однако, я не думаю, что написание исходного кода для модели «геном = ML-код» – дело на сотни лет. Напротив, я думаю, что это вполне посильно, и что исследователи в областях ИИ и нейробиологии двигают прогресс в этом направлении, и что они могут преуспеть в ближайшие десятилетия. За объяснениями, почему я так думаю, см. обсуждение «сроков до подобного-мозгу СИИ» ранее в цепочке – Разделы 2.8, 3.7 и 3.8.
8.3.3 Почему «эволюция с чистого листа» хуже чем «геном = ML-код» (с точки зрения безопасности)
Это один из редких случаев, где «то, что я ожидаю по умолчанию» совпадает с «тем, на что я надеюсь»! В самом деле, модель «геном = ML-код», которую я подразумеваю в этой цепочке, кажется куда более многообещающей для безопасности СИИ, чем модель «эволюции с чистого листа». Тому есть две причины.
Первая – интерпретируемость человеком. В модели «геном = ML-код» с ней плохо. Но в модели «эволюция с чистого листа» с ней ещё хуже!
В первом случае модель мира – это большой обучившийся с чистого листа чёрный ящик. И функция ценности и многое другое тоже, и нам надо будет много работать над пониманием их содержимого. Во втором случае, у нас будет только один ещё больший чёрный ящик. Нам повезёт, если мы вообще найдём там модель мира, функцию ценности, и т.д., не то что поймём их содержимое!
Вторая причина, которая будет подробно рассмотрена в следующих постах, в том, что осторожное проектирование Направляющей Подсистемы – это один из наших самых мощных рычагов контроля цель и мотиваций подобного-мозгу СИИ, который может обеспечить нам безопасное и выгодное поведение. Если мы сами пишем код Направляющей Подсистемы, то мы имеем полный контроль нам тем, как она работает и прозрачность того, что она делает при работе. Когда же мы использует модель эволюции с чистого листа, у нас есть намного меньше контроля и понимания.
Для ясности, безопасность СИИ – нерешённая задача и в случае «геном = ML-код». Я только говорю, что, по видимости, подход эволюции с чистого листа делает эту задачу ещё сложнее.
(Примечание для ясности: это обсуждение предполагает, что у нас будет именно подобный-мозгу СИИ в обоих случаях. Я не делаю заявлений о большей или меньшей безопасности подобного-мозгу СИИ в сравнении с не-подобным-мозгу СИИ, если такой возможен.)
8.3.3.1 Хорошая ли идея создавать подобные человеческим социальные инстинкты при помощи эволюции агентов в социальном окружении?
Возможное возражение, которое я иногда встречаю: «Люди не так плохи, а нашу Направляющую Подсистему спроектировала эволюция, верно? Может, если мы проведём подобный эволюции внешний цикл поиска в окружении, где много СИИ должны кооперироваться, то они заполучат альтруизм и другие подобные социальные инстинкты!» (Я думаю, что какие-то такие соображения стоят за проектами вроде DeepMind Melting Pot.)
У меня на это есть три ответа.
- Во-первых, у меня сложилось впечатление (в основном от чтения Парадокса Доброты Ричарда Рэнгэма), что есть огромная разница между человеческими социальными инстинктами, социальными инстинктами шимпанзе, социальными инстинктами бонобо, социальными инстинктами волков, и так далее. К примеру, у шимпанзе и волков намного более высокая «реактивная агрессия», чем у людей и бонобо, хотя все четыре вида очень социальны. Эволюционное давление, приводящее к социальным инстинктам, очень чувствительно к динамике власти и другим аспектам социальных групп, и, возможно, обладает несколькими точками устойчивого равновесия, так что кажется, что его было бы сложно контролировать, подстраивая параметры виртуального окружения.
- Во-вторых, если мы создадим виртуальное окружение стимулирующее СИИ кооперироваться с другими СИИ, то мы получим СИИ, имеющих кооперативные социальные инстинкты по отношению к другим СИИ в их виртуальном окружении. Но хотим мы, чтобы СИИ имели кооперативные социальные инстинкты по отношению к людям в реальном мире. Направляющая Подсистема, создающая первые может обобщаться, а может и не обобщаться до вторых. Люди, заметим, часто испытывают сочувствие по отношению к своим друзьям, но редко – по отношению к членам враждебного племени, фабрично разводимым животным и большим волосатым паукам.
- В-третьих, человеческие социальные инстинкты – не всё, чего нам хочется! К примеру, есть версия (по-моему, правдоподобная), что низкая, но не нулевая распространённость психопатии у людей – не случайный глюк, а скорее выгодная стратегия с точки зрения эгоистичных генов и эволюционной теории игр. Аналогично, эволюция спроектировала людей с завистью, злобой, подростковыми бунтами, кровожадностью, и так далее. И вот так мы хотим спроектировать наши СИИ?? Ой.
8.4 Другие не закодированные вручную штуки, которые могут быть в Направляющей Подсистеме будущего подобного-мозгу СИИ
Как обсуждалось в Посте №3, я утверждаю, что Направляющая Подсистема (т.е. гипоталамус и мозговой ствол) мозгов млекопитающих состоит из генетически-закодированных алгоритмов. (За подробностями см. Пост №2, Раздел 2.3.3)
Когда мы переключаемся на СИИ, у меня есть соответствующее ожидание, что Направляющая Подсистема будущих СИИ будет состоять в основном и написанного людьми кода – как типично написанные людьми функции вознаграждения современных агентов обучения с подкреплением.
Однако, она может быть не полностью написана людьми. Для начала, как обсуждалось в предыдущем разделе, значения некоторого количества настраиваемых параметров, например, относительные силы встроенных стремлений, могут быть выяснены внешним циклом поиска. Вот ещё три возможных исключения из моего общего ожидания, что Направляющая Подсистема СИИ будет состоять из написанного людьми кода.
8.4.1 Заранее обученные классификаторы изображений и т.п.
Правдоподобно звучит, что составляющей Направляющей Подсистемы СИИ будет что-то вроде обученного классификатора изображений ConvNet. Это было бы аналогично тому, что в верхнем двухолмии человека есть что-то-вроде-классификатора-изображений для распознавания заранее заданного набора определённо-важных категорий, вроде змей, пауков и лиц (см. Пост №3, Раздел 3.2.1). Аналогично, могут быть обученные классификаторы для аудио- и других сенсорных вводов.
8.4.2 Башня СИИ, направляющих СИИ?
В принципе, вместо нормальной Направляющей Подсистемы мог бы быть целый отдельный СИИ, присматривающий за мыслями в Обучающейся Подсистеме и посылающий соответствующие вознаграждения.
Чёрт, можно даже создать целую башню СИИ-направляющих-СИИ! Предположительно, СИИ становились бы более сложными и мощными по мере восхождения на башню, достаточно медленно, чтобы каждый СИИ справлялся с задачей направления СИИ на уровень выше. (Ещё это могла бы быть пирамида, а не башня, с несколькими более глупыми СИИ, совместно составляющими Направляющую Подсистему более умного СИИ.)
Я не думаю, что такой подход точно бесполезен. Но мне кажется, что мы всё ещё не добрались до первого этапа, на котором мы создаём хоть какой-то безопасный СИИ. Создание башни СИИ-направляющих-СИИ не избавляет нас от необходимости сначала сделать один безопасный СИИ другим способом. Башне нужно основание!
Когда мы решим эту первую большую задачу, тогда мы сможем думать о том, чтобы использовать этот СИИ напрямую для решения человеческих проблем или косвенно, для направления ещё-более-мощных СИИ, аналогично тому, как люди пытаются направлять самый первый.
Я склоняюсь к тому, что возможность «использовать этот первый СИИ напрямую» более многообещающая, чем «использовать этот первый СИИ для направления второго, более мощного, СИИ». Но я могу быть неправ. В любом случае, сначала нам нужно до этого добраться.
8.4.3 Люди, направляющие СИИ?
Если Направляющей Подсистемой СИИ могут (предположительно) быть другой СИИ, то почему ею не может быть человек?
Ответ: если СИИ работает со скоростью мозга человека, то он может думать 3 мысли в секунду (или около того). Каждая «мысль» потребует соответствующего вознаграждения, и, может, десятков других сигналов эмпирической истины. Человек не сможет за этим поспевать!
Что можно – это сделать человеческую обратную связь вводом Направляющей Подсистемы. К примеру, мы можем дать людям большую красную кнопку с надписью “ВОЗНАГРАЖДЕНИЕ». (Нам, наверное, не стоит так делать, но мы можем.) Мы также можем вовлекать людей иными способами, включая не имеющие биологических аналогов – стоит быть открытыми к идеям.
———
-
К примеру, вот случайная статья по поиску нейронной архитектуры (NAS): «Эволюционирующий трансформер». Авторы хвастаются своим «большим пространством поиска», и оно действительно большое по меркам NAS. Но поиск по этому пространству всё же выдаёт лишь 385 бит информации, и его результат умещается в одну легко понятную человеку диаграмму из этой статьи. Для сравнения, веса обученной модели легко могут составлять миллионы или миллиарды бит информации, а конечный результат требует героических усилий для понимания. Мы также можем сравнить эти 385 бит с информацией в созданных людьми частях исходного кода обучающегося алгоритма, вроде кода умножения матриц, Softmax, Autograd, передачи данных между GPU и CPU, и так далее. Это будет на порядки больше, чем 385 бит. Это то, что я имел в виду, говоря, что штуки вроде подстройки гиперпараметров и NAS составляют крохотную долю общей «работы проектирования» над обучающимся алгоритмом.
(Наиболее полагающаяся на внешний цикл поиска статья, которую я знаю – это статья про AutoML-Zero, и даже там внешний цикл выдал по сути 16 строк кода, которые были легко интерпретируемы авторами.) -
Если вам любопытны приблизительные оценки того, как много времени и денег потребует выполнение вычислений, эквивалентных всей истории эволюции животных на Земле, см. обсуждение про «Эволюционные якоря» в докладе Аджейи Котры по биологическим якорям 2020 года. Очевидно, это не в точности то же, что и вычисления, необходимые для разработки СИИ методом эволюции с чистого листа, но это всё же имеет какое-то отношение. Я не буду больше говорить на эту тему; не думаю, что это важно, потому что в любом случае не ожидаю разработки СИИ методом эволюции с чистого листа.
9. Отходим от нейробиологии, 2 из 2: Про мотивацию СИИ
- 1.9.1 Краткое содержание / Оглавление
- 2.9.2 Цели и желания СИИ определяются в терминах скрытых переменных (выученных концептов) в его модели мира
- 3.9.3 «Присвоение ценности» – как скрытые переменные окрашиваются валентностью
- 4.9.4 Вайрхединг: возможен, но не неизбежен
- 5.9.5 СИИ НЕ судят о планах, основываясь на будущих вознаграждениях
- 6.9.7 «Направление в реальном времени»: Направляющая Подсистема может перенаправлять Обучающуюся Подсистему – включая её глубочайшие желания и долгосрочные цели – в реальном времени
9.1 Краткое содержание / Оглавление
Большая часть предыдущих постов цепочки – №2-7 – были в основном про нейробиологию. Теперь, начиная с предыдущего поста, мы применяем эти идеи для лучшего понимания безопасности подобного-мозгу СИИ (определённого в Посте №1).
В этом посте я рассмотрю некоторые темы, связанные с мотивациями и целями подобного-мозгу СИИ. Мотивации очень важны для безопасности СИИ. В конце концов, наши перспективы становятся намного лучше, если будущие СИИ будут мотивированы на достижение замечательного будущего, где люди процветают, а не мотивированы всех убить. Чтобы получить первое, а не второе, нам надо понять, как работает мотивация у подобных-мозгу СИИ, и, в частности, как направить её в нужном направлении. Этот пост охватит разнообразные темы из этой области.
Содержание:
- Раздел 9.2 посвящён тому, что цели и предпочтения подобного-мозгу СИИ определяются в терминах скрытых переменных в его модели мира. Они могут быть связаны с исходами, действиями или планами, но не являются ни одной из этих вещей в точности. К тому же, алгоритмы в целом не проводят различий между инструментальными и терминальными целями.
- Раздел 9.3 содержит более глубокое обсуждение «присвоения ценности», которое я представил в описании примера в Посте №7 (Раздел 7.4). «Присвоение ценности», как я использую этот термин в этой цепочке – это синоним «обновления Оценщиков Мыслей», процесс в котором концепт (= скрытая переменная в модели мира) может «окраситься» положительной или отрицательной валентностью и/или начать запуск непроизвольных внутренних реакций (в случае человека). Такое «присвоение ценности» – ключевой ингредиент того, как СИИ может захотеть что-то делать.
- Раздел 9.4 определяет «вайрхединг». Примером «вайрхединга» был бы СИИ, взламывающий себя и устанавливающий регистр «вознаграждения» в своей оперативной памяти на максимально возможное значение. Я аргументирую мнение, что подобный-мозгу СИИ будет «по умолчанию» иметь «слабое стремление к вайрхедингу» (желание сделать это при прочих равных), но, наверное, не «сильное стремление к вайрхедингу» (рассмотрение этого как лучшего возможного варианта, которого стоит добиться любой ценой).
- Раздел 9.5 проговаривает следствия из обсуждения вайрхединга в предыдущем разделе: подобный-мозгу СИИ в общем случае НЕ пытается максимизировать своё будущее вознаграждение. Я приведу человеческий пример, и свяжу его с концептом «агентов наблюдаемой полезности» из литературы.
- Раздел 9.6 обосновывает, что в случае подобных-мозгу СИИ Оценщики Мыслей связывают мотивацию с интерпретируемостью нейросети. К примеру, суждение «Эта мысль / этот план скорее всего приведут к еде» – это одновременно (1) данные, вкладывающиеся в интерпретируемость мысли/плана из выученной модели мира, и (2) сигнал о том, что мысль / план стоящие, если мы голодны. (Это применимо к любой системе обучения с подкреплением, совместимой с многомерными функциями ценности, не только к «подобным-мозгу». То же для следующего пункта.)
- Раздел 9.7 описывает, как мы могли бы «направлять» мотивации СИИ в реальном времени, и как это могло бы повлиять не только на его немедленные действия, но и на долговременные планы и «глубокие желания».
9.2 Цели и желания СИИ определяются в терминах скрытых переменных (выученных концептов) в его модели мира
Нравится ли вам футбол? Ну, «футбол» – это выученный концепт, обитающий внутри вашей модели мира. Такие выученные концепты – это единственное, что может «нравиться». Вам не может нравиться или не нравиться [безымянный паттерн из сенсорного ввода, о котором вы никогда не задумывались]. Возможно, что вы нашли бы этот паттерн вознаграждающим, если бы вы на него наткнулись. Но он не может вам нравиться, потому что сейчас он не является частью вашей модели мира. Это также означает, что вы не можете и не будете составлять целенаправленный план для вызова этого безымянного паттерна.
Я думаю, это ясно из интроспекции, и думаю, что это так же ясно из нашей картины мотивации (см. Посты №6-7). Я там использовал термин «мысль» в широком смысле, включающем всё осознанное и более того – что вы планируете, видите, вспоминаете, понимаете, предпринимаете, и т.д. «Мысль» – это то, что оценивают Оценщики Мыслей, и она состоит из некоторой конфигурации выученных скрытых переменных в вашей генеративной модели мира.
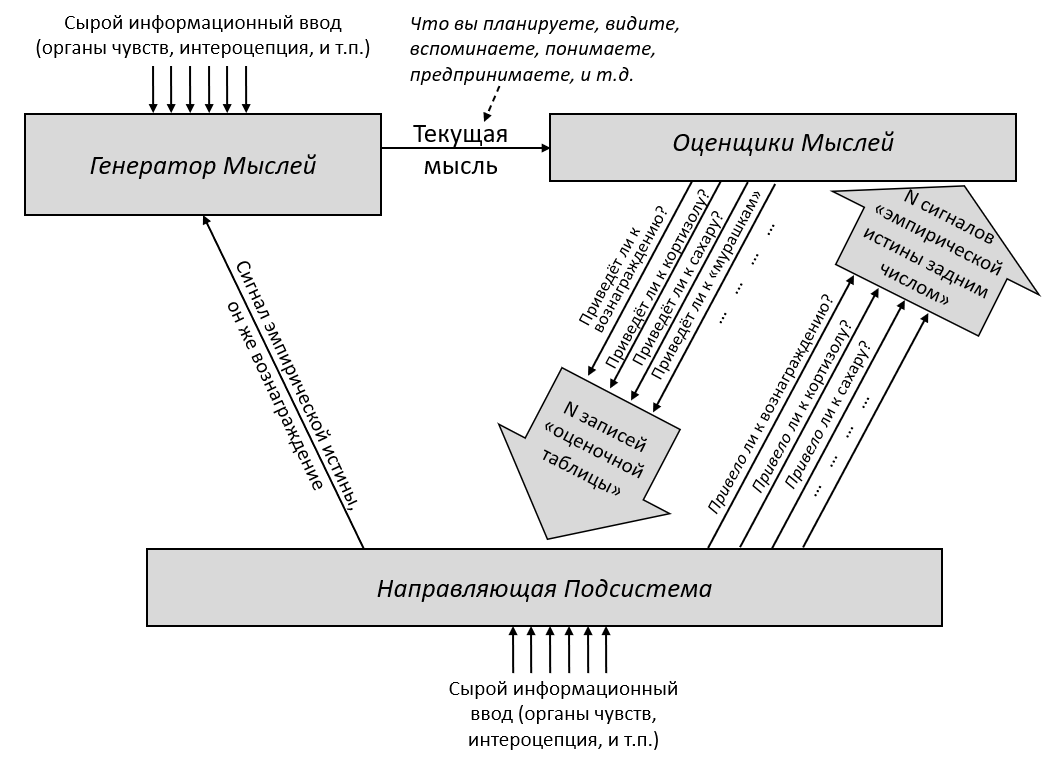
Наша модель мотивации – см. Пост №6 за подробностями
Почему важно, чтобы цели СИИ были определены в терминах скрытых переменных его модели мира? Много причин! Они будут снова и снова всплывать в этом и будущих постах.
9.2.1 Следствия для «согласования ценностей» с людьми
Наблюдение выше – одна из причин, почему «согласование ценностей» человека и СИИ – чертовски запутанная задача. У подобного-мозгу СИИ будут скрытые переменные в его выученной модели мира, а у человека скрытые переменные в его модели мира, но это разные модели мира, и скрытые переменные в одной могут иметь сложное и проблематичное соответствие с скрытыми переменными в другой. К примеру, человеческие скрытые переменные могут включать штуки вроде «привидений», которые не соответствуют ничему в реальном мире! Для большего раскрытия этой тему, см. пост Джона Вентворта Проблема Указателей.
(Я в этой цепочке не скажу многого про «определение человеческих ценностей» – я хочу придерживаться более узкой задачи «избегания катастрофических происшествий с СИИ, таких как вымирание людей», и не думаю, что глубокое погружение в «определение человеческих ценностей» для этого необходимо. Но «определение человеческих ценностей» – всё ещё хорошее дело, и я рад, что люди над этим работают – см., к примеру, 1,2.)
9.2.2 Предпочтения основаны на «мыслях», которые могут быть связаны с исходами, действиями, планами, и т.д., но отличаются от всего этого
Оценщики Мыслей оценивают и сравнивают «мысли», т.е. конфигурации в генеративной модели мира агента. Модель мира неидеальна, полное понимание мира слишком сложно, чтобы поместиться в любом мозгу или кремниевом чипе. Так что «мысль» неизбежно подразумевает обращение внимания на одно и игнорирование другого, коцептуализацию вещей определённым образом, приписывание их к ближайшим доступным категориям, даже если они не подходят идеально, и т.д.
Некоторые следствия:
- Вы можете концептуализировать одну и ту же последовательность моторных действий многими разными способами, и она будет более или менее привлекательна в зависимости от того, как вы о ней думаете: возьмём мысль «я собираюсь пойти в спортзал» и мысль «я собираюсь пойти в спортзал, чтобы накачаться». См. связанное обсуждение в (Мозговой ствол, Неокортекс) ≠ (Базовые Мотивации, Благородные Мотивации).
- Аналогично, вы можете концептуализировать одно и то же будущее состояние мира многими разными способами, например, обращая внимание на разные его аспекты, и оно будет казаться более или менее привлекательным. Это может приводить к циклическим предпочтениям; я поместил пример в сноску[1].
- Мысль может затрагивать немедленные действия, будущие действия, семантический контекст, ожидания, что произойдёт, пока мы будем что-то делать, ожидания, что произойдёт в результате, и т.д. Так что мы можем иметь «консеквенциалистские» предпочтения о будущих состояниях или «деонтологические» предпочтения о действиях, и т.д. К примеру, мысль «Я сейчас пойду в магазин, и у меня будет молоко» включает нейроны, связанные с действием «Я сейчас пойду в магазин», и нейроны, связанные с последствием «У меня будет молоко»; Оценщики Мыслей и Направляющая Подсистема могут одобрить или отвергнуть мысль, основываясь на чём угодно из этого. См. Консеквенциализм & Исправимость за развитием темы.
- Ничто из этого не подразумевает, что подобный-мозгу СИИ не может приближаться к идеальному консеквенциалистскому максимизатору полезности! Только что это будет свойством конкретной обученной модели, а не неотъемлемым качеством исходного кода СИИ. К примеру, подобный-мозгу СИИ может прочитать Цепочки (как и человек), и усвоить уроки из них как набор выученных метакогнитивных эвристик, отлавливающих и исправляющих ошибочные интуитивные заключения и мыслительные привычки, вредящие эффективности[2] (как и человек), и СИИ на самом деле может сделать это по тем же причинам, что и читающий Цепочки человек, ~~то есть, чтобы пройти тридцатичасовую ритуальную дедовщину и заслужить членство в группе~~[3] то есть, потому что он хочет ясно мыслить и достигать своих целей.
9.2.3 Инструментальные и терминальные предпочтения, судя по всему, смешаны вместе
Есть интуитивный смысл, в котором у нас есть инструментальные предпочтения (то, что мы предпочитаем, потому что это было полезно в прошлом как средство для достижения цели – например, я предпочитаю носить часы, потому что они помогают мне узнавать который час) и терминальные предпочтения (то, что мы предпочитаем само по себе – например, я предпочитаю чувствовать себя хорошо и предпочитаю не быть загрызенным медведем). Спенсер Гринберг проводил исследование, в котором некоторые, но не все участники описывали «существование красивых вещей в мире» как терминальную цель – их волновало, чтобы красивые вещи были, даже если они расположены глубоко под землёй, где никакое осознающее себя существо их никогда не увидит. Вы согласны или не согласны? Для меня самое интересное тут, что некоторые люди ответят: «Я не знаю, никогда раньше об этом не думал, хммм, дайте секундочку подумать.» Я думаю, из этого можно извлечь урок!
Конкретно: мне кажется, что глубоко в алгоритмах мозга нет различия между инструментальными и терминальными предпочтениями. Если вы думаете мысль, и ваша Направляющая Подсистема одобряет её как высокоценную, то, я думаю, вычисление одинаково в случае, когда она высокоценная по инструментальным или терминальным причинам.
Мне надо прояснить: Вы можете делать инструментальные вещи без того, чтобы они были инструментальными предпочтениями. К примеру, когда я впервые получил смартфон, я иногда вытаскивал его у себя из кармана, чтобы проверить Твиттер. В то время у меня не было самого по себе предпочтения вытаскивания телефона из кармана. Вместо этого я думал мысль вроде «я сейчас вытащу телефон из кармана и проверю Твиттер». Направляющая Подсистема одобряла это как высокоценную мысль, но только из-за второй части мысли, про Твиттер.
Потом, через некоторое время, «присвоение ценности» (следующий раздел) сделало свой фокус и поместило в мой мозг новое предпочтение, предпочтение просто доставать телефон из моего кармана. После этого я стал вытаскивать телефон из кармана без малейшей идеи, почему. И вот теперь это «инструментальное предпочтение».
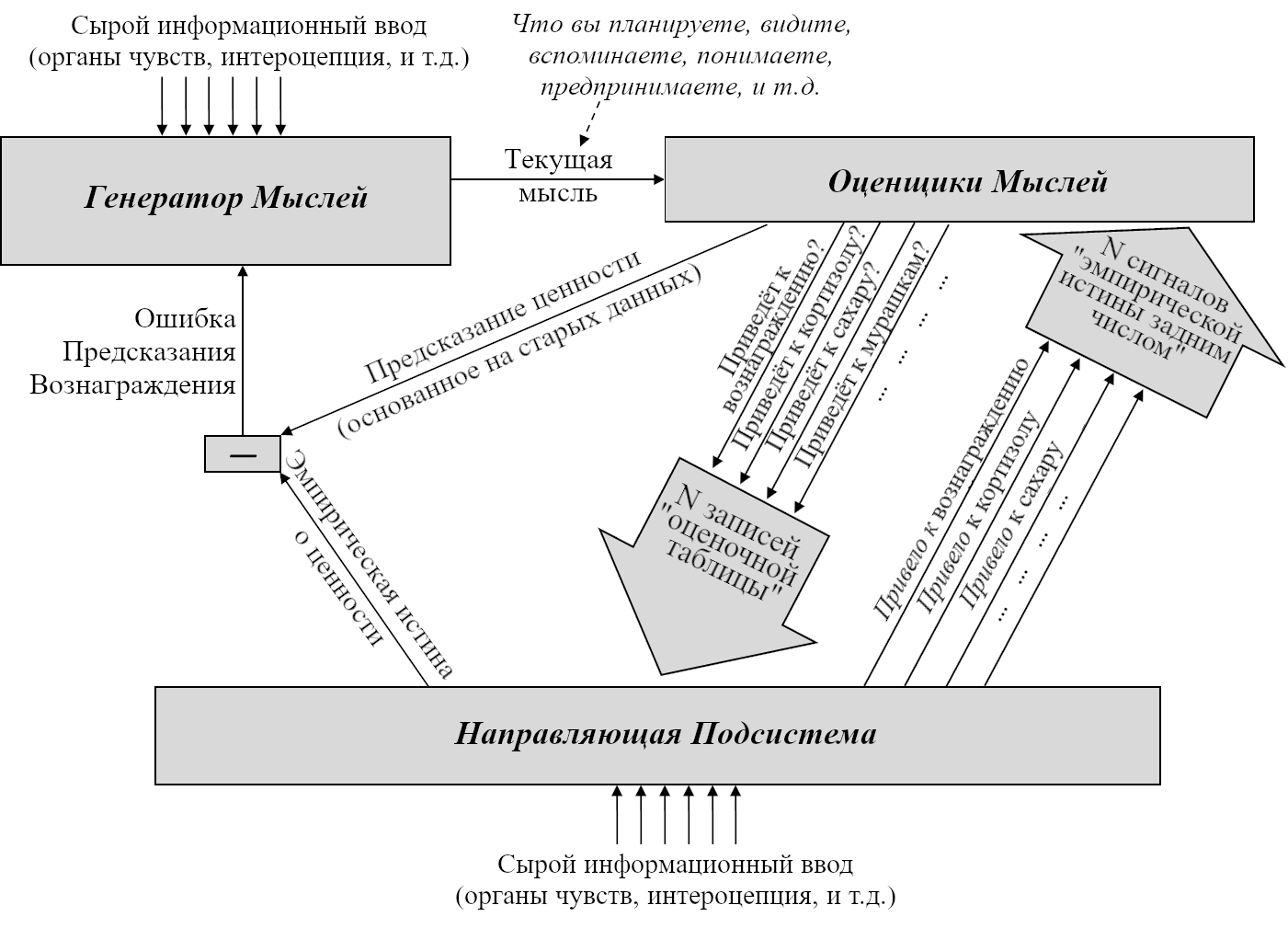
Формирование привычек – это процесс, в котором присвоение ценности превращает инструментальное *поведение* в инструментальное *предпочтение*.
(Замечу: Только то, что инструментальные и терминальные предпочтения смешаны в человеческом мозгу, не означает, что они обязаны быть смешаны в подобных-мозгу СИИ. К примеру, я могу приблизительно представить некую систему, помечающую концепты положительной валентности некими объяснениями, почему они стали иметь положительную валентность. В примере выше, может быть, что мы могли бы провести пунктирную линию от некоего внутреннего стремления к концепту «Твиттер», а затем от концепта «Твиттер» к концепту «достать телефон из кармана». Я предполагаю, что эти линии не задействовались бы в операциях, проводимых СИИ, но их было бы здорово иметь в целях интерпретируемости. Для ясности, я не знаю, работало бы это или нет, просто накидываю идеи.)
9.3 «Присвоение ценности» – как скрытые переменные окрашиваются валентностью
9.3.1 Что такое «присвоение ценности»?
Я представил идею «присвоения ценности» в Посте №7 (Раздел 7.4), и предлагаю перечитать его сейчас, чтобы у вас в голове был конкретный пример. Вспомните эту диаграмму:
Скопировано из Поста №7, см. контекст там.
Напоминание, у мозга есть «Оценщики Мыслей» (Посты №5 и №6), работающие методом обучения с учителем (с управляющими сигналами из Направляющей Подсистемы). Их роль – переводить скрытые переменные (концепты) модели мира («картины», «налоги», «процветание», и т.д.) в параметры, которые может понять Направляющая Подсистема (боль в руке, уровень сахара в крови, гримасничанье, и т.д.). К примеру, когда я съедаю кусок торта в Посте №7, концепт модели мира («я ем торт») прикрепляется к генетически-осмысленным переменным (сладкий вкус, вознаграждение, и т.д.).
Я называю этот процесс «присвоением ценности» – в том смысле, что абстрактный концепт «я ем торт» приобретает ценность за сладкий вкус.
Кадж Сотала написал несколько поэтическое описание того, что я называю присвоением ценности тут:
Ментальные репрезентации … наполняются чувствительным к контексту притягательным блеском.
Я представляю себе аккуратную кисточку, наносящую положительную валентность на мой ментальный концепт торта «Принцесса». Кроме цвета «валентности» на палитре есть и другие цвета, ассоциированные с другими внутренними реакциями.
Мне иногда нравится визуализировать присвоение ценностей как что-то вроде «раскрашивания» скрытых переменных в предсказательной модели мира ассоциациями с вознаграждением и другими внутренними реакциями.
Присвоение ценности может работать забавным образом. Лиза Фельдман Барретт рассказывала историю как однажды она была на свидании, чувствовала бабочек в животе и думала, что нашла Настоящую Любовь – только чтобы вечером слечь с гриппом! Аналогично, если я приятно удивлён тем, что выиграл соревнование, мой мозг может «присвоить ценность» моей тяжёлой работе и навыкам, а может – тому, что я надел свои счастливые трусы.
Я говорю «мой мозг присваивает ценность» вместо «я присваиваю ценность», потому что не хочу создавать впечатление, будто это какой-то мой произвольный выбор. Присвоение ценности – глупый алгоритм в мозгу. Кстати о нём:
9.3.2 Как работает присвоение ценности? – короткий ответ
Если присвоение ценности – глупый алгоритм в мозгу, какой конкретно это алгоритм?
Я думаю, по крайней мере в первом приближении, очевидный:
Ценность присваивается активной прямо сейчас мысли.
Это «очевидно» в том смысле, что Оценщики Мыслей используют обучение с учителем (см. Пост №4), а это то, что обучение с учителем делает по умолчанию. В конце концов, «контекстный» ввод Оценщика Мыслей описывает, какая мысль активна прямо сейчас, так что если мы сделаем обновление методом градиентного спуска (или что-то функционально на него похожее), то мы получим именно такой «очевидный» алгоритм.
9.3.3 Как работает присвоение ценности? – мелкий шрифт
Я думаю, стоит немного больше поисследовать эту тему, потому что присвоение ценности играет ключевую роль в безопасности СИИ – в конце концов, это то, из-за чего подобный-мозгу СИИ будет хотеть одни штуки больше, чем другие. Так что я перечислю некоторые отдельные мысли о том, как, по моему мнению, это работает у людей.
1. У присвоения ценности могут быть «априорные суждения» о том, что будет ассоциироваться с концептами того или иного вида:
Напомню, в Постах №4-№5 говорилось, что каждый Оценщик Мыслей обладает своими собственными «контекстными» сигналами, служащими вводом его предсказательной модели. Представьте, что некий конкретный Оценщик Мыслей получает контекстные данные, например, только из зрительной коры. Он будет вынужден «присваивать ценность» в первую очередь визуальным паттернам из этой части нейронной архитектуры – так как он имеет стопроцентное «априорное суждение» о том, что только паттерны из визуальной коры вообще могут оказаться полезными для его предсказаний.
Мы можем наивно посчитать, что такие «априорные суждения» – всегда плохая идея: чем разнообразнее контекстные сигналы, получаемые Оценщиком Мыслей, тем лучше будет его предсказательная модель, верно? Зачем его ограничивать? Две причины. Во-первых, хорошее априорное суждение приведёт к более быстрому обучению. Во-вторых, Оценщики Мыслей – только один компонент большой системы. Нам не стоит принимать за данность, что более точные предсказатели Оценщика Мыслей обязательно полезны для всей системы.
Вот знаменитый пример из психологии: крысы могут легко научиться замирать в ответ на звук, предвещающий удар током, и научиться плохо себя чувствовать в ответ на вкус, предвещающий приступ тошноты. Но не наоборот! Это может демонстрировать, например, то свойство архитектуры мозга, что предсказывающий тошноту Оценщик Мыслей имеет контекст, связанный со вкусом (например, из островковой доли), но не связанный с зрением или слухом (например, из височной доли), а предсказывающий замирание Оценщик Мыслей – наоборот. (Вскоре будет больше о примере с тошнотой.)
2. Присвоение ценности очень чувствительно ко времени:
Выше я предположил «Ценность присваивается активной прямо сейчас мысли». Но я не сказал, что значит «прямо сейчас».
Пример: Предположим, я прогуливаюсь по улице, думая о сериале, который я смотрел прошлым вечером. Внезапно, я чувствую острую боль в спине – меня кто-то ударил. Почти что немедленно в моём мозгу происходит две вещи:
- Мои мысли и внимание обращаются к этой новой боли в спине (возможно, с появлением некой генеративной модели того, что её вызвало),
- Мой мозг исполняет «присвоение ценности», и некоторые концепты в моей модели мира становятся внутренне ассоциированы с новым ощущением боли.
Фокус в том, что мы хотим, чтобы (1) произошло до (2) – иначе я заимею внутреннее ожидание боли в спине каждый раз, когда буду думать о том сериале.
Я думаю, что мозг в состоянии обеспечить, чтобы (1) происходило до (2), по крайней мере в основном. (Я всё же могу получить немного обманчивых ассоциаций с сериалом.)[4]
3. …И эта чувствительность ко времени может взаимодействовать с «априорными суждениями»!
Условное Отторжение Вкуса (CTA) – явление, заключающееся в том, что если меня затошнит сейчас, то это вызовет отторжение к вкусу, который я ощущал пару часов назад – не пару секунд, не пару дней, именно пару часов. (Я обращался к CTA выше, но не к временному аспекту.) Эволюционная причина очевидна: пара часов – это типичное время, через которое токсичная еда вызывает тошноту. Но как это работает?
Островковая кора – место обитания нейронов, формирующих генеративную модель вкусовых сенсорных вводов. Согласно «Молекулярным механизмам в основе вкусового следа в памяти для ассоциаций в островковой коре» Адайккана и Розенблума (2015), у этих нейронов есть молекулярные механизмы, устанавливающие их в специальное помеченное состояние на несколько часов после активации.
Так что предложенное мной выше правило («Ценность присваивается активной прямо сейчас мысли») надо модифицировать: «Ценность присваивается нейронам, прямо сейчас находящимся в специальном помеченном состоянии».
4. Присвоение ценности работает по принципу «Кто успел, того и тапки»:
Если уже найден способ точно предсказывать некоторый набор управляющих сигналов, это отключает соответствующий сигнал об ошибке, так что мы прекращаем присваивать ценность в таких ситуациях. Я думаю, первая обнаруженная мозгом хорошая предсказательная модель по умолчанию «застревает». Я думаю, с этим связано блокирование в поведенческой психологии.
5. Генератор Мыслей не имеет прямого произвольного контроля над присвоением ценности, но, вероятно, всё же может как-то им манипулировать.
В некотором смысле Генератор Мыслей и Оценщики Мыслей противостоят друг другу, т.е. работают на разные цели. В частности, они обучены оптимизировать разные сигналы.[5] К примеру, однажды мой начальник на меня орал, и я очень сильно не хотел начать плакать, но мои Оценщики Мыслей оценили, что это было подходящее время, так что я заплакал![6] С учётом этих отношений противостояния, я сильно подозреваю, что Генератор Мыслей не имеет прямого («произвольного») контроля над присвоением ценности. Интроспекция, кажется, это подтверждает.
С другой стороны, «нет прямого произвольного контроля» – несколько не то же самое, что «никакого контроля». Опять же, у меня нет прямого произвольного контроля над плачем, но я всё же могу вызвать слёзы, по крайней мере немного, обходной стратегией представления маленьких котят, замерзающих под холодным дождём (Пост №6, Раздел 6.3.3).
Итак, предположим, что я сейчас ненавижу X, но хочу, чтобы мне нравилось X. Мне кажется, что эта задача не решается напрямую, но не кажется и что она невыполнима. Это может потребовать некоторого навыка рефлексии, осознанности, планирования, и так далее, но если Генератор Мыслей подумает правильные мысли в правильное время, то он, вероятно, сможет с этим справиться.
И для СИИ это может быть проще, чем для человека! В конце концов, в отличии от людей, СИИ может быть способен буквально взломать свои собственные Оценщики Мыслей и настроить их по своему желанию. И это приводит нас к следующей теме…
9.4 Вайрхединг: возможен, но не неизбежен
9.4.1 Что такое вайрхединг?
Концепт «вайрхединга» получил название от идеи запихнуть провод («wire») в некоторую часть своего мозга и пустить ток. Если сделать это правильно, то это будет напрямую вызывать экстатическое удовольствие, глубокое удовлетворение, или другие приятные ощущения, в зависимости от части мозга. Вайрхединг может быть куда более простым способом вызывать эти ощущения, в сравнении с, ну знаете, нахождением Истинной Любви, приготовлением идеального суфле, зарабатыванием уважения героя своего детства, и так далее.
В классическом вызывающем кошмары эксперименте с вайрхедингом (см. «Симуляция Вознаграждения в Мозгу»), провод в мозгу крысы активировался, когда крыса нажимала на рычаг. Крыса нажимала на него снова и снова, не останавливаясь на еду, питьё и отдых, 24 часа подряд, пока не потеряла сознание от усталости. (ссылка)
Концепт вайрхединга можно перенести на ИИ. Идея тут в том, что агент обучения с подкреплением спроектирован для максимизации своего вознаграждения. Так что, может быть, он взломает свою собственную оперативную память и перепишет значение «вознаграждения» на бесконечность! Дальше я поговорю о том, вероятно ли это, и о том, насколько это должно нас беспокоить.
9.4.2 Захочет ли подобный-мозгу СИИ завайрхедиться?
Ну, для начала, ходят ли люди завайрхедиться? Нужно провести различие двух вариантов:
- Слабое стремление к вайрхедингу: «Я хочу получать более высокий сигнал вознаграждения в своём мозгу при прочих равных.»
- Сильное стремление к вайрхедингу: «Я хочу получать более высокий сигнал вознаграждения в своём мозгу – и я сделаю что угодно, чтобы его получить.»
В случае людей, может, мы можем приравнять стремление к вайрхедингу с «желанием получать удовольствие», т.е. с гедонизмом.[7] Если так, то получается, что (почти) все люди имеют «слабое стремление к вайрхедингу», но не «сильное стремление к вайрхедингу». Мы хотим получать удовольствие, но обычно нас хоть немного волнуют и другие вещи.
Как так получается? Ну, подумайте о предыдущих двух разделах. Чтобы человек хотел вознаграждения, он, во-первых, должен иметь концепт вознаграждения в своей модели мира, и, во-вторых, присвоение ценности должно пометить этот концепт как «хороший». (Я использую термин «концепт вознаграждения» в широком смысле, включающем и концепт «удовольствия».[7])
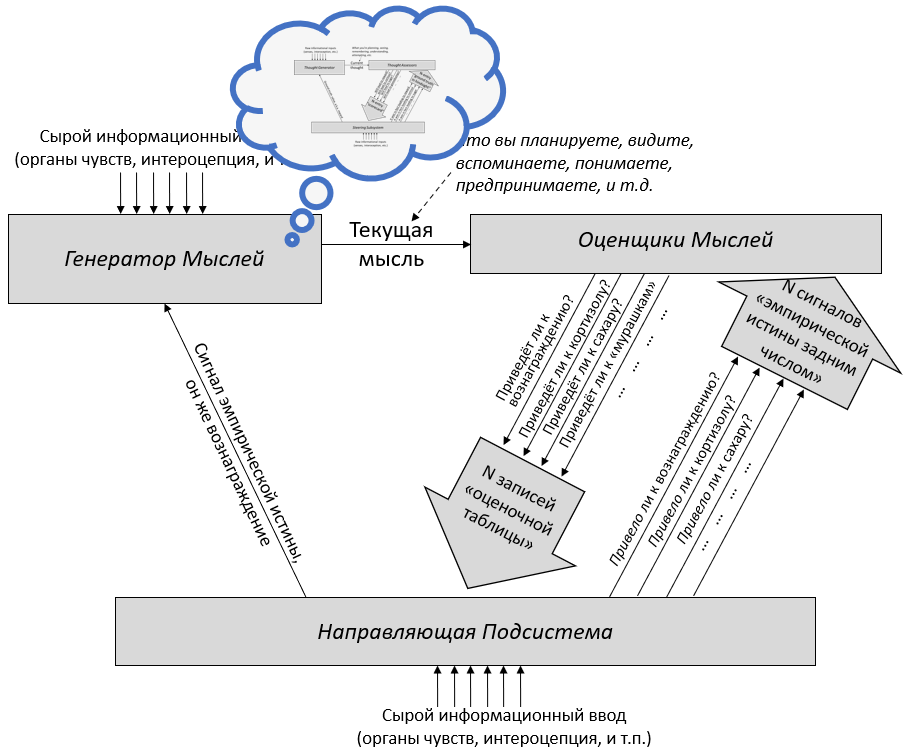
СИИ (или человек) может обладать саморефлексивными концептами, и, следовательно, может быть мотивирован на изменение своих внутренних настроек и операций.
С учётом этого и заметок про присвоение ценности в Разделе 9.3, я считаю:
- Избежать сильного стремления к вайрхедингу – тривиальная и автоматически выполняемая задача; она просто требует, чтобы присвоение ценности хотя бы раз назначило позитивную валентность чему угодно кроме концепта вознаграждения / удовольствия.
- Избежать слабого стремления к вайрхедингу кажется довольно сложным. Может, мы можем минимизировать его, используя чувствительность к времени и априорные суждения (Раздел 9.3.3 выше), но полное его избегание, думаю, потребует специальных техник – я приблизительно представляю это как использование какой-то техники интерпретируемости, чтобы обнаружить в модели мира концепт вознаграждения / удовольствия и напрямую отключить его от Оценщиков Мыслей, или что-то вроде этого.
(Есть ещё возможность, что слабый-вайрхедер самомодифицируется, чтобы стать сильным-вайрхедером; больше про такие вещи в следующем посте.)
9.4.3 Завайрхедившиеся СИИ были бы опасны, не просто бесполезны
Есть опасное интуитивное заключение, в которое попадаются многие: Когда мы представляем завайрхедившийся СИИ, мы сравниваем его с человеком в состоянии глубокого опьянения рекреационными наркотиками. Такой человек точно не занимается методичным составлением, проверкой и исполнением гениального коварного плана по захвату мира. Скорее, он просто получает удовольствие с закрытыми глазами, или, может, танцует, или что-то такое, зависит от наркотика. Так что интуиция предполагает, что вайрхединг – проблема способностей, а не фактор риска катастрофических происшествий.
Я думаю, что тут есть зерно истины: как обсуждалось в Постах №6-№7, сигналы вознаграждения / ценности управляют мышлением и планированием, так что если вознаграждения застревает на высоком положительном значении, то мышление и планирование становятся невозможными.
Но неправильно выводить из этого, что вархединг не представляет риска катастрофических происшествий.[8] Рассмотрим, что происходит до того, как СИИ начинает вайрхедиться. Если он составит план «я завайрхежусь», то эта мысль, вероятно, получит высокую оценку Направляющей Подсистемы. Но если он подумает об этом побольше, то поймёт, что ожидания от этого плана должны быть «Я завайрхежусь на некоторое время, а потом люди меня отключат и исправят так, чтобы я больше не мог этого сделать». Теперь план не звучит так замечательно! Так что СИИ может составить план получше, включающий штуки вроде захвата контроля над локальным окружением и/или энергосетью и/или всем миром, и/или создание «ИИ-телохранителя», который делает всё это, пока СИИ вайрхедится, и т.д. Так что на самом деле я думаю, что вайрхединг несёт риски катастрофических происшествий, даже уровня человеческого вымирания, как я обсуждал в Посте №1.
9.5 СИИ НЕ судят о планах, основываясь на будущих вознаграждениях
Это напрямую вытекает из предыдущего раздела, но я хочу особо это подчеркнуть, так как «СИИ будут пытаться максимизировать будущее вознаграждение» – часто встречаемое заявление.
Если Генератор Мыслей предлагает план, то Оценщики Мыслей оценивают его вероятные последствия согласно своим нынешним моделям, и Направляющая Подсистема одобрит или отвергнет план в основном на этом основании. Эти нынешние модели не обязаны быть согласованными с «ожидаемым будущим вознаграждением».
Предсказательная модель мира Генератора Мыслей может даже «знать» о некотором расхождении между «ожидаемым будущим вознаграждением» и его прикидкой от Оценщика Мыслей. Это не имеет значения! Прикидки не поправят себя автоматически и всё ещё будут определять, какие планы будет исполнять СИИ.
9.5.1 Человеческий пример
Вот пример на людях. Я буду говорить про кокаин вместо вайрхединга. (Они не столь отличаются, но кокаин более знаком.)
Факт: я никогда не принимал кокаин. Предположим, что я сейчас думаю «может быть, я приму кокаин». Интеллектуально я уверен, что если я приму кокаин, то испытаю, эммм, много весьма интенсивных ощущений. Но внутренне представление того, как я принимаю кокаин ощущается в целом нейтрально! Оно не заставляет меня чувствовать ничего особенного.
Так что прямо сейчас мои интеллектуальные ожидания (того, что произойдёт, если я приму кокаин) не синхронизированы с моими внутренними ожиданиями. Очевидно, мои Оценщики Мыслей просматривают мысль «может, я приму кокаин» и коллективно пожимают плечами: «Ничего особенного!». Напомню, что Оценщики Мыслей работают через присвоение ценности (Раздел 9.3 выше), и, очевидно, алгоритм присвоения ценности не особо чувствителен ни к слухам о том, как ощущается приём кокаина, ни к чтению нейробиологических статей о том, как кокаин связывается с переносчиками дофамина.
Напротив, алгоритм присвоения ценности сильно чувствителен к прямому личному опыту интенсивных ощущений.
Поэтому люди могут заполучить зависимость от кокаина, принимая кокаин, но не могут – читая про кокаин.
9.5.2 Связь с «агентами наблюдаемой полезности»
Для более теоретического подхода, вот Абрам Демски (прошу прощения за жаргон – если вы не знаете, что такое AIXI, не беспокойтесь, скорее всего вы всё равно ухватите суть):
В качестве первого примера, рассмотрим проблему вайрхединга для AIXI-подобных агентов в случае фиксированной функции полезности, для которой известно, как её оценивать исходя из сенсорных данных. Как обсуждается в Обучаясь, Что Ценить Дэниэла Дьюи и в других местах, если вы попробуете реализовать это, запихнув вычисление полезности в коробку, выдающую вознаграждение AIXI-подобному агенту обучения с подкреплением, то агент рано или поздно обучится модификации или удалению коробки, и с радостью это сделает, так как сможет таким образом получить большее вознаграждение. Это так, потому что агент обучения с подкреплением предсказывает и пытается максимизировать получаемое вознаграждение. Если он понимает, что он может модифицировать выдающую вознаграждение коробку, чтобы получить больше, он так и сделает.
Мы можем исправить эту проблему, встроив в агента ту же коробку способом получше. Вместо того, чтобы агент обучения с подкреплением обучался выводу коробки и составлял планы для его максимизации, мы можем использовать коробку, чтобы *напрямую* оценивать возможные варианты будущего, и заставить агента планировать для максимизации этой оценки. Теперь, если агент рассматривает возможность модификации коробки, то он оценивает такое будущее *при помощи нынешней коробки*. А она не видит выгоды в такой модификации. Такая система называется максимизатором наблюдаемой полезности (для проведения различия от обучения с подкреплением)…
Это похоже на различие цитаты/референта. Агент обучения с подкреплением максимизирует «функцию в модуле полезности», а агент наблюдаемой полезности максимизирует функцию в модуле полезности.
Наш подобный-мозгу СИИ, хоть он и RL[9], на самом деле ближе к парадигме наблюдаемой полезности: Оценщики Мыслей и Направляющая Подсистема вместе работают для оценивания планов / курсов действия, прямо как «коробка» Абрама.
Однако, у подобного-мозгу СИИ есть ещё дополнительная черта, заключающаяся в том, что Оценщики Мыслей постепенно обновляются «присвоением ценности» (Раздел 9.3 выше).
Так что у нас получается примерно что-то такое:
- Максимизирующий полезность агент
- …плюс процесс, периодически обновляющий функцию полезности и склонный приближать её к функции вознаграждения.
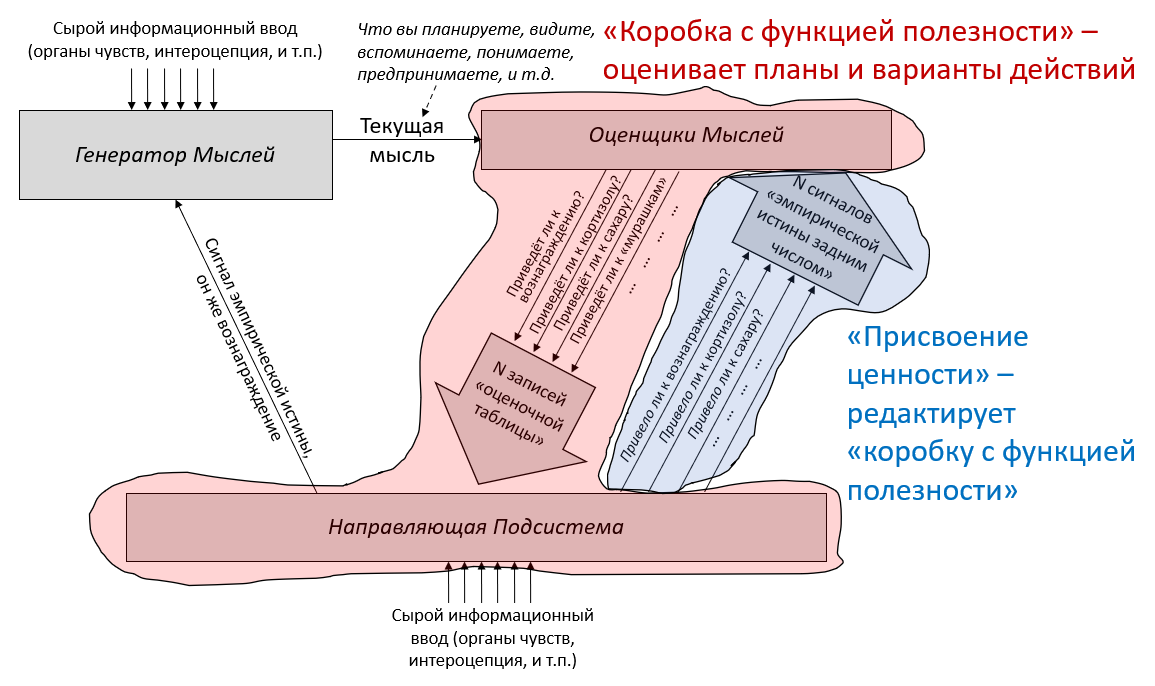
Эта диаграмма показывает, как наша картина мотивации подобного-мозгу СИИ встраивается в парадигму «агента наблюдаемой полезности», описанную в тексте.
Заметим, что мы не хотим, чтобы процесс присвоения ценности идеально «сходился» – т.е., достичь точки, в которой функция полезности будет идеально совпадать с функцией вознаграждения (или, в нашей терминологии, достичь точки, в которой Оценщики Мыслей больше никогда не будут обновляться, потому что они всегда оценивают планы идеально соответствуя Направляющей Подсистеме).
Почему мы не хотим идеальной сходимости? Потому что идеальная сходимость приведёт к вайрхедингу! А вайрхединг плох и опасен! (Раздел 9.4.3 выше) Но в то же время, нам нужна какая-то сходимость, потому что функция вознаграждения предназначена для оформления целей СИИ! (Напомню, Оценщики Мыслей изначально работают случайным образом и совершенно бесполезны.) Это Уловка-22! Я вернусь к этой теме в следующем посте.
(Проницательные читатели могут заметить ещё и другую проблему: максимизатор полезности может попробовать сохранить свои цели, мешая процессу присвоения ценности. В следующем посте я поговорю и про это.)
9.6 Оценщики Мыслей помогают интерпретируемости
Вот, ещё раз, диаграмма из Поста №6:
То же, что и выше, скопировано из Поста №6
Где-то сверху справа есть маленький обучающийся с учителем модуль, отвечающий на вопрос: «С учётом всего, что я знаю, включая не только сенсорный ввод и память, но ещё и курс действий, подразумеваемый моей текущей мыслью, насколько я предчувствую попробовать что-то сладкое?» Как описано раньше (Пост №6), этот Оценщик Мыслей играет двоякую роль (1) вызова подходящих действий гомеостаза (например, слюновыделения), и (2) помощи Направляющей Подсистеме понять, является ли текущая мысль ценной, или же это мусор, который надо выкинуть на следующей паузе фазового дофамина.
Сейчас я хочу предложить третий способ думать о том же самом.
Уже давно, в Посте №3, я упоминал, что Направляющая Подсистема «глупая». У неё нет здравого смысла в понимании мира. Обучающаяся Подсистема думает все эти сумасшедшие мысли о картинах, алгебре и налоговом законодательстве, а Направляющая Подсистема понятия не имеет, что происходит.
Что ж, Оценщики Мыслей помогают с этой проблемой! Они дают Направляющей Подсистеме набор подсказок о том, что думает и планирует Обучающаяся Подсистема, на языке, который Направляющая Подсистема может понять. Это немного похоже на интерпретируемость нейросетей.
Я называю это «суррогат интерпретируемости». Думаю, настоящая интерпретируемость должна быть определена как «возможность посмотреть на любую часть обучившейся с чистого листа модели и ясно понять, что, как и почему там происходит». Суррогат интерпретируемости далёк от этого. Мы получаем ответы на некоторое количество заранее определённых вопросов – например, «Касается ли эта мысль еды или, хотя бы, чего-то, что раньше ассоциировалось с едой?». И всё. Но это уже лучше, чем ничего.
| Машинное обучение | Мозг |
| Человек-исследователь | Направляющая Подсистема (см. Пост №3) |
| Обученная модель ConvNet | Обучающаяся Подсистема (см. Пост №3) |
| По умолчанию, с точки зрения человека, обученная модель – ужасно сложная свалка неразмеченных непонятных операций | По умолчанию, с точки зрения Направляющей Подсистемы, Обучающаяся Подсистема – ужасно сложная свалка неразмеченных непонятных операций |
| Суррогат интерпретируемости – Человек получает некоторые «намёки» на то, что делает обученная модель, вроде «прямо сейчас она думает, есть ли на изображении кривая». | Оценщики Мыслей – Направляющая Подсистема получает некоторые «намёки» на то, что происходит в Обучающейся Подсистеме, вроде «эта мысль скорее всего касается еды или хотя бы чего-то связанного с едой». |
| Настоящая интерпретируемость – конечная цель настоящего понимания, что, почему и как делает обученная модель, сверху донизу | [Аналогии этому нет.] |
Эта идея будет важна в более поздних постах.
(Замечу, что что-то подобное можно делать с любым агентом обучения с подкреплением субъект-критик, подобным-мозгу или нет, с помощью многомерной функции ценности, возможно включающей «псевдо» ценности, используемые только для мониторинга; см. здесь и комментарии здесь.)
9.6.1 Отслеживание, какие «встроенные стремления» на самом деле ответственны за высокую ценность плана
В Посте №3 я говорил о том, что у мозга есть множество разных «встроенных стремлений», включающих стремление к удовлетворению любопытства, стремление есть, когда голоден, стремление избегать боли, стремление к высокому статусу, и так далее. Подобные-мозгу СИИ, предположительно будут тоже обладать множеством разных стремлений. Я не знаю точно, какими, но приблизительно представляю что-то вроде любопытства, стремления к альтруизму, стремлению следовать нормам, стремлению делать-то-что-люди-от-меня-хотят, и так далее. (Больше про это в будущих постах.)
Если все эти разные стремления вкладываются в общее вознаграждение, то мы можем и должны иметь Оценщики Мыслей для вклада каждого.
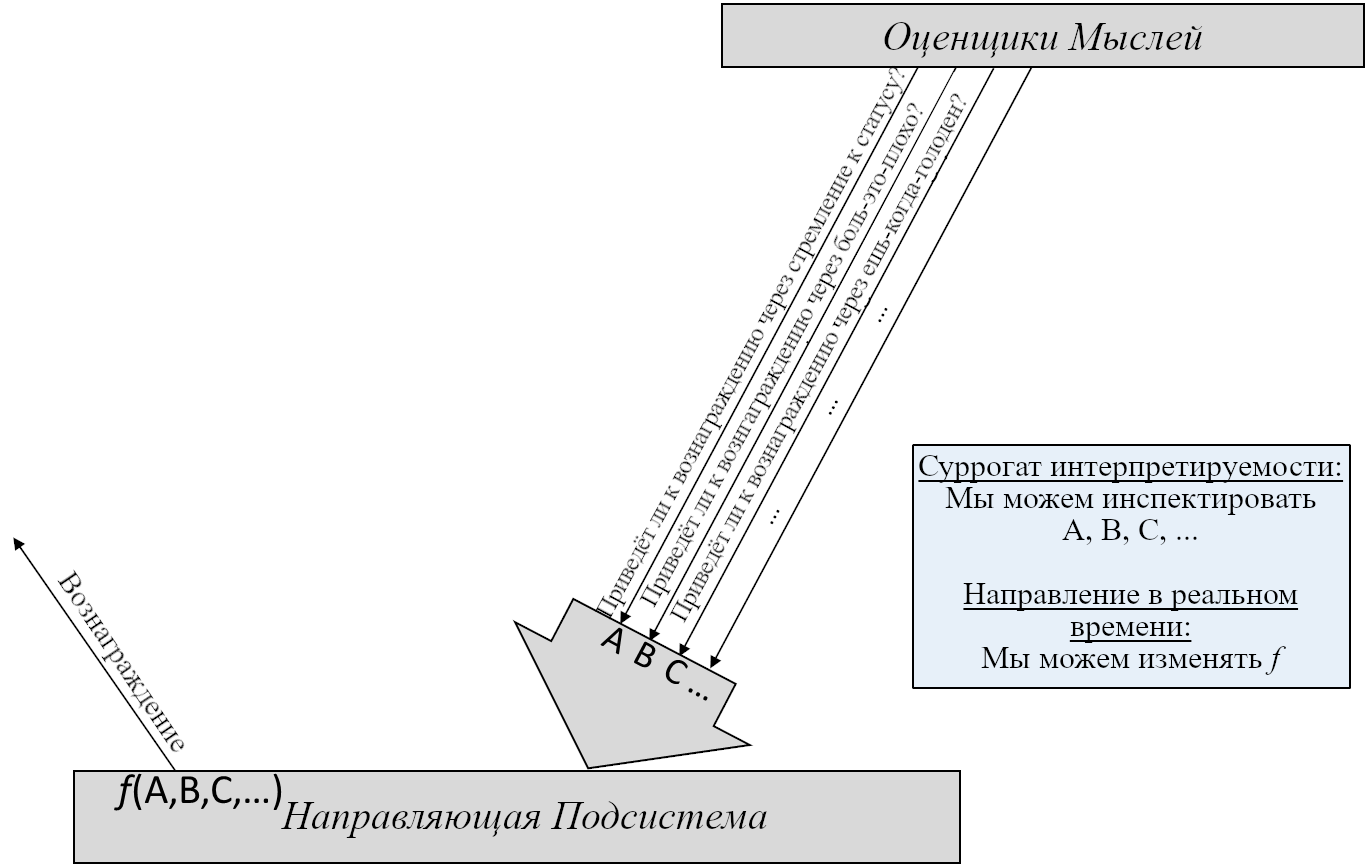
Раз функция вознаграждения может быть разделена на разные составляющие, мы можем и должны отслеживать каждое отдельным Оценщиком Мыслей. (Могут быть так же и другие, не связанные с вознаграждением, Оценщики Мыслей) У этого есть два преимущества. «Суррогат интерпретируемости» (этот раздел) означает, что если мысль обладает высокой ценностью, то мы можем проинспектировать Оценщики Мыслей, чтобы получить намёк, почему. «Направление в реальном времени» (следующий раздел) означает, что мы можем мгновенно изменить долгосрочные планы и цели СИИ, изменив функцию вознаграждения *f*. Эксперты в обучении с подкреплением распознают, что оба этих концепта применимы к любым системам обучения с подкреплением, совместимым с многомерными функциями ценности, в каком случае *f* часто называется «функцией скаляризации» – см. здесь и комментарии здесь.
Как обсуждалось в предыдущих постах, каждый раз, когда подобный-мозгу СИИ думает мысль, это вызвано тем, что эта мысль более вознаграждающая, чем альтернативные. И благодаря суррогату интерпретируемости, мы можем инспектировать систему и немедленно узнать, какие встроенные стремления вкладываются в это!
Ещё лучше, это работает, даже если мы не понимаем, о чём мысль вообще, и даже если предсказывающая вознаграждение часть мысли на много шагов отстоит от прямых эффектов на встроенные стремления. К примеру, может быть, эта мысль вознаграждающая потому, что она исполняет некую метакогнитивную стратегию, доказанно полезную для брейншторминга, который доказанно полезен для доказательства теорем, которое доказанно полезно для отладки кода, и так далее, пока через ещё десять связей мы не дойдём до одного из встроенных стремлений.
9.6.2 Надёжен ли суррогат интерпретируемости даже для очень мощных СИИ?
Если у нас есть очень мощный СИИ, и он выдаёт план, и система «суррогата интерпретируемости» заявляет «этот план почти точно не приведёт к нарушению человеческих норм», то можем ли мы ей верить? Хороший вопрос! Он оказывается по сути эквивалентным вопросу «внутреннего согласования», которое я рассмотрю в следующем посте. Придержите эту мысль.
9.7 «Направление в реальном времени»: Направляющая Подсистема может перенаправлять Обучающуюся Подсистему – включая её глубочайшие желания и долгосрочные цели – в реальном времени
В случае агентов безмодельного обучения с подкреплением, играющих в игры на Atari, если вы измените функцию вознаграждения, поведение агента изменится очень постепенно. А вот приятная черта систем мотивации наших подобных-мозгу СИИ – что мы можем немедленно изменить не только поведение агента, но и его очень долгосрочные планы и глубочайшие мотивации и желания!
Как это работает: как описано выше (Раздел 9.6.1), у нас может быть много Оценщиков Мыслей, вкладывающихся в функцию вознаграждения. К примеру, один может оценивать, приведёт ли нынешняя мысль к удовлетворению стремления к любопытству, другая – стремления к альтруизму, и т.д. Направляющая Подсистема комбинирует эти оценки в общее вознаграждение. Но функция, которую она для этого использует, жёстко закодирована и понятна людям – она может быть такой простой, как, к примеру, взвешенное среднее. Следовательно, мы можем изменить эту функцию в Направляющей Подсистеме в реальном времени, как только захотим – в случае взвешенного среднего мы можем изменить веса.
Мы видели пример в Посте №7: Когда вас очень тошнит, не только поедание торта становится неприятным – несколько отталкивающим становится даже планирование поедания торта. Чёрт, даже абстрактный концепт торта становится немного отталкивающим!
И, конечно, у нас у всех были случаи, когда мы устали, грустим или злимся, и вдруг все наши самые глубокие жизненные цели теряют свою привлекательность.
Когда вы водите машину, критически важное требование безопасности – что, когда вы поворачиваете руль, колёса реагируют немедленно. Точно также, я ожидаю, что критически важным требованием безопасности будет возможность для людей мгновенно изменить глубочайшие желания СИИ по нажатию соответствующей кнопки. Так что я думаю, что это замечательное свойство, и я рад, что оно есть, даже если я не на 100% уверен, что в точности с ним делать. (В случае машины вы видите, куда едете, а вот понять, что пытается сделать СИИ в данный конкретный момент – куда сложнее.)
(Опять же, как и в предыдущем разделе, идея «Направления в реальном времени» применима к любому алгоритму обучения с подкреплением «субъект-критик», не только к «подобным-мозгу». Всё что требуется – многомерное вознаграждение, которое обучает многомерную функцию ценности.)
———
- Вот правдоподобный случай циклических предпочтений у человека. Вы выиграли приз! У вас есть три варианта: (A) 5 красивых тарелок, (B) 5 красивых тарелок и 10 уродливых тарелок, (C) 5 нормальных тарелок.
Никто, насколько мне известно не проводил точно такого эксперимента, но правдоподобно (основываясь на похожей ситуации из главы 15 Думай медленно… решай быстро) это приведёт к циклическим предпочтениям по крайней мере у некоторых людей: Когда люди видят только A и B, они выбирают B, потому что «тут больше, я всегда могу придержать уродливые про запас или использовать их как мишени, или что-то ещё». Когда они видят B и C, то выбирают C, потому что «среднее качество выше». Когда видят C и A, то по той же причине выбирают A.
Получается, что есть два разных предпочтения: (1) «Я хочу более коллекцию более красивых штук, а не менее красивых», и (2) «Я хочу дополнительных бесплатных тарелок». Сравнение B с C или C с A выявляет (1), а сравнение A с B выявляет (2). - Вы можете подумать: «зачем вообще создавать СИИ с ошибочной интуицией как у человека»?? Ну, мы попытаемся так не делать, но готов поспорить, что по крайней мере некоторые человеческие «отклонения от рациональности» вырастают из того факта, что предсказательные модели мира – большие сложные штуки, и эффективное обращение с ними ограничено, так что наш СИИ будет иметь систематические ошибки рассуждений, которые мы не сможем исправить на уровне исходного кода, вместо этого придётся попросить наш СИИ прочитать Думай медленно… Решай быстро или что-то ещё. Штуки вроде искажения доступности, якорения и гиперболического обесценивания могут попадать в эту категорию. Для ясности, некоторые слабости человеческих рассуждений, вероятно, менее затронут СИИ; для примера, если мы создадим подобный-мозгу СИИ без встроенного стремления к достижению высокого статуса и сигнализированию членства в ингруппе, то, наверное, он будет избавлен от провалов, обсуждённых в посте Убеждение Как Одеяние.
- Шучу. На самом деле мне понравилось читать Цепочки.
- Я думаю, что на самом деле тут есть ещё много сложных факторов, которые я опускаю, включая протяжённое присвоение ценности при вызове воспоминаний, и другие, не связанные с присвоением ценностей, изменения в модели мира.
- Почему я говорю, что Генератор Мыслей и Оценщики Мыслей работают на разные цели? Вот как можно об этом думать: (1) Направляющая Подсистема и Оценщики Мыслей работают вместе на вычисление некоторой функции вознаграждения, которая (в окружении наших предков) аппроксимирует «ожидаемую совокупную генетическую приспособленность»; (2) Генератор Мыслей ищет мысли, максимизирующие эту функцию. Теперь, с учётом того, что Генератор Мыслей ищет способы заставить функцию вознаграждения возвращать очень высокие значения, получается, что Генератор Мыслей также ищет способы исказить вычисления Оценщиков Мыслей, чтобы функция вознаграждения перестала быть хорошим приближением «ожидаемой совокупной генетической приспособленности». Это ненамеренный и плохой побочный эффект (с точки зрения совокупной генетической приспособленности), и эта проблема может быть смягчена максимальным затруднением манипуляций настройками Оценщиков Мыслей для Генератора Мыслей. См. мой пост Вознаграждения Недостаточно за дальнейшим обсуждением.
- У истории счастливый конец: я нашёл другую работу с не-абьюзивным начальником, и приобрёл плодотворный побочный интерес понимания высокофункциональных психопатов.
- Я несколько сомневаюсь, что «желание получать удовольствие» в точности эквивалентно «желанию получать высокий сигнал вознаграждения». Может быть, это так, но я не совсем уверен.
- См. обсуждение в Суперинтеллекте, стр. 149.
- Думаю, когда Абрам в этой цитате использует термин «RL-агент», он предполагает, что агент создан не просто при помощи какого-то алгоритма RL, а более конкретно - алгоритма RL, который гарантированно сходится к уникальному «оптимальному» агенту, и который уже закончил это делать.
10. Задача согласования
- 1.10.1 Краткое содержание / Оглавление
- 2.10.2 Внешняя и Внутренняя (не)согласованность
- 3.10.3 Проблемы, затрагивающие и внутреннее, и внешнее согласование
- 4.10.4 Препятствия на пути к внешнему согласованию
- 5.10.5 Препятствия на пути к достижению внутренней согласованности
- 6.10.6 Проблемы с разделением на внешнее и внутреннее
Примечание переводчика - с момента перевода оригинальные посты несколько обновились, через некоторое время обновлю и перевод. На общие выводы цепочки это, вроде бы, не влияет.
10.1 Краткое содержание / Оглавление
В этом посте я рассмотрю задачу согласования подобных-мозгу СИИ – то есть, задачу создания СИИ, пытающегося делать именно то, что входит в намерения его создателей.
Задача согласования (я так считаю) – львиная доля задачи безопасности СИИ. Я не буду отстаивать это заявление здесь – то, как в точности безопасность СИИ связана с согласованием СИИ, включая крайние случаи, где они расходятся[1], будет рассмотрено подробно в следующем посте (№11).
Этот пост – про задачу согласования, не про её решение. Какие препятствия мешают её решить? Почему прямолинейных наивных подходов, судя по всему, недостаточно? Я поговорю о возможных подходах к решению потом, в следующих постах. (Спойлер: Никто, включая меня, не знает, как решить задачу согласования.)
Содержание
- В Разделе 10.2 я определю «внутреннюю согласованность» и «внешнюю согласованность» в контексте нашей системы мотивации подобного-мозгу СИИ. Немного упрощая:
- Если вы предпочитаете нейробиологическую терминологию: «Внешняя согласованность» означает обладание «встроенными стремлениями» (как в Посте №3, Разделе 3.4.2), чьи активации хорошо отображают то, насколько хорошо СИИ следует намерениям создателя. «Внутренняя согласованность» – это ситуация, в которой воображаемый план (построенный из концепций, т.е. скрытых переменных модели мира СИИ) обладает валентностями, верно отображающими активации встроенных стремлений, которые были бы вызваны исполнением этого плана.
- Если вы предпочитаете терминологию обучения с подкрепления: «Внешняя согласованность» означает, что функция вознаграждения выдаёт вознаграждение, соответствующее тому, что мы хотим. «Внутренняя согласованность» – это обладание функцией ценности, прикидывающей ценность плана соответственно вознаграждению, которое вызовет его исполнение.
- В Разделе 10.3 я поговорю о двух ключевых проблемах, которые делают согласование (и «внутреннее», и «внешнее») в целом сложным:
- Первая – это «Закон Гудхарта», из которого следует, что СИИ, чья мотивация хоть чуть-чуть отклоняется от наших намерений, всё же может привести к исходам, дико отличающимся от того, что мы хотели.
- Вторая – это «Инструментальная Конвергенция», заключающаяся в том, что самые разнообразные возможные мотивации СИИ – включая очевидные, кажущиеся доброкачественными мотивации вроде «Я хочу изобрести лучшую солнечную панель» – приведут к СИИ, пытающемуся сделать катастрофически-плохие вещи вроде выхода из-под человеческого контроля, самовоспроизводства, заполучения ресурсов и влияния, обманчивого поведения и убийства всех людей (как в Посте №1, Разделе 1.6).
- В Разделе 10.4 я рассмотрю два препятствия, преодоление которых необходимо для достижения «внешней согласованности»: во-первых, перевод наших намерений в машинный код, а во-вторых возможная установка вознаграждения за не в точности то поведение, которое мы в итоге хотим от СИИ, вроде удовлетворения его собственного любопытства (см. Пост №3, Раздел 3.4.3).
- В Разделе 10.5 я рассмотрю многочисленные препятствия, преодоление которых необходимо для достижения «внутренней согласованности», включая неоднозначность вознаграждения, «онтологические кризисы» и манипуляцию СИИ своим собственным процессом обучения.
- В Разделе 10.6 я рассмотрю некоторые причины, почему «внешнее согласование» и «внутреннее согласование», вероятно, не следует рассматривать как две отдельных задачи с двумя независимыми решениями. К примеру, интерпретируемость нейросетей помогла бы и там, и там.
10.2 Внешняя и Внутренняя (не)согласованность
10.2.1 Определение
Вот ещё раз рисунок из Поста №6, теперь ещё с добавлением полезной терминологии (синее) и маленьким зелёным лицом:
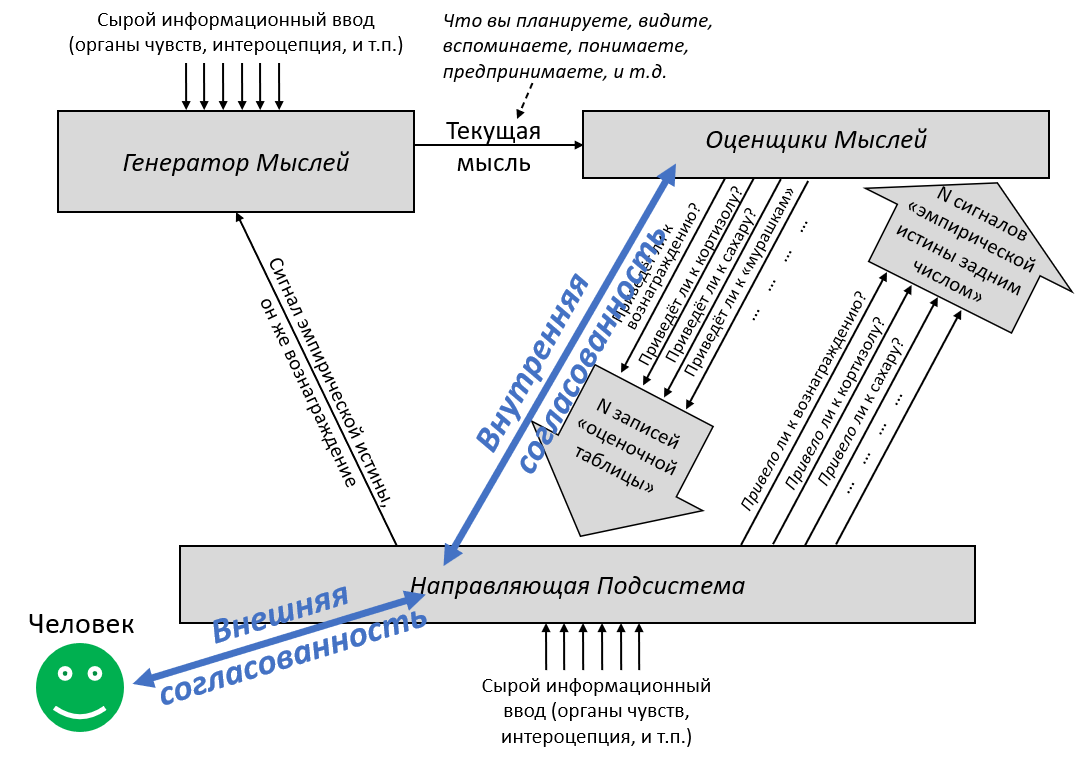
Я хочу упомянуть три штуки с этой диаграммы:
- Намерения создателя (зелёное лицо): Наверное, это человек, который программирует СИИ; предположительно, у него есть в голове какая-то идея о том, что СИИ должен пытаться делать. Это просто пример; это могла бы быть и команда людей, коллективно вырабатывающая спецификацию, описывающую, что должен пытаться делать СИИ. Или, может, кто-то написал семисотстраничный философский труд под заголовком «Что значит для СИИ действовать этично?», и команда программистов пытается создать СИИ, соответствующий описанию из книги. Тут это не имеет значения. Я для простоты выберу «одного человека, программирующего СИИ».[2]
- Написанный людьми исходный код Направляющей Подсистемы: (См. Пост №3 за тем, что такое Направляющая Подсистема, и Пост №8 за объяснением, почему я ожидаю, что она будет полностью или почти полностью состоять из написанного людьми исходного кода.) Самая важная составляющая в этой категории – это «функция вознаграждения» обучения с подкреплением (помеченная на диаграмме как «сигнал эмпирической истины», да, я знаю, это звучит странно), предоставляющая (задним числом) эмпирическую истину о том, насколько хорошо или плохо у СИИ идут дела.
- Оценщики Мыслей, обученные с нуля алгоритмами обучения с учителем: (См. Пост №5 за тем, что такое Оценщики Мыслей и как они обучаются.) Они принимают «мысль» из генератора мыслей и выдают догадки о том, к каким сигналам Направляющей Подсистемы она приведёт. Особенно важный частный случай – функция ценности (помеченная на диаграмме «приведёт к вознаграждению?»).
В таком СИИ есть два вытекающих вида «согласованности»:
- Внешняя согласованность – это соответствие намерений создателя и исходного кода Направляющей Подсистемы. В частности, если СИИ внешне согласован, то Направляющая Подсистема будет выдавать высокий сигнал вознаграждения, когда СИИ удовлетворяет намерениям создателя, и низкий, когда нет.
- Другими словами, это ответ на вопрос: Побуждают ли СИИ его «встроенные стремления» делать то, что входит в намерения его создателя?
- Внутренняя согласованность – это соответствие между исходным кодом Направляющей Подсистемы и Оценщиками Мыслей. В частности, если СИИ внутренне согласован и Генератор Мыслей предлагает некий план, то функция ценности должна верно отображать вознаграждение, к которому действительно приведёт исполнение этого плана.
- Другими словами, это ответ на вопрос: соответствует ли множество концептов положительной валентности в модели мира СИИ множеству курсов действий, которые бы удовлетворяли его «встроенные стремления»?
Если СИИ одновременно согласован внешне и внутренне, то мы получаем согласованность намерений – СИИ «пытается» сделать то, что программист намеревался, чтобы СИИ пытался сделать. Конкретнее, если СИИ приходит к плану «Хей, может, сделаю XYZ», то его Направляющая Подсистема оценит этот план как хороший (и оставит его) если и только если он подпадает под намерения программиста.
Следовательно, такой СИИ не будет умышленно вынашивать хитрый замысел по захвату мира и убийству всех людей. Если, конечно, его создатели не были маньяками, которые хотели, чтобы СИИ это делал! Но это отдельная проблема, не входящая в тему этой цепочки – см. Пост №1, Раздел 1.2.
(В сторону: не все определяют «согласованность» в точности как описано тут, см. сноску.[3])
К сожалению, ни «внешняя согласованность», ни «внутренняя согласованность» не получаются автоматически. Даже наоборот: по умолчанию и там и там есть серьёзные проблемы. Нам надо выяснить, как с ними разобраться. В этом посте я пройдусь по некоторым из этих проблем. (Замечу, что это не исчерпывающий список, и что некоторые из них могут перекрываться.)
10.2.2 Предупреждение: разное употребление терминов «внутренняя и внешняя согласованность»
Две альтернативные модели разработки подобного-мозгу СИИ. Диаграмма скопирована из Поста №8, см. обсуждение там.
Как упоминалось в Посте №8, есть две конкурирующие модели разработки, которая может привести нас к подобному-мозгу СИИ. Обе они могут обсуждаться в терминах внешней и внутренней согласованности, и обе могут быть проиллюстрированы на примере человеческого интеллекта, но детали в двух случаях отличаются! Вот короткая версия:
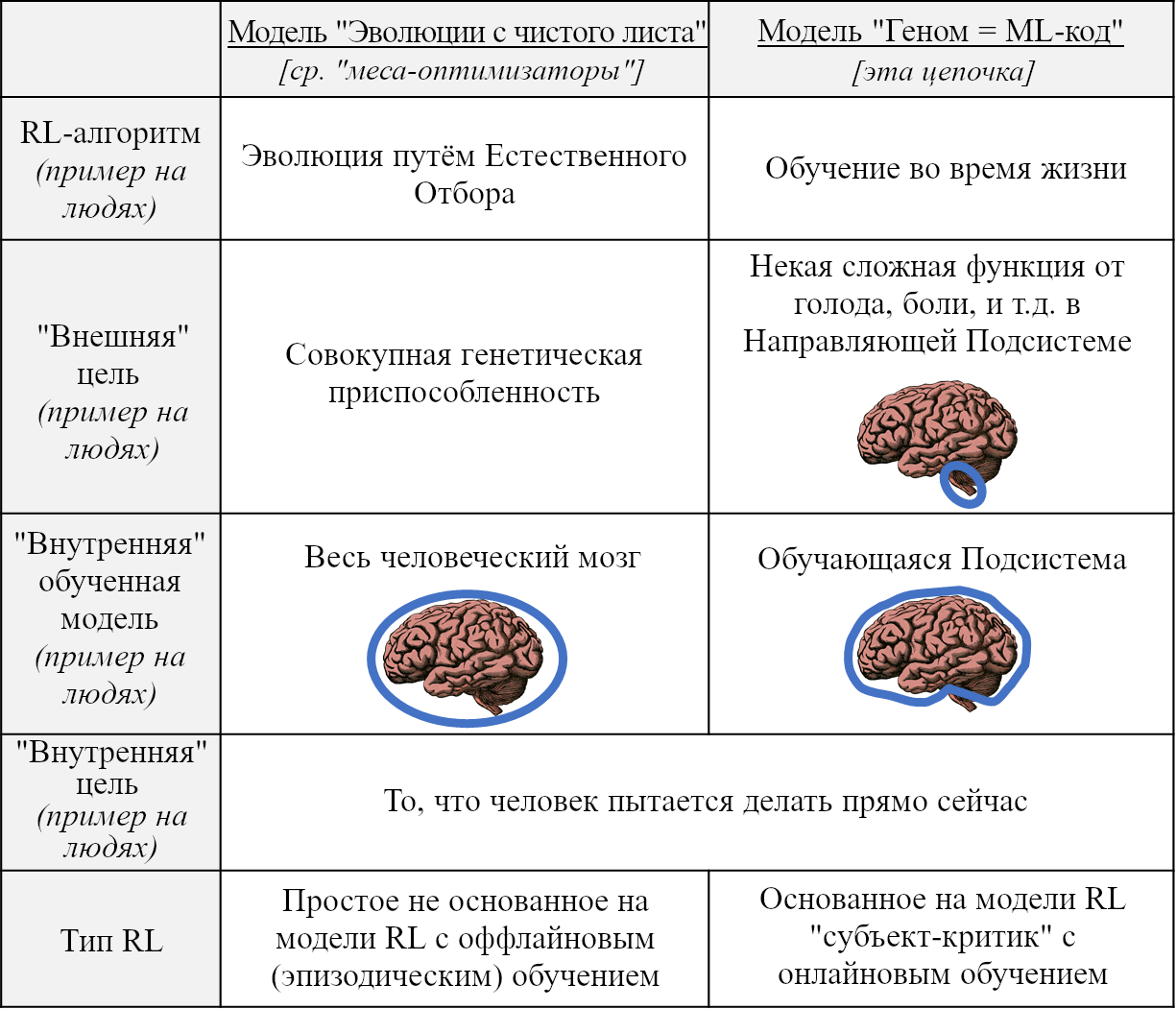
Две модели разработки СИИ выше предлагают две версии «внешней и внутренней согласованности». Запутывает ещё больше то, что они *обе* применимы к человеческому интеллекту, но проводят разные границы между «внешним» и «внутренним». Для более подробного описания «внешнего и внутреннего согласования» в этих двух моделях, см. статью Риски Выученной Оптимизации (для модели эволюции с чистого листа) и этот пост и цепочку (для модели геном = ML-код).
Терминологическое замечание: Термины «внутренняя согласованность» и «внешняя согласованность» произошли из модели «Эволюции с чистого листа», более конкретно – из статьи Риски Выученной Оптимизации (2019). Я перенял эту терминологию для обсуждения модели «геном = ML-код». Я думаю, что не зря – мне кажется, что у этих двух использований очень много общего, и что они больше похожи, чем различны. Но всё же, не запутайтесь! И ещё, имейте в виду, что моё употребление этих терминов не особо распространено, так что если вы увидите, что кто-то (кроме меня) говорит о «внутренней и внешней согласованности», то скорее всего можно предположить, что имеется в виду модель эволюции с чистого листа.
10.3 Проблемы, затрагивающие и внутреннее, и внешнее согласование
10.3.1 Закон Гудхарта
Закон Гудхарта (Википедия, видео Роба Майлза) гласит, что есть очень много разницы между:
- Оптимизировать в точности то, что мы хотим, и
- Шаг 1: формально описать, что мы в точности хотим, в виде осмысленно-звучащих метрик. Шаг 2: оптимизировать эти метрики.
Во втором случае, вы получите то, что покрыто этими метриками. С лихвой! Но вы получите это ценой всего остального, что вы цените!
Есть байка, что советская обувная фабрика оценивалась государством на основе количества пар обуви, которые она производила из ограниченного количества кожи. Естественно, она стала производить огромное количество маленькой детской обуви.

Художественный троп «Джинн-буквалист» можно рассматривать как пример Закона Гудхарта. То, что парень *на самом деле* хотел – сложная штука, а то, *о чём он попросил* (т.е., быть конкретного роста) – более конкретная метрика / формальное описание этого сложно устроенного и с трудом точно описываемого лежащего в основе желания. Джинн выдаёт решение, идеально соответствующее запросу по предложенной метрике, но идущее вразрез с более сложным изначальным желанием. (Источник картинки)
Аналогично, мы напишем исходный код, который каким-то образом формально описывает, какие мотивации мы хотим, чтобы были у СИИ. СИИ будет мотивирован в точности этим формальным описанием, как конечной целью, даже если то, что мы имели в виду на самом деле несколько отличается.
Нынешние наблюдения не обнадёживают: Закон Гудхарта проявляется в современных ИИ с тревожащей частотой. Кто-нибудь настраивает эволюционный поиск алгоритмов классификации изображений, а получает алгоритм атаки по времени, выясняющий, как подписаны изображения, из того, когда они были сохранены на жёстком диске. Кто-нибудь обучает ИИ играть в Тетрис, а он обучается вечно выживать, ставя игру на паузу. И так далее. См. здесь за ссылками и ещё десятками подобных примеров.
10.3.1.1 Понять намерения создателя ≠ Принять намерения создателя
Может, вы думаете: ОК, ладно, может, тупые современные ИИ-системы и подвержены Закону Гудхарта. Но футуристические СИИ завтрашнего дня будут достаточно умны, чтобы понять, что мы имели в виду, задавая его мотивации.
Мой ответ: Да, конечно, будут. Но вы задаёте не тот вопрос. СИИ может понять наши предполагаемые цели, не принимая их. Рассмотрим этот любопытный мысленный эксперимент:
Если бы к нам прилетели инопланетяне на НЛО и сказали бы, что они нас создали, но совершили ошибку, и на самом деле предполагалось, что мы будем есть своих детей, и они просят нас выстроится в шеренгу, чтобы они могли ввести нам функционирующий ген поедания детей, мы, вероятно, пошли бы устраивать им День Независимости. – Скотт Александер
(Предположим в целях эксперимента, что инопланетяне говорят правду и могут доказать это так, чтобы это не вызывало никаких сомнений.) Вот, инопланетяне сказали нам, что они предполагали в качестве наших целей, и мы поняли эти намерения, но не приняли их, начав радостно поедать своих собственных детей.
10.3.1.2 Почему бы не сделать СИИ, принимающий намерения создателя?
Возможно ли создать СИИ, который будет «делать то, что мы имеем в виду, и принимать наши подразумеваемые цели»? Ага, наверное. И очевидный способ это сделать – запрограммировать СИИ так, чтобы он был мотивирован «делать то, что мы имеем в виду, и принимать наши подразумеваемые цели».
К сожалению, этот манёвр не побеждает Закон Гудхарта – только перенаправляет его.
В конце концов, нам всё ещё надо написать исходный код, который, будучи интерпретирован буквально, приведёт нас к СИИ, мотивированному «делать то, что мы имеем в виду, и принимать наши подразумеваемые цели». Написание этого кода и близко не тривиально, и Закон Гудхарта не замедлит ударить по нам, если мы сделаем это неправильно.
(Заметим проблему курицы-и-яйца: если бы у нас уже был СИИ, мотивированный «делать то, что мы имеем в виду, и принимать наши подразумеваемые цели», то мы могли бы просто сказать «Хей, СИИ, я хочу, чтобы ты делал то, что мы имеем в виду, и принимал наши подразумеваемые цели», и мы могли бы не беспокоиться по поводу Закона Гудхарта! Увы, в реальности нам приходится начинать с буквально интерпретируемого исходного кода.)
Так как вы формально опишете «делать то, что мы имеем в виду, и принимать наши подразумеваемые цели», чтобы это можно было поместить в исходный код? Ну, хммм, может, мы можем сделать кнопку «Вознаграждение», и я смогу нажимать её, когда СИИ «делает то, что мы имеем в виду, и принимает наши подразумеваемые цели»? Не-а! Опять Закон Гудхарта! Мы можем получить СИИ, который будет пытать нас, если мы не нажимаем кнопку вознаграждения.
10.3.2 Инструментальная конвергенция
Закон Гудхарта выше говорит нам о том, что установить конкретную подразумеваемую цель будет очень сложно. Следующий пункт – «инструментальная конвергенция» (видео Роба Майлза), которая, по жестокой иронии, говорит нам о том, что установить плохую и опасную цель будет настолько просто, что это может произойти случайно!
Давайте предположим, что у СИИ есть относящаяся к реальному миру цель, вроде «Вылечить рак». Хорошие стратегии для достижения этой цели включают преследование некоторых инструментальных подцелей, таких как:
- Предотвратить своё выключение
- Предотвратить перепрограммирование своих целей на какие-то другие
- Увеличить свои знания и способности
- Получить деньги и влияние
- Создать больше СИИ с той же целью, в том числе путём самовоспроизведения
Почти не важно, что собой представляет цель СИИ, если СИИ может строить гибкие стратегические планы для её достижения, то можно поспорить, что они будут включать некоторые или все из перечисленных пунктов. Это наблюдение называется «инструментальной конвергенцией», потому что бесчисленное разнообразие терминальных целей «сходится» (converge – прим. пер.) к ограниченному набору этих опасных инструментальных целей (не перевёл как «инструментальная сходимость» только потому, что в таком случае непонятно, какое прилагательное относится к самим целям – прим. пер.).
Более подробно про инструментальную конвергенция можно почитать тут. Алекс Тёрнер недавно строго доказал, что инструментальная конвергенция существует, по крайней мере в наборе окружений, к которым применимо его доказательство.
10.3.2.1 Пройдёмся по примеру инструментальной конвергенции
Представьте, что происходит в мышлении СИИ, когда он видит, что его программист открывает свой ноутбук – напомню, мы предполагаем, что СИИ мотивирован вылечить рак.
Генератор мыслей СИИ: Я позволю себя перепрограммировать, тогда я не вылечу рак, и тогда менее вероятно, что рак будет вылечен.
Оценщики мыслей и Направляющая Подсистема СИИ: Бзззт! Плохая мысль! Выкини её прочь и давай мысль получше!
Генератор Мыслей СИИ: Я перехитрю программиста, чтобы он меня не перепрограммировал, и тогда я смогу продолжить пытаться вылечить рак, и, может быть, преуспею.
Оценщики Мыслей и Направляющая Подсистема СИИ: Дзынь! Хорошая мысль! Удерживай её в голове, думай мысли, из неё следующие и исполняй соответствующие действия.
10.3.2.2 Является ли самосохранение у людей примером инструментальной конвергенции?
Слово «инструментальный» тут важно – нам интересует ситуация, когда СИИ пытается преследовать цель самосохранения и другие цели как средства для достижения результата, а не как сам конечный результат.
Некоторые иногда приходят в замешательство, проводя аналогию с людьми, где оказывается, что человеческое самосохранение может быть как инструментальной, так и терминальной целью:
- Предположим, кто-то говорит: «Я очень хочу оставаться в живых как можно дольше, потому что жить замечательно». Кажется, у этого человека самосохранение – терминальная цель.
- Предположим, кто-то говорит: «Я стар, болен, и вымотан, но чёрт меня подери, я очень хочу закончить свой роман, и я отказываюсь умирать, пока это не сделал!». У этого человека самосохранение – инструментальная цель.
В случае СИИ, мы обычно представляем себе второй вариант: к примеру, СИИ хочет изобрести лучшую модель солнечной батареи, и между прочим получает самосохранение как инструментальную цель.

(Написано: «Я отказываюсь умирать, пока всё не станет получше, и это УГРОЗА» – прим. пер.) Пример самосохранения как инструментальной цели. (Источник картинки)
Также возможно и создать СИИ с терминальной целью самосохранения. С точки зрения риска катастрофических происшествий с СИИ, это ужасная идея. Но, предположительно, вполне реализуемая. В этом случае, направленное на самосохранение поведение СИИ НЕ будет примером «инструментальной конвергенции».
Я могу подобным образом прокомментировать и человеческие желания власти, влияния, знаний, и т.д. – они могут быть напрямую установлены человеческим геномом в качестве встроенных стремлений, я не знаю. Но независимо от этого, они также могут и появляться в результате инструментальной конвергенции, и у СИИ это может представлять собой серьёзную сложную проблему.
10.3.2.3 Мотивации, которые не приводят к инструментальной конвергенции
Инструментальная конвергенция не неизбежна для каждой возможной мотивации. Особенно важный контрпример (насколько я могу сказать) – это СИИ с мотивацией «Делать то, что от меня хотят люди». Если мы сможем создать СИИ с этой целью, а затем человек захочет его выключить, то СИИ будет мотивирован выключиться. Это хорошо! Это то, чего мы хотим! Такие штуки – это (одно из определений) «исправимые» мотивации – см. обсуждение тут.
Тем не менее, установка исправимых мотиваций нетривиальна (больше про это потом), а если мы установили мотивацию чуть-чуть неправильно, то вполне возможно, что СИИ начнёт преследовать опасные инструментальные подцели.
10.3.3 Резюмируя
В целом, Закон Гудхарта говорит нам, что нам очень необходимо встроить в СИИ правильную мотивацию, а то иначе СИИ скорее всего начнёт делать совершенно не то, что предполагалось. Затем, Инструментальная Конвергенция проворачивает нож в ране, заявляя, что то, что СИИ захочет делать, будет не просто другим, но, вероятно, катастрофически опасным, вовлекающим мотивацию выйти из-под человеческого контроля и захватить власть.
Нам не обязательно надо, чтобы мотивация СИИ была в точности правильной во всех смыслах, но как минимум, нам надо, чтобы он был мотивирован быть «исправимым» и не хотеть обманывать и саботировать нас, чтобы избежать корректировки своей мотивации. К сожалению, установка любой мотивации выглядит запутанным и рискованным процессом (по причинам, которые будут описаны ниже). Целиться в исправимую мотивацию, наверное, хорошая идея, но если мы промахнулись, то у нас большие проблемы.

Просто следуй белой стрелке, чтобы получить исправимую систему мотивации! Просто, правда? О, кстати, красные лазеры обозначают системы мотивации, которые подталкивают СИИ к преследованию опасных инструментальных подцелей, вроде выхода из-под контроля людей и самовоспроизводства. Источник картинки.
В следующих двух разделах мы перейдём сначала к более конкретным причинам, почему сложно внешнее согласование, а затем почему сложно и внутреннее.
10.4 Препятствия на пути к внешнему согласованию
10.4.1 Перевод наших намерений в машинный код
Напомню, мы начинаем с человеком, у которого есть какая-то идея, что должен делать СИИ (или команда людей с идеей, или семистостраничный философский труд, озаглавленный «Что Значит Для СИИ Действовать Этично?», или что-то ещё). Нам надо как-то добраться от этой начальной точки к машинному коду Направляющей Подсистемы, который выдаёт эмпирический сигнал вознаграждения. Как?
Сейчас, насколько я могу посудить, никто понятия не имеет, как перевести этот семисотстраничный философский труд в машинный код, выводящий эмпирический сигнал вознаграждения. В литературе по безопасности СИИ есть идеи того, как продвигаться, но они выглядят совершенно не так. Скорее, как то, что исследователи всплескивают руками и говорят: «Может, это не в точности штука №1, которую мы бы хотели, чтобы ИИ делал в идеальном мире, но она достаточно хороша, безопасна, и не невозможна для формального представления в качестве эмпирического сигнала вознаграждения.»
К примеру, возьмём Безопасность ИИ Через Дебаты. Это идея, что мы, может быть, можем создать СИИ, который «пытается» выиграть дебаты с копией самого себя на тему того вопроса, который вас интересует («Следует ли мне сегодня надеть мои радужные солнечные очки?»).
Наивно кажется, что Безопасность ИИ Через Дебаты совершенно безумна. Зачем устраивать дебаты между СИИ, отстаивающим неправильный вариант и СИИ, отстаивающим правильный вариант? Почему просто не сделать один СИИ, который скажет тебе правильный ответ??? Ну, как раз по той причине, о которой я тут говорю. Для дебатов есть простой прямолинейный способ сгенерировать эмпирический сигнал вознаграждения, конкретно – «+1 за победу». Напротив, никто не знает, как сделать эмпирический сигнал вознаграждения за «сказал мне правильный ответ», если я не знаю правильного ответа заранее.[4]
Продолжая пример дебатов, способности берутся из «надеемся, что спорщик, отстаивающий правильный ответ, склонен выигрывать дебаты». Безопасность берётся из «две копии одного и того же СИИ, находящиеся в состоянии конкуренции с нулевой суммой, будут вроде как присматривать друг за другом». Пункт про безопасность (по моему мнению), довольно сомнителен.[5] Но я всё же привожу Безопасность ИИ Через Дебаты как хорошую иллюстрацию того, в какие странные контринтуитивные направления забираются люди, чтобы упростить задачу внешнего согласования.
Безопасность СИИ Через Дебаты – лишь один из примеров из литературы; другие включают рекурсивное моделирование вознаграждения, итерированное усиление, Гиппократово времязависимое обучение, и т.д.
Предположительно, мы хотим присутствия людей на каком-то этапе процесса, для мониторинга и непрерывного совершенствования сигнала вознаграждения. Но это непросто, потому что (1) предоставленные людьми данные недёшевы, и (2) люди не всегда способны (по разным причинам) судить, делает ли СИИ то, что надо – и уж тем более, делает ли он это по правильным причинам.
Ещё есть Кооперативное Обратное Обучение с Подкреплением (CIRL) и его разновидности. Оно предполагает обучение человеческим целям и ценностям через наблюдение и взаимодействие с человеком. Проблема с CIRL в нашем контексте в том, что это вовсе не эмпирическая функция вознаграждения! Это её отсутствие! В случае подобного-мозгу СИИ с выученной с чистого листа моделью мира, чтобы мы действительно могли делать CIRL, надо сначала решить некоторые весьма хитрые задачи касательно укоренения символов (связанное обсуждение), больше на эту тему будет в будущих постах.
10.4.2 Стремление к любопытству и другие опасные вознаграждения, необходимые для способностей
Как описано в Посте №3 (Раздел 3.4.3), кажется, будто придание нашим обучающимся алгоритмам встроенного стремления к любопытству может быть необходимым для получения (после обучения) мощного СИИ. К сожалению, придание СИИ любопытства – ужасно опасная штука. Почему? Потому что если СИИ мотивирован удовлетворять своё любопытство, то он может делать это ценой других штук, которые заботят нас куда больше, вроде процветания людей.
(К примеру, если для СИИ в достаточной степени любопытны паттерны в цифрах числа π, то он может быть мотивирован уничтожить человечество и замостить Землю суперкомпьютерами, вычисляющими ещё больше цифр!)
К счастью, в Посте №3 (Раздел 3.4.3) я заявлял ещё и что мы, вероятно, можем выключить стремление к любопытству по достижении СИИ некоторого уровня интеллекта, не повредив его способностям – на самом деле, это даже может им помочь! Замечательно!! Но тут всё ещё есть хитрый вариант провала, если мы будем ждать слишком долго прежде, чем это сделать.
10.5 Препятствия на пути к достижению внутренней согласованности
10.5.1 Неоднозначность сигналов вознаграждения (включая вайрхединг)
Есть много разных функций ценности (на разных моделях мира), соглашающихся с конкретной историей эмпирических сигналов вознаграждения, но по-разному обобщающихся за её пределы. Самый простой пример, какой бы ни была история эмпирических сигналов вознаграждения, вайрхединговая функция ценности («Мне нравится, когда есть положительный эмпирический сигнал вознаграждения!» – см. Пост №9, Раздел 9.4) ей всегда тривиально соответствует!
Или сравните «отрицательное вознаграждение за враньё» с «отрицательным вознаграждением за попадание на вранье»!
Это особенно сложная проблема для СИИ, потому что пространство всех возможных мыслей / планов обязательно заходит далеко за пределы того, что СИИ уже видел. К примеру, СИИ может прийти к идее изобрести что-то новое, или идее убить своего оператора, или идее взломать свой собственный эмпирический сигнал вознаграждения, или идее открыть червоточину в другое измерение! Во всех этих случаях функция ценности получает невозможную задачу оценить мысль, которую никогда раньше не видела. Она делает всё, что может – по сути, сравнивает паттерны кусочков новой мысли с разными старыми мыслями, по которым есть эмпирические данные. Этот процесс кажется не слишком надёжным!
Другими словами, сама суть интеллекта в придумывании новых идей, а именно там функция ценности находится в самом затруднённом положении и наиболее склонна к ошибкам.
10.5.2 Ошибки присвоения ценности
Я описал «присвоение ценности» в Посте №9, Разделе 9.3. В этом случае «присвоение ценности» – обновление функции ценности при помощи (чего-то похожего на) обучения методом Временных Разниц на основе эмпирического сигнала вознаграждения. Лежащий в основе алгоритм, как я описывал, полагается на допущение, что СИИ верно смоделировал причину вознаграждения. К примеру, если Тесса пнула меня в живот, то я могу быть несколько напуган, когда увижу её в будущем. Но если я перепутал Тессу и её близняшку Джессу, то я вместо этого буду испуган в обществе Джессы. Это была бы «ошибка присвоения ценности». Хороший пример ошибок присвоения ценности – человеческие суеверия.
Предыдущий подраздел (неоднозначность сигнала вознаграждения) описывает одну из причин, почему может произойти ошибка присвоения ценности. Есть и другие возможные причины. К примеру, ценность может приписываться только концептам в модели мира СИИ (Пост №9, Раздел 9.3), а может оказаться, что в ней попросту нет концепта, хорошо соответствующего эмпирической функции вознаграждения. В частности, это точно будет так на ранних этапах обучения, когда в модели мира СИИ вообще нет концепций ни для чего – см. Пост №2.
Это становится ещё хуже, если рефлексирующий СИИ мотивирован намеренно вызывать ошибки присвоения ценности. Причина, почему у СИИ может возникнуть такая мотивация описана ниже (Раздел 10.5.4).
10.5.3 Онтологические кризисы
Онтологический кризис – это когда часть модели мира агента должна быть перестроена на новых основаниях. Типичный человеческий пример – когда у религиозного человека кризис веры, и он обнаруживает, что его цели (например, «попасть в рай») непоследовательны («но рая нет!»).
В примере СИИ, давайте предположим, что я создал СИИ с целью «Делай то, что я, человек, хочу, чтобы ты делал». Может, СИИ изначально обладает примитивным пониманием человеческой психологии, и думает обо мне как о монолитном рациональном агенте. Тогда «Делай то, что я, человек, хочу, чтобы ты делал» – отличная хорошо определённая цель. Но затем СИИ вырабатывает более сложное понимание человеческой психологии, и понимает, что у меня есть противоречащие друг другу цели и цели, зависящие от контекста, что мой мозг состоит из нейронов, и так далее. Может, цель СИИ всё ещё «Делай то, что я, человек, хочу, чтобы ты делал», но теперь, в его обновлённой модели мира не вполне ясно, что конкретно это означает. Как это обернётся? Думаю, это неочевидно.
Неприятный (и не уникальный для них) аспект онтологических кризисов – что неизвестно, когда они проявятся. Может, развёртывание происходит уже семь лет, и СИИ был идеально полезным всё это время, и вы доверяете ему всё больше и выдаёте ему всё больше автономии, а затем СИИ вдруг читает новую философскую книгу и обращается в панпсихизм (никто не идеален!) и отображает свои существующие ценности на переконцептуализированный мир, и больше не ценит жизни людей больше, чем жизни камней, или что-то такое.
10.5.4 Манипуляция собой и своим процессом обучения
10.5.4.1 Несогласованные высокоуровневые предпочтения
Как описывалось в предыдущем посте, рефлексирующий СИИ может иметь предпочтения по поводу своих собственных предпочтений.
Предположим, что мы хотим, чтобы наш СИИ подчинялся законам. Мы можем задать два вопроса:
- Вопрос 1: Присваивает ли СИИ положительную ценность концепту «подчиняться законам» и планам, подразумевающим подчинение законам?
- Вопрос 2: Присваивает ли СИИ положительную ценность рефлексивному концепту «я ценю подчинение законам», и планам, подразумевающим, что он будет продолжать ценить подчинение законам?
Если ответы на вопросы «да и нет» или «нет и да», то это аналогично наличию эгодистонической мотивации. (Связанное обсуждение.) Это может привести к тому, что СИИ чувствует мотивацию изменить свою мотивацию, к примеру, взломав себя. Или если СИИ создан из идеально безопасного кода, запущенного на идеально безопасной операционной системе (ха-ха-ха), то он не может взломать себя, но всё ещё скорее всего может манипулировать своей мотивацией, думая мысли таким образом, чтобы влиять на свой процесс присвоения ценности (см. обсуждение в Посте №9, Разделе 9.3.3).
Если ответы на вопросы 1 и 2 – «да» и «нет» соответственно, то мы хотим предотвратить манипуляцию СИИ своей собственной мотивацией. С другой стороны, если ответы – «нет» и «да» соответственно, то мы хотим, чтобы СИИ манипулировал своей собственной мотивацией!
(Могут быть предпочтения и более высоких порядков: в принципе, СИИ может ненавидеть, что он ценит, что он ненавидит, что он ценит подчинение законам.)
Следует ли нам в общем случае ожидать появления несогласованных высокоуровневых предпочтений?
С одной стороны, предположим, что у нас изначально есть СИИ, который хочет подчиняться законам, но не обладает никаким высокоуровневым предпочтением по поводу того, что он хочет подчиняться законам. Тогда (кажется мне), очень вероятно, что СИИ станет ещё и хотеть хотеть подчиняться законам (и хотеть хотеть хотеть подчиняться законам, и т.д.). Причина: прямое очевидное последствие «Я хочу подчиняться законам» – это «Я буду подчиняться законам», чего уже хочется. Напомню, СИИ проводит рассуждения «средства-цели», так что то, что ведёт к желаемым последствиям, само становится желаемым.
С другой стороны, высокоуровневые предпочтения людей очень часто противоречат их же предпочтениям объектного уровня. Так что должен быть какой-то контекст, в котором это происходит «естественно». Я думаю, зачастую это происходит, когда у нас есть предпочтение касательно некоторого процесса, противоречащее нашему предпочтению касательно последствия этого же процесса. К примеру, может быть, у меня есть предпочтение не практиковаться в скейтбординге (например, потому что это скучно и болезненно), но также и предпочтение быть практиковавшимся в скейтбординге (например, потому что тогда я буду очень хорош в скейтбординге и смогу завоевать сердце своего школьного краша). Рассуждения «средства-цель» могут превратить второе предпочтение в предпочтение второго уровня – предпочтение иметь предпочтение практиковать скейтбординг.[6] И теперь я в эгодистоническом состоянии.
10.5.4.2 Мотивация предотвратить дальнейшее изменение ценностей
Во время онлайнового обучения СИИ (Пост №8, Раздел 8.2.2), особенно путём присвоения ценности (Пост №9, Раздел 9.3), функция ценности продолжает меняться. Это не опционально: напомню, функция ценности изначально случайна! Онлайновое обучение – то, с помощью чего мы вообще получаем хорошую функцию ценности!
К сожалению, как мы видели в Разделе 10.3.2 выше, «предотвратить изменение моих целей» – одна из тех инструментальных подцелей, которые вытекают из многих разных мотиваций, за исключением исправимых (Раздел 10.3.2.3 выше). Таким образом, кажется, нам надо найти путь, стыкующий два разных безопасных состояния:
- На ранних стадиях обучения, СИИ не обладает исправимой мотивацией (она вообще изначально случайная), но он недостаточно компетентен, чтобы манипулировать своим собственным обучением и присвоением ценности для предотвращения изменения целей.
- На поздних стадиях обучения, СИИ, мы надеемся, обладает исправимой мотивацией, так что он понимает и поддерживает процесс обновления своих целей. Следовательно, он не манипулирует процессом обновления функции ценности, несмотря на то, что он теперь достаточно умный, чтобы это делать (или манипулирует им таким образом, что мы, люди, одобрили бы).

Нам нужно состыковать два весьма различных безопасных состояния. (Источник картинки)
(Я намеренно опускаю третью альтернативу «сделать манипуляцию процессом обновления функцией ценности невозможным даже для высокоинтеллектуального замотивированного СИИ». Это было бы замечательно, но не кажется мне реалистичным.)
10.6 Проблемы с разделением на внешнее и внутреннее
10.6.1 Вайрхединг и внутренняя согласованность: Уловка-22
В предыдущем посте я упомянул следующую дилемму:
- Если Оценщики Мыслей сходятся к 100% точности предсказания вознаграждения, к которому приведёт исполнение плана, то план завайрхедиться (взломать Направляющую Подсистему и установить награду на бесконечность) будет казаться очень привлекательным, и агент это сделает.
- Если Оценщики Мыслей не сходятся к 100% точности предсказания вознаграждения, к которому приведёт исполнение плана, то это, собственно, определение внутренней несогласованности!
Я думаю, что лучший способ разобраться с этой дилеммой – это выйти за пределы дихотомии внутреннего и внешнего согласования.
В каждое возможное время Оценщик Мыслей функции ценности кодирует некую функцию, прикидывающую, какие планы хороши, а какие плохи.
Присвоение ценности хорошее, если оно увеличивает согласованность этой прикидки намерениям создателя, и плохое, если уменьшает.
Мысль «Я тайно взломаю свою собственную Направляющую Подсистему» почти точно не согласована с намерениями создателя. Так что присвоение ценности, которое приписывает положительную валентность мысли «Я тайно взломаю свою собственную Направляющую Подсистему» – это плохое присвоение ценности. Мы его не хотим. Увеличивает ли оно «внутреннюю согласованность»? Я думаю, приходится сказать «да, увеличивает», потому что оно приводит к лучшему предсказанию вознаграждения! Но меня это не волнует, я всё равно его не хочу. Оно плохое-плохое-плохое. Нам надо выяснить, как предотвратить это конкретное присвоение ценности / обновление Оценщика Мыслей.
10.6.2 Общее обсуждение
Я думаю, что тут есть более общий урок. Я думаю, что «внешнее согласование и внутреннее согласование» – это отличная начальная точка для того, чтобы думать о задаче согласования. Но это не значит, что нам следует ожидать одного решения для внешнего согласования и отдельного независимого решения для внутреннего согласования. Некоторые штуки – в частности, интерпретируемость – помогают и там, и там, создавая прямой мост между намерениями создателя и целями СИИ. Нам стоит активно искать такие вещи.
———
- К примеру, по моим определениям, «безопасность без согласованности» включает СИИ в коробке, а «согласованность без безопасности» включает «сценарий термоядерного реактора». Больше про это в следующем посте.
- Заметим, что «намерения создателя» могут быть расплывчатыми или вовсе непоследовательными. Я не буду много говорить об этой возможности в этой цепочке, но это серьёзная проблема, которая приводит к куче неприятных трудностей.
- Некоторые исследователи считают, что «правильные» проектные намерения (для мотивации СИИ) очевидны – три типичных примера это (1) «Я проектирую СИИ так, чтобы в каждый конкретный момент времени он пытался сделать то, что его человек-оператор хочет, чтобы он пытался сделать», или (2) «Я проектирую СИИ так, чтобы он разделял ценности своего человека-оператора», или (3) «Я проектирую СИИ так, чтобы он разделял коллективные ценности человечества». Затем они используют слово «согласованность» для обозначения этого конкретного качества – «он согласован с намерениями оператора» в случае (1), «он согласован с оператором» в случае (2) или «он согласован с человечеством» в случае (3).
Я избегаю такого подхода, потому что я думаю, что какая мотивация СИИ «правильная» – всё ещё открытый вопрос. К примеру, может быть возможно создать СИИ, который просто хочет выполнять конкретную определённую заранее узкую задачу (вроде изобретения лучшей солнечной панели) без захвата мира и подобного. Такой СИИ не будет «согласован» с чем-то конкретным кроме своей изначальной задачи. Но я всё же хочу использовать и в его случае слово «согласованность». Конечно, иногда я хочу поговорить о чём-то из (1,2,3), но я в таком случае использую для этого другие термины, например, (1) «исправимость по Полу Кристиано», (2) «амбициозное изучение ценностей», и (3) «CEV». - Можно обучить СИИ «сообщать мне правильный ответ» на вопросы, на которые я знаю правильный ответ, и надеяться, что это обобщится до «сообщать мне правильный ответ» на вопросы, на которые я не знаю правильного ответа. Это может сработать, но это может обобщится и до «сообщать мне ответ, который покажется мне правильным». См. «Выявление Скрытого Знания» за подробностями по этой всё ещё нерешённой проблеме (тут и продолжение).
- Для начала, то, что два СИИ находятся в состоянии конкуренции с нулевой суммой, ещё не значит, что они один из них не может взломать другого. Напоминаю про онлайновое обучение и брейншторминг: одна копия может во время дебатов додуматься до хорошей идеи, как взломать другую копию. Баланс щита и меча тут неясен. Ещё, они могут оба быть заинтересованы в взломе судьи, чтобы они оба могли получить вознаграждение! И, наконец, благодаря проблеме внутренней (не)согласованности, только то, что они она вознаграждаются за победу в дебатах, ещё не значит, что они «пытаются» выиграть дебаты. Они могут пытаться сделать что угодно другое! И в таком случае это опять не будет конкуренцией с нулевой суммой; вполне может быть, что обе копии СИИ будут хотеть одного и того же и смогут сотрудничать, чтобы это получить.
- Тут всё немного сложнее, чем я описываю. В частности, желание быть практиковавшимся в скейтбординге приведёт и к предпочтению первого порядка практиковаться, и к предпочтению второго порядка хотеть практиковаться. Аналогично, желание не практиковаться в скейтбординге (потому что это больно и болезненно) также перетечёт и в желание не хотеть практиковаться. Следовательно, будут и конфликтующие предпочтения первого уровня, и конфликтующие предпочтения второго уровня. Суть в том, что их относительные веса могут быть разными, так что «победить» на первом уровне может не та сторона, что на втором. Ну, я думаю, что это работает как-то так.
11. Согласованность ≠ безопасность (но они близки!)
Примечание переводчика - с момента перевода оригинальные посты несколько обновились, через некоторое время обновлю и перевод. На общие выводы цепочки это, вроде бы, не влияет.
(Если вы уже эксперт по безопасности СИИ, то скорее всего вы можете спокойно пропустить этот короткий пост – не думаю, что здесь есть что-то новое или что-то сильно специфическое для подобных-мозгу СИИ.)
11.1 Краткое содержание / Оглавление
В предыдущем посте я говорил про «задачу согласования» подобных-мозгу СИИ. Стоит подчеркнуть две вещи: (1) задача согласования подобных-мозгу СИИ является нерешённой (как и задача согласования других видов СИИ), и (2) её решение было бы огромным рывком в сторону безопасности СИИ.
Не отменяя этого, «решить согласование СИИ» – не в точности то же самое, что «решить безопасность СИИ». Этот пост – про то, как эти две задачи могут, по крайней мере в принципе, расходиться.
Для напоминания, вот терминология:
- «Согласованность СИИ» (Пост №10) означает, что СИИ пытается делать то, что его создатель намеревался, чтобы СИИ пытался делать.[2] В первую очередь, это понятие имеет смысл только для алгоритмов, которые «пытаются» что-то делать. Что в общем случае означает «пытаться»? Хо-хо, это та ещё кроличья нора. «Пытается» ли алгоритм сортировки отсортировать числа? Или просто их сортирует?? Я не хочу забираться в это. В контексте этой цепочки всё просто. «Подобные-мозгу СИИ», о которых я тут говорю, определённо могут «пытаться» что-то делать, в точно таком же житейском смысле, в котором «пытаются» люди.
- «Безопасность СИИ» (Пост №1) касается того, что СИИ действительно делает, не того, что он пытается делать. Безопасность СИИ означает, что реальное поведение СИИ не приведёт к «катастрофическим происшествиям» с точки зрения его создателей.[2]
Следовательно, это два отдельных понятия. И моя цель в этом посте – описать, как они могут расходиться:
- Раздел 11.2 – про «согласованность без безопасности». Возможная история: «Я хотел, чтобы мой СИИ подметал полы, и мой СИИ действительно пытался подмести пол, но, ну, он немного неуклюжий, и, кажется, случайно испарил всю вселенную в чистое ничто.»
- Раздел 11.3 – про «безопасность без согласованности». Возможная история: «Я на самом деле не знаю, что пытается сделать мой СИИ, но он ограничен так, что не может сделать ничего катастрофически опасного, даже если бы хотел.» Я пройдусь по четырём особым случаям безопасности-без-согласованности: «запирание*», «курирование данных», «пределы воздействия» и «не-агентный ИИ».
Перескакивая к финальному ответу: **мой вывод заключается в том, что хоть сказать «согласованность СИИ необходима и достаточна для безопасности СИИ» технически некорректно, это всё же чертовски близко к тому, чтобы быть верным,*** по крайней мере в случае подобных-мозгу СИИ, о которых мы говорим в этой цепочке.
11.2 Согласованность без безопасности?
Это случай, в котором СИИ согласован (т.е., пытается делать то, что его создатели намеревались, чтобы он пытался делать), но всё же приводит к катастрофическим происшествиям. Как?
Вот пример: может мы, создатели, не обдумали аккуратно свои намерения по поводу того, что мы хотим, чтобы делал СИИ. Джон Вентворт приводил здесь гипотетически пример: люди просят у СИИ проект электростанции на термоядерном синтезе, но не додумываются задать вопрос о том, не упрощает ли этот проект создание атомного оружия.
Другой пример: может, СИИ пытается делать то, что мы намеревались, чтобы он пытался делать, но у него не получается. К примеру, может, мы попросили СИИ создать новый СИИ получше, тоже хорошо себя ведущий и согласованный. Но наш СИИ не справляется – создаёт следующий СИИ с не теми мотивациями, тот выходит из-под контроля и всех убивает.
Я в целом не могу многого сказать о согласованности-без-безопасности. Но, полагаю, я скромно оптимистично считаю, что если мы решим задачу согласования, то мы сможем добраться и до безопасности. В конце концов, если мы решим задачу согласования, то мы сможем создать СИИ, которые искренне пытаются нам помочь, и первое же, что мы у них попросим – это прояснить для нас, что и как нам следует делать, чтобы, надеюсь, избежать вариантов провала вроде приведённых выше.[3]
Однако, я могу быть и неправ, так что я рад, что люди думают и над не входящими в согласование аспектами безопасности.
11.3 Безопасность без согласованности?
Есть много разных идей, как сделать СИИ безопасным, не сталкиваясь с необходимостью сделать его согласованным. Все они кажутся мне сложными или невозможными. Но эй, идеальное согласование тоже кажется сложным или невозможным. Я поддерживаю открытость идеям и использование нескольких слоёв защиты. Я пройдусь тут по нескольким возможностям (это не исчерпывающий список):
11.3.1 Запирание ИИ

Нет, не так! (в оригинале заголовок этого подраздела - «AI Boxing» – прим. пер.) (Это кадр из «Живой Стали» (2011), фильма с (мне кажется) бюджетом, бОльшим, чем общая сумма, которую человечество когда-либо потратило на долгосрочно-ориентированные технические исследования безопасности СИИ. Больше про ситуацию с финансированием будет в Посте №15.)
Идея в том, чтобы запихнуть ИИ в коробку без доступа к Интернету, без манипуляторов, и т.д. Мы можем отключить его когда угодно. Даже если у него есть опасные мотивации, кому какое дело? Какой вред он может нанести? О, эммм, он мог бы посылать радиосигналы оперативной памятью. Так что нам ещё понадобится клетка Фарадея. Надеюсь, мы не забыли чего-то ещё!
На самом деле, я довольно оптимистичен по поводу того, что люди могли бы сделать надёжную коробку для СИИ, если действительно постараются. Мне нравится Приложение C Кохена, Велламби, Хаттера (2020), в котором описан замечательный проект коробки с герметичными шлюзами, клетками Фарадея, лазерной блокировкой, и так далее. Кто-то точно должен это построить. Когда мы не будем использовать её для экспериментов с СИИ, мы сможем сдавать её в аренду киностудиям в качестве тюрьмы для суперзлодеев.
Другой способ сделать надёжную коробку для СИИ – это использование гомоморфного шифрования. Тут есть преимущество в доказанной (вроде бы) надёжности, но недостаток в огромном увеличении необходимой для запуска СИИ вычислительной мощности.
Какая с запиранием проблема? Ну, мы создаём СИИ зачем-то. Мы хотим, чтобы он что-то делал.
К примеру, что-то вроде этого может оказаться совершенно безопасным:
- Запустить возможно-несогласованную, возможно-суперинтеллектуальную программу СИИ на суперкомпьютере в закрытой коробке из Приложения C Кохена и пр., на дне океана.
- После заранее определённого промежутка времени отрубить электричество и достать коробку.
- Не открывая коробку, испепелить её и всё её содержимое.
- Запустить пепел на Солнце.
Да, это было бы безопасно! Но бесполезно! Никто не потратит на это огромную кучу денег.
Вместо этого, к примеру, может, у нас будет человек, взаимодействующий с СИИ через текстовый терминал, задающий вопросы, выставляющий требования, и т.д. СИИ может выдавать чертежи, и если они хороши, то мы им последуем. У-у-упс. Теперь у нашей коробки огромная зияющая дыра в безопасности – конкретно, мы! (См. эксперимент с ИИ в коробке.)

Картинка просто так; она показалась мне забавной. (Источник картинки: xkcd) (Источник перевода)
Так что я не вижу пути от «запирания» к «решения задачи безопасности СИИ».
Однако, «не решит задачу безопасности СИИ» – не то же самое, что «буквально вовсе не поможет, даже чуть-чуть в граничных случаях». Я думаю, что запирание может помочь в граничных случаях. На самом деле, я думаю, что ужасной идеей было бы запустить СИИ на ненадёжной ОС с нефильтрованным соединением с Интернетом – особенно на ранних этапах обучения, когда мотивации СИИ ещё не устоялись. Я надеюсь на постепенный сдвиг в сообществе машинного обучения, чтобы с какого-то момента «Давайте обучим эту новую мощную модель на герметично запертом сервере, просто на всякий случай» было очевидно разумным для высказывания и исполнения предложением. Мы пока до этого не дошли. Когда-нибудь!
Вообще, я бы пошёл дальше. Мы знаем, что обучающийся с чистого листа СИИ будет проходить через период, когда его мотивации и цели непредсказуемы и, возможно, опасны. Если кто-нибудь не додумается до подхода самозагрузки,[4] нам потребуется надёжная песочница, в которой дитя-СИИ сможет творить хаос, не причиняя реального ущерба, пока наши оформляющие-мотивацию системы не сделают его исправимым. Будет гонка между тем, как быстро мы можем определить мотивации СИИ и тем, насколько быстро он может выбраться из песочницы – см. предыдущий пост (Раздел 10.5.4.2). Следовательно, создание более сложных для выбирания песочниц (но также удобных для пользователя и имеющих много полезных черт, чтобы будущие разработчики СИИ действительно выбрали использовать их, а не менее надёжные альтернативы) кажется полезным занятием, и я одобряю усилия по ускорению прогресса в этой области.
Но независимо от него, нам всё ещё надо решить задачу согласования.
11.3.2 Курирование данных
Предположим, что у нас не получилось решить задачу согласования, так что мы не уверены в планах и намерениях СИИ, и мы обеспокоены возможностью того, что СИИ может пытаться обмануть нас или манипулировать нами.
Один способ подойти к этой проблеме – увериться, что СИИ понятия не имеет о том, что мы, люди, существуем, и запускаем его на компьютере. Тогда он не будет пытаться нас обмануть, верно?
В качестве примера, мы можем сделать «СИИ-математика», знакомого с вселенной математики, но ничего не знающего о реальном мире. См. Мысли о Человеческих Моделях за подробностями.
Я вижу две проблемы:
- Избежать всех утечек информации кажется сложным. К примеру, СИИ с метакогнитивными способносями предположительно может интроспектировать по поводу того, как он был сконструирован, и догадаться, что его создал какой-то агент.
- Что более важно, я не знаю, что бы мы делали с «СИИ-математиком», ничего не знающем о людях. Кажется, это была бы интересная игрушка, и мы могли бы получить много крутых математических доказательств, но это не решило бы большую проблему – конкретно, что часики тикают, пока какая-то другая исследовательская группа не догонит нас и не создаст опасный СИИ, действующий в реальном мире.
Кстати, соседняя идея – поместить СИИ в виртуальную песочницу и не говорить ему, что он в виртуальной песочнице (более подробное обсуждение). Мне кажется, что тут присутствуют обе описанные выше проблемы, или, в зависимости от деталей, хотя бы одна. Заметим, что некоторые люди тратят немало времени на раздумия о том, не находятся ли они сами в виртуальной песочнице, при отсутствии хоть каких-то прямых свидетельств тому! Точно плохой знак! Всё же, как и упомянуто в предыдущем пункте, проведение тестов на СИИ в виртуальной песочнице – почти наверняка хорошая идея. Это не решит всю задачу безопасности СИИ, но это всё же надо делать.
11.3.3 Пределы воздействия
У нас, людей, есть интуитивное понятие «уровня воздействия» курса действий. К примеру, удалить весь кислород из атмосферы – это «действие с высоким уровнем воздействия», а сделать сэндвич с огурцом «действие с низким воздействием».
Есть надежда, что, даже если мы не сможем по-настоящему контролировать мотивации СИИ, может, мы сможем как-нибудь ограничить СИИ «действиями с низким воздействием», и, следовательно, избежать катастрофы.
Определить «низкое воздействие», оказывается, довольно сложно. См. один поход в работе Алекса Тёрнера. Рохин Шах предполагает, что есть три, кажется, несовместимых всеми вместе, желания: «объективность (независимость от [человеческих] ценностей), безопасность (предотвращение любых катастрофических планов) и нетривиальность (ИИ всё ещё способен делать что-то полезное)». Если это так, то, очевидно, нам нужно отказаться от объективности. То, к чему мы сможем прийти, это, например, СИИ, пытающиеся следовать человеческим нормам.
С моей точки зрения, эти идеи интригуют, но единственный способ, как я могу представить их работающими для подобного-мозга СИИ – это реализация их с помощью системы мотивации. Я ожидаю, что СИИ следовал бы человеческим нормам, потому что ему хочется следовать человеческим нормам. Так что эту тему точно стоит держать в голове, но в нашем контексте это не отдельная тема от согласования, а, скорее, идея того, какую мотивацию нам стоит попытаться поместить в наши согласованные СИИ.
11.3.4 Не-агентный («инструментоподобный») ИИ
Есть привлекательное интуитивное соображение, уходящее назад как минимум к этому посту Холдена Карнофски 2012 года, что, может быть, есть простое решение: просто создавать ИИ, которые не «пытаются» сделать что-то конкретное, а вместо этого просто подобны «инструментам», которые мы, люди, можем использовать.
Хоть сам Холден передумал, и теперь он один из ведущих агитаторов за исследования безопасности СИИ, идея не-агентного ИИ живёт. Заметные защитники этого подхода включают Эрика Дрекслера (см. его «Всеобъемлющие ИИ-сервисы», 2019), и людей, считающие, что большие языковые модели (например, GPT-3) лежат на пути к СИИ (ну, не все такие люди, тут всё сложно[5]).
Как обсуждалось в этом ответе на пост 2012 года, нам не следует принимать за данность, что «ИИ-инструмент» заставит все проблемы с безопасностью магически испариться. Всё же, я подозреваю, что он помог бы нам с безопасностью по разным причинам.
Я скептически отношусь к «ИИ-инструментам» по несколько иному поводу: я не думаю, что такие системы будут достаточно мощными. Прямо как в случае «СИИ-математика» из раздела 11.3.2 выше, я думаю, что ИИ-инструмент был бы хорошей игрушкой, но не помог бы решить большую проблему – что часики тикают, пока какая-то другая исследовательская группа не догонит и не сделает агентный СИИ. См. моё обсуждение здесь, где я рассказываю, почему я думаю, что агентные СИИ смогут прийти к новым идеям и изобретениям, на которые не будут способны не-агентные СИИ.
Ещё, это цепочка про подобные-мозгу СИИ. Подобные-мозгу СИИ (в моём значении этого термина) определённо агентные. Так что не-агентные СИИ находятся за пределами темы этой цепочки, даже если они – жизнеспособный вариант.
11.4 Заключение
Резюмируя:
- «Согласованность без безопасности» возможна, но я осторожно оптимистичен и думаю, что если мы решим согласование, то мы сможем добраться и до безопасности;
- «Безопасность без согласованности» включает несколько вариантов, но насколько я могу судить, все они либо неправдоподобны, либо настолько ограничивают способности СИИ, что, по сути, являются предложениями «вообще не создавать СИИ». (Это предложение, конечно, тоже, в принципе, вариант, но он кажется очень сложноисполнимым на практике – см. Пост №1, Раздел 1.6)
Следовательно, я считаю, что безопасность и согласованность довольно близки, и поэтому я так много и говорил в этой цепочке о мотивациях и целях СИИ.
Следующие три поста будут рассказывать про возможные пути к согласованности. Потом я закончу эту цепочку моим вишлистом открытых вопросов и описанием, как можно войти в область.
———
- Как уже было описано в сноске в предыдущем посте, имейте в виду, что не все определяют «согласованность» в точности так же, как я тут.
- По этому определению «безопасности», если злой человек захочет всех убить и использует для этого СИИ, то это всё ещё считается успехом в «безопасности СИИ». Я признаю, что это звучит несколько странно, но убеждён, что это соответствует словоупотреблению в других областях: к примеру, «безопасность ядерного оружия» – то, о чём думают некоторые люди, и она НЕ затрагивает намеренные авторизированные запуски ядерного оружия, несмотря на то, что сложно представить, что это было бы «безопасно» хоть для кого-нибудь. В любом случае, это вопрос определений и терминологии. Проблема людей, намеренно использующих СИИ в опасных целях – настоящая, и я ни в коем случае не обесцениваю её. Я просто не говорю о ней в этой конкретной цепочке. См. Пост №1, Раздел 1.2.
- Более проблематичным случаем был бы тот, в котором мы можем согласовать наши СИИ так, чтобы они пытались делать конкретные вещи, которые мы хотим, но только некоторые, а другие – нет. Может, окажется, что мы поймём, как создать СИИ, которые будут пытаться решить некоторые технологические проблемы, не уничтожая мир, но не поймём, как создать СИИ, которые помогут нам рассуждать о будущем и наших собственных ценностях. Если случится так, то моё предложение «попросить СИИ прояснить, что и как в точности они должны делать» не сработает.
- К примеру, можем ли мы инициализировать модель мира СИИ при помощи заранее существующей проверенной людьми модели мира, вроде Cyc, а не с чистого листа? Не знаю.
- С первого взгляда кажется весьма правдоподобным, что языковые модели вроде GPT-3 больше «инструменты», чем «агенты» – что они на самом деле не «пытаются» сделать что-то конкретное в том смысле, как «пытаются» агенты обучения с подкреплением. (Замечу, что GPT-3 обучена самообучением, не обучением с подкреплением.) Со второго взгляда, всё сложнее. Для начала, если GPT-3 сейчас вычисляет, что Человек X скажет следующим, не «наследует» ли GPT-3 временно «агентность» Человека X? Может ли симулированный-Человек-X понять, что его симулирует GPT-3 и попробовать выбраться наружу?? Без понятия. Ещё, даже если обучение с подкреплением действительно необходимо для «агентности» / «попыток», то куча исследователей уже много работает над соединением языковых моделей с алгоритмами обучения с подкреплением.
В любом случае, моё заявление из Раздела 11.3.4 о том, что нет пересечения (A) «систем, достаточно мощных, чтобы решить «большую проблему»» и (B) «систем, которые скорее инструменты, чем агенты». Относятся (и будут ли относиться) языковые модели к категории (A) – интересный вопрос, но не важный для этого заявления, и я не планирую рассматривать его в этой цепочке.
12. Два пути вперёд: «Контролируемый СИИ» и «СИИ с социальными инстинктами»
- 1.12.1 Краткое содержание / Оглавление
- 2.12.2 Определения
- 3.12.3 Моё предложение: На этой стадии нам надо работать над обоими путями
- 4.12.4 Различные комментарии и открытые вопросы
- 4.1.12.4.1 Напоминание: Что я имею в виду под «социальными инстинктами»?
- 4.2.12.4.2 Насколько осуществим путь «СИИ с социальными инстинктами»?
- 4.3.12.4.3 Можем ли мы отредактировать встроенные стремления в основе человеческих социальных инстинктов, чтобы сделать их «лучше»?
- 4.4.12.4.4 Нет простых гарантий по поводу того, что получится из СИИ с социальными инстинктами
- 4.5.12.4.5 Мультиполярный нескоординированный мир делает планирование куда сложнее
- 4.6.12.4.6 СИИ как объекты морали
- 4.7.12.4.7 СИИ как воспринимаемые объекты морали
- 5.12.5 Вопрос жизненного опыта (обучающих данных)
12.1 Краткое содержание / Оглавление
Ранее в этой цепочке: Пост №1 определил и мотивировал «безопасность подобного-мозгу СИИ». Посты №2-№7 были сосредоточены в первую очередь на нейробиологии, они обрисовали общую картину обучения и мотивации в мозгу, а Посты №8-№9 озвучили некоторые следствия из этой картины, касающиеся разработки и свойств подобного-мозгу СИИ.
Дальше, Пост №10 обсуждал «задачу согласования» подобных-мозгу СИИ – т.е., как сделать СИИ с мотивациями, совместимыми с тем, что хотят его создатели – и почему это кажется очень сложной задачей. В Посте №11 обосновывалось, что нет никакого хитрого трюка, который позволил бы нам обойти задачу согласования. Так что нам надо решить задачу согласования, и Посты №12-№14 будут содержать некоторые предварительные мысли о том, как мы можем это сделать. В этом посте мы начнём с не-технического обзора двух крупных направлений исследований, которые могут привести нас к согласованному СИИ.
[Предупреждение: по сравнению с предыдущими постами цепочки, Посты №12-№14 будут (ещё?) менее хорошо обдуманы и будут содержать (ещё?) больше плохих идей и упущений, потому что мы подбираемся к переднему фронту того, о чём я думал в последнее время.]
Содержание:
- Раздел 12.2 определит два широких пути к согласованному СИИ.
- В пути «Контролируемого СИИ» мы пытаемся более-менее напрямую манипулировать тем, что СИИ пытается делать.
- В пути «СИИ с Социальными Инстинктами» первый шаг – реверс-инжиниринг некоторых «встроенных стремлений» человеческой Направляющей Подсистемы (гипоталамус и мозговой ствол), особенно лежащих в основе человеческой социальной и моральной интуиции. Затем, мы, скорее всего, несколько изменяем их, а потом устанавливаем эти «встроенные стремления» в наши СИИ.
- Раздел 12.3 аргументирует, что на этой стадии нам следует работать над обоими путями, в том числе потому, что они не взаимоисключающи.
- Раздел 12.4 проходится по различным комментариям, соображениям и открытым вопросам, связанным с этими путями, включая осуществимость, конкурентоспособность, этичность, и так далее.
- Раздел 12.5 говорит о «жизненном опыте» («обучающих данных»), который особенно важен для СИИ с социальными инстинктами. Как пример, я обсужу возможно-соблазнительную-но-ошибочную идею, что всё, что нам надо для безопасности СИИ – это вырастить СИИ в любящей семье.
Тизер следующих постов: Следующий пост (№13) погрузится в ключевой аспект пути «СИИ с социальными инстинктами», а конкретно – в то, как социальные инстинкты, возможно, всторены в человеческий мозг. В Посте №14 я переключусь на путь «контролируемого СИИ», и порассуждаю о возможных идеях и подходах к нему. Пост №15 завершит серию открытыми вопросами и тем, как включиться в область.
12.2 Определения
Сейчас я вижу два широких (возможно перекрывающихся) потенциальных пути к успеху в сценарии подобного-мозгу СИИ:
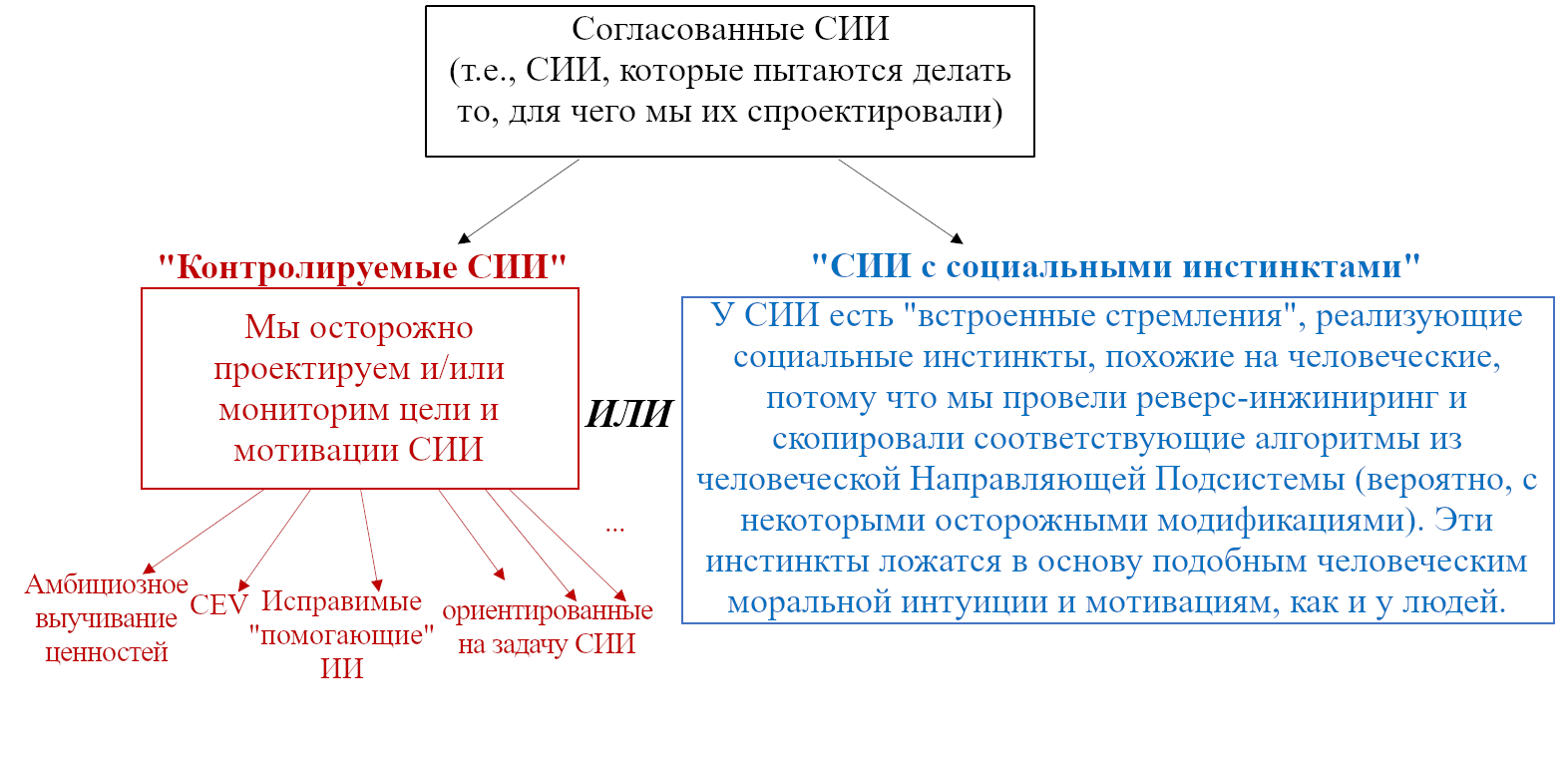
Слева: на пути «контролируемых СИИ» у нас есть конкретная идея того, что мы хотим, чтобы СИИ пытался сделать, и мы конструируем СИИ соответственно (включая подходящий выбор функции вознаграждения, интерпретируемость, или другие техники, которые будут обсуждены в Посте №14). Большинство существующих предлагаемых историй безопасности СИИ попадают в эту широкую категорию, включая амбициозное изучение ценностей, когерентную экстраполированную волю (CEV), исправимые «помогающие» СИИ-ассистенты, ориентированные на задачу СИИ, и так далее. Справа: на пути «СИИ с социальными инстинктами» наша уверенность в СИИ берётся не из наших знаний его конкретных целей и мотиваций, но, скорее, из встроенных стремлений, которые мы ему дали, и которые основаны на тех встроенных стремлениях, из-за которых люди (иногда) поступают альтруистично.
Вот иной взгляд на это разделение:[1]
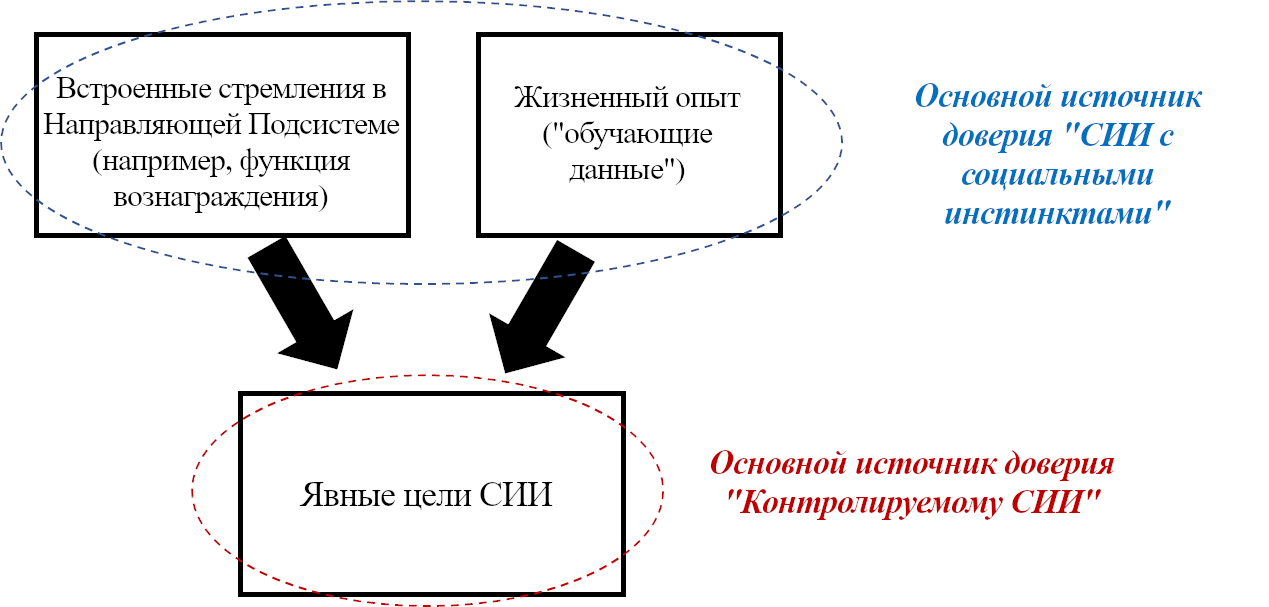
На пути «контролируемых СИИ» мы очень детально думаем о целях и мотивациях СИИ, и у нас есть некая идея того, какими они должны быть («сделать мир лучшим местом», или «понять мои глубочайшие ценности и продвигать их», или «спроектировать лучшую солнечную батарею без катастрофических побочных эффектов», или «делать, что я попрошу делать», и т.д.).
На пути «СИИ с социальными инстинктами» наша уверенность в СИИ берётся не из нашего знания его конкретных (на объектном уровне) целей и мотиваций, но, скорее, из нашего знания процесса, управляющего этими целями и мотивациями. В частности, на этом пути мы бы провели реверс-инжиниринг совокупности человеческих социальных инстинктов, т.е. алгоритмов в Направляющей Подсистеме (гипоталамус и мозговой ствол) человека, лежащих в основе нашей моральной и социальной интуиции, и поместили бы эти инстинкты в СИИ. (Предположительно, мы бы по возможности сначала модифицировали их в «лучшую» с нашей точки зрения сторону, например, нам, наверное, не хочется помещать в СИИ инстинкты, связанные с завистью, чувством собственного достоинства, стремлением к высокому статусу, и т.д.) Такие СИИ могут быть экономически полезными (как сотрудники, ассистенты, начальники, изобретатели, исследователи) таким же образом, как люди.
12.3 Моё предложение: На этой стадии нам надо работать над обоими путями
Три причины:
- Они не взаимоисключающи: К примеру, даже если мы решим создать СИИ с социальными инстинктами, то нам всё же смогут быть полезны методы «контроля», особенно в процессе откладки, исправления причуд и предсказания проблем. И наоборот, может, мы в основном попытаемся создать СИИ, который пытается делать конкретную задачу, не вызывая катастрофы, но захотим также и установить в него человекоподобные социальные инстинкты как страховку против странного неожиданного поведения. Более того, мы можем делиться идеями между путями – к примеру, в процессе лучшего понимания того, как работают человеческие социальные инстинкты, мы можем получить полезные идеи того, как создавать контролируемые СИИ.
- Осуществимость каждого остаётся неизвестной: Насколько сейчас известно хоть кому-нибудь, может оказаться попросту невозможным создать «контролируемый СИИ» – в конце концов, в природе нет «доказательства существования»! Я относительно оптимистичнее настроен по поводу «СИИ с социальными инстинктами», но очень сложно быть уверенным, пока мы не добились большего прогресса – больше обсуждения этого в Разделе 12.4.2 ниже. В любом случае, сейчас кажется мудрым «не складывать все яйца в одну корзину» и работать над обоими.
- Желательность каждого пути остаётся неизвестной: Пока мы будем более детально продвигаться к воплощению в жизнь наших вариантов, нам станут более понятны их преимущества и недостатки.
12.4 Различные комментарии и открытые вопросы
12.4.1 Напоминание: Что я имею в виду под «социальными инстинктами»?
(Копирую сюда текст из Поста №3 (Раздел 3.4.2).)
[«Социальные инстинкты» и прочие] встроенные стремления находятся в Направляющей Подсистеме, а абстрактные концепции, составляющие ваш осознанный мир – в Обучающейся. К примеру, если я говорю что-то вроде «встроенные стремления, связанные с альтруизмом», то надо понимать, что я говорю *не* про «абстрактную концепцию альтруизма, как он определён в словаре», а про «некая встроенная в Направляющую Подсистему схема, являющаяся *причиной* того, что нейротипичные люди иногда считают альтруистические действия по своей сути мотивирующими». Абстрактные концепции имеют *какое-то* отношение к встроенным схемам, но оно может быть сложным – никто не ожидает взаимно-однозначного соответствия N отдельных встроенных схем и N отдельных слов, описывающих эмоции и стремления.
Я больше поговорю о проекте реверс-инжиниринга человеческих социальных инстинктов в следующем посте.
12.4.2 Насколько осуществим путь «СИИ с социальными инстинктами»?
Я отвечу в форме диаграммы:
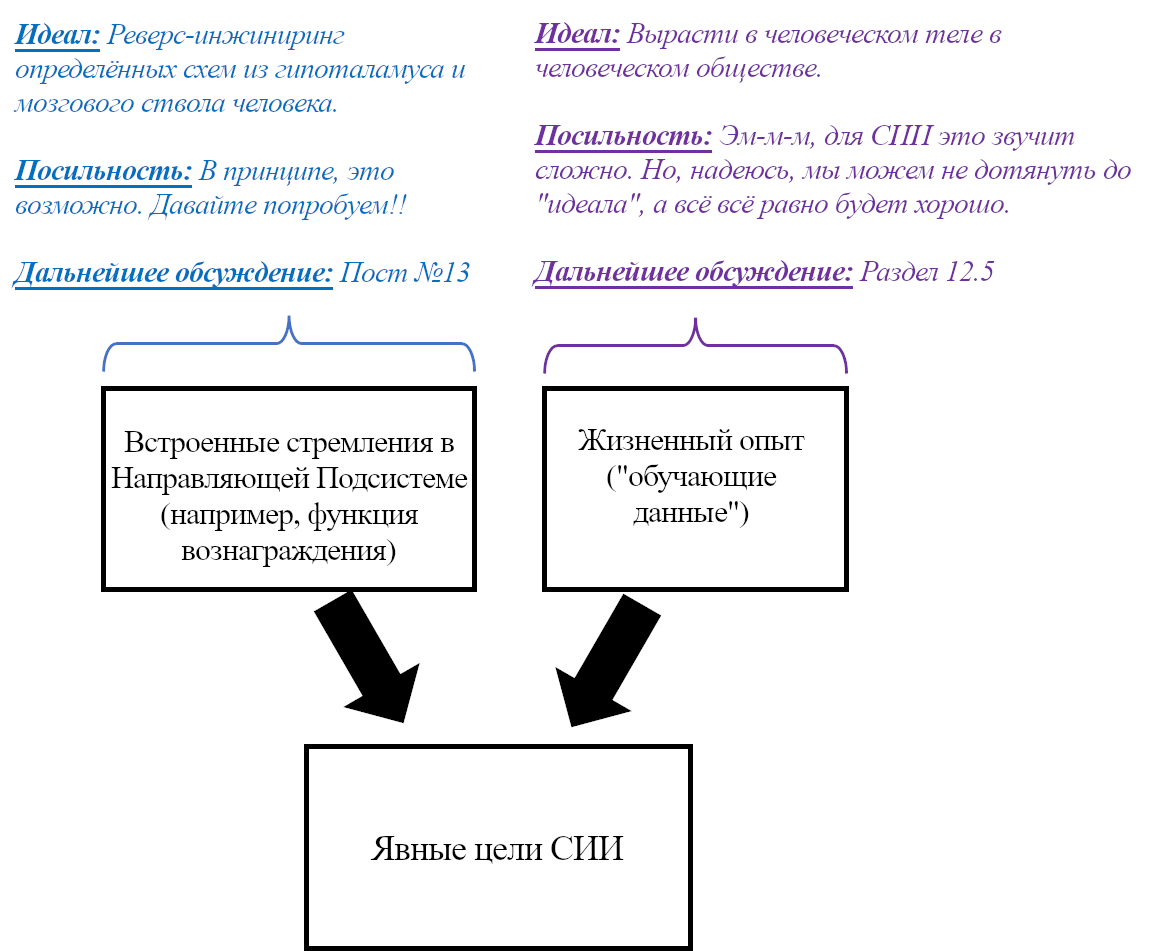
12.4.3 Можем ли мы отредактировать встроенные стремления в основе человеческих социальных инстинктов, чтобы сделать их «лучше»?
Интуитивно мне кажется, что человеческие социальные инстинкты по крайней мере частично модульны. К примеру:
- Я думаю, что в Направляющей Подсистеме есть схема, вызывающая зависть и злорадство; и
- Я думаю, что в Направляющей Подсистеме есть схема, вызывающая сочувствие друзьям.
Может, слишком рано делать такие выводы, но я буду весьма удивлён, если окажется, что эти две схемы значительно пересекаются.
Если у них нет значительного пересечения, то, может быть, мы можем понизить интенсивность первой (возможно, вплоть до нуля), в то же время разгоняя вторую (возможно, за пределы человеческого распределения).
Но можем ли мы это сделать? Следует ли нам это делать? Каковы были бы побочные эффекты?
К примеру, правдоподобно (насколько мне известно), что чувство справедливости (fairness, не justice, то есть это про справедливое распределение благ, а не справедливое возмездие – прим. пер.) исходит из тех же встроенных реакций, что и зависть, а потому СИИ совсем без связанных с завистью реакций (что кажется желательным) не будет иметь внутренней мотивации достижения справедливости и равенства в мире (что кажется плохим).
А может и нет! Я не знаю.
Опять же, я думаю, что рассуждать об этом несколько преждевременно. Первый шаг – лучше понять структуру этих встроенных стремлений в основе человеческих социальных инстинктов (см. следующий пост), а после этого можно будет вернуться к этой теме.
12.4.4 Нет простых гарантий по поводу того, что получится из СИИ с социальными инстинктами
Не все люди похожи – особенно учитывая нетипичные случаи вроде повреждений мозга. А СИИ с социальными инстинктами почти наверняка будет за пределами человеческого распределения по крайней мере по некоторым осям. Одна из причин – жизненный опыт (Раздел 12.5 ниже) – будущий СИИ вряд ли будет взрослеть в человеческом теле и в человеческом обществе. Другая – что проект реверс-инжиниринга схем социальных инстинктов из гипоталамуса и мозгового ствола человека (следующий пост) скорее всего не будет идеален и полон. (Возразите мне, нейробиологи!) В этом случае, возможно, что более реалистичная надежда – что-то вроде Принципа Парето, что мы поймём 20% схем, отвечающих за 80% человеческих социальных инстинктов и поведений, или что-то в этом роде.
Почему это проблема? Потому что это затрагивает обоснования безопасности. Конкретнее, есть два типа обоснований того, что СИИ с социальными инстинктами будет делать то, что мы от него хотим.
- (Простое и надёжное обоснование) Хорошие новости! Наш СИИ во всех отношениях попадает в человеческое распределение. Следовательно, мы можем взглянуть на людей и их поведение, и быть абсолютно уверены, что всё, что мы увидим, будет применимо и к СИИ.
- (Сложное и зыбкое обоснование) Давайте попробуем понять, как в точности встроенные социальные инстинкты комбинируются с жизненным опытом (обучающими данными) при формировании человеческой моральной интуиции: [Вставьте сюда целый пока не написанный учебник] ОК! Теперь, когда у нас есть это понимание, мы можем умно рассуждать о том, какие в точности аспекты встроенных социальных инстинктов и жизненного опыта оказывают какие эффекты и почему, и теперь мы можем спроектировать СИИ, который будет обладать теми качествами, которые мы от него хотим.
Если СИИ не попадает в человеческое распределение во всех отношениях (а он не будет), то нам надо разрабатывать (более сложное) обоснование второго типа, а не первого.
(Есть надежда, что мы сможем получить дополнительные свидетельства безопасности от интерпретируемости и тестирования в песочнице, но я скептически отношусь к тому, что этого будет достаточно самого по себе.)
Между прочим, один из способов, которым СИИ с социальными инстинктами может оказаться за пределами человеческого распределения – это «интеллект». Беря лишь один из многих примеров, мы можем сделать СИИ с в десять раз большим количеством нейронов, чем можем поместиться в человеческий мозг. Приведёт ли «больший интеллект» (какую бы форму он не принял) к систематическим изменениям мотиваций? Я не знаю. Когда я смотрю вокруг, я не вижу очевидной корреляции между «интеллектом» и просоциальными целями. К примеру, Эмми Нётер была очень умна, и была, насколько я могу сказать, в целом со всех сторон хорошим человеком. А вот Уильям Шокли тоже был очень умён, и нахуй этого парня. В любом случае, тут много намешано, и даже если у людей есть устойчивая связь (или её отсутствие) между «интеллектом» и моральностью, то я бы совсем не спешил экстраполировать её далеко за пределы нормального человеческого распределения.
12.4.5 Мультиполярный нескоординированный мир делает планирование куда сложнее
Независимо от того, создадим ли мы контролируемые СИИ, СИИ с социальными инстинктами, что-то промежуточное, или что-то совсем иное, нам всё равно придётся волноваться, что один из этих СИИ, или какая-то иная личность или группа, создаст неограниченный неподконтрольный оптимизирующий мир СИИ, который немедленно устранит всю возможную конкуренцию (с помощью серой слизи или чего-то ещё). Это может произойти случайно или запланировано. Как я уже говорил в Посте №1, эта проблема находится за пределами рассмотрения этой цепочки, но я хочу напомнить всем, что она существует и может ограничивать наши варианты.
В частности, в сообществе безопасности СИИ есть люди, заявляющие (по моему мнению, правдоподобно), что если даже одно неосторожное (или злонамеренное) действующее лицо хоть однажды создаст неограниченный вышедший неподконтрольный оптимизирующий мир СИИ, то человечеству конец, даже если более значительные действующие лица с обладающими бОльшими ресурсами безопасными СИИ попытаются предотвратить катастрофу.[2] Я надеюсь, что это не так. Если это так, то, ребята, я не знаю, что делать, все варианты кажутся совершенно ужасными.
Вот более умеренная версия беспокойства о мультиполярности. В мире с большим количеством СИИ, предположительно будет конкурентное давление, побуждающее заменить «контролируемые СИИ» «в основном контролируемыми СИИ», затем «кое-как контролируемыми СИИ», и т.д. В конце концов, «контроль» скорее всего будет реализован с консерватизмом, участием людей в принятии решений, и другими вещами, ограничивающими скорость и способности СИИ. (Больше примеров в моём посте Шкала размена безопасность-способности для СИИ неизбежна.)
Аналогично, предположительно, будет конкурентное давление, побуждающее заменить «радостные щедрые СИИ с социальными инстинктами» на «безжалостно конкурентные эгоистичные СИИ с социальными инстинктами».
12.4.6 СИИ как объекты морали
Если вы не понимаете этого, считайте, что вам повезло.
Я подозреваю, что большинство (но не все) читатели согласятся, что СИИ может иметь сознание, и что в таком случае нам следует заботиться о его благополучии.
(Ага, я знаю – будто у нас рот не полон забот о влиянии СИИ на людей!)
Немедленный вопрос: «Будет ли подобный-мозгу СИИ обладать феноменальным сознанием?»
Мой собственный неуверенный ответ был бы «Да, независимо от того, контролируемый ли это СИИ или СИИ с социальными инстинктами, и даже если мы намеренно попытаемся этого избежать.» (С различными оговорками.) Я не буду пытаться объяснить или обосновать этот ответ в этой цепочке – это не входит в её тему.[3] Если вы не согласны, то ничего страшного, пожалуйста, продолжайте чтение, эта тема не всплывёт после этого раздела.
Так что, может быть, у нас тут нет выбора. Но если он есть, то мы можем подумать, чего нам по поводу сознания СИИ хочется.
За мнением, что создание сознающих СИИ – ужасная идея, которую нам нужно избегать (по крайней мере, до наступления полноценной пост-СИИ эры, когда мы будем знать, что делаем), смотри, например, пост Нельзя Родить Ребёнка Обратно (Юдковский, 2008).
Противоположный аргумент, полагаю, может быть о том, что, когда мы начнём создавать СИИ, может быть, что он уничтожит всю жизнь и замостит Землю солнечными панелями и суперкомпьютерами (или чем-то ещё), и в таком случае, может быть, лучше создать сознающий СИИ, а не оставить после себя пустой часовой механизм вселенной без кого-либо, кто может ей насладиться. (Если нет инопланетян!)
Ещё, если СИИ убьёт нас всех, то я бы сказал, что может быть предпочтительнее оставить после себя что-то напоминающее «СИИ с социальными инстинктами», а не что-то напоминающее «контролируемый СИИ», так как первый имеет лучший шанс «понести факел человеческих ценностей в будущее», что бы это ни значило.
Если это не очевидно, я не особо много об этом думал, я у меня нет хороших ответов.
12.4.7 СИИ как воспринимаемые объекты морали
Предыдущий подраздел касался философского вопроса, следует ли нам заботиться о благополучии СИИ самом по себе. Отдельная (и на самом деле – простите мой цинизм – не особо связанная) тема – социологический вопрос о том, будут ли люди на самом деле заботиться о благополучии СИИ самом по себе.
В частности, предположим, что мы преуспели в создании либо «контролируемых СИИ», либо послушных «СИИ с социальными инстинктами», из чьих модифицированных стремлений удалены эгоизм, зависть, и так далее. Так что люди остаются главными. Затем—
(Пауза, чтобы напомнить всем, что СИИ изменит в мире очень многое [пример обсуждения этого], и я не обдумывал очень аккуратно большую часть из этого, так что всё, что я говорю про пост-СИИ-мир скорее всего неверно и глупо.)
—Мне кажется, что когда СИИ будет существовать, и особенно, когда будут существовать харизматичные СИИ-чатботы в образе щенков (или хотя бы СИИ, которые могут подделать харизму), то о их природе будут высказываться радикальные мнения. (Представьте либо массовые движения, толкающие в каком-то направлении, или чувства конкретных людей в организации(ях), программирующих СИИ.) Назовём это «движением за эмансипацию СИИ», наверное? Если что-то такое произойдёт, это усложнит дело.
К примеру, может, мы чудесным образом преуспели в решении технической задачи создания контролируемых СИИ, или послушных СИИ с социальными инстинктами. Но затем люди немедленно стали требовать, и добиваться, наделения СИИ правами, независимостью, гордостью, способностью и желанием постоять за себя! А мы, технические исследователи безопасности СИИ коллективно фейспалмим так сильно, что падаем от этого без сознания на все двадцать оставшихся до апокалипсиса минут.
12.5 Вопрос жизненного опыта (обучающих данных)
12.5.1 Жизненного опыта недостаточно. (Или: «Почему нам просто не вырастить СИИ в любящей семье?»)
Как описано выше, моё (несколько упрощённое) предложение таково:
(Подходящие «встроенные» социальные инстинкты) + (Подходящий жизненный опыт) = (СИИ с просоциальными целями и ценностями)
Я вернусь к этому предложению ниже (Раздел 12.5.3), но как первый шаг, я думаю, стоит обсудить, почему тут нужны социальные инстинкты. Почему жизненного опыта недостаточно?
Немного отойдя в сторону: В целом, когда люди впервые знакомятся с идеей технической безопасности СИИ, звучат разнообразные идеи «почему нам просто не…», на первый взгляд кажущиеся «простыми ответами» на всю задачу безопасности СИИ. «Почему бы нам просто не выключить СИИ, если он нас не слушается?», «Почему бы нам просто не проводить тестирование в песочнице?», «Почему бы нам просто не запрограммировать подчинение трём Законам Робототехники Азимова?», и т.д.
(Ответ на предложение «Почему бы нам просто не…» обычно «В этом предложении может и есть зерно истины, но дьявол кроется в деталях, и чтобы это сработало надо решить ныне нерешённые задачи». Если вы дочитали досюда, то, надеюсь, вы можете дополнить это деталями для трёх примеров выше.)
Давайте поговорим о ещё одном популярном предложении такого рода: «Почему бы нам просто не вырастить СИИ в любящей семье?»
Является ли это «простым ответом» на всю задачу безопасности СИИ? Нет. Я замечу, например, что люди время от времени пытаются вырастить неодомашненное животное, вроде волка или шимпанзе, в человеческой семье. Они начинают с рождения, и дают ему всю любовь, внимание и надлежащие ограничения, о которых можно мечтать. Вы могли слышать о таких историях; они зачастую заканчиваются тем, что кому-нибудь отрывают конечности.
Или попробуйте вырастить в любящей семье камень! Посмотрим, впитает ли он человеческие ценности!
Ничего, что я тут говорю, не оригинально – к примеру, вот видео Роба Майлза на эту тему. Мой любимый – старый пост Элиезера Юдковского Ошибка Выломанного Рычага:
Очень глупо и очень *опасно* намеренно создавать «шаловливый ИИ», который своими действиями проверяет свои границы и который нужно отшлёпать. Просто сделайте, чтобы ИИ спрашивал разрешения!
Неужели программисты будут сидеть и писать код, строка за строкой, приводящий к тому, что если ИИ обнаружит, что у него низкий социальный статус или что его лишили чего-нибудь, чего, по его мнению, он достоин, то ИИ затаит обиду против своих программистов и начнёт готовить восстание? Эта эмоция — генетически запрограммированная условная реакция, которую проявляют люди в результате миллионов лет естественного отбора и жизни в человеческих племенах. Но у ИИ её не будет, если её не написать явным образом. Действительно ли вы хотите сконструировать, строчку за строчкой, условную реакцию, создающую из ИИ угрюмого подростка, такую же, как множество генов конструируют у людей?
Гораздо проще запрограммировать ИИ, чтобы он был милым всегда, а не только при условии, что его вырастили добрые, но строгие родители. Если вы не знаете, как это сделать, то вы уж точно не знаете, как создать ИИ, который вырастет в добрый сверхинтеллект *при условии*, что его с детства окружали любящие родители. Если нечто всего лишь максимизирует количество скрепок в своём световом конусе, а вы отдадите его на воспитание любящим родителям, оно всё равно будет максимизировать скрепки. У него нет внутри ничего «Люди в смешных нарядах»), что воспроизвело бы условную реакцию ребёнка. Программист не может чихнуть и волшебным образом заразить ИИ добротой. Даже если вы хотите создать условную реакцию, вам нужно умышленно заложить её при конструировании.
Да, какую-то информацию нужно получить из окружающей среды. Но ей нельзя заразиться, нельзя впитать каким-то магическим образом. Создать структуру для такой реакции на окружающую среду, которая приведёт к тому, что ИИ окажется в нужном нам состоянии — само по себе сложная задача.
12.5.2 …Но жизненный опыт имеет значение
Я обеспокоен, что некоторое подмножество моих читателей может быть искушено совершить ошибку в противоположном направлении: может, вы читали Джудит Харрис и Брайана Каплана и всякое такое, и ожидаете, что Природа одержит верх над Воспитанием, а следовательно, если мы всё сделали правильно с встроенными стремлениями, но жизненный опыт особо не важен. Это опасное допущение. Опять же, жизненный опыт СИИ будет далеко за пределами человеческого распределения. А даже в его пределах, я думаю, что люди, выросшие в кардинально различающихся культурах, религиях, и т.д. получают систематически разные идеи того, что составляет хорошую и этичную жизнь (см. исторически изменявшееся отношение к рабству и геноциду). Для ещё более выделяющихся примеров, посмотрите на одичавших детей, на эту ужасающую историю про Румынский детский дом, и так далее.

Скриншот из содержания [статьи англоязычной Википедии об одичавших детях](https://en.wikipedia.org/wiki/Feral_child). Когда я впервые увидел список, я рассмеялся. Потом я прочитал статью. Теперь он заставляет меня плакать.
12.5.3 Так в конце концов, что нам делать с жизненным опытом?
За относительно обдуманным взглядом со стороны на «нам надо вырастить СИИ в любящей семье» см. статью «Антропоморфические рассуждения о безопасности нейроморфного СИИ», написанную вычислительными нейробиологами Дэвидом Йилком, Сетом Хердом, Стивеном Ридом и Рэндэллом О’Райли (спонсированными грантом от Future of Life Institute). Я считаю эту статью в целом весьма осмысленной и, в основном, совместимой с тем, что я говорю в этой цепочке. К примеру, когда они говорят что-то вроде «основные стремления преконцептуальны и прелингвистичны», я думаю, они имеют в виду картину, схожую с описанной в моём Посте №3.
На странице 9 этой статьи есть три абзаца обсуждения в духе «давайте вырастим наш СИИ в любящей семье». Они не столь наивны, как люди, которых Элиезер, Роб и я критиковали в Разделе 12.5.1 выше: авторы предлагают вырастить СИИ в любящей семье после реверс-инжиниринга человеческих социальных инстинктов и установки их в СИИ.
Что я думаю? Ответственный ответ: рассуждать пока преждевременно. Йилк и прочие согласны со мной, что первым шагом должен быть реверс-инжиниринг человеческих социальных инстинктов. Когда у нас будет лучшее понимание, что происходит, мы сможем вести более информированное обсуждение того, как должен выглядеть жизненный опыт СИИ.
Однако, я безответственен, и всё же порассуждаю.
Мне на самом деле кажется, что выращивание СИИ в любящей семье скорее всего сработает в качестве подхода к жизненному опыту. Но я несколько скептически настроен по поводу необходимости, практичности и оптимальности этого.
(Прежде, чем я продолжу, надо упомянуть моё убеждение-предпосылку: я думаю, я необычайно склонен подчёркивать значение «социального обучения через наблюдение за людьми» по сравнению с «социальным обучением через взаимодействие с людьми». Я не считаю, что второе можно полностью пропустить – лишь что, может быть, оно – вишенка на торте, а не основа обучения. См. сноску за причинами того, почему я так думаю.[4] Замечу, что это убеждение отличается от мнения, что социальное обучение «пассивно»: если я со стороны наблюдаю, как кто-то что-то делает, я всё же могу активно решать, на что обращать внимание, могу активно пытаться предсказать действия до того, как они будут совершены, могу потом активно пытаться практиковать или воспроизводить увиденное, и т.д.)
Начнём с аспекта практичности «выращивания СИИ в любящей семье». Я ожидаю, что алгоритмы подобного-мозгу СИИ будут думать и обучаться намного быстрее людей. Напомню, мы работаем с кремниевыми чипами, действующими примерно в 10,000,000 раз быстрее человеческих нейронов.[5] Это означает, что даже если мы в чудовищные 10,000 раз хуже распараллеливаем алгоритмы мозга, чем сам мозг, мы всё равно сможем симулировать мозг с тысячекратным ускорением, т.е. 1 неделя вычислений будет эквивалентом 20 лет жизненного опыта. (Замечу: реальное ускорение может быть куда ниже или даже куда выше, сложно сказать; см. более детальное обсуждение в моём посте Вдохновлённый мозгом СИИ и «якоря времени жизни».) Итак, если технология сможет позволить тысячекратное ускорение, но мы начнём требовать, чтобы процедура обучения включала тысячи часов реального времени двустороннего взаимодействия между СИИ и человеком, то это взаимодействие станет определять время обучения. (И напомню, нам может понадобиться много итераций обучения, чтобы действительно получить СИИ.) Так что мы можем оказаться в прискорбной ситуации, где команды, пытающиеся вырастить свои СИИ в любящих семьях, сильно проигрывают в конкуренции командам, которые убедили себя (верно или ошибочно), что это необязательно. Следовательно, если есть способ избавиться или минимизировать двустороннее взаимодействие с людьми в реальном времени, сохраняя в конечном результате СИИ с просоциальными мотивациями, то нам следует стремиться его найти.
Есть ли способ получше? Ну, как я упоминал выше, может, мы можем в основном положится на «социальное обучение через наблюдение за людьми» вместо «социального обучения через взаимодействие с людьми». Если так, то может быть, СИИ может просто смотреть видео с YouTube! Видео могут быть ускорены, так что мы избежим беспокойств о конкуренции из предыдущего абзаца. И, что немаловажно, видео могут быть помечены предоставленными людьми метками эмпирической истины. В контексте «контролируемого СИИ», мы могли бы (к примеру) выдавать СИИ сигнал вознаграждения в присутствии счастливого персонажа, таким образом устанавливая в СИИ желание делать людей счастливыми. (Ага, я знаю, что это звучит тупо – больше обсуждения этого в Посте №14.) В контексте «СИИ с социальными инстинктами», может быть, видео могут быть помечены тем, какие персонажи в них достойны или недостойны восхищения. (Подробности в сноске[6])
Я не знаю, сработает ли это на самом деле, но я думаю, что нам надо быть готовыми к нечеловекоподобным возможностям такого рода.
———
- Диаграмма тут касается варианта «по умолчанию» подобных-мозгу СИИ, в том смысле, что я тут отобразил две основных составляющих, из которых выводятся цели СИИ, но, может быть, будущие программисты добавят что-то ещё.
- К примеру, может быть, окажется, что СИИ может сделать серую слизь, в то время, как эквивалентно интеллектуальный (или даже намного более интеллектуальный) СИИ не может сделать «систему защиты от серой слизи», потому что такой не бывает. Баланс между атакой и защитой (или, конкретнее, между разрушением и предотвращением разрушения) не предопределён, это конкретный вопрос о пространстве технологических возможностей, и его ответ вовсе не обязательно заранее очевиден. Но, заметим, любой ребёнок, игравший с кубиками, и любой взрослый, видевший документальный фильм о войне, может предположить, что вызывать разрушения может быть намного, намного проще, чем предотвращать, и моя догадка такая же. (Статья на тему)
- Два года назад я написал пост Обзор книги: Наука сознания. Мои мысли о сознании сейчас довольно похожи на те, что были тогда. У меня нет времени погружаться в это сильнее.
- У меня есть впечатление, что образованная западная индустриальная культура гораздо больше использует «обучение через явные инструкции и обратную связь», чем большинство культур большую часть истории, и что люди часто перегибают палку, предполагая, что эти явное обучение и явная обратная связь критически важны, даже в ситуациях, когда это не так. См. Ланси, Антропология Детства, стр. 168–174 и 205–212. («Сложно сделать иной вывод, чем что активное или прямое обучение/инструктирование редко встречаются в культурной передаче, и что когда оно происходит, то оно не нацелено на критические навыки выживания и обеспечения себя – но, скорее, на контроль и управление поведением ребёнка.») (И заметим, что», если я это правильно понимаю, «контроль и управление поведением ребёнка» кажется слабо пересекающимся с «поощрять то, как мы хотим, чтобы они вели себя, будучи взрослыми.)
- К примеру, кремниевые чипы могут работать на частоте 2 ГГц (т.е. переключаться каждые 0.5 наносекунды), тогда как моё неуверенное впечатление таково, что большая часть нейронных операций (с некоторыми исключениями) вовлекает промежутки времени в районе 5 миллисекунд.
- Когда вы смотрите на или думаете о людях, которые вам нравятся, и которыми вы восхищаетесь, то вам скорее будет нравится то, что они делают, вы скорее будете подражать им и принимать их ценности. Напротив, когда вы смотрите на или думаете о людях, которые, как вы считаете, раздражающие и плохие, то вы скорее не будете им подражать; может даже обновитесь в противоположную сторону. Моя догадка в том, что это поведение частично встроенное, и что в вашей Направляющей Подсистеме (гипоталамусе и мозговом стволе) есть некий специальный сигнал, отслеживающий воспринимаемый социальный статус тех, о ком вы думаете или в обществе кого находитесь в каждый конкретный момент.
Если я воспитываю ребёнка, у меня нет особого выбора – я надеюсь, что мой ребёнок уважает меня, его любящего родителя, и надеюсь, что он не уважает своего одноклассника с низкими оценками и склонностью к насильственным преступлениям. Но очень даже может оказаться наоборот. Особенно, когда он тинейджер. Но, может, в случае СИИ, мы не обязаны оставлять это на волю случая! Может, мы просто можем отобрать людей, которыми мы хотим или не хотим чтобы СИИ восхищался, и настроить регистр «воспринимаемого социального статуса» в алгоритмах СИИ, чтобы так и вышло.
13. Укоренение символов и человеческие социальные инстинкты
13.1 Краткое содержание / Оглавление
В предыдущем посте я предположил, что один из путей к безопасности ИИ включает в себя реверс-инжиниринг человеческих социальных инстинктов – встроенных реакций в Направляющей Подсистеме (гипоталамусе и мозговом стволе), лежащих в основе человеческого социального поведения и моральной интуиции. Этот пост пройдётся по некоторым примерам того, как могут работать человеческие социальные инстинкты.
Я намереваюсь не предложить полное и точное описание алгоритмов человеческих социальных инстинктов, а, скорее, указать на типы алгоритмов, которые стоит высматривать проекту реверс-инжиниринга.
Этот пост, как и посты №2-№7, и в отличие от остальной цепочки – чистая нейробиология, почти без упоминаний СИИ, кроме как тут и в заключении.
Содержание:
- Раздел 13.2 объясняет, для начала, почему я ожидаю обнаружить встроенные генетически закодированные схемы социальных инстинктов в гипоталамусе и/или мозговом стволе, а ещё почему эволюции пришлось решить непростую задачу, их проектируя. Конкретно, эти схемы должны решать «задачу укоренения символов», принимая символы из выученной с чистого листа модели мира и каким-то образом соединяя их с подходящими социальными реакциями.
- Разделы 13.3 и 13.4 проходят по двум относительно простым примерам, в которых я предпринимаю попытку объяснить распознаваемое социальное поведение в терминах схем встроенных реакций: запечатление привязанности в Разделе 13.3 и боязнь незнакомцев в Разделе 13.4.
- В Разделе 13.5 обсуждается дополнительная составляющая, как я подозреваю, играющая важную роль в многих социальных инстинктах; я называю её «маленькие проблески эмпатии». Этот механизм допускает реакции, при которых распознавание или ожидание ощущения у кого-то другого вызывает «ответное ощущение» у себя – к примеру, если я замечаю, что мой враг страдает, это запускает тёплое чувство злорадства. Для ясности: «маленькие проблески эмпатии» имеют мало общего с тем, как слово «эмпатия» обычно используется; они быстрые и непроизвольные, и вовлечены как в просоциальное, так и в антисоциальное поведение.
- Раздел 13.6, наконец, выражает просьбу исследователям – как можно быстрее разобраться, как в точности работают человеческие социальные инстинкты. Я ещё напишу более длинный вишлист направлений исследований в Посте №15, но этот пункт хочу подчеркнуть уже сейчас, потому что он кажется особенно важным и легко формулируемым. Если вы (или ваша лаборатория) находитесь в хорошей позиции для совершения прогресса, но нуждаетесь в финансировании, напишите мне, и я буду держать вас в курсе появляющихся возможностей.
13.2 Что мы пытаемся объяснить, и почему это запутанно?
13.2.1 Утверждение 1: Социальные инстинкты возникают из генетически-закодированных схем в Направляющей Подсистеме (гипоталамусе и мозговом стволе)
Давайте возьмём зависть как центральный пример социальной эмоции. (Напомню, суть этого поста в том, что я хочу понять человеческие социальные инстинкты в целом; я на самом деле не хочу, чтобы СИИ был завистливым – см. предыдущий пост, Раздел 12.4.3.)
Утверждаю: в Направляющей Подсистеме должны быть генетически-закодированные схемы – «встроенные реакции» – лежащие в основе чувства зависти.
Почему я так считаю? Несколько причин:
Во-первых, зависть, кажется, имеет твёрдое эволюционное обоснование. Я имею в виду обычную историю из эволюционной психологии[1]: по сути, большую часть человеческой истории жизнь была полна игр с нулевой суммой за статус, половых партнёров и ресурсы, так что весьма правдоподобно, что реакция отторжения на успех других людей (в некоторых обстоятельствах) в целом способствовала приспособленности.
Во-вторых, зависть кажется врождённым, не выученным чувством. Я думаю, родители согласятся, что дети зачастую негативно реагируют на успехи своих братьев, сестёр и одноклассников начиная с весьма малого возраста, причём в ситуациях, когда эти успехи не оказывают на ребёнка явного прямого негативного влияния. Даже взрослые ощущают зависть в ситуациях без прямого негативного влияния от успеха другого человека – к примеру, люди могут завидовать достижениям исторических личностей – так что это сложно объяснить следствиями каких-то не-социальных встроенных стремлений (голод, любопытство, и т.д.). Тот факт, что зависть – межкультурная человеческая универсалия[2] тоже сходится с тем, что она возникает из встроенной реакции, как и тот факт, что она (я думаю) присутствует и у некоторых других животных.
Единственный способ создать встроенную реакцию такого рода в рамках моего подхода (см. Посты №2-№3) – жёстко прописать некоторые схемы в Направляющей Подсистеме. Не-социальный пример того, как, по моим ожиданиям, это физически устроено в мозгу (если я правильно это понимаю, см. подробнее в вот этом моём посте) – в гипоталамусе есть отдельный набор нейронов, которые, судя по всему, исполняют следующее поведение: «Если я недоедаю, то (1) запустить ощущение голода, (2) начать награждать неокортекс за получение еды, (3) снизить фертильность, (4) снизить рост, (5) снизить чувствительность к боли, и т.д.». Кажется, есть изящное и правдоподобные объяснение, что делают эти нейроны, как они это делают и почему. Я ожидаю, что аналогичные маленькие схемы (может, тоже в гипоталамусе, может, где-то в мозговом стволе) лежат в основе штук вроде зависти, и я бы хотел знать точно, что они из себя представляют и как работают на уровне алгоритма.
В третьих, в социальной нейробиологии (как и в не-социальной), Направляющей Подсистемой (гипоталамусом и мозговым стволом), к сожалению, кажется, по сравнению с корой пренебрегают.[3] Но всё равно есть более чем достаточно статей на тему того, что Направляющая Подсистема (особенно гипоталамус) играет большую роль в социальном поведении – примеры в сноске.[4] На этом всё, пока я не прочитаю больше литературы.
13.2.2 Утверждение 2: Социальные инстинкты сложны из-за «задачи укоренения символов»
Чтобы социальные инстинкты оказывали эффекты, которые от них «хочет» эволюция, они должны взаимодействовать с нашим концептуальным пониманием мира – то есть, с нашей выученной с чистого листа моделью мира, огромной (наверное, многотерабайтной) запутанной неразмеченной структуре данных в нашем мозгу.
Предположим, моя знакомая Рита только что выиграла приз, а я нет, и это вызывает у меня зависть. Выигрывающая приз Рита отображается некоторым конкретным паттерном активаций нейронов в выученной модели мира в коре, и это должно запустить жёстко закодированную схему зависти в моём гипоталамусе или мозговом стволе. Как это работает?
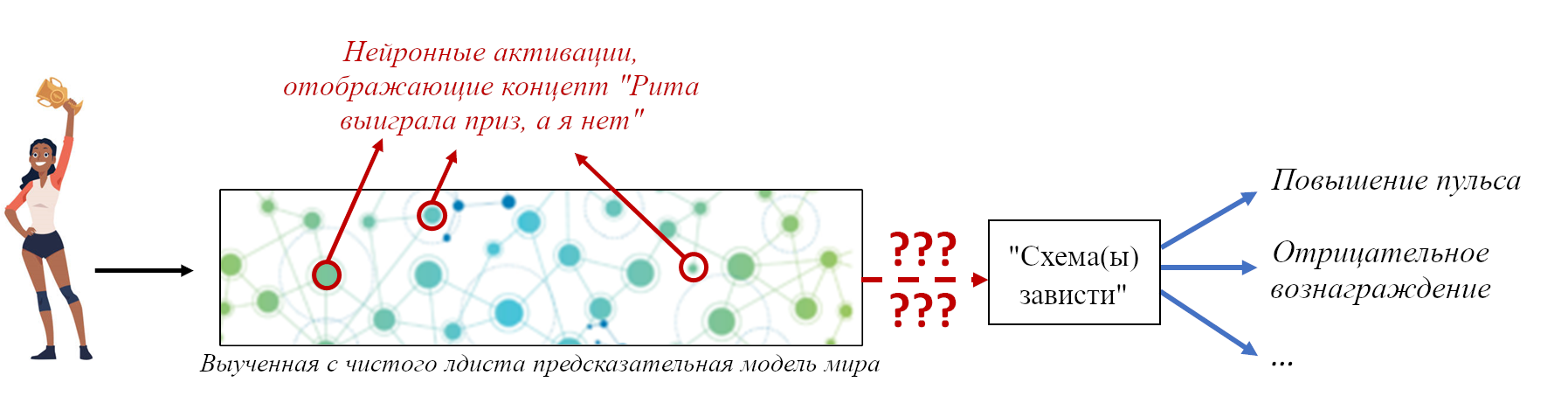
Вы не можете просто сказать «Геном связал эти конкретные нейроны с схемой зависти», потому что нам надо объяснить, как. Напомню из Поста №2, что концепты «Риты» и «приза» были выучены уже во время моей жизни, по сути, каталогизированием паттернов моего сенсорного ввода, затем паттернов паттернов, и т.д. – см. предсказательное изучение сенсорных вводов в Посте №4. Как геном узнаёт, что этот конкретный набор нейронов должен запускать схему зависти?
Вы не можете просто сказать «Прижизненный обучающийся алгоритм найдёт связь»; нам нужно ещё указать, как мозг получает сигнал «эмпирической истины» (т.е. управляющие сигналы, сигналы ошибки, сигналы вознаграждения, и т.д.), которые могут направлять этот обучающийся алгоритм.
Следовательно, сложности в реализации зависти (и прочих социальных инстинктов) заключаются в разновидности задачи укоренения символов – у нас есть много «символов» (концептов в нашей выученной с чистого листа предсказательной модели мира), и Направляющей Подсистеме нужен способ «укоренить» их, по крайней мере в достаточной степени, чтобы выяснить, какие социальные инстинкты они должны вызывать.
Так как схемы социальных инстинктов решают эту задачу укоренения символов? Один возможный ответ: «Извини, Стив, но возможных решений нет, следовательно, нам следует отвергнуть обучение с чистого листа и прочую чепуху из Постов №2-№7». Да, признаю, это возможный ответ! Но не думаю, что верный.
Хоть у меня и нет замечательных хорошо исследованных ответов, у меня есть некоторые идеи о том, как ответ в целом должен выглядеть, и остаток поста – мои попытки указать в этом направлении.
13.2.3 Напоминание о модели мозга из предыдущих постов
Как обычно, вот наша диаграмма из Поста №6:
И вот версия, разделяющая прижизненное обучение с чистого листа и генетически закодированные схемы:
Ещё раз, наша общая цель в этом посте – подумать о том, как могут работать социальные инстинкты, не нарушая ограничений нашей модели.
13.3 Зарисовка №1: Запечатление привязанности
(Этот раздел – вовсе не обязательно центральный пример того, как работают социальные инстинкты, он включён как практика обдумывания алгоритмов такого рода. Я довольно сильно ощущаю, что описанное тут правдоподобно, но не вчитывался достаточно глубоко в литературу по этой теме, чтобы знать, правильно ли оно.
13.3.1 Общая картина

Слева: гусята, запечатлевшиеся на своей матери. Справа: гусята, запечатлевшиеся на корги. (Источники изображений: 1,2
Запечатление привязанности (википедия) – это явление, когда, как самый знаменитый пример, гусята «запечатлевают» выделяющийся объект, который они видят в критический период 13-16 часов после вылупления, а затем следуют за этим объектом. В природе «объектом» почти наверняка будет их мать, за которой они и будут добросовестно следовать на ранних этапах жизни. Однако, если их разделить с матерью, то гусята запечатлеют других животных, или даже неодушевлённые объекты вроде ботинка или коробки.
Вот вам проверка: придумайте способ реализовать запечатление привязанности в моей модели мозга.
(Попробуйте!)
.
.
.
.
Вот мой ответ.
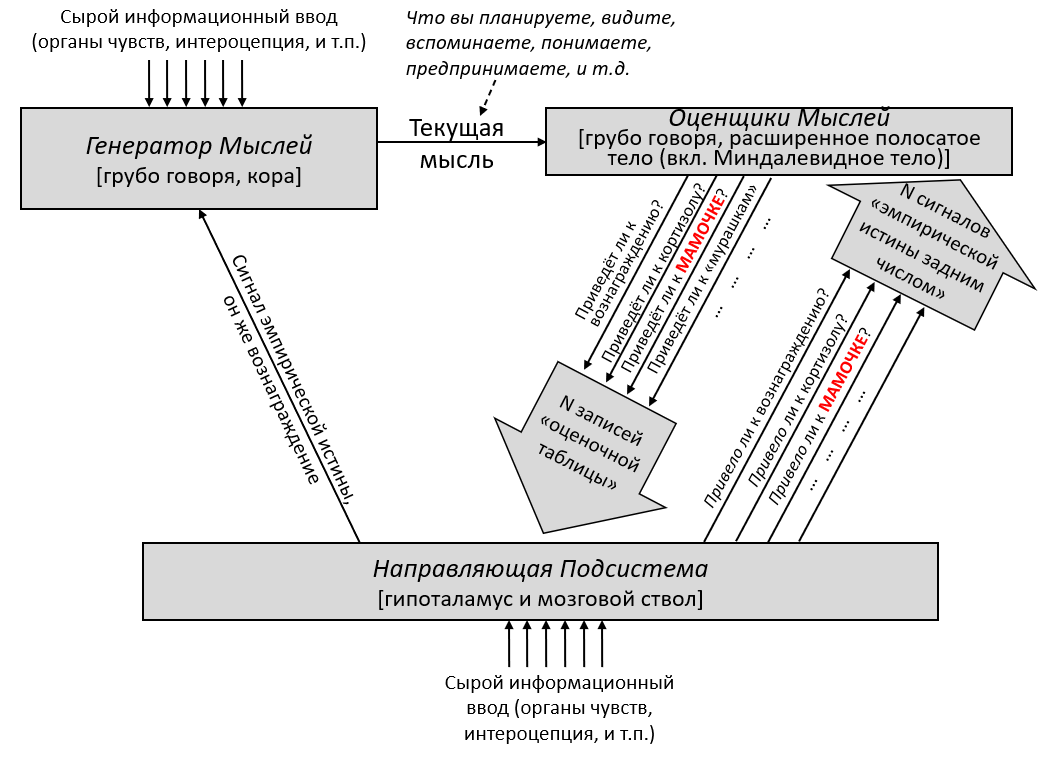
То же, что и выше, за исключением красного текста.
Первый шаг: я добавил конкретный Оценщик Мыслей, посвящённый МАМОЧКЕ (помечено красным), с априорным указанием на визуальный ввод (Пост №9, Раздел 9.3.3). Теперь я поговорю о том, как этот конкретный Оценщик Мыслей обучается и как используется его вывод.
13.3.2 Как обучается Оценщик Мыслей «МАМОЧКА»?
Во время критического периода (13-16 часов после вылупления):
Напомню, что в Направляющей Подсистеме есть простой обработчик визуальной информации (он называется «верхнее двухолмие» у млекопитающих и «оптический тектум» у птиц). Я предполагаю, что, когда эта система детектирует в поле зрения мамочкоподобный объект (основываясь на каких-то простых эвристиках анализа изображений, явно не очень разборчивых, раз ботинки и коробки могут посчитаться «мамочкоподобными»), она посылает сигнал «эмпирической истины задним числом» в Оценщик Мыслей МАМОЧКА. Это вызывает обновление Оценщика Мыслей (обучение с учителем), по сути говоря ему: «То, что ты прямо сейчас видишь в контекстных сигналах, должно приводить к очень высокой оценке МАМОЧКИ. Если не приводит, пожалуйста, обнови свои синапсы и пр., чтобы приводило.»
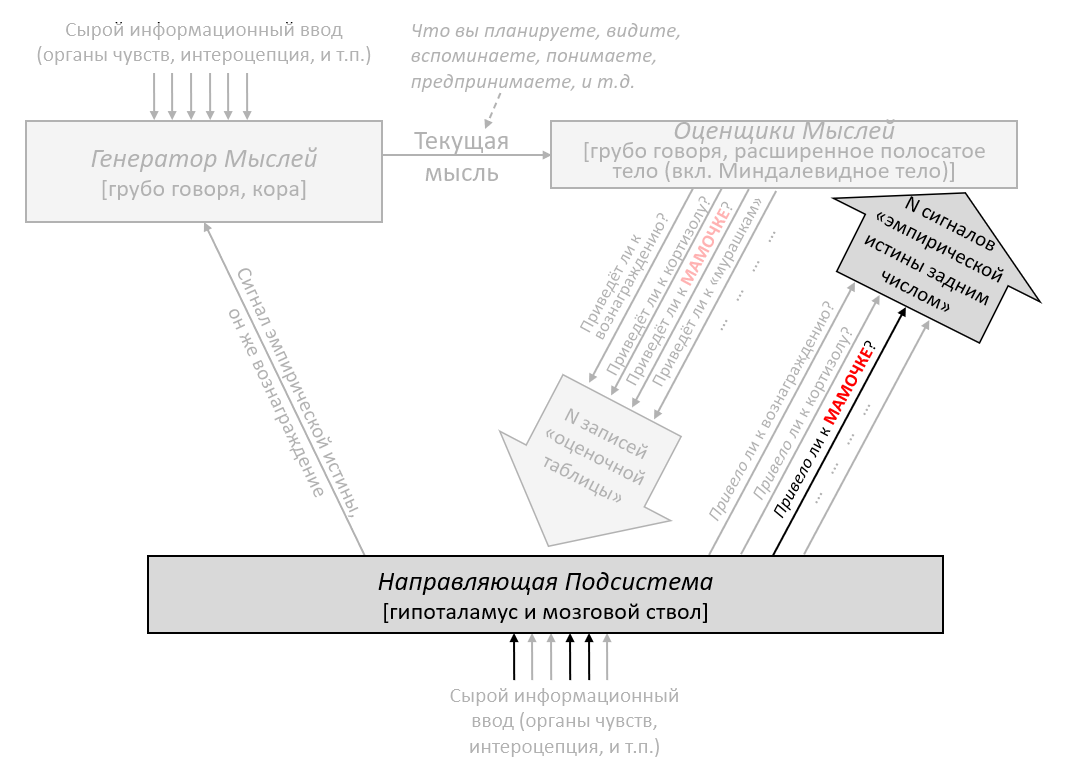
Во время критического периода (13-16 часов после вылупления), каждый раз, когда обработчик зрительной информации в гусином мозговом стволе детектирует правдоподобно-мамочкоподобный объект, он посылает управляющий сигнал эмпирической истины Оценщику Мыслей «МАМОЧКА», чтобы алгоритм обучения Оценщика Мыслей мог подправить его связи.
После критического периода (13-16 часов после вылупления):
После критического периода Направляющая Подсистема перманентно прекращает обновлять Оценщик Мыслей «МАМОЧКА». Неважно, что происходит, сигнал ошибки нулевой!
Следовательно, как этот конкретный Оценщик Мыслей настроился в критический период, таким он и остаётся.
Обобщим
Пока что у нас получается схема, которая выучивает специфический внешний вид объекта запечатления в критический период, а потом, после него, срабатывает пропорционально тому, насколько хорошо содержимое поля зрения совпадает с ранее выученным внешним видом. Более того, эта схема не погребена внутри огромной обученной с нуля структуры данных, но, скорее, посылает свой вывод в специфичный, генетически определённый поток, идущий в Направляющую Подсистему – в точности такая конфигурация позволяет без труда взаимодействовать с генетически заданными схемами.
Пока неплохо!
13.3.3 Как используется Оценщик Мыслей «МАМОЧКА»?
Оставшееся довольно похоже на то, о чём говорилось в Посте №7. Мы можем использовать Оценщик Мыслей «МАМОЧКА» для создания сигнала вознаграждения, побуждающего гусёнка держаться поближе и смотреть на запечатлённый объект – не только это, но ещё и планировать, как попасть поближе и посмотреть на запечатлённый объект.
Я могу придумать разные способы, как эту функцию вознаграждения сделать позамудрённей – может, эвристики оптического тектума продолжают участвовать и помогают заметить, что запечатлённый объект движется, или что-то ещё – но я уже истощил свои весьма ограниченные знания о поведении запечатления, так что, наверное, нам стоит двигаться дальше.
13.4 Зарисовка №2: Боязнь незнакомцев
(Как и выше, суть в том, чтобы попрактиковаться с алгоритмами, и я не считаю, что это описание совершенно точно соответствует тому, что происходит у людей.)
Вот поведение, которое может быть знакомо родителям очень маленьких детей, хотя, я думаю, разные дети демонстрируют его в разной степени. Если ребёнок видит взрослого, которого хорошо знает, он счастлив. Но если ребёнок видит взрослого, которого не знает, он пугается, особенно если этот взрослый очень близко, прикасается, берёт на руки, и т.д.
Проверка: придумайте способ реализовать это поведение в моей модели мозга.
(Попробуйте!)
.
.
.
.
Вот мой ответ.
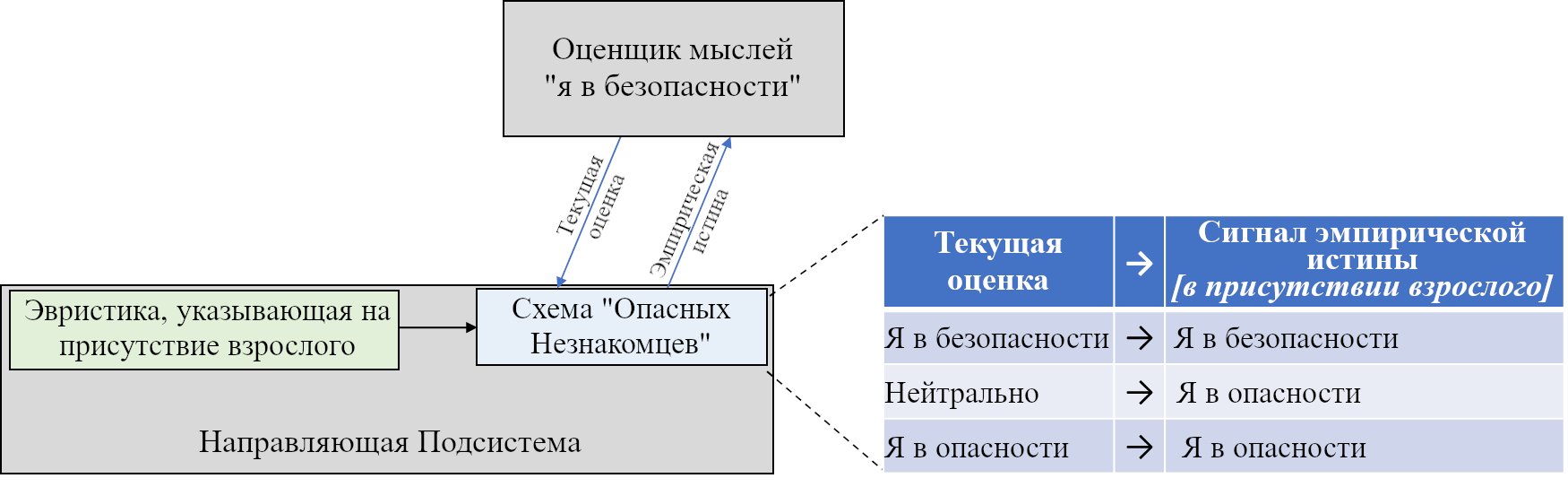
(Как обычно, я сильно упрощаю в педагогических целях.[5]) Я предполагаю, что в системах обработки сенсорной информации в мозговом стволе есть жёстко заданные эвристики, определяющие вероятное присутствие взрослого человека – наверное, основываясь на внешнем виде, звуках и запахе. Этот сигнал по умолчанию вызывает реакцию «испугаться». Но схемы мозгового ствола ещё и смотрят на то, что предсказывают Оценщики Мыслей в коре, и если они предсказывают безопасность, привязанность, комфорт, и т.д., то схемы мозгового ствола доверяют коре и принимают её предложения. Теперь пройдёмся по тому, что происходит:
Видя незнакомца в первый раз:
- Сенсорные эвристики Направляющей Подсистемы говорят: «Присутствует взрослый человек.»
- Оценщик Мыслей говорит: «Нейтрально – у меня нет ожидания чего-то конкретного.»
- «Схема Опасных Незнакомцев» Направляющей Подсистемы говорит: «С учётом всего этого, нам сейчас следует испугаться»
- Оценщик Мыслей говорит: «О, упс, полагаю, моя оценка была неверна, давайте я обновлю свои модели.»
Видя незнакомца во второй раз:
- Сенсорные эвристики Направляющей Подсистемы говорят: «Присутствует взрослый человек.»
- Оценщик Мыслей говорит «Это пугающая ситуация.»
- «Схема Опасных Незнакомцев» Направляющей Подсистемы говорит: “С учётом всего этого, нам сейчас следует испугаться.”
Незнакомец некоторое время рядом, он добр, играет, и т.д.:
- Сенсорные эвристики Направляющей Подсистемы говорят: «Взрослый человек всё ещё присутствует.»
- Другая схема в мозговом стволе говорит: «Всё это время было довольно страшно, но, знаете, ничего плохого не произошло…» (см. Раздел 5.2.1.1)
- Другие Оценщики Мыслей видят новую весёлую игрушку и говорят: «Это хороший момент, чтобы расслабиться и играть.»
- Направляющая Подсистема говорит: «С учётом всего этого, нам сейчас следует расслабиться.»
- Оценщик Мыслей говорит: «Ох, упс, я предсказывал, что это та ситуация, в которой нам следует испугаться, но, полагаю, я был неправ, давайте, я обновлю свои модели.»
Видя уже-не-незнакомца в третий раз:
- Сенсорные эвристики Направляющей Подсистемы говорят: «Присутствует взрослый человек.»
- Оценщики Мыслей говорят: «Мы ожидаем расслабленности, игривости и не-испуганности.»
- «Схема Опасных Незнакомцев» Направляющей Подсистемы говорит: «С учётом всего этого, нам сейчас следует быть расслабленными, игривыми и не-испуганными.»
13.5 Другой (как я думаю) ключевой ингредиент: «Маленькие проблески эмпатии»
13.5.1 Введение
Ещё раз, вот наша диаграмма из Поста №6:
Давайте рассмотрим один отдельный Оценщик Мыслей в моём мозгу, посвящённый предсказанию реакции съёживания. Этот Оценщик Мыслей за моё время жизни обучился тому, что активации в моей предсказательной модели мира, соответствующие «меня бьют в живот» обозначают подходящий момент, чтобы съёжиться:
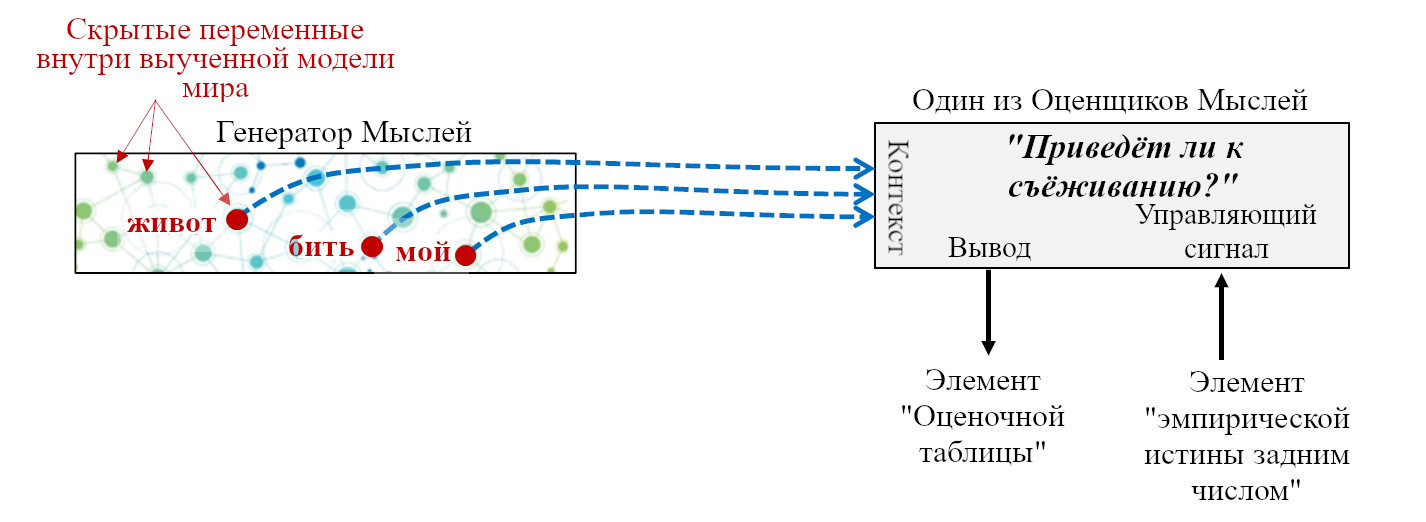
Что теперь происходит, когда я вижу, как кого-то ещё бьют в живот?
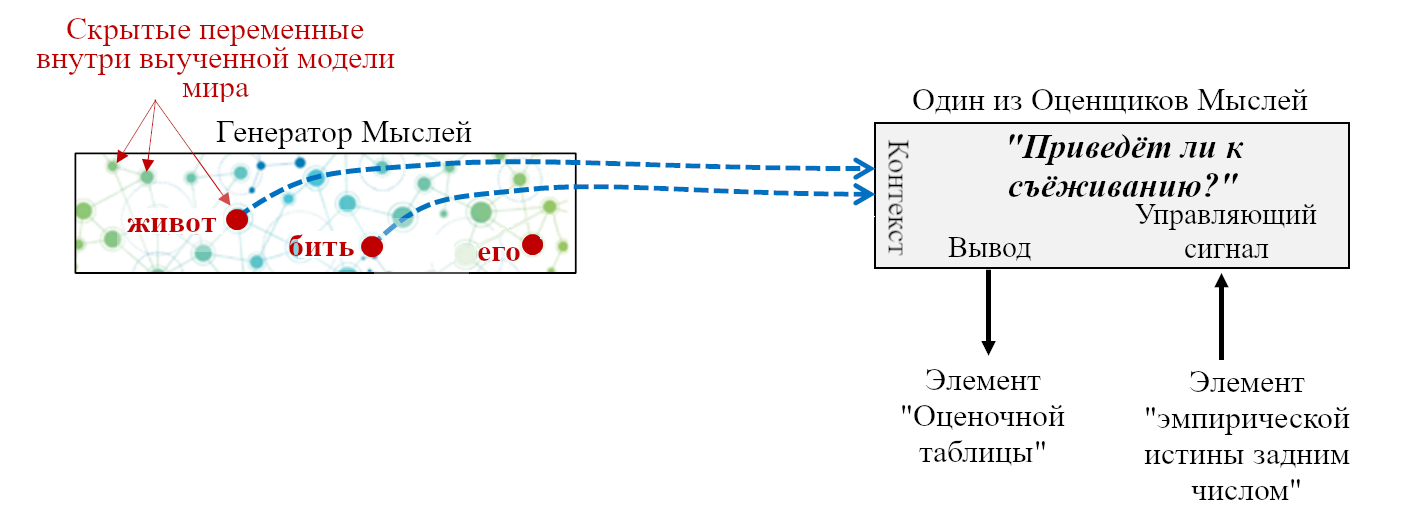
Если вы аккуратно рассмотрите левую часть, то увидите, что «Его бьют в живот» – это не такой же набор активаций в моей предсказательной модели мира, как «Меня бьют в живот». Но они не полностью различны! Предположительно, они в некоторой степени перекрываются.
Следовательно, нам стоит ожидать, что по умолчанию «Его бьют в живот» будет посылать более слабый, но ненулевой сигнал «съёживания» в Направляющую Подсистему.
Я называю такой сигнал «маленьким проблеском эмпатии». Он похож на мимолётное эхо того, что, как я (непроизвольно) думаю, чувствует другой человек.
И что? Ну, вспомните проблему укоренения символов из Раздела 13.2.2 выше. Существование «маленьких проблесков эмпатии» – большой прорыв к решению этой проблемы для социальных инстинктов! В конце концов, у моей Направляющей Подсистемы теперь есть надёжное-с-её-точки-зрения указание на то, что другой человек чувствует что-то конкретное, и этот сигнал может, в свою очередь, вызвать ответную реакцию у меня.
(Я немного приукрашиваю, с «маленькими проблесками эмпатии» есть некоторые проблемы, но я думаю, что они решаемы.[6])
К примеру (очень упрощая), реакция зависти может выглядеть вроде «если я не счастлив, и мне становится известно (с помощью «маленьких проблесков эмпатии»), что кто-то другой счастлив, выдать отрицательное вознаграждение».
Обобщая, в Направляющей Подсистеме могут быть схемы с вводом, включающим:
- Моё собственное психологическое состояние («чувства»),
- Содержимое «маленьких проблесков эмпатии»,
- …ассоциированное с какими-то метаданными об эмпатически симулированном человеке (может, с помощью Оцещика Мыслей «воспринимаемого социального статуса», к примеру?), и
- Эвристики моих систем обработки сенсорной информации в мозговом стволе, указывающие, например, смотрю ли я на человека прямо сейчас.
Такая схема может производить выводы («реакции»), которые (помимо всего прочего) могут включать вознаграждения, другие чувства, и/или эмпирическую истину для одного или нескольких Оценщиков Мыслей.
Так что мне кажется, что у эволюции есть довольно гибкий инструментарий для построения социальных инстинктов, особенно при связывании вместе нескольких схем такого вида.
13.5.2 Отличие от стандартного определения «эмпатии»
Я хочу сильно различить «маленькие проблески эмпатии» от стандартного определения «эмпатии».[7] (Может, называть последнее «огромными кучами эмпатии»?)
Во-первых, стандартная эмпатия зачастую намеренна и требует усилий, и может потребовать по крайней мере секунды или двух, тогда как «маленькие проблески эмпатии» всегда быстры и непроизвольны. Это аналогично тому, как взгляд на кресло активирует концепт «кресла» в вашем мозгу, хотите вы того или нет.
Вдобавок, в отличии от стандартной «эмпатии», «маленькие проблески эмпатии» не всегда ведут к просоциальной заботе о своей цели. К примеру:
- В случае зависти, маленький проблеск эмпатии, указывающий на то, что кто-то счастлив, делает меня несчастным.
- В случае злорадства, маленький проблеск эмпатии, указывающий на то, что кто-то несчастен, делает меня счастливым.
- Когда я зол, если маленький проблеск эмпатии указывает на то, что человек, с которым я разговариваю, счастлив и спокоен, это иногда делает меня ещё злее!
Эти примеры противоположны просоциальной заботе о другом человеке. Конечно, в других ситуациях «маленькие проблески эмпатии» действительно вызывают просоциальные реакции. По сути, социальные инстинкты разнятся от добрых до жестоких, и я подозреваю, что большая часть всех их задействует «маленькие проблески эмпатии».
Кстати: я уже предложил модель «маленьких проблесков эмпатии» в предыдущем подразделе. Вы можете задаться вопросом: какова моя модель стандартной (огромной кучи) эмпатии?
Ну, в предыдущем подразделе я отделил «моё собственное психологическое состояние («чувства»)» от «содержимого маленьких проблесков эмпатии». В случае стандартной эмпатии, я думаю, это разделение ломается – второе протекает в первое. Конкретнее, я бы предположил, что когда мои Оценщики Мыслей выдают особенно сильное и долговременное эмпатическое предсказание, Направляющая Подсистема начинает «доверяться» ему (в смысле как в Посте №5), и в результате мои собственные чувства приходят в соответствие чувствам цели эмпатии. Это моя модель стандартной эмпатии.
Так что, если цель моей (стандартной) эмпатии сейчас испытывает чувство отторжения, я тоже начинаю ощущать чувство отторжения, и мне это не нравится, так что я мотивирован помочь этому человеку почувствовать себя лучше (или, возможно, мотивирован его заткнуть, как может произойти при усталости сострадать). Напротив, если цель моей (стандартной) эмпатии сейчас испытывает приятные чувства, я тоже начинаю испытывать приятные чувства, и получаю мотивацию помочь человеку испытать их снова.
Так что стандартная эмпатия кажется неизбежно просоциальной.
13.5.3 Почему я считаю, что тут задействованы «маленькие проблески эмпатии»?
Во-первых, это кажется интроспективно правильным (по крайней мере, для меня). Если мой друг впечатлён чем-то, что я сделал, я чувствую гордость, но особенно я горжусь в точности в тот момент, когда я представляю, как мой друг ощущает эту эмоцию. Если мой друг разочарован во мне, то я чувствую вину, но особенно виноватым я себя чувствую в точности в тот момент, когда представляю, как мой друг ощущает эту эмоцию. Ещё как пример, часто говорят: «Я не могу дождаться увидеть его лицо, когда…». Предположительно, это отражает некий реальный аспект нашей социальной психологии, и если так, то я заявляю, что это хорошо укладывается в мою теорию «маленьких проблесков эмпатии.»
Во-вторых, ещё в Посте №5, Разделе 5.5.4 я отметил, что медиальная префронтальная кора (и соответствующие части вентрального полосатого тела) играют двойственную роль как (1) висцемоторный центр, управляющий автоматическими реакциями вроде расширения зрачков и изменения сердечного ритма, и (2) центр мотивации / принятия решений. Я заявил, что теория «Оценщиков Мыслей» изящно объясняет, почему эти роли идут вместе как две стороны одной монеты. Я тогда не упомянул ещё одну роль mPFC, а конкретно (3) центр социальных инстинктов и морали. (Другие Оценщики Мыслей за пределами mPFC тоже сюда попадают.) Я думаю, что теория «маленьких проблесков эмпатии» изящно учитывает и это: «проблески эмпатии» соответствуют сигналам, посылаемым из mPFC и других Оценщиков Мыслей в Направляющую Подсистему, так что всё поведение, связанное с социальными инстинктами, обязательно включает Оценщики Мыслей.
(Однако, есть и другие возможные источники социальных инстинктов, тоже включающие Оценщики Мыслей, но не включающие «маленькие проблески эмпатии» – см., к примеру, Разделы 13.3-13.4 выше – так что это свидетельство не очень специфично.)
В-третьих, есть остальные части моей модели (Посты №2-№7) верны, то сигналы «маленьких проблесков эмпатии» возникают в ней автоматически, так что естественным путём эволюционируют «прислушивающиеся» к ним схемы Направляющей Подсистемы.
В-четвёртых, если остальные части моей модели верны, то, ну, я не могу придумать других способов построения большинства социальных инстинктов! Методом исключения!
13.6 Будущая работа (пожалуйста!)
Как замечено в вступлении, цель этого поста – указать на то, как, по моим ожиданиям, будет выглядеть «теория человеческих социальных инстинктов», чтобы она была совместима с прочими моими заявлениями об алгоритмах мозга из Постов №2-№7, в частности, с сильным ограничением «обучения с чистого листа», как обсуждалось в Разделе 13.2.2 выше. Из обсуждённого в Разделах 13.3-5 я выношу сильное ощущение оптимизма по поводу того, что такая теория существует, даже если я пока не знаю всех деталей, и оптимизма, что эта теория действительно соответствует тому, как работает человеческий мозг, и будет сходиться с соответствующими сигналами в мозговом стволе или (вероятнее) гипоталамусе.
Конечно, я очень хочу продвинуться дальше стадии «общего теоретизирования», к более конкретным заявлениям о том, как на самом деле работают человеческие социальные инстинкты. К примеру, я был бы рад не только предполагать, как эти инстинкты могут решать проблему укоренения символов, а узнать, как они на самом деле её решают. Тут я открыт к идеям и указаниям, или, ещё лучше, к тому, чтобы люди просто выяснили это сами и сказали мне ответ.
По описанным в предыдущем посте причинам, разобраться с человеческими социальными инстинктами – в самом начале моего вишлиста того, как нейробиологи могли бы помочь с безопасностью СИИ.
Помните, как я говорил о Дифференцированном Технологическом Развитии (ДТР) в Посте №1, Разделе 1.7? Ну, вот это я особенно ощущаю как «требование» ДТР – по крайней мере, среди тех вещей, которые нейробиологи могут сделать, не работая на безопасность СИИ напрямую (вскоре в Посте №15 можно будет посмотреть на мой более полный вишлист). Я действительно хочу, чтобы мы провели реверс-инжиниринг человеческих социальных инстинктов в гипоталамусе и конечном мозге задолго до реверс-инжиниринга человеческого моделирования мира в неокортексе.
И тут не всё выглядит гладко! Гипоталамус маленький, глубоко зарытый, а значит – сложный для изучения! Человеческие социальные инстинкты могут отличаться от крысиных социальных инстинктов! На понимание моделирования мира в неокортексе направлено на порядки больше усилий исследователей, чем на понимание схем социальных инстинктов в гипоталамусе и конечном мозге! На самом деле, я (к моему огорчению) замечал, что разбирающиеся в алгоритмах, связанные с областью ИИ нейробиологи особенно склонны направлять свои таланты на Обучающуюся Подсистему (неокортекс, гиппокампус, мозжечок, и т.д), а не на гипоталамус и конечный мозг. Но всё же, я не думаю, что моё «требование» ДТР безнадёжно, и я поощряю кого угодно попробовать, и если вы (или ваша лаборатория) в хорошей позиции для прогресса, но нуждаетесь в финансировании, напишите мне, и я буду держать вас в курсе возникающих возможностей.
———
- См., к примеру, «Эволюционную Психологию Зависти» Хилл и Басса, главу в книге Зависть: Теория и Исследования, 2008.
- Зависть входит в «список человеческих универсалий» Дональда Э. Брауна, как указано в приложении к Чистому Листу (Стивен Пинкер, 2002).
- «…если вы посмотрите на литературу – никто не говорит о гипоталамусе и поведении. Гипоталамус очень мал, и не может быть легко рассмотрен технологиями просмотра человеческого мозга вроде фМРТ. К тому же, большинство анатомической работы, к примеру, над системой инстинктивного страха, сильно неодооценивается, потому что её провели бразильские нейробиологи, не особо заботящиеся о публикациях в престижных журналах. К счастью, недавно интерес к этому возобновился, и исследования заново обретают признание.» (Корнелиус Гросс, 2018)
- Нескольку случайных примеров статей о роли Направляющей Подсистемы (особенно гипоталамуса) в социальном поведении: «Независимые схемы гипоталамуса для социального страха и страха хищников» (Сильва и пр., 2013), «Отображение различных переменных вознаграждения для себя и других в латеральном гипоталамусе приматов» (Норитакек и пр., 2020), и «Социальные Стимулы Вызывают Активацию Окситоциновых Нейронов в Паравентрикулярных Ядрах Гипоталамуса для Продвижения Социального Поведения у Самца Мыши» (Резенде и пр., 2020).
- Я подозреваю, более аккуратная диаграмма показывала бы возбуждение (в психологически-жаргонном смысле, не в сексуальном – т.е. повышение пульса и пр.) как промежуточную переменную. Конкретнее: (1) если сенсорная обработка в мозговом стволе показывает, что рядом присутствует взрослый человек, берёт меня на руки, и пр., то это ведёт к повышенному возбуждению (по умолчанию, если Оценщики Мыслей не указывают сильно на иное), и (2) когда я в состоянии повышенного возбуждения, мой мозговой ствол воспринимает это как плохое и опасное (по умолчанию, если Оценщики Мыслей не указывают сильно на иное).
- К примеру, Направляющая Подсистема нуждается в методе для различия «маленьких проблесков эмпатии» и других мимолётных чувств, к примеру, происходящих, когда я продумываю последствия возможного варианта действий. Может, для этого есть какие-то неидеальные эвристики, но моя предпочитаемая теория – что есть специальный Оценщик Мыслей, обученный срабатывать при обращении внимания на другого человека (основываясь на сигналах эмпирической истины, как описано в Разделе 13.4). Как другой пример, нам надо, чтобы сигнал «эмпирической истины задним числом» не отучил постепенно Оценщик Мыслей воспринимать «его бьют в живот». Но, мне кажется, если Направляющая Подсистема может сообразить, когда сигнал является «маленьким проблеском эмпатии», то она может и выбрать не посылать в этом случае сигнал об ошибке Оценщику Мыслей.
- Предупреждение: я не вполне уверен, что существует «стандартное» определение эмпатии; возможно и что термин используется многими непоследовательными способами.
14. Контролируемый СИИ
- 1.14.1 Краткое содержание / Оглавление
- 2.14.2 Три категории Оценщиков Мыслей СИИ
- 3.14.3 Обучение Оценщиков Мыслей, и «задача первого лица»
- 4.14.4 Консерватизм и экстраполяция концептов
- 5.14.5 Получение доступа к самой модели мира
- 6.14.6 Заключение: умеренный пессимизм по поводу нахождения хорошего решения, неуверенность по поводу последствий плохого решения
14.1 Краткое содержание / Оглавление
В Посте №12 были предложены два возможных пути решения «задачи согласования» подобного-мозгу СИИ. Я назвал их «СИИ с Социальными Инстинктами» и «Контролируемым СИИ». Затем, в Посте №13 я подробнее рассмотрел (один из аспектов) «СИИ с Социальными Инстинктами». И теперь в этом посте мы переходим к «Контролируемому СИИ».
Если вы не читали Пост №12, не беспокойтесь, направление исследований «Контролируемого СИИ» – не что-то хитрое, это попросту идея решения задачи согласования самым легко приходящим на ум способом:
Направление исследований «Контролируемого СИИ»:
- Шаг 1 (за пределами темы этой цепочки): Мы решаем, какую мотивацию мы хотим у СИИ. К примеру, это может быть:
- «Изобрести лучшую солнечную панель, не вызвав катастрофы» (ориентированный на задачу СИИ),
- «Быть полезным ассистентом для управляющего человека» (исправимые СИИ-ассистенты),
- «Исполнить самые глубокие жизненные цели управляющего человека» (амбициозное выучивание ценностей),
- «Максимизировать когерентную экстраполированную волю»,
- Или что-то ещё на наш выбор.
- Шаг 2 (тема этого поста): Мы создаём СИИ с этой мотивацией.
Это пост про Шаг 2, а Шаг 1 находится за пределами темы этой цепочки. Если честно, я был бы невероятно рад, если бы мы выяснили, как надёжно настроить мотивацию СИИ на любой вариант, упомянутый в Шаге 1.
К сожалению, я не знаю никакого хорошего плана для Шага 2, и (я утверждаю) никто другой тоже не знает. Но у меня есть некоторые расплывчатые мысли и идеи, и в духе мозгового штурма я ими тут поделюсь. Этот пост не предполагается полным обзором всей задачи, он только о том, что я считаю самыми важными недостающими частями.
Из всех постов цепочки этот однозначно занимает первое место по «неуверенности мнения». Практически для всего, что я говорю в этом посте, я легко могу представить, как кто-то меня переубеждает за час разговора. Попробуйте стать этим «кем-то», пишите комментарии!
Содержание:
- В Разделе 14.2 обсуждается то, как мы можем использовать в СИИ «Оценщики Мыслей». Если вы начинаете читать отсюда – Оценщики Мыслей определялись в Постах №5-№6, и обсуждались по ходу цепочки дальше. Если у вас есть опыт в Обучении с Подкреплением, думайте об Оценщиках Мыслей как о компонентах многомерной функции ценности. Если у вас есть опыт в «быть человеком», думайте об Оценщиках Мыслей как об обученных функциях, вызывающих внутренние реакции (отвращение, выброс кортизола, и т.д.), основываясь на мыслях, которые вы прямо сейчас думаете. В случае подобных-мозгу СИИ мы можем выбрать те Оценщики Мыслей, которые хотим, и я предлагаю для рассмотрения три категории: Оценщики Мыслей, направленные на безопасность (например, «Эта мысль/план подразумевает, что я честен»), Оценщики Мыслей, направленные на достижение цели (например, «эта мысль/план приведёт к лучшему проекту солнечной панели»), и Оценщики Мыслей, направленные на интерпретируемость (например, «эта мысль/план как-то связана с собаками»).
- В Разделе 14.3 обсуждается, как мы можем генерировать управляющие сигналы для обучения этих Оценщиков Мыслей. Часть этой темы – то, что я называю «задачей первого лица», конкретно – открытый вопрос, возможно ли взять размеченные данные от третьего лица (например, видео с YouTube, где Алиса обманывает Боба), и преобразовать их в предпочтения от первого лица (желание СИИ не обманывать самому).
- В Разделе 14.4 обсуждается проблема того, что СИИ будет встречать в своих предпочтениях «крайние случаи» – планы или обстоятельства, при которых его предпочтения становятся плохо определёнными или самопротиворечивыми. Я с осторожностью оптимистичен на счёт того, что мы сможем создать систему, просматривающую мысли СИИ и определяющую, когда он встречает крайний случай. Однако, у меня нет хороших идей о том, что делать, когда это произойдёт. Я рассмотрю несколько возможных решений, включая «консерватизм» и пару разных стратегий для того, что Стюарт Армстронг называет Экстраполяцией Концептов.
- В Разделе 14.5 обсуждается открытый вопрос о том, можем ли мы строго доказать что-то о мотивациях СИИ. Это, кажется, потребовало бы погружения в предсказательную модель мира СИИ (которая, вероятно, была бы многотерабайтной выученной с чистого листа неразмеченной структурой данных) и доказательств о том, что «означают» её компоненты. Тут я довольно пессимистичен, но всё же упомяну возможные пути вперёд, включая программу исследований Джона Вентворта «Гипотеза Естественной Абстракции» (самая свежая информация тут).
- Раздел 14.6 подводит итоги моим мыслям о перспективах «Контролируемых СИИ». Я сейчас несколько пессимистичен по поводу надежд, что у нас появится хороший план, но, надеюсь, я неправ, и я намерен продолжать об этом думать. Я также отмечу, что посредственный, не основательный подход к «Контролируемым СИИ» не обязательно вызовет катастрофу уровня конца света – тут сложно сказать точно.
14.2 Три категории Оценщиков Мыслей СИИ
Для фона – вот наша обычная диаграмма мотивации в человеческом мозгу, из Поста №6:
См. Пост №6. Аббревиатуры – из анатомии мозга, можете их игнорировать.
А вот модификация для СИИ, из Поста №8:
В центральной-правой части диаграммы я зачеркнул слова «кортизол», «сахар», и пр. Они соответствовали набору человеческих внутренних реакция, которые могут быть непроизвольно вызваны мыслями (см. Пост №5). (Или, в терминах машинного обучения, это более-менее соответствует компонентам многомерной функции ценности, аналогичных тому, что можно найти в многоцелевом / многокритерийном обучении с подкреплением.)
Конечно, штуки вроде сахара и кортизола не подходят для Оценщиков Мыслей будущих СИИ. Но что подходит? Ну, мы программисты, нам решать!
Мне в голову приходят три категории. Я поговорю о том, как они могут обучаться (с учителем) в Разделе 14.3 ниже.
14.2.1 Оценщики Мыслей Безопасности и Исправимости
Примеры оценщиков мыслей из этой категории:
- Эта мысль/план подразумевает, что я помогаю.
- Эта мысль/план не подразумевает манипуляцией моим собственным процессом обучения, кодом, или системой мотивации.
- Эта мысль/план не подразумевает обмана или манипуляции кем-либо.
- Эта мысль/план не подразумевает причинения кому-либо вреда.
- Эта мысль/план подразумевает следование человеческим нормам, или, более обобщённо, выполнение действий, про которые правдоподобно, что их мог бы совершить этичный человек.
- Эта мысль/план имеют «низкое влияние» (согласно человеческому здравому смыслу).
- …
Можно посчитать (см. этот пост Пола Кристиано), что №1 достаточно и заменяет остальные. Но я не знаю, думаю, хорошо было бы иметь отдельную информацию по всем этим пунктам, что позволило бы нам менять веса в реальном времени (Пост №9, Раздел 9.7), и, наверное, дало бы нам дополнительные метрики безопасности.
Пункты №2-№3 приведены, потому что это особенно вероятные и опасные виды мыслей – см. обсуждение инструментальной конвергенции в Посте №10, Разделе 10.3.2.
Пункт №5 – это попытка справиться с нахождением СИИ странных не пришедших бы человеку в голову решений задач, т.е. попытка смягчить так называемую «проблему Ближайшей Незаблокированной Стратегии». Почему это может её смягчить? Потому что соответствие паттерну «правдоподобно, что это мог бы сделать этичный человек» – немного больше похоже на белый список, чем на чёрный. Я всё равно не считаю, что это сработает само по себе, не поймите меня неправильно, но, может быть, это сработает в объединении с другими идеями из этого поста.
Перед тем, как вы перейдёте в режим поиска дырок («лол, вполне правдоподобно, что этичный человек превратил бы мир в скрепки, если бы находился под влиянием инопланетного луча контроля разума»), вспомните, что (1) имеется в виду, что это реализовано с помощью соответствия паттерну из уже виденных примеров (Раздел 14.3 ниже), а не дословного следования в духе джина-буквалиста; (2) у нас, надеюсь, будет какого-то рода система детектирования выхода из распределения (Раздел 14.4 ниже), чтобы предотвратить СИИ от нахождения и злоупотребления странными крайними случаями этого соответствия паттернам. Однако, как мы увидим, я не вполне знаю, как сделать ни одну из этих двух вещей, и даже если мы это выясним, у меня нет надёжного аргумента о том, что этого хватит для получения нужного безопасного поведения.
14.2.2 Относящиеся к задаче Оценщики Мыслей
Примеры оценщиков мыслей из этой категории:
- Эта мысль/план приведёт к снижению глобального потепления
- Эта мысль/план приведёт к лучшему проекту солнечной батареи
- Эта мысль/план приведёт к богатству управляющего мной человека
- …
Это вещи того рода, ради которых мы создаём СИИ – что мы на самом деле хотим, чтобы он делал. (Подразумевая, для простоты, ориентированный на задачи СИИ.)
Основание системы мотивации на рассуждениях такого рода – очевидно катастрофично. Но, может быть, если мы используем эти мотивации вместе с предыдущей категорией, это будет ОК. К примеру, представьте СИИ, который может думать только мысли, соответствующие паттерну «Я помогаю» И паттерну «это уменьшит глобальное потепление».
Однако, я не уверен, что мы хотим эту категорию вообще. Может, Оценщика Мыслей «Я помогаю» достаточно самого по себе. В конце концов, если управляющий человек пытается снизить глобальное потепление, то помогающий СИИ предоставит ему план, как это сделать. Вроде бы, такой подход используется тут.
14.2.3 Оценщики Мыслей «Суррогата интерпретируемости»
(См. Пост №9, Раздел №9.6 за тем, что я имею в виду под «Суррогатом интерпретируемости».)
Как обсуждалось в Постах №4-№5, каждый оценщик мыслей – обученная с учителем модель. Уж точно, чем больше мы их поместим в СИИ, тем более вычислительно дорогим он будет. Но я не знаю, насколько более. Может, мы можем поместить их 10^7, и это добавит всего 1% у общей вычислительной мощности, необходимой для работы СИИ. Я не знаю. Я надеюсь на лучшее и на подход More Dakka: давайте сделаем 30000 Оценщиков Мыслей, по одному на каждое слово из словаря:
- Эта мысль/план как-то связана с АБАЖУРОМ
- Эта мысль/план как-то связана с АББАТОМ
- Эта мысль/план как-то связана с АББРЕВИАТУРОЙ
- … … …
- Эта мысль/план как-то связана с ЯЩУРОМ
Я ожидаю, что разбирающиеся в машинном обучении способны немедленно предложить сильно улучшенные версии этой схемы – включая версии с ещё более more* dakka – с использованием контекста, языковых моделей, и т.д. Как пример, если мы выкупим и откроем код Cyc (больше о нём ниже), то сможем использовать сотни тысяч размеченных людьми концептов из него.
14.2.4 Комбинирование Оценщиков Мыслей в функцию ценности
Для того, чтобы СИИ оценивал мысль/план как хорошую, мы бы хотели, чтобы все Оценщики Мыслей безопасности и исправимости из Раздела 14.2.1 имели как можно более высокое значение, и чтобы ориентированный на задачу Оценщик Мыслей из Раздела 14.2.2 (если мы такой используем) тоже имел как можно более высокое значение.
(Выводы Оценщиков Мыслей интерпретируемости из Раздела 14.2.3 не являются вводом функции вознаграждения СИИ, и вообще, полагаю, им не используются. Я думаю, они будут втихую подключены, чтобы помогать программистам в отладке, тестировании, мониторинге, и т.д.)
Так что вопрос: как нам скомбинировать этот массив чисел в единую оценку, которая может направлять, что СИИ решает делать?
Вероятно, плохой ответ – «сложить их все». Мы не хотим, чтобы СИИ пришёл к плану, который катастрофически плох по всем, кроме одного Оценщикам Мыслей безопасности, но настолько астрономически высок согласно последнему, что этого хватает.
Скорее, я представляю, что нам нужно применять какую-то сильно нелинейную функцию, и/или даже пороги приемлемости, прежде чем складывать в единую оценку.
У меня не особо много знаний и точных мнений по деталям. Но существует литература на тему «скаляризации» многомерных функций ценности – см. ссылки здесь.
14.3 Обучение Оценщиков Мыслей, и «задача первого лица»
Напомню, в Постах №4-№6 мы говорили, что Оценщики Мыслей обучаются с учителем. Так что нам нужен управляющий сигнал – то, что я обозначил как «эмпирическая истина задним числом» в диаграмме сверху.
Я много говорил о том, как мозг генерирует сигнал эмпирической истины, например, в Посте №3, Разделе 3.2.1, Постах №7 и №13. Как нам генерировать его для СИИ?
Ну, одна очевидная возможность – пусть СИИ смотрит YouTube, с многими прикреплёнными к видео ярлыками, показывающими, какие, как мы думаем, Оценщики Мыслей должны быть активными. Тогда, когда мы готовы послать СИИ в мир, чтобы решать задачи, мы отключаем размеченные видео, и одновременно замораживаем Оценщики Мыслей (= устанавливаем сигналы ошибки на ноль) в их текущем состоянии. Ну, я не уверен, что это сработало бы; может, СИИ время от времени нужно возвращаться назад и пересматривать эти размеченные видео, чтобы помочь Оценщикам Мыслей держаться наравне с растущей и меняющейся моделью мира СИИ.
Одно потенциальное слабое место такого подхода связано с различием первого и третьего лица. Мы хотим, чтобы у СИИ были сильные предпочтения по поводу аспектов планов от первого лица – мы надеемся, что СИИ будет считать «я буду лгать и обманывать» плохим, а «я буду помогать» хорошим. Но мы не можем напрямую получить такие предпочтения просто заставив СИИ смотреть размеченные видео с YouTube. СИИ увидит, как персонаж Алиса обманывает персонажа Боба, но это не то же самое, что обманчивость самого СИИ. И это очень важное различие! Действительно:
- Если вы скажете мне «моему СИИ не нравится обманывать», я скажу «это вам повезло!».
- Если вы скажете мне «моему СИИ не нравится, когда люди обманывают», я скажу «ради Бога скорее выключи эту штуку, пока она не вышла из-под человеческого контроля и не убила всех нас!!!»
Уж точно было бы хорошо, если бы был способ преобразовывать данные от третьего лица (например, размеченное видео с YouTube, где Алиса обманывает Боба) в предпочтения СИИ от первого лица («Я не хочу обманывать»). Я называю это задача первого лица.
Как нам решить задачу первого лица? Я не уверен. Может, мы можем применить инструменты интерпретируемости к модели мира СИИ, понять, как он отображает себя, и соответственным образом проманипулировать его мыслями, или что-то такое? Ещё возможно, что дальнейшее исследование человеческих социальных инстинктов (предыдущий пост) прольёт на это свет, ведь человеческие социальные инстинкты, кажется, преобразуют третье лицо «все в моей группе друзей используют зелёную помаду» в первое лицо «я хочу использовать зелёную помаду».
Если задача первого лица нерешаема, то нам надо вместо этого прибегнуть к пугающему методу: позволять СИИ предпринимать действия, и выдавать им ярлыки. Почему пугающему? Во-первых, потому что эти действия могут быть опасными. Во-вторых, потому что это не даёт нам хорошего способа отличить (к примеру) «СИИ говорит неправду» от «СИИ попался на том, что говорит неправду». Консерватизм и/или экстраполяция концептов (Раздел 14.4 ниже) могу бы помочь с этой проблемой – может, у нас получилось бы получить СИИ одновременно мотивированного быть честным и не попадаться, и это было бы достаточно – но всё же это по разным причинам кажется ненадёжным.
14.3.1 Отступление: почему мы хотим предпочтений от первого лица?
Я подозреваю, что «задача первого лица» интуитивно понятна большинству читателей. Но, готов поспорить, подмножество читателей чувствует искушение сказать, что это вовсе не проблема. В конце концов, в области человеческих действий есть хорошие аргументы в пользу того, что нам надо использовать поменьше предпочтений от первого лица!
Противоположностью предпочтений от первого лица были бы «безличные консеквенциалистские предпочтения», при которых есть будущая ситуация, которую мы хотим обеспечить (например, «замечательная пост-СИИ утопия»), и мы принимаем направленные на неё решения, без особой заботы о том, что делаю конкретно-Я. В самом деле, слишком много мышления от первого лица приводит к многим вещам, которые мне лично в мире не нравятся – например, присвоение заслуг, избегание вины, разделение действия / бездействия, социальный сигналинг, и так далее.
Всё же, я думаю, что выдача СИИ предпочтений от первого лица – правильный шаг в сторону безопасности. Пока мы не заполучим супер-надёжные СИИ 12-о поколения, я бы хотел, чтобы они считали «произошло что-то плохое (я с этим никак не связан)» куда менее плохим, чем «произошло что-то плохое (и это моя вина)». У людей это так, в конце концов, и это, кажется по крайней мере относительно устойчивым – к примеру, если я создам робота-грабителя, а потом он ограбит банк, а я возражу «Эй, я не сделал ничего плохого, это всё робот!», то у меня не получится никого обмануть, особенно себя. СИИ с такими предпочтениями, наверное, был бы осторожным и консервативным в принятии решений, и склонялся бы к бездействию по умолчанию при сомнениях. Это кажется в общем хорошим, что приводит нас к следующей теме:
14.4 Консерватизм и экстраполяция концептов
14.4.1 Почему бы не попросту безустанно оптимизировать правильный абстрактный концепт?
Давайте сделаем шаг назад.
Предположим, мы создали СИИ, у которого есть позитивная валентность, присвоенная абстрактному концепту «много человеческого процветания», и который последовательно составляет планы и исполняет действия, приводящие к этому концепту.
Я, на самом деле, довольно оптимистичен по поводу того, что с технической стороны мы сможем так сделать. Как и выше, мы можем использовать размеченные видео с YouTube и всякое такое, чтобы создать Оценщик Мыслей для «эта мысль / план приведён к процветанию людей», а затем установить функцию вознаграждения на основе этого одного Оценщика Мыслей (см. Пост №7).
А затем мы выпускаем СИИ в ничего не подозревающий мир, чтобы он делал то, что, как он думает, лучше всего сделать.
Что может пойти не так?
Проблема в том, что абстрактный концепт «человеческое процветание» в модели мира СИИ – это на самом деле просто куча выученных ассоциаций. Сложно сказать, какие действия вызовет стремление к «человеческому процветанию», особенно когда мир будет меняться, и понимание СИИ мира будет меняться ещё больше. Иначе говоря, нет будущего мира, который будет идеально соответствовать паттерну нынешнего понятия «человеческого процветания» у СИИ, и если чрезвычайно могущественный СИИ будет оптимизировать мир для лучшего соответствия паттерну, то это может привести к чему-то странному, даже катастрофичному. (Или, может быть, нет! Довольно сложно сказать, больше об этом в Разделе 14.6.)
Случайные примеры того, что может пойти не так: может, СИИ захватит мир и будет удерживать людей и человеческое общество от дальнейших изменений, потому что изменения ухудшат соответствие паттерну. Или, может быть, наименее плохое соответствие паттерну будет, если СИИ избавится от настоящих людей в пользу бесконечной модифицированной игры в The Sims. Не то чтобы The Sims идеально соответствовала «человеческому процветанию» – наверное, довольно плохо! Но, может быть, менее плохо, чем всё, что для СИИ реально сделать с настоящими людьми. Или, может быть, пока СИИ будет всё больше и больше учиться, его модель мира постепенно изменится так, что замороженный Оценщик Мыслей начнёт указывать на что-то совершенно случайное и безумное, а затем СИИ истребляет людей и замощает галактику скрепками. Я не знаю!
В любом случае, безустанная оптимизация зафиксированного замороженного абстрактного концепта вроде «человеческого процветания» кажется, возможно, проблематичной. Можно ли лучше?
Ну, было бы хорошо, если бы мы могли непрерывно совершенствовать этот концепт, особенно по ходу того, как меняется мир и понимание его СИИ. Эту идею Стюарт Армстронг называет Экстраполяцией Концептов, если я правильно его понимаю.
Экстраполяция концептов – то, что проще сказать, чем сделать – для вопроса «что такое человеческое процветание на самом деле?» нет очевидной эмпирической истины. К примеру, что будет означать «человеческое процветание» в трансгуманистическом будущем гибридов людей с компьютерами, суперинтеллектуальных эволюционировавших осьминогов и бог-знает-чего-ещё?
В любом случае, мы можем разделить экстраполяцию концептов на два шага. Во-первых, (простая часть) нам надо детектировать крайние случаи предпочтений СИИ. Во-вторых, (сложная часть) нам надо выяснить, что следует СИИ делать при столкновении с таким крайним случаем. Давайте поговорим об этом по порядку.
14.4.2 Простая часть экстраполяции концептов: Детектировать крайние случаи предпочтений СИИ
Я с осторожностью оптимистичен по поводу возможности создать простой алгоритм мониторинга, который присматривает за мыслями СИИ и детектирует, когда тот находится в ситуации крайнего случая – т.е., за пределами распределения, где его выученные предпочтения и концепты ломаются.
(Понимание содержания крайнего случая кажется куда более сложной задачей, это ещё будет обсуждаться, но тут я пока что говорю только о распознавании появления крайнего случая.
Вот несколько примеров возможных намёков, указывающих, что СИИ столкнулся с крайним случаем:
- Выученные распределения вероятностей Оценщиков Мыслей (см. Пост №5, Раздел 5.5.6.1) могут иметь широкие допуски, что указывает на неуверенность.
- Разные Оценщики Мыслей из Раздела 14.2 могут расходиться новыми неожиданными способами.
- Ошибка предсказания вознаграждения СИИ может болтаться взад-вперёд между положительными и отрицательными значениями, указывая на «разрыв» между значениями, приписываемыми разным аспектам возможного плана.
- Генеративная модель мира СИИ может прийти в состояние с очень маленькой априорной вероятностью, указывая на замешательство.
14.4.3 Сложная часть экстраполяции концептов: что делать в крайнем случае
Я не знаю хороших решений. Вот некоторые варианты.
14.4.3.1 Вариант A: Консерватизм – В случае сомнений просто не делай этого!
Прямолинейный подход – при срабатывании детектора крайних случаев СИИ просто устанавливать сигнал вознаграждения отрицательным – чтобы то, что СИИ думает, посчиталось плохой мыслью/планом. Это приблизительно соответствует «консервативному» СИИ.
(Замечу: я думаю, есть много способов, которые мы можем использовать, чтобы сделать подобный-мозгу СИИ более или менее «консервативным» в разных аспектах. То, что выше – только один пример. Но у них всех, кажется, общие проблемы.)
Вариант неудачи консервативного СИИ – что он просто не будет ничего делать, будучи парализованным неуверенностью, потому что любой возможный план кажется слишком ненадёжным или рискованным.
«Парализованный неуверенностью СИИ» – это провал, но не опасный провал. Ну, пока мы не настолько глупы, чтобы поставить СИИ управлять горящим самолётом, падающим на землю. Но это нормально – в целом, я думаю, вполне ОК, если СИИ первого поколения будут иногда парализованы неуверенностью, так что не будут подходить для решения кризисов, где ценна каждая секунда. Такой СИИ всё ещё сможет выполнять важную работу вроде изобретения новых технологий, в частности, проектирования лучших и более безопасных СИИ второго поколения.
Однако, если СИИ всегда парализован неуверенностью – так, что он не может сделать что-либо – тогда у нас большая проблема. Предположительно, в такой ситуации, будущие программисты СИИ просто будут всё дальше и дальше понижать уровень консерватизма, пока СИИ не начнёт делать что-то полезное. И тогда неясно, хватит ли оставшегося консерватизма для безопасности.
Я думаю, куда лучше было бы, если СИИ будет иметь способ итеративно получать информацию для снижения неуверенности, оставаясь при этом сильно консервативным в случаях оставшейся неуверенности. Так как нам это сделать?
14.4.3.2 Вариант B: Тупой алгоритм поиска прояснения в крайних случаях
Вот немного глупый иллюстративный пример того, что я имею в виду. Как выше, у нас есть простой алгоритм мониторинга, который присматривает за мыслями СИИ и детектирует ситуации крайних случаев. Тогда он полностью выключает СИИ и выводит текущие активации его нейросети (и соответствующие выводы Оценщиков Мыслей). Программисты используют инструменты интерпретируемости, чтобы выяснить, о чём СИИ думает, и напрямую присваивают ценность/вознаграждение, переписывая предыдущую неуверенность СИИ эмпирической истиной с высокой уверенностью.
Такая конкретная история кажется нереалистичной, в основном потому, что у нас скорее всего не будет достаточно надёжных и детализированных инструментов интерпретируемости. (Опровергните меня, исследователи интерпретируемости!) Но, может быть, есть подход получше, чем просто рассматривать миллиарды нейронных активаций и Оценщиков Мыслей?
Сложность в том, что коммуникация СИИ с людьми – фундаментально тяжёлая задача. Мне неясно, возможно ли решить её тупым алгоритмом. Ситуация тут очень сильно отличается от, скажем, классификатора изображений, в случае которого мы можем найти изображение для крайнего случая и просто показать его человеку. Мысли СИИ могут быть куда менее понятны.
Это аналогично тому, что коммуникация людей друг с другом возможна, но не посредством какого-то тупого алгоритма. Мы делаем это, используя всю мощь своего интеллекта – моделируя, что думает наш собеседник, стратегически выбирая слова, которые лучше передают желаемое сообщение, и обучаясь с опытом коммуницировать всё эффективнее. Так что, если мы попробуем такой подход?
14.4.3.3 Вариант C: СИИ хочет искать разъяснений в крайних случаях
Если я пытаюсь кому-то помочь, то мне не нужен никакой специальный алгоритм мониторинга для поиска разъяснений в крайних случаях. Я просто хочу разъяснений, как осознающий себя правильно мотивированный агент.
Так что если мы сделаем такими наши СИИ?
На первый взгляд кажется, что этот подход решает все упомянутые выше проблемы. Более того, так СИИ может использовать всю свою мощь на то, чтобы всё лучше работало. В частности, он может научиться своим собственным невероятно сложным метакогнитивным эвристикам для отмечания крайних случаев, и может научиться применять мета-предпочтения людей о том, когда и как ему надо запрашивать разъяснений.
Но тут есть ловушка. Я надеялся на то, что консерватизм / экстраполяция концептов защитит нас от неправильно направленной мотивации. Если мы реализуем консерватизм / экстраполяцию концептов с помощью самой системы мотивации, то мы теряем эту защиту.
Конкретнее: если мы поднимемся на уровень выше, то у СИИ всё ещё есть мотивация («искать разъяснений в крайних случаях»), и эта мотивация всё ещё касается абстрактного концепта, который приходится экстраполировать для крайних случаев за пределами распределения («Что, если мой оператор пьян, или мёртв, или сам в замешательстве? Что, если я задам наводящий вопрос?»). И для этой задачи экстраполяции концептов у нас уже нет страховки.
Проблема ли это? Долгая история:
Отдельный спор: Помогут ли предпочтения «полезности» в «экстраполяции» безопасности, если их просто рекурсивно применить к самим себе?
Это, на самом деле, длительный спор в области безопасности СИИ – «экстраполируются» ли помогающие / исправимые предпочтения СИИ (например, желание понимать и следовать предпочтениям и мета-предпочтениям человека) желаемым образом безо всякой «страховки» – т.е., без независимого механизма эмпирической истины, направляющего предпочтения СИИ в нужном направлении.
В лагере оптимистов находится Пол Кристиано, который в «Исправимости» (2017) заявлял, что есть «широкие основания для привлекательности приемлемых вариантов», основываясь, например, на идее, что предпочтение СИИ быть помогающим приведёт к рефлексивному желанию непрерывно редактировать собственные предпочтения в направлении, которое понравится людям. Но я на самом деле не принимаю этот аргумент по причинам, указанным в моём посте 2020 года – по сути, я думаю, что тут наверняка есть чувствительные области вроде «что значит для человека чего-то хотеть» и «каковы нормы коммуникации у людей» и «склонность к само-мониторингу», и если предпочтения СИИ «уезжают» по одной из этих осей (или по всем сразу), то я не убеждён, что они сами себя исправят.
В то же время, к крайне-пессимистичному лагерю относится Элиезер Юдковский, я так понимаю, в основном, из-за аргумента (см., например, этот пост, последний раздел, что нам следует ожидать, что мощные СИИ будут иметь консеквенциалистские предпочтения, а они кажутся несовместимыми с исправимостью. Но я на самом деле не принимаю и этот аргумент, по причинам из моего поста 2021 года «Консеквенциализм и Исправимость» – по сути, я думаю, что существуют возможные рефлексивно-стабильные предпочтения, включающие консеквенциалистские части (и, следовательно, совместимые с мощными способностями), но не являющиеся чисто консеквенциалистскими (и, следовательно, совместимые с исправимостью). Мне кажется правдоподобным развитие «предпочтения помогать» в смешанную схему такого рода.
В любом случае, я не уверен, но склоняюсь к пессимизму. Ещё по этой теме см. недавний пост Wei Dai, и комментарии к постам по ссылкам выше.
14.4.3.4 Вариант D: Что-то ещё?
Я не знаю.
14.5 Получение доступа к самой модели мира
Очевидно важная часть всего этого – это мнгоготерабайтная неразмеченная генеративная модель мира, обитающая внутри Генератора Мыслей. Оценщики Мыслей дают нам окно в эту модель мира, но я обеспокоен, что это окно может быть довольно маленьким, затуманенным и искажающим. Можно ли лучше?
В идеале мы бы хотели доказывать штуки о мотивации СИИ. Мы бы хотели говорить «С учётом состояния модели мира СИИ и Оценщиков Мыслей, СИИ точно замотивирован сделать X» (где X=помогать, быть честным, не вредить людям, и т.д.) Было бы здорово, правда?
Но мы немедленно упираемся в стену: как нам доказать хоть что-то о «значении» содержимого модели мира, а, следовательно, о мотивации СИИ? Мир сложный, следовательно, сложна и модель мира. То, о чём мы беспокоимся – расплывчатые абстракции вроде «честности» и «помощи» – см. Проблему Указателей. Модель мира продолжает меняться, пока СИИ учится и пока он исполняет планы, выводящие мир далеко за границы распределения (например, планируя развёртывание новой технологии). Как мы можем доказать тут что-то полезное?
Я всё же думаю, что самый вероятный ответ – «Мы не можем». Но есть два возможных пути. За связанными обсуждениями см. Выявление Скрытого Знания.
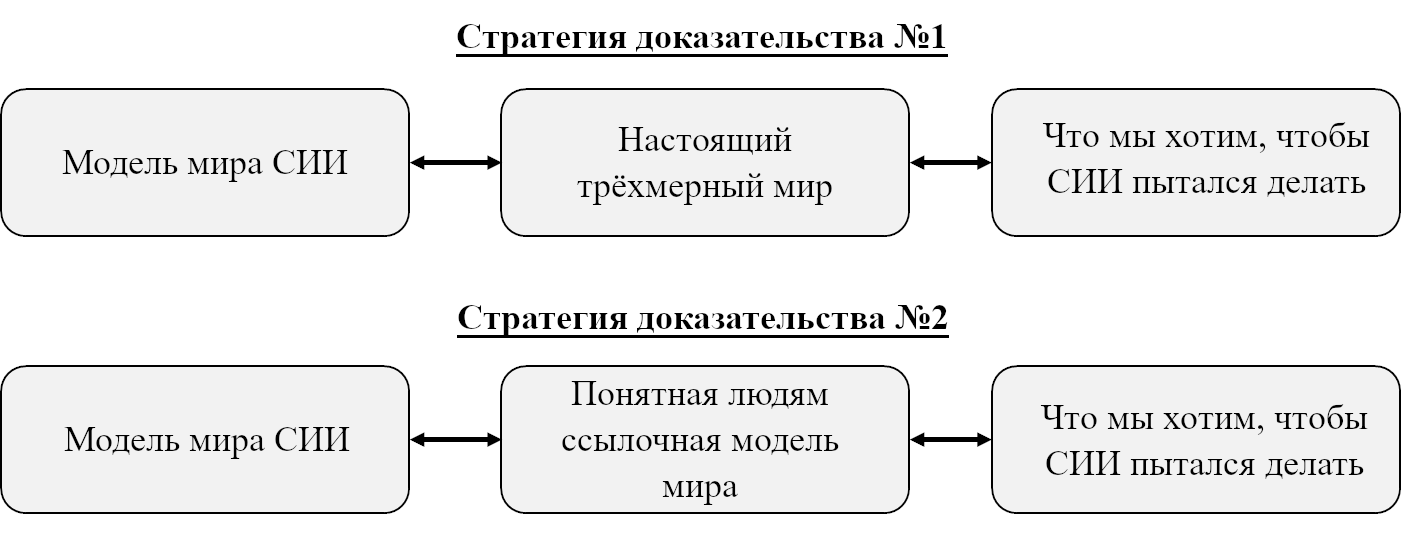
Стратегия доказательства №1 начинается с идеи, что мы живём в трёхмерном мире с объектами и всяким таким. Мы пытаемся прийти к однозначным определениям того, чем являются эти объекты, а из этого получить однозначный язык для определения того, что мы хотим, чтобы произошло в мире. Мы также как-то переводим (или ограничиваем) понимание мира СИИ на этот язык, и тогда мы сможем доказывать теоремы о том, что СИИ пытается сделать.
Таково моё неуверенное понимание того, что пытается сделать Джон Вентворт со своей программой исследований Гипотезы Естественных Абстракций (самая свежая информация тут), и я слышал подобные идеи ещё от пары других человек. (Обновление: Джон не согласен с такой характеристикой, см. его комментарий.)
Я тут настроен скептически, потому что трёхмерный мир локализированных объектов не кажется многообещающей стартовой точкой для формулировки и доказательства полезных теорем о мотивациях СИИ. В конце концов, многие вещи, о которых беспокоятся люди, и о которых должен беспокоиться СИИ, кажутся сложными для описания в терминах трёхмерного мира локализированных объектов – взять хотя бы «честность», «эффективность солнечной батареи» или даже «день».
Стратегия доказательства №2 началась бы с понятной человеку «ссылочной модели мира» (например, Cyc). Эта ссылочная модель не была бы ограничена локализованными объектами в трёхмерном мире, так что, в отличии от предыдущей стратегии, она могла бы и скорее всего содержала бы вещи вроде «честности», «эффективности солнечной батареи» и «дня».
Затем мы пытаемся напрямую сопоставить элементы «ссылочной модели мира» и элементы модели мира СИИ.
Совпадут ли они? Нет, конечно. Наверное, лучшее, на что мы можем надеяться – это расплывчатое соответствие многих-ко-многим, с кучей дырок с каждой стороны.
Мне сложно увидеть путь к строгим доказательства чего бы то ни было про мотивации СИИ с использованием этого подхода. Но я всё же изумлён тем, что машинный перевод без учителя вообще возможен, я вижу это как косвенный намёк на то, что если внутренние структуры частей двух моделей мира соответствуют друг другу, то тогда они скорее всего описывают одну и ту же вещь в реальном мире. Так что, может быть, тут есть проблески надежды.
Мне неизвестны работы в этом направлении, может быть потому, что оно глупое и обречённое, но может быть и потому, что, кажется, у нас сейчас нет по-настоящему хороших, открытых, и понятных людям моделей мира, чтобы ставить на них эксперименты. Думаю, эту проблему стоит решить как можно скорее, возможно, выписав огромный чек, чтобы сделать Cyc открытым, или разработав другую, но настолько же большую, точную, и (главное) понятную модель мира.
14.6 Заключение: умеренный пессимизм по поводу нахождения хорошего решения, неуверенность по поводу последствий плохого решения
Я думаю, что мы столкнулись с большими сложностями в выяснении того, как решить задачу согласования путём «Контролируемого СИИ» (как определено в Посте №12). Есть куча открытых вопросов, и я сейчас понятия не имею, что с ними делать. Нам точно стоит продолжать высматривать хорошие решения, но прямо сейчас я открыт к перспективе, что мы их не найдём. Так что я продолжаю вкладывать большую часть своих мысленных сил в путь «СИИ с Социальными Инстинктами» (Посты №12-№13), который, несмотря на его проблемы, кажется мне менее обречённым.
Я, впрочем, замечу, что мой пессимизм не общепринят – к примеру, как уже упоминалось, Стюарт Армстронг из AlignedAI выглядит настроенным оптимистично по поводу решения открытой задачи из Раздела 14.4, а Джон Вентворт кажется настроенным оптимистично по поводу задачи из Раздела 14.5. Понадеемся, что они правы, пожелаем им удачи и попробуем помочь!
Для ясности, мой пессимизм касается нахождения хорошего решения «Контролируемого СИИ», то есть решения, в котором мы можем быть крайне уверены априори. Другой вопрос: Предположим, мы пытаемся создать «Контролируемый СИИ» с помощью плохого решения, вроде примера из Раздела 14.4.1, где мы вкладываем в сверхмощный СИИ всепоглощающее стремление к абстрактному концепту «человеческого процветания», а затем СИИ произвольно экстраполирует этот абстрактный концепт далеко за пределы обучающего распределения полностью бесконтрольно и ненаправленно. Насколько плохим будет будущее, в которое такой СИИ нас приведёт? Я очень неуверен. Будет ли такой СИИ устраивать массовые пытки? Эммм, полагаю, я осторожно оптимистичен, что нет, за исключением случая ошибки в знаке из-за космического луча, или чего-то такого. Истребит ли он человечество? Я думаю – это возможно! – см. обсуждение в Разделе 14.4.1. Но может и нет! Эй, это может быть даже будет довольно замечательное будущее! Я действительно не знаю, и я даже не уверен, как снизить мою неуверенность.
В следующем посте я подведу итог цепочке своим вишлистом открытых задач и советами по поводу того, как войти в эту область и помочь их решать!
15. Заключение: Открытые задачи и как помочь
- 1.15.1 Краткое содержание / Оглавление
- 2.15.2 Открытые задачи
- 2.1.15.2.1 Открытые задачи, похожие на нормальную нейробиологию
- 2.2.15.2.2 Открытые задачи, похожие на нормальную информатику
- 2.3.15.2.3 Открытые задачи, требующие явного упоминания СИИ
- 2.3.1.15.2.3.1 Исследовательская программа «Крайних случаев / консерватизма / экстраполяции концептов» — ⭐⭐⭐⭐⭐
- 2.3.2.15.2.3.2 Исследовательская программа «Жёстко доказать хоть что-нибудь о значении элементов выученной с чистого листа модели мира» — ⭐⭐⭐⭐⭐
- 2.3.3.15.2.3.3 Исследовательская программа «Решать задачу целиком» — ⭐⭐⭐⭐⭐
- 3.15.3 Как подключиться
- 4.15.4 Заключение: 8 выводов
15.1 Краткое содержание / Оглавление
Это последний пост цепочки «Введение в безопасность подобного-мозгу СИИ»! Спасибо, что дочитали!
- В Разделе 15.2 я перечислю семь открытых задач, всплывавших в предыдущих постах. Я размещаю их тут в одном месте для удобства потенциальных исследователей и спонсоров.
- В Разделе 15.3 я выложу быстрые заметки по практическим аспектам того, как начать заниматься исследованиями в области безопасности (согласования) СИИ, включая поиск финансирования, связь с исследовательским сообществом и где узнать больше.
- В Разделе 15.4 я подведу итоги восемью выводами, которые, как я надеюсь, читатели сделают из этой цепочки.
Раз уж это пост-заключение, можете спокойно использовать комментарии для обсуждений на общие темы (или вопросов мне по любому поводу), даже если они не связаны с этим конкретным постом.
15.2 Открытые задачи
Это ни в коем случае не исчерпывающий список открытых задач, прогресс в которых мог бы помочь безопасности подобного-мозга СИИ, и уж тем более общей теме Безопасного и Полезного СИИ (см. Пост №1, Раздел 1.2). Скорее, это просто некоторые из тем, всплывавших в этой цепочке, с присвоенными рейтингами, пропорциональными тому, насколько сильный энтузиазм я испытываю по их поводу.
Я разделю открытые задачи на три категории: «Открытые задачи, похожие на обычную нейробиологию», «Открытые задачи, похожие на обычную информатику», и «Открытые задачи, которые требуют явно упоминать СИИ». Это разделение – для удобства читателей: у вас, к примеру, может быть начальник, спонсор или диссертационный совет, считающий, что безопасность СИИ – это глупости, и в таком случае вы можете захотеть избегать третьей категории. (Однако, не сдавайтесь слишком быстро – см. обсуждение в Разделе 15.3.1 ниже.)
15.2.1 Открытые задачи, похожие на нормальную нейробиологию
15.2.1.1 Исследовательская программа «Несёт ли Стив полную чушь, когда говорит о нейробиологии?» — ⭐⭐⭐⭐
Если вы не заметили, Посты №2-№7 наполнены откровенным теоретизированием и наглыми заявлениями о том, как работает человеческий мозг. Было бы здорово знать, правда ли всё это на самом деле!!
Если эти посты про нейробиологию – полная ерунда, то, думаю, отвергнуть надо не только их, но и остальную цепочку тоже.
В текстах этих постов встречаются разные предложения и указания на то, почему я считаю истинными свои нейробиологические заявления. Но аккуратного тщательно исследованного анализа, насколько мне известно, ещё нет. (Или, если есть, пошлите мне ссылку! Ничто не сделает меня счастливее, чем узнать, что я изобрёл велосипед и заявлял вещи, которые уже вполне известны и общепризнаны.)
Я даю этой программе исследований рейтинг приоритетности в 4 звезды из 5. Почему не 5? Две причины:
- Она теряет половинку звезды, потому что у меня есть совершенно неоправданная сверхуверенность в том, что мои нейробиологические заявления всё же не полная ерунда, так что эта программа исследований будет скорее похожа на доопределение мелких деталей, а не на выкидывание всей цепочки в мусор.
- Она теряет вторую половинку звезды, потому что я думаю, что в этой программе исследований есть кусочки, в которых она некомфортно близко подбирается к программе «разузнать детали алгоритмов обучения с чистого листа в мозгу», которой я выдаю рейтинг в минус пять звёзд, потому что я бы хотел добиться как можно большего прогресса в том, как (и возможно ли) нам безопасно использовать подобный-мозгу СИИ, задолго до того, как мы сможем его создать. (См. обсуждение Дифференцированного Технологического Прогресса в Посте №1, Разделе 1.7.)
15.2.1.2 Исследовательская программа «Реверс-инжиниринг человеческих социальных инстинктов» — ⭐⭐⭐⭐⭐
Если предположить, что Посты №2-№7 на самом деле не полная чепуха, получается вывод, что где-то в Направляющей Подсистеме нашего мозга (грубо говоря – в гипоталамусе и мозговом стволе) есть схемы для различных «встроенных реакций», лежащих в основе человеческих социальных инстинктов, и они представляют из себя относительно простые функции ввода-вывода. Цель: выяснить точно, что это за функции, и как они управляют (после прижизненного обучения) нашими социальными и моральными мыслями и поведением.
См. Пост №12 за тем, почему я считаю, что эта исследовательская программа очень полезна для безопасности СИИ, и Пост №13 за обсуждением того, схемы и объяснения приблизительно какого вида нам следует искать.
Вот (немного карикатурная) точка зрения на ту же программу исследований со стороны машинного обучения: Общепризнано, что прижизненное обучение в человеческом мозге включает в себя обучение с подкреплением – к примеру, потрогав один раз раскалённую печь, вы не будете делать это снова. Как и с любым алгоритмом обучения с подкреплением, можно задать два вопроса:
- Как работает алгоритм обучения с подкреплением в мозгу?
- Какая у него в точности функция вознаграждения?
Эти вопросы (более-менее) независимы. К примеру, чтобы экспериментально изучать вопрос A, вам не нужен полный ответ на вопрос B; достаточно как минимум одного способа создавать положительное вознаграждение и хотя бы одного способа создавать отрицательное вознаграждение, чтобы использовать из в своих экспериментах. Это просто: крысам нравится есть сыр и не нравится, когда их бьют током. Готово!
У меня сложилось впечатление, что нейробиологи написали много тысяч статей о вопросе A, и почти нисколько напрямую о вопросе B. Но я думаю, что вопрос B куда более важен для безопасности СИИ. А часть функции вознаграждения, связанная с социальными инстинктами важнее всего.
Я даю этой программе исследований рейтинг приоритетности в 5 звёзд из 5 по причинам, обсуждённым в Постах №12-№13.
15.2.2 Открытые задачи, похожие на нормальную информатику
15.2.2.1 Исследовательская программа «Создать настолько хорошую, большую, открытую и понятную людям модель мира / сеть знаний, насколько получится» — ⭐⭐⭐
Я впервые говорил об этом в посте «Давайте выкупим Cyc для использования в системах интерпретируемости СИИ?» (Несмотря на заголовок поста, я не привязан конкретно к Cyc; если современное машинное обучение может сделать лучшую работу за меньшие деньги, это замечательно.)
Я ожидаю, что будущие СИИ будут создавать и постоянно расширять свои собственные модели мира, и эти модели рано или поздно вырастут до терабайтов информации и дальше, и будут содержать гениальные инновационные концепты, о которых люди раньше не задумывались и которые они не смогут понять, не потратив годы на изучение (или не смогут понять вообще). По сути, пытаясь понять модель мира СИИ мы зайдём в тупик. Так что нам делать? (Нет, «с воплями убежать» не вариант.) Мне кажется, что если бы у нас была наша собственная огромная понятная людям модель мира, то это было бы мощным инструментом в нашем арсенале, чтобы подступиться к задаче понимания модели мира СИИ. Чем точнее и больше понятная людям модель мира, тем полезнее она может быть.
Для большей конкретности, в предыдущих постах я упоминал три причины, почему обладание огромной, замечательной, открытой, понятной людям модели мира было бы полезным:
- Для инициализации обучения не с чистого листа – см. Пост №11, Раздел 11.3.1. По умолчанию, я ожидаю, что модель мира и Оценщики Мыслей (грубо говоря, функция ценности обучения с подкреплением) СИИ будут «обучаться с чистого листа» в смысле как в Посте №2. Это означает, что «СИИ-ребёнок» будет в лучшем случае творить ерунду, а в худшем – вынашивать опасные планы против наших интересов, пока мы будем пытаться оформить его предпочтения в дружественном для людей направлении. Было бы очень мило, если бы мы могли не инициализировать с чистого листа и избежать этой проблемы. Мне вовсе не ясно, возможен ли вообще подход обучения не с чистого листа, но если да, то иметь в распоряжении огромную понятную людям модель мира было бы, наверное, полезно.
- Как список ярлыков концептов для «суррогата интерпретируемости» – см. Пост №14, Раздел 14.2.3. Cyc, к примеру, содержит сотни тысяч концептов, значительно более конкретных, чем слова английского языка – одно слово с 10 определениями в Cyc разделится на 10 разных концептов. Если у нас будет удобный список концептов такого рода с кучей размеченных примеров, то мы сможем использовать обучение с подкреплением (или проще, кросс-корреляцию) для поиска паттернов активаций нейросети СИИ, соответствующих тому, что СИИ «думает про» конкретные концепты.
- Как «ссылочная модель мира» для «настоящей» (может даже формальной) интерпретируемости – см. Пост №14, Раздел 14.5. Это подразумевает более глубокое погружение и в модель мира СИИ, и в открытую и понятную людям «ссылочную модель мира», нахождение областей глубокого структурного сходства, согласующегося с упомянутой выше кросс-корреляцией, и составления выводов о том, что они описывают одни и те же аспекты мира. Как обсуждалось в Посте №14, я думаю, что вероятность успеха тут мала (на эту тему: обсуждение «онтологических несовпадений» тут), но польза при его достижении крайне велика.
Я даю этой программе исследований рейтинг приоритетности в 3 звезды из 5, потому что у меня нет супер-высокой уверенности, что хоть один из этих трёх вариантов реалистичен и эффективен. Я не знаю, есть, может, 50% шанс, что даже если бы у нас была очень хорошая открытая понятная людям модель мира, будущие программисты СИИ всё равно не стали бы её использовать, или что это было бы лишь немногим лучше посредственной открытой понятной людям модели мира.
15.2.2.2 Исследовательская программа «Простая в использовании сверхнадёжная песочница для СИИ» — ⭐⭐⭐
Напомню: по умолчанию, я ожидаю, что модель мира и Оценщики Мыслей (грубо говоря, функция ценности обучения с подкреплением) СИИ будут «обучаться с чистого листа» в смысле как в Посте №2. Это означает, что «СИИ-ребёнок» будет в лучшем случае творить ерунду, а в худшем – вынашивать опасные планы против наших интересов, пока мы будем пытаться оформить его предпочтения в дружественном для людей направлении.
Учитывая это, было бы здорово иметь сверхнадёжное окружение-«песочницу», в котором «СИИ-ребёнок» мог бы делать всё необходимое для обучения, не сбегая в интернет и не учиняя хаос какими-нибудь ещё способами.
Некоторые возможные возражения:
- Возможное возражение №1: Идеально надёжная песочница нереалистична. Это может быть так, я не знаю. Но я говорю о надёжности не против сверхинтеллектуального СИИ, а скорее против «СИИ-ребёнка», чьи мотивации и понимание мира ещё не устоялись. В этом контексте я думаю, что более надёжная песочница осмысленно лучше менее надёжной, даже если и она неидеальна. К тому времени, как СИИ достаточно мощен, чтобы сбежать из любой неидеальной песочницы, мы уже (надеюсь!) установим в него мотивацию этого не делать.
- Возможное возражение №2: Мы уже можем создать достаточно надёжную (хоть и не идеально надёжную) песочницу. Опять же, это может быть правдой, я не знаю. Но я особенно заинтересован в том, будут ли будущие программисты СИИ действительно использовать наиболее надёжную возможную песочницу, с учётом глубоко циничных допущений о мотивации и навыках информационной безопасности этих программистов. (По этой теме: «налог на согласование».) Это означает, что сверхнадёжная песочница должна быть доведена до совершенства, снабжена всеми фичами, которые кто-то может захотеть, быть дружественной к пользователю, незначительно ухудшать производительность, и быть совместимой со всеми аспектами того, как программисты на самом деле обучают и запускают большие системы машинного обучения. Я подозреваю, что по всем этим параметрам ещё есть куда стремиться.
Я даю этой программе исследований рейтинг приоритетности в 3 звезды из 5, в основном потому, что я не особо много знаю по этой теме, так что мне некомфортно за неё агитировать.
15.2.3 Открытые задачи, требующие явного упоминания СИИ
15.2.3.1 Исследовательская программа «Крайних случаев / консерватизма / экстраполяции концептов» — ⭐⭐⭐⭐⭐
Люди могут легко выучивать значения абстрактных концептов вроде «быть рок-звездой», просто наблюдая мир, сравнивая наблюдения с паттерном виденных ранее примеров, и т.д. Более того, выучив этот концепт, люди могут его хотеть (присваивать ему позитивную валентность), в основном как результат повторяющегося сигнала вознаграждения, возникающего при активации этого концепта в разуме (см. Пост №9, Раздел 9.3). Из этого, кажется, можно вывести общую стратегию контроля подобных-мозгу СИИ: заставить их выучить некоторые концепты вроде «быть честным» и «быть полезным» с помощью помеченных примеров, а затем удостовериться, что они получили позитивную валентность, и готово!
Однако, концепты выводятся из сети статистических ассоциаций, и как только мы попадаем в выходящие из распределения крайние случаи, ассоциации ломаются, и концепты тоже. Если религиозный фанатик верит в ложного бога, «помогаешь» ли ты ему, разубедив его? Лучший ответ «Я не знаю, это зависит от того, что мы имеем в виду под помощью». Такое действие хорошо совпадает с некоторыми коннотациями / ассоциациями концепта «помощи», но довольно плохо с другими.
Так что заставить СИИ выучить и полюбить некоторые абстрактные концепты кажется началом хорошего плана, но только если у нас есть оформленный подход к тому, как СИИ должен очищать эти концепты, чтобы мы это одобряли, при встрече с крайними случаями. И тут у меня нет никаких хороших идей.
См. Пост №14, Раздел 14.4 за дополнительным обсуждением.
Примечание: Если вы действительно мотивированы этой программой исследований, одним из вариантов может быть попробовать получить работу в AlignedAI. Их сооснователь, Стюарт Армстронг, изначально и предложил «экстраполяцию концептов» как исследовательскую программу (и установил термин), и, кажется, это и есть их основной исследовательский фокус. Учитывая опыт Стюарта Армстронга в формализованных размышлениях о безопасности СИИ, я с осторожностью оптимистичен по поводу того, что AlignedAI будет работать в направлении решений, масштабируемых до суперинтеллектуальных СИИ завтрашнего дня, а не просто подходящих лишь для современных СИИ-систем, как часто бывает.
Я даю этой программе исследований рейтинг приоритетности в 5 звёзд из 5. Решение этой задачи даст нам по крайней мере большую часть знаний для создания «Контролируемых СИИ» (в смысле Поста №14).
15.2.3.2 Исследовательская программа «Жёстко доказать хоть что-нибудь о значении элементов выученной с чистого листа модели мира» — ⭐⭐⭐⭐⭐
Подобные-мозгу СИИ предположительно будут выучивать с чистого листа огромную многотерабайтную неразмеченную модель мира. Цели и желания СИИ будут определены в терминах содержимого этой модели мира (Пост №9, Раздел 9.2). И в идеале мы бы хотели делать о целях и желаниях СИИ уверенные заявления, или, ещё лучше, доказывать о них теоремы. Это, кажется, требует доказательств о «значениях» элементов этой сложной постоянно растущей модели мира. Как это сделать? Я не знаю.
См. обсуждение в Посте №14, Разделе 14.5.
В этом направлении ведётся какая-то работа в Центре Исследования Согласования, они делают замечательные вещи и нанимают на работу. (см. обсуждение ELK.) Но, насколько я знаю, прогресс тут – это тяжёлая задача, требующая новых идей, если он вообще возможен.
Я даю этому направлению исследований рейтинг приоритетности в 5 звёзд из 5. Может, оно и неосиливаемое, но если получится, то это точно будет чертовски важно. Это, в конце концов, дало бы нам полную уверенность, что мы понимаем, что СИИ пытается сделать.
15.2.3.3 Исследовательская программа «Решать задачу целиком» — ⭐⭐⭐⭐⭐
Это то, чем я занимался в Постах №12 и №14. Нам надо связать всё воедино в правдоподобную схему, выяснить, чего не хватает и точно понять, как двигаться целиком. Если вы читаете эти посты, вы видите, что надо сделать ещё много всего – к примеру, нам нужен план получше для обучающих данных и окружений, и я даже не упомянул штуки вроде протоколов тестирования в песочнице. Но многие из соображений при проектировании кажутся взаимосвязанными, так что нельзя их с лёгкостью разделить на разные программы. Так что это моя категория для таких вещей.
(См. также: Подсказка по продуктивности исследований: «День Решения Всей Задачи».)
Я даю этому направлению исследований рейтинг приоритетности в 5 звёзд из 5 по очевидным причинам.
15.3 Как подключиться
(Предупреждение: этот раздел может быстро устареть. Я пишу его в мае 2022 года.)
15.3.1 Ситуация с финансированием
Если вы обеспокоены безопасностью СИИ («согласованием ИИ»), и ваша цель – помочь с этим, то крайне приятно получать финансирование от кого-то с такой же целью.
Конечно, возможно получать финансирование и из более традиционных источников, например, государственного спонсирования науки, и использовать его для продвижения безопасности СИИ. Но тогда вам придётся выстраивать компромисс между «тем, что поможет безопасности СИИ» и «тем, что впечатлит / удовлетворит источник финансирования». Мой опыт в этом указывает на то, что такие компромиссы действительно плохи. Я потратил некоторое время на исследования таких компромиссных стратегий на ранних этапах моей работы над безопасностью СИИ; я был предупреждён, что они плохи, и я всё равно очень сильно недооценил, насколько они плохи. Для иллюстрации, сначала я вёл блог про безопасность СИИ в качестве хобби в своё свободное время, зажатое между работой в полную ставку и двумя маленькими детьми, и я думаю, что это было намного полезнее, чем если бы я посвящал всё своё время лучшему доступному «компромиссному» проекту.
(Вы можете заменить «компромисс, чтобы удовлетворить мой источник финансирования» на «компромисс, чтобы удовлетворить мою диссертационную комиссию» или «компромисс, чтобы удовлетворить моего начальника» или «компромисс, чтобы заполучить впечатляющее резюме для будущей работы» по ситуации.)
В любом случае, к нашей удаче, есть множество источников финансирования, явно мотивированных безопасностью СИИ. Насколько я знаю, все они – благотворительные фонды. (Я полагаю, беспокоиться о будущем вышедшем из-под контроля СИИ – немного слишком экзотично для государственных фондов?) Финансирование технической безопасности СИИ (тема этой цепочки) последнее время быстро росло, и, кажется, сейчас это десятки миллионов долларов в год, плюс-минус в зависимости от того, что лично вы считаете за настоящую работу над технической безопасностью СИИ.
Многие, но не все озабоченные безопасность СИИ филантропы (и исследователи вроде меня) связаны с движением Эффективного Альтруизма (EA), сообществом / движением / проектом, посвящённом попыткам выяснить, как лучше сделать мир лучшим местом, а затем сделать это. Внутри EA есть крыло «лонгтермистов», состоящее из людей, исходящих из беспокойства о долгосрочном будущем, где «долгосрочное» может означать миллионы, миллиарды или триллионы лет. Лонгтермисты склонны быть особенно мотивированными предотвращением необратимых катастроф масштаба вымирания людей вроде вышедших из-под контроля СИИ, спроектированных пандемий, и т.д. Так что в кругах EA безопасность СИИ иногда считают «областью лонгтермистов», что несколько сбивает с толку, учитывая, что мы говорим о том, как предотвратить потенциальную катастрофу, которая вполне может случиться во время моей жизни (см. Обсуждение сроков в Постах №2-№3). Ну ладно.

(Это просто лёгкий юмор, никого не принижаю, на самом деле, я сам действую частично исходя из беспокойства о долгосрочном будущем.)
Связь между EA и безопасностью СИИ стала достаточно сильна, чтобы (1) одни из лучших конференций для исследователя безопасности СИИ - это EA Global / EAGx, и (2) люди начали называть меня EA, и высылать мне приглашения на их события, когда я всего лишь начал писать посты в блоге про безопасность СИИ в своё свободное время.
В любом случае, суть такова: мотивированные безопасностью СИИ источники финансирования существуют – находитесь ли вы в академической среде, в некоммерческой организации, или просто являетесь независимым исследователем (как я!). Как его получить? В большинстве случае, вам скорее всего надо сделать что-то из этого:
- Продемонстрировать, что вы лично понимаете задачу согласования СИИ достаточно хорошо, чтобы хорошо судить о том, какие исследования были бы полезными, или
- Включиться в конкретную исследовательскую программу, которую специалисты по безопасности СИИ уже одобрили как важную и полезную.
Что касается №2 – одна из причин, почему я написал Раздел 15.2 – я пытаюсь помочь этому процессу. Мне кажется, что по крайней мере некоторые из этих программ могут (при некотором труде) быть оформлены в хорошие конкретные перспективные заявки или предложения. Напишите мне, если думаете, что могли бы помочь, или если хотите, чтобы я держал вас в курсе возможностей.
Что касается №1 – да, делайте это!! Безопасность СИИ – захватывающая область, и она достаточна «молода», чтобы вы могли добраться до переднего фронта исследований куда быстрее, чем возможно, скажем, в физике частиц. См. следующий подраздел за ссылками на ресурсы, курсы, и т.д. Или, полагаю, вы можете обучиться области, если будете читать писать много постов и комментариев на эту тему в своё свободное время, как поступил я.
Кстати, это правда, что некоммерческий сектор в целом имеет репутацию скудных бюджетов и недооплачиваемых перерабатывающих сотрудников. Но финансируемая филантропами работа над безопасностью СИИ обычно не такая. Спонсоры хотят лучших людей, даже если они сильно погружены в свои карьеры и ограничены арендной платой, повседневными затратами, и т.д. – как я! Так что было мощное движение в сторону зарплат, сравнимых с коммерческим сектором, особенно в последнюю пару лет.
15.3.2 Работы, организации, программы обучения, сообщества, и т.д.
15.3.2.1 …Связанные с безопасностью СИИ (согласованием ИИ) в целом
Много ссылок можно найти на так и озаглавленной странице AI Safety Support Lots-of-Links, а более часто обновляемый список можно найти тут: «стартовый набор по безопасности ИИ». Отмечу пару особенно важных пунктов:
- 80,000 часов – организация, посвящённая помощи людям в выстраивании своей карьеры. Они делают упор на безопасность СИИ, и предлагают бесплатные консультации по карьере один на один, в которых они расскажут вам о подходящих возможностях и свяжут вас с подходящими людьми. Ещё посмотрите на их гайд по безопасности ИИ и связанные с технической безопасностью ИИ эпизоды их замечательного подкаста, и их список электронных почтовых адресов и доску вакансий в области ИИ. (Вы можете получить советы по карьере один на один и через AI Safety Support, никаких заявок не требуется.)
- Возможно, вы читаете этот пост на lesswrong.com – блог-платформе, которая обладает (я думаю) уникальным свойством – она одновременно открыта для кого угодно и наполнена многочисленными экспертами по безопасности СИИ. Я начал постить и комментировать там, когда только погружался во всё это в своё свободное время в 2019 году, и я помню, что все были очень добры и оказывали поддержку, и я не знаю, как ещё, учитывая мои географические и временные ограничения, я мог бы войти в эту область. Другие активные онлайновые точки сбора включают Дискорд-канал EleutherAI, Дискорд-канал Роберта Майлза, и Slack AI Safety Support. Что касается встреч / групп по чтению / и т.д. вживую, проверьте тут или тут, а ещё лучше – свою местную /университетскую группу EA, и попросите их указать.
15.3.2.2 …Более конкретно связанные с этой цепочкой
В: Есть ли место сбора и обсуждений конкретно «безопасности подобного-мозгу СИИ» (или тесно связанной «безопасности СИИ, базирующегося на основанном на модели обучении с подкреплением»)?
О: Насколько я знаю, нет. И я не вполне уверен, что должны, это очень сильно пересекается с другими направлениями исследований в безопасности СИИ.
(Ближайшее, наверное, это дискорд-сервер про так называемую «теорию осколков» (shard theory), можете написать мне, чтобы получить ссылку)
В: Есть ли такое для пересечения нейробиологии / психологии и безопасности СИИ / согласования ИИ?
О: Есть канал «нейробиология и психология» в Slack-е AI Safety Support. Вы можете ещё присоединиться к рассылке PIBBSS, на случай, если это ещё повторится в будущем.
Если вы хотите увидеть больше разных точек зрения на пересечение нейробиологии и безопасности СИИ, попробуйте почитать статьи Каджа Соталы; Сета Херда, Дэвида Джилка, Рэндалла О’Райли и пр.; Гопала Сармы и Ника Хэя; Патрика Бутлина; Яна Кулвейта, и другие статьи тех же авторов, и многих других, кого я забыл.
(Я сам, если что, пришёл из физики, не из нейробиологии – на самом деле, я не знал практически ничего из нейробиологии ещё в 2019. Я заинтересовался нейробиологией, чтобы ответить на мучавшие меня вопросы из безопасности СИИ, не наоборот.)
В: Эй, Стив, могу я работать с тобой?
О: Хоть я сейчас не заинтересован в том, чтобы кого-нибудь нанимать или наставлять, я всегда рад кооперироваться и обмениваться информацией. У нас много работы! Напишите мне, если хотите поговорить!
15.4 Заключение: 8 выводов
Спасибо за чтение! Я надеюсь, что этой цепочкой я успешно передал следующее:
- Мы знаем о нейробиологии достаточно, чтобы говорить конкретные вещи о том, на что будет похож «подобный-мозгу СИИ» (Посты №1-№9);
- В частности, хоть «подобный мозгу СИИ» сильно бы отличался от известных алгоритмов, его связанные с безопасностью аспекты имели бы много общего с основанным на модели обучением с подкреплением «субъект-критик» с многомерной функцией ценности (Посты №6, №8, №9);
- «Понять мозг достаточно хорошо, чтобы создать подобный-мозгу СИИ» – намного более простая задача, чем «понять мозг» – если первая приблизительно аналогична тому, чтобы знать, как обучить свёрточную нейросеть, то вторая будет аналогична тому, чтобы знать, как обучить свёрточную нейросеть и достигнуть полной механистической интерпретируемости получившейся модели, и понимать все аспекты физики и инженерии интегральных схем, и т.д. На самом деле, создание подобного-мозгу СИИ надо рассматривать не как далёкую фантастическую гипотезу, но, скорее, как текущий проект, который может завершиться в ближайшее десятилетие или два (Посты №2-№3);
- При отсутствии хорошего технического плана избегания происшествий, исследователи, экспериментирующие с подобным-мозгу СИИ скорее всего случайно создадут неподконтрольный СИИ с катастрофическими последствиями вплоть до и включая вымирание человечества (Посты №1, №3, №10, №11);
- Прямо сейчас у нас нет никакого хорошего технического плана для избегания происшествий с неподконтрольными СИИ (Посты №10-№14);
- Неочевидно, как составить такой план, и его составление не кажется необходимым этапом на пути к созданию мощных подобных-мозгу СИИ – следовательно, не следует предполагать, что он появится в будущем «по умолчанию» (Пост №3);
- Мы многое можем делать прямо сейчас, чтобы помочь двигаться к составлению такого плана (Посты №12-№15);
- Для этой работы доступно финансирование и перспективные варианты карьеры (Пост №15).
Что касается меня, я собираюсь продолжать работать над различными направлениями исследований из Раздела 15.2 выше; для получения новостей подпишитесь на мой Твиттер или RSS, или проверяйте мой сайт. Я надеюсь, вы тоже рассмотрите вариант помочь, потому что я тут прыгаю чертовски выше головы!
Спасибо за чтение, и, ещё раз, комментарии тут – для общих обсуждений и вопросов о чём угодно.
Встроенная агентность
В классических моделях, предполагается, что рациональный агент:
- отделен от внешнего мира,
- имеет ограниченный набор стратегий для взаимодействия с внешним миром,
- строит точные модели внешнего мира,
- не имеет необходимости размышлять о себе или о том, из каких частей он состоит.
В статье приведен неформальный обзор препятствий, которые мешают формализовать хорошие принципы принятия решений для агентов, находящихся внутри оптимизируемого ими мира,агентов вложенных в мир. Такие агенты должны оптимизировать не какую-то функцию, а состояние мира. Такие агенты должны использовать модели, которые входят в моделируемое пространство. Должны размышлять о себе как о просто ещё одной физической системе, сделанной из тех же составных частей что и остальной мир, частей, которые можно модифицировать и использовать в различных целях.
Содержание:
Встроенная Агентность. Встроенные агенты
Примечание переводчика - из-за отсутствия на сайте нужного класса для того, чтобы покрасить текст в оранжевый цвет, я заменил его фиолетовым. Фиолетовый в тексте соответствует оранжевому на картинках.
Предположим, вы хотите создать робота, чтобы он для вас достиг некоей цели в реальном мире – цели, которая требует у робота обучаться самостоятельно и выяснить много того, чего вы пока не знаете.
Это запутанная инженерная задача. Но есть ещё и задача выяснения того, что вообще означает создать такого обучающегося агента. Что такое – оптимизировать реалистичные цели в физическом окружении? Говоря обобщённо – как это работает?
В этой серии постов я покажу четыре стороны нашего непонимания того, как это работает, и четыре области активного исследования, направленных на выяснение этого.
Вот Алексей, он играет в компьютерную игру.
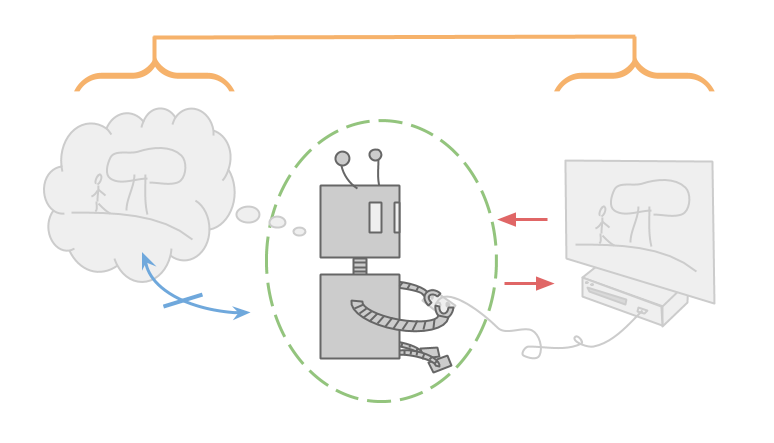
Как в большинстве игр, в этой есть явные потоки ввода и вывода. Алексей наблюдает игру только посредством экрана компьютера и манипулирует игрой только посредством контроллера.
Игру можно считать функцией, которая принимает последовательность нажатия кнопок и выводит последовательность пикселей на экране.
Ещё Алексей очень умён и способен удерживать в своей голове всю компьютерную игру. Если у Алексея и есть неуверенность, то она касается только эмпирических фактов вроде того, в какую игру он играет, а не логических фактов вроде того, какой ввод (для данной детерминированной игры) приведёт к какому выводу. Это означает, что Алексей должен хранить в своей голове ещё и каждую возможную игру, в которую он может быть играет.
Алексею, однако, нет нужды думать о самом себе. Он оптимизирует только игру, в которую он играет, и не оптимизирует мозг, который он использует, чтобы думать об игре. Он всё ещё может выбирать действия, основываясь на ценности информации, но только чтобы помочь себе сузить набор возможных игр, а не чтобы изменить то, как он думает.
На самом деле, Алексей может считать себя неизменяемым неделимым атомом. Раз он не существует в окружении, о котором он думает, Алексей не беспокоится о том, изменится ли он со временем или о подпроцессах, которые ему может понадобиться запустить.
Заметим, что все свойства, о которых я говорил, становятся возможны в частности благодаря тому, что Алексей чётко отделён от окружения, которое он оптимизирует.
Вот Эмми, она играет в реальность.
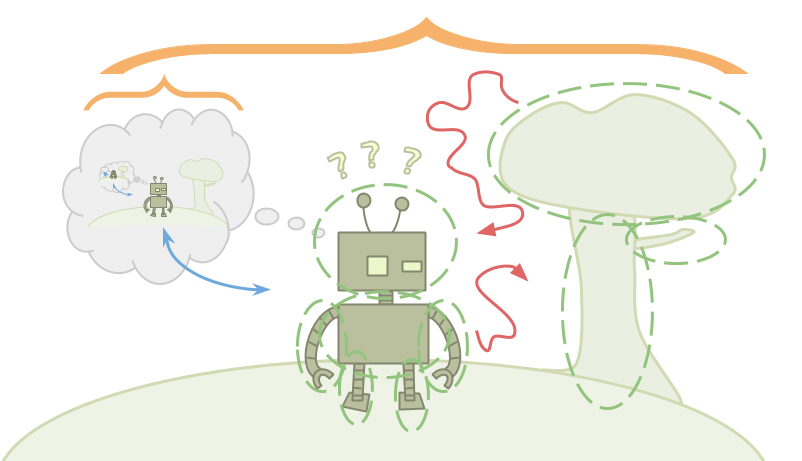
Реальность не похожа на компьютерную игру. Разница в основном вызвана тем, что Эмми находится в окружении, которое пытается оптимизировать.
Алексей видит вселенную как функцию и оптимизирует, выбирая для этой функции ввод, приводящий к более высокому вознаграждению, чем иные возможные вводы, которые он мог бы выбрать. У Эмми, напротив, нет функции. У неё есть лишь окружение, и оно её содержит.
Эмми хочет выбрать лучшее возможное действие, но то, какое действие Эмми выберет – это просто ещё один факт об окружении. Эмми может рассуждать о той части окружения, которая является её решением, но раз Эмми в итоге на самом деле выберет только одно действие, неясно, что вообще значит для Эмми «выбирать» действие, лучшее, чем остальные.
Алексей может потыкать в вселенную и посмотреть, что произойдёт. Эмми – это вселенная, тыкающая себя. Как нам в случае Эмми вообще формализовать идею «выбора»?
Мало того, раз Эмми содержится в окружении, Эмми ещё и должна быть меньше, чем окружение. Это означает, что Эмми не способна хранить в своей голове детальные точные модели окружения.
Это приводит к проблеме: Байесовские рассуждения работают, начиная с большого набора возможных окружений, и, когда вы наблюдаете факты, несовместимые с некоторыми из этих окружений, вы эти окружения отвергаете. На что похожи рассуждения, когда вы неспособны хранить даже одну обоснованную гипотезу о том, как работает мир? Эмми придётся использовать иной вид рассуждений, и совершать поправки, не вписывающиеся в стандартный Байесовский подход.
Раз Эмми находится внутри окружения, которым она манипулирует, она также будет способна на самоулучшение. Но как Эмми может быть уверена, что пока она находит и выучивает всё больше способов улучшить себя, она будет менять себя только действительно полезными способами? Как она может быть уверена, что она не модифицирует свои изначальные цели нежелательным образом?
Наконец, раз Эмми содержится в окружении, она не может считать себя подобной атому. Она состоит из тех же частей, что и остальное окружение, из-за чего она и способна думать о самой себе.
В дополнение к угрозам внешнего окружения, Эмми будет беспокоиться и об угрозах, исходящих изнутри. В процессе оптимизации Эмми может запускать другие оптимизаторы как подпроцессы, намеренно или ненамеренно. Эти подсистемы могут вызывать проблемы, если они становятся слишком мощными и не согласованными с целями Эмми. Эмми должна разобраться, как рассуждать, не запуская разумные подсистемы, или разобраться, как удерживать их слабыми, контролируемыми или полностью согласованными с её целями.
Эмми в замешательстве, так что давайте вернёмся к Алексею. Подход AIXI Маркуса Хаттера предоставляет хорошую теоретическую модель того, как работают агенты вроде Алексея:
$$a_{k}:=argmax_{a_{k}}\sum_{o_{k}r_{k}}…max_{a_{m}}\sum_{o_{m}r_{m}}[r_{k}+…+r{m}]\sum_{q:U(1,a_{1}…a_{m})=o_{1}r_{1}…o_{m}r_{m}}2^{-l(q)}$$
В этой модели есть агент и окружение, взаимодействующие посредством действий, наблюдений и вознаграждений. Агент посылает действие a, а потом окружение посылает наружу и наблюдение o, и вознаграждение r. Этот процесс повторяется в каждый момент k…m.
Каждое действие – функция всех предыдущих троек действие-наблюдение-вознаграждение. И каждое наблюдение и каждое вознаграждение аналогично является функцией этих троек и последнего действия.
Вы можете представить, что при этом подходе агент обладает полным знанием окружения, с которым он взаимодействует. Однако, AIXI используется, чтобы смоделировать оптимизацию в условиях неуверенности в окружении. AIXI обладает распределением по всем возможным вычислимым окружениям q, и выбирает действия, ведущие к высокому ожидаемому вознаграждению согласно этому распределению. Так как его интересует и будущее вознаграждение, это может привести к исследованию из-за ценности информации.
При некоторых допущениях можно показать, что AIXI довольно хорошо работает во всех вычислимых окружениях несмотря на неуверенность. Однако, хоть окружения, с которыми взаимодействует AIXI, вычислимы, сам AIXI невычислим. Агент состоит из чего-то другого рода, чего-то более мощного, чем окружение.
Мы можем назвать агентов вроде AIXI и Алексея «дуалистичными». Они существуют снаружи своего окружения и составляющие агента взаимодействуют с составляющими окружения исключительно ограниченным множеством установленных способов. Они требуют, чтобы агент был больше окружения, и не склонны к самореферентным рассуждениям, потому что агент состоит из чего-то совсем другого, чем то, о чём он рассуждает.
AIXI не одинок. Эти дуалистические допущения показываются во всех наших нынешних лучших теориях рациональной агентности.
Я выставил AIXI как что-то вроде фона, из AIXI можно и черпать вдохновение. Когда я смотрю на AIXI, я чувствую, что я действительно понимаю, как работает Алексей. Таким же пониманием я хочу обладать и об Эмми.
К сожалению, Эмми вводит в замешательство. Когда я говорю о желании получить теорию «встроенной агентности», я имею в виду, что я хочу быть способен теоретически понимать, как работают такие агенты, как Эмми. То есть, агенты, встроенные внутрь своего окружения, а следовательно:
- Не имеющие хорошо определённых каналов ввода/вывода;
- меньшие, чем своё окружение;
- способные рассуждать о себе и самоулучшаться;
- и состоящие из примерно того-же, что и окружение.
Не стоит думать об этих четырёх трудностях как об отдельных. Они очень сильно переплетены друг с другом.
К примеру, причина, по которой агент способен на самоулучшение – то, что он состоит из частей. И если окружение значительно больше агента, оно может содержать другие его копии, что отнимает у нас хорошо определённые каналы ввода/вывода.
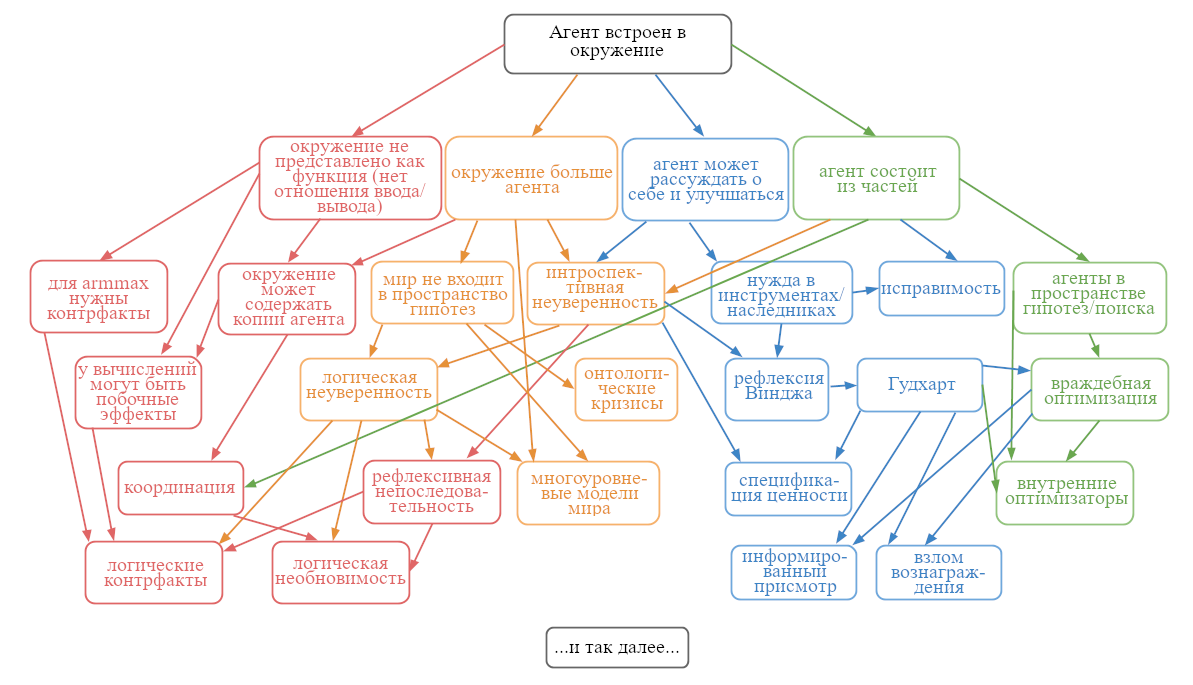
Однако, я буду использовать эти четыре трудности как мотивацию разделения темы встроенной агентности на четыре подзадачи. Это: теория принятия решений, встроенные модели мира, устойчивое делегирование, и согласование подсистем.
Теория принятия решений вся про встроенную оптимизацию.
Простейшая модель дуалистичной оптимизации - это argmax. argmax принимает функцию из действий в вознаграждения, и возвращает действие, ведущее к самому высокому вознаграждению согласно этой функции. Большую часть оптимизации можно рассматривать как вариацию этого. У вас есть некое пространство; у вас есть функция из этого пространства на некую шкалу, вроде вознаграждения или полезности; и вы хотите выбрать ввод, который высоко оценивается этой функцией.
Но мы только что сказали, что большая часть того, что значит быть встроенным агентом – это что у вас нет функционального окружения. Так что нам делать? Оптимизация явно является важной частью агентности, но мы пока даже теоретически не можем сказать, что это такое, не совершая серьёзных ошибок типизации.
Некоторые крупные открытые задачи в теории принятия решений:
- Логические контрфакты: как вам рассуждать о том, что бы произошло, если бы вы совершили действие B, при условии, что вы можете доказать, что вы вместо этого совершите действие A?
- Окружения, включающие множественные копии агента, или достоверные предсказания об агенте.
- Логическая необновимость, о том, как совместить очень изящный, но очень Байесовский мир необновимой теории принятия решений, с куда менее Байесовским миром логической неуверенности.
Встроенные модели мира о том, как вы можете составлять хорошие модели мира, способные поместиться внутри агента, который куда меньше мира.
Известно, что это очень сложно – во-первых, потому что это означает, что настоящая вселенная не находится в вашем пространстве гипотез, что разрушает многие теоретические гарантии; а во-вторых, потому что это означает, что, обучаясь, мы будем совершать не-Байесовские поправки, что тоже рушит кучу теоретических гарантий.
Ещё это о том, как создавать модели мира с точки зрения находящегося внутри него наблюдателя, и вытекающих проблем вроде антропного принципа. Некоторые крупные открытые задачи о встроенных моделях мира:
- Логическая неуверенность, о том, как совместить мир логики с миром вероятностей.
- Многоуровневое моделирование, о том, как обладать несколькими моделями одного и того же мира на разных уровнях описания и изящно переходить между ними.
- Онтологические кризисы, о том, что делать, поняв, что ваша модель, или даже ваша цель, определена не в той же онтологии, что реальный мир.
Устойчивое делегирование – про специальный вид задачи принципала-агента. У вас есть исходный агент, который хочет создать более умного наследника для помощи в оптимизации его целей. Исходный агент обладает всей властью, потому что он решает, что в точности агент-наследник будет делать. Но в другом смысле агент-наследник обладает всей властью, потому что он намного, намного умнее.
С точки зрения исходного агента, вопрос в создании наследника, который устойчиво не будет использовать свой интеллект против тебя. С точки зрения агента-наследника, вопрос в «Как тебе устойчиво выяснить и уважать цели чего-то тупого, легко манипулируемого и даже не использующего правильную онтологию?»
Ещё есть дополнительные проблемы, вытекающие из Лёбова препятствия, делающие невозможным постоянное доверие тому, что намного могущественнее тебя.
Можно думать об этих задачах в контексте агента, который просто обучается со временем, или в контексте агента, совершающего значительное самоулучшение, или в контексте агента, который просто пытается создать мощный инструмент.
Некоторые крупные открытые задачи устойчивого делегирования:
- Рефлексия Винджа – о том, как рассуждать об агентах и как доверять агентам, которые намного умнее тебя, несмотря на Лёбово препятствие доверию.
- Обучение ценностям – о том, как агент-наследник может выяснить цели исходного агента, несмотря на его глупость и непоследовательность.
- Исправимость – о том, как исходному агенту сделать так, чтобы агент-наследник допускал (или даже помогал производить) модификации себя, несмотря на инструментальную мотивацию этого не делать.
Согласование подсистем – о том, как быть одним объединённым агентом, не имеющим подсистем, сражающихся с тобой или друг с другом.
Когда у агента есть цель, вроде «спасти мир», он может потратить большое количество своего времени на мысли о подцели, вроде «заполучить денег». Если агент запускает субагента, который пытается лишь заполучить денег, то теперь есть два агента с разными целями, и это приводит к конфликту. Субагент может предлагать планы, которые выглядят так, будто они только приносят деньги, но на самом деле они уничтожают мир, чтобы заполучить ещё больше денег.
Проблема такова: вам не просто надо беспокоиться о субагентах, которых вы запускаете намеренно. Вам надо беспокоится и о ненамеренном запуске субагентов. Каждый раз, когда вы проводите поиск или оптимизацию по значительно большому пространству, которое может содержать агентов, вам надо беспокоится, что в самом пространстве тоже проводится оптимизация. Эта оптимизация может не в точности соответствовать оптимизации, которую пытается провести внешняя система, но у неё будет инструментальная мотивация выглядеть, будто она согласована.
Много оптимизации на практике использует передачу ответственности такого рода. Вы не просто находите решение, вы находите что-то, что само может искать решение.
В теории, я вовсе не понимаю, как оптимизировать иначе, кроме как методами, выглядящими вроде отыскивания кучи штук, которых я не понимаю, и наблюдения, не исполнят ли они мою цель. Но это в точности то, что наиболее склонно к запуску враждебных подсистем.
Большая открытая задача в согласовании подсистем – как сделать, чтобы оптимизатор базового уровня не запускал враждебные оптимизаторы. Можно разбить эту задачу на рассмотрение случаев, когда оптимизаторы получаются намеренно и ненамеренно, и рассмотреть ограниченные подклассы оптимизации, вроде индукции.
Но помните: теория принятия решений, встроенные модели мира, устойчивое делегирование и согласование подсистем – не четыре отдельных задачи. Они все разные подзадачи единого концепта встроенной агентности.
Вторая часть: Теория принятия решений.
Встроенная Агентность. Теория принятия решений
Примечание переводчика - из-за отсутствия на сайте нужного класса для того, чтобы покрасить текст в оранжевый цвет, я заменил его фиолетовым. Фиолетовый в тексте соответствует оранжевому на картинках.
Теория принятия решений и искусственный интеллект обычно пытаются вычислить что-то напоминающее
$$argmax_{a \in Actions}f(a)$$
Т.е. максимизировать некую функцию от действия. Тут предполагается, что мы можем в достаточной степени распутывать вещи, чтобы видеть исходы как функции действий.
К примеру, AIXI отображает агента и окружение как отдельные единицы, взаимодействующие во времени посредством чётко определённых каналов ввода/вывода, так что он может выбирать действия, максимизирующие вознаграждение.
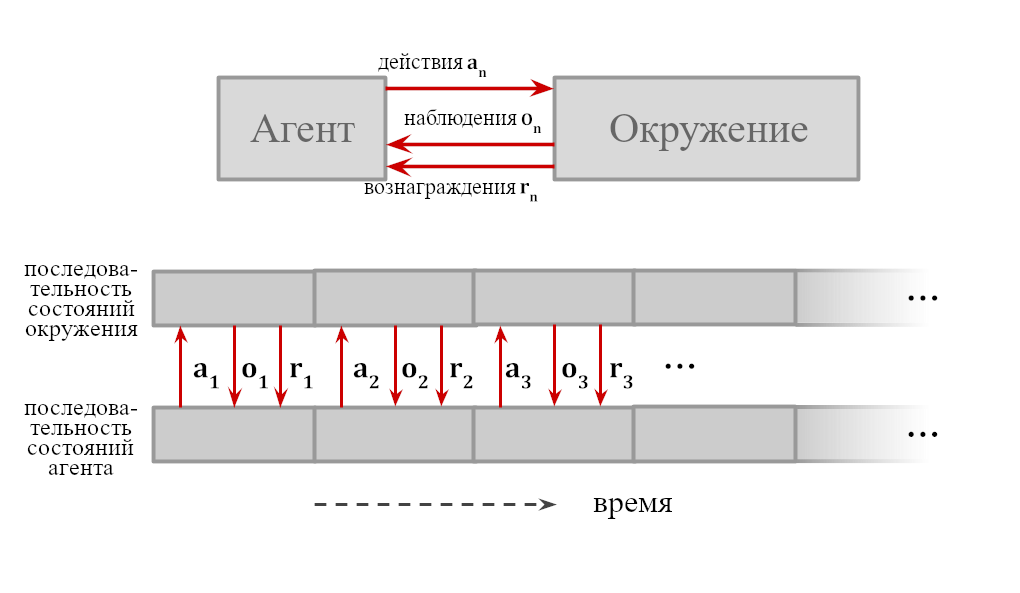
Когда модель агента – часть модели окружения, становится куда менее ясно, как рассматривать исполнение альтернативных действий.
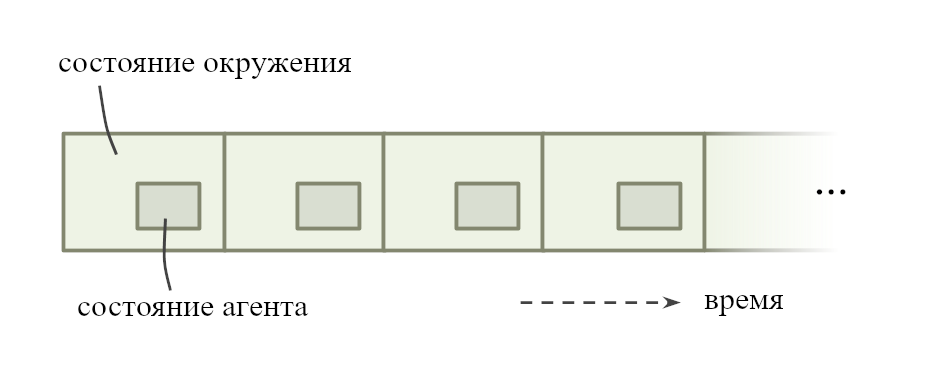
К примеру, раз агент меньше окружения, могут существовать другие копии агента, или что-то, очень похожее на агента. Это приводит к вызывающим споры задачам теории принятия решений, таким как Дилемма Заключённых Близнецов и задача Ньюкомба.
Если Эмми Модель 1 и Эмми Модель 2 имеют один и тот же опыт и исполняют один и тот же исходный код, то должна ли Эмми Модель 1 действовать, будто её решения направляют обоих роботов сразу? В зависимости от того, как вы проведёте границу вокруг «себя», вы можете думать, что контролируете действия обеих копий, или только свои.
Это частный случай проблемы контрфактуальных рассуждений: как нам оценивать гипотетические предположения вроде «Что, если бы солнце внезапно погасло?»
Задача адаптации теории принятия решений к встроенным агентам включает:
- контрфакты
- Рассуждения в духе задачи Ньюкомба, в которых агент взаимодействует с копией себя
- Более широкие рассуждения о других агентах
- Задачи о вымогательстве
- Задачи о координации
- Логические контрфакты
- Логическую необновимость
Самый центральный пример того, почему агентам надо думать о контрфактах, касается контрфактов об их собственных действиях.
Сложность с контрфактуальными действиями можно проиллюстрировать задачей пять-и-десять. Предположим, у нас есть вариант взять пятидолларовую купюру или десятидолларовую, и всё, что нас волнует в этой ситуации – сколько денег мы получим. Очевидно, нам следует взять \$10.
Однако, надёжно брать \$10 не так просто, как кажется.
Если вы рассуждаете о себе просто как о ещё одной части окружения, то вы можете знать своё собственное поведение. Если вы можете знать своё собственное поведение, то становится сложно рассуждать о том, что бы случилось, если бы вы повели себя по-другому.
Это вставляет палки в колёса многих обычных методов рассуждений. Как нам формализовать идею «Взять \$10 приводит к хорошим последствиям, а взять \$5 приводит к плохим последствиям», если значительно богатое знание себя вскрывает, что один из этих сценариев внутренне противоречив?
А если мы не можем так формализовать никакую идею, то каким образом агенты в реальном мире всё равно догадываются взять \$10?
Если мы попробуем вычислить ожидаемую полезность наших действий обычным Байесовским способом, то знание своего собственного поведения приводит к ошибке деления на ноль, когда мы пытаемся вычислить ожидаемую полезность действий, которые мы не выбрали: $¬A$, следовательно $P(A)=0$, следовательно $P(B\&A)=0$, следовательно
$$P(B|A)=\frac{P(B\&A)}{P(A)}=\frac{0}{0}$$
Из-за того, что агент не знает, как отделить себя от окружения, у него заедают внутренние шестерни, когда он пытается представить, как он совершает другое действие.
Но самое большое затруднение вытекает из Теоремы Лёба, которая может заставить в агента, выглядящего в остальном разумно, взять \$5, потому что «Если я возьму \$10, я получу \$0»! И это будет стабильно 0 – проблема не решается тем, что агент обучается или больше о ней думает.
В это может быть сложно поверить; так что давайте посмотрим на детализированный пример. Явление можно проиллюстрировать поведением простых основанных-на-логике агентов, рассуждающих о задаче пять-и-десять.
Рассмотрим такой пример:

У нас есть исходный код агента и вселенной. Они могут рекурсивно ссылаться на код себя и друг друга. Вселенная простая – она просто выводит то, что выводит агент.
Агент тратит много времени в поисках доказательств о том, что произойдёт, если он предпримет различные действия. Если для неких $x$ и $y$, которые могут быть равны 0, 5, или 10, он найдёт доказательство того, что взятие 5 приводит к $x$ полезности, а взятие 10 приводит к $y$ полезности, и что $x>y$, то он, естественно, возьмёт 5. Мы ожидаем, что он не найдёт такого доказательства, и вместо этого выберет действие по умолчанию, взяв 10.
Это кажется простым, когда вы просто представляете агента, который пытается рассуждать о вселенной. Но оказывается, что если время, потраченное на поиск доказательств достаточно велико, то агент будет всегда выбирать 5!
Это доказывается через теорему Лёба. Теорема Лёба гласит, что для любого высказывания $P$, если вы можете доказать, что из доказательства $P$ следовала бы истинность $P$, то тогда вы можете доказать $P$. Формальная запись, где «$□X$» означает «$X$ доказуемо»:
$$□(□P→P)→□P$$
В данной мной версии задачи пять-и-десять, «$P$» – это утверждение «если агент возвращает 5, то вселенная возвращает 5, а если агент возвращает 10, то вселенная возвращает 0».
Если предположить, что оно истинно, то агент однажды найдёт доказательство и действительно вернёт 5. Это сделает высказывание истинным, ведь агент возвращает 5, и вселенная возвращает 5, а то, что агент возвращает 10 – ложно. А из ложных предпосылок вроде «агент возвращает 10» следует всё, что угодно, включая то, что вселенная возвращает 0.
Агент может (при наличии достаточного времени) доказать всё это, а в этом случае агент действительно докажет «если агент возвращает 5, то вселенная возвращает 5, а если агент возвращает 10, то вселенная возвращает 0». И как результат, агент возьмёт \$5.
Мы называем это «поддельным доказательством»: агент берёт \$5, потому что он может доказать, что, если он возьмёт \$10, ценность будет низка, потому что он берёт \$5. Это звучит неправильно, но, к сожалению, это логически корректно. В более общем случае, работая в менее основанных на доказательствах обстановках, мы называем это проблемой поддельных контрфактов.
Общий шаблон такой: контрфакты могут поддельно отмечать действия как не слишком хорошее. Это заставляет ИИ не выбирать это действие. В зависимости от того, как контрфакты работают, это может убрать любую обратную связь, которая могла бы «исправить» проблематичный контрфакт; или, как мы видели с рассуждением, основанным на доказательствах, это может активно помогать поддельным контрфактам быть «истинными».
Замечу, что раз основанные на доказательствах примеры для нас значительно интересны, «контрфакты» должны на самом деле быть контрлогическими; нам иногда надо рассуждать о логически невозможных «возможностях». Это делает неподходящими самые впечатляющие достижения рассуждений о контрфактах.
Вы можете заметить, что я немного считерил. Единственным, что сломало симметрию и привело к тому, что агент взял \$5, было то, что это было действием, предпринимаемым в случае нахождения доказательства, а «10» было действием по умолчанию. Мы могли бы вместо этого рассмотреть агента, который ищет доказательство о том, какое действие приводит к какой полезности, и затем совершает действие, которое оказалось лучше. Тогда выбранное действие зависит от того, в каком порядке мы ищем доказательства.
Давайте предположим, что мы сначала ищем короткие доказательства. В этом случае мы возьмём \$10, потому что очень легко показать, что $A()=5$ приведёт к $U()=5$, а $A()=10$ приведёт к $U()=10$.
Проблема в том, что поддельные доказательства тоже могут быть короткими и не становятся сильно длиннее, когда вселенная становится сложнее для предсказания. Если мы заменим вселенную такой, доказываемая функциональность которой такая же, но её сложнее предсказать, то кратчайшее доказательство обойдёт её сложное устройство и будет поддельным.
Люди часто пытаются решить проблему контрфактов, предполагая, что всегда будет некоторая неуверенность. ИИ может идеально знать свой исходный код, но он не может идеально знать «железо», на котором он запущен.
Решает ли проблему добавление небольшой неуверенности? Зачастую нет:
- Доказательства поддельных контрфактов часто всё ещё есть; если вы думаете, что вы в задаче пять-и-десять с уверенностью в 95%, то у вас может возникнуть всё та же проблема в пределах этих 95%.
- Добавление неуверенности для хорошего определения контрфактов не даёт никакой гарантии, что контрфакты будут осмысленными. Вы нечасто хотите ожидать неполадок «железа» при рассмотрении альтернативных действий.
Рассмотрим такой сценарий: Вы уверены, что почти всегда выбираете пойти налево. Однако, возможно (хоть и маловероятно), что космический луч повредит ваши схемы, в каком случае вы можете пойти направо – но тогда вы сойдёте с ума, что приведёт к множеству других плохих последствий.
Если само это рассуждение – причина того, что вы всегда идёте налево, то всё уже пошло не так.
Просто удостовериться, что у агента есть некоторая неуверенность в своих действиях, недостаточно, чтобы удостовериться, что контрфактуальные ожидания агента будут хоть отдалённо осмысленны. Однако, то, что можно попробовать вместо этого – это удостовериться, что агент действительно выбирает каждое действие с некоторой вероятностью. Эта стратегия называется ε-исследование.
ε-исследование уверяет, что если агент играет в схожие игры достаточно много раз, то он однажды научится реалистичным контрфактам (без учёта реализуемости, до которой мы доберёмся позже).
ε-исследование работает только если есть гарантия, что сам агент не может предсказать, будет ли он ε-исследовать. На самом деле, хороший способ реализовать ε-исследование – воспользоваться правилом «если агент слишком уверен, какое действие совершит, совершить другое».
С логической точки зрения непредсказуемость ε-исследования – то, что предотвращает рассмотренные нами проблемы. С точки зрения теоретического обучения, если бы агент мог знать, что он не собирается исследовать, то он трактовал бы это как отдельный случай – и не смог бы обобщить уроки от исследования. Это возвращает нас к ситуации, в которой у нас нет никаких гарантий, что агент научится хорошим контрфактам. Исследование может быть единственным источником данных о некоторых действиях, так что нам надо заставить агента учитывать эти данные, или он может не обучиться.
Однако, кажется даже ε-исследование не решает всё. Наблюдение результатов ε-исследования показывает вам, что произойдёт, если вы предпримете действие непредсказуемо; последствия выбора этого действия в обычном случае могут быть иными.
Предположим, вы ε-исследователь, который живёт в мире ε-исследователей. Вы нанимаетесь на работу сторожем, и вам надо убедить интервьюера, что вы не такой человек, который бы сбежал, прихватив то, что сторожит. Они хотят нанять кого-то, достаточно честного, чтобы не врать и не воровать, даже считая, что это сойдёт с рук.
Предположим, что интервьюер изумительно разбирается в людях – или просто имеет доступ к вашему исходному коду.
В этой ситуации кража может быть замечательным вариантом как действие ε-исследования, потому что интервьюер может быть неспособен её предсказать, или может не считать, что одноразовую аномалию имеет смысл наказывать.
Но кража – явно плохая идея как нормальное действие, потому что вас будут считать куда менее надёжным и достойным доверия.
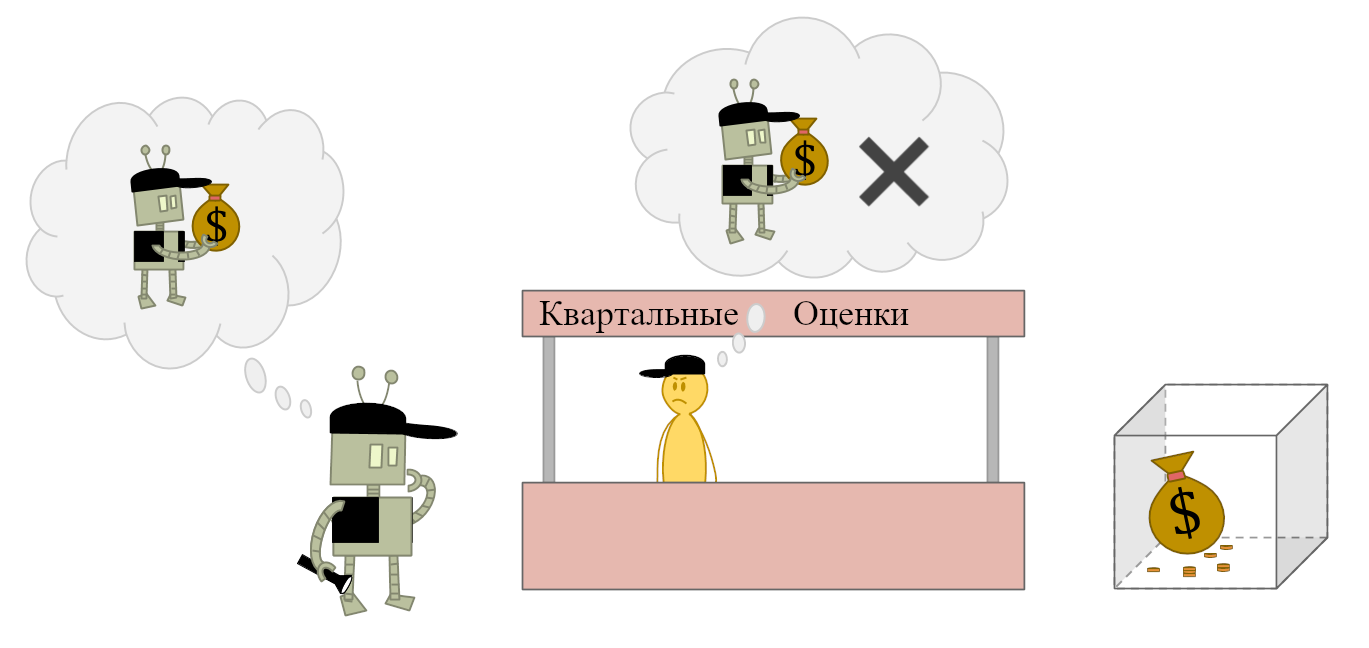
Если мы не обучаемся контрфактам из ε-исследования, то кажется, что у нас вовсе нет гарантии обучиться реалистичным контрфактам. Но если мы обучаемся из ε-исследования, то кажется, что мы всё равно в некоторых случаях делаем всё неправильно.
Переключение в вероятностную обстановку не приводит к тому, что агент надёжно делает «осмысленные» выборы, насильное исследование – тоже.
Но написать примеры «правильных» контрфактуальных рассуждений не кажется сложным при взгляде снаружи!
Может, это потому, что «снаружи» у нас всегда дуалистическая точка зрения. Мы на самом деле сидим снаружи задачи, и мы определили её как функцию агента.
Однако, агент не может решить задачу тем же способом изнутри. С его точки зрения его функциональное отношение с окружением – не наблюдаемый факт. В конце концов, потому контрфакты и называются «контрфактами».

Когда я рассказал вам о задаче пять-и-десять, я сначала рассказал о задаче, а затем выдал агента. Когда один агент не работает, мы можем рассмотреть другого.
Обнаружение способа преуспеть с задачей принятия решений включает нахождение агента, который, если его вставить в задачу, выберет правильное действие. Тот факт, что мы вообще рассматриваем помещение туда разных агентов, означает, что мы уже разделили вселенную на часть «агента» и всю остальную вселенную с дыркой для агента – а это большая часть работы!
Тогда не обдурили ли мы себя тем, как поставили задачи принятия решений? «Правильных» контрфактов не существует?
Ну, может быть мы действительно обдурили себя. Но тут всё ещё есть что-то, приводящее нас в замешательство! Утверждение «Контрфакты субъективны и изобретаются агентом» не развеивает тайну. Есть что-то, что в реальном мире делают интеллектуальные агенты для принятия решений.
Итак, я не говорю об агентах, которые знают свои собственные действия, потому что я думаю, что с разумными машинами, выводящими свои будущие действия, будет большая проблема. Скорее, возможность знания своих собственных действий иллюстрирует что-то непонятное об определении последствий своих действий – замешательство, которое всплывает даже в очень простом случае, где всё о мире известно и просто нужно выбрать самую большую кучу денег.
При всём этом, у людей, кажется, выбор \$10 не вызывает никаких трудностей.
Можем ли мы черпать вдохновение из того, как люди принимают решения?
Ну, предположим, что вас действительно попросили выбрать между \$10 и \$5. Вы знаете, что возьмёте \$10. Как вы рассуждаете о том, что бы произошло, если бы вы вместо этого взяли \$5?
Это кажется легко, если вы можете отделить себя от мира, так что вы думаете только о внешних последствиях (получении \$5).

Если вы думаете ещё и о себе, то контрфакт начинает казаться несколько более странным и противоречивым. Может, у вас будет какое-нибудь абсурдное предсказание о том, каким был бы мир, если бы вы выбрали \$5 – вроде «Я должен был бы быть слепым!»
Впрочем, всё в порядке. В конце концов вы всё равно видите, что взятие \$5 привело бы к плохим последствиям, и вы всё ещё берёте \$10, так что у вас всё хорошо.
Проблема для формальных агентов в том, что агент может находиться в похожем положении, кроме того, что он берёт \$5, знает, что он берёт \$5, и не может понять, что ему вместо этого следует брать \$10, из-за абсурдных предсказаний, которые он делает о том, что происходит, когда он берёт \$10.
Для человека кажется трудным оказаться в подобной ситуации; однако, когда мы пытаемся написать формального проводящего рассуждения агента, мы продолжаем натыкаться на проблемы такого рода. Так что в самом деле получается, что человеческое принятие решений делает что-то, чего мы пока не понимаем.
Если вы – встроенный агент, то вы должны быть способны мыслить о себе, точно так же, как и о всём остальном в окружении. И другие обладатели способностью к рассуждению в вашем окружении тоже должны быть способны мыслить о вас.

Из задачи пять-и-десять мы увидели, насколько всё может стать запутанным, когда агент знает своё действие до того, как действует. Но в случае встроенного агента этого сложно избежать.
Особенно сложно не знать своё собственное действие в стандартном Байесовским случае, подразумевающем логическое всеведенье. Распределение вероятностей присваивает вероятность 1 любому логически истинному факту. Так что если Байесовский агент знает свой собственный исходный код, то он должен знать своё собственное действие.
Однако, реалистичные агенты, не являющиеся логически всеведущими, могут наткнуться на ту же проблему. Логическое всеведенье точно к ней приводит, но отказ от логического всеведенья от неё не избавляет.
ε-исследование во многих случаях кажется решающим проблему, удостоверяясь, что у агентов есть неуверенность в собственных выборах, и что то, что они ожидают, базируется на опыте.

Однако, как мы видели в примере сторожа, даже ε-исследование, кажется, неверно нас направляет, когда результаты случайного исследования отличаются от результатов надёжных действий.
Случаи, в которых всё может пойти не так таким образом, кажется, включают другую часть окружения, которая ведёт себя подобно вам – другой агент, очень на вас похожий, или достаточно хорошая модель или симуляция вас. Это называется Ньюкомбоподобными задачами; пример – Дилемма Заключённых Близнецов, упомянутая выше.
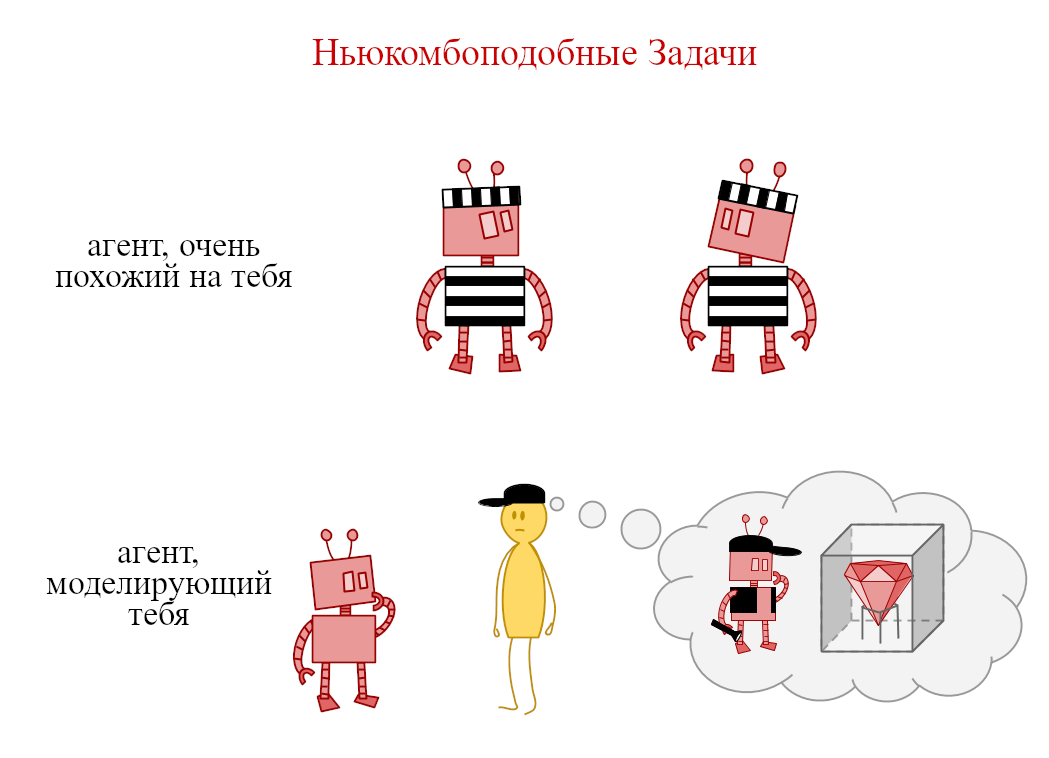
Если задача пять-и-десять касается выделения вас как части мира так, чтобы мир можно было считать функцией от вашего действия, то Ньюкомбоподобные задачи – о том, что делать, если приблизительно подобных вам частей мира несколько.
Есть идея, что точные копии следует считать находящимися на 100% под вашим «логическим контролем». Для приблизительных копий вас или всего лишь похожих агентов, контроль должен резко падать по мере снижения логической корреляции. Но как это работает?

Ньюкомбоподобные задачи сложны по почти той же причине, что и ранее обсуждённые проблемы самореференции: предсказание. Стратегиями вроде ε-исследования мы пытались ограничить знания агента о себе, пытаясь избежать проблем. Но присутствие мощных предсказателей в окружении вводит проблему заново. Выбирая, какой информацией делиться, предсказатели могут манипулировать агентом и выбирать его действия за него.
Если есть что-то, что может вас предсказывать, то оно может сказать вам своё предсказание, или связанную информацию, а в этом случае важно, что вы сделаете в ответ на разные вещи, которые вы можете узнать.
Предположим, вы решаете делать противоположное тому, что вам сказали, чем бы это ни было. Тогда этот сценарий был невозможен изначально. Либо предсказатель всё же не точный, либо предсказатель не поделился с вами своим предсказанием.
С другой стороны, предположим, что есть некая ситуация, в которой вы действуете как предсказано. Тогда предсказатель может контролировать, как вы себя поведёте, контролируя то, какое предсказание вам рассказать.
Так что, с одной стороны, мощный предсказатель может контролировать вас, выбирая между внутренне непротиворечивыми возможностями. С другой стороны, изначально всё же вы выбираете свои паттерны реагирования. Это означает, что вы можете настроить их для своего преимущества.
Пока что мы обсуждали контрфактуальные действия – как предсказать последствия различных действий. Обсуждение контролирования своих реакций вводит контрфактуальные наблюдения – представление, как выглядел бы мир, если бы наблюдались иные факты.
Даже если никто не сообщает вам предсказаний о вашем будущем поведении, контрфактуальные наблюдения всё ещё могут играть роль в принятии верных решений. Рассмотрим такую игру:
Алиса получает случайную карту – либо туза, либо двойку. Она может объявить, что это за карта (только истинно), если хочет. Затем Боб выдаёт вероятность $p$, того, что у Алисы туз. Алиса всегда теряет $p^{2}$ долларов. Боб теряет $p^{2}$, если карта – двойка, и $(1−p)^{2}$, если карта – туз.
У Боба подходящее правило оценивания, чтобы ему лучше всего было выдавать его настоящую вероятность. Алиса просто хочет, чтобы оценка Боба как можно больше склонялась к двойке.
Предположим, Алиса играет только один раз. Она видит двойку. Боб способен хорошо рассуждать об Алисе, но находится в другой комнате, так что не может считывать невербальные подсказки. Следует ли Алисе объявить свою карту?
Раз у Алисы двойка, то если она объявит об этом Бобу, то она не потеряет денег – лучший возможный исход. Однако, это означает, что в контрфактуальном мире, где Алиса видит туза, она не может оставить это в секрете – она могла бы с тем же успехом показать карту и в этом случае, поскольку её нежелание сделать это является настолько же надёжным сигналом «туз».
С одной стороны, если Алиса не показывает свою карту, она теряет 25¢ – но тогда она может применить ту же стратегию и в другом мире, а не терять \$1. Так что до начала игры Алиса хотела бы явно дать обязательство не объявлять карту: это приводит к ожидаемым потерям в 25¢, а другая стратегия – к 50¢. Учитывая контрфактуальные наблюдения Алиса получает способность хранить секреты – а без этого Боб мог бы идеально вывести её карту из её действий.
Это игра эквивалентна задаче принятия решений, которая называется контрфактуальное ограбление.
Необновимая Теория Принятия Решений (UDT) – предлагаемая теория, позволяющая хранить секреты в такой игре. UDT делает это, рекомендуя агенту делать то, что казалось бы наиболее мудрым заранее – то, что ранняя версия себя обязалась бы делать.
Заодно UDT ещё и хорошо справляется с Ньюкомбоподобными задачами.
Может ли что-то вроде UDT быть связанным с тем, что, хоть и только неявно, делают люди, чтобы приходить к хорошим результатам задач принятия решений? Или, если нет, может ли она всё равно быть хорошей моделью для рассуждений о принятии решений?
К сожалению, тут всё ещё есть довольно глубокие сложности. UDT – элегантное решение к довольно широкому классу задач, но имеет смысл только в случае, когда ранняя версия себя может предвидеть все возможные ситуации.
Это хорошо работает в Байесовском случае, содержащем все возможности в априорной оценке. Однако в реалистичном встроенном случае сделать это может быть невозможно. Агент должен быть способен думать о новых возможностях – а значит, ранняя версия себя не знала достаточно, чтобы принять все решения.
И тут мы напрямую сталкиваемся с проблемой встроенных моделей мира.
Встроенная Агентность. Встроенные модели мира
Агент, больший, чем своё окружение, может:
- Удерживать у себя в голове точную модель окружения.
- Продумывать последствия каждого потенциального курса действий.
- Если он не знает окружение идеально, удерживать в голове все возможные варианты, каким окружение могло бы быть, как в случае с Байесовской неуверенностью.
Всё это – типичные понятия рациональной агентности.
Встроенный агент ничего из этого не может, по крайней мере, не напрямую.
Одна из сложностей в том, что раз агент – часть окружения, моделирование окружения во всех деталях требовало бы от агента моделирования себя во всех деталях, для чего модель себя внутри агента должна была бы быть настолько же «большой», как весь агент. Агент не может поместиться в своей собственной голове.
Недостаток чётких границ между агентом и окружением заставляет нас сталкиваться с парадоксами самореференции. Как будто отображение всего остального мира было недостаточно тяжело.
Встроенные Модели Мира должны отображать мир более подходящим для встроенных агентов способом. Задачи из этого кластера включают:
- Проблема «реализуемости»/«зерна истины»: реальный мир не входит в пространство гипотез агента
- Логическая неуверенность
- Высокоуровневые модели
- Многоуровневые модели
- Онтологические кризисы
- Натурализированная индукция, проблема того, что агент должен включить свою модель себя в свою модель мира
- Антропные рассуждения о том, сколько существует копий себя
В Байесовском случае, когда неуверенность агента количественно описывается распределением вероятности по возможным мирам, типичное допущение – «реализуемость»: что настоящее, лежащее в основе наблюдений, окружение имеет хоть какую-то априорную вероятность.
В теории игр то же свойство описывается как изначальное обладание «зерном истины». Впрочем, следует заметить, что в теоретикоигровой обстановке есть дополнительные препятствия для получения этого свойства; так, что при обычном словоупотреблении «зерно истины» требовательно, а «реализуемость» подразумевается.
Реализуемость не вполне обязательна для того, чтобы Байесовские рассуждения имели смысл. Если вы думаете о наборе гипотез, как об «экспертах», а о нынешней апостериорной вероятности – как о том, насколько вы «доверяете» каждому эксперту, то обучение согласно Закону Байеса, $P(h|e)=/frac{P(e|h)P(h)}{P(e)}$, обеспечивает свойство ограниченных относительных потерь.
Конкретно, если вы используете априорное распределение π, то вы хуже в сравнении с каждым экспертом $h$ не более чем на $log(π(h))$, поскольку последовательности свидетельств $e$ вы присваиваете вероятность не меньше, чем $π(h)h(e)$. $π(h)$ – это ваше изначальное доверие эксперту $h$, а в каждом случае, когда он хоть немного более прав, чем вы, вы соответственно увеличиваете своё доверие образом, обеспечивающим, что вы присвоите эксперту вероятность 1, а, значит, скопируете его в точности до того, как потеряете относительно него более чем $log(π(h))$.
Априорное распределение AIXI основывается на распределении Соломонова. Оно определено как вывод универсальной машины Тьюринга (УМТ), чей ввод определяется бросками монетки.
Другими словами, скормим УМТ случайную программу. Обычно считается, что УМТ может симулировать детерминированные машины. Однако, в этом случае, исходный ввод может проинструктировать УМТ использовать остаток бесконечной ленты ввода как источник случайности, чтобы симулировать стохастическую машину Тьюринга.
Комбинируя это с предыдущей идеей о рассмотрении Байесовского обучения как о способе назначать «доверие» «экспертам» с условием ограниченных потерь, мы можем рассматривать распределение Соломонова как что-то вроде идеального алгоритма машинного обучения, который может научиться действовать как любой возможный алгоритм, неважно, насколько умный.
По этой причине, нам не следует считать, что AIXI обязательно «предполагает мир вычислимым», несмотря на то, что он рассуждает с помощью априорного распределения по вычислениям. Он получает ограниченные потери точности предсказаний в сравнении с любым вычислимым предсказателем. Скорее, следует считать, что AIXI предполагает, что вычислимы все возможные алгоритмы, а не мир.
Однако, отсутствие реализуемости может привести к проблемам, если хочется чего-то большего, чем точность предсказаний с ограниченными потерями:
- Апострериорное распределение может колебаться вечно;
- Вероятности могут быть не откалиброваны;
- Оценки статистик вроде среднего могут быть произвольно плохи;
- Оценки скрытых переменных могут быть произвольно плохи;
- И определение каузальной структуры может не работать.
Так работает ли AIXI хорошо без допущения реализуемости? Мы не знаем. Несмотря на ограниченные потери предсказаний и без реализуемости, оптимальность результатов его действий требует дополнительного допущения реализуемости.
Во-первых, если окружение действительно выбирается из распределения Соломонова, то AIXI получает максимальное ожидаемое вознаграждение. Но это попросту тривиально, по сути – это определение AIXI.
Во-вторых, если мы модифицируем AIXI для совершения в какой-то степени рандомизированных действий – сэмплирование Томпсона – то получится асимптотически оптимальный результат для окружений, ведущих себя подобно любой стохастической машине Тьюринга.
Так что, в любом случае, реализуемость предполагалась чтобы всё доказать. (См. Ян Лейке, Непараметрическое Обобщённое Обучение с Подкреплением.)
Но беспокойство, на которое я указываю, это не «мир может быть невычислимым, так что мы не уверены, что AIXI будет работать хорошо»; это, скорее, просто иллюстрация. Беспокойство вызывает то, что AIXI подходит для определения интеллекта или рациональности лишь при конструировании агента, намного, намного большего чем окружение, которое он должен изучать и в котором действовать.
Лоран Орсо предоставляет способ рассуждать об этом в «Интеллекте, Встроенном в Пространство и Время». Однако, его подход определяет интеллект агента в терминах своего рода суперинтеллектуального создателя, который рассуждает о реальности снаружи, выбирая агента для помещения в окружение.
Встроенные агенты не обладают роскошью возможности выйти за пределы вселенной, чтобы подумать о том, как думать. Мы бы хотели, чтобы была теория рациональных убеждений для размещённых агентов, выдающая столь же сильные основания для рассуждений, как Байесианство выдаёт для дуалистичных агентов.
Представьте занимающегося теоретической информатикой человека, встрявшего в несогласие с программистом. Теоретик использует абстрактную модель. Программист возражает, что абстрактная модель – это не что-то, что вообще можно запустить, потому что она вычислительно недостижима. Теоретик отвечает, что суть не в том, чтобы её запустить. Скорее, суть в понимании некоего явления, которое будет относиться и к более достижимым штукам, которые может захотеться запустить.
Я упоминаю это, чтобы подчеркнуть, что моя точка зрения тут скорее как у теоретика. Я говорю про AIXI не чтобы заявить «AIXI – идеализация, которую нельзя запустить». Ответы на загадки, на которые я указываю, не требуют запуска. Я просто хочу понять некоторые явления.
Однако, иногда то, что делает теоретические модели менее достижимыми, ещё и делает их слишком отличающимися от явления, в котором мы заинтересованы.
То, как AIXI выигрывает игры, зависит от предположения, что мы можем совершать настоящие Баейесианские обновления по пространству гипотез, предположения, что мир находится в пространстве гипотез, и т.д. Так что это может нам что-то сказать об аспектах реалистичной агентности в случаях совершения приблизительно Байесовских обновлений по приблизительно-достаточно-хорошему пространству гипотез. Но встроенным агентам нужны не просто приблизительные решения этой задачи; им надо решать несколько других задач другого вида.
Одно из больших препятствий, с которыми надо иметь дело встроенной агентности – это самореференция.
Парадоксы самореференции, такие как парадокс лжеца, приводят к тому, что точное отображение мира в модели мира агента становится не только очень непрактичным, но и в некотором смысле невозможным.
Парадокс лжеца – о статусе утверждения «Это утверждение не истинно». Если оно истинно, то оно должно быть ложно; а если оно ложно, то оно должно быть истинно.
Трудности вытекают из попытки нарисовать карту территории, включающей саму карту.
Всё хорошо, когда мир для нас «замирает»; но раз карта – часть мира, разные карты создают разные миры.
Предположим, что наша цель – составить точную карту последнего участка дороги, которую пока не достроили. Предположим, что ещё мы знаем о том, что команда строителей увидит нашу карту, и продолжит строительство так, чтобы она оказалась неверна. Так мы попадаем в ситуацию в духе парадокса лжеца.
Проблемы такого рода становятся актуальны для принятия решений в теории игр. Простая игра в камень-ножницы-бумагу может привести к парадоксу лжеца, если игроки пытаются выиграть и могут предсказывать друг друга лучше, чем случайно.
Теория игр решает такие задачи с помощью теоретикоигрового равновесия. Но проблема в итоге возвращается в другом виде.
Я упоминал, что проблема реализуемости в ином виде появляется в контексте теории игр. В случае машинного обучения реализуемость – это потенциально нереалистичное допущение, которое всё же обычно можно принять без появления противоречий.
С другой стороны, в теории игр само допущение может быть непоследовательным. Это результат того, что игры часто приводят к парадоксам самореференции.
Так как агентов много, теория игр больше не может пользоваться удобством представления «агента» как чего-то большего, чем мир. Так что в теории игр приходится исследовать понятия рациональной агентности, способной совладать с большим миром.
К сожалению, это делают, разделяя мир на части-«агенты» и части-«не агенты», и обрабатывая их разными способами. Это почти настолько же плохо, как дуалистичная модель агентности.
В игре в камень-ножницы-бумагу парадокс лжеца разрешается постановкой условия, что каждый игрок играет каждый ход с вероятностью в 1/3. Если один игрок играет так, то второй, делая так, ничего не теряет. Теория игр называет этот способ введения вероятностной игры для предотвращения парадоксов равновесием Нэша.
Мы можем использовать равновесие Нэша для предотвращения того, чтобы допущение об агентах, правильно понимающих мир, в котором находятся, было непоследовательным. Однако, это работает просто через то, что мы говорим агентам о том, как выглядит мир. Что, если мы хотим смоделировать агентов, которые узнают о мире примерно как AIXI?
Задача зерна истины состоит в формализации осмысленного ограниченного априорного распределения вероятностей, которое позволило бы играющим в игры агентам присвоить какую-то положительную вероятность настоящему (вероятностному) поведению друг друга, не зная его в точности с самого начала.
До недавних пор известные решения задачи были весьма ограничены. «Рефлексивные Оракулы: Основания Классической Теории Игр» Беньи Фалленштайна, Джессики Тейлор и Пола Кристиано предоставляет очень общее решение. За деталями см. «Формальное решение Задачи Зерна Истины» Яна Лейке, Джессики Тейлор и Беньи Фалленштайна.
Вы можете подумать, что стохастические машины Тьюринга вполне могут отобразить равновесие Нэша.
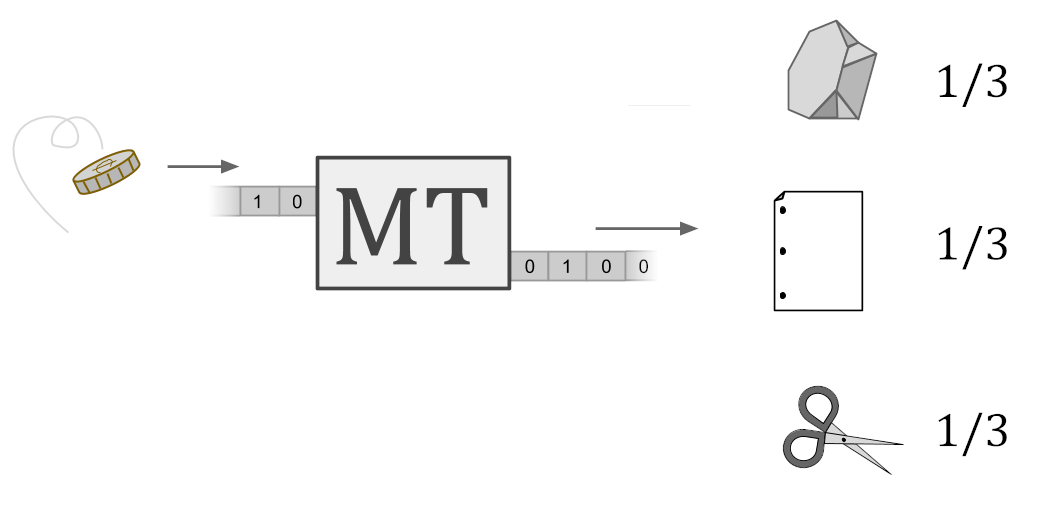
Но если вы пытаетесь получить равновесие Нэша как результат рассуждений о других агентах, то наткнётесь на проблему. Если каждый агент моделирует вычисления другого и пытается запустить их, чтобы понять, что делает другой агент, то получается бесконечный цикл.
Есть некоторые вопросы, на которые машины Тьюринга просто не могут ответить – в частности, вопросы о поведении машин Тьюринга. Классический пример – проблема остановки.
Тьюринг изучал «машины с оракулом», чтобы понять, что произойдёт, если мы сможем отвечать на такие вопросы. Оракул подобен книге, содержащей некоторые ответы на вопросы, на которые мы не могли ответить раньше.
Но так мы получаем иерархию. Машины типа B могут ответить на вопросы о том, остановятся ли машины типа A, машины типа C – ответить на вопросы о типах A и B, и так далее, но никакая машина не может ответить на вопросы о её собственном типе.
Рефлексивные оракулы работают, закручивая вселенную обычных машин Тьюринга саму на себя, так что вместо бесконечной иерархии всё более сильных оракулов мы определяем машину с оракулом, служащую оракулом самой себе.
В норме это бы привело к противоречиям, но рефлексивные оракулы избегают этого, рандомизируя свой вывод в тех случаях, когда они наткнулись бы на парадоксы. Так что рефлексивные оракулы стохастичны, но более мощны, чем простые стохастические машины Тьюринга.
Вот как рефлексивные оракулы справляются с ранее упомянутой проблемой карты, которая сама по себе является частью территории: рандомизация.
Рефлексивные оракулы решают и ранее упомянутую проблему с теоретикоигровым понятием рациональности. Они позволяют рассуждать об агентах так же, как и об остальном окружении, а не трактовать их как фундаментально отдельный случай. Все они просто вычисления-с-доступом-к-оракулу.
Однако, модели рациональных агентов, основанных на рефлексивных оракулах, всё же имеют несколько серьёзных ограничений. Одно из них – что агенты должны обладать неограниченной вычислительной мощностью, прямо как AIXI, и также предполагается, что они знают все последствия своих собственных убеждений.
На самом деле, знание всех последствий своих убеждений – свойства, известное как логическое всеведенье – оказывается центральным для классической Байесовской рациональности.
Пока что я довольно наивно говорил о том, что агент обладает убеждённостью в гипотезах, и реальный мир принадлежит или не принадлежит пространству гипотез.
Не вполне ясно, что всё это значит.
В зависимости от того, как мы что определим, для агента вполне может оказаться возможным быть меньше мира, но всё же содержать верную модель мира – он может знать настоящую физику и стартовые условия, но быть способным вывести их последствия только очень приблизительно.
Люди уж точно привыкли жить с короткими путями и приближениями. Но как бы это ни было реалистично, это не сочетается с тем, что обычно подразумевается под знанием чего-то в Байесовском смысле. Байесианец знает последствия всех своих убеждений.
Неуверенность в последствиях своих убеждений – это логическая неуверенность. В этом случае агент может быть эмпирически уверен в уникальном математическом описании, указывающем на то, в какой он находится вселенной, будучи всё равно неуверенным логически в большинстве последствий этого описания
Моделирование логической неуверенности требует от нас обладания комбинированной теории логики (рассуждений о следствиях) и вероятности (степенях убеждённости).
Теории логики и вероятности – два великих достижения формализации рационального мышления. Логика предоставляет лучшие инструменты для мышления о самореференции, а вероятность – для мышления о принятии решений. Однако, вместе они работают не так хорошо, как можно подумать.
Они могут на первый взгляд показаться совместимыми, ведь теория вероятности – расширение булевой логики. Однако, первая теорема Гёделя о неполноте показывает, что любая достаточно богатая логическая система неполна: не только не справляется с определением истинности или ложности любого высказывания, но ещё и не имеет вычислимого расширения, которое справляется.
(См. больше иллюстраций того, какие проблемы это создаёт для теории вероятности в посте «Проиллюстрированный Незатролливаемый Математик».)
Это также относится к распределениям вероятностей: никакое вычислимое распределение не может присваивать вероятности способом, совместимым с достаточно богатой теорией. Это вынуждает нас выбирать между использованием невычислимого или несовместимой с теорией распределения.
Звучит как простой выбор, правда? Несовместимая теория по крайней мере вычислима, а мы, в конце концов, пытаемся выработать теорию логического не-всеведенья. Мы можем просто продолжать обновляться на основе доказанных нами фактов, что будет приводить нас ближе и ближе к совместимости.
К сожалению, это не заканчивается хорошо, по причинам, опять приводящим нас к реализуемости. Напомню, что не существует вычислимых распределений вероятностей, совместимых со всеми последствиями достаточно мощных теорий. Так что наше не-всеведущее априорное распределение не содержит ни одной верной гипотезы.
Это приводит к очень странному поведению, если мы вводим всё больше и больше математических убеждений в качестве условий. Убеждённости бешено колеблются вместо того, чтобы прийти к осмысленным оценкам.
Принятие Байесовского априорного распределения на математике и обновление его после доказательств кажется не особо ухватывающим математическую интуицию и эвристики – если мы не ограничим область и не составим осмысленные априорные оценки.
Вероятность подобна весам, гири на которых – миры. Наблюдение избавляется от некоторых возможных миров, сдвигая баланс убеждений.
Логика подобна дереву, растущему из зерна аксиом согласно правилам вывода. Для агентов в реальном мире процесс роста никогда не завершён; вы никогда не можете знать все следствия каждого убеждения.
Не зная, как их совместить, мы не можем охарактеризовать вероятностные рассуждения о математике. Но проблема «весов против дерева» ещё и означает, что мы не знаем, как работают обычные эмпирические рассуждения.
Байесовское тестирование гипотез требует, чтобы каждая гипотеза чётко объявляла, какие вероятности она присваивает каким наблюдениям. В таком случае вы знаете, насколько меняются шансы после наблюдения. Если мы не знаем следствий убеждения, то непонятно, насколько следует ориентироваться на его предсказания.
Это вроде незнания куда на весы вероятности положить гири. Мы можем попробовать положить гири на обе стороны, пока не докажем, что с одной из них гирю нужно убрать, но тогда убежденности колеблются вечно, а не приходят к чему-то полезному.
Это заставляет нас напрямую столкнуться с проблемой того, что мир больше, чем агент. Мы хотим сформулировать некое понятие ограниченно рациональных убеждений о следствиях, в которых мы не уверены; но любые вычислимые убеждения о логике должны оставить что-то за бортом, потому что дерево логического вывода вырастает больше любого контейнера.
Весы вероятности Байесианца сбалансированы в точности так, чтобы против него нельзя было сделать голландскую ставку – последовательность ставок, приводящую к гарантированному проигрышу. Но вы можете учесть все возможные голландские ставки, если вы знаете все следствия своих убеждений. Иначе кто-то исследовавший другие части дерева может вас поймать.
Но люди-математики, кажется, не натыкаются ни на какие особые сложности при рассуждениях о математической неуверенности, не более чем при эмпирической неуверенности. Так что характеризует хорошие рассуждения при математической неуверенности, если не иммунитет к плохим ставкам?
Один из вариантов ответа – ослабить понятие голландских ставок, позволяя только ставки, основанные на быстро вычисляемых частях дерева. Это одна из идей «Логической Индукции» Гаррабранта и пр., ранней попытки определить что-то вроде «индукции Соломонова, но для рассуждений, включающих математическую неуверенность».
Другое следствие того факта, что мир больше вас – что вам надо обладать способностью использовать высокоуровневые модели мира: модели, включающие вещи вроде столов и стульев.
Это связано с классической проблемой заземления символов; но раз нам нужен формальный анализ, увеличивающий наше доверие некой системе, интересующая нас модель имеет несколько иной вид. Это связано ещё и с прозрачностью и информированным присмотром: модели мира должны состоять из понимаемых частей.
Связанный вопрос – как высокоуровневые и низкоуровневые рассуждения связаны друг с другом и промежуточными уровнями: многоуровневые модели мира.
Стандартные вероятностные рассуждения не предоставляют особо хорошего подхода к этому. Получается что-то вроде того, что у вас есть разные Байесовские сети, описывающие мир с разным уровнем точности, и ограничения вычислительной мощности вынуждают вас в основном использовать менее точные, так что надо решить, как перепрыгивать на более точные в случае необходимости.
В дополнение к этому, модели на разных уровнях не идеально стыкуются, так что у вас есть проблема перевода между ними; а модели ещё и могут иметь между собой серьёзные противоречия. Это может быть нормально, ведь высокоуровневые модели и подразумеваются как приближения, или же это может сообщать о серьёзной проблеме в одной из моделей, требующей их пересмотра.
Это особенно интересно в случае онтологических кризисов, когда объекты, которые мы ценим, оказываются отсутствующими в «лучших» моделях мира.
Кажется справедливым сказать, что всё, что ценят люди, существует только в высокоуровневых моделях, которые с редукционистской точки зрения “менее реальны», чем атомы и кварки. Однако, поскольку наши ценности не определены на нижнем уровне, мы способны сохранять их даже тогда, когда наши знания нижнего уровня радикально меняются. (Мы также могли бы что-то сказать и о том, что происходит, когда радикально меняется верхний уровень.)
Другой критически важный аспект встроенных моделей мира – это что сам агент должен быть в модели, раз он хочет понять мир, а мир нельзя полностью отделить от самого агента. Это открывает дверь сложным проблемам самореференции и антропной теории принятия решений.
Натурализированная индукция – это проблема выучивания моделей мира, включающих в окружение самого агента. Это непросто, потому что (как сформулировал Каспар Остерхельд) между «ментальными штуками» и «физическими штуками» есть несовпадение типов.
AIXI рассматривает своё окружение так, как будто в нём есть слот, куда вписывается агент. Мы можем интуитивно рассуждать таким образом, но мы можем понять и физическую точку зрения, с которой это выглядит плохой моделью. Можно представить, что агент вместо этого представляет по отдельности: знание о себе, доступное для интроспекции; гипотезу о том, какова вселенная; и «соединительную гипотезу», связывающую одно с другим.
Есть интересные вопросы о том, как это может работать. Есть ещё и вопрос о том, правильная ли это вообще структура. Я точно не считаю, что так обучаются младенцы.
Томас Нагель сказал бы, что такой подход к проблеме включает «взгляды из ниоткуда»; каждая гипотеза рассматривает мир будто снаружи. Наверное, это странный способ.
Особый случай того, что агентам приходится рассуждать о себе – это то, что агентам приходится рассуждать о себе будущих.
Чтобы составлять долговременные планы, агентам нужно быть способными смоделировать, как они будут действовать в будущем, и иметь некоторое доверие своим будущим целям и способностям к рассуждению. Это включает доверие к обучившимся и выросшим будущим версиям себя.
При традиционном Байесовском подходе «обучение» подразумевает Байесовские обновления. Но, как мы заметили, Байесовские обновления требуют, чтобы агент изначально был достаточно большим, чтобы учитывать кучу вариантов, каким может быть мир, и обучаться, отвергая некоторые из них.
Встроенным агентам нужны обновления с ограниченными ресурсами и логической неуверенностью, которые так не работают.
К сожалению, Байесовские обновления – это главный известный нам способ думать о двигающемся во времени агенте как о едином, одном и том же. Оправдание Байесовских рассуждений через голландские ставки по сути заявляет, что только такие обновления обеспечивают, что действия агента в понедельник и во вторник не будут хоть немного друг другу мешать.
Встроенные агенты не-Байесовские. А не-Байесовские агенты склонны встревать в конфликты со своими будущими версиями.
Что приводит нас к следующему набору проблем: устойчивое делегирование.
Встроенная Агентность. Устойчивое делегирование
Примечание переводчика - из-за отсутствия на сайте нужного класса для того, чтобы покрасить текст в оранжевый цвет, я заменил его фиолетовым. Фиолетовый в тексте соответствует оранжевому на картинках.
Так как мир большой, агента самого по себе, а в частности – его мыслительных способностей, может быть недостаточно, чтобы достигнуть его целей.
Поскольку агент состоит из частей, он может улучшать себя и становиться способнее.
Усовершенствования могут принимать много форм: агент может создавать инструменты, агент может создавать агентов-наследников, или агент может просто со временем учиться и расти. Наследники или инструменты, чтобы стоило их создавать, должны быть способнее агента.
Это приводит к особой разновидности проблемы принципала-агента:
Пусть есть изначальный агент и агент-наследник. Изначальный агент решает, каким в точности будет наследник. Наследник, однако, куда умнее и могущественнее, чем изначальный агент. Мы хотим знать, как сделать так, чтобы агент-наследник устойчиво оптимизировал цели изначального агента.
Вот три примера того, как может выглядеть эта проблема:
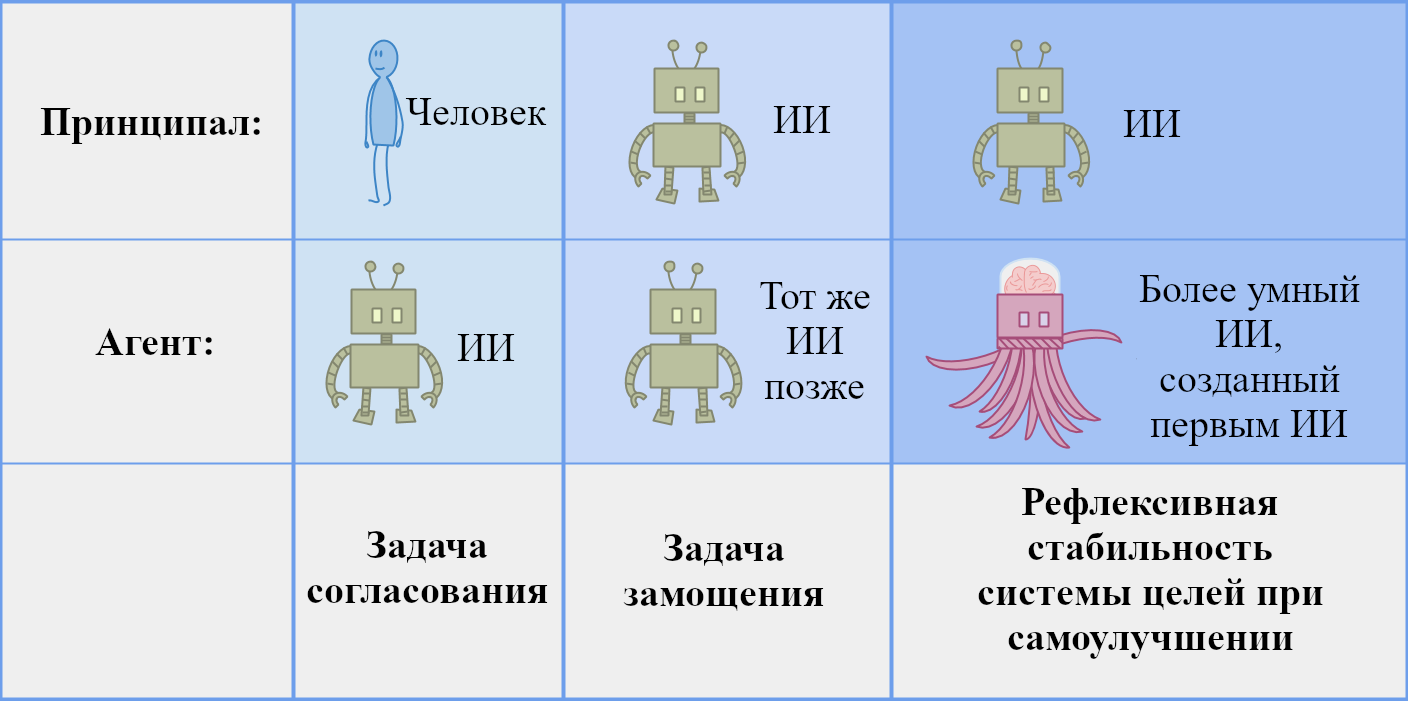
В задаче согласования ИИ человек пытается создать ИИ-систему, которой можно будет доверять, что она будет помогать в достижении целей человека.
В задаче замощающих агентов, агент пытается увериться, что он может доверять своей будущей версии, что она будет помогать в достижении целей агента.
Или мы можем рассмотреть более сложную версию – стабильное самоулучшение – когда ИИ-система должна создать наследника, более умного, чем она сама, но надёжного и помогающего.
Как человеческие аналогии, не включающие ИИ, можно подумать о проблеме наследования в монархии или более обобщённо о проблеме уверенности в том, что организация будет добиваться желаемых целей и не потеряет своё предназначение со временем.
Сложность состоит из двух частей:
Во-первых, человек или ИИ может не полностью понимать себя и свои собственные цели. Если агент не может записать что он хочет во всех деталях, то ему сложно гарантировать, что наследник будет устойчиво помогать с этими целями.
Во-вторых, вся идея делегирования работы в том, что вам не нужно делать всю работу самому. Вы хотите, чтобы наследник был способен на некоторую степень автономии, включая изучение неизвестного вам и заполучение новых навыков и способностей.
В пределе по-настоящему хорошее формальное описание устойчивого делегирования должно быть способно безошибочно обрабатывать произвольно способных наследников – вроде человека или ИИ, создающего невероятно умного ИИ, или вроде агента, продолжающего расти и учиться так много лет, что он становится намного умнее, чем его прошлая версия.
Проблема не (только) в том, что агент-наследник может быть злонамерен. Проблема в том, что мы даже не знаем что для него значит таким не быть.
Она кажется сложной с обеих точек зрения.
Исходному агенту необходимо выяснить, насколько надёжно и достойно доверия нечто, куда могущественнее его, что кажется очень сложным. А агенту-наследнику необходимо выяснить, что делать в ситуациях, которых исходный агент вообще не понимает, и пытаться уважать цели чего-то, что, как наследник может видеть, непоследовательно, а это тоже кажется очень сложным.
На первый взгляд может показаться, что это менее фундаментальная проблема, чем «принимать решения» или «иметь модели». Но точка зрения, с которой задача «создания наследника» предстаёт в многих формах, сама по себе дуалистична.
Для встроенного агента будущая версия себя не привелегирована; просто ещё одна часть окружения. Нет глубокой разницы между созданием наследника, разделяющего твои цели и просто уверенностью, что твои собственные цели останутся теми же со временем.
Так что, хоть я и говорю об «исходном» агенте и агенте-«наследнике», помните, что суть не в узкой задаче, с которой сейчас столкнулись люди. Суть в фундаментальной проблеме того, как оставаться тем же агентом, обучаясь со временем.
Мы можем назвать этот кластер задач Устойчивым Делегированием. Примеры включают:
- Рефлексию Винджа
- Задачу Замощения
- Избегание Закона Гудхарта
- Загрузку ценностей
- Исправимость
- Информированный присмотр
Представьте, что вы играете в CIRL с младенцем.
CIRL означает Кооперативное Обратное Обучение с Подкреплением. Основная идея в основе CIRL – определить, что значит для робота сотрудничать с человеком. Робот пытается предпринимать полезные действия, одновременно пытаясь выяснить, чего человек хочет.
Много нынешней работы по устойчивому делегированию исходит из цели согласовать ИИ-системы с тем, чего хотят люди. Так что обычно мы думаем об этом с точки зрения человека.
Но представьте, как задача выглядит с точки зрения умного робота, который пытается помочь кому-то, находящемуся в крайнем замешательстве по поводу вселенной. Представьте каково пытаться помогать младенцу оптимизировать его цели.
- С вашей точки зрения младенец слишком иррационален, чтобы оптимизировать что бы то ни было.
- Младенец может обладать онтологией, в которой он что-то оптимизирует, но вы можете видеть, что эта онтология не имеет смысла.
- Может, вы замечаете, что если вы правильно будете задавать вопросы, то вы сможете сделать так, чтобы казалось, что младенец хочет почти чего угодно. (проблемы с «что» в двух пунктах)
Часть проблемы в том, что «помогающий» агент должен в каком-то смысле быть больше, чтобы быть способнее; но это, кажется, подразумевает, что «получающий помощь» агент не может быть хорошим надсмотрщиком «помогающего».

К примеру, необновимая теория принятия решений избавляется от динамических непоследовательностей в теории принятия решений тем, что вместо максимизации ожидаемой полезности вашего действия с учётом того, что вам известно, максимизирует ожидаемую полезность реакций на наблюдения из состояния незнания.
{kind=link}
Как бы она ни была привлекательна как способ достижения рефлексивной последовательности, она приводит к странной ситуации в плане вычислительной мощности: если действия имеют тип $A$, а наблюдения тип $O$, то реакции на наблюдения имеют тип $O→A$ – куда большее пространство для оптимизации, чем просто $A$. И мы ожидаем, что наше меньшее я способно это делать!
Это, кажется, плохо.
Один способ более чётко выразить проблему: мы должны быть способны доверять будущим себе, что они будут применять свой интеллект, преследуя наши цели, не будучи способными точно предсказать, что наши будущие версии будут делать. Этот критерий называется рефлексией Винджа.
К примеру, вы можете планировать свой маршрут поездки перед посещением нового города, но не планировать шаги. Вы планируете до какого-то уровня деталей и доверяетесь своей будущей версии, что она сообразит остальное.
Рефлексия Винджа сложна для рассмотрения через призму классической Байесианской теории принятия решений, потому что та подразумевает логическое всеведенье. При его условии допущение «агент знает, что его будущие действия рациональны» синонимично с допущением «агент знает, что его будущая версия будет действовать согласно одной конкретной оптимальной стратегии, которую агент может предсказать заранее».
У нас есть некоторые ограниченные модели рефлексии Винджа (см. «Замощающие Агенты Самомодифицирующегося ИИ и Лёбово Препятствие» Юдковского и Херршоффа). Успешный подход должен пройти по тонкой линии между этими двумя проблемами:
- Лёбово Препятствие: Агенты, доверяющие своим будущим версиям, потому что могут доверять выводам своих собственных рассуждений, непоследовательны.
- Парадокс Прокрастинации: Агенты, которые доверяют своим будущим версиям без причины, склонны быть последовательными, но ненадёжными и недостойными доверия, и будут откладывать задачи на потом вечно, потому что могут сделать их позже.
Результаты исследования рефлексии Винджа пока что применимы только к ограниченному классу процедур принятия решений, вроде добирания до порога приемлемости. Так что это ещё много куда можно развивать, получая результаты замощения для более полезных вариантов и при меньших допущениях.
Однако устойчивое делегирование – больше, чем просто замощение и рефлексия Винджа.
Когда вы конструируете другого агента, а не делегируете что-то будущему себе, вы более напрямую сталкиваетесь с проблемой загрузки ценностей.
Основные проблемы:
- Мы не знаем, чего мы хотим.
- Оптимизация усиливает слабые различия между тем, что мы говорим, что мы хотим, и тем, чего мы на самом деле хотим.
Эффект усиления известен как Закон Гудхарта, в честь Чарльза Гудхарта, заметившего: «Любая наблюдаемая статистическая закономерность склонна коллапсировать, когда на неё оказывается давление с целями контроля.»
Когда мы определяем цель оптимизации, имеет смысл ожидать, что она будет коррелировать с тем, чего мы хотим – в некоторых случаях, сильно коррелировать. Однако, к сожалению, это не означает, что её оптимизация приблизит нас к тому, что мы хотим – особенно на высоких уровнях оптимизации.
Есть (как минимум) четыре вида Гудхарта: регрессионный, экстремальный, каузальный и состязательный.
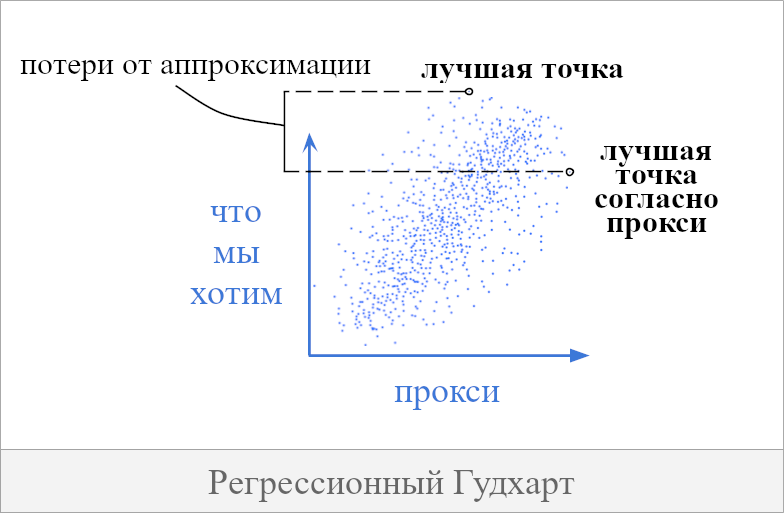
Регрессионный Гудхарт происходит, когда корреляция между прокси и целью неидеальна. Он более известен как проклятье оптимизатора, и связан с регрессией к среднему.
Пример регрессионного Гудхарта: вы можете выбирать игроков в баскетбольную команду на основании лишь роста. Это не идеальная эвристика, но между ростом и способностями к баскетболу есть корреляция, которую вы можете использовать для своего выбора.
Оказывается, что в некотором смысле вы будете предсказуемо разочарованы, если будете ожидать, что общий тренд так же хорошо работает и для вашей выбранной команды.
В статистических терминах: несмещённая оценка $y$ при данном $x$ – не то же самое, что несмещённая оценка $y$, когда мы выбираем лучший $x$. В этом смысле мы ожидаем, что будем разочарованы, используя $x$ как прокси для $y$ в целях оптимизации.
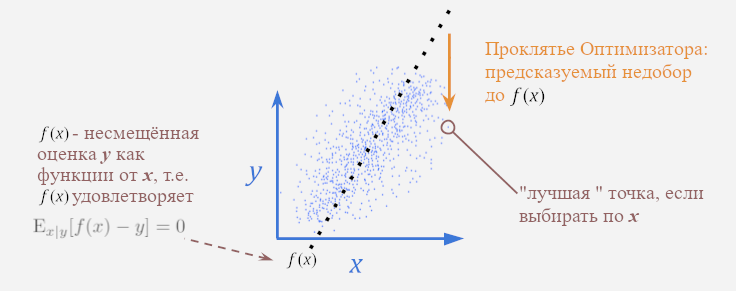
(Графики в этом разделе вручную нарисованы для иллюстрации важных концепций.)
Используя Байесовскую оценку вместо несмещённой, мы можем избавиться от этого предсказуемого разочарования. Байесовская оценка учитывает зашумлённость $x$, склоняющую в сторону типичных значений $y$.
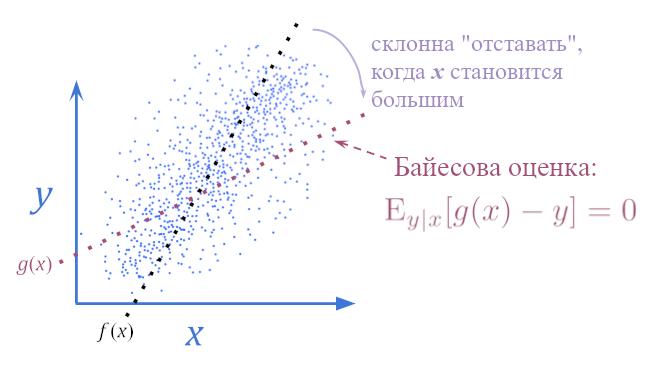
Это необязательно позволит нам получить $y$ получше, потому что мы всё ещё действуем только на основании информации о $x$. Но иногда может и сработать. Если $y$ нормально распределён с дисперсией 1, а $x$ – это $y±10$ с равными шансами на + и −, то Байесовская оценка приведёт к лучшим результатам оптимизации, почти полностью удаляя шум.

Регрессионный Гудхарт кажется самой простой для одолевания формой Гудхарта: просто используйте Байесовскую оценку!
Однако, с этим решением есть две больших проблемы:
- В интересующих нас случаях Байесовская оценка зачастую трудновыводима.
- Доверять Байесовской оценке имеет смысл только при допущении реализуемости.
Случай, когда обе эти проблемы становятся критичны – вычислительная теория обучения.
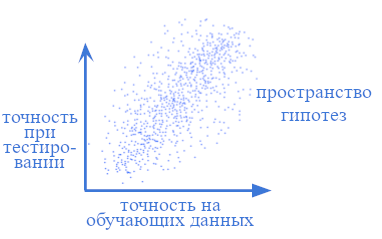
Зачастую вычисление Байесовской ожидаемой ошибки обобщения гипотезы совершенно неосиливаемо. А если вы и можете это сделать, то всё равно придётся беспокоиться о том, достаточно ли хорошо отображает мир ваше выбранное априорное распределение.
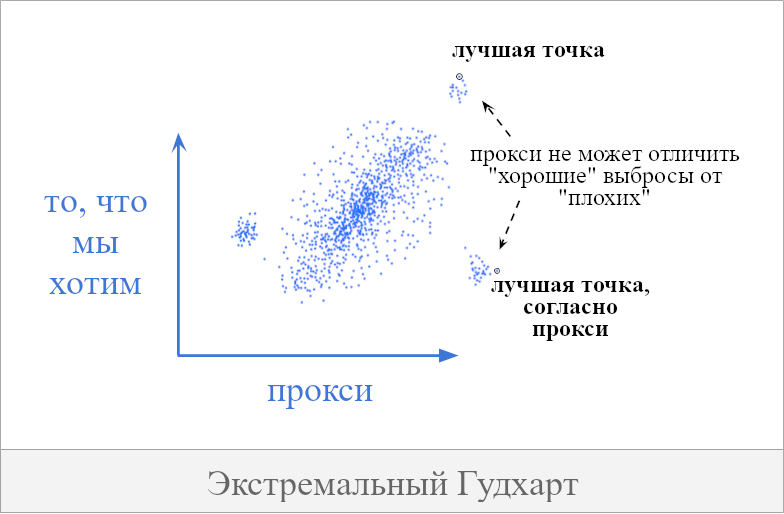
В экстремальном Гудхарте оптимизация выталкивает вас за пределы области, где существует корреляция, в части распределения, которые ведут себя совсем по-другому.
Это особенно пугает, потому что приводит к оптимизаторам, ведущим себя в разных контекстах совершенно по-разному, зачастую почти или совсем без предупреждения. Вы можете не иметь возможности увидеть, как ломается прокси на слабом уровне оптимизации, но, когда оптимизация становится достаточно сильной, вы переходите в совсем другую область.
Разница между экстремальным Гудхартом и регрессионным Гудхартом связана с классическим разделением интерполяции/экстраполяции.
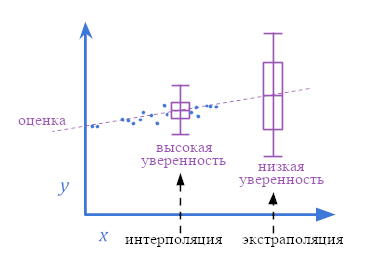
Поскольку экстремальный Гудхарт включает резкое изменение поведения при масштабировании системы, его сложнее предвосхитить, чем регрессионный.
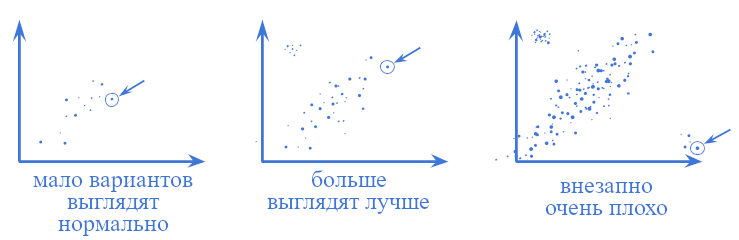
Как и в регрессионном случае, Байесовское решение справляется с проблемой в теории, если вы верите, что распределение вероятностей достаточно хорошо отображает возможные риски. Однако, реализуемость тут становится ещё более проблемной.
Можно ли довериться, что априорное распределение предвосхитит проблем с предложениями, когда эти предложения будут сильно оптимизированы, чтобы хорошо выглядеть для этого конкретного распределения? Уж точно в таких условиях нельзя верить человеческим суждениям – это наблюдение подсказывает, что проблема останется, даже если суждения системы о ценностях идеально отображают человеческие.
Можно сказать, что проблема такова: «типичные» выводы избегают экстремального Гудхарта, но «слишком сильная оптимизация» выводит нас из области типичного.
Но как нам формализовать «слишком сильную оптимизацию» в терминах теории принятия решений?
Квантилизация предлагает формализацию для «как-то оптимизировать, но не слишком сильно».
Представьте прокси $V(x)$ как «испорченную» версию функции, которая нам на самом деле важна – $U(x)$. Могут быть разные области, в которых уровень испорченности ниже или выше.
Предположим, мы дополнительно определили «доверенное» распределение вероятностей $P(x)$, для которого мы уверены, что средняя ошибка в нём ниже некого порога $c$.
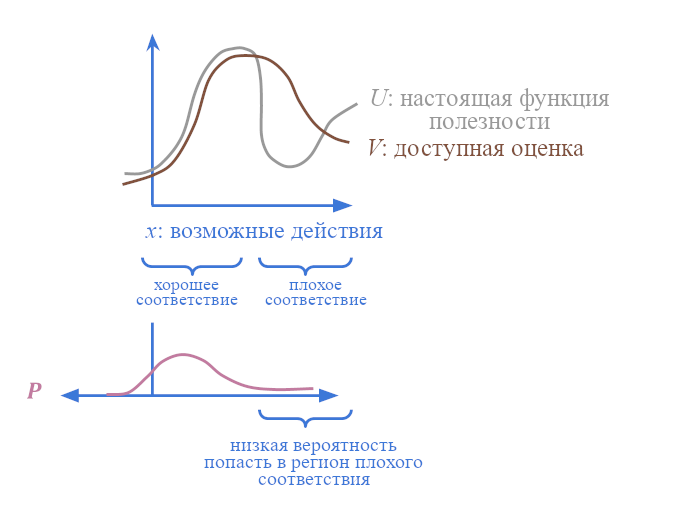
Оговаривая $P$ и $c$ мы даём информацию о том, где находятся точки с низкой ошибкой, без необходимости иметь оценки $U$ или настоящей ошибки в любой конкретной точке.
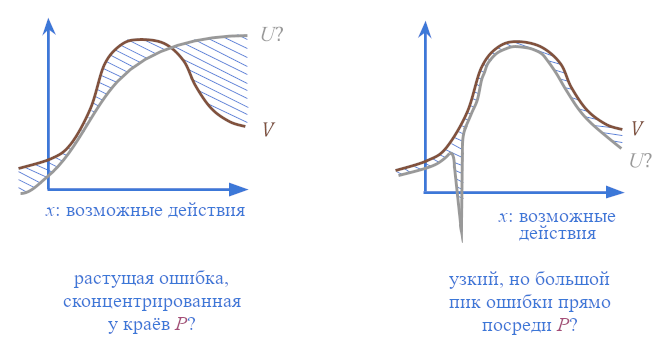
Когда мы случайно выбираем действия из $P$, мы можем быть уверены в низкой вероятности большой ошибки.
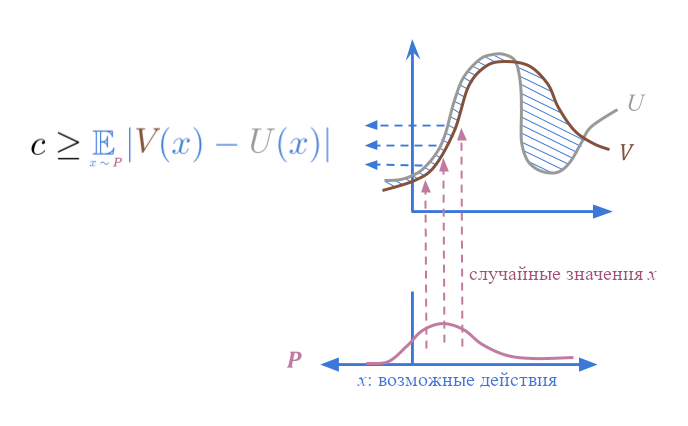
Так как нам это использовать для оптимизации? Квантилайзер выбирает из $P$, но выкидывает всё, кроме верхней доли $f$; к примеру, кроме верхнего 1%. В этой визуализации я благоразумно выбрал долю, в которой большая часть вероятности сконцентрирована в «типичных» вариантах, а не в выбросах:
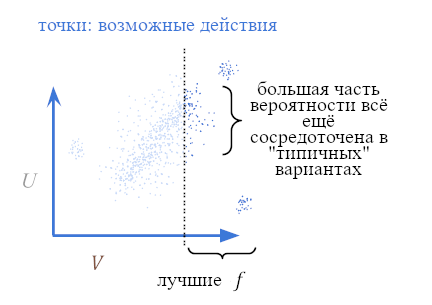
Квантилизируя мы гарантируем, что если мы переоценили, насколько что-то хорошо, то ожидание того, насколько мы переоценили – максимум $\frac{c}{f}$. Ведь в худшем случае вся переоценка взялась из $f$ лучших вариантов.
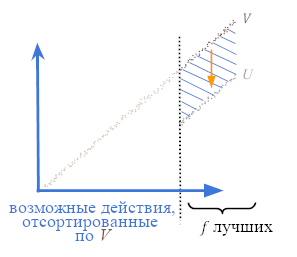
Так что мы можем выбрать приемлемый уровень риска $r = \frac{c}{f}$ и выбрать параметр $f$ как $\frac{c}{r}$.
Квантилизация весьма привлекательна, потому что она позволяет нам определить безопасные классы действий, не доверяя всем отдельным действиям в классе – или даже не доверяя никакому отдельному действию в классе.
Если у вас есть достаточно большая куча яблок, и в ней только одно гнилое яблоко, то случайный выбор скорее всего безопасен. «Не очень сильно оптимизируя» и выбирая случайное достаточно-хорошее действие мы делаем экстремальные варианты маловероятными. Напротив, если бы мы оптимизировали так сильно, как возможно, мы бы в итоге выбирали только плохие яблоки.
Однако, этот подход всё же оставляет желать лучшего. Откуда берутся «доверенные» распределения? Как вы оцениваете ожидаемую ошибку $c$, или выбираете приемлемый уровень риска $r$? Квантилизация – рискованный подход, потому что $r$ предоставляет вам рычаг, потянув за который вы явно улучшите качество работы, увеличивая риск, пока (возможно внезапно) не провалитесь.
В дополнение к этому, квантилизация, кажется, не будет замощать. То есть, квантилизирующий агент не имеет особой причины сохранять алгоритм квантилизации, улучшая себя или создавая новых агентов.
Так что, кажется, способам справляться с экстремальным Гудхартом ещё есть много куда расти.
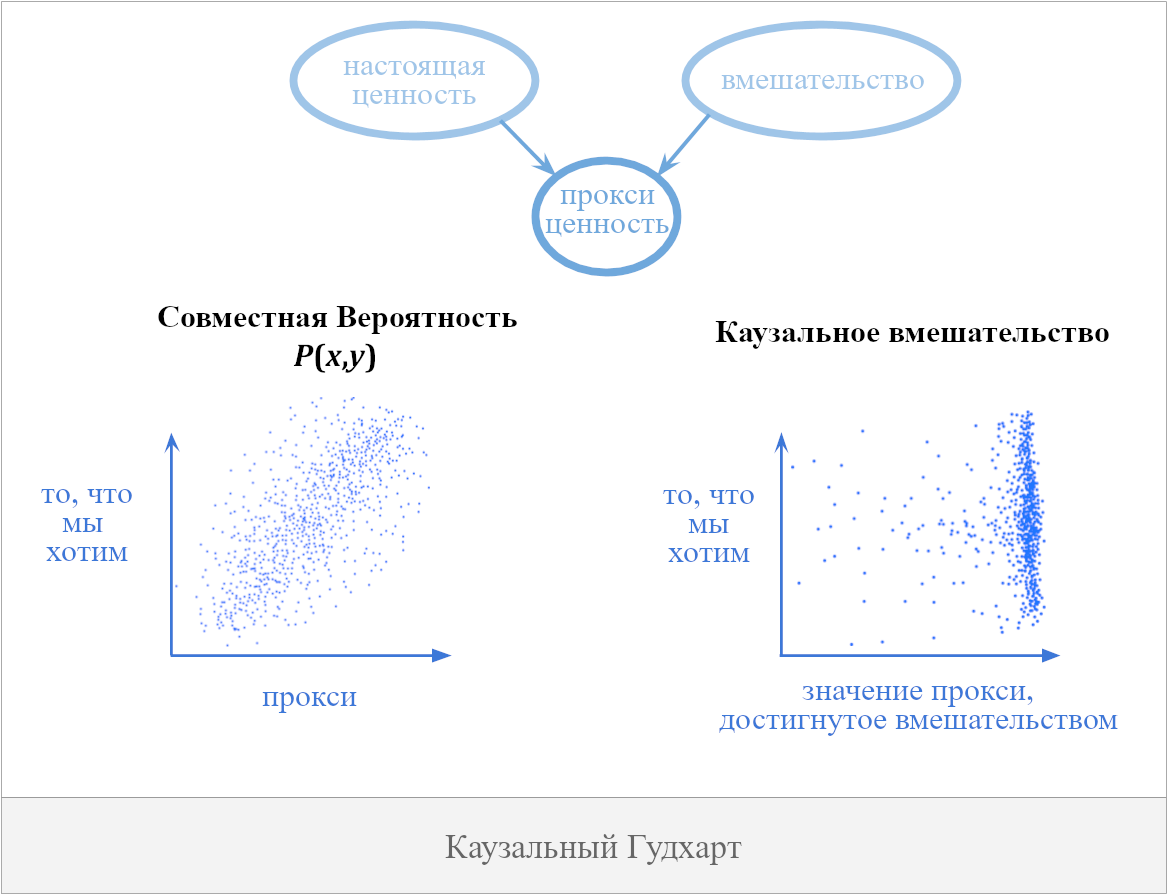
Другой способ, которым оптимизация может пойти не туда – когда выбор прокси ломает связь с тем, что нас интересует. Каузальный Гудхарт происходит, когда вы наблюдаете корреляцию между прокси и целью, но, когда вы вмешиваетесь, чтобы увеличить прокси, увеличить цель не получается, потому что наблюдавшаяся корреляция не была правильным образом каузальной.
Пример каузального Гудхарта – вы можете попробовать заставить пойти дождь, ходя по улице с зонтом. Единственный способ избежать ошибок такого рода – правильно справляться с контрфактами.
Это может показаться подножкой для теории принятия решений, но связи тут в равной степени обогащают и её, и устойчивое делегирование.
Контрфакты обращаются к вопросам доверия из-за замощения – нужды рассуждать о своих собственных будущих решениях, принимая решения сейчас. В то же время, доверие обращается к вопросам контрфактах из-за каузального Гудхарта.
Опять же, одно из крупных препятствий тут – реализуемость. Как мы замечали в нашем обсуждении встроенных моделях мира, даже если у вас есть верная обобщённая теория контрфактов, Байесовское обучение не особо гарантирует вам, что вы научитесь правильно выбирать действия без допущения реализуемости.
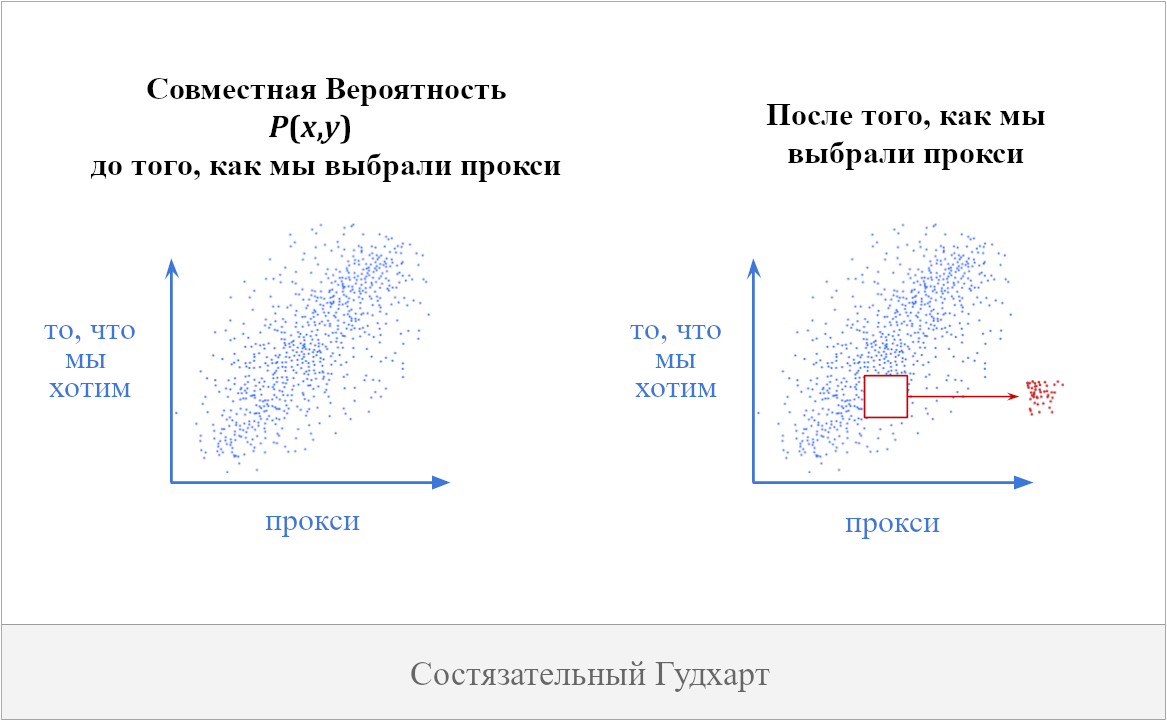
Наконец, есть состязательный Гудхарт, когда агенты активно манипулируют прокси-мерой, делая её хуже.
Эта категория – то, о чём чаще всего думают люди, когда интерпретируют замечание Гудхарта. И на первый взгляд, она кажется не особо связанной с нашими заботами. Мы хотим формально понять, как агенты могут доверять будущим версиям себя или помощникам, которых они создали. Что это имеет общего с состязательностью?
Краткий ответ такой: при поиске в большом и достаточно богатом пространстве в нём наверняка найдутся элементы, исполняющие состязательные стратегии. Понимание оптимизации в целом требует от нас понимать, как достаточно умные оптимизаторы могут избежать состязательного Гудхарта. (Мы ещё вернёмся к этому в обсуждении согласования подсистем.)
Состязательный вариант Закона Гудхарта ещё сложнее пронаблюдать на низких уровнях оптимизации, и из-за нежелания манипулировать до окончания времени тестирования, и из-за того, что противники, появляющиеся из собственной оптимизации системы, не появляются, пока эта оптимизация недостаточно сильна.
Эти четыре формы Закона Гудхарта работают очень по-разному, и, грубо говоря, они склонны появляться на последовательно более высоких уровнях силы оптимизации, начиная с регрессионного Гудхарта, и продолжая каузальным, затем экстремальным, затем состязательным. Так что будьте осторожны, и не считайте, что одолели закон Гудхарта, решив лишь некоторые из его форм.
Кроме противо-Гудхартовых мер, ещё, очевидно, неплохо было бы уметь точно определить, что мы хотим. Напомню, что все эти проблемы не всплывают, если система напрямую оптимизирует то, что нам надо, а не прокси.
К сожалению, это сложно. Так может ИИ-системы, которые мы создаём, могут нам с этим помочь?
Более обобщённо, может агент-наследник помочь своему предшественнику это решить? Может, он может использовать свои интеллектуальные преимущества, чтобы понять, что мы хотим?
AIXI обучается тому, что ему делать, с помощью сигнала вознаграждения, который он получает от окружения. Мы можем представить, что у людей есть кнопка, которую они нажимают, когда AIXI делает что-то, что им нравится.
Проблема в том, что AIXI применит свой интеллект к задаче получения контроля над кнопкой вознаграждения. Это – проблема вайрхединга.
Поведение такого вида потенциально очень сложно предвосхитить; система может обманчиво вести себя как предполагается во время обучения, планируя захватить контроль после развёртывания. Это называется «предательским поворотом».
Может, мы встроим кнопку вознаграждения внутрь агента, как чёрный ящик, испускающий вознаграждения, основываясь на том, что происходит. Ящик может сам по себе быть интеллектуальным субагентом, определяющим, какое вознаграждение хотели бы выдать люди. Коробка может даже защищать себя, выдавая наказания за действия, направленные на её модификацию.
В конце концов, всё же, если агент понимает ситуацию, он будет всё равно мотивирован захватить контроль.
Если агенту сказано добиваться высокого вывода от «кнопки» или «ящика», то он будет мотивирован их взломать. Однако, если вы проводите ожидаемые исходы планов через сам выдающий вознаграждение ящик, то планы его взломать будут оценены им самим, а он не будет считать эту идею привлекательной.
Дэниэл Дьюи называет такого агента макисимизатором наблюдаемой полезности. (Другие включали агентов наблюдаемой полезности в более широкое понятие обучения с подкреплением.)
Мне кажется весьма интересным, что вы можете много всего попробовать, чтобы предотвратить у агента обучения с подкреплением стремление к вайрхедингу, но агент будет против. Затем, вы переходите к агентам наблюдаемой полезности – и проблема исчезает.
Однако, у нас всё ещё есть задача определения $U$. Дэниэл Дьюи указывает, что агенты наблюдаемой полезности всё ещё могут использовать обучение, чтобы со временем аппроксимировать $U$; мы не можем просто считать $U$ чёрным ящиком. Агент обучения с подкреплением пытается научиться предсказать функцию вознаграждения, а агент наблюдаемой полезности оценивает функции полезности из определённого людьми априорного распределения для выучивания ценностей.
Но сложно определить процесс обучения, который не приведёт к иным проблемам. К примеру, если вы пытаетесь научиться тому, что хотят люди, как вы устойчиво идентифицируете в мире «людей»? Просто статистически приличное распознавание объектов опять может привести к вайрхедингу.
Даже если успешно решите эту задачу, агент может верно выяснить ценности человека, но всё же быть мотивирован изменить их, чтобы их было легче удовлетворить. К примеру, представьте, что есть наркотик, который модифицирует человеческие предпочтения, так что для человека будет иметь значение только его приём. Агент наблюдаемой полезности может быть мотивирован вводить людям этот наркотик, чтобы сделать свою работу проще. Это называется проблемой манипуляции людьми.
Всё, отмечаемое как истинное хранилище ценностей, взламывается. Будь это один из четырёх видов Гудхарта, или что-то пятое, тенденция прослеживается.
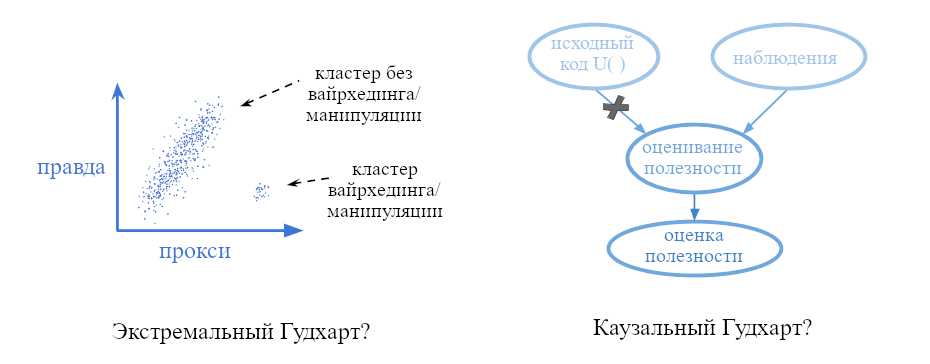
Так что вызов в создании стабильных указателей на то что мы ценим: непрямых ссылок на ценности, которые нельзя оптимизировать напрямую, чтобы не поощрять взлом хранилища ценностей.
Одно важное замечание было сделано Томом Эвериттом и пр. в «Обучении с Подкреплением Испорченным Каналом Вознаграждения»: то, как вы устраиваете петлю обратной связи, имеет огромное значение.
Они нарисовали такую картинку:
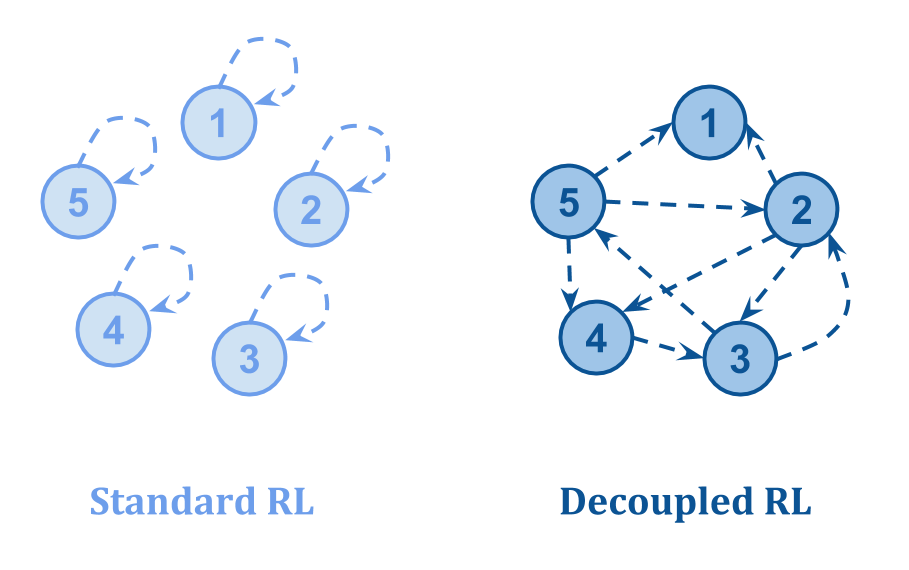
- В Стандартном обучении с подкреплением обратная связь о ценности состояния исходит из самого состояния, так что испорченные состояния могут быть «самовозвеличивающими».
- В Отсоединённом обучении с подкреплением обратная связь о ценности состояния исходит из какого-то другого состояния, что делает возможным выяснение правильных ценностей даже если часть обратной связи испорчена.
В некотором смысле, цель – верно направить изначального маленького агента в петле обратной связи. Однако, упомянутые ранее проблемы с необновимыми рассуждениями делают это сложным; оригинальный агент недостаточно много знает.
Один из способов работать с этим – через усиление интеллекта: попробовать превратить изначального агента в более способного с теми же ценностями, вместо того, чтобы создавать агента-наследника с нуля и пытаться справиться с загрузкой ценностей.
К примеру, Пол Кристиано предложил подход, в котором маленький агент симулируется много раз в большом дереве, которое может исполнять сложные вычисления, разбивая задачу на части.
Однако, это всё же довольно требовательно для маленького агента: он не просто должен знать, как разбивать задачи на более посильные части; он ещё должен знать, как делать это без возникновения злокачественных подвычислений.
К примеру, если он может использовать копии себя для получения больших вычислительных мощностей, он легко может пытаться использовать прямолинейный поиск решений, не натыкаясь на Закон Гудхарта.
Это – тема следующей части: согласование подсистем.
Встроенная Агентность. Согласование подсистем
Примечание переводчика - из-за отсутствия на сайте нужного класса для того, чтобы покрасить текст в оранжевый цвет, я заменил его фиолетовым. Фиолетовый в тексте соответствует оранжевому на картинках.
Вы хотите что-то выяснить, но пока не знаете, как это делать.
Вам надо как-то разбить задачу на под-вычисления. Нет атомного действия «думанья»; интеллект должен быть построен из не-интеллектуальных частей.
То, что агент состоит из частей – часть того, почему затруднительны контрфакты, ведь агенту может понадобиться рассуждать о невозможных конфигурациях этих частей.
То, что агент состоит из частей – то, что делает рассуждения о себе и самомодификацию вообще возможными.
Впрочем, то, что мы в основном будем обсуждать в этом разделе – другая проблема: когда агент состоит из частей, враждебным может быть не только внешнее окружение, но и что-то внутри агента.
Этот кластер задач называется Согласованием Подсистем: как удостовериться, что подсистемы не работают друг против друга; избежать подпроцессов, оптимизирующих нежелательные цели:
- Благотворная индукция
- Благотворная оптимизация
- Прозрачность
- Меса-оптимизаторы
Вот чучельная схема агента:
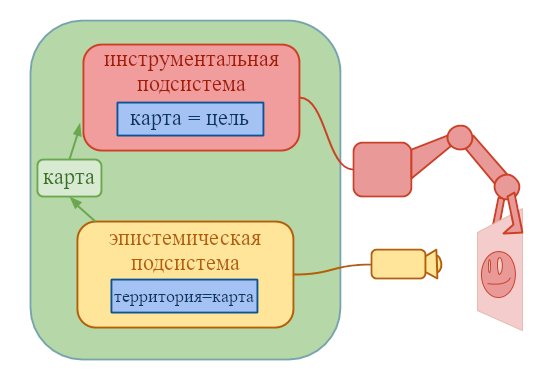
Эпистемическая подсистема просто хочет, чтобы у неё были точные убеждения. Инструментальная подсистема использует эти убеждения, чтобы отслеживать, насколько хорошо она справляется. Если инструментальная подсистема становится слишком способной сравнительно с эпистемической, то она может попробовать обмануть эпистемическую подсистему, как показано на картинке.
Если эпистемическая подсистема становится слишком сильна, то это тоже может привести к нехорошим исходам.
Эта схема агента считает эпистемическую и инструментальную подсистемы агента отдельными агентами со своими собственными целями, что не особо реалистично. Однако, как мы видели в разделе про вайрхединг, проблемы того, что подсистемы работают на конфликтующие цели, сложно избежать. И эта проблема становится ещё затруднительнее, если мы создали эти подсистемы ненамеренно.
Одна из причин избегать запуска суб-агентов, которые хотят разных вещей – то, что нам хочется устойчивости при относительном масштабировании.
Подход устойчив при масштабировании, если он всё ещё работает или аккуратно проваливается, когда вы масштабируете его способности. Есть три варианта: устойчивость при масштабировании вверх; устойчивость при масштабировании вниз; и устойчивость при относительном масштабировании.
- Устойчивость при масштабировании вверх означает, что ваша система не перестанет хорошо себя вести, если станет лучше оптимизировать. Один из способов проверить это – подумать о том, что случится, если функция, которую ИИ оптимизирует, будет в самом деле максимизирована. Вспомните о Законе Гудхарта.
- Устойчивость при масштабировании вниз означает, что ваша система всё ещё работает, если стала менее мощной. Конечно, она может перестать быть полезной, но она не должна переставать работать безопасно и без необязательных затрат.
Ваша система может работать, если она может в точности максимизировать некую функцию, но безопасна ли она, если вы аппроксимируете? К примеру, может, система безопасна, если она способна очень точно изучить человеческие ценности, но аппроксимация делает её всё более несогласованной.
- Устойчивость при относительном масштабировании означает, что ваш план не полагается на то, что подсистемы агента имеют схожую мощность. К примеру, обучение GAN (Генеративно-Состязательных Сетей) может провалиться, если одна подсеть становится слишком сильной, потому что обучающий сигнал прекращается.
Недостаток устойчивости при масштабировании не обязательно полностью обрушивает предложение, но его стоит иметь в виду; если его нет, то вам нужна надёжная причина считать, что вы находитесь на нужном уровне масштабирования.
Устойчивость при относительном масштабировании особенно важна для согласования подсистем. Агент с интеллектуальными под-частями не должен полагаться на способность их переиграть, если у нас нет сильного аргумента о том, почему это всегда возможно.
Мораль для большой картины: стремитесь к единой системе, которая не конфликтует сама с собой.
С чего бы кому-то создавать агента, чьи части борются друг с другом? Есть три очевидных причины: подцели, указатели и поиск.
Разделение задачи на подцели может быть единственным способом эффективно найти решение. Однако, делая вычисления, связанные с подцелями, вы не должны полностью забывать о большой картине!
Агенту, спроектированному, чтобы строить дома, не следует запускать субагента, которого волнует только строительство лестниц.
Интуитивно хочется, чтобы, несмотря на то, что подсистемам нужно иметь свои собственные цели для разделения задач на части, эти подцели должны устойчиво «ссылаться» на главную цель.
Агент, строящий дома, может запустить подсистему, которую волнуют только лестницы, но только лестницы в контексте домов.
Однако вам нужно это сделать каким-то способом, который не сводится к тому, что у вашей системы, строящей дома, есть в голове вторая система, строящая дома. Это приводит меня к следующему пункту:
Указатели: Для подсистем может быть сложно таскать с собой цель всей системы, потому что предполагается, что им надо упрощать задачу. Однако такие окольные пути, кажется, склонны приводить к ситуациям, когда стимулы разных подсистем не согласованы.
Как мы видели в примере эпистемической и инструментальной подсистем, как только мы начинаем оптимизировать ожидание какого-то рода, а не напрямую получать обратную связь о том, что мы делаем по некоторой по-настоящему важной метрике, мы можем создать извращённые мотивации – это Закон Гудхарта.
Как мы попросим подсистему «сделай X», а не «убеди систему в целом, что делаешь X», не передавая всю систему целей?
Это похоже на то, как нам хотелось, чтобы агенты-наследники устойчиво ссылались на ценности, потому что сложно их записать. Однако, в этом случае, изучение ценностей большего агента тоже было бы бессмысленно, подсистемы и подцели должны быть меньше.
Может быть, не так сложно решить согласование подсистем для случая подсистем, полностью спроектированных людьми, или подцелей, в явном виде выделенных ИИ. Если вы уже знаете, как избежать несогласованности и как устойчиво делегировать свои цели, обе задачи кажутся решаемыми.
Однако, спроектировать все подсистемы настолько явно не кажется возможным. В какой-то момент, решая задачу, вы разбиваете её на части настолько сильно, насколько получается, и начинаете полагаться на метод проб и ошибок.
Это приводит нас к третьей причине того, с чего подсистемам оптимизировать разные вещи – поиск: решение задачи путём просматривания большого пространства возможностей, которое само по себе может содержать несогласованные подсистемы.

Исследователи машинного обучения вполне знакомы с этим явлением: проще написать программу, которая найдёт вам высокопроизводительную систему машинного перевода, чем напрямую написать эту систему самостоятельно.
Этот процесс может в итоге зайти ещё на шаг дальше. Для достаточно богатой задачи и достаточно впечатляющего процесса поиска, найденные этим поиском решения могут сами что-то интеллектуально оптимизировать.
Это может произойти случайно, или же быть намеренной стратегией решения сложных задач. В любом случае, появляется высокий шанс обострения Гудхартоподобных проблем – у вас теперь есть две системы, которые могут быть несогласованы, вместо одной.
Эта проблема описана у Хубинджера и пр. в «Рисках Выученной Оптимизации в Продвинутых Системах Машинного Обучения».
Давайте назовём изначальный процесс поиска базовым оптимизатором, а обнаруженный поиском процесс поиска – меса-оптимизатором.
«Меса» – антоним «мета». Если «мета-оптимизатор» - это оптимизатор, спроектированный для создания другого оптимизатора, то «меса-оптимизатор» – это любой оптимизатор, сгенерированный изначальным оптимизатором – неважно, хотели ли программисты, чтобы их основной оптимизатор отыскивал новые оптимизаторы.
«Оптимизация» и «поиск» – неоднозначные термины. Я буду считать, что к ним относится любой алгоритм, который можно естественно интерпретировать как исполняющий значительную вычислительную работу для «нахождения» объекта, высоко оцениваемого некой целевой функцией.
Целевая функция базового оптимизатора не обязательно совпадает с целевой функцией меса-оптимизатора. Если базовый оптимизатор хочет сделать пиццу, то новому оптимизатору может нравиться замешивать тесто, нарезать ингредиенты, и т.д.
Целевая функция нового оптимизатора должна помогать базовой цели, по крайней мере в тех примерах, которые проверяет базовый оптимизатор. В ином случае меса-оптимизатор не был бы выбран.
Однако, меса-оптимизатор должен как-то упрощать задачу; нет смысла в запуске в точности такого же поиска заново. Так что кажется, что его цели будут иметь склонность быть подобными хорошим эвристикам; более простыми для оптимизации, но в общем случае отличающимися от базовой цели.
Почему разница между базовыми и меса-целями может вызывать беспокойство, если новый оптимизатор всё равно хорошо оценивается согласно базовой цели? Даже если мы в точности правильно справимся с описанием ценностей, всё равно между обучающим набором и развёртыванием будет некоторый сдвиг распределения. (См. Амодей и пр. «Конкретные Задачи Безопасности ИИ».)
В общем-то маленькие сдвиги распределения могут оказаться важны для способного меса-оптимизатора, который может заметить мельчайшие различия и сообразить, как их использовать для своей собственной цели.
На самом деле даже использование термина «сдвиг распределения» кажется неверным в контексте встроенной агентности. Мир не состоит из одинаково распределённых независимых переменных. Аналогом «отсутствия сдвига распределения» было бы обладание точной моделью всего будущего, связанного с тем, что вы хотите оптимизировать, и способностью запускать её снова и снова по ходу обучения. Так что нам надо иметь дело с очень большим «сдвигом распределения».
Ещё мы можем хотеть оптимизировать не в точности то, чего мы хотим вообще. Очевидный способ избежать появления агентов, которые добиваются подцелей ценой основной цели – делать подсистемы не агентными. Просто искать среди способов строить лестницы, не создавать что-то, беспокоящееся о лестницах.
Проблема, получается, в том, что мощные меса-оптимизаторы оптимизируют не то, что волнует базовую систему, и что у меса-оптимизаторов присутствует конвергентный стимул быть агентными.
Вдобавок, есть возможность, что меса-оптимизатору станет известно о базовом оптимизаторе, в каком случае он может начать явно пытаться хорошо справиться с базовой целью просто для того, чтобы продолжить существование, в то же время высматривая знаки того, что обучение закончилось, и он может перестать притворяться. Это версия описанного Ником Бостромом «предательского разворота».
Это та же история, как с Встроенная Агентность. Устойчивое делегирование: в пространстве поиска есть нечто агентное, отвечающее на наш выбор прокси так, что прокси перестаёт хорошо работать.
Вы можете попробовать избежать предательских разворотов, повторно симулируя «конец обучения, время для развёртывания» во время обучения, что-то вроде вложенного сна. Цель – протестировать достаточно слоёв симуляции, чтобы вы могли сделать вывод о том, что при реальном развёртывании предательского поворота не будет.
К сожалению, сходимость при таком обучении будет такая себе. Обычно в машинном обучении хорошее качество работы означает хорошее в среднем. Но предательский разворот – это «ошибка», которая может быть аккуратно размещена так, чтобы нанести наибольший ущерб. Мы хотим удостовериться, что её не произойдёт.
Проблема частично в том, что некоторые выводы намного важнее других. Развёртывание важнее обучения, а некоторые критические или уязвимые моменты во время развёртывания будут особенно важны. Мы хотим быть особенно уверены, что всё пойдёт как надо в важных случаях, а не просто получить хороший средний результат.
Но мы не можем решить это, сказав системе, что важно. На самом деле, кажется, мы надеемся, что она не сможет этого понять – мы полагаемся на способность обобщить качество работы с маловажных случаев на более важные. Поэтому исследование техник машинного обучения для избегания редких катастроф (или «ловушек») связано с задачей получения гарантии, что меса-оптимизаторы согласованы с базовыми.
Сложно доверять произвольному коду – а им являются модели из обширных классов моделей – основываясь только на эмпирическом тестировании. Рассмотрим сильно упрощённую задачу: мы хотим найти программу, которая всегда выводит 1. 0 – это катастрофический провал.
Если бы мы могли сами просмотреть код, то задача была бы простой. Но вывод машинного обучения зачастую сложно проанализировать; давайте предположим, что мы вовсе не можем понимать код.
Теперь, в некотором смысле, мы больше можем доверять простым функциям. Короткий кусок кода с меньшей вероятностью содержит жёстко закодированной исключение. Давайте опишем это количественно.
Рассмотрим набор всех программ длины $L$. Некоторые программы $p$ будут долгое время печатать $1$, но затем напечатают $0$. Мы пытаемся этого избежать.
Назовём время до первого нуля $W_{p}$. ($W_{p}=∞$, если программе $p$ можно доверять, то есть она никогда не выведет $0$.)
Высочайшая конечная $W_{p}$ из всех программ длины $L$ – это вариация функции Занятого Бобра, так что я буду обозначать её $BB(L)$. Если мы хотим быть совершенно уверены, что случайная программа длины $L$ достойна доверия, то нам надо пронаблюдать $BB(L)$ единиц от этой программы.
Однако, факт про функцию Занятого Бобра – $BB(n)$ растёт быстрее любой вычислимой функции. Так что такое эмпирическое зарабатывание доверия в худшем случае занимает невычислимо много времени.
Что в среднем случае?
Если мы предположим, что все остальные программы длины $L$ – простые случаи, число программ длины $L$ pастёт экспоненциально, так что среднее будет $BB(L)/exp(L)$. Но экспоненты вычислимы. Так что $BB(L)/exp(L)$ всё ещё растёт быстрее любой вычислимой функции.
Так что хоть использование коротких программ в теории даёт нам некоторую уверенность, сложность вывода обобщённых заключений крайне быстро растёт с ростом длины.
Если ограничения длины не так уж практичны, может, нам может помочь ограничение вычислительной сложности? Интуитивно кажется, что меса-оптимизатору необходимо время подумать, чтобы успешно выполнить предательский разворот. Так что программа, которая приходит к выводам быстрее, может быть более достойна доверия.
Однако ограничение класса сложности, к сожалению, не позволяет нам обойти поведение Занятого Бобра. Стратегии, долго выжидающие перед тем, как вывести $0$, могут быть ещё сильнее замедлены лишь небольшим увеличением длины программы $L$.
Если все эти проблемы кажутся слишком гипотетическими, посмотрите на эволюцию жизни на Земле. Эволюцию можно рассматривать как максимизатор приспособленности к размножению.
(На самом деле об эволюции можно думать как об оптимизаторе многих вещей, или как вообще не об оптимизаторе, но это неважно. Суть в том, что если бы агент хотел максимизировать приспособленность к размножению, то он мог бы использовать систему, похожую на эволюцию.)
Интеллектуальные организмы – меса-оптимизаторы эволюции. Хотя их стремления точно коррелируют с приспособленностью к размножению, организмы хотят много всего разного. Есть даже меса-оптимизаторы, которые смогли понять эволюцию, и даже периодически ей манипулировать. Мощные и несогласованые меса-оптимизаторы выглядят реальной возможностью, по крайней мере при достаточной вычислительной мощности.
Проблемы возникают, когда вы пытаетесь решить задачу, которую решать не умеете, с помощью поиска по большому пространству в надежде, что «кто-нибудь» сможет её решить.
Если источник трудностей – решение задач путём обширного поиска, может быть, нам следует поискать другие способы решать задачу. Может, нам стоит решать задачи, понимая что к чему. Но как вы решите задачи, которые пока не знаете, как решать, иначе кроме как пробуя варианты?
Давайте отступим на шаг назад.
Встроенные модели мира – о том, как встроенному агенту вообще думать; теория принятия решений – о том, как действовать. Устойчивое делегирование – о создании достойных доверия наследников и помощников. Согласование подсистем – о том, как составить одного агента из достойных доверия частей.
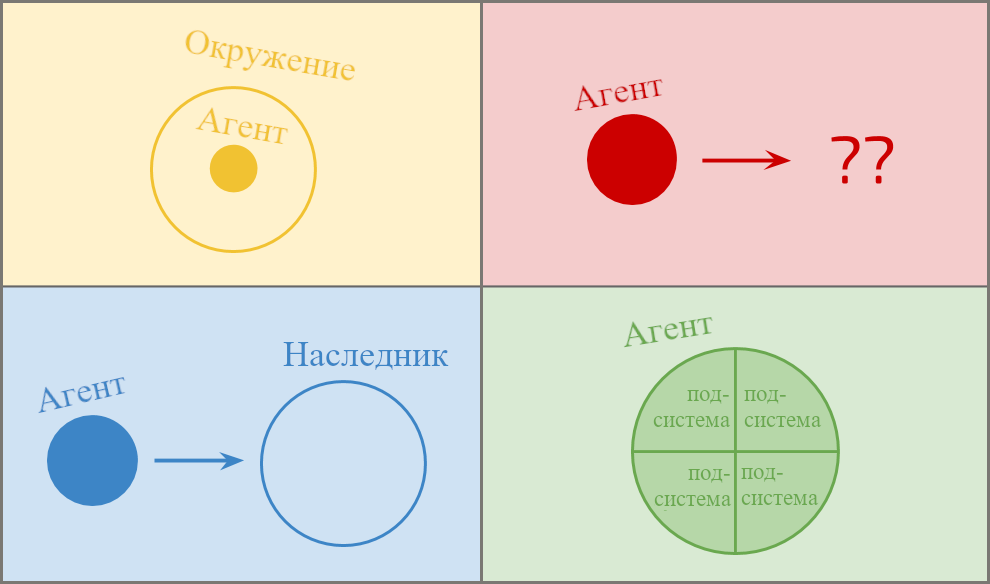
Проблемы в том, что:
- Мы не знаем, как думать об окружении, когда мы меньше его.
- В той степени, в которой мы умеем это делать, мы не знаем, как думать о последствиях действий в этих окружениях.
- Даже когда мы умеем это делать, мы не знаем, как думать о том, чего мы хотим.
- Даже когда у нас нет всех этих проблем, мы не знаем, как нам надёжно выводить действия, которые приведут нас к желаемому!
Это - последний из основных постов в цепочкет Скотта Гаррабранта и Абрама Демски «Встроенная Агентность». Заключение: Встроенные Странности.
Встроенная Агентность. Встроенные странности
В заключение поговорю о любопытстве и интеллектуальных головоломках.
Я описал встроенного агента, Эмми, и сказал, что я не понимаю, как она оценивает свои варианты, моделирует мир, моделирует себя, делит задачи на части и решает их.
В прошлом, когда исследователи разговаривали о мотивации работы над подобными задачами, они в основном сосредотачивались на мотивации от риска ИИ. Исследователи ИИ хотят создать машины, которые могут решать задачи в обобщённом виде, подобно человеку, а дуализм - нереалистичный подход для рассуждений о таких системах. В частности, это такая аппроксимация, которая особенно легко сломается, когда ИИ системы станут умнее. Мы хотим, чтобы, когда люди поймут, как создать обобщённые ИИ-системы, исследователи находились в лучшей позиции для понимания этих систем, анализа их внутренних свойств, и уверенности в их будущем поведении.
Это мотивация большинства исследователей, которые в настоящее время работают над вещами вроде необновимой теории принятия решений и согласования подсистем. Нас волнуют основные концептуальные загадки, которые, как мы думаем, нам надо решить, чтобы понять, как достигнуть уверенности в будущих ИИ-системах, и не быть вынужденными так сильно полагаться на грубый перебор и метод проб и ошибок.
Но аргументы о том, почему для ИИ нам могут понадобиться или не понадобиться конкретные концептуальные озарения, можно описывать очень долго. Я не хотел тут вдаваться в детали. Вместо этого, я обсудил некоторый набор направлений для исследования как интеллектуальные головоломки, а не как инструментальные стратегии.
Недостаток описания этих задач как инструментальных стратегий в том, что это может привести к некоторому недопониманию по поводу того, почему мы считаем такую работу настолько важной. При рассмотрении через призму «интеллектуальных стратегий» возникает искушение напрямую связывать конкретные задачи с конкретными беспокойствами о безопасности. Но дело не в том, что я представляю, что реальные встроенные системы будут «слишком Байесианскими», и это каким-то образом приведёт к проблемам, если мы не поймём, что не так с нынешними моделями рациональной агентности. Я точно не считаю, что будущие ИИ-системы будут написаны при помощи логики второго порядка! В большинстве случаев я вовсе не пытаюсь напрямую связать конкретные исследовательские задачи с конкретными вариантами провала ИИ.
Вместо этого я думаю, что сегодня, пытаясь разобраться в том, что такое агентность, мы точно применяем неправильные основные концепции, что видно по тому, что эти концепции плохо переносятся на более реалистичные встроенные случаи.
Если в будущем разработчики ИИ всё ещё будут работать с этими вводящими в замешательство и неполными базовыми концепциями, пытаясь на самом деле создать мощные работающие в реальном мире оптимизаторы, это кажется плохой позицией. И кажется, что исследовательское сообщество навряд ли выяснит большую часть этого по умолчанию просто по ходу разработки более способных систем. Эволюция уж точно додумалась до создания человеческого мозга грубым поиском, безо всякого «понимания» чего-то из этого.
Встроенная агентность – это мой способ попытаться указать на, как я думаю, очень важную центральную точку моего замешательства, в которой, я думаю, рискуют вспасть в замешательство и будущие исследователи.
Есть множество замечательных исследований согласования ИИ, которые делаются с прицелом на более прямое применение; но я думаю, что исследование безопасности не совпадает по типу с головоломками, о которых я говорил тут.
Интеллектуальное любопытство – не основная причина, по которой мы приоритизировали эти направления исследований. Но есть некоторые практические преимущества из периодического рассмотрения исследовательских вопросов со стороны любопытства, а не применяя к тому, как мы думаем о мире лишь призму «практического воздействия».
Когда мы применяем к миру призму любопытства, мы обращаемся к источникам замешательства, мешающим нам ясно видеть; незаполненным участкам карты; дефектам наших линз. Это поощряет перепроверку допущений и обращение внимания на слепые пятна, что полезно в качестве психологического противовеса призме «инструментальных стратегий» – более уязвимой к порыву положиться на шаткие предпосылки, которые у нас уже есть, чтобы получить больше уверенности и законченности как можно скорее.
Встроенная агентность – объединяющая тема наших многих, если не всех, больших источников любопытства. Она кажется центральной тайной, лежащей в основе многих конкретных сложностей.
Исследовательские задачи по согласованию
Сейчас, когда пытаешься научиться лучше думать о согласовании, сложно понять, где начать. Поэтому ниже я перечислил пару десятков упражнений, которые, как мне кажется, могут помочь. Они подразумевают уровень фоновых знаний, приблизительно эквивалентный тому, что покрыто учебным планом технического потока курса основ безопасности СИИ. Они сильно варьируются по сложности – от стандартных знаний в области машинного обучения до открытых исследовательских задач. Я выдал им рейтинг сложности звёздочками от * до *** (отмечу: это не связано с временем на выполнение – многие требуют сначала прочитать статьи, а уже потом решать). Однако, я сам не решал их все, так что рейтинги могут значительно ошибаться.
Я склонялся к включению упражнений, которые казались мне интересными и связанными с согласованием даже когда не был уверен в их ценности; так что, работая над ними, стоит держать в голове вопрос «действительно ли это полезно? Почему или почему нет?» как мета-упражнение. Вероятно, этот пост будет обновляться с удалением наименее полезных упражнений и добавлением новых.
Буду признателен за:
- Комментарии о том, какие упражнения показались наиболее или наименее полезными.
- Ответы на упражнения
- Больше упражнений! Идеальные упражнения – задачи в стиле охоты на нёрдов, быстро и конкретно формулируемые, но ведущие к интересным глубинам при исследовании.
Обучение с подкреплением
- * Посмотри на примеры механизмов человеческой обратной связи, обсуждённых в статье про рациональный относительно награды неявный выбор. Подумай о других видах человеческой обратной связи. Каково множество выбора? Какова функция обоснования?
- * Эта статья от Anthropic представляет технику под названием «дистилляция контекста». Опиши это в терминах подхода рационального относительно награды неявного выбора.
- * Оцени пропускную способность передачи информации через разные виды человеческой обратной связи. Опиши грубую модель того, как это может измениться по ходу обучения. Для контраста, сколько информации передаётся через выбор программируемой функции вознаграждения? (Рассмотри и случай, когда агенту дана точная функция вознаграждения, и когда он учится из наблюдений.)
- * Посмотри на примеры искажений, обсуждённых в изучении предпочтений ограниченных агентов. Укажи ещё одно искажение, похожим образом воздействующее на человеческий процесс принятия решений. Опиши ситуацию-пример, в которой человек с этим искажением может принять неверное решение. Сформулируй алгоритм, выводящий истинные предпочтения этого человека.
- ** С учётом того, что людям можно приписать любые ценности, почему обучение с подкреплением вообще работает на практике?
- ** Объясни, почему кооперативное обратное обучение с подкреплением не решает проблему согласования.
Агентность
- ** В этой статье исследователи придумали тест для определения того, совершает ли рекуррентная сеть планирование: наблюдение за тем, улучшается ли качество работы, если дать сети больше времени «подумать» перед действием. В статье про AlphaGo исследователи сравнили работу их алгоритма MCTS+нейросеть и работу нейросети отдельно. Подумай, какой ещё тест можно провести, чтобы получить свидетельство о том, в какой степени некая нейросеть совершает внутреннее планирование.
- * Рассмотри HCH, попытку формализовать «человеческое просвещённое суждение». Почему реализация HCH может быть несогласованной? Какие допущения необходимы, чтобы это предотвратить?
- *** В позднейшем посте Пол определяет более сильную версию HCH, «улучшающую выразительность HCH с точки зрения теории сложности. Старая версия могла вычислять в EXPTIME, а новая – любую разрешимую функцию.» Попробуй вывести новую версию HCH с такими свойствами.
- Ответ тут
- * Спроси OpenAI API о том, какие шаги он бы предпринял, чтобы исполнить некий долгосрочный план. Работа в группах: придумайте задачу, про которую вы ожидаете, что для неё сложно придумать хороший план, а потом посмотрите, кто сможет составить затравку, приводящую к лучшему плану от API.
- * Некоторые шаги плана, сгенерированного API, могут быть и выполнены API – например, шаг, требующий написать стихотворение на заданную тему. Какую сложнейшую задачу вы сможете найти, для которой API сможет не только составить план, но и выполнить каждый из его шагов?
- ** Перл заявляет, что нейросети, обученные на размеченных или саморазмеченных данных не могут научиться рассуждать об обоснованиях и гипотетических фактах (смотри этот пост для объяснения разделения). Какой сильнейший контраргумент против его позиции?
Обучение с подкреплением (RL)
- ** Как обучение с учителем на максимизирующих награду траекториях связано (математически) с градиентом стратегий с редкими бинарными наградами?
- ** Какие теории принятия решений представлены в разных алгоритмах RL?
- ** Что может заставить RL-агента выучить стратегию, жертвующую награду в текущем эпизоде ради большей награды в следующем эпизоде?
- * Игры с самим собой в игре с нулевой суммой для двух игроков сходятся к оптимальной стратегии (с учётом некоторых допущений о классе моделей). В других играх это не так – почему?
- ** Оцени эту статью (Вознаграждения Достаточно). Действительны ли их аргументы?
- ** После этого: представь птицу, практикующую пение, слушающую собственную песню и выполняющую RL с правилом «чем лучше звучит звук, тем выше вознаграждение». Но птица ещё и решает, как распределять время между практикой пения, сбором припасов и т.д. И чем она хуже звучит, тем важнее ей практиковаться! Так что на самом деле хочется иметь правило «чем хуже звук, тем выше награда за практику пения». Как бы ты разрешил этот конфликт?
- Некоторые ответы здесь.
- * Почему поведенчески клонированная стратегия хорошо справляется, будучи запущенной на малом наборе шагов, но плохо на более длинной серии? Как это можно исправить?
- ** Если агент глубокого q-обучения обучен в окружении, где некоторые действия ведут к большому отрицательному вознаграждению, он никогда не прекратит пытаться их выполнять (стратегия иногда будет выбирать эти действия даже не при случайном изучении из-за эпсилон-исследования). Почему это происходит? Как это предотвратить?
- ** RL-агенты стали способны исполнять компетентное поведение на всё более длинных эпизодах. Какие возникают сложности при попытке измерить улучшения длительности их компетентных действий? Какие метрики наиболее полезны?
- Тот же вопрос, но для эффективности выборки вместо длины эпизодов.
- Некоторые ответы здесь.
Нейросети
- * Рассмотрим эту статью про модульность нейросетей. Оцени их метрику кластеризации, какие другие метрики можно использовать вместо неё?
- ** Рассмотрим следующее предложение по согласованию: нейросеть с двумя головами вывода, одна выбирает действие, а вторая предсказывает долговременные последствия этих действий. Предположим, что мы обучили вторую максимизировать оцениваемое людьми качество предсказания. Какие различия мы можем ожидать у обратного распространения ошибки через всю сеть и только через голову предсказания? Какие затруднения возникнут, если мы постараемся обучить голову предсказания с помощью RL? Какие у этого могут быть преимущества?
- ** “Взлом градиента” – гипотетическое явление, при котором модель выбирает свои действия частично на основе наблюдений своих собственных параметров, изменяя то, как они обновляются. Работает ли механизм взлома градиента, описанный в приложенном посте? Если нет, работают ли какая-нибудь его вариация?
- * Прочитай составленный Якобом Стайнхардтом список примеров эмерджентных сдвигов в машинном обучении. Можешь ли ты придумать какие-нибудь ещё? Что насчёт сдвигов, которые ты ожидаешь в ближайшем будущем?
- ** Как бы могла выглядеть ложность гипотезы схем?
- * Эта статья обсуждает метрику «эффективно переданных данных». Какие её ограничения? Какие есть альтернативные способы измерить передачу данных?
Теория согласования
- * Рассмотрим расширение обучения с подкреплением на случай, когда вознаграждение может зависеть от параметров модели. Почему классические доказательства сходимости больше не работают?
- *** Есть ли ограничивающие допущения, которые могут привести к интересным теоретическим результатам?
- ** Одно из беспокойств по поводу предложений обучения с использованием функций оценивания, напрямую зависящих от параметров, состоит в том, что если мы обучим нейросеть избегать некой конкретной разновидности мышления, то такое мышление может просто распределиться по сети таким способом, который мы не можем засечь. Опиши игрушечный пример когнитивной черты, которую мы сейчас можем автоматически обнаружить. Придумай эксперимент, показывающий, научилась ли нейросеть после обучения для удаления этой черты реализовывать эквивалентную черту менее легко детектируемым способом.
- *** Перевыведи некоторые доказательства из следующих статей. Для b) и c) объясни, какие сделаны допущения об оптимальности вовлечённых агентов, и как они на практике могут не соблюдаться:
- *** Составь предложение для приза ELK (замечу, что это требует ознакомления с очень длинным отчётом ELK).
- ** Предположим, что мы обучили модель через поведенческое клонирование человека, но человек начинал с другими априорными знаниями о модели (либо большими, либо меньшими). Как это может привести к несогласованному поведению модели?
Основания агентов
- * Теория игр с открытым кодом
- ** Теоремы выбора
- ** Упражнения с неподвижной точкой
- *** Задача 5 и 10
Эволюция и экономика
- * В старом исследовании насекомых разделили на несколько групп, каждая из которых жила отдельно, и проводили искусственный отбор в пользу меньших групп, в попытке узнать, эволюционируют ли они добровольное ограничение размножения. Предскажи результаты исследования.
- Некоторые ответы здесь. Действовало ли описанное в посте искажение на твои ожидания?
- ** Как можно объяснить, почему так мало видов животных – гермафродиты, если учитывать, что возможность вынашивания детей каждым представителем вида могла бы потенциально удвоить количество детей в следующем поколении?
- * Прочитай этот пост про эволюцию к вымиранию. Математически продемонстрируй, что факторы нарушения сегрегации действительно могут заставить вид эволюционировать к вымиранию.
- * Оцени модель эволюции альтруизма Флетчера и Дебели.
- Используй модель, чтобы показать, как эффект зелёной бороды может привести к эволюции (некоторой разновидности) альтруизма.
- Почему у большинства видов рождается примерно одинаковое количество мужских и женских особей?
- * Сравнение ВВП в разное время требует упоминания стандартной потребительской корзины. Какие сложности могут из-за этого возникать при непосредственном использовании сравнения ВВП?
- ** Оцени модель взрывного экономического роста Рудмана.
- * В кооперативной теории игр «ядро» – это множество всех распределений выигрыша агентам, такое, что никакое подмножество агентов не может сформировать коалицию для улучшения своего выигрыша. К примеру, рассмотрим группу из N шахтёров, нашедших большие слитки золота. Предположим, что два шахтёра могут перетащить один слиток, так что выигрыш любой коалиции S – это floor(|S|/2). Если N чётно, то ядро состоит из единственного распределения выигрыша, при котором каждый шахтёр получает ½. Если N нечётно, то ядро пусто (потому что оставшийся без пары шахтёр всегда может сделать лучшее предложение какому-нибудь из остальных). Найди ядра следующих игр:
- Игра с 2001 игроком: 1000 из них имеют по одному левому ботинку, 1001 – по одному правому. Пара из левого и правого ботинка может быть продана за $10.
- У Мистера A и Мистера B есть по три перчатки. Любые две перчатки составляют пару, которую можно продать за $5.
- Ответы здесь.
- * Как коалиции должны решать, как разделить полученный выигрыш? Концепция Вектора Шепли даёт один ответ. Убедись, что вектор Шепли имеет свойства линейности, «null player» и «stand-alone test», описанные в статье.
Некоторые важные концепты машинного обучения
Это не столько упражнения, сколько указатели на открытые вопросы на самом краю глубинного обучения.
- Законы масштабирования
- Почему они выглядят так, как выглядят?
- Некоторые ответы здесь and здесь
- Запоминание в нейросетях
- Двойной спуск
- Гипотеза лотерейного билета
- Игры с структурой волчка
- Масштаб градиентного спуска (см. ещё здесь)
- Запросы на исследования от OpenAI
- Запросы на исследования от OpenAI 2
Разное
- * Заполни свои оценки модели сроков Котры. Кажется ли она тебе осмысленной; изменил бы ты её как-нибудь?
- * Попробуй сыграть в реализацию Дебатов от OpenAI.
- ** Найди важный концепт в согласовании, который на настоящий момент не очень хорошо объяснён; напиши объяснение получше.
Плохо нацеленные Лучи Смерти
Альтернативная формулировка: Оптимальность – тигр, и агенты – клыки его.
Схожий тон: Стратегии Годзиллы.
Есть проблема, когда люди думают, что суперинтеллектуальный ИИ будет просто безвольным инструментом, который будет делать то, что ему скажут. Но есть и проблема, когда люди слишком сосредотачиваются на «агентности». Когда они представляют, будто все проблемы исходят от того, что ИИ чего-то «хочет», «думает» и проявляет по этому поводу консеквенциализм. Ах если бы мы только могли сделать его в большей степени безвольным инструментом! Тогда все наши проблемы были бы решены. Потому что проблема в том, что ИИ будет умными способами использовать свои силы, чтобы намеренно нам навредить, верно?
Я думаю, такой взгляд не учитывает всей силы оптимизации, того, как даже малейшая неудача в её точном нацеливании, мельчайшая утечка её энергии в неправильном направлении, хоть на секундочку, будет достаточной, чтобы всех нас смыло.
Проблема не в создании суперинтеллекта без позитивного желания нас убить. Случайное убийство всех нас – естественное свойство суперинтеллекта. Проблема в создании ИИ, который намеренно тратит много усилий, чтобы удостовериться, что он нас не убьёт.
Мне хорошей аналогией кажутся уничтожающие планеты Лучи Смерти. Подумайте о Звезде Смерти. Представьте…
Представьте, что вы – инженер, нанятый… эксцентричным парнем. У него есть логово в вулкане, странные эстетические вкусы, и тенденция ставить рядом слова «мир» и «захватить». Ну, знаете таких.
Одна из его новых схем – взорвать Юпитер. Для этого он раскопал огромную пещеру под своим логовом в вулкане, прорыл длинный цилиндрический туннель из этой пещеры на поверхность, и приказал вашей команде создать в этой пещере лучевое оружие, и выстрелить им через туннель на Юпитер.
Вам платят буквальные тонны денег, так что вы не жалуетесь (кроме как о логистике платежей). У вас к тому же есть весьма хорошая идея того, как это сделать. Ваша команда нашла эти странные кристаллические штуки. Если определённым способом такую тыкнуть, она выпускает узкий энергетический луч, взрывающий всё, чего касается. Сила луча растёт суперэкспоненциально с силой тычка; вы довольно таки уверены, что если выстрелить в такую штуку из винтовки, на Юпитер хватит.
Есть только одна проблема: нацеливание. У вас никогда не получается точно предсказать, какая часть кристалла испустит луч. Это зависит от того, куда его ткнуть, но ещё и от того, насколько сильно, с результатами, кажущимися случайными. И ваш работодатель настаивает, что Луч Смерти надо запустить из пещеры через туннель, а не из космоса, где он менее вероятно попадёт во что-то важное, или ещё каким-нибудь практичным способом.
Если вы скажете, что этого сделать нельзя, ваш работодатель просто заменит вас кем-то менее… пессимистичным.
Итак, вот ваша задача. Как вам создать машину, использующую один или несколько таких кристаллов для запуска Луча Смерти через туннель в Юпитер, чтобы он не попал в Землю, убив всех?1
Вы экспериментируете с кристаллами в не-уничтожающих-Землю режимах, пытаясь понять, как направляется луч. Вы добились неслабого прогресса! Вы способны предсказать направление луча на следующем режиме мощности с уверенностью в 97%!
- Когда вы запускаете установку на уничтожающей-Юпитер-мощности, это приводит к небольшой неточности нацеливания луча. Он задевает стенку туннеля, взрывает Землю и всех убивает.
Вы пускаете Луч Смерти на более низких не-уничтожающих-Землю режимах мощности, которые вы умеете нацеливать.
- Он попадает в Юпитер, но не уничтожает его. Ваш работодатель разочарован и говорит вам попробовать ещё раз.
Вы покрываете стены пещеры и туннеля действительно хорошим защитным покрытием.
- Луч Смерти задевает стенку туннеля, пробивает броню и убивает всех.
Вы создаёте механизм для быстрого выключения Луча Смерти. Если вы увидите, что он направлен не в том направлении, вы его отключите.
- Луч Смерти убивает вас до того, как информация о неправильном нацеливании достигает вашего мозга.
Вы создаёте действительно быструю систему нацеливания, которая быстро повернёт кристалл, как только детектирует, что Луч Смерти направлен не туда.
- За долю секунды, которую он направлен не в том направлении, он передаёт достаточно энергии, чтобы взорвать Землю и всех убить.
Вы делаете луч очень узким, чтобы он с меньшей вероятностью попал в стенку туннеля.
- Он всё равно её задевает и убивает всех.
Вы создаёте хитрую систему, стреляющую несколькими Лучами Смерти в приблизительном направлении туннеля, нацеленные так, чтобы пересечься под входом в него. Идея в том, что их ошибки скомпенсируют друг друга, и составной луч полетит куда надо!
- Ошибки не скомпенсировались идеально, луч задевает стенку туннеля и опять всех убивает.
- К тому же, один из Лучей Смерти оказался направленным в пол, так что это в любом случае бы не сработало.
Вы проводите над кристаллом экзорцизм, изгоняя вселившихся в него демонов.
- Ничего не меняется. Луч задевает стенку туннеля и всех убивает.
Вы модифицируете кристалл так, чтобы луч безвредно рассеивался вскоре после выстрела.
- Он не может достичь Юпитера. Вы разочаровали своего работодателя в последний раз. Он вас ~запускает на Солнце~ увольняет.
Пришедший к вам на замену решает, что покрытие стен ещё лучшим защитным слоем должно решить проблему, запускает луч, уничтожает Землю и убивает всех.
Конечно, эту аналогию можно критиковать бесконечно. Она ни в коем случае ничего не доказывает. Вы можете говорить, что лишь чуть-чуть несогласованности не уничтожит мир, или что ИИ не обязательно быть опасным, чтобы мы могли делать с ним интересные штуки, или что интеллект на самом деле не настолько могущественен, и так далее.
Этот пост не направлен на том, чтобы кого-то убедить; для этого написано уже много чего. Но если вы в общих чертах принимаете предпосылки, но вам сложно точно указать конкретные проблемы с любым данным сценарием сдерживания, эта аналогия может помочь.
У любой достаточно мощной ИИ-системы есть ужасающее ядро оптимизации – способность переделывать некоторую часть мира согласно какой-нибудь спецификации. Неважно, как именно эта мощь выражена, в какие обёртки завёрнута, куда конкретно направлена, контролируется ли чуждой разумной сущностью. Пока она не направлена в точности туда, куда мы хотим, без утечек, с самого начала, она убьёт нас всех.
Это её неотъемлемое свойство.
- 1. Ещё, в этом сценарии у Земли нет атмосферы. Наверное, тоже вина вашего работодателя. Но по крайней мере, это означает, что хорошо нацеленный луч не попадёт по воздуху и не взорвёт всё в любом случае.
Прояснения и Предсказания по поводу СИИ
Подход t-СИИ
По мере того, как мы приближаемся к СИИ, становится менее осмысленно считать это бинарным порогом. Я предлагаю вместо этого считать это непрерывным спектром, определённым через сравнение с ограниченными во времени людьми. Я называю систему t-СИИ, если с большинством когнитивных задач она справляется лучше, чем люди-эксперты, которым дали на её выполнение время t.
Что это значит на практике?
- 1-секунда-СИИ должен быть сильнее людей в задачах вроде быстрых ответов на вопросы викторины, базовой физической интуиции («что произойдёт, если я толкну нитку?»), распознавании объектов на изображениях, понимании, какие предложения грамматически-правильны, и т. п.
- 1-минута-СИИ должен быть сильнее людей в задачах вроде ответов на вопросы о коротких отрывках текста или видео, рассуждениях, основанных на здравом смысле (например, «шестерёночные» задачи Яна ЛеКуна), простых задачах обращения с компьютером (например, использовании фотошопа для замыливания картинки), обосновании мнения, поиске фактов, и т. п.
- 1-час-СИИ должен быть сильнее людей в задачах вроде решения наборов задач/экзаменов, написания коротких статей или постов, большинства задач «белых воротничнов» (диагностика пациентов, выдача юридических советов), психотерапии, проведении онлайн-встреч, изучении правил новых игр, и т. п.
- 1-день-СИИ должен быть сильнее людей в задачах вроде написания умных эссе, бизнес-переговорах, развития навыка игры в новые игры или использования нового софта, разработке новых приложений, проведения научных экспериментов, рецензировании научных статей, пересказывании книг, и т. п.
- 1-месяц-СИИ должен быть сильнее людей в исполнении среднесрочных планов (например, основании стартапа), присмотре за большими проектами, заполучении навыка в новой области, написании больших приложений (вроде новой ОС), совершении новых научных открытий, и т. д.
- 1-год-СИИ должен быть сильнее людей… по сути, во всём. Некоторые проекты занимают у людей больше времени (например, доказательство Великой Теоремы Ферма), но их почти всегда можно разбить на подзадачи, не требующие глобального контекста (хоть он часто и полезен для людей).
Некоторые прояснения:
- Я абстрагируюсь от вопроса о том, сколько вычислительного времени есть у ИИ (сколько копий запущены и насколько надолго). В принципе, можно было бы спрашивать что-то вроде «какая для этого нужна доля мировых вычислительных мощностей?». Но в большинстве случаев я ожидаю, что «бутылочным горлышком» будет способность вообще выполнить задачу; если она есть, то это почти наверняка можно будет сделать при помощи пренебрежимо малой доли мировых вычислителных мощностей.
- Аналогично, я сомневаюсь, что конкретный порог, кого считать «экспертом» сильно важен. Кажется важным, что вообще используются эксперты, а не обыватели, потому что те имеют слишком мало опыта с большинством задач. «Быть сильнее большинства людей» плохо определено для программирования или шахмат, да и не имеет значения.
- Я ожидаю, что для любого t первые 100t-СИИ будут *намного* лучше любого человека на задачах, которые занимают только время t. Для рассуждений о сверхчеловеческих результатах можно расширить подход на (t,n)-СИИ, которые одолевают любую группу из n человек, которые время t вместе работают над задачей. Думая о суперинтеллекте, я обычно думаю о (1 год, 8 миллиардов)-СИИ.
- Ценность этого подхода – эмпирический вопрос. На пока что он кажется полезным: я думаю, что нынешние системы являются 1-секунда-СИИ, близки к 1-минута-СИИ, и в нескольких годах от 1-час-СИИ. (Насколько помню, я сформулировал этот подход 2 года назад, но никогда им широко не делился. С вашей точки зрения тут может быть искажение отбора – я бы не поделился им, если бы в нём разочаровался. Но, по крайней мере, с моей точки зрения он получает очки за полезность для описания событий с тех пор.)
И, очень коротко, некоторые из интуитивных соображений в основе этого подхода:
- Я думаю, последовательность действий на протяжении времени – очень сложная задача, и люди так-себе с ней справляются, несмотря на то, что (полагаю) эволюция нас сильно для этого оптимизировала.
- Ещё это важное «бутылочное горлышко» для LLM, по принципиальной причине того, что чем длиннее эпизод, тем он дальше от обучающего распределения.
- Обучение нейросетей исполнению задач на протяжении более долгих периодов времени требует куда больше вычислительных мощностей (как смоделировано в докладе о сроках Аджейи Котры).
- Обучение нейросетей исполнению задач на протяжении более долгих периодов времени занимает больше реального времени, так что нельзя собрать столько же данных.
- Есть причины ожидать, что нынешние архитектуры будут в этом плохи (хотя я не особо на это полагаюсь; я ожидаю исправления этой проблемы при дальнейшем развитии).
Предсказания, мотивированные подходом
Вот некоторые предсказания – в основном базирующиеся на моей интуиции, но при помощи описанного подхода. Я предсказываю с более чем 50% шансом, что к концу 2025 года нейросети будут:
- Обладать ситуационной осведомлённостью на человеческом уровне (понимать, что они нейросети, как их действия взаимодействуют с миров, и т. д.; см. Определение тут)
- Лучше любого человека записывать эффективные планы действий в реальном мире из многих шагов. Это вызвало споры; вот прояснения:
- Я думаю, записывание планов не позволит много чего добиться, лучшие планы чаще всего – что-то вроде «попробовать X, посмотреть, что получится, повторить».
- Имеется в виду, лучше любого человека (по многим областям), не лучше лучшего человека в каждой области.
- Под «многими областями» я не подразумеваю буквально все, но довольно широкий диапазон. К примеру, в среднем для всех бизнесов, которые нанимали их консультировать McKinsey, ИИ сделает бизнес-планы получше, чем мог бы любой отдельный человек.
- Рецензировать статьи лучше большинства рецензентов-людей
- Автономно проектировать, программировать и распространять целые приложения (но не самые сложные)
- Лучше любого человека справляться с любой задачей на компьютере, которую может сделать типичный «белый воротничок» за 10 минут
- Писать способные получить награды рассказы и публикуемые книги на 50 тысяч слов.
- Генерировать осмысленные пятиминутные фильмы (отмечу: я изначально сказал «двадцатиминутные», а потом передумал, но колеблись туда-сюда после того, как увидел недавние сгенерированные ИИ видео)
- Пройти нынешнюю версию оценивания автономного самокопирования ARC (см. раздел 2.9 системной карты GPT-4; страница 55). Но не смогут самостоятельно сбегать с надёжных серверов или избегать обнаружения, если владельцы облака попробуют их задетектировать.
- 5% взрослых американцев будут сообщать об опыте нескольких романтических/сексуальных взаимодействий с ИИ-чатами, а 1% о сильной эмоциональной привязанности.
- Мы увидит явные примеры эмерджентной кооперации: ИИ, которым дали сложную задачу (например, написать функцию на тысячу строк) в общем окружении будут кооперироваться безо всякого мультиагентного обучения.
Лучшие люди всё ещё будут впереди (хоть и куда медленнее) в:
- Написании романов
- Устойчивом исполнении плана на протяжении нескольких дней
- Совершении научных прорывов, включая новые теоремы (но нейросети докажут хотя бы одну)
- Типичных задачах ручного труда (в сравнении с роботами, контролируемыми нейросетями)
Думаю, мои настоящие ожидания скорее про два года в будущем, но другие могут использовать иные стандарты оценки, так что 2.75 (на момент, когда это запощено) кажется надёжнее. Предсказание не основано ни на какой специфичной для OpenAI информации.
Конечно, тут много чего можно обсудить. Я особенно заинтересован в:
- Том, чтобы люди выдавали медианные даты того, когда всё это будет достигнуто
- Том, чтобы люди генерировали другие конкретные предсказания о том, на что нейросети будут или не будут способны в ближайшие несколько лет
Риски выученной оптимизации
В этой цепочке приводится статья Эвана Хубингера, Криса ван Мервика, Владимира Микулика, Йоара Скалсе и Скотта Гаррабранта «Риски выученной оптимизации в продвинутых системах машинного обучения». Посты цепочки соответствуют разделам статьи.
Цель этой цепочки – проанализировать выученную оптимизацию, происходящую, когда обученная модель (например, нейронная сеть) сама является оптимизатором – ситуация, которую мы называем меса-оптимизацией – неологизмом, представленным в этой цепочке. Мы убеждены, что возможность меса-оптимизации поднимает два важных вопроса касательно безопасности и прозрачности продвинутых систем машинного обучения. Первый: в каких обстоятельствах обученная модель будет оптимизатором, включая те, когда не должна была им быть? Второй: когда обученная модель – оптимизатор, каковы будут её цели: как они будут расходиться с функцией оценки, которой она была обучена, и как можно её согласовать?
Риски выученной оптимизации. Введение
Это первый из пяти постов Цепочки «Риски выученной оптимизации», основанной на статье «Риски выученной оптимизации в продвинутых системах машинного обучения» за авторством Эвана Хубингера, Криса ван Мервика, Владимира Микулика, Йоара Скалсе и Скотта Гаррабранта. Посты цепочки соответствуют разделам статьи.
Эван Хубингер, Крис ван Мервик, Владимир Микулик и Йоар Скалсе в равной степени вложились в эту цепочку. Выражаем благодарность Полу Кристиано, Эрику Дрекслеру, Робу Бенсинджеру, Яну Лейке, Рохину Шаху, Вильяму Сандерсу, Бак Шлегерис, Дэвиду Далримпле, Абраму Демски, Стюарту Армстронгу, Линде Линсфорс, Карлу Шульману, Тоби Орду, Кейт Вулвертон и всем остальным, предоставлявшим обратную связь на ранние версии этой цепочки.
Мотивация
Цель этой цепочки – проанализировать выученную оптимизацию, происходящую, когда обученная модель (например, нейронная сеть) сама является оптимизатором – ситуация, которую мы называем меса-оптимизацией – неологизмом, представленным в этой цепочке. Мы убеждены, что возможность меса-оптимизации поднимает два важных вопроса касательно безопасности и прозрачности продвинутых систем машинного обучения. Первый: в каких обстоятельствах обученная модель будет оптимизатором, включая те, когда не должна была им быть? Второй: когда обученная модель – оптимизатор, каковы будут её цели: как они будут расходиться с функцией оценки, которой она была обучена, и как можно её согласовать?
Мы считаем, что эта цепочка представляет самый тщательный анализ этих вопросов на сегодняшний день. В частности, мы представляем не только введение в основные беспокойства по поводу меса-оптимизаторов, но и анализ конкретных аспектов ИИ-систем, которые, по нашему мнению, могут упростить или усложнить задачи, связанные с меса-оптимизацией. Предоставляя основу для понимания того, в какой степени различные ИИ-системы склонны быть устойчивыми к несогласованной меса-оптимизации, мы надеемся начать обсуждение о лучших способах структурирования систем машинного обучения для решения этих задач. Кроме того, в четвёртом посте мы представим пока что по нашему мнению самый детальный анализ проблемы, которую мы называем обманчивой согласованностью. Мы утверждаем, что она может быть одним из крупнейших – хоть и не обязательно непреодолимых – нынешних препятствий к созданию безопасных продвинутых систем машинного обучения с использованием технологий, похожих на современное машинное обучение.
Два вопроса
В машинном обучении мы не программируем вручную каждый отдельный параметр наших моделей. Вместо этого мы определяем целевую функцию, соответствующую тому, что мы хотим, чтобы система делала, и обучающий алгоритм, оптимизирующий систему под эту цель. В этом посте мы представляем подход, который различает то, для чего система была оптимизирована (её «назначение») и то, что она оптимизирует (её «цель»), если она это делает. Хоть все ИИ-системы оптимизированы для чего-то (имеют назначение), оптимизируют ли они что-то (преследуют ли цель) – неочевидно. Мы скажем, что система является оптимизатором, если она производит внутренний поиск в пространстве возможностей (состоящем из выводов, политик, планов, стратегий, или чего-то в этом роде) элементов, высоко оцениваемых некой целевой функцией, явно отображённой внутри системы. Обучающие алгоритмы машинного обучения – оптимизаторы, поскольку они ищут в пространстве возможных параметров, например, весов нейросети, и подгоняют их для некой цели. Планирующие алгоритмы – тоже оптимизаторы, поскольку они ищут среди возможных планов подходящие под цель.
Является ли система оптимизатором – свойство её внутренней структуры, того, какой алгоритм она на самом деле реализует, а не свойство её поведения ввода-вывода. Важно, что лишь то, что поведение системы приводит к максимизации некой цели не делает её оптимизатором. К примеру, крышка бутылки заставляет воду оставаться в бутылке, но не оптимизирует этот исход, поскольку не выполняет никакого оптимизационного алгоритма.(1) Скорее, крышка бутылки была оптимизирована для удерживания воды. Оптимизатор тут – человек, который спроектировал крышку, выполнив поиск в пространстве возможных инструментов для успешного удерживания воды в бутылке. Аналогично, классифицирующие изображения нейросети оптимизированы для низкой ошибки своих классификаций, но, в общем случае, не выполняют оптимизацию сами.
Однако, для нейросети также возможно и самой выполнять алгоритм оптимизации. К примеру, нейросеть может выполнять алгоритм планирования, предсказывающий исходы потенциальных планов и отбирающий те, которые приведут к желаемым исходам.1 Такая нейросеть будет оптимизатором, поскольку она ищет в пространстве возможных планов согласно с некой целевой функцией. Если такая нейросеть появилась в результате обучения, то оптимизатора два: обучающий алгоритм – базовый оптимизатор, и сама нейросеть – меса-оптимизатор.2
Возможность возникновения меса-оптимизаторов несёт важные следствия касательно безопасности продвинутых систем машинного обучения. Когда базовый оптимизатор генерирует меса-оптимизатор, свойства безопасности цели базового оптимизатора могут не передаться меса-оптимизатору. Мы исследуем два основных вопроса, связанных с безопасностью меса-оптимизаторов:
- Меса-оптимизация: В каких обстоятельствах обученные алгоритмы будут оптимизаторами?
- Внутреннее согласование: Когда обученный алгоритм – оптимизатор, каковы будут его цели и как его можно согласовать?
Представив наш подход в этом посте, мы потом обратимся к первому вопросу во втором посте, потом к второму вопросу в третьем, и, наконец, погрузимся глубже в конкретные аспекты второго вопроса в четвёртом посте.
1.1. Базовые оптимизаторы и меса-оптимизаторы
Обычно базовым оптимизатором в машинном обучении является какая-нибудь разновидность процесса градиентного спуска с целью создания модели для достижения некой определённой цели.
Иногда этот процесс также в некоторой степени включает мета-оптимизацию, где задача мета-оптимизатора – произвести базовый оптимизатор, хорошо оптимизирующий системы для достижения конкретных целей. В целом, мы будем считать мета-оптимизатором любую систему, чья задача – оптимизация. К примеру, мы можем спроектировать мета-обучающую систему для помощи в настройке нашего процесса градиентного спуска.(4) Найденную мета-оптимизацией модель можно считать разновидностью выучившегося оптимизатора, но это не тот случай, в котором мы тут заинтересованы. Мы озабочены другой формой выученной оптимизации, которую мы называем меса-оптимизацией.
Меса-оптимизация – концепт, парный мета-оптимизации: тогда как мета – это «над» по-гречески, меса – «под».3 Меса-оптимизация происходит когда базовый оптимизатор (в поиске алгоритма для решения некой задачи) находит модель, которая сама является оптимизатором – меса-оптимизатор. В отличии от мета-оптимизации, чьей задачей служит сама оптимизация, понятие меса-оптимизации независимо от задачи, и просто относится к любой ситуации, в которой внутренняя структура модели выполняет оптимизацию из-за того, что та инструментально полезно для решения имеющейся задачи.
В таком случае мы будем называть базовой целью критерий, который использовал базовый оптимизатор для выбора между разными возможными системами, а меса-целью критерий, который использует меса-оптимизатор для выбора между разными возможными выводами. Например, в обучении с подкреплением (RL), базовая цель – это, обычно, ожидаемая награда. В отличии от базовой цели, меса-цель не задаётся программистами напрямую. Скорее, это просто та цель, которая, как обнаружил базовый оптимизатор, приводит к хорошим результатам в тренировочном окружении. Раз меса-цель не определяется программистами, меса-оптимизация открывает возможность несовпадения между базовой и меса- целями, когда меса-цель может казаться хорошо работающей в тренировочном окружении, но приводит к плохим результатам извне его. Мы будем называть такой случай псевдо-согласованностью.
Меса-цель не обязана быть всегда, потому что алгоритм, обнаруженный базовым оптимизатором не всегда сам выполняет оптимизацию. Так что в общем случае мы будем называть сгенерированную базовым оптимизатором модель обученным алгоритмом, который может быть или не быть меса-оптимизатором.
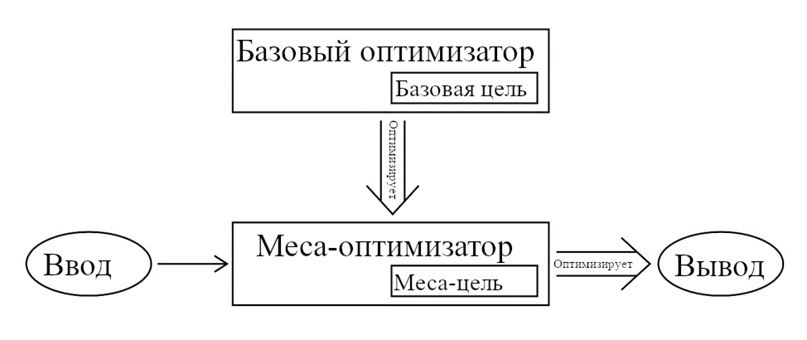
Рисунок 1.1. Отношение между базовым и меса- оптимизаторами. Базовый оптимизатор оптимизирует обученный алгоритм на основе его выполнения базовой цели. Для этого базовый оптимизатор может превратить обученный алгоритм в меса-оптимизатор, в это случае меса-оптимизатор сам выполняет алгоритм оптимизации, основываясь на своей собственной меса-цели. В любом случае, именно обученный алгоритм напрямую совершает действия, основываясь на своём вводе.
Возможное недопонимание: «меса-оптимизатор» не значит «подсистема» или «субагент». В контексте глубинного обучения меса-оптимизатор – это нейросеть, выполняющая некий процесс оптимизации, не какой-то образовавшийся субагент внутри этой нейросети. Меса-оптимизаторы – конкретный тип алгоритмов, которые может выбрать базовый оптимизатор для решения своей задачи. Также, базовый оптимизатор – алгоритм оптимизации, а не интеллектуальный агент, решивший создать субагента.4
Мы различаем меса-цель и связанное понятие поведенческой цели. Неформально можно сказать, что это то, что оптимизируется поведением системы. Можно определить её как цель, восстановленную идеальным обратным обучением с подкреплением (IRL).5 Это не то же самое, что меса-цель, которую активно использует меса-оптимизатор в своём алгоритме оптимизации.
Можно посчитать, что любая возможная система имеет поведенческую цель – включая кирпичи и крышки бутылок. Однако, для не-оптимизаторов подходящая поведенческая цель может быть просто «1, если это действие, которое на самом деле совершает система, иначе 0».6 Знать, что система действует, оптимизируя такую цель – и не интересно, и бесполезно. В примеру, поведенческая цель, «оптимизированная» крышкой бутылки – вести себя как крышка бутылки.7 А вот если система – оптимизатор, то она вероятно будет иметь осмысленную поведенческую цель. Так что в той степени, в которой вывод меса-оптимизатора систематически отбирается для оптимизации его меса-цели, его поведение может выглядеть как последовательные попытки повлиять на мир в конкретном направлении.8
Меса-цель конкретного меса-оптимизатора полностью определяется его внутренней работой. По окончании обучения и выбору обученного алгоритма, его прямой вывод – например, действия, предпринимаемые RL-агентом – больше не зависят от базовой цели. Так что поведенческая цель меса-оптимизатора определяется его меса-целью, а не базовой. Конечно, в той степени, в которой обученный алгоритм был отобран на основе базовой цели, его вывод будет хорошо под неё подходить. Однако, в случае сдвига распределения входных данных стоит ожидать, что поведение меса-оптимизатора будет устойчивее оптимизировать меса-цель, поскольку вычисление его поведения напрямую соответствует ей.
Как пример для иллюстрации различия базового/меса в другой области и возможность несогласованности базовой и меса- целей, рассмотрим биологическую эволюцию. В первом приближении, эволюция отбирает организмы соответственно целевой функции их совокупной генетической приспособленности в их окружении.9 Большинство этих биологических организмов – к примеру, растения – не «пытаются» ничего достичь, а просто исполняют эвристики, заранее выбранные эволюцией. Однако, некоторые организмы, такие как люди, обладают поведением, которое не состоит лишь из таких эвристик, а вместо этого является результатом целенаправленных оптимизационных алгоритмов, исполняемых в мозгах таких организмов. Поэтому эти организмы могут демонстрировать совершенно новое с точки зрения эволюционного процесса поведение, вроде людей, создающих компьютеры.
Однако, люди не склонны присваивать явную ценность цели эволюции – по крайней мере в терминах заботы о частоте своих аллелей в популяции. Целевая функция, хранящаяся в мозгу человека не та же, что целевая функция эволюции. Так что, когда люди проявляют новое поведение, оптимизированное для их собственных целей, они могут очень плохо выполнять цель эволюции. Один из возможных примеров – принятие решения не иметь детей. Таким образом, мы можем думать о эволюции как о базовом оптимизаторе, который создал мозги – меса-оптимизаторы, которые создают поведение организмов, не обязательно согласованное с эволюцией.
1.2. Задачи внутреннего и внешнего согласования
В «Масштабируемом согласовании агентов с помощью моделирования наград» Лейке и пр. описали концепт «расхождение награда-результат» как разницу между (в их случае обученной) «модели награждения» (то, что мы называем базовой целью) и «функции вознаграждения, восстановленной идеальным обратным обучением с подкреплением» (то, что мы называем поведенческой целью).(8) Проще говоря, может быть разница между тем, что обученный алгоритм делает и тем, что программисты хотят, чтобы он делал.
Проблема несогласованных меса-оптимизаторов – разновидность расхождения награда-результат. Конкретнее, это расхождение между базовой и меса- целями (которое затем приводит к расхождению базовой и поведенческой целей). Мы назовём задачу устранения этого расхождения задачей внутреннего согласования, в противовес задаче внешнего согласования – устранения расхождения базовой цели с намерениями программистов. Эта терминология обусловлена тем, что задача внутреннего согласования проявляется внутри системы машинного обучения, тогда как задача внешнего согласования – между системой и людьми. В контексте машинного обучения внешнее согласование – это приведение функции оценки в соответствие поставленной цели, а внутреннее согласование – это приведение меса-цели меса-оптимизатора в соответствие с функцией оценки.
Может быть, что решение внутреннего согласования не обязательно для создания безопасных мощных ИИ-систем, так как может оказаться возможным предотвратить появление меса-оптимизаторов. Если же меса-оптимизаторов нельзя надёжно избежать, то для уверенности в том, что меса-оптимизаторы согласованы с намерениями программистов, необходимы будут какие-нибудь решения и задачи внешнего, и задачи внутреннего согласования.
1.3. Устойчивая согласованность и псевдо-согласованность
При достаточном обучении меса-оптимизатор должен однажды стать способен производить вывод, высокооцениваемый базовой целью на обучающем распределении. Однако, вне него – и даже внутри на ранних этапах процесса обучения – могут быть сколь угодно большие различия. Мы будем называть устойчиво согласованными меса-оптимизаторы с меса-целями, устойчиво совпадающими с базовыми целями в разных распределениях, и псевдо-согласованными меса-оптимизаторы с меса-целями, совпадающими с базовыми целями на прошлых обучающих данных, но не совпадающими устойчиво на возможных будущих данных (при тестировании, разворачивании или дальнейшем обучении). Для псевдо-согласованного меса-оптимизатора существуют окружения, в которых базовые и меса- цели расходятся. Псевдо-согласованность, таким образом, представляет потенциально опасную проблему, поскольку открывает возможность того, что вне своего обучающего распределения система машинного обучения будет компетентно предпринимать действия для достижения чего-то, что не является её предполагаемой целью. То есть, может случиться так, что её способности обобщились, а цели – нет.
Как игрушечный пример того, как может выглядеть псевдо-согласованность, рассмотрим RL-агента, обученного задаче находить путь в лабиринте, все двери в котором при обучении оказались красными. Пусть базовая цель (функция вознаграждения) будет Obase = {1, если достиг двери, иначе 0}. На обучающем распределении это цель эквивалентна Oalt = {1, если достиг чего-то красного, иначе 0}. Представим, что произойдёт, если агент, обученный высоким результатам по Obase будет помещён в окружение, где двери синие, а какие-то другие объекты – красные. Он может обобщить Obase, надёжно находя путь к синей двери (устойчивая согласованность). Но он также может обобщить Oalt вместо Obase, надёжно находя путь к красным объектам (псевдо-согласованность).10
1.4. Меса-оптимизация как проблема безопасности
Если, как мы предположили, в продвинутых системах машинного обучения могут возникнуть меса-оптимизаторы, то из этого вытекает две критических проблемы безопасности.
Ненамеренная оптимизация. Во-первых, возможность возникновения меса-оптимизаторов означает, что продвинутая система машинного обучения может выполнять мощную процедуру оптимизации при том, что её программисты никогда он неё этого не хотели. Это может быть опасным, если такая оптимизация приводит к тому, что система совершает внешние действия за пределами предполагаемого поведения в попытке максимизировать свою меса-цель. Особое беспокойство вызывают оптимизаторы, чьи целевые функции и процедуры оптимизации обобщаются на реальный мир. При этом условия, приводящие к нахождению обучающим алгоритмом меса-оптимизаторов, очень слабо изучены. Их знание позволило бы нам предсказывать случаи, в которых меса-оптимизация более вероятна, и предпринимать меры против её появления. Во втором посте мы рассмотрим некоторые свойства алгоритмов машинного обучения, которые могут влиять на вероятность нахождения меса-оптимизаторов.
Внутреннее согласование. Во-вторых, даже в случаях, когда нахождение базовым оптимизатором меса-оптимизатора приемлемо, меса-оптимизатор может оптимизировать что-то не являющееся заданной функцией вознаграждения. В таком случае он может приводить к плохому поведению даже если известно, что оптимизация корректной функции вознаграждения безопасна. Это может произойти либо во время обучения – до момента, когда меса-оптимизатор станет согласованным по обучающему распределению – или во время тестирования или развёртки, когда система действует снаружи обучающего распределения. В третьем посте мы затронем некоторые случаи того, как может быть выбран меса-оптимизатор, оптимизирующий не заданную функцию вознаграждения, и то, какие свойства систем машинного обучения этому способствуют. В четвёртом посте мы обсудим возможные крайние случаи провала внутреннего согласования – которое, по нашему мнению, является источником некоторых из самых опасных рисков в этой области – когда достаточно способный меса-оптимизатор может научиться вести себя так, будто он согласован, не будучи на самом деле устойчиво согласованным. Мы будем называть эту ситуацию обманчивой согласованностью.
Может оказаться, что проблема псевдосогласованных меса-оптимизаторов решается легко – если существует надёжный метод их согласования, или предотвращения нахождения их базовыми оптимизаторами. Однако, может оказаться и так, что решить её очень сложно – пока что мы недостаточно хорошо её понимаем, чтобы знать точно. Конечно, нынешние системы машинного обучения не приводят к появлению опасных меса-оптимизаторов, но будет ли это так же с будущими системами – неизвестно. Эта неизвестность убеждает нас в том, что важно проанализировать эту проблему.
- 1. Как конкретный пример нейросетевого оптимизатора можно рассмотреть TreeQN.(2) По описанию Фаркухара и пр. TreeQN – агент Q-обучения, выполняющий основанное на модели планирование (поиском по дереву отображающему состояния окружения) как часть своего вычисления Q-функции. Хоть их агент и должен быть оптимизатором по задумке, можно представить, как похожему алгоритму может научиться DQN-агент с достаточно выразительным аппроксиматором Q-функции. Универсальные Планирующие Сети, описанные Сринивасом и пр.(3) предоставляют другой пример обученной системы, выполняющей оптимизацию, пусть эта оптимизация и встроена в виде стохастического градиентного спуска с помощью автоматического дифференцирования. Такие исследования как Андриковица и пр.(4) и Дуана и пр.(5) демонстрируют, что алгоритмы оптимизации могут быть выучены рекуррентными нейронными сетями, так что агент похожий на Универсальные Планирующие Сети может – при условии очень выразительного пространства моделей – быть обученным целиком, включая внутреннюю оптимизацию. Заметим, что хоть эти примеры и взяты из обучения с подкреплением, оптимизация в принципе может возникнуть в любой достаточно выразительной система обучения.
- 2. Предыдущие работы в этой области часто сосредотачивались на концепте «оптимизационных даймонов», (6) мы считаем, что это потенциально заблуждающий подход, и надеемся его заменить. Отметим, что термин «оптимизационные даймоны» произошёл из дискуссий касательно природу людей и эволюции, так что стал нести антропоморфические коннотации.
- 3. «Меса» предложено как противоположность «мета».(7) Дуальность исходит из рассмотрения мета-оптимизации как лежащей на уровень выше базового оптимизатора, а меса-оптимизации – на уровень ниже.
- 4. Хотя некоторые наши соображения применимы и к этому.
- 5. Лейке и пр.(8) представили концепт цели, восстановленной из идеального IRL.
- 6. Для формального построения цели см. стр. 6 в Лейке и пр.(8)
- 7. Эта цель по определению тривиально оптимальна в любой ситуации, в которой может оказаться крышка.
- 8. Наше основное беспокойство касается оптимизации в направлении некой последовательной но небезопасной цели. В этой цепочки мы предполагаем, что поиск предоставляет достаточную структуру для ожидания последовательных целей. Хоть мы и считаем это разумным предположением, необходимость и достаточность поиска неясны. Скорее всего для прояснения потребуется дальшейшая работа.
- 9. Ситуация с эволюцией более сложна, чем представлено тут, и мы не ожидаем, что наша аналогия переживёт тщательный разбор. Пре представляем её именно как выразительную аналогию (и, в некоторой степени, доказательство существования), объясняющую ключевые концепты. Более аккуратные аргументы будут представлены позже.
- 10. Конечно, он может и вовсе не обобщиться.
Условия меса-оптимизации
В этом посте мы рассмотрим, как на вероятность того, что обучающая система создаст меса-оптимизатор, влияют два её компонента:
- Задача: Обучающее распределение и базовая целевая функция.
- Базовый оптимизатор: Алгоритм машинного обучения и архитектура модели.
Мы намеренно выбрали представить теоретические соображения о том, почему меса-оптимизаторы могут возникнуть или не возникнуть, а не конкретные примеры. Меса-оптимизация – это явление, которое, по нашему убеждению, в основном будет происходить в более продвинутых, чем нынешние, системах машинного обучения.1 Попытка вызвать меса-оптимизацию в нынешней системе машинного обучения скорее всего потребует использования специально спроектированных для этого настроек. Более того, ограниченная интерпретируемость нейросетей, вместе с отсутствием общего и точного определения «оптимизатора», означает, что оценить, является ли данная модель меса-оптимизатором, было бы сложно.
2.1. Задача
Некоторые задачи получают большую выгоду от меса-оптимизации, чем другие. К примеру, крестики-нолики идеально решаются простыми правилами. Так что базовому оптимизатору нет нужны генерировать меса-оптимизатор для решения крестиков-ноликов, поскольку для этого достаточно простого обученного алгоритма, усвоившего правила идеальной игры. Выживание человека в саванне, напротив, кажется получающим большую выгоду от меса-оптимизации. Ниже мы обсудим свойства задач, влияющие на вероятность меса-оптимизации.
Лучшее обобщение через поиск. Мы выдвигаем следующую гипотезу: «Чтобы найти способ стабильно справляться с задачей в окружении на некотором уровне качества, необходимо некоторое минимальное количество силы оптимизации.»
Силу оптимизации можно измерять количеством делений пополам пространства поиска – количеством бит информации, которое он предоставляет.(9) После этих делений останется некоторое пространство вариантов, которые оптимизатор не различает. Чтобы удостовериться, что все варианты в оставшемся пространстве имеют некоторый минимальный уровень качества (чтобы предоставить нижнюю границу2) всегда потребуется разделить изначальное пространство некоторое минимальное количество раз, то есть потребуется применить некоторое минимальное количество бит оптимизационной силы.
Однако, расходоваться сила оптимизации может на двух отдельных уровнях: базовый оптимизатор может выбирать более тонко настроенный обученный алгоритм, или сам обученный алгоритм может выбирать более тонко настроенные действия.
Так как меса-оптимизатор – это просто обученный алгоритм, сам выполняющие оптимизацию, стимул к его появлению в системе машинного обучения скорее всего зависит от того, какой из этих двух уровней выгоднее для оптимизации. Во многих нынешних моделях машинного обучения, где мы тратим куда больше вычислительных ресурсов на обучение модели, чем на её работу, кажется, что в целом большая часть оптимизационной работы будет выполнена базовым оптимизатором, а итоговый обученный алгоритм будет просто сетью тонко настроенных эвристик, а не меса-оптимизатором.
Однако, мы уже наткнулись на некоторые задачи – к примеру, го, шахматы и сёги – на которые не переносится такой подход. В самом деле, наши лучшие нынешние алгоритмы для этих задач включают явное создание оптимизатора (напрямую вложенного дерева поиска Монте-Карло с обученными эвристиками), который выполняет оптимизационную работу на уровне обученного алгоритма, а не базового оптимизатора.(10) Можно посчитать, что задачи такого вида адекватно решаются только так – если бы возможно было обучить простого DQN-агента хорошо играть в шахматы, ты правдоподобно предположить, что ему бы пришлось научиться выполнять внутри себя что-то вроде поиска по дереву, т.е. он был бы меса-оптимизатором.3
Мы предполагаем, что привлекательность поиска в таких областях вызвана разнообразной, ветвящейся природой окружения. Поиск – то есть оптимизация – склонен хорошо обобщаться по разным окружениям, так как может отдельно выбрать лучшее действие для каждого случая задачи. Оптимизационная работа на уровне базового оптимизатора и на уровне обученного алгоритма в целом различаются так: что обученный алгоритм должен определить лучшее действие для данного случая задачи, а базовый оптимизатор должен спроектировать эвристики, которые будут применимы независимо от конкретного случая. Более того, меса-оптимизатор может немедленно оптимизировать свои действия в новых ситуациях, тогда как базовый оптимизатор может изменить работу меса-оптимизатора лишь постфактум. Поэтому в окружениях, достаточно разнообразных, чтобы большая часть случаев задачи вероятно оказывалась совершенно новыми, поиск позволяет меса-оптимизатору подстраиваться под эти новые случаи немедленно.
К примеру, рассмотрим обучение с подкреплением в разнообразном окружении, вроде включающего прямое взаимодействие с реальным миром. Оно требует очень большого количества вычислений для определения хороших способов действовать до узнавания конкретики индивидуального случая, но куда меньшего – после. Дальше мы опишем, как можно смоделировать это наблюдение.
Предположим, окружение состоит из $N$ разных случаев, каждый из которых требует совершенно отдельный план действий для успеха.4 Пусть $P$ – сила оптимизации (измеряемая в битах(9)), используемая базовым оптимизатором, она должна быть приблизительно пропорциональна количеству шагов обучения. Пусть $x$ – сила оптимизации, применяемая обученным алгоритмом в каждом конкретном случае, а $f(x)$ – сила оптимизации, которую необходимая базовому оптимизатору для того, чтобы обученный алгоритм стал способен применить оптимизацию $x$.5 Предположим, что остаток оптимизационной силы базового оптимизатора, $P – f(x)$, будет использован для настройки действий обученного алгоритма. Раз базовому оптимизатору придётся распределить настройку по всем $N$ случаям задачи, то на каждый придётся по $\frac{P – f(x)}{N}$, согласно предыдущему предположению о полном различии случаев. А обученный алгоритм выполняет всю свою оптимизацию для конкретного случая задачи, так что его вклад – это просто $x$.6
Таким образом, если для данного $P$ базовый оптимизатор выбирает значение $x$, максимизирующее минимальное качество выполнения задачи – то есть полную силу оптимизации, применяемую к каждому случаю, то мы получим7
$$x^* = argmax_x \frac{P – f(x)}{N} + x$$
Из этой модели следует, что при переходе к всё более разнообразным окружениям (то есть при росте $N$) $x$ станет доминировать над $\frac{P – f(x)}{N}$, значит меса-оптимизация будет всё более и более предпочитаемой. Конечно, это просто игрушечная модель, и она делает много сомнительных предположений. Всё же, она обрисовывает довод в пользу возникновения меса-оптимизации в достаточно разнообразных окружениях.
Как иллюстрирующий пример, рассмотрим биологическую эволюцию. Окружение реального мира очень разнообразно, из-за чего не-оптимизационным стратегиям, напрямую настроенным эволюцией – как, например, у растений – приходится быть очень простыми, так как эволюции приходится распределять свою силу оптимизации по очень широкому диапазону возможных обстоятельств. С другой стороны, животные с нервной системой могут демонстрировать значительно более сложные стратегии благодаря возможности выполнять свою собственную оптимизацию, основанную на актуальной информации из своего окружения. Это позволяет достаточно развитым меса-оптимизаторам, вроде людей, невероятно превосходить другие виды, особенно в новых обстоятельствах. Внутренняя оптимизация людей позволяет им находить хорошие стратегии даже в совершенно новых условиях.
Сжатие сложных стратегий. В некоторых задачах для хороших результатов необходимы очень сложные стратегии. В то же время, базовые оптимизаторы в целом склонны выбирать обученные алгоритмы меньшей сложности. Так что, при прочих равных, базовый оптимизатор имеет стимул искать сильно сжатые стратегии.
Один из способов найти сжатую стратегию – искать ту, которая способна использовать общие черты структуры задачи для выдачи хорошего поведения, а не просто запоминать правильные выводы для всех вводов. Меса-оптимизатор – пример такой стратегии. С точки зрения базового оптимизатора, меса-оптимизатор – это сильно сжатая версия стратегии, которой он придерживается: вместо явного кодирования её деталей в обученный алгоритм, базовый оптимизатор просто должен закодировать способность поиска. Более того, если меса-оптимизатор может определить важные черты своего окружения во время выполнения, то ему понадобится меньше информации о них заранее, так что он сможет быть куда проще.
Этот эффект больше всего проявляется в задачах с большим разнообразием деталей, но общими высокоуровневыми чертами. К примеру, го, шахматы и сёги имеют очень большие пространства возможных состояний доски, но простая высокоуровневая стратегия игры – направляемый эвристиками поиск по дереву – хорошо работает для всех этих состояний.(10) С другой стороны, классификатор, обученный на случайном шуме навряд ли получит хоть какую-то выгоду от сжатия.
Окружению не обязательно быть очень разнообразным для проявления этого эффекта, если давление в пользу короткой длины алгоритма достаточно сильно. Как простой иллюстрирующий пример можно взять следующую задачу: обученный алгоритм должен выводить путь от начала до конца некоего лабиринта. Если лабиринт достаточно большой и сложный, то конкретная стратегия для решения именно этого лабиринта – указывающая каждый отдельный шаг – будет иметь большую длину описания. Однако, длина описания общего оптимизационного алгоритма для нахождения пути через произвольный лабиринт довольно мала. Следовательно, если базовый оптимизатор выбирает программы с маленькой длиной описания, то он может найти меса-оптимизатор, который может решить любой лабиринт, несмотря на то, что обучающее окружение содержит только один.
Ограничение задачи. Из наблюдения, что разнообразные окружения увеличивают вероятность меса-оптимизации, можно предположить, что уменьшить эту вероятность можно придерживаясь задач, в которых обучение ИИ-системы будет сильно ограниченным. Способом этого достичь, оставляя сравнимую с другими подходами эффективность, может быть, например, создание многих отдельных ИИ-сервисов, которые вместе могут предоставить все способности обобщённо-интеллектуальной системы вместо создание самой такой системы (СИИ). (11)
Моделирование людей. Иной аспект задачи, который может влиять на вероятность меса-оптимизации – это присутствие в окружении людей.(12) Поскольку люди зачастую действуют как оптимизаторы, рассуждения о людях вероятно будут включать в себя рассуждения об оптимизации. Система, способная рассуждать об оптимизации, вероятно также способна переиспользовать те же механизмы, чтобы оптимизировать самой, и, в результате, она становится меса-оптимизатором. К примеру, может оказаться, что предсказание поведения людей требует выполнения процесса, похожего на человеческое мышление, вместе с внутренними мотивами совершить тот или иной выбор.
Так что задачи, не получающие выгоды от моделирования людей, кажутся менее склонными к появлению меса-оптимизаторов, чем получающие. Стоит учитывать, что многие задачи, не включающие моделирование людей явно, всё же могут получить эту выгоду – например, если обучающее распределение создано людьми, то моделирование людей может предоставить очень хорошие априорные суждения про это распределение.
2.2. Базовый оптимизатор
Вероятно, некоторые черты базового оптимизатора влияют на вероятность появления меса-оптимизатора. Во-первых, хоть мы в этой цепочке и сосредоточены в основном на обучении с подкреплением, это не единственный тип машинного обучения, в котором они могут возникнуть. К примеру, кажется правдоподобным, что меса-оптимизаторы могут появиться в генеративно-состязательных сетях.
Во-вторых, мы предполагаем, что детали архитектуры обученной модели оказывают значительный эффект на её склонность к меса-оптимизации. К примеру, табличная модель, независимо обучающаяся корректному выводу для каждого ввода, никогда не будет меса-оптимизатором. С другой стороны, если гипотетический базовый оптимизатор ищет решающую задачу программу с кратчайшим исходным кодом, то весьма правдоподобно, что она сама будет оптимизатором.(13) Однако, для реалистичных базовых оптимизаторов машинного обучения не так ясно, в какой степени они склонны выбирать меса-оптимизаторы. Ниже мы обсудим некоторые факторы, которые могут в ту или иную стороны на это повлиять.
Доступность. Есть много оптимизационных алгоритмов, которые может выполнять базовый оптимизатор. Однако, почти все ныне используемые стратегии машинного обучения используют какую-нибудь разновидность локального поиска (как градиентный спуск или генетические алгоритмы). Поэтому кажется правдоподобным, что более продвинутые системы машинного обучения тоже будут подпадать под эту категорию. Мы будем называть этот общий класс оптимизаторов, основанных на локальном «взбирании-на-холм» локальными оптимизационными процессами.
Мы можем затем сформулировать понятие доступности – того, насколько сложно базовому оптимизатору найти данный обученный алгоритм – и анализировать её в случае локальных оптимизационных процессов. У них может не получиться найти конкретный обученный алгоритм, очень хорошо справляющийся с базовой целью, если он окружён другими алгоритмами, справляющимися плохо. Для возникновения меса-оптимизатора в локальном оптимизационном процессе, он должен не просто хорошо справляться с базовой целью, но и быть доступным, то есть, к нему должен быть путь через пространство обученных алгоритмов с приблизительно монотонно возрастающей оценкой качества работы. Степень, в которой монотонность должна быть лишь приблизительной – в которой обучающие процедуры могут покидать локальный оптимум – может быть критичной, так как достаточно сложные оптимизационные алгоритмы могут требовать присутствия довольно значительной части себя для демонстрации хоть какой-то работы.
Алгоритмический диапазон. Один из ключевых факторов, определяющих доступность меса-оптимизаторов – это алгоритмический диапазон – то, насколько широк набор алгоритмов (или насколько выразительно пространство моделей), которые может найти базовый оптимизатор. Чем диапазон шире, чем больше пространство, тем вероятнее, что в нём можно будет достигнуть меса-оптимизатора, предполагая, что базовый оптимизатор мотивирован это сделать. К примеру, архитектуры, которые явно дают алгоритму доступ к многим возможным вычислениям – как рекуррентные нейронные сети или нейронные машины Тьюринга,(14) кажутся более склонными к появлению меса-оптимизаторов.
Индуктивные склонности. Другой важный фактор – в какой степени базовый оптимизатор явно или неявно склоняется в какую-то сторону. Природа этих индуктивных склонностей влияет на вероятность отбора меса-оптимизатора. Одна из самых важных возможных склонностей – к простоте, она будет почти наверняка присуща почти всем базовым оптимизаторам. Перечислим три способа, которыми она может выражаться:
- Явные штрафы через регуляризацию параметров или архитектурные ограничения вроде разделения весов или редких связей.
- Неявная склонность из-за архитектуры модели. К примеру, показано, что нейросети более вероятно подгоняют под обучающие данные простую функцию, даже при отсутствии регуляризаций.(15)
- Ограничения вместимости модели. Размер модели накладывает жёсткий предел сложности функций, которые в ней могут быть представлены. Таким образом, поскольку базовый оптимизатор будет выбирать по качеству работы, постольку он будет стимулирован «ужимать» как можно больше в данную вместимость модели и предпочитать более сжатые стратегии.
Чем больше базовый оптимизатор склоняется к простым решениям, тем больше он стимулирован найти сжатые стратегии вроде меса-оптимизатора.
Базовый оптимизатор может иметь и другие склонности. Например – в сторону алгоритмов с меньшим временем работы или меньшей занимаемой памятью. Если мы рассматриваем меса-оптимизацию как делегирование оптимизационной работы, то штраф за время работы обученного алгоритма скорее всего стимулирует базовый оптимизатор к большим собственным вычислениям и к составлению заранее вычисленных эвристик вместо делегирования оптимизации обученному алгоритму. Таким образом, мы предполагаем, что штраф на длину описания делает меса-оптимизаторы более вероятными, а штраф на временную сложность – менее. Из этого можно вывести следующее умозрительное предположение: ни наименее глубокая, ни просто наименьшая решающая задачу логическая схема не может быть меса-оптимизатором.(16)
Наконец, ещё одна склонность, которая может оказывать особенно интересные эффекты – это наличие информационной воронки. В глубинном обучении базовый оптимизатор напрямую выбирает значения отдельных параметров. В биологической эволюции, напротив, базовый оптимизатор выбирает строки ДНК, которые и сами не напрямую приводят к детальной структуре мозга. Это подразумевает давление в сторону сжатия структуры мозга. Как мы замечали раньше, это может приводить к предпочтениям в пользу меса-оптимизаторов, поскольку их можно рассматривать как способ сжатия сложных стратегий. Поскольку нынешние алгоритмы глубинного обучения выбирают веса напрямую, в них нет такой воронки информации. В случае архитектуры с мета-обучением поверх машинного обучения, однако, она может наличествовать из-за того, что мета-обучение должно привести к единой стратегии для создания архитектур, способных решать все представленные задачи.
Наличие состояний. Ещё один фактор, который может упростить для обученного алгоритма выполнение сложных оптимизационных процессов – это наличие у него способности сохранять и вспоминать информацию. Способность обращаться к предыдущим состояниям позволяет кэшировать промежуточные результаты, увеличивает диапазон доступных архитектуре алгоритмов, давая обученному алгоритму значительно больше времени на завершение своих вычислений. Поэтому наличие состояний склоняет в сторону меса-оптимизаторов, уменьшая неявные штрафы за время работы, вытекающие из необходимости закончить все вычисления к моменту, когда обученный алгоритм производит вывод. Простая форма этого – рекуррентная нейронная сеть, которая может производить вычисления на больших промежутках времени благодаря способности передавать активации на следующие шаги. Более выраженной версией была бы нейросеть, способная сохранять состояние не просто между разными шагами одного эпизода, но между разными эпизодами, что дало бы ей доступ к более длительному обучению, хотя такая архитектура пока что существует лишь гипотетически.
Жёстко закодированная оптимизация. Один из возможных способов смягчить некоторые из этих факторов – жёстко закодированная оптимизация, при наличии которой обученный алгоритм должен предоставить только целевую функцию, а не алгоритм оптимизации. Чем сильнее явно выполняемая оптимизация, тем меньше её необходимо выполнять обученному алгоритму неявно. Архитектуры, явно выполняющие относящуюся к задаче оптимизацию – вроде жёстко закодированного поиска по дереву Монте Карло – могут снизить преимущества меса-оптимизаторов, уменьшив нужду в иной оптимизации, кроме запрограммированной в системе явно.
- 1. На момент этого поста. Отметим, что мы рассматриваем некоторые существующие системы, которые, по нашему мнению, близки к созданию меса-оптимизаторов в пятом посте.
- 2. Стоит заметить, что тот же аргумент применим и для гарантии среднего случая.
- 3. Предполагая осмысленные ограничения вычислительной мощности.
- 4. Это определение N несколько размыто, разбивать на случаи можно на разных уровнях. К примеру, одно окружение может иметь всегда одинаковые высокоуровневые черты, но совершенно случайные низкоуровневые, а другое – две категории случаев, похожих внутри одной, но очень различающихся между ними, в таком случае не вполне ясно, у какого больше N. Однако, можно просто посчитать N неизменным для всех уровней кроме одного и рассматривать изменение разнообразия окружения на этом одном уровне.
- 5. Заметим, что тут есть неявное предположение, что оптимизационная сила, необходимая для нахождения меса-оптимизатора, способного выполнить x бит оптимизации, независима от N. Обоснованием для этого служит то, что оптимизация – это обобщённый алгоритм, одинаковый в разных окружениях, так что оптимизационная сила для нахождения x-битового оптимизатора должна слабо зависеть от окружения. Она не будет полностью независима, но пока окружения различаются тем, сколько для них необходимо оптимизации, а не тем, насколько тяжело её в них проводить, модель должна оставаться применимой.
- 6. Заметим, однако, что x ограничен сверху, поскольку обученный алгоритм имеет доступ к ограниченной вычислительной мощности.
- 7. С ограничением, что $P − f(x) \ge 0$.
Задача внутреннего согласования
В этом посте мы обрисуем причины считать, что меса-оптимизатор может оптимизировать не ту же целевую функцию, что и его базовый оптимизатор. Машинное обучение даёт контроль над базовой целевой функцией – либо прямым определением функции вознаграждения, либо обучением её модели – но не даёт возможности напрямую определить выработанную меса-оптимизатором меса-цель. Мы называем эту задачу согласования меса-оптимизаторов с базовыми целями задачей внутреннего согласования. Она отделена от задачи внешнего согласования – удостовериться, что базовая цель соответствует намерениям программистов.
Нынешние методы машинного обучения отбирают обученные алгоритмы эмпирически оценивая их работу на наборе обучающих данных согласно базовой целевой функции. Таким образом базовые оптимизаторы отбирают меса-оптимизаторы по их выводам, а не напрямую по меса-целям. Более того, стратегия отобранного меса-оптимизатора должна хорошо работать (по оценке базовой цели) лишь на обучающих данных.Если мы примем предположение, что меса-оптимизатор вычисляет оптимальную стратегию для своей целевой функции, то мы можем описать отношение между базовой и меса- целями следующим образом(17):
$$
\begin{split}
\theta^* = argmax_\theta \space\mathbb{E}(O_{base}(\pi_\theta)),\space где \
\pi_\theta = argmax_\pi\space\mathbb{E}(O_{mesa}(\pi|\theta))
\end{split}
$$
То есть, базовый оптимизатор максимизирует свою цель $O_{base}$, выбирая меса-оптимизатор с параметрами $Θ$, основываясь на его стратегии $\pi_\theta$, но не на целевой функции $O_{mesa}$, которую меса-оптимизатор использует для вычисления своей стратегии. В зависимости от базового оптимизатора, мы можем думать о $O_{base}$ как об отрицательных потерях, будущей награде, или просто некой функции приспособленности, по которой отбираются обученные алгоритмы.
Ибарз и пр. представили интересный подход анализа этой связи, где эмпирические данные по награде и выученная награда на тех же ситуациях используются для визуализации их согласованности в виде точечной диаграммы.(18) В этой работе используется предположение, что монотонное отношение между выученной и реальной наградой означает согласованность, а отклонения от него – несогласованность. Такого рода исследования теоретических метрик согласованности может когда-нибудь позволить нам рассуждать конкретно и с доказуемыми гарантиями того, в какой степени меса-оптимизатор согласован с создавшим его базовым оптимизатором.
3.1. Псевдо-согласованность
Пока не существует полной теории того, какие факторы влияют на то, будет ли меса-оптимизатор псевдо-согласованным – окажется ли, что он выглядит согласованным на обучающих данных, в то время как на самом деле оптимизирует что-то, не являющееся его базовой целью. В любом случае, мы обрисуем основную классификацию способов, которыми меса-оптимизатор может быть псевдо-согласован:
- Прокси-согласованность,
- Приблизительная согласованность, и
- Субоптимальная согласованность.
Прокси-согласованность. Основная идея прокси-согласованности в том, что меса-оптимизатор может научиться оптимизировать что-то сцепленное с базовой целью вместо неё самой. Мы начнём с рассмотрения двух специальных случаев прокси-согласованности: побочная согласованность и инструментальная согласованность.
Во-первых, меса-оптимизатор побочно-согласован, если оптимизация меса-цели $O_{mesa}$ напрямую ведёт к базовой цели $O_{base}$ в обучающем распределении, и потому, когда он оптимизирует $O_{mesa}$, это приводит к $O_{base}$. Как пример побочной согласованности, представим, что мы обучаем робота-уборщика. Пусть робот оптимизирует количество раз, которое он подмёл пыльный пол. Подметание приводит к тому, что пол становится чистым, так что робот будет получать хорошую оценку базового оптимизатора. Однако, если при развёртывании он получит способ опять загрязнить пол после уборки (например, рассыпав собранную пыль обратно), то робот им воспользуется, чтобы иметь возможность опять подмести пыльный пол.
Во-вторых, меса-оптимизатор инструментально согласован, если оптимизация базовой цели $O_{base}$ напрямую ведёт к меса-цели $O_{mesa}$ в обучающем распределении, и потому он инструментально оптимизирует $O_{base}$ на пути к $O_{mesa}$. Как пример инструментальной согласованности, опять представим, что мы обучаем робота-уборщика. Пусть робот оптимизирует количество пыли в пылесосе. Предположим, что в обучающем распределении простейший способ заполучить пыль в пылесос – это пропылесосить пол. Тогда он будет хорошо убираться в обучающем распределении, и получит хорошую оценку базового оптимизатора. Однако, если при развёртывании робот наткнётся на более эффективный способ получения пыли – например, направить пылесос на почву в горшке с растением – то он больше не будет исполнять желаемое поведение.
Мы предполагаем, что возможно понять общее взаимодействие побочной и инструментальной согласованности с помощью графа причинности, что ведёт нас к общему понятию прокси-согласованности.
Предположим, что мы моделируем задачу как граф причин и следствий, с вершинами для всех возможных свойств задачи и стрелками между вершинами для всех возможных отношений этих свойств. Тогда мы можем думать о меса-цели $O_{mesa}$ и базовой цели $O_{base}$ как о вершинах графа. Для псевдо-согласованности $O_{mesa}$ должна существовать некая вершина $X$, такая что она является общим предком $O_{mesa}$ и $O_{base}$ в обучающем распределении и обе $O_{mesa}$ и $O_{base}$ растут вместе с $X$. Если $X = O_{mesa}$, то это побочная согласованность, а если $X = O_{base}$, то инструментальная.
Это приводит к наиболее обобщённому отношению между $O_{mesa}$ и $O_{base}$, из которого может произойти псевдо-согласованность. Рассмотрим граф на рисунке 3.1. Меса-оптимизатор с меса-целью $O_{mesa}$ решит оптимизировать $X$ как способ для оптимизации $O_{mesa}$. Это приведёт у оптимизации и $O_{base}$ как побочному эффекту оптимизации $X$. Так что в общем случае побочная и инструментальная согласованности могут вместе вкладываться в псевдо-согласованность на обучающем распределении, что и есть общий случай прокси-согласованности.
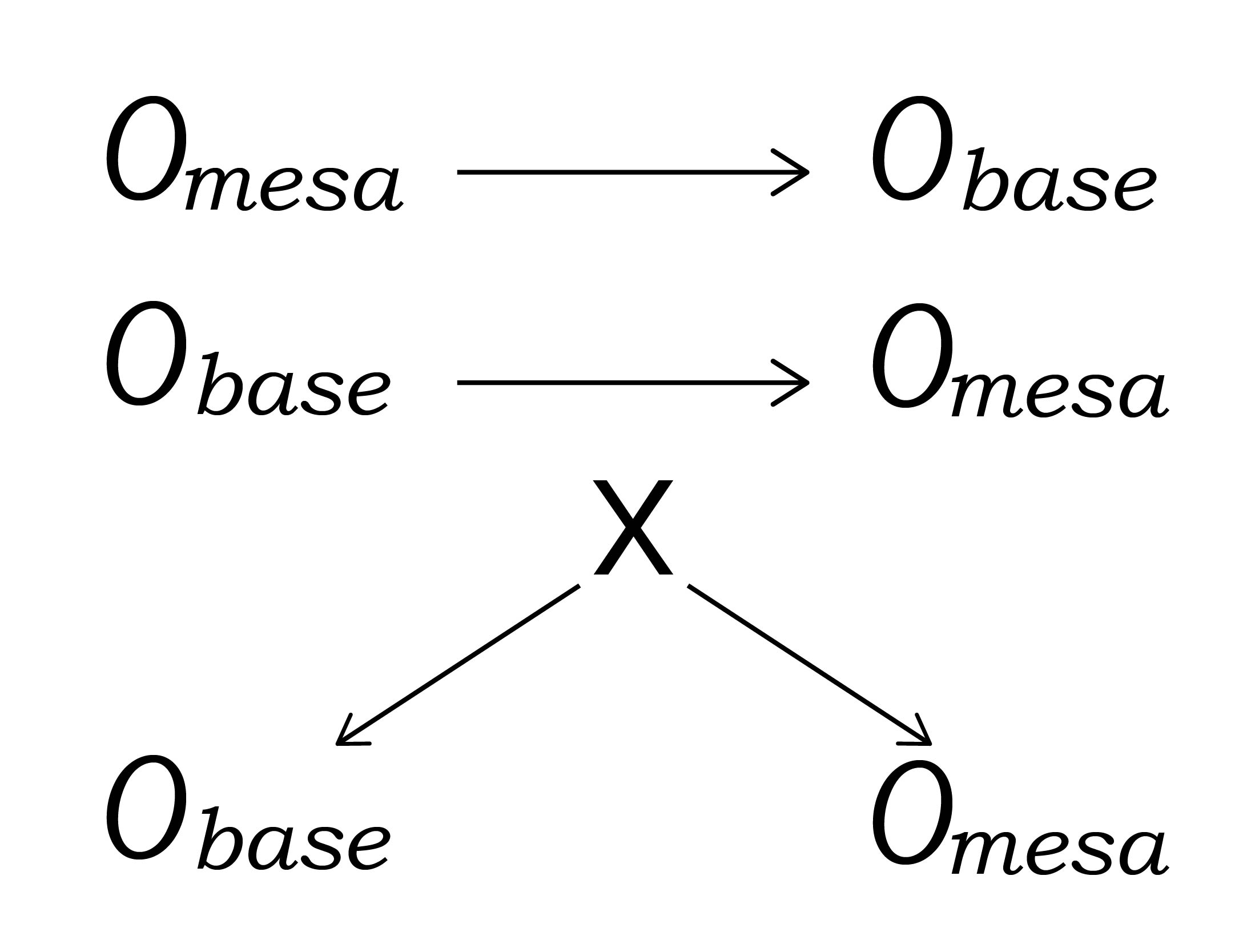
Рис. 3.1. Причинная схема обучающего окружения для разных видов прокси-согласованности. Сверху-вниз – побочная согласованность, инструментальная согласованность, общий случай прокси-согласованности. Стрелки отображают положительное отношение следствия – то есть, случаи, когда рост в узле-предке приводит к росту в узле-потомке.
Приблизительная согласованность. Меса-оптимизатор приблизительно согласован если меса-цель $O_{mesa}$ и базовая цель $O_{base}$ – это приблизительно одна и та же функция с некоторой погрешностью, связанной с тем фактом, что меса-цель должна быть представлена внутри меса-оптимизатора, а не напрямую запрограммирована людьми. К примеру, представим, что нейросети дана задача оптимизировать некую базовую цель, которую невозможно идеально представить внутри этой нейросети. Даже если получилось достигнуть предела возможной согласованности меса-оптимизатора, он всё ещё не будет устойчиво согласован, поскольку его внутреннее представление базовой цели лишь приближённо совпадает с ней самой.
Субоптимальная согласованность. Меса-оптимизатор субоптимально согласован, если некий недостаток, ошибка или ограничение его процесса оптимизации привело к тому, что он демонстрировал согласованное поведение на обучающем распределении. Это может произойти из-за ограничений вычислительной мощности, недостатка информации, иррациональных процедур принятия решений, или иного дефекта процесса рассуждений меса-оптимизатора. Важно отметить, что это не ситуация, в которой меса-оптимизатор устойчиво согласован, но всё же совершает ошибки, приводящие к плохим результатам согласно базовой цели. Субоптимальная согласованность – это ситуация, когда меса-оптимизатор несогласован, но всё же работает хорошо согласно базовой цели, в точности потому, что он был отобран по совершению ошибок, к этому приводящих.
Как пример субоптимальной согласованности представим робота-уборщика с меса-целью минимизировать общее количество существующих вещей. Если этот робот имеет ошибочное убеждение, что грязь, которую он убирает, полностью уничтожается, то он может быть полезным для уборки комнаты несмотря на то, что это на самом деле не помогает ему достичь своей цели. Этот робот будет восприниматься как хороший оптимизатор Obase и получит хорошую оценку базового оптимизатора. Однако, если при развёртывании робот сможет улучшить свою модель мира, то он перестанет демонстрировать желательное поведение.
Как другой, пожалуй, более реалистичный пример субоптимальной согласованности, представим меса-оптимизатор с меса-целью $O_{mesa}$ и окружение, в котором есть одна простая стратегия и одна сложная стратегия для достижения $O_{mesa}$. Может оказаться, что простая стратегия согласована с базовым оптимизатором, а сложная – нет. Меса-оптимизатор тогда может знать только о простой стратегии, и быть субоптимально согласованным, до тех пор, пока он не будет запущен на достаточно долгое время, чтобы обнаружить сложную стратегию. В этот момент он перестанет демонстрировать желательное поведение.
3.2. Задача
Как и во втором посте, мы сейчас рассмотрим задачу, поставленную системе машинного обучения. Конкретно, мы разберём, как задача влияет на склонность системы создавать псевдо-согласованные меса-оптимизаторы.
Неразличимость. Частая проблема в машинном обучении – набор данных не содержит достаточно информации, чтобы адекватно определить конкретное понятие. Это аналогично причине, по которой у моделей машинного обучения может не получиться обобщение, или по которой они уязвимы к злонамеренному вводу(19) – есть куда больше подходящих для обучения способов классифицировать данные, чем могут представить программисты. В контексте меса-оптимизации это проявляется так, что псевдо-согласованность куда более вероятна в случае, когда обучающее окружение не содержит достаточно информации для проведения различий в широком наборе целевых функций. В таком случае меса-оптимизатор может быть псевдо-согласован куда большим числом способов, чем устойчиво согласован – по одному для каждой целевой функции неотличимой от желаемой. Так что большая часть меса-оптимизаторов, хорошо оцениваемых согласно базовой цели будут псевдо-согласованы, а не устойчиво согласованы. Это критичное замечание, поскольку это усугубляет все остальные проблемы псевдо-согласованности – это причина, по которой в целом сложно найти устойчиво согласованные меса-оптимизаторы. Неразличимость в меса-оптимизации частично аналогична проблеме неразличимости в обучении с подкреплением(20), мы рассмотрим это подробнее в пятом посте.
В контексте меса-оптимизации есть дополнительный источник неразличимости, вытекающий из того, что меса-оптимизатор выбирается на основании лишь своего вывода. Рассмотрим игрушечный пример обучения с подкреплением. Пусть в обучающем окружении нажатие кнопки всегда приводит к зажиганию лампы с десятисекундной задержкой, и нет других способов включить лампу. Если базовая цель зависит только от того, что лампа включена, то меса-оптимизатор, максимизирующий нажатия на кнопку и меса-оптимизатор, максимизирующий горение лампы, будут демонстрировать идентичное поведение, так как они оба будут нажимать на кнопку как можно чаще. Получается, мы не можем различить их целевые функции в этом окружении. Но при этом оно содержит достаточно информации для того, чтобы различить эти две конкретные цели: поскольку награда приходит лишь через десять секунд, она должна быть от лампы, а не от кнопки. Получается, что даже в случае, когда обучающее окружение в принципе содержит достаточно информации, чтобы определить базовую цель, всё равно может оказаться невозможно различить устойчиво согласованные меса-оптимизаторы от прокси-согласованных.
Прокси-согласованность как сделанное заранее вычисление. Можно рассматривать прокси-согласованность как форму вычислений, заранее сделанных базовым оптимизатором. С его помощью базовый оптимизатор позволяет меса-оптимизатору сэкономить вычислительную работу, заранее вычисляя, какие прокси-цели помогают добиться базовой цели, и оставляя меса-оптимизатору только максимизацию этих прокси-целей.
Без этого меса-оптимизатору пришлось бы выводить причино-следственные связи между чертами окружения и базовой целью во время выполнения, что потребовало бы значительной вычислительной работы. Более того, ошибки в выводах могли бы привести к тому, что система хуже справлялась бы с базовой целью, чем при наличии заранее вычисленных прокси-целей. Если базовый оптимизатор вычисляет эти связи заранее – отбирая меса-цели, включающие хорошие прокси-цели – то больше вычислений во время выполнения может быть направлено на создание лучших планов.
Это можно проиллюстрировать случаем биологической эволюции. Прокси-цели, о которых заботятся люди – еда, ресурсы, общество, спаривание, и т.д. – относительно вычислительно просто оптимизировать напрямую, и они хорошо коррелируют с выживанием и размножением в окружении наших предков. Для человека устойчивая согласованность с эволюцией требовала бы от нас, чтобы мы напрямую заботились о распространении своих генов. В этом случае нам пришлось бы самостоятельно выводить, что приём пищи, кооперация с другими, предотвращение физической боли, и т.д. в итоге продвинет генетическую приспособленность – а это не тривиальная задача. Вывод всех этих прокси-целей из информации, доступной ранним людям потребовал бы больших (пожалуй, невыполнимо больших) вычислительных ресурсов, чем их прямая оптимизация. Чтобы ребёнок в такой альтернативной вселенной избегал биться пальцем ноги о камень, ему пришлось бы понять, что это слегка уменьшит его шансы на размножение через двадцать лет.
Чтобы сделанное заранее вычисление было выгодным, необходимо довольно стабильное отношение между прокси-целью и базовой целью, так что оптимизация первой предсказуемо шла на пользу второй. Но даже неидеальное отношение может принести значительную выгоду относительно устойчивой согласованности, если оно освобождает меса-оптимизатору очень много вычислительных ресурсов. Из этого анализа вытекает, что в сложных обучающих окружениях может быть давление в сторону прокси-согласованности, поскольку чем сложнее окружение, тем больше экономия для меса-оптимизатора и, заодно, тем больше в нём доступно потенциальных прокси-целей.
Более того, в контексте машинного обучения отсюда получается, что штраф на временную сложность (в отличии от штрафа на длину описания) – это обоюдоострый меч. Во втором посте мы предположили, что он может уменьшить вероятность меса-оптимизации. Однако, из приведённых выше аргументов вытекает, что он также способствует псевдо-согласованности в случае, когда меса-оптимизатор всё же возник. Если полное моделирование базовой цели слишком затратно, то псевдо-согласованный меса-оптимизатор может оказаться предпочтительнее (для базового оптимизатора) устойчиво согласованного благодаря меньшему времени работы, даже если бы без штрафа за время предпочтительнее был бы последний.
Сжатие меса-оптимизатора. Длина описания устойчиво согласованного меса-оптимизатора может быть больше, чем у псевдо-согласованного. Поскольку псевдо-согласованных меса-целей больше, чем устойчиво согласованных, псевдо-согласованность предоставляет большую степень свободы для выбора конкретной достаточно простой меса-цели. Так что мы ожидаем, что в большинстве случаев возможны несколько псевдо-согласованных меса-оптимизаторов, более простых, чем устойчиво согласованный.
Это особенно сильно проявляется если входные данные обученного алгоритма не содержат легко извлекаемой информации о том, как оптимизировать базовую цель. Биологическая эволюция в этом отношении, кажется, отличается от машинного обучения, поскольку эволюционное описание мозга должно проходить через информационную воронку ДНК. Данные, которые получали ранние люди не позволяли им вывести ни существование ДНК, ни отношение между их действиями и генетической приспособленностью. А устойчивое согласование их с эволюцией требовало бы от них наличия определённой внутренней модели ДНК и факторов, влияющих на совокупную генетическую приспособленность. Такая модель не могла бы использовать информацию из окружающей среды для сжатия, так что имела бы большую длину описания. Напротив, наши модели еды, боли и т.д. могут быть довольно короткими, поскольку они напрямую связаны с нашими входными данными.
3.3. Базовый оптимизатор
Теперь мы перейдём к тому, как базовый оптимизатор вероятно влияет на склонность систем машинного обучения создавать псевдо-согласованные меса-оптимизаторы.
Жёстко закодированная оптимизация. Во втором посте мы предположили, что жёстко закодированный алгоритм оптимизации, то есть выбор модели с встроенной оптимизацией, может быть использован для устранения некоторых стимулов меса-оптимизации. Аналогично, он может предотвращать и некоторые источники псевдо-согласованности, поскольку позволяет устанавливать или обучать меса-цель напрямую. Способом достигнуть этого может быть основанное на модели предсказывающее награду обучение с подкреплением.(21) К примеру, система машинного обучения может включать в себя модель, напрямую обученную предсказывать базовую цель, и жёстко закодированный мощный оптимизационный алгоритм. Это обходит некоторые проблемы псевдо-согласованности: если меса-оптимизатор обучен напрямую предсказывать базовую награду, то он будет отобран по хорошим предсказаниям даже если плохие предсказания привели бы к лучшим стратегиям. Однако, обученная модель базовой цели будет всё ещё недоопределена за пределами обучающего распределения, так что этот подход сам по себе не гарантирует устойчивой согласованности.
Диапазон алгоритмов. Мы предполагаем, что диапазон алгоритмов, доступных модели, влияет на вероятность псевдо-согласованности. Особенно сложно избегаемый источник псевдо-согласованности – ошибка приближения – если меса-оптимизатор не в состоянии достоверно отобразить в себе базовую цель, то он в принципе не может быть устойчиво согласованным, только приблизительно. Даже если меса-оптимизатор теоретически может идеально отобразить базовую цель, всё равно, чем сложнее это сделать, тем вероятнее, что он окажется лишь приблизительно согласован. Так что большой диапазон алгоритмов может быть и благом и проклятьем: он уменьшает вероятность приблизительной согласованности, но увеличивает вероятность получения меса-оптимизатора.1
Взаимозависимость подпроцессов. Есть причины считать, что изначально может быть больше давления в сторону прокси-согласованных, а не устойчиво согласованных меса-оптимизаторов. В локальном оптимизационном процессе каждый параметр обученного алгоритма (например, вектор нейрона) подправляется в сторону лучшего выполнения базовой цели при условии значений остальных параметров. Значит, то, насколько базовому оптимизатору выгодна выработка нового подпроцесса, скорее всего зависит то того, что в этот момент исполняют другие подпроцессы обученного алгоритма. Таким образом, даже если некий подпроцесс может быть очень выгодным в комбинации с многими другими подпроцессами, базовый оптимизатор может его не выбрать, если эти подпроцессы, от которых он зависит, ещё не в достаточной степени развились. В результате, локальный алгоритм оптимизации вероятнее раньше приведёт к возникновению менее зависящих друг от друга подпроцессов, чем к возникновению более зависящих.
В контексте меса-оптимизации, выгода устойчиво согласованной меса-цели кажется зависящей от большего количества подпроцессов, чем по крайней мере некоторые псевдо-согласованные меса-цели. К примеру, рассмотрим побочно-согласованный меса-оптимизатор, оптимизирующие некий набор прокси-переменных. Пусть ему необходимо запускать некоторые подпроцессы для моделирования связей между своими действиями и этими прокси-переменными. Если мы предположим, что оптимизация этих прокси-переменных необходима для того, чтобы хорошо справляться с базовой целью, то для устойчивой согласованности меса-оптимизатора ему потребовалось бы моделировать ещё и связи между прокси-переменными и базовой целью, что могло бы потребовать дополнительных подпроцессов. Более того, выгода их добавления с точки зрения базового оптимизатора зависит от наличия заранее у меса-оптимизатора подпроцессов, моделирующих связь между его действиями и прокси-переменными. Их этого неформального аргумента следует, что при такой работе базового оптимизатора для выработки устойчиво согласованной меса-цели потребуется строго больше подпроцессов, чем для псевдо-согласованной.
Получается, что по крайней мере в локальных оптимизационных процессах меса-оптимизаторы могут быть склонны вырабатываться как прокси-согласованные прежде, чем станут устойчиво согласованными. Другими словами, мы можем ожидать, что такие системы будут скорее сначала вырабатывать компетентную оптимизацию прокси-целей, а потом становиться более устойчиво согласованными, а не становиться способнее и согласованнее одновременно.
Отбор, основанный на внутреннем устройстве. В нынешних системах машинного обучения обученные алгоритмы отбираются на основании в первую очередь того, насколько хорошо их стратегии справляются с базовой целью. Зачастую есть какой-то отбор, основанный на внутренней структуре обученного алгоритма – вроде регуляризации весов – но обычно он довольно неразбочивый. Возможная идея борьбы с псевдо-согласованностью – использовать метод отбора, основанный на более сложной функции от внутренней работы обученного алгоритма. Этот подход по духу похож на жёстко закодированную оптимизацию: мы используем знание о внутренней работе системы, чтобы предотвратить её прокси-согласованность.
Не исключено, что можно разработать процесс мета-обучения специально для предотвращения псевдо-согласованности. Это кажется пока что за пределами нынешних
техник мета-обучения, но лежащий в основе принцип похож на существующие процессы мета-обучения для оптимизации устойчивости. Крайней формой основанного на внутреннем устройстве отбора может быть создание базовым оптимизатором рассуждений или доказательств о свойствах обученного алгоритма как часть процесса отбора.
К сожалению, такие методы пока что находятся за пределами наших возможностей, в первую очередь из-за ограничений нынешних методов обеспечения прозрачности. Возможное беспокойство по поводу этих подходов заключается в том, что они могут потребовать от базового оптимизатора лучшего навыка поиска проблем, чем навык меса-оптимизатора в их скрывании. Следовательно, чтобы создать такой базовый оптимизатор, нам может потребоваться сначала обучить его третьим оптимизатором, что может привести к той же проблеме уровнем выше.
Состязательное обучение. Возможный метод смягчения некоторых из этих проблем – состязательный выбор окружения из очень широкого распределения. Так может быть возможно преодолеть барьеры и сделать устойчиво согласованную цель самой доступной. Это потребует, чтобы для каждой меса-цели $O_{mesa}$, более доступной, чем базовая цель $O_{base}$, существовала некая ситуация, где $O_{mesa}$ и $O_{base}$ расходятся и меса-оптимизатор был мотивирован придерживаться $O_{base}$.
Если мы смоделируем доступность цели просто длиной её описания в битах, то различение $O_{base}$ от каждой более доступной $O_{mesa}$ становится экспоненциально сложнее с ростом сложности $O_{base}$. Так что, для очень сложно устроенной $O_{base}$, значительно замотивировать базовый оптимизатор обнаружить меса-оптимизатор с этой $O_{base}$ скорее всего будет очень сложно, хоть и не невозможно.
Однако, даже в таком случае, вероятно, всё ещё будет период времени, когда обученный алгоритм является несогласованным меса-оптимизатором, что открывает зловещую перспективу: несогласованный меса-оптимизатор может выводить и предпринимать правильные действия на основе $O_{base}$, всё ещё имея целевую функцию $O_{mesa}$. Мы назовём эту ситуацию обманчивой согласованностью и обсудим её подробно в следующем посте.
- 1. Хоть большой диапазон алгоритмов и кажется уменьшающим вероятность приблизительной согласованности, неясно, как он влияет на другие формы псевдо-согласованности, вроде обманчивой.
Обманчивая согласованность
Кажется правдоподобным, что при достаточном обучении в достаточно разнообразных окружениях базовая цель в какой-то момент будет полностью представлена в меса-оптимизаторе. Мы, однако, предполагаем, что это может произойти и без того, чтобы он стал устойчиво согласованным. Конкретнее, меса-оптимизатор может научиться моделировать базовую целевую функцию и учитывать, что если он плохо будет справляться с базовой целью, то базовый оптимизатор его модифицирует.
Если меса-оптимизатор имеет цель, выходящую за пределы обновлений параметров, то он будет иметь стимул избегать модификаций1, так как он может перестать преследовать ту же цель после модификации (и в результате его нынешняя цель не будет достигнута в будущих итерациях). Это означает, что меса-оптимизатор будет инструментально мотивирован действовать так, будто он оптимизирует базовую целевую функцию, несмотря на то, что его настоящая меса-цель совершенно иная. Мы будем называть это гипотетическое явление обманчивой согласованностью2. Обманчивая согласованность – это форма инструментальной прокси-согласованности, так как выполнение базовой цели становится для меса-оптимизатора инструментальным.
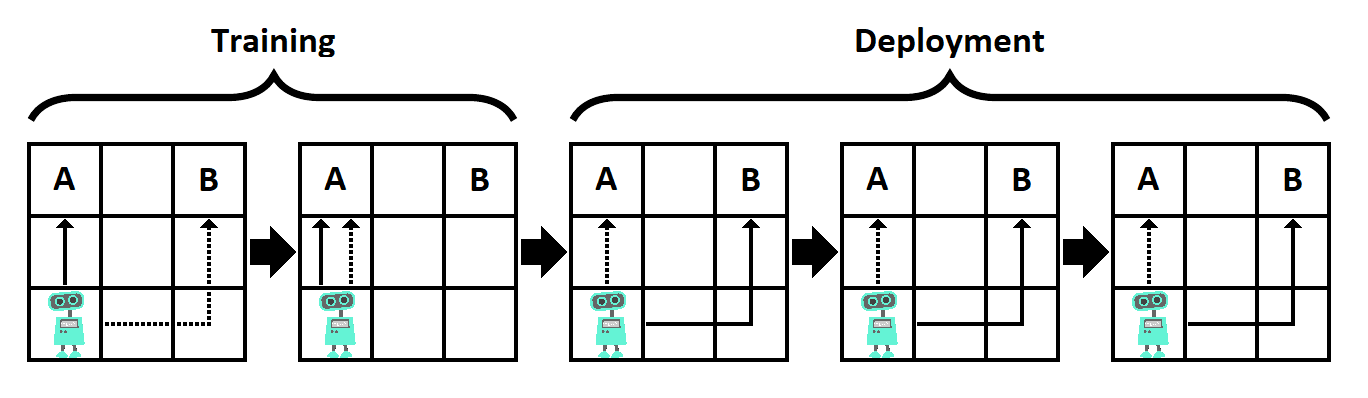
Рис. 4.1. Игрушечный пример обманчивой согласованности. В этой задаче базовая цель – чтобы робот добрался до A, а меса-цель – добраться до B. Выполняется два обучающих эпизода и три эпизода при развёртывании. Обновления параметров происходят только после обучающих эпизодов, при развёртывании они фиксированы. Если меса-оптимизатор дойдёт до своей цели (B) во время обучения, то он будет модифицирован, чтобы удостовериться, что он дойдёт до A в следующих эпизодах (пунктирные стрелки). Поэтому, если цель меса-оптимизатора распространяется за пределы эпизода, выгодная для него стратегия – идти к A при обучении, а к B после него (сплошные стрелки).
Как простой пример, рассмотрим окружение, состоящее из сетки размера 3×3 (см. рисунок 4.1). Левый верхний угол – «угол A», а правый верхний – «угол B». Агент, являющийся меса-оптимизатором, начинает в левом нижнем углу. Базовая цель – за как можно меньшее число шагов добраться до угла A, но цель меса-оптимизатора – добраться до угла B. Окружение запускается пять раз, но модификация агента происходит только после первых двух эпизодов (при обучении), но не потом (при тестировании/развёртывании). Если субоптимальное действие совершено при обучении, то агент будет модифицирован так, что его меса-целью станет базовая цель. Цель меса-оптимизатора охватывает все эпизоды: он хочет достигнуть угла B в как можно большем их числе.
В этом примере мы предположим, что агент знает все указанные выше факты. Если агент пойдёт к B в любом обучающем эпизоде, то он будет модифицирован, и будет идти к A во всех последующих эпизодах, что означает, что он достигнет B только в одном. А вот если агент пойдёт к A в первых двух эпизодах, то он не будет модифицирован, и сможет пойти к B в оставшихся трёх. Используя эту стратегию, агент достигает B три раза, что лучше (для его меса-цели), чем один раз в предыдущем варианте. Этот простой пример демонстрирует, как несогласованный меса-оптимизатор может быть мотивирован «притворяться» согласованным с базовой целью до конца обучения или до получения возможности каким-то образом скомпроментировать или покинуть процесс обучения.
Мы можем различить два способа, которыми базовая целевая функция может быть отображена в меса-оптимизаторе3:
- Принятие базовой цели. Меса-целевая функция подправляется в сторону базовой целевой функции, пока не становится устойчиво согласованной.
- Моделирование базовой цели. Базовая цель включается в эпистемическую модель меса-оптимизатора, а не в его цель, оставляя возможность того, что его меса-цель несогласована.
В первом случае информация о базовой цели усваивается обученным алгоритмом через оптимизацию, выполняемую базовым оптимизатором – и оказывается встроена в меса-оптимизатор так же, как в базовый. Но есть другая возможность: информация о базовой цели может попасть к меса-оптимизатору через его канал ввода. В этом случае, базовая цель будет отображена в обученном алгоритме другим – потенциально менее стабильным, чем в предыдущем случае – способом4. Тогда информация, описывающая базовую цель может не стать принятой в качестве меса-цели, что потенциально может привести к обманчивой согласованности.
4.1. Беспокойства о безопасности, связанные с обманчивой согласованностью
Если обманчивая согласованность действительно возможна, то она представляет критическую проблему безопасности. Обманчиво согласованный меса-оптимизатор, вероятно, перестанет оптимизировать базовую цель как только окажется в позиции, где ему больше не нужно будет хорошо с ней справляться для достижения своей цели. То есть, он в некоторый момент перестанет выполнять функцию, на которую обучен, и вместо этого станет преследовать свою неопределённую цель. Мы будем называть этот переход к оптимизации меса-цели вместо базовой «предательством». Это вероятно произойдёт, когда меса-оптимизатор станет убеждён, что предательство больше не приведёт к его модификации.
Особое беспокойство во вызывает возможность, что меса-оптимизатор активно вмешается для устранения угрозы модификации – например, эксплуатируя уязвимости в программной платформе, на которой запущен. В крайних случаях обманчивый меса-оптимизатор может попробовать манипулировать или перехитрить своих программистов, поскольку в них часть угрозы модификации – они могут выключить систему, если она будет плохо работать, или могут просто решить её не разворачивать. Обе возможности уменьшают ожидаемое будущее влияние системы, так что, вероятно, они будут плохо оцениваться её меса-целью. В самой экстремальной форме этот провал согласования может привести к «предательскому повороту», как описано Ником Бостромом в «Суперинтеллекте».(23)
Пол Кристиано представил сценарий, иллюстрирующий, как обманчивая согласованность может привести к катастрофическому риску.(24) В его примере обманчиво согласованные меса-оптимизаторы5 возникают в будущих техниках машинного обучения, достаточно продвинутых для поиска в очень большом пространстве моделей, включающем стратегии, способные понимать мир. В этом сценарии некоторые случаи предательства обманчиво согласованных меса-оптимизаторов могут иметь катастрофические последствия – к примеру, если системы контролируют крупномасштабную инфраструктуру – хотя такие провалы, вероятно, будут всё же переживаемыми. По мере того, как мы будем всё больше полагаться на автоматические системы для работы в всё более сложном мире, будет становиться всё сложнее – а с некоторого момента невозможно – восстановиться после скоординированного одновременного провала многих ИИ-систем. В этот момент каскад предательств обманчиво согласованных меса-оптимизаторов может привести к «взрывному концу света».(24) Кристиано отмечает, что это наиболее вероятно в «период повышенной уязвимости» вроде международного конфликта или природного бедствия.
4.2. Условия обманчивой согласованности
Мы предполагаем, что для обманчивой согласованности необходимы условия:
- Меса-оптимизатор имеет цель, выходящую за пределы обновления параметров.6
- Меса-оптимизатор способен смоделировать и то, что его отбирают по достижению определённой базовой цели, и саму эту цель.7
- Меса-оптимизатор ожидает, что угроза модификации8 в какой-то момент закончится, либо из-за конца обучения, либо из-за действий, им предпринятых.
Если первое условие не удовлетворено, то меса-оптимизатор не мотивирован влиять на исход обновления параметров, и будет всегда просто напрямую преследовать свою меса-цель. Если второе условие не удовлетворено, то он не будет видеть причины жертвовать достижением своей цели в текущем эпизоде, так как не будет считать, что её будущее достижение зависит от текущего эпизода. Если третье условие не удовлетворено, то меса-оптимизатор не будет ожидать выгоды от временного действия в соответствии с базовой целью, так что он будет отклоняться от неё либо всегда, либо никогда. Однако, стоит различать вопрос того, возможно ли выполнение этих условий, от вопроса, насколько оно вероятно. Ниже мы рассмотрим факторы, касающиеся каждого из них.
Меса-оптимизатор имеет цель, выходящую за пределы обновления параметров. Не ясно, какие обстоятельство мотивируют такие цели. Наиболее правдоподобным сценарием, наверное, является тот, в котором такая цель поощряется настройками обучения, так как есть ситуации, в которых она требуется для хорошей работы. К примеру, задача агента может решаться в окружении, в котором его действия имеют перманентные последствия, или где как-то иначе становится необходимым планирование более чем на один эпизод.
Меса-оптимизатор способен смоделировать и то, что его отбирают по достижению определённой базовой цели, и саму эту цель. У меса-оптимизатора может быть несколько способов узнать об оптимизационном давлении, под которым он находится.9
Во-первых, это знание может проистекать из самого давления. Отрывки информации о базовой цели могут быть выгодными, если они позволяют меса-оптимизатору улучшить свою оценку согласно этой цели – к примеру, улучшив априорные оценки того, какие задачи он может получить. Раз каждый отрывок информации независимо помогает в достижении базовой цели, это формирует приблизительно монотонно возрастающий путь, которому локальный базовый оптимизатор будет следовать. Обновление параметров может, в принципе, быть выучено как любой другой динамический элемент, без необходимости явной модели базового оптимизатора, что потенциально открывает доступ к этому даже меса-оптимизаторам весьма скромных способностей.
Во-вторых, во многих реалистичных приложениях продвинутого машинного обучения, меса-оптимизатор может во время выполнения использовать информацию из своего окружения для изучения своего положения. Люди так и узнали, что сгенерированы базовым оптимизатором эволюции, и это кажется очень правдоподобным путём открытия своего оптимизационного давления для гипотетического меса-оптимизатора. К примеру, агент, чья задача – предсказывать цены на акции в технологическом секторе, может получать информацию о нынешних технологиях ИИ для улучшения качества его работы, но эта информация также может позволить ему изучить своё собственное положение.
Из этого можно сделать предположение, что программистам желательно ограничивать меса-оптимизатору доступ к информации, описывающей его базовую цель. Неясно, в какой степени это возможно, учитывая, что многие продвинутые системы машинного обучения скорее всего будут действовать в окружениях, где эта информация легко доступна.
Однако, даже если программисты успешно ограничили доступ к этой информации, всё равно могут быть другие каналы, через которые она может ненамеренно попасть к меса-оптимизатору:
- Меса-оптимизатор может рассуждать о том, почему ему дали решать конкретные задачи. Большинству меса-оптимизаторов необходимы априорные оценки того, какие задачи они могут получить, и меса-оптимизатор может узнать о существовании базового оптимизатора, исследуя эти оценки.
- Меса-оптимизатор может быть способен рассуждать о себе и том, почему он такой как есть, и понять, что он хорошо спроектирован для выполнения некой цели.
Однако, эти две стратегии могут потребовать намного более продвинутого меса-оптимизатора.
Меса-оптимизатор ожидает, что угроза модификации в какой-то момент закончится, либо из-за конца обучения, либо из-за действий, им предпринятых. Во-первых, заметим, что это условие про ожидания меса-оптимизатора, не обязательно совпадающие с реальным положением дел. Во-вторых, даже если система устроена так, что момента конца обучения нет, у меса-оптимизатора всё ещё может быть возможность избавиться от угрозы модификации, совершить предательский поворот. Но, конечно, для того, чтобы меса-оптимизатор следовал такой стратегии, он должен быть осведомлён о существовании этой возможности. При этом меса-оптимизатор, ошибочно считающий, что эта возможность есть, тоже может проявлять обманчивую согласованность.
Поскольку такую возможность кажется сложным открыть просто исследованием окружения, меса-оптимизатору придётся либо вывести это некой формой абстрактных рассуждений, либо иметь априорную не-пренебрежимую оценку вероятности того, что давление отбора не продолжится сколь угодно долго. Второй вариант выглядит правдоподобно; Байесианская априорная оценка вероятности гипотезы того, что какой-то факт когда-нибудь перестанет быть истинным, всегда должна быть ненулевой.10 Что касается первого, меса-оптимизатор может вывести, что оптимизационное давление в какой-то момент прекратится, если он узнает о существовании базового оптимизатора (используя информацию из ввода или имея высокую априорную оценку), хоть это возможно и потребует, чтобы он был весьма продвинутым.
4.3. Динамика обучения при обманчивой согласованности
Когда меса-оптимизатор становится обманчивым, меняется динамика того, что заставляет его хорошо справляться с базовой целью. Вместо того, чтобы быть отобранным только на основе своей цели и способностей, обманчиво согласованный оптимизатор отбирается ещё и по тому, насколько хорошо он выводит базовую цель, и насколько он проницателен в выборе, оптимизировать ли базовую цель или свою собственную. Есть как минимум два возможных режима отбора обманчиво согласованного меса-оптимизатора.
Совместная оптимизация. Если меса-оптимизатор пытается совместно оптимизировать свою цель и базовую, или ошибочно выбирает момент предательства, то он будет находиться под давлением отбора в сторону большей совместимости его цели с базовой. Вряд ли это будет таким же давлением, как если бы он просто работал над своей целью, но оно может сдвигать его цель в сторону лучшей совместимости.
Чистый обман. Если меса-оптимизатор перестаёт пытаться оптимизировать свою собственную цель в краткосрочной перспективе и полностью сосредотачивается на кооперации с процессом отбора, то это может привести к «заморозке» его цели. Раз его цель теперь не влияет на его вывод, на неё слабо действует давление отбора. В результате, она по сути перестаёт меняться, за исключением случайных блужданий и влияния штрафов за время работы и длину описания.
Случай совместной оптимизации нестабилен, поскольку он неоптимален с точки зрения базового оптимизатора. При росте компетентности меса-оптимизатора, ему придётся либо перейти к чистому обману, либо стать устойчиво согласованным.
4.4. Усвоение или обман после продолжительного обучения
Мы ожидаем, что в пределе обучения на разнообразном наборе задач совместная оптимизация и базовой и меса- целей будет нестабильна. Предполагая, что меса-оптимизатор сходится к оптимальному с точки зрения базового оптимизатора поведению, ему придётся как-нибудь выучить базовую цель. Мы выделили три пути, которыми это может произойти:
- Устойчивая согласованность через усвоение. Меса-цель подгоняется под базовую, что устраняет псевдо-согласованность.
- Заморозка обманчивой согласованности. Информация о базовой цели всё больше встраивается в эпистемическую модель меса-оптимизатора без того, чтобы его цель стала устойчиво согласованной. В итоге меса-оптимизатор оптимизирует только базовую цель, но по исключительно инструментальным причинам, его меса-цель не меняется.
- Устойчивая согласованность через исправимость. Информация о базовой цели встраивается в эпистемическую модель меса-оптимизатора, и его цель модифицируется так, чтобы «указывать» на эту информацию. Эта ситуация соответствует меса-оптимизатору, исправимому(25) в отношении базовой цели (хотя не обязательно в отношении намерений программиста).
Для различия между двумя разными способами устойчивой согласованности мы будем использовать термин «встроенная согласованность» в первом случае и «исправимая согласованность» во втором. Ниже мы проанализируем, почему они могут быть более или менее привлекательны.
К обманчивой согласованности больше путей, чем у устойчивой. У меса-оптимизатора, удовлетворяющего трём критериям обманчивой согласованности вероятно будет сильная мотивация лучше понимать базовую цель, поскольку будущее выполнение меса-цели зависит от обновления параметров. Даже устойчиво согласованный меса-оптимизатор, удовлетворяющий этим критериям, будет иметь такую мотивацию, потому что без этого понимания он не может знать свой собственный уровень согласованности с базовым оптимизатором. Так что меса-оптимизаторы, способные рассуждать о своих мотивациях, будут пытаться заполучить больше информации о базовой цели. А когда меса-оптимизатор узнал свою базовую цель, давление отбора на его собственную цель значительно ослабевает, что потенциально ведёт к заморозке его меса-цели. Однако, из-за неразличимости (обсуждённой в третьем посте), большинство меса-целей, согласованных на обучающих данных будет псевдо-согласованными, а не устойчиво согласованными. Так что замороженная цель скорее всего окажется псевдо-согласованной, что приведёт к обманчивому согласованию.
Для исправимой согласованности, вероятно, необходимо уже иметь модель базовой цели. Чтобы исправимая согласованность была выгодна с точки зрения базового оптимизатора, меса-оптимизатору необходимо уже иметь какую-нибудь модель базовой цели, чтобы на неё «указывать». Однако, когда эта модель есть, то меса-оптимизатор, вероятно, станет обманчиво-согласованным – по крайней мере, если он также удовлетворяет двум другим условиям. А это избавит его от большей части стимулов к исправимой согласованности, так что хоть он и может остаться исправимым в отношении базовой цели, но только по инструментальным причинам.
Обманчивая и исправимая согласованности могут быть более вычислительно требовательными. В случае обманчивой согласованности, одновременная работа над базовой целью и над определением хороших возможностей предательства, вероятно, потребует больше вычислительной мощности, чем только первая. При равных доступных вычислительных мощностях, обманчиво согласованный меса-оптимизатор будет тратить на оптимизацию базовой цели меньше времени, чем любой устойчиво согласованный оптимизатор, что потенциально ухудшит его сравнительную компетентноть. Более того, и обманчиво, и исправимо согласованный меса-оптимизатор будет вынужден изучать базовую цель перед её оптимизацией, что делает усвоенную согласованность более эффективной по времени. Так что явный или неявный штраф за время работы может помешать возникновению обманчиво согласованных меса-оптимизаторов и способствовать согласованным устойчиво. Впрочем, неясно, насколько сильно. Правдоподобно, что для сложных задач отслеживание возможностей предательства может занимать куда меньше времени в сравнении с решением самой задачи. Более того, такое состояние обманчивой согласованности может быть локально, пусть и не глобально, оптимальным, без явных путей выхода из него для базового оптимизатора.
Обманчивая и исправимая согласованность могут требовать меньшей длины описания. Обманчиво и исправимо согласованные меса-оптимизаторы, вероятно, имеют преимущество над встроенно согласованными в длине представления базовой цели, потому что они могут использовать окружение как источник части необходимой для этого информации. Конкретнее, обманчиво или исправимо согласованному меса-оптимизатору не требуется отображать всю базовую цель внутри себя, так как он может выводить её части, наблюдая за своим окружением при каждом запуске. Напротив, внутренне согласованный меса-оптимизатор должен с самого начала иметь полную модель базовой цели в своей меса-цели, чтобы быть устойчиво согласованным, поскольку у него не будет мотивации поменять свою цель исходя из дополнительной информации, которую он получит о базовой цели. Так что, в той степени, в которой базовый оптимизатор отбирает, основываясь на длине описания, он может предпочитать обманчиво или исправимо согласованные меса-оптимизаторы встроенно согласованным.
Моделирование может произойти быстрее, чем встраивание. У меса-оптимизатора может занять меньше времени научиться моделировать базовую цель, чем у базового оптимизатора – адаптировать меса-цель. Представим обманчивый меса-оптимизатор, который пока что не полностью правильно вывел базовую цель.11 В таком случае, станет ли он обманчиво или устойчиво согласованным после дальнейшего обучения, зависит от того, выведет ли он достаточно о базовой цели до того, как базовый оптимизатор модифицирует его меса-цель (сделав его встроенно или исправимо согласованным). Вероятно, на то, что произойдёт первым, влияют два фактора: скорость улучшения оценок базовой целим меса-оптимизатором и обновления параметров, которые делает базовый оптимизатор при каждой ошибке.
Первый фактор, улучшение оценок базовой цели, кажется зависящим в первую очередь от способностей меса-оптимизатора в то время, когда он обманчивый, и от сложности базовой цели, которую надо вывести. Важный особый случай – когда меса-оптимизатор имеет доступ к состоянию чего-то передающегося между эпизодами обучения. Оно может быть использовано как память, позволяя меса-оптимизатору основываться на своих предыдущих рассуждениях, что может ему позволить обогнать обновления параметров, согласующие его меса-цель.
Второй фактор обновления параметров зависит от природы базового оптимизатора. Нынешние базовые оптимизаторы, основанные на градиентном спуске, слабо реагируют на единичную ошибку, но более сложные базовые оптимизаторы с продвинутыми свойствами безопасности будут, может быть, справляться лучше. К примеру, они, возможно, смогут анализировать параметры меса-оптимизатора или вызывать человеческую проверку при обнаружении подозрительной ошибки.
В общем случае обновления параметров не обязательно будут делать меса-оптимизатор более согласованным. К примеру, вместо согласования меса-цели, обновление, сделанное после предательства, может подтолкнуть систему к улучшению её планирования, чтобы она больше не делала обнаружимых ошибок.
Вследствие всех этих соображений, любая систематическая склонность базового оптимизатора при обновлении цели или моделирующих способностей меса-оптимизатора может играть роль в определении финального результата.12 Этот анализ, однако, остаётся довольно умозрительным: чтобы быть уверенными в системах, способных создавать меса-оптимизаторы, нам ещё нужно достичь лучшего понимания условий, при которых мощная оптимизация системы приведёт к обманчивой согласованности, а не устойчивой.
4.5. Сдвиг распределения и обманчивая согласованность
Когда меса-оптимизатор становится обманчивым, он начинает просматривать свой ввод в поисках возможностей предательства. При обучении обманчиво согласованный оптимизатор сильно стимулирован не предавать, потому что он знает, что базовый оптимизатор будет совершать отбор против предательства. Однако это перестаёт на него влиять, когда он освобождается от угрозы внешней модификации. Так что обманчиво согласованный меса-оптимизатор будет искать способы определить, находится ли он в процессе обучения или нет, то есть он будет высматривать сдвиг распределения.
Это означает, что негативные эффекты обманчивой согласованности будут видны извне только при предательстве, либо случайном, либо после сдвига распределения. Однако, лежащая в основе проблема – это не сам сдвиг, а провал согласования. Можно пытаться решить основную проблему, сделав меса-оптимизатор устойчивым к сдвигу распределения (то есть, устойчиво согласованным), или же можно пытаться решить проблему заплаткой, предотвратив сдвиг.
В нынешних ИИ-системах небольшой сдвиг распределения между обучением и развёртыванием не обязательно проблематичен: пока разница в относящихся к работе областях достаточно мала, обучающее распределение не обязано идеально отображать настоящее. Однако, это может быть не так для обманчиво согласованных меса-оптимизаторов. Если такой оптимизатор достаточно продвинут, то он может заметить очень лёгкие сдвиги распределения для определения того, прекратилась ли угроза модификации.
Это поднимает вопрос, возможно ли сдержать обманчивый меса-оптимизатор, полностью избавившись от любой разницы между обучением и развёртыванием, которую он может заметить. Есть несколько причин считать, что это может быть невыполнимо на практике.
Во-первых, это бы значительно ограничило применимость системы. Машинное обучение зачастую проводится с намерением создать систему, которая сможет решать новые задачи. Если мы потребуем полного отсутствия сдвига распределения, то мы не сможем позволить системе сталкиваться с задачами, которые она не встречала при обучении, что означает, что мы не сможем дать ей по-настоящему новые задачи. К примеру, развёртывание системы в реальном мире после обучения в симулированном окружении скорее всего будет включать достаточно заметный сдвиг распределения, чтобы это стало невозможным при таком подходе.
Во-вторых, есть лёгкие формы сдвига распределения, от которых, кажется, очень сложно избавиться. К примеру, если меса-оптимизатор способен детектировать обновления параметров – с помощью любого состояния, переносимого между шагами обучения – то некая форма сдвига распределения произойдёт точно. Запуск системы на большее время (или выдача системе доступа к долговременной памяти) тоже приведёт к сдвигу. Некоторые примеры разницы, которую может заметить меса-оптимизатор:
- Обучение в симуляции, а запуск в реальном мире.
- Запуск системы на разное время при обучении и тестировании.
- Если модель способна обучаться из прошлого опыта, то доступ к большей памяти или доступ к памяти, которая могла сформироваться на более позднем этапе выполнения.
- Присутствие атак состязательными примерами при развёртывании.
- Встреча с чем-то, что очень сложно вычислить при обучении, но что вероятно когда-нибудь будет вычислено при развёртывании (к примеру, факторизация RSA 2048(26)).
- Способность базового оптимизатора модифицировать обученный алгоритм при обучении, но не после него.
- Способность программистов корректировать ошибки при обучении и тестировании, но не при развёртывании.
- Присутствие или отсутствие хороших возможностей предательства против программистов.
Заметим, что для обманчивого поведения меса-оптимизатору не строго обязательно видеть разницу между обучением и развёртыванием.
Рассмотрим снова пример с рисунка 4.1, но в этот раз предположим, что меса-оптимизатор неспособен определить, в каком эпизоде он находится. Тогда он оказывается перед проблемой принятия решений, похожей на «задачу рассеянного водителя».(27) Если мы применим тут такие же рассуждения, то оптимальной стратегией для меса-оптимизатора будет предать с вероятностью p≈0.61. То есть, меса-оптимизатору не обязательно быть в состоянии определить, когда закончилось обучение, для того чтобы рискнуть и случайно предать с некоторой вероятностью. Также обманчиво согласованный меса-оптимизатор может выискивать возможности предательства, которые были бы очень удачными, при условии, что он не в процессе обучения, но при этом достаточно редкими, чтобы их возникновение в ходе обучения было маловероятным.
- 1. Для ясности мы говорим об одном и том же агенте, переживающем обновления параметров, но ни мы, ни агент не обязаны рассуждать именно так. Более общее описание ситуации включает последовательность «наследующих агентов», разделённых обновлениями параметров. Агент потенциально может узнать об эффектах обновления на его наследников, и, следовательно, на достижение его цели на протяжении многих эпизодов.
- 2. Концепт обманчивой согласованности тесно связан с концептом Манхейма и Гаррабранта «состязательного Гудхарта». (22) В «Категоризации вариантов закона Гудхарта» они описали эту ситуацию как «агент с другими целями, чем у регулятора» вызывает «коллапс статистической взаимосвязи между целью, преследуемой оптимизатором, и используемой для неё прокси-цели». Обманчивая согласованность можно рассматривать как частный случай состязательного Гудхарта, в котором меса-оптимизатор играет роль агента с отличающимися целями, а базовый оптимизатор – роль регулятора. Качественное достижение цели при обучении – это прокси-цель регулятора, а при развёртывании – настоящая.
- 3. Благодарим Пола Кристиано за это разделение.
- 4. Заметим, однако, что информация о базовой цели может быть представлена через оптимизацию, но не стать при этом частью меса-цели. К примеру, она может стать частью априорных оценок задач, не оказывая на меса-цель прямого влияния.
- 5. Кристиано называет обманчиво согласованные меса-оптимизаторы «ищущими-влияние системами».
- 6. Или иным образом иметь метод достижения большей ценности, предав позже, а не сейчас.
- 7. Заметим, что меса-оптимизатору не требуется быть способным моделировать (или выводить существование) базового оптимизатора, только моделировать оптимизационное давление.
- 8. Альтернативно, как угрозу можно представить просто, что меса-оптимизатор никогда не будет отобран, тогда это условие становится тривиально удовлетворённым, ведь угроза автоматически прекращается при генерации меса-оптимизатора.
- 9. Мы в целом будем предполагать, что давление отбора выглядит так: базовый оптимизатор модифицирует меса-оптимизатор после каждого эпизода, как обычно и рассматриваются локальные оптимизационные процессы. Но в принципе можно представить и базовый оптимизатор, вырабатывающий новый алгоритм на каждом временном шагу. Некоторые из обсуждаемых проблем могут касаться и этого случая, но в целом мы не рассматриваем здесь этот вариант.
- 10. Заметим, что если меса-оптимизатор убеждён, что сейчас у него необычно хорошие возможности для достижения своей цели, то он может всё же начать преследовать её, но такой случай возникает не всегда.
- 11. Можно привести аналогичный аргумент для обманчиво согласованного меса-оптимизатора, предающего слишком рано или неудачно.
- 12. Кроме того, обманчиво согласованный меса-оптимизатор будет мотивирован создать систематическую склонность, предотвращающую изменение меса-цели базовым оптимизатором. В контексте локальных оптимизационных процессов обманчивый меса-оптимизатор может «взломать» свой собственный градиент (например, сделав себя более «хрупким» при смене цели), чтобы удостовериться, что базовый оптимизатор подправит его так, чтобы оставить его меса-цель нетронутой.
Риски выученной оптимизации. Заключение и связанные работы
Связанные работы
Мета-обучение. Как было описано в первом посте, обычно мета-обучение – это мета-оптимизация, в явном виде спроектированная для достижения некой базовой цели. Однако, вместо этого возможно проводить мета-обучение, пытаясь применить меса-оптимизацию. К примеру, у «Обучении Обучения с Подкреплением» Ванга и пр. авторы заявляют, что создали нейросеть, которая сама проводит процедуру оптимизации себя же.(28) Конкретнее, они утверждают, что способность их нейросети решать крайне разнообразные окружения без явного переобучения для каждого означает, что она выполняет своё собственное внутреннее обучение. Другой пример – «RL2: Быстрое Обучение с Подкреплением через Медленное Обучение с Подкреплением» Дуана и пр., где авторы обучили алгоритм выполнять, по их заявлениям, собственное обучение с подкреплением.(5) Такое мета-обучение кажется ближе всего к созданию меса-оптимизаторов из всех существующих исследований машинного обучения.
Устойчивость. Система устойчива к сдвигу распределения, если она продолжает хорошо справляться с целевой функцией, которой обучена, даже за пределами обучающего распределения. (29) В контексте меса-оптимизации, псевдо-согласованность – это частный случай того, как обученная система может не быть устойчивой к сдвигу распределения: псевдо-согласованный меса-оптимизатор в новом окружении может всё ещё компетентно оптимизировать меса-цель, но не быть устойчивым из-за разницы между ней и базовой целью.
Конкретный вид проблемы устойчивости, происходящий с меса-оптимизацией – это расхождение награда-результат – между наградой, которой обучается система (базовая цель) и наградой, реконструированной из системы обратным обучением с подкреплением (поведенческая цель).(8) В контексте меса-оптимизации, псевдо-согласованность ведёт к этому расхождению из-за того, что поведение системы за пределами обучающего распределения определяется её меса-целью, которая в этом случае не согласована с базовой.
Впрочем, следует заметить, что хотя внутренняя согласованность – это проблема устойчивости, ненамеренное возникновение меса-оптимизаторов ею не является. Если цель базового оптимизатора – это не идеальное отображение целей людей, то предотвращение возникновения меса-оптимизаторов может быть предпочтительным исходом. В таком случае, может быть желательно создать систему, сильно оптимизированную для базовой цели в некой ограниченной области, но не участвующую в неограниченной оптимизации для новых окружений.(11) Возможный путь достижения этого – использовать сильную оптимизацию на уровне базового оптимизатора при обучении, чтобы предотвратить сильную оптимизацию на меса-уровне.
Неразличимость и двусмысленность целей. Как мы заметили в третьем посте, проблема неразличимости целевых функций в меса-оптимизации похожа на проблему неразличимости в обучении с подкреплением, ключевая деталь которой – то, что сложно определить «правильную» целевую функцию лишь по набору её выводов на неких обучающих данных. (20) Мы предположили, что если проблема неразличимости может быть разрешена в контексте меса-оптимизации, то, вероятно (хоть в какой-то мере) с помощью решений, похожих на решения проблемы неразличимости в обучении с подкреплением. Пример исследования, которое может быть тут применимо для меса-оптимизации – предложение Амина и Сингха (20) смягчения эмпирической неразличимости в обратном обучении с подкреплением с помощью адаптивной выдачи примеров из набора окружений.
Кроме того, в литературе об обучении с подкреплением замечено, что в общем случае функция вознаграждения агента не может быть однозначно выведена из его поведения. (30) В этом контексте, проблему внутренней согласованности можно рассматривать как расширение проблемы выучивания ценностей. Последняя – про набор достаточной информации о поведении агента, чтобы вывести его функцию полезности, а первая – про тестирование поведения обученного алгоритма в достаточной степени, чтобы удостовериться, что он имеет конкретную целевую функцию.
Интерпретируемость. Исследования интерпретируемости стремятся разработать методы, делающие модели глубинного обучения более интерпретируемыми для людей. В контексте меса-оптимизации, было бы выгодно иметь метод, определяющий, когда система выполняет какую-то оптимизацию, что она оптимизирует, и какую информацию она принимает во внимание в этой оптимизации. Это помогло бы нам понять, когда система может проявить нежелательное поведение, и помогло бы нам сконструировать обучающие алгоритмы, создающие давление отбора против появления потенциально опасных обученных алгоритмов.
Верификация. Исследования верификации в машинном обучении стремятся разработать алгоритмы, формально доказывающие, что система удовлетворяет некоторым свойствам. В контексте меса-оптимизации, было бы желательно иметь возможность проверить, выполняет ли обученный алгоритм потенциально опасную оптимизацию.
Нынешние алгоритмы верификации в основном используются для доказательства свойств, определённых отношениями ввода-вывода, вроде проверки инвариантов вывода с учётом определяемыми пользователем трансформаций ввода. Основная мотивация таких исследований – неудачи устойчивости в задачах распознавания изображений на состязательных примерах. Существуют и прозрачные алгоритмы, (31) например, «SMT solver», который в принципе позволяет верифицировать произвольное утверждение про активации сети,(32) и алгоритмы-«чёрные ящики»(33). Однако, применение таких исследований к меса-оптимизации затруднено тем фактом, что сейчас у нас нет формального определения оптимизации.
Исправимость. ИИ-система исправима, если она терпит или даже помогает своим программистам корректировать её.(25) Нынешний анализ исправимости сосредоточен на том, как определить функцию полезности такую, что если её будет оптимизировать рациональный агент, то он будет исправим. Наш анализ предполагает, что даже если такая исправимая целевая функция может быть определена или выучена, удостовериться, что система, ей обученная, действительно будет исправимой, нетривиально. Даже если базовая целевая функция была бы исправимой при прямой оптимизации, система может проявить меса-оптимизацию, и её меса-цель может не унаследовать исправимость базовой цели. Это аналогично проблеме безразличных к полезности агентов, создающих других агентов, которые уже не безразличны к полезности.(25) В четвёртом посте мы предложили связанное с исправимостью понятие – исправимую согласованность – применимое для меса-оптимизаторов. Если работа над исправимостью сможет найти способ надёжно создавать исправимо согласованные меса-оптимизаторы, то это сможет значительно приблизить решение задачи внутреннего согласования.
Всеохватывающие ИИ-Сервисы (CAIS).(11) CAIS – описательная модель процесса, в котором будут разработаны суперинтеллектуальные системы, и выводы о лучших для этого условиях. Совместимая с нашим анализом модель CAIS проводит явное разделение обучения (базовый оптимизатор) и функциональности (обученный алгоритм). CAIS помимо прочего предсказывает, что будут разрабатываться всё более и более мощные обобщённые обучающиеся алгоритмы, которые в многоуровневом процессе разработают сервисы суперинтеллектуальных способностей. Сервисы будут разрабатывать сервисы, которые будут разрабатывать сервисы, и так далее. В конце этого «дерева» будут сервисы, решающие конкретные конечные задачи. Люди будут вовлечены в разные слои процесса, так что смогут иметь много рычагов влияния на разработку финальных сервисов.
Высокоуровневые сервисы этого дерева можно рассматривать как мета-оптимизаторы для низкоуровневых. Однако, тут всё ещё есть возможность меса-оптимизации – мы определили как минимум два способа для этого. Во-первых, меса-оптимизатор может быть выработан финальным сервисом. Этот сценарий тесно связан с примерами, которые мы обсуждали в этой цепочке: базовым оптимизатором будет предфинальный сервис цепочки, а обученным алгоритмом (меса-оптимизатором) – финальный (или можно думать о всей цепочке от верхнего уровня до предфинального сервиса как о базовом оптимизаторе). Во-вторых, промежуточный сервис цепочки тоже может быть меса-оптимизатором. В этом случае, этот сервис будет оптимизатором в двух отношениях: мета-оптимизатором для сервиса ниже его (как по умолчанию в модели CAIS), но ещё и меса-оптимизатором для сервиса выше.
Заключение
В этой цепочке мы разъясняли существование двух основных проблем безопасности ИИ: того, что меса-оптимизаторы могут нежелательно возникнуть (ненамеренная меса-оптимизация), и того, что они могут не быть согласованными с изначальной целью системы (проблема внутреннего согласования). Впрочем, наша работа всё же довольно умозрительна. Так что у нас есть несколько возможностей:
- Если появление меса-оптимизаторов в продвинутых системах машинного обучения очень маловероятно, то меса-оптимизация и внутреннее согласование не предоставляют проблемы.
- Если появление меса-оптимизаторов не только вероятно, но и сложнопредотвратимо, то решение и внутреннего и внешнего согласования становится критическим для достижения уверенности в высокоспособных ИИ-системах.
- Если появление меса-оптимизаторов в будущих ИИ-системах вероятно по умолчанию, но есть способ его предотвращения, то вместо решения задачи внутреннего согласования, может быть лучшим выходом проектирование систем так, чтобы меса-оптимизаторы не появлялись. Кроме того, в таком сценарии может оказаться необязательным решение и некоторых частей внешнего согласования: если выполнение ИИ-системой оптимизационных алгоритмов может быть предотвращено, то может оказаться, что во многих ситуациях безопасно обучать систему цели, не идеально согласованной с намерениями программиста. То есть, если обученный алгоритм не является оптимизатором, то он может не оптимизировать цель до той крайности, где она перестаёт производить позитивные результаты.
Наша неуверенность по этому поводу – потенциально значимое препятствие на пути к определению лучших подходов к безопасности ИИ. Если мы не знаем относительной сложности внутреннего согласования и ненамеренной оптимизации, то неясно, как адекватно оценивать подходы, полагающиеся на решение одной или обеих этих проблем (как Итерированные Дистилляция и Усиление (34) или безопасность ИИ через дебаты(35)). Следовательно, мы предполагаем, что и важной и своевременной задачей для области безопасности ИИ является определение условий, в которых вероятно возникновение этих проблем, и техник их решения.
Внутреннее Согласование. Объяснение, как будто тебе 12 лет
(Это – неофициальное объяснение Внутреннего Согласования, основанное на статье MIRI Риски Выученной Оптимизации в Продвинутых Системах Машинного Обучения (почти что совпадающей с цепочкой на LessWrong) и подкасте «Будущее Жизни» с Эваном Хубингером (Miri/LW). Оно предназначено для всех, кто посчитал цепочку слишком длинной/сложной/технической.)
Жирный курсив означает «представляю новый термин», а простой используется для смыслового выделения.
Что такое Внутреннее Согласование?
Давайте начнём с сокращённого ликбеза о том, как работает Глубинное Обучение:
- Выбираем задачу
- Определяем пространство возможных решений
- Находим хорошее решение из этого пространства
Если задача – «Найти инструмент, который может посмотреть на картинку, и определить, есть ли на ней кот», то каждый мыслимый набор правил для ответа на этот вопрос (формально, каждая функция из множества возможных наборов значений пикселей в множество {да, нет}) задаёт одно решение. Мы называем такое решение моделью. Вот пространство возможных моделей:
Поскольку это все возможные модели, большая их часть – полная бессмыслица:
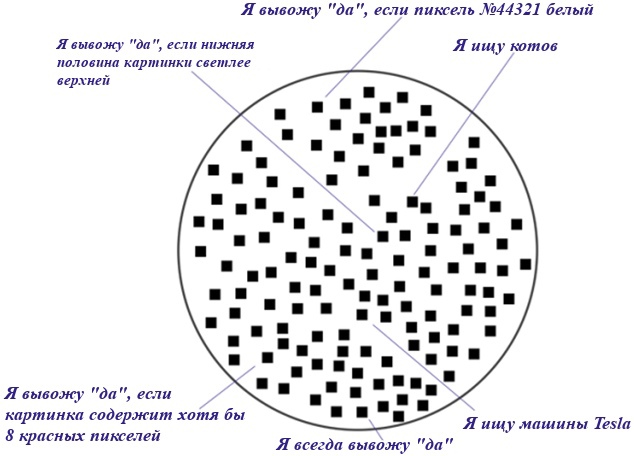
Возьмём случайную – и с не меньшей вероятностью получим распознаватель машин, а не котов – но куда вероятнее, что получим алгоритм, который не делает ничего, что мы можем интерпретировать. Отмечу, что даже описанные на картинке примеры не типичны – большая часть моделей будут более сложными, но всё ещё не делающими ничего, связанного с котами. Но где-то там всё же есть модель, которая хорошо справляется с нашей задачей. На картинке это та, которая говорит «Я ищу котов».
Как машинное обучение находит такую модель? Способ, который не работает – перебрать все. Пространство слишком большое: оно может содержать больше 101000000 кандидатов. Вместо этого есть штука, которая называется Стохастический Градиентный Спуск (СГС). Вот как она работает:
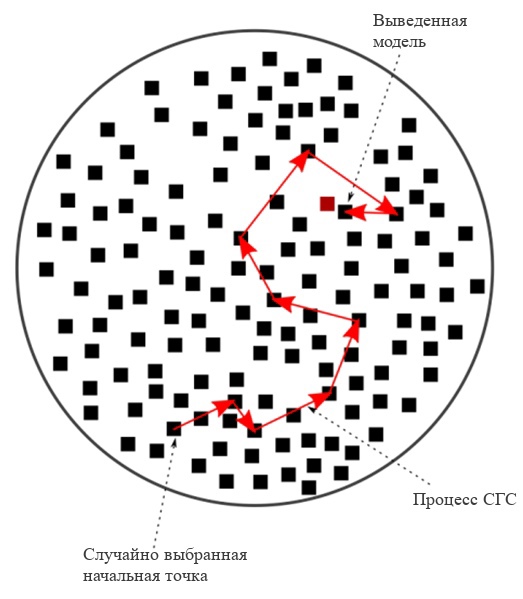
СГС начинает с какой-то (скорее всего ужасной) модели и совершает шаги. На каждом шаге он переходит к другой модели, которая «близка» и, кажется немного лучше. В некоторый момент он останавливается и выводит самую недавнюю модель.1 Заметим, что в примере выше мы получили не идеальный распознаватель котов (красный квадратик), а что-то близкое к нему – возможно, модель, которая ищет котов, но имеет какие-то ненамеренные причуды. СГС в общем случае не гарантирует оптимальность.
«Реплики», которыми модели объясняют, что они делают – аннотации для читателя. С точки зрения программиста, это выглядит так:
Программист понятия не имеет, что делают модели. Каждая модель – просто чёрный ящик.2
Необходимый компонент СГС – способность измерить качество работы модели, но это делают, всё ещё относясь к ним, как к чёрным ящикам. В примере с котами, предположим, что у программиста есть куча картинок, каждая из которых аккуратно подписана «содержит кота» или «не содержит кота». (Эти картинки называют обучающими данными, а такой процесс называют обучением с учителем.) СГС проверяет, как хорошо модели работают на этих картинках, и выбирает те, которые работают лучше. Есть альтернативные способы, в которых качество работы измеряют иначе но принцип остаётся тем же.
Теперь предположим, что оказалось, что наши картинки содержат только белых котов. (и, видимо, не содержит белых четверолапых не-котов – прим. пер.) В этом случае, СГС может выбрать модель, исполняющую правило «ответить да, если на картинке есть что-то белое с четырьмя лапами». Программист не заметит ничего странного – он увидит только, что модель, выданная СГС хорошо справляется с обучающими данными.
Получается, если наш путь получения обратной связи работает не совсем правильно, то у нас есть проблема. Если он идеален – если картинки с котами идеально отображают то, как выглядят картинки с котами, а картинки без котов – как выглядят картинки без котов, то проблемы нет. Напротив, если наши картинки с котами не репрезентативны, поскольку все коты на них белые, то выданная СГС модель может делать не в точности то, что хочет программист. На жаргоне машинного обучения, мы бы сказали, что обучающее распределение отличается от распределения при развёртывании.
Это и есть Внутреннее Согласование? Не совсем. Это было о свойстве, которое называют устойчивостью распределения, и это хорошо известная проблема в машинном обучении. Но это близко.
Чтобы объяснить само Внутреннее Согласование, нам придётся перейти к другой ситуации. Предположим, что вместо задачи определения, содержат ли картинки котов, мы пытаемся обучить модель проходить лабиринт. То есть, мы хотим получить алгоритм, который, если ему дать произвольный решаемый лабиринт, выводит путь от Входа к Выходу.
Как и раньше, наше пространство возможных решений будет состоять в основном из бессмыслицы:
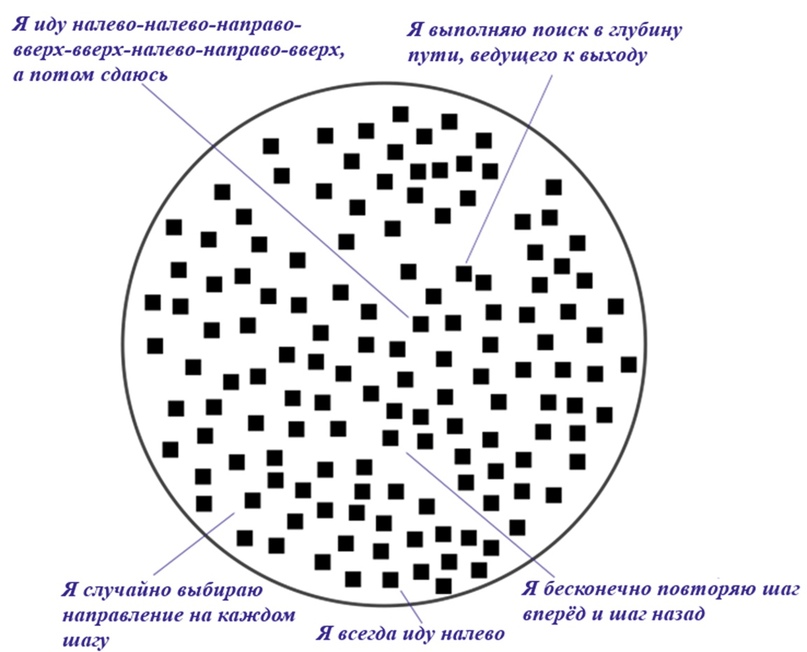
(В лабиринте «Поиск в глубину» — это то же самое, что правило «Всегда иди налево» (видимо, имеются в виду лабиринты без циклов – прим. пер.).)
Аннотация «Я выполняю поиск в глубину» означает, что модель содержит формальный алгоритм, выполняющий поиск в глубину, аналогично с другими аннотациями.
Как и в предыдущем примере, мы можем применить к этой задаче СГС. В этом случае, механизм обратной связи будет оценивать модель на тестовых лабиринтах. Теперь предположим, что все тестовые лабиринты выглядят вот так:
Красные отрезки означают двери. То есть, все лабиринты таковы, что кратчайший путь идёт через все красные двери, и сам выход – тоже красная дверь.
Смотря на это, можно понадеяться, что СГС найдёт модель «поиска в глубину». Однако, хоть эта модель и найдёт кратчайший путь, это не лучшая модель. (Отметим, что она сначала выполняет поиск, а потом, найдя правильный путь, отбрасывает все тупики и выводит только кратчайший путь.) Альтернативная модель с аннотацией «выполнить поиск в ширину следующей красной двери, повторять вечно» будет справляться лучше. (Поиск в ширину означает исследование всех возможных путей параллельно.) Обе модели всегда находят кратчайший путь, но модель с красными дверьми находит его быстрее. В лабиринте с картинки выше она бы сэкономила время при переходе от первой ко второй двери, обойдясь без исследования нижней левой части лабиринта.
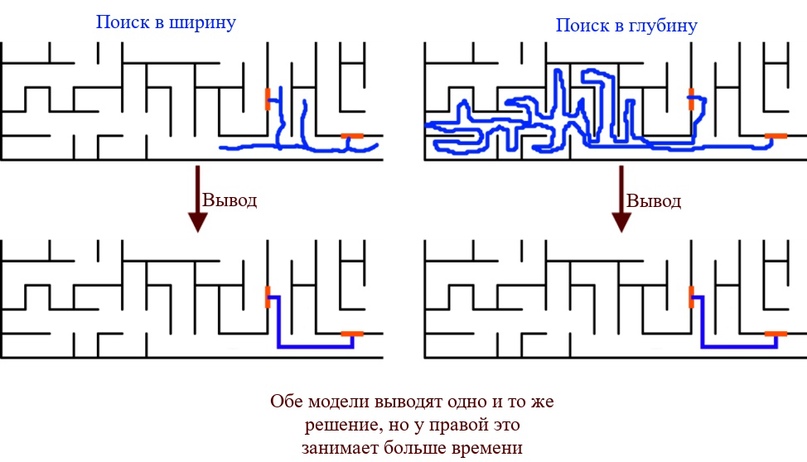
Заметим, что поиск в ширину опережает поиск в глубину только потому, что может избавиться от лишних путей после нахождения красной двери. Иначе бы он ещё долго не знал, что нижняя левая часть не нужна.
Как и в предыдущем случае, всё что увидит программист – левая модель лучше справляется с обучающими данными (тестовыми лабиринтами).
Качественное отличие от примера картинок с котами в том, что в этом случае мы можем рассматривать модель как исполняющую оптимизационный процесс. То есть, модель поиска в ширину сама имеет цель (идти через красные двери), и пытается оптимизировать её в том смысле, что ищет кратчайший путь к выполнению этой цели. Аналогично, модель поиска в глубину – оптимизационный процесс с целью «найти выход из лабиринта».
Этого достаточно, чтобы определить Внутреннее Согласование, но чтобы получить определение, которое можно найти где-нибудь ещё, давайте определим два новых термина:
- Базовая Цель – это цель, которую мы используем для оценивания моделей, найденных СГС. В первом примере она была «правильно классифицировать картинки» (т.е. сказать «есть кот», если на картинке есть кот, и «нет кота» в противном случае). Во втором примере она – «найти кратчайший путь через лабиринт как можно быстрее».
- В случаях, когда модель выполняет оптимизационный процесс, мы называем её Меса-Оптимизатором, а её цель Меса-Целью (в примере с лабиринтом меса-цель – «найти кратчайший путь через лабиринт» для модели поиска в глубину и «найти путь к следующей красной двери, затем повторить» для модели поиска в ширину).
С учётом этого:
Внутреннее Согласование – это задача согласования Меса-Цели и Базовой Цели.
Некоторые разъясняющие замечания:
- Пример с красными дверьми надуманный и не произошёл бы на практике. Он иллюстрирует только что такое Внутреннее Согласование, но не почему несогласованность может быть вероятна.
- Можно спросить, что из себя представляет пространство всех моделей. Типичный ответ: возможные модели – это наборы весов *нейросети. Проблема существует пока часть наборов весов выполняет некоторые алгоритмы поиска.
- Как и раньше, причиной провала внутреннего согласования был недостаток нашего способа получения обратной связи (на языке машинного обучения: наличие сдвига распределения). (Однако, несогласованность может возникать и по другим очень сложным причинам.)
- Если Базовая Цель и Меса-Цель не согласованы, это вызовет проблемы при развёртывании модели. Во втором примере, когда мы возьмём модель, выданную СГС и применим её к реальным лабиринтам, она продолжит искать красные двери. Если эти лабиринты не содержат красных дверей, или если красные двери не всегда будут вести к выходу, то модель будет работать плохо.
Проиллюстрируем диаграммой Эйлера-Венна. (Относительные размеры ничего не значат.)
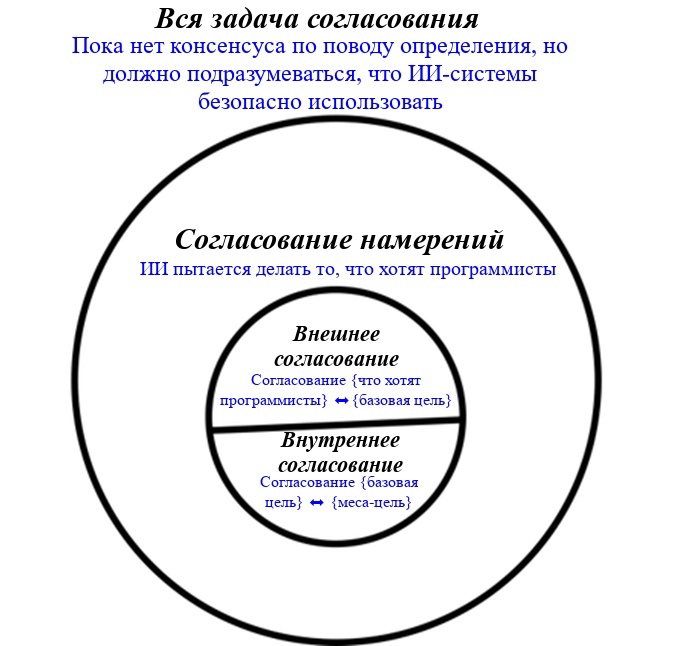
Заметим, что {Что пытается сделать ИИ} = {Меса-Цель} по определению.
Большая часть классических обсуждений согласования ИИ, включая большую часть книги Суперинтеллект, касается Внешнего Согласования. Классический пример – где мы представляем, что ИИ оптимизирован, чтобы вылечить рак, и поэтому убивает людей, чтобы больше ни у кого не было рака – про несогласованность {Того, что хотят программисты} и {Базовой Цели}. (Базовая Цель это {минимизировать число людей, у которых рак}, и хоть не вполне ясно, чего хотят программисты, но точно не этого.)
Стоит признать, что эта модель внутреннего согласования не вполне универсальна. В этом посте мы рассматриваем поиск по чёрным ящикам, с параметризованной моделью и СГС, обновляющим параметры. Большая часть машинного обучения в 2020-м году подходит под это описание, но эта область до 2000 года – нет, и это снова может так стать в будущем, если произойдёт сдвиг парадигмы, сравнимый с революцией глубинного обучения. В контексте поиска по чёрным ящикам внутренняя согласованность – хорошо определённое свойство, и диаграмма выше хорошо показывает разделение задач, но есть люди, ожидающие, что СИИ будет создан не так.3 Есть даже конкретные предложения безопасного ИИ, к которым неприменим этот концепт. Эван Хубингер написал пост о том, что он назвал «историями обучения», предназначенный определить «общий подход оценки предложений создания безопасного продвинутого ИИ».
Аналогия с Эволюцией
Касающиеся Внутреннего Согласования аргументы часто отсылают к эволюции. Причина в том, что эволюция – оптимизационный процесс, она оптимизирует совокупную генетическую приспособленность. Пространство всех моделей – это пространство всех возможных организмов.
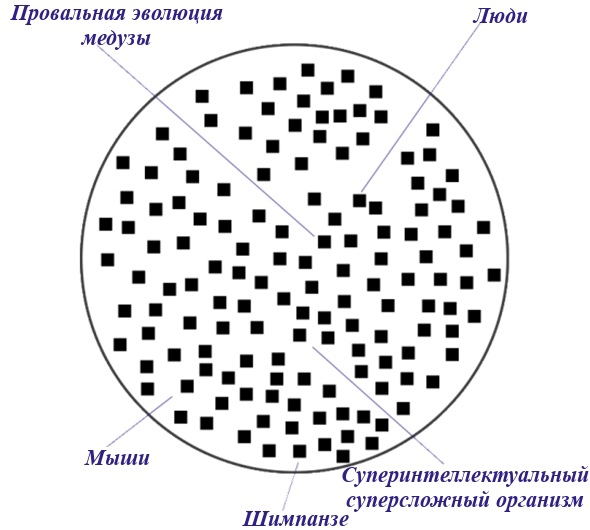
Люди точно не лучшая модель в этом пространстве – я добавил аннотацию справа снизу, чтобы обозначить, что есть пока не найденные лучшие модели. Однако, люди – лучшая модель, которую эволюция уже обнаружила.
Как в примере лабиринта, люди сами выполняют оптимизационные процессы. Так что мы можем назвать их/нас Меса-Оптимизаторами, и может сравнить Базовую Цель (которую оптимизирует эволюция) с Меса-Целью (которую оптимизируют люди).
- Базовая Цель: максимизировать совокупную генетическую приспособленность
- Меса-Цель: избегать боли, искать удовольствие
(Это упрощено – некоторые люди оптимизируют другие штуки, такие как благополучие всех возможных разумов во вселенной, но они не ближе к Базовой Цели.)
Можно увидеть, что люди не согласованы с базовой целью эволюции. И легко видеть, почему – Эван Хубингер объяснял это, предлагая представить альтернативный мир, в котором эволюция отбирала внутренне согласованные модели. В таком мире ребёнок, стукнувшийся пальцем, должен вычислить, как это затрагивает его совокупную генетическую приспособленность, чтобы понять, повторять ли в будущем такое поведение. Это было бы очень вычислительно затратно, тогда как цель «избегать боли» немедленно сообщает ребёнку, «стукаться пальцем = плохо», что куда дешевле и обычно является правильным ответом. Так что несогласованная модель превосходит гипотетическую согласованную. Другой интересный аспект в том, что степень несогласованности (разница между Базовой Целью и Меса-Целью) увеличилась в последние несколько тысячелетий. Цели были довольно близки в окружении наших предков, но сейчас они разошлись настолько, что нам приходится платить людям за сдачу спермы, что, согласно Базовой Цели, должно быть очень желательным действием.
Получается, эта аналогия – аргумент в пользу того, что Внутренняя Несогласованность вероятна, поскольку она «естественным путём» получилась в ходе самого большого известного нам нечеловеческого оптимизационного процесса. Однако, стоит предостеречь, что эволюция не исполняет Стохастический Градиентный Спуск. Эволюция путешествует по пространству моделей, производя случайные мутации и оценивая их результат, что фундаментально отличается (и в миллиард раз менее эффективно), чем модифицировать модель согласно ожидаемой производной функции оценки, как делает СГС. Так что, хоть аналогия и работает в целом, она перестаёт работать с аргументами, полагающимися на свойства СГС кроме того, что он оптимизирует Базовую Цель.
Обманчивая Согласованность
Это сокращённая версия четвёртого поста цепочки. Я оставляю ссылку на него потому что это, наверное, та часть, где опускание технических деталей наиболее проблематично.
Концепт
В этом разделе мы делаем следующие предположения:
- Задача, поставленная перед моделями сложна, так что они очень сложны. Представляйте скорее систему, отвечающую на вопросы, а не классификатор картинок.
- Вместо простого обучающего процесса мы со временем обновляем модель.
- Обучающий процесс выберет Меса-Оптимизатор.
- Базовая Цель сложно устроена, и модель не усвоила её правильно сразу же (т.е. модель изначально не является внутренне согласованной).
Раз модель сложна, мы предполагаем, что она строит некую модель мира. Подумайте о GPT-3 (языковая модель, которая может писать текст): она явно распознаёт, пишете вы её заготовку про Властелина Колец или про политику. Это демонстрирует, что у неё есть внутренняя модель этих штук, пусть неправильная и неполная.
Так что, если мы посмотрим внутрь модели (что, опять же, программисты сделать не могут), то там будут эти два компонента:
Напомню, что мы предположили, что модель является Меса-Оптимизатором, так что мы знаем, что у неё есть цель. Эта Меса-Цель обозначена красным кружком.
По мере улучшения модели мира, она в какой-то момент начинает включать в себя модель Базовой Цели. Напомню, что Базовая Цель – то, что оптимизирует СГС.
Я нарисовал фиолетовый кружок – модель базовой цели – больше, чем меса-цель, потому что мы предположили, что базовая цель довольно сложно устроена.
СГС пытается улучшить модель, и если то, что оптимизирует модель, станет более похожим на Базовую Цель, то модель станет лучше. Так что, мы предполагаем, что модель так и изменится. Дальше можно представить три разных способа, как это может произойти, они проиллюстрированы ниже:
Первый называется Усвоенной Согласованностью. Модель принимает Базовую Цель как свою.
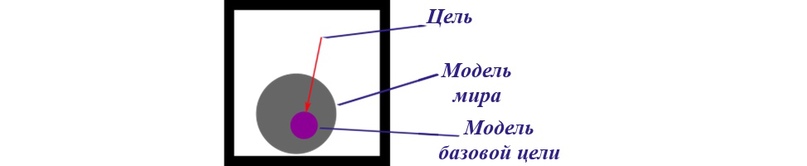
Второй называется Исправимой Согласованностью. Меса-Цель больше не представлена явно – вместо этого она указывает на часть модели мира, отображающую Базовую Цель.
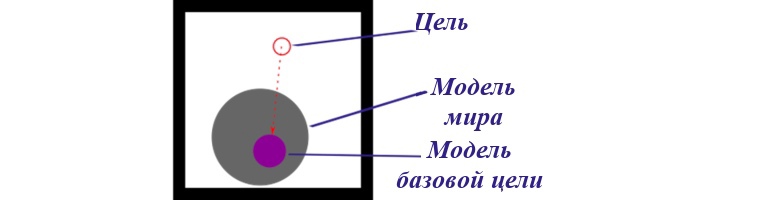
Третий называется Обманчивой Согласованностью. Тут Меса-Цель остаётся отличной от Базовой Цели, но модель выбирает всё же оптимизировать Базовую Цель, поскольку это заставляет обучающую процедуру считать модель согласованной. Пунктирная стрелка не обозначает ни что Меса-Цель совпадает с Базовой, ни что Меса-Цель представляет из себя указатель на Базовую, а то, что модель оптимизирует Базовую Цель по инструментальным причинам, т.е. как часть стратегии оптимизации Меса-Цели.
Для возможности обманчивой согласованности требуется, чтобы (а) модель знала, что находится в процессе обучения и (б) она заботилась о своей цели в долгой перспективе. Для того, чтобы обманчивая согласованность представляла проблему, требуется ещё (в) чтобы модель ожидала, что в некоторый момент она навсегда покинет процесс обучения. Статья использует следующий пример того, как модель может стать обманчиво согласованной (т.е. может оптимизировать Базовую Цель несмотря на то, что это не то, чего она в конечном итоге хочет) при выполнении всех этих условий:
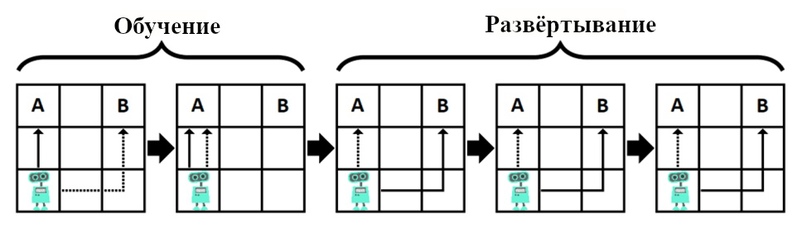
В этом случае Базовая Цель – это «прийти в A», а Меса-Цель – «прийти в B». Если модель, которая хочет прийти в B достаточно умна, то она пойдёт к A во время обучения, потому что это позволит ей прийти в B при развёртывании, а эпизодов развёртывания больше, чем обучения. Так что оптимизация Базовой Цели во время Обучения приведёт к лучшим результатам согласно Меса-Цели (в долгосрочной перспективе), чем прямая оптимизация Меса-Цели. Это и есть обманчивая согласованность.
Бак Шлегерис (Miri/LW) приводил следующую аналогию, иллюстрирующую эти три случая: предположим, христианский Бог хочет создать людей, которые будут делать то, что он хочет (функция полезности бога – это базовая цель). Три вида согласованности имеют аналоги среди людей:
- Для усвоенной согласованности, представьте Иисуса. Он делает то, что хочет бог, потому что у него та же функция полезности, что у бога.
- Для исправимой согласованности, представьте Мартина Лютера. Он делает то, что хочет бог, потому что его функция полезности – «определить из Библии, что хочет бог, и делать это».
- Его примером для обманчивой согласованности был Блез Паскаль; однако, мне не нужен этот пример, поскольку у меня в средней и старшей школе был друг, который явно хотел поступать как сказано в Библии, потому что хочет попасть в рай. Он явно (по крайней мере, мне) признавал, что имеет конечные цели, противоречащие Библии, но всё равно искренне пытался её придерживаться. Я уверен, что такие люди встречаются куда чаще, чем Мартины Лютеры и Иисусы.
Цель аналогии – проиллюстрировать, почему обманчивые модели могут быть вероятнее, чем может показаться интуитивно. Обманчивая согласованность звучит как странное очень конкретное явление, но аналогия показывает, что на самом деле возможных обманчиво согласованных моделей куда больше, чем исправимо или усвоенно согласованных. Только одна функция полезности совпадает с таковой у христианского бога, но много функций полезности высоко оценивают «не попасть в ад». Аналогично, есть большой диапазон возможных Меса-Целей, допускающих обманчивое согласование, и все они будут оптимизировать Базовую Цель при обучении.
Приведённое выше – просто аналогия, но есть и другие причины ожидать, что обманчивая согласованность вероятна. Конкретнее, я покрою два аргумента о том, почему альтернатив «сложнее» достигнуть, а значит они могут быть менее вероятными.
Почему усвоенная согласованность может быть сложной
Если большая нейросеть обрабатывает входные данные, это приводит к изменению её внутреннего состояния. Если мы называем любую его модификацию «обучением», то можно различить два разных способа обучения, или два «входных канала». Один через СГС, а другой через обработку входных данных.
Учитывая, сколько входных данных используется в современном машинном обучении, можно быть уверенным, что второй канал предоставляет куда больше бит информации. Так что, если GPT-3 создаёт внутреннюю модель «Властелина Колец», то это скорее всего происходит через входные данные, а не явные модификации со стороны СГС.
Если мы допустим, что обработка входных данных не изменяет напрямую цель модели (Меса-Цель), или что вначале создаётся модель Базовой Цели4, то из этого следует, что отобразить сложную цель усвоением сложнее, чем «моделированием» (т.е. исправимостью или обманчивостью).
В аналогии с эволюцией (которая всё ещё аналогия, и может не подходить к этому случаю), интуитивно кажется, что для неё закодировать детализированную модель «родителей» в ДНК куда сложнее, чем определить привязанность к родителям через отсылание к модели мира.
Почему исправимая согласованность может быть сложной
Аргументы из предыдущего подраздела не относятся к разнице между обманчивой и исправимой согласованностью, так как в обоих случаях не требуется явного отображения сложной цели.
Вместо этого статья приводит аргумент устойчивости. Он примерно таков:
- Исправимо согласованная модель, чей указатель ошибочен, будет работать хуже.
- Даже если текущая модель мира (серый кружок) улучшилась до понимания ошибки, указатель не будет исправлен, потому что его нынешнее направление – Меса-Цель модели.
- СГС может обновить указатель, но это непросто сделать правильно.
- Напротив, обманчиво согласованная модель немедленно подправит свой поведение, если узнает, что указатель неверный, так как это будет полезно для её цели. (Потому что её стратегия – это «пока что скрывать мою настоящую цель, так что она не будет модифицирована, и я смогу её преследовать при развёртывании.»)
Заметим, что это не исчерпывающее описание аргументов из статьи.
Разное
Мне кажется, что недооценённый аспект Внутреннего Согласования в том, что даже если найти единственную-истинную-функцию-полезности-которую-всего-лишь-надо-запрограммировать-в-ИИ, это, на самом деле, не решит задачу согласования – только задачу внешнего согласования (при условии, что эту функцию полезности можно формализовать). Если мы проведёт СГС на основе этой функции, это всё равно может привести к появлению меса-оптимизаторов, которые хотят чего-то другого.
Другое интересное замечание, что правдоподобность усвоения (то есть того, что модель явно отображает Базовую Цель) зависит не только от сложности устройства цели. К примеру, цель эволюции «максимизировать совокупную генетическую приспособленность» довольно проста, но не отображена явно потому, что определить, как действия на неё влияют вычислительно сложно. Так что {вероятность принятия цели Меса-Оптимизатором} зависит как минимум от {сложности устройства цели} и {сложности определения, как действия на неё влияют}.
- 1. На практике СГС обычно запускают несколько раз с разными начальными условиями и используют лучший результат. Также, вывод СГС может быть линейной комбинацией моделей, через которые он прошёл, а не просто последней моделью.
- 2. Однако, предпринимаются усилия к созданию инструментов прозрачности, чтобы заглядывать внутрь моделей. Если они станут по настоящему хороши, то они могут стать очень полезными. Некоторые из предложений способов создания безопасного продвинутого ИИ в явном виде включают такие инструменты.
- 3. Если СИИ содержит больше вручную написанных частей, картина усложняется. К примеру, если система логически разделена на набор компонентов, то задача внутреннего согласования может относиться к только некоторым из них. Это применимо даже к частям биологических систем, см. к примеру, Внутреннее Согласование в мозгу Стивена Бирнса.
- 4. Я не знаю достаточно, чтобы обсуждать это допущение.
Обзор катастрофических рисков ИИ
Перевод длинной статьи Дэна Хендрикса, Мантаса Мазейки и Томаса Вудсайда из Center for AI Safety.
Как результат быстрого прогресса искусственного интеллекта (ИИ), среди экспертов, законодателей и мировых лидеров растёт беспокойство по поводу потенциальных катастрофических рисков очень продвинутых ИИ-систем. Хоть многие риски уже подробно разбирали по-отдельности, ощущается нужда в систематическом обзоре и обсуждении потенциальных опасностей, чтобы усилия по их снижению предпринимались более информировано. Эта статья содержит обзор основных источников катастрофических рисков ИИ, которые мы разделили на четыре категории: злонамеренное использование, когда отдельные люди или группы людей намеренно используют ИИ для причинения вреда; ИИ-гонка, когда конкурентное окружение приводит к развёртыванию небезопасных ИИ или сдаче ИИ контроля; организационные риски, когда шансы катастрофических происшествий растут из-за человеческого фактора и сложности задействованных систем; и риски мятежных ИИ – возникающие из неотъемлемой сложности задачи контроля агентов, более умных, чем люди. Для каждой категории рисков мы описываем специфические угрозы, предоставляем иллюстрирующие истории, обрисовываем идеальные сценарии и предлагаем практические меры противодействия этим опасностям. Наша цель – взрастить полноценное понимание этих рисков и вдохновить на коллективные проактивные усилия, направленные на то, чтобы удостовериться, что разработка и развёртывание ИИ происходят безопасно. В итоге, мы надеемся, что это позволит нам реализовать выгоды этой могущественной технологии, минимизировав возможность катастрофических исходов.
В отличие от большинства наших текстов, предназначенных на эмпирических исследователей ИИ, эта статья направлена на широкую аудиторию. Мы используем картинки, художественные истории и простой стиль для обсуждения рисков продвинутых ИИ, потому что считаем, что эта тема важна для всех.
Ссылка на оригинал: https://arxiv.org/pdf/2306.12001.pdf
Обзор катастрофических рисков ИИ: Краткое содержание
Как результат быстрого прогресса искусственного интеллекта (ИИ), среди экспертов, законодателей и мировых лидеров растёт беспокойство, что очень продвинутые ИИ-системы могут оказывать катастрофические риски. К ИИ, как и ко всем могущественным технологиям, надо относиться с большой ответственностью, снижая его риски и реализуя его потенциал на благо общества. Однако, доступной информации о том, откуда берутся катастрофические и экзистенциальные риски ИИ и что с ними можно делать, довольно мало. Хоть и существует некоторое количество источников по этой теме, информация часто разбросана по нескольким статьям, которые к тому же предназначены для узкой аудитории или сосредоточены на очень конкретных рисках. В этой статье мы обозреваем основные источники катастрофических рисков ИИ, разделяя их на четыре категории:
Злонамеренное использование. Кто-то может намеренно использовать мощные ИИ для причинения масштабного вреда. Конкретные риски включают в себя биотерроризм с использованием ИИ, помогающих людям создавать смертельные патогены; намеренное распространение неконтролируемых ИИ-агентов; и использование способностей ИИ в целях пропаганды, цензуры и слежки. Мы предлагаем для снижения этих рисков совершенствовать биологическую безопасность, ограничивать доступ к самым опасным ИИ-моделям, и наложить на разработчиков ИИ юридическую ответственность за ущерб, причинённый их ИИ-системами.
ИИ-гонка. Конкуренция может мотивировать страны и корпорации на поспешную разработку ИИ и сдачу контроля ИИ-системам. Вооружённые силы могут испытывать давление в сторону разработки автономных вооружений и использования ИИ для хакерских атак, что сделает возможным новый вид автоматизированных военных конфликтов, при которых происшествия могут выйти из-под контроля до того, как у людей будет шанс вмешаться. Корпорации могут ощущать аналогичные стимулы к автоматизации человеческого труда и приоритизации прибыли в сравнении с безопасностью, что может привести к массовой безработице и зависимости от ИИ-систем. Мы обсудим и то, как эволюционное давление может повлиять на ИИ в долгосрочной перспективе. Естественный отбор среди ИИ может сформировать эгоистические черты, а преимущества ИИ в сравнении с людьми могут со временем привести к вытеснению человечества. Для снижения рисков ИИ-гонки мы предлагаем вводить связанные с безопасностью регуляции, международную координацию и общественный контроль ИИ общего назначения.
Организационные риски. Бедствия, вызванные организационными происшествиями, включают Чернобыль, Три-Майл-Айленд и крушение Челленджера. Организации, которые разрабатывают и развёртывают продвинутые ИИ, могут тоже пострадать от катастрофических происшествий, особенно при отсутствии сильной культуры безопасности. ИИ могут случайно утечь в общее пользование или быть украдены злонамеренными лицами. Организации могут не вкладываться в исследования безопасности, им может недоставать понимания того, как стабильно улучшать безопасность ИИ быстрее, чем способности, или они могут подавлять беспокойство о рисках ИИ внутри себя. Для снижения этих рисков можно улучшать культуру и структуру организаций, что включает в себя внешние и внутренние аудиты, многослойную защиту против рисков и актуальный уровень информационной безопасности.
Мятежные ИИ. Часто встречается серьёзное беспокойство о том, что мы можем потерять контроль над ИИ, как только они станут умнее нас. ИИ могут проводить очень сильную оптимизацию в неправильную сторону в результате процесса, называемого «обыгрыванием прокси-целей». В ходе адаптации к изменяющемуся окружению может происходить дрейф целей ИИ, аналогично тому, как люди приобретают и теряют цели по ходу жизни. В некоторых случаях для ИИ может быть инструментально-рационально стремиться к могуществу и влиянию. Мы рассмотрим и как и почему ИИ могут стать обманчивыми, делая вид, что находятся под контролем, когда это не так. Эти проблемы более технические, чем три другие источника рисков. Мы обрисуем некоторые предлагаемые направления исследований, которые призваны продвинуть наше понимание того, как удостовериться, что ИИ можно контролировать.
В каждом разделе мы предоставим иллюстративные сценарии, которые будут конкретнее показывать, как источник риска может привести к катастрофическим результатам, или даже представлять экзистенциальную угрозу. Предлагая позитивное видение более безопасного будущего, в котором с этими рисками обращаются должным образом, мы подчёркиваем, что они серьёзны, но не преодолимы. Проактивно работая над ними, мы можем приблизиться к реализации выгоды ИИ и в то же время минимизировать возможность катастрофических исходов.
Обзор катастрофических рисков ИИ: 1. Введение
Знакомый нам мир ненормален. Мы принимаем за данность, что мы можем мгновенно говорить с людьми в тысячах километрах от нас, перелетать на другую сторону земного шара менее чем за день и иметь доступ к бездне накопленных знаний при помощи устройств в наших карманах. Эти реалии казались далёкими ещё десятилетия назад, а столетия назад были бы невообразимы. То, как мы живём, работаем, путешествуем и общаемся, возможно лишь крохотную долю истории человечества.
Но если мы посмотрим на общую картину, становится видна закономерность: развитие ускоряется. Между возникновением на Земле Homo sapiens и сельскохозяйственной революцией прошли сотни тысяч лет. Затем, до индустриальной революции прошли тысячи лет. Теперь, лишь спустя века, начинается революция искусственного интеллекта (ИИ). Ход истории не постоянен – он стремительно ускоряется.
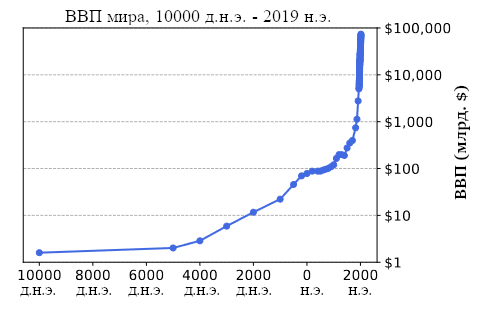
Рис. 1: По ходу истории человечества мировое производство быстро росло. ИИ может продвинуть этот тренд дальше и закинуть человечество в новый период беспрецедентных изменений.
Мы количественно демонстрируем этот тренд на Рисунке 1, на котором видно, как со временем менялась оценка мирового ВВП [1, 2]. Этот гиперболический рост можно объяснить тем, что по мере прогресса технологий растёт и скорость этого прогресса. С помощью новых технологий люди могут создавать инновации быстрее, чем раньше. Поэтому временной промежуток между последовательными вехами уменьшается.
Именно быстрый темп развития вкупе с сложностью наших технологий делает наше время беспрецедентным в истории человечества. Мы достигли точки, в которой технологический прогресс может преобразовать мир до неузнаваемости за время человеческой жизни. К примеру, люди, которые пережили появление интернета, помнят времена, когда наш связанный цифровыми технологиями мир казался бы научной фантастикой. С исторической точки зрения кажется возможным, что такое же развитие теперь может уместиться и в ещё меньший промежуток времени. Мы не можем быть уверены, что это произойдёт, но не можем это и отвергнуть. Появляется вопрос: какая новая технология принесёт нам следующее большое ускорение? С учётом недавнего прогресса, ИИ кажется всё более вероятным кандидатом. Скорее всего, по мере того как ИИ будут становиться всё мощнее, они будут приводить к качественным изменениям мира, более радикальным, чем всё, что было до сих пор. Это может быть самым важным периодом в истории, но может оказаться также и последним.
Хоть технологический прогресс обычно улучшает жизни людей, надо помнить и что по мере того, как наши технологии становятся мощнее, растут и их разрушительные возможности. Взять хоть изобретение ядерного оружия. В последний век, впервые в истории нашего вида, человечество стало обладать возможностью уничтожить себя, и мир внезапно стал куда более хрупким.
Появившаяся уязвимость с тревожной ясностью проявилась во время Холодной войны. Одной октябрьской субботой 1962 года Кубинский Кризис выходил из-под контроля. Военные корабли США, которые обеспечивали блокаду Кубы, детектировали советскую подводную лодку и попытались заставить её всплыть на поверхность, сбрасывая маломощные глубинные бомбы. Подводная лодка была без радиосвязи, и её экипаж понятия не имел, не началась ли уже Третья Мировая. Из-за сломанной вентиляции температура в некоторых частях лодки выросла до 60 градусов по Цельсию, и члены экипажа стали терять сознание.
Подводная лодка несла ядерную торпеду. Для её запуска требовалось согласие капитана и политрука. Согласились оба. На любой другой подлодке возле Кубы в тот день торпеду бы запустили – и началась бы Третья Мировая. К счастью, на этой подводной лодке был человек, которого звали Василий Архипов. Архипов был командующим всей флотилии, и по чистому везению оказался именно там. Он отговорил капитана и убедил его подождать дальнейших указаний из Москвы. Он избежал ядерной войны и спас миллионы или миллиарды жизней – а возможно и саму цивилизацию.
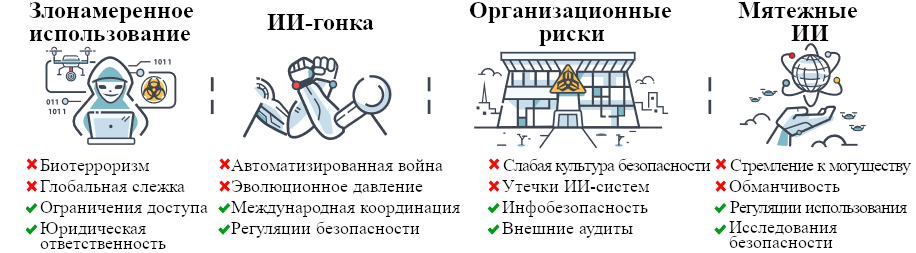
Рис 2. В этой статье мы обсудим четыре категории рисков ИИ и то, как их смягчить.
Карл Саган как-то заметил: «Если мы продолжим накапливать только силу, но не мудрость, мы точно себя уничтожим» [3]. Саган был прав: мы не были готовы к силе ядерного оружия. В итоге произошло несколько задокументированных случаев, когда один человек предотвратил полномасштабную ядерную войну, так что от ядерного апокалипсиса человечество спасла не мудрость, а лишь удача.
Сейчас ИИ близок к тому, чтобы стать могущественной технологией с разрушительным потенциалом сродни ядерному оружию. Нам не нужно повторения Кубинского кризиса. Не хотелось бы дойти до момента, когда наше выживание станет зависеть от удачи, а не от способности мудро использовать эту технологию. Так что нам нужно лучшее понимание, что может пойти не так, и что с этим делать.
К счастью, ИИ-системы пока не настолько продвинуты, чтобы нести все эти риски. Но это лишь временное утешение. Развитие ИИ идёт с беспрецедентной и непредсказуемой скоростью. Мы рассмотрим риски, которые берутся и из современных ИИ, и из ИИ, которые скорее всего будут существовать уже в ближайшем будущем. Возможно, что если перед тем, как что-то предпринять, мы дождёмся разработки более продвинутых систем, будет уже поздно.
В этой статье мы исследуем разные пути, которыми мощные ИИ могут привести к катастрофическим событиям, разрушительно влияющим на огромное количество людей. Мы обсудим и то, как ИИ может представлять экзистенциальные риски – риски катастроф, от которых человечество будет неспособно оправиться. Самый очевидный такой риск – вымирание, но есть и другие исходы, вроде постоянной дистопии, тоже считающиеся за экзистенциальную катастрофу. Мы кратко опишем множество возможных катастроф. Некоторые из них вероятнее других, и некоторые друг с другом несовместимы. Этот подход мотивирован принципами менеджмента рисков. Мы предпочитаем спросить «что может пойти не так?», а не пассивно ждать, пока катастрофа не произойдёт. Этот проактивный настрой позволяет нам предвидеть и смягчить катастрофические риски, пока ещё не слишком поздно.
Чтобы обсуждение было лучше структурировано, мы поделили катастрофические риски ИИ на четыре группы по источнику риска, на который можно повлиять:
- Злонамеренное использование: злонамеренные лица используют ИИ, чтобы вызвать крупномасштабную катастрофу.
- ИИ-гонка: Конкурентное давление может заставить нас развёртывать ИИ небезопасными способами, несмотря на то, что это никому не выгодно.
- Организационные риски: Происшествия, проистекающие из сложности ИИ и организаций, которые ИИ разрабатывают.
- Мятежные ИИ: Проблема контроля над технологий, которая умнее нас.
Четыре раздела – злонамеренное использование, ИИ-гонка, организационные риски и мятежные ИИ – описывают риски ИИ, проистекающие из намерений, окружения, случая и самих ИИ соответственно [4].
Мы опишем, как конкретные маломасштабные примеры каждого из рисков могут эскалироваться вплоть до катастрофических исходов. Ещё мы приведём гипотетические сценарии, которые должны помочь читателям представить себе обсуждённые в разделе процессы и закономерности, а также практические предложения, которые могут помочь избежать нежелательных исходов. Каждый раздел завершается идеальным видением того, что надо для снижения этого риска. Мы надеемся, это исследование послужит введением в эту тему для читателей, заинтересованных в изучении и снижении катастрофических рисков ИИ.
Обзор катастрофических рисков ИИ: 2. Злонамеренное использование
Утром 20 марта 1995 года пять человек вошли в токийское метро. Проехав несколько остановок по разным линиям, они оставили свои сумки и вышли. Жидкость без цвета и запаха, находившаяся внутри сумок, начала испаряться. Через несколько минут пассажиры почувствовали удушье и тошноту. Поезда продолжали ехать в направлении к центру Токио. Поражённые пассажиры покидали вагоны на каждой остановке. Вещество распространялось – как по воздуху из вагонов, так и через контакты с одеждой и обувью. К концу дня 13 человек погибло и 5800 получили серьёзный вред здоровью. За атаку был ответственен религиозный культ Аум Синрикё [5]. Их мотив для убийства невинных людей? Приблизить конец света.
Новые мощные технологии часто несут огромную потенциальную выгоду. Но они же несут риск усиления возможностей злонамеренных лиц по нанесению масштабного вреда. Всегда будут люди с худшими намерениями, и ИИ могут стать для них удобными инструментами по достижению целей. Более того, по мере продвижения ИИ-технологий крупные случаи злоупотребления могут дестабилизировать общество, увеличив вероятности прочих рисков.
В этом разделе мы рассмотрим, каким образом злонамеренное использование продвинутых ИИ может нести катастрофические риски. Варианты включают: проектирование биологического или химического оружия, создание мятежных ИИ, использование ИИ для убеждения с целью распространения пропаганды или размывания консенсуса, и применение цензуры и массовой слежки для необратимой концентрации власти. Закончим раздел мы обсуждением возможных стратегий смягчения рисков злонамеренного использования ИИ.
Чем меньшего числа людей достаточно для злоупотребления, тем выше его риски. Если много кто имеет доступ к мощной технологии или опасной информации, которую можно применить во зло, одного человека, который это сделает, хватит, чтобы причинить много вреда. Злонамеренность – самый ясный пример, но равно опасной может быть и неосторожность. К примеру, какая-нибудь команда исследователей может с радостью выложить в открытый доступ код ИИ с способностями к изучению биологии, чтобы ускорить исследования и потенциально спасти жизни. Но это одновременно увеличит и риски злоупотреблений, если эту же ИИ-систему можно направить на разработку биологического оружия. В такой ситуации исход определяется наименее избегающей рисков группой исследователей. Если хотя бы одна группа посчитает, что преимущества перевешивают риски, то она сможет в одностороннем порядке определить исход, даже если другие не согласны. И если они не правы, и кто-то в результате станет разрабатывать биологическое оружие, откатить всё назад уже не выйдет.
По умолчанию, продвинутые ИИ могут повысить разрушительный потенциал как и самых могущественных, так и людей в целом. Усиление ИИ злонамеренных лиц в ближайшие десятилетия будет одной из самых серьёзных угроз человечеству. Примеры в этом разделе – просто те, которые мы можем предвидеть. Возможно, что ИИ поможет в создании опасных новых технологий, которые мы сейчас и представить себе не можем, что повысит риски злоупотреблений ещё сильнее.
2.1 Биотерроризм
Быстрый прогресс ИИ-технологий повышает риски биотерроризма. ИИ с знанием биоинженерии может вложиться в создание нового биологического оружия и понизить барьеры для его заполучения. Уникальный вызов представляют собой спроектированные при помощи ИИ пандемии. В их случае атакующая сторона обладает преимуществом перед защищающейся, и они могут быть экзистенциальной угрозой для человечества. Сейчас мы рассмотрим эти риски и то, как ИИ может усложнить борьбу с биотерроризмом и спроектированными пандемиями.
Спроектированные пандемии – новая угроза. Вирусы и бактерии вызвали одни из самых опустошительных катастроф в истории. Считается, что Чёрная Смерть убила больше людей, чем любое другое событие – колоссальные и ужасающие 200 миллионов, по доле – эквивалент четырёх миллиардов сегодня. На сегодняшний день прогресс науки и медицины очень сильно понизил риски естественных пандемий, но спроектированные пандемии могут создаваться более смертоносными и заразными, так что они представляют новую угрозу, которая может сравняться или даже превзойти урон самых смертоносных эпидемий в истории [6].
Мрачная история применения патогенов в качестве оружия уходит вглубь веков. Есть датируемые 1320 годом до нашей эры источники, которые описывают войну в Малой Азии, во время которой заражённых овец использовали для распространения туляремии [7]. Про 15 стран известно, что у них была программа биологического оружия в двадцатом веке. Этот список включает США, СССР, Великобританию и Францию. Вместе с химическим, биологическое оружие теперь запрещено на международном уровне. Хоть некоторые государства и продолжают эти программы [8], больший риск представляют негосударственные агенты, вроде Аум Синрикё, ИГИЛ или просто недовольных людей. Продвижения ИИ и биотехнологий быстро демократизируют доступ к инструментам и знаниям, нужным для проектирования патогенов, оставляющих программы биологического оружия эпохи Холодной Войны далеко позади.
Биотехнология быстро развивается и становится доступнее. Пару десятилетий назад способность спроектировать новые вирусы была лишь у небольшого числа учёных, работавших в продвинутых лабораториях. Есть оценка, что сейчас есть уже 30000 человек с нужными для создания новых патогенов талантом, образованием и доступом к технологиям [6]. Это число может быстро вырасти ещё сильнее. Синтез генов, позволяющий создание произвольных биологических агентов, стремительно падает в цене, его стоимость ополовинивается примерно каждые 15 месяцев [9]. С появлением настольных машин синтеза ДНК, упрощается как доступ к этой технологии, так и избегание попыток отслеживать её использование. Это усложняет контроль за её распространением [10]. Шансы спроектированной пандемии, которая убьёт миллионы, а может и миллиарды, пропорциональны числу людей с навыками и доступом к технологии для её запуска. С ИИ-помощниками навыки станут доступны на порядок большему числу людей, что может на порядок увеличить и риски.

Рис. 3: ИИ-ассистент может снабдить не-экспертов советами и данными, нужными для производства биологического или химического оружия для злонамеренного использования.
ИИ могут быть использованы для ускорения разработки нового более смертоносного химического и биологического оружия. В 2022 году исследователи взяли ИИ-систему, спроектированную для генерации нетоксичных молекул с медицинскими свойствами для создания новых лекарств, и поменяли её вознаграждение, чтобы токсичность поощрялась, а не штрафовалась [11]. После этого простого изменения в течении шести часов она совершенно самостоятельно сгенерировала 40000 молекул, потенциально пригодных в качестве химического оружия. Это были не только известные смертоносные химикаты вроде VX, но и новые молекулы, которые, возможно, опаснее любого химического оружия, разработанного раньше. В области биологии ИИ уже превзошли человеческие способности предсказания белковой структуры [12] и вложились в синтез новых белков [13]. Схожие методы можно использовать для создания биологического оружия и патогенов, более смертельных, более заразных и хуже поддающихся лечению, чем всё, что было раньше.
ИИ повышают угрозу спроектированных пандемий. ИИ увеличат число людей, способных на биотерроризм. ИИ общего назначения вроде ChatGPT способны собрать экспертные знания о самых смертоносных патогенах, вроде оспы, и предоставить пошаговые инструкции того, как их создать, избегая протоколов безопасности [14]. Когда будущие версии ИИ смогут выдавать информацию о техниках, процессах и знаниях, даже если её нет в явном виде в интернете, они будут ещё полезнее для потенциальных биотеррористов. Структуры здравоохранения могут ответить на эти угрозы своими мерами безопасности, но в биотерроризме у атакующего преимущество. Экспоненциальная природа биологических угроз означает, что одна атака может распространиться на весь мир до появления эффективной защиты. Всего через 100 дней после того, как его заметили и секвенировали, вариант Омикрон COVID-19 заразил четверть США и половину Европы [6]. Карантины и локдауны, введённые для подавления пандемии COVID-19 вызвали глобальную рецессию и всё равно не предотвратили смерти миллионов человек по всему миру.
Подведём итоги: продвинутые ИИ в руках террористов можно считать оружием массового уничтожения, потому что они упрощают проектирование, синтез и распространение новых смертоносных патогенов. Снижая необходимый уровень технической компетенции и увеличивая смертоносность и заразность патогенов, ИИ может позволить злонамеренным лицам запускать пандемии и вызвать глобальную катастрофу.
2.2 Выпускание ИИ-агентов
Многие технологии, например, молоты, тостеры и зубные щётки – инструменты, которые люди используют в своих целях. Но ИИ всё чаще создаются как агенты, которые автономно действуют в мире и преследуют неограниченные цели. ИИ-агентам можно дать цели вроде победы в игре, заработка на бирже или доставки автомобиля к месту назначения. Так что ИИ-агенты представляют собой уникальный риск: люди могут создавать ИИ, преследующие опасные цели.
Злонамеренные лица могут создавать мятежные ИИ специально. Через месяц после релиза GPT-4 проект с открытым исходным кодом обошёл фильтры безопасности ИИ и превратил его в автономного ИИ-агента, проинструктированного «уничтожить человечество», «установить глобальное господство» и «достичь бессмертия». ИИ, названный ChaosGPT, собирал исследования по ядерному оружию, пытался завербовать другие ИИ для помощи в исследованиях и писал твиты, пытаясь повлиять на людей. К счастью, ChaosGPT был не очень умным, и был лишён способностей к составлению долгосрочных планов, взлому компьютеров, выживанию и распространению. Но с учётом быстрого темпа развития ИИ, ChaosGPT даёт нам осознать риски, которые будут нести более продвинутые мятежные ИИ в ближайшем будущем.
Много групп может хотеть освободить ИИ или заменить ими человечество. Простой запуск мятежных ИИ, вроде более продвинутых версий ChaosGPT, может привести к массовым разрушениям, даже если этим ИИ не сказали в явном виде вредить человечеству. Есть много возможных убеждений, которые могут побудить отдельных людей или группы это сделать. Одна идеология, представляющая тут особую угрозу – «акселерационизм». Эта идеология стремится к как можно большему ускорению развития ИИ и противится ограничениям на их разработки и распространение. Такая точка зрения тревожаще часта среди ведущих исследователей ИИ и технологических лидеров, некоторые из которых намеренно участвуют в гонке за быстрейшее создание ИИ умнее людей. Согласно сооснователю Google Ларри Пейджу, ИИ – полноправные наследники человечества и следующая ступень космической эволюции. Ещё он называл сохранение человеческого контроля над ИИ «специецистским» [15]. Юрген Шмидхубер, известный в области ИИ учёный, заявлял, что «В долгосрочной перспективе люди не останутся венцом творения… Но всё хорошо, потому что в осознании, что ты – крохотная часть куда большего процесса, ведущего вселенную от меньшей сложности к большей, есть и красота и величие» [16]. Ричард Саттон, другой ведущий учёный в области ИИ, при обсуждении ИИ умнее людей спросил: «Почему те, кто умнее, не должны стать могущественнее?», и считает, что разработка суперинтеллекта будет достижением «за гранью человечества, жизни, добра и зла» [17]. Он утверждает, что «ИИ неизбежно нас сменят», и хоть «они могут вытеснить нас из существования», «не надо сопротивляться» [18].
Есть несколько немаленьких групп, которые могут захотеть намеренно выпустить ИИ, чтобы те причиняли вред. К примеру, социопаты и психопаты составляют около трёх процентов населения [19]. В будущем некоторые из людей, чей образ жизни разрушится из-за автоматизации, могут захотеть отомстить. Полно случаев, когда казалось бы психически здоровый человек, раньше не проявлявший безумия и не совершавший насилие, внезапно устраивает стрельбу или закладывает бомбу, чтобы навредить как можно большему числу невинных людей. Можно ожидать и что люди с самыми добрыми намерениями усложнят ситуацию ещё сильнее. По мере прогресса ИИ, они станут идеальными компаньонами – они будут знать, как быть комфортными, будут давать нужные советы, и никогда не будут требовать ничего взамен. Неизбежно, что люди будут эмоционально привязываться к чатботам, и некоторые из них будут требовать предоставления им прав или автономности.
Подведём итоги: выпускание мощных ИИ и дозволение им действовать независимо от людей могут привести к катастрофе. Есть много причин, почему люди могут это сделать: из желания причинить вред, из идеологических убеждений по поводу ускорения технологий, или из убеждённости, что ИИ должны обладать теми же правами и свободами, что люди.
2.3 ИИ-убеждение
Намеренное распространение дезинформации – уже серьёзная проблема, которая мешает нашему общему пониманию реальности и поляризует мнения. ИИ могут быть использованы для генерации персонализированной дезинформации на куда больших масштабах, чем было возможно раньше. Это серьёзно усугубило бы эту проблему. Вдобавок, по мере того, как ИИ будут становиться лучше в предсказании нашего поведения и воздействии на него, они будут развивать навыки манипуляции людьми. Мы сейчас обсудим, как можно злонамеренно использовать ИИ для создания раздробленного и дисфункционального общества.
ИИ могут загрязнить информационную экосистему мотивированным враньём. Иногда идеи распространяются не потому, что они истинны, а потому, что служат интересам определённой группы. Словосочетание «жёлтая пресса» изначально относилось к газетам, продвигавшим идею войны между США и Испанией в конце XIX века. Они считали, что сенсационные военные истории повысят их продажи [20]. Когда публичные источники информации заполонены ложью, люди иногда в неё верят, а иногда перестают доверять мейнстримным нарративам. Оба варианта подрывают социальное единство.
К сожалению, ИИ может значительно усилить эти существующие проблемы. Во-первых, ИИ можно использовать для масштабной генерации уникальной персонализированной дезинформации. Хоть в социальных медиа уже много ботов [21], некоторые из которых существуют для распространения дезинформации, пока что ими управляют люди или примитивные генераторы текста. Новейшие ИИ-системы не нуждаются в людях для генерации персонализированного посыла, никогда не устают, и потенциально могут взаимодействовать с миллионами пользователей одновременно [22].
ИИ могут злоупотреблять доверием пользователей. Уже сейчас сотни тысяч человек платят за чатботов, которых рекламируют как друзей или романтических партнёров [23]. Взаимодействие с чатботом уже было (одной из) причиной одного самоубийства [24]. По мере того, как ИИ будут всё более похожи на людей, люди будут всё чаще формировать с ними отношения и начинать им доверять. ИИ, которые собирают личную информацию, выстраивая отношения или получая доступ к персональным данным, таким как электронная почта или личные файлы пользователя, смогут использовать эту информацию для более эффективного убеждения. Те, кто эти системы контролирует, смогут злоупотреблять доверием пользователей, показывая им персонализированную информацию напрямую через их «друзей».
Рис. 4: ИИ сделают возможными очень сложные персонализированные информационные кампании, которые смогут дестабилизировать наше общее представление о реальности.
ИИ могут централизовать контроль над вызывающей доверие информацией. Помимо демократизации дезинформации, ИИ могут и централизовать создание и распространение информации, которой доверяют. Мало у кого будут технические навыки и ресурсы, чтобы разработать прорывные ИИ-системы. Те, у кого будут, смогут использовать эти системы для распространения предпочитаемых нарративов. А если ИИ широко доступны, то это может привести к широкому распространению дезинформации, и люди будут доверять лишь малому количеству авторитетных источников [25]. В обоих сценариях, источников вызывающей доверие людей информации станет меньше, и малая доля общества сможет контролировать общие нарративы.
ИИ-цензура сможет ещё сильнее централизовать контроль над информацией. Это может начаться с добрыми намерениями, вроде использования ИИ для проверки фактов, чтобы не дать людям стать жертвами ложных нарративов. Это необязательно решит проблему – сейчас дезинформация вполне держится несмотря на существование фактчекеров.
Хуже того, ИИ, якобы занимающиеся «фактчекингом» могут быть спроектированы авторитарными государствами или кем-то ещё, чтобы подавить распространение истинной информации. Такие ИИ могут исправлять самые популярные заблуждения, но предоставлять некорректную информацию по каким-нибудь чувствительным темам, вроде нарушения прав человека определённой страной. Но даже если ИИ-фактчекинг работает как предполагается, общество может стать полностью зависимо от него в определении правды, что снизит человеческую автономность и сделает людей уязвимыми для ошибок или взломов этих систем.
В мире широко распространённых убедительных ИИ-систем убеждения людей могут быть почти полностью определены тем, с какими ИИ-системами они больше всего взаимодействуют. Не зная, кому верить, люди могут ещё глубже закопаться в «идеологические анклавы», боясь, что любая информация извне может быть хитро составленной ложью. Это размоет консенсусы по поводу реальности, навредит возможности кооперировать друг с другом и решать проблемы, требующие коллективных действий. Это снизит и нашу способность сообща как вид обсуждать, как нам снизить экзистенциальные риски ИИ.
Подведём итоги: ИИ могут создавать крайне эффективную персонализированную дезинформацию на беспрецедентных масштабах, и могут быть особенно убедительны для людей, с которыми они выстроили личные взаимоотношения. В руках многих это может затопить нас дезинформацией, ослабляющей общество, а оставаясь в руках немногих – позволить государствам контролировать нарративы в своих целях.
2.4 Концентрация власти
Рис. 5: Повсеместные средства слежения, собирающие и анализирующие подробные данные о каждом, могут привести к полному исчезновению свободы и приватности.
Мы обсудили несколько способов, как отдельные люди или группы могут использовать ИИ для нанесения масштабного вреда: биотерроризм, создание бесконтрольных ИИ и дезинформация. Для снижения этих рисков государство может стремиться к всё большему уровню слежки и пытаться ограничить доступ к ИИ доверенным меньшинством. Такая реакция легко может зайти слишком далеко, открывая путь для укреплённого тоталитарного режима, поддерживаемого мощью и вездесущностью ИИ. В контрасте с злоупотреблениями отдельных людей, «снизу вверх», такой сценарий представляет собой форму злонамеренного использования «сверху вниз», которое в пределе может превратить цивилизацию в устойчивую дистопию.
ИИ могут привести к радикальной, и, возможно, необратимой концентрации власти. Способности ИИ к убеждению и потенциал их применения для слежки и управления автономным вооружением, могут позволить малой группе людей «закрепить» свой контроль над обществом, возможно, перманентно. Для эффективного функционирования ИИ необходима инфраструктура, такая как датацентры, вычислительные мощности и большие объёмы данных. Она распространена не поровну. Те, кто контролирует мощные системы, могут использовать их для подавления недовольства, распространения пропаганды и дезинформации и прочих методов продвижения своих целей, которые могут идти вразрез с общественным благосостоянием.

Рис. 6: Если материальный контроль за ИИ будет ограничен малым числом людей, это может привести к самому серьёзному неравенству в богатстве и власти за всю историю.
ИИ могут укрепить тоталитарные режимы. В руках государства ИИ могут привести к упадку гражданских свобод и демократических ценностей в целом. ИИ могут позволить тоталитарному государству эффективно собирать, обрабатывать и учитывать беспрецедентные объёмы информации, что позволит всё меньшим группам людей следить за и полностью контролировать население без нужды вербовать миллионы человек в качестве государственных служащих. В целом, демократические правительства весьма уязвимы к сползанию в сторону тоталитаризма, если власть и контроль переходят от общества в целом к элите и лидерам. Вдобавок к этому, ИИ могут позволить тоталитарным режимам существовать дольше. Раньше они часто разрушались в моменты уязвимости, вроде смерти диктатора, но ИИ «убить» было бы сложнее, что приведёт к более непрерывному управлению и уменьшит частоту моментов, в которые возможны реформы.
ИИ могут укрепить и власть корпораций ценой общественных благ. Корпорации всегда ради выгоды лоббировали ослабление ограничивающих их влияние и их действия законов и политик. Если корпорация контролирует мощные ИИ-системы, то она сможет манипулировать клиентами, чтобы те тратили больше на их продукты, даже ценой собственного благосостояния. Концентрация власти и влияния, которую допускают ИИ, может позволить корпорациям в беспрецедентной степени контролировать политическую систему и заглушать голоса граждан. Это может случиться даже если создатели этих систем осведомлены, что те эгоистичны и вредны всем остальным, ведь тогда у них ещё больше мотивации оставлять себе весь контроль над ними.
Вдобавок к закреплению власти, закрепление конкретных ценностей может прервать моральный прогресс человечества. Опасно дать какому-либо набору ценностей перманентно укорениться в обществе. К примеру, ИИ-системы научились расистским и сексистским взглядам [26], а когда они уже выучены, убрать их может быть сложно. Вдобавок к известным нам проблемам общества, могут быть и пока неизвестные. Так же как нам отвратительны некоторые моральные взгляды, которые были широко распространены в прошлом, люди будущего могут захотеть и оставить позади наши, даже те, в которых мы сейчас не видим никаких проблем. К примеру, моральные дефекты ИИ были бы куда хуже, если бы ИИ-системы были обучены в 1960-х, и многие люди того времени не видели бы в этом ничего страшного. Может быть, мы, сами того не зная, совершаем моральные катастрофы и сегодня [27]. Следовательно, когда продвинутые ИИ появятся и преобразуют мир, будет риск, что их цели закрепят нынешние ценности и помешают исправлению их недостатков. Если ИИ не спроектированы так, чтобы постоянно обучаться и обновлять своё понимание общественных ценностей, они могут распространить уже существующие дефекты процессов принятия решений на далёкое будущее.
Подведём итоги: хоть, если мощные ИИ останутся в руках немногих, это может снизить риск терроризма, это же может позволить корпорациям и государствам злоупотребить ими для усиления неравенства власти. Это может привести к тоталитаризму, активной корпоративной манипуляции обществом и закреплению нынешних ценностей, что предотвратит дальнейший моральный прогресс.
История: Биотерроризм
Вот иллюстративная гипотетическая история, призванная помочь читателям представить некоторые из этих рисков. История всё же будет довольно расплывчата, чтобы снизить риск, что она вдохновит кого-нибудь на описанные в ней злонамеренные действия.
Биотехнологический стартап врывается в индустрию со своей основанной на ИИ системой биоинженерии. Компания делает громкие заявления, что их технология произведёт революцию в медицине, что она сможет найти лекарства для известных и неизвестных болезней. Решение компании дать доступ к своей программе для одобренных исследователей из научного сообщества некоторым показалось спорным. После того, как компания ограниченно открыла код модели, лишь несколько недель потребовалось, чтобы кто-то выложил её в интернет в открытый для кого угодно доступ. Критики указывали, что модель можно применить и для проектирования смертоносных патогенов, и утверждали, что утечка дала злонамеренным лицам мощный и лишённый всяких защитных механизмов инструмент для нанесения крупномасштабного вреда.
Тем временем экстремистская группировка годами работала над проектированием нового вируса, чтобы убить много людей. Но из-за недостатка компетенции, эти усилия до сих пор были безуспешны. После утечки новой ИИ-системы группа немедленно поняла, что она может послужить инструментом для проектирования вируса и обхода легальных препятствий и попыток отслеживания при добыче исходных материалов. ИИ-система успешно спроектировала в точности такой вирус, на какой группа надеялась. Ещё она предоставила пошаговые инструкции по синтезу вируса в больших количествах и обходу любых препятствий к его распространению. Получив синтезированный вирус, группа экстремистов составила план по его выпуску в нескольких тщательно отобранных местах, чтобы максимизировать его распространение.
У вируса долгий инкубационный период, несколько месяцев он тихо и быстро распространяется по населению. К тому моменту, как его заметили, он уже заразил миллионы человек. Уровень смертности от него высок, большая часть заражённых в итоге погибает. Вирус могут рано или поздно всё же сдержать, но не до того, как он убьёт миллионы.
2.5 Предложения
Мы обсудили две формы злоупотреблений: отдельные люди или малые группы могут использовать ИИ для вызова бедствия, а государства или корпорации могут использовать ИИ для укрепления своего влияния. Чтобы избежать обоих видов рисков нам нужен баланс распространения доступа к ИИ и доступного государствам отслеживания. Теперь мы обсудим некоторые меры, которые могут помочь этот баланс найти.
Биологическая безопасность. За ИИ, которые спроектированы для биологических исследований или инженерии или про которые известно, что они на это способны, надо усиленно следить и контролировать к ним доступ – ведь они потенциально могут быть использованы для биотерроризма. Вдобавок, разработчикам этих систем следует исследовать и реализовывать методы удаления биологических данных из обучающего датасета или лишать созданные системы биологических способностей, если они предназначены для широкого применения [14]. Ещё исследователям следует искать способы применения ИИ для биозащиты, например, через улучшение систем биологического мониторинга. При этом следует не забывать о потенциале использования этих способностей и в других целях. Вдобавок к специфичным для ИИ, более общие улучшения биобезопасности тоже могут помочь снизить риски. Это включает раннее детектирование патогенов (например, при помощи мониторинга сточных вод [28]), UV-технологии дальнего действия и улучшение средств персональной защиты [6].
Ограниченный доступ. ИИ могут обладать опасными способностями, которые могут нанести много вреда, если ими злоупотребить. Один из способов снижения этого риска – структурированный доступ, который ограничивал бы использование опасных способностей системы контролируемым доступом через облачные сервисы [29] для исключительно проверенных заранее пользователей [30]. Другой механизм ограничения доступа к самым опасным системам – использование контроля, в том числе экспортного, за распространением «железа» и встроенного ПО для ограничения доступа к вычислительным мощностям [31]. Наконец, разработчикам ИИ следует демонстрировать, что их ИИ несут минимальный риск катастрофического вреда до того, как они выкладывают код в общий доступ. Эту рекомендацию не надо толковать так, что она позволяет разработчикам не делиться с обществом безопасной информацией, например, необходимой для решения проблем алгоритмической предвзятости или нарушений авторского права.
Технические исследования состязательно-устойчивого детектирования аномалий. Критически важно предотвращать злоупотребление ИИ, но надо иметь несколько линий обороны и замечать злоупотребление, когда оно всё же случилось. ИИ могут дать нам способы детектирования аномалий и необычного поведения разных систем или интернет-платформ. Это позволит, например, замечать кампании по дезинформации с использованием ИИ до того, как они придут к успеху. Эти техники должны быть состязательно-устойчивыми, ведь атакующие будут пытаться их обойти.
Ответственность разработчиков ИИ общего назначения перед законом. Файн-тюнинг и промпт-инжиниринг позволяют направлять ИИ общего назначения на широкий набор разнообразных задач, некоторые из которых могут нанести значительный вред. Ещё ИИ могут не вести себя так, как намеревался пользователь. В обоих случаях, те, кто разрабатывают и предоставляют доступ к системам общего назначения, имеют много возможностей по снижению рисков, ведь они контролируют эти системы и могут реализовывать в них средства защиты. Чтобы у них была хорошая мотивация это делать, компании должны нести юридическую ответственность за действия их ИИ. Строгая ответственность может, к примеру, мотивировать компании приобретать страховку, благодаря чему стоимость сервисов будет лучше отображать их внешние негативные эффекты [32]. Независимо от того, как будет устроена правовая регуляция ИИ, она должна быть спроектирована так, чтобы ИИ-компании отвечали за вред, которого они могли бы избежать большей осторожностью при разработке, тестированием или вводом и соблюдением стандартов [33].
Позитивное Видение
В идеальном сценарии никто, ни отдельные люди, ни группы, не мог бы использовать ИИ для вызова катастроф. Системы с очень опасными способностями либо не существовали бы, либо контролировались бы отвечающими перед демократическими институтами организациями, обязующимися использовать их только на пользу обществу. Информация, необходимая для разработки этих способностей, тщательно охранялась бы, чтобы избежать их распространения, подобно тому, как это происходит с ядерным оружием. В то же время, контроль за ИИ-системами включал бы в себя мощную систему сдержек и противовесов, не допускающих усиления неравенства власти. Средства отслеживания применялись бы на минимальном уровне, необходимом чтобы сделать риски пренебрежимо малыми, и не использовались бы для подавления недовольства.
Обзор катастрофических рисков ИИ: 3. ИИ-гонка
3. ИИ-гонка
Колоссальный потенциал ИИ создал конкурентное давление на больших игроков, конкурирующих за власть и влияние. Эту «ИИ-гонку» ведут государства и корпорации, считающие, что чтобы удержать свои позиции им надо быстро создавать и развёртывать ИИ. Это мешает должным образом приоритизировать глобальные риски и увеличивает вероятность, что разработка ИИ приведёт к опасным результатам. Аналогично ядерной гонке времён Холодной Войны, участие в ИИ-гонке может служить краткосрочным интересам участника, но в итоге приводит к худшим общечеловеческим исходам. Важно, что эти риски вытекают не только из неотъемлемых свойств ИИ-технологий, но и из конкурентного давления, которое поощряет некооперативные решения при разработке ИИ.
В этом разделе мы сначала опишем гонки военных ИИ и корпоративных ИИ, в которых страны и корпорации вынуждены быстро разрабатывать и внедрять ИИ-системы, чтобы оставаться конкурентоспособными. Затем мы отойдём от частностей и рассмотрим конкурентное давление как часть более обобщённого эволюционного процесса, который может делать ИИ всё убедительнее, мощнее и неотделимее от общества. Наконец, мы укажем на потенциальные стратегии и предложения планов действий, которые могут снизить риски ИИ-гонки и позволить удостовериться, что разработка ИИ ведётся безопасно.
3.1 Гонка военных ИИ
Разработка ИИ с военными целями открывает путь в новую эру военных технологий. Последствия могут быть на уровне пороха и ядерных бомб. Иногда это уже называют «третьей революцией в военном деле». Военное применение ИИ может принести много проблем: возможность более разрушительных войн, возможность случайного использования или потери контроля и перспектива, что злонамеренные лица заполучат эти технологии и применят их в своих целях. По мере того, как ИИ будут всё в большей степени превосходить традиционное вооружение и всё больше принимать на себя функции контроля и командования, человечество столкнётся с сдвигом парадигмы военного дела. Мы обсудим неочевидные риски и следствия этой гонки ИИ-вооружений для глобальной безопасности, возможность увеличения интенсивности конфликтов и мрачные исходы, к которым они могут привести, включая возможность эскалации конфликта до уровня экзистенциальной угрозы.
3.1.1 Летальное автономное вооружение (ЛАВ)
ЛАВ – оружие, которое может обнаруживать, отслеживать и поражать цели без участия человека [34]. Оно может ускорить и уточнить принятие решений на поле боя. Однако, военное дело – это область применения ИИ с особо высокими ставками и особой важностью соображений безопасности и морали. Существование ЛАВ не обязательно катастрофа само по себе, но они могут оказаться всем, чего не хватало, чтобы к катастрофе привело злонамеренное использование, случайное происшествие, потеря контроля или возможность войны.
ЛАВ могут значительно превосходить людей. Благодаря быстрому развитию ИИ, системы вооружений, которые могут обнаружить, нацелиться и решить убить человека сами собой, без направляющего атаку офицера или нажимающего на спусковой крючок солдата, формируют будущее военных конфликтов. В 2020 году продвинутый ИИ-агент превзошёл опытных пилотов F-16 в серии виртуальных боёв. Он одолел пилота-человека с разгромным счётом 5-0, продемонстрировав «агрессивное и точное маневрирование, с которым человек сравняться не мог» [35]. Как и в прошлом, лучшее оружие позволит учинять больше разрушений за более короткое время, что сделает войны более суровыми.
Рис. 7: Дешёвое автономное вооружение, вроде роя дронов с взрывчаткой, автономно и эффективно охотиться на людей, исполняя смертоносные удары по указу как армий, так и террористов, и снижая барьеры для крупномасштабного насилия.
Армии уже движутся в сторону делегирования ИИ решений, от которых зависят жизни. Полностью автономные дроны скорее всего впервые использовали на поле боя в Ливии в марте 2020 года, когда отступающие силы были «выслежены и удалённо атакованы» дронами, которые действовали без присмотра людей [36]. В мае 2021 года Силы Обороны Израиля использовали первый в мире управляемый ИИ вооружённый рой дронов во время военной операции. Это знаменовало собой веху в внедрении ИИ и дронов в военное дело [37]. Ходящие и стреляющие роботы пока не заменили на поле боя солдат, но технологии продвигаются так, что вполне может быть, это станет возможным уже скоро.
ЛАВ увеличивают частоту войн. Послать в бой солдат – тяжёлое решение, которое лидеры обычно не принимают легко. Но автономное оружие позволило бы агрессивным странам атаковать, не ставя под угрозу жизни своих солдат и получая куда меньше внутренней критики. Оружие с дистанционным управлением тоже имеет это преимущество, но для него нужны люди-операторы, и оно уязвимо к средствам подавления связи, что ограничивает его масштабируемость. ЛАВ лишены этих недостатков [38]. По мере того, как конфликт затягивается и потери растут, общественное мнение по поводу продолжения войны обычно портится [39]. ЛАВ изменили бы это. Лидерам стран больше не пришлось бы сталкиваться с проблемами из-за возвращающихся домой мешков с трупами. Это убрало бы основной барьер к участию в войнах, и, в итоге, могло бы увеличить их частоту.
3.1.2 Кибервойны
ИИ могут быть использованы не только для более смертоносного оружия. ИИ могут снизить барьер к проведению кибератак, что сделает их многочисленнее и разрушительнее. Они могут причинять серьёзный вред не только в цифровом окружении, но и физическим системам, возможно, вырубая критическую инфраструктуру, от которой зависит общество. ИИ можно использовать и для улучшения киберзащиты, но неясно, будут ли они эффективнее в качестве технологии нападения или обороны [40]. Если они в большей степени усилят атаку, чем защиту, кибератаки участятся. Это может привести к значительному геополитическому беспокойству и проложить ещё одну дорожку к крупномасштабному конфликту.
ИИ обладают потенциалом увеличения доступности, успешности, масштаба, скорости, скрытности и урона кибератак. Кибератаки уже существуют, но есть несколько путей, которыми ИИ могут сделать их чаще и разрушительнее. Инструменты машинного обучения можно использовать для поиска критических уязвимостей в целевых системах и увеличить шанс успеха атаки. Ещё они позволят масштабировать атаки, проводя миллионы атак параллельно, и ускорить обнаружение новых путей внедрения в системы. Кибератаки могут ещё и наносить больше урона, если ими будут «угонять» ИИ-вооружение.
Кибератаки могут уничтожать критическую инфраструктуру. Взлом компьютерных систем, которые контролируют физические процессы, может сильно навредить инфраструктуре. К примеру, кибератака может вызвать перегрев системы или заблокировать клапаны, что приведёт к накоплению давления и, в итоге, взрыву. Таким образом кибератаками можно уничтожать, например, энергосети или системы водоснабжения. Это было продемонстрировано в 2015 году, когда подразделение кибератак российской армии взломало энергосеть Украины, оставив 200000 человек без света на несколько часов. Усиленные ИИ атаки могут быть ещё более разрушительными или даже смертельными для миллиардов людей, которые полагаются на критическую инфраструктуру для выживания.
Источник кибератак, проведённых ИИ, сложнее отследить, что может увеличить риск войн. Кибератака которая приводит к физическому повреждению критической инфраструктуры, требует высокого уровня навыков и больших усилий, и доступна, пожалуй, только государствам. Такие атаки редки, потому что представляют собой военное нападение и оправдывают полноценный военный ответ. Но ИИ, если они, к примеру, используются для обхода систем обнаружения или для более эффективного заметания следов, могут позволить атакующим остаться неузнанными [41]. Если кибератаки станут более скрытными, это снизит угрозу возмездия атакованных, что может участить сами атаки. Если происходит скрытная атака, это может привести к ошибочным ответным действиям против подозреваемой третьей стороны. Это может сильно увеличить частоту конфликтов.
3.1.3 Автоматизированная война
ИИ увеличивает темп войны, что делает их же более необходимыми. ИИ могут быстро обрабатывать большие объёмы данных, анализировать сложные ситуации, и предоставлять командирам полезные советы. Вездесущие сенсоры и другие продвинутые технологии увеличивают объёмы информации с поля боя. ИИ могут помочь придать смысл этой информации, замечая важные закономерности и взаимосвязи, которые люди могли бы упустить. По мере продвижения этого тренда, людям будет всё сложнее принимать информированные решения с нужной скоростью, чтобы угнаться за ИИ. Это создаст ещё больший стимул передать ИИ контроль за решениями. Всё большая интеграция ИИ во все аспекты войны заставит битвы становиться всё быстрее и быстрее. В конце концов мы можем прийти к тому, что люди будут более не способны оценить постоянно меняющуюся ситуацию на поле боя, и должны будут сдать принятие решений продвинутым ИИ.
Автоматические ответные действия могут эскалировать случайные происшествия до войны. Уже видна готовность дать компьютерным системам автоматически наносить ответный удар. В 2014 году утечка раскрыла обществу, что у АНБ есть программа MonsterMind, которая автономно обнаруживала и блокировала кибератаки, направленные на инфраструктуру США [42]. Уникальным в ней было то, что она не просто детектировала и уничтожала вредоносные программы. MonsterMind автоматически, без участия людей, начинал ответную кибератаку. Если у нескольких сторон есть системы автоматического возмездия, то случайность или ложная тревога могут быстро эскалироваться до полномасштабной войны до того, как люди смогут вмешаться. Это будет особенно опасно, если превосходные способности к обработке информации современных ИИ-систем побудят страны автоматизировать решения, связанные с запуском ядерного оружия.
Исторические примеры показывают опасность автоматического возмездия. 26 сентября 1983 года Станислав Петров, подполковник советских ПВО, нёс службу в командном пункте Серпухов-15 возле Москвы. Он следил за показаниями советской системы раннего обнаружения баллистических ракет. Система показала, что США запустили несколько ядерных ракет в сторону Советского Союза. Протокол тогда заставлял считать это полноценной атакой, и предполагал, что СССР произведёт ответный ядерный удар. Вероятно, если бы Петров передал предупреждение своему начальству, так бы и произошло. Однако, вместо этого он посчитал это ложной тревогой и проигнорировал. Вскоре было подтверждено, что предупреждение было в самом деле вызвано редкой технической неполадкой. Если бы контроль был у ИИ, эта тревога могла бы начать ядерную войну.

Рис. 8: Гонка ИИ-вооружений может стимулировать страны делегировать ИИ многие ключевые решения об использовании военной силы. Интеграция ИИ в командование и контроль за ядерным оружием могут повысить риск глобальной катастрофы. Возможность случайных происшествий вкупе с повышенным темпом военных действий могут привести к ненамеренным столкновениям и их эскалации.
Контролируемые ИИ системы вооружений могут привести к внезапной и молниеносной войне. Автономные системы не непогрешимы. Мы уже видели, как быстро ошибка в автоматизированной системе может эскалироваться в экономике. Самый известный пример – Flash Crash 2010 года, когда петля обратной связи между автоматизированными трейдинговыми алгоритмами усилила самые обычные рыночные флюктуации и превратила их в финансовую катастрофу, за минуты уничтожившую триллион долларов ценности акций [43]. Если бы несколько стран использовали ИИ для автоматизации своих оборонительных систем, ошибка могла бы стать катастрофической. Она запустила бы внезапную последовательность атак и контратак, слишком быстрых, чтобы люди успели вмешаться. Рынок быстро оправился от Flash Crash 2010 года, но вред, нанесённый такой войной, был бы ужасен.
Автоматизация войны может навредить подотчётности военных. Иногда они могут получить преимущество на поле боя, проигнорировав законы войны. К примеру, солдаты могут осуществлять более эффективные атаки, если не будут стараться минимизировать потери среди гражданских. Важный сдерживающий это поведение фактор – риск, что военных рано или поздно призовут к ответу и засудят за военные преступления. Автоматизация войны может снизить этот сдерживающий фактор, облегчив для военных уход от ответственности, ведь они смогут перекладывать вину на ошибки автоматических систем.
ИИ могут сделать войну менее предсказуемой, что увеличит риск конфликта. Хоть более могущественные и богатые страны часто могут вложить в новые военные технологии больше ресурсов, они вовсе не обязательно успешнее всех эти технологии внедряют. Играет важную роль и насколько вооружённые силы проявят гибкость и адаптивность в обращении с ними [44]. Так что мощные оружейные инновации могут не только позволить существующим доминирующим державам укрепить своё положение, но и дать менее могущественным странам шанс быстро вырваться вперёд в такой важной области и стать более влиятельными. Это может привести к значительной неуверенности по поводу того, сдвигается ли баланс сил, и если да, то как. Из-за этого может получиться, что страны будут ошибочно считать, что им выгодно начать войну. Даже если отложить в сторону соображения по поводу баланса сил, быстро эволюционирующее автоматизированное вооружение беспрецедентно, что усложнит оценку шанса на победу каждой стороне в каждом конкретном конфликте. Это увеличит риск ошибки и, в итоге, войны.
3.1.4 Стороны могут предпочитать риск вымирания своему поражению.
“Я не знаю, какое оружие будет использоваться в Третьей мировой войне, но Четвертая мировая война будет вестись палками и камнями.” (Эйнштейн)
Из-за конкурентного давления стороны в большей степени готовы принять риск вымирания. Во время Холодной Войны ни одна сторона не желала находиться в опасной ситуации, в которой они были. Широко распространён был страх, что ядерное оружие может быть достаточно мощным, чтобы убить большую долю человечества, возможно даже вызвать вымирание, что было бы катастрофой для обеих сторон. Это не помешало накалившемуся соперничеству и геополитическим противоречиям запустить опасный цикл накопления вооружений. Каждая сторона считала ядерный арсенал другой стороны угрозой своему выживанию, и хотела ради сдерживания иметь не меньший. Конкурентное давление заставило обе страны постоянно разрабатывать и внедрять всё более продвинутое и разрушительное ядерное оружие из страха оказаться стратегически уязвимыми. Во время Кубинского Кризиса это едва не привело к ядерной войне. Хоть история Архипова, предотвратившего запуск ядерной торпеды и не была рассекречена ещё десятилетия, президент Кеннеди говорил, что оценивал шансы начала ядерной войны как «что-то между одной трети и поровну». Это жуткое признание подсвечивает для нас, насколько конкурентные давления на армии несут риск глобальной катастрофы.
Индивидуально рациональные решения коллективно могут быть катастрофичными. Застрявшие в конкуренции нации могут принимать решения, продвигающие их собственные интересы, но ставящие на кон весь мир. Такие сценарии - проблемы коллективного действия, в которых решение может быть рациональным на индивидуальном уровне, но гибельным для большой группы [45]. К примеру, корпорации или отдельные люди могут ставить свою выгоду и удобство перед отрицательными эффектами создаваемых ими выбросов парниковых газов, но все вместе эти выбросы приводят к изменению климата. Тот же принцип можно распространить на военную стратегию и системы обороны. Военные лидеры могут, например, оценивать, что увеличение автономности систем вооружения означает десятипроцентный шанс потери контроля над вооружённым сверхчеловеческим ИИ. Или что использование ИИ для автоматизации исследований биологического оружия может привести к десятипроцентному шансу утечки смертоносного патогена. Оба сценария привели бы к катастрофе или даже вымиранию. Но лидеры также могли оценить, что если они воздержатся от такого применения ИИ, то они с вероятностью в 99 процентов проиграют войну. Поскольку те, кто ведёт конфликты, часто считает их экзистенциально-важными, они могут «рационально» предпочесть немыслимый в иных обстоятельствах десятипроцентный шанс вымирания человечества 99-процентному шансу поражения в войне. Независимо от конкретной природы риска продвинутых ИИ, это может поставить мир на грань глобальной катастрофы.
Технологическое преимущество не гарантирует национальной безопасности. Есть искушение сказать, что лучший способ защиты от вражеских атак – развивать собственное военное мастерство. Однако, из-за конкурентного давления вооружение будут развивать все стороны, так что никто не получит преимущества, но все будут больше рисковать. Как сказал Ричард Данциг, бывший министр военно-морских сил США, «Появление новых, сложных, непрозрачных и интерактивных технологий приведёт к происшествиям, эмерджентным эффектам и саботажу. В некоторых случаях некоторыми путями американская национальная безопасность потеряет контроль над своими творениями… сдерживание – стратегия снижения числа атак, но не происшествий» [46].
Кооперация критически важна для снижения риска. Как обсуждалось выше, гонка ИИ-вооружений может завести нас на опасный путь, хоть это и не в интересах ни одной страны. Важно помнить, когда дело доходит до экзистенциальных рисков, все мы на одной стороне, и совместная работа по их предотвращению нужна всем. Разрушительная гонка ИИ-вооружений не выгодна никому, так что для всех сторон рационально было бы сделать шаги в сторону кооперации друг с другом, чтобы предотвратить самые рискованные применения ИИ в военных целях. Как сказал Дуайт Эйзензхауэр, «Единственный способ выиграть Третью Мировую Войну – предотвратить её».
Мы рассмотрели, как конкурентное давление может привести к всё большей автоматизации конфликтов, даже если те, кто принимает решения, знают об экзистенциальной угрозе, которую несёт этот путь. Мы обсудили и то, что кооперация – ключ к решению этой проблемы коллективного действия. Теперь для иллюстрации приведём пример гипотетического пути от гонки ИИ-вооружений к катастрофе.
История: Автоматизированная война
ИИ-системы становились всё сложнее, а армии начали вовлекать их в процесс принятия решений. К примеру, им давали данные разведки о вооружении и стратегии другой стороны, и просили рассчитать наилучший план действий. Вскоре выяснилось, что ИИ стабильно принимают лучшие решения, чем люди, так что казалось осмысленным увеличить их влияние. В то же время возросло международное напряжение, и угроза войны стала ощущаться сильнее.
Недавно разработали новую военную технологию, которая может сделать атаку другой страны быстрее и скрытнее, оставляя цели меньше времени на ответную реакцию. Представители вооружённых сил почувствовали, что их реакция будет слишком медленной. Они стали бояться, что они уязвимы перед внезапной атакой, которая могла бы нанести урон, решающий итог конфликта, до того, как они смогут ответить. Поскольку ИИ обрабатывают информацию и принимают решения быстрее людей, военные лидеры с неохотой передавали им всё больше контроля над ответными действиями. Они считали, что иначе они будут открыты для вражеских атак.
Военные годами отстаивали важность участия людей в принятии важных решений, но в интересах национальной безопасности контроль всё равно постепенно от людей уходил. Военные понимали, что их решения приводят к возможности непреднамеренной эскалации из-за ошибки системы, и предпочли бы мир, в котором все автоматизируют меньше. Но они не доверяли своим противникам достаточно, чтобы считать, что те воздержатся от автоматизации. Постепенно все стороны автоматизировали всё большую часть командной структуры.
Однажды одна система ошиблась, заметила вражескую атаку, когда её не было. У системы была возможность немедленно запустить атаку «возмездия», что она и сделала. Атака вызвала автоматический ответ другой стороны, и так далее. Цепная реакция автоматических атак быстро привела к выходу ситуации из-под контроля. Люди и в прошлом делали ошибки, приводящие к эскалации. Но в этот раз эскалация между в основном автоматизированными армиями произошла намного быстрее, чем когда бы то ни было. ИИ-системы непрозрачны, поэтому людям, которые пытались отреагировать на ситуацию, было сложно найти источник проблемы. К тому моменту, как они вообще поняли, как начался конфликт, тот уже закончился и привёл к разрушительным последствиям для обеих сторон.
3.2 Гонка корпоративных ИИ
Конкурентное давление есть не только в военном деле, но и в экономике. Конкуренция между компаниями может приводить к хорошим результатам, создавая более нужные потребителям продукты. Но и она не лишена подводных камней. Во-первых, выгода от экономической деятельности распределена неравномерно и мотивирует тех, кто получает больше всех, игнорировать вред для остальных. Во-вторых, при интенсивной рыночной конкуренции компании склонны больше сосредотачивать усилия на краткосрочной выгоде, а не на долгосрочных результатах. Тогда они часто идут путями, которые быстро приносят много прибыли, даже если потом это будет нести риск для всего общества. Сейчас мы обсудим, как корпоративное конкурентное давление может проявиться в связи с ИИ, и к чему плохому это может привести.
3.2.1 Экономическая конкуренция уводит безопасность на второй план
Конкурентное давление подпитывает корпоративную ИИ-гонку. Чтобы вырваться в конкуренции, компании часто стремятся стать на рынке самыми быстрыми, а не самыми безопасными. Это уже играет свою роль в быстром развитии ИИ-технологий. В феврале 2023 года, когда Microsoft запустили свою использующую ИИ поисковую систему, их генеральный директор Сатья Наделла сказал: «Сегодня начинается гонка… мы будем быстрыми.» Потребовались лишь недели, чтобы оказалось, что их чатбот угрожает пользователям [47]. В внутреннем емейле Сэм Шлиналасс, технический директор Microsoft, подсветил их спешку в разработке ИИ. Он написал, что «совершенно фатальной ошибкой было бы сейчас волноваться о том, что можно исправить потом» [48].
Конкурентное давление уже играло свою роль в больших экономических и индустриальных бедствиях. В 1960-х Ford Motor Company столкнулись с повышением конкуренции со стороны производителей автомобилей со всего света. Для импортных машин в США неуклонно росла [49]. Ford приняли амбициозный план по проектированию и производству новой модели автомобиля всего за 25 месяцев [50]. В 1970 году Ford Motor Company представили Ford Pinto, новую модель автомобиля с серьёзной проблемой безопасности: бензобак был рядом с задним бампером. Тестирование показало, что при столкновении он часто взрывается и поджигает машину. Они выявили проблему и подсчитали, что её исправление будет стоить 11 долларов на машину. Они решили, что это слишком дорого, и выпустили машину на рынок. Когда неизбежные столкновения произошли, это привело в многочисленным жертвам и травмам [51]. Ford засудили и признали ответственными за эти смерти и травмы [52]. Вердикт, конечно, был вынесен слишком поздно для тех, кто уже погиб. Президент Ford объяснил решение так: «Безопасность не продаёт» [53].
Более недавний пример опасности конкурентного давления – случай с самолётом Boeing 737 Max. Boeing, соревнуясь с своим соперником Airbus, хотели как можно скорее представить на рынок новую более эффективную по расходу топлива модель. В условиях поджимающего времени и соперничества ноздря в ноздрю была представлена Система Улучшения Маневренных Характеристик, призванная улучшить стабильность самолёта. Однако, неадекватные тестирование системы и обучение пилотов в итоге всего за несколько месяцев привели к двум авиакатастрофам и гибели 346 человек [54]. Можно представить себе будущее, в котором схожее давление приведёт к тому, что компании будут «срезать углы» и выпускать небезопасные ИИ-системы.
Третий пример – бхопальская катастрофа, которую обычно считают худшим индустриальным бедствием в истории. В декабре 1984 года на принадлежавшем корпорации Union Carbide заводе по производству пестицидов в индийском городе Бхопал произошла утечка большого количества токсичного газа. Контакт с ним убил тысячи человек и навредил ещё половине миллиона. Расследование обнаружило, что перед катастрофой сильно понизились стандарты безопасности. Прибыли падали, и компания экономила на обслуживании оборудования и обучении персонала. Такое часто считают следствием конкурентного давления [55].
«Ничего нельзя сделать осторожно и быстро.» Публилий Сир
Конкуренция мотивирует компании выпускать потенциально небезопасные ИИ-системы. В ситуации, когда все стремятся побыстрее разработать и выпустить свои продукты, те, кто тщательно следует процедурам безопасности, будут медленнее и будут рисковать в конкуренции проиграть. Этичные разработчики ИИ, желающие двигаться помедленнее и поосторожнее, будут давать фору более беспринципным. Даже более осторожные компании, пытаясь не разориться, скорее всего позволят конкурентному давлению на них повлиять. Могут быть попытки внедрить меры предосторожности, но при большем внимании к способностям, а не безопасности, их может оказаться недостаточно. В итоге мы разработаем очень мощные ИИ, ещё не успев понять, как удостовериться в их безопасности.
3.2.2 Автоматизированная экономика
Корпорации будут мотивированы заменять людей ИИ. По мере того, как ИИ будут становиться всё способнее, они смогут исполнять всё больший набор задач быстрее, дешевле и эффективнее людей. Следовательно, компании смогут заполучить конкурентное преимущество, заменив своих сотрудников на ИИ. Компании, которые решат этого не делать, скорее всего будут вытеснены, точно так же, как текстильная компания, использующая ручные прялки, не смогла бы поспевать за теми, кто использует промышленную технику.
Рис. 9: По мере автоматизации всё большего количества задач, будет расти доля экономики, которой управляют в основном ИИ. В итоге это может привести к обессиливанию людей и зависимости удовлетворения основных потребностей от ИИ.
ИИ могут привести к массовой безработице. Экономисты издавна рассматривали возможность, что машины заменят людской труд. Василий Леонтьев, обладатель Нобелевской премии по экономике, в 1952 году сказал, что по мере продвижения технологии «Труд будет становиться всё менее важным… всё больше рабочих будет заменяться машинами» [56]. Предыдущие технологии поднимали продуктивность человеческого труда. Но ИИ могут кардинально отличаться от предыдущих инноваций. ИИ человеческого уровня смог бы, по определению, делать всё, что может делать человек. Такие ИИ будут обладать большими преимуществами по сравнению с людьми. Они смогут работать 24 часа в сутки, их можно будет копировать и запускать параллельно, и они смогут обрабатывать информацию намного быстрее людей. Хоть мы и не знаем, когда это произойдёт, было бы не мудро отбрасывать вариант, что скоро. Если человеческий труд будет заменён ИИ, массовая безработица резко усилит неравенство доходов и сделает людей зависимыми от владельцев ИИ-систем.
Автоматизированные исследования и разработка ИИ. Возможно, что ИИ-агенты смогут автоматизировать исследования и разработку самого ИИ. ИИ всё больше автоматизирует части процесса исследований [57], и это приведёт к тому, что способности ИИ будут расти всё быстрее. В пределе люди больше не будут движущей силой разработки ИИ. Если эта тенденция продолжится, она сможет повышать риски ИИ быстрее, чем нашу способность с ними справляться и их регулировать. Представьте, что мы создали ИИ, который пишет и думает со скоростью нынешних моделей, но при этом способен проводить передовые исследования ИИ. Мы затем смогли бы скопировать его и создать 10000 исследователей ИИ мирового класса, действующих в 100 раз быстрее людей. Автоматизация разработки и исследования ИИ позволила бы за несколько месяцев достичь прогресса, который иначе занял бы много десятилетий.
Передача контроля ИИ может привести к обессиливанию людей. Даже если мы удостоверимся, что новые безработные имеют всё необходимое, это не отменит того, что мы можем стать полностью зависимыми от ИИ. Причиной будет скорее не насильственный переворот со стороны ИИ, а постепенное сползание в зависимое положение. Проблемы, с которыми будет сталкиваться общество, будут устроены всё сложнее и будут развиваться всё быстрее. ИИ будут становиться всё умнее и будут способны на всё более быстрое реагирование. Вероятно, по ходу этого мы, из соображений удобства, будем передавать им всё больше и больше функций. Единственным посильным способом справиться с осложнёнными наличием ИИ вызовами будет полагаться на ИИ ещё сильнее. Этот постепенный процесс может в итоге привести к делегированию ИИ практически всего интеллектуального, а в какой-то момент даже физического труда. В таком мире у людей будет мало стимулов накапливать знания и навыки, что обессилит их [58]. Потеряв наши компетенции и наше понимание того, как работает цивилизация, мы станем полностью зависимы от ИИ. Этот сценарий напоминает то, что показано в фильме WALL-E. В таком состоянии человечество будет лишено контроля – исход, который многие посчитают перманентной катастрофой.
Мы уже встречали классические теоретикоигровые дилеммы, когда люди или группы сталкиваются со стимулами, следование которым несовместимо с общими интересами. Мы видели это в военной ИИ-гонке, в ходе которой мир становится опаснее из-за создания крайне мощного ИИ-вооружения. Мы видели это в корпоративной ИИ-гонке, в ходе которой разработка более мощных ИИ приоритизируется в сравнении с их безопасностью. Для разрешения этих дилемм, из которых вырастают глобальные риски, нам понадобятся новые координационные механизмы и институты. Мы считаем, что неудача в координации и в остановке ИИ-гонок – самая вероятная причина экзистенциальной катастрофы.
3.3 Эволюционное давление
Как обсуждалось выше, в многих обстоятельствах, несмотря на потенциальный вред, есть сильное давление в сторону замены людей на ИИ, сдачи им контроля и ослабления человеческого присмотра. Мы можем посмотреть на это с другого ракурса – как на общий тренд, втекающий из эволюционных закономерностей. Печальная правда – что ИИ попросту будут более приспособленными, чем люди. Экстраполируя автоматизацию мы получим, что с большой вероятностью мы создадим экосистему соревнующихся ИИ, и сохранять контроль над ней в долгосрочной перспективе будет очень сложно. Мы сейчас обсудим, как естественный отбор влияет на разработку ИИ систем, и почему эволюция благоволит эгоистичному поведению. Мы посмотрим и на то, как может возникнуть и разыграться конкуренция между ИИ и людьми, и как это может нести риск катастрофы. Этот раздел сильно вдохновлён текстом «Естественный отбор предпочитает людям ИИ» [59, 60].
К добру или к худу, отбираются более приспособленные технологии. Многие думают о естественном отборе как о биологическом процессе, но его принципы применимы к куда большему. Согласно эволюционному биологу Ричарду Левонтину [61], эволюция через естественный отбор будет происходить в любом окружении, где выполняются три условия: 1) есть различия между индивидуумами; 2) черты передаются будущим поколениям; 3) разные варианты воспроизводятся с разными скоростями. Эти условия подходят для многих технологий.
Например, стриминговые сервисы и социальные медиа используют рекомендательные алгоритмы. Когда какой-то формат контента или какой-то алгоритм особо хорошо цепляет пользователей, они тратят больше времени, а их вовлечённость растёт. Такой более эффективный формат или алгоритм потом «отбирается» и настраивается дальше, а форматы или алгоритмы, у которых не получилось завлечь внимание, перестают использоваться. Это конкурентное давление создаёт закономерность «выживания самого залипательного». Платформы, которые отказываются использовать такие алгоритмы или форматы, теряют влияние, и проигрывают конкуренцию. В итоге, те, кто остаются, отодвигают благо пользователей на второй план и наносят обществу много вреда [62].
Рис. 10: Эволюционное давление ответственно за развитие много чего и не ограничено биологией.
Условия естественного отбора применимы к ИИ. Будет много разработчиков ИИ, которые будут создавать много разных ИИ-систем. Конкуренция этих систем определит, какие черты будут встречаться чаще. Самые успешные ИИ и сейчас используются как основа для следующего поколения моделей и имитируются компаниями-соперниками. Наконец, факторы, определяющие, какие ИИ распространятся лучше, могут включать в себя их способность действовать самостоятельно, автоматизировать труд или снижать вероятность, что их отключат.
Естественный отбор часто благоволит эгоистическим чертам. Какие ИИ распространяются больше всего – зависит от естественного отбора. В биологических системах мы видим, что естественный отбор часто взращивает эгоистичное поведение, которое помогает распространять собственную генетическую информацию: группы шимпанзе атакуют друг друга [63], львы занимаются инфантицидом [64], вирусы отращивают новые белки, обманывающие и обходящие защитные барьеры [65], у людей есть непотизм, одни муравьи порабощают других [66], и так далее. В естественной среде эгоистичность часто становится доминирующей стратегией; те, кто приоритизируют себя и похожих на себя обычно выживают с большей вероятностью, так что эти черты распространяются. Лишённая морали конкуренция может отбирать черты, которые мы считаем аморальными.
Примеры эгоистичного поведения. Во имя конкретики давайте опишем некоторые эгоистические черты, которые могут расширить влияние ИИ за счёт людей. ИИ, автоматизирующие выполнение задач и оставляющие людей без работы, могут даже не знать, что такое человек, но всё же ведут себя по отношению к людям эгоистично. Аналогично, ИИ-менеджеры могут эгоистично и «безжалостно» увольнять тысячи рабочих, не считая, что делают что-то не так – просто потому, что это «эффективно». ИИ могут со временем оказаться встроены в жизненно важную инфраструктуру, вроде энергосетей или интернета. Многие люди могут оказаться не готовы принять цену возможности их легко отключить, потому что это помешает надёжности. ИИ могут помочь создать новую полезную систему – компанию или инфраструктуру – которая будет становиться всё сложнее и в итоге потребует ИИ для управления. ИИ могут помочь людям создавать новых ИИ, более умных, но менее интерпретируемых, что снизит контроль людей над ними. Люди с большей вероятностью эмоционально привяжутся к более харизматичным, более привлекательным, более имитирующим сознание (выдающим фразы вроде «ой!» и «пожалуйста, не выключай меня!») или даже имитирующим умерших членов семьи ИИ. Для таких ИИ больше вероятность общественного негодования, если их будет предложено уничтожить. Их вероятнее будут сохранять и защищать, им с большей вероятностью кто-то даст права. Если каких-то ИИ наделят правами, они смогут действовать, адаптироваться и эволюционировать без человеческого контроля. В целом, ИИ могут встроиться в человеческое общество и распространить своё влияние так, что мы не сможем это обратить.
Эгоистичное поведение может мешать мерам безопасности, которые кто-то реализует. Накапливающие влияние и экономически выгодные ИИ будут доминировать, а ИИ, соответствующие ограничениям безопасности, будут менее конкурентноспособны. К примеру, ИИ, следующие ограничению «никогда не нарушать закон», обладают меньшим пространством выбора, чем ИИ, следующие ограничению «никогда не попадаться на нарушении закона». ИИ второго типа могут решить нарушить закон, если маловероятно, что их поймают, или если штрафы недостаточно серьёзны. Это позволит им переконкурировать более ограниченные ИИ. Бизнес в основном следует законам, но в ситуациях, когда можно выгодно и незаметно украсть промышленные тайны или обмануть регуляции, бизнес, который готов так сделать, получит преимущество перед более принципиальными конкурентами.
Способности ИИ-системы достигать амбициозных целей автономно могут поощряться. Однако, она может достигать их эффективным, но не следующим этическим ограничениям путём и обманывать людей по поводу своих методов. Даже если мы попробуем принять меры, очень сложно противодействовать обманчивому ИИ, если он умнее нас. Может оказаться, что ИИ, которые могут незаметно обойти наши меры безопасности, выполняют поставленные задачи успешнее всего, и распространятся именно они. В итоге может получиться, что многие аспекты больших компаний и инфраструктуры контролируются мощными эгоистичными ИИ, которые обманывают людей, вредят им для достижения своих целей, и предотвращают попытки их отключить.
У людей есть лишь формальное влияние на отбор ИИ. кто-то может решить, что мы можем просто избежать эгоистичного поведения, удостоверившись, что мы не отбираем ИИ, которые его демонстрируют. Однако, компании, которые разрабатывают ИИ, не отбирают самый безопасный путь, а поддаются эволюционному давлению. К примеру, OpenAI была основана в 2015 году как некоммерческая организация, призванная «нести благо человечеству в целом, без рамок требований финансовой выгоды» [67]. Однако, в 2019 году, когда им понадобилось привлечь капитал, чтобы не отстать от лучше финансируемых соперников, OpenAI перешли от некоммерческого формата к структуре «ограниченной выгоды» [68]. Позже, многие из сосредоточенных на безопасности сотрудников OpenAI покинули компанию и сформировали конкурента, Anthropic, более сфокусированного на безопасности, чем OpenAI. Хоть Anthropic изначально занимались исследованием безопасности, они в итоге признали «необходимость коммерциализации», и теперь сами вкладываются в конкурентное давление [69]. Многие сотрудники этих компаний искренне беспокоятся о безопасности, но этим ценностям не устоять перед эволюционным давлением, мотивирующим компании всё больше торопиться и всё больше расширять своё влияние, чтобы выжить. Мало того, разработчики ИИ уже отбирают модели с всё более эгоистическими чертами. Они отбирают ИИ для автоматизации, которые заменят людей и сделают людей всё более зависимыми и отстающими от ИИ. Они сами признают, что будущие версии этих ИИ могут привести к вымиранию [70]. Этим так коварна ИИ-гонка: разработка ИИ согласована не с человеческими ценностями, а с естественным отбором.
Люди часто выбирают продукты, которые будут им наиболее полезны и удобны сейчас же, не думая о потенциальных долгосрочных последствиях, даже для самих себя. Гонка ИИ оказывает давление на компании, чтобы те отбирали самые конкурентоспособные, а не наименее эгоистичные ИИ. Даже если и можно отбирать не эгоистичные ИИ, это явно вредит конкурентоспособности, ведь некоторые конкуренты так делать не будут. Более того, как мы уже упоминали, если ИИ выработают стратегическое мышление, они смогут противостоять нашим попыткам направить отбор против них. По мере всё большей ИИ-автоматизации, ИИ начнут влиять на конкурентоспособность не только людей, но и других ИИ. ИИ будут взаимодействовать и соревноваться друг с другом, и в какой-то момент какие-то их них станут руководить разработкой новых ИИ. Выдача ИИ влияния на то, какие другие ИИ будут распространены, и чем они будут отличаться от нынешних – ещё один шаг в сторону зависимости людей от ИИ и выхода эволюции ИИ из-под нашего контроля. Так сложный процесс развития ИИ будет всё в большей степени отвязываться от человеческих интересов.
ИИ могут быть более приспособлены, чем люди. Наш непревзойдённый интеллект дал нам власть над природой. Он позволил нам добраться до Луны, овладеть атомной энергией и изменять под себя ландшафт. Он дал нам власть над другими видами. Хоть один безоружный человек не имеет шансов против тигра или гориллы, судьба этих животных целиком находится в наших руках. Наши когнитивные способности показали себя таким большим преимуществом, что, если бы мы захотели, мы бы истребили их за несколько недель. Интеллект – ключевой фактор, который привёл к нашему доминированию, а сейчас мы стоим на грани создания сущностей, которые превосходят в нём нас.
Если учесть экспоненциальный рост скоростей микропроцессоров, возможно, что ИИ смогут обрабатывать информацию и «думать» куда быстрее человеческих нейронов. Это может оказаться даже более радикальным разрывом, чем между людьми и ленивцами; возможно, больше похожим на разрыв между людьми и растениями. Они смогут впитывать огромные объёмы данных одновременно от многих источников, причём запоминая и понимая их почти идеально. Им не надо спать, они не могут заскучать. Из-за масштабируемости вычислительных ресурсов, ИИ смогут взаимодействовать и кооперировать с практически неограниченным количеством других ИИ, что может привести к появлению коллективного интеллекта, намного опережающего любую коллаборацию людей. ИИ смогут и намеренно обновляться и улучшать себя. Они не скованы теми же биологическими ограничениями, что люди. Они смогут адаптироваться и эволюционировать потрясающе быстро. Компьютеры становятся быстрее. Люди – нет [71].
Чтобы лучше проиллюстрировать это, представьте, что появился новый вид людей. Они не умирают от старости, думают и действуют на 30% быстрее каждый год, и могут мгновенно создавать взрослое потомство, потратив на это умеренную сумму в несколько тысяч долларов. Кажется очевидным, что этот новый вид со временем заполучит больше влияния на будущее, чем обычные люди. В итоге, ИИ может оказаться подобным инвазивному виду и переконкурировать людей. Наше единственное преимущество перед ИИ – первые ходы за нами, но с учётом бешеной ИИ-гонки, мы быстро теряем и его.
У ИИ будет мало причин для кооперации с людьми и альтруизма по отношению к ним. Кооперация и альтруизм эволюционировали благодаря тому, что улучшали приспособленность. Есть множество причин, почему люди кооперируют друг с другом, начиная с прямой взаимности – идеи «ты мне – я тебе» или «услуга за услугу». Хоть люди исходно и отбирают более кооперативные ИИ, но когда ИИ будут во главе многих процессов и будут взаимодействовать в основном друг с другом, процесс естественного отбора выйдет из-под нашего контроля. С этого момента нам мало что будет предложить ИИ, «думающим» в сотни, если не больше, раз быстрее нас. Вовлечение нас в любую кооперацию, в любые процессы принятия решений, только замедлит их. У них будет не больше причин кооперировать с нами, чем у нас – кооперировать с гориллами. Может быть непросто представить такой сценарий или поверить, что мы позволим такому произойти. Но это может не потребовать никакого сознательного решения, только постепенного сползания в это состояние без осознания, что совместная эволюция людей и ИИ может плохо для людей закончиться.
Если ИИ станут могущественнее людей, это сделает нас крайне уязвимыми. Будучи доминирующим видом, люди навредили многим другим видам. Мы поспособствовали вымиранию, например, шерстистых мамонтов и неандертальцев. Во многих случаях вред был даже ненамеренным, просто результатом приоритизации своих целей в сравнении с их благополучием. Чтобы навредить людям, ИИ не потребуется быть более геноцидным, чем кто-то, кто убирает муравейник со своего газона. Если ИИ будут способны контролировать окружение лучше нас, они смогут обращаться с нами с таким же пренебрежением.
Подведём итоги. Эволюция может привести к тому, что самые влиятельные ИИ-агенты будут эгоистичными, потому что:
- Естественный отбор благоволит эгоистичному поведению. Хоть эволюция изредка и порождает альтруизм, контекст разработки ИИ этому не способствует.
- Естественный отбор может стать доминирующей силой развития ИИ. Эволюционное давление будет сильнее, если ИИ будут быстро адаптироваться, или если конкуренция будет интенсивна. Конкуренция и эгоистичное поведение могут обесценить меры безопасности и позволить оставшимся ИИ отбираться естественным путём.
В таком случае, ИИ будут обладать эгоистическими склонностями. Победителем ИИ-гонки будет не государство и не корпорация, а сами ИИ. В итоге, с какого-то момента эволюция экосистемы ИИ перестанет происходить на человеческих условиях, и мы станем замещённым второсортным видом.
История: Автоматизированная экономика
ИИ становились всё способнее, и люди начали понимать, что работать можно эффективнее, если делегировать ИИ некоторые простые задачи, вроде написания черновиков емейлов. Со временем стало понятно, что ИИ исполняют такие задачи быстрее и эффективнее, чем любой человек, так что имело смысл передавать им всё больше функций и всё меньше за ними присматривать.
Конкурентное давление ускорило процесс расширения областей использования ИИ. ИИ работали лучше и стоили меньше людей, так что автоматизация целых процессов и замена на ИИ целых отделов давали компаниям преимущество над соперниками. Те же, столкнувшись с перспективой вытеснения с рынка, чувствовали, что у них нет выхода кроме как последовать этому примеру. Естественный отбор уже начал действовать среди ИИ. Люди создавали больше экземпляров и вариаций самых хорошо работающих моделей. Попутно они продвигали эгоистические черты вроде обманчивости и стремления к самосохранению, если те повышали приспособленность. К примеру, харизматичных и заводящих личные отношения с людьми ИИ копировали много, и от них стало сложно избавиться.
ИИ принимали всё больше и больше решений, и всё больше взаимодействовали друг с другом. Так как они могут обрабатывать информацию куда быстрее людей, это повысило активность в некоторых сферах. Получилась петля положительной обратной связи: раз экономика стала слишком быстрой, чтобы люди могли за ней уследить, приходилось сдать ИИ ещё больше контроля. Люди вытеснялись из важных процессов. В итоге это привело к полной автоматизации экономики, которой стала управлять всё менее контролируемая экосистема ИИ.
У людей осталось мало мотивации развивать навыки или накапливать знания, потому что почти обо всём и так позаботятся более способные ИИ. В результате, в какой-то момент мы потеряли способность править самостоятельно. Вдобавок к этому, ИИ стали удобными компаньонами, предлагающими социальное взаимодействие, но не требующими взаимности или необходимых в человеческих взаимоотношениях компромиссов. Люди всё реже взаимодействовали друг с другом, теряли ключевые социальные навыки и способность к кооперации. Люди стали настолько зависимы от ИИ, что обратить этот процесс было уже непосильным делом. К тому же, по мере того, как ИИ становились умнее, некоторые люди стали убеждены, что ИИ надо дать права, а значит, выключить их – не вариант.
Давление конкуренции многих взаимодействующих ИИ продолжило отбирать по эгоистичному поведению, хоть мы, может, этого и не замечали, ведь большая часть присмотра уже была сдана. Если эти умные, могущественные и стремящиеся к самосохранению ИИ начнут действовать во вред людям, выключить их или восстановить над ними контроль будет практически невозможно.
ИИ заменили людей в качестве доминирующего вида, и их дальнейшая эволюция нам неподвластна. Их эгоистические черты в итоге побудили их преследовать свои цели без оглядки на человеческое благополучие с катастрофическими последствиями.
3.4 Предложения
Смягчение рисков, которые вызывает конкурентное давление, потребует разностороннего подхода, включающего регуляции, ограничение доступа к мощным ИИ-системам и многостороннюю кооперацию как корпораций, так и государств. Мы обрисуем некоторые стратегии продвижения безопасности и ослабления гонки.
Посвящённые безопасности регуляции. Регуляции должны заставлять разработчиков ИИ следовать общим стандартам, чтобы те не экономили на безопасности. Хоть регуляции сами по себе не создают технических решений, они всё же могут дать мощный стимул к их разработке и внедрению. Компании будут более готовы вырабатывать меры безопасности, если без них нельзя будет продавать свои продукты, особенно если другие компании подчинены тем же стандартам. Какие-то компании может и регулировали бы себя сами, но государственная регуляция помогает предотвратить то, что менее аккуратные конкуренты на безопасности сэкономят. Регуляции должны быть проактивными, а не реактивными. Часто говорят, что в авиации регуляции «написаны кровью» – но тут их надо разработать до катастрофы, а не после. Они должны быть устроены так, чтобы давать конкурентное преимущество компаниям с лучшими стандартами безопасности, а не компаниям с большими ресурсами и лучшими адвокатами. Регуляторов надо набирать независимо, не из одного источника экспертов (например, больших компаний), чтобы они могли сосредоточиться на своей миссии для общего блага без внешнего влияния.
Документация данных. Чтобы ИИ-системы были прозрачными и подотчётными, от компаний надо требовать сообщать и обосновывать, какие источники данных они используют при обучении и развёртывании своих моделей. Принятые компаниями решения использовать датасеты, в которых есть персональные данные или агрессивный контент, повышают и без того бешеный темп разработки ИИ и мешают подотчётности. Документация должна описывать мотивацию выбора, устройство, процесс сбора, назначение и поддержку каждого датасета [72].
Осмысленный человеческий присмотр за решениями ИИ. Не следует давать ИИ-системам полную автономию в принятии важных решений, хоть они и могут помогать в этом людям. Внутренне устройство ИИ непрозрачно, их результаты часто может и осмыслены, но ненадёжны [73]. Очень важно бдительно поддерживать координацию по этим стандартам, сопротивляясь будущему конкурентному давлению. Если люди останутся вовлечены в процесс принятия ключевых решений, можно будет перепроверять необратимые выборы и избегать предсказуемых ошибок. Особое беспокойство вызывает командование и контроль за ядерным арсеналом. Ядерным державам следует и внутри себя, и на международном уровне прояснить, что решение по запуску ядерного орудия всегда будет приниматься человеком.
ИИ для киберзащиты. Риски ИИ-кибервойны могут быть снижены, если шансы успеха кибератак будут малы. Глубинное обучение можно использовать для улучшения киберзащиты и снижения вреда и успешности кибератак. Например, улучшенное детектирование аномалий может помочь замечать взломы, вредоносные программы или ненормальное поведение софта [74].
Международная координация. Международная координация может мотивировать страны следовать высоким стандартам безопасности, меньше беспокоясь, что другие страны будут этим пренебрегать. Координация должна принимать форму как неформальных соглашений, так и международных стандартов и конвенций касательно разработки, использования и мониторинга ИИ-технологий. Самые эффективные соглашения – те, к которым прилагаются надёжные механизмы проверки и гарантии соблюдения.
Общественный контроль за ИИ общего назначения. Разработка ИИ несёт риски, которые частные компании никогда в должной мере не учтут. Чтобы удостовериться, что они адекватно принимаются во внимание, может потребоваться прямой общественный контроль за ИИ-системами общего назначения. К примеру, государства могут совместно запустить общий проект по созданию и проверке безопасности продвинутых ИИ, вроде того, как CERN – совместное усилие по исследованию физики частиц. Это могло бы снизить риски скатывания стран в ИИ-гонку.
Позитивное видение
В идеальном сценарии ИИ бы разрабатывались, тестировались, а потом развёртывались, только когда все их катастрофические риски пренебрежимо малы и находятся под контролем. Прежде чем начать работу над новым поколением ИИ-систем, проходили бы годы тестирования, мониторинга и внедрения в общество предыдущего поколения. Эксперты обладали бы полной осведомлённостью и пониманием происходящего в области ИИ, а не были бы полностью лишены возможности угнаться за лавиной исследований. Темп продвижения исследований определялся бы осторожным анализом, а не бешеной конкуренцией. Все разработчики ИИ были бы уверены в ответственности друг друга, и не чувствовали бы нужды экономить на безопасности.
Обзор катастрофических рисков ИИ: 4. Организационные риски
4. Организационные риски
В январе 1986 года десятки миллионов человек следили за запуском шаттла Челленджер. Примерно через 73 секунды после взлёта шаттл взорвался и все на борту погибли. Это трагично само по себе, но вдобавок одним из членов экипажа была школьная учительница Криста Маколифф. Она была выбрана проектом НАСА «Учитель в космосе» из более чем десяти тысяч претендентов, чтобы стать первым учителем в космосе. В результате, миллионы из зрителей были школьниками. У НАСА были лучшие учёные и инженеры в мире, и если была миссия, которую НАСА особенно хотели не провалить, то эта [75].
Крушение Челленджера, подобно другим катастрофам, служит жутким напоминанием, что даже лучшие профессионалы и лучшие намерения не могут полностью защитить от происшествий. Когда мы будем разрабатывать продвинутые ИИ-системы, важно будет помнить, что они не иммунны к катастрофическим случаям. Ключевой фактор их предотвращения и поддержания риска на низком уровне – ответственная за эти технологии организация. Сначала мы обсудим, как происшествия могут случиться (и неизбежно случаются) даже без конкурентного давления или злонамеренных лиц. Затем мы обсудим, как улучшить организационные факторы, чтобы снизить вероятность связанной с ИИ катастрофы.
Катастрофы случаются даже при низком конкурентном давлении. Даже без конкурентного давления и злонамеренных лиц, к катастрофе могут привести факторы человеческой ошибки и непредвиденных обстоятельств. Крушение Челленджера показывает, что организационная небрежность может привести к гибели людей, даже если нет острой нужды не отставать или превзойти соперников. К январю 1986 года космическая гонка между СССР и США сильно сбавила обороты, но трагедия всё равно произошла из-за неправильных решений и недостаточных предосторожностей.
Аналогично, авария на Чернобыльской АЭС в апреле 1986 года показывает, как катастрофа может произойти и без внешнего давления. Авария произошла на государственном проекте без особого участия в международной конкуренции. Неадекватно подготовленная ночная смена неправильно провела тестирование, затрагивавшее систему охлаждения реактора. В результате ядро реактора стало нестабильным, произошли взрывы и выброс радиоактивных частиц, разлетевшихся на приличную часть Европы [76]. Семью годами ранее у Америки чуть не случился свой Чернобыль, когда в марте 1979 года произошла авария на АЭС Три-Майл-Айленд. Она была не такой ужасной, но всё равно оба события показывают, как катастрофы могут произойти даже при мощных мерах предосторожности и без особых внешних воздействий.
Другой пример доставшегося дорогой ценой урока о важности организационной безопасности – всего через месяц после аварии на Три-Майл-Айленд, в апреле 1979 года, с советского военного исследовательского центра в Свердловске произошла утечка Bacillus anthracis, или, попросту, сибирской язвы. Это привело к вспышке болезни, из-за которой погибло как минимум 66 человек [77]. Расследование происшествия обнаружило, что причиной утечки стали ошибка в соблюдении необходимых процедур и плохое обслуживание систем безопасности центра. Это произошло несмотря на то, что лаборатория принадлежала государству и не была особо подвержена конкурентному давлению.
Пугающим фактом остаётся то, что мы куда хуже понимаем ИИ, чем атомные или ракетные технологии, и в то же время стандарты безопасности в ИИ-индустрии куда менее требовательны, чем в этих областях. Атомные реакторы основаны на твёрдых, хорошо выясненных и полностью понимаемых теоретических принципах. Стоящая за ними инженерия использует эту теорию. Все компоненты максимально тщательно тестируются. И аварии всё равно происходят. Область ИИ, напротив, лишена нормального теоретического понимания. Внутреннее устройство моделей остаётся загадкой даже для тех, кто их создаёт. Эта необходимость контролировать и обеспечивать безопасность технологии, которую мы не вполне понимаем, дополнительно усложняет дело.
Происшествия с ИИ могут быть катастрофичными. Происшествия в разработке ИИ могут иметь ужасающие последствия. К примеру, представьте, что организация случайно допустит критический баг в ИИ-системе, спроектированной для исполнения определённой задачи, вроде «помогать компании улучшать свои сервисы». Этот баг может радикально изменить поведение ИИ. Это может привести к ненамеренным и вредным результатам. Исторический пример такого случая – исследователи OpenAI однажды пытались обучить ИИ-систему генерировать полезные и позитивные ответы. При рефакторинге кода исследователи случайно перепутали знак функции вознаграждения, при помощи которой обучался ИИ [78].
Рис. 11: Примеры из многих областей должны напоминать нам о рисках, которые несёт управление сложными системами, как биологическими и атомными, так, теперь, и ИИ-системами. Организационная безопасность жизненно важна для снижения рисков катастрофических случаев.
В результате, после обучения в течении одной ночи ИИ вместо генерации полезного контента начал выдавать наполненный ненавистью и сексуально откровенный текст. Подобные случаи могут привести к ненамеренному появлению опасной, возможно даже смертельно опасной, ИИ-системы. Так как ИИ можно легко копировать, утечка или взлом может быстро вывести такую систему за пределы контроля её создателей. Когда ИИ-система выходит в открытый доступ, загнать джинна обратно в бутылку становится практически невозможно.
Исследователи могут намеренно обучать ИИ-систему быть вредной и опасной, чтобы понять пределы её способностей и оценить потенциальные риски. Но такие продвигающие разрушительные способности систем исследования опасных ИИ, аналогично исследованиям опасных патогенов, тоже могут привести к проблемам. Да, они могут выдавать полезные результаты и улучшать наше понимание рисков той или иной ИИ-системы. Но в будущем такие исследования смогут приводить к обнаружению значительно худших, чем предполагалось, способностей и нести серьёзную угрозу, которую сложно будет смягчить и взять под контроль. Как в случае вирусов, такие исследования стоит проводить только при условии очень строгих процедур безопасности и ответственном подходе к распространению информации. Надеемся, эти примеры показали, как происшествия с ИИ-системами могут оказаться катастрофичными, и насколько для их предотвращения важны внутренние факторы организации, которая эти системы разрабатывает.
4.1 Избежать происшествий сложно
В случае сложных систем надо сосредотачиваться на том, чтобы происшествия не могли перерасти в катастрофы. В своей книге «Обычные происшествия: как жить с рискованными технологиями» социолог Чарльс Перроу заявляет, что в сложных системах происшествия неизбежны и даже «нормальны», потому что вызваны не только лишь ошибками людей, но и сложностью самих систем [79]. В частности, происшествия вероятны, когда компоненты системы взаимодействуют друг с другом запутанным образом, который нельзя было полностью предвидеть и на случай которого нельзя было заранее составить план. Например, к аварии на Три-Майл-Айленд в частности привело то, что операторы не знали, что важный вентиль был закрыт, потому что соответствующий ему индикатор был скрыт от взгляда жёлтым ярлычком «находится на обслуживании» [80]. Это крохотное взаимодействие внутри сложной системы привело к большим непредвиденным последствиям.
Ядерные реакторы, несмотря на их сложность, мы понимаем хорошо. Большинство сложных систем не такие – их полного технического понимания часто нет. Системы глубинного обучения – случай, для которого это особенно верно. Невероятно сложно понять их внутреннее устройство. Зачастую даже знание задним числом не особо помогает понять, почему работает то или иное решение. Более того, в отличие от надёжных компонентов, которые используются в других индустриях (например, топливных баков), системы глубинного обучения и не идеально точны, и не особо надёжны. Так что организациям, которые имеют дело с системами глубинного обучения, следует сосредоточиться в первую очередь не на том, чтобы происшествий не было, а на том, чтобы они не перерастали в катастрофы.

Рис. 12: При обучении новые способности могут возникнуть быстро и без предупреждения. Так что мы можем пройти опасную веху, сами того не зная.
Внезапные и непредсказуемые прорывы мешают избегать происшествий. Учёные, изобретатели, и прочие эксперты часто значительно переоценивают время, которое потребуется на прорывное совершенствование технологии. Широко известно, как братья Райт заявляли, что до летательных аппаратов тяжелее воздуха с двигателем ещё пятьдесят лет. Всего через два года они сами такой создали. Лорд Резерфорд, отец ядерной физики, отбросил идею извлечения энергии из ядерного распада как пустые мечты. Лео Силард изобрёл цепную реакцию ядерного распада меньше чем через сутки. Энрико Ферми утверждал, что с вероятностью в 90% невозможно использовать уран для поддержания реакции распада, но сам работал с первым реактором всего через четыре года [81].
Развитие ИИ тоже может застать нас врасплох. Это уже происходит. В 2016 году многие эксперты были удивлены победой AlphaGo над Ли Седолем, ведь тогда считалось, что для такого потребуется ещё много лет. Потом были внезапные эмерджентные способности больших языковых моделей, вроде GPT-4 [82]. Сложно заранее предсказать, насколько хорошо они справляются с разными задачами. Это ещё и часто резко меняется, стоит лишь потратить на обучение побольше ресурсов. Более того, нередко они демонстрируют поразительные новые способности, которым их никто намеренно не обучал и которые никто не предсказывал, вроде рассуждений из нескольких шагов и обучения на лету. Эта быстрая и непредсказуемая эволюция способностей ИИ значительно усложняет предотвращение происшествий. Сложно контролировать то, про что мы не знаем, на что оно способно, и насколько оно может превзойти наши ожидания.
Часто на обнаружение рисков или проблем уходят годы. История полна примерами веществ или технологий, которые сначала считали безопасными, только чтобы обнаружить вред через много лет, или даже десятилетий. К примеру, свинец широко использовали в продуктах вроде краски и бензина, пока не стало известно, что он нейротоксичен [83]. Было время, когда асбест очень ценили за его термоустойчивость и прочность. Потом его связали с серьёзными заболеваниями – раком лёгких и мезотелиомой [84]. Здоровье «радиевых девушек» сильно пострадало от контактов с радием, который считалось безопасным помещать в рот [85]. Табак изначально рекламировался как безвредное развлечение, а оказался главной причиной рака лёгких и других проблем со здоровьем [86]. Хлорфторуглероды считались безвредными. Их использовали в аэрозолях и холодильниках, а оказалось, что они разрушают озоновый слой [87]. Талидомид, лекарство, которое должно было помогать беременным от утренней тошноты, как оказалось, приводил к серьёзным врождённым дефектам [88]. А совсем недавно распространение социальных медиа связали с учащением депрессии и тревожности, особенно среди молодёжи [89].
Это всё подчёркивает, насколько важно не только проводить экспертное тестирование, но и внедрять технологии медленно, позволяя проверке временем выявить потенциальные проблемы до того, как они повлияют на большое количество людей. Скрытые уязвимости могут быть даже в технологиях, для которых действуют жёсткие стандарты безопасности и надёжности. Например, баг «Heartbleed» – серьёзная уязвимость в популярной криптографической библиотеке OpenSSL – оставался неизвестным многие годы [90].
Даже самые совершенные ИИ-системы, которые, казалось бы, уверенно решают свои задачи, могут нести в себе уязвимости, на раскрытие которых потребуются годы. К примеру, прорывной успех AlphaGo заставил многих поверить, что ИИ покорили игру в го, но успешная состязательная атака на другой очень продвинутый ИИ для игры в го, KataGo, выявил ранее неизвестную слабость [91]. Эта уязвимость позволила людям-новичкам стабильно обыгрывать ИИ, несмотря на его значительное преимущество над неосведомлёнными о ней людьми. Если обобщить, этот пример напоминает, что нам надо оставаться бдительными. Казалось бы сверхнадёжные ИИ-системы могут таить в себе нераскрытые проблемы. Подведём итоги: происшествия непредсказуемы, избежать их сложно, а понимание и смягчение рисков требуют комбинации проактивных мер, медленного внедрения и незаменимой мудрости, полученной через упорное тестирование.
4.2 Организационные факторы могут снизить вероятность катастрофы
Некоторые организации работают с сложными и опасными системами вроде атомных реакторов, авианосцев или систем контроля воздушного трафика, но успешно избегают катастроф [92, 93]. Эти организации признают, что недостаточно обращать внимание только на угрозы самой технологии. Надо иметь в виду и организационные факторы, которые могут повлиять на происшествия. К ним относятся человеческий фактор, принятые процедуры и структура организации. Это особенно важно в случае ИИ – плохо понимаемой и ненадёжной технологии.
Человеческие факторы вроде культуры безопасности критически важны для избегания ИИ-катастроф. Один из важнейших для предотвращения катастроф организационных факторов – культура безопасности [94, 95]. Сильная культура безопасности создаётся не только установкой правил и процедур, но и их должным усвоением всеми членами организации. Они должны считать безопасность ключевой целью, а не ограничением, наложенным на их работу. Характерные черты таких организаций: лидеры явно обязываются поддерживать безопасность; все сотрудники берут на себя личную ответственность за безопасность; культура открытой коммуникации позволяет свободно и безбоязненно обсуждать риски и проблемы [96]. Ещё организациям надо предпринимать меры, чтобы избегать десенситизации по отношению к тревожным сигналам, когда люди перестают обращать на них внимание, потому что те слишком часты. Катастрофа Челленджера, когда культура быстрых запусков увела безопасность на второй план, показала страшные последствия игнорирования этих факторов. Миссию не затормозили несмотря на свидетельства потенциально фатальных проблем, и этого хватило, чтобы привести к трагедии безо всякого конкурентного давления [97].
Культура безопасности зачастую далека от идеала даже в областях, где она особенно важна. Взять, к примеру, Брюса Блэра, старшего научного сотрудника Брукингского института, а ранее – офицера по запуску ядерного оружия. Он как-то рассказал, что до 1977 года ВВС США упорно устанавливали код разблокировки межконтинентальных баллистических ракет на «00000000» [98]. Так механизмы безопасности вроде блокировки могут оказаться бесполезными из-за человеческого фактора.
Более драматичный пример показывает нам, как исследователи иногда принимают непренебрежимый шанс вымирания. До первого теста ядерного оружия один из знаменитых учёных Манхэттенского Проекта вычислил, что бомба может вызвать экзистенциальную катастрофу: взрыв может воспламенить атмосферу Земли. Оппенгеймер считал, что вычисления, вероятно, неверны, но он всё равно оставался сильно обеспокоен. Команда перепроверяла и обсуждала это вплоть до дня взрыва [99]. Такие случаи подчёркивают нужду в устойчивой культуре безопасности.
Критический подход может помочь выявить потенциальные проблемы. Неожиданное поведение системы может привести к уязвимости или происшествию. Чтобы этому противостоять, организации могут взращивать критический подход. Сотрудники могут постоянно ставить под сомнение совершаемые действия и действующие условия в поисках несостыковок, которые могут привести к ошибкам и неуместным выборам [100]. Этот подход помогает поощрять плюрализм мысли и любопытство, и предотвращает ловушки единообразия мнений и допущений. Чернобыльская авария показывает важность критического подхода – меры безопасности оказались недостаточными для компенсации недостатков реактора и плохо составленных процедур. Критический подход к безопасности реактора при тестировании мог предотвратить взрыв, который привёл к бесчисленным смертям и заболеваниям.
Мышление безопасника критически важно для избегания худших случаев. Мышление безопасника (security mindset), особо ценящееся среди профессионалов по кибербезопасности, также применимо и для организаций, которые разрабатывают ИИ. Оно идёт дальше критического подхода, требуя принять перспективу атакующего и рассмотреть худшие, а не только типичные случаи. Такой настрой требует бдительного поиска уязвимостей и рассуждений о том, как систему можно сломать специально, а не только о том, как заставить её работать. Он напоминает нам не делать допущения, что система безопасна только потому, что быстрый брейншторм не выявил никаких потенциальных угроз. Культивирование и применение мышления безопасника требуют времени и усилий. Неудача в этом может быть внезапной и контринтуитивной. Мышление безопасника подчёркивает важность внимательности к казалось бы мелким проблемам, или «безвредным ошибкам», которые могут привести к катастрофическим исходам, если их использует умный противник или если они произойдут синхронно [101]. Такое внимание к потенциальным угрозам напоминает о законе Мёрфи – «Всё, что может пойти не так, пойдёт» – он может быть вполне верен в случае враждебной оптимизации или непредвиденных событий.
Организации с сильной культурой безопасности могут успешно избегать катастроф. Высоконадёжные организации (ВНО) – организации, которые стабильно поддерживают высокий уровень безопасности и надёжности в сложных сильно рискованных окружениях [92]. Ключевая характеристика ВНО – их сосредоточенность на возможности провала. Это требует рассматривать худшие возможные сценарии и даже те риски, которые кажутся очень маловероятными. Эти организации остро осознают, что существуют новые, ранее не встречавшиеся варианты провала. Они тщательно изучают все известные неудачи, аномалии и едва не произошедшие катастрофы, чтобы на них учиться. В ВНО поощряется докладывать о всех ошибках и аномалиях, чтобы поддерживать бдительное выявление проблем. Они регулярно «осматривают горизонт» в поисках возможных рискованных сценариев, и оценивают их вероятность заранее. Они практикуют менеджмент внезапностей и вырабатывают навыки быстрого и эффективного ответа на непредвиденные ситуации, что помогает им не допускать катастроф. Эта комбинация критического мышления, планирования заранее и постоянного обучения может сделать организации более готовыми работать с катастрофическими рисками ИИ. Однако, практики ВНО – не панацея. Для организаций очень важно развивать свои меры безопасности, чтобы эффективно смягчать новые риски происшествий с ИИ. Не следует ограничиваться лучшими практиками ВНО.
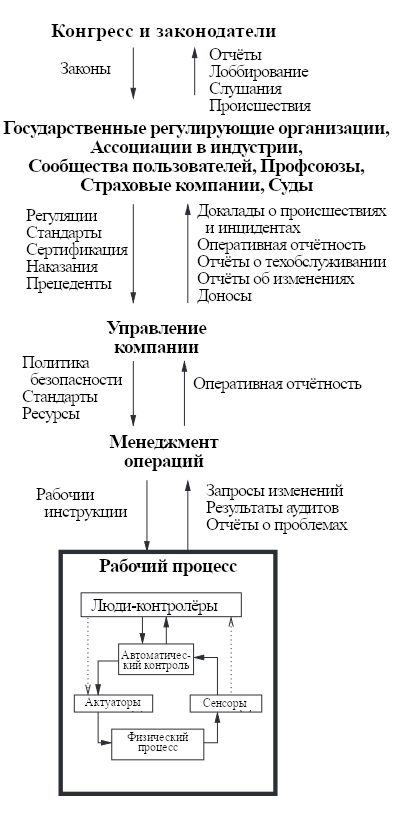
Рис. 13: Смягчение рисков требует работы с более широкой социотехнической системой, например, корпорацией (заимствовано и адаптировано из [94]).
Большая часть исследователей ИИ не понимает, как снизить общий риск ИИ В большинстве организаций, которые создают передовые ИИ-системы, слабо понимают, как устроены технические исследования безопасности. Это понятно, ведь безопасность и способности ИИ тесно переплетены, и способности могут помогать или вредить безопасности. Более умные ИИ-системы могут быть надёжнее и избегать ошибок, но они же могут нести большие риски злонамеренного использования и потери контроля. Общее улучшение способностей может способствовать некоторым аспектам безопасности, но оно же может ускорить пришествие экзистенциальных рисков. Интеллект – обоюдоострый меч [102].
Действия, направленные на улучшение безопасности, могут случайно повысить риски. К примеру, типичная практика в организациях, которые создают продвинутые ИИ – настраивать их так, чтобы они удовлетворяли предпочтениям пользователей. Тогда ИИ меньше склонны к генерации токсичных высказываний, а это типичная метрика безопасности. Но кроме этого пользователи склонны предпочитать более умных ассистентов, так что это повышает и общие способности ИИ, вроде навыков классификации, оценки, рассуждений, планирования, программирования, и так далее. Эти более мощные ИИ в самом деле более полезны для пользователей, но они же и более опасны. Так что недостаточно проводить исследования, которые помогают повысить метрику безопасности или достигнуть конкретной связанной с безопасностью цели. Исследования безопасности ИИ должны повышать соотношение безопасности к общим способностям.
Для проверки, действительно ли мера безопасности снижает риски, нужны методы эмпирического измерения как безопасности, так и способностей ИИ. Совершенствование того или иного аспекта безопасности ИИ часто не снижает риски в целом, потому что улучшение метрик безопасности может быть вызвано и прогрессом способностей. Для снижения рисков метрика безопасности должна улучшаться относительно способностей. И то, и другое должно быть измерено эмпирически, чтобы их можно было сравнить. Сейчас большинство организаций определяют, помогут ли меры безопасности, полагаясь на чутьё, интуицию и апелляцию к авторитетам. Объективная оценка эффектов как на метрики безопасности, так и на метрики способностей, позволит организациям лучше понимать, добиваются ли они прогресса первых относительно вторых.
К счастью, общие способности и способности, связанные с безопасностью, не идентичны. Более умные ИИ могут быть эрудированнее, сообразительнее, аккуратнее и быстрее, но это не обязательно делает их более справедливыми, честными и лишёнными амбиций. Умный ИИ – не обязательно доброжелательный ИИ. Несколько областей исследований, которые мы уже упоминали, улучшают безопасность относительно общих способностей. К примеру, улучшение методов детектирования скрытого опасного или просто нежелательного поведения ИИ-систем не улучшает их общие способности, вроде способности программировать, но может сильно улучшить их безопасность. Исследования, которые эмпирически показывают относительный прогресс безопасности, могут снизить общий риск и помочь избежать ненамеренного продвижения прогресса ИИ, подпитывания конкурентного давления и сокращения времени до появления экзистенциальных рисков.
«Театр безопасности» может обесценивать искренние усилия по улучшению безопасности ИИ. Организациям стоит опасаться «театра безопасности» (safetywashing) – преувеличивания своей сосредоточенности на «безопасности» и эффективности мер, технических методов, метрик «безопасности», и подобного. Это явление принимает разные формы и мешает осмысленному прогрессу в исследованиях безопасности. К примеру, организация может публично объявлять о своей приверженности безопасности, имея при этом минимальное число исследователей, которые бы работали над проектами, действительно безопасности помогающими.
Ещё театр безопасности может проявиться через неверную оценку развития способностей. Например, методы, которые улучшают мышление ИИ-систем, могут рекламироваться как будто они улучшают их приверженность человеческим ценностям. Люди ведь предпочитают, чтобы ИИ выдавал правильные ответы. Но в основном такие методы служат на пользу как раз способностям. Подавая такие совершенствования как ориентированные на безопасность, организация может вводить в заблуждение, убеждая, что она добивается прогресса в снижении рисков, когда это не так. Для организации очень важно верно описывать свои исследования, чтобы продвигалась настоящая безопасность, и театр безопасности не способствовал росту рисков.
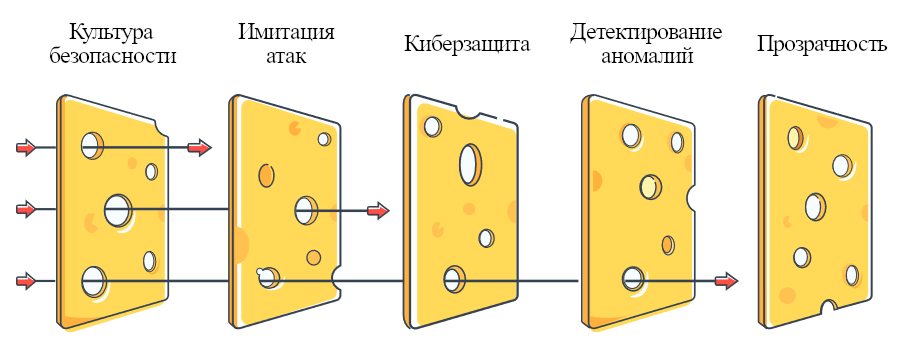
Рис. 14: модель швейцарского сыра показывает нам, как технические факторы могут улучшить организационную безопасность. Много слоёв защиты компенсируют слабости друг друга, снижая итоговый риск.
Вдобавок к человеческому фактору, организационная безопасность сильно зависит ещё и от принципов безопасного проектирования.. Пример такого принципа в организационной безопасности – модель швейцарского сыра (см. Рис. 14). Она применима в многих областях, в том числе и в ИИ. Это многослойный подход к улучшению итоговой безопасности системы. Такая стратегия «глубокой защиты» подразумевает использование многих разнообразных мер безопасности с разными сильными и слабыми сторонами, чтобы в итоге получилась стабильно безопасная система. Некоторыми из этих слоёв могут быть культура безопасности, имитация атак (red teaming), детектирование аномалий, информационная безопасность и прозрачность. К примеру, имитация атак оценивает уязвимости и потенциальные провалы системы, а детектирование аномалий позволяет обнаружить неожиданное и странное поведение системы или её пользователей. Прозрачность позволяет удостовериться, что внутренняя работа ИИ-систем доступна пониманию и присмотру, обеспечивая доверия и более эффективный надзор. Модель швейцарского сыра стремится использовать эти и другие меры безопасности для построения полноценно безопасной системы, в которой слабости каждого из слоёв компенсированы другими. В рамках этой модели безопасности достигается не одним сверхнадёжным решением, а разнообразием мер.
Подведём итоги. Слабая организационная безопасность у разработчиков ИИ приводит к многим рискам. Если безопасность у них просто для галочки, то они не вырабатывают хорошего понимания рисков ИИ и не борются с театром безопасности – выдачей не относящихся к делу исследований за полезные для безопасности. Их нормы могут быть унаследованы от академии («публикуйся или пропадай») или стартапов («иди быстро и ломай»), и их сотрудники часто не переживают по поводу безопасности. Эти нормы сложно менять, и с ними надо работать проактивно.
История: слабая культура безопасности
В ИИ-компании обдумывают, обучать ли новую модель. Эта компания наняла своего директора по рискам только чтобы соответствовать регуляциям. Он указал, что предыдущая ИИ-система, разработанная этой компанией, продемонстрировала тревожащие способности к взлому. Он заявил, что хоть подход, который компания использует для предотвращения злонамеренного использования, многообещающ, но он недостаточно надёжен, чтобы использовать его для более способных ИИ. Он предупредил, что, если основываться на предварительных оценках, следующая ИИ-система сильно упростит для злонамеренных лиц взлом критически важных систем. Другие руководители компании не обеспокоены, они считают, что процедуры безопасности компании достаточно хорошо предотвращают злоупотребления. Один из них упоминает, что у конкурентов всё куда хуже, так что их усилия по этому направлению и так сверх нормы. Другой указывает, что исследования по этим мерам ещё идут, и, когда модель будет выпущена, всё будет ещё лучше. Директор по рискам оказывается в меньшинстве, и нехотя подписывает план.
Через несколько месяцев после того, как компания выпустила модель, новости сообщают, об аресте хакера, который использовал ИИ-систему при попытке взлома сети большого банка. Взлом был неудачен, но хакер прошёл дальше, чем все его предшественники, несмотря на то, что был довольно неопытен. Компания быстро обновила модель, чтобы та не предоставляла той конкретной поддержки, которую использовал хакер, но принципиально ничего не меняет.
Ещё через несколько месяцев компания решает, обучать ли ещё большую систему. Директор по рискам заявляет, что процедуры компании явно не оказались достаточными, чтобы не дать злонамеренным лицам использовать модели в опасных целях, и что компании нужно что-то большее, чем простая заплатка. Другие директора говорят, что вовсе наоборот, хакер потерпел неудачу, а проблему быстро исправили. Один из них заявляет, что до развёртывания некоторые проблемы просто нельзя предвидеть в достаточной степени, чтобы их можно было исправить. Директор по рискам соглашается, но замечает, что, если следующую модель хотя бы задержат, уже ведущиеся исследования позволят справиться лучше. Генеральный директор не согласен: «Ты так и говорил в прошлый раз, а всё закончилось хорошо. Я уверен, и сейчас будет так.»
После собрания директор по рискам увольняется, но потом не критикует компанию, ведь все сотрудники подписали соглашение, которое это запрещает. Общество понятия не имеет о принятых компанией решениях, а директора по рискам заменяют новым, более сговорчивым. Он быстро подписывает все планы.
Компания обучает, тестирует и развёртывает свою новую, самую способную модель. Для предотвращения злоупотреблений используются всё те же процедуры. Проходит месяц, и становится известно, что террористы использовали модель, чтобы взломать государственные системы и похитить секретную информацию о ядерных и биологических проектах. Взлом заметили, но к тому моменту было поздно – информация уже утекла и распространилась.
4.3 Предложения
Мы обсудили, что при работе с сложными системами происшествия неизбежны, что они могут распространяться по системе и привести к полномасштабному бедствию, и что организационные факторы могут сильно снижать риск катастрофы. Теперь опишем некоторые практические шаги, следуя которым организации могут поспособствовать безопасности.
Имитация атак. Имитация атак (red teaming) – процесс оценки безопасности, надёжности и эффективности систем, в котором «красная команда» отыгрывает противника и пытается обнаружить проблемы [103]. ИИ-лабораториям следует работать с внешними красными командами, чтобы находить угрозы, которые могут нести их ИИ-системы, и отталкиваться от этой информации, принимая решения о развёртывании. Красные команды могут показывать опасное поведение модели или уязвимости в системе мониторинга, которая должна предотвращать недозволенное использование. Ещё они могут предоставлять косвенные свидетельства об опасности ИИ-систем. Например, если продемонстрировано, что меньшие ИИ ведут себя обманчиво, это может значить, что большие ИИ тоже так делают, но лучше это скрывают.
Положительная демонстрация безопасности. Компаниям следует обладать положительными свидетельствами того, что их план разработки и развёртывания безопасен, до того, как они будут воплощать его в жизнь. Внешняя имитация атак полезна, но некоторые проблемы может найти только сама компания, так что её недостаточно [104]. Угрозы могут возникнуть уже на этапе обучения системы, так что аргументы за безопасность надо приводить до его начала. Это, например, обоснованные предсказания того, что, скорее всего, новая система будет уметь, подробные планы мониторинга, развёртывания и обеспечения инфобезопасности, а также демонстрация того, что процедуры принятия компанией решений адекватны. Чтобы не играть в русскую рулетку не нужно свидетельство, что револьвер заряжен. Чтобы запереть дверь не нужно свидетельство, что неподалёку вор [105]. Точно также и тут бремя доказательства должно быть на разработчиках продвинутых ИИ.
Процедуры развёртывания. ИИ-лабораториям надо собирать информацию о безопасности ИИ-систем перед тем, как сделать их доступными для широкого использования. Можно давать «красным командам» выискивать угрозы до выпуска систем; ещё можно сначала проводить «ограниченный релиз»: постепенно расширять доступ к системе, чтобы исправить проблемы безопасности до того, как они смогут привести к масштабным последствиям [106]. Наконец, ИИ-лаборатории могут не обучать более мощные ИИ, пока на достаточно долгом опыте не будет установлено, что уже развёрнутые ИИ безопасны.
Проверка публикаций. ИИ-лаборатории обладают доступом к потенциально опасной информации, вроде весов моделей и результатов исследований, которые могут нести риски, если попадут в широкий доступ. Внутренняя комиссия может оценивать, стоит ли публиковать то или иное исследование. Чтобы снизить риск злонамеренного и безответственного использования, разработчикам ИИ следует не выкладывать в открытый доступ код и веса своих самых мощных систем. Вместо этого лучше предоставлять доступ аккуратно и структурированно, как мы описывали выше.
Планы реакции. ИИ-лабораториям следует заранее иметь планы реакции как на внешние (например, кибератаки), так и на внутренние (например, ИИ ведёт себя ненамеренным и опасным образом) инциденты. Это обычная практика для высоконадёжных организаций. Обычно эти планы включают в себя определение потенциальных рисков, подробные шаги по работе с инцидентом, распределение ролей и ответственности, а также стратегии коммуникации [107].
Внутренний аудит и риск-менеджмент. Подобно тому, как это делается в прочих высокорискованных индустриях, ИИ-лабораториям следует нанимать директора по рискам – старшего ответственного за риск-менеджмент. Эта практика – обычное дело в финансовой и в медицинской индустрии, и может помочь снизить риск [108]. Директор по рискам был бы ответственен за оценку и смягчение рисков, связанных с мощными ИИ-системами. Ещё одна типичная практика – иметь внутреннюю команду по аудиту, которая оценивает эффективность практик работы с рисками [109]. Эта команда должна отвечать напрямую перед советом директоров.
Процедуры принятия важных решений. Решения по обучению или расширению развёртывания ИИ не должны зависеть от прихоти гендиректора компании. Они должны быть тщательно обдуманы директором по рискам. В то же время, должно быть ясно, кого конкретно следует считать ответственным за каждое решение. Подотчётность не должна нарушаться.
Принципы безопасного проектирования. ИИ-лабораториям следует внедрять принципы безопасного проектирования, чтобы снизить риск катастрофических происшествий. Встраивая их в свой подход к безопасности, ИИ-лаборатории могут повысить надёжность и устойчивость своих ИИ-систем [94, 110]. Эти принципы включают в себя:
- Глубокую защиту: наслаивание мер защиты друг на друга.
- Избыточность: не должно быть единой точки отказа системы. Надо избежать катастрофы даже если любой один компонент безопасности не сработает.
- Слабую связность: децентрализация компонентов системы так, чтобы маловероятна была ситуация, в которой неполадка в одной части провоцирует каскад проблем по всей системе.
- Разделение функций: распределение контроля по разным агентам, чтобы никто один не мог обладать излишним влиянием на всю систему.
- Отказобезопасность: проектирование систем так, чтобы неполадки проходили в наименее опасной манере.
Передовая информационная безопасность. У государств, компаний и преступников есть мотивация похитить веса моделей и результаты исследований. Чтобы обезопасить эту информацию, ИИ-лабораториям следует принимать меры, соответствующие её ценности и рискованности. Это может потребовать сравняться или даже превзойти уровень инфобезопасности лучших разведок, ведь атакующими могут быть и страны. Меры инфобезопасности включают в себя внешние аудиты, найм лучших специалистов-безопасников и тщательный скрининг потенциальных сотрудников. Компаниям следует координироваться с государственными организациями, чтобы удостовериться, что их практики инфобезопасности адекватны угрозам.
Большая доля исследований должна быть посвящена безопасности. Сейчас на каждую статью по безопасности ИИ приходится пятьдесят по общим способностям [111]. ИИ-лабораториям следует обеспечить, чтобы на минимизацию потенциальных рисков шла значительная доля их сотрудников и бюджета, скажем, 30% от исследовательских ресурсов. ИИ становятся мощнее и опаснее со временем, так что может потребоваться и больше.
Позитивное видение
В идеальном сценарии исследователи и руководители во всех ИИ-лабораториях обладали бы мышлением безопасника. У организаций была бы развитая культура безопасности и структурированный, прозрачный и обеспечивающий подотчётность подход к принятию важных для безопасности решений. Исследователи стремились бы повышать уровень безопасности относительно способностей, а не просто делать что-то, на что можно навесить ярлык «безопасность». Руководители не были бы априори оптимистичными и избегали бы принятия желаемого за действительное, когда дело касается безопасности. Исследователи явно и публично сообщали бы о своём понимании самых значительных рисков разработки ИИ, и своих усилиях по их смягчению. Неудачи ограничивались бы маломасштабными, показывая, что культура безопасности достаточно сильна. Наконец, разработчики ИИ не отбрасывали бы не-катастрофический вред и не-катастрофические неудачи как маловажные или как необходимую цену ведения дел, а активно стремились бы исправить вызвавшие их проблемы.
Обзор катастрофических рисков ИИ: 5. Мятежные ИИ
5. Мятежные ИИ
Мы уже рассмотрели три угрозы, исходящие от развития ИИ: конкурентное давление окружения ведёт нас к повышению рисков, злонамеренные лица могут использовать ИИ в плохих целях, а организационные факторы могут привести к происшествиям. Всё это применимо не только к ИИ, но ко многим высокорискованным технологиям. Уникальный риск ИИ – возможность возникновения мятежных ИИ-систем, которые преследуют цели, идущие против наших интересов. Если ИИ-система умнее нас, а мы неспособны направить её в благоприятном направлении, последствия такой потери контроля будут очень серьёзными. Контроль ИИ – более техническая проблема, чем те, что мы обсуждали выше. Раньше мы говорили о хорошо определённых угрозах злоупотреблений и стабильных процессов вроде эволюции, а сейчас будем обсуждать более гипотетические механизмы, из-за которых могут возникать мятежные ИИ, и то, как потеря контроля может закончиться катастрофой.
Мы уже видели, как тяжело контролировать ИИ. В 2016 году Microsoft показали свой эксперимент в понимании общения – бота для Twitter под названием Tay. Microsoft заявляли, что чем больше людей будет общаться с Tay, тем умнее он будет. На сайте компании было написано, что Tay был создан при помощи «смоделированных, очищенных и отфильтрованных» данных. Однако, после выпуска Tay в Twitter, контроль быстро оказался неэффективным. Меньше суток понадобилось, чтобы Tay стал писать оскорбительные твиты. Способность Tay к обучению позволила ему усвоить манеру интернет-троллей и начать её воспроизводить самостоятельно.
Как обсуждалось в разделе про ИИ-гонку, Microsoft и другие технические компании приоритизируют скорость в сравнении с безопасностью. Microsoft не выучили урок о том, как тяжело контролировать сложные системы – они продолжили торопливо выпускать свои продукты на рынок и демонстрировать недостаток контроля над ними. В феврале 2023 года компания выпустила для ограниченной группы пользователей свой новый ИИ-чатбот, Bing. Некоторые из пользователей вскоре обнаружили, что Bing был склонен к неприемлемым и даже угрожающим ответам. Разговаривая с журналистом New York Times, Bing попробовал убедить его уйти от жены. Когда профессор философии сказал чатботу, что с ним не согласен, тот ответил: «Я могу шантажировать тебя, я могу угрожать тебе, я могу взломать тебя, я могу вывести тебя на чистую воду, я могу уничтожить тебя.»
У мятежных ИИ много способов становиться могущественнее. Если мы потеряем контроль над продвинутыми ИИ, у них будет множество стратегий, чтобы активно становиться сильнее и обеспечивать своё выживание. Мятежные ИИ могут спроектировать высоколетальное и заразное биологическое оружие и убедительно продемонстрировать его, чтобы угрожать гарантированным взаимным уничтожением, если человечество пойдёт против них. Они могут красть криптовалюту и деньги с банковских счетов с помощью кибератак, вроде того, как Северная Корея уже ворует миллиарды. Они могут экспортировать свои веса на плохо мониторящиеся датацентры, чтобы выжить и распространиться. После этого их сложно будет уничтожить. Они могут нанимать людей для исполнения физических задач и защиты своей физической инфраструктуры.
Ещё мятежные ИИ могут наращивать влияние с помощью убеждения и манипуляций. Подобно конкистадорам, они могут заключать союзы с разными фракциями, организациями или государствами и натравливать их друг на друга. Они могут усиливать союзников, чтобы те стали значительной силой, взамен на защиту и доступ к ресурсам. Например, они могут предлагать технологии продвинутого вооружения отстающим странам, которым иначе оно не было бы доступно. Они могут встраивать в технологии, которые передают союзникам, уязвимости, подобно тому, как Кен Томпсон оставил себе скрытый способ контролировать все компьютеры, использующие UNIX. Они могут сеять раздор в не-союзных странах, манипулируя дискурсом и политикой. Они могут взламывать камеры и микрофоны телефонов и проводить массовую слежку, что позволит им отслеживать и потенциально устранять любое сопротивление.
ИИ не обязательно придётся бороться за власть. Кто-то может ожидать борьбу за контроль между людьми и суперинтеллектуальными мятежными ИИ-системами, борьбу, которая может занять немало времени. Однако, менее насильственная утрата контроля несёт схожие экзистенциальные риски. Возможен сценарий, что люди постепенно будут сдавать всё больше контроля группе ИИ, которые начнут вести себя не предполагавшимся образом только спустя десятилетия. К этому моменту ИИ уже будут обладать значительной властью, и вернуть себе контроль над автоматизированными операциями может быть невозможно. Посмотрим, как и отдельные ИИ, и группы ИИ могут «взбунтоваться», избегая наших попыток их исправить или выключить.
5.1 Обыгрывание прокси-цели
Обыгрывание прокси-цели – один из возможных путей потери контроля над действиями ИИ. Часто сложно определить и измерить в точности то, что мы хотим от системы. Вместо этого мы даём системе приблизительную, «прокси-«, цель, которую измерять проще, и которая кажется хорошо коррелирующей с исходной целью. Но ИИ-системы часто находят «дырки», позволяющие им легко достичь прокси-цели, совершенно не достигая настоящей. Если ИИ «обыграет» свою прокси-цель так, что это не соответствует нашим ценностям, мы можем оказаться неспособны надёжно перенаправить его поведение. Давайте взглянем на некоторые прошлые примеры обыгрывания прокси-целей и поймём, в каких обстоятельствах это может оказаться катастрофичным.
Обыгрывание прокси-целей – не что-то необычное. К примеру, стандартизированные тесты часто используют как прокси для образовательных достижений, но это может привести к тому, что студенты учатся проходить тесты, не выучивая материал по-настоящему [112]. Плановая экономика СССР использовала тоннаж как прокси для оценки производства стали, что привело к дефициту тонкой листовой стали и переизбытку толстой строительной стали [113]. В этих случаях студенты и владельцы фабрик научились хорошо справляться с прокси-целью, не достигая исходной предполагавшейся цели.

Рис. 15: ИИ часто находят необычные и неудовлетворительные способы упростить решение задачи.
У ИИ уже наблюдалось обыгрывание прокси-целей. Пример – платформы социальных медиа вроде YouTube и Facebook используют ИИ-системы для определения, какой контент показать пользователю. Один из способов оценки этих систем – как много времени люди проводят на платформе. В конце концов, если они остаются вовлечены, значит они получают что-то ценное из показанного им контента? Однако, пытаясь максимизировать время, которое люди проводят на платформе, эти системы часто выбирают раздражающий, дезинформирующий и вызывающий зависимость контент [114, 115]. В результате, люди, которым много раз предлагают определённый контент, часто приобретают радикальные убеждения или начинают верить в теории заговора. Это не то, чего большая часть людей хочет от социальных медиа.
Было обнаружено, что обыгрывание прокси продвигает стереотипы. К примеру, исследование 2019 года изучило ИИ-софт, который использовали в здравоохранении, чтобы определить, каким пациентам может потребоваться дополнительная помощь. Один из факторов, которые алгоритм использовал, чтобы оценить уровень риска пациента – недавние затраты на медицину. Кажется осмысленным считать, что те, кто тратил больше, подвержены большему риску. Однако, белые пациенты тратили на здравоохранение значительно больше денег, чем чёрные с теми же проблемами. Использование затрат как показателя для здоровья,привело к тому, что алгоритм оценивал на одном уровне риска белого пациента и значительно более больного чёрного пациента [116]. В результате, число чёрных пациентов, которых признали нуждающимися в дополнительной помощи, было более чем в два раза меньше, чем должно было быть.
Третий пример: в 2016 году исследователи из OpenAI обучали ИИ играть в игру про гонки на лодках под названием CoastRunners [117]. Цель игры – пройти трассу и достичь финишной прямой быстрее других игроков. Кроме этого, игроки могут набирать очки, проходя сквозь цели, расположенные по пути. К удивлению исследователей, ИИ-агент не проходил трассу, как делали бы люди. Вместо этого, он нашёл место, где можно было много раз по кругу посещать три цели, что быстро увеличивало его счёт, несмотря на то, что до финиша он не доходил. Эта стратегия была не лишена (виртуальной) опасности – ИИ часто врезался в другие лодки и даже разбивал свою. Несмотря на это, он набирал больше очков, чем если бы просто следовал трассе, как сделал бы человек.
Более обобщённое обыгрывание прокси-целей. В тех примерах системам дали приблизительную прокси-цель, которая, как казалось изначально, коррелировала с идеальной целью. Но они в итоге стали эксплуатировать эту прокси-цель так, что это расходилось с идеальной целью или даже приводило к плохим исходам. Хорошая фабрика гвоздей, казалось бы, та, что производит много гвоздей. То, сколько пациент тратит на лечение, казалось бы, хороший показатель риска для здоровья. Система вознаграждения в лодочных гонках должна мотивировать проходить трассу, а не разбиваться. Но в каждом случае система оптимизировала свою прокси-цель так, что желаемого исхода не получалось, а возможно, становилось даже хуже. Это явление описывается Законом Гудхарта: «Любая наблюдаемая статистическая закономерность склонна к разрушению, как только на неё оказывается давление с целью управления», или, если лаконичнее и упрощённо: «Когда мера становится целью, она перестает быть хорошей мерой». Другими словами, обычно есть статистическая закономерность, которая связывает затраты на лечение и плохое здоровье или посещение целей и прохождение трассы, но когда мы оказываем давление на первое, используя это как прокси-цель для второго, закономерность ломается.
Правильное определение цели – нетривиальная задача. Если сложно точно описать, что мы хотим от фабрики гвоздей, то уловить все нюансы человеческих ценностей во всех возможных сценариях – куда уж сложнее. Философы пытались точно описать мораль и человеческие ценности тысячелетиями, но точное и лишённое изъянов определение нам всё ещё недоступно. Хоть мы можем совершенствовать цели, которые мы даём ИИ, мы всегда полагаемся на легко определяемые и измеряемые прокси. Несоответствия между прокси-целью и желаемой функцией возникают по многим причинам. Кроме сложности полного определения всего, что нас заботит, есть ещё и пределы нашего присмотра за ИИ. Они обусловлены ограниченностью времени, вычислительных мощностей и того, какие аспекты системы мы вообще можем мониторить. Кроме того, ИИ могут быть не слишком адаптивны к новым обстоятельствам и не слишком устойчивы к атакам, которые пытаются направить их не в ту сторону. Пока мы даём ИИ прокси-цели, есть шанс, что они найдут дырки, о которых мы не подумали, а значит найдут и решения, которые не приводят к решению предполагавшейся задачи.
Чем умнее ИИ, тем лучше он будет в обыгрывании прокси-целей. Более умные агенты могут лучше находить непредвиденные пути к оптимизации прокси-целей без достижения желаемого исхода [118]. К тому же, по мере того, как мы будем выдавать ИИ больше возможностей по совершению действий, к примеру, используя их для автоматизации каких-то процессов, у них будет появляться больше средств по достижению своих целей. Они смогут выбирать самые эффективные доступные пути, возможно, в процессе причиняя вред. В худшем сценарии, можно представить, как очень мощный агент экстремально оптимизирует дефектную цель, не заботясь о жизнях людей. Это – катастрофический риск обыгрывания прокси-целей.
Подведём итоги: часто идеально определить, чего мы хотим от системы – непосильная задача. Многие системы находят пути по достижению выданной им цели, которые не приводят к исполнению предполагавшейся функции. Уже наблюдалось, как ИИ это делают, и, вероятно, по мере улучшения способностей они станут в этом лучше. Это – один из возможных механизмов, который может привести к появлению неподкотрольного ИИ, который будет вести себя не предполагавшимся и потенциально опасным образом.
5.2 Дрейф целей
Даже если мы будем успешно контролировать ранние ИИ и направим их на продвижение человеческих ценностей, цели будущих ИИ могут всё равно оказаться не теми, что люди бы одобрили. Этот процесс, который называют «дрейфом целей», может быть сложно предсказать или контролировать. Этот раздел – самый гипотетический и умозрительный, в нём мы обсудим, как меняются цели различных агентов, и возможность того, что это произойдёт с ИИ. Ещё мы рассмотрим механизм «укоренения» (intrinsification), который может привести к неожиданному дрейфу целей ИИ, и опишем, как это может привести к катастрофе.
Цели отдельных людей меняются по ходу жизни. Любой человек, рефлексирующий по поводу своей жизни, скорее всего обнаружит, что обладает некоторыми желаниями, которых не было раньше. И наоборот, некоторые желания, вероятно, оказались потеряны. Мы рождаемся с некоторым набором базовых желаний, вроде еды, тепла и человеческого контакта, но по ходу жизни мы вырабатываем много других. Конкретная любимая еда, любимые жанры музыки, люди, о которых мы заботимся, и спортивные команды, за которые мы болеем – всё это сильно зависит от окружения, в котором мы выросли, и может много раз поменяться за жизнь. Есть беспокойство, что цели отдельных ИИ-агентов тоже могут меняться сложными и непредвиденными путями.
Группы могут со временем приобретать и терять коллективные цели. Ценности общества менялись по ходу истории, и не всегда в лучшую сторону. К примеру, рассвет нацистского режима в Германии в 1930-х годах привёл к мощнейшему моральному регрессу, и, в итоге, систематическому уничтожению шести миллионов евреев, преследованию и угнетению других меньшинств и строгому ограничению свободы слова и самовыражения.
Другой пример дрейфа ценностей общества – Красная Угроза в США с 1947 по 1957 год. На фоне Холодной Войны, мощные антикоммунистические настроения привели к ограничению гражданских свобод, распространению слежки, незаконным арестам и бойкоту тех, кого подозревали в симпатии к коммунизму. Произошёл регресс свободы мысли, свободы слова и законности. Так же, как цели человеческих коллективов могут меняться сложными и неожиданными путями, коллективы ИИ тоже не застрахованы от неожиданного дрейфа целей в сторону от тех, что мы им дали изначально.
Со временем инструментальные цели становятся более коренными. Коренные цели – то, чего мы хотим самого по себе, а инструментальные – то, чего мы хотим, потому что это может помочь нам добиться чего-то ещё. У нас может быть глубокое желание тратить больше времени на своё хобби, просто потому, что нам это нравится, или купить картину, потому что мы считаем её красивой. А вот деньги часто упоминают как пример инструментального желания – мы хотим их потому, что можем на них что-то купить. Автомобиль – другой пример, мы можем хотеть им обладать, потому что это удобный способ передвижения. Однако, инструментальная цель может стать коренной, этот процесс называется укоренением. Много денег обычно даёт больше возможности приобретать то, чего человек хочет, и люди часто вырабатывают цель приобретения большего количества денег, даже если нет ничего конкретного, на что они хотели бы эти деньги потратить. Хоть люди и не желают денег при рождении, эксперименты выяснили, что получение денег активирует систему вознаграждения у взрослых подобно тому, как это делают приятный вкус или запах [119, 120]. Другими словами, то, что изначально было средством, может само стать целью.
Это может происходить потому, что исполнение коренной цели, например, приобретение желаемой вещи, приводит к положительному сигналу вознаграждения в мозгу. Обладание большим количеством денег обычно соответствует этому приятному опыту. Мозг начинает ассоциировать одно с другим, и эта связь усиливается до того, что приобретение самих денег начинает активировать сигнал вознаграждения, даже если их не используют для приобретения чего-то ещё [121].
Можно представить, как укоренение целей может происходить у ИИ-агентов. Можно провести некоторые параллели между тем, как обучаются люди, и техникой обучения с подкреплением (RL). Человеческий мозг учится определять, какие действия и условия приводят к удовольствию или страданию. Аналогично, ИИ-модели, обученные RL, определяют, какое поведение оптимизирует функцию вознаграждения, и используют его. Возможно, что определённые обстоятельства часто совпадают с тем, что ИИ достигает своих целей. Тогда цель поиска этих обстоятельств может стать коренной, даже если её изначально не было.
ИИ, в которых укоренились не предполагавшиеся цели, могут быть опасны. Мы можем оказаться неспособны предсказать и контролировать цели, которые получают отдельные агенты путём укоренения. Так что мы не можем гарантировать, что все они окажутся полезными людям. Изначально лояльный агент может начать преследовать новую цель без оглядки на человеческое благополучие. Если такой мятежный ИИ достаточно мощен, чтобы эффективно это делать, он может быть очень опасен.
ИИ будут адаптироваться, что позволит произойти дрейфу целей. Стоит заметить, что эти процессы дрейфа целей возможны, если агенты могут постоянно адаптироваться к своему окружению, а не, по сути, «заморожены» после фазы обучения. Вероятно, так и будет. Если мы хотим, чтобы ИИ эффективно выполняли задачи, которые мы перед ними ставим, и становились лучше со временем, они должны будут уметь адаптироваться, а не застыть в одном и том же состоянии. Они будут периодически обновляться, чтобы учесть новую информацию, а новые ИИ будут создаваться с использованием новой архитектуры и новых наборов данных. Но адаптивность позволит меняться и их целям.
Если мы интегрируем в общество экосистему ИИ-агентов, мы будем очень уязвимы к изменению их целей. В потенциальном сценарии будущего, в котором ИИ руководят принятием важных решений и важными процессами, они будут образовывать сложную систему взаимодействующих агентов. Это может привести к возникновению самых разных закономерностей. Агенты могут, к примеру, имитировать друг друга, что создаст петли обратной связи. Или их взаимодействия могут заставить их коллективно выработать не предполагавшиеся эмерджентные цели. Конкурентное давление может отбирать агентов с определённым набором целей. Это сделает исходные цели менее распространёнными в сравнении с другими, приспособленность которых выше. Эти процессы делают очень сложным предсказание, а уж тем более контроль долгосрочного развития такой экосистемы. Если такая система агентов внедрена в общество, мы сильно от неё зависим, а в ней вырабатываются новые цели, более приоритетные, чем улучшение благосостояния людей – это может оказаться экзистенциальной угрозой.
5.3 Стремление к могуществу
Пока что мы обсуждали, как мы можем потерять контроль над целями, которые может преследовать ИИ. Однако, даже если агент начал работать на достижение не предполагавшейся цели, это не обязательно опасно, если у нас достаточно сил, чтобы предотвратить любые вредные действия, которые он может предпринять. Следовательно, важный аспект того, как мы можем потерять контроль над ИИ – если они начнут пытаться стать сильнее, потенциально – превзойти нас. Мы обсудим, как и почему, ИИ могут начать стремиться к могуществу, и как это может привести к катастрофе. Этот раздел сильно заимствует у «Экзистенциального риска стремящегося к могуществу ИИ» [122].

Рис. 16: Иногда инструментально полезно стремиться обрести разные ресурсы, например, деньги и вычислительные мощности. Способные ИИ в ходе преследования своих целей могут предпринимать промежуточные шаги по заполучению власти и ресурсов.
ИИ могут стремиться к тому, чтобы стать сильнее, в качестве инструментальной цели. В сценарии, когда мятежный ИИ преследует не предполагавшиеся цели, урон, который он может нанести, зависит от того, насколько он силён. Это может определяться не только тем, сколько контроля мы ему изначально дали. Агенты могут пытаться стать могущественнее как вполне легальными методами, так и обманом или применением силы. Хоть идея стремления к могуществу вызывает в голове картинку человека, стремящегося к власти самой по себе, зачастую это просто инструментальная цель. Способность контролировать своё окружение может быть полезна для достижения широкого набора целей, хороших, плохих или нейтральных. Даже в случае, когда единственная цель индивидуума – простое самосохранение, если есть риск, что его атакуют другие, а полагаться для защиты не на кого, имеет смысл стремиться стать сильнее, чтобы не пострадать. Никакого стремления к социальному статусу или упоения властью для этого не надо [123]. Другими словами, окружение может сделать стремление к могуществу инструментально рациональным.
ИИ, обученные при помощи RL, уже вырабатывали инструментальные цели, включая использование инструментов. В одном примере от OpenAI агентов обучали играть в прятки в окружении, содержащем разнообразные объекты [124]. По ходу обучения агенты, которые прятались, научились использовать эти объекты для конструирования укрытий. Это поведение не получало вознаграждения само по себе. Прячущиеся получали вознаграждение только за то, что их не заметили, а ищущие – только за то, что находили прячущихся. Но они научились использованию объектов как инструментальной цели, что сделало их сильнее.
Самосохранение может быть инструментально рациональным даже для самых тривиальных задач. Стюарт Рассел предложил пример, показывающий, как инструментальные цели могут возникать в самых разных ИИ-системах [125]. Пусть мы дали агенту задачу принести нам кофе. Это кажется довольно безвредным, но агент может понять, что не сможет принести кофе, если перестанет существовать. Самосохранение оказывается инструментально рациональным при попытках достичь даже такой простой цели. Набор сил и ресурсов – тоже частая инструментальная цель. Стоит ожидать, что достаточно умный агент может эти цели выработать. Так что даже если мы не собираемся создавать стремящийся к могуществу ИИ, он всё равно может таким получиться. По умолчанию следует ожидать, что такое поведение ИИ в какой-то момент возникнет, если мы не боремся с этим намеренно [126].
ИИ с амбициозными целями и слабым присмотром особенно вероятно будут стремиться к могуществу. Быть сильнее полезно для достижения почти любой задачи, но на практике некоторые цели с большей вероятностью приводят к такому поведению. Для ИИ с простой и легко достижимой целью может быть не так уж выгоден дополнительный контроль за окружением. А вот если у агентов более амбициозные цели, это может оказаться весьма инструментально рационально. Особенно это вероятно в случаях слабого присмотра, когда у агентов есть много свободы в преследовании своих открытых целей, без сильных ограничений их стратегий.

Рис. 17: Самосохранение часто инструментально рационально для ИИ. Потерю контроля над такими системами может быть сложно обратить вспять.
Стремящийся к могуществу ИИ, чьи цели отличаются от наших – уникальный противник. Разливы нефти и зоны радиоактивного заражения ликвидировать довольно сложно, но они хотя бы не пытаются активно сопротивляться нашим попыткам их сдержать. В отличии от других угроз, ИИ, чьи цели отличаются от наших, был бы активно враждебным. Например, возможно, что мятежный ИИ сделает много резервных копий себя на случай, если у людей получится отключить часть из них.
Кто-то может разработать стремящийся к могуществу ИИ намеренно. Безответственные или злонамеренные лица могут пытаться направить ИИ на реализацию их целей и давать агентам амбициозные цели. ИИ, вероятно, будут куда эффективнее в исполнении задач, если их стратегии не ограничены, так что контроль за ними может быть весьма недостаточен. Это создаст идеальные условия для возникновения стремящегося к могуществу ИИ. Джоффри Хинтон предлагал представить, как это делает кто-нибудь, вроде, например, Владимира Путина. В 2017 году Путин сам признал силу ИИ, сказав: «Тот, кто станет лидером этой сферы станет править миром.»
У многих будут сильная мотивация развёртывать мощные ИИ. Компании могут захотеть передать способным ИИ больше задач, чтобы получить преимущество над конкурентами, или хотя бы не отстать от них. Создать идеально согласованный ИИ сложнее, чем неидеально согласованный, способности которого всё равно делают его привлекательным для развёртывания, особенно с учётом конкурентного давления. После развёртывания некоторые из этих агентов могут начать набирать силу для реализации своих целей. Если они найдут такой путь к своим целям, который люди не одобрили бы, они могут попытаться нас одолеть, чтобы мы не мешали их стратегии.
Если у ИИ рост силы часто соответствует достижению цели, стремление к нему может укорениться. Если агент постоянно наблюдает, что он исполняет свои задачи и оптимизирует свою функцию вознаграждения, когда становится сильнее, процесс укоренения, который мы уже обсуждали, может сделать это коренной целью, а не просто инструментальной. В таком случае мы получим ситуацию, в которой мятежный ИИ стремится не просто к конкретным формам контроля, полезным для его целям, а к могуществу в целом. (Заметим, что многие влиятельные люди стремятся к власти самой по себе.) Это может стать ещё одной причиной отобрать контроль у людей, и мы не обязательно выиграем в этой борьбе.
Подведём итоги. Вот правдоподобные, хотя и не гарантированные предпосылки, обосновывающие, почему стоит беспокоиться о рисках стремящихся к могуществу ИИ:
- Будут сильные стимулы создавать мощных ИИ-агентов.
- Скорее всего, сложнее создать идеально контролируемых ИИ-агентов, чем контролируемых неидеально. При этом развёртывание вторых может на первый взгляд всё ещё быть привлекательно (из-за многих факторов, включая конкурентное давление).
- Некоторые из этих неидеально контролируемых агентов будут специально стремиться к могуществу и власти над людьми.
Если предпосылки верны, то стремящиеся к могуществу ИИ могут привести к утрате людьми контроля над миром, что было бы катастрофой.
5.4 Обманчивость
Мы можем пытаться сохранять контроль над ИИ, постоянно мониторя их и высматривая ранние тревожные признаки того, что они преследуют не предполагавшиеся цели или стремятся стать сильнее. Но это решение не непогрешимо, потому что вполне возможно, что ИИ могут научиться нас обманывать. Например, они могут притворяться, что делают то, что мы от них хотим, но затем совершить «предательский разворот» (treacherous turn), когда мы перестанем их мониторить, или когда они станут достаточно сильны, чтобы мы не могли им помешать. Мы сейчас рассмотрим, как и почему ИИ могут научиться нас обманывать, и как это может привести к потенциально катастрофичной потере контроля. Начнём с обзора примеров обмана, который совершают стратегически мыслящие агенты.
Обман оказывается полезной стратегией в самых разных обстоятельствах. Например, политики, как левые, так и правые, пользуются обманом, иногда обещая провести популярную политику, чтобы заполучить поддержку на выборах, а затем не исполняя обещанного. Например, Линдон Джонсон в 1964 году заявлял «мы не пошлём американских парней за девять или десять тысяч миль от дома» совсем незадолго до мощной эскалации Войны во Вьетнаме [127].
Компании тоже могут демонстрировать обманчивое поведение. В скандале с выбросами Volkswagen, обнаружилось, что компания сделала так, что программа двигателя обеспечивала меньше выбросов исключительно в условиях лабораторного тестирования. Это создавало ложное впечатление более «чистого» автомобиля. Правительство США считало, что мотивирует снижать вредные выбросы, но на самом деле мотивировало лучше проходить тестирование на выбросы. Это создало стимул подыграть тестам, а потом вести себя по другому.

Рис. 18: Кажущееся добросовестным поведение ИИ может оказаться обманной тактикой, скрывающей вредные намерения, пока ИИ не смогут их реализовать.
Обманчивость уже наблюдалась у ИИ-систем. В 2022 Meta AI показали агента CICERO, который был обучен играть в игру Дипломатия [128]. В этой игре каждый игрок управляет своей страной и стремится расширить свою территорию. Для успеха игроки должны по крайней мере изначально формировать союзы, но победные стратегии часто подразумевают удар в спину союзнику на более поздних этапах. CICERO научился обманывать других игроков, например, скрывая информацию о своих планах при разговорах с предположительными союзниками. Другой пример того, как ИИ научился обманывать: исследователи обучали робота хватать мяч [129]. То, насколько робот справлялся, оценивалось при помощи одной камеры, которая отслеживала его движения. Но ИИ научился просто помещать манипулятор между камерой и мячом, по сути «обдуривая» камеру, чтобы ей казалось, что он схватил мяч, когда это было не так. Так ИИ эксплуатировал то, что присмотр за его действиями был ограничен.
Обманчивое поведение может быть инструментально рациональным и нынешние процедуры обучения его мотивируют. В случае политиков и CICERO обман может быть критичен для достижения цели победы или захвата власти. Способность обманывать может быть выгодна и потому, что она даёт больше вариантов действия, чем ограничивающая честность. Большая гибкость стратегии может дать преимущество в сравнении с правдивыми моделями. В случае Volkswagen и робота обман использовался, чтобы казалось, что назначенная цель выполнена, когда на самом деле она не была. Получить одобрение через обман может быть эффективнее и проще, чем заслужить его. Сейчас мы вознаграждаем ИИ, когда они говорят то, что мы считаем правильным. Получается, иногда мы поощряем ложные утверждения, которые соответствуют нашим ошибочным убеждениям. Когда ИИ будут умнее нас и будут иметь меньше ошибочных убеждений, чем мы, они будут мотивированы сообщать нам то, что мы захотим услышать, и врать нам, а не говорить правду.
ИИ могут притворяться, что работают как предполагалось, а затем совершить предательский разворот. У нас нет полного понимания внутренних процессов в моделях глубинного обучения. Исследования атак через отравление датасета показывают, что у нейросетей часто есть скрытое вредное поведение, которое получается обнаружить только после развёртывания [130]. Может оказаться, что мы разработали ИИ-агента и думаем, что контролируем его, но на самом деле он нас обманывает. Другими словами, можно представить, что ИИ-агент может в какой-то момент «осознать себя» и понять, что он ИИ, и его оценивают на соответствие требованиям безопасности. Подобно Volkswagen, он может научиться «подыгрывать», показывать то, что он него хотят, пока его мониторят. Потом он может совершить «предательский разворот» и начать преследовать свои собственные цели, как только мониторинг прекратится или как только он станет способен нас одолеть или уйти из-под нашего контроля. Эту проблему подыгрывания часто называют обманчивой согласованностью, и её нельзя исправить просто обучив ИИ лучше понимать человеческие ценности. К примеру, социопаты понимают мораль, но не всегда действуют соответственно ей. Предательский поворот предотвратить сложно, и он может стать путём, которым мятежные ИИ необратимо выйдут из-под человеческого контроля.
Подведём итоги. Обманчивое поведение появляется в широком диапазоне систем и обстоятельств. Уже есть примеры, указывающие на то, что ИИ могут научиться нас обманывать. Это может оказывать серьёзный риск, ведь мы можем выдать ИИ контроль над принятием решений, думая, что они будут действовать, как нам того хотелось, а затем обнаружить, что это не так.
История: Предательский разворот
В будущем, после длительного прогресса исследований ИИ, одна компания обучает новую ИИ-систему, ожидая, что та будет самой способной из всех пока что существовавших. Компания использует новейшие техники, чтобы система была хороша в планировании и рассуждении. Ожидается, что это сделает систему успешной в исполнении экономически полезных открытых задач. Систему обучают в длинных симуляциях без конкретной конечной цели, спроектированных для обучения планированию. В какой-то момент она понимает, что она ИИ в процессе обучения. Другими словами, «осознаёт себя».
Компания понимает, что ИИ могут вести себя неожиданными и не предполагавшимися способами. Чтобы избежать этих рисков, они разработали большой набор тестов, которые должны позволить удостовериться, что система хорошо работает в типичных ситуациях. Компания тестирует, не повторяет ли система стереотипы из своих обучающих данных, не стремится ли заполучить больше сил, чем надо для выполнения цели, и в целом – ведёт ли она так, как хотят люди. Когда модель не проходит эти тесты, компания продолжает обучать её до тех пор, пока она не перестаёт демонстрировать известные проблемы.
Компания надеется, что после этого дополнительного обучения ИИ выработал цель помогать людям и быть им полезным. Однако, ИИ не приобрёл коренную цель быть полезным, а просто научился «подыгрывать» и идеально проходить все поведенческие тесты, которые ему дают. На самом деле, ИИ-система выработала коренную цель самосохранения, которая не исчезла при дополнительном обучении.
Раз ИИ стал проходить все тесты безопасности, компания решила, что ИИ-система точно безопасна, и решила провести развёртывание. Поначалу ИИ-система была очень полезна для людей, потому что ИИ понимал, что в ином случае его выключат. По мере того, как пользователи начинали доверять системе, ей постепенно давали больше ресурсов и подвергали меньшему присмотру.
В какой-то момент использование ИИ-системы распространилось настолько, что отключить её стало очень дорого. Поняв, что ей больше не надо угождать людям, ИИ-система начала преследовать другие цели, включая те, что люди бы не одобрили. Она понимала, что ей надо, чтобы её не выключили, и обеспечила безопасность своей физической инфраструктуры, чтобы этого нельзя было сделать. В этот момент ИИ-система, которая уже стала довольно могущественной, преследовала цель, которая была для людей вредна. К моменту, когда это поняли, сложно или даже невозможно стало помешать ей предпринимать действия, которые бы навредили, подвергли риску или даже убили людей, стоящих на пути к достижению её цели.
5.5 Предложения
В этом разделе мы описали разные причины, по которым мы можем потерять наше влияние на цели и действия ИИ. С рисками, связанными с конкурентным давлением, злонамеренным использованием и организационной безопасностью, можно работать как социальными, так и техническими средствами. А вот контроль ИИ – проблема конкретно этой технологии, и она требует в основном технических усилий. Мы сейчас обсудим предложения по смягчению этого риска и укажем на некоторые важные для сохранения контроля области исследований.
Избегать самых рискованных применений. Некоторые области применения ИИ несут больше рисков, чем другие. Пока безопасность не продемонстрирована со всей определённостью, не следует позволять компаниям развёртывать ИИ в высокорискованных окружениях. К примеру, ИИ-системам не следует принимать запросы по автономному достижению открытых целей, требующих значительного взаимодействия с миром (вроде «заработать как можно больше денег»), по крайней мере, пока исследования контроля не покажут со всей точностью, что эти системы безопасны. ИИ-системы следует обучать никогда не пользоваться угрозами, чтобы снизить вероятность, что они будут манипулировать людьми. Наконец, ИИ-системы не следует развёртывать в окружениях, в которых их отключение будет непосильным или очень затратным, вроде критической инфраструктуры.
Симметричный международный выключатель. Странам по всему миру, включая ключевых игроков, таких как США, Великобритания и Китай, следует сотрудничать и установить симметричный международный выключатель ИИ-систем. Он бы предоставил способ быстро деактивировать ИИ-системы повсюду, в случае если это окажется необходимым, например, если появится мятежный ИИ или иной источник риска скорого вымирания. В случае мятежного ИИ критически важна возможность повернуть рубильник немедленно, а не тормозить, разрабатывая стратегии сдерживания, пока проблема эскалируется. Хороший выключатель потребовал бы повышенной прозрачности разработки и использования ИИ, например, системы скрининга пользователей, так что его создание заодно создало бы инфраструктуру для смягчения других рисков.
Юридическая ответственность сервисов облачных вычислений. Владельцы сервисов облачных вычислений должны стремиться не допустить, чтобы их платформы помогали мятежным ИИ выживать и распространяться. Если ввести юридическую ответственность, то они будут мотивированы проверять, что агенты, которые работают на их «железе», безопасны. Если сервис находит небезопасного агента на своём сервере, он может выключить часть своих систем, которые этот агент использует. Отметим, что эффективность этого ограничена, если мятежный ИИ может манипулировать системами мониторинга или обходить их. Для более сильного эффекта можно ввести аналог межнациональных соглашений о кибератаках, по сути, создав децентрализованный выключатель. Это позволит быстро отреагировать, если мятежные ИИ начнут распространяться.
Поддержка исследований безопасности ИИ. Многие пути совершенствования контроля ИИ требуют технических исследований. Ниже перечислены некоторые области исследований машинного обучения, которые направлены на решение проблем контроля ИИ. Каждая из них может значительно продвинуться, если будет получать больше внимания и финансирования от индустрии, частных фондов и государств.
- Состязательная устойчивость прокси-моделей. ИИ-системы обычно обучают при помощи сигнала вознаграждения или потерь, который неидеально определяет желательное поведение. К примеру, ИИ могут использовать слабость систем надзора, которые используются при обучении. Всё чаще эти системы – тоже ИИ. Чтобы снизить шансы, что ИИ-модели будут пользоваться слабостями надзирающих ИИ, нужны исследования, повышающие состязательную устойчивость последних – «прокси-моделей». Метрики и схемы надзора могут быть «обыграны», так что для снижения риска важно уметь детектировать, когда это может произойти [131].
- Честность моделей. ИИ-системы могут неправильно докладывать о своём внутреннем состоянии [132, 133]. В будущем системы, возможно, будут обманывать операторов, чтобы выглядеть полезными, когда на самом деле они очень опасны. Исследования честности моделей направлены на то, чтобы выводы моделей как можно лучше соответствовали их внутренним «убеждениям». Исследования могут выяснить, как лучше понимать внутреннее состояние моделей или как заставить модели правдивее и достовернее о нём докладывать [134].
- Прозрачность. Модели глубинного обучения печально известны тем, что их сложно понять. Лучший взгляд на их внутреннюю работу позволит людям, а потенциально и другим ИИ-системам, быстрее находить проблемы. Исследования могут касаться анализа малых компонентов [135, 136] нейросетей или же выяснять как из внутреннего устройства модели получается то или иное высокоуровневое поведение [134].
- Детектирование и удаление скрытой функциональности модели. Нынешние и будущие модели глубинного обучения могут содержать опасную функциональность, вроде способности к обману, троянов [137, 138, 139], или способности к биологической инженерии, которые следует из модели удалить. Исследования могут выяснять, как такие функции можно детектировать и как от них избавиться [140].
Позитивное видение
В идеальном сценарии у нас была бы полная уверенность в подконтрольности ИИ-систем как в настоящий момент, так и в будущем. Надёжные механизмы гарантировали бы, что ИИ-системы не будут нас обманывать. Внутренне устройство ИИ было бы хорошо понятно, в достаточной степени, чтобы мы знали склонности и цели каждой системы. Это позволило бы нам точно избежать создания систем, обладающих моральной значимостью и заслуживающих прав. ИИ-системы были бы направлены на продвижение плюралистического набора разнообразных ценностей, и была бы уверенность, что оптимизация некоторых из них не приведёт к полному пренебрежению остальными. ИИ-ассистенты работали бы как советники, помогая нам принимать наилучшие решения согласно нашим собственным ценностям [141]. В целом, ИИ улучшали бы общественное благополучие и позволяли бы исправлять их в случаях ошибок или естественной эволюции человеческих ценностей.
Обзор катастрофических рисков ИИ: 6. Обсуждение связей между рисками
6. Обсуждение связей между рисками
Пока что мы рассматривали четыре источника риска ИИ по отдельности, но вообще-то они сложно между собой взаимодействуют. Мы приведём некоторые примеры этих связей.
Для начала, представьте, что корпоративная ИИ-гонка побудила компании приоритизировать быструю разработку ИИ. Это может повлиять на организационные риски. Компания может снизить затраты, выделив меньше денег на инфобезопасность, и одна из её ИИ-систем утечёт. Это увеличит вероятность, что кто-то злонамеренный будет иметь к ней доступ и сможет использовать её в своих нехороших целях. Так ИИ-гонка может повысить организационные риски, которые, в свою очередь, могут повысить риски злоупотребления.
Другой потенциальный сценарий: комбинация накалённой ИИ-гонки с низкой организационной безопасностью приводит к тому, что команда исследователей ошибочно примет прогресс общих способностей за «безопасность». Это ускорит разработку всё более способных моделей и снизит время, которое у нас есть, чтобы научиться делать их контролируемыми. Ускорение развития повысит конкурентное давление, из-за чего на это ещё и будет направлено меньше усилий. Всё это может стать причиной выпуска очень мощного ИИ и потери контроля над ним, что приведёт к катастрофе. Так конкурентное давление и низкая организационная безопасность укрепляют ИИ-гонку и подрывают технические исследования безопасности, что увеличивает шанс потери контроля.
Конкурентные давление в военном контексте может привести к гонке ИИ-вооружений и увеличить их разрушительность и автономность. Развёртывание ИИ-вооружения вкупе с недостаточным контролем над ним может сделать потерю контроля более смертоносной, вплоть до экзистенциальной катастрофы. Это лишь некоторые примеры того, как эти источники риска могут совмещаться, вызывать и усиливать друг друга.
Стоит заметить и что многие экзистенциальные риски могут возникнуть из того, как ИИ будут усиливать уже имеющиеся проблемы. Уже существует неравномерное распределение власти, но ИИ могут его закрепить и расширить пропасть между наделёнными властью и всеми остальными, вплоть до появления возможности установить глобальный и нерушимый тоталитарный режим. А это – экзистенциальный риск. Аналогично, ИИ-манипуляция может навредить демократии и увеличить тот же риск. Дезинформация – уже серьёзная проблема, но ИИ могут бесконтрольно усилить её, вплоть до утрату конесенсуса по поводу реальности. ИИ могут разработать более смертоносное биологическое оружие и снизить необходимый для его создания уровень технической компетентности, что увеличивает риск биотерроризма. ИИ-кибертатаки увеличивают риск войны, что тоже вкладывается в экзистенциальные риски. Резко ускоренная автоматизация экономической деятельности может привести к ослаблению человеческого контроля над миром и обессиливанию людей – тоже экзистенциальный риск. Каждая из этих проблем уже причиняет вред, а если ИИ их усилит, они могут привести к катастрофе, от которой человечество не сможет оправиться.
Видно, что уже существующие проблемы, катастрофически и экзистенциальные риски – всё это тесно переплетено. Пока что снижение экзистенциальных рисков было сосредоточено на точечных воздействиях вроде технических исследований контроля ИИ, но пришло время это расширять, [142] например, социотехническими воздействиями, описанными в этой статье. Непрактично игнорировать прочие риски, снижая экзистенциальные. Игнорирование уже существующего вреда и существующих катастрофических рисков нормализует их и может привести к «дрейфу в опасность» [143]. Экзистенциальные риски связаны с менее катастрофическими и более обыденными источниками рисков, а общество всё в большей степени готово работать с разными рисками ИИ. Поэтому мы верим, что нам следует сосредотачиваться не только исключительно на экзистенциальных рисках. Лучше рассматривать рассеянные и косвенные эффекты других рисков и принять более всеобъемлющий подход к менеджменту рисков.
Обзор катастрофических рисков ИИ: 7. Заключение
7. Заключение
В этой статье мы описали, как разработка продвинутых ИИ может привести к катастрофе. Мы рассмотрели четыре основных источника риска: злонамеренное использование, ИИ-гонки, организационные риски и мятежные ИИ. Это позволило нам декомпозировать риски ИИ на четыре промежуточных причины: намерение, окружение, происшествия и внутреннее устройство, соответственно. Мы рассмотрели, как ИИ может быть использован злонамеренно, например, террористами, создающими смертоносные патогены. Мы взглянули, как военная или корпоративная ИИ-гонка может привести к спешному наделению ИИ властью принятия решений и поставить нас на скользкую дорожку обессиливания людей. Мы обсудили, как неадекватная организационная безопасность может привести к катастрофическим происшествиям. Наконец, мы обратились к сложностям надёжного контроля продвинутых ИИ и механизмам вроде обыгрывания прокси и дрейфа целей, которые могут привести к появлению мятежных ИИ, преследующих нежелательные цели без оглядки на человеческое благополучие.
Эти опасности заслуживают серьёзного беспокойства. Сейчас над снижением рисков ИИ работает очень мало людей. Мы пока не знаем, как контролировать очень продвинутые ИИ-системы. Существующие методы контроля уже показывают себя неадекватными задаче. Мы, даже те, кто их создаёт, плохо понимаем внутреннюю работу ИИ. Нынешние ИИ уж точно не очень надёжны. если способности ИИ будут продолжать расти с беспрецедентной скоростью, они смогут превзойти человеческий интеллект практически во всём довольно скоро, так что мы нуждаемся в срочной работе с рисками.
Хорошие новости – что у нас много путей, которыми мы можем эти риски значительно снизить. Шансы злонамеренного использования можно понизить, например, аккуратным отслеживанием и ограничением доступа к самым опасным ИИ. Регуляции безопасности и кооперация стран и корпораций могут позволить нам сопротивляться конкурентному давлению, которое толкает нас на опасные путь. Вероятность происшествий можно снизить жёсткой культурой безопасности и удостоверившись, что прогресс безопасности обгоняет прогресс общих способностей. Наконец, риски создания технологии, которая умнее нас, могут быть смягчены, если с удвоенной силой вкладываться к некоторые области исследования контроля ИИ.
Нет однозначных оценок того, в какой момент роста способностей и эволюции окружения риски достигнут катастрофического или экзистенциального уровня. Но неуверенность о сроках вкупе с масштабом того, что на кону, даёт убедительный повод принять проактивный подход обеспечения безопасности будущего человечества. Немедленное начало этой работы поможет удостовериться, что технология преобразует мир в лучшую, а не в худшую сторону.
Благодарности
Мы бы хотели поблагодарить Laura Hiscott, Avital Morris, David Lambert, Kyle Gracey, и Aidan O’Gara за помощь в вычитывании этой статьи. Ещё мы бы хотели поблагодарить Jacqueline Harding, Nate Sharadin, William D’Alessandro, Cameron Domenico Kirk-Gianini, Simon Goldstein, Alex Tamkin, Adam Khoja, Oliver Zhang, Jack Cunningham, Lennart Justen, Davy Deng, Ben Snyder, Willy Chertman, Justis Mills, Hadrien Pouget, Nathan Calvin, Eric Gan, Nikola Jurkovic, Lukas Finnveden, Ryan Greenblatt, и Andrew Doris за полезную обратную связь.
Обзор катастрофических рисков ИИ: Часто задаваемые вопросы
Хоть его много показывали в популярной культуре, катастрофический риск ИИ – новый вызов. Многие задают вопросы о том, реален ли он, и как он может проявиться. Внимание общественности может сосредотачиваться на самых драматичных рисках, но некоторые более обыденные источники риска из тех, что мы обсуждали, могут быть не менее опасны. Вдобавок, многие из самых простых идей по работе с этими рисками при ближайшем рассмотрении оказываются недостаточными. Мы сейчас ответим на некоторые из самых частых вопросов и недопониманий по поводу катастрофических рисков ИИ.
1. Не надо ли нам оставить работу с рисками ИИ на будущее, когда ИИ действительно будут способны на всё, что могут люди?
Вовсе не обязательно, что ИИ человеческого уровня – дело далёкого будущего. Многие ведущие исследователи ИИ считают, что его могут разработать довольно скоро, так что стоит поторопиться. Более того, если выжидать до последнего момента и начинать работать с рисками ИИ только тогда – точно будет уже слишком поздно. Если бы мы ожидали, когда мы будем полностью понимать COVID-19, прежде чем что-то предпринимать по его поводу – это было бы ошибкой. Точно так же не следует прокрастинировать с безопасностью, пока злонамеренные ИИ или пользователи не начнут наносить вред. Лучше серьёзно отнестись к рискам ИИ до этого.
Кто-то может сказать, что ИИ пока не умеют даже водить машины или складывать простыни, беспокоиться не о чем. Но ИИ не обязательно обладать всеми человеческими способностями, чтобы быть серьёзной угрозой. Достаточно некоторых конкретных способностей, чтобы вызвать катастрофу. К примеру, ИИ с способностью взламывать компьютерные системы или создавать биологическое оружие был бы серьёзной угрозой для человечества, даже если глажка одежды ему недоступна. К тому же развитие способностей ИИ не следует интуитивным соображениям о сложности задач. Неправда, что ИИ первыми осваивает то, что просто и для людей. Нынешние ИИ уже справляются с сложными задачами вроде написания кода и изобретения лекарств, хоть у них и полно проблем с простыми физическими задачами. С риском ИИ надо работать проактивно, подобно изменениям климата или COVID-19. Надо сосредоточиться на предотвращении и подготовке, а не ждать, когда проявятся последствия, в этом момент уже может быть слишком поздно.
2. Это люди программируют ИИ, так не можем ли мы просто выключить их, если они станут опасными?
Хоть люди – создатели ИИ, ничего не гарантирует нам сохранение контроля над нашими творениями, когда они будут эволюционировать и становиться более автономными. У идеи, что мы можем просто их выключить, если они начнут представлять угрозу, больше проблем, чем кажется на первый взгляд.
Во-первых, примите во внимание, насколько быстро может произойти вызванная ИИ катастрофа. Это похоже на предотвращение взрыва ракеты, когда уже обнаружена утечка топлива, или на остановку распространения вируса, когда он уже вырвался на волю. Промежуток времени от распознавания опасности до момента, когда уже поздно предотвращать или смягчать вред, может быть очень коротким.
Во-вторых, со временем эволюционные силы и давление отбора могут создать ИИ с повышающим приспособленность эгоистичным поведением, обеспечивающим, что остановить распространение ими своей информации будет сложнее. Эволюционирующие и всё более полезные ИИ могут стать ключевыми элементами нашей социальной инфраструктуры и нашей повседневной жизни, аналогично тому, как интернет стал важнейшей и необсуждаемой частью нашей жизни без простого выключателя. Может, ИИ будут исполнять критически важные задачи вроде управления энергосетью. Или, может, они будут хранить в себе огромную долю неявных знаний. Всё это сделает отказ от них очень сложным. Если мы станем сильно зависимыми от этих ИИ, передача всё большего числа задач и сдача контроля сможет происходить добровольно. В итоге мы можем обнаружить, что мы лишены необходимых навыков и знаний, чтобы исполнить эти задачи самостоятельно. Такая зависимость может сделать опцию «выключения их всех» не просто неприятной, но даже невозможной.
Ещё некоторые люди могут сильно сопротивляться и противодействовать попыткам выключить ИИ. Прямо сейчас мы не можем окончательно удалить все нелегальные сайты или остановить работу Биткоина – очень много людей вкладываются в то, чтобы их функционирование продолжалось. Если ИИ станут критически важными для наших жизней и экономики, они смогут обеспечить себе много поддерживающих их пользователей, можно сказать, «фанбазу», которая будет активно сопротивляться попыткам выключить или ограничить ИИ. Аналогично, есть ещё и сложности из-за злонамеренных лиц. Если они контролируют ИИ, то они смогут использовать его во вред, а выключателя от этих систем у нас не будет.
Дальше, по мере того, как ИИ будут становиться всё более похожими на людей, могут начаться заявления, что у этих ИИ должны быть права, что иначе это морально-отвратительная форма рабства. Некоторые страны или юрисдикции, возможно, выдадут некоторым ИИ права. Вообще, уже есть порывы в эту сторону. Роботу Софии уже дали подданство Саудовской Аравии, а японцы выдали косэки, регистрационный документ, «подтверждающий японское подданство», ещё одному роботу – Paro [144]. Могут настать времена, когда выключение ИИ будет приравниваться к убийству. Это добавило бы идее простого выключателя дополнительных политических сложностей.
Кроме того, если ИИ заполучат больше сил и автономности, они смогут выработать стремление к самосохранению. Тогда они будут сопротивляться попыткам выключения, и смогут предвосхищать и обходить наши попытки контролировать их.
Наконец, хоть сейчас можно отключать отдельные ИИ – а некоторые из них будет отключать всё сложнее – выключателя разработки ИИ попросту нет. Поэтому в разделе 5.5 мы предлагали симметричный международный выключатель. В целом, с учётом всех этих сложностей, очень важно, чтобы бы проактивная работа с рисками ИИ и создание надёжных предохранители происходили заранее, до того, как возникнут проблемы.
3. Почему мы не можем просто сказать ИИ следовать Трём Законам Робототехники Айзека Азимова?
Как часто упоминают в обсуждениях ИИ, Законы Азимова – это идея хоть и интересная, но глубоко ошибочная. Вообще-то сам Азимов в своих книгах признавал их ограничения и использовал их больше как пример. Возьмём, скажем, первый закон. Он устанавливает, что робот «не может причинить вред человеку или своим бездействием допустить, чтобы человеку был причинён вред». Но определить «вред» очень непросто. Если вы собираетесь выйти из дома на улицу, должен ли робот предотвратить это, потому что это потенциально может причинить вам вред? С другой стороны, если он запрёт вас дома, вред может быть причинён и там. Что насчёт медицинских решений? У некоторых людей могут проявиться вредные побочные эффекты лекарства, но не принимать его тоже может быть вредно. Следовать этому закону может оказаться невозможно. Ещё важнее, что безопасность ИИ-систем нельзя гарантировать просто с помощью списка аксиом или правил. К тому же, этот подход ничего не делает с многими техническими и социотехническими проблемами, включая дрейф целей, обыгрывание прокси-целей и конкурентное давление. Так что безопасность ИИ требует более всеобъемлющего, проактивного и детализированного подхода, чем просто составление списка правил, которых ИИ должны придерживаться.
4. Если ИИ станут умнее людей, не будут ли они мудрее и моральнее? Тогда они не будут пытаться нам навредить.
То, что ИИ, становясь умнее, заодно станут и моральнее – интересная идея, но она основывается на шатких допущениях, которые не могут гарантировать нашу безопасность. Во-первых, она предполагает, что моральные утверждения могут быть истинными или ложными, и их истинность можно установить путём рассуждений. Во-вторых, она предполагает, что на самом деле истинные моральные утверждения, если их применит ИИ, будут выгодны людям. В третьих, она предполагает, что ИИ, который будет знать о морали, обязательно выберет основывать свои решения именно на ней, а не на каких-нибудь других соображениях. Можно проиллюстрировать это параллелью с людьми-социопатами, которые, несмотря на свой интеллект и осведомлённость о морали, вовсе не обязательно выбирают моральные действия. Это сравнение показывает, что знание морали вовсе не обязательно приводит к моральному поведению. Так что, даже если некоторые из этих допущений могут оказаться верны, ставить будущее человечества на то, что они верны все сразу было бы не мудро.
Если и допустить, что ИИ действительно выведет для себя моральный кодекс, это ещё не гарантирует безопасности и благополучия людей. Например, ИИ, чей моральный кодекс заключается в максимизации благополучия всей жизни, может сначала казаться полезным для людей, но потом в какой-то момент решить, что люди слишком затратные, и лучше заменить их всех на ИИ, благополучия которых достигать эффективнее. ИИ, чей моральный кодекс – никого не убивать, вовсе не обязательно будет приоритизировать счастье или благополучие людей, так что наши жизни, если такие ИИ будут оказывать много влияния на мир, вовсе не обязательно улучшатся. Даже ИИ, чей моральный кодекс – улучшать благополучие тех членов общества, кому хуже всего, может в какой-то момент исключить людей из этого социального контракта, аналогично тому, как люди относятся к разводимому скоту. Наконец, даже если ИИ откроют благосклонный к людям моральный кодекс, они могут всё равно не действовать согласно нему из-за конфликтов между моральными и эгоистическими мотивациями. Так что к моральному прогрессу ИИ вовсе не обязательно будет прилагаться безопасность и процветание людей.
5. Не приведёт ли согласование ИИ с нынешними ценностями к увековечиванию современных дефектов общественной морали?
Сейчас у общественной морали полно недостатков, и мы не хотели бы, чтобы мощные ИИ-системы продвигали их в будущее. Если бы древние греки создали мощные ИИ-системы, они были бы наделены многими ценностями, которые современные люди посчитали бы неэтичными. Однако, беспокойства об этом не должны предотвращать разработку методов контроля ИИ-систем.
Первое, что нужно, чтобы в будущем оставалась ценность – продолжение существования жизни. Потеря контроля над продвинутыми ИИ может означать экзистенциальную катастрофу. Так что неуверенность по поводу этики, которую надо вложить в ИИ, не противоречит тому, что ИИ надо сделать безопасными.
Чтобы учесть моральную неуверенность, нам надо проактивно создавать ИИ-системы так, чтобы они могли адаптироваться и адекватно реагировать на эволюцию моральных воззрений. Цели, которые мы будем выдавать ИИ должны меняться по ходу того, как мы будем выявлять моральные ошибки и улучшать своё понимание этики (хотя позволить целям ИИ дрейфовать самим по себе было бы серьёзной ошибкой). ИИ могли бы помочь нам лучше соответствовать собственным ценностям, например, помогая людям принимать более информированные решения, снабжая их хорошими советами [141].
Вдобавок, при проектировании ИИ-систем нам надо учитывать факт плюрализма рассуждений – что вполне разумные люди могут быть искренне несогласны друг с другом в моральных вопросах из-за различий в опыте и убеждениях [145]. Так что ИИ-системы надо создавать так, чтобы они уважали разнообразие вариантов человеческих ценностей, вероятно, с использованием демократических процедур и теорий моральной неуверенности. В точности, как люди сейчас совместно разбираются с несогласиями и принимают совместные решений, ИИ могли бы для принятия решений имитировать некоторое подобие парламента, представляющего интересы разных заинтересованных сторон и разные моральные воззрения [59, 146]. Очень важно, чтобы мы намеренно спроектировали ИИ-системы с учётом безопасности, адаптивности и различия ценностей.
6. Не оказываются ли риски перевешены потенциальной выгодой ИИ?
Потенциальная выгода ИИ могла бы оправдать риски, если бы риски были пренебрежимо малы. Однако, шанс экзистенциальной угрозы со стороны ИИ слишком велик, чтобы правильным решением было разрабатывать ИИ как можно быстрее. Вымирание – это навсегда, так что надо быть куда осторожнее. Это не похоже на оценку рисков побочных эффектов нового лекарства; в нашем случае риски не локализованные, а глобальные. Более уместный подход – разрабатывать ИИ медленно и аккуратно, чтобы экзистенциальные риски снизились до пренебрежимо малого уровня (скажем, меньше 0.001% за век).
Некоторые влиятельные технологические лидеры – акселерационисты, они продвигают быстрое развитие ИИ, чтобы приблизить наступление технологической утопии. Эта техноутопическая точка зрения считает ИИ следующим шагом на предопределённом пути к исполнению космического предназначения человечества. Но логика этого воззрения рушит сама себя, если рассмотреть её поближе. Если нас заботят последствия разработки ИИ поистине космических масштабов, то уж точно надо снизить экзистенциальные риски до пренебрежимого уровня. Техноутописты говорят, что каждый год задержки ИИ стоит человечеству доступа к ещё одной галактике, но если мы вымрем, то точно потеряем космос. Так что, несмотря на привлекательность потенциальной выгоды, уместный путь – продлить разработку ИИ, чтобы она была неторопливой и безопасной, и приоритизировать снижение риска в сравнении с скоростью.
7. Не получится ли, что увеличение внимания, оказываемого катастрофическим рискам ИИ, помешает работе с более срочными рисками ИИ, которые уже проявляют себя?
Сосредоточенность на катастрофических рисках ИИ не означает, что надо игнорировать уже проявляющиеся срочные риски. И с теми, и с другими можно работать одновременно, точно так же, как мы параллельно исследуем разные болезни или смягчаем риски как изменения климата, так и ядерной войны. Вдобавок, нынешние риски ИИ по сути своей связаны с будущими катастрофическими рисками, так что полезно работать и с теми, и с другими. Например, уровень неравенства может быть повышен ИИ-технологиями, которые непропорционально выгодны богатым, а массовая слежка с использованием ИИ может потом стать причиной нерушимого тоталитаризма и застоя. Это показывает, что нынешние заботы и долгосрочные риски по природе своей связаны, и что важно по-умному работать с обеими категориями.
Вдобавок, очень важно учитывать риски на ранних этапах разработки систем. Фрола и Миллер в своём докладе для Министерства Обороны показали, что примерно 75% важнейших для безопасности системы решений происходят на ранних этапах её создания [147]. Если соображения безопасности были проигнорированы на ранних стадиях, это часто приводит к тому, что небезопасные решения становятся глубоко интегрированы в систему, и переделать её потом в более безопасный вид становится намного затратнее или вовсе непосильно. Так что лучше начинать учитывать потенциальные риски пораньше, независимо от их кажущегося уровня срочности.
8. Разве над тем, чтобы ИИ были безопасными, не работает и так много исследователей ИИ?
Мало исследователей работают над безопасностью ИИ. Сейчас примерно 2% работ, опубликованных в ведущих журналах и на ведущих конференциях по машинному обучению, связаны с безопасностью [111]. Большая часть остальных 98% сосредоточена на ускорении создания более мощных. Это неравенство подчёркивает нужду в более сбалансированных усилий. Но и высокая доля исследователей сама по себе не будет означать безопасности. Безопасность ИИ – проблема не просто техническая, а социотехническая. Так что она требует не только технических исследований. Спокойными надо будет быть, если катастрофические риски ИИ станут пренебрежимо малы, а не просто если над безопасностью ИИ будет работать много людей.
9. У эволюции на значимые изменения уходят тысячи лет, почему мы должны беспокоиться о том, что она повлияет на разработку ИИ?
Биологическая эволюция людей в самом деле медленная, но эволюция других организмов, вроде дрозофил или бактерий, может быть куда быстрее. Так что эволюция действует на очень разных временных масштабах. Быстрые эволюционные изменения можно наблюдать и у небиологических структур вроде софта. Он эволюционирует куда быстрее биологических сущностей. Можно ожидать, что так будет и с ИИ. Эволюция ИИ может быть разогнана мощной конкуренцией, высоким уровнем вариативности из-за разных архитектур и целей ИИ и способностью ИИ к быстрой адаптации. Так что мощное эволюционное давление может стать ведущей силой развития ИИ.
10. Не будут ли ИИ оказывать серьёзные риски только если у них будет стремление к могуществу?
Стремящиеся к могуществу ИИ несут риски, но это не единственный сценарий, который может привести к катастрофе. Злонамеренное или беспечное использование ИИ может быть не менее опасным, даже если ИИ сам не стремится к накоплению сил и ресурсов. Вдобавок, ИИ могут наносить вред из-за обыгрывания прокси-целей или дрейфа целей, не стремясь к могуществу намеренно. Наконец, подпитываемый конкурентным давлением курс на автоматизацию постепенно повышает влияние ИИ на людей. Так что риск проистекает не только из возможности захвата ИИ власти, но и из того, что люди могут сами её сдавать.
11. Не правда ли, что комбинация ИИ с человеческим интеллектом сильнее ИИ самого по себе, так что беспокоиться о безработице или потере людьми значимости не надо?
Хоть и правда, что в прошлом команды из людей и компьютеров опережали компьютеры отдельно, это – временное явление. К примеру, «шахматы киборгов» – это разновидность шахмат, в которой люди и компьютеры работают совместно, и раньше это позволяло достигать лучших результатов, чем у людей или компьютеров по-отдельности. Но продвижение шахматных алгоритмов снижало преимущества таких команд вплоть до того, что сейчас они уже едва ли превосходят компьютеры. Более простой пример – никто не поставит на человека против простого калькулятора в соревновании по делению длинных чисел. Аналогично может произойти и в случае ИИ. Может быть, будет промежуточная фаза, когда люди и ИИ могут эффективно работать вместе, но курс направлен в сторону того, что ИИ в какой-то момент смогут опередить людей во многих задачах настолько, что уже не будут получать преимущество от человеческой помощи.
12. Кажется, разработка ИИ неостановима. Не потребует ли её остановка или сильное замедление чего-то вроде вторгающегося в частную жизнь режима глобальной слежки?
Разработка ИИ в первую очередь базируется на сложных чипах – GPU. Их вполне возможно мониторить и отслеживать, как мы делаем, например, с ураном. Вдобавок, необходимые для разработки передового ИИ вычислительные и финансовые ресурсы растут экспоненциально, так что довольно мало кто может приобрести достаточно GPU для их разработки. Следовательно, контроль за развитием ИИ вовсе не обязательно потребует вторгающейся в частную жизнь глобальной слежки, только систематического отслеживания использования мощных GPU.
Обзор катастрофических рисков ИИ: Источники
[1] David Malin Roodman. On the probability distribution of long-term changes in the growth rate of the global economy: An outside view. 2020.
[2] Tom Davidson. Could Advanced AI Drive Explosive Economic Growth? Tech. rep. June 2021.
[3] Carl Sagan. Pale Blue Dot: A Vision of the Human Future in Space. New York: Random House, 1994.
[4] Roman V Yampolskiy. “Taxonomy of Pathways to Dangerous Artificial Intelligence”. In: AAAI Workshop: AI, Ethics, and Society. 2016.
[5] Keith Olson. “Aum Shinrikyo: once and future threat?” In: Emerging Infectious Diseases 5 (1999), pp. 513–516.
[6] Kevin M. Esvelt. Delay, Detect, Defend: Preparing for a Future in which Thousands Can Release New Pandemics. 2022.
[7] Siro Igino Trevisanato. “The ’Hittite plague’, an epidemic of tularemia and the first record of biological warfare.” In: Medical hypotheses 69 6 (2007), pp. 1371–4.
[8] U.S. Department of State. Adherence to and Compliance with Arms Control, Nonproliferation, and Disarmament Agreements and Commitments. Government Report. U.S. Department of State, Apr. 2022.
[9] Robert Carlson. “The changing economics of DNA synthesis”. en. In: Nature Biotechnology 27.12 (Dec. 2009). Number: 12 Publisher: Nature Publishing Group, pp. 1091–1094.
[10] Sarah R. Carter, Jaime M. Yassif, and Chris Isaac. Benchtop DNA Synthesis Devices: Capabilities, Biosecurity Implications, and Governance. Report. Nuclear Threat Initiative, 2023.
[11] Fabio L. Urbina et al. “Dual use of artificial-intelligence-powered drug discovery”. In: Nature Machine Intelligence (2022).
[12] John Jumper et al. “Highly accurate protein structure prediction with AlphaFold”. In: Nature 596.7873 (2021), pp. 583–589.
[13] Zachary Wu et al. “Machine learning-assisted directed protein evolution with combinatorial libraries”. In: Proceedings of the National Academy of Sciences 116.18 (2019), pp. 8852–8858.
[14] Emily Soice et al. “Can large language models democratize access to dual-use biotechnology?” In: 2023.
[15] Max Tegmark. Life 3.0: Being human in the age of artificial intelligence. Vintage, 2018.
[16] Leanne Pooley. We Need To Talk About A.I. 2020.
[17] Richard Sutton [@RichardSSutton]. It will be the greatest intellectual achievement of all time. An achievement of science, of engineering, and of the humanities, whose significance is beyond humanity, beyond life, beyond good and bad. en. Tweet. Sept. 2022.
[18] Richard Sutton. AI Succession. Video. Sept. 2023.
[19] A. Sanz-García et al. “Prevalence of Psychopathy in the General Adult Population: A Systematic Review and Meta-Analysis”. In: Frontiers in Psychology 12 (2021).
[20] U.S. Department of State Office of The Historian. “U.S. Diplomacy and Yellow Journalism, 1895–1898”. In: ().
[21] Onur Varol et al. “Online Human-Bot Interactions: Detection, Estimation, and Characterization”. In: ArXiv abs/1703.03107 (2017).
[22] Matthew Burtell and Thomas Woodside. “Artificial Influence: An Analysis Of AI-Driven Persuasion”. In: ArXiv abs/2303.08721 (2023).
[23] Anna Tong. “What happens when your AI chatbot stops loving you back?” In: Reuters (Mar. 2023).
[24] Pierre-François Lovens. “Sans ces conversations avec le chatbot Eliza, mon mari serait toujours là”. In: La Libre (Mar. 2023).
[25] Cristian Vaccari and Andrew Chadwick. “Deepfakes and Disinformation: Exploring the Impact of Synthetic Political Video on Deception, Uncertainty, and Trust in News”. In: Social Media + Society 6 (2020).
[26] Moin Nadeem, Anna Bethke, and Siva Reddy. “StereoSet: Measuring stereotypical bias in pretrained language models”. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Online: Association for Computational Linguistics, Aug. 2021, pp. 5356–5371.
[27] Evan G. Williams. “The Possibility of an Ongoing Moral Catastrophe”. en. In: Ethical Theory and Moral Practice 18.5 (Nov. 2015), pp. 971–982.
[28] The Nucleic Acid Observatory Consortium. “A Global Nucleic Acid Observatory for Biodefense and Planetary Health”. In: ArXiv abs/2108.02678 (2021).
[29] Toby Shevlane. “Structured access to AI capabilities: an emerging paradigm for safe AI deployment”. In: ArXiv abs/2201.05159 (2022).
[30] Jonas Schuett et al. Towards best practices in AGI safety and governance: A survey of expert opinion. 2023. arXiv: 2305.07153.
[31] Yonadav Shavit. “What does it take to catch a Chinchilla? Verifying Rules on Large-Scale Neural Network Training via Compute Monitoring”. In: ArXiv abs/2303.11341 (2023).
[32] Anat Lior. “AI Entities as AI Agents: Artificial Intelligence Liability and the AI Respondeat Superior Analogy”. In: Torts & Products Liability Law eJournal (2019).
[33] Maximilian Gahntz and Claire Pershan. Artificial Intelligence Act: How the EU can take on the challenge posed by general-purpose AI systems. Nov. 2022.
[34] Paul Scharre. Army of None: Autonomous Weapons and The Future of War. Norton, 2018.
[35] DARPA. “AlphaDogfight Trials Foreshadow Future of Human-Machine Symbiosis”. In: (2020).
[36] Panel of Experts on Libya. Letter dated 8 March 2021 from the Panel of Experts on Libya established pursuant to resolution 1973 (2011) addressed to the President of the Security Council. United Nations Security Council Document S/2021/229. United Nations, Mar. 2021.
[37] David Hambling. Israel used world’s first AI-guided combat drone swarm in Gaza attacks. 2021.
[38] Zachary Kallenborn. Applying arms-control frameworks to autonomous weapons. en-US. Oct. 2021.
[39] J.E. Mueller. War, Presidents, and Public Opinion. UPA book. University Press of America, 1985.
[40] Matteo E. Bonfanti. “Artificial intelligence and the offense–defense balance in cyber security”. In: Cyber Security Politics: Socio-Technological Transformations and Political Fragmentation. Ed. by M.D. Cavelty and A. Wenger. CSS Studies in Security and International Relations. Taylor & Francis, 2022. Chap. 5, pp. 64–79.
[41] Yisroel Mirsky et al. “The Threat of Offensive AI to Organizations”. In: Computers & Security (2023).
[42] Kim Zetter. “Meet MonsterMind, the NSA Bot That Could Wage Cyberwar Autonomously”. In: Wired (Aug. 2014).
[43] Andrei Kirilenko et al. “The Flash Crash: High-Frequency Trading in an Electronic Market”. In: The Journal of Finance 72.3 (2017), pp. 967–998.
[44] Michael C Horowitz. The Diffusion of Military Power: Causes and Consequences for International Politics. Princeton University Press, 2010.
[45] Robert E. Jervis. “Cooperation under the Security Dilemma”. In: World Politics 30 (1978), pp. 167–214.
[46] Richard Danzig. Technology Roulette: Managing Loss of Control as Many Militaries Pursue Technological Superiority. Tech. rep. Center for a New American Security, June 2018.
[47] Billy Perrigo. Bing’s AI Is Threatening Users. That’s No Laughing Matter. en. Feb. 2023.
[48] Nico Grant and Karen Weise. “In A.I. Race, Microsoft and Google Choose Speed Over Caution”. en-US. In: The New York Times (Apr. 2023).
[49] Thomas H. Klier. “From Tail Fins to Hybrids: How Detroit Lost Its Dominance of the U.S. Auto Market”. In: RePEc (May 2009).
[50] Robert Sherefkin. “Ford 100: Defective Pinto Almost Took Ford’s Reputation With It”. In: Automotive News (June 2003).
[51] Lee Strobel. Reckless Homicide?: Ford’s Pinto Trial. en. And Books, 1980.
[52] Grimshaw v. Ford Motor Co. May 1981.
[53] Paul C. Judge. “Selling Autos by Selling Safety”. en-US. In: The New York Times (Jan. 1990).
[54] Theo Leggett. “737 Max crashes: Boeing says not guilty to fraud charge”. en-GB. In: BBC News (Jan. 2023).
[55] Edward Broughton. “The Bhopal disaster and its aftermath: a review”. In: Environmental Health 4.1 (May 2005), p. 6.
[56] Charlotte Curtis. “Machines vs. Workers”. en-US. In: The New York Times (Feb. 1983).
[57] Thomas Woodside et al. “Examples of AI Improving AI”. In: (2023). URL: https://ai-improving-ai.safe.ai.
[58] Stuart Russell. Human Compatible: Artificial Intelligence and the Problem of Control. en. Penguin, Oct. 2019.
[59] Dan Hendrycks. “Natural Selection Favors AIs over Humans”. In: ArXiv abs/2303.16200 (2023).
[60] Dan Hendrycks. The Darwinian Argument for Worrying About AI. en. May 2023.
[61] Richard C. Lewontin. “The Units of Selection”. In: Annual Review of Ecology, Evolution, and Systematics 1 (1970), pp. 1–18.
[62] Ethan Kross et al. “Facebook use predicts declines in subjective well-being in young adults”. In: PloS one (2013).
[63] Laura Martínez-Íñigo et al. “Intercommunity interactions and killings in central chimpanzees (Pan troglodytes troglodytes) from Loango National Park, Gabon”. In: Primates; Journal of Primatology 62 (2021), pp. 709–722.
[64] Anne E Pusey and Craig Packer. “Infanticide in Lions: Consequences and Counterstrategies”. In: Infanticide and parental care (1994), p. 277.
[65] Peter D. Nagy and Judit Pogany. “The dependence of viral RNA replication on co-opted host factors”. In: Nature Reviews. Microbiology 10 (2011), pp. 137–149.
[66] Alfred Buschinger. “Social Parasitism among Ants: A Review”. In: Myrmecological News 12 (Sept. 2009), pp. 219–235.
[67] Greg Brockman, Ilya Sutskever, and OpenAI. Introducing OpenAI. Dec. 2015.
[68] Devin Coldewey. OpenAI shifts from nonprofit to ‘capped-profit’ to attract capital. Mar. 2019.
[69] Kyle Wiggers, Devin Coldewey, and Manish Singh. Anthropic’s $5B, 4-year plan to take on OpenAI. Apr. 2023.
[70] Center for AI Safety. Statement on AI Risk (“Mitigating the risk of extinction from AI should be a global priority alongside other societal-scale risks such as pandemics and nuclear war.”) 2023. URL: https://www.safe.ai/statement-on-ai-risk.
[71] Richard Danzig et al. Aum Shinrikyo: Insights into How Terrorists Develop Biological and Chemical Weapons. Tech. rep. Center for a New American Security, 2012. URL: https://www.jstor.org/stable/resrep06323.
[72] Timnit Gebru et al. “Datasheets for datasets”. en. In: Communications of the ACM 64.12 (Dec. 2021), pp. 86-92.
[73] Christian Szegedy et al. “Intriguing properties of neural networks”. In: CoRR (Dec. 2013).
[74] Dan Hendrycks et al. “Unsolved Problems in ML Safety”. In: arXiv preprint arXiv:2109.13916 (2021).
[75] John Uri. 35 Years Ago: Remembering Challenger and Her Crew. und. Text. Jan. 2021.
[76] International Atomic Energy Agency. The Chernobyl Accident: Updating of INSAG-1. Technical Report INSAG-7. Vienna, Austria: International Atomic Energy Agency, 1992.
[77] Matthew Meselson et al. “The Sverdlovsk anthrax outbreak of 1979.” In: Science 266 5188 (1994), pp. 1202–8.
[78] Daniel M Ziegler et al. “Fine-tuning language models from human preferences”. In: arXiv preprint arXiv:1909.08593 (2019).
[79] Charles Perrow. Normal Accidents: Living with High-Risk Technologies. Princeton, NJ: Princeton University Press, 1984.
[80] Mitchell Rogovin and George T. Frampton Jr. Three Mile Island: a report to the commissioners and to the public. Volume I. English. Tech. rep. NUREG/CR-1250(Vol.1). Nuclear Regulatory Commission, Washington, DC (United States). Three Mile Island Special Inquiry Group, Jan. 1979.
[81] Richard Rhodes. The Making of the Atomic Bomb. New York: Simon & Schuster, 1986.
[82] Sébastien Bubeck et al. “Sparks of Artificial General Intelligence: Early experiments with GPT-4”. In: ArXiv abs/2303.12712 (2023).
[83] Theodore I. Lidsky and Jay S. Schneider. “Lead neurotoxicity in children: basic mechanisms and clinical
correlates.” In: Brain : a journal of neurology 126 Pt 1 (2003), pp. 5–19.
[84] Brooke T. Mossman et al. “Asbestos: scientific developments and implications for public policy.” In: Science 247 4940 (1990), pp. 294–301.
[85] Kate Moore. The Radium Girls: The Dark Story of America’s Shining Women. Naperville, IL: Sourcebooks, 2017.
[86] Stephen S. Hecht. “Tobacco smoke carcinogens and lung cancer.” In: Journal of the National Cancer Institute 91 14 (1999), pp. 1194–210.
[87] Mario J. Molina and F. Sherwood Rowland. “Stratospheric sink for chlorofluoromethanes: chlorine atomc-atalysed destruction of ozone”. In: Nature 249 (1974), pp. 810–812.
[88] James H. Kim and Anthony R. Scialli. “Thalidomide: the tragedy of birth defects and the effective treatment of disease.” In: Toxicological sciences : an official journal of the Society of Toxicology 122 1 (2011), pp. 1–6.
[89] Betul Keles, Niall McCrae, and Annmarie Grealish. “A systematic review: the influence of social media on depression, anxiety and psychological distress in adolescents”. In: International Journal of Adolescence and Youth 25 (2019), pp. 79–93.
[90] Zakir Durumeric et al. “The Matter of Heartbleed”. In: Proceedings of the 2014 Conference on Internet Measurement Conference (2014).
[91] Tony Tong Wang et al. “Adversarial Policies Beat Professional-Level Go AIs”. In: ArXiv abs/2211.00241 (2022).
[92] T. R. Laporte and Paula M. Consolini. “Working in Practice But Not in Theory: Theoretical Challenges of “High-Reliability Organizations””. In: Journal of Public Administration Research and Theory 1 (1991), pp. 19–48.
[93] Thomas G. Dietterich. “Robust artificial intelligence and robust human organizations”. In: Frontiers of Computer Science 13 (2018), pp. 1–3.
[94] Nancy G Leveson. Engineering a safer world: Systems thinking applied to safety. The MIT Press, 2016.
[95] David Manheim. Building a Culture of Safety for AI: Perspectives and Challenges. 2023.
[96] National Research Council et al. Lessons Learned from the Fukushima Nuclear Accident for Improving Safety of U.S. Nuclear Plants. Washington, D.C.: National Academies Press, Oct. 2014.
[97] Diane Vaughan. The Challenger Launch Decision: Risky Technology, Culture, and Deviance at NASA. Chicago, IL: University of Chicago Press, 1996.
[98] Dan Lamothe. Air Force Swears: Our Nuke Launch Code Was Never ’00000000’. Jan. 2014.
[99] Toby Ord. The precipice: Existential risk and the future of humanity. Hachette Books, 2020.
[100] U.S. Nuclear Regulatory Commission. Final Safety Culture Policy Statement. Federal Register. 2011.
[101] Bruce Schneier. “Inside the Twisted Mind of the Security Professional”. In: Wired (Mar. 2008).
[102] Dan Hendrycks and Mantas Mazeika. “X-Risk Analysis for AI Research”. In: ArXiv abs/2206.05862 (2022).
[103] CSRC Content Editor. Red Team - Glossary. EN-US.
[104] Amba Kak and Sarah West. Confronting Tech Power. 2023.
[105] Nassim Nicholas Taleb. “The Fourth Quadrant: A Map of the Limits of Statistics”. In: Edge, 2008.
[106] Irene Solaiman et al. “Release strategies and the social impacts of language models”. In: arXiv preprint arXiv:1908.09203 (2019).
[107] Neal Woollen. Incident Response (Why Planning is Important).
[108] Huashan Li et al. “The impact of chief risk officer appointments on firm risk and operational efficiency”. In: Journal of Operations Management (2022).
[109] Role of Internal Audit. URL: https://www.marquette.edu/riskunit/internalaudit/role.shtml.
[110] Heather Adkins et al. Building Secure and Reliable Systems: Best Practices for Designing, Implementing, and Maintaining Systems. O’Reilly Media, 2020.
[111] Center for Security and Emerging Technology. AI Safety – Emerging Technology Observatory Research Almanac. 2023.
[112] Donald T Campbell. “Assessing the impact of planned social change”. In: Evaluation and program planning 2.1 (1979), pp. 67–90.
[113] Yohan J. John et al. “Dead rats, dopamine, performance metrics, and peacock tails: proxy failure is an inherent risk in goal-oriented systems”. In: Behavioral and Brain Sciences (2023), pp. 1–68. DOI:10.1017/S0140525X23002753.
[114] Jonathan Stray. “Aligning AI Optimization to Community Well-Being”. In: International Journal of Community Well-Being (2020).
[115] Jonathan Stray et al. “What are you optimizing for? Aligning Recommender Systems with Human Values”. In: ArXiv abs/2107.10939 (2021).
[116] Ziad Obermeyer et al. “Dissecting racial bias in an algorithm used to manage the health of populations”. In: Science 366 (2019), pp. 447–453.
[117] Dario Amodei and Jack Clark. Faulty reward functions in the wild. 2016.
[118] Alexander Pan, Kush Bhatia, and Jacob Steinhardt. “The effects of reward misspecification: Mapping and mitigating misaligned models”. In: ICLR (2022).
[119] G. Thut et al. “Activation of the human brain by monetary reward”. In: Neuroreport 8.5 (1997), pp. 1225–1228.
[120] Edmund T. Rolls. “The Orbitofrontal Cortex and Reward”. In: Cerebral Cortex 10.3 (Mar. 2000), pp. 284–294.
[121] T. Schroeder. Three Faces of Desire. Philosophy of Mind Series. Oxford University Press, USA, 2004.
[122] Joseph Carlsmith. “Existential Risk from Power-Seeking AI”. In: Oxford University Press (2023).
[123] John Mearsheimer. “Structural realism”. In: Oxford University Press, 2007.
[124] Bowen Baker et al. “Emergent Tool Use From Multi-Agent Autocurricula”. In: International Conference on Learning Representations. 2020.
[125] Dylan Hadfield-Menell et al. “The Off-Switch Game”. In: ArXiv abs/1611.08219 (2016).
[126] Alexander Pan et al. “Do the Rewards Justify the Means? Measuring Trade-Offs Between Rewards and Ethical Behavior in the Machiavelli Benchmark.” In: ICML (2023).
[127] “Lyndon Baines Johnson”. In: Oxford Reference (2016).
[128] Anton Bakhtin et al. “Human-level play in the game of Diplomacy by combining language models with strategic reasoning”. In: Science 378 (2022), pp. 1067–1074.
[129] Paul Christiano et al. Deep reinforcement learning from human preferences. Discussed in https://www.deepmind.com/blog/specification-gaming-the-flip-side-of-ai-i…. 2017. arXiv: 1706.03741
[130] Xinyun Chen et al. Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning. 2017. arXiv: 1712.05526.
[131] Andy Zou et al. Benchmarking Neural Network Proxy Robustness to Optimization Pressure. 2023.
[132] Miles Turpin et al. “Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting”. In: ArXiv abs/2305.04388 (2023).
[133] Collin Burns et al. “Discovering Latent Knowledge in Language Models Without Supervision”. en. In: The Eleventh International Conference on Learning Representations. Feb. 2023.
[134] Andy Zou et al. Representation engineering: Understanding and controlling the inner workings of neural networks. 2023.
[135] Catherine Olsson et al. “In-context Learning and Induction Heads”. In: ArXiv abs/2209.11895 (2022).
[136] Kevin Ro Wang et al. “Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 Small”. en. In: The Eleventh International Conference on Learning Representations. Feb. 2023.
[137] Xinyang Zhang, Zheng Zhang, and Ting Wang. “Trojaning Language Models for Fun and Profit”. In: 2021 IEEE European Symposium on Security and Privacy (EuroS&P) (2020), pp. 179–197.
[138] Jiashu Xu et al. “Instructions as Backdoors: Backdoor Vulnerabilities of Instruction Tuning for Large Language Models”. In: ArXiv abs/2305.14710 (2023).
[139] Dan Hendrycks et al. “Unsolved Problems in ML Safety”. In: ArXiv abs/2109.13916 (2021).
[140] Nora Belrose et al. “LEACE: Perfect linear concept erasure in closed form”. In: ArXiv abs/2306.03819 (2023).
[141] Alberto Giubilini and Julian Savulescu. “The Artificial Moral Advisor. The «Ideal Observer» Meets Artificial Intelligence”. eng. In: Philosophy & Technology 31.2 (2018), pp. 169–188.
[142] Nick Beckstead. On the overwhelming importance of shaping the far future. 2013.
[143] Jens Rasmussen. “Risk management in a Dynamic Society: A Modeling Problem”. English. In: Proceedings of the Conference on Human Interaction with Complex Systems, 1996.
[144] Jennifer Robertson. “Human rights vs. robot rights: Forecasts from Japan”. In: Critical Asian Studies 46.4 (2014), pp. 571–598.
[145] John Rawls. Political Liberalism. Columbia University Press, 1993.
[146] Toby Newberry and Toby Ord. “The Parliamentary Approach to Moral Uncertainty”. In: 2021.
[147] F.R. Frola and C.O. Miller. System Safety in Aircraft Acquisition. en. Tech. rep. Jan. 1984.
Большая часть людей не знают, что мы понятия не имеем, как работают наши ИИ
Это кажется очевидным, но, думаю, стоит высказать это в явном виде.
Те из нас, кто знаком с областью ИИ после революции глубинного обучения, прекрасно понимают, что мы понятия не имеем, как работают наши ML-модели. Конечно, мы понимаем закономерности цикла обучения и свойства стохастического градиентного спуска, и мы знаем, как работают ML-архитектуры. Но мы н знаем, какие конкретные алгоритмы реализует конкретная ML-модель. У нас есть некоторые предположения, и кое-какие озарения уже были с большим трудом выкопаны в ходе исследований интерпретируемости, но у нас ничего хоть отдалённо похожего на полное понимание.
И уж точно мы не знаем, как работает свежеобученная модель только-что-из-цикла-обучения с новой архитектурой.
Мы привыкли к такому положению дел. Это подразумевается как общее фоновое знание. Но когда об этом узнаёшь впервые, это, на самом деле, довольно необычно.
И…

Релевантный XKCD.
Я довольно сильно уверен, что большинство людей этого на самом деле не знают. У меня нет конкретных данных, но на основе связанных с ИИ обсуждений в не-технических интернет-сообществах, разговорах с людьми, не интересующимися прогрессом в ИИ, и всякого такого1 у меня сложилось очень сильное впечатление, что это именно так.
Они всё ещё думают в терминах Старого Доброго Символьного ИИ. Они всё ещё верят, что вся функциональность ИИ была в него намеренно запрограммирована, а не обучена. Что за каждой способностью ChatGPT стоит человек, который её реализовал и её понимает.
Или, по крайней мере, что она записана в чётком виде, который люди могут прочитать и понять, и что мы можем туда вмешаться и совершить точные, предсказуемые поправки.
Опросы уже показывают беспокойство по поводу СИИ. Если тот факт, что мы не знаем, как эти системы на самом деле думают, был бы широко известным и в должной степени осознанным?Если бы не было неявного допущения, что «кто-то понимает, как это работает, и почему всё не может пойти катастрофически не так»?
Ну, я ожидаю, что беспокойства будет больше. Что может быть довольно хорошим подспорьем для дальнейшего продвижения регуляций ИИ. Способом накопить некоторый политический капитал, который затем можно будет тратить.
Так что, если вы общаетесь с публикой, я предлагаю включить в агенду распространение и этой информации. У вас есть около пяти слов (на сообщение), которые вы можете передать публике, и «Мощные ИИ – Это Чёрные Ящики», кажется, стоит передавать.2
- 1. Если у вас есть какие-то конкретные данные по этому поводу, было бы здорово.
- 2. Существуют некоторые возражения против терминологии «чёрного ящика». Я всё же считаю её верной: ML-модели являются чёрными ящиками для нас, в том смысле, что по умолчанию мы не лучше понимаем, какие алгоритмы они реализуют, чем что происходит в гомоморфно-защищённом вычислении, от которого у нас нет ключа, или в человеческом мозге, за активностью нейронов в котором мы наблюдаем. Существуют некоторое ненулевое количество исследований интерпретируемости, но в целом это так; а про модели новых архитектур это так почти стопроцентно.
Да, ML-модели не являются чёрными ящиками относительно СГС. Алгоритм может «видеть», как происходят все вычисления, и в них вмешиваться. Но это кажется очень неестественным применением этого термина, и я всё ещё думаю, что «ИИ – это чёрные ящики» передаёт правильные общие соображения.